x265探索与研究(五):如何用VS调试x265?
最后更新于:2022-04-01 16:05:50
# 如何用VS调试x265?
### 1、设置cli为启动项
用VS打开工程项目,如下图:

右击cli,设置为启动项,如下图:

### 2、配置路径和命令行参数
右击cli选择Properties,如下图所示

进入如下界面:

将Command Arguments和Working Directory中的内容填写好即可。
示例如下:
**Command Arguments:**
~~~
--preset fast --input hall_cif_352x288_300.yuv --fps 30 --input-res 352x288 --output out.bin --psnr --ssim --bitrate 128
~~~
**Working Directory:**
~~~
C:\Users\Fred\Desktop\DaHuaTech\x265\x265_1.8\build\vc10-x86\Release
~~~
### 3、Build与Debug
进行build solution后直接调试即可,如下图:


x265探索与研究(四):如何编码视频?
最后更新于:2022-04-01 16:05:48
# 如何编码视频?
本文介绍x265中的两种编码视频方法,一是采用命令行的方法;二是GUI的方式。
### 1、命令行的方法
**(1)、第一种方式生成*.265格式的视频文件**
第一种方式可以生成*.265格式的视频文件,对应的命令为:
~~~
x265 --input-res 352x288 --fps 30 hall_cif_352x288_300.yuv -o hall_cif_352x288_300.h265
~~~
**(2)、第二种方式可以生成*.bin格式的视频流文件**
第二种方式可以生成*.bin格式的视频流文件,对应的命令为:
~~~
x265.exe --preset fast --input hall_cif_352x288_300.yuv --fps 30 --input-res 352x288 --output out.bin --psnr --ssim --bitrate 128
~~~
两种方式生成的对应文件如下图所示:

除了这两种经测试可以使用的方式外,网址:[http://x265.ru/en/encode/](http://x265.ru/en/encode/)还提供了两种略有区别的命令行方式,如下图所示:

**(3)、第三种命令行的方式,可以生成*.x265和*.csv**
下面对其进行测试,第三种命令行的方式,可以生成*.x265和*.csv,对应的命令为:
~~~
x265.exe hall_cif_352x288_300.yuv --input-res 352x288 --fps 30 -o out.x265 --csv results.csv --no-rect --max-merge 3 --rd 0 --tu-intra-depth 2 --tu-inter-depth 1 --no-tskip --frame-threads 2
~~~
需要注意的是:该方式输入的视频必须是YUV或Y4M格式,帧的宽和高也必须指定且FPS也必须设定。测试过程如下图:

测试结果如下图:

**(4)、第四种命令行方式输出是*.hevc格式**
该命令行的方式,输入是*.y4m的视频,可以获得高质量的*.hevc格式视频,对应的命令为:
~~~
x265.exe hall_cif_352x288_300.y4m --q 17 --merange 64 --frames all --ref 4 --max-merge 3 --rect-hash 2 --me 3 --b 6 --b-adapt 1 --rd 2 --rc-lookahead 60 --input-depth 16 --tu-inter-depth 3 --tu-intra-depth 3 --no-tskip-fast --wpp --subme 2 --s 32 --F 6 -o video.hevc
~~~
(注:由于我这边没有*.y4m格式视频,故没有测试,后续测试,补充在此。)
### 2、GUI的方法
采用“Baka Encoder”,下载网址:[http://x265.ru/en/baka-encoder/](http://x265.ru/en/baka-encoder/)

配置方式是修改Baka Encoder.config.xml,对应的代码如下所示:
~~~
<?xml version="1.0" encoding="utf-8"?>
<!-- Baka Encoder configuration file reference can be found at http://vtt.to/baka%20encoder%20configuration%20reference -->
<baka_encoder logging="0">
<presets>
<preset name="preview" suffix="_preview" on="1">
<hint quality="7" compression="14" speed="6" streaming="1"/>
<audio cmd="-br 60000"/>
<video tool="x264" bit_depth="8" pass_count="2" max_width="480" max_height="360" resize_method="spline" base_bitrate="0" max_bitrate="0"
cmd="--preset placebo --no-mbtree --ratetol 100.0 --keyint 60 --ref 3 --bitrate 500 --level 4.1 --vbv-bufsize 50000 --vbv-maxrate 62500"/>
<muxing container="mp4" cmd=" --optimize-pd"/>
</preset>
<preset name="normal" suffix="_normal" on="1">
<hint quality="11" compression="9" speed="3" streaming="1"/>
<audio cmd="-q 0.6"/>
<video tool="x264" bit_depth="8" pass_count="2" max_width="1280" max_height="960" resize_method="spline" base_bitrate="1500" max_bitrate="3500"
cmd="--preset placebo --no-mbtree --ratetol 100.0 --keyint 60 --ref 4 --level 4.1 --vbv-bufsize 50000 --vbv-maxrate 62500"/>
<muxing container="mp4" cmd=" --optimize-pd"/>
</preset>
<preset name="normal h265" suffix="_normal.h265" on="1">
<hint quality="12" compression="9" speed="1" streaming="0"/>
<audio cmd="-q 0.6"/>
<video tool="x265" bit_depth="8" pass_count="2" max_width="1280" max_height="960" resize_method="spline" base_bitrate="1200" max_bitrate="10000"
cmd="--preset slow --bframes 4 --ref 4"/>
<muxing container="mp4" cmd=""/>
</preset>
<preset name="deluxe" suffix="_deluxe" on="0">
<hint quality="14" compression="5" speed="4" streaming="0"/>
<audio cmd="-q 1.0"/>
<video tool="x264" bit_depth="10" pass_count="1" max_width="0" max_height="0" resize_method="" base_bitrate="0" max_bitrate="0"
cmd="--crf 12 --preset placebo --no-mbtree --deblock 0:-1"/>
<muxing container="mp4" cmd=""/>
</preset>
<preset name="deluxe h265" suffix="_deluxe.h265" on="0">
<hint quality="15" compression="7" speed="1" streaming="0"/>
<audio cmd="-q 1.0"/>
<video tool="x265" bit_depth="10" pass_count="1" max_width="0" max_height="0" resize_method="" base_bitrate="0" max_bitrate="0"
cmd="--crf 12 --preset slow"/>
<muxing container="mp4" cmd=""/>
</preset>
<preset name="express" suffix="_express" on="0">
<hint quality="7" compression="7" speed="10" streaming="0"/>
<audio cmd="-q 0.5"/>
<video tool="x264" bit_depth="8" pass_count="1" max_width="0" max_height="0" resize_method="" base_bitrate="1500" max_bitrate="5000"
cmd="--preset fast --deblock 1:0 --bframes 4 --b-adapt 1 --rc-lookahead 36 --ref 3 --level 4.1 --vbv-bufsize 50000 --vbv-maxrate 62500"/>
<muxing container="mp4" cmd=""/>
</preset>
<preset name="lossless" suffix="_lossless" on="0" console="0">
<hint quality="16" compression="3" speed="8" streaming="0"/>
<audio cmd="-q 1.0"/>
<video tool="x264" bit_depth="8" pass_count="1" max_width="0" max_height="0" resize_method="spline" base_bitrate="0" max_bitrate="0"
cmd="--crf 0 --preset placebo --log-level none --quiet"/>
<muxing container="mp4" cmd=""/>
</preset>
</presets>
</baka_encoder>
~~~

x265探索与研究(三):如何播放*.265格式的视频或解码视频流
最后更新于:2022-04-01 16:05:45
# 如何播放*.265格式的视频或解码视频流
如下图,在得到.265格式的视频或视频流后应如何播放265格式的视频呢?本博文总结出5种播放265格式视频或视频流的基本方法。
### 方式一:Elecard HEVC Player Sample
软件下载地址:[http://download.csdn.net/detail/frd2009041510/9387068](http://download.csdn.net/detail/frd2009041510/9387068)
下载后直接双击安装即可,播放效果如下图所示。

### 方式二:GitlHEVCAnalyzer
我们可以更改“make-solutions.bat”中的内容,让生成的是*.bin文件,之后解码*.bin文件亦可播放,更改后的命令如下:
~~~
x265.exe --preset fast --input hall_cif_352x288_300.yuv --fps 30 --input-res 352x288 --output out.bin --psnr --ssim --bitrate 128
~~~
如下图是生产的*.bin文件。
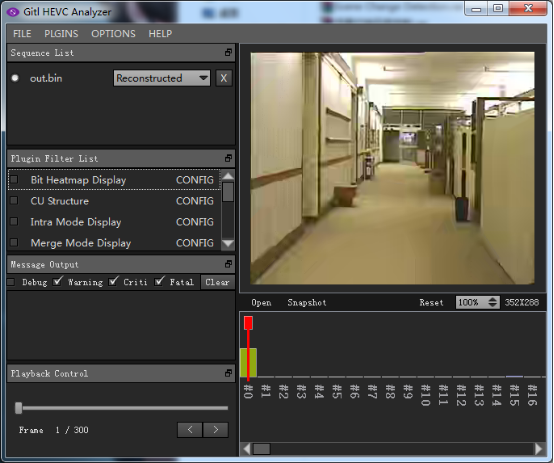
接下来,下载GitlHEVCAnalyzer。
地址:[http://download.csdn.net/detail/frd2009041510/8113987](http://download.csdn.net/detail/frd2009041510/8113987)
最后,用GitlHEVCAnalyzer打开out.bin进行解码即可,如下图所示。
### 方式三:VLC
下载地址:[http://download.csdn.net/detail/frd2009041510/9387112](http://download.csdn.net/detail/frd2009041510/9387112)
需要特别注意的是:VLC编译的时候必须开启x265支持(主要是打开ffmpeg的编译选项)。**此部分在后续博文中会详细介绍具体步骤。**
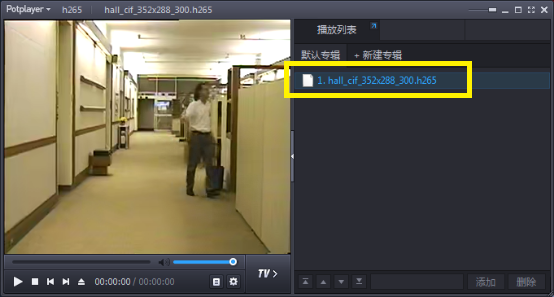
### 方式四:potplayer
下载地址:[http://download.csdn.net/detail/frd2009041510/9387103](http://download.csdn.net/detail/frd2009041510/9387103)
Potplayer对于*.265或*.bin的265格式均可播放,如下图所示。
### 方式五:HM解码器
x265编码器产生的str.bin码流文件还可以采用HM中TAppDecoder.exe解码并利用YUV播放器查看。
x265探索与研究(二):x265使用基本方法
最后更新于:2022-04-01 16:05:43
# x265使用基本方法
首先,完成x265的下载安装与配置。
(参考网址:[http://blog.csdn.net/frd2009041510/article/details/50446007](http://blog.csdn.net/frd2009041510/article/details/50446007))
接下来介绍x265编解码视频的基本方法。
**第一步:**
进入“...x265_1.8\build\vc10-x86”,双击“build-all.bat”,则进行编译。文件夹中的内容变化如下两图所示。


**第二步:**
用VS打开上一步中生成的x265.sln,其具体位置在“...\x265_1.8\build\vc10-x86”(如下图,根据平台选择)

打开后,VS出现如下界面:

**第三步:**
Build Solution(可以先调为Release模式),Release文件夹下出现编译出来的一些执行文件和库,如下图所示。

其中,
x265.exe是可以直接使用的编码H.265的命令行程序;
libx265.dll、libx265.lib是可以用于程序开发的编码H.265的类库(lib和dll分开);
x265-static.lib是可以用于程序开发的编码H.265的类库(单独一个lib)。
**第四步:**
将make-solution.bat拷贝至Release文件夹下,并且拷贝一个YUV420的测试序列至Release文件夹下,如下图所示。

**第五步:**
修改make-solution.bat内容,内容如下(运行的指令将在后续博文中介绍):
~~~
x265 --input-res 352x288 --fps 30 hall_cif_352x288_300.yuv -o hall_cif_352x288_300.h265
~~~
**第六步:**
双击make-solution.bat,出现如下界面,说明成功。

成功过后,会多出一个*.h265的文件,该文件就是h.265格式的视频,如下图所示:


OK了。
x265探索与研究(一):x265下载安装与配置
最后更新于:2022-04-01 16:05:41
# x265下载安装与配置
研究了这么久的HEVC Test Model(HM),相信大家对x265开源代码的实现与框架早就充满了好奇,接下来的日子,我将把自己入手学习与探索“x265开源代码的实现与框架”的过程记录下来,与大家共同进步学习。
### 1、x265下载地址与参考资料

x265的官网为: [http://x265.org/](http://x265.org/)
x265下载地址: [https://bitbucket.org/multicoreware/x265/downloads](https://bitbucket.org/multicoreware/x265/downloads)
或 [http://ftp.videolan.org/pub/videolan/x265/](http://ftp.videolan.org/pub/videolan/x265/)
或 [https://bitbucket.org/multicoreware/x265/src](https://bitbucket.org/multicoreware/x265/src)
x265 Documentation: [http://x265.readthedocs.org/en/default/](http://x265.readthedocs.org/en/default/)
### 2、x265安装与配置
(注:以下步骤所采用的平台是:Win7 32 bit PC、VS2010)
**Step1:将x265开源代码下载下来;**
(网址:[http://download.csdn.net/detail/frd2009041510/9385441](http://download.csdn.net/detail/frd2009041510/9385441))
**Step2:下载Cmake(尽量采用高版本);**
(网址:[https://cmake.org/download/](https://cmake.org/download/))
**Step3:下载YASM(后续可能会用到。。。。);**
(地址:[http://download.csdn.net/detail/frd2009041510/9385752](http://download.csdn.net/detail/frd2009041510/9385752))
下载后只需将“vsyasm.exe”放在:C:\Program Files\Microsoft Visual Studio 10.0\VC\bin即可。
**Step4:编译x265。**
具体步骤如下:
(1)、进入你的Cmake软件安装包“...\cmake-3.4.1-win32-x86\bin”,双击cmake-gui.exe,出现如下界面;

(2)、选择源码地址与binaries地址,分别为:..\x265_1.8\source和...x265_1.8\build\vc10-x86(第二个地址要根据采用的平台选择,我这儿采用的是32位PC、VS2010),如下图所示;

(3)、点击Configure,出现项目编译器平台选择(根据自己的平台进行选择),如下图;

(4)、点击Configure,完成后界面如下,说明成功;

(5)、点击Generate,界面变为如下图所示说明成功;

此时进入“...\x265_1.8\build\vc10-x86”,发现多出了很多东西就对了,如下图所示。

### 3、“...\x265_1.8\build\vc10-x86”内容变化
最后,给出“...\x265_1.8\build\vc10-x86”文件夹中的内容在整个过程中的变化:
**(1)、原始内容**

**(2)、“Configure”后**

**(3)、“Generate”后**



截至目前,x265平台下载、安装、配置就基本完成了。。。


HEVC算法和体系结构:预测编码之帧间预测
最后更新于:2022-04-01 16:05:38
# 预测编码之帧间预测(Inter-Picture Prediction)
帧间预测是指利用视频时间域相关性,使用临近已编码图像像素预测当前图像的像素,以达到有效去除视频时域冗余的目的。由于视频序列通常包括较强的时域相关性,因此预测残差值接近于0,将残差信号作为后续模块的输入进行变换、量化、扫描及熵编码,可实现对视频信号的高效压缩。
### 一、帧间预测编码原理
目前主要的视频编码标准帧间预测部分都采用了基于块的运动补偿技术,如下图所示,其基本原理为:当前图像的每个像素块在之前已编码图像中寻找一个最佳匹配块,该过程称为运动估计ME(Motion Estimation)。其中用于预测的图像称为参考图像,参考块到当前像素块的位移称为运动向量MV(Motion Vector),当前像素块与参考块的差值称为预测残差(Prediction Residual)。将残差信号作为后续模块的输入进行变换、量化、扫描及熵编码,可实现对视频信号的高效压缩。根据运动矢量MV,将前一帧(或前几帧、后几帧)的运动位移块图像做相应的位移得到当前帧当前块的运动预测估计值,这样就可以得到当前帧的帧间预测帧,这一过程称为运动补偿MC(Motion Compensation)。
需要注意的是:运动估计得到的运动矢量不只用于运动补偿,而且还被传送至解码器中,解码器根据运动矢量经过运动补偿可以得到和编码端完全相同的预测图像,从而实现正确图像解码。

其实,帧内预测和帧间预测有很多类似的地方,只不过帧内预测所采用的参考像素来源于当前帧已编码的像素值,而帧间预测的参考像素来源于已编码的前一帧(或前几帧、后几帧)。类似于帧间预测中编码器需要将运动矢量MV传给解码端,解码端根据运动矢量可以获取和编码端完全相同的预测块;在帧内编码模式下,编码器需要把实际采用的帧内预测模式信息传给解码器,解码端可以根据这个预测模式信息获得与编码器完全相同的帧内预测块。由此可见,运动矢量和帧内预测模式有着完全相同的重要性,它们都在宏块头中用特定的语法元素表示。
### 二、帧间预测编码的关键技术
在帧间预测编码过程中,最重要的操作就是运动估计、MV预测以及多参考帧和加权预测,下面对它们一一进行分析。
### 1、运动估计
所谓运动估计ME就是指提取当前图像运动信息的过程。在运动估计中,常见的运动表示法主要包括:基于像素的运动表示法、基于区域的运动表示法和基于块的运动表示法。
(1)、基于像素的运动表示法:直接为每个像素指定一个运动向量。此法普遍适用,但是需要估计出大量的未知量,而且其解通常不能反映场景中物体真实的运动情况,此外,该方法需要为每一个像素附加传送一个MV,数据量很高。
(2)、基于区域的运动表示法:把一幅图像分为多个区域,使得每个区域恰好表征了一个完整的运动物体。此法默认每个区域中的像素具有相同的运动形式,适用于包含多个运动物体的场景,然而,运动物体的形状往往是不规则的,因此区域划分需要大量的信息来表征,而且准确的划分方式需要大量的计算才能确定,因而基于区域的表示法在实际中较少使用。
(3)、基于块的运动表示法:将图像分成不同大小的像素块,只要块大小合适,则各个块的运动形式可以看成是统一的,同时每个块的运动参数可以独立地进行估计。此法兼顾了运动估计精度和复杂度,在二者之间进行了一个折中,因此该方法是视频编码国际标准中的核心技术。
基于块的运动估计方法有三个核心问题需要特别注意。一是运动估计的准则;二是搜索算法;三是亚像素精度运动估计。
#### 1.1、运动估计准则
运动估计的目的是为当前块在参考图像中寻找一个最佳匹配块,因此需要一个准则来判定两个块的匹配程度。常用的匹配准则主要有最小均方误差MSE(Mean Square Error)、最小平均绝对误差MAD(Mean Absolute Difference)和最大匹配像素数MPC(Matching-Pixel Count)等。
为了简化计算,一般用绝对误差和SAD(Sum of Absolute Difference)来代替MAD。此外,最小变换域绝对误差和SATD(Sum of Absolute Transformed Difference)也是一种性能优异的匹配准则。
#### 1.2、搜索算法
在某些应用环境下,视频编码传输对实时性要求较高,而运动估计的运算复杂度通常较高,因此高性能、低复杂度的运动搜索算法显得尤为重要。
常用的搜索算法有:全搜索算法、二维对数搜索算法、三步搜索算法等。全搜索算法是指对搜索窗内所有可能的位置计算两个块的匹配误差,所得的最小匹配误差对应的MV一定是全局最优的MV。
然而,全搜索算法复杂度极高,无法满足实时编码。除全搜索算法外,其余算法统称为快速搜索算法,快速搜索算法具有速度快的优点,但是其搜索过程容易落入局部最优点,从而无法找到全局最优点。为了避免这一现象的发生,需要在搜索算法中的每一个步骤尽量搜索更多的点,相关的算法有JM中的UMHexagonS算法以及HM中的TZSearch算法。
#### 1.3、亚像素精度运动估计
由于自然界物体运动具有连续性,因此相邻两幅图像之间的运动不一定以整像素为基本单位,而有可能以半像素、1/4像素甚至是1/8像素为单位。此时若仅仅使用整像素精度运动估计会出现匹配不准确的问题,导致运动补偿残差幅度较大,影响编码效率。
为了解决上述问题,应将运动估计的精度提升到亚像素级别,这可以通过对参考图像像素点进行插值来实现。1/4像素精度相比于1/2像素精度时的编码效率有明显地提高,但是1/8像素精度相比于1/4像素精度时的编码效率除了高码率情况以外并没有明显地提升且1/8像素精度运动估计更为复杂。因此现有标准H.264以及HEVC都使用了1/4像素精度进行运动估计。
### 2、MV预测技术
在大多数图像和视频中,一个运动物体可能会覆盖多个运动补偿块,因此空间域相邻块的运动向量具有较强的相关性。若使用相邻已编码块对当前块MV进行预测,将二者差值进行编码,则会大幅度节省编码MV所需的比特数。同时,由于物体运动具有连续性,因此相邻图像同一位置的MV也具有一定的相关性。在H.264中就使用了空域和时域两种MV预测方式。
在HEVC中,为了充分利用空域和时域相邻块的MV对当前块的MV进行预测以便节省MV的编码比特数,HEVC在MV的预测方面提出了两种新技术:Merge技术和AMVP(Advanced Motion Vector Prediction)技术。
Merge技术和AMVP技术都使用了空域和时域MV预测的思想,通过建立候选MV列表,选取性能最优的一个作为当前PU的预测MV,二者的区别主要表现在以下两个方面。
(1)、Merge可以看出是一种编码模式,在该模式下,当前PU的MV直接由空域或时域上临近的PU预测得到,不存在MVD;而AMVP可以看成一种MV预测技术,编码器只需要对实际MV与预测MV的差值进行编码,因此是存在MVD的;
(2)、二者候选MV列表长度不同,构建候选MV列表的方式也有区别。
#### 2.1、Merge技术
Merge模式会为当前PU建立一个MV候选列表,列表中存在5个候选MV及其对应的参考图像。通过遍历这5个候选MV,并进行率失真代价的计算,最终选取率失真代价最小的一个作为该Merge模式的最优MV。若边解码端依照相同的方式建立该候选列表,则编码器只需要传输最优MV在候选列表中的索引即可,这样大幅度节省了运动信息的编码比特数。Merge模式建立的MV候选列表中包含了空域和时域两种情形,而对于B Slice则包含组合列表的方式。
#### 2.2、AMVP(Advanced Motion Vector Prediction)技术
AMVP利用空域、时域上运动矢量的相关性,为当前PU建立了候选预测MV列表。编码器从中选出最优的预测MV,并对MV进行差分编码;解码端通过建立相同的列表,仅需要运动矢量残差(MVD)与预测MV在该列表中的序号即可算出当前PU的MV。
类似于Merge模式,AMVP候选MV列表也包含空域和时域两种情形,不同的是AMVP列表长度仅为2。
### 3、多参考图像及加权预测
对于某些场景,如物体周期性变化等,多参考帧可以大幅提高预测精度。早期的视频编码标准只支持单个参考图像,H.263+开始支持多参考图像预测技术,而H.264最多支持15个参考图像,随着参考数目的增加,编码性能也随之提高,但是提高的速度日益缓慢,因此为了权衡编码效率和编码时间,一般采用4~6个参考图像。
此外,H.264还使用了加权预测技术。加权预测表示预测像素可以用一个(适用于P Slice情形)或两个(适用于B Slice)参考图像中的像素通过与加权系数相乘得出。HEVC沿用了H.264中的加权预测技术并做了进一步的发展。
HEVC算法和体系结构:预测编码之帧内预测
最后更新于:2022-04-01 16:05:36
# 预测编码之帧内预测(Intra-Picture Prediction)
预测编码(Prediction Coding)是视频编码的核心技术之一,指利用已编码的一个或几个样本值,根据某种模型或方法,对当前的样本值进行预测,并对样本真实值和预测值之间的差值进行编码。视频编码器对预测后的残差而不是原始像素值进行变换、量化、熵编码,由此大幅度提高编码效率。
对于视频信号来说,一帧图像内临近像素之间有着较强的空间相关性,即空域冗余;相邻图像之间也有很强的相关性,即时域冗余。去除空域冗余和时域冗余的技术分别是帧内预测技术和帧间预测技术。
本博文首先介绍预测编码的原理,其次重点分析帧内预测技术相关知识点。
### 一、预测编码的原理
我们可以简单地将视频当做是一种有记忆信源,预测编码通过预测模型消除像素间的相关性,得到的差值信号可以认为是没有相关性的,因此可以作为无记忆信源进行编码。
在预测编码时,不直接传送图像样值本身,而是对实际样值与它的预测值间的差值进行编码、传送,如果这一差值(预测误差)被量化后再编码,这种预测编码方式叫做差分脉冲编码调制(DPCM)。从统计上看,需要传输的预测误差主要集中在0附近的一个小范围内,由于人眼的“掩蔽效应”,对出现在纹理或运动较复杂区域的较大误差不易察觉,因此,预测误差量化所需要的量化层数要比直接传送图像样值本身减少很多。DPCM就是通过去除临近像素间的相关性和减少差值信号量化层数来实现码率压缩的。
预测差分编码的原理框架如下图所示,在预测编码系统中,预测器和量化器是非常关键的两部分。

预测编码的基本过程:对于输入像素值x(n),首先利用已编码像素的重建值得到当前像素的预测值p(n),然后对二者的差值e(n)进行量化、熵编码,同时利用量化后的残差e’(n)与预测值p(n)得到当前像素的重建值x’(n),用于预测之后待编码的像素。对应的解码过程为:经熵解码可以得到当前像素预测误差的重建值e’(n),将其与预测值p(n)相加即可得到当前像素的重建值x’(n)。
为了保证编码器和解码器中预测有完全相同的参考基准,在利用空时域相关性进行预测时,需要用含失真的解码像素x’(n)作为参考像素,从而避免编码器和解码器中因不同预测参考产生误差累积,也就是说,在编码器内部需要内嵌一个解码器。
### 二、帧内预测技术
视频序列的时域相关性往往大于空域相关性,所以帧间预测技术的贡献往往大于帧内预测技术,但是这并不意味着可以对所有视频帧都采用帧间预测技术进行预测编码,其原因主要包括:
(1)、几乎所有的视频编码标准都支持I帧,这一帧可以不依赖临近参考帧进行独立解码,这一特点使得视频应用可以支持快进或快退播放,同时还避免了因编码失真累积而导致的图像逐渐恶化以及后续图像运动预测的效果逐渐恶化。
(2)、基于刚体平动的模型并不适用于所有场景,因为实际中的视频序列的运动是非常复杂的,尽管可变大小块分像素运动预测在一定程度上改善这一不足,但是还是有部分宏块或块不能获得很好地运动预测效果,而这些区域空间相关性也许比时域相关性强,采用帧内预测的预测效果往往好于帧间预测效果。研究表明,P帧和B帧中也有少数比例(1%~3%)的宏块实际上采用了帧内预测模式。
### 1、HEVC与H.264在帧内预测编码时尺寸、预测模式种类的区别
HEVC帧内预测与H.264类似,都是利用相邻块的重建值进行预测,因此,编码模式的选择与编码是帧内编码需要重点解决的问题。HEVC与H.264在帧内预测上最大的不同在于:HEVC采用了更大更多的尺寸以适应高清视频的内容特征,支持更多种的帧内预测模式以适应更加丰富的纹理。
H.264一共规定了3种大小的亮度帧内预测块:4*4、8*8和16*16,色度分量的帧内预测块都是基于8*8大小的块进行的。其中,4*4和8*8大小的亮度块包含9种预测模式(垂直、水平、DC、左下对角线模式、右下对角线模式、垂直向右模式、水平向下模式、垂直向左模式和水平向上模式),而16*16大小的亮度块和8*8大小的色度块只有4种预测模式(DC、水平、垂直和Plane)。需要注意的是“4*4和8*8大小的亮度块支持的9种预测模式”与“16*16大小的亮度块和8*8大小的色度块只支持的4种预测模式”二者模式编号顺序是不同的。
HEVC亮度分量帧内预测支持5种大小的PU(Prediction Unit):4 * 4、8 * 8、16 * 16、32 * 32、64 * 64,其中每一种大小的PU都对应35种预测模式,包括Planar模式、DC模式以及33种角度模式,如下图所示。对于色度分量,支持PU的大小为4 * 4/8 * 8/16 * 16/32 * 32,一共有5种模式,即Planar模式、垂直模式、水平模式、DC模式以及对应亮度分量的预测模式,若对应亮度预测模式为前4种中的一种,则将其替换为角度预测中的模式34。

总而言之,当预测模式选择为帧内时,对于所有的块尺寸,PB尺寸与CB尺寸相同。对于最小的CB尺寸,存在一个标志,用于表明CB是否被分成4个PB,每个PB均有自己的帧内预测模式,采用这种分割方式的原因是能为4 * 4大小的块选择帧内预测模式,当亮度的帧内预测模式以4 * 4大小块进行处理时,色度的帧内预测也采用4 * 4块。
所有的预测模式都使用相同的模板,如下图所示。从图中我们可以看出,与H.264相比,HEVC增加使用了左下方块的边界像素作为当前块的参考。这是由于H.264以固定大小的宏块为单元进行编码,在对当前块进行帧内预测时,其左下边方块很有可能尚未进行编码,无法用于参考,而HEVC的四叉树编码结构使得这一区域成为可用像素。

### 2、帧内预测过程
在HEVC中,35种预测模式是在PU的基础上定义的,而具体帧内预测过程的实现则是以TU为单位的。HEVC规定PU可以以四叉树的形式划分TU,且一个PU内的所有TU共享同一种预测模式。
HEVC的帧内预测过程可分为以下三个步骤:
(1)、相邻参考像素的获取
如下图所示,当前TU的大小为N * N,其参考像素按区域可分成5部分,左下、左侧、左上、上方和右上,一共4 * N+1个点,若当前TU位于图像边界或Slice、Tile边界,则相邻参考像素可能会不存在或不可用,并且在某些情况下,左下或右上所在的块可能尚未编码,此时这些参考像素也是不可用的。当像素不存在或不可用时,HEVC规定了可以使用最邻近的像素进行填补,例如左下的参考像素不存在,则左下区域的所有参考像素可使用左侧区域最下方的像素进行填补,若右上区域的参考像素不存在,则可以使用上方区域最右侧的像素进行填补(如下图中右侧示例)。需要说明的是,若所有参考像素都不可用,则参考像素都用固定值填充,对于8比特像素,该预测值为128,对于10比特像素,则该预测值为512。

(2)、参考像素的滤波
H.264在帧内预测时对某些模式下的参考像素进行了滤波,以便更好地利用临近像素之间的相关性,提高预测精度。HEVC沿用这一方法并进行了拓展:一是针对不同大小的TU选择了不同数量的模式进行滤波;二是增加使用了一种强滤波方法。
(3)、预测像素的计算
预测像素的计算就是针对不同的预测模式采用不同的计算方式得到预测像素值。
HEVC算法和体系结构:编码结构之编码完后码流的语法架构
最后更新于:2022-04-01 16:05:34
# 编码结构之编码完后码流的语法架构
本博文主要介绍HEVC编码结构,从编码完后码流的语法架构这一方面进行描述。
在码流结构方面,HEVC采用了类似于H.264的分层结构,将属于GOP层、Slice层中共用的大部分语法游离出来,组成序列参数集SPS(Sequence Parameter Set)和图像参数集PPS(Picture Parameter Set)。此外,为了兼容标准在其他应用上的扩展,例如可分级视频编码器、多视点视频编码器,HEVC的语法架构中增加了视频参数集VPS(Video Parameter Set)。
参数集是一个独立的数据单元,它包含视频的不同层级编码单元的共享信息,只有当参数集直接或间接被片段SS(Slice Segment)引用时才有效。SS是视频编码数据的基本单位,对于一个SS,通过引用它所使用的PPS,该PPS又引用其对应的SPS,该SPS又引用它对应的VPS,最终得到SS的公用信息,HEVC的压缩码流结构如下图所示。

### 1、视频参数集VPS(Video Parameter Set)
VPS的内容大致包括多个子层共享的语法元素,其他不属于SPS的特定信息等。
在H.264的码流结构中,没有类似VPS这样的参数集去描述时域各层之间的依赖关系。它的扩展部分可伸缩视频编码中,SEI信息提供了相关各层信息,以用于不同业务和不同终端的访问。但是在某些场合,例如广播和多播,由于SEI中的部分信息会重复出现在SPS中,这样会造成参数重传而引起延迟等问题,因此在HEVC中引入了VPS。
VPS主要用于传输视频分级信息,有利于兼容标准在可分级视频编码或多视点视频编码的扩展。一个给定的视频序列,无论它每一层的SPS是否相同,都参考相同的VPS,VPS包含的信息有:
(1)、多个子层和操作点共享的语法元素;
(2)、会话所需的有关操作点的关键信息,如档次、级别;
(3)、其他不属于SPS的操作点特性信息,例如与多层或子层相关的虚拟参考解码器HRD(Hypothetical Reference Decoder)参数。
### 2、序列参数集SPS(Sequence Parameter Set)
SPS的内容大致包括解码相关信息,如档次级别、分辨率、某档次中编码工具开关标识和涉及的参数、时域可分级信息等。SPS还包含了一个CVS(Coded Video Sequence)中所有图像共用的信息,其中CVS被定义为一个GOP编码后所生产的压缩数据。
### 3、图像参数集PPS(Picture Parameter Set)
PPS的内容大致包括初始图像控制信息,如量化参数QP、分块信息等。即PPS包含了一幅图像所用的公共参数,也就是说,一幅图像中的所有SS引用同一个PPS。
### 4、扩展知识点:档次(Profile)、层(Tier)和级别(Level)
档次主要规定编码器可采用哪些编码工具或算法。
级别则是指根据解码端的负载和存储空间情况对关键参数(最大采样率、最大图像尺寸、分辨率、最小压缩比、最大比特率、解码缓冲区DPB大小等)加以限制。
考虑到应用可根据最大的码率和CPB大小来区分,因此有些级别定义了两个层Tier:主层和高层,主层用于大多数应用,而高层用于那些最严苛的应用。
HEVC算法和体系结构:编码结构之编码时的分层处理架构
最后更新于:2022-04-01 16:05:32
# 编码结构之编码时的分层处理架构
本博文主要介绍HEVC编码结构中的“编码时的分层处理架构”。HEVC编码结构的主要目的就是为了各种应用下操作的灵活性以及数据损失的鲁棒性(所谓“鲁棒性”,是指控制系统在一定的参数摄动下,维持其它某些性能的特性)。从GOP(Group of Pictures)至Slice,从Slice至SS(Slice Segment),从SS至CTU(Coding Tree Unit),从CTU至CU(Coding Unit)的过程就是编码时的分层处理架构。
### 1、图像组GOP
视频序列由若干时间连续的图像构成,在对其进行压缩时,先将该视频序列分割为若干个小的图像组(Group of Pictures,GOP),GOP分为:封闭式GOP(Closed GOP)和开放式GOP(Opened GOP)。
封闭式GOP如下图所示,每个GOP以IDR(Instantaneous Decoding Refresh)图像开始,各个GOP之间独立编解码。

开放式GOP如下图所示,第一个GOP的第一个帧内编码图像为IDR图像,后续GOP中的第一个帧内编码图像为non-IDR图像,也就是说,后面GOP中的帧间编码图像可以越过non-IDR图像,使用前一个GOP中的已编码图像做参考图像。

### 2、片Slice
每个GOP又被划分为多个片(Slice),片与片之间进行独立编码。其主要目的之一是在数据丢失情况下进行重新同步。在HEVC中,默认情况下,一个GOP分为4个片,每个片就是一帧图像。
如下图所示,每个片由一个或多个片段(Slice Segment,SS)组成。在HEVC中,默认情况下,一个片中只包含一个片段,也就是说,一帧图像就是一个片,也是一个片段。

### 3、Tile
Tile是HEVC中新提出的概念,一幅图像不仅仅可以划分为若干个Slice,还可以划分为若干个Tile,即从水平和垂直方向将一幅图像分割为若干个矩形区域,一个矩形区域就是一个Tile,如下图所示。每个Tile包含整数个CTU,其可以独立解码。划分Tile的主要目的是在增强并行处理能力的同时又不引入新的错误扩散。Tile提供比CTB更大程度的并行(在图像或者子图像层面上),在使用时无需进行复杂的线程同步。

Tile的划分并不要求水平和垂直边界均匀分布,可根据并行计算和差错控制的要求灵活掌握。通常情况下,每一个Tile中包含的CTU数据是近似相等的。在编码时,图像中的所有Tile按照扫描顺序进行处理,每个Tile中的CTU也按照扫描顺序进行编码。需要注意的是:一个Tile包含的CTU个数与Slice中的CTU个数互不影响,在同一幅图像中,可以同时存在某些Slice中包含多个Tile和某些Tile中包含多个Slice的情况。
Slice与Tile划分的目的都是为了进行独立解码,但是二者的划分方式又有所不同。Tile形状基本上为矩形,Slice的形状则为条带状。Slice由一系列的SS组成,一个SS由一系列的CTU组成。Tile则直接由一系列的CTU组成。
Slice/SS和Tile之间也必须遵循一些基本原则,每个Slice/SS和Tile至少要满足以下两个条件之一:
(1)、一个Slice/SS中的所有CTU属于同一个Tile;
(2)、一个Tile中的所有CTU属于同一个Slice/SS。
### 4、编码树单元CTU
为了更灵活、更有效地表示视频内容,HEVC中还引入了编码树单元CTU(Coding Tree Unit),每个CTU包括一个亮度CTB(Coding Tree Block)和两个色度CTB。
如下图所示,一个SS在编码时,首先被分割为相同大小的CTU,每个CTU按照四叉树分割方式被划分为不同类型的编码单元CU(Coding Units)。

### 5、编码树单元CTU和编码树块CTB
在H.264中,视频编码是基于宏块实现的,对于4:2:0采样格式的视频,一个宏块包含一个16*16大小的亮度块和两个8*8大小的色度块。考虑到高清/超清视频的自身特性,HEVC标准中引入了树形编码单元CTU,其尺寸由编码器指定,且可大于宏块尺寸。同一处位置的一个亮度CTB和两个色度CTB,再加上相应的语法元素形成一个CTU。
对于一个L * L大小的亮度CTB,L的取值可以是8或16或32或64,也就是说,亮度CTB的大小可以为8 * 8或16 * 16或32 * 32或64 * 64,而色度CTB的大小可以为4 * 4或8 * 8或16 * 16或32 * 32。在高分辨率视频编码过程中,使用较大的CTB可以获得更好的压缩效果。
为了高效灵活地表示视频场景中的不同纹理细节、运动变化的视频内容或视频对象。HEVC为图像划分定义了一套全新的语法单元,包括编码单元CU(Coding Unit)、预测单元PU(Prediction Unit)和变换单元TU(Transform Unit)。其中CU是进行预测、变换量化和熵编码等处理的基本单元,PU是进行帧内/帧间预测编码的基本单元,TU是进行变换和量化的基本单元。这三个单元的分离,不仅使得变换、预测和编码的各个处理环节更加灵活,也使得各环节的划分更加符合视频图像的纹理特征,保证编码性能的最优化。
### 6、编码单元CU和编码块CB
在H.264中,编码块CB的大小是固定的,固定大小的CB并没有完全挖掘出图像的特点,尤其是大尺寸平缓区域的图像,用较大的块进行编码能够极大地提升编码效率。在HEVC中,一个CTB可以直接作为一个CB,亦可进一步以四叉树的形式划分为多个小的CB。所以,在HEVC中CB的大小是可变的,亮度CB最大为64 * 64,最小为8 * 8,大的CB可以使得平缓区域的编码效率大大提升,小的CB能很好地处理图像局部的细节,从而使得复杂图像的预测更加准确。
一个亮度CB和两个色度CB以及它们相应的语句元素共同组成一个编码单元CU。在HEVC中,一幅图像可以被划分为若干不重叠的CTU,在CTU内部采用基于四叉树的循环分层结构,同一层次的CU具有相同的划分深度。一个CTU可能只包含一个CU(没有划分),也可能被划分为多个CU,如下图所示是一个CTU划分为多个CU的示意图。

CU是否继续划分取决于分割标志Split Flag,这种灵活地单元表示方法相比于H.264中的宏块划分具有以下优点:
(1)、CU大小可以大于传统的宏块大小(16*16),对于平坦区域,较大的编码单元可以减少所用的比特数,提高了编码效率,尤其适用于高清/超高清视频。
(2)、通过合理地选择CTU的大小和最大层次深度,编码器的结构可以根据不同图片内容、图片大小以及应用需求获得较大程度的优化。
(3)、所有的单元类型都统称为CU,消除了宏块与亚宏块之分,并且编码单元的结构可以根据CTU大小、最大编码深度以及一系列划分标志Split Flag简单地表示出来。
### 7、预测单元PU和预测块PB
预测单元PU规定了编码单元的所有预测模式,一切与预测有关的信息都定义在预测单元部分,比如,帧内预测方向、帧间预测的分割方式、运动矢量预测,以及帧间预测参考图像索引号都属于预测单元的范畴。
一个2N*2N的编码单元所包含的预测单元划分模式如下图所示。

对于一个2N * 2N的CU模式,帧内预测单元PU的可选模式有两种:2N * 2N和N * N。对于帧间单元PU,可选择的模式有9种,包块4种对称模式、4种不对称模式和Skip模式。当需要编码的运动信息只有运动参数集索引(采用运动合并技术),编码残差信息不需要编码时,为2N * 2N的Skip模式。
### 8、变换单元TU和变换块TB
TU是独立完成变换和量化的基本单元,其尺寸也是灵活变化的。HEVC突破了原有的变换尺寸限制,可支持大小为4 * 4至32 * 32的编码变换,以TU为基本单元进行变换和量化,它的模式依赖于CU模式,在一个CU内,允许TU跨越多个PU,以四叉树形式递归划分,如下图所示。

对于一个2N*2N大小的CU,有一个标志位决定其是否划分为4个N*N的TU,是否可以进一步划分由SPS中的TU的最大划分深度决定。根据预测残差的局部变化特性,TU可以自适应地选择最优的模式,大块的TU模式能够将能量更好地集中,小块的TU模式能够保存更多的图像细节,这种灵活地分割结构,可以使变换后的残差能量得到充分压缩,以进一步提高编码增益。



以上就是编码结构中的分层处理架构,相对而言比较简单~~~但是非常重要!!!



HEVC算法和体系结构:编码框架
最后更新于:2022-04-01 16:05:29
# 编码框架
2013年4月13日HEVC/H.265被ITU-T正式接受为国际标准。类似以往的国际标准,HEVC仍旧采用“预测+变换”的混合编码框架,如下图所示,包括变换、量化、熵编码、帧内预测、帧间预测以及环路滤波等模块。在HEVC中,几乎每个模块都引入了新的编码技术。

本博文主要介绍HEVC编码框架,从整体结构出发介绍HEVC各个模块的大致功能以及相应的特色编码技术。
HEVC的编码框架主要包括变换、量化、熵编码、帧内预测、帧间预测以及环路滤波等模块。下面依次对各个模块做简单介绍。
### 1、帧内预测
帧内预测的主要功能是去除图像的空间相关性,通过编码后的重构信息块来预测当前像素块以去除空间冗余信息,提高图像的压缩效率。
在H.264/AVC中,基于4x4大小的编码块采用9种预测模式,而基于16x16大小的编码块采用4种预测模式。
在HEVC中,为了更准确地反映纹理特性,降低预测误差,提出了更为精确的帧内预测技术。对于亮度信号,HEVC提供了35种帧内预测模式,包括33种角度预测以及DC预测模式和Planar预测模式。增加的预测模式可以更好地匹配视频中复杂的纹理,得到更好的预测效果,更加有效地去除空间冗余。
### 2、帧间预测
帧间预测的主要功能是去除时间相关性,通过将已编码的图像作为当前帧的参考图像,来获取各个块的运动信息,从而去除时间冗余,提高压缩效率。
为了提升帧间预测性能,HEVC引入了一些新的技术,包括运动信息融合技术(Merge)、先进的运动矢量预测技术(Advanced Motion Vector Predictor,AMVP)和基于Merge的Skip模式。
运动信息融合技术(Merge):利用空域相关性和时域相关性来减少相邻块之间的运动参数冗余,具体来说就是取其相邻PU的运动参数作为当前PU的运动参数。
先进的运动矢量预测技术(Advanced Motion Vector Predictor,AMVP):AMVP技术的作用与Merge技术类似,也是利用空域相关性和时域相关性来减少运动参数的冗余。AMVP技术得到的运动矢量一方面为运动估计提供搜索起点,另一方面作为预测运动矢量使用。
基于Merge的Skip模式:后续重点介绍。。。
在HEVC中,帧间预测可以采用单向和双向的参考图像来进行预测,包括类似H.264/AVC中的分层B帧的预测结构。
### 3、变换量化
通过对残差数据进行变换量化以去除频域相关性,对数据进行有损压缩。变换编码将图像从时域信号变换至频域,将能量集中至低频区域。量化模块可以减小图像编码的动态范围。
RQT(Residual Quad-tree Transform)技术是一种基于四叉树结构的自适应变换技术,它为最优TU模式选择提供了很高的灵活性。大块的TU模式能够将能量更好地集中,小块的TU模式能够保存更多的图像细节。根据当前CU内残差特性,自适应选择变换块大小,可以在能量集中和细节保留两者做最优的折中,与传统的固定块大小的变换相比,RQT对编码效率贡献更大。
变换编码和量化模块从原理上属于两个相互独立的过程,但是在HEVC中,两个过程相互结合,减少了计算的复杂度。
### 4、环路滤波
在HEVC中,环路滤波模块主要包括去块滤波器(DBF)和样点自适应补偿滤波(SAO)。DBF的主要作用是去方块效应,而SAO的主要作用是去除振铃效应。这部分的具体分析在[《HEVC算法和体系结构:环路滤波技术》](http://blog.csdn.net/frd2009041510/article/details/49736199)中已有详细介绍。
### 5、熵编码
熵编码模块将编码控制数据、量化变换系数、帧内预测数据、运动数据、滤波器控制数据编码为二进制进行存储和传输。熵编码模块的输出数据即是原始视频压缩后的码流。
在HEVC中,采用了基于上下文的自适应二进制算术编码(CABAC)进行熵编码,引入了并行处理架构,在速度、压缩率和内存占用等方面均得到了大幅度改善。
接下来介绍HEVC的两个容易被忽略的新技术:ACS和IBDI。
### 6、ACS技术
ACS(Adaptive Coefficient Scanning)包括三类:对角扫描、水平扫描和垂直扫描。ACS技术是基于4x4块单元进行的,将一个TU划分为多个4x4块单元,每个4x4块单元内部以及各个4x4块单元之间都按照相同的扫描顺序进行扫描。
对于帧内预测区域的4x4和8x8尺寸的TU,根据所采用的帧内预测方向来选择扫描方法:当预测方向接近水平方向时采用垂直扫描;当预测方向接近于垂直方向时就选用水平扫描,对于其他预测方向使用对角扫描。
对于帧间预测区域,无论TU尺寸多大都采用对角扫描方式。
### 7、IBDI技术
IBDI(Internal Bit Depth Increase)技术是指在编码器的输入端将未压缩图像像素深度由P比特增加到Q比特(Q>P),在解码器的输出端又将解压缩图像像素深度从Q比特恢复至P比特。
IBDI技术提高了编码器的编码精度,降低了帧内/帧间预测误差。但由于要建立参考队列,像素深度为Q比特的重构图像须占用较大的内存空间。此外,在进行帧间运动估计和补偿时,需要较多的内存访问带宽,这样会给内存受限的系统带来不便,解决的方法是引入参考帧压缩算法,来减小重构图像的数据量。
HEVC算法和体系结构:环路滤波技术
最后更新于:2022-04-01 16:05:27
**环路滤波(In-Loop Filtering)技术**
类似于以往的视频编码标准,HEVC仍采用基于块的混合编码框架,一些失真效应仍然存在,如方块效应、振铃效应、颜色偏差以及图像模糊等等。为了解决这些问题,HEVC中采用了环路滤波技术,它其实是一种用于解码端的后处理滤波技术,主要包括去块滤波(Deblocking Filter,DBF)和样点自适应补偿(Sample Adaptive Offset,SAO)。其中,DBF的作用与H.264类似,主要是去除块效应,但是相比于H.264,其决策与滤波过程大大地被简化了,而SAO是HEVC中的新技术。
此处有一点需要注意的是,帧内预测采用的是解码宏块像素作为下个帧内预测的参考,而帧间预测则是采用经环路滤波后的解码宏块像素作为运动预测参考图像。这一点可以由环路滤波这个模块所处在编码框架的位置加以验证(如下图红色圈圈内)。当然这样做(经过环路滤波的重构像素才能作为后续编码像素的参考使用)是有原因的,即环路滤波处理后的重建像素更有利于参考,进一步减小后续编码像素的预测残差,有效地提高了视频的主客观质量。

下面对环路滤波中的去块滤波技术和样点自适应补偿技术做重点解析。
**一、去块滤波技术**
去块滤波(Deblocking Filter,DBF)用于降低方块效应(所谓方块效应就是图像中编码块边界的不连续性),造成方块效应的主要原因有三个:
①、各个块的变换、量化编码过程相互独立(相当于对各个块使用了不同参数的滤波器分别滤波,因此各块引入的量化误差大小及其分布特性相互独立,导致相邻块边界的不连续);
②、运动补偿预测过程中,相邻块的预测值可能来自于不同图像的不同位置,导致预测残差信号在块边界产生数值的不连续;
③、时域预测技术使得参考图像中存在的边界不连续可能会传递到后续编码图像。
正是由于块效应的产生原因才使得DBF只应用于块边界上的样本,即被用于所有与PU或TU边界相邻的样本,该选项可以在编码器中进行设置(设置的位置在编码结构配置文件中,如encoder_lowdelay_P_main.cfg文件的“Deblock Filter”部分,如下所示),需要注意的是,需要同时考虑PU和TU的边界,因为在某些帧间预测CB中,PU边界不一定总能和TU边界对齐。
~~~
#=========== Deblock Filter ============
DeblockingFilterControlPresent: 0 # Dbl control params present (0=not present, 1=present)
LoopFilterOffsetInPPS : 0 # Dbl params: 0=varying params in SliceHeader, param = base_param + GOP_offset_param; 1=constant params in PPS, param = base_param)
LoopFilterDisable : 0 # Disable deblocking filter (0=Filter, 1=No Filter)
LoopFilterBetaOffset_div2 : 0 # base_param: -6 ~ 6
LoopFilterTcOffset_div2 : 0 # base_param: -6 ~ 6
DeblockingFilterMetric : 0 # blockiness metric (automatically configures deblocking parameters in bitstream)
~~~
有没有使能DBF,得到的效果图如下图所示(此处需要插一句话,经本人在HM平台上测试,发现DBF的效果并不是很明显,貌似几乎没什么改变,这一点的具体原因是去块滤波器的强度受限于很多因素,并不是每次试验都能成功得到与理论结论完全契合的结果)。

在H.264中,DBF应用于4x4大小块,而在HEVC中,无论亮度还是色度样本均只应用于8x8大小块。这一限定可以在不影响视觉质量的情况下,降低计算复杂度,同时通过防止相邻滤波操作之间的交互,便于并行处理的实现。
在HEVC中,DBF的处理顺序是:首先对整个图像的垂直边缘进行水平滤波,然后对水平边缘进行垂直滤波。该顺序使得多次水平滤波或者垂直滤波过程可以通过并行处理实现,或者仍可以以逐CTB的方式执行,这时会引入很小的处理延迟。
总结一句,对块边界进行平滑滤波可以有效地降低、去除方块效应。
**二、样点自适应补偿技术**
SAO是HEVC中的新技术,所以是我们重点学习的对象。
样点自适应补偿(Sample Adaptive Offset,SAO)用于改善振铃效应,SAO被自适应地用于所有满足特定条件的样本上。
造成振铃效应的原因是:高频信息的丢失(HEVC仍采用基于块的DCT变换,并在频域对变换系数进行量化,对于图像里的强边缘,由于高频交流系数的量化失真,解码后会在边缘周围产生波纹现象,即吉布斯现象,如下图所示,这种失真就是振铃效应,振铃效应会严重影响视频的主客观质量)。

正是由于高频信息的丢失才导致的振铃效应,因此要抑制振铃效应,就必须减小高频分量的失真,而直接精细量化高频分量势必导致压缩效率的降低。
SAO的解决方法如下(基本原理):从像素域入手降低振铃效应,对重构曲线中出现的波峰像素添加负值进行补偿,波谷添加正值进行补偿,由于在解码端只能得到重构图像信息,因此可以根据重构图像的特征点,通过将其划分类别,然后在像素域进行补偿处理。
在HEVC中,SAO以CTB为基本单位,通过选择一个合适的分类器将重建像素划分类别,然后对不同类别像素使用不同的补偿值,可以有效提高视频的主客观质量。它包括两大类补偿形式,分别是边界补偿(Edge Offset,EO)和边带补偿(Bang Offset,BO),此外还引入了参数融合技术。
(1)、边界补偿(Edge Offset,EO)
通过比较当前像素值与相邻像素值的大小,对当前像素进行分类,然后对同类像素补偿相同数值。为了均衡复杂度与编码效率,边界补偿选用了一维三像素分类模式,根据选取像素位置的差异,分为4种模式,即水平方向(EO_0)、垂直方向(EO_1)、135度方向(EO_2)和45度方向(EO_3)。在任意一种模式下,EO根据一个规则将所有的像素分成5类,然后对种类1至种类4进行补偿,即增加或减少一定数值(补偿值),而对于种类0的像素不进行补偿。并且还要遵循一个原则:不同种类的像素值可以采用不同的补偿值,但同一种类的像素必须采用相同的补偿。
对于边界补偿来讲,只需要传递补偿值的绝对值即可,解码器会根据像素补偿种类即可判断它的符号(原因是实验结果表明超过90%的补偿值,其符号与种类相匹配,因此按照不同种类对补偿值的符号进行了限制)。
(2)、边带补偿(Bang Offset,BO)
BO根据像素强度进行归类,它将像素范围等分成32条边带。然后每个条带根据自身像素特点进行补偿,且同一个边带使用相同的补偿值。HEVC中规定了一个CTB只能选择4条连续的边带,并只对属于这4个边带的像素进行补偿,这样边带补偿值数量与边界补偿值数量进行了统一,可以减少对线性存储器的要求,最终选择哪4条边带可以通过率失真优化方法来确定,然后将最小边带号以及4个补偿值传至解码端即可。
(3)、SAO参数融合
参数融合(Merge)是指对一个CTB块,其SAO参数直接使用相邻块的SAO参数,这时只需要标识采用了哪个相邻的SAO参数即可。
(4)、SAO在HM中的实现过程
SAO过程的重点是利用拉格朗日优化选择最优的SAO参数,为了降低计算复杂度,该过程采用了快速模式判别方法。一个CTU的SAO过程如下图所示:

SAO技术对应于HM中的代码如下:
**TComSampleAdaptiveOffset.cpp**
~~~
/* The copyright in this software is being made available under the BSD
* License, included below. This software may be subject to other third party
* and contributor rights, including patent rights, and no such rights are
* granted under this license.
*
* Copyright (c) 2010-2014, ITU/ISO/IEC
* All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
*
* * Redistributions of source code must retain the above copyright notice,
* this list of conditions and the following disclaimer.
* * Redistributions in binary form must reproduce the above copyright notice,
* this list of conditions and the following disclaimer in the documentation
* and/or other materials provided with the distribution.
* * Neither the name of the ITU/ISO/IEC nor the names of its contributors may
* be used to endorse or promote products derived from this software without
* specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
* AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
* ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS
* BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
* CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
* SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
* INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
* CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
* ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF
* THE POSSIBILITY OF SUCH DAMAGE.
*/
/**\file TComSampleAdaptiveOffset.cpp
\brief sample adaptive offset class
*/
#include "TComSampleAdaptiveOffset.h"
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
#include <math.h>
//! \ingroup TLibCommon
//! \{
UInt g_saoMaxOffsetQVal[NUM_SAO_COMPONENTS];
SAOOffset::SAOOffset()
{
reset();
}
SAOOffset::~SAOOffset()
{
}
Void SAOOffset::reset()
{
modeIdc = SAO_MODE_OFF;
typeIdc = -1;
typeAuxInfo = -1;
::memset(offset, 0, sizeof(Int)* MAX_NUM_SAO_CLASSES);
}
const SAOOffset& SAOOffset::operator= (const SAOOffset& src)
{
modeIdc = src.modeIdc;
typeIdc = src.typeIdc;
typeAuxInfo = src.typeAuxInfo;
::memcpy(offset, src.offset, sizeof(Int)* MAX_NUM_SAO_CLASSES);
return *this;
}
SAOBlkParam::SAOBlkParam()
{
reset();
}
SAOBlkParam::~SAOBlkParam()
{
}
Void SAOBlkParam::reset()
{
for(Int compIdx=0; compIdx< 3; compIdx++)
{
offsetParam[compIdx].reset();
}
}
const SAOBlkParam& SAOBlkParam::operator= (const SAOBlkParam& src)
{
for(Int compIdx=0; compIdx< 3; compIdx++)
{
offsetParam[compIdx] = src.offsetParam[compIdx];
}
return *this;
}
TComSampleAdaptiveOffset::TComSampleAdaptiveOffset()
{
m_tempPicYuv = NULL;
for(Int compIdx=0; compIdx < NUM_SAO_COMPONENTS; compIdx++)
{
m_offsetClipTable[compIdx] = NULL;
}
#if !SAO_SGN_FUNC
m_signTable = NULL;
#endif
m_lineBufWidth = 0;
m_signLineBuf1 = NULL;
m_signLineBuf2 = NULL;
}
TComSampleAdaptiveOffset::~TComSampleAdaptiveOffset()
{
destroy();
if (m_signLineBuf1) delete[] m_signLineBuf1; m_signLineBuf1 = NULL;
if (m_signLineBuf2) delete[] m_signLineBuf2; m_signLineBuf2 = NULL;
}
Void TComSampleAdaptiveOffset::create( Int picWidth, Int picHeight, UInt maxCUWidth, UInt maxCUHeight, UInt maxCUDepth )
{
destroy();
m_picWidth = picWidth;
m_picHeight= picHeight;
m_maxCUWidth= maxCUWidth;
m_maxCUHeight= maxCUHeight;
m_numCTUInWidth = (m_picWidth/m_maxCUWidth) + ((m_picWidth % m_maxCUWidth)?1:0);
m_numCTUInHeight= (m_picHeight/m_maxCUHeight) + ((m_picHeight % m_maxCUHeight)?1:0);
m_numCTUsPic = m_numCTUInHeight*m_numCTUInWidth;
//temporary picture buffer
if ( !m_tempPicYuv )
{
m_tempPicYuv = new TComPicYuv;
m_tempPicYuv->create( m_picWidth, m_picHeight, m_maxCUWidth, m_maxCUHeight, maxCUDepth );
}
//bit-depth related
for(Int compIdx =0; compIdx < NUM_SAO_COMPONENTS; compIdx++)
{
Int bitDepthSample = (compIdx == SAO_Y)?g_bitDepthY:g_bitDepthC;
m_offsetStepLog2 [compIdx] = max(bitDepthSample - MAX_SAO_TRUNCATED_BITDEPTH, 0);
g_saoMaxOffsetQVal[compIdx] = (1<<(min(bitDepthSample,MAX_SAO_TRUNCATED_BITDEPTH)-5))-1; //Table 9-32, inclusive
}
#if !SAO_SGN_FUNC
//look-up table for clipping
Int overallMaxSampleValue=0;
#endif
for(Int compIdx =0; compIdx < NUM_SAO_COMPONENTS; compIdx++)
{
Int bitDepthSample = (compIdx == SAO_Y)?g_bitDepthY:g_bitDepthC; //exclusive
Int maxSampleValue = (1<< bitDepthSample); //exclusive
Int maxOffsetValue = (g_saoMaxOffsetQVal[compIdx] << m_offsetStepLog2[compIdx]);
#if !SAO_SGN_FUNC
if (maxSampleValue>overallMaxSampleValue) overallMaxSampleValue=maxSampleValue;
#endif
m_offsetClipTable[compIdx] = new Int[(maxSampleValue + maxOffsetValue -1)+ (maxOffsetValue)+1 ]; //positive & negative range plus 0
m_offsetClip[compIdx] = &(m_offsetClipTable[compIdx][maxOffsetValue]);
//assign clipped values
Int* offsetClipPtr = m_offsetClip[compIdx];
for(Int k=0; k< maxSampleValue; k++)
{
*(offsetClipPtr + k) = k;
}
for(Int k=0; k< maxOffsetValue; k++ )
{
*(offsetClipPtr + maxSampleValue+ k) = maxSampleValue-1;
*(offsetClipPtr -k -1 ) = 0;
}
}
#if !SAO_SGN_FUNC
m_signTable = new Short[ 2*(overallMaxSampleValue-1) + 1 ];
m_sign = &(m_signTable[overallMaxSampleValue-1]);
m_sign[0] = 0;
for(Int k=1; k< overallMaxSampleValue; k++)
{
m_sign[k] = 1;
m_sign[-k]= -1;
}
#endif
}
Void TComSampleAdaptiveOffset::destroy()
{
if ( m_tempPicYuv )
{
m_tempPicYuv->destroy();
delete m_tempPicYuv;
m_tempPicYuv = NULL;
}
for(Int compIdx=0; compIdx < NUM_SAO_COMPONENTS; compIdx++)
{
if(m_offsetClipTable[compIdx])
{
delete[] m_offsetClipTable[compIdx]; m_offsetClipTable[compIdx] = NULL;
}
}
#if !SAO_SGN_FUNC
if( m_signTable )
{
delete[] m_signTable; m_signTable = NULL;
}
#endif
}
Void TComSampleAdaptiveOffset::invertQuantOffsets(Int compIdx, Int typeIdc, Int typeAuxInfo, Int* dstOffsets, Int* srcOffsets)
{
Int codedOffset[MAX_NUM_SAO_CLASSES];
::memcpy(codedOffset, srcOffsets, sizeof(Int)*MAX_NUM_SAO_CLASSES);
::memset(dstOffsets, 0, sizeof(Int)*MAX_NUM_SAO_CLASSES);
if(typeIdc == SAO_TYPE_START_BO)
{
for(Int i=0; i< 4; i++)
{
dstOffsets[(typeAuxInfo+ i)%NUM_SAO_BO_CLASSES] = codedOffset[(typeAuxInfo+ i)%NUM_SAO_BO_CLASSES]*(1<<m_offsetStepLog2[compIdx]);
}
}
else //EO
{
for(Int i=0; i< NUM_SAO_EO_CLASSES; i++)
{
dstOffsets[i] = codedOffset[i] *(1<<m_offsetStepLog2[compIdx]);
}
assert(dstOffsets[SAO_CLASS_EO_PLAIN] == 0); //keep EO plain offset as zero
}
}
Int TComSampleAdaptiveOffset::getMergeList(TComPic* pic, Int ctu, SAOBlkParam* blkParams, std::vector<SAOBlkParam*>& mergeList)
{
Int ctuX = ctu % m_numCTUInWidth;
Int ctuY = ctu / m_numCTUInWidth;
Int mergedCTUPos;
Int numValidMergeCandidates = 0;
for(Int mergeType=0; mergeType< NUM_SAO_MERGE_TYPES; mergeType++)
{
SAOBlkParam* mergeCandidate = NULL;
switch(mergeType)
{
case SAO_MERGE_ABOVE:
{
if(ctuY > 0)
{
mergedCTUPos = ctu- m_numCTUInWidth;
if( pic->getSAOMergeAvailability(ctu, mergedCTUPos) )
{
mergeCandidate = &(blkParams[mergedCTUPos]);
}
}
}
break;
case SAO_MERGE_LEFT:
{
if(ctuX > 0)
{
mergedCTUPos = ctu- 1;
if( pic->getSAOMergeAvailability(ctu, mergedCTUPos) )
{
mergeCandidate = &(blkParams[mergedCTUPos]);
}
}
}
break;
default:
{
printf("not a supported merge type");
assert(0);
exit(-1);
}
}
mergeList.push_back(mergeCandidate);
if (mergeCandidate != NULL)
{
numValidMergeCandidates++;
}
}
return numValidMergeCandidates;
}
Void TComSampleAdaptiveOffset::reconstructBlkSAOParam(SAOBlkParam& recParam, std::vector<SAOBlkParam*>& mergeList)
{
for(Int compIdx=0; compIdx< NUM_SAO_COMPONENTS; compIdx++)
{
SAOOffset& offsetParam = recParam[compIdx];
if(offsetParam.modeIdc == SAO_MODE_OFF)
{
continue;
}
switch(offsetParam.modeIdc)
{
case SAO_MODE_NEW:
{
invertQuantOffsets(compIdx, offsetParam.typeIdc, offsetParam.typeAuxInfo, offsetParam.offset, offsetParam.offset);
}
break;
case SAO_MODE_MERGE:
{
SAOBlkParam* mergeTarget = mergeList[offsetParam.typeIdc];
assert(mergeTarget != NULL);
offsetParam = (*mergeTarget)[compIdx];
}
break;
default:
{
printf("Not a supported mode");
assert(0);
exit(-1);
}
}
}
}
Void TComSampleAdaptiveOffset::reconstructBlkSAOParams(TComPic* pic, SAOBlkParam* saoBlkParams)
{
m_picSAOEnabled[SAO_Y] = m_picSAOEnabled[SAO_Cb] = m_picSAOEnabled[SAO_Cr] = false;
for(Int ctu=0; ctu< m_numCTUsPic; ctu++)
{
std::vector<SAOBlkParam*> mergeList;
getMergeList(pic, ctu, saoBlkParams, mergeList);
reconstructBlkSAOParam(saoBlkParams[ctu], mergeList);
for(Int compIdx=0; compIdx< NUM_SAO_COMPONENTS; compIdx++)
{
if(saoBlkParams[ctu][compIdx].modeIdc != SAO_MODE_OFF)
{
m_picSAOEnabled[compIdx] = true;
}
}
}
}
Void TComSampleAdaptiveOffset::offsetBlock(Int compIdx, Int typeIdx, Int* offset
, Pel* srcBlk, Pel* resBlk, Int srcStride, Int resStride, Int width, Int height
, Bool isLeftAvail, Bool isRightAvail, Bool isAboveAvail, Bool isBelowAvail, Bool isAboveLeftAvail, Bool isAboveRightAvail, Bool isBelowLeftAvail, Bool isBelowRightAvail)
{
if(m_lineBufWidth != m_maxCUWidth)
{
m_lineBufWidth = m_maxCUWidth;
if (m_signLineBuf1) delete[] m_signLineBuf1; m_signLineBuf1 = NULL;
m_signLineBuf1 = new Char[m_lineBufWidth+1];
if (m_signLineBuf2) delete[] m_signLineBuf2; m_signLineBuf2 = NULL;
m_signLineBuf2 = new Char[m_lineBufWidth+1];
}
Int* offsetClip = m_offsetClip[compIdx];
Int x,y, startX, startY, endX, endY, edgeType;
Int firstLineStartX, firstLineEndX, lastLineStartX, lastLineEndX;
Char signLeft, signRight, signDown;
Pel* srcLine = srcBlk;
Pel* resLine = resBlk;
switch(typeIdx)
{
case SAO_TYPE_EO_0:
{
offset += 2;
startX = isLeftAvail ? 0 : 1;
endX = isRightAvail ? width : (width -1);
for (y=0; y< height; y++)
{
#if SAO_SGN_FUNC
signLeft = (Char)sgn(srcLine[startX] - srcLine[startX-1]);
#else
signLeft = (Char)m_sign[srcLine[startX] - srcLine[startX-1]];
#endif
for (x=startX; x< endX; x++)
{
#if SAO_SGN_FUNC
signRight = (Char)sgn(srcLine[x] - srcLine[x+1]);
#else
signRight = (Char)m_sign[srcLine[x] - srcLine[x+1]];
#endif
edgeType = signRight + signLeft;
signLeft = -signRight;
resLine[x] = offsetClip[srcLine[x] + offset[edgeType]];
}
srcLine += srcStride;
resLine += resStride;
}
}
break;
case SAO_TYPE_EO_90:
{
offset += 2;
Char *signUpLine = m_signLineBuf1;
startY = isAboveAvail ? 0 : 1;
endY = isBelowAvail ? height : height-1;
if (!isAboveAvail)
{
srcLine += srcStride;
resLine += resStride;
}
Pel* srcLineAbove= srcLine- srcStride;
for (x=0; x< width; x++)
{
#if SAO_SGN_FUNC
signUpLine[x] = (Char)sgn(srcLine[x] - srcLineAbove[x]);
#else
signUpLine[x] = (Char)m_sign[srcLine[x] - srcLineAbove[x]];
#endif
}
Pel* srcLineBelow;
for (y=startY; y<endY; y++)
{
srcLineBelow= srcLine+ srcStride;
for (x=0; x< width; x++)
{
#if SAO_SGN_FUNC
signDown = (Char)sgn(srcLine[x] - srcLineBelow[x]);
#else
signDown = (Char)m_sign[srcLine[x] - srcLineBelow[x]];
#endif
edgeType = signDown + signUpLine[x];
signUpLine[x]= -signDown;
resLine[x] = offsetClip[srcLine[x] + offset[edgeType]];
}
srcLine += srcStride;
resLine += resStride;
}
}
break;
case SAO_TYPE_EO_135:
{
offset += 2;
Char *signUpLine, *signDownLine, *signTmpLine;
signUpLine = m_signLineBuf1;
signDownLine= m_signLineBuf2;
startX = isLeftAvail ? 0 : 1 ;
endX = isRightAvail ? width : (width-1);
//prepare 2nd line's upper sign
Pel* srcLineBelow= srcLine+ srcStride;
for (x=startX; x< endX+1; x++)
{
#if SAO_SGN_FUNC
signUpLine[x] = (Char)sgn(srcLineBelow[x] - srcLine[x- 1]);
#else
signUpLine[x] = (Char)m_sign[srcLineBelow[x] - srcLine[x- 1]];
#endif
}
//1st line
Pel* srcLineAbove= srcLine- srcStride;
firstLineStartX = isAboveLeftAvail ? 0 : 1;
firstLineEndX = isAboveAvail? endX: 1;
for(x= firstLineStartX; x< firstLineEndX; x++)
{
#if SAO_SGN_FUNC
edgeType = sgn(srcLine[x] - srcLineAbove[x- 1]) - signUpLine[x+1];
#else
edgeType = m_sign[srcLine[x] - srcLineAbove[x- 1]] - signUpLine[x+1];
#endif
resLine[x] = offsetClip[srcLine[x] + offset[edgeType]];
}
srcLine += srcStride;
resLine += resStride;
//middle lines
for (y= 1; y< height-1; y++)
{
srcLineBelow= srcLine+ srcStride;
for (x=startX; x<endX; x++)
{
#if SAO_SGN_FUNC
signDown = (Char)sgn(srcLine[x] - srcLineBelow[x+ 1]);
#else
signDown = (Char)m_sign[srcLine[x] - srcLineBelow[x+ 1]] ;
#endif
edgeType = signDown + signUpLine[x];
resLine[x] = offsetClip[srcLine[x] + offset[edgeType]];
signDownLine[x+1] = -signDown;
}
#if SAO_SGN_FUNC
signDownLine[startX] = (Char)sgn(srcLineBelow[startX] - srcLine[startX-1]);
#else
signDownLine[startX] = (Char)m_sign[srcLineBelow[startX] - srcLine[startX-1]];
#endif
signTmpLine = signUpLine;
signUpLine = signDownLine;
signDownLine = signTmpLine;
srcLine += srcStride;
resLine += resStride;
}
//last line
srcLineBelow= srcLine+ srcStride;
lastLineStartX = isBelowAvail ? startX : (width -1);
lastLineEndX = isBelowRightAvail ? width : (width -1);
for(x= lastLineStartX; x< lastLineEndX; x++)
{
#if SAO_SGN_FUNC
edgeType = sgn(srcLine[x] - srcLineBelow[x+ 1]) + signUpLine[x];
#else
edgeType = m_sign[srcLine[x] - srcLineBelow[x+ 1]] + signUpLine[x];
#endif
resLine[x] = offsetClip[srcLine[x] + offset[edgeType]];
}
}
break;
case SAO_TYPE_EO_45:
{
offset += 2;
Char *signUpLine = m_signLineBuf1+1;
startX = isLeftAvail ? 0 : 1;
endX = isRightAvail ? width : (width -1);
//prepare 2nd line upper sign
Pel* srcLineBelow= srcLine+ srcStride;
for (x=startX-1; x< endX; x++)
{
#if SAO_SGN_FUNC
signUpLine[x] = (Char)sgn(srcLineBelow[x] - srcLine[x+1]);
#else
signUpLine[x] = (Char)m_sign[srcLineBelow[x] - srcLine[x+1]];
#endif
}
//first line
Pel* srcLineAbove= srcLine- srcStride;
firstLineStartX = isAboveAvail ? startX : (width -1 );
firstLineEndX = isAboveRightAvail ? width : (width-1);
for(x= firstLineStartX; x< firstLineEndX; x++)
{
#if SAO_SGN_FUNC
edgeType = sgn(srcLine[x] - srcLineAbove[x+1]) -signUpLine[x-1];
#else
edgeType = m_sign[srcLine[x] - srcLineAbove[x+1]] -signUpLine[x-1];
#endif
resLine[x] = offsetClip[srcLine[x] + offset[edgeType]];
}
srcLine += srcStride;
resLine += resStride;
//middle lines
for (y= 1; y< height-1; y++)
{
srcLineBelow= srcLine+ srcStride;
for(x= startX; x< endX; x++)
{
#if SAO_SGN_FUNC
signDown = (Char)sgn(srcLine[x] - srcLineBelow[x-1]);
#else
signDown = (Char)m_sign[srcLine[x] - srcLineBelow[x-1]] ;
#endif
edgeType = signDown + signUpLine[x];
resLine[x] = offsetClip[srcLine[x] + offset[edgeType]];
signUpLine[x-1] = -signDown;
}
#if SAO_SGN_FUNC
signUpLine[endX-1] = (Char)sgn(srcLineBelow[endX-1] - srcLine[endX]);
#else
signUpLine[endX-1] = (Char)m_sign[srcLineBelow[endX-1] - srcLine[endX]];
#endif
srcLine += srcStride;
resLine += resStride;
}
//last line
srcLineBelow= srcLine+ srcStride;
lastLineStartX = isBelowLeftAvail ? 0 : 1;
lastLineEndX = isBelowAvail ? endX : 1;
for(x= lastLineStartX; x< lastLineEndX; x++)
{
#if SAO_SGN_FUNC
edgeType = sgn(srcLine[x] - srcLineBelow[x-1]) + signUpLine[x];
#else
edgeType = m_sign[srcLine[x] - srcLineBelow[x-1]] + signUpLine[x];
#endif
resLine[x] = offsetClip[srcLine[x] + offset[edgeType]];
}
}
break;
case SAO_TYPE_BO:
{
Int shiftBits = ((compIdx == SAO_Y)?g_bitDepthY:g_bitDepthC)- NUM_SAO_BO_CLASSES_LOG2;
for (y=0; y< height; y++)
{
for (x=0; x< width; x++)
{
resLine[x] = offsetClip[ srcLine[x] + offset[srcLine[x] >> shiftBits] ];
}
srcLine += srcStride;
resLine += resStride;
}
}
break;
default:
{
printf("Not a supported SAO types\n");
assert(0);
exit(-1);
}
}
}
Void TComSampleAdaptiveOffset::offsetCTU(Int ctu, TComPicYuv* srcYuv, TComPicYuv* resYuv, SAOBlkParam& saoblkParam, TComPic* pPic)
{
Bool isLeftAvail,isRightAvail,isAboveAvail,isBelowAvail,isAboveLeftAvail,isAboveRightAvail,isBelowLeftAvail,isBelowRightAvail;
if(
(saoblkParam[SAO_Y ].modeIdc == SAO_MODE_OFF) &&
(saoblkParam[SAO_Cb].modeIdc == SAO_MODE_OFF) &&
(saoblkParam[SAO_Cr].modeIdc == SAO_MODE_OFF)
)
{
return;
}
//block boundary availability
pPic->getPicSym()->deriveLoopFilterBoundaryAvailibility(ctu, isLeftAvail,isRightAvail,isAboveAvail,isBelowAvail,isAboveLeftAvail,isAboveRightAvail,isBelowLeftAvail,isBelowRightAvail);
Int yPos = (ctu / m_numCTUInWidth)*m_maxCUHeight;
Int xPos = (ctu % m_numCTUInWidth)*m_maxCUWidth;
Int height = (yPos + m_maxCUHeight > m_picHeight)?(m_picHeight- yPos):m_maxCUHeight;
Int width = (xPos + m_maxCUWidth > m_picWidth )?(m_picWidth - xPos):m_maxCUWidth;
for(Int compIdx= 0; compIdx < NUM_SAO_COMPONENTS; compIdx++)
{
SAOOffset& ctbOffset = saoblkParam[compIdx];
if(ctbOffset.modeIdc != SAO_MODE_OFF)
{
Bool isLuma = (compIdx == SAO_Y);
Int formatShift= isLuma?0:1;
Int blkWidth = (width >> formatShift);
Int blkHeight = (height >> formatShift);
Int blkYPos = (yPos >> formatShift);
Int blkXPos = (xPos >> formatShift);
Int srcStride = isLuma?srcYuv->getStride():srcYuv->getCStride();
Pel* srcBlk = getPicBuf(srcYuv, compIdx)+ (yPos >> formatShift)*srcStride+ (xPos >> formatShift);
Int resStride = isLuma?resYuv->getStride():resYuv->getCStride();
Pel* resBlk = getPicBuf(resYuv, compIdx)+ blkYPos*resStride+ blkXPos;
offsetBlock( compIdx, ctbOffset.typeIdc, ctbOffset.offset
, srcBlk, resBlk, srcStride, resStride, blkWidth, blkHeight
, isLeftAvail, isRightAvail
, isAboveAvail, isBelowAvail
, isAboveLeftAvail, isAboveRightAvail
, isBelowLeftAvail, isBelowRightAvail
);
}
} //compIdx
}
Void TComSampleAdaptiveOffset::SAOProcess(TComPic* pDecPic)
{
if(!m_picSAOEnabled[SAO_Y] && !m_picSAOEnabled[SAO_Cb] && !m_picSAOEnabled[SAO_Cr])
{
return;
}
TComPicYuv* resYuv = pDecPic->getPicYuvRec();
TComPicYuv* srcYuv = m_tempPicYuv;
resYuv->copyToPic(srcYuv);
for(Int ctu= 0; ctu < m_numCTUsPic; ctu++)
{
offsetCTU(ctu, srcYuv, resYuv, (pDecPic->getPicSym()->getSAOBlkParam())[ctu], pDecPic);
} //ctu
}
Pel* TComSampleAdaptiveOffset::getPicBuf(TComPicYuv* pPicYuv, Int compIdx)
{
Pel* pBuf = NULL;
switch(compIdx)
{
case SAO_Y:
{
pBuf = pPicYuv->getLumaAddr();
}
break;
case SAO_Cb:
{
pBuf = pPicYuv->getCbAddr();
}
break;
case SAO_Cr:
{
pBuf = pPicYuv->getCrAddr();
}
break;
default:
{
printf("Not a legal component ID for SAO\n");
assert(0);
exit(-1);
}
}
return pBuf;
}
/**PCM LF disable process.
* \param pcPic picture (TComPic) pointer
* \returns Void
*
* \note Replace filtered sample values of PCM mode blocks with the transmitted and reconstructed ones.
*/
Void TComSampleAdaptiveOffset::PCMLFDisableProcess (TComPic* pcPic)
{
xPCMRestoration(pcPic);
}
/**Picture-level PCM restoration.
* \param pcPic picture (TComPic) pointer
* \returns Void
*/
Void TComSampleAdaptiveOffset::xPCMRestoration(TComPic* pcPic)
{
Bool bPCMFilter = (pcPic->getSlice(0)->getSPS()->getUsePCM() && pcPic->getSlice(0)->getSPS()->getPCMFilterDisableFlag())? true : false;
if(bPCMFilter || pcPic->getSlice(0)->getPPS()->getTransquantBypassEnableFlag())
{
for( UInt uiCUAddr = 0; uiCUAddr < pcPic->getNumCUsInFrame() ; uiCUAddr++ )
{
TComDataCU* pcCU = pcPic->getCU(uiCUAddr);
xPCMCURestoration(pcCU, 0, 0);
}
}
}
/**PCM CU restoration.
* \param pcCU pointer to current CU
* \param uiAbsPartIdx part index
* \param uiDepth CU depth
* \returns Void
*/
Void TComSampleAdaptiveOffset::xPCMCURestoration ( TComDataCU* pcCU, UInt uiAbsZorderIdx, UInt uiDepth )
{
TComPic* pcPic = pcCU->getPic();
UInt uiCurNumParts = pcPic->getNumPartInCU() >> (uiDepth<<1);
UInt uiQNumParts = uiCurNumParts>>2;
// go to sub-CU
if( pcCU->getDepth(uiAbsZorderIdx) > uiDepth )
{
for ( UInt uiPartIdx = 0; uiPartIdx < 4; uiPartIdx++, uiAbsZorderIdx+=uiQNumParts )
{
UInt uiLPelX = pcCU->getCUPelX() + g_auiRasterToPelX[ g_auiZscanToRaster[uiAbsZorderIdx] ];
UInt uiTPelY = pcCU->getCUPelY() + g_auiRasterToPelY[ g_auiZscanToRaster[uiAbsZorderIdx] ];
if( ( uiLPelX < pcCU->getSlice()->getSPS()->getPicWidthInLumaSamples() ) && ( uiTPelY < pcCU->getSlice()->getSPS()->getPicHeightInLumaSamples() ) )
xPCMCURestoration( pcCU, uiAbsZorderIdx, uiDepth+1 );
}
return;
}
// restore PCM samples
if ((pcCU->getIPCMFlag(uiAbsZorderIdx)&& pcPic->getSlice(0)->getSPS()->getPCMFilterDisableFlag()) || pcCU->isLosslessCoded( uiAbsZorderIdx))
{
xPCMSampleRestoration (pcCU, uiAbsZorderIdx, uiDepth, TEXT_LUMA );
xPCMSampleRestoration (pcCU, uiAbsZorderIdx, uiDepth, TEXT_CHROMA_U);
xPCMSampleRestoration (pcCU, uiAbsZorderIdx, uiDepth, TEXT_CHROMA_V);
}
}
/**PCM sample restoration.
* \param pcCU pointer to current CU
* \param uiAbsPartIdx part index
* \param uiDepth CU depth
* \param ttText texture component type
* \returns Void
*/
Void TComSampleAdaptiveOffset::xPCMSampleRestoration (TComDataCU* pcCU, UInt uiAbsZorderIdx, UInt uiDepth, TextType ttText)
{
TComPicYuv* pcPicYuvRec = pcCU->getPic()->getPicYuvRec();
Pel* piSrc;
Pel* piPcm;
UInt uiStride;
UInt uiWidth;
UInt uiHeight;
UInt uiPcmLeftShiftBit;
UInt uiX, uiY;
UInt uiMinCoeffSize = pcCU->getPic()->getMinCUWidth()*pcCU->getPic()->getMinCUHeight();
UInt uiLumaOffset = uiMinCoeffSize*uiAbsZorderIdx;
UInt uiChromaOffset = uiLumaOffset>>2;
if( ttText == TEXT_LUMA )
{
piSrc = pcPicYuvRec->getLumaAddr( pcCU->getAddr(), uiAbsZorderIdx);
piPcm = pcCU->getPCMSampleY() + uiLumaOffset;
uiStride = pcPicYuvRec->getStride();
uiWidth = (g_uiMaxCUWidth >> uiDepth);
uiHeight = (g_uiMaxCUHeight >> uiDepth);
if ( pcCU->isLosslessCoded(uiAbsZorderIdx) && !pcCU->getIPCMFlag(uiAbsZorderIdx) )
{
uiPcmLeftShiftBit = 0;
}
else
{
uiPcmLeftShiftBit = g_bitDepthY - pcCU->getSlice()->getSPS()->getPCMBitDepthLuma();
}
}
else
{
if( ttText == TEXT_CHROMA_U )
{
piSrc = pcPicYuvRec->getCbAddr( pcCU->getAddr(), uiAbsZorderIdx );
piPcm = pcCU->getPCMSampleCb() + uiChromaOffset;
}
else
{
piSrc = pcPicYuvRec->getCrAddr( pcCU->getAddr(), uiAbsZorderIdx );
piPcm = pcCU->getPCMSampleCr() + uiChromaOffset;
}
uiStride = pcPicYuvRec->getCStride();
uiWidth = ((g_uiMaxCUWidth >> uiDepth)/2);
uiHeight = ((g_uiMaxCUWidth >> uiDepth)/2);
if ( pcCU->isLosslessCoded(uiAbsZorderIdx) && !pcCU->getIPCMFlag(uiAbsZorderIdx) )
{
uiPcmLeftShiftBit = 0;
}
else
{
uiPcmLeftShiftBit = g_bitDepthC - pcCU->getSlice()->getSPS()->getPCMBitDepthChroma();
}
}
for( uiY = 0; uiY < uiHeight; uiY++ )
{
for( uiX = 0; uiX < uiWidth; uiX++ )
{
piSrc[uiX] = (piPcm[uiX] << uiPcmLeftShiftBit);
}
piPcm += uiWidth;
piSrc += uiStride;
}
}
//! \}
~~~
**TEncSampleAdaptiveOffset.cpp**
~~~
/* The copyright in this software is being made available under the BSD
* License, included below. This software may be subject to other third party
* and contributor rights, including patent rights, and no such rights are
* granted under this license.
*
* Copyright (c) 2010-2014, ITU/ISO/IEC
* All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
*
* * Redistributions of source code must retain the above copyright notice,
* this list of conditions and the following disclaimer.
* * Redistributions in binary form must reproduce the above copyright notice,
* this list of conditions and the following disclaimer in the documentation
* and/or other materials provided with the distribution.
* * Neither the name of the ITU/ISO/IEC nor the names of its contributors may
* be used to endorse or promote products derived from this software without
* specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
* AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
* ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS
* BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
* CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
* SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
* INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
* CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
* ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF
* THE POSSIBILITY OF SUCH DAMAGE.
*/
/**
\file TEncSampleAdaptiveOffset.cpp
\brief estimation part of sample adaptive offset class
*/
#include "TEncSampleAdaptiveOffset.h"
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
#include <math.h>
//! \ingroup TLibEncoder
//! \{
/**rounding with IBDI
* \param x
*/
inline Double xRoundIbdi2(Int bitDepth, Double x)
{
return ((x)>0) ? (Int)(((Int)(x)+(1<<(bitDepth-8-1)))/(1<<(bitDepth-8))) : ((Int)(((Int)(x)-(1<<(bitDepth-8-1)))/(1<<(bitDepth-8))));
}
inline Double xRoundIbdi(Int bitDepth, Double x)
{
return (bitDepth > 8 ? xRoundIbdi2(bitDepth, (x)) : ((x)>=0 ? ((Int)((x)+0.5)) : ((Int)((x)-0.5)))) ;
}
TEncSampleAdaptiveOffset::TEncSampleAdaptiveOffset()
{
m_pppcRDSbacCoder = NULL;
m_pcRDGoOnSbacCoder = NULL;
m_pppcBinCoderCABAC = NULL;
m_statData = NULL;
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
m_preDBFstatData = NULL;
#endif
}
TEncSampleAdaptiveOffset::~TEncSampleAdaptiveOffset()
{
destroyEncData();
}
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
Void TEncSampleAdaptiveOffset::createEncData(Bool isPreDBFSamplesUsed)
#else
Void TEncSampleAdaptiveOffset::createEncData()
#endif
{
//cabac coder for RDO
m_pppcRDSbacCoder = new TEncSbac* [NUM_SAO_CABACSTATE_LABELS];
m_pppcBinCoderCABAC = new TEncBinCABACCounter* [NUM_SAO_CABACSTATE_LABELS];
for(Int cs=0; cs < NUM_SAO_CABACSTATE_LABELS; cs++)
{
m_pppcRDSbacCoder[cs] = new TEncSbac;
m_pppcBinCoderCABAC[cs] = new TEncBinCABACCounter;
m_pppcRDSbacCoder [cs]->init( m_pppcBinCoderCABAC [cs] );
}
//statistics
m_statData = new SAOStatData**[m_numCTUsPic];
for(Int i=0; i< m_numCTUsPic; i++)
{
m_statData[i] = new SAOStatData*[NUM_SAO_COMPONENTS];
for(Int compIdx=0; compIdx < NUM_SAO_COMPONENTS; compIdx++)
{
m_statData[i][compIdx] = new SAOStatData[NUM_SAO_NEW_TYPES];
}
}
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
if(isPreDBFSamplesUsed)
{
m_preDBFstatData = new SAOStatData**[m_numCTUsPic];
for(Int i=0; i< m_numCTUsPic; i++)
{
m_preDBFstatData[i] = new SAOStatData*[NUM_SAO_COMPONENTS];
for(Int compIdx=0; compIdx < NUM_SAO_COMPONENTS; compIdx++)
{
m_preDBFstatData[i][compIdx] = new SAOStatData[NUM_SAO_NEW_TYPES];
}
}
}
#endif
#if SAO_ENCODING_CHOICE
::memset(m_saoDisabledRate, 0, sizeof(m_saoDisabledRate));
#endif
for(Int typeIdc=0; typeIdc < NUM_SAO_NEW_TYPES; typeIdc++)
{
m_skipLinesR[SAO_Y ][typeIdc]= 5;
m_skipLinesR[SAO_Cb][typeIdc]= m_skipLinesR[SAO_Cr][typeIdc]= 3;
m_skipLinesB[SAO_Y ][typeIdc]= 4;
m_skipLinesB[SAO_Cb][typeIdc]= m_skipLinesB[SAO_Cr][typeIdc]= 2;
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
if(isPreDBFSamplesUsed)
{
switch(typeIdc)
{
case SAO_TYPE_EO_0:
{
m_skipLinesR[SAO_Y ][typeIdc]= 5;
m_skipLinesR[SAO_Cb][typeIdc]= m_skipLinesR[SAO_Cr][typeIdc]= 3;
m_skipLinesB[SAO_Y ][typeIdc]= 3;
m_skipLinesB[SAO_Cb][typeIdc]= m_skipLinesB[SAO_Cr][typeIdc]= 1;
}
break;
case SAO_TYPE_EO_90:
{
m_skipLinesR[SAO_Y ][typeIdc]= 4;
m_skipLinesR[SAO_Cb][typeIdc]= m_skipLinesR[SAO_Cr][typeIdc]= 2;
m_skipLinesB[SAO_Y ][typeIdc]= 4;
m_skipLinesB[SAO_Cb][typeIdc]= m_skipLinesB[SAO_Cr][typeIdc]= 2;
}
break;
case SAO_TYPE_EO_135:
case SAO_TYPE_EO_45:
{
m_skipLinesR[SAO_Y ][typeIdc]= 5;
m_skipLinesR[SAO_Cb][typeIdc]= m_skipLinesR[SAO_Cr][typeIdc]= 3;
m_skipLinesB[SAO_Y ][typeIdc]= 4;
m_skipLinesB[SAO_Cb][typeIdc]= m_skipLinesB[SAO_Cr][typeIdc]= 2;
}
break;
case SAO_TYPE_BO:
{
m_skipLinesR[SAO_Y ][typeIdc]= 4;
m_skipLinesR[SAO_Cb][typeIdc]= m_skipLinesR[SAO_Cr][typeIdc]= 2;
m_skipLinesB[SAO_Y ][typeIdc]= 3;
m_skipLinesB[SAO_Cb][typeIdc]= m_skipLinesB[SAO_Cr][typeIdc]= 1;
}
break;
default:
{
printf("Not a supported type");
assert(0);
exit(-1);
}
}
}
#endif
}
}
Void TEncSampleAdaptiveOffset::destroyEncData()
{
if(m_pppcRDSbacCoder != NULL)
{
for (Int cs = 0; cs < NUM_SAO_CABACSTATE_LABELS; cs ++ )
{
delete m_pppcRDSbacCoder[cs];
}
delete[] m_pppcRDSbacCoder; m_pppcRDSbacCoder = NULL;
}
if(m_pppcBinCoderCABAC != NULL)
{
for (Int cs = 0; cs < NUM_SAO_CABACSTATE_LABELS; cs ++ )
{
delete m_pppcBinCoderCABAC[cs];
}
delete[] m_pppcBinCoderCABAC; m_pppcBinCoderCABAC = NULL;
}
if(m_statData != NULL)
{
for(Int i=0; i< m_numCTUsPic; i++)
{
for(Int compIdx=0; compIdx< NUM_SAO_COMPONENTS; compIdx++)
{
delete[] m_statData[i][compIdx];
}
delete[] m_statData[i];
}
delete[] m_statData; m_statData = NULL;
}
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
if(m_preDBFstatData != NULL)
{
for(Int i=0; i< m_numCTUsPic; i++)
{
for(Int compIdx=0; compIdx< NUM_SAO_COMPONENTS; compIdx++)
{
delete[] m_preDBFstatData[i][compIdx];
}
delete[] m_preDBFstatData[i];
}
delete[] m_preDBFstatData; m_preDBFstatData = NULL;
}
#endif
}
Void TEncSampleAdaptiveOffset::initRDOCabacCoder(TEncSbac* pcRDGoOnSbacCoder, TComSlice* pcSlice)
{
m_pcRDGoOnSbacCoder = pcRDGoOnSbacCoder;
m_pcRDGoOnSbacCoder->setSlice(pcSlice);
m_pcRDGoOnSbacCoder->resetEntropy();
m_pcRDGoOnSbacCoder->resetBits();
m_pcRDGoOnSbacCoder->store( m_pppcRDSbacCoder[SAO_CABACSTATE_PIC_INIT]);
}
Void TEncSampleAdaptiveOffset::SAOProcess(TComPic* pPic, Bool* sliceEnabled, const Double *lambdas
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
, Bool isPreDBFSamplesUsed
#endif
)
{
TComPicYuv* orgYuv= pPic->getPicYuvOrg();
TComPicYuv* resYuv= pPic->getPicYuvRec();
m_lambda[SAO_Y]= lambdas[0]; m_lambda[SAO_Cb]= lambdas[1]; m_lambda[SAO_Cr]= lambdas[2];
TComPicYuv* srcYuv = m_tempPicYuv;
resYuv->copyToPic(srcYuv);
srcYuv->setBorderExtension(false);
srcYuv->extendPicBorder();
//collect statistics
getStatistics(m_statData, orgYuv, srcYuv, pPic);
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
if(isPreDBFSamplesUsed)
{
addPreDBFStatistics(m_statData);
}
#endif
//slice on/off
decidePicParams(sliceEnabled, pPic->getSlice(0)->getDepth());
//block on/off
SAOBlkParam* reconParams = new SAOBlkParam[m_numCTUsPic]; //temporary parameter buffer for storing reconstructed SAO parameters
decideBlkParams(pPic, sliceEnabled, m_statData, srcYuv, resYuv, reconParams, pPic->getPicSym()->getSAOBlkParam());
delete[] reconParams;
}
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
Void TEncSampleAdaptiveOffset::getPreDBFStatistics(TComPic* pPic)
{
getStatistics(m_preDBFstatData, pPic->getPicYuvOrg(), pPic->getPicYuvRec(), pPic, true);
}
Void TEncSampleAdaptiveOffset::addPreDBFStatistics(SAOStatData***blkStats)
{
for(Int n=0; n< m_numCTUsPic; n++)
{
for(Int compIdx=0; compIdx < NUM_SAO_COMPONENTS; compIdx++)
{
for(Int typeIdc=0; typeIdc < NUM_SAO_NEW_TYPES; typeIdc++)
{
blkStats[n][compIdx][typeIdc] += m_preDBFstatData[n][compIdx][typeIdc];
}
}
}
}
#endif
Void TEncSampleAdaptiveOffset::getStatistics(SAOStatData***blkStats, TComPicYuv* orgYuv, TComPicYuv* srcYuv, TComPic* pPic
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
, Bool isCalculatePreDeblockSamples
#endif
)
{
Bool isLeftAvail,isRightAvail,isAboveAvail,isBelowAvail,isAboveLeftAvail,isAboveRightAvail,isBelowLeftAvail,isBelowRightAvail;
for(Int ctu= 0; ctu < m_numCTUsPic; ctu++)
{
Int yPos = (ctu / m_numCTUInWidth)*m_maxCUHeight;
Int xPos = (ctu % m_numCTUInWidth)*m_maxCUWidth;
Int height = (yPos + m_maxCUHeight > m_picHeight)?(m_picHeight- yPos):m_maxCUHeight;
Int width = (xPos + m_maxCUWidth > m_picWidth )?(m_picWidth - xPos):m_maxCUWidth;
pPic->getPicSym()->deriveLoopFilterBoundaryAvailibility(ctu, isLeftAvail,isRightAvail,isAboveAvail,isBelowAvail,isAboveLeftAvail,isAboveRightAvail,isBelowLeftAvail,isBelowRightAvail);
//NOTE: The number of skipped lines during gathering CTU statistics depends on the slice boundary availabilities.
//For simplicity, here only picture boundaries are considered.
isRightAvail = (xPos + m_maxCUWidth < m_picWidth );
isBelowAvail = (yPos + m_maxCUHeight < m_picHeight);
isBelowRightAvail = (isRightAvail && isBelowAvail);
isBelowLeftAvail = ((xPos > 0) && (isBelowAvail));
isAboveRightAvail = ((yPos > 0) && (isRightAvail));
for(Int compIdx=0; compIdx< NUM_SAO_COMPONENTS; compIdx++)
{
Bool isLuma = (compIdx == SAO_Y);
Int formatShift= isLuma?0:1;
Int srcStride = isLuma?srcYuv->getStride():srcYuv->getCStride();
Pel* srcBlk = getPicBuf(srcYuv, compIdx)+ (yPos >> formatShift)*srcStride+ (xPos >> formatShift);
Int orgStride = isLuma?orgYuv->getStride():orgYuv->getCStride();
Pel* orgBlk = getPicBuf(orgYuv, compIdx)+ (yPos >> formatShift)*orgStride+ (xPos >> formatShift);
getBlkStats(compIdx, blkStats[ctu][compIdx]
, srcBlk, orgBlk, srcStride, orgStride, (width >> formatShift), (height >> formatShift)
, isLeftAvail, isRightAvail, isAboveAvail, isBelowAvail, isAboveLeftAvail, isAboveRightAvail, isBelowLeftAvail, isBelowRightAvail
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
, isCalculatePreDeblockSamples
#endif
);
}
}
}
Void TEncSampleAdaptiveOffset::decidePicParams(Bool* sliceEnabled, Int picTempLayer)
{
//decide sliceEnabled[compIdx]
for (Int compIdx=0; compIdx<NUM_SAO_COMPONENTS; compIdx++)
{
// reset flags & counters
sliceEnabled[compIdx] = true;
#if SAO_ENCODING_CHOICE
#if SAO_ENCODING_CHOICE_CHROMA
// decide slice-level on/off based on previous results
if( (picTempLayer > 0)
&& (m_saoDisabledRate[compIdx][picTempLayer-1] > ((compIdx==SAO_Y) ? SAO_ENCODING_RATE : SAO_ENCODING_RATE_CHROMA)) )
{
sliceEnabled[compIdx] = false;
}
#else
// decide slice-level on/off based on previous results
if( (picTempLayer > 0)
&& (m_saoDisabledRate[SAO_Y][0] > SAO_ENCODING_RATE) )
{
sliceEnabled[compIdx] = false;
}
#endif
#endif
}
}
Int64 TEncSampleAdaptiveOffset::getDistortion(Int ctu, Int compIdx, Int typeIdc, Int typeAuxInfo, Int* invQuantOffset, SAOStatData& statData)
{
Int64 dist=0;
Int inputBitDepth = (compIdx == SAO_Y) ? g_bitDepthY : g_bitDepthC ;
Int shift = 2 * DISTORTION_PRECISION_ADJUSTMENT(inputBitDepth-8);
switch(typeIdc)
{
case SAO_TYPE_EO_0:
case SAO_TYPE_EO_90:
case SAO_TYPE_EO_135:
case SAO_TYPE_EO_45:
{
for (Int offsetIdx=0; offsetIdx<NUM_SAO_EO_CLASSES; offsetIdx++)
{
dist += estSaoDist( statData.count[offsetIdx], invQuantOffset[offsetIdx], statData.diff[offsetIdx], shift);
}
}
break;
case SAO_TYPE_BO:
{
for (Int offsetIdx=typeAuxInfo; offsetIdx<typeAuxInfo+4; offsetIdx++)
{
Int bandIdx = offsetIdx % NUM_SAO_BO_CLASSES ;
dist += estSaoDist( statData.count[bandIdx], invQuantOffset[bandIdx], statData.diff[bandIdx], shift);
}
}
break;
default:
{
printf("Not a supported type");
assert(0);
exit(-1);
}
}
return dist;
}
inline Int64 TEncSampleAdaptiveOffset::estSaoDist(Int64 count, Int64 offset, Int64 diffSum, Int shift)
{
return (( count*offset*offset-diffSum*offset*2 ) >> shift);
}
inline Int TEncSampleAdaptiveOffset::estIterOffset(Int typeIdx, Int classIdx, Double lambda, Int offsetInput, Int64 count, Int64 diffSum, Int shift, Int bitIncrease, Int64& bestDist, Double& bestCost, Int offsetTh )
{
Int iterOffset, tempOffset;
Int64 tempDist, tempRate;
Double tempCost, tempMinCost;
Int offsetOutput = 0;
iterOffset = offsetInput;
// Assuming sending quantized value 0 results in zero offset and sending the value zero needs 1 bit. entropy coder can be used to measure the exact rate here.
tempMinCost = lambda;
while (iterOffset != 0)
{
// Calculate the bits required for signaling the offset
tempRate = (typeIdx == SAO_TYPE_BO) ? (abs((Int)iterOffset)+2) : (abs((Int)iterOffset)+1);
if (abs((Int)iterOffset)==offsetTh) //inclusive
{
tempRate --;
}
// Do the dequantization before distortion calculation
tempOffset = iterOffset << bitIncrease;
tempDist = estSaoDist( count, tempOffset, diffSum, shift);
tempCost = ((Double)tempDist + lambda * (Double) tempRate);
if(tempCost < tempMinCost)
{
tempMinCost = tempCost;
offsetOutput = iterOffset;
bestDist = tempDist;
bestCost = tempCost;
}
iterOffset = (iterOffset > 0) ? (iterOffset-1):(iterOffset+1);
}
return offsetOutput;
}
Void TEncSampleAdaptiveOffset::deriveOffsets(Int ctu, Int compIdx, Int typeIdc, SAOStatData& statData, Int* quantOffsets, Int& typeAuxInfo)
{
Int bitDepth = (compIdx== SAO_Y) ? g_bitDepthY : g_bitDepthC;
Int shift = 2 * DISTORTION_PRECISION_ADJUSTMENT(bitDepth-8);
Int offsetTh = g_saoMaxOffsetQVal[compIdx]; //inclusive
::memset(quantOffsets, 0, sizeof(Int)*MAX_NUM_SAO_CLASSES);
//derive initial offsets
Int numClasses = (typeIdc == SAO_TYPE_BO)?((Int)NUM_SAO_BO_CLASSES):((Int)NUM_SAO_EO_CLASSES);
for(Int classIdx=0; classIdx< numClasses; classIdx++)
{
if( (typeIdc != SAO_TYPE_BO) && (classIdx==SAO_CLASS_EO_PLAIN) )
{
continue; //offset will be zero
}
if(statData.count[classIdx] == 0)
{
continue; //offset will be zero
}
quantOffsets[classIdx] = (Int) xRoundIbdi(bitDepth, (Double)( statData.diff[classIdx]<<(bitDepth-8))
/
(Double)( statData.count[classIdx]<< m_offsetStepLog2[compIdx])
);
quantOffsets[classIdx] = Clip3(-offsetTh, offsetTh, quantOffsets[classIdx]);
}
// adjust offsets
switch(typeIdc)
{
case SAO_TYPE_EO_0:
case SAO_TYPE_EO_90:
case SAO_TYPE_EO_135:
case SAO_TYPE_EO_45:
{
Int64 classDist;
Double classCost;
for(Int classIdx=0; classIdx<NUM_SAO_EO_CLASSES; classIdx++)
{
if(classIdx==SAO_CLASS_EO_FULL_VALLEY && quantOffsets[classIdx] < 0) quantOffsets[classIdx] =0;
if(classIdx==SAO_CLASS_EO_HALF_VALLEY && quantOffsets[classIdx] < 0) quantOffsets[classIdx] =0;
if(classIdx==SAO_CLASS_EO_HALF_PEAK && quantOffsets[classIdx] > 0) quantOffsets[classIdx] =0;
if(classIdx==SAO_CLASS_EO_FULL_PEAK && quantOffsets[classIdx] > 0) quantOffsets[classIdx] =0;
if( quantOffsets[classIdx] != 0 ) //iterative adjustment only when derived offset is not zero
{
quantOffsets[classIdx] = estIterOffset( typeIdc, classIdx, m_lambda[compIdx], quantOffsets[classIdx], statData.count[classIdx], statData.diff[classIdx], shift, m_offsetStepLog2[compIdx], classDist , classCost , offsetTh );
}
}
typeAuxInfo =0;
}
break;
case SAO_TYPE_BO:
{
Int64 distBOClasses[NUM_SAO_BO_CLASSES];
Double costBOClasses[NUM_SAO_BO_CLASSES];
::memset(distBOClasses, 0, sizeof(Int64)*NUM_SAO_BO_CLASSES);
for(Int classIdx=0; classIdx< NUM_SAO_BO_CLASSES; classIdx++)
{
costBOClasses[classIdx]= m_lambda[compIdx];
if( quantOffsets[classIdx] != 0 ) //iterative adjustment only when derived offset is not zero
{
quantOffsets[classIdx] = estIterOffset( typeIdc, classIdx, m_lambda[compIdx], quantOffsets[classIdx], statData.count[classIdx], statData.diff[classIdx], shift, m_offsetStepLog2[compIdx], distBOClasses[classIdx], costBOClasses[classIdx], offsetTh );
}
}
//decide the starting band index
Double minCost = MAX_DOUBLE, cost;
for(Int band=0; band< NUM_SAO_BO_CLASSES- 4+ 1; band++)
{
cost = costBOClasses[band ];
cost += costBOClasses[band+1];
cost += costBOClasses[band+2];
cost += costBOClasses[band+3];
if(cost < minCost)
{
minCost = cost;
typeAuxInfo = band;
}
}
//clear those unused classes
Int clearQuantOffset[NUM_SAO_BO_CLASSES];
::memset(clearQuantOffset, 0, sizeof(Int)*NUM_SAO_BO_CLASSES);
for(Int i=0; i< 4; i++)
{
Int band = (typeAuxInfo+i)%NUM_SAO_BO_CLASSES;
clearQuantOffset[band] = quantOffsets[band];
}
::memcpy(quantOffsets, clearQuantOffset, sizeof(Int)*NUM_SAO_BO_CLASSES);
}
break;
default:
{
printf("Not a supported type");
assert(0);
exit(-1);
}
}
}
Void TEncSampleAdaptiveOffset::deriveModeNewRDO(Int ctu, std::vector<SAOBlkParam*>& mergeList, Bool* sliceEnabled, SAOStatData***blkStats, SAOBlkParam& modeParam, Double& modeNormCost, TEncSbac**cabacCoderRDO, Int inCabacLabel)
{
Double minCost, cost;
Int rate;
UInt previousWrittenBits;
Int64 dist[NUM_SAO_COMPONENTS], modeDist[NUM_SAO_COMPONENTS];
SAOOffset testOffset[NUM_SAO_COMPONENTS];
Int compIdx;
Int invQuantOffset[MAX_NUM_SAO_CLASSES];
modeDist[SAO_Y]= modeDist[SAO_Cb] = modeDist[SAO_Cr] = 0;
//pre-encode merge flags
modeParam[SAO_Y ].modeIdc = SAO_MODE_OFF;
m_pcRDGoOnSbacCoder->load(cabacCoderRDO[inCabacLabel]);
m_pcRDGoOnSbacCoder->codeSAOBlkParam(modeParam, sliceEnabled, (mergeList[SAO_MERGE_LEFT]!= NULL), (mergeList[SAO_MERGE_ABOVE]!= NULL), true);
m_pcRDGoOnSbacCoder->store(cabacCoderRDO[SAO_CABACSTATE_BLK_MID]);
//------ luma --------//
compIdx = SAO_Y;
//"off" case as initial cost
modeParam[compIdx].modeIdc = SAO_MODE_OFF;
m_pcRDGoOnSbacCoder->resetBits();
m_pcRDGoOnSbacCoder->codeSAOOffsetParam(compIdx, modeParam[compIdx], sliceEnabled[compIdx]);
modeDist[compIdx] = 0;
minCost= m_lambda[compIdx]*((Double)m_pcRDGoOnSbacCoder->getNumberOfWrittenBits());
m_pcRDGoOnSbacCoder->store(cabacCoderRDO[SAO_CABACSTATE_BLK_TEMP]);
if(sliceEnabled[compIdx])
{
for(Int typeIdc=0; typeIdc< NUM_SAO_NEW_TYPES; typeIdc++)
{
testOffset[compIdx].modeIdc = SAO_MODE_NEW;
testOffset[compIdx].typeIdc = typeIdc;
//derive coded offset
deriveOffsets(ctu, compIdx, typeIdc, blkStats[ctu][compIdx][typeIdc], testOffset[compIdx].offset, testOffset[compIdx].typeAuxInfo);
//inversed quantized offsets
invertQuantOffsets(compIdx, typeIdc, testOffset[compIdx].typeAuxInfo, invQuantOffset, testOffset[compIdx].offset);
//get distortion
dist[compIdx] = getDistortion(ctu, compIdx, testOffset[compIdx].typeIdc, testOffset[compIdx].typeAuxInfo, invQuantOffset, blkStats[ctu][compIdx][typeIdc]);
//get rate
m_pcRDGoOnSbacCoder->load(cabacCoderRDO[SAO_CABACSTATE_BLK_MID]);
m_pcRDGoOnSbacCoder->resetBits();
m_pcRDGoOnSbacCoder->codeSAOOffsetParam(compIdx, testOffset[compIdx], sliceEnabled[compIdx]);
rate = m_pcRDGoOnSbacCoder->getNumberOfWrittenBits();
cost = (Double)dist[compIdx] + m_lambda[compIdx]*((Double)rate);
if(cost < minCost)
{
minCost = cost;
modeDist[compIdx] = dist[compIdx];
modeParam[compIdx]= testOffset[compIdx];
m_pcRDGoOnSbacCoder->store(cabacCoderRDO[SAO_CABACSTATE_BLK_TEMP]);
}
}
}
m_pcRDGoOnSbacCoder->load(cabacCoderRDO[SAO_CABACSTATE_BLK_TEMP]);
m_pcRDGoOnSbacCoder->store(cabacCoderRDO[SAO_CABACSTATE_BLK_MID]);
//------ chroma --------//
//"off" case as initial cost
cost = 0;
previousWrittenBits = 0;
m_pcRDGoOnSbacCoder->resetBits();
for (Int component = SAO_Cb; component < NUM_SAO_COMPONENTS; component++)
{
modeParam[component].modeIdc = SAO_MODE_OFF;
modeDist [component] = 0;
m_pcRDGoOnSbacCoder->codeSAOOffsetParam(component, modeParam[component], sliceEnabled[component]);
const UInt currentWrittenBits = m_pcRDGoOnSbacCoder->getNumberOfWrittenBits();
cost += m_lambda[component] * (currentWrittenBits - previousWrittenBits);
previousWrittenBits = currentWrittenBits;
}
minCost = cost;
//doesn't need to store cabac status here since the whole CTU parameters will be re-encoded at the end of this function
for(Int typeIdc=0; typeIdc< NUM_SAO_NEW_TYPES; typeIdc++)
{
m_pcRDGoOnSbacCoder->load(cabacCoderRDO[SAO_CABACSTATE_BLK_MID]);
m_pcRDGoOnSbacCoder->resetBits();
previousWrittenBits = 0;
cost = 0;
for(compIdx= SAO_Cb; compIdx< NUM_SAO_COMPONENTS; compIdx++)
{
if(!sliceEnabled[compIdx])
{
testOffset[compIdx].modeIdc = SAO_MODE_OFF;
dist[compIdx]= 0;
continue;
}
testOffset[compIdx].modeIdc = SAO_MODE_NEW;
testOffset[compIdx].typeIdc = typeIdc;
//derive offset & get distortion
deriveOffsets(ctu, compIdx, typeIdc, blkStats[ctu][compIdx][typeIdc], testOffset[compIdx].offset, testOffset[compIdx].typeAuxInfo);
invertQuantOffsets(compIdx, typeIdc, testOffset[compIdx].typeAuxInfo, invQuantOffset, testOffset[compIdx].offset);
dist[compIdx]= getDistortion(ctu, compIdx, typeIdc, testOffset[compIdx].typeAuxInfo, invQuantOffset, blkStats[ctu][compIdx][typeIdc]);
m_pcRDGoOnSbacCoder->codeSAOOffsetParam(compIdx, testOffset[compIdx], sliceEnabled[compIdx]);
const UInt currentWrittenBits = m_pcRDGoOnSbacCoder->getNumberOfWrittenBits();
cost += dist[compIdx] + (m_lambda[compIdx] * (currentWrittenBits - previousWrittenBits));
previousWrittenBits = currentWrittenBits;
}
if(cost < minCost)
{
minCost = cost;
for(compIdx= SAO_Cb; compIdx< NUM_SAO_COMPONENTS; compIdx++)
{
modeDist [compIdx] = dist [compIdx];
modeParam[compIdx] = testOffset[compIdx];
}
}
}
//----- re-gen rate & normalized cost----//
modeNormCost = 0;
for(UInt component = SAO_Y; component < NUM_SAO_COMPONENTS; component++)
{
modeNormCost += (Double)modeDist[component] / m_lambda[component];
}
m_pcRDGoOnSbacCoder->load(cabacCoderRDO[inCabacLabel]);
m_pcRDGoOnSbacCoder->resetBits();
m_pcRDGoOnSbacCoder->codeSAOBlkParam(modeParam, sliceEnabled, (mergeList[SAO_MERGE_LEFT]!= NULL), (mergeList[SAO_MERGE_ABOVE]!= NULL), false);
modeNormCost += (Double)m_pcRDGoOnSbacCoder->getNumberOfWrittenBits();
}
Void TEncSampleAdaptiveOffset::deriveModeMergeRDO(Int ctu, std::vector<SAOBlkParam*>& mergeList, Bool* sliceEnabled, SAOStatData***blkStats, SAOBlkParam& modeParam, Double& modeNormCost, TEncSbac**cabacCoderRDO, Int inCabacLabel)
{
Int mergeListSize = (Int)mergeList.size();
modeNormCost = MAX_DOUBLE;
Double cost;
SAOBlkParam testBlkParam;
for(Int mergeType=0; mergeType< mergeListSize; mergeType++)
{
if(mergeList[mergeType] == NULL)
{
continue;
}
testBlkParam = *(mergeList[mergeType]);
//normalized distortion
Double normDist=0;
for(Int compIdx=0; compIdx< NUM_SAO_COMPONENTS; compIdx++)
{
testBlkParam[compIdx].modeIdc = SAO_MODE_MERGE;
testBlkParam[compIdx].typeIdc = mergeType;
SAOOffset& mergedOffsetParam = (*(mergeList[mergeType]))[compIdx];
if( mergedOffsetParam.modeIdc != SAO_MODE_OFF)
{
//offsets have been reconstructed. Don't call inversed quantization function.
normDist += (((Double)getDistortion(ctu, compIdx, mergedOffsetParam.typeIdc, mergedOffsetParam.typeAuxInfo, mergedOffsetParam.offset, blkStats[ctu][compIdx][mergedOffsetParam.typeIdc]))
/m_lambda[compIdx]
);
}
}
//rate
m_pcRDGoOnSbacCoder->load(cabacCoderRDO[inCabacLabel]);
m_pcRDGoOnSbacCoder->resetBits();
m_pcRDGoOnSbacCoder->codeSAOBlkParam(testBlkParam, sliceEnabled, (mergeList[SAO_MERGE_LEFT]!= NULL), (mergeList[SAO_MERGE_ABOVE]!= NULL), false);
Int rate = m_pcRDGoOnSbacCoder->getNumberOfWrittenBits();
cost = normDist+(Double)rate;
if(cost < modeNormCost)
{
modeNormCost = cost;
modeParam = testBlkParam;
m_pcRDGoOnSbacCoder->store(cabacCoderRDO[SAO_CABACSTATE_BLK_TEMP]);
}
}
m_pcRDGoOnSbacCoder->load(cabacCoderRDO[SAO_CABACSTATE_BLK_TEMP]);
}
Void TEncSampleAdaptiveOffset::decideBlkParams(TComPic* pic, Bool* sliceEnabled, SAOStatData***blkStats, TComPicYuv* srcYuv, TComPicYuv* resYuv, SAOBlkParam* reconParams, SAOBlkParam* codedParams)
{
Bool isAllBlksDisabled = false;
if(!sliceEnabled[SAO_Y] && !sliceEnabled[SAO_Cb] && !sliceEnabled[SAO_Cr])
{
isAllBlksDisabled = true;
}
m_pcRDGoOnSbacCoder->load(m_pppcRDSbacCoder[ SAO_CABACSTATE_PIC_INIT ]);
SAOBlkParam modeParam;
Double minCost, modeCost;
for(Int ctu=0; ctu< m_numCTUsPic; ctu++)
{
if(isAllBlksDisabled)
{
codedParams[ctu].reset();
continue;
}
m_pcRDGoOnSbacCoder->store(m_pppcRDSbacCoder[ SAO_CABACSTATE_BLK_CUR ]);
//get merge list
std::vector<SAOBlkParam*> mergeList;
getMergeList(pic, ctu, reconParams, mergeList);
minCost = MAX_DOUBLE;
for(Int mode=0; mode < NUM_SAO_MODES; mode++)
{
switch(mode)
{
case SAO_MODE_OFF:
{
continue; //not necessary, since all-off case will be tested in SAO_MODE_NEW case.
}
break;
case SAO_MODE_NEW:
{
deriveModeNewRDO(ctu, mergeList, sliceEnabled, blkStats, modeParam, modeCost, m_pppcRDSbacCoder, SAO_CABACSTATE_BLK_CUR);
}
break;
case SAO_MODE_MERGE:
{
deriveModeMergeRDO(ctu, mergeList, sliceEnabled, blkStats , modeParam, modeCost, m_pppcRDSbacCoder, SAO_CABACSTATE_BLK_CUR);
}
break;
default:
{
printf("Not a supported SAO mode\n");
assert(0);
exit(-1);
}
}
if(modeCost < minCost)
{
minCost = modeCost;
codedParams[ctu] = modeParam;
m_pcRDGoOnSbacCoder->store(m_pppcRDSbacCoder[ SAO_CABACSTATE_BLK_NEXT ]);
}
} //mode
m_pcRDGoOnSbacCoder->load(m_pppcRDSbacCoder[ SAO_CABACSTATE_BLK_NEXT ]);
//apply reconstructed offsets
reconParams[ctu] = codedParams[ctu];
reconstructBlkSAOParam(reconParams[ctu], mergeList);
offsetCTU(ctu, srcYuv, resYuv, reconParams[ctu], pic);
} //ctu
#if SAO_ENCODING_CHOICE
Int picTempLayer = pic->getSlice(0)->getDepth();
Int numLcusForSAOOff[NUM_SAO_COMPONENTS];
numLcusForSAOOff[SAO_Y ] = numLcusForSAOOff[SAO_Cb]= numLcusForSAOOff[SAO_Cr]= 0;
for (Int compIdx=0; compIdx<NUM_SAO_COMPONENTS; compIdx++)
{
for(Int ctu=0; ctu< m_numCTUsPic; ctu++)
{
if( reconParams[ctu][compIdx].modeIdc == SAO_MODE_OFF)
{
numLcusForSAOOff[compIdx]++;
}
}
}
#if SAO_ENCODING_CHOICE_CHROMA
for (Int compIdx=0; compIdx<NUM_SAO_COMPONENTS; compIdx++)
{
m_saoDisabledRate[compIdx][picTempLayer] = (Double)numLcusForSAOOff[compIdx]/(Double)m_numCTUsPic;
}
#else
if (picTempLayer == 0)
{
m_saoDisabledRate[SAO_Y][0] = (Double)(numLcusForSAOOff[SAO_Y]+numLcusForSAOOff[SAO_Cb]+numLcusForSAOOff[SAO_Cr])/(Double)(m_numCTUsPic*3);
}
#endif
#endif
}
Void TEncSampleAdaptiveOffset::getBlkStats(Int compIdx, SAOStatData* statsDataTypes
, Pel* srcBlk, Pel* orgBlk, Int srcStride, Int orgStride, Int width, Int height
, Bool isLeftAvail, Bool isRightAvail, Bool isAboveAvail, Bool isBelowAvail, Bool isAboveLeftAvail, Bool isAboveRightAvail, Bool isBelowLeftAvail, Bool isBelowRightAvail
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
, Bool isCalculatePreDeblockSamples
#endif
)
{
if(m_lineBufWidth != m_maxCUWidth)
{
m_lineBufWidth = m_maxCUWidth;
if (m_signLineBuf1) delete[] m_signLineBuf1; m_signLineBuf1 = NULL;
m_signLineBuf1 = new Char[m_lineBufWidth+1];
if (m_signLineBuf2) delete[] m_signLineBuf2; m_signLineBuf2 = NULL;
m_signLineBuf2 = new Char[m_lineBufWidth+1];
}
Int x,y, startX, startY, endX, endY, edgeType, firstLineStartX, firstLineEndX;
Char signLeft, signRight, signDown;
Int64 *diff, *count;
Pel *srcLine, *orgLine;
Int* skipLinesR = m_skipLinesR[compIdx];
Int* skipLinesB = m_skipLinesB[compIdx];
for(Int typeIdx=0; typeIdx< NUM_SAO_NEW_TYPES; typeIdx++)
{
SAOStatData& statsData= statsDataTypes[typeIdx];
statsData.reset();
srcLine = srcBlk;
orgLine = orgBlk;
diff = statsData.diff;
count = statsData.count;
switch(typeIdx)
{
case SAO_TYPE_EO_0:
{
diff +=2;
count+=2;
endY = (isBelowAvail) ? (height - skipLinesB[typeIdx]) : height;
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
startX = (!isCalculatePreDeblockSamples) ? (isLeftAvail ? 0 : 1)
: (isRightAvail ? (width - skipLinesR[typeIdx]) : (width - 1))
;
#else
startX = isLeftAvail ? 0 : 1;
#endif
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
endX = (!isCalculatePreDeblockSamples) ? (isRightAvail ? (width - skipLinesR[typeIdx]) : (width - 1))
: (isRightAvail ? width : (width - 1))
;
#else
endX = isRightAvail ? (width - skipLinesR[typeIdx]): (width - 1);
#endif
for (y=0; y<endY; y++)
{
#if SAO_SGN_FUNC
signLeft = (Char)sgn(srcLine[startX] - srcLine[startX-1]);
#else
signLeft = (Char)m_sign[srcLine[startX] - srcLine[startX-1]];
#endif
for (x=startX; x<endX; x++)
{
#if SAO_SGN_FUNC
signRight = (Char)sgn(srcLine[x] - srcLine[x+1]);
#else
signRight = (Char)m_sign[srcLine[x] - srcLine[x+1]];
#endif
edgeType = signRight + signLeft;
signLeft = -signRight;
diff [edgeType] += (orgLine[x] - srcLine[x]);
count[edgeType] ++;
}
srcLine += srcStride;
orgLine += orgStride;
}
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
if(isCalculatePreDeblockSamples)
{
if(isBelowAvail)
{
startX = isLeftAvail ? 0 : 1;
endX = isRightAvail ? width : (width -1);
for(y=0; y<skipLinesB[typeIdx]; y++)
{
#if SAO_SGN_FUNC
signLeft = (Char)sgn(srcLine[startX] - srcLine[startX-1]);
#else
signLeft = (Char)m_sign[srcLine[startX] - srcLine[startX-1]];
#endif
for (x=startX; x<endX; x++)
{
#if SAO_SGN_FUNC
signRight = (Char)sgn(srcLine[x] - srcLine[x+1]);
#else
signRight = (Char)m_sign[srcLine[x] - srcLine[x+1]];
#endif
edgeType = signRight + signLeft;
signLeft = -signRight;
diff [edgeType] += (orgLine[x] - srcLine[x]);
count[edgeType] ++;
}
srcLine += srcStride;
orgLine += orgStride;
}
}
}
#endif
}
break;
case SAO_TYPE_EO_90:
{
diff +=2;
count+=2;
Char *signUpLine = m_signLineBuf1;
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
startX = (!isCalculatePreDeblockSamples) ? 0
: (isRightAvail ? (width - skipLinesR[typeIdx]) : width)
;
#endif
startY = isAboveAvail ? 0 : 1;
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
endX = (!isCalculatePreDeblockSamples) ? (isRightAvail ? (width - skipLinesR[typeIdx]) : width)
: width
;
#else
endX = isRightAvail ? (width - skipLinesR[typeIdx]) : width ;
#endif
endY = isBelowAvail ? (height - skipLinesB[typeIdx]) : (height - 1);
if (!isAboveAvail)
{
srcLine += srcStride;
orgLine += orgStride;
}
Pel* srcLineAbove = srcLine - srcStride;
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
for (x=startX; x<endX; x++)
#else
for (x=0; x< endX; x++)
#endif
{
#if SAO_SGN_FUNC
signUpLine[x] = (Char)sgn(srcLine[x] - srcLineAbove[x]);
#else
signUpLine[x] = (Char)m_sign[srcLine[x] - srcLineAbove[x]];
#endif
}
Pel* srcLineBelow;
for (y=startY; y<endY; y++)
{
srcLineBelow = srcLine + srcStride;
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
for (x=startX; x<endX; x++)
#else
for (x=0; x<endX; x++)
#endif
{
#if SAO_SGN_FUNC
signDown = (Char)sgn(srcLine[x] - srcLineBelow[x]);
#else
signDown = (Char)m_sign[srcLine[x] - srcLineBelow[x]];
#endif
edgeType = signDown + signUpLine[x];
signUpLine[x]= -signDown;
diff [edgeType] += (orgLine[x] - srcLine[x]);
count[edgeType] ++;
}
srcLine += srcStride;
orgLine += orgStride;
}
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
if(isCalculatePreDeblockSamples)
{
if(isBelowAvail)
{
startX = 0;
endX = width;
for(y=0; y<skipLinesB[typeIdx]; y++)
{
srcLineBelow = srcLine + srcStride;
srcLineAbove = srcLine - srcStride;
for (x=startX; x<endX; x++)
{
#if SAO_SGN_FUNC
edgeType = sgn(srcLine[x] - srcLineBelow[x]) + sgn(srcLine[x] - srcLineAbove[x]);
#else
edgeType = m_sign[srcLine[x] - srcLineBelow[x]] + m_sign[srcLine[x] - srcLineAbove[x]];
#endif
diff [edgeType] += (orgLine[x] - srcLine[x]);
count[edgeType] ++;
}
srcLine += srcStride;
orgLine += orgStride;
}
}
}
#endif
}
break;
case SAO_TYPE_EO_135:
{
diff +=2;
count+=2;
Char *signUpLine, *signDownLine, *signTmpLine;
signUpLine = m_signLineBuf1;
signDownLine= m_signLineBuf2;
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
startX = (!isCalculatePreDeblockSamples) ? (isLeftAvail ? 0 : 1)
: (isRightAvail ? (width - skipLinesR[typeIdx]) : (width - 1))
;
#else
startX = isLeftAvail ? 0 : 1 ;
#endif
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
endX = (!isCalculatePreDeblockSamples) ? (isRightAvail ? (width - skipLinesR[typeIdx]): (width - 1))
: (isRightAvail ? width : (width - 1))
;
#else
endX = isRightAvail ? (width - skipLinesR[typeIdx]): (width - 1);
#endif
endY = isBelowAvail ? (height - skipLinesB[typeIdx]) : (height - 1);
//prepare 2nd line's upper sign
Pel* srcLineBelow = srcLine + srcStride;
for (x=startX; x<endX+1; x++)
{
#if SAO_SGN_FUNC
signUpLine[x] = (Char)sgn(srcLineBelow[x] - srcLine[x-1]);
#else
signUpLine[x] = (Char)m_sign[srcLineBelow[x] - srcLine[x-1]];
#endif
}
//1st line
Pel* srcLineAbove = srcLine - srcStride;
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
firstLineStartX = (!isCalculatePreDeblockSamples) ? (isAboveLeftAvail ? 0 : 1) : startX;
firstLineEndX = (!isCalculatePreDeblockSamples) ? (isAboveAvail ? endX : 1) : endX;
#else
firstLineStartX = isAboveLeftAvail ? 0 : 1;
firstLineEndX = isAboveAvail ? endX : 1;
#endif
for(x=firstLineStartX; x<firstLineEndX; x++)
{
#if SAO_SGN_FUNC
edgeType = sgn(srcLine[x] - srcLineAbove[x-1]) - signUpLine[x+1];
#else
edgeType = m_sign[srcLine[x] - srcLineAbove[x-1]] - signUpLine[x+1];
#endif
diff [edgeType] += (orgLine[x] - srcLine[x]);
count[edgeType] ++;
}
srcLine += srcStride;
orgLine += orgStride;
//middle lines
for (y=1; y<endY; y++)
{
srcLineBelow = srcLine + srcStride;
for (x=startX; x<endX; x++)
{
#if SAO_SGN_FUNC
signDown = (Char)sgn(srcLine[x] - srcLineBelow[x+1]);
#else
signDown = (Char)m_sign[srcLine[x] - srcLineBelow[x+1]] ;
#endif
edgeType = signDown + signUpLine[x];
diff [edgeType] += (orgLine[x] - srcLine[x]);
count[edgeType] ++;
signDownLine[x+1] = -signDown;
}
#if SAO_SGN_FUNC
signDownLine[startX] = (Char)sgn(srcLineBelow[startX] - srcLine[startX-1]);
#else
signDownLine[startX] = (Char)m_sign[srcLineBelow[startX] - srcLine[startX-1]];
#endif
signTmpLine = signUpLine;
signUpLine = signDownLine;
signDownLine = signTmpLine;
srcLine += srcStride;
orgLine += orgStride;
}
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
if(isCalculatePreDeblockSamples)
{
if(isBelowAvail)
{
startX = isLeftAvail ? 0 : 1 ;
endX = isRightAvail ? width : (width -1);
for(y=0; y<skipLinesB[typeIdx]; y++)
{
srcLineBelow = srcLine + srcStride;
srcLineAbove = srcLine - srcStride;
for (x=startX; x< endX; x++)
{
#if SAO_SGN_FUNC
edgeType = sgn(srcLine[x] - srcLineBelow[x+1]) + sgn(srcLine[x] - srcLineAbove[x-1]);
#else
edgeType = m_sign[srcLine[x] - srcLineBelow[x+1]] + m_sign[srcLine[x] - srcLineAbove[x-1]];
#endif
diff [edgeType] += (orgLine[x] - srcLine[x]);
count[edgeType] ++;
}
srcLine += srcStride;
orgLine += orgStride;
}
}
}
#endif
}
break;
case SAO_TYPE_EO_45:
{
diff +=2;
count+=2;
Char *signUpLine = m_signLineBuf1+1;
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
startX = (!isCalculatePreDeblockSamples) ? (isLeftAvail ? 0 : 1)
: (isRightAvail ? (width - skipLinesR[typeIdx]) : (width - 1))
;
#else
startX = isLeftAvail ? 0 : 1;
#endif
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
endX = (!isCalculatePreDeblockSamples) ? (isRightAvail ? (width - skipLinesR[typeIdx]) : (width - 1))
: (isRightAvail ? width : (width - 1))
;
#else
endX = isRightAvail ? (width - skipLinesR[typeIdx]) : (width - 1);
#endif
endY = isBelowAvail ? (height - skipLinesB[typeIdx]) : (height - 1);
//prepare 2nd line upper sign
Pel* srcLineBelow = srcLine + srcStride;
for (x=startX-1; x<endX; x++)
{
#if SAO_SGN_FUNC
signUpLine[x] = (Char)sgn(srcLineBelow[x] - srcLine[x+1]);
#else
signUpLine[x] = (Char)m_sign[srcLineBelow[x] - srcLine[x+1]];
#endif
}
//first line
Pel* srcLineAbove = srcLine - srcStride;
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
firstLineStartX = (!isCalculatePreDeblockSamples) ? (isAboveAvail ? startX : endX)
: startX
;
firstLineEndX = (!isCalculatePreDeblockSamples) ? ((!isRightAvail && isAboveRightAvail) ? width : endX)
: endX
;
#else
firstLineStartX = isAboveAvail ? startX : endX;
firstLineEndX = (!isRightAvail && isAboveRightAvail) ? width : endX;
#endif
for(x=firstLineStartX; x<firstLineEndX; x++)
{
#if SAO_SGN_FUNC
edgeType = sgn(srcLine[x] - srcLineAbove[x+1]) - signUpLine[x-1];
#else
edgeType = m_sign[srcLine[x] - srcLineAbove[x+1]] - signUpLine[x-1];
#endif
diff [edgeType] += (orgLine[x] - srcLine[x]);
count[edgeType] ++;
}
srcLine += srcStride;
orgLine += orgStride;
//middle lines
for (y=1; y<endY; y++)
{
srcLineBelow = srcLine + srcStride;
for(x=startX; x<endX; x++)
{
#if SAO_SGN_FUNC
signDown = (Char)sgn(srcLine[x] - srcLineBelow[x-1]);
#else
signDown = (Char)m_sign[srcLine[x] - srcLineBelow[x-1]] ;
#endif
edgeType = signDown + signUpLine[x];
diff [edgeType] += (orgLine[x] - srcLine[x]);
count[edgeType] ++;
signUpLine[x-1] = -signDown;
}
#if SAO_SGN_FUNC
signUpLine[endX-1] = (Char)sgn(srcLineBelow[endX-1] - srcLine[endX]);
#else
signUpLine[endX-1] = (Char)m_sign[srcLineBelow[endX-1] - srcLine[endX]];
#endif
srcLine += srcStride;
orgLine += orgStride;
}
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
if(isCalculatePreDeblockSamples)
{
if(isBelowAvail)
{
startX = isLeftAvail ? 0 : 1 ;
endX = isRightAvail ? width : (width -1);
for(y=0; y<skipLinesB[typeIdx]; y++)
{
srcLineBelow = srcLine + srcStride;
srcLineAbove = srcLine - srcStride;
for (x=startX; x<endX; x++)
{
#if SAO_SGN_FUNC
edgeType = sgn(srcLine[x] - srcLineBelow[x-1]) + sgn(srcLine[x] - srcLineAbove[x+1]);
#else
edgeType = m_sign[srcLine[x] - srcLineBelow[x-1]] + m_sign[srcLine[x] - srcLineAbove[x+1]];
#endif
diff [edgeType] += (orgLine[x] - srcLine[x]);
count[edgeType] ++;
}
srcLine += srcStride;
orgLine += orgStride;
}
}
}
#endif
}
break;
case SAO_TYPE_BO:
{
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
startX = (!isCalculatePreDeblockSamples)?0
:( isRightAvail?(width- skipLinesR[typeIdx]):width)
;
endX = (!isCalculatePreDeblockSamples)?(isRightAvail ? (width - skipLinesR[typeIdx]) : width )
:width
;
#else
endX = isRightAvail ? (width- skipLinesR[typeIdx]) : width;
#endif
endY = isBelowAvail ? (height- skipLinesB[typeIdx]) : height;
Int shiftBits = ((compIdx == SAO_Y)?g_bitDepthY:g_bitDepthC)- NUM_SAO_BO_CLASSES_LOG2;
for (y=0; y< endY; y++)
{
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
for (x=startX; x< endX; x++)
#else
for (x=0; x< endX; x++)
#endif
{
Int bandIdx= srcLine[x] >> shiftBits;
diff [bandIdx] += (orgLine[x] - srcLine[x]);
count[bandIdx] ++;
}
srcLine += srcStride;
orgLine += orgStride;
}
#if SAO_ENCODE_ALLOW_USE_PREDEBLOCK
if(isCalculatePreDeblockSamples)
{
if(isBelowAvail)
{
startX = 0;
endX = width;
for(y= 0; y< skipLinesB[typeIdx]; y++)
{
for (x=startX; x< endX; x++)
{
Int bandIdx= srcLine[x] >> shiftBits;
diff [bandIdx] += (orgLine[x] - srcLine[x]);
count[bandIdx] ++;
}
srcLine += srcStride;
orgLine += orgStride;
}
}
}
#endif
}
break;
default:
{
printf("Not a supported SAO types\n");
assert(0);
exit(-1);
}
}
}
}
//! \}
~~~
HEVC算法和体系结构:HEVC概括性介绍
最后更新于:2022-04-01 16:05:25
1、HEVC高级语法:提供了一个稳健、灵活和可扩展的框架,用于携带编码的视频及其相关信息,确保在不同的应用环境中,视频内容都能够以最有效的方式传输。
2、HEVC块结构和并行特性:确保了HEVC编码设计的基本结构。
3、HEVC帧内预测:在之前的编码标准中已经取得实质性的技术进步,即使是静态场景。
4、HEVC帧间预测:视频编码的核心问题,高效的帧间预测对HEVC的强大性和灵活性起着决定性的作用。
5、HEVC变换和量化:HEVC拥有更加灵活和自适应地变换和量化设计。
6、HEVC环内滤波器:包括环内去块滤波器(DBF)和样点自适应补偿(SAO)滤波器,在主观和客观上对视频内容都有所改善。
7、HEVC熵编码:采用基于上下文的算术编码(CABAC)方式。
8、HEVC压缩性能分析:在不同应用上的主观和客观测试分析。
9、HEVC解码器硬件结构设计:解码器的数量在实际应用中会比编码器的数量多得多,降低其功耗和成本在实际应用中至关重要。
10、HEVC编码器硬件结构设计:设计符合标准语法元素的编码器,使解码器能够根据语法元素正确解码出视频内容;压缩性能优异;没有实际应用平台的限制。
HEVC算法和体系结构:资源获取和章节安排
最后更新于:2022-04-01 16:05:22
从今天开始,将陆续更新自己学习总结的最新版HEVC著作《High Efficiency Video Coding (Hevc): Algorithms and Architectures》中的相关知识点,原书英文电子版需要的可在下面评论留言。
本书封面如下:

章节安排如下:1~9章主要讲述HEVC的算法和工具,10和11两章主要主要讲述构建HEVC硬件的体系结构。


前言
最后更新于:2022-04-01 16:05:20
> 原文出处:[HEVC算法和体系结构](http://blog.csdn.net/column/details/hevc-fred.html)
作者:[frd2009041510](http://blog.csdn.net/frd2009041510)
**本系列文章经作者授权在看云整理发布,未经作者允许,请勿转载!**
# HEVC算法和体系结构
> 最新国际视频编码标准HEVC(High Efficiency Video Coding)在未来十年内势必成为成为一种趋势,并日益普及到各类多媒体领域,本专栏从理论、实现、实践的三大角度深入浅出地分析HEVC相关技术和算法等,并根据实际应用来进一步剖析该标准的实际用途。