数据库面试常问的一些基本概念
最后更新于:2022-04-01 09:55:23
**1、超键、候选键、主键、外键**
超键:在关系中能唯一标识元组的属性集称为关系模式的超键。一个属性可以为作为一个超键,多个属性组合在一起也可以作为一个超键。超键包含候选键和主键。
候选键:是最小超键,即没有冗余元素的超键。
主键:数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合。一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null)。
外键:在一个表中存在的另一个表的主键称此表的外键。
**2、什么是事务?什么是锁?**
事务:就是被绑定在一起作为一个逻辑工作单元的 SQL 语句分组,如果任何一个语句操作失败那么整个操作就被失败,以后操作就会回滚到操作前状态,或者是上有个节点。为了确保要么执行,要么不执行,就可以使用事务。要将有组语句作为事务考虑,就需要通过 ACID 测试,即原子性,一致性,隔离性和持久性。
锁:在所以的 DBMS 中,锁是实现事务的关键,锁可以保证事务的完整性和并发性。与现实生活中锁一样,它可以使某些数据的拥有者,在某段时间内不能使用某些数据或数据结构。当然锁还分级别的。
**3、数据库事务的四个特性及含义**
原子性:整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性:在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
隔离性:隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。如果有两个事务,运行在相同的时间内,执行 相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称为串行化,为了防止事务操作间的混淆,必须串行化或序列化请 求,使得在同一时间仅有一个请求用于同一数据。
持久性:在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
**4、什么是视图?**
视图是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增,改,查,操作,试图通常是有一个表或者多个表的行或列的子集。对视图的修改不影响基本表。它使得我们获取数据更容易,相比多表查询。
如下两种场景一般会使用到视图:
(1)不希望访问者获取整个表的信息,只暴露部分字段给访问者,所以就建一个虚表,就是视图。
(2)查询的数据来源于不同的表,而查询者希望以统一的方式查询,这样也可以建立一个视图,把多个表查询结果联合起来,查询者只需要直接从视图中获取数据,不必考虑数据来源于不同表所带来的差异。
注:这个视图是在数据库中创建的 而不是用代码创建的。
**5、触发器的作用?**
触发器是一中特殊的存储过程,主要是通过事件来触发而被执行的。它可以强化约束,来维护数据的完整性和一致性,可以跟踪数据库内的操作从而不允许未经许可的更新和变化。可以联级运算。如,某表上的触发器上包含对另一个表的数据操作,而该操作又会导致该表触发器被触发。
**6、 维护数据库的完整性和一致性,你喜欢用触发器还是自写业务逻辑?为什么?**
尽可能使用约束,如 check, 主键,外键,非空字段等来约束,这样做效率最高,也最方便。其次是使用触发器,这种方法可以保证,无论什么业务系统访问数据库都可以保证数据的完整新和一致性。最后考虑的是自写业务逻辑,但这样做麻烦,编程复杂,效率低下。
**7、索引的作用?和它的优点缺点是什么?**
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
为表设置索引要付出代价的:一是增加了数据库的存储空间,二是在插入和修改数据时要花费较多的时间(因为索引也要随之变动)。
**创建索引可以大大提高系统的性能(优点):**
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
也许会有人要问:增加索引有如此多的优点,为什么不对表中的每一个列创建一个索引呢?因为,增加索引也有许多不利的方面:
第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
索引是建立在数据库表中的某些列的上面。在创建索引的时候,应该考虑在哪些列上可以创建索引,在哪些列上不能创建索引。
一**般来说,应该在这些列上创建索引:**
(1)在经常需要搜索的列上,可以加快搜索的速度;
(2)在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
(3)在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;
(4)在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
(5)在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
(6)在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
**同样,对于有些列不应该创建索引:**
第一,对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
第二,对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
第三,对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
第四,当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
**8、drop,delete与truncate的区别**
drop直接删掉表 。
truncate删除表中数据,再插入时自增长id又从1开始 。
delete删除表中数据,可以加where字句。
(1) DELETE语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存以便进行进行回滚操作。TRUNCATE TABLE 则一次性地从表中删除所有的数据并不把单独的删除操作记录记入日志保存,删除行是不能恢复的。并且在删除的过程中不会激活与表有关的删除触发器。执行速度快。
(2) 表和索引所占空间。当表被TRUNCATE 后,这个表和索引所占用的空间会恢复到初始大小,而DELETE操作不会减少表或索引所占用的空间。drop语句将表所占用的空间全释放掉。
(3) 一般而言,drop > truncate > delete
(4) 应用范围。TRUNCATE 只能对TABLE;DELETE可以是table和view
(5) TRUNCATE 和DELETE只删除数据,而DROP则删除整个表(结构和数据)。
(6) truncate与不带where的delete :只删除数据,而不删除表的结构(定义)drop语句将删除表的结构被依赖的约束(constrain),触发器(trigger)索引(index);依赖于该表的存储过程/函数将被保留,但其状态会变为:invalid。
(7) delete语句为DML(data maintain Language),这个操作会被放到 rollback segment中,事务提交后才生效。如果有相应的 tigger,执行的时候将被触发。
(8) truncate、drop是DLL(data define language),操作立即生效,原数据不放到 rollback segment中,不能回滚。
(9) 在没有备份情况下,谨慎使用 drop 与 truncate。要删除部分数据行采用delete且注意结合where来约束影响范围。回滚段要足够大。要删除表用drop;若想保留表而将表中数据删除,如果于事务无关,用truncate即可实现。如果和事务有关,或老师想触发trigger,还是用delete。
(10) Truncate table 表名 速度快,而且效率高,因为:
truncate table 在功能上与不带 WHERE 子句的 DELETE 语句相同:二者均删除表中的全部行。但 TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少。DELETE 语句每次删除一行,并在事务日志中为所删除的每行记录一项。TRUNCATE TABLE 通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。
(11) TRUNCATE TABLE 删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用 DELETE。如果要删除表定义及其数据,请使用 DROP TABLE 语句。
(12) 对于由 FOREIGN KEY 约束引用的表,不能使用 TRUNCATE TABLE,而应使用不带 WHERE 子句的 DELETE 语句。由于 TRUNCATE TABLE 不记录在日志中,所以它不能激活触发器。
SQL实例整理
最后更新于:2022-04-01 09:55:21
本文适合将w3school的SQL教程([http://www.w3school.com.cn/sql/sql_create_table.asp](http://www.w3school.com.cn/sql/sql_create_table.asp))都基本看过一遍的猿友阅读。
说说博主的情况吧。毕业找工作之前确实有大概看过w3school的SQL教程,然后参加校园招聘,每次遇到一些SQL笔试题,立马懵逼了(大写的)。其实我那时候大概知道怎么写的,只是总是写不正确,或者是对一些特定的而且没有见过的场景的SQL语句,根本写不出来。相信不少猿友工作之后,其实挺多都用得不熟吧(如果白板编写的话)。
因为大部分Java猿友工作做的事情,其实比较少情况自己去动手写特定场景的SQL(可能有也是百度,接触过一个会一个),简单SQL也是直接由框架(hibernate和Mybatis)提供接口。当然,那种专门做后台,经常跟数据打交道的Java猿友除外,因此只能说大部分。
如果还是继续保持这样的状态的话,下次自己找工作遇到SQL笔试题,估计也会继续懵逼(大写的)。
下面小宝鸽整理了一些实例(实例主要来自网上),以提升自己写SQL的某些关键字的理解。
**1、用一条SQL 语句 查询出每门课都大于80 分的学生姓名。(表结构如下图)**

答案可以有如下两种:
~~~
select distinct student_name from table_test_one where student_name not in
(select distinct student_name from table_test_one where score<=80);
~~~
或者
~~~
select student_name from table_test_one group by student_name having min(score)>80;
~~~
第二种方法是group by 、min函数 结合 having的使用,w3school教程里面也提到过(在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用)
似乎看懂了,但是还是没有自己运行一遍深刻!!!自己能动手敲一遍就更好了!
下面我们自己造数据,后面的例子也会用到。
建表然后倒入初始数据:
~~~
DROP TABLE IF EXISTS `table_test_one`;
CREATE TABLE `table_test_one` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`student_no` varchar(10) NOT NULL,
`student_name` varchar(10) NOT NULL,
`subject_no` varchar(10) NOT NULL,
`subject_name` varchar(10) NOT NULL,
`score` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
~~~
~~~
INSERT INTO `table_test_one` VALUES ('1', '201601', '张三', '0001', '数学', '98');
INSERT INTO `table_test_one` VALUES ('2', '201601', '张三', '0002', '语文', '66');
INSERT INTO `table_test_one` VALUES ('3', '201602', '李四', '0001', '数学', '60');
INSERT INTO `table_test_one` VALUES ('4', '201602', '李四', '0003', '英语', '78');
INSERT INTO `table_test_one` VALUES ('5', '201603', '王五', '0001', '数学', '99');
INSERT INTO `table_test_one` VALUES ('6', '201603', '王五', '0002', '语文', '99');
INSERT INTO `table_test_one` VALUES ('7', '201603', '王五', '0003', '英语', '98');
~~~
可以运行一下上面两个语句试试结果是不是你想要的。
**2、删除除了id不同, 其他都相同的学生冗余信息,表如下:**

答案:
~~~
delete table_test_one where id not in
(select min(id) from table_test_one group by
student_no, student_name, subject_no, subject_name, score);
~~~
是否有看懂?如果没能看懂的话,继续往下看:
先来造数据,题1中的数据只需要执行如下SQL就变成题2中的数据了:
~~~
update table_test_one set subject_no = '0001', subject_name = '数学' where id = 6;
~~~
然后我们先执行这个看看:
~~~
select min(id) from table_test_one group by
student_no, student_name, subject_no, subject_name, score
~~~
这个的执行结果如下:

如果还不懂就再看看几次吧。
PS:GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组。刚刚就是GROUP BY 对多列的使用场景。
**3、行转列:**
表数据如下:

希望查询到结果如下:

答案:
~~~
select year,
(select amount from table_test_two t where t.month = 1 and t.year = table_test_two.year) as month1,
(select amount from table_test_two t where t.month = 2 and t.year = table_test_two.year) as month2,
(select amount from table_test_two t where t.month = 3 and t.year = table_test_two.year) as month3
from table_test_two group by year;
~~~
利用group by 实现行转列,这种场景在数据统计的时候经常用到。
猿友可以造数据自己运行试试:
~~~
-- ----------------------------
-- Table structure for `table_test_two`
-- ----------------------------
DROP TABLE IF EXISTS `table_test_two`;
CREATE TABLE `table_test_two` (
`year` int(11) NOT NULL,
`month` int(11) NOT NULL,
`amount` decimal(10,1) NOT NULL,
PRIMARY KEY (`year`,`month`,`amount`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- ----------------------------
-- Records of table_test_two
-- ----------------------------
INSERT INTO `table_test_two` VALUES ('1991', '1', '1.1');
INSERT INTO `table_test_two` VALUES ('1991', '2', '1.2');
INSERT INTO `table_test_two` VALUES ('1991', '3', '1.3');
INSERT INTO `table_test_two` VALUES ('1992', '1', '2.1');
INSERT INTO `table_test_two` VALUES ('1992', '2', '2.2');
INSERT INTO `table_test_two` VALUES ('1992', '3', '2.3');
~~~
**4、复制表( 只复制结构, 源表名:table_test_two 新表名:table_test_three)**
答案:
~~~
create table table_test_three as
select * from table_test_two where 1=2;
~~~
PS:如果需要将数据也复制过去,则上面改成where 1=1
**5、复制表数据(将表 table_test_two 的数据复制到表table_test_three 里面)**
答案:
~~~
insert into table_test_three (year,month,amount)
select year,month,amount from table_test_two;
~~~
**6、两张关联表,删除主表中已经在副表中没有的信息**
答案:
~~~
delete from table_test_student where not exists
(select * from table_test_class where table_test_student.class_id = table_test_class.calss_id);
~~~
我们先造点数据吧:
~~~
-- ----------------------------
-- Table structure for `table_test_class`
-- ----------------------------
DROP TABLE IF EXISTS `table_test_class`;
CREATE TABLE `table_test_class` (
`calss_id` int(11) NOT NULL AUTO_INCREMENT,
`calss_name` varchar(10) CHARACTER SET utf8 NOT NULL,
PRIMARY KEY (`calss_id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=latin1;
-- ----------------------------
-- Records of table_test_class
-- ----------------------------
INSERT INTO `table_test_class` VALUES ('1', '一班');
~~~
~~~
-- ----------------------------
-- Table structure for `table_test_student`
-- ----------------------------
DROP TABLE IF EXISTS `table_test_student`;
CREATE TABLE `table_test_student` (
`student_id` int(11) NOT NULL AUTO_INCREMENT,
`student_name` varchar(10) CHARACTER SET utf8 NOT NULL,
`class_id` int(11) NOT NULL,
PRIMARY KEY (`student_id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=latin1;
-- ----------------------------
-- Records of table_test_student
-- ----------------------------
INSERT INTO `table_test_student` VALUES ('1', '罗国辉', '1');
INSERT INTO `table_test_student` VALUES ('2', '小宝鸽', '2');
~~~
执行后数据如下:


显然副表student中小宝鸽这条数据的calss_id,主表没有对应的class_id.
执行对应SQL语句就会把小宝鸽这条数据删除掉了。
* * *
未完待续……….(TODO),边学习边写博客真的很花时间,累并快乐着~~~
Java内存管理
最后更新于:2022-04-01 09:55:18
前一段时间粗略看了一下《深入Java虚拟机 第二版》,可能是因为工作才一年的原因吧,看着十分的吃力。毕竟如果具体到细节的话,Java虚拟机涉及的内容太多了。可能再过一两年去看会合适一些吧。
不过看了一遍《深入Java虚拟机》再来理解Java内存管理会好很多。接下来一起学习下Java内存管理吧。

请注意上图的这个:

我们再来复习下进程与线程吧:
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
似乎现在更好理解了一些:
方法区和堆是分配给进程的,也就是所有线程共享的。
而栈和程序计数器,则是分配给每个独立线程的,是运行过程中必不可少的资源。
下面我们逐个看下栈、堆、方法区和程序计数器。
**1、方法区(Method Area)**
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应该是与Java堆区分开来。
**2、程序计数器(Program Counter Register)**
程序计数器(Program Counter Register)是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的行号指示器。在虚拟机的概念模型里(仅是概念模型,各种虚拟机可能会通过一些更高效的方式去实现),字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
下面重点解下Java内存管理中的栈和堆。
**3、栈(Stacks)**
在Java中,JVM中的栈记录了线程的方法调用。每个线程拥有一个栈。在某个线程的运行过程中,如果有新的方法调用,那么该线程对应的栈就会增加一个存储单元,即帧(frame)。在frame中,保存有该方法调用的参数、局部变量和返回地址。
Java的参数和局部变量只能是基本类型的变量(比如int),或者对象的引用(reference)。因此,在栈中,只保存有基本类型的变量和对象引用。引用所指向的对象保存在堆中。(引用可能为Null值,即不指向任何对象)。
当被调用方法运行结束时,该方法对应的帧将被删除,参数和局部变量所占据的空间也随之释放。线程回到原方法,继续执行。当所有的栈都清空时,程序也随之运行结束。
**本地方法栈与虚拟机栈的区别:**
本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的Native方法服务。虚拟机规范中对本地方法栈中的方法使用的语言、使用方式与数据结构并没有强制规定,因此具体的虚拟机可以自由实现它。甚至有的虚拟机(譬如Sun HotSpot虚拟机)直接就把本地方法栈和虚拟机栈合二为一。与虚拟机栈一样,本地方法栈区域也会抛出StackOverflowError和OutOfMemoryError异常。
**4、堆(Heap)**
堆是JVM中一块可自由分配给对象的区域。当我们谈论垃圾回收(garbage collection)时,我们主要回收堆(heap)的空间。
Java的普通对象存活在堆中。与栈不同,堆的空间不会随着方法调用结束而清空。因此,在某个方法中创建的对象,可以在方法调用结束之后,继续存在于堆中。这带来的一个问题是,如果我们不断的创建新的对象,内存空间将最终消耗殆尽。
**垃圾回收(Garbage Collection,GC)**
垃圾回收(garbage collection,简称GC)可以自动清空堆中不再使用的对象。垃圾回收机制最早出现于1959年,被用于解决Lisp语言中的问题。垃圾回收是Java的一大特征。并不是所有的语言都有垃圾回收功能。比如在C/C++中,并没有垃圾回收的机制。程序员需要手动释放堆中的内存。
由于不需要手动释放内存,程序员在编程中也可以减少犯错的机会。利用垃圾回收,程序员可以避免一些指针和内存泄露相关的bug(这一类bug通常很隐蔽)。但另一方面,垃圾回收需要耗费更多的计算时间。垃圾回收实际上是将原本属于程序员的责任转移给计算机。使用垃圾回收的程序需要更长的运行时间。
在Java中,对象的是通过引用使用的(把对象相像成致命的毒物,引用就像是用于提取毒物的镊子)。如果不再有引用指向对象,那么我们就再也无从调用或者处理该对象。这样的对象将不可到达(unreachable)。垃圾回收用于释放不可到达对象所占据的内存。这是垃圾回收的基本原则。
早期的垃圾回收采用引用计数(reference counting)的机制。每个对象包含一个计数器。当有新的指向该对象的引用时,计数器加1。当引用移除时,计数器减1。当计数器为0时,认为该对象可以进行垃圾回收。
然而,一个可能的问题是,如果有两个对象循环引用(cyclic reference),比如两个对象互相引用,而且此时没有其它(指向A或者指向B)的引用,我们实际上根本无法通过引用到达这两个对象。
因此,我们以栈和static数据为根(root),从根出发,跟随所有的引用,就可以找到所有的可到达对象。也就是说,一个可到达对象,一定被根引用,或者被其他可到达对象引用。
Java经典设计模式之十一种行为型模式(附实例和详解)
最后更新于:2022-04-01 09:55:16
Java经典设计模式共有21中,分为三大类:创建型模式(5种)、结构型模式(7种)和行为型模式(11种)。
本文主要讲行为型模式,创建型模式和结构型模式可以看博主的另外两篇文章:[Java经典设计模式之五大创建型模式(附实例和详解)](http://blog.csdn.net/u013142781/article/details/50816245)、[ Java经典设计模式之七大结构型模式(附实例和详解)](http://blog.csdn.net/u013142781/article/details/50821155)。
行为型模式细分为如下11种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
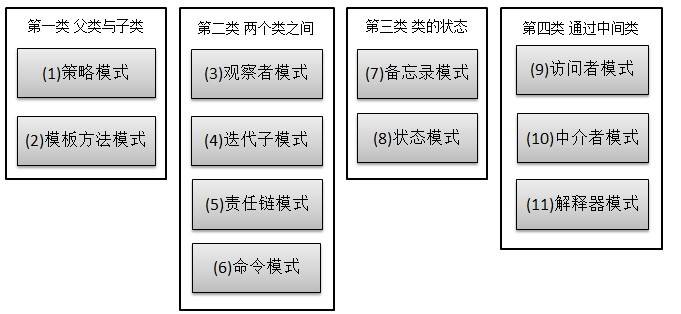
接下来对11种行为型模式逐个进行介绍。
### 一、策略模式
策略模式定义了一系列算法,并将每个算法封装起来,使他们可以相互替换,且算法的变化不会影响到使用算法的客户。需要设计一个接口,为一系列实现类提供统一的方法,多个实现类实现该接口,设计一个抽象类(可有可无,属于辅助类,视实际需求是否添加),提供辅助函数。
首先统一接口:
~~~
package com.model.behaviour;
public interface ICalculator {
public int calculate(String exp);
}
~~~
辅助类:
~~~
package com.model.behaviour;
public abstract class AbstractCalculator {
public int[] split(String exp, String opt) {
String array[] = exp.split(opt);
int arrayInt[] = new int[2];
arrayInt[0] = Integer.parseInt(array[0]);
arrayInt[1] = Integer.parseInt(array[1]);
return arrayInt;
}
}
~~~
三个实现类:
~~~
package com.model.behaviour;
public class Plus extends AbstractCalculator implements ICalculator {
@Override
public int calculate(String exp) {
int arrayInt[] = split(exp, "\\+");
return arrayInt[0] + arrayInt[1];
}
}
~~~
~~~
package com.model.behaviour;
public class Minus extends AbstractCalculator implements ICalculator {
@Override
public int calculate(String exp) {
int arrayInt[] = split(exp, "\\-");
return arrayInt[0] - arrayInt[1];
}
}
~~~
~~~
package com.model.behaviour;
public class Multiply extends AbstractCalculator implements ICalculator {
@Override
public int calculate(String exp) {
int arrayInt[] = split(exp,"\\*");
return arrayInt[0]*arrayInt[1];
}
}
~~~
测试类:
~~~
package com.model.behaviour;
public class StrategyTest {
public static void main(String[] args) {
String exp = "8-2";
ICalculator cal = new Minus();
int result = cal.calculate(exp);
System.out.println(exp + "=" + result);
}
}
~~~
策略模式的决定权在用户,系统本身提供不同算法的实现,新增或者删除算法,对各种算法做封装。因此,策略模式多用在算法决策系统中,外部用户只需要决定用哪个算法即可。
### 二、模板方法模式
解释一下模板方法模式,就是指:一个抽象类中,有一个主方法,再定义1…n个方法,可以是抽象的,也可以是实际的方法,定义一个类,继承该抽象类,重写抽象方法,通过调用抽象类,实现对子类的调用。
就是在AbstractCalculator类中定义一个主方法calculate,calculate()调用spilt()等,Plus和Minus分别继承AbstractCalculator类,通过对AbstractCalculator的调用实现对子类的调用,看下面的例子:
~~~
package com.model.behaviour;
public abstract class AbstractCalculator {
/*主方法,实现对本类其它方法的调用*/
public final int calculate(String exp,String opt){
int array[] = split(exp,opt);
return calculate(array[0],array[1]);
}
/*被子类重写的方法*/
abstract public int calculate(int num1,int num2);
public int[] split(String exp,String opt){
String array[] = exp.split(opt);
int arrayInt[] = new int[2];
arrayInt[0] = Integer.parseInt(array[0]);
arrayInt[1] = Integer.parseInt(array[1]);
return arrayInt;
}
}
~~~
~~~
package com.model.behaviour;
public class Plus extends AbstractCalculator {
@Override
public int calculate(int num1,int num2) {
return num1 + num2;
}
}
~~~
~~~
package com.model.behaviour;
public class StrategyTest {
public static void main(String[] args) {
String exp = "8+8";
AbstractCalculator cal = new Plus();
int result = cal.calculate(exp, "\\+");
System.out.println(result);
}
}
~~~
### 三、观察者模式
包括这个模式在内的接下来的四个模式,都是类和类之间的关系,不涉及到继承。
观察者模式很好理解,类似于邮件订阅和RSS订阅,当我们浏览一些博客或wiki时,经常会看到RSS图标,就这的意思是,当你订阅了该文章,如果后续有更新,会及时通知你。其实,简单来讲就一句话:当一个对象变化时,其它依赖该对象的对象都会收到通知,并且随着变化!对象之间是一种一对多的关系。
~~~
package com.model.behaviour;
public interface Observer {
public void update();
}
~~~
~~~
package com.model.behaviour;
public class Observer1 implements Observer {
@Override
public void update() {
System.out.println("observer1 has received!");
}
}
~~~
~~~
package com.model.behaviour;
public class Observer2 implements Observer {
@Override
public void update() {
System.out.println("observer2 has received!");
}
}
~~~
~~~
package com.model.behaviour;
public interface Subject {
/*增加观察者*/
public void add(Observer observer);
/*删除观察者*/
public void del(Observer observer);
/*通知所有的观察者*/
public void notifyObservers();
/*自身的操作*/
public void operation();
}
~~~
~~~
package com.model.behaviour;
import java.util.Enumeration;
import java.util.Vector;
public abstract class AbstractSubject implements Subject {
private Vector<Observer> vector = new Vector<Observer>();
@Override
public void add(Observer observer) {
vector.add(observer);
}
@Override
public void del(Observer observer) {
vector.remove(observer);
}
@Override
public void notifyObservers() {
Enumeration<Observer> enumo = vector.elements();
while(enumo.hasMoreElements()){
enumo.nextElement().update();
}
}
}
~~~
~~~
package com.model.behaviour;
public class MySubject extends AbstractSubject {
@Override
public void operation() {
System.out.println("update self!");
notifyObservers();
}
}
~~~
~~~
package com.model.behaviour;
public class ObserverTest {
public static void main(String[] args) {
Subject sub = new MySubject();
sub.add(new Observer1());
sub.add(new Observer2());
sub.operation();
}
}
~~~
运行结果:
~~~
update self!
observer1 has received!
observer2 has received!
~~~
也许看完实例之后还是比较抽象,再将文字描述和代码实例看一两遍吧,然后结合工作中看哪些场景可以使用这种模式以加深理解。
### 四、迭代子模式
顾名思义,迭代器模式就是顺序访问聚集中的对象,一般来说,集合中非常常见,如果对集合类比较熟悉的话,理解本模式会十分轻松。这句话包含两层意思:一是需要遍历的对象,即聚集对象,二是迭代器对象,用于对聚集对象进行遍历访问。
具体来看看代码实例:
~~~
package com.model.behaviour;
public interface Collection {
public Iterator iterator();
/* 取得集合元素 */
public Object get(int i);
/* 取得集合大小 */
public int size();
}
~~~
~~~
package com.model.behaviour;
public interface Iterator {
// 前移
public Object previous();
// 后移
public Object next();
public boolean hasNext();
// 取得第一个元素
public Object first();
}
~~~
~~~
package com.model.behaviour;
public class MyCollection implements Collection {
public String string[] = { "A", "B", "C", "D", "E" };
@Override
public Iterator iterator() {
return new MyIterator(this);
}
@Override
public Object get(int i) {
return string[i];
}
@Override
public int size() {
return string.length;
}
}
~~~
~~~
package com.model.behaviour;
public class MyIterator implements Iterator {
private Collection collection;
private int pos = -1;
public MyIterator(Collection collection){
this.collection = collection;
}
@Override
public Object previous() {
if(pos > 0){
pos--;
}
return collection.get(pos);
}
@Override
public Object next() {
if(pos<collection.size()-1){
pos++;
}
return collection.get(pos);
}
@Override
public boolean hasNext() {
if(pos<collection.size()-1){
return true;
}else{
return false;
}
}
@Override
public Object first() {
pos = 0;
return collection.get(pos);
}
}
~~~
~~~
package com.model.behaviour;
public class Test {
public static void main(String[] args) {
Collection collection = new MyCollection();
Iterator it = (Iterator) collection.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
~~~
输出结果:
~~~
A
B
C
D
E
~~~
此处我们貌似模拟了一个集合类的过程,感觉是不是很爽?其实JDK中各个类也都是这些基本的东西,加一些设计模式,再加一些优化放到一起的,只要我们把这些东西学会了,掌握好了,我们也可以写出自己的集合类,甚至框架!
### 五、责任链模式
责任链模式,有多个对象,每个对象持有对下一个对象的引用,这样就会形成一条链,请求在这条链上传递,直到某一对象决定处理该请求。但是发出者并不清楚到底最终那个对象会处理该请求,所以,责任链模式可以实现,在隐瞒客户端的情况下,对系统进行动态的调整。
~~~
package com.model.behaviour;
public interface Handler {
public void operator();
}
~~~
~~~
package com.model.behaviour;
public abstract class AbstractHandler {
private Handler handler;
public Handler getHandler() {
return handler;
}
public void setHandler(Handler handler) {
this.handler = handler;
}
}
~~~
~~~
package com.model.behaviour;
public class MyHandler extends AbstractHandler implements Handler {
private String name;
public MyHandler(String name) {
this.name = name;
}
@Override
public void operator() {
System.out.println(name + "deal!");
if (getHandler() != null) {
getHandler().operator();
}
}
}
~~~
~~~
package com.model.behaviour;
public class Test {
public static void main(String[] args) {
MyHandler h1 = new MyHandler("h1");
MyHandler h2 = new MyHandler("h2");
MyHandler h3 = new MyHandler("h3");
h1.setHandler(h2);
h2.setHandler(h3);
h1.operator();
}
}
~~~
运行结果:
~~~
h1deal!
h2deal!
h3deal!
~~~
此处强调一点就是,链接上的请求可以是一条链,可以是一个树,还可以是一个环,模式本身不约束这个,需要我们自己去实现,同时,在一个时刻,命令只允许由一个对象传给另一个对象,而不允许传给多个对象。
### 六、命令模式
命令模式很好理解,举个例子,司令员下令让士兵去干件事情,从整个事情的角度来考虑,司令员的作用是,发出口令,口令经过传递,传到了士兵耳朵里,士兵去执行。这个过程好在,三者相互解耦,任何一方都不用去依赖其他人,只需要做好自己的事儿就行,司令员要的是结果,不会去关注到底士兵是怎么实现的。
~~~
package com.model.behaviour;
public interface Command {
public void exe();
}
~~~
~~~
package com.model.behaviour;
public class MyCommand implements Command {
private Receiver receiver;
public MyCommand(Receiver receiver) {
this.receiver = receiver;
}
@Override
public void exe() {
receiver.action();
}
}
~~~
~~~
package com.model.behaviour;
public class Invoker {
private Command command;
public Invoker(Command command) {
this.command = command;
}
public void action() {
command.exe();
}
}
~~~
~~~
package com.model.behaviour;
public class Test {
public static void main(String[] args) {
Receiver receiver = new Receiver();
Command cmd = new MyCommand(receiver);
Invoker invoker = new Invoker(cmd);
invoker.action();
}
}
~~~
命令模式的目的就是达到命令的发出者和执行者之间解耦,实现请求和执行分开,熟悉Struts的同学应该知道,Struts其实就是一种将请求和呈现分离的技术,其中必然涉及命令模式的思想!
### 七、备忘录模式
主要目的是保存一个对象的某个状态,以便在适当的时候恢复对象,个人觉得叫备份模式更形象些,通俗的讲下:假设有原始类A,A中有各种属性,A可以决定需要备份的属性,备忘录类B是用来存储A的一些内部状态,类C呢,就是一个用来存储备忘录的,且只能存储,不能修改等操作。
~~~
package com.model.behaviour;
public class Original {
private String value;
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
public Original(String value) {
this.value = value;
}
public Memento createMemento(){
return new Memento(value);
}
public void restoreMemento(Memento memento){
this.value = memento.getValue();
}
}
~~~
~~~
package com.model.behaviour;
public class Memento {
private String value;
public Memento(String value) {
this.value = value;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}
~~~
~~~
package com.model.behaviour;
public class Storage {
private Memento memento;
public Storage(Memento memento) {
this.memento = memento;
}
public Memento getMemento() {
return memento;
}
public void setMemento(Memento memento) {
this.memento = memento;
}
}
~~~
~~~
package com.model.behaviour;
public class Test {
public static void main(String[] args) {
// 创建原始类
Original origi = new Original("egg");
// 创建备忘录
Storage storage = new Storage(origi.createMemento());
// 修改原始类的状态
System.out.println("初始化状态为:" + origi.getValue());
origi.setValue("niu");
System.out.println("修改后的状态为:" + origi.getValue());
// 回复原始类的状态
origi.restoreMemento(storage.getMemento());
System.out.println("恢复后的状态为:" + origi.getValue());
}
}
~~~
输出结果:
~~~
初始化状态为:egg
修改后的状态为:niu
恢复后的状态为:egg
~~~
如果还不能理解,可以给Original类添加一个属性name,然后其他类进行相应的修改试试。
### 八、状态模式
核心思想就是:当对象的状态改变时,同时改变其行为,很好理解!就拿QQ来说,有几种状态,在线、隐身、忙碌等,每个状态对应不同的操作,而且你的好友也能看到你的状态,所以,状态模式就两点:1、可以通过改变状态来获得不同的行为。2、你的好友能同时看到你的变化。
~~~
package com.model.behaviour;
public class State {
private String value;
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
public void method1(){
System.out.println("execute the first opt!");
}
public void method2(){
System.out.println("execute the second opt!");
}
}
~~~
~~~
package com.model.behaviour;
public class Context {
private State state;
public Context(State state) {
this.state = state;
}
public State getState() {
return state;
}
public void setState(State state) {
this.state = state;
}
public void method() {
System.out.println("状态为:" + state.getValue());
if (state.getValue().equals("state1")) {
state.method1();
} else if (state.getValue().equals("state2")) {
state.method2();
}
}
}
~~~
~~~
package com.model.behaviour;
public class Test {
public static void main(String[] args) {
State state = new State();
Context context = new Context(state);
//设置第一种状态
state.setValue("state1");
context.method();
//设置第二种状态
state.setValue("state2");
context.method();
}
}
~~~
运行结果:
~~~
状态为:state1
execute the first opt!
状态为:state2
execute the second opt!
~~~
根据这个特性,状态模式在日常开发中用的挺多的,尤其是做网站的时候,我们有时希望根据对象的某一属性,区别开他们的一些功能,比如说简单的权限控制等。
### 九、访问者模式
访问者模式把数据结构和作用于结构上的操作解耦合,使得操作集合可相对自由地演化。访问者模式适用于数据结构相对稳定算法又易变化的系统。因为访问者模式使得算法操作增加变得容易。若系统数据结构对象易于变化,经常有新的数据对象增加进来,则不适合使用访问者模式。访问者模式的优点是增加操作很容易,因为增加操作意味着增加新的访问者。访问者模式将有关行为集中到一个访问者对象中,其改变不影响系统数据结构。其缺点就是增加新的数据结构很困难。
访问者模式算是最复杂也是最难以理解的一种模式了。它表示一个作用于某对象结构中的各元素的操作。它使你可以在不改变各元素类的前提下定义作用于这些元素的新操作。
涉及角色:
1.Visitor 抽象访问者角色,为该对象结构中具体元素角色声明一个访问操作接口。该操作接口的名字和参数标识了发送访问请求给具体访问者的具体元素角色,这样访问者就可以通过该元素角色的特定接口直接访问它。
2.ConcreteVisitor.具体访问者角色,实现Visitor声明的接口。
3.Element 定义一个接受访问操作(accept()),它以一个访问者(Visitor)作为参数。
4.ConcreteElement 具体元素,实现了抽象元素(Element)所定义的接受操作接口。
5.ObjectStructure 结构对象角色,这是使用访问者模式必备的角色。它具备以下特性:能枚举它的元素;可以提供一个高层接口以允许访问者访问它的元素;如有需要,可以设计成一个复合对象或者一个聚集(如一个列表或无序集合)。
~~~
abstract class Element
{
public abstract void accept(IVisitor visitor);
public abstract void doSomething();
}
~~~
~~~
class ConcreteElement1 extends Element{
public void doSomething(){
System.out.println("这是元素1");
}
public void accept(IVisitor visitor){
visitor.visit(this);
}
}
~~~
~~~
class ConcreteElement2 extends Element{
public void doSomething(){
System.out.println("这是元素2");
}
public void accept(IVisitor visitor){
visitor.visit(this);
}
}
~~~
~~~
interface IVisitor{
public void visit(ConcreteElement1el1);
public void visit(ConcreteElement2el2);
}
~~~
~~~
class Visitor implements IVisitor{
public void visit(ConcreteElement1 el1){
el1.doSomething();
}
public void visit(ConcreteElement2 el2){
el2.doSomething();
}
}
~~~
~~~
class ObjectStruture{
public static List<Element> getList(){
List<Element>list = new ArrayList<Element>();
Random ran = newRandom();
for(int i = 0 ; i < 10 ; i ++){
int a=ran.nextInt(100);
if(a>50){
list.add (newConcreteElement1());
}else{
list.add (newConcreteElement2());
}
}
return list;
}
}
~~~
~~~
public class Client{
public static void main (String[]args){
List<Element> list = ObjectStruture.getList();
for(Elemente:list){
e.accept(newVisitor());
}
}
}
~~~
### 十、中介者模式
中介者模式(Mediator):用一个中介对象来封装一系列的对象交互。中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
举例:在一个公司里面,有很多部门、员工(我们统称他们互相为Colleague“同事”),为了完成一定的任务,“同事”之间肯定有许多需要互相配合、交流的过程。如果由各个“同事”频繁地到处去与自己有关的“同事”沟通,这样肯定会形成一个多对多的杂乱的联系网络而造成工作效率低下。
此时就需要一位专门的“中介者”给各个“同事”分配任务,以及统一跟进大家的进度并在“同事”之间实时地进行交互,保证“同事”之间必须的沟通交流。很明显我们知道此时的“中介者”担任了沟通“同事”彼此之间的重要角色了,“中介者”使得每个“同事”都变成一对一的联系方式,减轻了每个“同事”的负担,增强工作效率。
同事类族:
~~~
package com.model.behaviour;
public abstract class AbstractColleague {
protected AbstractMediator mediator;
/**既然有中介者,那么每个具体同事必然要与中介者有联系,
* 否则就没必要存在于 这个系统当中,这里的构造函数相当
* 于向该系统中注册一个中介者,以取得联系
*/
public AbstractColleague(AbstractMediator mediator) {
this.mediator = mediator;
}
// 在抽象同事类中添加用于与中介者取得联系(即注册)的方法
public void setMediator(AbstractMediator mediator) {
this.mediator = mediator;
}
}
~~~
~~~
//具体同事A
package com.model.behaviour;
public class ColleagueA extends AbstractColleague {
//每个具体同事都通过父类构造函数与中介者取得联系
public ColleagueA(AbstractMediator mediator) {
super(mediator);
}
//每个具体同事必然有自己分内的事,没必要与外界相关联
public void self() {
System.out.println("同事A --> 做好自己分内的事情 ...");
}
//每个具体同事总有需要与外界交互的操作,通过中介者来处理这些逻辑并安排工作
public void out() {
System.out.println("同事A --> 请求同事B做好分内工作 ...");
super.mediator.execute("ColleagueB", "self");
}
}
~~~
~~~
//具体同事B
package com.model.behaviour;
public class ColleagueB extends AbstractColleague {
public ColleagueB(AbstractMediator mediator) {
super(mediator);
}
public void self() {
System.out.println("同事B --> 做好自己分内的事情 ...");
}
public void out() {
System.out.println("同事B --> 请求同事A做好分内工作 ...");
super.mediator.execute("ColleagueA", "self");
}
}
~~~
中介者类族:
~~~
package com.model.behaviour;
public abstract class AbstractMediator {
//中介者肯定需要保持有若干同事的联系方式
protected Hashtable<String, AbstractColleague> colleagues = new Hashtable<String, AbstractColleague>();
//中介者可以动态地与某个同事建立联系
public void addColleague(String name, AbstractColleague c) {
this.colleagues.put(name, c);
}
//中介者也可以动态地撤销与某个同事的联系
public void deleteColleague(String name) {
this.colleagues.remove(name);
}
//中介者必须具备在同事之间处理逻辑、分配任务、促进交流的操作
public abstract void execute(String name, String method);
}
~~~
~~~
//具体中介者
package com.model.behaviour;
public class Mediator extends AbstractMediator{
//中介者最重要的功能,来回奔波与各个同事之间
public void execute(String name, String method) {
if("self".equals(method)){ //各自做好分内事
if("ColleagueA".equals(name)) {
ColleagueA colleague = (ColleagueA)super.colleagues.get("ColleagueA");
colleague.self();
}else {
ColleagueB colleague = (ColleagueB)super.colleagues.get("ColleagueB");
colleague.self();
}
}else { //与其他同事合作
if("ColleagueA".equals(name)) {
ColleagueA colleague = (ColleagueA)super.colleagues.get("ColleagueA");
colleague.out();
}else {
ColleagueB colleague = (ColleagueB)super.colleagues.get("ColleagueB");
colleague.out();
}
}
}
}
~~~
测试类:
~~~
//测试类
package com.model.behaviour;
public class Client {
public static void main(String[] args) {
//创建一个中介者
AbstractMediator mediator = new Mediator();
//创建两个同事
ColleagueA colleagueA = new ColleagueA(mediator);
ColleagueB colleagueB = new ColleagueB(mediator);
//中介者分别与每个同事建立联系
mediator.addColleague("ColleagueA", colleagueA);
mediator.addColleague("ColleagueB", colleagueB);
//同事们开始工作
colleagueA.self();
colleagueA.out();
System.out.println("======================合作愉快,任务完成!\n");
colleagueB.self();
colleagueB.out();
System.out.println("======================合作愉快,任务完成!");
}
}
~~~
运行结果:
~~~
同事A --> 做好自己分内的事情 ...
同事A --> 请求同事B做好分内工作 ...
同事B --> 做好自己分内的事情 ...
======================合作愉快,任务完成!
同事B --> 做好自己分内的事情 ...
同事B --> 请求同事A做好分内工作 ...
同事A --> 做好自己分内的事情 ...
======================合作愉快,任务完成!
~~~
### 十一、解释器模式
解释器模式:给定一种语言,定义他的文法的一种表示,并定义一个解释器,该解释器使用该表示来解释语言中句子。
解释器模式是一个比较少用的模式。
~~~
package com.model.behaviour;
public class Context {
private int num1;
private int num2;
public Context(int num1, int num2) {
this.num1 = num1;
this.num2 = num2;
}
public int getNum1() {
return num1;
}
public void setNum1(int num1) {
this.num1 = num1;
}
public int getNum2() {
return num2;
}
public void setNum2(int num2) {
this.num2 = num2;
}
}
~~~
~~~
package com.model.behaviour;
public interface Expression {
public int interpret(Context context);
}
~~~
~~~
package com.model.behaviour;
public class Minus implements Expression {
@Override
public int interpret(Context context) {
return context.getNum1()-context.getNum2();
}
}
~~~
~~~
package com.model.behaviour;
public class Plus implements Expression {
@Override
public int interpret(Context context) {
return context.getNum1()+context.getNum2();
}
}
~~~
~~~
package com.model.behaviour;
public class Test {
public static void main(String[] args) {
// 计算9+2-8的值
int result = new Minus().interpret((new Context(new Plus()
.interpret(new Context(9, 2)), 8)));
System.out.println(result);
}
}
~~~
注,本文参考了另外一位博主的文章,某些地方有结合自己的一些理解加以修改:
[http://blog.csdn.net/zhangerqing/article/details/8194653](http://blog.csdn.net/zhangerqing/article/details/8194653)
Java经典设计模式之七大结构型模式(附实例和详解)
最后更新于:2022-04-01 09:55:14
博主在大三的时候有上过设计模式这一门课,但是当时很多都基本没有听懂,重点是也没有细听,因为觉得没什么卵用,硬是要搞那么复杂干嘛。因此设计模式建议工作半年以上的猿友阅读起来才会理解的比较深刻。当然,你没事做看看也是没有坏处的。
总体来说设计模式分为三大类:创建型模式、结构型模式和行为型模式。
博主的上一篇文章已经提到过创建型模式,此外该文章还有设计模式概况和设计模式的六大原则。设计模式的六大原则是设计模式的核心思想,详情请看博主的另外一篇文章:[ Java经典设计模式之五大创建模式(附实例和详解)](http://blog.csdn.net/u013142781/article/details/50816245)。
接下来我们看看结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。其中适配器模式主要分为三类:类的适配器模式、对象的适配器模式、接口的适配器模式。其中的对象的适配器模式是各种结构型模式的起源。
### 一、适配器模式
适配器模式主要分为三类:类的适配器模式、对象的适配器模式、接口的适配器模式。
适配器模式将某个类的接口转换成客户端期望的另一个接口表示,目的是消除由于接口不匹配所造成的类的兼容性问题。有点抽象,我们来看看详细的内容。
**1.1、类的适配器模式**
类的适配器模式核心思想就是:有一个Source类,拥有一个方法,待适配,目标接口是Targetable,通过Adapter类,将Source的功能扩展到Targetable里。
~~~
package com.model.structure;
public class Source {
public void method1() {
System.out.println("this is original method!");
}
}
~~~
~~~
package com.model.structure;
public interface Targetable {
/* 与原类中的方法相同 */
public void method1();
/* 新类的方法 */
public void method2();
}
~~~
~~~
package com.model.structure;
public class Adapter extends Source implements Targetable {
public void method2() {
System.out.println("this is the targetable method!");
}
}
~~~
~~~
package com.model.structure;
public class AdapterTest {
public static void main(String[] args) {
Targetable target = new Adapter();
target.method1();
target.method2();
}
}
~~~
AdapterTest的运行结果:

**1.2、对象的适配器模式**
对象的适配器模式的基本思路和类的适配器模式相同,只是将Adapter类作修改成Wrapper,这次不继承Source类,而是持有Source类的实例,以达到解决兼容性的问题。
~~~
package com.model.structure;
public class Wrapper implements Targetable {
private Source source;
public Wrapper(Source source) {
super();
this.source = source;
}
@Override
public void method2() {
System.out.println("this is the targetable method!");
}
@Override
public void method1() {
source.method1();
}
}
~~~
~~~
package com.model.structure;
public class AdapterTest {
public static void main(String[] args) {
Source source = new Source();
Targetable target = new Wrapper(source);
target.method1();
target.method2();
}
}
~~~
运行结果跟类的适配器模式例子的一样。
**1.3、接口的适配器模式**
接口的适配器是这样的:有时我们写的一个接口中有多个抽象方法,当我们写该接口的实现类时,必须实现该接口的所有方法,这明显有时比较浪费,因为并不是所有的方法都是我们需要的,有时只需要某一些,此处为了解决这个问题,我们引入了接口的适配器模式,借助于一个抽象类,该抽象类实现了该接口,实现了所有的方法,而我们不和原始的接口打交道,只和该抽象类取得联系,所以我们写一个类,继承该抽象类,重写我们需要的方法就行了。
这里看文字描述已经试够清楚的了,因此就不贴代码实例了。
### 二、装饰模式
装饰模式:在不必改变原类文件和使用继承的情况下,动态地扩展一个对象的功能。它是通过创建一个包装对象,也就是装饰来包裹真实的对象。
装饰模式的特点:
(1) 装饰对象和真实对象有相同的接口。这样客户端对象就能以和真实对象相同的方式和装饰对象交互。
(2) 装饰对象包含一个真实对象的引用(reference)
(3) 装饰对象接受所有来自客户端的请求。它把这些请求转发给真实的对象。
(4) 装饰对象可以在转发这些请求以前或以后增加一些附加功能。这样就确保了在运行时,不用修改给定对象的结构就可以在外部增加附加的功能。在面向对象的设计中,通常是通过继承来实现对给定类的功能扩展。继承不能做到这一点,继承的功能是静态的,不能动态增删。
具体看看代码实例
~~~
package com.model.structure;
public interface Sourceable {
public void method();
}
~~~
~~~
package com.model.structure;
public class Source implements Sourceable {
@Override
public void method() {
System.out.println("the original method!");
}
}
~~~
~~~
package com.model.structure;
public class Decorator implements Sourceable {
private Sourceable source;
public Decorator(Sourceable source) {
super();
this.source = source;
}
@Override
public void method() {
System.out.println("before decorator!");
source.method();
System.out.println("after decorator!");
}
}
~~~
~~~
package com.model.structure;
public class DecoratorTest {
public static void main(String[] args) {
//(1) 装饰对象和真实对象有相同的接口。这样客户端对象就能以和真实对象相同的方式和装饰对象交互。
//(2) 装饰对象包含一个真实对象的引用(reference)
//(3) 装饰对象接受所有来自客户端的请求。它把这些请求转发给真实的对象。
//(4) 装饰对象可以在转发这些请求以前或以后增加一些附加功能。这样就确保了在运行时,不用修改给定对象的结构就可以在外部增加附加的功能。
// 在面向对象的设计中,通常是通过继承来实现对给定类的功能扩展。
// 继承不能做到这一点,继承的功能是静态的,不能动态增删。
Sourceable source = new Source();
Sourceable obj = new Decorator(source);
obj.method();
}
}
~~~
**运行结果:**
~~~
before decorator!
the original method!
after decorator!
~~~
### 三、代理模式
代理模式就是多一个代理类出来,替原对象进行一些操作。代理类就像中介,它比我们掌握着更多的信息。
具体看看代码实例。
~~~
package com.model.structure;
public interface Sourceable {
public void method();
}
~~~
~~~
package com.model.structure;
public class Source implements Sourceable {
@Override
public void method() {
System.out.println("the original method!");
}
}
~~~
~~~
package com.model.structure;
public class Proxy implements Sourceable {
private Source source;
public Proxy() {
super();
this.source = new Source();
}
@Override
public void method() {
before();
source.method();
atfer();
}
private void atfer() {
System.out.println("after proxy!");
}
private void before() {
System.out.println("before proxy!");
}
}
~~~
~~~
package com.model.structure;
public class ProxyTest {
public static void main(String[] args) {
Sourceable source = new Proxy();
source.method();
}
}
~~~
**运行结果:**
~~~
before proxy!
the original method!
after proxy!
~~~
### 四、外观模式
外观模式是为了解决类与类之间的依赖关系的,像spring一样,可以将类和类之间的关系配置到配置文件中,而外观模式就是将他们的关系放在一个Facade类中,降低了类类之间的耦合度,该模式中没有涉及到接口。
我们以一个计算机的启动过程为例,看看如下的代码:
~~~
package com.model.structure;
public class CPU {
public void startup() {
System.out.println("cpu startup!");
}
public void shutdown() {
System.out.println("cpu shutdown!");
}
}
~~~
~~~
package com.model.structure;
public class Disk {
public void startup() {
System.out.println("disk startup!");
}
public void shutdown() {
System.out.println("disk shutdown!");
}
}
~~~
~~~
package com.model.structure;
public class Memory {
public void startup() {
System.out.println("memory startup!");
}
public void shutdown() {
System.out.println("memory shutdown!");
}
}
~~~
~~~
package com.model.structure;
public class Computer {
private CPU cpu;
private Memory memory;
private Disk disk;
public Computer() {
cpu = new CPU();
memory = new Memory();
disk = new Disk();
}
public void startup() {
System.out.println("start the computer!");
cpu.startup();
memory.startup();
disk.startup();
System.out.println("start computer finished!");
}
public void shutdown() {
System.out.println("begin to close the computer!");
cpu.shutdown();
memory.shutdown();
disk.shutdown();
System.out.println("computer closed!");
}
}
~~~
~~~
package com.model.structure;
public class User {
public static void main(String[] args) {
Computer computer = new Computer();
computer.startup();
computer.shutdown();
}
}
~~~
**运行结果:**
~~~
start the computer!
cpu startup!
memory startup!
disk startup!
start computer finished!
begin to close the computer!
cpu shutdown!
memory shutdown!
disk shutdown!
computer closed!
~~~
### 五、桥接模式
在软件系统中,某些类型由于自身的逻辑,它具有两个或多个维度的变化,那么如何应对这种“多维度的变化”?如何利用面向对象的技术来使得该类型能够轻松的沿着多个方向进行变化,而又不引入额外的复杂度?这就要使用Bridge模式。
在提出桥梁模式的时候指出,桥梁模式的用意是”将抽象化(Abstraction)与实现化(Implementation)脱耦,使得二者可以独立地变化”。这句话有三个关键词,也就是抽象化、实现化和脱耦。
**抽象化:**存在于多个实体中的共同的概念性联系,就是抽象化。作为一个过程,抽象化就是忽略一些信息,从而把不同的实体当做同样的实体对待。
**实现化:**抽象化给出的具体实现,就是实现化。
**脱耦:**所谓耦合,就是两个实体的行为的某种强关联。而将它们的强关联去掉,就是耦合的解脱,或称脱耦。在这里,脱耦是指将抽象化和实现化之间的耦合解脱开,或者说是将它们之间的强关联改换成弱关联。
下面我们来看看代码实例:
~~~
package com.model.structure;
public interface Driver {
public void connect();
}
~~~
~~~
package com.model.structure;
public class MysqlDriver implements Driver {
@Override
public void connect() {
System.out.println("connect mysql done!");
}
}
~~~
~~~
package com.model.structure;
public class DB2Driver implements Driver {
@Override
public void connect() {
System.out.println("connect db2 done!");
}
}
~~~
~~~
package com.model.structure;
public abstract class DriverManager {
private Driver driver;
public void connect() {
driver.connect();
}
public Driver getDriver() {
return driver;
}
public void setDriver(Driver driver) {
this.driver = driver;
}
}
~~~
~~~
package com.model.structure;
public class MyDriverManager extends DriverManager {
public void connect() {
super.connect();
}
}
~~~
~~~
package com.model.structure;
public class Client {
public static void main(String[] args) {
DriverManager driverManager = new MyDriverManager();
Driver driver1 = new MysqlDriver();
driverManager.setDriver(driver1);
driverManager.connect();
Driver driver2 = new DB2Driver();
driverManager.setDriver(driver2);
driverManager.connect();
}
}
~~~
执行结果:
~~~
connect mysql done!
connect db2 done!
~~~
如果看完代码实例还不是很理解,我们想想如下两个维度扩展:(1)假设我想加一个OracleDriver,这是一个维度,很好理解,不多解释。(2)假设我们想在连接前后固定输出点什么,我们只需要加一个MyDriverManager2,代码如下:
~~~
package com.model.structure;
public class MyDriverManager2 extends DriverManager {
public void connect() {
System.out.println("before connect");
super.connect();
System.out.println("after connect");
}
}
~~~
再将Client代码中的MyDriverManager 改成 MyDriverManager2 ,执行结果如下:
~~~
before connect
connect mysql done!
after connect
before connect
connect db2 done!
after connect
~~~
### 六、组合模式
组合模式,将对象组合成树形结构以表示“部分-整体”的层次结构,组合模式使得用户对单个对象和组合对象的使用具有一致性。掌握组合模式的重点是要理解清楚 “部分/整体” 还有 ”单个对象“ 与 “组合对象” 的含义。
组合模式让你可以优化处理递归或分级数据结构。
《设计模式》:将对象组合成树形结构以表示“部分整体”的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性。
**涉及角色:**
**Component:**是组合中的对象声明接口,在适当的情况下,实现所有类共有接口的默认行为。声明一个接口用于访问和管理Component子部件。
**Leaf:**在组合中表示叶子结点对象,叶子结点没有子结点。
**Composite:**定义有枝节点行为,用来存储子部件,在Component接口中实现与子部件有关操作,如增加(add)和删除(remove)等。
比如现实中公司内各部门的层级关系,请看代码:
**Component:**是组合中的对象声明接口,在适当的情况下,实现所有类共有接口的默认行为。声明一个接口用于访问和管理Component子部件。
~~~
package com.model.structure;
public abstract class Company {
private String name;
public Company() {
}
public Company(String name) {
super();
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
protected abstract void add(Company company);
protected abstract void romove(Company company);
protected abstract void display(int depth);
}
~~~
**Composite:**定义有枝节点行为,用来存储子部件,在Component接口中实现与子部件有关操作,如增加(add)和删除(remove)等。
~~~
package com.model.structure;
import java.util.ArrayList;
import java.util.List;
public class ConcreteCompany extends Company {
private List<Company> cList;
public ConcreteCompany() {
cList = new ArrayList();
}
public ConcreteCompany(String name) {
super(name);
cList = new ArrayList();
}
@Override
protected void add(Company company) {
cList.add(company);
}
@Override
protected void display(int depth) {
StringBuilder sb = new StringBuilder("");
for (int i = 0; i < depth; i++) {
sb.append("-");
}
System.out.println(new String(sb) + this.getName());
for (Company c : cList) {
c.display(depth + 2);
}
}
@Override
protected void romove(Company company) {
cList.remove(company);
}
}
~~~
**Leaf:**在组合中表示叶子结点对象,叶子结点没有子结点。
~~~
package com.model.structure;
public class HRDepartment extends Company {
public HRDepartment(String name) {
super(name);
}
@Override
protected void add(Company company) {
}
@Override
protected void display(int depth) {
StringBuilder sb = new StringBuilder("");
for (int i = 0; i < depth; i++) {
sb.append("-");
}
System.out.println(new String(sb) + this.getName());
}
@Override
protected void romove(Company company) {
}
}
~~~
~~~
package com.model.structure;
public class FinanceDepartment extends Company {
public FinanceDepartment(String name) {
super(name);
}
@Override
protected void add(Company company) {
}
@Override
protected void display(int depth) {
StringBuilder sb = new StringBuilder("");
for (int i = 0; i < depth; i++) {
sb.append("-");
}
System.out.println(new String(sb) + this.getName());
}
@Override
protected void romove(Company company) {
}
}
~~~
Client:
~~~
package com.model.structure;
public class Client {
public static void main(String[] args) {
Company root = new ConcreteCompany();
root.setName("北京总公司");
root.add(new HRDepartment("总公司人力资源部"));
root.add(new FinanceDepartment("总公司财务部"));
Company shandongCom = new ConcreteCompany("山东分公司");
shandongCom.add(new HRDepartment("山东分公司人力资源部"));
shandongCom.add(new FinanceDepartment("山东分公司账务部"));
Company zaozhuangCom = new ConcreteCompany("枣庄办事处");
zaozhuangCom.add(new FinanceDepartment("枣庄办事处财务部"));
zaozhuangCom.add(new HRDepartment("枣庄办事处人力资源部"));
Company jinanCom = new ConcreteCompany("济南办事处");
jinanCom.add(new FinanceDepartment("济南办事处财务部"));
jinanCom.add(new HRDepartment("济南办事处人力资源部"));
shandongCom.add(jinanCom);
shandongCom.add(zaozhuangCom);
Company huadongCom = new ConcreteCompany("上海华东分公司");
huadongCom.add(new HRDepartment("上海华东分公司人力资源部"));
huadongCom.add(new FinanceDepartment("上海华东分公司账务部"));
Company hangzhouCom = new ConcreteCompany("杭州办事处");
hangzhouCom.add(new FinanceDepartment("杭州办事处财务部"));
hangzhouCom.add(new HRDepartment("杭州办事处人力资源部"));
Company nanjingCom = new ConcreteCompany("南京办事处");
nanjingCom.add(new FinanceDepartment("南京办事处财务部"));
nanjingCom.add(new HRDepartment("南京办事处人力资源部"));
huadongCom.add(hangzhouCom);
huadongCom.add(nanjingCom);
root.add(shandongCom);
root.add(huadongCom);
root.display(0);
}
}
~~~
运行结果:
~~~
北京总公司
--总公司人力资源部
--总公司财务部
--山东分公司
----山东分公司人力资源部
----山东分公司账务部
----济南办事处
------济南办事处财务部
------济南办事处人力资源部
----枣庄办事处
------枣庄办事处财务部
------枣庄办事处人力资源部
--上海华东分公司
----上海华东分公司人力资源部
----上海华东分公司账务部
----杭州办事处
------杭州办事处财务部
------杭州办事处人力资源部
----南京办事处
------南京办事处财务部
------南京办事处人力资源部
~~~
### 七、享元模式
享元模式的主要目的是实现对象的共享,即共享池,当系统中对象多的时候可以减少内存的开销,通常与工厂模式一起使用。
一提到共享池,我们很容易联想到Java里面的JDBC连接池,想想每个连接的特点,我们不难总结出:适用于作共享的一些个对象,他们有一些共有的属性,就拿数据库连接池来说,url、driverClassName、username、password及dbname,这些属性对于每个连接来说都是一样的,所以就适合用享元模式来处理,建一个工厂类,将上述类似属性作为内部数据,其它的作为外部数据,在方法调用时,当做参数传进来,这样就节省了空间,减少了实例的数量。
看下数据库连接池的代码:
~~~
package com.model.structure;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.Vector;
public class ConnectionPool {
private Vector<Connection> pool;
/* 公有属性 */
private String url = "jdbc:mysql://localhost:3306/test";
private String username = "root";
private String password = "root";
private String driverClassName = "com.mysql.jdbc.Driver";
private int poolSize = 100;
private static ConnectionPool instance = null;
Connection conn = null;
/* 构造方法,做一些初始化工作 */
private ConnectionPool() {
pool = new Vector<Connection>(poolSize);
for (int i = 0; i < poolSize; i++) {
try {
Class.forName(driverClassName);
conn = DriverManager.getConnection(url, username, password);
pool.add(conn);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/* 返回连接到连接池 */
public synchronized void release() {
pool.add(conn);
}
/* 返回连接池中的一个数据库连接 */
public synchronized Connection getConnection() {
if (pool.size() > 0) {
Connection conn = pool.get(0);
pool.remove(conn);
return conn;
} else {
return null;
}
}
}
~~~
通过连接池的管理,实现了数据库连接的共享,不需要每一次都重新创建连接,节省了数据库重新创建的开销,提升了系统的性能!
**注,本文参考了另外一位博主的文章,某些地方有结合自己的一些理解加以修改:**
[http://blog.csdn.net/zhangerqing/article/details/8194653](http://blog.csdn.net/zhangerqing/article/details/8194653)
Java经典设计模式之五大创建型模式(附实例和详解)
最后更新于:2022-04-01 09:55:12
### 一、概况
总体来说设计模式分为三大类:
(1)创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
(2)结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
(3)行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
### 二、设计模式的六大原则
**1、开闭原则(Open Close Principle)**
开闭原则就是说对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代码,实现一个热插拔的效果。
**2、里氏代换原则(Liskov Substitution Principle)**
其官方描述比较抽象,可自行百度。实际上可以这样理解:(1)子类的能力必须大于等于父类,即父类可以使用的方法,子类都可以使用。(2)返回值也是同样的道理。假设一个父类方法返回一个List,子类返回一个ArrayList,这当然可以。如果父类方法返回一个ArrayList,子类返回一个List,就说不通了。这里子类返回值的能力是比父类小的。(3)还有抛出异常的情况。任何子类方法可以声明抛出父类方法声明异常的子类。
而不能声明抛出父类没有声明的异常。
**3、依赖倒转原则(Dependence Inversion Principle)**
这个是开闭原则的基础,具体内容:面向接口编程,依赖于抽象而不依赖于具体。
**4、接口隔离原则(Interface Segregation Principle)**
这个原则的意思是:使用多个隔离的接口,比使用单个接口要好。还是一个降低类之间的耦合度的意思,从这儿我们看出,其实设计模式就是一个软件的设计思想,从大型软件架构出发,为了升级和维护方便。所以上文中多次出现:降低依赖,降低耦合。
**5、迪米特法则(最少知道原则)(Demeter Principle)**
为什么叫最少知道原则,就是说:一个实体应当尽量少的与其他实体之间发生相互作用,使得系统功能模块相对独立。
**6、合成复用原则(Composite Reuse Principle)**
原则是尽量使用合成/聚合的方式,而不是使用继承。
### 三、创建型模式
**创建型模式,共五种:**工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
**3.1、工厂方法模式**
工厂方法模式分为三种:普通工厂模式、多个工厂方法模式和静态工厂方法模式。
**3.1.1、普通工厂模式**
普通工厂模式就是建立一个工厂类,对实现了同一接口的一些类进行实例的创建。
~~~
package com.mode.create;
public interface MyInterface {
public void print();
}
~~~
~~~
package com.mode.create;
public class MyClassOne implements MyInterface {
@Override
public void print() {
System.out.println("MyClassOne");
}
}
~~~
~~~
package com.mode.create;
public class MyClassTwo implements MyInterface {
@Override
public void print() {
System.out.println("MyClassTwo");
}
}
~~~
~~~
package com.mode.create;
public class MyFactory {
public MyInterface produce(String type) {
if ("One".equals(type)) {
return new MyClassOne();
} else if ("Two".equals(type)) {
return new MyClassTwo();
} else {
System.out.println("没有要找的类型");
return null;
}
}
}
~~~
~~~
package com.mode.create;
public class FactoryTest {
public static void main(String[] args){
MyFactory factory = new MyFactory();
MyInterface myi = factory.produce("One");
myi.print();
}
}
~~~
FactoryTest的运行结果我想应该很明显了。
再回头来理解这句话:普通工厂模式就是建立一个工厂类,对实现了同一接口的一些类进行实例的创建。
**3.1.2、多个工厂方法模式**
多个工厂方法模式,是对普通工厂方法模式的改进,多个工厂方法模式就是提供多个工厂方法,分别创建对象。
直接看代码吧,我们修改MyFactory和FactoryTest如下:
~~~
package com.mode.create;
public class MyFactory {
public MyInterface produceOne() {
return new MyClassOne();
}
public MyInterface produceTwo() {
return new MyClassTwo();
}
}
~~~
~~~
package com.mode.create;
public class FactoryTest {
public static void main(String[] args){
MyFactory factory = new MyFactory();
MyInterface myi = factory.produceOne();
myi.print();
}
}
~~~
运行结果也是十分明显了。
再回头来理解这句话:多个工厂方法模式,是对普通工厂方法模式的改进,多个工厂方法模式就是提供多个工厂方法,分别创建对象。
**3.1.3、静态工厂方法模式**
静态工厂方法模式,将上面的多个工厂方法模式里的方法置为静态的,不需要创建实例,直接调用即可。
直接看代码吧,我们修改MyFactory和FactoryTest如下:
~~~
package com.mode.create;
public class MyFactory {
public static MyInterface produceOne() {
return new MyClassOne();
}
public static MyInterface produceTwo() {
return new MyClassTwo();
}
}
~~~
~~~
package com.mode.create;
public class FactoryTest {
public static void main(String[] args){
MyInterface myi = MyFactory.produceOne();
myi.print();
}
}
~~~
运行结果依旧很明显。
再回顾:静态工厂方法模式,将上面的多个工厂方法模式里的方法置为静态的,不需要创建实例,直接调用即可。
**3.2、抽象工厂模式**
工厂方法模式有一个问题就是,类的创建依赖工厂类,也就是说,如果想要拓展程序,必须对工厂类进行修改,这违背了闭包原则。
为解决这个问题,我们来看看抽象工厂模式:创建多个工厂类,这样一旦需要增加新的功能,直接增加新的工厂类就可以了,不需要修改之前的代码。
这样就符合闭包原则了。
下面来看看代码:
MyInterface、MyClassOne、MyClassTwo不变。
新增如下接口和类:
~~~
package com.mode.create;
public interface Provider {
public MyInterface produce();
}
~~~
~~~
package com.mode.create;
public class MyFactoryOne implements Provider {
@Override
public MyInterface produce() {
return new MyClassOne();
}
}
~~~
~~~
package com.mode.create;
public class MyFactoryTwo implements Provider {
@Override
public MyInterface produce() {
return new MyClassTwo();
}
}
~~~
修改测试类FactoryTest如下:
~~~
package com.mode.create;
public class FactoryTest {
public static void main(String[] args){
Provider provider = new MyFactoryOne();
MyInterface myi = provider.produce();
myi.print();
}
}
~~~
运行结果依旧显然。
再回顾:抽象工厂模式就是创建多个工厂类,这样一旦需要增加新的功能,直接增加新的工厂类就可以了,不需要修改之前的代码。
**3.3、单例模式**
单例模式,不需要过多的解释。
直接看代码吧:
~~~
package test;
public class MyObject {
private static MyObject myObject;
private MyObject() {
}
public static MyObject getInstance() {
if (myObject != null) {
} else {
myObject = new MyObject();
}
return myObject;
}
}
~~~
但是这样会引发多线程问题,详细解说可以看《Java多线程编程核心技术》书中的第六章。博主之前推荐过这本书,里面有电子完整版下载地址:[http://blog.csdn.net/u013142781/article/details/50805655](http://blog.csdn.net/u013142781/article/details/50805655)
**3.4、建造者模式**
建造者模式:是将一个复杂的对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
字面看来非常抽象,实际上它也十分抽象!!!!
建造者模式通常包括下面几个角色:
(1) Builder:给出一个抽象接口,以规范产品对象的各个组成成分的建造。这个接口规定要实现复杂对象的哪些部分的创建,并不涉及具体的对象部件的创建。
(2) ConcreteBuilder:实现Builder接口,针对不同的商业逻辑,具体化复杂对象的各部分的创建。 在建造过程完成后,提供产品的实例。
(3)Director:调用具体建造者来创建复杂对象的各个部分,在指导者中不涉及具体产品的信息,只负责保证对象各部分完整创建或按某种顺序创建。
(4)Product:要创建的复杂对象。
在游戏开发中建造小人是经常的事了,要求是:小人必须包括头,身体和脚。
下面我们看看如下代码:
Product(要创建的复杂对象。):
~~~
package com.mode.create;
public class Person {
private String head;
private String body;
private String foot;
public String getHead() {
return head;
}
public void setHead(String head) {
this.head = head;
}
public String getBody() {
return body;
}
public void setBody(String body) {
this.body = body;
}
public String getFoot() {
return foot;
}
public void setFoot(String foot) {
this.foot = foot;
}
}
~~~
Builder(给出一个抽象接口,以规范产品对象的各个组成成分的建造。这个接口规定要实现复杂对象的哪些部分的创建,并不涉及具体的对象部件的创建。):
~~~
package com.mode.create;
public interface PersonBuilder {
void buildHead();
void buildBody();
void buildFoot();
Person buildPerson();
}
~~~
ConcreteBuilder(实现Builder接口,针对不同的商业逻辑,具体化复杂对象的各部分的创建。 在建造过程完成后,提供产品的实例。):
~~~
package com.mode.create;
public class ManBuilder implements PersonBuilder {
Person person;
public ManBuilder() {
person = new Person();
}
public void buildBody() {
person.setBody("建造男人的身体");
}
public void buildFoot() {
person.setFoot("建造男人的脚");
}
public void buildHead() {
person.setHead("建造男人的头");
}
public Person buildPerson() {
return person;
}
}
~~~
Director(调用具体建造者来创建复杂对象的各个部分,在指导者中不涉及具体产品的信息,只负责保证对象各部分完整创建或按某种顺序创建。):
~~~
package com.mode.create;
public class PersonDirector {
public Person constructPerson(PersonBuilder pb) {
pb.buildHead();
pb.buildBody();
pb.buildFoot();
return pb.buildPerson();
}
}
~~~
测试类:
~~~
package com.mode.create;
public class Test {
public static void main(String[] args) {
PersonDirector pd = new PersonDirector();
Person person = pd.constructPerson(new ManBuilder());
System.out.println(person.getBody());
System.out.println(person.getFoot());
System.out.println(person.getHead());
}
}
~~~
运行结果:

回顾:建造者模式:是将一个复杂的对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
**3.5、原型模式**
该模式的思想就是将一个对象作为原型,对其进行复制、克隆,产生一个和原对象类似的新对象。
说道复制对象,我将结合对象的浅复制和深复制来说一下,首先需要了解对象深、浅复制的概念:
**浅复制:**将一个对象复制后,基本数据类型的变量都会重新创建,而引用类型,指向的还是原对象所指向的。
**深复制:**将一个对象复制后,不论是基本数据类型还有引用类型,都是重新创建的。简单来说,就是深复制进行了完全彻底的复制,而浅复制不彻底。
写一个深浅复制的例子:
~~~
package com.mode.create;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class Prototype implements Cloneable, Serializable {
private static final long serialVersionUID = 1L;
private int base;
private Integer obj;
/* 浅复制 */
public Object clone() throws CloneNotSupportedException {
// 因为Cloneable接口是个空接口,你可以任意定义实现类的方法名
// 如cloneA或者cloneB,因为此处的重点是super.clone()这句话
// super.clone()调用的是Object的clone()方法
// 而在Object类中,clone()是native(本地方法)的
Prototype proto = (Prototype) super.clone();
return proto;
}
/* 深复制 */
public Object deepClone() throws IOException, ClassNotFoundException {
/* 写入当前对象的二进制流 */
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
/* 读出二进制流产生的新对象 */
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return ois.readObject();
}
public int getBase() {
return base;
}
public void setBase(int base) {
this.base = base;
}
public Integer getObj() {
return obj;
}
public void setObj(Integer obj) {
this.obj = obj;
}
}
~~~
测试类:
~~~
package com.mode.create;
import java.io.IOException;
public class Test {
public static void main(String[] args) throws CloneNotSupportedException,
ClassNotFoundException, IOException {
Prototype prototype = new Prototype();
prototype.setBase(1);
prototype.setObj(new Integer(2));
/* 浅复制 */
Prototype prototype1 = (Prototype) prototype.clone();
/* 深复制 */
Prototype prototype2 = (Prototype) prototype.deepClone();
System.out.println(prototype1.getObj()==prototype1.getObj());
System.out.println(prototype1.getObj()==prototype2.getObj());
}
}
~~~
运行结果:

Java I/O学习(附实例和详解)
最后更新于:2022-04-01 09:55:09
### 一、Java I/O类结构以及流的基本概念
在阅读Java I/O的实例之前我们必须清楚一些概念,我们先看看Java I/O的类结构图:

Java I/O主要以流的形式进行读写数据。
流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。
根据处理数据的数据类型的不同可以分为:字符流和字节流。
字符流和字节流的主要区别:
1.字节流读取的时候,读到一个字节就返回一个字节; 字符流使用了字节流读到一个或多个字节(中文对应的字节数是两个,在UTF-8码表中是3个字节)时。先去查指定的编码表,将查到的字符返回。
2.字节流可以处理所有类型数据,如:图片,MP3,AVI视频文件,而字符流只能处理字符数据。只要是处理纯文本数据,就要优先考虑使用字符流,除此之外都用字节流。
3.实际上字节流在操作时本身不会用到缓冲区(内存),是文件本身直接操作的,而字符流在操作时使用了缓冲区,通过缓冲区再操作文件。
下面我们以文件操作作为实例进一步了解。
### 二、字符流实例
之前提到过“只要是处理纯文本数据,就要优先考虑使用字符流,除此之外都用字节流”。因此本字符流操作实例是操作txt文件。对其进行读写操作。
**2.1、一些概念**
此前,我们需要了解一些概念。
Java采用16位的Unicode来表示字符串和字符的。在写入字符流时我们都可以指定写入的字符串的编码。
这里博主贴出字符流类图结构,方便猿友阅读:

在文件操作的时候我们主要使用到FileReader和FileWriter或BufferedReader和BufferedWriter。
从类结构图来看:
FileReader是InputStreamReader的子类,而InputStreamReader是Reader的子类;
FileWriter是OutputStreamWriter的子类,而OutputStreamWriter则是Writer的子类。
**2.2、FileReader和BufferedReader的使用**
FileReader的常用构造包括以下两种:
(1)FileReader(String fileName):根据文件名创建FileReader对象。
(2)FileReader(File file):根据File对象创建FileReader对象。
**FileReader的常用方法包括以下几种:**
(1)int read():读取单个字符。返回字符的整数值,如果已经到达文件尾,则返回-1.
(2)int read(char[] cbuf):将字符读入cbuf字符数组。返回读取到的字符数,如果已经到达文件尾,则返回-1.
(3)int read(char[] cbuf,int off,int len):将读取到的字符存放到cbuf字符数组从off标识的偏移位置开始处,最多读取len个字符。
**BufferedReader有以下两种构造方法:**
(1)BufferedReader(Reader in):根据in代表的Reader对象创建BufferReader实例,缓冲区大小采用默认值。
(2)BufferedReader(Reader in,int sz):根据in代表的Reader对象创建BufferedReader实例,缓冲区大小采用指定sz值。
**BufferedReader的常用方法包括以下几种:**
(1)int read():返回字符的整数值,如果已经到达文件尾,则返回-1.
(2)int read(char[], int, int):将读取到的字符存放到cbuf字符数组从off标识的偏移位置开始处,最多读取len个字符。
(3)String readLine():读取一文本行。该方法遇到以下字符或者字符串认为当前行结束:‘\n’(换行符),’\r’(回车符),’\r\n’(回车换行)。返回值为该行内容的字符串,不包含任何行终止符,如果已到达流末尾,则返回null。
**代码实例:**
~~~
package java_io;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
public class TestReader {
public static void main(String[] args) {
TestReader testReader = new TestReader();
String path = "C:\\Users\\luoguohui\\Desktop\\readerTest.txt";
testReader.readFileByFileReader(path);
testReader.readFileByBufferedReader(path);
}
public void readFileByFileReader(String path){
FileReader fileReader = null;
try {
fileReader = new FileReader(path);
char[] buf = new char[1024]; //每次读取1024个字符
int temp = 0;
System.out.println("readFileByFileReader执行结果:");
while ((temp = fileReader.read(buf)) != -1) {
System.out.print(new String(buf, 0, temp));
}
System.out.println();
} catch (Exception e) {
e.printStackTrace();
} finally { //像这种i/o操作尽量finally确保关闭
if (fileReader!=null) {
try {
fileReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
public void readFileByBufferedReader(String path){
File file = new File(path);
if (file.isFile()) {
BufferedReader bufferedReader = null;
FileReader fileReader = null;
try {
fileReader = new FileReader(file);
bufferedReader = new BufferedReader(fileReader);
String line = bufferedReader.readLine();
System.out.println("readFileByBufferReader执行结果:");
while (line != null) {
System.out.println(line);
line = bufferedReader.readLine();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
fileReader.close();
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
~~~
上面代码用到finally,关于finally虽然与I/O无关,不过这里还是说一下:
1、不管有木有出现异常,finally块中代码都会执行;
2、当try和catch中有return时,finally仍然会执行;
3、finally是在return后面的表达式运算后执行的(此时并没有返回运算后的值,而是先把要返回的值保存起来,管finally中的代码怎么样,返回的值都不会改变,任然是之前保存的值),所以函数返回值是在finally执行前确定的;
4、finally中最好不要包含return,否则程序会提前退出,返回值不是try或catch中保存的返回值。
**readerTest.txt文本内容:**

**执行结果:**

**2.3、FileWriter和BufferWriter的使用**
**FileWriter的常用构造有以下四种:**
(1)FileWriter(String fileName):根据文件名创建FileWriter对象。
(2)FileWriter(String fileName,boolean append):根据文件名创建FileWriter对象,append参数用来指定是否在原文件之后追加内容。
(3)FileWriter(File file):根据File对象创建FileWriter对象。
(4)FileWriter(File file,boolean append):根据File对象创建FileWriter对象,append参数用来指定是否在原文件之后追加内容。
**FileWriter的常用方法包括以下几种:**
(1)void writer(int c):向文件中写入正整数c代表的单个字符。
(2)void writer(char[] cbuf):向文件中写入字符数组cbuf。
(3)void writer(char[] cbuf,int off, in len):向文件中写入字符数组cbuf从偏移位置off开始的len个字符。
(4)void writer(String str):向文件中写入字符串str,注意此方法不会在写入完毕之后自动换行。
(5)void writer(String str,int off,int len):向文件中写入字符串str的从位置off开始、长度为len的一部分子串。
(6)Writer append(char c):向文件中追加单个字符c。
(7)Writer append(CharSequence csq):向文件中追加csq代表的一个字符序列。CharSequence是从JDK1.4版本开始引入的一个接口,代表字符值的一个可读序列,此接口对许多不同种类的字符序列提供统一的只读访问。
(8)Writer append(CharSequence csq,int start,int end):向文件中追加csq字符序列的从位置start开始、end结束的一部分字符。
(9)void flush():刷新字符输出流缓冲区。
(10)void close():关闭字符输出流。
**BufferedWriter也拥有如下两种形式的构造方法:**
(1)BufferedWriter(Writer out): 根据out代表的Writer对象创建BufferedWriter实例,缓冲区大小采用默认值。
(2)BufferedWriter(Writer out,int sz):根据out代表的Writer对象创建BufferedWriter实例,缓冲区大小采用指定的sz值。
**BufferedWriter的常用方法包括以下几种:**
(1)void close() :关闭字符输出流。
(2)void flush() :刷新字符输出流缓冲区。
(3)void newLine(): 写入文本行。
(4)void write(char[] cbuf, int offset, int count) :向文件中写入字符数组cbuf从偏移位置off开始的len个字符。
(5)void write(int oneChar) :写入单个字符。
(6)void write(String str, int offset, int count) :向文件中写入字符串str的从位置off开始、长度为len的一部分子串。
(7)以上的方法都是重写了Writer的,还有继承自java.io.Writer 的方法:Writer append(char c)、Writer append(CharSequence csq)、Writer append(CharSequence csq, int start, int end)、void write(char[] cbuf)、write(String str)等方法。
**代码实例:**
~~~
package java_io;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileWriter;
import java.io.IOException;
public class TestWriter {
public static void main(String[] args) {
TestWriter testWriter = new TestWriter();
String path = "C:\\Users\\luoguohui\\Desktop\\readerTest.txt";
testWriter.writeFileByFileWriter(path);
testWriter.writeFileByBufferWriter(path);
}
public void writeFileByFileWriter(String path){
FileWriter fileWriter = null;
try {
fileWriter = new FileWriter(path,true);
//将字符串写入到流中,\r\n表示换行
//因为fileWriter不会自动换行
fileWriter.write("本行是通过fileWriter加入的行\r\n");
//如果想马上看到写入效果,则需要调用w.flush()方法
fileWriter.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(fileWriter != null) {
try {
fileWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
public void writeFileByBufferWriter(String path){
File file = new File(path);
if (file.isFile()) {
BufferedWriter bufferedWriter = null;
FileWriter fileWriter = null;
try {
fileWriter = new FileWriter(file,true);
bufferedWriter = new BufferedWriter(fileWriter);
bufferedWriter.write("本行是通过bufferedWriter加入的行\r\n");
bufferedWriter.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
fileWriter.close();
bufferedWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
~~~
我们先把readerTest.txt文件的内容清空,运行结果如下(不清空也行,只是运行结果博主的不一样):

### 三、字节流实例
**3.1、实例之前**
再次声明之前提到过的“只要是处理纯文本数据,就要优先考虑使用字符流,除此之外都用字节流”。
这里博主贴出字节流类图结构,方便猿友阅读:

下面我们依旧以文件读写为例。
**3.2、FileInputStream的使用**
**FileInputStream的构造方法:**
(1)FileInputStream(File file) :通过打开一个到实际文件的连接来创建一个 FileInputStream,该文件通过文件系统中的 File 对象 file 指定。
(2)FileInputStream(FileDescriptor fdObj) :通过使用文件描述符 fdObj 创建一个 FileInputStream,该文件描述符表示到文件系统中某个实际文件的现有连接。
(3)FileInputStream(String name) 通过打开一个到实际文件的连接来创建一个 FileInputStream,该文件通过文件系统中的路径名 name 指定。
**FileInputStream的常用方法:**
(1)int available():返回下一次对此输入流调用的方法可以不受阻塞地从此输入流读取(或跳过)的估计剩余字节数。
(2)void close():关闭此文件输入流并释放与此流有关的所有系统资源。
(3)protected void finalize():确保在不再引用文件输入流时调用其 close 方法。
(4)FileChannel getChannel():返回与此文件输入流有关的唯一 FileChannel 对象。
(5)FileDescriptor getFD():返回表示到文件系统中实际文件的连接的 FileDescriptor 对象,该文件系统正被此 FileInputStream 使用。
(6)int read():从此输入流中读取一个数据字节。
(7)int read(byte[] b):从此输入流中将最多 b.length 个字节的数据读入一个 byte 数组中。
(8)int read(byte[] b, int off, int len):从此输入流中将最多 len 个字节的数据读入一个 byte 数组中。
(9)long skip(long n):从输入流中跳过并丢弃 n 个字节的数据。
**代码实例:**
~~~
package java_io;
import java.io.FileInputStream;
import java.io.IOException;
public class TestFileInputStream {
public static void main(String[] args) {
TestFileInputStream testFileInputStream = new TestFileInputStream();
String path = "C:\\Users\\luoguohui\\Desktop\\readerTest.txt";
testFileInputStream.readFileByFileInputStream(path);
}
public void readFileByFileInputStream(String path) {
FileInputStream fileInputStream = null;
try {
// 创建文件输入流对象
fileInputStream = new FileInputStream(path);
// 设定读取的字节数
int n = 1024;
byte buffer[] = new byte[1024];
// 读取输入流
System.out.println("readFileByFileInputStream执行结果:");
while ((fileInputStream.read(buffer, 0, n) != -1) && (n > 0)) {
System.out.print(new String(buffer));
}
System.out.println();
} catch (IOException ioe) {
ioe.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关闭输入流
if (fileInputStream != null) {
try {
fileInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
~~~
**readerTest.txt内容:**

**运行结果:**

**3.3、FileOutputStream 的使用**
**FileOutputStream的构造方法:**
(1)FileOutputStream(File file) :创建一个向指定 File 对象表示的文件中写入数据的文件输出流。
(2)FileOutputStream(File file, boolean append) :创建一个向指定 File 对象表示的文件中写入数据的文件输出流。append参数用来指定是否在原文件之后追加内容。
(3)FileOutputStream(FileDescriptor fdObj) :创建一个向指定文件描述符处写入数据的输出文件流,该文件描述符表示一个到文件系统中的某个实际文件的现有连接。
(4)FileOutputStream(String name) :创建一个向具有指定名称的文件中写入数据的输出文件流。
(5)FileOutputStream(String name, boolean append) : 创建一个向具有指定 name 的文件中写入数据的输出文件流。append参数用来指定是否在原文件之后追加内容。
**FileOutputStream的常用方法:**
(1)void close() :关闭此输出流并释放与此流有关的所有系统资源。
(2)void flush() :刷新此输出流并强制写出所有缓冲的输出字节。
(3)void write(byte[] b) :将 b.length 个字节从指定的字节数组写入此输出流。
(4)void write(byte[] b, int off, int len) :将指定字节数组中从偏移量 off 开始的 len 个字节写入此输出流。
(6)abstract void write(int b) :将指定的字节写入此输出流。
**代码实例:**
~~~
package java_io;
import java.io.FileOutputStream;
public class TestFileOutputStream {
public static void main(String[] args) {
TestFileOutputStream testFileOutputStream = new TestFileOutputStream();
String path = "C:\\Users\\luoguohui\\Desktop\\readerTest.txt";
testFileOutputStream.readFileByFileOutputStream(path);
}
public void readFileByFileOutputStream(String path) {
FileOutputStream fos = null;
try {
fos = new FileOutputStream(path,true);
String str = "这是使用FileOutputStream添加的内容\r\n";
byte[] b = str.getBytes();
fos.write(b);
fos.flush();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
fos.close();
} catch (Exception e2) {
e2.printStackTrace();
}
}
}
}
~~~
**运行结果:**

关于跳槽,是我心浮气躁?还是我确实该离开了?
最后更新于:2022-04-01 09:55:07
最近可能要跳槽了所以准备整理一下JVM、多线程、I/O、设计模式、内存管理以及使用过的一些框架知识点以应付笔试面试吧。即便不为面试,也是必须要整理并学习的。只是现在需要急促点罢了。原本想细细品味,现在只能粗糙阅读了。即便不能细细品味,这些东西的了解也要准备一两个月左右吧。
说到跳槽,博主刚毕业不够一年就想着跳槽,似乎有点太心浮气躁了,然而其实博主还是一个比较慎重的人,此决定是经过深思熟虑的,原因有:
(1)导火线:博主加上实习辛辛苦苦工作了一年,这个月调薪,居然说入职(拿到毕业证算起)不满一年,不在本次调薪计划之内,所有应届毕业生都这样,难道还要等一年?当然这仅仅是导火线,往往导火线都并不是至关重要的。
(2)假设,我们没有调薪,那么等到6月份,16年的应届毕业生薪资比我们还高,说实话,这点上,我觉得自己受委屈了。
(3)刚刚说到,薪资问题其实不是至关重要的。更让我心寒的是我工作的内容,开发的东西领导不重视、产品还经常给你加需求,但是风控又觉得产品设计的模式有漏洞,不让上线,而且也没有推广。
(4)说说用到的技术吧,什么前端:html、css、javascript、bui、jquery,后台:springmvc、spring、mybatis、dubbo、maven、redis、rabbitmq、shiro…..,还有什么微信企业号开发。用到的技术确实多,然而都是一些很低级的使用。说实话假设我自己空闲时间多花时间去学习,可能都仅仅是会在公司的环境里面使用,自己搭建实例都不会。用到的技术确实多,但是一个不运营的产品,自然没有高并发、也没有多线程、更没有数据库优化。这一年我确实学到不多东西,但是我觉得我继续在这工作下去,一年后我的技术水平还是现在的样子。这点上,我是非常渴望技术提高的,我渴望在工作上能接触到一些比较深入的技术(起码高并发、多线程、数据库优化是要有的),我也十分愿意贡献自己的空闲时间去学习,但是公司目前似乎在这点上给不了我。也许,很多公司都会有类似情况,但是我会去尝试我也相信我可以找到我想要的公司。
(5)除了钱、技术,另外一个非常重要的东西就是工作环境,从实习到现在,我已经被调动过两次了。第一次是部门老大去创业了,然后部门小组有变动,就被调去做某个微信企业号的项目开发了(美其名曰我学习能力比较强,我也就相信了),从此之后,我就前端、后台、微信端都要弄了。当然,这次的变动我并不怎么抵触。年前,可能是因为原来的产品部做得太差了(毕竟部门老大走了去创业,几乎全部产品都带走了,后面的产品都是新招的),然后又进行了一次变动,我参与开发的项目被分配到另外一个部门的某个大组,于是又被调过去了,去到之后发现特别没有存在感。
(6)个人危机感:对我而言毕业后的前三年非常重要,如果前三年都平平无奇的过去了,之后也就不会有大的突破了(大部分的人都这样)。最忌讳的是不外乎温水煮青蛙。既然这在这公司起码现在看来是无法实现我的想法了,倒不如早点摆脱面前的状况。
马云曾说过员工的离职原因只有两点最真实:“1、钱,没给到位;2、心,委屈了。这些归根到底就一条:干得不爽。员工临走还费尽心思找靠谱的理由,就是为给你留面子,不想说穿你的管理有多烂、他对你已失望透顶。仔细想想,真是人性本善。”
除了钱和心里受了委屈外,我在这公司根本看不到未来的希望。目前公司也有不少人才流失了(产品、数据库老大、风控老二)。我虽为菜鸟,却也有雄鹰的梦想啊。
刚毕业还不到一年,而且第一次跳槽,有点惶恐。是我心浮气躁?还是我确实该离开了?希望路过的前辈可以给点建议。
《Java多线程编程核心技术》推荐
最后更新于:2022-04-01 09:55:05
写这篇博客主要是给猿友们推荐一本书《Java多线程编程核心技术》。
之所以要推荐它,主要因为这本书写得十分通俗易懂,以实例贯穿整本书,使得原本抽象的概念,理解起来不再抽象。
只要你有一点点Java基础,你就可以尝试去阅读它,相信定会收获甚大!
博主之前网上找了很久都没完整pdf电子版的,只有不全的试读版,这里博主提供免费、清晰、完整版供各位猿友下载:
[http://download.csdn.net/detail/u013142781/9452683](http://download.csdn.net/detail/u013142781/9452683)
刚刚已经提到,《Java多线程编程核心技术》以实例贯穿整个本书,因此博主这里也准备好了整本书的实例源码供大家下载:
[http://download.csdn.net/detail/u013142781/9453047](http://download.csdn.net/detail/u013142781/9453047)
相信看完这本书,猿友们可以知道并理解Java多线程中的许多概念,以及其用法!
目前博主只看了前两章,但是已经博不急待地想将《Java多线程编程核心技术》推荐给大家。
书本的具体内容就不详列了,猿友们下载后阅读便知。
**阅读建议:**
(1)像深入Java虚拟机这种书籍,可能需要阅读三遍才能基本理解其中的知识点。《Java多线程编程核心技术》建议猿友们读两遍,因为其写得没有那么抽象,第一遍有些概念不是很理解,可以先跳过并记录起来,第一遍阅读的目的主要是了解整个架构。第二遍再慢慢品味,并贯穿全部是指点来思考,并将之前不理解的概念弄明白。
(2)尽量不要跳读,别直接跳过整个小节,这部书阅读起来其实内容不是很多。
(3)希望能够坚持将它读完!!!我知道很多猿友还没有将一般书从头到尾细细读完,等你有过完完整整读完一本书的经历,发现你阅读的耐心会大大提升!!
tomcat内存溢出解决,java.lang.OutOfMemoryError: PermGen space
最后更新于:2022-04-01 09:55:02
今天遇到了一个java.lang.OutOfMemoryError: PermGen space异常问题,一直解决不了,根据网上修改了tomcat的配置文件,但是还是解决不了,最后是通过如下方式解决的,解决步骤如下:eclipse–》
window–》show view –》server–》双击图一将会跳转到图二界面–》双击图二的Open launch configuration将跳转到图三–》在图三的Arguments的VM arguments顶行加上“-Xmx1024m -Xms512m -Xmn256m -XX:MaxPermSize=256m”(大小自己可以调),然后重启tomcat,问题解决。



java.lang.ClassNotFoundException:org.springframework.web.context.ContextLoaderListener问题解决
最后更新于:2022-04-01 09:55:00
今天搭建SSH项目的时候出现了如下错误:
~~~
严重: Error configuring application listener of class org.springframework.web.context.ContextLoaderListener
java.lang.ClassNotFoundException: org.springframework.web.context.ContextLoaderListener
~~~
网上查了一下,有些人说是没有spring的相关包,但是我检查这个包确实有进行依赖的。双击web.xml的“org.springframework.web.context.ContextLoaderListener”也能跳转到对应class文件里面。显然并不是缺少包的原因。
后面也花了挺长时间也没有解决,偶然在某篇博客的评论发现了解决方案,如果各位猿友也是使用maven的话可以试试如下解决方案:
其实可能是你的jar文件没有同步发布到自己项目的lib目录中(如果你是用Maven进行构建的话) 可以试试 下面的办法 项目点击右键 点击 Properties 选择Deployment Assembly 再点击右边的Add按钮 选择Java Build Path Entries后点击Next按钮 然后选择你的Maven Dependencies 确定即可。
开发人员系统功能设计常用办公软件分享
最后更新于:2022-04-01 09:54:58
大多数开发人员随着经验的增长,会进入一个管理层的岗位(开发小组的组长,当然啦博主才毕业大半年,还不是开发组长,只是提前了解了一下分享给大家),需要负责软件系统的设计(系统功能设计和数据库设计)。然后将你的设计思路传递给其他同事(也是一个讨论并完善的过程),让他们协助编码完成软件的开发。在设计思路的传递时,图文结合表述会更加直观清晰些。
下面博主分享三个软件,主要用于快速整理处系统功能图和数据库设计:XMind、Microsoft Office Visio、Power Designer。当然这三个软件的功能远远不止博主所说的那些,猿友们可以自行深入了解。下面看看这三个软件的大概介绍吧。
### 一、XMind
**1.1、XMind的介绍**
XMind 是一款非常实用的商业思维导图软件,应用全球最先进的Eclipse RCP 软件架构,全力打造易用、高效的可视化思维软件,强调软件的可扩展、跨平台、稳定性和性能,致力于使用先进的软件技术帮助用户真正意义上提高生产率。
XMind 的文件扩展名为.XMAP 。.XMAP 本质上是由XML+ZIP的结构组成,是一种开放的文件格式,用户可以通过XMind开放的API为其开发插件或进行二次开发。
XMind 能与用户其它的Office软件紧密集成,保护用户的投资。“XMind 文件”可以被导出成Word / PowerPoint / PDF / TXT /图片格式等,也可以在导出时选择仅导出图片,还是仅文字,还是图文混排,所得到的成果直接可以纳入用户的资料库,也可用 Word/Powerpoint/Acrobat等工具直接打开编辑,这样用户就可以和没有安装XMIND的其它用户分享思维图。此外,XMind 还支持导入用户的MindManager和FreeMind文件,使得大量用户在从这两个软件转向XMind时,不会丢失之前绘制的思维导图。
XMind 不仅可以绘制思维导图,还能绘制鱼骨图、二维图、树形图、逻辑图、组织结构图(Org、Tree、Logic Chart、Fishbone)。并且,可以方便地从这些展示形式之间进行转换。可以导入MindManager、FreeMind数据文件。灵活的定制节点外观、插入图标。丰富的样式和主题。输出格式有:HTML、图片。
总之很牛逼……..
**1.2、XMind使用实例**
猿友们可自行下载一个XMind进行安装,博主使用的版本是:XMind 2013 (v3.4.1.201401221918)。
打开XMind的初始界面如下图所示,里面有很多模板供大家选择:

博主一般用它来画功能模块图。下面博主就说说怎么画个功能模块图吧。最终效果如下图:

首先,我们选择一个空白的模板,一开始里面有一个中心主题,双击可编辑其文字,编辑成你想要的。选中该中心主题,然后右键—插入–子主题。然后按照这种方式插入子主题的子主题。子主题也是双击可编辑文字,然后整个功能模块图就出来了。
**注意哦,XMind 文件可以被导出成Word / PowerPoint / PDF / TXT /图片格式等**
XMind最强大的一点是什么呢?颜值高!
更多强大功能使用猿友自己去挖掘啦~~~
### 二、Microsoft Office Visio
**2.1、Microsoft Office Visio 的介绍**
Microsoft Office Visio 是一款便于IT和商务专业人员就复杂信息、系统和流程进行可视化处理、分析和交流的软件。使用具有专业外观的 Microsoft Office Visio 图表,可以促进对系统和流程的了解,深入了解复杂信息并利用这些知识做出更好的业务决策。
Microsoft Office Visio 帮助您创建具有专业外观的图表,以便理解、记录和分析信息、数据、系统和过程。
使用 Microsoft Office Visio,可以通过多种图表,包括业务流程图、软件界面、网络图、工作流图表、数据库模型和软件图表等直观地记录、设计和完全了解业务流程和系统的状态。通过使用 Microsoft Office Visio 将图表链接至基础数据,以提供更完整的画面,从而使图表更智能、更有用。
2000年1月7日,微软公司以15亿美元股票交换收购Visio。此后Visio并入MicrosoftOffice一起发行。
必须很牛逼……..
**2.2、Microsoft Office Visio 使用实例**
猿友们可自行下载一个Microsoft Office Visio进行安装,博主使用的版本是:Microsoft Office Visio 2013。
打开Microsoft Office Visio的初始界面如下图所示,里面也是有很多模板供大家选择:

博主一般用它来进行功能点的详细设计。最终效果图如下:

首先我们在模板里面选择跨职能流程图模板,新建。然后如下图,跨职能流程图模板提供了泳道、垂直泳道、分隔符、垂直分割符。利用这些拖动过来就可以打起一个大概架构了。然后其他流程圈、框、线是在基本形状和箭头形状中的。(如果想要更多形状,点击更多形状去获取就好,另外每个构建都可以双击编辑其文字)

更多强大功能使用待猿友自己去挖掘啦~~~
### 三、Power Designer
**3.1、Power Designer 的介绍**
PowerDesigner是Sybase的企业建模和设计解决方案,采用模型驱动方法,将业务与IT结合起来,可帮助部署有效的企业体系架构,并为研发生命周期管理提供强大的分析与设计技术。
PowerDesigner独具匠心地将多种标准数据建模技术(UML、业务流程建模以及市场领先的数据建模)集成一体,并与 .NET、WorkSpace、PowerBuilder、Java™、Eclipse 等主流开发平台集成起来,从而为传统的软件开发周期管理提供业务分析和规范的数据库设计解决方案。
此外,它支持60多种关系数据库管理系统(RDBMS)/版本。PowerDesigner运行在Microsoft Windows平台上,并提供了Eclipse插件。
在数据库建模的过程中,需要运用PowerDesigner进行数据库设计,这个不但可以让人直观的理解模型,而且可以充分的利用数据库技术,优化数据库的设计。第一次用PowerDesigner并不感到很陌生,里面与SQLServer建立数据库差不多。
其次就是E-R图,在数据库系统概论中有涉及到,这个实体关系图中,一个实体对于一个表,实体、属性与联系是进行系统设计时要考虑的三个要素,也是一个好的数据库设计的核心。
已久很牛逼…….
**3.2、Power Designer 使用实例**
猿友们可自行下载一个Power Designer破解版进行安装,博主使用的版本是:Power Designer 16.5。
打开Power Designer的初始界面如下图所示,然而一开始并没有列出模板共大家选择,而且比较丑:

博主一般用它来进行数据库设计。最终效果图如下(博主比较懒):

首先我们新建一个New Physocal Data Model,这里需要输入Model name,数据库选择mysql:

然后新建表,然后双击表,编辑columns,然后确定就得到最终结果啦:

由于时间不是很充足,网上找了一篇更加详细的文章供大家参考:
[http://blog.csdn.net/wangpeng047/article/details/7164643](http://blog.csdn.net/wangpeng047/article/details/7164643)
更多强大功能使用待猿友自己去挖掘啦~~~
最后的总结:其实这三个软件都有些详细的功能,比如基本流程图,三个软件肯定都可以画,只是各有长处吧,大家看情况使用咯,因为使用得并不是很熟练,不足之处还望指正,谢谢~
Servlet再度学习
最后更新于:2022-04-01 09:54:55
虽然Servlet已经使用很多了,但是一直都仅局限在其使用操作上。
最近有空想对它进行一个相对全面的了解。
下面是博主整理的一篇博文。
### 一、Servlet简介
Servlet(Server Applet),全称Java Servlet,未有中文译文。是用Java编写的服务器端程序。其主要功能在于交互式地浏览和修改数据,生成动态Web内容。狭义的Servlet是指Java语言实现的一个接口,广义的Servlet是指任何实现了这个Servlet接口的类,一般情况下,人们将Servlet理解为后者。
Servlet运行于支持Java的应用服务器中。从原理上讲,Servlet可以响应任何类型的请求,但绝大多数情况下Servlet只用来扩展基于HTTP协议的Web服务器。
### 二、Servlet 工作原理
**web应用的初始化工作(创建servlet对象)**
一般在Java Web项目中,我们使用Servlet,其配置是在web.xml中的。而应用的初始化主要是解析web.xml文件。
Web应用的初始化工作是在ContextConfig的configureStart方法中实现的,应用的初始化主要是解析web.xml文件,这个文件描述了一个Web应用的关键信息,也是一个Web应用的入口。web.xml文件中的各个配置项将会解析成相应的属性保存在WebXml对象中。WebXml对象中的属性又会被设置到Context容器中,这里包括创建Servlet对象、filter、listener等,所以说Context容器才是真正运行Servlet的Servlet容器。一个Web应用对应一个Context容器,容器的配置属性由应用的web.xml指定。
**Servlet如何工作**
用户从浏览器向服务器发起的一个请求通常会包含如下信息:[http://hostname:port/contextpath/servletpath](http://hostname:port/contextpath/servletpath),hostname和port用来与服务器建立TCP连接,后面的URL才用来选择在服务器中哪个子容器服务用户的请求。在Tomcat中URL与Servlet容器通过类org.apache.tomcat.util.http.mapper来完成映射,Mapper会根据请求的hostname和contextpath将host和context容器设置到Request的mappingData属性中。
Servlet能帮我们完成所有工作,但是现在的Web应用很少直接将交互的全部页面用Servlet来实现,而是采用更加高效的MVC框架来实现。这些MVC框架的基本原理是将所有的请求都映射到一个Servlet,然后去实现service方法,这个方法也就是MVC框架的入口。
当Servlet从Servlet容器中移除时,也表明该Servlet的生命周期结束了,这时Servlet的destroy方法将被调用,做一些扫尾工作
**Servlet 生命周期**
Servlet 生命周期可被定义为从创建直到毁灭的整个过程。以下是 Servlet 遵循的过程:
~~~
Servlet 通过调用 init () 方法进行初始化。
Servlet 调用 service() 方法来处理客户端的请求。
Servlet 通过调用 destroy() 方法终止(结束)。
最后,Servlet 是由 JVM 的垃圾回收器进行垃圾回收的。
~~~
~~~
init() 方法
init 方法被设计成只调用一次。它在第一次创建 Servlet 时被调用,在后续每次用户请求时不再调用。因此,它是用于一次性初始化,就像 Applet 的 init 方法一样。
Servlet 创建于用户第一次调用对应于该 Servlet 的 URL 时,但是您也可以指定 Servlet 在服务器第一次启动时被加载。
当用户调用一个 Servlet 时,就会创建一个 Servlet 实例,每一个用户请求都会产生一个新的线程,适当的时候移交给 doGet 或 doPost 方法。init() 方法简单地创建或加载一些数据,这些数据将被用于 Servlet 的整个生命周期。
~~~
~~~
service() 方法
service() 方法是执行实际任务的主要方法。Servlet 容器(即 Web 服务器)调用 service() 方法来处理来自客户端(浏览器)的请求,并把格式化的响应写回给客户端。
每次服务器接收到一个 Servlet 请求时,服务器会产生一个新的线程并调用服务。service() 方法检查 HTTP 请求类型(GET、POST、PUT、DELETE 等),并在适当的时候调用 doGet、doPost、doPut,doDelete 等方法。
~~~
~~~
doGet() 方法
GET 请求来自于一个 URL 的正常请求,或者来自于一个未指定 METHOD 的 HTML 表单,它由 doGet() 方法处理。
~~~
~~~
doPost() 方法
POST 请求来自于一个特别指定了 METHOD 为 POST 的 HTML 表单,它由 doPost() 方法处理。
~~~
~~~
destroy() 方法
destroy() 方法只会被调用一次,在 Servlet 生命周期结束时被调用。destroy() 方法可以让您的 Servlet 关闭数据库连接、停止后台线程、把 Cookie 列表或点击计数器写入到磁盘,并执行其他类似的清理活动。
~~~
### 三、Servlet使用实例
实例使用前提:已经配置好了JDK和Tomcat
下面我们准备好如下东西:
**(1)Servlet:HelloWorld.java**
~~~
// 导入必需的 java 库
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
// 扩展 HttpServlet 类
public class HelloWorld extends HttpServlet {
private String message;
public void init() throws ServletException
{
// 执行必需的初始化
message = "Hello World";
}
public void doGet(HttpServletRequest request,
HttpServletResponse response)
throws ServletException, IOException
{
// 设置响应内容类型
response.setContentType("text/html");
// 实际的逻辑是在这里
PrintWriter out = response.getWriter();
out.println("<h1>" + message + "</h1>");
}
public void destroy()
{
// 什么也不做
}
}
~~~
**(2)servlet-api.jar**
需要依赖servlet-api.jar包无须做过多解释,这里面包含了Servlet相关接口类。
博主已经提供了相应的jar包供猿友们下载:
[http://download.csdn.net/detail/u013142781/9446459](http://download.csdn.net/detail/u013142781/9446459)
接下来还需要如下操作:
(1)将HelloWorld.java和servlet-api.jar放到D:\servlettest下。(猿友如果放到其他目录,下面的设置应作相应修改)
(2)环境变量CLASSPATH中添加servlet-api.jar存放路径,博主的是D:\servlettest\servlet-api.jar
(3)打开cmd,进入到D:\servlettest(cd D:\servlettest),然后执行命令javac HelloWorld.java,编译 Servlet。
(4)编译成功后发现D:\servlettest下多了个HelloWorld.class文件。
(5)将HelloWorld.class文件放到tocmat的webapps\ROOT\WEB-INF\classes下(如果没有classes,自己新建一个放进去)
(6)tocmat的webapps\ROOT\WEB-INF\web.xml文件添加如下配置:
~~~
<servlet>
<servlet-name>HelloWorld</servlet-name>
<servlet-class>HelloWorld</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>HelloWorld</servlet-name>
<url-pattern>/HelloWorld</url-pattern>
</servlet-mapping>
~~~
博主的web.xml配置后是这样的:
~~~
<?xml version="1.0" encoding="ISO-8859-1"?>
<!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<web-app xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd"
version="3.0"
metadata-complete="true">
<display-name>Welcome to Tomcat</display-name>
<description>
Welcome to Tomcat
</description>
<servlet>
<servlet-name>HelloWorld</servlet-name>
<servlet-class>HelloWorld</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>HelloWorld</servlet-name>
<url-pattern>/HelloWorld</url-pattern>
</servlet-mapping>
</web-app>
~~~
(7)接下来双击tomcat的bin目录下的startup.sh来启动tomcat。
(8)访问路径:[http://localhost:8080/HelloWorld](http://localhost:8080/HelloWorld),效果如下:

JSP九大内置对象
最后更新于:2022-04-01 09:54:53
虽然现在基本上使用SpringMVC+AJAX进行开发了Java Web了,但是还是很有必要了解一下JSP的九大内置对象的。像request、response、session这些对象,即便使用其他框架也是会经常用到的。因此十分有了解的必要。
这些对象可以在JSP页面中调用,而不需要事先定义,这使得JSP编程更加的方便和快捷。其实这些内置对象都对应着某个Servlet类,在JSP被翻译成Servlet之后,这些内置对象会相应转换成对应的类实例。
**JSP中使用到的内置对象主要有如下九个:**
~~~
request内置对象
response内置对象
page内置对象
session内置对象
application内置对象
out内置对象
exception内置对象
config内置对象
pageContext内置对象
~~~
在jsp开发当中使用比较多的就request、response、session和out对象。
下面是各个对象的介绍和使用实例。
### 一、request内置对象
request内置对象是最常用的对象之一,它代表的是java.servlet.HttpServletRequest类的对象。request内置对象中包含了有关浏览器请求的信息,并提供了多个用于获取cookie、header以及session内数据的方法。
**request对象常用方法**
request对象主要用于客户端请求处理,其中,该对象中所包含的方法有:
~~~
request对象主要用于客户端请求处理,其中,该对象中所包含的方法有:
getMethod():返回HTTP请求信息中所使用到的方法名称;
getServletPath():返回请求信息中调用Servlet的URL部分;
getQueryString():返回HTTP GET请求信息中URL之后的查询字符串;
getContentType():返回请求实体的MIME类型;
getProtocol():返回请求信息中的协议名名字与版本号;
getPathInfo():返回有关任何路径信息;
getServletName():返回接受请求的服务器主机;
getServletPort():返回服务器的端口号;
getRemoteHost():返回提交请求的客户机的规范名字;
getRemoteAddr():返回提交请求的客户机的IP地址;
getScheme():返回请求使用的模式(协议)名字;
getParameter():返回客户端通过表单提交过来的参数值。例如request.getParameter(“myname”),通过该语句来获取客户端传递过来的myname 参数。
getContextPath():返回HTTP 请求中指示请求上下文的部分。
getHeaderNames():返回一个枚举类型,此枚举集合中包含了请求所含有的所有请求名。
getAuthType():返回用于保护Servlet 的认证模式的名字。例如,BASIC,SSL 或者NULL(没有保护)。
gtRequestURL():返回HTTP 请求信息中的第一行从协议名开始直至查询字符串之间的URL 部分。例如,对HTTP GET 请求http://www.zzbsite.com/helloworld?name=johnson&age=20,这个方法将返回http://www.zzbsite.com/helloworld 字符串。
gtCountLength():返回整数,表示请求实体的长度(以字节为单位)。
gtUestPrincipal():返回java.security 类的Principal 对象,其中包含有目前授权用户的名字。
iUserInRole(String role):返回一个布尔值,指示某个授权用户是否包含在某个具体的逻辑角色role 中。
gtRemoteHost():如果用户已经被授权,则返回提交请求的用户的注册名字,否则返回一个NULL。
~~~
**request常用方法的实例**
下面通过一个实例讲解来让读者了解有关request内置对象中的常见调用方法。创建一个request.jsp文件,该文件的详细源代码如下:
~~~
<%@ page contentType="text/html;charset=GBK" %>
<html>
<head><title> request 内置对象的实例 </title></head>
<body>
<form aciton="request.jsp">
<br>Get request results:
<br><input type="text" name="myname">
<br><input type="submit" name="get value">
</form>
返回HTTP 请求信息中使用的方法名称:<%=request.getMethod()%>
<br>
返回请求信息中调用Servlet 的URL 部分:<%=request.getServletPath()%>
<br>
返回HTTP GET 请求信息中URL 之后的查询字符串:<%=request.getQueryString()%>
<br>
返回请求实体的MIME 类型:<%=request.getContentType()%>
<br>
返回请求信息中的协议名名字和版本号:<%=request.getProtocol()%>
<br>
有关任何路径信息:<%=request.getPathInfo()%>
<br>
返回接受请求的服务器主机:<%=request.getServerName()%>
<br>
返回服务器的端口号:<%=request.getServerPort()%>
<br>
返回提交请求的客户机的规范名字:<%=request.getRemoteHost()%>
<br>
返回提交请求的客户机的IP地址:<%=request.getRemoteAddr()%>
<br>
返回请求中使用的模式(协议)名字:<%=request.getScheme()%>
<br>
返回这个request值,提交过来的值:<%=request.getParameter("myname")%>
</body>
</html>
~~~
程序说明:request中的getParameter()方法是最为常用的,使用此方法获取到上一页面所提交的参数值。此处,页面通过提交了一个myname参数给本页面,并调用request.getParameter(“myname”)获取到这个参数值。页面中的其他request方法是用来获取各种请求信息。
### 二、response内置对象
response对象与request对象相对应,它是用于响应客户请求,向客户端输出信息。response是javax.servlet.HttpServletResponse类的对象。
**response对象的常用方法**
response对象提供了多个方法用来处理HTTP响应,可以调用response中的方法修改ContentType中的MIME类型以及实现页面的跳转等等,
比较常用的方法如下:
setContentLength(int len):此方法用于设置响应头的长度。
setContentType(String type):用于设置HTTP响应的contentType中的MIME类型,其中可以包含字符编码的规则。例如可以把contentType设置为“text/html;charset=GBK”。在Servelet编写过程中,需要调用此方法进行设置,但是在JSP中一般都是使用page指令直接指定contentType的属性。
getOutputStream():此方法返回一个Servlet的输出流。用于在响应中写入二进制数据。Servlet容器不对二进制数据进行编码。
getWriter():此方法返回一个PrintWriter对象,在Servlet编写过程使用的比较频繁,而在JSP文件中,由于out是用getWriter()创建的PrintWriter对象的隐含对象,所以可以直接调用out对象作输出响应。
getCharacterEncoding():该方法获得此时响应所采用的字符编码类型。
sendError(int status):使用指定错误状态码向客户机发送相应的错误信息。
sendError(int status, String message):使用自定义的错误状态码以及描述信息向客户机发送错误的提示信息。
sendRedirect(String location):将请求重新定位到一个不同的URL(页面)上。此方法在实际开发过程中会经常使用到。
setDateHeader(String headername, long date):把指定的头名称以及日期设置为响应头信息。其中日期是用long值表示的,这是按照从新纪元开始算起的毫秒数。
ContainsHeader(String name):检测指定的头信息是否存在。返回一个布尔类型。
setHeader(String headername, String value):此方法使用指定的头名字以及相应的值来设置头信息。如果此头信息已经设置,则新的值会覆盖掉旧的值。如果头信息已经被发送出去,则此方法的设置将被忽略。
addheader(String headername, String value):把指定的头名字以及相应值添加到头信息当中去。
addIntHeader(String headername, int value):把指定的头名字以及整数值设置为头信息。如果头信息已经设置了,则新的设置值将覆盖掉以前的值。
setStatus(int sc):给响应设置状态的代码。
setStatus(int sc, String sm):为响应设置状态代码以及信息。这是在没有错误的时候使用的。
这些方法中,getWriter()和sendRedirect(String location)在实际开发中使用的最为频繁。getWriter()常出现在Servlet编写中。
**response对象的getWriter()方法实例**
在服务器端的Servlet类文件中,会经常使用getWriter()方法来获取一个PrintWriter对象,从而调用其中的println()方法来向客户端输出内容。下面一段Servlet的代码实例:
~~~
package com.helloworld;
import java.io.PrintWriter; //引入PrintWriter类
import javax.servlet.http.HttpServletResponse; //引入HttpServletResponse类
public class PrintHTML { //打印出HTML代码的方法
public static void printHTML(HttpServletResponse response) throws Exception{
PrintWriter out = response.getWriter(); //调用HttpServletResponse类中的getWriter()方法。
out.println("<table border='0' cellpadding='0' cellspacing='0' width='150' align='center'>");
out.println("<tr><td height='5'>这是HttpServletResponse类中的getWriter()方法的例子</td></tr>");
out.println("</table>");
}
}
~~~
程序说明:该Java代码动态地向客户端返回一个简单的HTML页面。
注意:在JSP页面中,response就是HttpServletResponse类的一个对象,可以直接使用response在JSP页面中调用HttpServletResponse类中所有方法。
**页面重定向实例**
下面再通过一个例子来加深对用于页面重定向的sendRedirect(String location)方法的理解。在helloworld模块下创建一个index4.jsp文件:
~~~
<%@ page language="java" contentType="text/html;charSet=GBK" %>
<html>
<body>
<center><h3>response.sendRedirect()使用例子</h3></center>
<form action="index4.jsp">
<table border=1>
<tr>
<td>
<select name="pg">
<option value=0>本页</option>
<option value=1>hello页面</option>
<option value=2>goodbye页面</option>
</select>
</td>
</tr>
<tr><td><input type="submit" value="提交"></td></tr>
</table>
</form>
<%
String pg = request.getParameter("pg"); //获取传递参数pg
if("1".equals(pg)) //如果pg等于1
response.sendRedirect("hello.jsp"); //则页面重定向为hello.jsp
else if("2".equals(pg)) //如果pg等于2
response.sendRedirect("goodbye.jsp"); //则页面重定向为goodbye.jsp
else //否则不进行页面重定向,即还显示本页
out.println("没有进行页面重定向");
%>
</body>
</html>
~~~
程序说明:页面中有个下拉菜单,选择需要跳转的页面。request内置对象通过getParameter()方法获取到传递过来的参数值,response对象再根据参数值不同调用sendRedirect()方法进行页面跳转。
重定向的hello.jsp页面代码如下:
~~~
<html>
<body>
<%out.print("<center><h2>Hello!</h2></center>");%>
</body>
</html>
~~~
Goodbye.jsp页面代码为:
~~~
<html>
<body>
<%out.println("<center><h2>Goodbye!</h2></center>");%>
</body>
</html>
~~~
### 三、page内置对象
page对象有点类似于Java编程中的this指针,就是指当前JSP页面本身。page是java.lang.Object类的对象。
**page对象的常用方法**
比较常用的page内置对象的方法有:
~~~
getClass():返回当时Object的类。
hashCode():返回此Object的哈希代码。
toString():把此时的Object类转换成字符串。
equals(Object o):比较此对象是否和指定的对象是否相等。
copy(Object o):把此对象复制到指定的对象当中去。
clone():对此对象进行克隆。
~~~
由于page内置对象在实际开发过程并不经常使用,所以page对象的其他方法在这里就不一一列举出来了。
**page的常用方法实例**
下面举一个实例来加深对page内置对象使用的理解。创建一个page.jsp文件,其详细源代码如下:
~~~
<%@ page language="java" contentType="text/html;charSet=GBK" %>
<%@ page import="java.lang.Object" %>
<html>
<body>
<center><h3>Page内置对象的实例</h3></center>
<%!Object obj; %> <!-- 对象申明 -->
getClass:<%=page.getClass() %>
<br>hashCode:<%=page.hashCode()%>
<br>toString:<%=page.toString()%>
<br>equals:<%=page.equals(obj) %>
<br>equlas2:<%=page.equals(this) %>
</body>
</html>
~~~
### 四、session内置对象
session是与请求有关的会话期,它是java.servlet.http.HttpSession类的对象,用来表示和存储当前页面的请求信息。
在实际的Web应用开发过程会经常遇到这样的一个问题:会话状态的维持。当然有很多种方法可以用来解决这个问题,例如:Cookies、隐藏的表单输入域或者将状态信息直接附加到URL当中去,但是这些方法使用非常不便。
Java Servlet提供了一个可以在多个请求之间持续有效的会话对象HttpSession,此对象允许用户存储和提取会话状态的信息。JSP同样也支持了Servlet中的这个概念。JSP中的session内置对象就是对应于Servlet中的HttpSession对象。当Web应用系统希望通过多个页面完成一个事务的时候,session的使用是非常有用和方便的。
**session对象的常用方法**
session内置对象中的常用方法如下:
~~~
getId():此方法返回唯一的标识,这些标识为每个session而产生。当只有一个单一的值与一个session联合时,或当日志信息与先前的sessions有关时,它被当作键名用。
getCreationTime():返回session被创建的时间。最小单位为千分之一秒。为得到一个对打印输出很有用的值,可将此值传给Date constructor 或者GregorianCalendar的方法setTimeInMillis。
getLastAccessedTime():返回session最后被客户发送的时间。最小单位为千分之一秒。
getMaxInactiveInterval():返回总时间(秒),负值表示session永远不会超时。
getAttribute(String key):通过给定的关键字获取一个存储在session中相对应的信息。例如,Integer item = (Integer) session.getAttrobute("item")。
setAttribute(String key, Object obj):提供一个关键词和一个对象值,然后存在session当中。例如,session.setAttribute("ItemValue", itemName)。
~~~
session一般在服务器上设置了一个30分钟的过期时间,当客户端停止操作后30分钟,session中存储的信息会自动失效。
另外读者要非常注意的,session中保存和查找的信息不能是基本的类型,如int、double等,而必须是Java相对应的对象,例如Integer、Double等。
**问题回答操作实例**
接下来本书将创建三个页面来模拟一个多页面的Web应用,使得读者能够对session的使用有深入的了解。第一个页面(session1.jsp)仅仅包含了一个要求输入用户名的HTML表单,代码如下:
~~~
<%@ page contentType="text/html;charSet=GBK" %>
<html>
<body>
<center><h3>用户名输入页面</h3></center>
<!—提交表单 -->
<form action="session2.jsp">
<table border="1" align="center">
<tr><td>用户名:<input type="text" name="username" size="10"></td></tr>
<tr><td align="center"><input type="submit" value="提交"></td></tr>
</table>
</form>
</body>
</html>
~~~
程序说明:通过<form>把参数提交给session2.jsp页面进行处理。这一页面的效果如图8.4所示。
第二个页面(session2.jsp)需要通过request对象获取session1.jsp页面中的username参数值,并把它保存在session中。session对象是以哈希表存储信息的。session2.jsp的另外一个操作是询问第二个问题,具体的代码如下:
~~~
<%@ page contentType="text/html;charSet=GBK" %>
<html>
<body>
<center><h3>回答问题页面</h3></center>
<%
String username = request.getParameter("username"); //获得传递参数username
session.setAttribute("theusername",username); //把用户名保存在session中,String可以当着对象
%>
<p>您的用户名为:<%=username%><p>
<!—提交表单 -->
<form action="session3.jsp">
<table border="1" align="center">
<tr><td>您喜欢吃什么:<input type="text" name="food" size="10"></td></tr>
<tr><td align="center"><input type="submit" value="提交"></td></tr>
</table>
</form>
</body>
</html>
~~~
程序说明:使用request内置对象中的getParameter()方法获取到session1.jsp页面传递过来的参数值,并使用session对象中的setAttribute()方法把用户名当着对象存储在session的哈希表中,这里需要指定一个关键字theusername。另外页面使用<form>向session3.jsp页面递交了另外一个参数food。
第三个页面(session3.jsp)主要任务是显示回答结果。具体代码如下:
~~~
<%@ page contentType="text/html;charSet=GBK" %>
<html>
<body>
<center><h3>显示答案</h3></center>
<%! String food="";%>
<%
food = request.getParameter("food"); //取得food参数值
String name = (String)session.getValue("theusername"); //从session取出关键字为theusername的对象
%>
您的用户名:<%=name%>
<br>您喜欢吃:<%=food%>
</body>
</html>
~~~
程序说明:通过关键字theusername使用session对象中的getAttribute(String key)方法获取到用户名,并把用户名和第二个问题的答案显示出来。
session内置对象的使用非常频繁,例如,使用session来存储用户的信息,并可以根据session中的用户对象是否为空来判断用户是否已经登陆。所以读者对此对象的使用要熟练掌握。
### 五、application内置对象
application是javax.servlet.ServletContext类对象的一个实例,用于实现用户之间的数据共享(多使用于网络聊天系统)。
**application对象与session对象的区别**
它的作用有点类似于前一节介绍的session内置对象。但是它们之间还是有区别的,一般来说,一个用户对应着一个session,并且随着用户的离开session中的信息也会消失,所以不同客户之间的会话必须要确保某一时刻至少有一个客户没有终止会话;而applicat则不同,它会一直存在,类似于系统的“全局变量”,而且只有一个实例。
**application对象的常用方法**
application内置对象的常用方法如下:
~~~
getAttribute(String key):通过一个关键字返回用户所需要的信息,返回类型为对象(Object),类似于session中的getAttribute(String key)方法。
getAttributeNames():返回所有可用的属性名,返回类型为枚举(Enumeration)。
setAttribute(String key, Object obj):保存一个对象信息,并指定给一个关键字。
removeAttribute(String key):通过关键字来删除一个对象信息。
getServletInfo():返回JSP引擎的相关信息。
getRealPath(String path):返回虚拟路径的真实路径。
getContext(String URLPath):返回执行Web应用的application对象。
getMajorVersion()和getMinorVersion():返回服务器所支持的Servlet API最大和最小版本号。
getMineType(String file):返回指定文件的MIME类型。
getResource(String path):返回指定资源的URL路径。
getResourceAsStream(String path):返回指定资源的输入流。
getRequestDispatcher(String URLPath):返回指定资源的RequestDispatcher对象。
getServlet(String name):返回指定名称的Servlet。
getServlets():返回所有的Servlet,返回类型为枚举型。
getServletNames():返回所有的Servlet名称,返回类型为枚举型。
log(String msg):把指定信息写入到Servlet的日志文件中。
log(String msg, Throwable throwable):把栈轨迹以及给出的Throwable异常的说明信息写入Servlet的日志文件。
~~~
**网站计数器实例**
同样,下面将通过一个实例来讲解Application内置对象中常用方法的使用。
在模块helloworld中创建一个setappattr.jsp页面,用于获取application内置对象中的信息以及设置计数初始值,详细代码如下:
~~~
<%@ page contentType="text/html;charSet=GBK" %>
<html>
<h4>获得application信息</h4>
<br>ServletInfo:<%=application.getServerInfo()%>
<br>application.jsp real path: <%=application.getRealPath("/application.jsp")%>
<br>HelloServlet Real Path: <%=application.getRealPath("/servletsample/HelloServlet")%>
<br>Major Version: <%=application.getMajorVersion()%>
<br>get MIME: <%=application.getMimeType("/servletsample/demo.htm")%>
<br>getResource: <%=application.getResource("/HelloJSP.jsp")%>
<%
out.println("<br><h4>设置数值</h4>");
application.setAttribute("name","zzb"); //把字符串“zzb”对象保存在application中
application.setAttribute("counter","1"); //把字符串值“1”保存在application中
out.println("set name=zzb");
out.println("<br>set counter=1");
%>
</body>
</html>
~~~
程序说明:此处调用了application内置对象中的setAttribute()方法来存储用户名信息以及计数初始值。
另外在相同目录下创建另外一个getappattr.jsp文件,用于获取计数值。具体的代码如下:
~~~
<%@ page contentType="text/html;charSet=GBK"%>
<html>
<body>
<br>获得用户名:<%=application.getAttribute("name")%>
<br>计数值:
<%
//将保存在application中的关键字为counter的字符串对象取出,然后强制转化成整数型
int mycounter = Integer.valueOf(application.getAttribute("counter").toString()).intValue();
out.println(mycounter);
//将数值加一,然后用新的值来更新保存再application中的counter对象
application.setAttribute("counter",Integer.toString(mycounter+1));
%>
</body>
</html>
~~~
程序说明:和session对象一样,application存储的是对象类型而不是普通的数值类型。此处调用了application对象中的getAttribute()方法来获取前一个页面所存储的信息,并把读取出的计数值加一,然后重新存储在application当中去。
当关闭以上运行的两个浏览器窗口,再多次交替地打开和关闭getappattr.jsp窗口,会看到计数值一直在递增,只用tomcat服务不关闭。而session对象存储的信息会随着窗口的关闭而释放。
### 六、out内置对象
out对象是在JSP开发过程中使用得最为频繁的对象,但使用也是最为简单的。
**out对象的常用方法**
out对象的常用方法如下:
~~~
print():在页面中打印出字符串信息,不换行;
println():在页面中打印出字符串信息,并且换行;
clear():清除掉缓冲区中尚存在的内容。
clearBuffer():此方法清除掉当前缓冲区中尚存在的内容。
flush():清除掉数据流。
getBufferSize():返回缓冲区的内存大小,单位为字节流。如果不进行缓冲区的设置,大小为0。
getRemaining():此方法返回缓冲区还剩下多少字节数可以使用。
isAutoFlush():检查当前缓冲区是设置为自动清空,还是满了就抛出异常。
close():关闭输出流。
~~~
其中print()与println()两个方法是使用最为频繁的。
**数据输出实例**
下面,同样将举一个例子来讲解out内置对象的使用方法。创建一个out.jsp文件,详细代码如下:
~~~
<%@ page buffer=”1kb” autoFlush=”true” contentType=”text/html;charSet=GBK” %>
<html>
<body>
<%
for(int i=0;i<135;i++) //迭代输出
Out.println(“Hello world, “+i+” “);
%>
<br>BufferSize: <%=out.getBufferSize() %>
<br>BufferRemain: <%=out.getRemaining() %>
<br>AutoFlush: <%=out.isAutoFlush() %>
<% out.clearBuffer(); %>
</body>
</html>
~~~
程序说明:page指令中的buffer属性用来设置缓冲区的大小。autoFlush属性为true表示缓冲区是自动清空的。在浏览器中运行这个JSP页面将会发现,程序只能输出到i=106,后面的数字以及内容将全部被清空了,显示不出来。这是因为out对象调用的clearBuffer()方法把缓冲区当前内容全部清除掉了。
把程序中的clearBuffer()方法换成clear()方法,再运行会报错。这是因为在调用clear()方法之前,缓冲区已经自动清除过了(autoFlush=true)。如果把程序中的循环次数改小一点,则不管程序调用的是clear()还是clearBuffer()方法,浏览器上将什么也不显示。因为内容已经被clear()或者clearBuffer()方法清空掉了。但这时使用clear()方法却不会出错,因为缓冲区这时还没有满,autoFlush没有起到作用。
### 七、exception内置对象
exception内置对象是用来处理页面出现的异常错误,它是java.lang.Throwable类的一个对象。前面已经讲过,在实际JSP网站开发过程中,通常是在其页面中加入page指令的errorPage属性来将其指向一个专门处理异常错误的页面。如果这个错误处理页面已经封装了这个页面收到的错误信息,并且错误处理页面页面含有的isErrorpage属性设置为true,则这个错误处理页面可以使用以下方法来访问错误的信息:
~~~
getMessage()和getLocalizedMessage():这两种方法分别返回exception对象的异常消息字符串和本地化语言的异常错误。
printStackTrace():显示异常的栈跟踪轨迹。
toString():返回关于异常错误的简单消息描述。
fillInStackTrace():重写异常错误的栈执行轨迹。
~~~
异常错误一般都是开发人员无法避免的,所以对各种可能的异常进行后期的处理和提示是非常必要的。读者要养成及时处理各种异常错误的习惯。
### 八、config内置对象
config内置对象是ServletConfig类的一个实例。在Servlet初始化的时候,JSP引擎通过config向它传递信息。这种信息可以是属性名/值匹配的参数,也可以是通过ServletContext对象传递的服务器的有关信息。
~~~
config内置对象中常用的方法如下。
getServletContext():此方法将返回一个含有服务器相关信息的ServletContext对象。
getInitParameter(String name):返回初始化参数的值。
getInitParameterNames():返回包含了Servlet初始化所需要的所有参数,返回类型是枚举型。
~~~
一般在JSP开发过程很少使用到config内置对象。只有在编写Servlet时,需要重载Servlet的init()方式时才用到。
### 九、pageContext内置对象
pageContext对象是一个比较特殊的对象。它相当于页面中所有其他对象功能的最大集成者,即使用它可以访问到本页面中所有其他对象,例如前面已经描述的request、response以及application对象等。
**pageContext对象的常用方法**
这个对象中常使用的方法如下:
~~~
getRequest():返回当前页面中的request对象。
getResponse():使用此方法将返回当前页面中的response对象。
getPage():此方法返回当前页面中的page对象。
getSession():返回当前页面中的session对象。
getOut():返回当前页面中的out对象。
getException():返回当前页面中的exception对象。
getServletConfig():返回当前页的config对象。
getServletContext():返回当前页中的application对象。
setAttribute(String name):给指定的属性名设置属性值。
getAttribute(String name):根据属性名称找到相应的属性值。
setAttribute(String name, Object obj, int scope):在给定的范围内设置相应的属性值。
getAttribute(String name, int scope):在指定的范围内获取到相应的属性值。
findAttribute(String name):寻找一个属性并返回,如果没有找到则返回一个null。
removeAttribute(String name):通过属性名删除掉某个属性。
removeAttribute(String name, int scope):在指定的某个范围内删除某个属性。
getAttributeScope(String scope):返回某属性的作用域。
getAttributeNamesInScope(int scope):返回指定范围内的所有属性名的枚举。
release():释放掉pageContext()所占的所有资源。
forward(String relativeURLpath):使用当前页面重导到另一个页面。
include(String relativeURLpath):使用当前位置包含的另一个页面。
~~~
之上提到的scope范围的取值含义:
~~~
1:Page scope
2:Request scope
3:Session scope
4:Application scope
~~~
**pageContext对象的简单实例**
下面为应用pageContext对象的示范例子:
~~~
<html>
<body>
<%
request.setAttribute(“MyName”,”zzb1”); //把MyName保存在request范围中
session.setAttribute(“MyName”,”zzb2”); //将MyName再保存再session范围中
application.setAttribute(“MyName”,”zzb3”); //将MyName保存在application范围中
%>
request: <%=pageContext.getRequest().getAttribute(“MyName”)%>
<br>session: <%=pageContext.getSession().getValue(“MyName”)%>
<br>application: <%=pageContext.getServletContext().getAttribute(“MyName”)%>
</body>
</html>
~~~
pageContext对象在实际JSP开发过程中很少使用,因为像request和response等对象本来就可以直接调用方法进行使用,如果通过pageContext来调用其他对象就有点舍近求远。
linux下安装apache(httpd-2.4.3版本)各种坑
最后更新于:2022-04-01 09:54:51
博主的linux是ubuntu 14.04.3。
在安装apache最新版httpd-2.4.3的时候遇到各种坑。
先提供安装apache httpd-2.4.3所需要的包,博主已经整理好,下载地址:[http://download.csdn.net/download/u013142781/9445609](http://download.csdn.net/download/u013142781/9445609)
里面包含了:
apache 安装包:httpd-2.4.3.tar.gz
依赖的包:apr-1.4.6.tar.gz、apr-util-1.4.1.tar.gz、pcre-8.20.tar.bz2
一开始没有添加依赖包的时候安装httpd-2.4.3报“apr not found”错误!
然后添加了apr-1.4.6依赖,再次安装,又报“apr-util not found”错误!
然后又添加了apr-util-1.4.1依赖,再次安装,又报“pcre-config for libpcre not found”错误!!!
然后又添加了pcre-8.20依赖最后才安装成功!!!
接下来介绍详细的安装过程:
**(1)先在/usr/local目录下创建这四个目录:**
apache2
apr
apr-util
pcre
如果对linux命令不熟悉的猿友可以看博主的另外一篇文章:[项目部署、配置、查错常用到的Linux命令](http://blog.csdn.net/u013142781/article/details/50748814)
**(2)接下来:**
将httpd-2.4.3.tar.gz解压到/usr/local/apache2
apr-1.4.6.tar.gz解压到/usr/local/apr
apr-util-1.4.1.tar.gz解压到/usr/local/apr-util
pcre-8.20.tar.bz2解压到/usr/local/pcre
这时候如果你到/usr/local/apache2/httpd-2.4.3目录下执行如下命令:
~~~
./configure --prefix=/usr/local/apache2
~~~
将会报“apr not found”错误。因此我们为保证不报错。先安装apr、apr-util和pcre这三个依赖。
下面我们依次安装apr、apr-util和pcre,必须是依次安装。
**(3)安装apr:**
到/usr/local/apr/apr-1.4.6目录下依次执行如下命令:
~~~
./configure --prefix=/usr/local/apr
make
make install
~~~
**(4)接下来安装apr-util:**
到/usr/local/apr-util/apr-util-1.4.1目录下依次执行如下命令:
~~~
./configure --prefix=/usr/local/apr-util -with-apr=/usr/local/apr/bin/apr-1-config
make
make install
~~~
**(5)接下来安装pcre:**
到/usr/local/pcre/pcre-8.20目录下依次执行如下命令:
~~~
./configure --prefix=/usr/local/pcre
make
make install
~~~
**(6)最后安装apache:**
到/usr/local/apache2/httpd-2.4.3目录下依次执行如下命令:
~~~
./configure --prefix=/usr/local/apache2 --with-apr=/usr/local/apr --with-apr-util=/usr/local/apr-util/ --with-pcre=/usr/local/pcre
make
make install
~~~
**启动apache:**
接下来进入/usr/local/apache2/bin目录下,执行如下命令启动apache
apachectl -k start
启动失败,发现报错了。
解决方案,进入到/usr/local/apache2/conf下,vi httpd.conf编辑该文件,找到”#ServerName www.example.com:80“,在其下面一行添加”ServerName localhost:80“,然后保存退出。然后再次启动apache。
如果对linux编辑命令不熟悉的可以阅读博主的另外一篇博客:[Linux文件编辑命令详细整理](http://blog.csdn.net/u013142781/article/details/50735470)
~~~
•启动Apache:/usr/local/apache2/bin/apachectl -k start
•停止Apache:/usr/local/apache2/bin/apachectl -k stop
•重启Apache:/usr/local/apache2/bin/apachectl -k restart
~~~
启动apache成功后,打开linux的浏览器访问:[http://localhost:80](http://localhost/)
博主的是阿里云服务器,所以访问地址为:[http://120.25.235.171:80](http://120.25.235.171/)
访问结果:

[](http://blog.csdn.net/u013142781/article/details/50753534#)[](http://blog.csdn.net/u013142781/article/details/50753534# "分享到QQ空间")[](http://blog.csdn.net/u013142781/article/details/50753534# "分享到新浪微博")[](http://blog.csdn.net/u013142781/article/details/50753534# "分享到腾讯微博")[](http://blog.csdn.net/u013142781/article/details/50753534# "分享到人人网")[](http://blog.csdn.net/u013142781/article/details/50753534# "分享到微信")
Ajax原理学习
最后更新于:2022-04-01 09:54:48
### 一、AJAX 简介
AJAX即“Asynchronous Javascript And XML”(异步JavaScript和XML),是指一种创建交互式网页应用的网页开发技术。
AJAX 是一种用于创建快速动态网页的技术。
通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。传统的网页(不使用 AJAX)如果需要更新内容,必须重载整个网页页面。AJAX 技术的广泛使用,对B/S模式应用慢慢取代了桌面软件起到了很大的推动作用。
### 二、同步、异步传输的区别
异步传输是面向字符的传输,它的单位是字符;而同步传输是面向比特的传输,它的单位是桢,它传输的时候要求接受方和发送方的时钟是保持一致的。
**异步传输**
具体来说,异步传输是将比特分成小组来进行传送。一般每个小组是一个8位字符,在每个小组的头部和尾部都有一个开始位和一个停止位,它在传送过程中接收方和发送方的时钟不要求一致,也就是说,发送方可以在任何时刻发送这些小组,而接收方并不知道它什么时候到达。
一个最明显的例子就是计算机键盘和主机的通信,按下一个键的同时向主机发送一个8比特位的ASCII代 码,键盘可以在任何时刻发送代码,这取决于用户的输入速度,内部的硬件必须能够在任何时刻接收一个键入的字符。这是一个典型的异步传输过程。
异步传输存在 一个潜在的问题,即接收方并不知道数据会在什么时候到达。在它检测到数据并做出响应之前,第一个比特已经过去了。这就像有人出乎意料地从后面走上来跟你说 话,而你没来得及反应过来,漏掉了最前面的几个词。因此,每次异步传输的信息都以一个起始位开头,它通知接收方数据已经到达了,这就给了接收方响应、接收 和缓存数据比特的时间;在传输结束时,一个停止位表示该次传输信息的终止。按照惯例,空闲(没有传送数据)的线路实际携带着一个代表二进制1的信号。步传输的开始位使信号变成0,其他的比特位使信号随传输的数据信息而变化。最后,停止位使信号重新变回1,该信号一直保持到下一个开始位到达。例如在键盘上数字“1”,按照8比特位的扩展ASCII编码,将发送“00110001”,同时需要在8比特位的前面加一个起始位,后面一个停止位。
**同步传输**
同步传输的比特分组要大得多。它不是独立地发送每个字符,每个字符都有自己的开始位和停止位,而是把它们组合起来一起发送。我们将这些组合称为数据帧,或简称为帧。
数据帧的第一部分包含一组同步字符,它是一个独特的比特组合,类似于前面提到的起始位,用于通知接收方一个帧已经到达,但它同时还能确保接收方的采样速度和比特的到达速度保持一致,使收发双方进入同步。
帧的最后一部分是一个帧结束标记。与同步字符一样,它也是一个独特的比特串,类似于前面提到的停止位,用于表示在下一帧开始之前没有别的即将到达的数据了。
同步传输通常要比异步传输快速得多。接收方不必对每个字符进行开始和停止的操作。一旦检测到帧同步字符,它就在接下来的数据到达时接收它们。另外,同步传输的开销也比较少。例如,一个典型的帧可能有500字节(即4000比特)的数据,其中可能只包含100比特的开销。这时,增加的比特位使传输的比特总数增加2.5%,这与异步传输中25 %的增值要小得多。随着数据帧中实际数据比特位的增加,开销比特所占的百分比将相应地减少。但是,数据比特位越长,缓存数据所需要的缓冲区也越大,这就限制了一个帧的大小。另外,帧越大,它占据传输媒体的连续时间也越长。在极端的情况下,这将导致其他用户等得太久。
了解了同步和异步的概念之后,大家应该对ajax为什么可以提升用户体验应该比较清晰了,它是利用异步请求方式的。打个比方,如果现在你家里所在的小区因 某种情况而面临停水,现在有关部门公布了两种方案,一是完全停水8个小时,在这8个小时内完全停水,8个小时后恢复正常。二是不完全停水10 个小时,在这10个小时内水没有完全断,只是流量比原来小了很多,在10个小时后恢复正常流量,那么,如果是你你会选择哪种方式呢?显然是后者。
### 三、AJAX 所包含的技术
大家都知道ajax并非一种新的技术,而是几种原有技术的结合体。它由下列技术组合而成。
1.使用CSS和XHTML来表示。
2\. 使用DOM模型来交互和动态显示。
3.使用XMLHttpRequest来和服务器进行异步通信。
4.使用javascript来绑定和调用。
在上面几中技术中,除了XmlHttpRequest对象以外,其它所有的技术都是基于web标准并且已经得到了广泛使用的,XMLHttpRequest虽然目前还没有被W3C所采纳,但是它已经是一个事实的标准,因为目前几乎所有的主流浏览器都支持它。
### 四、XMLHttpRequest 对象
Ajax的原理简单来说通过XmlHttpRequest对象来向服务器发异步请求,从服务器获得数据,然后用javascript来操作DOM而更新页面。这其中最关键的一步就是从服务器获得请求数据。要清楚这个过程和原理,我们必须对 XMLHttpRequest有所了解。
XMLHttpRequest是ajax的核心机制,它是在IE5中首先引入的,是一种支持异步请求的技术。简单的说,也就是javascript可以及时向服务器提出请求和处理响应,而不阻塞用户。达到无刷新的效果。
所以我们先从XMLHttpRequest讲起,来看看它的工作原理。
首先,我们先来看看XMLHttpRequest这个对象的属性。
它的属性有:
~~~
onreadystatechange 每次状态改变所触发事件的事件处理程序。
responseText 从服务器进程返回数据的字符串形式。
responseXML 从服务器进程返回的DOM兼容的文档数据对象。
status 从服务器返回的数字代码,比如常见的404(未找到)和200(已就绪)
status Text 伴随状态码的字符串信息
readyState 对象状态值
0 (未初始化) 对象已建立,但是尚未初始化(尚未调用open方法)
1 (初始化) 对象已建立,尚未调用send方法
2 (发送数据) send方法已调用,但是当前的状态及http头未知
3 (数据传送中) 已接收部分数据,因为响应及http头不全,这时通过responseBody和responseText获取部分数据会出现错误,
4 (完成) 数据接收完毕,此时可以通过通过responseXml和responseText获取完整的回应数据
~~~
**创建 XMLHttpRequest 对象**
所有现代浏览器 (IE7+、Firefox、Chrome、Safari 以及 Opera) 都内建了 XMLHttpRequest 对象。
通过一行简单的 JavaScript 代码,我们就可以创建 XMLHttpRequest 对象。
创建 XMLHttpRequest 对象的语法:
~~~
xmlhttp=new XMLHttpRequest();
~~~
老版本的 Internet Explorer (IE5 和 IE6)使用 ActiveX 对象:
~~~
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
~~~
**实例一**
~~~
<html>
<head>
<script type="text/javascript">
var xmlhttp;
function loadXMLDoc(url)
{
xmlhttp=null;
if (window.XMLHttpRequest)
{// code for IE7, Firefox, Opera, etc.
xmlhttp=new XMLHttpRequest();
}
else if (window.ActiveXObject)
{// code for IE6, IE5
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
if (xmlhttp!=null)
{
xmlhttp.onreadystatechange=state_Change;
xmlhttp.open("GET",url,true);
xmlhttp.send(null);
}
else
{
alert("Your browser does not support XMLHTTP.");
}
}
function state_Change()
{
if (xmlhttp.readyState==4)
{// 4 = "loaded"
if (xmlhttp.status==200)
{// 200 = "OK"
document.getElementById('A1').innerHTML=xmlhttp.status;
document.getElementById('A2').innerHTML=xmlhttp.statusText;
document.getElementById('A3').innerHTML=xmlhttp.responseText;
}
else
{
alert("Problem retrieving XML data:" + xmlhttp.statusText);
}
}
}
</script>
</head>
<body>
<h2>Using the HttpRequest Object</h2>
<p><b>Status:</b>
<span id="A1"></span>
</p>
<p><b>Status text:</b>
<span id="A2"></span>
</p>
<p><b>Response:</b>
<br /><span id="A3"></span>
</p>
<button onclick="loadXMLDoc('/example/xdom/note.xml')">Get XML</button>
</body>
</html>
~~~
执行结果:

注释:onreadystatechange 是一个事件句柄。它的值 (state_Change) 是一个函数的名称,当 XMLHttpRequest 对象的状态发生改变时,会触发此函数。状态从 0 (uninitialized) 到 4 (complete) 进行变化。仅在状态为 4 时,我们才执行代码。
为什么使用 Async=true ?
我们的实例在 open() 的第三个参数中使用了 “true”。
该参数规定请求是否异步处理。
True 表示脚本会在 send() 方法之后继续执行,而不等待来自服务器的响应。
onreadystatechange 事件使代码复杂化了。但是这是在没有得到服务器响应的情况下,防止代码停止的最安全的方法。
通过把该参数设置为 “false”,可以省去额外的 onreadystatechange 代码。如果在请求失败时是否执行其余的代码无关紧要,那么可以使用这个参数。
**XML / ASP实例**
您也可以把 XML 文档打开并发送到服务器上的 ASP 页面,分析此请求,然后传回结果。
~~~
<html>
<body>
<script type="text/javascript">
xmlHttp=null;
if (window.XMLHttpRequest)
{// code for IE7, Firefox, Opera, etc.
xmlHttp=new XMLHttpRequest();
}
else if (window.ActiveXObject)
{// code for IE6, IE5
xmlHttp=new ActiveXObject("Microsoft.XMLHTTP");
}
if (xmlHttp!=null)
{
xmlHttp.open("GET", "note.xml", false);
xmlHttp.send(null);
xmlDoc=xmlHttp.responseText;
xmlHttp.open("POST", "demo_dom_http.asp", false);
xmlHttp.send(xmlDoc);
document.write(xmlHttp.responseText);
}
else
{
alert("Your browser does not support XMLHTTP.");
}
</script>
</body>
</html>
~~~
ASP 页面,由 VBScript 编写:
~~~
<%
set xmldoc = Server.CreateObject("Microsoft.XMLDOM")
xmldoc.async=false
xmldoc.load(request)
for each x in xmldoc.documentElement.childNodes
if x.NodeName = "to" then name=x.text
next
response.write(name)
%>
~~~
通过使用 response.write 属性把结果传回客户端。
执行结果:
~~~
<to> : George
~~~
### 五、AJAX 的缺点
AJAX的优点不言而喻。
下面所阐述的ajax的缺陷都是它先天所产生的。
1、ajax干掉了back按钮,即对浏览器后退机制的破坏。后退按钮是一个标准的web站点的重要功能,但是它没法和js进行很好的合作。这是ajax所带来的一个比较严重的问题,因为用户往往是希望能够通过后退来取消前一次操作的。那么对于这个问题有没有办法?答案是肯定的,用过Gmail的知道,Gmail下面采用的ajax技术解决了这个问题,在Gmail下面是可以后退的,但是,它也并不能改变ajax的机制,它只是采用的一个比较笨但是有效的办法,即用户单击后退按钮访问历史记录时,通过创建或使用一个隐藏的IFRAME来重现页面上的变更。(例如,当用户在Google Maps中单击后退时,它在一个隐藏的IFRAME中进行搜索,然后将搜索结果反映到Ajax元素上,以便将应用程序状态恢复到当时的状态。)
但是,虽然说这个问题是可以解决的,但是它所带来的开发成本是非常高的,和ajax框架所要求的快速开发是相背离的。这是ajax所带来的一个非常严重的问题。
2、安全问题
技术同时也对IT企业带来了新的安全威胁,ajax技术就如同对企业数据建立了一个直接通道。这使得开发者在不经意间会暴露比以前更多的数据和服务器逻辑。ajax的逻辑可以对客户端的安全扫描技术隐藏起来,允许黑客从远端服务器上建立新的攻击。还有ajax也难以避免一些已知的安全弱点,诸如跨站点脚步攻击、SQL注入攻击和基于credentials的安全漏洞等。
3、对搜索引擎的支持比较弱。
4、破坏了程序的异常机制。至少从目前看来,像ajax.dll,ajaxpro.dll这些ajax框架是会破坏程序的异常机制的。关于这个问题,我曾经在开发过程中遇到过,但是查了一下网上几乎没有相关的介绍。后来我自己做了一次试验,分别采用ajax和传统的form提交的模式来删除一条数据……给我们的调试带来了很大的困难。
5、另外,像其他方面的一些问题,比如说违背了url和资源定位的初衷。例如,我给你一个url地址,如果采用了ajax技术,也许你在该url地址下面看到的和我在这个url地址下看到的内容是不同的。这个和资源定位的初衷是相背离的。
6、一些手持设备(如手机、PDA等)现在还不能很好的支持ajax,比如说我们在手机的浏览器上打开采用ajax技术的网站时,它目前是不支持的,当然,这个问题和我们没太多关系。
注:”二、同步、异步传输的区别“、”三、ajax所包含的技术“和”五、AJAX 的缺点“主要来自于文章:
[http://www.cnblogs.com/mingmingruyuedlut/archive/2011/10/18/2216553.html](http://www.cnblogs.com/mingmingruyuedlut/archive/2011/10/18/2216553.html)
Shell脚本了解
最后更新于:2022-04-01 09:54:46
### 一、什么是Shell
Shell 是一个用C语言编写的程序,它是用户使用Linux的桥梁。Shell既是一种命令语言,又是一种程序设计语言。
Shell 是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问操作系统内核的服务。
Ken Thompson的sh是第一种Unix Shell,Windows Explorer是一个典型的图形界面Shell。
### 二、Shell 脚本
Shell 脚本(shell script),是一种为shell编写的脚本程序。
业界所说的shell通常都是指shell脚本,但读者朋友要知道,shell和shell script是两个不同的概念。
由于习惯的原因,简洁起见,本文出现的”shell编程”都是指shell脚本编程,不是指开发shell自身。
### 三、Shell 环境
Shell 编程跟java、php编程一样,只要有一个能编写代码的文本编辑器和一个能解释执行的脚本解释器就可以了。
Linux的Shell种类众多,常见的有:
~~~
Bourne Shell(/usr/bin/sh或/bin/sh)
Bourne Again Shell(/bin/bash)
C Shell(/usr/bin/csh)
K Shell(/usr/bin/ksh)
Shell for Root(/sbin/sh)
……
~~~
本教程关注的是 Bash,也就是 Bourne Again Shell,由于易用和免费,Bash在日常工作中被广泛使用。同时,Bash也是大多数Linux系统默认的Shell。
在一般情况下,人们并不区分 Bourne Shell 和 Bourne Again Shell,所以,像 #!/bin/sh,它同样也可以改为#!/bin/bash。
~~~
#!告诉系统其后路径所指定的程序即是解释此脚本文件的Shell程序。
~~~
### 四、第一个shell脚本
打开文本编辑器(可以使用vi/vim命令来创建文件),新建一个文件test.sh,扩展名为sh(sh代表shell),扩展名并不影响脚本执行,见名知意就好,如果你用php写shell 脚本,扩展名就用php好了。
输入一些代码,第一行一般是这样:
~~~
#!/bin/bash
echo "Hello World !"
~~~
“#!” 是一个约定的标记,它告诉系统这个脚本需要什么解释器来执行,即使用哪一种Shell。
echo命令用于向窗口输出文本。
运行Shell脚本有两种方法:
1、作为可执行程序
将上面的代码保存为test.sh,并cd到相应目录:
~~~
chmod +x ./test.sh #使脚本具有执行权限
./test.sh #执行脚本
~~~
注意,一定要写成./test.sh,而不是test.sh,运行其它二进制的程序也一样,直接写test.sh,linux系统会去PATH里寻找有没有叫test.sh的,而只有/bin, /sbin, /usr/bin,/usr/sbin等在PATH里,你的当前目录通常不在PATH里,所以写成test.sh是会找不到命令的,要用./test.sh告诉系统说,就在当前目录找。
2、作为解释器参数
这种运行方式是,直接运行解释器,其参数就是shell脚本的文件名,如:
~~~
/bin/sh test.sh
/bin/php test.php
~~~
这种方式运行的脚本,不需要在第一行指定解释器信息,写了也没用。
还有关于更多Shell脚本学习内容:
~~~
Shell 变量
Shell 传递参数
Shell 数组
Shell 运算符
Shell echo命令
Shell printf命令
Shell test命令
Shell 流程控制
Shell 函数
Shell 输入/输出重定向
Shell 文件包含
~~~
可参考如下教程:[http://www.runoob.com/linux/linux-shell.html](http://www.runoob.com/linux/linux-shell.html)
里面还有个Shell 在线工具,可以实际操作尝试哦
项目部署、配置、查错常用到的Linux命令
最后更新于:2022-04-01 09:54:44
### 一、常用命令
ls 显示文件或目录
-l 列出文件详细信息l(list)
-a 列出当前目录下所有文件及目录,包括隐藏的a(all)
ll 会列出该文件下的所有文件信息,包括隐藏的文件的文件详细信息,使用ls -l -a也可以达到同样效果
mkdir 创建目录
-p 创建目录,若无父目录,则创建p(parent)
cd 切换目录
touch 创建空文件
cat 查看文件内容
more、less 分页显示文本文件内容(与cat不同,cat是显示全部内容)
cp 拷贝
mv 移动或重命名
rm 删除文件或目录
-r 递归删除,可删除子目录及文件,如果删除目录-r参数是必须的
-f 强制删除
rmdir 删除空目录
find 在文件系统中搜索某文件
wc 统计文本中行数、字数、字符数
grep 在文本文件中查找某个字符串(如grep “jdk” serclasspath.sh,其中jdk为需要查询的字符串,在serclasspath.sh中查找)
-e 后面被查找的字符串可以为正则表达式
pwd 显示当前目录
head 显示文件头内容
tail 显示文件尾内容(当文件内容改变的时候,会动态打印,查看日志的时候经常用到)
-数字f,显示末尾设定的行
source 在当前bash环境下读取并执行FileName中的命令。
命令用法:source FileName
注:该命令通常用命令“.”来替代。
### 二、系统管理命令
stat 显示指定文件的详细信息,比ls更详细
who 显示在线登陆用户
whoami 显示当前操作用户
hostname 显示主机名
uname 显示系统信息
top 动态显示当前耗费资源最多进程信息
ps 显示瞬间进程状态 ps -aux
du 查看目录大小 du -h /home带有单位显示目录信息
df 查看磁盘大小 df -h 带有单位显示磁盘信息
ifconfig 查看网络情况
ping 测试网络连通
netstat 显示网络状态信息
man 帮助命令,语法:man [命令或配置文件]
clear 清屏
alias 对命令重命名 如:alias showmeit=”ps -aux” ,另外解除使用unaliax showmeit
kill 杀死进程,可以先用ps 或 top命令查看进程的id,然后再用kill命令杀死进程。
### 三、打包压缩相关命令
gzip:
bzip2:
tar: 打包压缩
-c 归档文件
-x 压缩文件
-z gzip压缩文件
-j bzip2压缩文件
-v 显示压缩或解压缩过程 v(view)
-f 使用档名
例:
tar -cvf /home/abc.tar /home/abc 只打包,不压缩
tar -zcvf /home/abc.tar.gz /home/abc 打包,并用gzip压缩
tar -jcvf /home/abc.tar.bz2 /home/abc 打包,并用bzip2压缩
当然,如果想解压缩,就直接替换上面的命令 tar -cvf / tar -zcvf / tar -jcvf 中的“c” 换成“x” 就可以了
### 四、关机/重启机器
shutdown
-r 关机重启
-h 关机不重启
now 立刻关机
halt 关机
reboot 重启
### 五、Linux管道
将一个命令的标准输出作为另一个命令的标准输入。也就是把几个命令组合起来使用,后一个命令除以前一个命令的结果。
如我们想查看tomcat相关的进程信息:ps -ef|gref tomcat
### 六、Linux软件包管理
dpkg (Debian Package)管理工具,软件包名以.deb后缀。这种方法适合系统不能联网的情况下。
比如安装tree命令的安装包,先将tree.deb传到Linux系统中。再使用如下命令安装。
sudo dpkg -i tree_1.5.3-1_i386.deb 安装软件
sudo dpkg -r tree 卸载软件
APT(Advanced Packaging Tool)高级软件工具。这种方法适合系统能够连接互联网的情况。
依然以tree为例
sudo apt-get install tree 安装tree
sudo apt-get remove tree 卸载tree
sudo apt-get update 更新软件
sudo apt-get upgrade
将.rpm文件转为.deb文件
.rpm为RedHat使用的软件格式。在Ubuntu下不能直接使用,所以需要转换一下。
sudo alien abc.rpm
### 七、vim使用
vim三种模式:命令模式、插入模式、编辑模式。使用ESC或i或:来切换模式。
命令模式下:
:q 退出
:q! 强制退出
:wq 保存并退出
:set number 显示行号
:set nonumber 隐藏行号
/apache 在文档中查找apache 按n跳到下一个,shift+n上一个
yyp 复制光标所在行,并粘贴
h(左移一个字符←)、j(下一行↓)、k(上一行↑)、l(右移一个字符→)
更多vim命令使用请访问博主博客:
Linux文件编辑命令详细整理 :[http://blog.csdn.net/u013142781/article/details/50735470](http://blog.csdn.net/u013142781/article/details/50735470)
### 八、用户及用户组管理
/etc/passwd 存储用户账号
/etc/group 存储组账号
/etc/shadow 存储用户账号的密码
/etc/gshadow 存储用户组账号的密码
useradd 用户名
userdel 用户名
adduser 用户名
groupadd 组名
groupdel 组名
passwd root 给root设置密码
su root
su - root
/etc/profile 系统环境变量
bash_profile 用户环境变量
.bashrc 用户环境变量
su user 切换用户,加载配置文件.bashrc
su - user 切换用户,加载配置文件/etc/profile ,加载bash_profile
### 九、更改文件的用户及用户组
sudo chown [-R] owner[:group] {File|Directory}
例如:还以jdk-7u21-linux-i586.tar.gz为例。属于用户hadoop,组hadoop
要想切换此文件所属的用户及组。可以使用命令。
sudo chown root:root jdk-7u21-linux-i586.tar.gz
### 十、文件权限管理
三种基本权限
R 读 数值表示为4
W 写 数值表示为2
X 可执行 数值表示为1

如图所示,jdk-7u21-linux-i586.tar.gz文件的权限为-rw-rw-r–
-rw-rw-r–一共十个字符,分成四段。
第一个字符“-”表示普通文件;这个位置还可能会出现“l”链接;“d”表示目录
第二三四个字符“rw-”表示当前所属用户的权限。 所以用数值表示为4+2=6
第五六七个字符“rw-”表示当前所属组的权限。 所以用数值表示为4+2=6
第八九十个字符“r–”表示其他用户权限。 所以用数值表示为2
所以操作此文件的权限用数值表示为662
### 十一、更改权限
sudo chmod [u所属用户 g所属组 o其他用户 a所有用户] [+增加权限 -减少权限] [r w x] 目录名
例如:有一个文件filename,权限为“-rw-r—-x” ,将权限值改为”-rwxrw-r-x”,用数值表示为765
sudo chmod u+x g+w o+r filename
上面的例子可以用数值表示
sudo chmod 765 filename
本文大量参考了如下文章:[http://www.cnblogs.com/laov/p/3541414.html](http://www.cnblogs.com/laov/p/3541414.html)
阿里云服务器云数据库免费体验(Java Web详细实例)
最后更新于:2022-04-01 09:54:41
### 一、效果展示
博主部署了两个war包到阿里云服务器上,一个是没有连接数据库的,另外一个是连接了数据库的。
(由于阿里云服务器免费使用15天,下面链接约2016年3月9日后无效)
(1)无数据库版访问地址:[http://120.25.235.171:8080/web_exception_project-0.0.1-SNAPSHOT/login.jhtml](http://120.25.235.171:8080/web_exception_project-0.0.1-SNAPSHOT/login.jhtml)
只能用luoguohui,123456登录,在controller写死了。
(2)有连接数据库版访问地址:[http://120.25.235.171:8080/web_exception_project-0.0.3-SNAPSHOT/login.jhtml](http://120.25.235.171:8080/web_exception_project-0.0.3-SNAPSHOT/login.jhtml)
这个可以使用
liulang 123456
langlang 123456
langsan 123456
luoguohui 123456
zhangsan 123456
中任意一个登录。
(3)页面效果

### 二、阿里云服务器部署Java Web实例
**2.1、申请体验服务器**
申请地址:[https://free.aliyun.com/](https://free.aliyun.com/)

免费试用15天,所以要抓紧时间了解玩~~
如果还没有阿里云账号的,需要先注册然后实名认证,然后才能免费试用

实名认证后即可进行免费试用了:

上图可以看到,博主之前就是因为没有实名认证就申请免费试用,所以没能申请成功,后面实名认证后就可以啦。
注意:这里博主选择的操作系统是Ubuntu 14.04 64位,猿友们也可以采用这个操作系统。
**2.2、重置密码**
成功申请服务器后,我们需要设置一个登陆到服务器主机root的密码。
来到:[https://ecs.console.aliyun.com/#/server/region/cn-shenzhen](https://ecs.console.aliyun.com/#/server/region/cn-shenzhen)
已经给你建好了一个实例,点击对应实例,来到如下界面:

**2.3、SSH登陆云主机**
在实例详情里面应该可以看到你的云主机的公网IP,博主的是: 120.25.235.171。
博主可以网上下载个putty连接云主机,不过博主公司网络下ssh是无法连接到公网ip的。
因此,博主推荐直接使用云主机对应的控制台吧,这个公司没有限制,而且阿里的这个控制台体验效果很好。
就在重置密码的帮忙有个按钮(注意进去的时候会给你分配个控制台管理终端密码,猿友需要留意记住,每次进入控制台管理终端都需要输入那个密码的):

**2.4、将需要安装的软件上传到云主机上**
这里博主推荐Tunnelier这个软件,博主上传到了csdn,下载地址:
[http://download.csdn.net/detail/u013142781/9443756](http://download.csdn.net/detail/u013142781/9443756)
安装成功后打开Tunnelier输入host和和Username,然后点击Login:

然后输入登录信息连接成功后来到如下页面:

左边为你window系统的目录,右边为你云主机的目录。
左边选择文件,右键,upload即可上传到云主机上。
点击这里可以看到上传进度:

这里需要上传jdk安装包,tomcat安装包和web工程war包。
jdk和tomcat猿友们自行下载linux版的
这里博主选用jdk是jdk1.8.0_71,tomcat-7.0.67。
war猿友可使用博主的下载地址:[http://download.csdn.net/detail/u013142781/9443752](http://download.csdn.net/detail/u013142781/9443752)
**2.5、安装jdk**
登录云主机后
在”/”目录下新建好软件安装的目录,这里把tomcat安装的目录也提前建好:
~~~
cd /
cd usr
mkdir java
cd java
mkdir jdk
mkdir tomcat
~~~
然后将jdk解压到相应目录就好了(根据自己的jdk文件修改下面命令相应地方):
~~~
tar zxvf jdk-8u71-linux-x64.gz -C /usr/java/jdk
~~~
然后配置环境变量,打开文件:
~~~
vi /etc/profile
~~~
在其末尾添加如下内容(根据自己的jdk文件修改下面命令相应地方):
~~~
export JAVA_HOME=/usr/java/jdk/jdk1.8.0_71
export JRE_HOME=/usr/java/jdk/jdk1.8.0_71/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$JAVA_HOME:$PATH
~~~
如果不会linux下编辑文件,可看博主的另外一篇文章:[Linux文件编辑命令详细整理](http://blog.csdn.net/u013142781/article/details/50735470)。
编辑保存后执行如下命令:
~~~
source /etc/profile
~~~
执行如下命令如果显示对应的jdk版本就表明安装配置成功了:
~~~
java -version
~~~
**2.6、安装tomcat**
将tomcat解压到对应目录(根据自己的tomcat文件修改下面命令相应地方):
~~~
tar zxvf apache-tomcat-7.0.67.tar.gz -C /usr/java/tomcat
~~~
然后进入到tomcat的bin目录下,编辑setclasspath.sh文件
在末尾添加如下内容(根据自己的jdk版本修改下面命令相应地方):
~~~
export JAVA_HOME=/usr/java/jdk/jdk1.8.0_71
export JRE_HOME=/usr/java/jdk/jdk1.8.0_71/jre
~~~
保存退出,然后tomcat就安装成功啦
2.7、部署war包:
将war复制到/usr/java/tomcat/apache-tomcat-7.0.67/webapps下:
~~~
cp web_exception_project-0.0.1-SNAPSHOT.war /usr/java/tomcat/apache-tomcat-7.0.67/webapps
~~~
然后进入到tomcat的bin目录执行如下命令启动tomat:
~~~
./startup.sh
~~~
启动tomcat成功后,即可访问:
~~~
http://你的主机公网ip:8080/web_exception_project-0.0.1-SNAPSHOT/login.jhtml
~~~
如博主的:[http://120.25.235.171:8080/web_exception_project-0.0.1-SNAPSHOT/login.jhtml](http://120.25.235.171:8080/web_exception_project-0.0.1-SNAPSHOT/login.jhtml)
即可来到如下页面:

### 三、阿里云数据库
**3.1、申请免费体验阿里云数据库**
申请地址:[https://free.aliyun.com/](https://free.aliyun.com/)

免费试用30天。
申请免费体验:

**3.2、设置白名单、账号、数据库**
申请成功之后,访问:[https://rdsnew.console.aliyun.com/console/index#/rdsList/basic/all/normal](https://rdsnew.console.aliyun.com/console/index#/rdsList/basic/all/normal)
看到如下页面:

点击实例,进入到如下页面:

然后依次:
(1)在基本信息中的连接信息中设置白名单,将云主机的内网ip添加进去
(2)然后在账号管理中创建账号
(3)然后在数据库管理中创建数据库
**3.3、创建表并插入数据**
然后点击如下,登录数据库(使用上面(2)中创建的账号):

然后创建表并插入数据:
~~~
CREATE TABLE `t_user` (
`USER_ID` int(11) NOT NULL AUTO_INCREMENT,
`USER_NAME` char(30) NOT NULL,
`USER_PASSWORD` char(10) NOT NULL,
PRIMARY KEY (`USER_ID`),
KEY `IDX_NAME` (`USER_NAME`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8
~~~
~~~
INSERT INTO t_user (USER_ID, USER_NAME, USER_PASSWORD) VALUES (1, 'luoguohui', '123456');
INSERT INTO t_user (USER_ID, USER_NAME, USER_PASSWORD) VALUES (2, 'zhangsan', '123456');
~~~
3.4、部署war包
如果猿友们没有连接数据库的工程可下载博主的。
博主的工程采用eclipse+maven环境。
下载地址:[http://download.csdn.net/detail/u013142781/9443753](http://download.csdn.net/detail/u013142781/9443753)
下载导入成功后修改数据库连接文件jdbc.properties:

其中rdsc0o40f965ee3nibjh.mysql.rds.aliyuncs.com你的可以在基本信息-连接信息中获取到。
配置好连接信息后用maven命令打包war包。
然后将war包上传到tomcat的webapps目录下,过一分钟后访问:
~~~
http://你的云主机公网ip:8080/web_exception_project-0.0.3-SNAPSHOT/login.jhtml
~~~
账号luoguohui 123456和zhangsan 123456 都可以登录。
Linux文件编辑命令详细整理
最后更新于:2022-04-01 09:54:39
刚接触Linux,前几天申请了个免费体验的阿里云服务器,选择的是Ubuntu系统,配置jdk环境变量的时候需要编辑文件。
vi命令编辑文件,百度了一下,很多回答不是很全面,因此编辑文件话了一些时间。
这里博主整理了一下,分享给大家。
### 一、vi编辑器有3种基本工作模式
首先需要知道vi编辑器有3种基本工作模式,分别是:命令模式、文本输入模式、和末行模式。
第一:命令行模式:该模式是进入vi编辑器后的默认模式。任何时候,不管用户处于何种模式,按下ESC键即可进入命令模式。在该模式下,用户可以输入vi命令,用户管理自己的文档。此时从键盘上输入的任何字符都被当作编辑命令来解释。若输入的字符是合法的vi命令,则vi在接受用户命令之后完成相应的动作。但需要注意的是,所输入的命令并不回显在屏幕上。若输入的字符不是vi命令,vi会响铃报警。
第二:文本输入模式:在命令模式下输入命令i、附加命令a、打开命令o、修改命令c、取代命令r或替换命令s都可以进入文本输入模式。在该模式下,用户输入的任何字符都被vi当作文件内容保护起来,并将其显示在屏幕上。在文本输入过程中,若想回到命令模式下,按ESC键即可。
第三:末行模式:末行模式也称ex转义模式。在命令模式下,用户按“:”键即可进入末行模式下,此时vi会在显示窗口的最后一行(通常也是屏幕的最后一行)显示一个“:”作为末行模式的说明符,等待用户输入命令。多数文件管理命令都是在此模式下执行的(如把编辑缓冲区的内容写到文件中等)。末行命令在执行完后,vi自动回到命令模式。如果要从命令模式转换到编辑模式,可以键入a或者i。如果需要从文本模式返回,则按ESC即可。在命令模式下输入“:”即可切换到末行模式,然后输入命令。
综上,一般我们使用命令打开文件的时候,是进入到命令模式。在命令模式下,可以切换到文本输入模式和末行模式,但是文本输入模式和末行模式之间是不可以直接相互切换了,因此文本输入模式切换到末行模式,需要先回到命令模式再切换,反之亦然。
此外,编辑文本可以在文本输入模式下,键盘输入对文编进行编辑,或者在命令模式下使用vi命令也是可以起到编辑效果的。
### 实例演示
首先我们使用命令 vi filename 打开一个文件,这个时候进入到的是命令模式
接下来我们按i,然后键盘随便输入写内容。
然后按ESC重新进入到命令模式。
在命令模式的情况下,我们按:,进入到了末行模式。
我们输入wq!,然后回车,强行保存退出。
下次我们再打开对应文件(可用less filename命令打开),即可看到内容已经更改。
补充:
(1)末行模式下:q! 【强制退出不保存】 q【退出不保存】 wq【退出并保存后面也可以加个!】
(2)如果你不想保存直接退出有可以在命令模式下使用“ctrl+z”快捷键或者按住“shift”键,输入两个z即可退出。
### 更多命令
**进入vi的命令**
vi filename :打开或新建文件,并将光标置于第一行首
vi +n filename :打开文件,并将光标置于第n行首
vi + filename :打开文件,并将光标置于最后一行首
vi +/pattern filename:打开文件,并将光标置于第一个与pattern匹配的串处
vi -r filename :在上次正用vi编辑时发生系统崩溃,恢复filename
vi filename….filename :打开多个文件,依次进行编辑
**屏幕翻滚类命令**
Ctrl+u:向文件首翻半屏
Ctrl+d:向文件尾翻半屏
Ctrl+f:向文件尾翻一屏
Ctrl+b;向文件首翻一屏
nz:将第n行滚至屏幕顶部,不指定n时将当前行滚至屏幕顶部。
**插入文本类命令**
i :在光标前
I :在当前行首
a:光标后
A:在当前行尾
o:在当前行之下新开一行
O:在当前行之上新开一行
r:替换当前字符
R:替换当前字符及其后的字符,直至按ESC键
s:从当前光标位置处开始,以输入的文本替代指定数目的字符
S:删除指定数目的行,并以所输入文本代替之
ncw或nCW:修改指定数目的字
nCC:修改指定数目的行
**删除命令**
ndw或ndW:删除光标处开始及其后的n-1个字
do:删至行首
d$:删至行尾
ndd:删除当前行及其后n-1行
x或X:删除一个字符,x删除光标后的,而X删除光标前的
Ctrl+u:删除输入方式下所输入的文本
**搜索及替换命令**
/pattern:从光标开始处向文件尾搜索pattern
?pattern:从光标开始处向文件首搜索pattern
n:在同一方向重复上一次搜索命令
N:在反方向上重复上一次搜索命令
:s/p1/p2/g:将当前行中所有p1均用p2替代
:n1,n2s/p1/p2/g:将第n1至n2行中所有p1均用p2替代
:g/p1/s//p2/g:将文件中所有p1均用p2替换
**选项设置**
all:列出所有选项设置情况
term:设置终端类型
ignorance:在搜索中忽略大小写
list:显示制表位(Ctrl+I)和行尾标志($)
number:显示行号
report:显示由面向行的命令修改过的数目
terse:显示简短的警告信息
warn:在转到别的文件时若没保存当前文件则显示NO write信息
nomagic:允许在搜索模式中,使用前面不带“\”的特殊字符
nowrapscan:禁止vi在搜索到达文件两端时,又从另一端开始
mesg:允许vi显示其他用户用write写到自己终端上的信息
**末行模式命令**
:n1,n2 co n3:将n1行到n2行之间的内容拷贝到第n3行下
:n1,n2 m n3:将n1行到n2行之间的内容移至到第n3行下
:n1,n2 d :将n1行到n2行之间的内容删除
:w :保存当前文件
:e filename:打开文件filename进行编辑
:x:保存当前文件并退出
:q:退出vi
:q!:不保存文件并退出vi
:!command:执行shell命令command
:n1,n2 w!command:将文件中n1行至n2行的内容作为command的输入并执行之,若不指定n1,n2,则表示将整个文件内容作为command的输入
:r!command:将命令command的输出结果放到当前行
**寄存器操作**
“?nyy:将当前行及其下n行的内容保存到寄存器?中,其中?为一个字母,n为一个数字
“?nyw:将当前行及其下n个字保存到寄存器?中,其中?为一个字母,n为一个数字
“?nyl:将当前行及其下n个字符保存到寄存器?中,其中?为一个字母,n为一个数字
“?p:取出寄存器?中的内容并将其放到光标位置处。这里?可以是一个字母,也可以是一个数字
ndd:将当前行及其下共n行文本删除,并将所删内容放到1号删除寄存器中。