探索Lua5.2内部实现:Garbage Collection(2)
最后更新于:2022-04-01 07:10:06
# 探索Lua5.2内部实现:Garbage Collection(2)
## GCObject
Lua使用union GCObject来表示所有的垃圾回收对象:
~~~
182 /*
183 ** Union of all collectable objects
184 */
185 union GCObject {
186 GCheader gch; /* common header */
187 union TString ts;
188 union Udata u;
189 union Closure cl;
190 struct Table h;
191 struct Proto p;
192 struct UpVal uv;
193 struct lua_State th; /* thread */
194 };
~~~
这就相当于在C++中,将所有的GC对象从GCheader派生,他们都共享GCheader。
~~~
74 /*
75 ** Common Header for all collectable objects (in macro form, to be
76 ** included in other objects)
77 */
78 #define CommonHeader GCObject *next; lu_byte tt; lu_byte marked
79
80
81 /*
82 ** Common header in struct form
83 */
84 typedef struct GCheader {
85 CommonHeader;
86 } GCheader;
~~~
marked这个标志用来记录对象与GC相关的一些标志位。其中0和1位用来表示对象的white状态和垃圾状态。当垃圾回收的标识阶段结束后,剩下的white对象就是垃圾对象。由于lua并不是立即清除这些垃圾对象,而是一步步逐渐清除,所以这些对象还会在系统中存在一段时间。这就需要我们能够区分出同样为white状态的垃圾对象和非垃圾对象。Lua使用两个标志位来表示white,就是为了高效的解决这个问题。这个标志位会轮流被当作white状态标志,另一个表示垃圾状态。在global_State中保存着一个currentwhite,来表示当前是那个标志位用来标识white。每当GC标识阶段完成,系统会切换这个标志位,这样原来为white的所有对象不需要遍历就变成了垃圾对象,而真正的white对象则使用新的标志位标识。
第2个标志位用来表示black状态,而既非white也非black就是gray状态。
除了short string和open upvalue之外,所有的GCObject都通过next被串接到全局状态global_State中的allgc链表上。我们可以通过遍历allgc链表来访问系统中的所有GCObject。short string被字符串标单独管理。open upvalue会在被close时也连接到allgc上。
## 引用关系
垃圾回收过程通过对象之间的引用关系来标识对象。以下是lua对象之间在垃圾回收标识过程中需要遍历的引用关系:

所有字符串对象,无论是长串还是短串,都没有对其他对象的引用。
usedata对象会引用到一个metatable和一个env table。
Upval对象通过v引用一个TValue,再通过这个TValue间接引用一个对象。在open状态下,这个v指向stack上的一个TValue。在close状态下,v指向Upval自己的TValue。
Table对象会通过key,value引用到其他对象,并且如果数组部分有效,也会通过数组部分引用。并且,table会引用一个metatable对象。
Lua closure会引用到Proto对象,并且会通过upvalues数组引用到Upval对象。
C closure会通过upvalues数组引用到其他对象。这里的upvalue与lua closure的upvalue完全不是一个意思。
Proto对象会引用到一些编译期产生的名称,常量,以及内嵌于本Proto中的Proto对象。
Thread对象通过stack引用其他对象。
## barrier
在《[原理](http://blog.csdn.net/yuanlin2008/article/details/8558103)》中我们说过,incremental gc在mark阶段,为了保证“所有的black对象都不会引用white对象”这个不变性,需要使用barrier。
barrier被分为“向前”和“向后”两种。
luaC_barrier_函数用来实现“向前”的barrier。“向前”的意思就是当一个black对象需要引用一个white对象时,立即mark这个white对象。这样white对象就变为gray对象,等待下一步的扫描。这也就是帮助gc向前标识一步。luaC_barrier_函数被用在以下引用变化处:
* 虚拟机执行过程中或者通过api修改close upvalue对其他对象的引用
* 通过api设置userdata或table的metatable引用
* 通过api设置userdata的env table引用
* 编译构建proto对象过程中proto对象对其他编译产生对象的引用
luaC_barrierback_函数用来实现“向后”的barrier。“向后”的意思就是当一个black对象需要引用一个white对象时,将已经扫描过的black对象再次变为gray对象,等待重新扫描。这也就是将gc的mark后退一步。luaC_barrierback_目前只用于监控table的key和value对象引用的变化。Table是lua中最主要的数据结构,连全局变量都是被保存在一个table中,所以table的变化是比较频繁的,并且同一个引用可能被反复设置成不同的对象。对table的引用使用“向前”的barrier,逐个扫描每次引用变化的对象,会造成很多不必要的消耗。而使用“向后”的barrier就等于将table分成了“未变”和“已变”两种状态。只要一个table改变了一次,就将其变成gray,等待重新扫描。被变成gray的table在被重新扫描之前,无论引用再发生多少次变化也都无关紧要了。
引用关系变化最频繁的要数thread对象了。thread通过stack引用其他对象,而stack作为运行期栈,在一直不停地被修改。如果要监控这些引用变化,肯定会造成执行效率严重下降。所以lua并没有在所有的stack引用变化处加入barrier,而是直接假设stack就是变化的。所以thread对象就算被扫描完成,也不会被设置成black,而是再次设置成gray,等待再次扫描。
## Upvalue
Upvalue对象在垃圾回收中的处理是比较特殊的。
对于open状态的upvalue,其v指向的是一个stack上的TValue,所以open upvalue与thread的关系非常紧密。引用到open upvalue的只可能是其从属的thread,以及lua closure。如果没有lua closure引用这个open upvalue,就算他一定被thread引用着,也已经没有实际的意义了,应该被回收掉。也就是说thread对open upvalue的引用完全是一个弱引用。所以Lua没有将open upvalue当作一个独立的可回收对象,而是将其清理工作交给从属的thread对象来完成。在mark过程中,open upvalue对象只使用white和gray两个状态,来代表是否被引用到。通过上面的引用关系可以看到,有可能引用open upvalue的对象只可能被lua closure引用到。所以一个gray的open upvalue就代表当前有lua closure正在引用他,而这个lua closure不一定在这个thread的stack上面。在清扫阶段,thread对象会遍历所有从属于自己的open upvalue。如果不是gray,就说明当前没有lua closure引用这个open upvalue了,可以被销毁。
当退出upvalue的语法域或者thread被销毁,open upvalue会被close。所有close upvalue与thread已经没有弱引用关系,会被转化为一个普通的可回收对象,和其他对象一样进行独立的垃圾回收。
探索Lua5.2内部实现:Garbage Collection(1) 原理
最后更新于:2022-04-01 07:10:03
# 探索Lua5.2内部实现:Garbage Collection(1) 原理
Lua5.2采用垃圾回收机制对所有的lua对象(GCObject)进行管理。Lua虚拟机会定期运行GC,释放掉已经不再被被引用到的lua对象。
## 基本算法
基本的垃圾回收算法被称为"mark-and-sweep"算法。算法本身其实很简单。
首先,系统管理着所有已经创建了的对象。每个对象都有对其他对象的引用。root集合代表着已知的系统级别的对象引用。我们从root集合出发,就可以访问到系统引用到的所有对象。而没有被访问到的对象就是垃圾对象,需要被销毁。
我们可以将所有对象分成三个状态:
1. White状态,也就是待访问状态。表示对象还没有被垃圾回收的标记过程访问到。
2. Gray状态,也就是待扫描状态。表示对象已经被垃圾回收访问到了,但是对象本身对于其他对象的引用还没有进行遍历访问。
3. Black状态,也就是已扫描状态。表示对象已经被访问到了,并且也已经遍历了对象本身对其他对象的引用。
基本的算法可以描述如下:
~~~
当前所有对象都是White状态;
将root集合引用到的对象从White设置成Gray,并放到Gray集合中;
while(Gray集合不为空)
{
从Gray集合中移除一个对象O,并将O设置成Black状态;
for(O中每一个引用到的对象O1) {
if(O1在White状态) {
将O1从White设置成Gray,并放到到Gray集合中;
}
}
}
for(任意一个对象O){
if(O在White状态)
销毁对象O;
else
将O设置成White状态;
}
~~~
## Incremental Garbage Collection
上面的算法如果一次性执行,在对象很多的情况下,会执行很长时间,严重影响程序本身的响应速度。其中一个解决办法就是,可以将上面的算法分步执行,这样每个步骤所耗费的时间就比较小了。我们可以将上述算法改为以下下几个步骤。
首先标识所有的root对象:
~~~
1. 当前所有对象都是White状态;
2. 将root集合引用到的对象从White设置成Gray,并放到Gray集合中;
~~~
遍历访问所有的gray对象。如果超出了本次计算量上限,退出等待下一次遍历:
~~~
while(Gray集合不为空,并且没有超过本次计算量的上限){
从Gray集合中移除一个对象O,并将O设置成Black状态;
for(O中每一个引用到的对象O1) {
if(O1在White状态) {
将O1从White设置成Gray,并放到到Gray集合中;
}
}
}
~~~
销毁垃圾对象:
~~~
for(任意一个对象O){
if(O在White状态)
销毁对象O;
else
将O设置成White状态;
}
~~~
在每个步骤之间,由于程序可以正常执行,所以会破坏当前对象之间的引用关系。black对象表示已经被扫描的对象,所以他应该不可能引用到一个white对象。当程序的改变使得一个black对象引用到一个white对象时,就会造成错误。解决这个问题的办法就是设置barrier。barrier在程序正常运行过程中,监控所有的引用改变。如果一个black对象需要引用一个white对象,存在两种处理办法:
1. 将white对象设置成gray,并添加到gray列表中等待扫描。这样等于帮助整个GC的标识过程向前推进了一步。
2. 将black对象该回成gray,并添加到gray列表中等待扫描。这样等于使整个GC的标识过程后退了一步。
这种垃圾回收方式被称为"Incremental Garbage Collection"(简称为"IGC",Lua所采用的就是这种方法。使用"IGC"并不是没有代价的。IGC所检测出来的垃圾对象集合比实际的集合要小,也就是说,有些在GC过程中变成垃圾的对象,有可能在本轮GC中检测不到。不过,这些残余的垃圾对象一定会在下一轮GC被检测出来,不会造成泄露。
探索Lua5.2内部实现:编译系统(4) 表达式分类
最后更新于:2022-04-01 07:10:01
# 探索Lua5.2内部实现:编译系统(4) 表达式分类
## 常量表达式
常量表达式在Lua用来表示"nil",“true”,“false”,字符串和数字的值。在BNF中常量表达式属于终结符,也就是语法解析的最底端,在simpleexp函数中被解析出来,并创建对应类型的expdesc对象。VNIL,VTRUE和VFALSE这三个类型本身就对应3个固定的值,没有什么额外的数据。VKNUM类型代表数字常量,需要在nval中存放从词法分析中得到的lua_Number。VK类型用来表示一个通常意义上的常量表达式,使用info来存储他所代表的常量值在常量表中的id。字符串常量就被直接创建成VK类型,然后将其对应的字符串值保存到常量表中,并将id保存到info中。
由于常量表达式的值是一个常量,所以本身不需要生成任何用于估值计算的指令,完全为高层语义的指令生成提供服务。当高层语义要将常量装入一个寄存器时,比如local a="foo",会调用discharge2reg函数,生成OP_LOADK指令。Lua中的很多指令都可以直接使用常量作为操作数,比如算数指令。当高层语义要将常量当作其他指令的参数时,会调用luaK_exp2RK函数,返回这个常量对应的id。
其实Lua本身使用VK一种类型就可以表示所有的常量表达式,而其他类型常量表达式完全是为了优化才使用的。VNIL和VTRUE,VFALSE类型分别都有对应OP_LOADNIL和OP_LOADBOOL指令将常量值装入寄存器,所以不需要将其放到常量表中。我们在《[虚拟机指令](http://blog.csdn.net/yuanlin2008/article/details/8491112)》中讲过这些指令的特殊用法。而VNUM的作用是支持算数运算的常量优化(constfolding),如果被优化掉了,也就不需要在常量表中出现。VNUM会在discharge2reg的时候,也就是真正需要使用其常量值得时候,才被放到常量表中。当VNIL,VTRUE,VFALSE和VNUM需要被用在其他指令的参数时,luaK_exp2RK将其全部转化为VM类型,并在常量表中创建对应的常量值。VNIL,VTRUE和VFALSE还会在逻辑表达式中被用于优化。
## 变量表达式
VLOCAL代表局部变量表达式,在info中保存局部变量对应的寄存器id。
VUPVAL代表upvalue变量表达式,在info中保存upvalue的id。
VINDEXED代表对一个表进行索引的变量表达式,比如a.b或者a[1],使用ind结构体保存数据。idx保存用来索引的key的id,他可能是一个寄存器id或者常量id;t保存被索引表的id,他可能是一个寄存器id或者upvalue id;vt表示t的类型是寄存器id(VLOCAL)还是upvalue id(VUPVAL)。
singlevar函数用来解析一个变量表达式。singlevar调用函数singlevaraux,来查找变量名对应的表达式类型。singlevaraux首先在当前FuncState的局部变量中查找。如果找到,就创建一个VLOCAL表达式。否则,就递归向上查找外围函数的upvalue,并最终返回一个VUPVAL表达式。这个查找的过程也是创建upvalue的过程。当在外围函数中找到对应变量名的局部变量后,会在这个外围函数的所有内嵌函数中创建对应的upvalue。如下图所示:
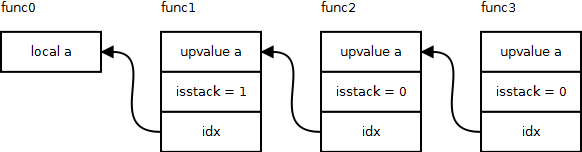
函数func(N)内嵌于func(N-1)。当func3使用了变量a,并在func0中找到了局部变量a时,会在func1~3中创建a对应的upvalue。func1中的upvalue是对上一级中的局部变量的直接引用,所以isstack为1,idx代表局部变量的寄存器id。其他的都是对上一级upvalue的引用,所以isstack为0,idx代表上一级upvalue的id。
如果singlevaraux最终没有能找到符合变量名的局部变量或者upvalue,singlevar函数就将这个变量名当作全局变量进行处理。首先singlevar会再次调用singlevaraux,查找名称为“_ENV”的upvalue。这个upvalue已经在最外层的mainfunc中创建了,所以一定能找到。然后将_ENV对应的upvalue变量表达式当作table,用变量名当作key,通过luaK_indexed函数创建一个VINDEXED表达式。这个操作等于将varname转化为_ENV.varname进行访问。
变量表达式的估值计算是从变量中获取值。luaK_dischargevars函数为变量表达式生成估值计算的指令。对于VLOCAL类型,值就存在于局部变量对应的寄存器中,不需要生成任何获取指令,也不需要分配寄存器来存储临时值。VLOCAL被转化为VNONRELOC类型,代表已经为这个表达式生成了指令,并且也分配了寄存器保存这个值。对于VUPVAL类型,需要产生指令OP_GETUPVAL来获取其值。而对于VINDEXED类型,根据vt的不同,需要产生OP_GETTABLE或者OP_GETTABUP指令来获取其值。VUPVAL和VINDEXED都被转化为VRELOCABLE类型,表示获取指令已经生成,但是指令的目标寄存器(A)还没有确定,等待回填。回填后,VRELOCABLE类型会转化成VNONRELOC类型。
变量表达式除了用来获取变量值,还有另外一个用途,就是在赋值语句中当作赋值的目标,也就是将其他表达式的值存储到这个变量表达式中。这个工作是由luaK_storevar函数完成的。luaK_storevar根据被赋值的变量表达式的不同类型,生成不同的赋值指令。对于VLOCAL,不需要额外的指令,只需要将赋值表达式的目标寄存器回填成局部变量对应的寄存器就可以了。对于VUPVAL,需要生成OP_SETUPVAL指令。而对于VINDEXED,则需要生成OP_SETTABLE或者OP_SETTABUP指令。
## 多返回值表达式
VCALL表达式对应着一个函数调用的OP_CALL指令。VVARARG表达式对应"...",也就是OP_VARARG指令。他们都可以有多个返回值。在需要单值的上下文中,通过调用luaK_setoneret函数,将表达式设置成单返回值。VCALL的返回值位置是固定的,就是用来存放被调用closure的寄存器,所以被转化为VNONRELOC类型。VVARARG的目标寄存器待定,被转化为VRELOCABLE类型。在需要多个返回值的上下文中,通过调用luaK_setreturns函数,回填指令中的返回值数量。
## 算数表达式
所有关于操作符的解析都在subexpr函数中进行,这里处理一元和二元操作符以及优先级关系。对于一元操作符,会调用luaK_prefix生成代码。对于二元操作符,会首先调用luaK_infix处理第一个前面的表达式,然后分析出后面的表达式,再调用luaK_posfix对这两个表达式进行处理。
算术表达式最终是在codearith函数中创建的。首先,codearith会调用constfolding函数,尝试优化。如果两个被操作表达式都是数字常量,就直接计算出结果赋给第一个常量表达式。如果不能被优化,codearith函数直接为算术表达式生成对应的算数指令,并且将表达式类型设置成VRELOCABLE,等待回填生成指令的目标寄存器。
## 关系表达式
关系表达式(>,>=,
关系表达式在codecomp函数中创建。首先,将需要比较的两个子表达式取出目标寄存器或者常量id。然后通过调用condjump函数,为表达式生成指令,并将表达式设置成VJMP类型。condjump函数会生成一个测试指令和一个跳转指令OP_JMP。测试指令包括OP_EQ,OP_LT,OP_LE。这些测试指令会比较两个表达式的值。如果满足测试条件,就继续执行;否则,就跳过下一条指令执行。测试指令与后面的OP_JMP指令配合到一起,就形成了一个条件跳转。这样的表示方法也是Lua中条件跳转的唯一表示方法。条件跳转形成了两个执行分支:
* 当测试条件满足,就跳转到一个现在还未知的位置,也就是true分支。
* 当测试条件不满足,就继续运行OP_JMP后面的指令,也就是false分支。
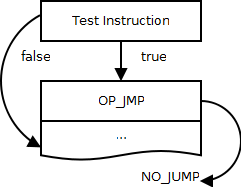
这个OP_JMP指令的位置会被保存到表达式的info中,等待后继的回填处理。
## 逻辑表达式
逻辑表达式(and,or)的处理是最复杂的。表达式e1 and e2的语义是:如果e1为true,整个表达式的值为e2;否则整个表达式的值为e1。表达式e1 or e2的语义与and相反:如果e1为false,整个表达式的值为e1;否则整个表达式的值为e2。所以,逻辑表达式其实是两个待评估表达式的二选一。
首先要先说明一下expdesc结构体中的t和f变量。这两个变量实际上是两个OP_JMP指令的链表(关于跳转链表,在[这里](http://blog.csdn.net/yuanlin2008/article/details/8518743)已经讲过),我们称之为patch list。由于关系表达式和逻辑表达式的特殊处理方式,这两个patch list代表本表达式被评估为true或者false时的跳出指令列表。通过将一个地址回填给patch list,就将对这个表达式的评估直接引导到对应的执行分支。任何类型的表达式都可能带有patch list。如果有patch list,说明这个表达式本身或者子表达式使用了关系或者逻辑表达式。
patch list中的元素是在luaK_goiftrue和luaK_goiffalse函数中被添加到patch list中的。luaK_goiftrue函数调用jumponcond生成一个OP_TESTSET和一个OP_JMP指令。与关系表达式的处理类似,这两个指令形成了两个执行分支:向下执行的true分支和跳出的false分支。这个跳出的OP_JMP指令会被连接到表达式的f中,代表表达式为false时执行的跳出,并等待回填。如果表达式有t存在,调用luaK_patchtohere,将所有true跳出回填到下面继续执行的代码。这代表了除了本表达式评估为true会继续执行外,所有该表达式被评估为true的跳出也应该跳转到此处继续执行。如果表达式是一个关系表达式,也就是VJMP类型,其本身就是一个逻辑跳转,直接将其info中指向的OP_JMP指令连接到f中,而不需要为其生成OP_TESTSET指令了。luaK_goiffalse与luaK_goifture相反,当表达式为true时跳出。
对于关系表达式e1 and e2,首先在luaK_infix中为e1调用luaK_goiftrue,生成对e1的测试跳转指令,这就代表如果e1为true,继续执行;否则跳出。此时e1中的f中已经包含了e1的false跳出。然后解析e2,并在luaK_posfix中,将e1的f串接到e2的f上,并将e2作为作为整个表达式解析返回给高层的表达式。
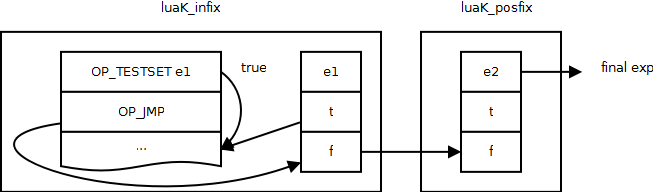
对于or的处理,与and类似,这里不再累述。
OP_TESTSET与其他测试指令类似,唯一的特殊点在于OP_TESTSET在执行跳转时会将被评估的表达式的值赋给一个未知的寄存器。这个操作时专门针对逻辑表达式的语义设计的。如果将逻辑表达式e1 and e2的值赋值给一个变量,那么这个变量的值并不是true或者false,而是e1或者e2。所以,在跳转时,说明此跳转已经取了e1的值,要先做一个对未知寄存器的赋值,然后等待回填这个寄存器。
## 表达式的用途
根据上面描述,表达式在Lua中本质上有两种用途。
首先是被当作跳转条件使用。在if,while等结构中,都需要一个表达式来代表跳转条件。在当作条状条件处理时,Lua会使用上面讲过的luaK_goiftrue或者luaK_goiffalse,来评估一个表达式。此时表达式本身的值已经没有意义,只需要将t或者f回填成分支起始指令未知就搞定了。如果t或f中有OP_TESTSET指令,会被替换成OP_TEST指令。
其次是将表达式的值保存到寄存器中,比如给变量赋值。由于上面关系和逻辑表达式的特殊处理,表达式的值已经不仅仅是对本身的估值,还要考虑到patch list所对应的值。我们可以将patch list中的条件跳转分为两种。使用OP_TESTSET作为条件指令的,也就是关系表达式产生的条件跳转,我们称之为赋值条件跳转TS。上面讲过,如果走到这个分支,表达式的最终值就是OP_TESTSET所设置的值。其他所有不使用OP_TESTSET的测试指令,也就是关系表达式所产生的跳转,我们称之为非赋值条件跳转T。分条件跳转最后应该产生true或者false值。
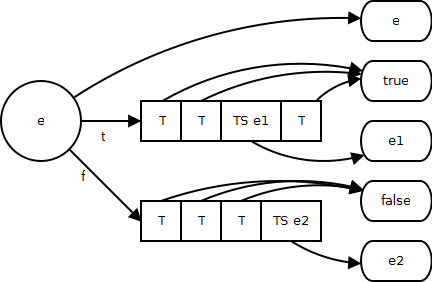
所以,表达式的值最终会由很多的分支导致很多的值。将表达式的值赋值给寄存器的操作,在exp2reg函数中完成。要将这些值赋给一个寄存器,首先调用discharge2reg,将自己的值存入指定寄存器,然后处理patch list。对于非赋值条件跳转,我们需要为true和false值各补上一个OP_LOADBOOL指令作为赋值操作,并将t中的所有T回填到true,将f中所有的T回填到false。而对于赋值条件跳转,不仅要将跳转回填到赋值的最后,并且需要回填所有OP_TESTSET指令的目标寄存器,也就是将这些值赋值给指定寄存器。patchlistaux (FuncState *fs, int list, int vtarget, int reg, int dtarget)函数就是回填patch list用的。此函数会遍历patchlist上的每个条件跳转,如果是OP_TESTSET,就回填寄存器reg,并回填跳转地址vtarget,否则,回填跳转地址dtarget。
探索Lua5.2内部实现:编译系统(3) 表达式
最后更新于:2022-04-01 07:09:59
# 探索Lua5.2内部实现:编译系统(3) 表达式
表达式(expression)在编程语言中代表一个可以返回值的语法单位,比如常量表达式,变量表达式,函数调用表达式,算术、关系和逻辑表达式等等。对于函数式编程语言来说,几乎所有的语句都是表达式,可以被估值。而对于命令式语言,一般会将语句分成表达式和陈述语句(statement)。表达式可以被估值,而普通的陈述语句用来执行命令。根据具体的语法,这两种类型不一定会有明确的界限。比如在C中,a = b既是一个用来赋值的陈述语句,又是一个表达式,而作为表达式的结果是最终的a值。所以,像c = a = b这样的语句是成立的,意思是将a = b作为表达式,并将值赋给c。
而在Lua中,表达式的描述要明确的多。a = b属于一个赋值statement,而不属于表达式,所以c = a = b会产生语法错误。唯一即可以当作expression又可以当作statement使用的就是call。call本身会调用函数,返回函数的返回值,而作为statement时,返回值被忽略。
根据Lua5.2完整的[BNF](http://www.lua.org/manual/5.2/manual.html#9),我们可以看到Lua中仅有以下地方需要使用表达式:
* 变量赋值,等号左边必须是一个变量表达式,右边是一个任意表达式
* 局部变量的初始化,等号右边是任意表达式
* if statement的条件表达式和循环的条件表达式
在需要表达式的地方,通过调用expr函数,并传入一个expdesc结构体对象,对表达式进行解析。表达式的解析是一个递归下降的过程。下降分析将高层的表达式分解成底层表达式或表达式的组合,而递归则发生在expr函数的递归调用上,也就是说在解析过程中还会用表达式本身来描述高层表达式。当解析到BNF的终结符时,会返回上一层处理,然后再一层层的处理后返回。expr函数最终会填充传入的expdesc结构体,作为最高层的根表达式,交给更高层的语义,也就是上面需要表达式的地方进行处理。
Lua关于递归下降分析的每个函数的注释中都有代表这个函数的BNF范式,我们可以很容易的浏览这些代码,不需要过多的解释。真正需要理解的是表达式与指令生成相关的部分,这也是整个Lua编译系统里面比较晦涩的地方。我们可以首先通过一个简单的例子,在宏观上了解一下语法分析和指令生成的全过程。
对于下面的chunk
` c = a.b + 1 `
我们最终可以生成如下指令
~~~
main (5 instructions at 0x80048eb8)
0+ params, 2 slots, 1 upvalue, 0 locals, 4 constants, 0 functions
1 [1] GETTABUP 0 0 -2 ; _ENV "a"
2 [1] GETTABLE 0 0 -3 ; "b"
3 [1] ADD 0 0 -4 ; - 1
4 [1] SETTABUP 0 -1 0 ; _ENV "c"
5 [1] RETURN 0 1
constants (4) for 0x80048eb8:
1 "c"
2 "a"
3 "b"
4 1
locals (0) for 0x80048eb8:
upvalues (1) for 0x80048eb8:
0 _ENV 1 0
~~~
整个的递归下降语法分析过程可以用下图表示。

由于我们目前需要讲解的是表达式,这里为了讲解方便,这里省略了一些过程。接下来我们对这些步骤逐一进行解说。
1. exprstat函数调用suffixedexp函数,对赋值语句的左边的后缀表达式进行分析。
2. 这里没有展开suffixedexp函数,我们目前只需要知道它会返回一个VINDEXED表达式。
3. exprstat调用expr函数,对赋值右面的表达式进行分析。如上所述,expr函数是解析表达式的总入口,他接受一个expdesc结构体,开始分析。
4. expr调用subexpr
5. subexpr函数首先调用simpleexp,来分析“+”号左边的表达式。
6. simpleexp调用suffixedexp函数,将这个表达式当成后缀表达式开始分析。
7. suffixedexp函数首先调用primaryexp函数,分析主表达式,也就是a。
8. primaryexp调用singlevar函数,将a当作一个变量进行分析。
9. singlevar没有找到名字为"a"的局部变量或upvalue,将"a"当作全局变量处理,也就是将"a"变成“_ENV.a"来处理。这里已经到了递归下降分析的最低端,最终创建一个VINDEXED的表达式给上层,table为upvalue "_ENV",key为常量”a“。
10. 继续返回VINDEXED表达式给上层。
11. suffixedexp将这个VINDEXED表达式传给fieldsel,对后缀进行分析。
12. fieldsel首先根据这个VINDEXED表达式的table和key生成指令1,这个指令的目标寄存器为临时分配的寄存器0。然后以寄存器0为table,”b“为key,生成一个新的VINDEXED表达式返回给上层。
13. 继续返回VINDEXED表达式给上层。
14. 继续返回VINDEXED表达式给上层。
15. subexp调用subexp本身,开始对”+“号右边的表达式进行分析。
16. subexp调用simpleexp,分析这个”1“。
17. simpleexp为这个"1"生成一个VKNUM表达式,返回给上层。
18. 继续返回VKNUM表达式给上层。
19. subexp首先根据+号左边的VINDEXED表达式的table和key生成指令2,这个指令的目标寄存器为临时分配的寄存器0。然后生成指令3的加法运算,操作数为寄存器0和VNUM表达式对应的常量id。指令3的目标寄存器还不能确定,所以创建一个VRELOCABLE表达式返回给上层。
20. 这时整个表达式已经解析完毕,返回VRELOCABLE表达式给上层,等待进一步的处理。
21. 将VRELOCABLE表达式对应的指令3的目标寄存器回填成临时分配的寄存器0,然后将寄存器0的内容赋值给左边的VINDEXED表达式,也就是生成指令4。
通过上面的分析过程我们可以看到,Lua整体的语法分析过程就是对语法树的一次性的先续遍历的过程。对于表达式的分析,首先要分析子表达式,并为其生成指令来获取表达式的值,存入临时寄存器,然后父表达式再使用子表达式的分析结果和临时寄存器作为参数,来生成获取值的指令。所有在过程中使用的子表达式的expdesc结构体对象全部在函数的调用栈上分配,待分析完成返回后,就被丢弃掉了。由于Lua本身的指令是基于寄存器的,一条指令所能完成的任务相对比较复杂,所以有些情况下在子表达式分析过程中不能完全获得所需要的信息。这是就需要将表达式分析所得的信息返回给上一层父表达式,也就是子表达式的使用者,由上一层做最终的指令生成。或者先生成子表达式指令,然后在上一层分析中进行指令的回填修改。我们在上例中就可以清晰地看到这种情况。
在《[虚拟机指令](http://blog.csdn.net/yuanlin2008/article/details/8423951)》中我们提到过,Lua使用的是register based vm,所以相对于stack based vm来说,整个编译和指令生成过程要更复杂。寄存器在Lua中的第一个用处就是存储局部变量的值,所有局部变量在编译后,都不再使用名称,而是寄存器id进行访问。而另一个用处就是存储表达式估值过程中的临时值。当对一个表达式进行估值时,可能先要对其子表达式进行估值,将估值结果存储到一个临时的寄存器,然后使用这个结果再进行下一步的估值计算。寄存器为一个id从0开始的数组。在编译过程中,Lua使用FuncState中的freereg变量记录当前空闲寄存器的起始id。在开始编译一个FuncState时,freereg被设置成0,表示所有寄存器都可以被分配。当遇到一个局部变量或者临时值时,就分配出一个id为当前freereg的寄存器,然后将freereg++。局部变量会在语法域内一直占用这个寄存器,而临时值会在使用完其值后立即被释放,也就是freereg--。由于临时值会在表达式估值完成后全部释放掉,所以局部变量被分配的寄存器肯定是从0开始并且是连续的,中间不会被临时值占用。
总的来说,局部变量与临时值没有什么本质区别,都是用来存放函数计算过程中表达式的值得,唯一区别就在于临时值不占用寄存器,而局部变量会一直占用寄存器,并且可以被程序访问。
上面的例子中,12,19和21步中都需要临时寄存器的分配。我们看到在需要临时寄存器的指令生成之后,临时寄存器就被被释放掉了,所以每次分配时都会将寄存器0分配给临时值使用,而不会一直占用寄存器0。
在后面的文章中,我将会按照分类对表达式进行详细的讲解。
探索Lua5.2内部实现:编译系统(2) 跳转的处理
最后更新于:2022-04-01 07:09:56
# 探索Lua5.2内部实现:编译系统(2) 跳转的处理
跳转用来控制程序的指令流程。Lua使用OP_JMP指令来执行一个跳转,有关OP_JMP的详细介绍,可以参见《[虚拟机指令](http://blog.csdn.net/yuanlin2008/article/details/8504200)》。跳转可以分为条件跳转和非条件跳转。非条件跳转比较简单,我们可以先从这里入手。
## goto
在Lua5.2中,goto和label是新加入的statement,用来执行非条件跳转。这两个statement分别在lparser.c中的gotostat和labelstat函数中被解析。上一篇中讲过,在全局数据Dyndata中,保存着一个goto列表和一个label列表,goto和label使用一个相同的数据结构Labeldesc表示。
~~~
/* description of pending goto statements and label statements */
typedef struct Labeldesc {
TString *name; /* label identifier */
int pc; /* position in code */
int line; /* line where it appeared */
lu_byte nactvar; /* local level where it appears in current block */
} Labeldesc;
~~~
name用来表示label的名称,用来相互查找。如果是label,pc表示这个label对应的当前函数指令集合的位置,也就是待跳转的指令位置;如果是goto,则代表为这个goto生成的OP_JMP指令的位置。nactvar代表解析此goto或者label时,函数有多少个有效的局部变量,用来在跳转时决定需要关闭哪些upvalue。
gotostat接受一个已经为之生成好了的OP_JMP指令的位置,首先通过newlabelentry为这个goto在ls->dyd->gt中生成一个Labeldesc,用来表示未处理的goto,然后调用findlabel尝试处理这个goto。findlabel会在当前的block中查找已经定义了的label。如果找到,就调用closegoto,将这个goto对应的OP_JMP指令的跳转位置设置成label的pc,并且还要决定是否需要在OP_JMP指令中关闭一些局部变量对应的upvalue;如果没有找到,这个goto对应的OP_JMP指令的跳转位置就是一个NO_JUMP,表示未决位置,等待后面再处理。
与gotostat的处理类似,labelstat在处理label时,也会首先查找已经定义但未决的goto。如果找到了goto,也要修改其OP_JMP指令的跳转位置。整个goto和label语法分析的代码比较直接,并不难理解。而这里比较晦涩的是Lua对OP_JMP指令的处理方法。对于OP_JMP的处理还会在后面的关系和逻辑运算,以及条件跳转中使用。所以,理解Lua对OP_JMP指令的处理是理解其他编译部分的基础。
## OP_JMP
前面讲过,由于Lua是一编编译,所以在真正生成指令时,很多东西是没法决定的。比如OP_JMP指令,要跳转的位置可能还没有定义,所以不能知道具体的跳转位置。Lua会将这些指令先生成到函数proto的指令列表中,然后记录下他们在指令列表的位置。当可以确定时,再通过这个位置找到生成好的指令,对其进行修改。这就是指令回填。
对于一个OP_JMP指令,有两个指令参数需要回填:待关闭的upvalue起始id A和跳转偏移量sBx。当通过luaK_jump函数生成一个OP_JMP指令时,这个指令的A会被初始化成0,而sBx被初始化成NO_JUMP,并返回一个int代表这个OP_JMP指令的位置。我们保存这个返回值就可以找到这个指令,对其进行回填。
在语法分析过程中(比如后面要讲到的关系和逻辑运算),有可能会生成一系列的OP_JMP指令,他们的跳转目标是一致的,从而形成一个跳转指令集合。Lua使用了链表的方式保存这种指令集合。这个链表每个节点就是OP_JMP指令本身,使用sBx来指向链表的下一个OP_JMP指令。如果sBx为NO_JUMP,表示链表的尾节点。所以我们只需要一个指向头节点的位置,就可以遍历整个OP_JMP指令链表。lcode.c中对于OP_JMP指令的处理函数,都是基于一个跳转链表的,只不过在一些情况下,链表中只有一个节点而已。如果需要回填一个具体的跳转地址,就会遍历链表,将每个节点的跳转地址都修正到目标位置。

回填跳转地址可以分为两类处理:
一种是已经生成的指令位置,Lua会立即将这些跳转指令修改成目标位置。
另一种是当前位置,也就是接下来要生成的指令的位置。在处理当前位置时,Lua并没有立即修改,而是将待修改的跳转指令串接到当前FuncState中的jpc链表上。当使用luaK_code生成下一条指令时,首先会调用dischargejpc函数,将jpc链表上的所有跳转指令修改到这个位置。这等于是延迟回填。之所以这样处理,其实是为了跳转的优化。我们回头看一下luaK_jump函数,它在生成OP_JMP指令时,会将当前jpc串接到新生成的jpc上,并且将jpc清空。这个处理实际的意思是,当生成一个OP_JMP指令时,如果有其他的OP_JMP指令需要跳转到此处,其实就等于间接跳转到新生成的跳转指令的目标位置。所以这些跳转指令不用再跳转到此处,而是直接跳转到新生成的OP_JMP的目标位置,将两步跳转合并成一步。这些指令与新生成跳转指令的目标是一致的,所以可以合并成一个跳转指令集合,等待后面一起回填。
我们接下来在来回顾一下与跳转相关的指令生成api。
luaK_jump用来生成一个新的跳转指令。luaK_concat函数用来将两个链表连接起来合成一个链表。luaK_patchlist用来回填一个链表的跳转位置。luaK_patchtohere用来将一个链表准备回填到当前位置。luaK_patchclose用来回填一个链表中的A,也就是需要关闭的upvalue id,具体可以查看goto的处理。
以上是Lua处理跳转的相关内容。跳转的处理还与逻辑和关系表达式密切相关,我们会在后面表达式部分再进行详细讲解。
探索Lua5.2内部实现:编译系统(1) 概述
最后更新于:2022-04-01 07:09:54
# 探索Lua5.2内部实现:编译系统(1) 概述
Lua是一个轻量级高效率的语言。这种轻量级和高效率不仅体现在它本身虚拟机的运行效率上,而且也体现在他整个的编译系统的实现上。因为绝大多数的lua脚本需要运行期动态的加载编译,如果编译过程本身非常耗时,或者占用很多的内存,也同样会影响到整体的运行效率,使你感觉这个语言不够“动态”。正是因为编译系统实现的非常出色,我们在实际使用lua时基本感觉不到这个过程的存在。
要实现一个Lua的编译系统可能不是很困难,但要高效的实现,还是有一定挑战的。这需要一些精妙的设计和实现技巧,也值得我们花一些时间去一探究竟。
## 输入与输出
编译系统的工作就是将符合语法规则的chunk转换成可运行的closure。要了解编译系统,首先要了解作为输入的chunk和最为输出的closure以及他们的对应关系。
说到closure,就不能不先说一下proto。closure对象是lua运行期一个函数的实例对象,我们在运行期调用的都是一个closure。而proto对象是lua内部代表一个closure原型的对象,有关函数的大部分信息都保存在这里。这些信息包括:
* 指令列表:包含了函数编译后生成的虚拟机指令。
* 常量表:这个函数运行期需要的所有常量,在指令中,常量使用常量表id进行索引。
* 子proto表:所有内嵌于这个函数的proto列表,在OP_CLOSURE指令中的proto id就是索引的这个表。
* 局部变量描述:这个函数使用到的所有局部变量名称,以及生命期。由于所有的局部变量运行期都被转化成了寄存器id,所以这些信息只是debug使用。
* Upvalue描述:设个函数所使用到的Upvalue的描述,用来在创建closure时初始化Upvalue。
每个closure都对应着自己的proto,而运行期一个proto可以产生多个closure来代表这个函数实例。

由此可见,closure是运行期的对象,与运行期关系更大;而与编译期相关的其实是proto对象,他才是编译过程真正需要生成的目标对象。
Chunk代表一段符合[Lua的语法](http://www.lua.org/manual/5.2/manual.html#9)的代码。我们可以调用lua_load api,将一个chunk进行编译。lua_load根据当前chunk生成一个mainfunc proto,然后为这个proto创建一个closure放到当前的栈顶,等待接下来的执行。Chunk内部的每个function statement也都会生成一个对应的proto,保存在外层函数的子函数列表中。所有最外层的function statement的proto会被保存到mainfunc proto的子函数列表中。所以,整个编译过程会生成一个以mainfunc为根节点的proto树。

## 简介
按照功能划分,整个编译系统被划分成以下3个模块:
* 词法分析模块llex.h .c
* 语法分析模块lparser.h .c
* 指令生成模块lcode.h .c
Lua并没有使用llex和yacc,而是使用完全手写的词法和语法分析器。使用手写分析器的原因首先是考虑到效率。并且yacc/bison本身生成的代码在可移植性上有一些问题,无发达到Lua高可移植性的设计目标。还有就是手写分析器可以在C stack上面分配编译过程中需要的数据对象,这个我们后面会讲到。对于一个chunk,Lua在对其分析的过程中直接生成最终的指令,没有多余的对源代码或语法结构的遍历。也就是说Lua对源代码进行一次遍历就生成最终结果。
## 词法分析
Lua的词法分析模块比较简单而且独立,就是将源代码拆分成一个个token,提供给语法分析使用。语法分析程序会调用luaX_next来获取下一个单词,然后进行语法分析。
~~~
typedef union {
lua_Number r;
TString *ts;
} SemInfo; /* semantics information */
typedef struct Token {
int token;
SemInfo seminfo;
} Token;
~~~
Token用来表示一个单词,它包括类型token和语义seminfo。类型使用一个int来表示,既可以是一个字符,也可以是一个enum RESERVED。enum RESERVED从257开始,就是为了留给字符使用。如果类型是一个TK_NUMBER,seminfo.r就用来表示这个数字;如果是TK_NAME或者TK_STRING,seminfo.ts就表示对应的字符串。
LexState结构体的用途其实与其名称不是很贴切。LexState不仅用于保存当前的词法分析状态信息,而且也保存了整个编译系统的全局状态,这个我们在后面会讲到。
## 语法分析和指令生成
语法分析器是整个编译过程的驱动器。通过对luaY_parser函数的调用,启动整个编译过程。语法分析采用“递归下降”的方法,从词法分析器中读取下一个token,然后根据这个token和lua的语法规则,将高层的语法规则分解成底层的语法规则,进一步进行分析。根据语法,“递归”在lua语法中只出现在两个地方,一个是statement函数,一个是subexpr函数。这也就是在这两个函数中调用enterlevel和leaveleavel,对当前调用深度进行检测的原因。如果递归太深,编译会报错。在分析的过程中,词法分析器会调用指令生成器,直接生成最终的指令。
从宏观上讲,整个编译过程就是生成proto tree的过程。语法分析器从mainfunc出发,开始分析和生成mainfunc的proto。在生成一个proto的过程中,生成的指令直接保存到proto的指令列表中。当遇到function statement或者local function statement时,首先生成子函数的proto,然后回来继续。通过这样的遍历方式,最终构建出一个proto tree。
在编译过程中,使用FuncState结构体来保存一个函数编译的状态数据。每个FuncState都有一个prev变量用来引用外围函数的FuncState,使当前所有没有分析完成的FuncState形成一个栈结构。栈底是mainfunc的FuncState,栈顶是当前正在分析的FuncState。每当开始分析一个新的函数时,会创建一个新的FuncState与之对应,将当前的FuncState保存在新的FuncState的prev中,并将当前的FuncState指向新的FuncState,这相当于压栈(open_func)。等待这个新函数分析完成后,当前的FuncState就没用了,将当前的FuncState恢复成原来的FuncState,这相当于弹栈(close_func)。
Dyndata是一个全局数据,他本身也是一个栈。对应上面的FuncState栈,Dyndata保存了每个FuncState对应的局部变量描述列表,goto列表和label列表。这些数据会跟着当前FuncState进行压栈和弹栈。
前面说过,整个编译系统的全局状态都保存在LexState中。LexState中与全局状态相关的主要是两个变量。fs指向当前正在编译的函数的FuncState。而dyd则指向全局的Dyndata数据。

FuncState本身通过f保存对于Proto的引用。所有过程中生成的指令都直接保存到Proto的指令列表中。FuncState还通过h引用到一个table,用于在编译过程中生成proto的常量表。这个table使用常量值作为key,常量的id作为value。当编译过程中发现一个常量时,会首先使用这个常量值在这个表中查找。如果找到,说明前面已经将这个常量加入到常量表了,直接使用其id。否者,向常量表中添加一个常量,并相应的添加到这个表中。
对于一个FuncState本身的分析也是有层次关系的。一个函数本身使用block来控制局部变量的有效范围。函数本身就是一个block,里面的想while statement,for statement等等,还会形成子block。函数内的这些block会形成一个以函数本身block为根节点的block tree。Lua使用BlockCnt来保存一个block的数据。与FuncState的分析方法类似,BlockCnt使用一个previous变量保存外围block的引用,形成一个栈结构。enterblock和leaveblock函数负责压栈和弹栈。在FuncState中,bl用来指向当前的block。

纵观整个语法分析过程,Lua其实就是按照深度优先的顺序,遍历了FuncState tree,以及子结构BlockCnt tree。在遍历的过程中,所有的编译状态(FuncState,BlockCnt)都是在C stack中保存,这就表示只保存当前正在处理的编译状态,而那些已经处理完成的在弹栈时被丢弃。在分析具体的语法结构时也是如此,Lua并被有完整的构建一个语法树对象,而是将过程中的语法结构保存在函数栈中,分析完立刻丢弃。所以就算用Lua来分析一个很大的程序,也不会占用过多的内存。不过,这也为指令生成带来了很多麻烦。比如向后跳转,在分析过程中还无法知道具体的跳转地址。如果构建了完整的语法树,就可以在最后去解决这些未决的地址。Lua使用了一些技巧来解决这些问题,我会在后面的文章中详细讲述。
在C stack中保存编译状态数据还有一个原因,是和编译系统的报错机制相关。编译系统整体的报错机制采用与虚拟机运行期一致的异常处理机制,也就是longjump。当出错时,直接跳出到最外层进行处理,此时所有当前的编译状态数据要能自动销毁掉。
探索Lua5.2内部实现:虚拟机指令(8) LOOP
最后更新于:2022-04-01 07:09:52
# 探索Lua5.2内部实现:虚拟机指令(8) LOOP
Lua5.2种除了for循环之外,其他的各种循环都使用关系和逻辑指令,配合JMP指令来完成。
~~~
local a = 0;
while(a
a = a + 1;
end
~~~
~~~
1 [1] LOADK 0 -1 ; 0
2 [2] LT 0 0 -2 ; - 10
3 [2] JMP 0 2 ; to 6
4 [3] ADD 0 0 -3 ; - 1
5 [3] JMP 0 -4 ; to 2
6 [4] RETURN 0 1
~~~
第二行使用LT对寄存器0和敞亮10进行比较,如果小于成立,跳过第三行的JMP,运行第四行的ADD指令,将a加1,然后运行第五行的JMP,跳转回第二行,重新判断条件。如果小于不成立,则直接运行下一个JMP指令,跳转到第六行结束。
对于for循环,Lua5.2使用了两套专门的指令,分别对应numeric for loop和generic for loop。
| name | args | desc |
|---|---|---|
| OP_FORLOOP | A sBx | R(A)+=R(A+2);if R(A) <?= R(A+1) then { pc+=sBx; R(A+3)=R(A) } |
| OP_FORPREP | A sBx | R(A)-=R(A+2); pc+=sBx |
~~~
local a;
for i = 1, 10 do
a = i;
end
~~~
~~~
main (8 instructions at 0x80048eb0)
0+ params, 5 slots, 1 upvalue, 5 locals, 2 constants, 0 functions
1 [1] LOADNIL 0 0
2 [2] LOADK 1 -1 ; 1
3 [2] LOADK 2 -2 ; 10
4 [2] LOADK 3 -1 ; 1
5 [2] FORPREP 1 1 ; to 7
6 [3] MOVE 0 4
7 [2] FORLOOP 1 -2 ; to 6
8 [4] RETURN 0 1
constants (2) for 0x80048eb0:
1 1
2 10
locals (5) for 0x80048eb0:
0 a 2 9
1 (for index) 5 8
2 (for limit) 5 8
3 (for step) 5 8
4 i 6 7
upvalues (1) for 0x80048eb0:
0 _ENV 1 0
~~~
Numeric for loop内部使用了3个局部变量来控制循环,他们分别是"for index",“for limit”和“for step”。“for index”用作存放初始值和循环计数器,“for limit”用作存放循环上限,“for step”用作存放循环步长。对于上面的程序,三个值分别是1,10和1。这三个局部变量对于使用者是不可见得,我们可以在生成代码的locals表中看到这3个局部变量,他们的有效范围为第五行道第八行,也就是整个for循环。还有一个使用到的局部变量,就是使用者自己指定的计数器,上例中为"i"。我们可以看到,这个局部变量的有效范围为6~7行,也就是循环的内部。这个变量在每次循环时都被设置成"for index"变量来使用。
上例中2~4行初始化循环使用的3个内部局部变量。第五行FORPREP用于准备这个循环,将for index减去一个for step,然后跳转到第七行。第七行的FORLOOP将for index加上一个for step,然后与for limit进行比较。如果小于等于for limit,则将i设置成for index,然后跳回第六行。否则就退出循环。我们可以看到,i并不用于真正的循环计数,而只是在每次循环时被赋予真正的计数器for index的值而已,所以在循环中修改i不会影响循环计数。
| name | args | desc |
|---|---|---|
| OP_TFORCALL | A C | R(A+3), ... ,R(A+2+C) := R(A)(R(A+1), R(A+2)); |
| OP_TFORLOOP | A sBx | if R(A+1) ~= nil then { R(A)=R(A+1); pc += sBx } |
~~~
for i,v in 1,2,3 do
a = 1;
end
~~~
~~~
main (8 instructions at 0x80048eb0)
0+ params, 6 slots, 1 upvalue, 5 locals, 4 constants, 0 functions
1 [1] LOADK 0 -1 ; 1
2 [1] LOADK 1 -2 ; 2
3 [1] LOADK 2 -3 ; 3
4 [1] JMP 0 1 ; to 6
5 [2] SETTABUP 0 -4 -1 ; _ENV "a" 1
6 [1] TFORCALL 0 2
7 [1] TFORLOOP 2 -3 ; to 5
8 [3] RETURN 0 1
constants (4) for 0x80048eb0:
1 1
2 2
3 3
4 "a"
locals (5) for 0x80048eb0:
0 (for generator) 4 8
1 (for state) 4 8
2 (for control) 4 8
3 i 5 6
4 v 5 6
upvalues (1) for 0x80048eb0:
0 _ENV 1 0
~~~
Generic for loop内部也使用了3个局部变量来控制循环,分别是"for generator”,“for state”和“for control”。for generator用来存放迭代使用的closure,每次迭代都会调用这个closure。for state和for control用于存放传给for generator的两个参数。Generic for loop还使用自定义的局部变量i,v,用来存储for generator的返回值。
上例中1~3行使用in后面的表达式列表(1,2,3)初始化3个内部使用的局部变量。第四行JMP调转到第六行。TFORCALL教用寄存器0(for generator)中的closure,传入for state和for control,并将结果返回给自定义局部变量列表i和v。第七行调用TFORLOOP进行循环条件判断,判断i是否为空。如果不为空,将i的值赋给for control,然后跳转到第五行,进行循环。
探索Lua5.2内部实现:虚拟机指令(7) 关系和逻辑指令
最后更新于:2022-04-01 07:09:49
# 探索Lua5.2内部实现:虚拟机指令(7) 关系和逻辑指令
| name | args | desc |
|---|---|---|
| OP_JMP | A sBx | pc+=sBx; if (A) close all upvalues >= R(A) + 1 |
JMP执行一个跳转,sBx表示跳转的偏移位置,被加到当前指向下一指令的指令指针上。如果sBx为0,表示没有任何跳转;1表示跳过下一个指令;-1表示重新执行当前指令。如果A>0,表示需要关闭所有从寄存器A+1开始的所有local变量。实际执行的关闭操作只对upvalue有效。
JMP最直接的使用就是对应lua5.2新加入的goto语句:
~~~
::l::
goto l;
~~~
~~~
1 [1] JMP 0 -1 ; to 1
2 [2] RETURN 0 1
~~~
这是一个无限循环。第一行JMP的sBx为-1,表示重新执行JMP。
~~~
do
local a;
function f() a = 1 end
end
~~~
~~~
main <test.lua:0,0> (5 instructions at 0x80048eb0)
0+ params, 2 slots, 1 upvalue, 1 local, 1 constant, 1 function
1 [2] LOADNIL 0 0
2 [3] CLOSURE 1 0 ; 0x80049128
3 [3] SETTABUP 0 -1 1 ; _ENV "f"
4 [3] JMP 1 0 ; to 5
5 [4] RETURN 0 1
constants (1) for 0x80048eb0:
1 "f"
locals (1) for 0x80048eb0:
0 a 2 5
upvalues (1) for 0x80048eb0:
0 _ENV 1 0
function <test.lua:3,3> (3 instructions at 0x80049128)
0 params, 2 slots, 1 upvalue, 0 locals, 1 constant, 0 functions
1 [3] LOADK 0 -1 ; 1
2 [3] SETUPVAL 0 0 ; a
3 [3] RETURN 0 1
constants (1) for 0x80049128:
1 1
locals (0) for 0x80049128:
upvalues (1) for 0x80049128:
0 a 1 0
~~~
上面的代码在do block中创建了一个局部变量a,并且a作为upvalue在函数f中被引用到。到退出do block是,a会退出他的有效域,并且关闭他对应的upvalue。Lua5.2中去除了以前专门处理关闭upvalue的指令CLOSE,而把这个功能加入到了JMP中。所以,生成的指令第四行的JMP在这里没有执行跳转,而只是为了关闭a的upvalue。
JMP其他的功能就是配合逻辑和关系指令(统称为test指令),实现程序的条件跳转。每个test辑指令与JMP搭配,都会将接下来生成的指令分为两个集合,满足条件的为true集合,否则为false集合。当test条件满足时,指令指针回+1,跳过后面紧跟的JMP指令,然后继续执行。当test条件不满足时,则继续执行,也就到了JMP,然后跳转到分支代码。

| name | args | desc |
|---|---|---|
| OP_EQ | A B C | if ((RK(B) == RK(C)) ~= A) then pc++ |
| OP_LT | A B C | if ((RK(B) < RK(C)) ~= A) then pc++ |
| OP_LE | A B C | if ((RK(B) <= RK(C)) ~= A) then pc++ |
关系指令对RK(B)和RK(C)进行比较,然后将比较结果与A指定的boolean值进行比较,来决定最终的boolean值。A在这里为每个关系指令提供了两种比较目标,满足和不满足。比如OP_LT何以用来实现“”。
~~~
local a,b,c;
a = b
~~~
~~~
1 [1] LOADNIL 0 2
2 [2] LT 1 1 2
3 [2] JMP 0 1 ; to 5
4 [2] LOADBOOL 0 0 1
5 [2] LOADBOOL 0 1 0
6 [2] RETURN 0 1
~~~
第二行的LT对寄存器1和2进行LT比较,如果结果为true,则继续执行后面的JMP,跳转到第五行的LOADBOOL,将寄存器0赋值为true;如果结果为false,则跳过后面的JMP,执行第四行的LOADBOOL,将寄存器0赋值为false。我们前面讲过关于LOADBOOL,第四行执行后会跳过第五行的赋值。
| name | args | desc |
|---|---|---|
| OP_TEST | A C | if not (R(A) C) then pc++ |
| OP_TESTSET | A B C | if (R(B) C) then R(A) := R(B) else pc++ |
逻辑指令用于实现and和or逻辑运算符,或者在条件语句中判断一个寄存器。TESTSET将寄存器B转化成一个boolean值,然后与C进行比较。如果不相等,跳过后面的JMP指令。否则将寄存器B的值赋给寄存器A,然后继续执行。TEST是TESTSET的简化版,不需要赋值操作。
~~~
local a,b,c;
a = b and c;
~~~
~~~
1 [1] LOADNIL 0 2
2 [2] TESTSET 0 1 0
3 [2] JMP 0 1 ; to 5
4 [2] MOVE 0 2
5 [2] RETURN 0 1
~~~
第二行的TESTSET将寄存器1的值与false比较。如果不成立,跳过JMP,执行第四行的MOVE,将寄存器2的值赋给寄存器0。否则,将寄存器1的值赋给寄存器0;然后执行后面的JMP。
上面的代码等价于
~~~
if b then
a = c
else
a = b
end
~~~
探索Lua5.2内部实现:虚拟机指令(4) Table
最后更新于:2022-04-01 07:09:47
# 探索Lua5.2内部实现:虚拟机指令(4) Table
| name | args | desc |
|---|---|---|
| OP_NEWTABLE | A B C | R(A) := {} (size = B,C) |
NEWTABLE在寄存器A处创建一个table对象。B和C分别用来存储这个table数组部分和hash部分的初始大小。初始大小是在编译期计算出来并生成到这个指令中的,目的是使接下来对table的初始化填充不会造成rehash而影响效率。B和C使用“floating point byte”的方法来表示成(eeeeexxx)的二进制形式,其实际值为(1xxx) * 2^(eeeee-1)。
` local a = {}; `
~~~
1 [1] NEWTABLE 0 0 0
2 [1] RETURN 0 1
~~~
上面代码生成一个空的table,放入local变量a,B和C参数都为0。
| name | args | desc |
|---|---|---|
| OP_SETLIST | A B C | R(A)[(C-1)*FPF+i] := R(A+i), 1 <= i <= B |
SETLIST用来配合NEWTABLE,初始化表的数组部分使用的。A为保存待设置表的寄存器,SETLIST要将A下面紧接着的寄存器列表(1--B)中的值逐个设置给表的数组部分。
当表需要初始化数组元素数量比较小的情况下,例如:
` local a = {1,1,1}; `
~~~
1 [1] NEWTABLE 0 3 0
2 [1] LOADK 1 -1 ; 1
3 [1] LOADK 2 -1 ; 1
4 [1] LOADK 3 -1 ; 1
5 [1] SETLIST 0 3 1 ; 1
6 [1] RETURN 0 1
constants (1) for 0x80048eb0:
1 1
~~~
第1行先用NEWTABLE构建一个具有3个数组元素的表,让到寄存器0中;然后使用3个LOADK向下面3个寄存器装入常量1;最后使用SETLIST设置表的1~3为寄存器1~寄存器3。
如果需要创建一个很大的表,其中包含很多的数组元素,使用如上方法就会遇到一个问题。将这些指按顺序放到寄存器时,会超出寄存器的范围。解决的办法就是按照一个固定大小,将这些数组元素分批进行设置。在Lua中,每批的数量由lopcodes.h中的LFIELDS_PER_FLUSH定义,数量为50。所以,大数量的设置会按照50个一批,先将值设置到表下面的寄存器,然后设置给对应的表项。C代表的就是这一次调用SETLIST设置的是第几批。回到上面的例子,因为只有3个表项,所以1批就搞定了,C的值为1。
下面是一个大表的设置:
~~~
local a =
{
1,2,3,4,5,6,7,8,9,0,
1,2,3,4,5,6,7,8,9,0,
1,2,3,4,5,6,7,8,9,0,
1,2,3,4,5,6,7,8,9,0,
1,2,3,4,5,6,7,8,9,0,
1,2,3
};
~~~
~~~
1 [1] NEWTABLE 0 30 0
2 [3] LOADK 1 -1 ; 1
3 [3] LOADK 2 -2 ; 2
...
50 [7] LOADK 49 -9 ; 9
51 [7] LOADK 50 -10 ; 0
52 [7] SETLIST 0 50 1 ; 1
53 [8] LOADK 1 -1 ; 1
54 [8] LOADK 2 -2 ; 2
55 [9] LOADK 3 -3 ; 3
56 [9] SETLIST 0 3 2 ; 2
57 [9] RETURN 0 1
constants (10) for 0x80048eb0:
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
10 0
~~~
可以看到,这个表的初始化使用了两个SETLIST指令。第一个处理前50个,C为1,设置id从(C-1)*50 + 1开始,也就是1。第二个处理余下的3个,C为2,设置的id从(C-1)*50 + 1开始,也就是51。
如果数据非常大,导致需要的批次超出了C的表示范围,那么C会被设置成0,然后在SETLIST指令后面生成一个EXTRAARG指令,并用其Ax来存储批次。这与前面说到的LOADKX的处理方法一样,都是为处理超大数据服务的。
如果使用核能产生多个返回值的表达式(... 和 函数调用)初始化数组项,如果这个初始化不是表构造的最后一项,那么只有第一个返回值会被设置到数组项;如果是最后一项,那么SETLIST中的B会被设置为0,表示从A+1到当前栈顶都用来设置。
SETLIST只负责初始化表的数组部分,对于hash部分,还是通过SETTABLE来初始化。
| name | args | desc |
|---|---|---|
| OP_GETTABLE | A B C | R(A) := R(B)[RK(C)] |
| OP_SETTABLE | A B C | R(A)[RK(B)] := RK(C) |
GETTABLE使用C表示的key,将寄存器B中的表项值获取到寄存器A中。SETTABLE设置寄存器A的表的B项为C代表的值。
~~~
local a = {};
a.x = 1;
local b = a.x;
~~~
~~~
1 [1] NEWTABLE 0 0 0
2 [2] SETTABLE 0 -1 -2 ; "x" 1
3 [3] GETTABLE 1 0 -1 ; "x"
~~~
探索Lua5.2内部实现:虚拟机指令(3) Upvalues & Globals
最后更新于:2022-04-01 07:09:45
# 探索Lua5.2内部实现:虚拟机指令(3) Upvalues & Globals
在编译期,如果要访问变量a时,会依照以下的顺序决定变量a的类型:
1. a是当前函数的local变量
2. a是外层函数的local变量,那么a是当前函数的upvalue
3. a是全局变量
local变量本身就存在于当前的register中,所有的指令都可以直接使用它的id来访问。而对于upvalue,lua则有专门的指令负责获取和设置。
全局变量在lua5.1中也是使用专门的指令,而5.2对这一点做了改变。Lua5.2种没有专门针对全局变量的指令,而是把全局表放到最外层函数的名字为"_ENV"的upvalue中。对于全局变量a,相当于编译期帮你改成了_ENV.a来进行访问。
| name | args | desc |
|---|---|---|
| OP_GETUPVAL | A B C | R(A) := UpValue[B] |
| OP_SETUPVAL | A B | UpValue[B] := R(A) |
| OP_GETTABUP | A B C | R(A) := UpValue[B][RK(C)] |
| OP_SETTABUP | A B C | UpValue[A][RK(B)] := RK(C) |
GETUPVAL将B为索引的upvalue的值装载到A寄存器中。SETUPVAL将A寄存器的值保存到B为索引的upvalue中。
GETTABUP将B为索引的upvalue当作一个table,并将C做为索引的寄存器或者常量当作key获取的值放入寄存器A。SETTABUP将A为索引的upvalue当作一个table,将C寄存器或者常量的值以B寄存器或常量为key,存入table。
~~~
local u = 0;
function f()
local l;
u = 1;
l = u;
g = 1;
l = g;
end
~~~
~~~
main (4 instructions at 0x80048eb0)
0+ params, 2 slots, 1 upvalue, 1 local, 2 constants, 1 function
1 [1] LOADK 0 -1 ; 0
2 [8] CLOSURE 1 0 ; 0x80049140
3 [2] SETTABUP 0 -2 1 ; _ENV "f"
4 [8] RETURN 0 1
constants (2) for 0x80048eb0:
1 0
2 "f"
locals (1) for 0x80048eb0:
0 u 2 5
upvalues (1) for 0x80048eb0:
0 _ENV 1 0
function (7 instructions at 0x80049140)
0 params, 2 slots, 2 upvalues, 1 local, 2 constants, 0 functions
1 [3] LOADNIL 0 0
2 [4] LOADK 1 -1 ; 1
3 [4] SETUPVAL 1 0 ; u
4 [5] GETUPVAL 0 0 ; u
5 [6] SETTABUP 1 -2 -1 ; _ENV "g" 1
6 [7] GETTABUP 0 1 -2 ; _ENV "g"
7 [8] RETURN 0 1
constants (2) for 0x80049140:
1 1
2 "g"
locals (1) for 0x80049140:
0 l 2 8
upvalues (2) for 0x80049140:
0 u 1 0
1 _ENV 0 0
~~~
上面的代码片段生成一个主函数和一个内嵌函数。根据前面说到的变量规则,在内嵌函数中,l是local变量,u是upvalue,g由于既不是local变量,也不是upvalue,当作全局变量处理。我们先来看内嵌函数,生成的指令从17行开始。
第17行的LOADNIL前面已经讲过,为local变量赋值。下面的LOADK和SETUPVAL组合,完成了u = 1。因为1是一个常量,存在于常量表中,而lua没有常量与upvalue的直接操作指令,所以需要先把常量1装在到临时寄存器1种,然后将寄存器1的值赋给upvalue 0,也就是u。第20行的GETUPVAL将upvalue u赋给local变量l。第21行开始的SETTABUP和GETTABUP就是前面提到的对全局变量的处理了。g=1被转化为_ENV.g=1。_ENV是系统预先设置在主函数中的upvalue,所以对于全局变量g的访问被转化成对upvalue[_ENV][g]的访问。SETTABUP将upvalue 1(_ENV代表的upvalue)作为一个table,将常量表2(常量"g")作为key的值设置为常量表1(常量1);GETTABUP则是将upvalue 1作为table,将常量表2为key的值赋给寄存器0(local l)。
探索Lua5.2内部实现:虚拟机指令(2) MOVE & LOAD
最后更新于:2022-04-01 07:09:43
# 探索Lua5.2内部实现:虚拟机指令(2) MOVE & LOAD
| name | args | desc |
|---|---|---|
| OP_MOVE | A B | R(A) := R(B) |
OP_MOVE用来将寄存器B中的值拷贝到寄存器A中。由于Lua是register based vm,大部分的指令都是直接对寄存器进行操作,而不需要对数据进行压栈和弹栈,所以需要OP_MOVE指令的地方并不多。最直接的使用之处就是将一个local变量复制给另一个local变量时:
~~~
local a;
local b = a;
~~~
~~~
1 [1] LOADNIL 0 0
2 [2] MOVE 1 0
3 [2] RETURN 0 1
~~~
在编译过程中,Lua会将每个local变量都分配到一个指定的寄存器中。在运行期,lua使用local变量所对应的寄存器id来操作local变量,而local变量的名字除了提供debug信息外,没有其他作用。
在这里a被分配给register 0,b被分配给register 1。第二行的MOVE表示将a(register 0)的值赋给b(register 1)。其他使用的地方基本都是对寄存器的位置有特殊要求的地方,比如函数参数的传递等等。
| name | args | desc |
|---|---|---|
| OP_LOADK | A Bx | R(A) := Kst(Bx) |
LOADK将Bx表示的常量表中的常量值装载到寄存器A中。很多其他指令,比如数学操作指令,其本身可以直接从常量表中索引操作数,所以可以不依赖于LOADK指令。
~~~
local a=1;
local b="foo";
~~~
~~~
1 [1] LOADK 0 -1 ; 1
2 [2] LOADK 1 -2 ; "foo"
3 [2] RETURN 0 1
onstants (2) for 0x80048eb0:
1 1
2 "foo"
~~~
| name | args | desc |
|---|---|---|
| OP_LOADKX | A | R(A) := Kst(extra arg) |
LOADKX是lua5.2新加入的指令。当需要生成LOADK指令时,如果需要索引的常量id超出了Bx所能表示的有效范围,那么就生成一个LOADKX指令,取代LOADK指令,并且接下来立即生成一个EXTRAARG指令,并用其Ax来存放这个id。5.2的这个改动使得一个函数可以处理超过262143个常量。
| name | args | desc |
|---|---|---|
| OP_LOADBOOL | A B C | R(A) := (Bool)B; if (C) pc++ |
LOADBOOL将B所表示的boolean值装载到寄存器A中。B使用0和1分别代表false和true。C也表示一个boolean值,如果C为1,就跳过下一个指令。
` local a = true; `
~~~
1 [1] LOADBOOL 0 1 0
2 [1] RETURN 0 1
~~~
C在这里的作用比较特殊。要了解C的具体用处,首先要知道lua中对于逻辑和关系表达式是如何处理的,比如:
` local a = 1 `
对于上面的代码,一般我们会认为lua应该先对1<2求出一个boolean值,然后放入到a中。然而实际上产生出来的代码为:
~~~
1 [1] LT 1 -1 -2 ; 1 2
2 [1] JMP 0 1 ; to 4
3 [1] LOADBOOL 0 0 1
4 [1] LOADBOOL 0 1 0
5 [1] RETURN 0 1
onstants (2) for 0x80048eb0:
1 1
2 2
~~~
可以看到,lua生成了LT和JMP指令,另外再加上两个LOADBOOL对于a赋予不同的boolean值。LT(后面会详细讲解)指令本身并不产生一个boolean结果值,而是配合后面紧跟的JMP实现true和false的不同跳转。如果LT评估为true,就继续执行,也就是执行到JMP,然后调转到4,对a赋予true;否则就跳过下一条指令到达第三行,对a赋予false,并且跳过下一个指令。所以上面的代码实际的意思被转化为:
~~~
local a;
if 1
a = true;
else
a = false;
end
~~~
逻辑或者关系表达式之所以被设计成这个样子,主要是为if语句和循环语句所做的优化。不用将整个表达式估值成一个boolean值后再决定跳转路径,而是评估过程中就可以直接跳转,节省了很多指令。
C的作用就是配合这种使用逻辑或关系表达式进行赋值的操作,他节省了后面必须跟的一个JMP指令。
| name | args | desc |
|---|---|---|
| OP_LOADNIL | A B | R(A), R(A+1), ..., R(A+B) := nil |
LOADNIL将使用A到B所表示范围的寄存器赋值成nil。用范围表示寄存器主要为了对以下情况进行优化:
~~~
local a,b,c;
~~~
~~~
1 [1] LOADNIL 0 2
2 [1] RETURN 0 1
~~~
对于连续的local变量声明,使用一条LOADNIL指令就可以完成,而不需要分别进行赋值。
对于一下情况
~~~
local a;
local b = 0;
local c;
~~~
~~~
1 [1] LOADNIL 0 0
2 [2] LOADK 1 -1 ; 0
3 [3] LOADNIL 2 0
~~~
在Lua5.2中,a和c不能被合并成一个LOADNIL指令。所以以上写法理论上会生成更多的指令,应该予以避免,而改写成
~~~
local a,c;
local b = 0;
~~~
探索Lua5.2内部实现:虚拟机指令(1) 概述
最后更新于:2022-04-01 07:09:40
# 探索Lua5.2内部实现:虚拟机指令(1) 概述
Lua一直把虚拟机执行代码的效率作为一个非常重要的设计目标。而采用什么样的指令系统的对于虚拟机的执行效率来说至关重要。
## Stack based vs Register based VM
根据指令获取操作数方式的不同,我们可以把虚拟机的实现分为stack based和register based。
### Stack based vm
对于大多数的虚拟机,比如JVM,Python,都采用传统的stack based vm。
Stack based vm的指令一般都是在当前stack中获取和保存操作数的。比如一个简单的加法赋值运算:a=b+c,对于stack based vm,一般会被转化成如下的指令:
~~~
push b; // 将变量b的值压入stack
push c; // 将变量c的值压入stack
add; // 将stack顶部的两个值弹出后相加,将结果压入stack
mov a; // 将stack顶部结果放到a中
~~~
由于Stack based vm的指令都是基于当前stack来查找操作数的,这就相当于所有操作数的存储位置都是运行期决定的,在编译器的代码生成阶段不需要额外为在哪里存储操作数费心,所以stack based的编译器实现起来相对比较简单直接。也正因为这个原因,每条指令占用的存储空间也比较小。
但是,对于一个简单的运算,stack based vm会使用过多的指令组合来完成,这样就增加了整体指令集合的长度。vm会使用同样多的迭代次数来执行这些指令,这对于效率来说会有很大的影响。并且,由于操作数都要放到stack上面,使得移动这些操作数的内存复制大大增加,这也会影响到效率。
### Register based vm
Lua 采用的是register based vm。
Register based vm的指令都是在已经分配好的寄存器中存取操作数。对于上面的运算,register based vm一般会使用如下的指令:
` add a b c; // 将b与c对应的寄存器的值相加,将结果保存在a对应的寄存器中 `
Register based vm的指令可以直接对应标准的3地址指令,用一条指令完成了上面多条指令的计算工作,并且有效地减少了内存复制操作。这样的指令系统对于效率有很大的帮助。
不过,在编译器设计上,就要在代码生成阶段对寄存器进行分配,增加了实现的复杂度。并且每条指令所占用的存储空间也相应的增加了。
## Lua虚拟机指令简介
Lua的指令使用一个32bit的unsigned integer表示。所有指令的定义都在lopcodes.h文件中,使用一个enum OpCode代表指令类型。在lua5.2中,总共有40种指令(id从0到39)。根据指令参数的不同,可以将所有指令分为4类:
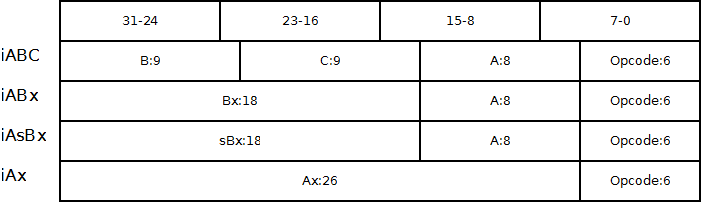
除了sBx之外,所有的指令参数都是unsigned integer类型。sBx可以表示负数,但表示方法比较特殊。sBx的18bit可表示的最大整数为262143,这个数的一半131071用来表示0,所以-1可以表示为-1+131071,也就是131070,而+1可以表示为+1+131071,也就是131072。
ABC一般用来存放指令操作数据的地址,而地址可以分成3种:
* 寄存器id
* 常量表id
* upvalue id
Lua使用当前函数的stack作为寄存器使用,寄存器id从0开始。当前函数的stack与寄存器数组是相同的概念。stack(n)其实就是register(n)。
每一个函数prototype都有一个属于本函数的常量表,用于存放编译过程中函数所用到的常量。常量表可以存放nil,boolean,number和string类型的数据,id从1开始。
每一个函数prototype中都有一个upvalue描述表,用于存放在编译过程中确定的本函数所使用的upvalue的描述。在运行期,通过OP_CLOSURE指令创建一个closure时,会根据prototype中的描述,为这个closure初始化upvalue表。upvalue本身不需要使用名称,而是通过id进行访问。
A被大多数指令用来指定计算结果的目标寄存器地址。很多指令使用B或C同时存放寄存器地址和常量地址,并通过最左面的一个bit来区分。在指令生成阶段,如果B或C需要引用的常量地址超出了表示范围,则首先会生成指令将常量装载到临时寄存器,然后再将B或C改为使用该寄存器地址。
在lopcodes.h中,对于每个指令,在源码注释中都有简单的操作描述。本文接下来将针对每一个指令做更详细的描述,并给出关于这个指令的示例代码。示例代码可以帮助我们构建出一个指令使用的具体上下文,有助于进一步理解指令的作用。对指令上下文的理解还可以作为进一步研究lua的编译和代码生成系统的基础。
在分析过程中,我们使用luac来显示示例代码所生成的指令。luac的具体使用方式为:
` luac -l -l test.lua `
探索Lua5.2内部实现:TString
最后更新于:2022-04-01 07:09:38
# 探索Lua5.2内部实现:TString
Lua使用TString结构体代表一个字符串对象。
~~~
/*
** Header for string value; string bytes follow the end of this structure
*/
typedef union TString {
L_Umaxalign dummy; /* ensures maximum alignment for strings */
struct {
CommonHeader;
lu_byte extra; /* reserved words for short strings; "has hash" for longs */
unsigned int hash;
size_t len; /* number of characters in string */
} tsv;
} TString;
~~~
hash用来记录字符串对应的哈希值,len用来记录字符串长度。
这个结构体其实只是字符串对象的头数据,后面紧跟着字符窜内容和一个'\0'结尾。字符串"abc"对应的TString对象应该如下图所示:

字符串对象的最终大小应该是TString的大小+字符串长度+1。
TString对应的lua对象类型为LUA_TSTRING。根据字符串长度(luaconf.h中的LUAI_MAXSHORTLEN,默认为40)的不同,TString对象还被分成两种子类型:LUA_TSHRSTR(短字符串)和LUA_TLNGSTR(长字符串)。
对于短字符串,在实际使用中一般用来作为索引或者需要进行字符串比较。不同于其他的对象,Lua并不是将其连接到全局的allgc对象链表上,而是将其放到全局状态global_State中的字符串表中进行管理。这个字符串表是一个stringtable类型的全局唯一的哈希表。当需要创建一个短字符串对象时,会首先在这个表中查找已有对象。所有的短字符串都是全局唯一的,不会存在两个相同的短字符串对象。如果需要比较两个短字符串是否相等,只需要看他们指向的是否是同一个TString对象就可以了,速度非常快。如果短字符串对象的extra > 0,表示这是一个系统保留的字符串。extra的值直接对应着词法分析时的一个token值,这样可以加速词法分析的速度。
对于长字符串,与短字符串相反,在实际使用中一般只是用来存储文本数据,很少需要比较或者索引。所以长字符串直接被挂接到allgc链表上当作普通的对象来处理。Lua不会对新创建的长字符串对象计算哈希值,也不保证长字符串对象的唯一性。当长字符串需要被用来当作索引时,会为其计算一次哈希值,并使用extra来记录是否已经为其计算了哈希值。
计算字符串的哈希值需要遍历字符串的每一个字符,如果字符串很长,会非常影响效率。对于大于等于32的字符串,Lua不会遍历每个字符,而是按照一定的间隔获取字符,最多遍历31次。这使得字符串的哈希值计算与字符串长度无关。
如果要将Lua部署到web上面来处理大量的基于文本的http请求,文本处理的安全性就变得尤为重要。为了防止Hash DoS攻击,字符串哈希值生成需要一个seed,这个seed是每次启动Lua时随机生成的。这就使不同的Lua实例对于同一个字符串会有不同的哈希值。
前言
最后更新于:2022-04-01 07:09:36
> 原文出处:[探索Lua5.2内部实现](http://blog.csdn.net/column/details/luainternals.html)
作者:[原林](http://blog.csdn.net/yuanlin2008)
**本系列文章经作者授权在看云整理发布,未经作者允许,请勿转载!**
# 探索Lua5.2内部实现
> 深入研究Lua5.2的源代码,探索Lua5.2内部的实现原理。