设计模式在C语言中的应用–读nginx源码
最后更新于:2022-04-01 14:48:02
市面上的“设计模式“书籍文章,皆针对Java/C++/C#等面向对象语言,似乎离开了面向对象的种种特性,设计模式就无法实现,没有用武之地了。
是这样吗?设计模式的概念是从建筑领域引入的,本身从没歧视过面向过程编程语言,它只是对一类问题的普遍解决方案而已。面向对象语言因为有类、多态等特点,使得开发者们容易达到:隐藏细节、封装变化,而这与设计模式的目的比较一致,所以大师们爱把设计模式与面向对象语言二位一体的使用。然而,存在即合理,C语言直到今日仍然在大型软件工程中担纲主角,其种种设计方法其实与我们通常见到的设计模式本质是相同的。例如nginx这个纯C语言写就的的高性能WEB服务器,就有许多地方使用到了市面书籍提到的设计模式。下面通过nginx源码来看看C语言是怎么做的。当然,UML图都是我根据代码意图所画,并不准确(C语言真没法画UML),只用于方便理解,呵呵。
strategy模式:
该模式用于客户代码在“无知”状态下,可以使用种种不同的实现。下面我们以nginx对网络IO操作的封装部分来看看C语言的实现吧。
设计模式就是通过封装变化来解耦,所以,我们先要找出网络IO操作的变化点来。nginx是跨平台的,它会支持linux、freebsd、solaris等操作系统,而每个操作系统的网络IO操作是不同的,这就是变化点了。
所以,nginx首先定义了ngx_os_io_t来封装这些变化。
~~~
typedef struct {
ngx_recv_pt recv;
ngx_recv_chain_pt recv_chain;
ngx_recv_pt udp_recv;
ngx_send_pt send;
ngx_send_chain_pt send_chain;
ngx_uint_t flags;
} ngx_os_io_t;
~~~
这里有五个函数指针(*_pt都是函数指针)和一个变量,用于收发网络数据,我把它理解为OO中的abstract class(每个ngx_os_io_t定义的变量都会重新实现这五个函数)。
拥有函数指针的struct,我通常认为它们是OO中的abstract class,实现它们的文件(一堆函数)要对应到OO上,我则喜欢把它们当做子类来看。对于void*这样的成员,要根据意图来看了,通常我会转换成聚合加继承的关系。

ngx_io会在相应的ngx_os_specific_init方法中,来策略性的选择到底使用哪个实现。客户代码只需要简单的调用ngx_io中的方法即可。
adapter模式:
这个模式用以适配接口,通常都是我们已经定义好一种接口了,有一个新的实现却有着不同的接口,接下来adapter就开始发力了。下面我们仍然以nginx对网络IO操作的封装部分来看。
linux平台下可能存在普通的IO或者异步IO方式。我们在最初已经封装好ngx_os_io_t接口了,客户代码都是这么直接使用的。现在linux实现了异步IO,而它的调用方式与普通的读写IO接口完全不同,所以,如果要支持aoi就需要一层adapter来适配ngx_os_io_t,这就是adapter方式了。

上图中,ngx_os_aio适配了原生的异步IO接口,这样,用户代码仍然像以前一样,只要直接使用ngx_io中的五个接口方法,当nginx的IO部分支持linux aio后,用户代码不需要修改。
bridge桥模式:
桥模式用于将抽象和实现分离,各自都能独立的变化。下面以nginx的核心概念module举例,虽然有些牵强,因为nginx的代码从来没这么用过:通常都是一个抽象module context只对应着一个实现module来用,但是,毕竟这种结构下还是可以达到抽象与实现分离的目的,桥模式只好对应到这上面了。
nginx是以module的概念贯穿始终的。它有一个基本的抽象层ngx_core_module_t(从意图上判断,context有抽象接口的功能,虽然简单从语法上看不出)。然后,nginx module有三个基本类型,分别是event(处理各种事件模型,如epoll/select等),http(处理各种http协议的事件),mail(处理mail相关的事件)。针对每种类型的module,都有许多个实现,比如event module就有9个实现,这里的每个实现其实也是个子类。
但是,在我们理解桥模式时,这些子类暂时要被看成是event module的实例。代码中看,像ngx_epoll_module这样的子类中,还是把一些通用的细节隐藏给ngx_event_core_module来做(管理这个词更合适)了。从这个角度可以认为,通过context接口,把三个基本module实现分开了。来看看类图:

nginx自己用时,是以ngx_module_t中的type成员来决定使用哪个实现的。目前的nginx代码中,如果用了一种接口就一定会指定相应的type。可是实际上,这也可以用来展示桥模式。以事件module为例来看看:

由于UML本就是针对OO语言的,所以以上我画的类图都比较牵强,什么是继承?什么是聚合?在C语言中,往往都是通过几个函数指针,或者void*指针实现各种封装和多态。没有什么语法上的关联,我就只能从代码意图中来判断了。而代码意图这个比较虚,因为不同的角度理解出来都不一样,所以这个确实不好画。太灵活了点,我只能从一个便于说明的角度来看,例如:上面的ngx_devpoll_module其实就是一个ngx_module_t,呵呵,但是,实际上它最关心的是ngx_event_actions_t的实现,如果完全根据语法来看,根本说不通的。但从代码意图中看,这些module并不关心ngx_module_t,所以我认为,它们只是在实现ngx_event_module_t了。
当然以上只是一家之言,不必当真,如果对nginx源码有研究的话,欢迎各位拍砖。
客观的说,C语言确实在封装上很差,就像nginx,如果我们要开发一个处理http协议的module嵌入进nginx进程,必须了解ngx_http_module里到底做了什么,真没隐藏啥细节,module开发者们表示很郁闷。上面的这些设计模式,只是做到了代码上的解藕。如果nginx用C++写的话,我相信,现在第三方module都能数以万计了。
“惊群”,看看nginx是怎么解决它的
最后更新于:2022-04-01 14:47:59
在说nginx前,先来看看什么是“惊群”?简单说来,多线程/多进程(linux下线程进程也没多大区别)等待同一个socket事件,当这个事件发生时,这些线程/进程被同时唤醒,就是惊群。可以想见,效率很低下,许多进程被内核重新调度唤醒,同时去响应这一个事件,当然只有一个进程能处理事件成功,其他的进程在处理该事件失败后重新休眠(也有其他选择)。这种性能浪费现象就是惊群。
惊群通常发生在server 上,当父进程绑定一个端口监听socket,然后fork出多个子进程,子进程们开始循环处理(比如accept)这个socket。每当用户发起一个TCP连接时,多个子进程同时被唤醒,然后其中一个子进程accept新连接成功,余者皆失败,重新休眠。
那么,我们不能只用一个进程去accept新连接么?然后通过消息队列等同步方式使其他子进程处理这些新建的连接,这样惊群不就避免了?没错,惊群是避免了,但是效率低下,因为这个进程只能用来accept连接。对多核机器来说,仅有一个进程去accept,这也是程序员在自己创造accept瓶颈。所以,我仍然坚持需要多进程处理accept事件。
其实,在linux2.6内核上,accept系统调用已经不存在惊群了(至少我在2.6.18内核版本上已经不存在)。大家可以写个简单的程序试下,在父进程中bind,listen,然后fork出子进程,所有的子进程都accept这个监听句柄。这样,当新连接过来时,大家会发现,仅有一个子进程返回新建的连接,其他子进程继续休眠在accept调用上,没有被唤醒。
但是很不幸,通常我们的程序没那么简单,不会愿意阻塞在accept调用上,我们还有许多其他网络读写事件要处理,linux下我们爱用epoll解决非阻塞socket。所以,即使accept调用没有惊群了,我们也还得处理惊群这事,因为epoll有这问题。上面说的测试程序,如果我们在子进程内不是阻塞调用accept,而是用epoll_wait,就会发现,新连接过来时,多个子进程都会在epoll_wait后被唤醒!
nginx就是这样,master进程监听端口号(例如80),所有的nginx worker进程开始用epoll_wait来处理新事件(linux下),如果不加任何保护,一个新连接来临时,会有多个worker进程在epoll_wait后被唤醒,然后发现自己accept失败。现在,我们可以看看nginx是怎么处理这个惊群问题了。
nginx的每个worker进程在函数ngx_process_events_and_timers中处理事件,(void) ngx_process_events(cycle, timer, flags);封装了不同的事件处理机制,在linux上默认就封装了epoll_wait调用。我们来看看ngx_process_events_and_timers为解决惊群做了什么:
~~~
void
ngx_process_events_and_timers(ngx_cycle_t *cycle)
{
。。。 。。。
//ngx_use_accept_mutex表示是否需要通过对accept加锁来解决惊群问题。当nginx worker进程数>1时且配置文件中打开accept_mutex时,这个标志置为1
if (ngx_use_accept_mutex) {
//ngx_accept_disabled表示此时满负荷,没必要再处理新连接了,我们在nginx.conf曾经配置了每一个nginx worker进程能够处理的最大连接数,当达到最大数的7/8时,ngx_accept_disabled为正,说明本nginx worker进程非常繁忙,将不再去处理新连接,这也是个简单的负载均衡
if (ngx_accept_disabled > 0) {
ngx_accept_disabled--;
} else {
//获得accept锁,多个worker仅有一个可以得到这把锁。获得锁不是阻塞过程,都是立刻返回,获取成功的话ngx_accept_mutex_held被置为1。拿到锁,意味着监听句柄被放到本进程的epoll中了,如果没有拿到锁,则监听句柄会被从epoll中取出。
if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) {
return;
}
//拿到锁的话,置flag为NGX_POST_EVENTS,这意味着ngx_process_events函数中,任何事件都将延后处理,会把accept事件都放到ngx_posted_accept_events链表中,epollin|epollout事件都放到ngx_posted_events链表中
if (ngx_accept_mutex_held) {
flags |= NGX_POST_EVENTS;
} else {
//拿不到锁,也就不会处理监听的句柄,这个timer实际是传给epoll_wait的超时时间,修改为最大ngx_accept_mutex_delay意味着epoll_wait更短的超时返回,以免新连接长时间没有得到处理
if (timer == NGX_TIMER_INFINITE
|| timer > ngx_accept_mutex_delay)
{
timer = ngx_accept_mutex_delay;
}
}
}
}
。。。 。。。
//linux下,调用ngx_epoll_process_events函数开始处理
(void) ngx_process_events(cycle, timer, flags);
。。。 。。。
//如果ngx_posted_accept_events链表有数据,就开始accept建立新连接
if (ngx_posted_accept_events) {
ngx_event_process_posted(cycle, &ngx_posted_accept_events);
}
//释放锁后再处理下面的EPOLLIN EPOLLOUT请求
if (ngx_accept_mutex_held) {
ngx_shmtx_unlock(&ngx_accept_mutex);
}
if (delta) {
ngx_event_expire_timers();
}
ngx_log_debug1(NGX_LOG_DEBUG_EVENT, cycle->log, 0,
"posted events %p", ngx_posted_events);
//然后再处理正常的数据读写请求。因为这些请求耗时久,所以在ngx_process_events里NGX_POST_EVENTS标志将事件都放入ngx_posted_events链表中,延迟到锁释放了再处理。
if (ngx_posted_events) {
if (ngx_threaded) {
ngx_wakeup_worker_thread(cycle);
} else {
ngx_event_process_posted(cycle, &ngx_posted_events);
}
}
}
~~~
从上面的注释可以看到,无论有多少个nginx worker进程,同一时刻只能有一个worker进程在自己的epoll中加入监听的句柄。这个处理accept的nginx worker进程置flag为NGX_POST_EVENTS,这样它在接下来的ngx_process_events函数(在linux中就是ngx_epoll_process_events函数)中不会立刻处理事件,延后,先处理完所有的accept事件后,释放锁,然后再处理正常的读写socket事件。我们来看下ngx_epoll_process_events是怎么做的:
~~~
static ngx_int_t
ngx_epoll_process_events(ngx_cycle_t *cycle, ngx_msec_t timer, ngx_uint_t flags)
{
。。。 。。。
events = epoll_wait(ep, event_list, (int) nevents, timer);
。。。 。。。
ngx_mutex_lock(ngx_posted_events_mutex);
for (i = 0; i < events; i++) {
c = event_list[i].data.ptr;
。。。 。。。
rev = c->read;
if ((revents & EPOLLIN) && rev->active) {
。。。 。。。
//有NGX_POST_EVENTS标志的话,就把accept事件放到ngx_posted_accept_events队列中,把正常的事件放到ngx_posted_events队列中延迟处理
if (flags & NGX_POST_EVENTS) {
queue = (ngx_event_t **) (rev->accept ?
&ngx_posted_accept_events : &ngx_posted_events);
ngx_locked_post_event(rev, queue);
} else {
rev->handler(rev);
}
}
wev = c->write;
if ((revents & EPOLLOUT) && wev->active) {
。。。 。。。
//同理,有NGX_POST_EVENTS标志的话,写事件延迟处理,放到ngx_posted_events队列中
if (flags & NGX_POST_EVENTS) {
ngx_locked_post_event(wev, &ngx_posted_events);
} else {
wev->handler(wev);
}
}
}
ngx_mutex_unlock(ngx_posted_events_mutex);
return NGX_OK;
}
~~~
看看ngx_use_accept_mutex在何种情况下会被打开:
~~~
if (ccf->master && ccf->worker_processes > 1 && ecf->accept_mutex) {
ngx_use_accept_mutex = 1;
ngx_accept_mutex_held = 0;
ngx_accept_mutex_delay = ecf->accept_mutex_delay;
} else {
ngx_use_accept_mutex = 0;
}
~~~
当nginx worker数量大于1时,也就是多个进程可能accept同一个监听的句柄,这时如果配置文件中accept_mutex开关打开了,就将ngx_use_accept_mutex置为1。
再看看有些负载均衡作用的ngx_accept_disabled是怎么维护的,在ngx_event_accept函数中:
~~~
ngx_accept_disabled = ngx_cycle->connection_n / 8
- ngx_cycle->free_connection_n;
~~~
表明,当已使用的连接数占到在nginx.conf里配置的worker_connections总数的7/8以上时,ngx_accept_disabled为正,这时本worker将ngx_accept_disabled减1,而且本次不再处理新连接。
最后,我们看下ngx_trylock_accept_mutex函数是怎么玩的:
~~~
ngx_int_t
ngx_trylock_accept_mutex(ngx_cycle_t *cycle)
{
//ngx_shmtx_trylock是非阻塞取锁的,返回1表示成功,0表示没取到锁
if (ngx_shmtx_trylock(&ngx_accept_mutex)) {
//ngx_enable_accept_events会把监听的句柄都塞入到本worker进程的epoll中
if (ngx_enable_accept_events(cycle) == NGX_ERROR) {
ngx_shmtx_unlock(&ngx_accept_mutex);
return NGX_ERROR;
}
//ngx_accept_mutex_held置为1,表示拿到锁了,返回
ngx_accept_events = 0;
ngx_accept_mutex_held = 1;
return NGX_OK;
}
//处理没有拿到锁的逻辑,ngx_disable_accept_events会把监听句柄从epoll中取出
if (ngx_accept_mutex_held) {
if (ngx_disable_accept_events(cycle) == NGX_ERROR) {
return NGX_ERROR;
}
ngx_accept_mutex_held = 0;
}
return NGX_OK;
}
~~~
OK,关于锁的细节是如何实现的,这篇限于篇幅就不说了,下篇帖子再来讲。现在大家清楚nginx是怎么处理惊群了吧?简单了说,就是同一时刻只允许一个nginx worker在自己的epoll中处理监听句柄。它的负载均衡也很简单,当达到最大connection的7/8时,本worker不会去试图拿accept锁,也不会去处理新连接,这样其他nginx worker进程就更有机会去处理监听句柄,建立新连接了。而且,由于timeout的设定,使得没有拿到锁的worker进程,去拿锁的频繁更高。
nginx启动期做了哪些事
最后更新于:2022-04-01 14:47:57
nginx是个多进程web容器,不同的配置下它的启动方式也是不同的,这里我只说说最典型的启动方式。
它有1个master进程,和多个worker进程(最优配置的数量与CPU核数相关)。那么,首先我们要找到main函数,它在src/core/nginx.c文件中。谈到源码了,这时我们先简单看下源码的目录结构吧。
nginx主要有下列目录:
src/core,这个目录存放了基础的数据结构像LIST、红黑树、nginx字符串,贯穿始终的一些逻辑结构如ngx_cycle_s、ngx_connection_s等,还有对一些底层操作的封装如log、文件操作、共享内存、内存池等,最后还有个nginx.c这个main启动函数了。
src/event,这个目录下存放与抽象事件相关的结构和钩子函数。nginx是以事件驱动处理流程的,事件自然是整个体系的核心了,这里定义了最核心的ngx_event_s结构。
src/event/modules目录存放了具体的种种事件驱动方式,例如epoll、kqueue、poll、aio、select等,它们通过ngx_event_actions_t结构体中的钩子挂在nginx中。nginx启动时会根据配置来决定使用哪种实现方式。
src/os/unix中存放了unix系统下许多函数调用的UNIX实现。
src/http目录存放到http module的相关实现,这个module负责处理http请求,包括协议的解析以及访问backend server的代码。
src/http/module目录存放http module类型的一些特定用途的module,比如gzip处理加密,图片压缩等。
有个初步了解后,回到main函数中,顺序看看我们感兴趣的事情。它先执行了ngx_time_init,为什么要初始化时间呢?nginx考虑的还是很周到的,取系统时间gettimeofday是系统调用,这意味着,需要发送中断给linux内核,内核需要做进程间切换来处理这个调用。这是一个不能忽视成本的函数。nginx封装了时间函数,这样,每次我们需要处理时间时,并不是调用gettimeofday,而是nginx自己缓存的时间,这样大量减少了系统调用,取当前时间这事可是谁都爱干的。
那么,nginx是怎么维护自己的这个时钟呢?如何保证用户取到的当前时间是有意义的?nginx设计者的出发点是,nginx是事件驱动机制,当一批事件发生时,也就是epoll_wait返回时,会取一次gettimeofday来更新自己的时间,然后调用各个事件对应的处理函数。这些函数都会保证自己是无阻塞的,也就是毫秒级的处理能力,所以,在任何一个事件处理函数中,取到的时间都是之前epoll_wait刚返回时取到的时间,这样,即使拿到的时间慢了几毫秒也无所谓。关键是,每个函数都是无阻塞的,都要迅速的把控制权交还给nginx,这是基本设计原则哈。
main函数初始化时间后,建立了最核心的数据结构ngx_cycle,之后无论是worker进程还是master进程都是围绕着它进行的。下面,我们要超级关注ngx_init_cycle这个函数,启动过程中大量的工作是在这完成的,代码就不列了,这个函数有800行,超大,也可见其之关键。ngx_init_cycle里做的第一件事就是调用所有nginx module里的create_conf方法。好,现在我们才来详细看下nginx module是什么。
nginx 抽象出一个ngx_module_s结构用来描述各个module,每个module处理它感兴起的事件。nginx里共有多少个module既是写死在代码中的,也是可以灵活配置的,呵呵,nginx式的玩法。回想下,下载nginx源码包后,我们也要执行它提供的configure操作,这个命令会生成makefile和ngx_modules文件,makefilel决定编译哪些module源文件,而生成的ngx_modules.c文件决定编译出的执行文件究竟使用哪些module。ngx_modules.c里面会生成一个数组ngx_modules,这是整个nginx工程都在使用的全局变量,它的形式如下:
~~~
ngx_module_t *ngx_modules[] = {
&ngx_core_module,
&ngx_errlog_module,
&ngx_conf_module,
... ...
}
~~~
这个通过configure生成的全局变量很关键,只有它才知道,一个请求可能会用哪些module处理。
接上文,ngx_init_cycle就是通过ngx_modules数组来调用所有module的create_conf方法的(每个module有权力决定是否实现这个方法,如果不实现的话,当然不会调用了)。然后,开始处理配置文件,这里我们需要重点关注ngx_conf_parse函数,因为它里面调用了ngx_conf_handler方法,ngx_conf_handler方法会调用每个module里自己实现的set钩子函数,让每个module处理自己感兴趣的配置项。所以,如果你在nginx.conf里没有配置某个module想要的东东,这个module虽然编译进去了,却会一直不执行的。这里我们要看下module的结构了,不能总是干说哈。
~~~
struct ngx_module_s {
ngx_uint_t ctx_index;
ngx_uint_t index;
... ...
void *ctx;
ngx_command_t *commands;
ngx_uint_t type;
ngx_int_t (*init_master)(ngx_log_t *log);
ngx_int_t (*init_module)(ngx_cycle_t *cycle);
ngx_int_t (*init_process)(ngx_cycle_t *cycle);
ngx_int_t (*init_thread)(ngx_cycle_t *cycle);
void (*exit_thread)(ngx_cycle_t *cycle);
void (*exit_process)(ngx_cycle_t *cycle);
void (*exit_master)(ngx_cycle_t *cycle);
... ...
};
~~~
ctx_index用来表示我们定义的一个module在上下文数组中的序号,index就表示在ngx_modules这个数组中的序号。
ctx这个指针指向module的上下文,type表示这个module的类型(module是分类的,每种type可以有多个module的),下面8个钩子函数,表示对应的事件发生时会调用这些方法(当然,module也可以不实现)。commands指向这个module所属的command结构,例如,http module是这么定义自己的command的:
~~~
static ngx_command_t ngx_http_commands[] = {
{ ngx_string("http"),
NGX_MAIN_CONF|NGX_CONF_BLOCK|NGX_CONF_NOARGS,
ngx_http_block,
0,
0,
NULL },
ngx_null_command
};
~~~
我们再看看ngx_command_s的定义:
~~~
struct ngx_command_s {
ngx_str_t name;
ngx_uint_t type;
char *(*set)(ngx_conf_t *cf, ngx_command_t *cmd, void *conf);
ngx_uint_t conf;
ngx_uint_t offset;
void *post;
};
~~~
所以,上文我说过,ngx_conf_handler方法会调用每个module里自己实现的set钩子函数,如果我们编译了http module(默认都有),那么就会在ngx_conf_handler方法中调用上面的ngx_http_block函数。这个ngx_http_block函数值得详细说说,因为它这时读取配置文件,决定要监听哪些http端口,它会把这些信息通过传进来的ngx_conf_t指针塞给ngx_cycle这个核心变量。
ngx_event_core_module也是个核心module,之前说到的到底是由epoll、select、poll还是kqueue来实现IO多路复用,就是由这个module来搞定的。
继续向下。ngx_init_cycle函数再来调用所有module实现的init_conf钩子函数。之后,执行到现在nginx进程终于要开始监听端口了。这事很关键,刚刚调用过各个module的set钩子方法了,例如上面http module的ngx_http_block方法,这些方法已经给ngx_cycle的listening数组塞进了需要监听的端口。为什么要现在就开始listen呢?因为现在还没有fork出worker子进程哈。大家知道,linux系统下,fork出的子进程会共享父进程的地址空间,所以,需要在全部worker进程中做的事,就都放到ngx_init_cycle里来做吧。监听的句柄,会被所有nginx worker共享使用的。
监听完指定的端口后,开始调用所有module实现的init_module钩子函数。接下来,要准备进程间通讯的事了。一个master,多个worker,这些进程间通过什么方式通讯呢?这里不展开了,下次再细说。它们也通过共享内存交换数据,这时开始初始化共享内存。终于,ngx_init_cycle执行完了,松口气?
接着,main函数要初始化信号量,进程间的同步都是通过信号量来玩的。然后创建pidfile,这个文件用于启动完成以后通过nginx命令行,对nginx进程发送信号量来控制它。main函数的最后,开始执行ngx_master_process_cycle函数了,这个函数做master进程该做的事。它首先调用ngx_start_worker_processes去启动worker,按照配置文件中配置的worker数量,fork出许多子进程,每个子进程执行ngx_worker_process_cycle函数,这是个死循环函数,将开始处理真正的用户请求。
ngx_master_process_cycle函数再调用ngx_start_cache_manager_processes启动cache的管理进程,这块限于篇幅,下次有空再讲吧。最后,ngx_master_process_cycle进入死循环,开始准备接收信号量传来的命令,以及监控每一个worker的运行状态,如果有worker非正常死掉,还会重新拉起的。
最后声明下,我是以nginx-0.7.65版本做例子来说的,上面列到的源代码文件,都是针对这个版本的。当然,我说的这些都是核心函数,其实1.x版本与之差别非常小。
熟悉了nginx的启动过程,知道它干了哪些事,就可以研究worker进程如何处理用户请求了。下次再说吧。
nginx module开发利器:subrequest
最后更新于:2022-04-01 14:47:55
nginx是个高性能web server,很多时候我们会把它当成reverse proxy或者web server container使用,但有时我们也会开发它的第三方module,因为module才能完全使用nginx的全事件驱动、无阻塞调用机制,充分使用系统资源,达到SERVER最大处理吞吐量。
在开发nginx module时,我们最有可能遇到的一件事就是,在处理一个请求时,我们需要访问其他多个backend server网络资源,拉取到结果后分析整理成一个response,再发给用户。这个过程是无法使用nginx upstream机制的,因为upstream被设计为用来支持nginx reverse proxy功能,所以呢,upstream默认是把其他server的http response body全部返回给client。这与我们的要求不符,这个时候,我们可以考虑subrequest了,nginx http模块提供的这个功能能够帮我们搞定它。
先看看subrequest调用函数长什么样:
~~~
ngx_int_t
ngx_http_subrequest(ngx_http_request_t *r,
ngx_str_t *uri, ngx_str_t *args, ngx_http_request_t **psr,
ngx_http_post_subrequest_t *ps, ngx_uint_t flags)
~~~
挨个分析下参数吧。r是我们的module handler中,nginx调用时传给我们的请求,这时我们直接传给subrequest即可。uri和args是我们需要访问backend server的URL,而psr是subrequest函数执行完后返回给我们的新请求,即将要访问backend server的请求指针。ps指明了回调函数,就是说,如果这个请求执行完毕,接收到了backend server的响应后,就会回调这个函数。flags会指定这个子请求的一些特征。
看看ngx_http_post_subrequest的结构:
~~~
typedef struct {
ngx_http_post_subrequest_pt handler;
void *data;
} ngx_http_post_subrequest_t;
~~~
这里的handler你可以指向一个函数,这个函数会在这个子请求结束以后被nginx调用,这时传给函数的request是子请求,不是原始的父请求哈。
而flag我们一般只会感兴趣下面这个NGX_HTTP_SUBREQUEST_IN_MEMORY,flag设为这个宏时,表示发起的子请求,访问的网络资源返回的响应将全部放在内存中,我们可以从upstream->buffer里取到响应内容。所以这里如果用了这个flag,一定要确保返回内容不可以很大,例如不能去下载一个大文件。
所以,当我们写nginx的module时,需要去拉取某个网络资源,就可以这么写:
~~~
ngx_http_post_subrequest_t *psr = ngx_palloc(r->pool, sizeof(ngx_http_post_subrequest_t));
if (psr == NULL) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
psr->handler = ngx_http_my_post_subrequest;
psr->data = ctx;
ngx_flag_t flag = NGX_HTTP_SUBREQUEST_IN_MEMORY
ngx_str_t sub_location = ngx_string("/testlocation");
ngx_str_t sub_args = ngx_string("para=1");;
rc = ngx_http_subrequest(r, &sub_location, &url_args, &sr, psr, sr_flag);
~~~
这样,在这个subrequest执行完后,将会调用ngx_http_my_post_subrequest方法,再次注意,此时传给你的ngx_http_request_t上下文是子请求的,不是原始的父请求,所以,如果你需要在父请求的上下文中处理这个请求,可以在ngx_http_my_post_subrequest中找到父请求的handler,设置为一个处理函数即可。比如:
~~~
ngx_http_request_t *pr = r->parent;
pr->write_event_handler = ngx_http_parent_handler;
~~~
这样,这个ngx_http_my_post_subrequest执行完毕后,nginx开始换醒父请求,这时ngx_http_parent_handler将会被调用。
最后我们要注意,一个请求中,我们只能调用一次subrequest,不能一次生成多个subrequest。我们可以在儿子请求中再创建孙子请求,一直下去都行,但是不能一次创建多个子请求。为什么呢?因为nginx本身的设计就是,每处理完一个事件后,将会检查有没有它对应的一个post事件(一对一),如果有则处理。上面的subrequest就是用这个流程的。如果一个请求中我们想同时生成多个子请求,就不能用subrequest了,我们必须自己创建nginx事件来处理了。
nginx module开发5 (完结)
最后更新于:2022-04-01 14:47:53
### [upstream]()机制
Nginx提供的upstream机制,是nginx设计理念的忠实体现。异步、无阻塞,这是nginx的追求,任何对这种设计思想的违反,都会导致nginx达不到它预期的性能,包括nginx提供的fastCGI也是如此。
Upstream到底用来干什么呢?就是nginx在正常的请求处理过程中,需要访问其他SERVER,这时,nginx提供了这样的机制,把底层的http通讯全部做完。最重要的是,upstream保证了在这个请求中对其他SERVER的通讯,完全是无阻塞和异步的。个人认为,如果nginx没有提供upstream,当开发者遇到这种情形要么自己写一套多路复用IO处理机制来做,要么放弃异步去调用connection里的同步方法,就不能称为真正的高性能异步WEB SERVER了。
Upstream实现得其实非常狭隘,因为nginx试图把upstream做成一种proxy,也就是说nginx会对其他SERVER访问后,对client的返回也接管,这个很恶心。如果你不需要这个功能,需要在ngx_http_upstream_process_header里,调用你的module处理response后就返回,不要继续向下执行。
Upstream有六个需要module developer实现的方法,分别是:
ngx_int_t (*create_request)(ngx_http_request_t *r);
ngx_int_t (*reinit_request)(ngx_http_request_t *r);
ngx_int_t (*process_header)(ngx_http_request_t *r);
void (*abort_request)(ngx_http_request_t *r);
void (*finalize_request)(ngx_http_request_t *r,
ngx_int_t rc);
ngx_int_t (*rewrite_redirect)(ngx_http_request_t *r,
ngx_table_elt_t *h, size_t prefix);
upstream在真正实现HTTP通讯时会调用到这些函数。那么upstream的是如何进行的?首先,我们需要调用ngx_http_upstream_init来开始upstream之旅了。
ngx_http_upstream_init首先会去调用create_request函数,这时开发者可以在这里把HTTP请求构造好。构造完请求包后,nginx会去连接remote server,这又是一个异步事件,所以需要注册回调函数为ngx_http_upstream_handler,也就是说,当连接成功建立后,nginx的epoll会调用ngx_http_upstream_handler来处理建立好的这个连接,同时把发送HTTP请求的处理函数注册为ngx_http_upstream_send_request_handler。
现在与remote server建立好连接了,ngx_http_upstream_handle调用ngx_http_upstream_send_request_handler来发送create_request完成的HTTP请求包了。这里实际完成发送请求任务的是ngx_http_upstream_send_request方法,而ngx_http_upstream_send_request又是调用ngx_output_chain来把请求发送出去。成功以后,开始等待读事件的来临,如果有数据返回,则调用ngx_http_upstream_process_header来处理remote server的response了,等到确认接收到完整的response后,会调用我们实现的process_header注册函数来处理response。upstream处理完后会调用注册的finalize_request函数来清理开发者需要做的工作。
### [内存使用]()
Nginx给用户提供了内存池功能,所以developer在使用时,应当尽量避免绕过nginx内存池来操作内存。
这里不去分析nginx内存池的实现,只简要的说明如何使用它。
申请一块内存时,必须先拿到内存池的指针,然后传入内存块大小,nginx实际上会移动指针指向内存池中的空闲内存,如果失败则返回NULL,内存池大小有限且可配,所以我们必须每次申请内存都要检查是否申请成功。
我们看下最简单的一个分配buf函数:
~~~
ngx_buf_t *
ngx_create_temp_buf(ngx_pool_t *pool, size_t size)
{
ngx_buf_t*b;
b =ngx_calloc_buf(pool);
if (b ==NULL) {
returnNULL;
}
b->start= ngx_palloc(pool, size);
if(b->start == NULL) {
returnNULL;
}
b->pos =b->start;
b->last= b->start;
b->end =b->last + size;
b->temporary = 1;
return b;
}
~~~
可以看到,很简单的从内存池中申请到,释放则由pool自动进行,很好的垃圾回收机制。
### [配置文件的使用]()
在ngx_command_t中,定义好需要读取的配置项名称,以及处理该配置项的方法,这样就可以nginx.conf里放置相应的配置项,在module里使用。
例如:
在nginx.conf里加入下行配置:
dmsargname dcname filesize blobid;
则需要在module里的ngx_command_t数组里分配如下:
~~~
{
ngx_string("dmsargname"),
NGX_HTTP_MAIN_CONF|NGX_HTTP_SRV_CONF|NGX_HTTP_LOC_CONF|NGX_HTTP_LMT_CONF|NGX_CONF_TAKE1234,
ngx_read_dmsargname,
NGX_HTTP_LOC_CONF_OFFSET,
offsetof(ngx_webex_DMD_loc_conf_t,argnameFromDC),
NULL
},
~~~
实际的处理函数为ngx_read_dmsargname。NGX_CONF_TAKE1234意为最多读取四个参数。
读取参数函数简易实现:
~~~
static char * /* {{{ ngx_read_datastore */
ngx_read_dmsargname(ngx_conf_t *cf, ngx_command_t*cmd, void *conf)
{
ngx_http_core_loc_conf_t *clcf;
ngx_webex_DMD_loc_conf_t *ulcf = conf;
ngx_str_t *value;
value =cf->args->elts;
clcf =ngx_http_conf_get_module_loc_conf(cf, ngx_http_core_module);
ulcf->argnameFromDC= value[1];
ulcf->argnameFilesize= value[2];
ulcf->argnameBlobID= value[3];
returnNGX_CONF_OK;
}
~~~
### [Nginx]()封装的常用数据结构
这个必须要说下,因为处理http请求时,必须处理head,无论是读取head还是插入head,都需要和ngx_list_t这个数据结构打交道,nginx框架是把head都放到ngx_list_t headers;数据结构里的。
list一共有三种操作:
ngx_list_create();//创建及初始化队列
ngx_list_init(); //初始化队列
ngx_list_push();//找到下一个插入位置的指针并返回
很明显,设计者为了灵活性,没有提供遍历方法,那么首先,应该怎么遍历它?比如,拿到一个request后,最应该先分析head了。
画个图看看:
ngx_list_t
<table class="MsoTableGrid" border="1" cellspacing="0" cellpadding="0"><tbody><tr><td width="142" valign="top"><p class="MsoNormal"><span lang="EN-US">pool</span></p></td><td width="142" valign="top"><p class="MsoNormal"><span lang="EN-US">nalloc</span></p></td><td width="142" valign="top"><p class="MsoNormal"><span lang="EN-US">size</span></p></td><td width="142" valign="top"><p class="MsoNormal"><span lang="EN-US">part</span></p></td><td width="142" valign="top"><p class="MsoNormal"><span lang="EN-US">last</span></p></td></tr></tbody></table>
<!--[if gte vml 1]> <![endif]-->
ngx_list_part_s
<table class="MsoTableGrid" border="1" cellspacing="0" cellpadding="0"><tbody><tr><td width="237" valign="top"><p class="MsoNormal"><span lang="EN-US">nelts</span></p></td><td width="237" valign="top"><p class="MsoNormal"><span lang="EN-US">elts</span></p></td><td width="237" valign="top"><p class="MsoNormal"><span lang="EN-US">next</span></p></td></tr></tbody></table>
<!--[if gte vml 1]> <![endif]-->
ngx_table_elt_t
<table class="MsoTableGrid" border="1" cellspacing="0" cellpadding="0"><tbody><tr><td width="178" valign="top"><p class="MsoNormal"><span lang="EN-US">Key</span></p></td><td width="178" valign="top"><p class="MsoNormal"><span lang="EN-US">Value</span></p></td><td width="178" valign="top"><p class="MsoNormal"><span lang="EN-US">Hash</span></p></td><td width="178" valign="top"><p class="MsoNormal"><span lang="EN-US">lowcase</span></p></td></tr></tbody></table>
[图表]()<!--[if supportFields]> SEQ图表 /* ARABIC<![endif]-->5<!--[if supportFields]><![endif]-->-nginx封装的list结构
当然ngx_table_elt_t结构只是head里的ngx_list_t所用,实际上每个元素可以是任意类型,由elts指针所指。
ngx_list_t里的nalloc和size,分别表示元素桶的数量和每个元素的大小,所以这里大家可以看出,该数据结构是定长内存组成的了吧。元素桶这个概念,大家可以理解为ngx_list_part_s结构,这个结构里可以保存多个元素,元素数量由nelts决定。每个元素是由ngx_list_part_s->elts指向的,长度为ngx_list_t->size
给段遍历list取得每个head的代码看看:
~~~
part =&r->upstream->headers_in.headers.part;
header= part->elts;
for (i= 0; /* void */; i++) {
if (i >= part->nelts) {
if (part->next == NULL) {
break;
}
part = part->next;
header = part->elts;
i = 0;
}
if(header[i].hash == 0) {
continue;
}
//header[i].key就是head的名字,header[i].value就是head的值了
}
~~~
[总结]
开发nginx module,可以非常灵活的实现自己需要的功能。很多时候我们需要修改源码才能实现自己的特定功能,比如,nginx的thumbnail resize功能,不支持实时的对每一个请求按照指定的size来压缩,实际上在它的代码中完全可以做到,只需要稍微修改下源码而已。
又如upstream,nginx把它当足是个proxy机制,如果我们想让它只做为异步网络调用,也只需要在upstream_process_header里做些改动。
在需要某些特殊的功能时,我们最应该首先阅读nginx的源码,通常都会发现很多意想不到的收获。
Nginx的性能确实不错,对http协议的处理也很高效,在我们需要高性能webserver时,应该去优先考虑它。
nginx module 开发谈(4)
最后更新于:2022-04-01 14:47:50
3、对HTTP body的处理
上面我们已经开始处理http request header了,接下来,如果请求中有body内容,那么需要处理body了。这里你肯定不会想要去阻塞式的读取body吧?body的长度可大可小,网络环境也巨复杂,只要有阻塞操作肯定玩完。Nginx这时已经准备了一个现成的读取body的非阻塞模式给用户,就是ngx_http_read_client_request_body方法。
大家看下ngx_http_read_client_request_body方法的原型:
ngx_int_t
ngx_http_read_client_request_body(ngx_http_request_t r,ngx_http_client_body_handler_pt post_handler);
参数r就是要处理的请求,post_handler则是body接收完成后的回调方法。
所以,在worker进程中,调用ngx_http_read_client_request_body是不会阻塞的,要么读完socket上的buffer发现不完整立刻返回,等待下一次EPOLLIN事件,要么就是读完body了,调用用户定义的post_handler方法去处理body。
ngx_http_read_client_request_body提供两种保存body的方式,一种是把body存储在内存中,另一种是把body存储到临时文件里。这个临时文件也有不同的处理方法,一种是请求结束后nginx便清理掉,另外就是永久保留这个临时文件。例如下面这两个参数就会设定为每个body都存放到临时文件里,并且这个临时文件在请求结束后不会被删除:
r->request_body_in_persistent_file = 1;
r->request_body_in_file_only = 1;
貌似ngx_http_read_client_request_body已经提供了很足够的功能了,其实不然。比如,我现在实现的业务中,就要求针对不同的请求,我要把body放到不同的目录下,也就是不同的mountpoint点上。这样,如果我把临时body指定到同一个mountpoint点下,相当于已经存储到远程机器上了,但是nginx的ngx_http_read_client_request_body方法是不提供这个功能的,它的临时文件目录早在编译时已经通过--http-client-body-temp-path=指定了,无法在运行时更改,比较恶心的实现。我想实现这个功能,只能自己重构下接收body这套方法了。这里我把我的处理方法(修改自ngx_http_read_client_request_body处理步骤)说下,方便大家理解body的接收过程。
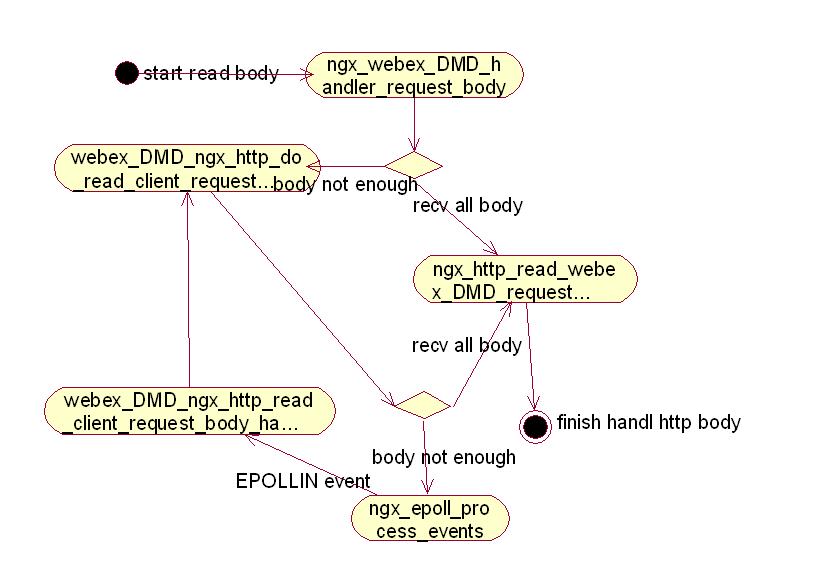
在我决定开始接收body后,首先调用ngx_http_read_webex_DMD_request_body方法,同时把处理完整body的勾子函数ngx_webex_DMD_handler_request_body也传进去。如果需要把temp body file放到指定目录,这时需要按照自己的方式把临时目录传进去,通过参数或者通过自定义的ngx_Module_ctx_t方式,这个随意。
ngx_http_read_webex_DMD_request_body方法首先判断是否存在body,如果不存在,立刻回调ngx_webex_DMD_handler_request_body方法;如果存在body,那么根据已经收到的buffer判断是否已经接收完body,如果已经收到完整的body,判断是否需要写入临时文件中,若需要则调用webex_DMD_ngx_http_write_request_body方法写临时文件,然后回调ngx_webex_DMD_handler_request_body。则如果没有收完,调用webex_DMD_ngx_http_do_read_client_request_body方法。
webex_DMD_ngx_http_do_read_client_request_body方法里,首先查看无阻塞的socket上是否仍有buffer,有则读出,再次判断是否body完整,如果已经收到完整的body,判断是否需要写入临时文件中,若需要则调用webex_DMD_ngx_http_write_request_body方法写临时文件,然后回调ngx_webex_DMD_handler_request_body。如果不完整,注册EPOLLIN事件的回调函数为webex_DMD_ngx_http_read_client_request_body_handler,把控制权交回给nginx epoll,等待下一次的EPOLLIN事件。下次EPOLLIN事件到达时,调用webex_DMD_ngx_http_read_client_request_body_handler,然后该函数会继续调用webex_DMD_ngx_http_do_read_client_request_body读取buffer,重复上一个步骤,直到body完整。
为了大家方便理解,我再画一幅活动图吧。
nginx module 开发谈(3)
最后更新于:2022-04-01 14:47:48
2、HTTP框架
继续上面这个例子,比如当nginx收到一个http请求时,我的module需要处理这个请求,那么我应该怎么做?实际这个问题还要再细分。如果是希望nginx收到完整的HTTP请求,再交给我的module处理?又或者只需要接收到完整的http header就给我呢?我把接收完header就交给module处理的code列下,再说下它的处理流程。
首先我要在ngx_XXX_init里注册对这种请求的处理函数。
~~~
static char * ngx_XXX_init(ngx_conf_t *cf, ngx_command_t *cmd, void *conf)
{
//... code 省略
clcf = ngx_http_conf_get_module_loc_conf(cf, ngx_http_core_module);
clcf->handler = ngx_XXX_handler;
return NGX_CONF_OK;
}
~~~
好了,现在有个简单的GET请求进入后,nginx在接收完header,就来调用ngx_XXX_handler方法了。好,现在我们调试下,看看nginx是如何进入ngx_XXX_handler方法的。
~~~
#0 ngx_XXX_handler (r=0x6d5650)
at nginx_XXX_module/ngx_XXX_module.c:646
#1 0x0000000000429e77 in ngx_http_core_content_phase (r=0x6d5650, ph=0x6e17d8)
at src/http/ngx_http_core_module.c:1262
#2 0x00000000004292d0 in ngx_http_core_run_phases (r=0x6d5650)
at src/http/ngx_http_core_module.c:800
#3 0x0000000000429284 in ngx_http_handler (r=0x6d5650)
at src/http/ngx_http_core_module.c:783
#4 0x000000000043165c in ngx_http_process_request (r=0x6d5650)
at src/http/ngx_http_request.c:1615
#5 0x0000000000430845 in ngx_http_process_request_headers (rev=0x6d60d0)
at src/http/ngx_http_request.c:1064
#6 0x00000000004303a0 in ngx_http_process_request_line (rev=0x6e3730)
at src/http/ngx_http_request.c:869
#7 0x000000000042fa8a in ngx_http_init_request (rev=0x6e3730)
at src/http/ngx_http_request.c:510
#8 0x0000000000422d6f in ngx_epoll_process_events (cycle=0x6cb1d0, timer=Variable "timer" is not available.
)
at src/event/modules/ngx_epoll_module.c:518
#9 0x00000000004181cb in ngx_process_events_and_timers (cycle=0x6cb1d0)
at src/event/ngx_event.c:245
#10 0x0000000000420351 in ngx_worker_process_cycle (cycle=0x6cb1d0, data=Variable "data" is not available.
)
at src/os/unix/ngx_process_cycle.c:791
#11 0x000000000041e19b in ngx_spawn_process (cycle=0x6cb1d0,
proc=0x420271 <ngx_worker_process_cycle>, data=0x0, name=0x5171a4 "worker process",
respawn=-3) at src/os/unix/ngx_process.c:194
#12 0x000000000041f8df in ngx_start_worker_processes (cycle=0x6cb1d0, n=1, type=-3)
at src/os/unix/ngx_process_cycle.c:355
#13 0x000000000041f24d in ngx_master_process_cycle (cycle=0x6cb1d0)
at src/os/unix/ngx_process_cycle.c:136
#14 0x0000000000403dea in main (argc=1, argv=Variable "argv" is not available.
) at src/core/nginx.c:396
~~~
上面这个栈信息,可以初步看到nginx是如果调用ngx_XXX_handler,我再详细说下。
ngx_epoll_process_events接收到网络IO事件EPOLLIN后(socket上有数据可读),rev->handler(rev);调用了这个回调方法(ngx_http_init_request)。ngx_http_init_request开始处理这个事件,首先它把基本的ngx_http_request_t变量(nginx HTTP框架中由始至终的东东)初始化,并从内存池中分配了第一块接收内存,然后开始调用ngx_http_process_request_line方法处理具体内容。
ngx_http_process_request_line开始处理具体接收到的消息了,它首先会调用ngx_http_read_request_header方法去读取socket上的字节,读完后(仅仅是当前socket上的缓冲)调用ngx_http_parse_request_line方法分析协议,ngx_http_parse_request_line方法就是一个HTTP协议的状态机实现,分析HTTP协议并赋值到ngx_http_request_t相应的字段里,如果不完整,就返回epoll等待这个socket上的下一次EPOLLIN事件。如果HTTP协议头完整了,就开始调用ngx_http_process_request_headers处理http header的内容了。
ngx_http_process_request_headers方法会先调用ngx_http_parse_header_line去分析http header。ngx_http_parse_header_line也是一个状态机,仅用来解析http header,之后开始调用ngx_http_process_request方法处理已经解析成功的ngx_http_request_t对象。ngx_http_process_request简单的调用ngx_http_handler方法,ngx_http_handler方法把事件发布到ngx_http_core_run_phases阶段,开始回调我们在ngx_XXX_init方法中注册的ngx_XXX_handle方法。
现在大家清楚一个最基本的module处理流程是怎样的了吧?如果大家还是不大明白,我画个活动图帮助大家理解下:

nginx module 开发谈(2)
最后更新于:2022-04-01 14:47:46
nginx的module开发很弱,首先它不是采用动态库的形式被主进程加载,而是要求module的源码必须和nginx的源码一起编译。我是第一次见到这么BT的家伙,呵呵。所以呢,对module开发者来说,nginx就是一个开发平台,可以把它理解为在nginx这个“OS”上用C语言开发application,而且要遵循nginx的框架。
既然是平台,那么像其他OS一样,我们需要搞明白几点:1、程序入口和调用方式。2、HTTP处理框架。3、对Http body的处理。4、Upstream机制。5、内存使用。6、配置文件的使用。7、LOG的API。
1、先要搞明白程序入口,就像在LINUX上写可执行程序会自动去找main方法一样。下面我会用一个例子来说明一下处理流程。
nginx的程序入口先要在module所在目录的config文件里配置,类似:
~~~
USE_SHA1=YES
ngx_addon_name=ngx_XXX_module
HTTP_MODULES="$HTTP_MODULES ngx_XXX_module"
NGX_ADDON_SRCS="$NGX_ADDON_SRCS $ngx_addon_dir/ngx_XXX_module.
~~~
同时在module源文件中,定义如下结构:
~~~
static ngx_command_t ngx_XXX_commands[] = {
{
ngx_string("XXX"),
NGX_HTTP_LOC_CONF|NGX_CONF_NOARGS,
ngx_XXX_init,
0,
0,
NULL
}
};
static ngx_http_module_t ngx_XXX_module_ctx = {
NULL, //ngx_XXX_add_variables, /* preconfiguration */
NULL, /* postconfiguration */
NULL, /* create main configuration */
NULL, /* init main configuration */
NULL, /* create server configuration */
NULL, /* merge server configuration */
ngx_XXX_create_loc_conf, /* create location configuration */
ngx_XXX_merge_loc_conf /* merge location configuration */
};
ngx_module_t ngx_XXX_module = {
NGX_MODULE_V1,
&ngx_XXX_module_ctx,
ngx_XXX_commands,
NGX_HTTP_MODULE,
NULL,
NULL,
NULL,
NULL,
NULL,
NULL,
NULL,
NGX_MODULE_V1_PADDING
};
~~~
那么,nginx主进程在启动时,就会在执行代码里找相应的ngx_module_t(ngx_XXX_module)变量,找到后,在其中ngx_command_t(ngx_XXX_commands)指定的函数ngx_XXX_init里开始初始化模块。所有的工作都要在这里进行了,包括后续对每个请求的处理订阅。
Nginx启动时,会先启动一个master管理进程,然后根据配置启动数个worker进程。实际的module里的勾子函数(例如ngx_XXX_handle),都是被worker进程所调用的。默认情况下,nginx并不是多线程的,所以,如果你的勾子函数被调用了,那么你绝对不可以有任何阻塞操作,否则会使得nginx worker不去处理已经在链表中的其他connection,这就完全毁了nginx,如果你去同步请求硬盘IO资源,否则其他SERVER的网络IO,那么它和apach+CGI这种低性能SERVER也没啥两样了,除了epoll可以hold住大量连接。
nginx module 开发谈(1)
最后更新于:2022-04-01 14:47:44
nginx是什么?可能很多人不是很了解,除非是做WEB服务器开发的朋友才可能涉猎,而且如果不懂C语言,又或者对WEB SERVER性能要求不高,也是没必要去研究它的。
说到这里,大家想必已经知道,nginx就是一个高性能的WEB SERVER,它的工作就像apache, tomcat一样。那么已经有apache这样的成熟产品了,nginx又有何存在必要呢?下面说下它的特点,各位就明白为何nginx在世界WEB服务里占有相当大的份额了。
1、nginx支持linux的epoll,以及其他常见OS的高性能IO处理方式。
2、nginx用纯C写成。
3、nginx核心代码全部用事件触发机制完成。
4、nginx是跨平台的。
大家从这4个主要特点,应该可以想见nginx到底是怎么玩的了吧?
第1点很清楚,nginx可以很轻松的支持2,3万个并发连接,这个是epoll等模式先天支持的,还能CPU占用率超低。
第2点可以想见,nginx是高性能的。C语言的高效谁不知道呢?呵呵,读它的代码也是相当累,如果想去写nginx的module,自然更累,下面会详述。
第3点很重要,nginx全部用事件触发写成,实际用到的,也就是epoll提供的一些网络IO事件的触发处理。这点是WEB开发者在写自己的module时,实现高性能web服务的关键。
第4点并不重要,因为写web的人都是做服务的,大家大多都是在免费的LINUX上玩的,没人会用nginx在windows上跑吧?如果在windows上跑,何必选开发难度大多了的nginx?所以这点不提。不过这一条让大家在开发起来很不爽,为了与nginx代码风格统一,不得不用大量的nginx封装好的用来跨平台的函数,比如ngx_memcpy之类。
解读完这四点,一个有经验的程序员应该明白何种情形应该选用nginx了吧?如果一个java小团队,对服务的并发能力要求不高,又或者机器巨多,自然不需要去选择开发成本较高的nginx了。而做习惯大规模高并发SERVER开发的同志们,则会心生疑惑,nginx的好处还有什么?上面的这些优点,完全可以自己写个server实现,要nginx何用?我觉得,如果是做WEB SERVER,还是需要nginx的。
nginx实际封装了基本的WEB SERVER功能,所以,首先它有良好的网络IO处理系统,还有稳定的HTTP协议状态机分析,内存池,进程间通讯,线程管理,并提供了基本的配置文件,LOG系统。在其上做不是特别复杂的WEB应用,还是很有优势的,至少可以上application开发者不用花太多的精力在较底层的协议上去。
粗略介绍完nginx,大家有何感想?估计有很多人会打算详细研究下它吧?
但nginx最大的不爽之处,就是资料极少,网上能搜到的文档就那么几份,如果不做module开发,那是足矣,可是如果有自己业务的特殊需求,并且希望按照nginx的设计理念去非阻塞化所有操作,把性能最大化,则必须边看源码边调试了,连蒙带猜,呵呵。
我就经过了这个痛苦过程,下面就给大家分享下nginx的module开发过程中的一些心得。
前言
最后更新于:2022-04-01 14:47:41
> 原文出处:[nginx 高性能module开发](http://blog.csdn.net/column/details/nginx-module-develop.html)
作者:[陶辉](http://blog.csdn.net/russell_tao)
**本系列文章经作者授权在看云整理发布,未经作者允许,请勿转载!**
# nginx 高性能module开发
> nginx是一个非常高效的web server,在其源码中编译进入自己的module可以让自己的module同样的达到高效处理海量并发请求的能力。这里我们看看如何开发nginx moduel。