C语言的角落——C之非常用特性(一)
最后更新于:2022-04-01 20:30:29
本文搜集整理了一些之前博客中没有提到的,C语言不常用的特性,算是对C系列的最后一次补充。
对C语言有兴趣的朋友可以浏览一下,查漏补缺。
变长参数列表
头文件定义了一些宏,当函数参数未知时去获取函数的参数
变量:typedef va_list
宏:
va_start()
va_arg()
va_end()
va_list类型通过stdarg宏定义来访问一个函数的参数表,参数列表的末尾会用省略号省略
(va_list用来保存va_start,va_end所需信息的一种类型。为了访问变长参数列表中的参数,必须声明va_list类型的一个对象 )
我们通过初始化(va_start)类型为va_list的参数表指针,并通过va_arg来获取下一个参数。
【例子:】
求任意个整数的最大值
~~~
#include
#include
int maxint(int n, ...) /* 参数数量由非变长参数n直接指定 */
{
va_list ap;
int i, arg, max;
va_start(ap, n); /* ap为参数指针,首先将其初始化为最后一个具名参数, 以便va_arg获取下一个省略号内参数 */
for (i = 0; i < n; i++) {
arg = va_arg(ap, int); /* 类型固定为int, 按照给定类型返回下一个参数 */
if (i == 0)
max = arg;
else {
if (arg > max)
max = arg;
}
}
va_end(ap);
return max;
}
void main()
{
printf("max = %d\n", maxint(5, 2, 6, 8, 11, 7));
}
~~~
可变长数组
历史上,C语言只支持在编译时就能确定大小的数组。程序员需要变长数组时,不得不用malloc或calloc这样的函数为这些数组分配存储空间,且涉及到多维数组时,不得不显示地编码,用行优先索引将多维数组映射到一维的数组。
**ISOC99引入了一种能力,允许数组的维度是表达式,在数组被分配的时候才计算出来**。
~~~
#include
int
main(void)
{
int n, i ;
scanf("%d", &n) ;
int array[n] ;
for (; i
int main(void)
{
int i=0;
scanf("%d", &i) ;
switch(i)
{
case 1 ... 9: putchar("0123456789"[i]);
case 'A' ... 'Z': //do something
}
return 0;
}
~~~
非局部跳转setjmp和longjmp
在C中,goto语句是不能跨越函数的,而执行这类跳转功能的是setjmp和longjmp**宏**。这两个**宏**对于处理发生在深层嵌套函数调用中的出错情况是非常有用的。
此即为:非局部跳转。非局部指的是,这不是由普通C语言goto语句在一个函数内实施的跳转,而是在栈上跳过若干调用帧,返回到当前函数调用路径的某个函数中。
#include
int **setjmp**(jmp_buf env) ; **/*设置调转点*/**
void **longjmp**(jmp_bufenv, int val) ; **/*跳转*/**
setjmp参数env的类型是一个特殊类型jmp_buf。这一数据类型是某种形式的数组,其中存放 在调用longjmp时能用来恢复栈状态的所有信息。因为需在另一个函数中引用env变量,所以应该将env变量定义为全局变量。
longjmp参数val,它将成为从setjmp处返回的值。(很神奇吧。setjmp根据返回值可知道是哪个longjmp返回来的)
~~~
#include
#include
static jmp_buf buf;
void second(void)
{
printf("second\n");
longjmp(buf,1);
// 跳回setjmp的调用处使得setjmp返回值为1
}
void first(void)
{
second();
printf("first\n");
// 不可能执行到此行
}
int main()
{
if (!setjmp(buf))
{
// 进入此行前,setjmp返回0
first();
}
else
{
// 当longjmp跳转回,setjmp返回1,因此进入此行
printf("main\n");
}
return 0;
}
~~~
直接调用setjmp时,返回值为0,这一般用于初始化(设置跳转点时)。以后再调用longjmp宏时用env变量进行跳转。程序会自动跳转到setjmp宏的返回语句处,此时setjmp的返回值为非0,由longjmp的第二个参数指定。
一般地,宏setjmp和longjmp是成对使用的,这样程序流程可以从一个深层嵌套的函数中返回。
volatile属性
如果你有一个自动变量,而又不想它被编译器优化进寄存器,则可定义其为有volatile属性。这样,就明确地把这个值放在存储器中,而不会被优化进寄存器。
setjmp会保存当前栈状态信息,也会保存此时寄存器中的值。(longjmp会回滚寄存器中的值)
【如果要编写一个使用非局部跳转的可移植程序,则必须使用volatile属性】
· IO缓冲问题
缓冲输出和内存分配
当一个程序产生输出时,能够立即看到它有多重要?这取决于程序。
例如,终端上显示输出并要求人们坐在终端前面回答一个问题,人们能够看到输出以知道该输入什么就显得至关重要了。另一方面,如果输出到一个文件中,并最终被发送到一个行式打印机,只有所有的输出最终能够到达那里是重要的。
立即安排输出的显示通常比将其暂时保存在一大块一起输出要昂贵得多。因此,C实现通常允许程序员控制产生多少输出后在实际地写出它们。
这个控制通常约定为一个称为setbuf()的库函数。如果buf是一个具有适当大小的字符数组,则
setbuf(stdout, buf);
将告诉I/O库写入到stdout中的输出要以buf作为一个输出缓冲,并且等到buf满了或程序员直接调用fflush()再实际写出。缓冲区的合适的大小在中定义为BUFSIZ。
因此,下面的程序解释了通过使用setbuf()来讲标准输入复制到标准输出:
~~~
#include
int main()
{
int c;
char buf[BUFSIZ];
setbuf(stdout, buf);
while((c = getchar()) != EOF)
putchar(c);
return 0 ;
}
~~~
不幸的是,这个程序是错误的,因为一个细微的原因。
要知道毛病出在哪,我们需要知道缓冲区最后一次刷新是在什么时候。答案:主程序完成之后,库将控制交回到操作系统之前所执行的清理的一部分。在这一时刻,缓冲区已经被释放了! (即main函数栈清空之后)
有两种方法可以避免这一问题。
首先,使用静态缓冲区,或者将其显式地声明为静态:
static char buf[BUFSIZ];
或者将整个声明移到主函数之外。
另一种可能的方法是动态地分配缓冲区并且从不释放它:
char *malloc();
setbuf(stdout, malloc(BUFSIZ));
注意在后一种情况中,不必检查malloc()的返回值,因为如果它失败了,会返回一个空指针。而**setbuf()可以接受一个空指针作为其第二个参数,这将使得stdout变成非缓冲的。这会运行得很慢,但它是可以运行的。**
预编译和宏定义
C/C++中几个罕见却有用的预编译和宏定义
**1:# error**
语法格式如下:
#error token-sequence
其主要的作用是**在编译的时候输出编译错误信息**token-sequence,从方便程序员检查程序中出现的错误。例如下面的程序
~~~
#include "stdio.h"
int main(int argc, char* argv[])
{
#define CONST_NAME1 "CONST_NAME1"
printf("%s\n",CONST_NAME1);
#undef CONST_NAME1
#ifndef CONST_NAME1
#error No defined Constant Symbol CONST_NAME1
#endif
{
#define CONST_NAME2 "CONST_NAME2"
printf("%s\n",CONST_NAME2);
}
printf("%s\n",CONST_NAME2);
return 0;
}
~~~
在编译的时候输出如编译信息
fatal error C1189: #error : No definedConstant Symbol CONST_NAME1
**2:#pragma**
其语法格式如下:
# pragma token-sequence
此指令的作用是触发所定义的动作。如果token-sequence存在,则触发相应的动作,否则忽略。此指令一般为编译系统所使用。例如在Visual C++.Net 中利用# pragma once 防止同一代码被包含多次。
**3:#line**
此命令主要是为**强制编译器按指定的行号,开始对源程序的代码重新编号**,在调试的时候,可以按此规定输出错误代码的准确位置。
形式1
语法格式如下:
# line constant “filename”
其作用是使得其后的源代码从指定的行号constant重新开始编号,并将当前文件的名命名为filename。例如下面的程序如下:
~~~
#include "stdio.h"
void Test();
#line 10 "Hello.c"
int main(int argc, char* argv[])
{
#define CONST_NAME1 "CONST_NAME1"
printf("%s\n",CONST_NAME1);
#undef CONST_NAME1
printf("%s\n",CONST_NAME1);
{
#define CONST_NAME2 "CONST_NAME2"
printf("%s\n",CONST_NAME2);
}
printf("%s\n",CONST_NAME2);
return 0;
}
~~~
~~~
void Test()
{
printf("%s\n",CONST_NAME2);
}
~~~
提示如下的编译信息:
Hello.c(15) : error C2065: 'CONST_NAME1' :undeclared identifier
表示当前文件的名称被认为是Hello.c, #line 10 "Hello.c"所在的行被认为是第10行,因此提示第15行出错。
形式2
语法格式如下:
# line constant
其作用在于编译的时候,准确输出出错代码所在的位置(行号),而在源程序中并不出现行号,从而方便程序员准确定位。
**4:运算符#和##**
在ANSI C中为预编译指令定义了两个运算符——#和##。
**# 的作用**是实现文本替换(字符串化),例如
#define HI(x)printf("Hi,"#x"\n");
void main()
{
HI(John);
}
程序的运行结果
Hi,John
在预编译处理的时候, #x的作用是将x替换为所代表的字符序列。(即把x宏变量字符串化)在本程序中x为John,所以构建新串“Hi,John”。
**##的作用**是串连接。
例如
#define CONNECT(x,y) x##y
void main()
{
int a1,a2,a3;
CONNECT(a,1)=0;
CONNECT(a,2)=12;
a3=4;
printf("a1=%d\ta2=%d\ta3=%d",a1,a2,a3);
}
程序的运行结果为
a1=0 a2=12 a3=4
在编译之前, CONNECT(a,1)被翻译为a1, CONNECT(a,2)被翻译为a2。
标准IO的妙用
~~~
//指定精确位数
#include
int main(void)
{
int m ; //精确位数
double input ; //用户输入小数
puts("请输入一个小数:") ;
scanf("%lf",&input) ;
puts("请输入精确到小数点后位数") ;
scanf("%d" ,&m) ;
puts("结果为");
printf("%.*lf" ,m,input) ;
return 0 ;
}
~~~
**打印printf:**
每一个printf函数的调用都返回一个值——要么是输出字符的个数,要么输出一个负数表示发生输出错误。
**带域宽和精度的打印**:
printf函数允许你为欲打印的数据指定精度。对于不同类型的数据而言,精度的含义是不一样的。
**精度与整型转换说明符**一起使用时,表示要打印的数据的最少数字位数。如果将要打印的数据所包含的数字的位数小于指定的精度,同时精度值前面带有一个0或者一个小数点,则加填充0.
**精度与浮点型转换说明符**一起使用时,表示将要打印的最大有效数字位数。
**精度与字符串转换说明符**s一起使用时,表示将要从一个字符串中打印出来的最大字符个数。(可用于控制打出的字符的个数)
表示精度的方法是:在百分号和转换说明符之间,插入一个表示精度的整数,并在整数的前面加上一个小数点。
**域宽和精度**可以放在一起使用,方法是:在百分号和转换说明符之间,先写上域宽,然后加上一个小数点,后面再写上精度。例如:
printf(“%9.3f”, 123.456789) ;
的输出结果是123.456
还可以**用变量来控制域宽和精度(可用于关于精度的舍入)**
在格式控制字符串中表示域宽或精度的位置上写上一个星号*,然后程序将会计算实参列表中相对应的整型实参值,并用其替换星号。
例如:
printf(“%*.*f”, 7, 2, 98.736) ; 将以7为域宽,2为精度,输出右对齐的98.74
表示域宽的值可以是正数,也可以是负数(将导致输出结果在域宽内左对齐)
**使用标记**
printf函数还提供了一些标记来增加它的输出格式控制功能,在格式控制字符串中可以使用的标记有:
-(减号) 在域宽内左对齐显示输出结果
+(加号) 在正数前面显示一个加号,在负数前面显示一个减号
空格 在不带加号标记的正数前面打印一个空格
# 当使用的是八进制转换说明符o时,在输出数据前面加上前缀0
当使用的是十六进制转换说明符x或X时,在输出数据前面加上前缀0x或0X
0(零) 在打印的数据前面加上前导0
**逆向打印参数**(POSIX扩展语法)
printf("%4$d %3$d %2$d %1$d", 1, 2, 3, 9); //将会打印9 3 2 1
**格式化输入scanf**
**扫描集(实用)**
一个字符序列可以用一个扫描集(Scanset)来输入。扫描集是位于格式控制字符串中,以百分号开头、用方括号[]括起来的一组字符。
寻找与扫描集中的字符相匹配的字符。一旦找到匹配的字符,那么这个字符将被存储到扫描集对应的实参(即指向一个字符数组的指针)中。只有遇到扫描集中没有包含的字符时,扫描集才会停止输入字符。
如果输入流中的第一个字符就不能与扫描集中包含的字符相匹配,那么只有空操作符被存储到字符数组中。
(如果输入的字符属于方括号内字符串中某个字符,那么就提取该字符;如果一经发现不属于就结束提取。该方法会自动加上一个'\0'到已经提取的字符后面。)
【例如】
char str[512] ;
printf(“Enter string:\n”) ;
scanf(“%[aeiou]”, str) ;
程序使用扫描集[aeiou]在输入流中寻找元音字符,直到遇到非元音字符。
我们还可以用缩写a-z表示abcd….xyz字母集。
scanf(“%[a-z]”, str) ;
同理,也可以用缩写0-9 缩写A-Z。
想只取字母,那就可以写成 %[A-Za-z]
对于字符串"abDEc123"如果想按照字母和数字读到两个字符串中就应该是 "%[a-zA-Z]%[0-9]",buf1,buf2 ;
**逆向扫描集**
逆向扫描集还可以用来扫描那些没有出现在扫描集中的字符。创建一个逆向扫描集的方法是,在方括号内扫描字符前面加一个“脱字符号”(^)。这个符号将使得那些没有出现在扫描集中的字符被保存起来。只有遇到了逆向扫描集中包含的字符时,输入才会停止。(即取其后字符们的补集作为扫描集)
scanf(“%[^aeiou]”, str) ;
即接受输入流中的非元音字符。
用这种方法还可以解决scanf的输入中不能有空格的问题。只要用
scanf("%[^\n]",str); 就可以了。很神奇吧。
【注意】
[]内的字符串可以是1或更多字符组成。空字符集(%[])是违反规定的,可导致不可预知的结果。%[^]也是违反规定的。
**指定域宽**
我们可以在scanf函数的转换说明符中指定域宽来从输入流中读取特定数目的字符。
【例】
scanf(“%2d%d”, &x, &y) ;
程序从输入流中读取一系列连续的数字,然后,将其前两位数字处理为一个两位的整数,将剩余的数字处理成另外一个整数。
**赋值抑制字符**
即*。赋值抑制字符使得scanf函数从输入流中读取任意类型的数据,并将其丢弃,而不是将其赋值给一个变量。如果你想忽略掉某个输入,使用在% 后使用* 。
%*[^=] 前面带 * 号表示不保存变量。跳过符合条件的字符串。
char s[]="notepad=1.0.0.1001";
char szfilename [32] = "" ;
int i = **sscanf( s, "%*[^=]", szfilename )**;
// szfilename=NULL,因为没保存
int i =**sscanf( s, "%*[^=]=%s", szfilename )**;
// szfilename=1.0.0.1001
所有对%s起作用的控制,都可以用于%[],比如"%*[^\n]%*c"就表示跳过一行,"%-20[^\n]"就表示读取\n前20个字符。
把扫描集、赋值抑制符和域宽等综合使用,可实现简单的正则表达式那样的分析字符串的功能。
scanf的返回值是读入数据的个数;
比如scanf("%d%d",&a,&b);读入一个返回1,读入2个返回2,读入0个返回0;读入错误返回EOF即-1
顺便提一句,**你应该非常小心的使用scanf 因为它可能会是你的输入缓冲溢出!通常你应该使用fgets 和sscanf 而不是仅仅使用scanf,使用fgets 来读取一行**,然后用sscanf 来解析这一行,就像上面演示的一样。
数据类型对应字节数
程序运行平台
不同的平台上对不同数据类型分配的字节数是不同的。
个人对平台的理解是CPU+OS+Compiler,是因为:
1、64位机器也可以装32位系统(x64装XP);
2、32位机器上可以有16/32位的编译器(XP上有tc是16位的,其他常见的是32位的);
3、即使是32位的编译器也可以弄出64位的integer来(int64)。
以上这些是基于常见的wintel平台,加上我们可能很少机会接触的其它平台(其它的CPU和OS),所以个人认为所谓平台的概念是三者的组合。
虽然三者的长度可以不一样,但显然相互配合(即长度相等,32位的CPU+32位的OS+32位的Compiler)发挥的能量最大。
理论上来讲 我觉得数据类型的字节数应该是由CPU决定的,但是实际上主要由编译器决定(占多少位由编译器在编译期间说了算)。
常用数据类型对应字节数可用如sizeof(char),sizeof(char*)等得出
32位编译器:
char :1个字节
char*(即指针变量): 4个字节(32位的寻址空间是2^32, 即32个bit,也就是4个字节。同理64位编译器)
short int : 2个字节
int: 4个字节
unsigned int : 4个字节
float: 4个字节
double: 8个字节
long: 4个字节
long long: 8个字节
unsigned long: 4个字节
64位编译器:
char :1个字节
char*(即指针变量): 8个字节
short int : 2个字节
int: 4个字节
unsigned int : 4个字节
float: 4个字节
double: 8个字节
long: 8个字节
long long: 8个字节
unsigned long: 8个字节
';
C之奇淫技巧——宏的妙用
最后更新于:2022-04-01 20:30:27
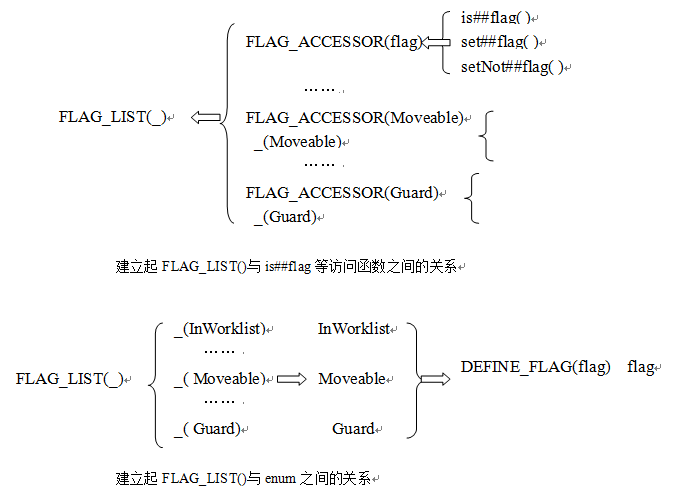
**一、宏列表**
当遇到这样的问题的时候:
有一个标记变量,其中的每个位代表相应的含义。我们需要提供一组函数来访问设置这些位,但是对于每个标记位的操作函数都是相似的。若有32个位,难道要搞32套相似的操作函数么?
你也许会说,用一套操作函数,根据传入的参数来判断对哪个位操作。这样固然可行,但是
①不够直观。例如访问Movable标记位,对于用户来说,is Movable()是很自然的方式,而我们只能提供这样的接口isFlag(Movable)
②扩展性差。若以后增加删改标记位,则需要更改isFlag等函数的代码。
我们想有这样的设计:
在头文件的宏定义中增删标记位的宏,我们为每个标记位设计的操作函数名就自动更改,增加的标记位也自动增加一套操作函数,删除的标记位也自动减去一套操作函数。
这样的设计就太爽了!
**但如何实现呢?**
首先,每个标记位的宏名一变,我们的操作函数名也要相应改变,这时我们可以想到用带参宏,并用宏的##符,把两个字符串合在一起。(使它们能被宏替换掉)
**#define FLAG_ACCESSOR(flag) \**
**bool is##flag() const {\**
** return hasFlags(1 << flag);\**
**}\**
**void set##flag() {\**
** JS_ASSERT(!hasFlags(1 << flag));\**
** setFlags(1 << flag);\**
**}\**
**void setNot##flag() {\**
** JS_ASSERT(hasFlags(1 << flag));\**
** removeFlags(1 << flag);\**
**}**
[这一步一般人都能想到的。]
这样,FLAG_ACCESSOR(Movable)就可得到操作Movable标记位的三个函数:is Movable(),set Movable(),setNot Movable()
但是,难道有多少个标记位,我们就要写多少个FLAG_ACCESSOR(flag)么?
如何用一个式子来扩展成多个种的FLAG_ACCESSOR(flag),**提取共性**,由于这多个FLAG_ACCESSOR(flag),flag是不同的,宏函数名是相同的。故用宏列表:
**#define FLAG_LIST(_) \**
** _(InWorklist) \**
** _(EmittedAtUses) \**
** _(LoopInvariant) \**
** _(Commutative) \**
** _(Movable) \**
** _(Lowered) \**
** _(Guard)**
这样一个式子:FLAG_LIST(FLAG_ACCESSOR)就搞定了。
但是,还有一个问题,我们还没有定义InWorklist、EmittedAtUses、LoopInvariant等,需要再用宏来定义这些标记位的名字。
例如:
**#define InWorklist 1**
**#define EmittedAtUses 2**
**……**
这样以来,若以后我们增改标记位的名字 就需要修改两处地方了:宏列表、标记名的宏定义。
**我们想要的最好的设计是,只改变一处 处处跟着一起改变。**
[yang]若是有新的标记位加入我们只在#define FLAG_LIST(_) 中添加一项就好了。例如,_(Visited) 自动添加#define Visited 8。
自动添加一项宏定义难以实现,那我们考虑有没有替代方案,观察发现此宏定义都是定义的数字,而枚举也有同样的功能。
这样,我们把这些展开的位标记名放在enum枚举中,让其自动赋上1,2,3……等数值,而不必用宏定义一个一个地定义。
现在问题变为:如何使我们在#defineFLAG_LIST(_) 中添加一项,enum枚举中就自动添加相应的一项?
我们只有把FLAG_LIST(_)放入enum枚举中,这样才能一增俱增。
若宏列表:
**#define FLAG_LIST(_) \**
** _(InWorklist) \**
** _(EmittedAtUses) \**
**_(LoopInvariant) **
**能再变为:**
**InWorklist**
**EmittedAtUses**
**LoopInvariant**
就好了。
这样,我们在#defineFLAG_LIST(_) 中添加一项_(Visited)。则enum中自动添加Visited。
也就是_(InWorklist)如何展开成InWorklist。这个很简单:#define DEFINE_FLAG(flag)flag,
**其具体实现方式如下:**
**#define FLAG_LIST(_) \**
** _(InWorklist) \**
** _(EmittedAtUses) \**
** _(LoopInvariant) \**
** _(Commutative) \**
** _(Movable) \**
** _(Lowered) \**
** _(Guard)**
它定义了一个FLAG_LIST宏,这个宏有一个参数称之为 _ ,这个参数本身是一个宏,它能够调用列表中的每个参数。举一个实际使用的例子可能更能直观地说明问题。假设我们定义了一个宏DEFINE_FLAG,如:
**#define DEFINE_FLAG(flag) flag, //注意flag后有逗号**
** enum Flag {**
** None = 0,**
** FLAG_LIST(DEFINE_FLAG)**
** Total**
** };**
**#undef DEFINE_FLAG**
对FLAG_LIST(DEFINE_FLAG)做扩展能够得到如下代码:
**enum Flag {**
** None = 0,**
** DEFINE_FLAG(InWorklist)**
** DEFINE_FLAG(EmittedAtUses)**
** DEFINE_FLAG(LoopInvariant)**
** DEFINE_FLAG(Commutative)**
** DEFINE_FLAG(Movable)**
** DEFINE_FLAG(Lowered)**
** DEFINE_FLAG(Guard)**
** Total**
** };**
接着,对每个参数都扩展DEFINE_FLAG宏,这样我们就得到了enum如下:
**enum Flag {**
** None = 0,**
** InWorklist,**
** EmittedAtUses,**
** LoopInvariant,**
** Commutative,**
** Movable,**
** Lowered,**
** Guard,**
** Total**
** };**
接着,我们可能要定义一些访问函数,这样才能更好的使用flag列表:
**#define FLAG_ACCESSOR(flag) \**
**bool is##flag() const {\**
** return hasFlags(1 << flag);\**
**}\**
**void set##flag() {\**
** JS_ASSERT(!hasFlags(1 << flag));\**
** setFlags(1 << flag);\**
**}\**
**void setNot##flag() {\**
** JS_ASSERT(hasFlags(1 << flag));\**
** removeFlags(1 << flag);\**
**}**
****
**FLAG_LIST(FLAG_ACCESSOR)**
**#undef FLAG_ACCESSOR**
(这样,我们只在宏列表一处更改增删位操作即可。)
【总结:yang】
一步步的展示其过程是非常有启发性的,如果对它的使用还有不解,可以花一些时间在gcc –E上。
【宏列表的优点有:可以把一个式子扩展成多个式子,且很容易扩展,只要再增加列表项即可。】
二、**指定的初始化**
很多人都知道像这样来静态地初始化数组:
int fibs[] = {1,2,3,4,5} ;
C99标准实际上支持一种更为直观简单的方式来初始化各种不同的集合类数据(如:结构体,联合体和数组)。
**数组的初始化**
我们可以**指定数组的元素来进行初始化**。这非常有用,**特别是当我们需要根据一组#define来保持某种映射关系的同步更新时**。来看看一组错误码的定义,如:
/* Entries may not correspond to actualnumbers. Some entries omitted. */
#define EINVAL 1
#define ENOMEM 2
#define EFAULT 3
/* ... */
#define E2BIG 7
#define EBUSY 8
/* ... */
#define ECHILD 12
/* ... */
现在,假设我们想为每个错误码提供一个错误描述的字符串。为了确保数组保持了最新的定义,无论头文件做了任何修改或增补,我们都可以用这个数组指定的语法。
char *err_strings[] = {
err_strings[0] = "Success",
err_strings [EINVAL] = "Invalid argument",
err_strings[ENOMEM] = "Not enough memory",
err_strings[EFAULT] = "Bad address",
/* ... */
err_strings[E2BIG ] = "Argument list too long",
err_strings[EBUSY ] = "Device or resource busy",
/* ... */
err_strings[ECHILD] = "No child processes"
/* ... */
};
**这样就可以静态分配足够的空间,且保证最大的索引是合法的,同时将特殊的索引初始化为指定的值,并将剩下的索引初始化为0。**
(注意:指定元素前面要有数组名,否则报错)
**结构体与联合体**
**用结构体与联合体的字段名称来初始化数据**是非常有用的。假设我们定义:
struct point {
int x;
int y;
int z;
} ;
然后我们这样初始化structpoint:
struct point p = {.x = 1, .z = 3}; //x为1,y为0,z为3
当我们不想将所有字段都初始化为0时,这种作法可以很容易的在编译时就生成结构体,而不需要专门调用一个初始化函数。
对联合体来说,我们可以使用相同的办法,只是我们只用初始化一个字段。
**三、编译时断言**
这其实是使用C语言的宏来实现的非常有“创意”的一个功能。有些时候,特别是在进行内核编程时,在编译时就能够进行条件检查的断言,而不是在运行时进行,这非常有用。不幸的是,C99标准还不支持任何编译时的断言。
但是,我们可以利用预处理来生成代码,这些代码只有在某些条件成立时才会通过编译(最好是那种不做实际功能的命令)。**有各种各样不同的方式都可以做到这一点,通常都是建立一个大小为负的数组或结构体**。最常用的方式如下:
#define STATIC_ZERO_ASSERT(condition)(sizeof(struct { int:-!(condition); }) )
#define STATIC_NULL_ASSERT(condition)((void *)STATIC_ZERO_ASSERT(condition) )
// 上面是用两种不同的方式来实现这个效果的,我们任选其中一种方式即可
【原理】
#define STATIC_ASSERT(condition)((void)STATIC_ZERO_ASSERT(condition))
如果(condition)计算结果为一个非零值(即C中的真值),即! (condition)为零值,那么代码将能顺利地编译,并生成一个大小为零的结构体。如果(condition)结果为0(在C真为假),那么在试图生成一个负大小的结构体时,就会产生编译错误。
【例子】
它的使用非常简单,如果任何某假设条件能够静态地检查,那么它就可以在编译时断言。例如,在上面提到的标志列表中,标志集合的类型为uint32_t,所以,我们可以做以下断言:
STATIC_ASSERT(Total <= 32)
它扩展为:
(void)sizeof(struct { int:-!(Total <=32) })
现在,假设Total<=32。那么-!(Total <= 32)等于0,所以这行代码相当于:
(void)sizeof(struct { int: 0 })
这是一个合法的C代码。现在假设标志不止32个,那么-!(Total <= 32)等于-1,所以这时代码就相当于:
(void)sizeof(struct { int: -1 } )
因为位宽为负,所以可以确定,如果标志的数量超过了我们指派的空间,那么编译将会失败。
**四、在指针中隐藏数据**
(这个技术有点变态,大家看看就好)
编写 C 语言代码时,指针无处不在。我们可以稍微额外利用指针,在它们内部暗中存储一些额外信息。为实现这一技巧,我们利用了数据在内存中的自然对齐特性。
假设系统中整型数据和指针大小均为 4 字节。
则指针的数值(即其中包含的地址值),都是4的整数倍,也就是说其二进制数都是以 00 结尾。那么这 2 比特没有承载任何信息。所以就有人脑动大开,利用这两个比特存点信息,在使用指针之前用位操作的方式存储2bit信息到此指针,当要对指针进行解引用操作时,把其原先值提取出来。
~~~
void put_data(int *p, unsigned int data)
{
assert(data < 4);
*p |= data;
}
unsigned int get_data(unsigned int p)
{
return (p & 3);
}
void cleanse_pointer(int *p)
{
*p &= ~3;
}
int main(void)
{
unsigned int x = 701;
unsigned int p = (unsigned int) &x;
printf("Original ptr: %un", p);
//把3存储到指针中
put_data(&p, 3);
printf("ptr with data: %un", p);
printf("data stored in ptr: %un", get_data(p)); //获取指针中的数据3
cleanse_pointer(&p); //在解引用指针前,把隐藏的2bit数据抹掉,恢复其原值
printf("Cleansed ptr: %un", p);
printf("Dereferencing cleansed ptr: %un", *(int*)p);
return 0;
}
~~~
这也太变态了吧,连这2个bit都不放过,现在是21世纪了,我们还缺这点内存么?
不过,在实际中还真有应用:Linux 内核中红黑树的实现。
树结点定义:
struct rb_node {
unsigned long __rb_parent_color;
struct rb_node *rb_right;
struct rb_node *rb_left;
} __attribute__((aligned(sizeof(long))));
此处 unsigned long __rb_parent_color 存储了如下信息:
父节点的地址,结点的颜色
色彩的表示用 0 代表红色,1 代表黑色。
和前面的例子一样,该数据隐藏在父指针“无用的”比特位中。
父指针和色彩信息的获取:
/* in rbtree.h */
#define rb_parent(r) **((struct rb_node *)((r)->__rb_parent_color & ~3))**
/* in rbtree_augmented.h */
#define __rb_color(pc) **((pc) & 1)**
#define rb_color(rb) **__rb_color((rb)->__rb_parent_color)**
【参考】
http://blog.jobbole.com/16035/
';
C语言图形编程–俄罗斯方块制作(二)源代码
最后更新于:2022-04-01 20:30:25
所有源代码文件,此为本人2年前所作,设计上还有些缺陷。希望大家不吝指正。
**[设计详解点击这里](http://blog.csdn.net/yang_yulei/article/details/17651737)**
**
**
**下面是头文件head.h**
~~~
/************(C) COPYRIGHT 2013 yang_yulei ************
* File Name : head.h
* Author : yang_yulei
* Date First Issued : 12/18/2013
* Description :
*
*
*****************************************/
/* Define to prevent recursive inclusion -------------------------------------*/
#ifndef _HEAD_H_
#define _HEAD_H_
/* Includes ------------------------------------------------------------------*/
#include
#include
#include
#include
#include
/* Macro ---------------------------------------------------------------------*/
#define TRUE 1
#define FALSE 0
//GUI游戏界面相关的参数
#define GUI_WALL_SQUARE_WIDTH 10 //外围围墙小方格的宽度(单位:像素)
#define GUI_xWALL_SQUARE_NUM 30 //横向(x轴方向)围墙小方格的数量(必须是偶数)
#define GUI_yWALL_SQUARE_NUM 46 //纵向(y轴方向)围墙小方格的数量(必须是偶数)
#define GUI_WALL_WIDTH_PIX (GUI_WALL_SQUARE_WIDTH*GUI_xWALL_SQUARE_NUM)
#define GUI_WALL_HIGH_PIX (GUI_WALL_SQUARE_WIDTH*GUI_yWALL_SQUARE_NUM)
#define WINDOW_WIDTH 480 //窗口的宽度
#define WINDOW_HIGH GUI_WALL_HIGH_PIX //窗口高度
//俄罗斯方块相关的参数
//移动的方向
#define DIRECT_UP 3
#define DIRECT_DOWN 2
#define DIRECT_LEFT -1
#define DIRECT_RIGHT 1
//每一个小方块的大小(是围墙小方格宽度的2倍)
#define ROCK_SQUARE_WIDTH (2*GUI_WALL_SQUARE_WIDTH)
//横向能容纳小方格的数量
#define X_ROCK_SQUARE_NUM ((GUI_xWALL_SQUARE_NUM-2)/2)
//纵向能容纳小方格的数量
#define Y_ROCK_SQUARE_NUM ((GUI_yWALL_SQUARE_NUM-2)/2)
/* Exported types ------------------------------------------------------------*/
typedef int BOOL ; //布尔值类型
/*数据结构-线性表(结构体数组)*/
typedef struct ROCK
{
//用来表示方块的形状(每一个字节是8位,用每4位表示方块中的一行)
unsigned int rockShapeBits ;
int nextRockIndex ; //下一个方块,在数组中的下标
} RockType ;
//方块在图形窗口中的位置(即定位4*4大块的左上角坐标)
typedef struct LOCATE
{
int left ;
int top ;
} RockLocation_t ;
/* Function prototypes -------------------------------------------------------*/
//源文件play.c中
void PlayGame(void) ;
//源文件init.c中
int InitProcParameters(void) ;
//源文件GUI.c中
void DrawRock(int, const struct LOCATE *, BOOL) ;
void DrawGameGUI(void) ;
void UpdataScore(void) ;
void UpdataGrade(int) ;
#endif /* _HEAD_H_ */
/*************(C) COPYRIGHT 2013 yang_yulei *****END OF FILE**/
~~~
**下面是源文件main.cpp**
~~~
/************(C) COPYRIGHT 2013 yang_yulei ************
* File Name : main.cpp
* Author : yang_yulei
* Date First Issued : 1/16/2012
* Description : 开发环境 VC++ 6.0 含EasyX图形库(http://www.easyx.cn)
* 俄罗斯方块
*
*
****************************************
* History:
* 1/16/2012 : V0.1
* 12/18/2013 : V0.2
****************************************
*
*****************************************/
/* Includes ------------------------------------------------------------------*/
#include "head.h"
#include
#include
/* Typedef -------------------------------------------------------------------*/
/* Variables -----------------------------------------------------------------*/
//全局变量-游戏板的状态描述(即表示当前界面哪些位置有方块)
//0表示没有,1表示有(多加了两行和两列,形成一个围墙,便于判断方块是否能够移动)
char g_gameBoard[Y_ROCK_SQUARE_NUM+2][X_ROCK_SQUARE_NUM+2] = {0} ;
//统计分数
int g_score = 0 ;
//等级
int g_grade = 0 ;
int g_rockTypeNum = 0 ; //共有多少种俄罗斯方块
RockType rockArray[50] = {(0,0)} ;
/*****************************************
* Function Name : main
* Description : Main program
* Input : None
* Output : None
* Return : None
*****************************************/
int
main(void)
{
//画出游戏界面
initgraph(WINDOW_WIDTH, WINDOW_HIGH) ; //初始化图形窗口
cleardevice() ;
DrawGameGUI() ;
//使用 API 函数修改窗口名称
HWND hWnd = GetHWnd();
SetWindowText(hWnd, "俄罗斯方块");
//初始化参数
InitProcParameters() ;
//游戏过程
PlayGame() ;
closegraph() ;
return 0 ;
}
~~~
**下面是源文件init.cpp---游戏运行前 初始化的一些方法**
~~~
/************(C) COPYRIGHT 2013 yang_yulei ************
* File Name : init.cpp
* Author : yang_yulei
* Date First Issued : 12/18/2013
* Description :
*
****************************************
*
*****************************************/
/* Includes ------------------------------------------------------------------*/
#include "head.h"
/* Variables -----------------------------------------------------------------*/
extern char g_gameBoard[][X_ROCK_SQUARE_NUM+2] ;
extern int g_rockTypeNum ;
extern RockType rockArray[] ;
/* Function prototypes -------------------------------------------------------*/
static int ReadRockShape(void) ;
static unsigned int ShapeStr2uInt(char* const);
/*****************************************
* Function Name : InitProcParameters
* Description : 在正式开始运行游戏前,初始化一些参数:g_gameBoard
从配置文件中读取系统中俄罗斯方块的形状
* Be called : main
* Input : None
* Output : g_gameBoard rockArray
* Return : None
*****************************************/
//初始化程序参数
int
InitProcParameters(void)
{
int i ;
//初始化游戏板(把这个二维数组的四周置1,当作围墙,用于判断边界)
for (i = 0; i < X_ROCK_SQUARE_NUM+2; i++)
{
g_gameBoard[0][i] = 1 ;
g_gameBoard[Y_ROCK_SQUARE_NUM+1][i]= 1 ;
}
for (i = 0; i < Y_ROCK_SQUARE_NUM+2; i++)
{
g_gameBoard[i][0] = 1 ;
g_gameBoard[i][X_ROCK_SQUARE_NUM+1]= 1 ;
}
//从配置文件中读取游戏中所有方块的形状点阵
ReadRockShape() ;
return 0 ;
}
/*****************************************
* Function Name : ReadRockShape
* Description : 从配置文件中读取系统中俄罗斯方块的形状 把它记录在rockArray中
* Be called : InitProcParameters
* Input : rockshape.ini
* Output : rockArray
* Return : 成功返回0 失败返回1
*****************************************/
int
ReadRockShape(void)
{
FILE* fp ;
int i = 0 ;
int len = 0 ;
int rockArrayIdx = 0 ;
int shapeNumPerRock = 0 ; //一种方块的形态数目(用于计算方块的nextRockIndex)
char rdBuf[128] ;
char rockShapeBitsStr[128] = {0};
unsigned int shapeBits = 0 ;
g_rockTypeNum = 0 ;
//打开配置文件 从中读取方块的形状
fp = fopen(".\\rockshape.ini", "r") ;
if (fp == NULL)
{
perror("open file error!\n") ;
return 1 ;
}
while (fgets(rdBuf, 128, fp) != NULL)
{
len = strlen(rdBuf) ;
rdBuf[len-1] = '\0' ;
switch (rdBuf[0])
{
case '@': case '#':
strcat(rockShapeBitsStr, rdBuf) ;
break ;
case 0 : //一个方块读取结束
shapeBits = ShapeStr2uInt(rockShapeBitsStr) ;
rockShapeBitsStr[0] = 0 ;
shapeNumPerRock++ ;
rockArray[rockArrayIdx].rockShapeBits = shapeBits ;
rockArray[rockArrayIdx].nextRockIndex = rockArrayIdx + 1 ;
rockArrayIdx++ ;
g_rockTypeNum++ ; //记录方块数量的全局变量+1
break ;
case '-'://一种方块读取结束(更新其nextRockIndex值)
rockArray[rockArrayIdx-1].nextRockIndex = rockArrayIdx - shapeNumPerRock ;
shapeNumPerRock = 0 ;
break ;
default :
break ;
}
}//while()
return 0 ;
}
/*****************************************
* Function Name : ShapeStr2uInt
* Description : 把配置文件中的描述方块形状的字符串 转化为 unsigned int型
* Be called :
* Input : shapeStr 描述方块形状的字符串(从文件中读取的)
* Output : None
* Return : unsigned int型的方块形状点阵(用其低16位表示)
*****************************************/
unsigned int
ShapeStr2uInt(char* const shapeStr)
{
unsigned int shapeBitsRet = 0 ;
char* p = shapeStr ;
for (p += 15; p >= shapeStr; p--)
{
if (*p == '@')
{
shapeBitsRet |= ((unsigned int)1 << (&shapeStr[15]-p)) ;
}
}
return shapeBitsRet ;
}
~~~
**下面是源文件GUI.cpp---一些关于在界面上画出界面的一些方法**
~~~
/************(C) COPYRIGHT 2013 yang_yulei ************
* File Name : GUI.cpp
* Author : yang_yulei
* Date First Issued : 12/18/2013
* Description :
*
****************************************
*
*****************************************/
/* Includes ------------------------------------------------------------------*/
#include "head.h"
/* Variables -----------------------------------------------------------------*/
//预览区位置
RockLocation_t previewLocation = {GUI_WALL_SQUARE_WIDTH*GUI_xWALL_SQUARE_NUM+70, 50} ;
extern RockType rockArray[] ;
/*****************************************
* Function Name : DrawRock
* Description : 在游戏区画出编号为rockIndex的方块
* Be called : PlayGame()
* Input : rockIndex :
currentLocatePtr: 此方块的位置
displayed : 此方块是否显示
* Output : None
* Return : None
*****************************************/
void
DrawRock(int rockIndex, const struct LOCATE * currentLocatePtr, BOOL displayed)
{
int i ;
int mask ;
int rockX ; //俄罗斯方块的4*4模型的左上角点x轴的坐标
int rockY ; //俄罗斯方块的4*4模型的左上角点y轴的坐标
int spaceFlag ; //占位标记(用于g_gameBoard,1表示某处有方块 0表示此处无方块)
int color ; //画出的方块的颜色
//若此方块是用于显示的,则设置其颜色为白色,其占位标记设为1
//否则设置其颜色为黑色(背景色),占位标记设为0
displayed ? (color = WHITE,spaceFlag = 1)
: (color = BLACK,spaceFlag = 0) ;
setcolor(color) ; //设置画笔颜色
setlinestyle(PS_SOLID, NULL, 2) ; //设置线形为1像素的实线
rockX = currentLocatePtr->left ;
rockY = currentLocatePtr->top ;
//逐位扫描由unsigned int的低2字节
//16个位组成的俄罗斯方块形状点阵(其代表4*4的方块形状)
mask = (unsigned int)1 << 15 ;
for (i=1; i<=16; i++)
{
//与掩码相与为1的 即为方块上的点
if ((rockArray[rockIndex].rockShapeBits & mask) != 0)
{
//在屏幕上画出此方块
rectangle(rockX+2,
rockY+2,
rockX+ROCK_SQUARE_WIDTH-2,
rockY+ROCK_SQUARE_WIDTH-2) ;
}
//每4次 换行 转到下一行继续画
i%4 == 0 ? (rockY += ROCK_SQUARE_WIDTH, rockX = currentLocatePtr->left)
: rockX += ROCK_SQUARE_WIDTH ;
mask >>= 1 ;
}
}
/*****************************************
* Function Name : DrawGameGUI
* Description : 画出游戏界面
* Be called : main()
* Input : None
* Output : None
* Return : None
*****************************************/
void
DrawGameGUI(void)
{
int i = 0 ;
int wallHigh = GUI_yWALL_SQUARE_NUM * GUI_WALL_SQUARE_WIDTH ;//围墙的高度(像素)
setcolor(RED) ; //设置围墙的颜色
setlinestyle(PS_SOLID, NULL, 0) ; //设置围墙方格的线形(1像素的实线)
//画出围墙(画矩形是 先确定左上顶点的坐标,再确定右下顶点坐标)
//先画出上下墙
for (i = GUI_WALL_SQUARE_WIDTH;
i <= GUI_WALL_WIDTH_PIX;
i += GUI_WALL_SQUARE_WIDTH)
{
rectangle(i-GUI_WALL_SQUARE_WIDTH,
0,
i,
GUI_WALL_SQUARE_WIDTH) ; //上墙
rectangle(i-GUI_WALL_SQUARE_WIDTH,
wallHigh-GUI_WALL_SQUARE_WIDTH,
i,
wallHigh) ; //下墙
}
//再画出左右墙
for (i = 2*GUI_WALL_SQUARE_WIDTH;
i <= wallHigh-GUI_WALL_SQUARE_WIDTH;
i += GUI_WALL_SQUARE_WIDTH)
{
rectangle(0,
i-GUI_WALL_SQUARE_WIDTH,
GUI_WALL_SQUARE_WIDTH,
i) ; //左墙
rectangle(GUI_WALL_WIDTH_PIX-GUI_WALL_SQUARE_WIDTH,
i-GUI_WALL_SQUARE_WIDTH,
GUI_WALL_WIDTH_PIX,
i) ; //右墙
}
//画分隔线
setcolor(WHITE) ; //设置画笔颜色
setlinestyle(PS_DASH, NULL, 2) ; //设置线形为2像素的虚线
line(GUI_WALL_WIDTH_PIX+20,0,GUI_WALL_WIDTH_PIX+20,wallHigh) ; //在偏移右围墙的20处画线
//画右边统计分数及版权信息栏
//先设置字体
LOGFONT f ; //定义字体属性结构体
getfont(&f) ; //获得当前字体
f.lfHeight = 18 ; //设置字体高度为 38(包含行距)
strcpy(f.lfFaceName, "黑体") ; //设置字体为“黑体”
f.lfQuality = ANTIALIASED_QUALITY ; //设置输出效果为抗锯齿
setfont(&f) ; //设置字体样式
//1,显示预览
outtextxy(GUI_WALL_WIDTH_PIX+80 , 20 , "预览") ;
//2,显示等级栏
outtextxy(GUI_WALL_WIDTH_PIX+80 , 140 , "等级") ;
//3,显示得分栏
outtextxy(GUI_WALL_WIDTH_PIX+80 , 190 , "得分") ;
//4,显示操作说明
outtextxy(GUI_WALL_WIDTH_PIX+65 , 255 , "操作说明") ;
getfont(&f) ;
strcpy(f.lfFaceName, "宋体") ;
f.lfHeight = 15 ;
setfont(&f) ;
outtextxy(GUI_WALL_WIDTH_PIX+45 , 290 , "w.a.s.d控制方向") ;
outtextxy(GUI_WALL_WIDTH_PIX+45 , 313 , "回车键 暂停") ;
outtextxy(GUI_WALL_WIDTH_PIX+45 , 336 , "空格键 快速下落") ;
//5.版权信息
line(GUI_WALL_WIDTH_PIX+20 , wallHigh-65 , WINDOW_WIDTH , wallHigh-65) ;
outtextxy(GUI_WALL_WIDTH_PIX+40 , wallHigh-50 , " 杨溢之 作品") ;
outtextxy(GUI_WALL_WIDTH_PIX+40 , wallHigh-30 , " QQ:702080167") ;
//显示等级,得分信息
setcolor(RED) ;
outtextxy(GUI_WALL_WIDTH_PIX+90 , 163 , "1") ;
outtextxy(GUI_WALL_WIDTH_PIX+90 , 223 , "0") ;
}
/*****************************************
* Function Name : UpdataScore
* Description : 增加一次得分,并把游戏界面的得分区显示 更新
* Be called : ProcessFullRow()
* Input : None
* Output : None
* Return : None
*****************************************/
void
UpdataScore(void)
{
char scoreStr[5] ; //用字符串的形式存储得分
extern int g_score ;
extern int g_grade ;
//分数的增长的单位是10
g_score += 10 ;
//得分是100的倍数,则等级加1 (等级在5级以上的就 保持不变)
if (g_score == (g_score/100)*100 && g_grade < 5)
UpdataGrade(++g_grade) ;
//删除原先信息
setfillstyle(BLACK) ;
bar(GUI_WALL_WIDTH_PIX+90,220,GUI_WALL_WIDTH_PIX+99,229) ;
//显示信息
setcolor(RED) ;
sprintf(scoreStr , "%d" , g_score) ;
outtextxy(GUI_WALL_WIDTH_PIX+90 , 223 , scoreStr) ;
}
/*****************************************
* Function Name : UpdataGrade
* Description : 增加一次等级,并把游戏界面的等级区显示 更新
* Be called :
* Input : grade :新的等级值
* Output : None
* Return : None
*****************************************/
void
UpdataGrade(int grade)
{
char gradeStr[5] ;
//删除原先信息
setfillstyle(BLACK) ;
bar(GUI_WALL_WIDTH_PIX+90,160,GUI_WALL_WIDTH_PIX+99,169) ;
//显示信息
setcolor(RED) ;
sprintf(gradeStr , "%d" , grade) ;
outtextxy(GUI_WALL_WIDTH_PIX+90 , 163 , gradeStr) ;
}
~~~
**下面是源文件play.cpp---控制游戏的重要方法**
~~~
/************(C) COPYRIGHT 2013 yang_yulei ************
* File Name : play.cpp
* Author : yang_yulei
* Date First Issued : 12/18/2013
* Description :
*
****************************************
*
*****************************************/
/* Includes ------------------------------------------------------------------*/
#include "head.h"
/* Variables -----------------------------------------------------------------*/
extern char g_gameBoard[][X_ROCK_SQUARE_NUM+2] ;
extern int g_rockTypeNum ;
extern RockType rockArray[] ;
/* Function prototypes -------------------------------------------------------*/
static BOOL MoveAble(int, const struct LOCATE *, int) ;
static void SetOccupyFlag(int, const struct LOCATE *) ;
static void ProcessFullRow(void) ;
static BOOL isGameOver() ;
static void ProccessUserHit(int, int*, struct LOCATE*) ;
static void FastFall(int, struct LOCATE *, struct LOCATE *) ;
static void DelFullRow(int f_row) ;
/*****************************************
* Function Name : PlayGame
* Description : 此程序的主要设计逻辑
* Be called : main
* Input : None
* Output : None
* Return : None
*****************************************/
void
PlayGame(void)
{
int userHitChar ; //用户敲击键盘的字符
int currentRockIndex ; //当前方块在rockArray数组中下标
int nextRockIndex ; //准备的下个方块的下标
BOOL moveAbled = FALSE ;//记录方块能否落下
DWORD oldtime = 0;
extern int g_grade ;
//当前方块位置
RockLocation_t currentRockLocation ;
//初始方块位置(由当中开始下落)
RockLocation_t initRockLocation = {(GUI_xWALL_SQUARE_NUM/2-4)*GUI_WALL_SQUARE_WIDTH,
GUI_WALL_SQUARE_WIDTH};
//预览区位置
extern RockLocation_t previewLocation ;
//为第一次下落,初始化参数
//随机选择当前的俄罗斯方块形状 和下一个俄罗斯方块形状
srand(time(NULL)) ;
currentRockIndex = rand()%g_rockTypeNum ;
nextRockIndex = rand()%g_rockTypeNum ;
currentRockLocation.left = initRockLocation.left ;
currentRockLocation.top = initRockLocation.top ;
while(1)
{
DrawRock(currentRockIndex, ¤tRockLocation, TRUE) ;
FlushBatchDraw(); //用批绘图功能,可以消除闪烁
//判断能否下落
moveAbled = MoveAble(currentRockIndex, ¤tRockLocation, DIRECT_DOWN) ;
//如果不能下落则生成新的方块
if (!moveAbled)
{
//设置占位符(此时方块已落定)
SetOccupyFlag(currentRockIndex, ¤tRockLocation) ;
//擦除预览
DrawRock( nextRockIndex, &previewLocation, FALSE) ;
//生成新的方块
currentRockIndex = nextRockIndex ;
nextRockIndex = rand()%g_rockTypeNum ;
currentRockLocation.left = initRockLocation.left ;
currentRockLocation.top = initRockLocation.top ;
}
//显示预览
DrawRock(nextRockIndex, &previewLocation, TRUE) ;
//如果超时(且能下落),自动下落一格
// 这个超时时间400-80*g_grade 是本人根据实验自己得出的
// 一个速度比较适中的一个公式(g_grade不会大于等于5)
DWORD newtime = GetTickCount();
if (newtime - oldtime >= (unsigned int)(400-80*g_grade) && moveAbled == TRUE)
{
oldtime = newtime ;
DrawRock(currentRockIndex, ¤tRockLocation, FALSE) ; //擦除原先位置
currentRockLocation.top += ROCK_SQUARE_WIDTH ; //下落一格
}
//根据当前游戏板的状况判断是否满行,并进行满行处理
ProcessFullRow() ;
//判断是否游戏结束
if (isGameOver())
{
MessageBox( NULL,"游戏结束", "GAME OVER", MB_OK ) ;
exit(0) ;
}
//测试键盘是否被敲击
if (kbhit())
{
userHitChar = getch() ;
ProccessUserHit(userHitChar, ¤tRockIndex, ¤tRockLocation) ;
}
Sleep(20) ; //降低CPU使用率
}//结束外层while(1)
}
/*****************************************
* Function Name : ProccessUserHit
* Description : 处理用户敲击键盘
* Be called : PlayGame()
* Input : userHitChar 用户敲击键盘的ASCII码
rockIndexPtr 当前俄罗斯方块在rockArray中的下标
rockLocationPtr 当前方块在游戏界面中的位置
* Output : rockIndexPtr 响应用户敲击后 新方块的下标
rockLocationPtr 响应用户敲击后 新方块的位置
* Return : None
*****************************************/
void
ProccessUserHit(int userHitChar, int* rockIndexPtr, struct LOCATE* rockLocationPtr)
{
switch (userHitChar)
{
case 'w' : case 'W' : //“上”键
//检查是否能改变方块形状
if (MoveAble(rockArray[*rockIndexPtr].nextRockIndex, rockLocationPtr, DIRECT_UP))
{
DrawRock(*rockIndexPtr, rockLocationPtr, FALSE) ;
*rockIndexPtr = rockArray[*rockIndexPtr].nextRockIndex ;
}
break ;
case 's' : case 'S' : //“下”键
DrawRock(*rockIndexPtr, rockLocationPtr, FALSE) ; //擦除原先位置
rockLocationPtr->top += ROCK_SQUARE_WIDTH ;
break ;
case 'a' : case 'A' : //“左”键
if (MoveAble(*rockIndexPtr, rockLocationPtr, DIRECT_LEFT))
{
DrawRock(*rockIndexPtr, rockLocationPtr, FALSE) ;
rockLocationPtr->left -= ROCK_SQUARE_WIDTH ;
}
break ;
case 'd' : case 'D' : //“右”键
if (MoveAble(*rockIndexPtr, rockLocationPtr, DIRECT_RIGHT))
{
DrawRock(*rockIndexPtr, rockLocationPtr, FALSE) ;
rockLocationPtr->left += ROCK_SQUARE_WIDTH ;
}
break ;
case ' ' : //空格(快速下落)
DrawRock(*rockIndexPtr, rockLocationPtr, FALSE) ;
FastFall(*rockIndexPtr, rockLocationPtr, rockLocationPtr) ;
break ;
case 13 : //回车键(暂停)
while(1)
{ userHitChar = getch() ;
if (userHitChar==13)
break ;
}
break ;
default :
break ;
}
}
/*****************************************
* Function Name : MoveAble
* Description : 判断编号为rockIndex 在位置currentLocatePtr的方块
能否向direction移动
* Be called :
* Input : None
* Output : None
* Return : TRUE 可以移动
FALSE 不可以移动
*****************************************/
BOOL
MoveAble(int rockIndex, const struct LOCATE* currentLocatePtr, int f_direction)
{
int i ;
int mask ;
int rockX ;
int rockY ;
rockX = currentLocatePtr->left ;
rockY = currentLocatePtr->top ;
mask = (unsigned int)1 << 15 ;
for (i=1; i<=16; i++)
{
//与掩码相与为1的 即为方块上的点
if ((rockArray[rockIndex].rockShapeBits & mask) != 0)
{
//判断能否移动(即扫描即将移动的位置 是否与设置的围墙有重叠)
//若是向上(即翻滚变形)
if( f_direction == DIRECT_UP )
{
//因为此情况下传入的是下一个方块的形状,故我们直接判断此方块的位置是否已经被占
if (g_gameBoard[(rockY-GUI_WALL_SQUARE_WIDTH)/ROCK_SQUARE_WIDTH+1]
[(rockX-GUI_WALL_SQUARE_WIDTH)/ROCK_SQUARE_WIDTH+1] == 1)
return FALSE ;
}
//如果是向下方向移动
else if( f_direction == DIRECT_DOWN )
{
if (g_gameBoard[(rockY-GUI_WALL_SQUARE_WIDTH)/ROCK_SQUARE_WIDTH+2]
[(rockX-GUI_WALL_SQUARE_WIDTH)/ROCK_SQUARE_WIDTH+1] ==1)
return FALSE ;
}
else //如果是左右方向移动
{ //f_direction的DIRECT_LEFT为-1,DIRECT_RIGHT为1,故直接加f_direction即可判断。
if (g_gameBoard[(rockY-GUI_WALL_SQUARE_WIDTH)/ROCK_SQUARE_WIDTH+1]
[(rockX-GUI_WALL_SQUARE_WIDTH)/ROCK_SQUARE_WIDTH+1+f_direction] ==1)
return FALSE ;
}
}
//每4次 换行 转到下一行继续
i%4 == 0 ? (rockY += ROCK_SQUARE_WIDTH, rockX = currentLocatePtr->left)
: rockX += ROCK_SQUARE_WIDTH ;
mask >>= 1 ;
}
return TRUE ;
}
/*****************************************
* Function Name : SetOccupyFlag
* Description : 更新游戏板状态(把一些位置设置为已占用)
* Be called :
* Input : rockIndex 方块的下标(定位了方块的形状)
currentLocatePtr 方块的位置(用来设定已占用标识)
* Output : None
* Return : None
*****************************************/
void
SetOccupyFlag(int rockIndex, const struct LOCATE * currentLocatePtr)
{
int i ;
int mask ;
int rockX ;
int rockY ;
rockX = currentLocatePtr->left ;
rockY = currentLocatePtr->top ;
mask = (unsigned int)1 << 15 ;
for (i=1; i<=16; i++)
{
//与掩码相与为1的 即为方块上的点
if ((rockArray[rockIndex].rockShapeBits & mask) != 0)
{
g_gameBoard[(rockY-GUI_WALL_SQUARE_WIDTH)/ROCK_SQUARE_WIDTH+1]
[(rockX-GUI_WALL_SQUARE_WIDTH)/ROCK_SQUARE_WIDTH+1] = 1 ;
}
//每4次 换行 转到下一行继续画
i%4 == 0 ? (rockY += ROCK_SQUARE_WIDTH, rockX = currentLocatePtr->left)
: rockX += ROCK_SQUARE_WIDTH ;
mask >>= 1 ;
}
}
/*****************************************
* Function Name : ProcessFullRow
* Description : 检查是否有满行,若有,则删除满行(并更新得分信息)
* Be called :
* Input : g_gameBoard
* Output : None
* Return : None
*****************************************/
void
ProcessFullRow(void)
{
int i = 1 ;
int cnt = 0 ;
BOOL rowFulled = TRUE ;
int rowIdx = Y_ROCK_SQUARE_NUM ; //从最后一行开始往上检查
while (cnt != X_ROCK_SQUARE_NUM) //直到遇到是空行的为止
{
rowFulled = TRUE ;
cnt = 0 ;
//判断是否有满行 并消除满行
for (i = 1; i <= X_ROCK_SQUARE_NUM; i++)
{
if( g_gameBoard[rowIdx][i] == 0 )
{
rowFulled = FALSE ;
cnt++ ;
}
}
if (rowFulled) //有满行 (并更新得分信息)
{
DelFullRow(rowIdx) ;
//更新得分信息
UpdataScore() ;
rowIdx++ ;
}
rowIdx-- ;
}
}
/*****************************************
* Function Name : DelFullRow
* Description : 删除游戏板的第rowIdx行
* Be called :
* Input : g_gameBoard
rowIdx 要删除的行 在g_gameBoard中的下标
* Output : None
* Return : None
*****************************************/
void
DelFullRow(int rowIdx)
{
int cnt = 0 ;
int i ;
//把此行擦除
setcolor(BLACK) ;
for (i=1; i<=X_ROCK_SQUARE_NUM; i++)
{
rectangle(GUI_WALL_SQUARE_WIDTH+ROCK_SQUARE_WIDTH*i-ROCK_SQUARE_WIDTH+2,
GUI_WALL_SQUARE_WIDTH+ROCK_SQUARE_WIDTH*rowIdx-ROCK_SQUARE_WIDTH+2,
GUI_WALL_SQUARE_WIDTH+ROCK_SQUARE_WIDTH*i-2,
GUI_WALL_SQUARE_WIDTH+ROCK_SQUARE_WIDTH*rowIdx-2) ;
}
//把此行之上的游戏板方块全向下移动一个单位
while (cnt != X_ROCK_SQUARE_NUM) //直到遇到是空行的为止
{
cnt =0 ;
for (i=1; i<=X_ROCK_SQUARE_NUM; i++)
{
g_gameBoard[rowIdx][i] = g_gameBoard[rowIdx-1][i] ;
//擦除上面的一行
setcolor(BLACK) ;
rectangle( GUI_WALL_SQUARE_WIDTH+ROCK_SQUARE_WIDTH*i-ROCK_SQUARE_WIDTH+2,
GUI_WALL_SQUARE_WIDTH+ROCK_SQUARE_WIDTH*(rowIdx-1)-ROCK_SQUARE_WIDTH+2,
GUI_WALL_SQUARE_WIDTH+ROCK_SQUARE_WIDTH*i-2,
GUI_WALL_SQUARE_WIDTH+ROCK_SQUARE_WIDTH*(rowIdx-1)-2 ) ;
//显示下面的一行
if (g_gameBoard[rowIdx][i] ==1)
{
setcolor(WHITE) ;
rectangle( GUI_WALL_SQUARE_WIDTH+ROCK_SQUARE_WIDTH*i-ROCK_SQUARE_WIDTH+2,
GUI_WALL_SQUARE_WIDTH+ROCK_SQUARE_WIDTH*rowIdx-ROCK_SQUARE_WIDTH+2,
GUI_WALL_SQUARE_WIDTH+ROCK_SQUARE_WIDTH*i-2,
GUI_WALL_SQUARE_WIDTH+ROCK_SQUARE_WIDTH*rowIdx-2 ) ;
}
if (g_gameBoard[rowIdx][i] == 0)
cnt++ ; //统计一行是不是 都是空格
}//for
rowIdx-- ;
}
}
/*****************************************
* Function Name : FastFall
* Description : 让编号为rockIndex 且初始位置在currentLocatePtr的方块
快速下落到底部
* Be called :
* Input : rockIndex currentLocatePtr
* Output : endLocatePtr 下落后方块的位置
* Return : None
*****************************************/
void
FastFall
(int rockIndex,
struct LOCATE * currentLocatePtr,
struct LOCATE * endLocatePtr)
{
int i ;
int mask ; //掩码,用于判断方块的形状
int rockX ; //方块的坐标(4*4方格的左上角点的x轴坐标)
int rockY ; //方块的坐标(4*4方格的左上角点的y轴坐标)
while (currentLocatePtr->top <= GUI_WALL_SQUARE_WIDTH+Y_ROCK_SQUARE_NUM*ROCK_SQUARE_WIDTH)
{
rockX = currentLocatePtr->left ;
rockY = currentLocatePtr->top ;
mask = (unsigned int)1 << 15 ;
for (i=1; i<=16; i++)
{
//与掩码相与为1的 即为方块上的点
if ((rockArray[rockIndex].rockShapeBits & mask) != 0)
{
if(g_gameBoard[(rockY-GUI_WALL_SQUARE_WIDTH)/ROCK_SQUARE_WIDTH+1]
[(rockX-GUI_WALL_SQUARE_WIDTH)/ROCK_SQUARE_WIDTH+1] == 1) //遇到底部
{
endLocatePtr->top = currentLocatePtr->top-ROCK_SQUARE_WIDTH ;
return ;
}
}
//每4次 换行 转到下一行继续画
i%4 == 0 ? (rockY += ROCK_SQUARE_WIDTH, rockX = currentLocatePtr->left)
: rockX += ROCK_SQUARE_WIDTH ;
mask >>= 1 ;
}
currentLocatePtr->top += ROCK_SQUARE_WIDTH ;
}//while()
}
/*****************************************
* Function Name : isGameOver
* Description : 判断是否游戏结束
* Be called :
* Input : None
* Output : None
* Return : TRUE 游戏结束
FALSE 游戏继续
*****************************************/
BOOL
isGameOver()
{
int i ;
BOOL topLineHaveRock = FALSE ; //在界面的最高行有方块的标记
BOOL bottomLineHaveRock = FALSE ; //在界面的最低行有方块的标记
for (i=1; i<=X_ROCK_SQUARE_NUM; i++)
{
if( g_gameBoard[1][i] == 1 )
topLineHaveRock = TRUE ;
if( g_gameBoard[Y_ROCK_SQUARE_NUM][i] == 1 )
bottomLineHaveRock = TRUE ;
}
//若底层行和顶层行都有方块 则说明在所有行都有方块,游戏结束
if (topLineHaveRock && bottomLineHaveRock)
return TRUE ;
else
return FALSE ;
}
~~~
**下面是配置文件rockshape.ini**
~~~
@###
@###
@@##
####
@@@#
@###
####
####
@@##
#@##
#@##
####
##@#
@@@#
####
####
-----
#@##
#@##
@@##
####
@###
@@@#
####
####
@@##
@###
@###
####
@@@#
##@#
####
####
-----
@###
@@##
#@##
####
#@@#
@@##
####
####
-----
#@##
@@##
@###
####
@@##
#@@#
####
####
-----
#@##
@@@#
####
####
@###
@@##
@###
####
@@@#
#@##
####
####
#@##
@@##
#@##
####
-----
#@##
#@##
#@##
#@##
@@@@
####
####
####
-----
####
@@##
@@##
####
-----
~~~
';
C语言图形编程–俄罗斯方块制作(一)详解
最后更新于:2022-04-01 20:30:22
效果图
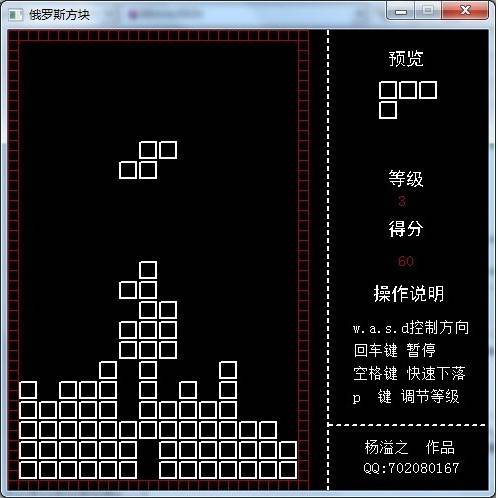
用C语言实现俄罗斯方块,需要先解决下面几个问题:
**1、如何用C语言绘制图形界面**
EasyX图形库(http://www.easyx.cn)即TC的图形库在VC下的移植。
包含库#include
先初始化图形窗口
initgraph(WINDOW_WIDTH, WINDOW_HIGH) ;WINDOW_WIDTH为窗口的宽带,WINDOW_HIGH为窗口的高度。
清空绘图设备
cleardevice();
设置画笔颜色
setcolor(RED) ;
设置线条风格
setlinestyle(PS_SOLID, NULL, 0);
画矩形
rectangle
还有画线、显示文字等函数,可以参照其帮助文档。
注意:由于我们用的是EasyX图形库,故源文件后缀要为.cpp,但其中内容都是C的语法。
**2、如何存储表示出俄罗斯方块的形状**
在计算机中如何让一串的01数字,代表俄罗斯方块?
一、我们可以用编号,不同的编号代表不同的俄罗斯方块,根据编号把不同方块的画法写在代码中,这样19种
方块就得有19种相应的代码来描绘。而且这样扩展性不好,若以后设计了新的方块,则需要更改大量源代码。
二、我们很自然的想到可用字模点阵的形式来表示,即设置一个4行4列的数组,元素置1即代表这个位置有小
方块,元素置0即代表这个位置无小方块,这个整个的4*4的数组组成俄罗斯方块的形状。
1000
1000
1100
0000

这个方法挺靠谱,但我们还可以优化一下:不用4*4的数组,而是用16个bit位来表示这个点阵。这样存储起来比较方便,故我们用unsigned int 的低16位来表示方块的点阵。
我们可以用掩码与表示俄罗斯方块的位进行操作,来识别并在屏幕上画出方块。
详情见GUI.cpp中的DrawRock函数。
~~~
//逐位扫描由unsigned int的低2字节
//16个位组成的俄罗斯方块形状点阵(其代表4*4的方块形状)
mask = (unsigned int)1 << 15 ;
for (i=1; i<=16; i++)
{
//与掩码相与为1的 即为方块上的点
if ((rockArray[rockIndex].rockShapeBits & mask) != 0)
{
//在屏幕上画出此方块
rectangle(rockX+2,
rockY+2,
rockX+ROCK_SQUARE_WIDTH-2,
rockY+ROCK_SQUARE_WIDTH-2) ;
}
//每4次 换行 转到下一行继续画
i%4 == 0 ? (rockY += ROCK_SQUARE_WIDTH, rockX = currentLocatePtr->left)
: rockX += ROCK_SQUARE_WIDTH ;
mask >>= 1 ;
}
~~~
我们把俄罗斯方块点阵的数位存在rockArray中,我们可以事先把这19种方块的字模点阵自己转化成十六进制,然后在rockArray数组的初始化时赋值进去。
但这样做未免有点太费力,且扩展性也不太好,若以后设计的新方块种类加入,要改变数组rockArray中的值。
我们可以考虑把所有俄罗斯方块的点阵**存储在配置文件中**,在程序初始化时读取文件,把这些点阵转换成unsigned int的变量存储在rockArray中。
这样,以后我们增添新的方块形状只需要在配置文件中增加新的点阵即可。
@###
@###
@@##
#### (为使得看起来更醒目,我们用@表示1,用#表示0)
**3、如何让图形动起来**
若没有按键的情况下,方块是自动下落的。
如何实现自动下落?在某位置处用函数DrawRock在屏幕上画出俄罗斯方块,然后再擦除掉(即用背景色在原位置处重绘一次方块),最后在下落的下一个位置处用函数DrawRock在屏幕上画出俄罗斯方块,如此循环,中间用计时器间隔一段时间以控制下落的速度。
同理,按下屏幕的左右键也是如此,只是在按下键盘时把方块的位置重新计算了。
那么按下上方向键时,如何让方块翻转呢?
我们在配置文件中就把方块的顺时针翻转形态放在了一起:
@###
@###
@@##
####
@@@#
@###
####
####
@@##
#@##
#@##
####
##@#
@@@#
####
####
我们每按一次上方向键改变一次方块的形状即可。若一直按上键,形状应该是循环地翻滚。
我们想到了循环链表的数据结构可实现这个效果。
可是我们若把这些一种类的方块的各种形态串成循环链表形式,那么每次重新生成方块时我们就难以随机地生成方块了。
故还是得用数组来存储,但又要有循环链表的功能,于是我们想到了**静态循环链表**。
我们用结构体来作为一个方块在rockArray中的元素
typedef struct ROCK
{ //用来表示方块的形状(每一个字节是8位,用每4位表示方块中的一行)
unsigned int rockShapeBits ;
int nextRockIndex ; //下一个方块,在数组中的下标
} RockType ;
这样,当我们按下上方向键时,把传入函数DrawRock中的rockIndex变为当前方块结构体中的nextRockIndex即可。
详情见play.cpp中的ProccessUserHit函数。
**4、如何判断方块什么时候停止什么时候满行得分**
方块一直下落,最终是要停下来的,我们要设置一个边界来约束方块的移动范围。我们把当前游戏界面划分成以俄罗斯方块中的小方格为单位的格子,用一个二维数组g_gameBoard来表示这些小方格的状态,1表示此位置有方块,0表示此位置为空。
我们按照界面的大小和方格的大小来计算此二维数组时,再多设置一圈“围墙”,即多加两行两列,并把它们的值初始化为1。
当方块准备下落或是左右移动的时候,前提前检查其即将落下的位置是否为空,若不为空,则停止下落,并把当前俄罗斯方块占用的方格都设置为1。
详情见play.cpp中的moveAbled函数。
判断满行:
从最后一行开始往上检查g_gameBoard,若有一行全为1,则说明此行满行,将此行擦出,把此行上面的所有行向下移动一个单位。
详情见play.cpp中的ProcessFullRow函数
**5、其他细节问题:**
如何快速下落
详情见play.cpp中的FastFall函数
如何暂停
详情见play.cpp中的ProccessUserHit函数
此游戏程序的主要逻辑在play.cpp中的PlayGame函数
[**源代码点击这里**](http://blog.csdn.net/yang_yulei/article/details/17651961)
';
关于C/C++中全局变量的初始化问题的深入思考
最后更新于:2022-04-01 20:30:20
**前言:**
前日,在一次C++课程上,刘老师在举例说明构造函数和析构函数的功能时,提到了全局变量初始化时的构造函数的行为。构造函数在main函数之前初始化全局变量。当然在C++下我是深信不疑的。但随后老师声称C语言下的全局变量也是如此,因为C没有构造和析构函数,所以我们无法看到这一过程,在C++下可以在构造和析构函数中向屏幕打印信息,进而可以观察全局变量的初始化和生存期。
这个观点无疑使我心头一震,作为C的痴迷者,长期以来在我头脑中的印象是,全局变量在编译期就完成初始化了。难道我的观念是错误的?!难道C真的也是在main函数之前,在程序运行初期才初始化?!
于是我翻看了《C语言参考手册》这本书上没有明确的答案,再翻看著名的K&R的《C程序设计语言》中只有括号里面的一句话“在概念上.......”也是含糊其辞。(现在想想这个问题可能和编译器有关,所以丹爷爷也没说明太多)
在网上查询了一下,关于这个问题,持什么观点的都有,没有一个权威的答案。
只能靠自己了,动手实验!
**先给出我的结论**:
C和C++中的一般全局变量(不包括类class)是在编译期确定的初始值,而不是在程序运行时,在main函数之前初始化的。
C++中的类的全局变量是在程序运行时,在main函数之前初始化的。
预热知识:
C或者C++语言,明面上的入口函数是main(argc,argv),或者tmain、wmain、WinMain等等。但实际上,是C Runtime的startup代码中的void mainCRTStartup(void)函数,调用了编程者写的main函数。这个函数定义在VisualC++安装目录的crt\src\目录下的某个.c文件中(视VC++的版本不同,存放的文件也不同)。它在执行一些初始化操作,如获取命令行参数、获取环境变量值、初始化全局变量、初始化io的所需各项准备之后,调用main(argc,argv)。main函数返回后,mainCRTStartup还需要调用全局变量的析构函数或者atexit()所登记的一些函数。往深里说,是在链接生成可执行文件时,告诉链接器这个可执行文件的entry就是mainCRTStartup。当然,我们也可以对编译器进行设置,使其不插入mainCRTStartup函数代码
以VC++6.0为例设置:Project->Settings->Link 在Category中选择Output,在Entry-point symbol中填上main 即可。
-------------------------
**实验一:**
1, C语言环境下:
**实验准备:**
~~~
int a ;
int main(void)
{
return a+3 ;
}
~~~
在编译器中设置入口函数为main(具体方法见上面)
这样,我们让编译器生成的程序,直接从main函数中进入,而不是先执行mainCRTStartup函数做一些准备工作。
**结果预测:**
这样,如果函数返回的是3,则说明此全局变量是在编译期就被初始化为0了,如果函数返回的是其它数字,则说明此全局变量是在程序运行时,main函数运行前进行的初始化。
**实验结果:**
进入控制台(运行cmd命令),运行编译后的程序(因为程序没有向屏幕输出结果,我们看不到任何现象),继续输入命令:echo %ERRORLEVEL% 则显示3,此即为函数的返回值。
(echo是显示其后的值,系统把前面运行的程序的返回值放在%ERRORLEVEL%中,故我们可以通过此方法获得主函数的返回值)
同理:对于结构体全局变量
~~~
struct A
{
int a ;
} sTest;
int main(void)
{
return sTest.a+3 ;
}
~~~
函数也返回3.
**实验结论:**
**在C语言中,全局变量是在编译期完成初始化的。**
(在本实验中我们没有使用I/O函数把结果打印出来,因为I/O函数的调用之前必须要初始化内存中的某堆空间,而这个工作是由main函数之前的mainCRTStartup函数来做的。而我们设置让编译器跳过这个函数,故会在运行时出错。)
**实验二:**
C++语言环境下
**实验准备:**
~~~
class A
{
public:
int a ;
A(){a=10;}
~A(){}
} ;
A cTest ;
int main(void)
{
return cTest.a ;
}
~~~
**结果预测:**
这样,如果函数返回的是0,则说明此全局变量是在编译期就被初始化为0了,如果函数返回的是其它数字,则说明此全局变量是在程序运行时,main函数运行前进行的初始化。
**实验结果:**
在编译器中设置入口函数为main,主函数返回一个其他值
在编译器中设置入口函数为默认,主函数返回值为10
**实验结论:**
**在C++中,类(class)的全局变量是在程序运行期,main函数开始之前,调用类的构造函数完成初始化的。**
同理:
把C中的代码放到C++下实验
~~~
int a ;
int main(void)
{
return a+3 ;
}
~~~
结果与C的结果相同。
说明:**在C++中一般全局变量的初始化(类除外),是在编译期完成的,而不是在运行期完成。(与C语言规则相同)**
mainCRTStartup函数不管一般全局变量的初始化,它管理类(class)的全局变量的初始化,调用类的析构函数。
编译器会在编译时,初始化一般全局变量为0.
**另:**具有全局生命期的局部静态变量的初始化,与局部变量相同都是在运行时,执行到该初始化语句完成初始化的,只是局部静态变量只初始化一次。
**后记:**
1、程序不是从主函数开始执行的,而是先要执行一些启动代码。(现在明白为什么要在在嵌入式软件编程时要在工程中添加类似于75x_init.s和75x_vect.s这两个汇编文件了吧)
2、你应该给主函数以返回值。实际上标准C只规定了两种形式的main函数:
int main( void ) 和 int main(int argc, char *argv[])
main返回0,告诉系统程序正常终止,返回非零值告诉系统程序异常关闭.
其作用:**我们可以利用程序的返回值,控制要不要执行下一个程序。**
例:程序名&&DOS命令
前面的程序正常执行后才执行后面的DOS命令。当然我们也可以用其它的逻辑符把程序和命令组织起来,来实现复杂的功能。
(UNIX中的shell命令也有类似功能)
';
玖(常用库函数)
最后更新于:2022-04-01 20:30:18
玖
***字符串处理的库函数***
**字符处理函数:**
int isdigit(int ch) ;//是否为数字,即ch是否是0-9中的字符
int isxdigit(int ch) ;//是否为十六进制数字,即ch是否是0-9 a-z A-Z 中的字符
int isalpha(int ch) ;//是否为字母
int isalnum(int ch) ;//是否为字母或数字
int islower(int ch) ;//是否为小写字母
int isupper(int ch) ;//是否为大写字母
int tolower(int ch) ;//转换为小写字母
int toupper(int ch) ;//转换为大写字母
**字符串转换函数:**
1,字符转换为数字:
(最好是符合要求的纯数字字符串,若数字与字母混搭,则待数字必须在前面)
double atof(char *str) ; //将字符串str转换为double型数字
int atoi (char *str) ; //将字符串str转换为int 型数字
long atol(char *str) ; //将字符串str转换为long int 型数字
2,数字转换为字符:
char * itoa (int digit, char *destStr, intradix) ; //将int型数字digit按radix进制转换成字符串destStr
char * ltoa (long digit, char *destStr, intradix) ; //同理将long型数字转换成字符串
char * ultoa (long digit, char *destStr,int radix) ; //同理将unsignedlong型数字转换成字符串
【以上库函数可以用于进制的转换】
类似函数还有:
double strtod(char *, char **) ;
long strtol(char *, char **, int) ;
unsigned long strtoul(char *, char **, int) ;
**★字符串操作函数:**
char * strcpy (char *s1, char *s2) ; //将字符串s2复制到数组s1中。
char * strncpy(char *s1,char *s2) ; //将字符串s2的最多n个字符复制到数组s1中
char * strcat (char *s1, char * s2) ; //将字符串s2连接在字符串s1尾部
char * strncat(char *s1, char *s2, size_tn) ; //将字符串s2中最多n个字符连接在s1之后
【注意:以上操作都要求目标字符数组有足够的存储空间】
**字符串比较函数:**
int strcmp(char *s1, char *s2 ) ;//比较字符串s1,s2.如果s1等于小于或大于s2,分别返回0,负值,正值
int stricmp(char *s1, char *s2) ;//不区分大小写地比较两字符串
int strncmp(char *s1, char *s2, size_t n) ;//比较两字符串的至多n个字符
**字符串查找函数:**
char *strchr(char *str, int ch) ;//在字符串str中查找字符ch第一次出现的位置,如果找到了,就返回str中ch的指针,否则返回NULL
char *strrchr(char *str, int ch) ;//查找字符串str中字符ch的最后一次出现的位置(即:从后往前查找)
char *strstr(char *str1, char *str2) ;//查找字符串str1中第一次出现字符串str2的位置
char *strpbrk(char *str2, char *str2) ;//查找字符串str2中任意字符在字符串str1中首次出现的位置。
**其它函数:**
char *strrev(char * ) ; //字符串逆序函数
size_t strlen(char * str) ;//测字符串str的长度
**注意:**
strncpy( ) , strncat( ) , strncmp( ) ,这些函数只能对两个不同的字符串操作,不能对同一字符串的不同部分操作,如果需要这么做,可以使用内存函数。
若把目标字符串初始置空,strncat()可以完成很多功能的操作。可以替代strncpy( )的功能,
还可以提取子串 等。
***内存函数***
【内存函数直接对内存操作,不仅可以处理字符串,还可以处理任何类型的数组、结构等。】
在标准C中,这些函数被认为是字符串函数的一部分,是在头文件string.h中声明的。
void * memcpy(void *dest, const void *src, size_t n) ;
从src地址处复制n个字节到dest , 并返回地址dest的值
void * memmove(void *dest, const void *src, size_t n) ;
其功能与上个函数相同,区别在于:memmove函数在源内存区域和目标内存区域重叠的情况下也能正确执行操作。
void * memchr(const void *ptr, int val, size_t len) ;
在地址ptr后的前len个字符中搜索val值的第一次出现。如果找到val,它返回一个指向包含val值的第一个字符的指针,否则返回一个null字符。
(每个字符根据表达式(unsigned char)c == (unsigned char)val 比较)
void * memset(void * ptr, int val, size_tlen) ;
把val复制到从ptr开始的len个字符中,ptr所指定的字符被认为是unsignedchar 类型
int memcmp(const void * ptr1, const void * ptr2, size_t len) ;
把ptr1的前len个字符与ptr2的前len个字符进行比较。如果第一个字符串按字典顺序小于第二字字符串,memcmp就返回一个负值。
**【后记】我的C书单列表**
《全国计算机等级考试二级C语言》
《C语言大学教程》
《C和指针》
《C语言深度剖析》
《你必须知道的495个C语言问题》
《C专家编程》
《C陷阱与缺陷》(如果上面的书你仔细研读过的话,那么这本书没什么意义,不推荐)
《高质量C/C++编程指南》
《C语言参考手册》(当做字典用,初学者不推荐)
《C标准库》(不推荐)
';
捌(预处理、程序调试、编程风格)
最后更新于:2022-04-01 20:30:15
捌
***预处理***
C预处理器是一种简单的宏处理器。它在编译器读取源程序之前对C程序的源文本进行处理。预处理器一般从源文件中删除所有的预处理器命令行,并在源文件中执行这些预处理命令所指定的转换操作。
【宏只是进行简单的文本替换】
**续行:**
所有的源文件行(包括预处理器命令行)都可以在行末加个反斜杠( \ )进行续行。这个操作发生在对预处理器命令进行扫描之前。
【注意:续行符反斜杠之后不能有任何字符,尤其注意检查不能有空格等空白符。】
***普通宏定义:***
~~~
#define 命令有两种形式,取决于被定义的宏名后面是不是紧随一个左括号。若没有左括号,则为无参宏定义。
~~~
无参宏定义常用于:
1、在程序中引入名称常量。这样,可以在一个地方编写,然后通过名称在其它地方被引用,这样,以后修改这个数字就非常方便了。
2、改变外部定义的函数名或变量名。(有些外部函数的函数名过于简短或是与当前程序的命名风格不符,我们可以用宏定义一个新的函数名来代替它)
例:#define error_handler eh73
//我们用一个更具描述性的函数名error_handler来表示外部函数eh73
***带参数的宏:***
左括号必须紧随宏名之后,中间不能有空格。如果宏名和左括号之间被一个空格所分隔,则这个宏被定义为不接受任何参数,并且宏体从左括号开始。
**注意**:
1、为了保证宏展开的正确性,应该给每个宏参数加上括号,且给整个表达式也加上括号。
(多余的括号保证了复杂的实际参数不会被编译器错误的解释)
2、使用类似函数的宏,可能存在一些陷阱。我们在调用宏函数时,会习惯地加一个分号,而额外的分号可能引发错误。
例:#define SWAP(type, x, y) { type _temp=x; x=y; y=_temp; }
若 if( x > y) SWAP(int , x, y) ;
elsex = y ;
//这将产生错误,宏展开后有一个多余的分号,将导致else悬空。
**★为了避免这个问题,可以把宏函数体定义为一条do-while语句**,后者可以接受在末尾添加分号。
~~~
#define SWAP(type, x, y) \
do { type _temp=x; x=y; y=_temp; } while(0)
~~~
3、宏参数的副作用。(当宏参数含++、--操作符时一定要小心)
例:#define SQUARE(x) ((x)*(x))
若 b =SQUARE(a++) ; //则结果是未定义的,因为(a++)*(a++)的行为取决于编译器。
真正的函数调用不会出现这样的问题,真正的函数调用是先计算参数值,然后再调用函数。而宏函数,只是简单的文本替换。
【宏是与类型无关的,即**其可以用类型做参数**。故:宏有时可以完成无法用函数实现的任务】
例:#defineMY_MALLOC( n, type ) ((type*)malloc((n)*sizeof(type)))
**取消宏定义:**
~~~
# undef命令可以取消定义一个名称为宏:undef name
~~~
***条件编译***
条件编译指令允许预处理器根据一个经过计算所得出的条件,来选择不同的语句参加编译。
if 常量表达式
文本行组1
else
文本行组2
endif
常量表达式包括整数常量以及所有的整数算术、关系、位和逻辑操作符。
如果它的值不是0,则“文本行组1”则被编译器进行编译,而“文本行组2”则被丢弃。
**defined操作符**
defined 操作符只能在#if和#elif表达式中使用,而不能用于别处。
形式:definedname 或 defined(name)
~~~
#if defined( VAX ) 可等同于 #ifdef VAX
~~~
但defined的使用更加灵活一些:
例:#ifdefined(VAX) && !defined(UNIX) && debugging
***预定义的宏***
标准C的预处理器定义了一些宏,这些宏的名称都是以两个下划线字符开始和结束的。程序员不能取消这些预定义宏的定义或对它们进行重新定义。
几个常用的预定义宏:
__LINE__ 当前源程序行的行号,用十进制整数常量表示
__FILE__ 当前源文件的名称,用字符串常量表示
__DATA__ 编译时的日期,用“Mmm dd yyyy”形式的字符串常量表示
__TIME__ 编译时的时间,用“hh:mm:ss”形式的字符串常量表示。
***程序调试***
**一、使用断点和单步执行**
详情请参阅具体的IDE使用说明
**二、条件编译**
~~~
#ifdef DEBUG
printf(“File:%s line:%d, x=%d, y=%d”, __FILE__, __LINE__, x, y ) ;
~~~
endif
如果要编译它,只要使用#defineDEBUG 即可,如果要忽略它,注释掉即可。
C99引入了一个预定义标识符:__func__
这个标识符可以由调试工具使用,打印出外层函数的名称。
例:if(failed) printf(“Function %s failed \n”, __func__) ;
**三、使用断言**
断言就是声明某种东西应该为真。(预测某个值为多少,符合条件则继续,否则中止程序)
void assert( int express ) ;
当它被执行时,对表达式参数进行测试。
如果它的值为假(零),它就向标准错误打印一条诊断信息并中止程序。
否则它不打印任何东西,程序继续执行。
例:assert(value != NULL ) ;
//如果它接受了一个NULL参数,则打印类似:assertfailed :value != NULL.file.c line 273
【注意:**断言只是在测试阶段,防御性地测试某个变量值的方法**,不要再断言中写一些会对程序造成影响的表达式。因为在release版编译器会删除断言,若断言中的表达式对程序有影响,可能会产生错误!】
**删除断言**:
当程序被完整地测试完毕之后,在源文件的头文件assert.h被包含之前,增加定义:
~~~
#define NDEBUG
~~~
当NDEBUG被定以后,预处理器将会丢弃所有断言。
***编程风格:***
以下内容摘自《代码大全》
**变量命名**:
该名字要完全、准确地表述出该变量所代表的事物。
一个好名字通常表达的是“什么”(what),而不是“如何”(how)。
如果一个名字反映了计算机的某些方面而不是问题本身,那么它反映的就是“how”而非“what”了,
请避免选取这样的名字,而应该**在名字中反映问题本身**!
(一条员工数据:称作:inputRec或employeeData。inputRec是一个反映输入、记录 这些计算机术语的,不能反映问题特征)
当变量名的长度在10到16个字符时,调试程序所花的力气是最小的。
记住**把限定词加到名字最后**,变量名最重要的部分,即**为变量赋予主要含义的部分应当位于最前面**。
特例: Num的限定词的位置是约定俗成的。
Num放在变量的开始位置代表一个总数;例:numCustomers表示员工总数
Num放在变量名的结束位置代表一个序号;例:customerNum表示员工号
避免此问题的方法:
用Conut或**Total来代表总数,用Index来代表序号**。
例:customerCount员工总数 customerIndex 员工序号
命名的一致性可提高可读性,简化维护工作。
**如果你发现自己需要猜测某段代码的含义时,就该考虑为变量重新命名。**
***变量名中的对仗词***:
next/previous
source/destination
。。。。。
1、为状态变量命名
标记的名字中不应该含有flag。标记应该用枚举类型、具名常量。
dataReady recalaNeeded 都是好名字
2、为布尔变量命名
以下是几个推荐的布尔变量名(可在其前加上具体的描述名称)
done:用done表示某件事已经完成。(在事情完成之前把done设为false,在完成之后设为true)
error:用error表示有错误发生。(在错误发生之前把变量值设置为false,在错误已经发生时把它设置为true)
found:用found来表示某个值已经找到了。(在还没有找到该值的时候把它设为false,找到之后设为true)
success或ok 用来表明一项操作时候成功。
(不要在布尔变量的前面加上Is)
命名规则可以根据局部数据、类数据、全局数据的不同而有所差别。
**命名规则可强调相关变量之间的关系**。
**★命名规则的指导原则**:
区分**变量名和子程序名**:
变量名和对象名以小写字母开始,子程序名以大写字母开头。
区分**类和对象**:
1、通过对对象采用更明确的名字区分类型和变量
例:Widget employWidget ;
2、通过给变量加"a"前缀区分类型和变量
例:Widget aWidget ;
标识**全局变量**:
在全局变量名前加上"g_"前缀
标识**成员变量**:
在成员变量名前加上"m_"前缀,可明确表示该变量既不是局部变量,也不是全局变量。
标识**自定义类型**:
在自定义类型名前加上"t_"前缀,可明确表示一个名字是类型名,可避免类型名与变量名的冲突
标识**枚举类型**:
在枚举类型名前加"e_"前缀,同时为该类型的成员名增加特定类型的前缀。
例:Color_或Planet_
标识**只读参数**:
在其前加上 const前缀,可防止给只读变量赋值的错误。例:constMax
**变量名要包含以下三类信息**:
1、变量的内容(它代表什么)
2、数据的种类(具名变量、简单变量、用户自定义类型、类)
3、变量的作用域(局部的、类的、全局的)
**关于子程序**
**好的子程序名**:
给子程序命名的重点是尽可能含义清晰,即:子程序的长短要视该名字是否清晰易懂而定。
子程序的名字应当描述其所有输出结果以及副作用。
(例:一个子程序的作用是计算报表总额并打开一个输出文件。若把它命名为computeReportTotals()还不算完整。computeReportTotalsAndOpenOutputFile()很完整但是名字太长。解决方法是 你应该换一种方式编写程序,直截了当地解决问题而不产生副作用。[即:UNIX的哲学,让一个模块只干一件事!])
给子程序起名时要用动词加宾语的形式。例:PrintDocument()
在面向对象语言中,不必在过程名中加入对象的名字,因为对象本身就已经包含在调用语句中了。例:Document.Print() ;
【子程序的名字是它质量的指示器,如果名字糟糕且又不准确,那么它就反映不出程序是干什么的。糟糕的名字都意味着程序需要修改】
**正确地使用输入参数**:
1、对于在函数体中不变更的参数,用const关键字来限制。
2、如果你假定了传递给子程序的参数具有某种特征,那就要对这种假定进行说明。比注释还好的方法是在代码中使用断言(assertions)
[对参数接口的假定进行说明:
1、参数是仅用于输入的、要被修改的、还是仅用于输出的
2、表示数量的参数的单位(英寸,米等)
3、所能接受的数值范围
4、不该出现的特定数值
5、说明状态代码和错误值的含义]
如果你向很多不同的子程序传递数据,就请把这些子程序组成一个类,并把那些经常使用的数据用作类的内部数据。
如果你觉得把输入、修改、输出参数区分开很重要,那么就建立一种命名规则来对它们进行区分。
可在这些参数名之前加上i_m_ o_ 前缀。也可以用Input_Modify_ Output_ 来当前缀
把对子程序的调用和对状态值的判断清楚地分开。把对子程序的调用和状态值的判断写在一行代码中,增加了该条语句的密度,也相应增加了其复杂度。
应该这样:
~~~
ouputStatus = report.FormatOutput(formattedReport ) ;
if( outputStatus = Success ) then ...
~~~
**关于宏:**
通常认为,用宏来代替函数调用的做法具有风险,而且不易理解,因此,除非必要,否则应该避免使用这种技术。
用给子程序命名的方法给宏函数命名,以便在需要时可以用子程序来替换宏。
宏对于支持条件编译非常有用,但对于细心的程序员来说,除非万不得已,否则是不会用宏来代替子程序的。(可用内联函数来实现宏函数的效果)
节制使用inline子程序!
**其它**:
建议在真正需要用空语句时这样写:
NULL ;
而不是单用一个分号,这就好比汇编里面的空指令,这样做可以明显的区分真正必须的空语句和不小心多写的分号。
在多重循环中,如果有可能,应当将最长的循环放在最内层,最短的循环放在最外层,以减少CPU跨切循环的次数。
循环要尽可能的短,要使代码清晰,一目了然。
(如果你写的一个循环的代码超过一屏,那么会让读代码的人抓狂的。解决的办法有两个:
第一:重新设计这个循环。确认是否这些操作都必须放在这个循环里;
第二:将这些代码改写成一个子函数。循环中只调用这个子函数即可)
对于全局数据(全局变量、常量定义等)必须要加注释。
注释代码段时应注重“为何做(why)”,而不是“怎么做(how)”
对于函数的入口出口参数及函数的功能给出注释。
如果你的全局变量不用来多文件共享,那么就加上static,防止同一个载入模块的两个不同外部对象的命名冲突。
';
柒(文件、输入输出函数)
最后更新于:2022-04-01 20:30:13
柒
***流***
流是什么?形象的比喻——水流,**`文件`和`程序`之间连接一个管道**,水流就在之间形成了,自然也就出现了方向:可以流进,也可以流出。
便于理解,这么定义流: 流就是一个管道里面有流水,这个管道连接了文件和程序。
UNIX系统认为一切皆文件,所有的外部设备都被看做文件。
***文件***
***文本文件和二进制文件***
实质:在计算机底层只有0和1。
**何谓文件?文件就是一些相关信息位的集合。**
文本文件只不过是把其文件存储空间按字节分割,即:它以字节为解释信息的单位,每个字节中存储的是一个ASCII码的小整数。
二进制文件则是把文件存储空间当做内存一样,可在其中按数据类型定义并存储数据。
例:把数据123存储到文件中。
若是按文本的方式来存储则会占用3字节,每个字节中的内容是:0x31 0x32 0x33 (即:数字49,50,51)它们对应着ASCII字符’1’ ‘2’ ‘3’
若是按二进制方式来存储则会占用4字节,这4字节即一个int型数据123
**信息就是:位+上下文**
**在计算机内部只有位,是我们根据需要赋予了这些位不同的解释规则(即上下文),所以会呈现出不同的结果。**
****
**★文本文件**就是我们用ASCII码的规则编码,然后再用ASCII码的规则解释,这样信息就可以反映出我们的实际意愿。
**★二进制文件**就是我们用程序制定的自定义的一套规则编码(程序会设置这些位代表的含义,比如哪些位表示的是一个浮点数,哪些位表示的是一个整数等),最后我们用先前自定义的规则来解释这些位,同样可以得到正确的信息。【实际上是,我们把文件当做内存区一样,按C语言定义的数据类型规则,该占多少位就占多少位,对数据不用转换处理】
所以:**文本文件和二进制文件的区别就是它们编码解码的规则不同,文本文件是按ASCII码的规则来编码解码的,而二进制文件是按自定义规则来编码解码的。**
故,用二进制的方式也可以建造一个文本文件,[只要我们按照ASCII码来编码即可。]
***打开和关闭文件***
fopen(文件名,文件打开方式)
有以文本模式打开文件,和以二进制模式打开文件。(每种模式又有很多种打开方式)
实质:这两种模式没有任何区别!它们都是向系统申请一段磁盘空间用以存储待写的数据。
而如何存储 即如何编码,将会导致它们是成为文本文件还是二进制文件。
不要根据文件的后缀名来判断一个文件的类型,后缀名只是方便应用程序识别文件。.txt文件也可以以二进制的形式编码,我们也可以把用ASCII编码的数据写入exe文件中。
后缀名只是文件名的一部分罢了。
fclose(文件指针) ; 关闭文件指针所指向的文件。
fcloseall( ) ; 关闭所有已打开的文件。
为什么要关闭文件:
1、操作系统允许打开的文件数是有限制的。若某程序忘记关闭文件,若其被多个程序调用,则可能导致文件数资源耗尽,其它程序无法打开文件。
2、若文件操作方式为“写”方式,则系统首先把该文件缓冲区(在内存中)中的剩余数据全部输出到文件中,然后使文件指针fp与文件断开联系。
若对文件操作后不关闭文件,则可能导致文件中数据的丢失。
【**无论是动态分配内存还是文件操作,使用完资源后要马上释放资源!**】
C语言系统定义了三个默认的文件指针:[它们都是文本文件,此即为一切皆文件的思想]
1、stdin 即标准输入文件,与键盘连接。(即把键盘当做文件)
2、stdout 即标准输出文件,与屏幕连接。(即把屏幕当做文件)
3、stderr 即标准出错文件,与屏幕连接。
(它们都是常量指针,故不能被重定向)
注意:
stdout和stderr是不是同设备描述符。stdout是块设备,stderr则不是。**对于块设备,只有当下面几种情况下才会被输入**,1)遇到回车,2)缓冲区满,3)flush被调用。而stderr则不会。
例:fprintf(stdout,"hello-std-out");//不一定会输出
fprintf(stderr,"hello-std-err");//一定会输出
***文本文件的读写操作***
①用fgetc()读取一个字符
int fget(FILE * stream) ;
功能:从文件stream中读一个字符,并把它作为函数返回值
②用fputc()写入一个字符
int fputc (int ch, FILE *stream) ;
功能:把字符ch写入到文件stream中。
③用fgets()从文件中读取字符串
char * fgets (char *string, int n, FILE *stream) ;
功能:从文件stream中读取n-1个字符放入以string为首地址的空间里。读入结束后,系统将自动在最后加’\0’,并以string作为函数值返回。
④用fputs()把一个字符串写入到文件中
int fputs (char *string, FILE *stream) ;
功能:把字符串string写入到文件stream中
文本格式化的输入输出
⑤用fscanf函数,从文本文件中按格式读取数据
fscanf(FILE *stream, 格式控制字符串, 参数列表) ;
[与从键盘输入的形式 格式 规则 一样]
⑥用fprintf函数,按格式向文本文件写入字符数据
fprintf(FILE *stream, 格式控制字符串, 参数列表) ;
[与输出到屏幕的形式 格式 规则 一样]
***二进制文件的读写操作***
①int fread (void *ptr, int size, int nitems, FILE *stream);
从文件stream中读取nitems个size大小的数据放到ptr指向的缓冲区中。
②int fwrite (void *ptr, int size, int nitems, FILE *stream);
从ptr指向的缓冲区中取出nitems个size大小的数据写到文件stream中
【这种类型的I/O效率很高,因为每个值中的位直接从流中读取或写入,不需要任何转换】
【实际上,二进制I/O函数也可以用来建立文本文件,只是在格式化I/O时,操作不太方便。
文本I/O函数也可以用来建立二进制文件,(要清楚数据的实际位表示情况),操作很不方便】
因为,在底层任何类型的文件都是用0和1表示的,只是文本I/O函数按照ASCII码的规则编码解码,但我们同样可以用二进制I/O函数 根据ASCII码的规则编码解码 也能做成文本文件,只是略显复杂。
所以,虽然这些函数可以完成其它的工作,但是让它们做适合它们的工作,我们操作起来会更方便,更顺手。
【**把数据写到文件中,效率最高的方法是用二进制的形式写入。**二进制的输出避免了在数值转换为字符过程中所涉及的开销和精度损失。但二进制文件非人眼所能阅读,我们必须记住它的存储格式才能读取其中的数据。】
【**注意:文件是流!故当读或写时,文件指针随着读写的流向而移动,它不是一直指向文件头部的!**】
文件指针的流动,是系统完成的,它有一些隐藏的复杂机制,不是像一般指针那样通过加减整数来实现的。fp++;的意思是指针移动一个文件的长度(因为它指向的对象是一个文件)
【文件是流, 字符串不是流。】
***文件指针定位***
因为文件指针比较特殊,我们无法通过取地址,增量操作来移动指针,故要改变指针的位置,需要利用专门的库函数。
这些函数一般用于二进制流文件,因为二进制流文件是值的真实反映,可精确定位到某位置,而文本流用以下函数定位指针,可能会出现偏差。
①int fseek (FILE *stream, long offset, int fromwhere) ;
把文件指针定位到,相对于fromwhere处距离offset字节的位置处
fromwhere 取值0 代表文件的开始位置;取值1 代表当前文件指针的位置;取值2代表文件尾部位置。
②long ftell (FILE *stream) ;
返回当前文件指针的位置(据文件头部的位置)
【在二进制流中,这个值准确反映了当前位置距离文件起始位置之间的字节数。但在文本流中,这个值不一定能准确表示当前位置距离文件起始位置之间的字节数。】
③int rewind (FILE *stream) ;
将文件指针重新指向一个流的开头位置
【若在主函数中打开一个流,把流指针传给多个函数调用时,注意:每个被调用函数的开始部分,最好用rewind(FILE *)把指针复位到文件开头[因为多次调用,可能会改变流指针的位置]】
检测流文件上的文件结束符:
int feof (FILE *stream) ;
若遇到文件结束符,函数feof返回1,否则返回0
【**注意:在C语言中,只有输入程序试图读取并失败以后才能得到EOF**】
故:依靠feof函数来检测文件结束,可能会产生BUG!
while( !feof( infp ) )
{ fgets(buf, MAXLINE, info ) ;
fputs(buf, outfp ) ;
}//因为程序读取文件失败后才能检测到文件结束,故此代码中的语句会多执行一次,产生BUG
【**一般情况,完全没有必要使用feof,我们可以通过检查文件I/O函数的返回值来判断文件是否结束**】
例:while(fgets( buf, MAXLINE, infp ) != NULL )
…… ;
***输入输出函数***
【注意:文件是一种流,输入输出的字符也是流。流的性质:你只能顺序地访问并提取流中的数据,未提取的数据只能阻塞在流中,等待下次被访问或提取。】
***一、格式化I/O函数***
scanf函数
①用scanf(“%s”,……) ; 读入字符串时,
前导空白将被丢弃忽略,当遇到空格回车等分隔符时,读入结束。空格或回车符留在流中,等待下次读入。
②用scanf(“%d”,……)读入数字;scanf(“%c”,……)读入字符时
一次读取一个数据,剩余的字符留在流中,等待下次读入。
停留在流中的字符可能会影响到下次的正确读入,丢弃输入流中字符的方法:
⑴输入结束后,把流中剩余的垃圾字符都读掉。
while( (ch = getchar())!=EOF && ch!= ‘\n’)
NULL ;
⑵用函数fflush(FILE *stream); 清除一个流。
对于输入流为fflush(stdin);
int scanf( char const *format, …… ) ;
int fscanf( FILE *stream, char const *format, …… ) ;
int sscanf( char const *string, char const *format, ……) ;
//以上函数的读入处理规则都相同,不同的是它们读取的流不同,一个是从键盘读取、一个从文件流读取、一个从字符串读取。(注意:字符串不是流,其没有流指针保存读取位置)
int printf( char const *format, …… ) ;
int fprintf ( FILE *stream, char const *format, …… ) ;
int sprintf ( char const *string, char const *format, ……) ;
//以上函数的输出字符规则都相同,不同的是它们写入的流不同,一个是向屏幕写入、一个向文件流写入、一个向字符串写入。
【注意:sprintf函数是一个潜在的错误根源,它可能会导致缓冲区溢出。(要提前估计好缓冲区的大小)】
【注意:**printf返回值是输出的字符个数**。】
~~~
#include
int main()
{
int i=43;
printf("%d\n",printf("%d",printf("%d",i)));
return 0;
}//程序会输出4321
~~~
***二、未格式化I/O函数***
fgetc( ) 接受一个输入流作为参数,它从这个流中读取一个字符(可读入回车等空白符),如果发生错误或流已到结尾,则返回EOF。
char * fgets( char *s, int n, FILE *fp ) ;
A、若输入由于遇到换行符而终止,则这个换行符也存储于缓冲数组中(就在’\0’符之前)
B、若未遇到换行符或文件尾,就读取了n-1个字符。则在缓冲数组末尾添加’\0’符。
gets( )和fgets( )不同,gets( )会丢弃换行符,并不把它存储在缓冲数组中。
但gets( )对于输入长度没有限制,很可能导致输入长度超过缓冲数组的长度,导致缓冲区溢出。
【故:**我们一般用fgets( )函数来接收用户输入。(这样可允许用户输入任意字符)再在程序中分析用户输入,提取数据**】
';
你精通C吗?test!
最后更新于:2022-04-01 20:30:11
以下这些题目是我曾遇到过的,觉得有深度的问题,对题目的解析绝大部分是本人的思考(引用的已注明出处),可能有不对的地方,希望大家不吝指正。
(PS:如果您对以下题目表示无压力,只能说您对C有一定的理解,至于是否精通C,不能由此文判断。)参考答案在文末。
1★先来个简单的:
~~~
#include
int main(void)
{
int a[3][2] = { (0,1), (2,3), (4,5) } ;
int *p ;
p = a[0] ;
printf(“%d”, p[0] ) ;
}
~~~
仔细看看花括号里面嵌套的是小括号,而不是花括号。即这花括号里嵌套了逗号表达式。(这考的是眼力^_^)
2★ int a[10]; 问下面哪些不可以表示 a[1] 的地址?
A. a+sizeof(int) B. &a[0]+1 C. (int*)&a+1 D. (int*)((char*)&a+sizeof(int))
//Tecent某年实习生笔试题目
此题对于理解了指针与数组的同学来说,很easy。(关于数组和指针那点事,可浏览本博客, [点这里](http://blog.csdn.net/yang_yulei/article/details/8071047))
3★下面的C程序是合法的吗?如果是,那么输出是什么?
~~~
#include
int main()
{
int a=3, b = 5;
printf(&a["Ya!Hello!how is this? %s\n"], &b["junk/super"]);
printf(&a["WHAT%c%c%c %c%c %c !\n"], 1["this"],
2["beauty"],0["tool"],0["is"],3["sensitive"],4["CCCCCC"]);
return 0;
}//来源于酷壳网http://coolshell.cn/articles/945.html
~~~
本例主要展示了一种另类的用法。下面的两种用法是相同的:
“hello”[2]
2["hello"]
如果你知道:a[i] 其实就是 *(a+i)也就是 *(i+a),所以如果写成 i[a] 应该也不难理解了。
4★ 32 位机上根据下面的代码,问哪些说法是正确的?(多选题类型)
~~~
signed char a = 0xe0;
unsigned int b = a;
unsigned char c = a;
~~~
A. a>0 && c>0 为真 B. a == c 为真 C. b 的十六进制表示是:0xffffffe0 D. 上面都不对
//Tencent某年实习生笔试题目
此题深入地考察了C的类型转换方式。(此为多选题类型,一般人不敢确定他的答案是正确的)
A 错:a 是负数,c 是正数,跟 0 比较要转换到 int。
signed char a 其实也就是char a,其转换到int负数还是负数(高位填充1)转换后结果为0xFFFFFFE0
unsigned char c 也为0xE0,但其是正数(signed char转unsigned char 底层位不变 只是改变了解释规则)
unsigned char 转int,正数还是正数(高位填充0)转换后结果为0x000000E0
B 错:B错?首先说 a 和 c 的二进制表示一模一样,都是 0xe0,那么比较就不相等?!是的。
一个char型和一个unsigned char比较,其中的类型如何转换?
C语言的整型提升规则:C的整型算数运算总是至少以缺省整型类型的精度来进行的。为了获得这个精度,表达式中的字符型和短整型操作数在使用之前被转换为普通整型。
本博的早期文章:http://blog.csdn.net/yang_yulei/article/details/8068210
所以,a == c中,a和c都要先转换成int型,再比较。有A选项分析知,a转int型为负数,b转int型为正数,故它俩不等。
C 对:C对?C 怎么就对了?a 是一个 signed char,赋值给 unsigned int 的 b,前若干个字节不是补 0 吗?
但实际情况是:首先 signed char 转换为 int,然后 int 转换成 unsigned int,所以最初是符号扩展,然后一个 int 赋值给了 unsigned int(其实还是整型提升规则)
D 不解释。
至于对这个问题的解释,我认为(只是我认为,不是权威的解释)是因为你使用的是32位的操作系统,我们说的操作系统的位数其实值的是CPU GPRs(General-Purpose Registers,通用寄存器)的数据宽度为32位,32位指令集就是运行32位数据的指令,也就是说处理器一次可以运行32bit数据。你传递参数的时候输入指定的格式为%hd,但是压栈的时候还是压入了32bit的数据,只不过高位是0。要不然我们为什么经常会说c语言中字节对齐的问题?
5★ 下面程序的输出结果(32位小端机)
~~~
#include
int main()
{
long long a = 1, b = 2, c = 3;
printf("%d %d %d\n", a, b, c);
return 0;
}
//Tencent某年实习生笔试题目
~~~
//以下是长篇大论
首先,sprintf/fprintf/printf/sscanf/fscanf/scanf等这一类的函数,它们的调用规则(calling conventions)是cdecl,cdecl调用规则的函数,所有参数从右到左依次入栈,这些参数由调用者清除,称为手动清栈。被调用函数不会要求调用者传递多少参数,调用者传递过多或者过少的参数,甚至完全不同的参数都不会产生编译阶段的错误。函数参数的传递都是放在栈里面的,而且是从右边的参数开始压栈,printf()是不会对传递的参数进行类型检查的,它只有一个format specification fields的字符串,而参数是不定长的,所以也没办法对传递的参数做类型检查,也没办法对参数的个数进行检查。所以了,压栈的时候,参数列表里的所有参数都压入栈中了,它不知道有多少个参数,所以它都压栈。
那么问题来了:编译器是怎么去定义压栈的行为的?是先把这longlong类型转换为int型再压栈么?还是直接压栈?
在32位机器上,64位的整数被拆分为两个32位整数,printf会把64位的按照两个32的参数来处理。此时printf会认为实际的参数为6个,而不是3个。
c,b,a压入之后,在最低的12字节处是a和b,a占2*4个bytes,b占1*4个byte。b先压入栈,a后压入栈。但是为什么a的布局是这样的?因为这是little endian,即每个数字的高字节在高地址,低字节在低地址。而栈的内存生长方向是从大到小的,也就是栈底是高地址,栈顶是低地址,所以a的低字节在低地址。(有条件的同学可以在big endian的机器上验证一下)
那么输出的时候,format specification fields字符串其匹配栈里面的内容,首先一个%d取出4个bytes出来输出,然后后面又有一个%d再取出4个bytes出来打印。所以结果就是这样了。也就是说刚开始压入栈的b的值在输出的时候根本都没有用到。
总结:
printf在压栈时,对于长度小于32位的参数,自动扩展成32位(由CPU的位数决定的)。
故在根据格式串解释时,对于%c %hd这样的小于32位数据的格式串,系统也会自动提取32位数据解释,而不会提取8位或16位来解释。(因为你把人家压入的时候就规定了扩展成32位嘛)
至于浮点参数压栈的规则:float(4 字节)类型扩展成double(8 字节)入栈。所以在输入时,需要区分float(%f)与double(%lf),而在输出时,用%f即可。printf函数将按照double型的规则对压入堆栈的float(已扩展成double)和double型数据进行输出。
至于longlong参数的规则:在32位机上,64位整数被拆分为两个32位整数压栈,在64位机上不存在这个问题,64位机上本题输出1,2,3
PS:
关于longlong型的输出:和平台和编译器有关
在**windows下需要用__int64配合%I64d**。而在**UNIX、Linux中必须使用标准C规定的long long配合%lld。**
unsigned __int64b= 9223372036854775808ll
printf("%I64u",b);
6★下面这段代码会挂么?会挂在哪一行?
~~~
#include
struct str{
int len;
char s[0];
};
struct foo {
struct str *a;
};
int main(int argc, char**argv) {
struct foo f={0};
if (f.a->s) {
printf( f.a->s);
}
return 0;
}
~~~
//详细分析请见本博客,[点这里](http://blog.csdn.net/yang_yulei/article/details/23395315)。
7★请问下面的程序的输出值是什么?
~~~
#include
#include
#define SIZEOF(arr)(sizeof(arr)/sizeof(arr[0]))
#define PrintInt(expr)printf("%s:%d\n",#expr,(expr))
int main()
{
/* The powers of 10*/
int pot[] = {
0001,
0010,
0100,
1000
};
int i;
for(i=0; i
int main(void)
{
char a[1000] ;
int i ;
for(i=0; i<1000; i++)
{
a[i]= -1-i ;
}
printf(“%d”,strlen(a)) ;
return 0 ;
}
~~~
按照负数补码规则,可知-1的补码为0xff,当i值为127时,a[127]的值为-128,此时右边整型转换后,正好是左边char型能够表示的最小负数。当i继续增加,右边为-129,对应的十六进制数为0xffffff7f 而char只有8位,故转换时高位被丢弃 左边得到0x7f。当i继续增加到255时,-256的低8位为0。然后当i增加到256时,-257的低8位为0xff 如此又开始一轮的循环。
从上面分析可知:a[0]到a[254]里面的值都不为0,而a[255]的值为0. 故strlen(a)为255
【char默认是有符号的,其表示的值的范围为[-128,127]】
9★在X86系统下,输出的值为多少?
~~~
#include
int main(void)
{
int a[5]={1,2,3,4,5} ;
int* ptr1 =(int *)(&a+1) ;
int* ptr2 =(int *)((int)a+1) ;
printf(“%x,%x”,ptr1[-1], *ptr2) ;
return 0 ;
}
~~~
若对于指针ptr1和ptr2具体指向不明白的,[请点击这里浏览。。](http://blog.csdn.net/yang_yulei/article/details/8071068)
对于ptr[-1]的值为5,没什么好说的了。
此题主要涉及的是大小端的问题,intel机器一般是小端模式,即:例如对整数来说,内存中的低地址字节存储整型的低地址部分,内存中的高地址字节存整型的高地址部分。(与我们平时的书写顺序相反)
a[0] a[1]在内存中的存储为:(地址从小到大增长)0x1000 0000 0x2000 0000
ptr2指向a[0]的第二个字节处,且它为int型指针,故提取从a[0]的第二个字节开始的后面4个字节。在内存中即为0x10**000000 0x20**00 0000(阴影部分) 打印来为0x2000000
10★
~~~
(*(void(*)( ))0 )( ) 这是什么?
~~~
//可参考:[请点击这里浏览函数指针部分](http://blog.csdn.net/yang_yulei/article/details/8071068)
这个是《C陷阱与缺陷》中的一个例子。
从内层到外层分析:
1,void(*)()这是一个函数指针。 这个函数没有返回值也没有参数
2,void(*)()0这是将整型0强制转换为函数指针类型。(即:0号地址处开始存储着一段函数)
3,(*(void(*)( ))0 ) 取出0号地址处的函数
4,(*(void(*)( ))0 )( ) 调用0号地址处的函数。
【由此可见 指针和强制类型转换联手双剑合璧威力无穷! 可以实现汇编级的操作】
**【相信程序员,不阻止程序员做他们想做的事】**
11★请问下面的程序的输出值是什么?
~~~
#include
int main()
{
int a[5][5] ;
int (*p)[4] ;
p=a ;
printf("%d", &p[4][2]-&a[4][2]) ;
return 0 ;
}
~~~
[详细分析请点击](http://blog.csdn.net/yang_yulei/article/details/8071068)
12★
~~~
struct S
{ char c ;
int i[2];
double v ;
} ;
~~~
在windows系统下成员i的偏移量是多少?在Linux系统下i的偏移量是多少?
[//请点击这里参考](http://blog.csdn.net/yang_yulei/article/details/8072567)
13★下面代码中有BUG,请找出:
~~~
int tadd_ok(int x, int y) //判断加法溢出
{
int sum = x+y ;
return (sum-x == y) && (sum-y == x) ;
}
int tsub_ok(int x, int y) //判断减法溢出
{
return tadd_ok(x, -y) ;
}
//此题来源于等重量黄金价值的书——《深入理解计算机系统》
~~~
有两个BUG:
1,tadd_ok判断加法溢出时,无论是否溢出,(x+y)-x都==y,若溢出结果sum再减y 再溢出得x。正确实现应为:分两种情况——正数运算是否溢出(即两正数相加为负数),负数运算是否溢出(即两负数相加为正数)。有两种情况之一者即判断溢出。
2,return tadd_ok(x, -y) ;当y为TMIN即int型所能表示的最小值,由于补码范围的不对称性,int的最小值无对应的正值,故y取TMIN时,对其取反会发生溢出,溢出的结果还是TMIN。
这样就导致判断结果错误。
14★
~~~
编写一些代码,确定一个变量是有符号数还是无符号数:
~~~
//来源于《C专家编程》
参考答案:
无符号数的本质特征是它永远不会是负的。
用宏定义的形式:#define ISUNSIGNED (type) ( (type)0 –1> 0 )
//也有其它方法实现,不过个人认为这种方法最简洁。
15★
再来一发关于复杂指针声明的,这是C中的难点:
写出变量abc的核心是什么,并用多个typedef改写下面的声明式
~~~
int *(*(*(*abc) ( ) ) [6]) ( ) ;
~~~
解析:
abc是一个函数指针,这类函数接收0个参数,返回一个指针,这个指针指向一个具有6个元素的数组,数组里的每个元素是函数指针,这类函数接收0个参数,返回值为int* 类型。abc的定义同下:
typedef int* (*type1)();
typedef type1 (*type2)[6];
typedef type2 (*type3)();
type3 abc;
【从内到外解读声明,从外到内typedef】
**关于变量的复杂声明:**
从外到内,层层剥开,先找核心,再向右看。(个人总结的,若有不妥请指正)
找到核心变量后,从右向左读。
* 读作”指向…的指针”
[] 读作”…的数组”
() 读作”返回…的函数”
简单的例子:
**int *f() ; // f: 返回指向int型的指针**
步骤:
1)找标识符f:读作”f是…”
2)向右看,发现”()”读作”f是返回…的函数”
3)向右看没有什么,向左看,发现*,读作”f是返回指向…的指针的函数”
4)继续向左看,发现int,读作”f是返回指向int型的指针的函数”
**int (*pf)() ; // pf是一个指针——指向返回值为int型的函数**
1)标识符pf,读作“pf是…”
2)向右看,发现),向左看,发现\*,读作 “pf是指向…的指针”
3)向右看,发现”()”,读作“pf是指向返回…的函数的指针”
4)向右看,没有,向左看发现int,读作”pf是指向返回int型的函数的指针
**部分答案:**
1题、答案应该是1.
2题、答案为A。
3题、本例是合法的,输出如下:
Hello! how is this? super
That is C !
4题、略
5题、结果为:1,0,2
6题、略
7题、本例的输出会是:1,8,64,1000
8题、答案是:255
8题、答案:5,2000000
9题、略
10题、略
11题、答案-4
12题、略
13题、略
';
陆(结构、联合、位段、位级操作)
最后更新于:2022-04-01 20:30:08
**陆**
***结构***
**数据对齐:**
许多计算机系统**对基本数据类型的合法地址做出了一些限制**:**要求某种类型对象的地址必须是某个值K(通常是2、4、8)的倍数,**这种对齐限制简化了 处理器和存储系统之间接口的硬件设计。
(因为:如果处理器经常从内存中取出8字节,若内存中一个存储器块单位是8个字节。则我们保证将所有double类型数据的地址对齐成8的倍数,那么就可以用一个存储器操作来读写值了! 否则,对象可能被分在两个存储器块中,我们就要执行两次存储器访问!)
**保持数据对齐能够提高效率。**
数据对齐 是与操作系统和硬件相关的。
在IA32平台下,Linux的对齐规则是:2字节数据类型(例如short)的地址必须是2的倍数,而其它数据类型的地址必须是4的倍数。
**WINDOWS对齐的要求更严格——任何n字节基本数据对象的地址 都必须是n的倍数,n=2,4,8。 **这种要求提高了存储器性能,而代价是浪费了一些空间。
~~~
struct S1
{ int i ;
char c ;
int j ;
} ;
~~~
//编译器可能需要在字段的分配中插入间隙,**以保证每个结构元素都满足它的对齐要求**,而结构本身对它的起始地址也有一些对齐要求。
(故为了满足字段i和j的4字节对齐要求,编译器在字段c和j之间插入一个3字节的间隙[可称之为:内存空洞] 结构的)
此外也要考虑结构体地址的对齐。
故结构体的数据对齐要考虑每个成员的对齐要求还要考虑整个结构体的对齐要求。
★但可归结为一个准则:**以结构体中最大数据类型元素的对齐为标准。**
**结构的总大小要满足最大元素 对齐的倍数**
~~~
struct S2
{ doubled ;
int i ;
int j ;
char c ;
} ;
~~~
//我们以成员中最大数据类型为标准来对齐,由此来计算整个结构的大小。最大对齐规则都满足了,小的对齐规则就好满足了。
此例中:d 占8个字节,i和j分别占4个字节,而c及尾部空洞共占8个字节。
因为:如此时c和上面一样还和空洞共占4字节的话,结构的总大小就不满足最大元素对齐的倍数了。这样若有结构体数组,则下个结构体的首位置就不会对齐了。
(可以这样思考:**以最大类型元素的对齐大小为单位 分割结构的存储空间**这样最后总的存储空间就是此单位的倍数了。)
★【**按照 数据对齐严格程度的大小有序排列结构中的成员,可最大限度地减少因边界对齐带来的损失**】
如果你必须**确定结构中某个成员的实际位置,可以使用offsetof宏**(定义于stddef.h)
offsetof(结构体类型名,成员名) 其返回指定成员据结构体首元素地址的字节数。
~~~
struct S1
{ char c ;
double d ;
} ; // offsetof(struct S1, d) ;表达式值为8
~~~
***联合***
联合提供了一种方式,能够规避C语言的类型系统,**允许以多种类型来引用一个对象**。
一个联合的总大小等于它最大字段的大小。**联合是用不同的字段来引用相同的存储器块。**
在某些情况下,联合十分用,但若使用不当,容易引发错误,因为它们绕过了C语言类型系统提供的安全措施。
联合可以被初始化,但这个值必须是联合的第1个成员类型。
例: union { inta ; char c[4]; } x = {5} ;
**应用:**
**1,我们事先知道一个结构中的两个不同字段是互斥的**,**那么我们将两个字段声明为联合的一部分,以减少存储空间。**(对于有较多类似情况的结构,会节省很多空间)
此时,我们一般引入一个枚举类型,来标记这个联合中当前的选择,然后再创建一个结构,包含一个标签字段和这个联合。
~~~
typedef enum { N_LEAF, N_INTERNAL } nodetype_t ;//定义枚举
struct NODE_T
{ nodetype_t type ; //可标记此结点是叶结点还是内部结点
union //联合
{ struct{ struct NODE_T * left ; structNODE_T * right } internal ;
double data ;
} info ;
} ;
~~~
**2,★可以用来访问不同数据类型的位模式**
~~~
//下面的代码返回的是:float作为unsigned的位表示
unsigned float2bit ( float f )
{ union
{ float f ;
unsigned u ;
}tmp ;
tmp.f= f ;
return tmp.u ;
}
~~~
//以上,**我们以一种数据类型来存储联合中的参数,又以另一种数据类型来访问它。(不同于强制类型转换)**
(实际对应的机器码为movl 8(%ebp), %eax
这就说明了 **机器码中没有类型信息**,无论参数是float还是unsigned,它们都在相对%ebp偏移量为8的地方,程序只是简单地将它们的值复制到返回值,**不修改任何位**[而强制类型转换 涉及浮点值的转换时 会修改位])
**3,可以深入到 数据内部的字节级来访问**
~~~
union
{ double d ;
unsignedu[2] ;
} tmp ;
tmp.u[0] = x1 ;
tmp.u[1] = x2 ; //分别访问了double型的数据d的低4字节与高4字节。
(注意在大端法机和小端法机上的结果相反)
~~~
【注意:如果联合中成员的长度相差悬殊,当存储较短成员时会浪费很多空间。
好的方法是:
在联合中存储指向不同成员的指针,而不是存储成员本身,当需要哪个成员时,动态分配空间】
***位段***
C允许程序员**把整数成员包装到比编译器正常所允许的更小的空间中。这种整数成分成为位段,**是通过在结构体的成员声明中使用一个冒号和一个常量表达式(指定了位段所占据的位数)指定的。
(位段就是允许我们自己定义某个整型的数据占据多少位,而对位的解释还是与其数据类型一样)
**ANSI标准C允许位段为unsigned int , signed int , int类型**,它们分别称为:无符号位段、有符号位段、普通位段(有可能是有符号或无符号的)。
有些编译器允许使用任何整数类型的位段,包括char型。
编译器可以选择地对位段的最大长度加以限制,并指定位段无法跨越的地址边界,当一个字段将跨越一个字的边界时,它可能会移动到下一个字。
【注意:取地址操作符&无法用于位段成员,因为计算机无法对任意长度的字段编址】
**关于填充:**
~~~
struct s
{ unsigned a :4 ;
unsigned :2 ;
unsigned b :6 ;
} ; //此位段结构共占4字节。
~~~
结构中也可以包含无名位段。作为相邻成员之间的填充。
**★注意:编译器是以字(int型大小)为单位,向位段结构分配存储空间的!一次分配一个字的空间**(32位机就是32个位),而不是根据定义的位的数量来分配(这是为了数据对齐)。若一个位段结构的总定义空间大于一个字,则再分配一个字。
(如此看来,使用位段不一定能节省空间,有可能还浪费空间。只是它可以对一个字的内部位方便地访问,**使具名访问深入到了位级!**)
**当然:若是定义char型的位段,则编译器是以字节(char型大小)为单位,来分配空间的!**
(这样,我们可以根据需要选用两种不同大小规格的位段结构)
**★为一个无名字段指定0长度 具有特殊含义**,它表示不应该有其它位段被包装到前一个位段所在的区域。如果有,它就被放置。
~~~
struct s
{ unsigned a :4 ;
unsigned :0 ;
unsigned b :6 ;
} ;
~~~
**【0长度字段就相当于是一个分隔线,把其前和其后的字段分隔到不同的字单位中】**
故:上面的unsigneda :4 与后面的空洞合占一个字的空间;unsigned b :6与后面的空洞合占一个字的空间。unsigned a :4,unsigned b :6两个成员分属不同的字空间。整个位段结构占2个字即8字节空间。
**移植性问题:**
使用位段的程序是无法移植的。因为其在不同计算机平台上的实现结果可能不同,依赖于硬件(大端小端,字长)和编译器。
**应用:**
用于一个结构体数组,由于数组太大,所以要求结构体的成员必须紧密包装,以节省内存。
(只有在内存空间问题上有严格要求的程序 才使用位段。 一般情况不用!)
***位级操作***
位段也是一种位级操作的方式,但位段不可移植(缺点),不过其能通过变量名来访问位,使操作上更简便,程序更清晰。(优点)
**我们通过掩码和移位操作可完全取代位段的功能**,且具有移植性。只是操作不及位段简单。
(这两种方法都可在位级操作,我们可根据情况,在程序清晰性和可移植性间做出考量)
位运算符:按位取反~ 、左移<< 、右移>> 、与运算&(逻辑乘) 、或运算|(逻辑加)、异或运算^(按位加)
【**注意:移位操作符的优先级问题**】
例t =a<<2 + a; 对于a<<2这个位操作,优先级要比加法要低,所以这个表达式就成了“t = a<< (2+a)”,而我们实际的意图可能是t= (a<<2) + a;
【涉及移位操作的表达式要警惕其优先级问题!】
**常用的位操作:**
**1、取出(检测)某位的值**
value & 掩码 (结果为0则某位为0,结果非0则某位为1)
**2、设置某位的值**
①把某位置1
value |= 掩码
②把某位置0
value &= ~掩码
【注意:以上掩码均意为——把要设置的位置1,其余位置0】
以上两类的操作(一类可对任意位访问,一类可对任意位赋值)组合起来可实现所有的位操作!
**掩码的生成**
**1,可用左移操作(<<)生成所需要的掩码**
例:value & ( 1<
';
伍(字符串、函数、动态内存分配)
最后更新于:2022-04-01 20:30:06
伍
***字符串***
字符串是一种特殊的数组类型。字符串必须用’\0’作为结束标识。’\0’占用存储空间,但不计入串的实际长度。
***字符串的初始化:***(编译器会自动在其尾部添加’\0’标识)
~~~
char str[] = {‘a’, ‘b’, ‘c’} ; //标准形式
char str[] = {“abc”} ; //简写
char str[] = “abc” ; //最简写
注意:
char a[3] = “abc” ; //在C中是合法的。但其不是字符串,它没有把’\0’存入。(C++中非法)
char a[3] = “abcdefg”; //也是合法的,但会产生警告。编译器会只取前三个字符放到数组中
int a[3] = {1,2,3,4,5}; //是非法的。
~~~
char a[] = “abcd” ; 与 char * p = “abcd” ; 的区别
***字符串字面量:***(也称字符串常量,即形如“abcd”的)**
①当作为数组初始值时,它指明该数组中字符的初始值。(只是定义字符串的一种简写形式)
②在其它情况下,它会转化为一个无名字符数组的首地址,且此字符数组存储在内存中的只读常量区中,这就导致它不能被修改。
故:上面,a[]是个字符串数组,而p是指向字符串首字符的指针。
例:”xyz”+1 的结果为:指向第二个字符的指针值
“xyz”[2]的结果为:字符z (方括号是一个后缀表达式的操作符)
注意:
ASCI C引入的另一个新特性是,**相邻的字符串常量将被自动合并成一个字符串。**
这样,后续的字符串也可以出现在每行的开头。
***字符数组:***
char laguage[3][10] = {“BASIC”, “C++”, “JAVA”};
//数组的第一个下标决定了字符串的个数,第二个下标是字符串的最大长度。
//其在内存中开辟了一个 3*10*sizeof(char)大小的存储区。
//由于字符串有长有短,故用数组会浪费一定的存储空间。
***字符指针数组:***
char *p[] = {“BASIC”, “C++”, “JAVA”} ;
p是由三个字符指针组成的数组。这三个指针分别指向只读区的三个无名字符串的首字符。
//字符指针数组可用于:单词的检索表。**
// char *p[] = {“BASIC”, “C++”, “JAVA”,NULL} ;若在表的末尾增加一个NULL指针作为结束标志,则可使在检索的时候能检测到表的结束,而无需预先知道表的长度。
***常用的字符串处理库函数陷阱:***
**函数strlen( )的返回值是size_t**,这个类型是在头文件stddef.h中定义的 是unsigned int 类型的别名。 故使用时一定要注意,隐私类型转换可能产生的错误!
例: if(strlen(s1) – strlen(s2) >= 0 ) {........}
表达式的左边的结果是无符号数,根据值的类型转换提升规则,右边的int型0会提升为无符号数。而无符号数是绝不可能为负的。故这个条件判断永远为真。
【为避免混用有符号数和无符号数 可能产生的问题,**在使用strlen( )时,设一个int型的变量来接收strlen( )的返回值,可避免错误。**】
**函数strncpy( )的结果将不会自动以’\0’字节结尾!你必须自己给结果字符串添加’\0’ 字节。**
函数strncat( )的结果会自动添加’\0’字节。(故:我们可把目的字符串先置空,然后就可用strncat( )来代替strncpy( )的功能 )
***函数***
***关于函数返回值***
**当设计函数返回指针时,一定要警惕!检查其返回指针的类型。被调函数绝对不能返回本局部变量的指针**,(因为函数返回后其开辟的运行时栈,被回收,其中所有的局部变量被抛弃,返回它们的指针是无效的)。
函数返回的指针可以是:
①静态分配的缓冲区。例:全局变量的指针 【少用】
②调入者传入的缓冲区。(在主调函数中) 【常用】
③用malloc()获得的内存 【记得要在不用的时候释放】
***主函数***
ANSI标准C规定了主函数的两种形式:
int main(void) ;
int main(int argc, char **argv) ;
main( )所需的实参是在命令行与程序名一同输入的。程序名和各实参之间用空格分隔。
格式为:含路径的可执行程序名 参数1 参数2 ......参数n
形参argc 为命令行中参数的个数(包括执行程序名)其值大于等于1。
形参argv为一个二级指针 指向一个指针数组的首元素,这个指针数组中的元素依次指向命令行中以空格分开的各参数字符串。(即第一个指针argv[0]指向的是程序名字符串,argv[1]指向的是参数1,......)
***可变参函数***(让函数可以接受不定数目的参数)
可变参数列表是通过宏来实现的,这些宏定义于stdarg.h头文件中,这个头文件声明了一个类型 va_list 和三个宏 va_start va_arg va_end
~~~
//计算不定数量值的平均值
#include
//注意:可变参数的类型必须保持一致!
double Average(int num, ...) //参数:第一个num为后面参数的个数,不定参数用3个点来表示。
{
va_list values ; //values是一个参数列表类型。其中包含着所有的不定参数。
int cnt=0 ;
float sum=0 ;
/*准备访问可变参数*/
va_start( values, num ) ; //初始化参数列表变量values
for(cnt=0; cnt < num; cnt++)
sum += va_arg( values, double) ; // double指明参数列表中参数的类型,每调用一次此语句此宏表示的参数就顺移到下一个参数。(如此,可顺序地处理每个传入的参数)
/*结束访问可变参数*/
va_end( values ) ;
return sum/num ;
}
~~~
***内联函数:***
函数指定符inline只能出现在函数声明中,这种函数便成为内联函数。使用inline是向编译器所提供的提示,表示应该采用措施来提高这个函数的调用速度。即,对一个函数的调用将被该函数的一份拷贝所替代。(有点类似宏函数,但有区别)这就消除了函数调用的开销。
【注意,编译器并不一定要执行内联展开,C程序不能依赖于一个函数调用将被内联展开】
***动态内存分配***
【**勿忘:及时释放不再使用的动态分配的内存!**】
***几个库函数:***
void * malloc(size_t bit) ; //函数名意为:memoryallocation
void * calloc(size_t num, size_t bit) ; //函数名意为:cleanallocation
此函数在返回指向内存的指针之前 把内存中的值初始化为0
void realloc(void *ptr, size_t new_size) ;
此函数用于修改一个原先已经分配的内存块大小。
①用于扩大内存块。(新增内存添加到原先内存块的后面)
②用于缩小内存块。(内存块的尾部部分被拿掉,剩余的内存内容保留)
③若原先内存块的大小无法改变,则recalloc重新分配新内存,并复制原先内容。
【故在使用realloc函数时,通常不应该立即将新指针赋给就指针,最好用一个临时指针】
void free(void *ptr) ;
将指针ptr所指的动态存储空间释放。
';
肆(数组与指针②)
最后更新于:2022-04-01 20:30:04
**肆**
***数组与指针(二)***
**数组与指针的纠葛**
***以指针的形式访问数组:***
下标表达式: 后缀表达式[表达式]
在C语言中,根据定义,**表达式e1[e2]准确地对应于表达式*((e1)+(e2))。**因此,要求表达式e1[e2]的其中一个操作数是指针,另一个操作数是整数。且这两个操作数的顺序可以颠倒。
故: a[4] 等同于 4[a] 等同于 *(a+4)
编译器把所有的e1[e2]表达式转换成*((e1)+(e2))。
所以,以下标的形式访问在本质上与以指针的形式访问没有区别,只是写法上不同罢了!
**多维数组**
二维数组a[i][j]
**编译器总是将二维数组看成是一个一维数组,而一维数组的每个元素又都是一个数组。**
多维数组定义的下标从前到后可以看做是 最宏观的维到最微观的维。例:三维数组a[i][j][k] 可理解为 共有i个大组,每个大组里有j个小组,每个小组里有k个元素。
故:
a 表示为整个三维数组,其值为&a[0][0][0],
&a+1为整个三维数组后面的第一个位置。(偏移整个三维数组的长度)
a+1 为第二个大组的首位置处(偏移一个大组的长度)【数组名a代表的是数组首元素的首地址,即:第一个大组的首地址】
a[0]表示为三维数组的i个大组中的第一个大组【可看做一个二维数组】,其值为&a[0][0][0],
&a[0]+1为第二个大组的首位置处(偏移一个大组的长度)
a[0]+1为第一个大组中第二个小组的首位置处(a[0]可看做是一个二维数组名,故其代表的是第一个小组的首地址)(偏移一个小组的长度)
a[0][0]表示为第一个大组中的第一个小组【可看做一个一维数组】其值为&a[0][0][0],
&a[0][0]+1为第一个大组中第二个小组的首位置处(偏移一个小组的长度)
a[0][0]+1为第一个大组中第一个小组的第二个元素位置处(偏移一个元素的长度)
a[0][0][0]表示为第一个大组中的第一个小组中的第一个元素。其值为&a[0][0][0],a[0][0][0]+1为首元素值加1。(因为a[0][0][0]为元素值而不是地址)
数组的数组(即:二维数组名)退化为数组的(常量)指针,而不是指针的指针。
同理,**n维数组名退化为n-1维数组的(常量)指针。**
【**总结:指针代表的是谁的首地址 就以谁的长度为偏移单位。**】
【**规律:与定义比较,缺少几对方括号,就是几维数组的数组名**,如上例:a缺少3对方括号,即为3维数组的数组名(代表的是2维数组的地址);a[0]缺少2对方括号,即为2维数组的数组名(代表的是1维数组的地址);a[0][0]缺少1对方括号,即为1维数组的数组名(代表的是数组元素的地址)】
【数组名与整数相加,首先要转换成数组的首元素地址与整数相加,而首元素的存储大小就是整数的单位】
对多维数组的解析:
我们可以用上面那种从前到后的解析方式来思考,a:就表示整个多维数组。a[m]:就表示第m+1大组(大组即数组最大的维),a[m][n]:就表示第m+1大组中的第n+1小组。(小组即次大的维),以此类推,即多维数组的解析是层层细化的。
**◎☆指针数组与数组指针:**
指针数组:首先它是一个数组。数组的元素都是指针。它是“存储指针的数组”的简称。
数组指针:首先它是一个指针。它指向一个数组。它是“指向数组的指针”的简称。
例:int * p1[10]; //它是指针数组。(因为[]的优先级比*高,p1先与[]结合,构成一个数组的定义)
int (*p2)[10] ; //它是数组指针。(括号的优先级较高,*与p2构成一个指针的定义)
它指向一个包含10个int型数据的数组。
若有:int(*p)[10][5] ; //则p指向一个int型的二维数组a[10][5]。
【**规律:数组指针,把定义中括号内的指针看成是一个普通的字母,则其表示的就是 数组指针所指的对象类型**】
◎☆
~~~
int a[5][5] ;
int (*p)[4] ;
p=a ;
问:&p[4][2]-&a[4][2]的值为多少?
~~~
设二维数组的首地址为0,则a[4][2]为第5组的第3个位置(以后见到多维数组要这么想,不要总想着是几排几列的模式),因为int a[5][5];即有5组,每组有5个元素。故:&a[4][2]是(4*5+2)*sizeof(int).
int (*p)[4] ; 指针指向一个含4个int型的元素的数组,故p[4]相对于p[0]向后移动了“4个int型数组”的长度,然后在此基础上再向后移动2个int型的长度(即,其步长按维度逐步递减,多维数组也可按此方式理解)。最后其值为(4*4+2)* sizeof(int)
最后**切记:地址值参与的加减运算(地址不能被乘),整数的单位是地址值代表的元素的存储大小!**
&p[4][2]-&a[4][2]结果为-4。若分开比较&p[4][2]和&a[4][2]则相差4* sizeof(int)个字节**
【**◎☆规律:数组指针的连续解引用**
数组指针的定义提供了其逐次解引用时的偏移单位,例int (*p)[m][n][k],则意为:数组指针的第一次解引用的偏移单位是m*n*k个int型长度,再次解引用的偏移单位是n*k个int型长度,又一次解引用的偏移单位是k个int型长度,最后一次解引用的偏移单位是1个int型长度。它只能连续解引用4次。 故:p[2][3][4][5]与四维数组首地址相距(2*m*n*k + 3*n*k + 4*k + 5 )个int型长度】
故:**数组指针指向的是哪个数组,就可以把它当做那个数组的数组名来用。**
例:inta[3][10][5] ; int (*p)[10][5] ; p = a ; 则:p[1][2][3] == a[1][2][3] ; p[1][2] ==a[1][2]
即:用数组指针访问数组和用数组名访问,效果是相同的。
**WHY?**以int(*p)[10][5]为例,它指向一个[10][5]的二维数组,故第一次解引用时以二维数组[10][5]的长度作为偏移单位,一次解引用后p[1]就是一个[10][5]二维数组了。(解引用就是提取出指针偏移后 指向的对象) 即为:一维数组[5]的首地址。故再次解引用就以一维数组[5]的长度作为偏移单位,二次解引用后p[1][2]就是一个[5]一维数组了,即是一维数组首元素的地址。所以三次引用后,偏移单位为1个元素。
**数组参数与指针参数:**
1,二维数组名做实参
~~~
int main(void)
{ int a[4][5] ;
……….
………
fun(a);
……….
}
被调函数:
①fun( inta[4][5] )
②fun( inta[ ][5] )
③fun( int(*a)[5] )
{ ……….
a[i][j]=……….
………
}
~~~
以上三种方式皆可。无论是那种方式,它们只是写法不同,但编译器的处理方式相同,都把它们看做是一维数组指针。
因为二维数组名退化为一个一维数组指针,故是以一维数组指针的形式来传递二维数组的。
2,指针数组做实参
~~~
int main(void)
{ int a[4][5] , i, *p[4] ;
for(i=0;i<4; i++)
p[i]= a[i] ;
……….
fun(p);
……….
}
被调函数:
①fun(int*q[4])
②fun(int *q[])
③fun(int **q)
{ ……….
q[i][j]=……….//取出指针数组中的第i个元素(为指针),再偏移j个单位
//也可从双重指针的角度理解:[i]为第一次解引用,偏移量是i个指针的大小(因为双重指针指向的是指针变量),[j]为第二次解引用,偏移量是j个int型变量大小(因为此时指针指向的是一个int型变量:某组的首元素)
………
}
~~~
以上三种方式皆可。无论是那种方式,写法不同,但编译器的处理方式相同,都把它们看做是二级指针。
因为指针数组名退化为数组首元素的地址,即二级指针,故是以二级指针的形式来传递指针数组的。
而多维数组名退化为次维数组的指针,即数组指针,故是以数组指针的形式来传递多维数组的。
【数组指针的连续解引用,其指针的步长对应数组的维度值 是逐渐减小的
多级指针的连续解引用,其指针的步长 前几次解引用的步长为1个指针的长度,最后一次解引用的步长为最终指向的对象长度。(操作系统常用多级指针在多张表中做查询操作)】
【C中函数实参与形参之间是传值引用的,所以你要改变这个值,就传递它的地址(无需多言)】
**函数指针**:
函数指针就是函数的指针。它是一个指针,指向一个函数。
(即函数在内存中的起始位置地址)
实际上,所有的函数名在表达式和初始化中,总是隐式地退化为指针。
例:int r , (*fp)( ) , func( ) ;
fp= func ; //函数名退化为指针
r= (*fp)( ) ; //等价于r=fp( ) ;
**无论fp是函数名还是函数指针,都能正确工作。因为函数总是通过指针进行调用的!**
例:int f(int) ; //函数声明
int (*fp)(int) = &f ;//此取地址符是可选的。编译器就把函数名当做函数的入口地址。
//在引用这个函数地址之前,f函数应先声明。
int ans ;
//以下三种方式可调用函数
ans= f(25) ; //函数名后的括号是“函数调用操作符”。
ans= (*fp)(25) ;
ans= fp(25) ;
**函数名就是一个函数指针常量,函数调用操作符(即一对括号)相当于解引用**
函数的执行过程:
函数名首先被转换为一个函数指针常量,该指针指定函数在内存中的位置。然后函数调用操作符调用该函数,执行开始于这个地址的代码。
**再说强制类型转换:**
~~~
void fun() { printf("Call fun "); }
int main(void)
{
void(*p)( ) ;
*(int*)&p = (int)fun ;
(*p)() ;
return0 ;
}
~~~
参见前面文章的强制类型转换。强制类型转换只不过是改变了编译器对位的解释方法罢了。
*(int *)&p = (int)fun ;中的fun是一个函数地址,被强制转换为int数字。左边的(int*)&p是把函数指针p转换为int型指针。*(int *)&p = (int)fun ;表示将函数的入口地址赋值给指针变量p。(*p)( ) ;表示对函数的调用。
**函数指针数组:**
即是存储函数指针的数组。(有时非常有用)
例:char *(*pf[3])(char *) ;
**函数指针的用途:**
1,**转移表**(转移表就是一个函数指针数组)
即可用来实现“菜单驱动系统”。系统提示用户从菜单中选择一个选项,每个选项由不同的函数提供服务。
【若每个选项包含许多操作,用switch操作,会使程序变得很长,可读性差。这时可用转移表的方式】
例:void(*f[3])(int) = {function1, function2, function3} ; //定义一个转移表
(*f[choice])( ) ; //根据用户的选择来调用相应的函数
2,**回调函数**(用函数指针做形参,用户根据自己的环境写个简单的函数模块,传给回调函数,这样回调函数就能在不同的环境下运行了,**提高了模块的复用性**)
【回调函数实现与环境无关的核心操作,而把与环境有关的简单操作留给用户完成,在实际运行时回调函数通过函数指针调用用户的函数,这样其就能适应多种用户需求】
例:C库函数中的快速排序函数
voidqsort(void *base, int nelem, size_t width, int (*fcmp)(void*, void*) );
//base为待排序的数组基址,nelem为数组中元素个数,width为元素的大小,fcmp为函数指针。
这样,由用户实现fcmp的比较功能(用户可根据需要,写整型值的比较、浮点值的比较,字符串的比较 等)这样qsort函数就能适应各种不同的类型值的排序。
**使用函数指针的好处在于:**
可以将实现同一功能的多个模块统一起来标识,这样一来更容易后期维护,系统结构更加清晰。或者归纳为:便于分层设计、利于系统抽象、降低耦合度以及使接口与实现分开。
**函数指针数组的指针:**(基本用不到)
例:char *(*(*pf)[3])(char *)
这个指针指向一个数组,这个数组里存储的都是指向函数的指针。它们指向的是一种返回值为字符指针,参数为字符指针的函数。
[对于这种复杂的声明,《C和指针》《C专家编程》中有专门的论述。我的方法就是:从核心到外层,层层分析。先找到这个声明的核心,看他的本质是什么。就像本例,最内层的括号里是一个指针,再看外层来确定它是个什么指针。外层是一个3个元素的数组,再看这个数组的元素类型是什么。是一个函数指针。 故总体来说此声明是一个函数指针数组的指针。]
**复杂指针的举例:**
int* (*a[5])(int, char*);
void (*b[10]) (void (*)());
doube(*)() (*pa)[9];
让我们一层一层剥开它的心。
第1个、首先找到核心,即标识符a,[ ] 优先级大于“*”,a与“[5]”先结合。所以a是一个数组,这个数组有5个元素,每一个元素都是一个指针。再往外层看:指针指向“(int,char*)”,对,指向一个函数,函数参数是“int, char*”,返回值是“int*”。完毕!
第2个、首先找到核心:b是一个数组,这个数组有10个元素,每一个元素都是一个指针,指针指向一个函数,函数参数是“void(*)()”【 这个参数又是一个指针,指向一个函数,函数参数为空,返回值是“void”】 返回值是“void”。完毕!
第3个、核心pa是一个指针,指针指向一个数组,这个数组有9个元素。再往外层看:每一个元素都是“doube(*)()”【也即一个指针,指向一个函数,函数参数为空,返回值是“double”】
**使用typedef简化声明:**
某大牛对typedef用法做过一个总结:“建立一个类型别名的方法很简单,在传统的变量声明表达式里用类型名替代变量名,然后把关键字typedef加在该语句的开头”。
举例:
例1,void (*b[10]) (void (*)());
typedef void (*pfv)(); //先把上式的后半部分用typedef换掉
typedef void (*pf_taking_pfv)(pfv); //再把前半部分用typedef换掉
pf_taking_pfv b[10]; //整个用typedef换掉
跟void (*b[10]) (void (*)());的效果一样!
例2,doube(*)() (*pa)[9];
typedef double(*PF)(); //先替换前半部分
typedef PF (*PA)[9]; //再替换后半部分
PA pa; //跟doube(*)() (*pa)[9];的效果一样!
**反思:**
1,我们为什么需要指针?
因为我们要访问一个对象,我们要改变一个对象。要访问一个对象,必须先知道它在哪,也就是它在内存中的地址。地址就是指针值。
所以我们有
函数指针:某块函数代码的起始位置(地址)
指针的指针:因为我要访问(或改变)某个变量,只是这个变量是指针罢了
2,为什么要有指针类型?
因为我们访问的对象一般占据多个字节,而代表它们的地址值只是其中最低字节的地址,我们要完整的访问对象,必须知道它们总共占据了多少字节。而指针类型即向我们提供这样的信息。
注意:一个指针变量向我们提供了三种信息**:**
①一个首字节的地址值
②这个指针的作用范围(步长)
③对这个范围中的数位的解释规则(解码规则)
【编译器就像一个以步数测量距离的盲人。故你要告诉它从哪开始走,走多少步。】
3,强制类型转换的真相?
学过汇编的人都知道,什么尼玛指针,什么char,int,double,什么数组指针,函数指针,指针的指针,在内存中都尼玛是一串二进制数罢了。**只是我们赋予了这些二进制数不同的含义,给它们设定一些不同的解释规则,让它们代表不同的事物。**(比如1000 0000 0000 0001 是内存中某4个字节中的内容,如果我们认为它是int型,则按int型的规则解释它为-231+ 1;如果我们认为它是unsigned int ,则被解释为231+ 1;当然我们也可把它解释为一个地址值,数组的地址,函数的地址,指针的地址等)
如果我们使用汇编编程,我们必须根据上下文需要,用大脑记住这个值当前的代表含义,当程序中有很多这样的值时,我们必须分别记清它们当前代表的含义。这样极易导致误用,所以编译器出现了,让它来帮我们记住这些值当前表示的含义。当我们想让某个值换一种解释的方案时,就用强制类型转换的方式来告诉编译器,编译器则修改解释它的规则,而内存中的二进制数位是不变的(涉及浮点型的强制转换除外,它们是舍掉一些位,保留一些位)
4,涉及浮点型的强制转
详情参见《深入理解计算机系统》
5,难点
多维数组、数组指针、多级指针。
**抓住问题的核心:指针值是谁的地址,这个地址代表的是哪个对象。**
搞清楚这个问题,关于指针移动时偏移量(步长)的计算就不会出错。
指针类型只是C语言提供的一种抽象,来帮助程序员避免寻址错误。
';
叁(数组与指针①)
最后更新于:2022-04-01 20:30:02
**叁**
***数组与指针(一)***
指针是C的精华,如果未能很好地掌握指针,那C也基本等于没学。
关于指针、数组、字符串,本人当年也是有过一段“惨绝人寰”的痛。好在多看书,多思考,多总结,多实践,方才有些心得。现在把当年的笔记摘录如下,希望能给初学者一些启发。
**先附上两句话:**
**第一句话:指针就是存放地址的变量。(就是这么简单。)**
**第二句话:指针是指针,数组是数组。(只是它们经常穿着相似的衣服来逗你玩罢了。)**
*轻松一下*:(见识一下数组和指针的把戏)
1、引用一维数组某个值的方式:(先定义指针p=a)
① a[2] ② *(a+2) ③ (&a[1])[1] ④ *(p+2) ⑤ p[2]
2、引用二维数组某个值的方式:
~~~
例:int a[4][5];
⑴ a[i][j]
⑵ *(a[i]+j)
⑶ *(*(a+i)+j)
⑷ (*(a+i))[j]
⑸ *(&a[0][0]+i*5+j)
又定义:int * p[4], m ;
for(m=0; m<4;m++) p[m] = a[m] ;
⑹ p[i][j]
⑺ *(p[i]+j)
⑻ *(*(p+i)+j)
⑼ (*(p+i))[j] //请与⑴-⑷对比
又定义 int (*q)[5]; q=a ;
⑽ q[i][j]
⑾ *(q[i]+j)
⑿ *(*(q+i)+j)
⒀ (*(q+i))[j] //请与⑴-⑷ ⑹-⑼对比
~~~
好了,看到这的朋友,如果你还没被搞晕的话,那么这篇文章可能不适合你。如果你已经晕头转向、意乱情迷的话,那么也请不要害怕,我不是猥琐的大叔。下面我会带着你揭穿数组和指针之间的把戏。
**进入正题:**
**数组:**
数组是指具有相同类型的数据组成的序列,是有序集合。(国内教科书上的定义)
(即:数组就是内存中一段连续的存储空间。那么我们怎么使用它呢?用数组名。也就是我们用数组名可以在内存中找到对应的数组空间,即数组名对应着地址。
那么数组中有这么多元素,对应的是哪个元素的地址呢?对应着首元素的地址。 故:我们可以通过数组的首元素地址来找到数组 )
故:**数组名是一个地址(首元素地址),即是一个指针常量。(不是指针变量)**
**只有在两种场合下,数组名并不用指针常量来表示:**
⑴**sizeof(数组名) **; sizeof返回整个数组的长度,而不是指向数组的指针长度。
⑵**&数组名**; 产生的是一个指向整个数组的指针,而不是一个指向某个指针常量的指针。
&a[0] 与 &a 的区别:
两者的值相同,但意义不同。&a[0]是指数组首元素的地址。&a是整个数组的地址。
(问题来了,整个数组跨越几个存储单位,怎么表示这几个存储单位组成的整体呢?如果你是编译器,你会怎么做?呃,取其第一个存储单位的值来代表会比较好点。没错,编译器是这么做的。 所以两者的值相同)
a+1 与 &a+1 的区别:
**数组名a除了在上述两种情况下,均用&a[0]来代替。**(实际上编译器也是这么做的)
a+1即等同于&a[0]+1。
注意:**指针(地址)与常数相加减,不是简单地算术运算,而是以当前指针指向的对象的存储长度为单位来计算的。**即:指向的地址+常数*(指向的对象的存储长度)
&a[0]为数组首元素的地址,故&a[0]+1 越过一个数组元素长度的位置。即:&a[0]+1*sizeof(a[0])
&a为整个数组的地址,(只是用首元素地址来表示,其实际代表的意义是整个数组) 故&a+1 越过整个数组长度的位置,到达数组a后面第一个位置。 即:&a+1*sizeof(a)
**指针**:
例:int *p=NULL; 与 *p=NULL ; 的区别
指针的定义与解引用都用到* ,这是让人晕的一个地方。
(不妨这样理解:在定义时 星号只是表示这是一个指针,int * 表示这是一个int型的指针,把int * 放在一起看,表示这是一个整型指针类型。 如果我是C的设计者,那么用$符号来定义指针类型 会不会让大家少些迷惑)
向指针变量赋值,右值必须是一个地址。例:int * p=&i ; 这样,编译器在变量表里查询变量i对应的地址,然后用地址值把&i替换掉。 那么我们能不能直接把地址值写出来作为右值呢?当然。指针不就是存储地址的变量嘛,直接把数字型的地址值赋给它有什么问题。(前提是这个地址值必须是程序可访问的)
例:**int * p=(int *)0x12ff7c ;**
*p= 0x100 ;
这里的0x12ff7c可看做某个变量的地址。
需要注意的是:将地址0x12ff7c赋值给指针变量p的时候必须强制转换。(我们要保证赋值号两边的数据类型一致)
***地址的强制转换:***
~~~
例:double * p ;假设p的值为 0x100000
求下列表达式的值:
p + 0x1 =___
(unsigned long)p + 0x1 = ___
(unsigned int *)p + 0x1 = ___
~~~
**注意:一个指针与一个整数相加减。这个整数的单位不是字节,而是指针所指向的元素的实际存储大小。**
故:p + 0x1:p指向的是一个double型变量,故值应为:0x100000+0x1*8=0x100008
(unsigned long)p则意为:将表示地址值的p强制转换成无符号的长整型。(即:告诉编译器,以前变量p里存储的是内存中的某个地址,现在变量p里存储的是一个长整型。即让编译器看待变量p的眼光改变一下,以后p是一个整型变量了,不是指针了,不要把它里面的值当做某个变量的地址了,不能根据这个地址去找某变量了。)
任何数值一旦被强制转换,其类型就变了。(即编译器解释其值代表的含义就变了)
故:(unsignedlong)p + 0x1 是一个长整型值加一个整型值,结果为:0x100001
(unsigned int *)p则意为:将一个表示double型变量的地址值的指针,转换成一个表示unsigned int型变量地址的指针。
故(unsigned int*)p + 0x1值为:0x100000+sizeof(unsignedint)*0x1 等于 0x100004
【**强制转换指针类型的目的是为了:改变指针的步长(偏移的单位长度)**】
注意:两个指针直接相加是不允许的。(你要真想把两个地址值相加,把它们先都强制转换为int型即可)
两个指针直接相减在语法上是允许的。(但必须相对于同一个数组,结果是两指针指向位置相隔的元素个数)
**指针表达式:**
**注意:*与++优先级相同,且它们的结合性都是从右向左的。**
例:char ch ;char *cp=&ch ;
指针表达式:
①*++cp 先运算++cp,再解引用*。
当其为右值时,是ch下一个存储单元的值(是一个垃圾值)
当其为左值时,是ch的下一个存储单元
②(*cp)++
当其为右值时,表达式的值等于ch的值,(但它使ch值自增1)
当其为左值时,非法。
【**注意:++,--的表达式(及大部分的表达式,数组的后缀表达式除外)的值都只是一种映像(暂存于寄存器),不在内存区中,故无法得到它们的地址,它们也无法做左值**】
★故:(*cp)++表达式的值虽与ch相同,但它只是ch值的一份拷贝,不是真正的ch
③++*cp++
当其为右值时:表达式的值等于ch+1,这个值只是一个映像(寄存器中)。(但这个表达式实际做了一些工作:使cp指向ch的下一个单元,使ch中的值增1)
当其为左值时:非法。
【++,--,与*组合的指针表达式只是把几个工作融合在一个表达式中完成,使代码简洁,但可读性差】
例:对于 *cp++ ; 我们可以把它分解为: *cp 之后再 cp++
对于 *++cp ; 我们可以把它分解为:++cp 之后再*cp
';
贰(几个关键字、几个运算符、隐式转换/溢出、表达式求值的顺序、左值和右值)
最后更新于:2022-04-01 20:29:59
**贰**
**几个关键字**
sizeof
1、sizeof是关键字而不是函数。
例:int i=3; sizeof(i) ; 与 sizeof i ; 是完全等同。
sizeof在计算变量所占空间大小时,括号可以省略,而计算类型大小时不能省略。(所以我们常在其后加上括号)
2、sizeof的作用域是紧跟它后面的一个变量或类型。
故:sizeof(int)*p;//p为指针,则此表达式会报错。此表达式的意思不是计算 *p强制转换成int类型之后值的存储大小,而意为sizeof(int)的值4 然后是*p的值 这两个值中间没有操作符故会报错。同理:sizeof i*i ;//int i=3 此表达式值为12
1、 ★sizeof的值在编译时就已经确定,故在程序执行时不会执行sizeof括号内的表达式。
~~~
#include
int main(void)
{
int i;
i = 10;
printf("sizeof(i++)is: %d\n",sizeof(i++));
printf("i :%d\n",i);
return 0;
}//最后打印i的值为10,因为程序不执行sizeof里的表达式i++
~~~
switch、case组合
注意:
1、每个case语句的结尾不要忘了加break,若是为了实现某功能故意不加,应该注释清楚
2、最后必须使用default分支。即使程序真的不需要default处理,也应该保留语句
default : break;
可以避免让人误认为你忘了default处理。
2、 case关键字后面只能是整型或字符型常量(小整型)或常量表达式。
3、 ★switch块中的case是一个标签,switch根据值来选择执行哪个case标签的语句。故编译器只对case和default标签里的语句编译,而写在而在case块之前的语句则忽视掉。
~~~
#include
int main(void)
{
inta=1;
switch(a)
{
intb=20; //此语句不被编译,C编译器会产生警告(C++编译器会报错)
case1:
printf("bis %d\n",b); //故此输出随机值
break;
default:
printf("bis %d\n",b);
break;
}
return 0;
}
~~~
void
void的字面意思是“空类型”,void * 则为“空指针类型”任何类型的指针都可以直接赋值给它,无需进行强制类型转换。但:void * 不可以不经强制类型转换地赋值给其它类型的指针。因为“空类型”可以包容“有类型”,而有类型则不能包容“空类型”。
如果函数的参数可以是任意类型的指针,那么应声明其参数为void *
void不能代表一个真实的变量。(因为定义变量时必须分配内存空间,定义void类型编译器不知道分配多少空间)故:void a ;//错误
void只是为了一种抽象的需要。
const
在C语言中,const修饰的值是只读变量,其值在编译的时候不能被使用,因为编译器在编译的时候不知道其存储的内容。
例:const intmax=100 ; int Array[max] ;
在C编译环境下,编译器会报错。因为在C中,const修饰的仍然是变量,只不过是只读属性罢了。
而在C++中,const则修饰的值是常量,完全可以取代宏定义,其效果和宏定义相同。故上面的代码在C++中是合法的。
volatile
volatile修饰的量就是很容易变化,不稳定的量,它可能被其它线程,操作系统,硬件等等在未知的时间改变,所以它被存储在内存中,每次取用它的时候都只能在内存中去读取,它不能被编译器优化放在内部寄存器中。
★const和volatile在类型声明中的位置
两者的规则一样。以const为例:
类型声明中const用来修饰一个常量,我们一般这样使用:
①const在前面
const int ; //int是const
const char* ; //char是const
char* const ; //*(指针)是const
const char* const ; //char和*都是const
【const所修饰的类型是 它后面的那一个】
②const在后面( 与上面的声明对等)
int const ; //int是const
char const* ; //char是const
char* const ; //*(指针)是const
char const* const ; //char和*都是const
**建议const写在后面:**
A. const所修饰的类型是正好在它前面的那一个。
B. 我们很多时候会用到typedef的类型别名定义。比如typedef char* pchar,如果用const来修饰的话,当const在前面的时候,就是const pchar,你会以为它就是const char* ,但是你错了,它的真实含义是char* const。是不是让你大吃一惊!但如果你采用const在后面的写法,意义就怎么也不会变,不信你试试!
***几个运算符***
逻辑运算符:**(一定要注意表达式的顺序)**
&& || 有“短路”现象 (有好处也有坏处)
**/*利用短路现象*/**
例:if( x>=0&& x5 ? b-6: c/2 ; //可读作“a是不是大于5?如果是,就执行b-6,否则执行c/2”
~~~
if(a>5)
b[2*c+d(e/5)]= 3 ;
else
b[2*c+d(e/5)]= -20 ;
//用条件运算符可写作:b[2*c+d(e/5)]= a>5 ? 3 : -20 ;
~~~
【在某些复杂的表达式写相似的两次时,用条件运算符更简洁,易修改会产生较小的目标代码, 可以简化表达式】
逗号运算符:
【**可用于循环判断中(多用于while),使多次重复的语句只写一次**】
~~~
a=get_value();
count_value(a);
while(a>0)
{ ……….
a=get_value();
count_value(a);
}
~~~
则可简化为: while(a=get_value() , count_value(a) , a>0){……}
(这些表达式自左向右逐个求值,整个逗号表达式的值就是最后那个表达式的值)
***隐式转换 / 溢出***
例1:char ch ;
While( (ch=getchar()) != EOF ) …..//错误!
注意:**getchar()返回一个整型值而不是字符值!**
若把getchar返回值存储于ch中,将导致它被截断!然后这个被截断的值被提升为整形并与EOF比较,循环会出错。
【用整形来定义一个字符变量更好!**字符就是一个小整数**】 sizeof(‘a’) ; 的值为4。
~~~
char a,b,c ;
a = b+c ; //b+c的值超过或等于128就会出错。
~~~
注意:C的整型算数运算总是至少以缺省整型类型的精度来进行的。为了获得这个精度,表达式中的字符型和短整型操作数在使用之前被转换为普通整型。即:**整型提升**
(上面b和c的值被提升为普通整型,然后再执行加法运算。加法运算的结果被截断再存储于a中)
【所以:**最好把字符型定义为int 尤其是涉及运算时**】
//WHY?在整数运算时,操作数是放到两个寄存器中进行的(32位计算机寄存器是32位 故字符型变量被提升为整型,计算的结果又被传回到内存中的字符型存储位置中故被截断)
~~~
int a=5000 ;
int b=25 ;
long c=a*b ;
~~~
表达式a*b以整型进行计算,若在16位的计算机上,这个乘法可能会产生溢出!
故应该显式转换: longc=(long)a*b ;
【在进行算术运算时一定要警惕乘法加法的可能溢出,尤其**注意赋值号两边的数据类型保持一致**】
在计算类似a*b/c 这样的表达式的时候,一些中间计算结果可能会溢出。
【**对于算术运算可能的溢出一定要保持警惕!!!**】
***对无符号类型的建议:***
1、尽量不要在你的代码中使用无符号类型,以免增加不必要的复杂性。
2、尽量使用像int那样的有符号类型,这样在涉及升级混合类型的复杂细节时,不必担心边界情况。
3、只有在使用位段和二进制掩码时,才可以使用无符号数。
***表达式求值的顺序***
***两个相邻操作符的执行顺序由它们的优先级决定。如果它们的优先级相同,它们的执行顺序由它们的结合性决定。(即从左还是从右运算),此外编译器可自由决定顺序对表达式求值!
~~~
a*b + c*d +e*f ;
//可能按下列顺序运行:
c*d
e*f
a*b
(a*b)+(c*d)
(a*b)+(c*d)+(e*f)
//加法运算的结合性要求两个加法运算按先左后右执行,但对表达式剩余部分执行顺序没有限制。 没有规则要求所有的乘法首先进行,没有规定其谁先执行。
~~~
【**优先级只对相邻的操作符的执行顺序起作用**】
【在C语言的众多运算符中,**ANSI标准只规定了4种运算符的操作数的求值顺序: && || 逗号运算符 和 ?:**】
警示:f( ) + g( )+ h( ) ; //应该避免!
如果函数执行有副作用,不同的结合顺序会产生不同的结果!
故 最好使用临时变量,让每个函数调用都在单独的语句中进行。
~~~
tmp = f( ) ;
tmp += g( ) ;
tmp += h( ) ; //良好的编程风格
~~~
【**避免编写 结果依赖于求值顺序的表达式**】
例:a[i] = i++; //应该避免!
//i在同一表达式的其它地方被引用无从判断该应用是旧值还是新值。
【**确保一个表达式只修改一个对象,如果要修改多个对象,要确保修改的对象互不相同**!(在一个表达式中,一个对象只能修改一次)】
~~~
printf(“%d%d”,f1(), f2() ) ; //应该避免!
//若函数f2( )的结果依赖于函数f1( ) 则printf的结果是不确定的!
//用逗号分隔的函数参数不是逗号运算符。
~~~
【**函数调用的参数的求值顺序是不确定的! 不要让有副作用的函数作为参数!**】
***左值和右值***
左值就是那些能够出现在赋值号左边的东西,右值就是那些可以出现在赋值号右边的东西。
【编译原理:编译器会把赋值号左边的部分解释成一个存储位置,把赋值号右边的部分解释成一个值。在编译过程中,编译器会维护一张变量表,其中是我们定义过的变量名及其在内存中分配的地址。 当编译器遇到一个变量名,若此变量名在赋值号的左边,则编译器查变量表得到其在内存中的地址;若此变量名在赋值号的右边,则编译器先查得其在内存中地址,再把地址中的内容提取出来。(不准确,但初学者可以这么理解)】
**变量作为右值时,编译器只是取变量的值。**
**左值标志了一个特定的位置来存储结果。**
例: a =b+25 ; // 正确
b+25 = a ;// 错误
当计算机计算b+25时,它的结果只是一个映像(暂存寄存器中),不在内存区中,我们无法得到它的地址,故这个表达式不是一个左值。
同理:*cp + 1 也不可做左值。(因为其值不存储于内存区中的一个特定的位置)
而字符串字面量虽然存储于内存区中,但其存储于内存的无名常量区,这个位置不是由我们设定的特定位置,而是由编译器随机分配的,故其也不能作为左值。
**表达式也可以是左值。**
例:int a[30] ; ……….a[b+10]=0 ; // 正确
下标引用实际是一个操作符,故左边实际上是个表达式,但它是一个合法的左值,因为它标志了一个特定的位置。
同理: int a, *p ; ……..p=&a; *p=20 ; // 正确
(含操作符的就是表达式。 sizeof(int) ; 也是表达式)
【**左值意味着一个位置,而右值意味着一个值(左值就是存储右值的位置)**】
';
壹(变量的作用域及存储方式)
最后更新于:2022-04-01 20:29:57
悟道系列之——C语言
这是我的第一篇博文。对我来说CSDN并不陌生,但一直以来我都是一个默默的潜水者,可是今天我要冒泡了。特意选了十月一日来重新注册账号,我想赋予这个日子以新的意义。在进入正题之前,我想有必要简单的向大家介绍一下自己。
本人80后后,刚毕业于一所普通师范类学校的化学专业。本人形象猥琐,身无长物,自觉难以为祖国的教育事业服务,遂混迹于程序猿们的队伍之中。
本科四年,前半段浑浑噩噩,后半段幡然悔悟。而正式决定踏入编程,则已是2011年的愚人节了。(我有意选择这个日子作为纪念)屈指算来今天竟刚满一年半,这真是一个让人惊喜的巧合。
写了这么多废话,无非是想让大家明白:这不是一个大牛的博客。如果您想从中寻找一些金玉良言,那么让您失望了。这里只是一个技术菜鸟对他一路以来在编程中思考和领悟的记录,分享给那些在学习中有些困惑的初学者。
从C讲起吧,以前学习时做了很多笔记,现在把它们筛选整理成电子版的形式分享出来,也方便自己以后查阅。
本系列文章中的读者应该是 C语言语法的入门者。
因为本文不是零基础扫盲贴。要熟悉C的语法 随便一本教材反复研读实践即可。
此文大多是个人的读书笔记、编程感悟及曾经遇到的问题,至于一些技巧和代码风格网上资源不在少数,故本文很少提及。
提纲:
**壹**:变量的作用域及存储方式
[**贰**:几个关键字、几个运算符、隐式转换/溢出、表达式求值的顺序、左值和右值](http://blog.csdn.net/yang_yulei/article/details/8068210)
[**叁**:数组与指针(一)](http://blog.csdn.net/yang_yulei/article/details/8071047)
[**肆**:数组与指针(二)](http://blog.csdn.net/yang_yulei/article/details/8071068)
[**伍**:字符串、函数、动态内存分配](http://blog.csdn.net/yang_yulei/article/details/8072552)
[**陆**:结构、联合、位段、位级操作](http://blog.csdn.net/yang_yulei/article/details/8072567)
[**柒**:文件、输入输出函数](http://blog.csdn.net/yang_yulei/article/details/8087957)
[**捌**:预处理、程序调试、编程风格](http://blog.csdn.net/yang_yulei/article/details/8098329)
[**玖**:常用库函数](http://blog.csdn.net/yang_yulei/article/details/8098357)
开场白:
**【C语言结合了汇编语言的所有威力和汇编语言的所有易用性】**
壹
**变量的作用域:**
1, 局部变量
局部变量是在函数内定义的变量,其作用域仅限于函数内,在函数内才引用,即可以对它赋值或取值。在作用域外,使用它们是非法的。
2, 全局变量
全局变量是定义在函数之外的变量,它的作用域是从定义处开始,到所在文件的结束。即从定义之处起,它可以在文本的所有函数中使用。
【全局变量的命名最好取有特殊含义的标识符(例如在变量名前加q_)。防止不经意间改变了它的值。***全局变量违反了最低特权原则,而且是糟糕的软件工程方法***】
3, 外部变量
全局变量的作用域是在所在文件的整个文件,而一个文件中的全局变量的作用域还可以扩展到其它文件。某个文件中引用另一个文件中的全局变量,只要用extern声明,说明这个变量是在其它文件中已经定义过的外部变量。那么,该文件中不会为外部变量分配内存。
几点说明:
(1)关于外部变量声明的定义和引用
C所存在的一个众所周知的缺陷是很难区分外部变量声明的定义和引用。(来源于《C语言参考手册》)
标准C:在顶层声明中,如果出现了初始化值,它就被认为是个定义性声明。其它的声明则是引用性声明。在C程序的所有文件中,同一个变量的定义性声明只能出现一次。
~~~
int x ; //引用 (C++认为其是定义)
int x=0; //定义
extern int x ; //引用
extern int x =0 ; //定义 (C++认为非法)
~~~
建议:
A,每个外部变量具有一个单独的定义点(在源文件中)。**在定义性声明中,省略extern类别,并提供一个显式的初始化值: int errcnt = 0 ;**
【所以说,全局变量就是外部变量】
B,在其它引用外部变量的每个源文件或头文件中,**在引用性声明中,使用存储类别extern,并且不要包含初始化值: extern int errcnt ;**
**【注意:】**
**外部变量的引用类型必须和其定义类型一致!**(分别编译的时候编译器无法检查两者类型是否一致,但是若不一致运行时会出错)
~~~
//file1.c------
intarr[80];
//file2.c--------
externint *arr;
intmain()
{
arr[1]= 100;
printf("%d\n",arr[1]);
return0;
}
~~~
该程序可以编译通过,但运行时会出错。原因是,在另一个文件中用 extern int *arr来外部声明一个数组并不能得到实际的期望值,因为他们的类型并不匹配。导致指针实际并没有指向那个数组。修改:extern int arr[]。
数组是数组指针是指针。虽然在函数间传递时数组名会退化为常量指针。在定义的时候它们是不同的,编译器给它们分配不同的空间。在外部声明引用时,编译器见到int*arr只会认为其是指针,由于其是全局变量,故给其初始化为0,而编译器见到extern int arr[]会知道arr为外部定义的数组。
(2)同一源文件中,允许全局变量和局部变量同名,但在局部变量的作用域内,全局变量不起作用。【**即当全局变量与局部变量相遇,局部变量屏蔽全局变量**】
~~~
#include
int a=1 , b=2, c=3 ;
int main(void)
{
{
int a=20, b=30 ;
c=(a-=10)+b++ ;
printf("%d,%d,%d\n",a,b,c) ; //输出10,31,40
}
printf("%d,%d,%d",a,b,c) ; //输出 1,2,40
return0 ;
}
//位于一个花括号之间的所有语句成为一个代码块,在代码块开始位置声明的变量的作用域只在此代码块中
//花括号的作用就是打包,使之成为一个整体,并与外界绝缘。
~~~
**变量的存储方式**
1, 动态存储:在程序的执行过程中,使用它时才分配存储单元,使用完毕立即释放。
(其存储空间在栈上)
自动变量的类型说明符为:auto自动变量是动态存储方式,凡未加存储类型说明的变量均视为自动变量。自动变量的作用域和生存期都局限于定义它的个体内。
2, 静态变量:在变量定义时就分定存储单元并一直保持不变,直至程序结束。
(其存储空间在堆上)
【**静态变量的初值是在编译时赋予的,不是在程序执行期间赋予的**】
(1) 静态局部变量
在局部变量的说明前加上static 就构成静态局部变量。
A,静态局部变量在函数内定义,但**它的生存期为整个程序**。
**B,**其生存期虽为整个程序,但其作用域与自动变量相同,**只能在定义的函数内使用。退出函数后,尽管该变量还在,但已不能再使用。**
C,允许对静态局部变量赋初值。若未赋初值,则由系统自动赋0值
D,只在第一次调用函数时给静态变量赋初值,再次调用定义它的函数时,其保存了前一次被调用后留下的值。
【因此,当多次调用一个函数且要求在调用之后保留某些变量的值时,可采用静态局部变量】
(2) 静态全局变量
在全局变量前加static,就构成了静态的全局变量。它们都是静态存储方式。但两者的区别在于:作用域的扩展上。
全局变量的作用域可以扩展到整个源程序。静态全局变量的作用域局限于一个源文件内。
【因此,全局变量加上static限制,是为了避免在其它源文件中被引用,防止出错】
C语言中static的作用:
1、 修饰变量。
静态全局变量,作用域仅限于变量被定义的文件中。
静态局部变量,在函数体中定义的,就只能在这个函数里用了。
2、 修饰函数。
指函数的作用域仅局限于本文件(内部函数),使用内部函数的好处是防止与其他文件中的函数命名冲突。
';
前言
最后更新于:2022-04-01 20:29:55
> 原文出处:[C之精华全记录](http://blog.csdn.net/column/details/the-c-language.html)
作者:[yang_yulei](http://blog.csdn.net/yang_yulei)
**本系列文章经作者授权在看云整理发布,未经作者允许,请勿转载!**
# C之精华全记录
> C语言 进阶,总结了C中的大部分语法,带你穿越指针的荆棘,拨开C的迷雾。
';