后话
最后更新于:2022-04-02 01:04:05
## **后话**
HTTP/2才刚刚正式发布不久,支持程度并没有那么好,以后应该有相当长的一段时间,HTTP/2要与HTTP/1.x共存。特别是,Win7快要成为下个XP的节奏,那么IE9就是下个IE6了。双协议部署上,可能会有不少麻烦之处。HTTP/1.x时代的很多优化,在HTTP/2是不必要的,也有冲突的,甚至是累赘。
* 比如子资源的位置,可以用HTTP/2优先级解决。
* 比如域名分区,在HTTP/2中本来可以用一个连接完成,却要用多个连接,这样就有性能损耗了。
* 比如合并、雪碧图,之前是为了减少请求,但在HTTP/2新起请求不费事,但拆分开来倒可以更好地利用浏览器缓存。还有类似的内联资源,可以用服务器推送,也同样可以更好地利用缓存。
更多具体的问题,需要在生产实践中得出了。
HTTP/2 demo

**参考资料**
* 《Web性能权威指南》
* https://httpwg.github.io/specs/rfc7540.html(HTTP/2协议)
* https://httpwg.github.io/specs/rfc7541.html(HPACK)
* https://imququ.com/post/http2-resource.html(HTTP/2资料汇总)
* https://imququ.com/post/server-push-in-http2.html(HTTP/2中的Server Push讨论)
* https://www.gitbook.com/book/ye11ow/http2-explained/details(HTTP2讲解)
* http://httparchive.org/
* http://segmentfault.com/a/1190000002642924
';
一次完整的HTTP/2通信
最后更新于:2022-04-02 01:04:02
## **一次完整的HTTP/2通信**

1. 在尚未知道服务器是否支持HTTP/2时,http请求头部加上upgrade: h2c,表明客户端支持HTTP/2,询问服务器要不要切换协议。
2. 浏览器同时发送HTTP2-Settings头部,带上base64编码的SETTINGS frame。
3. 对于https请求,是在TLS握手时进行协商,浏览器发送ClientHello时,带上h2标志,表明客户端支持HTTP/2。
4. 若服务器不支持,则忽略upgrade头部,正常响应。若支持,则发送101响应,以空行结束响应,并开始发送HTTP/2帧。
5. 服务器要先响应connection preface,带上SETTINGS frame。
6. 服务器创建新流,推送a.js。然后继续发送index.html和a.js的response header、response body。
7. 浏览器收到PUSH_PROMISE帧,发现服务器要推送的内容已经在浏览器缓存里了,遂发送RST_STREAM拒绝推送。
8. 服务器收到RST_STREAM后,不再推送a.js剩下的数据。
9. 服务器因为一些原因想要关闭连接,发送GOAWAY帧。也可以由浏览器关闭,只要浏览器觉得之后不再有请求了。
';
首部压缩
最后更新于:2022-04-02 01:04:00
## **首部压缩**
服务器推送,此推送非彼推送,一开始以为,是不是以后可以抛弃轮询这种技术了?并不是,该轮询还是要轮询。那么,在开启keep-alive的情况下,轮询在HTTP/2中的性能没什么提升吗?也并不是。
在HTTP/1.x中首部是没有压缩的,gzip只会压缩body,HTTP/2提供了首部压缩方案。一般轮询请求首部,特别是cookie占用很多大部份空间,首部压缩使得整个HTTP数据包小了很多,传输也就会更快。
刚开始spdy提出的首部压缩方案比较简单粗暴,直接像压缩body那样压缩首部,这看起来好像没什么不妥,但是有安全隐患,会有受到CRIME式攻击的可能性。这种攻击方法简单说,就是不断地利用已知数据去探测密文,达到破解的目的。无损压缩算法会有个特性,数据越冗余,压缩效率越好。而首部中的很多字段是已知的,我们只要构造个请求,请求中带有首部的某个字段,经压缩再加密后的密文长度就会有所变化,然后不断构造猜测该字段的值,同时观察密文的长度,慢慢地确定首部字段的值。
~~~
GET /pwd=0 HTTP/1.1
Cookie: pwd=123
GET /pwd=1 HTTP/1.1
Cookie: pwd=123
~~~
我们会发现,前者的密文长度比后者长,这样就确定了“d”,再慢慢的猜测,达到破解的目的。
HTTP/2中抛弃了这种方案,用专门设计的HPACK。它是在服务器和客户端各维护一个“首部表”,表中用索引代表首部名,或者首部键-值对,上一次发送两端都会记住已发送过哪些首部,下一次发送只需要传输差异的数据,相同的数据直接用索引表示即可,另外还可以选择地对首部值压缩后再传输。按照这样的设计,两次轮询请求的首部基本是一样的,那之后的请求基本只需要发送几个索引就可以了。

“首部表”有两种,一种是静态表,即HTTP/2协议内置了常用的一些首部名和首部键值对。另一种是动态表,保存自定义的首部或五花八门的键值对等,动态表可以通过`SETTINGS`帧的SETTINGS_HEADER_TABLE_SIZE规定大小。
';
服务器推送
最后更新于:2022-04-02 01:03:58
## **服务器推送**
作为HTTP/2的一个重磅新功能,我们不要简单理解字面意思,其实不是你想推,想推就能推的,服务器要遵循请求-响应这个模型,只不过服务器对同一请求可以推送多个响应。客户端在交换 `SETTINGS` 帧时,设置字段 `SETTINGS_ENABLE_PUSH(0x2)` 为1显式允许服务器推送。
在HTTP/1.x时代,其实我们已经体验过了“服务器推送”,就是资源内嵌到HTML里。服务器在响应HTML时,就已经知道浏览器会请求哪些子资源了,这时一并响应这些子资源,可以节省了服务器到浏览器以及浏览器解析再发请求的这段延迟。但是内联的问题是浏览器不会缓存这些数据,这意味要浪费很多流量,而且有缓存时网页性能还是很好的。
服务器推送解决了这个问题。服务器在接受到请求时,分析出要推送的资源,先发个 `PUSH_PROMISE` 帧给浏览器。此帧包含一个新的流ID,还有header block fragment字段,内容是请求的头部信息,可理解为服务器模拟浏览器发起请求,然后再发送各个response header和response body。浏览器收到 `PUSH_PROMISE` 帧时,根据header block fragment字段里的url,可以知道当前有没有缓存,从而判断是否要接收。如果不要,浏览器就要发送个 `RST_STREAM` 来终止服务器推送。
如果浏览器不要这个推送,就会出现浪费流量的现象,因为整个过程都是异步的,在服务器接收到`RST_STREAM`时,响应很有可能部份发出或者全部发出了。这种情况只能视场景而定,若是流量浪费不能容忍,我们可以使用prefetch来替代,让浏览器尽早发现需要的资源,而HTTP/2中创建新的请求并不需要多少时间,所以大概多了个RTT的时间。
';
多路复用
最后更新于:2022-04-02 01:03:56
## **多路复用**
在HTTP/2中,有两个非常重要的概念:帧(frame)和流(stream)。
**1、帧(frame)**
HTTP/2中数据传输的最小单位,因此帧不仅要细分表达HTTP/1.x中的各个部份,也优化了HTTP/1.x表达得不好的地方,同时还增加了HTTP/1.x表达不了的方式。
每一帧都包含几个字段,有length、type、flags、stream identifier、frame playload等,其中type代表帧的类型,在HTTP/2的标准中定义了10种不同的类型,包括上面所说的`HEADERS` frame和 `DATA` frame。此外还有
`PRIORITY`(设置流的优先级)
`RST_STREAM`(终止流)
`SETTINGS`(设置此连接的参数)
`PUSH_PROMISE`(服务器推送)
`PING`(测量RTT)
`GOAWAY`(终止连接)
`WINDOW_UPDATE`(流量控制)
`CONTINUATION`(继续传输头部数据)
**2、流(stream)**
“流”在HTTP/2中是一个逻辑上的概念,就是说在一个TCP连接上,我们可以向对方不断发送一个个的消息,这里每一个消息看成是一帧,而每一帧有个stream identifier的字段标明这一帧属于哪个“流”,然后在对方接收时,根据stream identifier拼接每个“流”的所有帧组成一整块数据。我们把HTTP/1.x每个请求都当作一个“流”,那么请求化成多个流,请求响应数据切成多个帧,不同流中的帧交错地发送给对方,这就是HTTP/2中的多路复用。
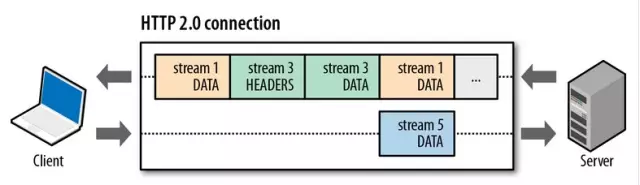
从上图我们可以留意到:
* 不同的流在交错发送;
* `HEADERS` 帧在 `DATA` 帧前面;
* 流的ID都是奇数,说明是由客户端发起的,这是标准规定的,那么服务端发起的就是偶数了。
多路复用让HTTP连接变得很廉价,只需要创建一个新流即可,这不需要多少时间,而在HTTP/1.x时代却要经历三次握手时间或者队首阻塞等问题。而且创建新流默认是无限制的,也就是可以无限制的并行请求下载。不过,HTTP/2还是提供了 `SETTINGS_MAX_CONCURRENT_STREAMS` 字段在 `SETTINGS` 帧上设置,可以限制并发流数目,标准上建议不要低于100以保证性能。
优化Web性能有一个常用的技术,就是图片延迟加载,目的是除了节省流量外,还能避免图片资源与其他重要的脚本资源竞争下载。
HTTP/2提供了流的优先级与依赖性这种机制,可用 `HEADERS` 帧或 `PRIORITY` 帧设置,不过协议并没有提供如何处理优先级的具体算法,这可由服务器灵活应对。我用个例子来说明这个机制。
~~~

 ~~~
浏览器是边下载边解析的,文档解析器首先遇到a.js,它就会去下载并且阻塞页面,同时,资源探测器会继续向下扫描,发现a.jpg、b.jpg和style.css并服务器发起请求。在没有优先级机制时,a.jpg、b.jpg会跟重要的a.js、style.css竞争下载,但在HTTP/2中,浏览器可以给a.jpg、b.jpg设置较低的优先级,另外依赖关系为
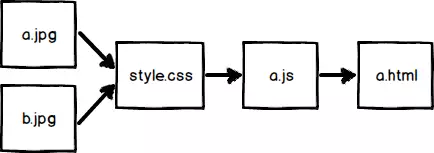
这样服务器根据优先级信息,首先吐出a.js、style.css,再吐出图片,因此页面在没有图片的情况下提前进入可交互状态。例子所说的是在浏览器层面上harcode的一个优先级策略,再比如上文提到的prefetch就可以给一个更低的优先级。在代码层面上,也许之后会提供一些控制优先级的特性,类似于目前只有IE支持的lazyload attribute。
~~~
浏览器是边下载边解析的,文档解析器首先遇到a.js,它就会去下载并且阻塞页面,同时,资源探测器会继续向下扫描,发现a.jpg、b.jpg和style.css并服务器发起请求。在没有优先级机制时,a.jpg、b.jpg会跟重要的a.js、style.css竞争下载,但在HTTP/2中,浏览器可以给a.jpg、b.jpg设置较低的优先级,另外依赖关系为

这样服务器根据优先级信息,首先吐出a.js、style.css,再吐出图片,因此页面在没有图片的情况下提前进入可交互状态。例子所说的是在浏览器层面上harcode的一个优先级策略,再比如上文提到的prefetch就可以给一个更低的优先级。在代码层面上,也许之后会提供一些控制优先级的特性,类似于目前只有IE支持的lazyload attribute。
';
~~~
浏览器是边下载边解析的,文档解析器首先遇到a.js,它就会去下载并且阻塞页面,同时,资源探测器会继续向下扫描,发现a.jpg、b.jpg和style.css并服务器发起请求。在没有优先级机制时,a.jpg、b.jpg会跟重要的a.js、style.css竞争下载,但在HTTP/2中,浏览器可以给a.jpg、b.jpg设置较低的优先级,另外依赖关系为

这样服务器根据优先级信息,首先吐出a.js、style.css,再吐出图片,因此页面在没有图片的情况下提前进入可交互状态。例子所说的是在浏览器层面上harcode的一个优先级策略,再比如上文提到的prefetch就可以给一个更低的优先级。在代码层面上,也许之后会提供一些控制优先级的特性,类似于目前只有IE支持的lazyload attribute。
bigpipe
最后更新于:2022-04-02 01:03:53
## **bigpipe**
目前大部分模型都是,服务器把逻辑处理完之后,一次性把整个响应输出。这里存在一个阻塞的过程,逻辑处理一般都涉及IO操作的都比较慢,而现代浏览器都支持边接收数据边渲染,所以其实服务器可以接收到请求时就把页面框架flush出来,如果页面包含多个较独立部分,也可以每处理完一部分就马上输出,这样可以缩短白屏。从用户感受上可能会更好,页面上一直有所反应,而不是一直白屏,完全不知道你在干嘛。
各种各样的优化,都在填HTTP/1.x留下的坑,HTTP/2带着填坑的使命,从根本上去解决这些问题。HTTP/1.x是一个文本协议,这注定它是非常冗余的协议,HTTP/2改变了这一点,在HTTP/1.x的语义上,将文本数据封装在帧里,并采用二进制编码。
下图中binary framing就是二进制分帧层,这里会将HTTP/1.x的header翻译成headers类型的帧,将body翻译成data类型的帧。

HTTP/2的性能怎样,akamai的这个demo(https://http2.akamai.com/demo)估计会让你很兴奋。
下面详细介绍下HTTP/2。
';
HTTP管线化
最后更新于:2022-04-02 01:03:51
## **HTTP管线化**
HTTP管线化可以克服同域并行请求限制带来的阻塞,它是建立在持久连接之上,是把所有请求一并发给服务器,但是服务器需要按照顺序一个一个响应,而不是等到一个响应回来才能发下一个请求,这样就节省了很多请求到服务器的时间。不过,HTTP管线化仍旧有阻塞的问题,若上一响应迟迟不回,后面的响应都会被阻塞到。

';
HTTP持久连接
最后更新于:2022-04-02 01:03:49
## **HTTP持久连接**
HTTP持久连接可以重用已建立的TCP连接,减少三次握手的RTT延迟。浏览器在请求时带上 `connection: keep-alive` 的头部,服务器收到后就要发送完响应后保持连接一段时间,浏览器在下一次对该服务器的请求时,就可以直接拿来用。
以往,浏览器判断响应数据是否接收完毕,是看连接是否关闭。在使用持久连接后,就不能这样了,这就要求服务器对持久连接的响应头部一定要返回content-length标识body的长度,供浏览器判断界限。有时,content-length的方法并不是太准确,也可以使用 `Transfer-Encoding: chunked` 头部发送一串一串的数据,最后由长度为0的chunked标识结束。

';
手动管理缓存
最后更新于:2022-04-02 01:03:46
## **手动管理缓存**
为了代码架构清晰,便于维护,我们都会用模块化的方式去编码,每个模块一个文件,这样带来的问题是一个页面需要很多文件,要很多请求,这对页面性能是不利的。合并是解决这个问题的好方法,但又因为HTTP缓存机制是基于URL的,只要某个模块一改动,整个合并资源都要重新下载。
在对性能要求较高,比如在移动设备环境上,我们可以利用HTML5中的localStorage特性,来实现手动控制缓存。大概的思路是,在定义模块时,同时将模块的代码和版本号分别储存到localStorage,在下一次打算请求模块之前,我们先判断模块的最新版本是不是在localStorage中,将不存在的模块组合在一起,请求动态合并的资源。
不过,这种方案可能会引发安全问题。假如同域下的其他页面被XSS攻击,坏人就可以篡改localStorage的内容,可能导致原来的页面代码被植入恶意程序。解决的方法是,在执行模块之前,算一下代码摘要,对比下服务器给的该模块的摘要,再决定是否使用。也可以使用SRI策略,由浏览器帮你做校验。
';
内联
最后更新于:2022-04-02 01:03:44
## **内联**
对于一些简单的页面,CSS样式和JavaScript脚本甚至图片,可以不必使用外联的方式引入,直接把子资源内嵌到HTML里,图片可以用base64编码内嵌,这相当于请求页面时,服务器顺便把子资源给一共推送过去了。传输的内容都一样,但减少好多请求了,自然节省不少时间。
不过这样做的缺点是浏览器无法缓存这些子资源,这种做法只能降低首次加载时间,所以需要看取舍了。可能比较适用于一次性的页面,类似活动之类的。
';
使用TCP、TLS最佳实践
最后更新于:2022-04-02 01:03:42
## **使用TCP、TLS最佳实践**
HTTP请求要经过建立TCP连接这一步,而TCP为了可靠传输,建立连接需要三次握手。如果网站又接入了HTTPS,那还要额外多两次RTT时间以建立安全通道,这样耗费了很多时间。HTTP是建立在TCP、TLS之上,那么TCP的最佳实践,SSL的优化都是适用于HTTP的优化。
比如TCP慢启动过程非常影响性能的,我们可以把初始窗口调大,让慢启动更快。对于TLS可用缓存session_ticket之类的优化可以减少一次RTT。
';
预加载
最后更新于:2022-04-02 01:03:40
## **预加载**
DNS查询需要个RTT时间,在浏览器级别,系统级别都会有层DNS缓存,之前解析过的可以直接从本机缓存获取,以减少延迟。
Web标准提供了一种DNS预解析技术,因为服务器是知道页面即将会发生哪些请求的,那我们可以在页面顶部,插入 ``,让浏览器先解析一下这个域名。那么,后续扫到同域的请求,就可以直接从DNS缓存获取了。
此外,Web标准也提供prefetch,prerender的预加载技术。prefectch会在浏览器空闲的时候,向所提供的链接发起请求,而prerender不仅会请求,还会帮你在后台渲染页面。如果在一个页面中,你知道用户有很大概率去点某个链接,可以尝试把这个链接加到prefetch或prerender,那么用户就会秒开这个页面了。
';
避免重定向
最后更新于:2022-04-02 01:03:37
## **避免重定向**
重定向意味着要重新发起请求,当然我们没事也不会乱跳。这里要说的一种重定向是,访问HTTP站点,跳转到HTTPS。
避免这种跳转,我们可以用**HSTS策略**,就是告诉浏览器,以后访问我这个站点,必须用HTTPS协议来访问,让浏览器帮忙做转换,而不是请求到了服务器后,才知道要转换。只需要在响应头部加上 `Strict-Transport-Security: max-age=31536000` 即可。
';
前言
最后更新于:2022-04-02 01:03:35
> 原文:[公众号coding.js](http://mp.weixin.qq.com/s?__biz=MjM5Mzc0MDAwNw==&mid=212340809&idx=1&sn=6d1b294f7f3c03907e68227d05920416#wechat_redirect)

如今,互联网上的内容越来越丰富,过去几年时间,一个页面产生请求和整个大小都一直增长,这个趋势还会一直保持,对页面性能优化也要马不停蹄。

一个页面,会经历过加载资源,执行脚本,渲染界面的过程。我们知道,100ms对于计算机来说,可以干很多事情了,但是对于网络请求,可能一次RTT就没了。因此,页面加载对于Web性能是重中之重。
加载的快慢可以总结成受两个因素影响:**阻塞**与**延迟**。
**1、阻塞。**浏览器在解析到脚本时,会阻塞页面,等到脚本下载执行完才继续解析文档。此外,浏览器还会限制同域下的并行请求数,超过这个限制后的请求就会被阻塞住。
**2、延迟。**网络请求都不可避免会有延迟,网页上的延迟有两种,一是DNS查询,二是TCP连接。
克服这些缺点,我们有一些约定俗成的方案:
* 静态资源要支持304,开启HTTP缓存控制
* 开启gzip,压缩HTTP body
* css放在html的head里,js在body底部
* 合并请求
* 使用雪碧图
* 域名分区(突破并行限制,也避免传输过多cookie)
* 使用cdn
这些方案基本都能立竿见影。但是,对于追求极致(KPI)的我们,这些还是远远不够的。我们从页面开始加载时说起。

';