【工具学习】——Maven的安装与配置
最后更新于:2022-04-01 11:27:40
## 【含义】
什么是构建?
构建,英文build。构建包括编译、运行、生成文档、打包、部署等等工作内容,如果我们每天手工去干这些事情,那会浪费很多的时间。因此,构建管理工具应运而生。
maven,作为项目构建和管理的工具,最初是用来简化构建过程的。
它的功能大致可以分为两大项:1)管理jar包 2)高效率的发布项目。
## 【安装】
maven是跨平台的,无论是Windows还是linux。
**1、Windows系统**
首先检查jdk是否配置成功,在命令窗口输入java -version.
下载地址:[http://maven.apache.org/download.cgi](http://maven.apache.org/download.cgi)
下载之后解压到指定路径即可。
配置环境变量:
新增:
变量名:MAVEN_HOME
变量值:E:\maven\apache-maven-3.2.3 (maven的解压路径)
修改Path变量路径:
在变量值后加上;%MVN_HOME%\bin;
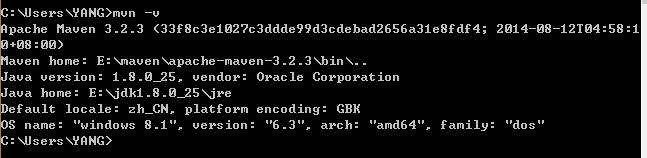
配置完成后输入mvn -v,显示如下信息,表明配置成功。
**2、Linux系统**
Linux系统与Windows的操作基本相同,但配置环境变量的方法稍有不同。
1)在终端命令行配置
export MAVEN_HOME=/usr/local/maven
export PATH=${PATH}:${MAVEN_HOME}/bin
2)在/etc/profile文件直接添加

最后不要忘了验证是否配置成功。
## 【目录结构】
下图是maven的文件结构图,有的习惯于将repository文件放在外面一层,只要配置路径正确即可,都不影响使用。
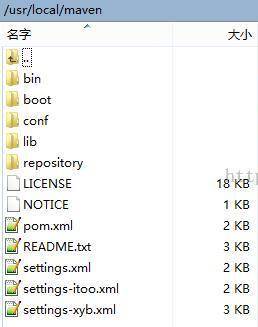
这里简单介绍几个常用的文件:
**1)conf**
目录下包含了一些配置文件,我们可以通过直接修改配置文件setting.xml在机器上全局设定maven。maven的setting.xml文件有两种,一种是系统级别的,一种是用户范围的。在ITOO中,我们推荐使用用户级别的配置文件,即上图与conf同级的setting.xml。在该配置文件中,配置了仓库的信息,关联私服等信息。
**2)lib**
包含了maven运行时需要的java类库。包括第三方的依赖包、maven的模块jar包等。
**3)repository**
repository本身就是个仓库,是一个本地仓库。本地仓库只有本机可以看到,主要的作用是缓存。
本地仓库的路径可在用户范围的setting.xml文件中进行修改,如下所示
~~~
<?xml version="1.0" encoding="UTF-8"?>
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd">
<localRepository>E:/maven/repository</localRepository>
~~~
## 【小结】
这篇博客主要介绍了maven的安装与配置内容,下篇博客将介绍maven的核心概念及其配置文件。
【SSH】——两种添加jar包方式的比较
最后更新于:2022-04-01 11:27:38
## 【前言】
在开发过程中,我们对Eclipse或MyEclipse等IDE越来越熟悉了。在使用的过程中,小编了解到两种添加jar包的方式,今天给大家说下这两种方式的差别。
### 方法一:
将所需要的jar包拷到本项目下的lib文件夹下,这种方式添加完成后,我们可以看到jar包的路径是在本项目的lib下。说明这种方式是将jar包直接Copy到该项目中了。
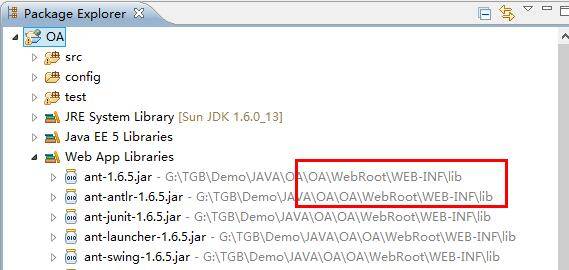
补充下这几个Libraries的含义:
1)JRE System Library:
Java SE 的常用库文件集合,建立普通的Java项目均会使用;
2)java EE 5 Libraries:
JavaEE的常用库文件的集合,建立Web项目会用到这个库集合与Java SE的库文件集合;
3)Web App Libraries:
动态管理WEB-INF/lib和WEB-INF/class目录下的库文件。
4)Referenced Libraries:
指你项目中所使用的第三方库文件集合
### 方法二:
1)建立一个用户自己的库User Library。
选中项目,右键Build Path——Add Libraries。
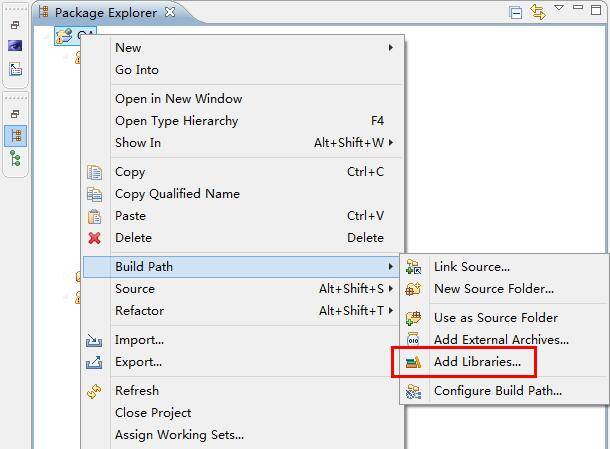
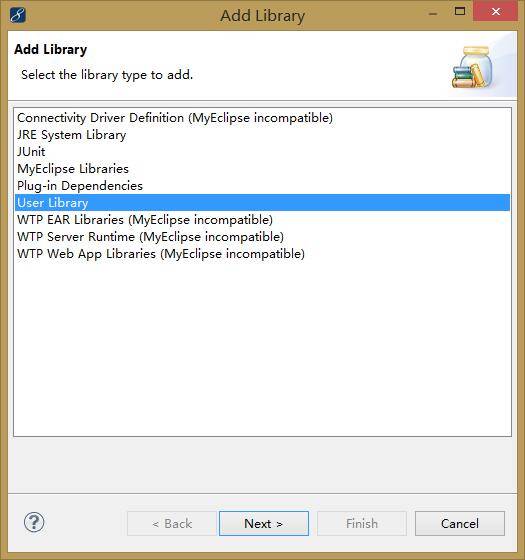

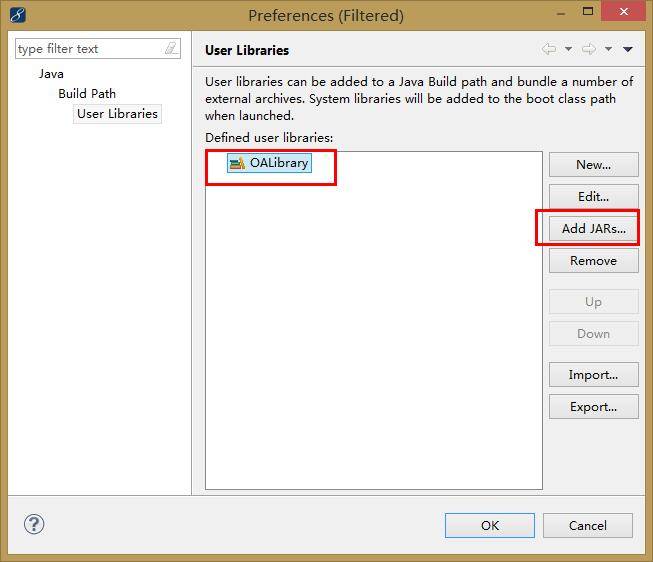
将所需要的jar包添加进去即可。
2)当然,如果没必要新建一个User Library,也可以直接加到MyEclipse自带的Library中。操作步骤与上面的方法类似,在这里就不展示了。
这种方式添加完jar包以后,我们也来看下他的jar包的路径。
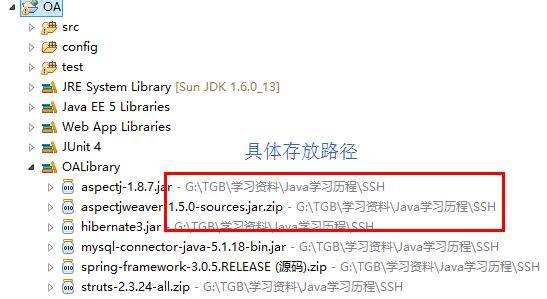
与方法一相比,第二种添加方式中,jar包的路径还是原来的路径。也就是说,方法一是直接Copy jar包,而方法二只是将jar包引用过来在项目中使用。
## 【小结】
虽然是一件很小的事,但结合我们之前学过的值栈,对象和引用的区别,不难发现,这些东西都是相通的。我们提供给开发人员不同的选择,他们根据不同的需求来做出较适合的取舍罢了。
【SSH】——hql的使用方式及实现原理
最后更新于:2022-04-01 11:27:35
## 【含义】
hql,即Hibernate Query Language。它与我们熟知的sql很类似,它最大的特点就是对查询进行了面向对象的封装,下面会在具体例子中说明。
sql查询的是数据库中的表或字段,而hql是**面向对象**的,具有继承、多态、关联等特性,他针对的是对象。
## 【使用】
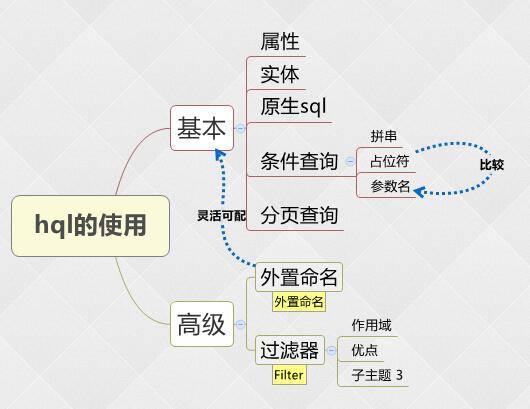
那么如何使用hql进行查询呢?首先,我们需要宏观看一下hql的几种使用方式:**基本使用、外置命名和过滤器。**
基本使用即我们将hql语句写在代码中,执行操作。配置文件的方式是将我们所写的hql语句转移到配置文件中,这样就很容易对其进行修改了。第三种过滤器,类似Struts中的Filter过滤器。它对查询的内容进行过滤,在映射文件中定义过滤器,程序中启用过滤器,并为过滤器参数赋值。
## 【基本使用】
我们先通过例子,了解下hql的基本使用,再介绍其实现原理。
~~~
/**
* 实体对象查询,
*/
public void testquery(){
Session session=null;
try{
//获得Hibernate Session
session=HibernateUtil.getSession();
//开启事务
session.beginTransaction();
//以hql语句创建Query对象,Query调用list方法返回全部实例
List shelfList=session.createQuery("from Shelf").list();
//迭代显示数据
for(Iterator iter=shelfList.iterator();iter.hasNext();){
Shelf shelf=(Shelf)iter.next();
System.out.println(shelf.getLocation());
}
//提交事务
session.getTransaction().commit();
}catch(Exception e){
//发生异常,事务回滚
e.printStackTrace();
session.getTransaction().rollback();
}finally{
//关闭Session
HibernateUtil.closeSession(session);
}
}
/**
* 封装类
*/
public class HibernateUtil {
private static SessionFactory factory;
/**
* 完成sessionFactory的初始化
*/
static{
try{
//读取hibernate.cfg.xml配置文件
Configuration cfg=new Configuration().configure();
//建立sessionFactory,可访问mysql
factory=cfg.buildSessionFactory();
}catch(Exception e){
e.printStackTrace();
}finally{
}
}
//获得session
public static Session getSession(){
return factory.openSession();
}
//关闭session
public static void closeSession(Session session){
if(session!=null){
if(session.isOpen()){
session.close();
}
}
}
//返回sessionFactory
public static SessionFactory getSessionFactory(){
return factory;
}
}
~~~
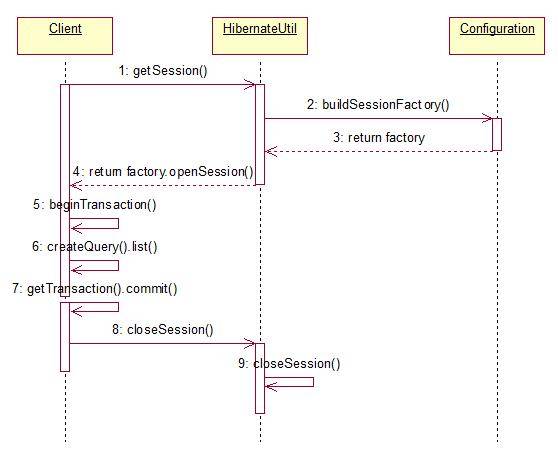
Session——对象的增删改查操作
Query,Criteria——执行数据库查询
SessionFactory——初始化Hibernate,创建Session对象。
Configuration——负责配置、启动Hibernate,创建SessionFactory对象。
## 【外置命名】
外置命名和下面要说的过滤器都是些在配置文件中的,灵活性较好。
需求是,查询Shelf中"code>1"的数据。我们需要在配置文件中,加入hql语句。
~~~
<hibernate-mapping >
<class name="com.hibernate.Shelf" table="t_shelf" >
<!-- 映射主键 -->
<id name="code">
<generator class="native"></generator>
</id>
</class>
<!--外置命名-->
<query name="queryShelf">
<![CDATA[
select s from Shelf s where s.code>?
]]>
</query>
</hibernate-mapping>
~~~
接下来,代码中就不需要再写hql语句了,但需要注意的是,要使用session的getNameQuery()方法,还要给hql中的问号占位符赋值,这里类似参数化查询的东西,也很好理解。
~~~
<span style="white-space:pre"> </span>List shelfList=session.getNamedQuery("queryShelf").setParameter(0, 1).list();
for(Iterator iter=shelfList.iterator();iter.hasNext();){
Shelf shelf=(Shelf)iter.next();
System.out.println(shelf.getLocation());
}
~~~
## 【过滤器】
过滤器的配置同样也是在配置文件中,这里,我们需要命名过滤器名称和参数名,以及哪个类使用过滤器
~~~
<hibernate-mapping >
<class name="com.hibernate.Shelf" table="t_shelf" >
<!-- 映射主键 -->
<id name="code">
<generator class="native"></generator>
</id>
<filter name="testFilter" condition="code < :myParam"></filter>
</class>
<!-- 过滤器 -->
<filter-def name="testFilter">
<filter-param name="myParam" type="integer"/>
</filter-def>
</hibernate-mapping>
~~~
代码中也和外置命名类似。
~~~
session.enableFilter("testFilter").setParameter("myParam", 2);//在session中都被启用
List shelfList=session.createQuery("from Shelf").list();
for(Iterator iter=shelfList.iterator();iter.hasNext();){
Book book=(Book)iter.next();
System.out.println(book.getName());
}
~~~
## 【小结】
在介绍基本使用方法时,主要是以理解hql的查询原理,不能只停留在会用而已。
外置命名将hql语句抽离出来放到配置文件中,并给了他一个参数名,我们只需要在代码中用这个参数名就可以了。这样如果需求有不太大的变动时,我们就能轻松应对了。
过滤器类似Filter,也是在配置文件中,我们需要开启过滤器,让他帮我们把符合条件的数据过滤出来。但这种方式在面对复杂条件查询的时候可能会不那么方便了。
【SSH】——Hibernate实现简单的自动建表
最后更新于:2022-04-01 11:27:33
## 【与ORM】
**Object Relational Mapping**,对象关系映射,将对象和关系联系了起来。面向对象是从耦合、聚合、封装等的基础上发展起来的,而关系数据库则是从数学理论发展而来的,两套理论存在显著的区别。为了解决这个不匹配的现象,对象关系映射技术应运而生,这样开发人员就可以以面向对象的思想来操作数据库。
实现ORM技术的框架有很多,.net的有NHibernate、EF、iBATIS.NET等,java的有mybatis、ibatis,当然还有Hibernate。
言归正传,我们这里介绍Hibernate,他是一个实现了ORM技术的框架。Hibernate对jdbc进行了封装,这使得我们操作数据库变得更加简单。本篇博客主要介绍Hibernate自动建表的功能。
## 【Demo】
我们以一个简单的例子来看,Hibernate是如何自动建表的。其中涉及到User类,以及他对应的映射文件User.hbm.xml,Hibernate的数据库配置文件hibernate.cfg.xml,后面我们会详细介绍各自的作用。
首先从实体开始,我们先来构造User类。
描述数据库表的结构,表中的字段对应类中的属性,数据库中的表对应一个类。
这里的User是一个java类,也可以叫作**POJO对象**。即Plain Ordinary Java Object,简单的Java对象,只有一些属性及其getter setter方法的类,没有业务逻辑。POJO对象可以方便程序员操作数据库中的表,进行get和set操作。
~~~
package com.hibernate;
import java.util.Date;
/**
* 用户类
* @author YANG
*
*/
public class User {
//用户id
private String id;
//用户名称
private String name;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
~~~
Uer类对应的映射文件User.hbm.xml,该配置文件中依据User实体类来建立的。具体建立时,可以一个实体一个映射文件,也可以多个实体配在一个映射文件中。
它指定数据库表(比如t_User)和映射类(User.java)之间的关系,包括映射类和数据库表的对应关系、表字段和类属性类型的对应关系以及表字段和类属性名称的对应关系等。
~~~
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping >
<!-- 数据库默认表的名称和类名相同,
如果需要改变或类名为关键字时,
可以添加table="t_user"给表重命名 -->
<class name="com.hibernate.User" ><!-- table="t_user" -->
<!-- 映射主键 -->
<id name="id">
<!-- 主键生成策略,利用生成器 -->
<generator class="uuid"></generator>
</id>
<!-- 利用property映射其他字段 -->
<property name="name" ></property><!-- 若加上column="user_name",数据库字段名为user_name -->
</class>
</hibernate-mapping>
~~~
现在实体类和对应的映射文件已经都准备好了,还差数据库的连接了。配置内容包括数据库的驱动类,连接数据库的url,用户名和密码等等。这里用的是mysql数据库,需要注意的是,我们一定要把实体类的映射文件加入,不然无法获取。
~~~
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 驱动类 -->
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<!-- 连接的url,数据库名称为hibernate_first -->
<property name="hibernate.connection.url">jdbc:mysql://localhost:3306/hibernate_first</property>
<property name="hibernate.connection.username">root</property>
<property name="hibernate.connection.password"></property>
<!-- 适配器,方言,用于翻译成mysql的语句 -->
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
<!-- 设置打印到控制台 -->
<property name="hibernate.show_sql">true</property>
<!-- 格式化sql -->
<property name="hibernate.format_sql">true</property>
<!-- 映射文件加入 -->
<mapping resource="com/hibernate/User.hbm.xml"/>
</session-factory>
</hibernate-configuration>
~~~
之后我们建立一个测试类,来测试是否能够生成表。不过在执行该类之前,需要手动在数据库中建立相应的数据库,数据库的名称需要和配置文件保持一致。因为Hibernate只会自动建表,不会自动建库。
~~~
public static void main(String[] args){
//读取的是properties文件
//Configuration cfg=new Configuration();
Configuration cfg=new Configuration().configure();
//工具类
SchemaExport export=new SchemaExport(cfg);
//打到控制台,输出到数据库
export.create(true, true);
}
~~~
这个方法主要功能是将hbm生成ddl语句,进行建表。DDL是用来操作数据库、表、视图等,所以最终需要转换成ddl语句来完成建表。这样也比较麻烦,每次建表都要单独执行该类。还有一种方法,修改配置文件。每次加载hibernate时都会删除上一次的生成的表,然后根据你的model类再重新来生成新表。但这个参数并不建议使用,正是因为每次加载都会重新生成表,会使得表中的数据丢失。
~~~
<properties>
<property name="hibernate.hbm2ddl.auto" value="create" />
</properties>
~~~
执行之后,控制台输入内容如下,去数据库里看一下,表就建好了。
~~~
drop table if exists User
create table User (
id varchar(255) not null,
name varchar(255),
primary key (id)
)
~~~
## 【小结】
之前就接触过自动建表这部分,但当时就只是照着做,没有去看是如何实现的,觉得好神奇啊。不过边用边总结一下,就会有恍然大悟的感觉,其实也就是这个样子啦。其实也是人家Hibernate-tool里面的工具类封装的好,像SchemaExport,如果没有这个东西,自动建表也是很麻烦的啊。不管是哪个巨人吧,还是先站在巨人的肩膀上了,然后再努力成为一个巨人!
【SSH】——梳理三大框架
最后更新于:2022-04-01 11:27:31
## 【前言】
去年软考,从System.out.println("Hello World!")开始,小编也算是进入java的世界了。转战java以后,虽然仍旧在学习.NET的知识,但越学越发现语言都是相通的。单从java的语法基础来看,他和C#语法就很类似,经常让人觉得傻傻分不清楚。OO的思想就更是这样了,抽象、继承、封装,这些东西更是不被语言所影响。最近接触到SSH框架,本着“囫囵吞枣”的学习理念,先做了两个小项目,才进行了理论性的学习。理论学习了一段时间了,还是觉得总体思路上有点乱,因此停下来,整理下思路。
## 【SSH】
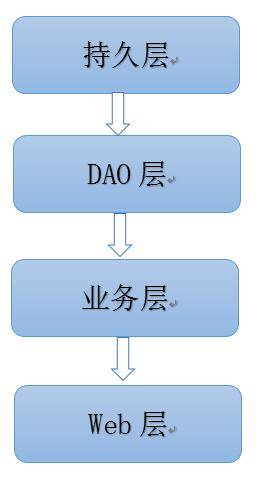
SSH,即Struts+Hibernate+Spring的一个集成框架。单从分层来看,ssh可以看作一个三层或者四层的架构,即Web(UI)层、业务逻辑层、(Dao层)、持久化层。如图:
那么具体每个框架的作用是什么呢?
Struts ——显示层(UI Layer/Presentation Layer)
Spring——业务逻辑层(Business Layer)
Hibernate——持久化层(Persistence Layer)
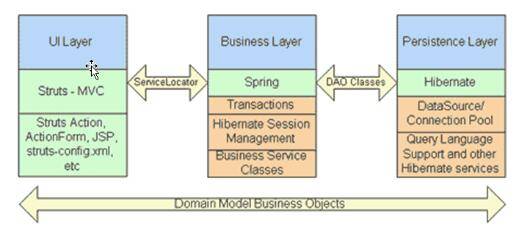
在表示层中,首先通过JSP页面实现交互界面,负责传送请求(Request)和接收响应(Response),然后Struts根据配置文件(struts-config.xml)将ActionServlet接收到的Request委派给相应的Action处理。
在业务逻辑层中,管理服务组件的Spring IoC容器负责向Action提供业务模型(Model)组件和该组件的协作对象数据处理(DAO)组件完成业务逻辑,并提供事务处理、缓冲池等容器组件以提升系统性能和保证数据的完整性。
数据持久层中,则依赖于Hibernate的对象化映射和数据库交互,处理DAO组件请求的数据,并返回处理结果。
## 【思维导图】
Struts,是整个系统的基础架构,实现了MVC的分离,主要用在MVC的视图层,控制转发。
Hibernate对JDBC进行了封装,使得开发人员可以用面向对象等程序思维来操纵数据库,如Hibernate提供自动建表,我们只需要编写类,而不需要关心表的内部结构和生成过程。
Spring是一个轻量级的容器框架,可以用来管理Struts和Hibernate。spring可以管理类与类之间的依赖关系,实现控制反转,而不需要在代码里操作。另外,AOP可以使业务逻辑更加清晰,团队开发的分工变得简单可行,也大大了解耦了。
详细的介绍参加下面的思维导图。由于空间原因,细节部分就不再展示了。

【SSH】——spring的控制反转和依赖注入
最后更新于:2022-04-01 11:27:29
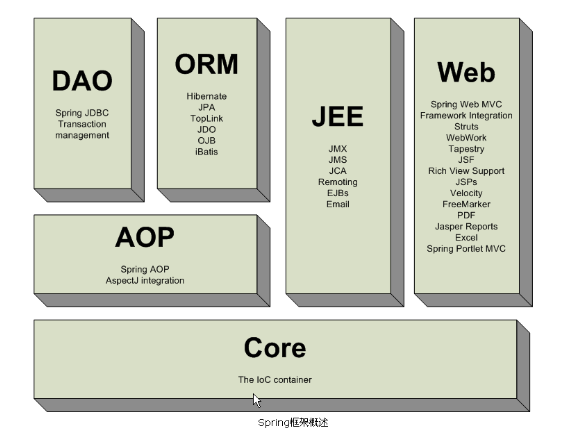
spring是一个轻量级的容器框架,主要是为了使企业的开发变得简单、高效。无论是从大小还是开销来讲,他都可以算是轻量级的,也是非侵入性的。
下图是spring的框架示意图,说到spring,就不得不提他的控制反转(IOC,Inversion of Control)。
那么他的控制反转是如何实现的呢?
**控制反转一般有两种类型,依赖注入(DI)和依赖查找。依赖注入应用比较广泛。**
首先来看,如果没有使用spring,我们的一般操作是怎样的。
client,dao和manager三个包,其中client为客户端调用,UserDao和UserManager为接口。
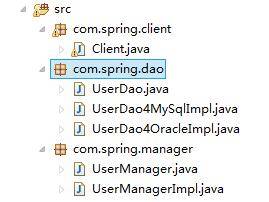
~~~
/*
* mysql的实现类
*/
public class UserDao4MySqlImpl implements UserDao {
//添加用户
public void addUser(String username, String password) {
System.out.println("UserDao4MySqlImpl.addUser()");
}
}
/*
* oracle的实现类
*/
public class UserDao4OracleImpl implements UserDao {
//添加用户
public void addUser(String username, String password) {
System.out.println("UserDao4OracleImpl.addUser()");
}
}
~~~
业务层的实现类
~~~
public class UserManagerImpl implements UserManager {
@Override
public void addUser(String username, String password) {
// 由我们的应用程序负责服务(对象)定位
//如果不使用mysql数据库,就需要修改该类的方法实现
// UserDao userDao = new UserDao4MySqlImpl();
UserDao userDao = new UserDao4OracleImpl();
userDao.addUser(username, password);
}
}
~~~
客户端调用方法:
~~~
public class Client {
public static void main(String[] args) {
// 由我们的应用程序负责服务(对象)定位
UserManager userManager = new UserManagerImpl();
userManager.addUser("张三", "123");
}
}
~~~
我们知道对象的创建过程,如果需求有变,可以进行更换。尽管可以进行修改,但始终是应用程序来管理对象之间的依赖关系,而spring的控制反转,将这个操作交给容器管理。
DI(Dependency Injection)
这里说两种DI注入的方式:setter注入和构造方法注入。
1)setter注入
我们还是举上面的例子,dao包中的内容都不需要改变,我们只需要将manager包中进行调整即可。如在UserManagerImpl类中,注入UserDao。
~~~
public class UserManagerImpl implements UserManager {
private UserDao userDao;
public void setUserDao(UserDao userDao) {
this.userDao = userDao;
}
....
<span style="font-size:18px;">}</span>
~~~
配置文件
~~~
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-2.0.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.0.xsd">
<bean id="userDao4Mysql" class="com.spring.dao.UserDao4MySqlImpl"/>
<bean id="usrDao4Oracle" class="com.spring.dao.UserDao4OracleImpl"/>
<bean id="userManager" class="com.spring.manager.UserManagerImpl">
<!--使用setter方法注入-->
<property name="userDao" ref="usrDao4Oracle"/>
</bean>
</beans>
~~~
2)构造方法注入
~~~
public class UserManagerImpl implements UserManager {
private UserDao userDao;
//构造方法
public UserManagerImpl(UserDao userDao) {
this.userDao = userDao;
}
...
}
~~~
将配置文件中的userManager的bean进行修改
~~~
<bean id="userManager" class="com.spring.manager.UserManagerImpl">
<!--
<constructor-arg ref="userDao4Mysql"/>
-->
<!-- 使用构造函数 -->
<constructor-arg ref="usrDao4Oracle"/>
</bean>
~~~
当然,DI还有其他的实现方式,在这里就不介绍了,跟这两种都很类似。
小结:
通过控制反转,我们将类与类之间的关系,对象的生成放到了配置文件中,这样既在一定程度上实现了解耦,也使得改变更加容易。
【SSH】——Struts2中的动态方法调用(二)
最后更新于:2022-04-01 11:27:26
当action中的方法有很多时,那应该怎么调用呢?上次我们提到的UserAction类中只有一个execute方法,如果我们需要增加用户的增删改查方法,如下:
~~~
public class UserAction extends ActionSupport{
...其他略去
/**
* 添加用户的方法
* @return
* @throws Exception
*/
public String add() throws Exception{
message="添加用户";
return SUCCESS;
}
public String del() throws Exception{
message="删除用户";
return SUCCESS;
}
public String edit() throws Exception{
message="编辑用户";
return SUCCESS;
}
}
~~~
我们保持struts.xml的配置不变,具体见上篇博客。
调用的页面index.jsp就采用action名+!+方法名称+后缀的格式来实现。
~~~
<body>
<a href="user!add.action">添加用户</a><br>
<a href="user!del.action">删除用户</a><br>
<a href="user!edit.action">编辑用户</a>
</body>
~~~
method属性
这种方法我们就能做到在一个action中动态调用多个方法。但是采用上面的写法容易出错,看着也必将麻烦,那可不可以直接写上具体要调用action中的方法名称呢,比如add.action?这时候我们就需要修改Struts的配置文件了,采用method属性来区分方法名称。
~~~
<struts>
<package name="Struts2_006" extends="struts-default" >
<action name="add" class="com.struts2.UserAction" method="add">
<result>/add_success.jsp</result>
</action>
<action name="del" class="com.struts2.UserAction" method="del">
<result>/add_success.jsp</result>
</action>
<action name="edit" class="com.struts2.UserAction" method="edit">
<result>/add_success.jsp</result>
</action>
</package>
</struts>
~~~
通配符
通过method属性虽然可以简化页面的调用,但他使得Struts配置文件中配置了大量的action,而且这些action中的很多内容都是相同的。如何解决呢?引入通配符的用法就可以解决。
现在将Struts.xml文件进行修改
~~~
<package name="Struts2_006" extends="struts-default" >
<action name="*user" class="com.struts2.UserAction" method="{1}">
<result>/add_success.jsp</result>
</action>
</package>
~~~
index.jsp页面也要进行修改
~~~
<a href="adduser.action">添加用户</a><br>
<a href="deluser.action">删除用户</a><br>
<a href="edituser.action">编辑用户</a>
~~~
比较这两种方式:若不使用通配符,配置文件会十分冗余,但有一个优点就是易于控制。而使用通配符使得配置文件中省去了重复多余的action配置。
【SSH】——Struts2中的动态方法调用(一)
最后更新于:2022-04-01 11:27:24
首先我们来看一个简单的调用:
1、在web.xml中配置拦截器StrutsPrepareAndExecuteFilter。StrutsPrepareAndExecuteFilter实现了filter接口,在执行action之前,利用filter做一些操作。
~~~
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://java.sun.com/xml/ns/javaee" xmlns:web="http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd" version="2.5">
<filter>
<filter-name>struts2</filter-name>
<filter-class>org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>struts2</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
</web-app>
~~~
2、提供Struts2的配置文件struts.xml
~~~
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.0//EN"
"http://struts.apache.org/dtds/struts-2.0.dtd">
<struts>
<package name="Struts2_006" extends="struts-default" >
<action name="user" class="com.struts2.UserAction">
<result>/add_success.jsp</result>
</action>
</package>
</struts>
~~~
注:<result>标签的默认值是success,此处省略。
3、页面显示部分。
index.jsp页面,转向到action中,调用action中的方法。
~~~
<body>
<a href="user.action">调用</a>
</body>
~~~
调用完后,跳转到成功页面,并显示message中的消息。
~~~
<body>
我的操作:${message} <br>
</body>
~~~
4、编写Action类 UserAction。
~~~
public class UserAction extends ActionSupport{
//消息字符串,用来显示调用结果
private String message;
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
/***
* execute方法
*/
public String execute() throws Exception{
message="执行execute方法";
return SUCCESS;
}
}
~~~
注意:这里我们让UserAction继承自ActionSupport类,从源码中可以看到ActionSupport类实现了Action接口。在ActionSupport类中也处理了execute()方法,但他并没有做什么操作,只是返回SUCCESS。因而,如果我们在UserAction中不写execute方法,也不会报错。
~~~
public class ActionSupport implements Action, Validateable, ValidationAware, TextProvider, LocaleProvider, Serializable {
protected static Logger LOG = LoggerFactory.getLogger(ActionSupport.class);
private final ValidationAwareSupport validationAware = new ValidationAwareSupport();
private transient TextProvider textProvider;
private Container container;
/**
* A default implementation that does nothing an returns "success".
* <p/>
* Subclasses should override this method to provide their business logic.
* <p/>
* See also {@link com.opensymphony.xwork2.Action#execute()}.
*
* @return returns {@link #SUCCESS}
* @throws Exception can be thrown by subclasses.
*/
public String execute() throws Exception {
return SUCCESS;
}
}
~~~
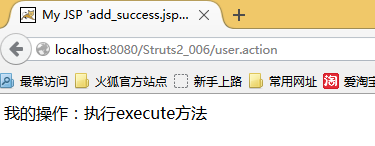
如果在UserAction中不写execute方法,message中没有值。
这篇博客介绍了Struts2的简单的方法调用,下篇博客将继续介绍,当action中有多个方法时,应该如何实现调用。
【SSH】——使用ModelDriven的利与弊
最后更新于:2022-04-01 11:27:22
在以往的web开发中,如果要在表单显示什么内容,我们就需要在Action中提前定义好表单显示的所有属性,以及一系列的get和set方法。如果实体类的属性非常多,那么Action中也要定义相同的属性。在Struts2中,ModelDriven模型驱动就提供了另一种方式,减少了重复性的代码。
下面我们就来具体看看在项目中如何使用:
以用户管理为例,除jsp页面外,四个包action、dao、service、vo。
调用关系:action——>service——>dao

首先,无论是哪种方法,vo包中的User类都是一样的。
~~~
public class User {
//用户id
private Integer uid;
//用户名
private String username;
//密码
private String password;
public Integer getUid() {
return uid;
}
public void setUid(Integer uid) {
this.uid = uid;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}
~~~
在Action中,如果不使用模型驱动,我们需要一一构造User对象的属性,作为参数传入调用。
使用模型驱动,就要实现ModelDriven这个接口,内部方法也很简单。
~~~
public abstract interface com.opensymphony.xwork2.ModelDriven {
public abstract java.lang.Object getModel();
}
~~~
~~~
public class UserAction {
private int uid;
private String username;
private String password;
public String login(){
//构造user对象
User user = new User();
user.setUId(id);
user.setUsername(username);
user.setPassword(password);
User exitUser=userService.login(user);
if(exitUser==null){
this.addActionError("登录失败");
return "login";
}else{
//用户信息存入session、
ServletActionContext.getRequest().getSession().setAttribute("exitUser",exitUser);
return "loginSuccess";
}
}
public int getUId() {
return uid;
}
public void setId(int uid) {
this.uid = uid;
}
//剩下的get和set方法省去
......
......
}
~~~
而如果使用模型驱动,我们只需要让Action类去实现ModelDriven接口。
~~~
public class UserAction extends ActionSupport implements ModelDriven<User> {
//模型驱动使用的对象
private User user=new User();
//MdoelDriven中的方法
public User getModel(){
return user;
}
//注入userservice
private UserService userService;
public void setUserService(UserService userService) {
this.userService = userService;
}
/**
* 登录
*/
public String login(){
User exitUser=userService.login(user);
if(exitUser==null){
this.addActionError("登录失败");
return "login";
}else{
//用户信息存入session、
ServletActionContext.getRequest().getSession().setAttribute("exitUser",exitUser);
return "loginSuccess";
}
}
}
~~~
另外,模型驱动的好处还体现在**数据回显**时的应用。
在Action中,模型驱动的实体是CategorySecond,因而在回显jsp页面数据的时候,不需要保存到ValueStack值栈中,而一级分类集合cList需要保存到值栈中,前台才可以获取到值。
~~~
public class AdminCategorySecondAction extends ActionSupport implements ModelDriven<CategorySecond>{
//
//
//其余代码省去
//编辑二级分类
public String edit(){
//查询二级分类
categorySecond=categorySecondService.findByCid(categorySecond.getCsid());
//查询一级分类
List<Category> cList=categoryService.findAll();
//保存到值栈中
ActionContext.getContext().getValueStack().set("cList", cList);
return "editSuccess";
}
}
~~~
前台的部分显示如下:
~~~
<tr>
<td width="18%" align="center" bgColor="#f5fafe" class="ta_01">
二级分类名称:
</td>
<td class="ta_01" bgColor="#ffffff" >
<input type="text" name="csname" value="<s:property value="model.csname"/>" id="userAction_save_do_logonName" class="bg"/>
</td>
<td width="18%" align="center" bgColor="#f5fafe" class="ta_01">
所属的一级分类:
</td>
<td class="ta_01" bgColor="#ffffff" >
<select name="category.cid">
<s:iterator var="c" value="cList">
<option value="<s:property value="#c.cid"/>" <s:if test="#c.cid==model.category.cid">selected</s:if>><s:property value="#c.cname"/></option>
</s:iterator>
</select>
</td>
</tr>
~~~
二级分类信息使用model来显示数据,而一级分类信息接收action中传来的cList。两种方法都可以实现数据显示,但模型驱动更为简单方便。
小结:
Struts2提供的两种方式:属性驱动和模型驱动。模型驱动可以提高代码的重用性,使得操作简便。但在小型项目中,表单比较少时,并不提倡使用模型驱动。还有一点,在上面的例子中也能看出,模型驱动只能对应一个对象,当表单数据来源比较复杂时,使用模型驱动也无法起到十分明显的作用。
Java中Model1和Model2
最后更新于:2022-04-01 11:27:20
Model1和Model2是java web的两种架构模式。这两种模式各有优缺点,都有各自适合使用的场景。
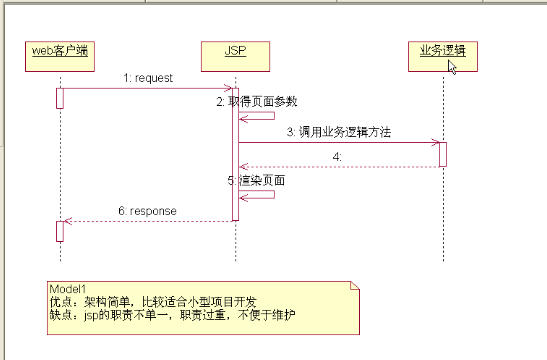
Model1
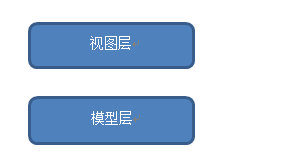
首先,从分层的角度说,Model1模式可以看作是由两层组成:视图层和模型层。
~~~
<%@ page language="java" contentType="text/html; charset=GB18030" pageEncoding="GB18030"%>
<%@ page import="com.bjpowermode.drp.sysmgr.*"%>
<%@ page import="com.bjpowermode.drp.domain.*"%>
<%
//取得参数
String command=request.getParameter("command");
String userId=request.getParameter("userId");
//调用业务逻辑中的查询用户代码是否存在的方法
User user=UserManager.getInstance().findUserById(userId);
//点击修改
if("modify".equals(command)){
//User user=new User();
user.setUserId(request.getParameter("userId"));
user.setUserName(request.getParameter("userName"));
user.setPassword(request.getParameter("password"));
user.setContactTel(request.getParameter("contactTel"));
user.setEmail(request.getParameter("email"));
//调用业务逻辑中的修改用户的方法
UserManager.getInstance().modifyUser(user);
System.out.println("修改成功");
}
%>
~~~
可以看出,model1是以jsp为中心的,在jsp页面调用了很多业务逻辑的方法。在例子中,我们选择一个用户,点击修改,就将数据提交到了jsp对象中。然后在jsp去调修改用户的方法,执行数据库操作,最后返回结果。这种模式让我想起了在没有用三层之前,
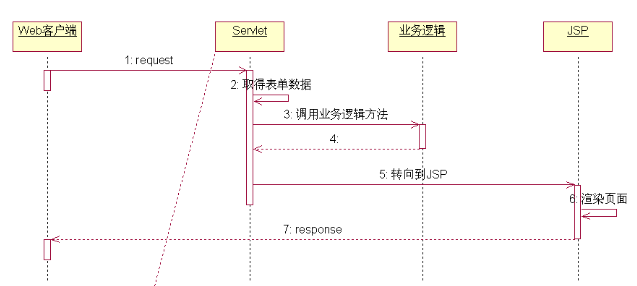
Model2
~~~
/**
* 修改物料Servlet
* @author Administrator
*
*/
public class ModifyItemServlet extends AbstractItemServlet {
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
//构造表单数据
String itemNo=request.getParameter("itemNo");
String itemName=request.getParameter("itemName");
String spec=request.getParameter("spec");
String pattern=request.getParameter("pattern");
String category=request.getParameter("category");
String unit=request.getParameter("unit");
//构造Item对象
Item item=new Item();
item.setItemNo(itemNo);
item.setItemName(itemName);
item.setSpec(spec);
item.setPattern(pattern);
//构造物料类别
ItemCategory itemCategory=new ItemCategory();
itemCategory.setId(category);
item.setItemCategory(itemCategory);
//构造物料单位
ItemUnit itemUnit=new ItemUnit();
itemUnit.setId(unit);
item.setItemUnit(itemUnit);
//调用后台业务逻辑
itemManager.modifyItem(item);
response.sendRedirect(request.getContextPath()+"/servlet/item/SearchItemServlet");
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doPost(request, response);
}
}
~~~
在例子中,我们在客户端请求修改的命令到servlet,把调用业务逻辑的方法放在ModifyItemServlet中。
小结:
Model1结构简单,容易上手,适合一些小型的项目。但也正是由于他的这个优点,也带来了很大的弊端。他把业务逻辑和表现都杂糅到了一起,使得耦合度大大增加,给维护带来了很大的困难。尤其是在大型的项目中,这点就尤为突出了。Model2弥补了Model1 的缺点,在大型项目开发中,可以更好的做到多人协作开发,互不影响。
前言
最后更新于:2022-04-01 11:27:17
> 原文出处:[SSH](http://blog.csdn.net/column/details/yangsaixing.html)
作者:[u010066934](http://blog.csdn.net/u010066934)
**本系列文章经作者授权在看云整理发布,未经作者允许,请勿转载!**
# SSH
> 该专栏主要介绍ssh框架中Struts2、Hibernate、spring的基本概念及框架之间的关系,并附上在项目实践中出现的问题以及相应的解决方案。