内存溢出案例
最后更新于:2022-04-01 21:03:05
在MySQL 5.0版本中,主机名长度超过16个字符,如果启用 统计的话,十有八九会出现内存溢出问题。其实早在2009年已经发现这个问题了,[CLIENT_STATISTICS are broken if hostname is > 16 chars](https://lists.launchpad.net/ourdelta-developers/msg00207.html "Re: [Bug 338012] [NEW] CLIENT_STATISTICS are broken if hostname is > 16 chars"),同时还会导致内存溢出,其他同事也刚刚在5.0.67版本上证实发现这个问题。
可以使用[Valgrind](http://valgrind.org/ "valgrind")来检查哪里导致了内存泄露。
';
大数据量时如何部署MySQL Replication从库
最后更新于:2022-04-01 21:03:03
我们在部署MySQL Replication从库时,通常是一开始就做好一个从库,然后随着业务的变化,数据也逐渐复制到从服务器。
但是,如果我们想对一个已经上线较久,有这大数据量的数据库部署复制从库时,应该怎么处理比较合适呢?
本文以我近期所做Zabbix数据库部署MySQL Replication从库为例,向大家呈现一种新的复制部署方式。由于Zabbix历史数据非常多,[在转TokuDB之前的InnoDB引擎时](http://imysql.com/2014/06/24/migrate-zabbix-db-to-tokudb.shtml "迁移Zabbix数据库到TokuDB"),已经接近700G,转成TokuDB后,还有300多G,而且主要集中在trends_uint、history_uint等几个大表上。做一次全量备份后再恢复耗时太久,怕对主库写入影响太大,因此才有了本文的分享。
我大概分为几个步骤来做Zabbix数据迁移的:
~~~
1、初始化一个空的Zabbix库
2、启动复制,但设置忽略几个常见错误(这几个错误代码对应具体含义请自行查询手册)
#忽略不重要的错误,极端情况下,甚至可以直接忽略全部错误,例如
#slave-skip-errors=all
slave-skip-errors=1032,1053,1062
3、将大多数小表正常备份导出,在SLAVE服务器上导入恢复。在这里,正常导出即可,无需特别指定 --master-data 选项
4、逐一导出备份剩下的几个大表。在备份大表时,还可以分批次并发导出,方便并发导入,使用mysqldump的"-w"参数,然后在SLAVE上导入恢复(可以打开后面的参考文章链接)
5、全部导入完成后,等待复制没有延迟了,关闭忽略错误选项,重启,正式对外提供服务
~~~
上述几个步骤完成后,可能还有个别不一致的数据,不过会在后期逐渐被覆盖掉,或者被当做过期历史数据删除掉。
本案例的步骤并不适用于全部场景,主要适用于:
不要求数据高一致性,且数据量相对较大,尤其是单表较大的情况,就像本次的Zabbix数据一样。
参考文章:
[迁移Zabbix数据库到TokuDB](http://imysql.com/2014/06/24/migrate-zabbix-db-to-tokudb.shtml "迁移Zabbix数据库到TokuDB")
[[MySQL FAQ]系列— mysqldump加-w参数备份](http://imysql.com/2014/06/22/mysql-faq-mysqldump-where-option.shtml "[MySQL FAQ]系列— mysqldump加-w参数备份")
';
你所不知的table is full那些事
最后更新于:2022-04-01 21:03:00
当我们要写入新数据而发生“The table is full”告警错误时,先不要着急,按照下面的思路来逐步分析即可:
1、查看操作系统以及MySQL的错误日志文件
确认操作系统的文件系统没有报错,并且MySQL的错误日志文件中是否有一些最直观的可见的错误提示。
有可能是数据库文件超过操作系统层的文件大小限制,比如fat/fat32以及低版本的Linux,文件最大不可以大于2G(最大扩展到4G),这就需要转换fat32为NTFS,或升级Linux版本。
2、确认磁盘空间没有满
执行 df -h 查看剩余磁盘空间,如果发现磁盘空间确实已经用完,则尽快删除不需要的文件。
如果通过 du 计算各个目录的总和却发现根本不会用完磁盘空间时,就需要注意了,可能是某个被删除的文件还没完全释放,导致 df 看起来已经用完,但 du 却又统计不到。
这时候可以执行 lsof | grep -i deleted 找到被删除的大文件,将其对应的进程杀掉,释放该文件描述符。
如果该进程不能被杀掉,例如是 mysqld 进程在占用的话,可以在 MySQL 里找到是哪个内部线程在用,停止该线程即可。
曾经发生过这样一个例子:
用vim打开MySQL的slow query log,退出时选择了 “wq” 指令,也就是保存退出,结果悲剧发生了。
因为在其打开的那段时间内,slow query log有新日志产生,会持续写入,但他退出时采用保存退出的方式,变成了一个“新”文件(或者说新文件句柄 file handler),这个“新”文件无法被mysqld进程识别,
mysqld进程依旧将slow query log写入到原来它打开的那个文件(或者说文件句柄)里,该日志文件在持续增长,但手工保存退出的文件却再也不增长了,直接查看文件看不出任何异常。
这时候只能用 lsof -p `pidof mysqld` 才能看到该文件。
解决方法很简单,将原来的文件备份一下,执行下面的指令:
~~~
FLUSH SLOW LOGS;
~~~
备注:MySQL 5.5开始才支持 BINARY/ENGINE/ERROR/GENERAL/RELAY/SLOW 等关键字,之前的版本只能刷新全部日志。
3、确认数据表状态
* 如果是MyISAM引擎
默认配置下,MyISAM引擎最大可支持256TB(myisam_data_pointer_size = 6,256^6 = 256TB),除非操作系统层有限制。
在MySQL5.0中,MyISAM引擎行记录默认是动态长度,单表最大可达256TB,MyISAM行指针(myisam_data_pointer_size)长度为6字节。
在这之前,MyISAM行指针默认长度为4字节,只支持4GB的数据。改行指针最大值可设为8字节。
在行指针设置较小不够用的时候,为提高MyISAM表最大容量,可以修改表定义设定MAX_ROWS的值:
~~~
ALTER TABLE `xx` ENGINE=MyISAM MAX_ROWS=_nn_
~~~
备注:表定义中,AVG_ROW_LENGTH 属性定义的是 BLOB/TEXT 字段类型的最大长度。
* 如果是InnoDB引擎
ibdata*共享表空间最后一个文件没有设置成自增长,或者超过32位系统的单文件大小限制。
解决方法:
1、ibdata*的最后一个文件(非最后一个文件无法设置为自动增长)设置成自动增长;
2、检查操作系统,迁移到64位操作系统下;
3、转成独立表空间;
4、删除历史数据,重整表空间;
* 如果是MEMORY引擎
1、适当提高max_heap_table_size设置(注意该值是会话级别,不要设置过大,例如1GB,一般不建议超过256MB);
2、执行ALTER TABLE t_mem ENGINE=MEMORY; 重整表空间,否则无法写入新数据;
3、删除部分历史数据或者直接清空,重整表空间;
4、设置 big_tables = 1,将所有临时表存储在磁盘,而非内存中,缺点是如果某个SQL执行时需要用到临时表,则性能会差很多;
顺便说下,如果数据表有一列自增INT做主键,但是该ID值达到了INT最大值的话,MyISAM、MEMORY、InnoDB三种引擎的告警信息是不一样的。
InnoDB引擎的告警信息类似这样:
ERROR 1467 (HY000): Failed to read auto-increment value from storage engine
而MyISAM和MEMORY引擎则都是这样:
ERROR 1062 (23000): Duplicate entry ‘4294967295’ for key ‘PRIMARY’
参考
MySQL手册:[B.5.2.12 The table is full](http://dev.mysql.com/doc/refman/5.6/en/full-table.html "The table is full")
';
SAVEPOINT语法错误一例
最后更新于:2022-04-01 21:02:58
前几天帮同事解决一个案例,在主从复制环境下,从库上的MySQL版本号是5.5.5,遇到下面的错误:
~~~
#其他非相关信息我都隐藏掉了
[(yejr@imysql.com)]> show slave status \G;
Slave_IO_Running: Yes
Slave_SQL_Running: No
Last_Errno: 1064
Last_Error: Error 'You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '6e86db84_14847168f19__8000' at line 1' on query. Default database: 'act'. Query: 'SAVEPOINT 6e86db84_14847168f19__8000'
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1064
Last_SQL_Error: Error 'You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '6e86db84_14847168f19__8000' at line 1' on query. Default database: 'act_log'. Query: 'SAVEPOINT 6e86db84_14847168f19__8000'
~~~
第一感觉是遇到保留关键字了,不过看到这么长的字符串,不应该是保留关键字才对。
经过尝试,最后发现是字符串中的 “e” 这个字符如果存在就可能会报错,看起来应该是bug才对了。
在MySQL的bug系统里确实找到了这个bug,不过看bug描述,在5.5版本中应该是已经修复了才对,看来太不靠谱了呀~~
关于这个bug:[Savepoint identifier is occasionally considered as floating point numbers](http://bugs.mysql.com/bug.php?id=55962 "Savepoint identifier is occasionally considered as floating point numbers")
其实除了升级版本外,解决方法也很简单,把savepoint后面的 identifier 字符串用反引号(波浪号的下档键,英文叫做 backticks 键)引用起来就行。
例如:
~~~
savepoint `6e86db84_14847168f19__8000`;
~~~
这样就可以了。
这个案例也提示我们,在写SQL时,涉及到数据库、表、字段、identifier 等名称时,最好是都能用反引号引用,确保可用。
曾经看到线上数据表有个字段名是 check ,这个名字在MySQL里很早就已经是保留关键字,幸好开发同学比较靠谱,都加上了反引号。
关于savepoint的2个bug:
[Savepoint Identifier should be enclosed with backticks](http://bugs.mysql.com/bug.php?id=55961 "Savepoint Identifier should be enclosed with backticks")
[Savepoint identifier is occasionally considered as floating point numbers](http://bugs.mysql.com/bug.php?id=55962 "Savepoint identifier is occasionally considered as floating point numbers")
';
MySQL联合索引是否支持不同排序规则
最后更新于:2022-04-01 21:02:56
> 篇首语:
> 截止到目前的5.7.4版本为止,MySQL的联合索引仍无法支持联合索引使用不同排序规则,例如:ALTER TABLE t ADD INDEX idx(col1, col2 DESC)。
先来了解下MySQL关于索引的一些基础知识要点:
~~~
• a、EXPLAIN结果中的key_len只显示了条件检索子句需要的索引长度,但 ORDER BY、GROUP BY 子句用到的索引则不计入 key_len 统计值;
• b、联合索引(composite index):多个字段组成的索引,称为联合索引;
例如:ALTER TABLE t ADD INDEX `idx` (col1, col2, col3)
• c、覆盖索引(covering index):如果查询需要读取到索引中的一个或多个字段,则可以从索引树中直接取得结果集,称为覆盖索引;
例如:SELECT col1, col2 FROM t;
• d、最左原则(prefix index):如果查询条件检索时,只需要匹配联合索引中的最左顺序一个或多个字段,称为最左索引原则,或者叫最左前缀;
例如:SELECT * FROM t WHERE col1 = ? AND col2 = ?;
• e、在老版本(大概是5.5以前,具体版本号未确认核实)中,查询使用联合索引时,可以不区分条件中的字段顺序,在这以前是需要按照联合索引的创建顺序书写SQL条件子句的;
例如:SELECT * FROM t WHERE col3 = ? AND col1 = ? AND col2 = ?;
• f、MySQL截止目前还只支持多个字段都是正序索引,不支个别字段持倒序索引;
例如:ALTER TABLE t ADD INDEX `idx` (col1, col2, col3 DESC),这里的DESC只是个预留的关键字,目前还不能真正有作用
• g、联合索引中,如果查询条件中最左边某个索引列使用范围查找,则只能使用前缀索引,无法使用到整个索引;
例如:SELECT * FROM t WHERE col1 = ? AND col2 >= ? AND col3 = ?; 这时候,只能用到 idx 索引的最左2列进行检索,而col3条件则无法利用索引进行检索
• h、InnoDB引擎中,二级索引实际上包含了主键索引值;
~~~
关于 key_len 的计算规则:
~~~
• 当索引字段为定长数据类型,比如:char,int,datetime,需要有是否为空的标记,这个标记需要占用1个字节;
• 当索引字段为变长数据类型,比如:varchar,除了是否为空的标记外,还需要有长度信息,需要占用2个字节;
• 当字段定义为非空的时候,是否为空的标记将不占用字节;
• 同时还需要考虑表所使用字符集的差异,latin1编码一个字符1个字节,gbk编码一个字符2个字节,utf8编码一个字符3个字节;
~~~
因此,key_len长度的计算公式
~~~
• varchr(10)变长字段且允许NULL : 10*(Character Set:utf8=3,gbk=2,latin1=1)+1(NULL标记位)+2(变长字段)
• varchr(10)变长字段且不允许NULL : 10*(Character Set:utf8=3,gbk=2,latin1=1)+2(变长字段)
• char(10)固定字段且允许NULL : 10*(Character Set:utf8=3,gbk=2,latin1=1)+1(NULL标记位)
• char(10)固定字段且不允许NULL : 10*(Character Set:utf8=3,gbk=2,latin1=1)
~~~
附,关于 filesort 排序算法:
光看 filesort 字面意思,可能以为是要利用磁盘文件进行排序,实则不全然。
当MySQL不能使用索引进行排序时,就会利用自己的排序算法(快速排序算法)在内存(sort buffer)中对数据进行排序,如果内存装载不下,它会将磁盘上的数据进行分块,再对各个数据块进行排序,然后将各个块合并成有序的结果集(实际上就是外排序)。
对于filesort,MySQL有两种排序算法:
1、两遍扫描算法(Two passes)
实现方式是先将须要排序的字段和可以直接定位到相关行数据的指针信息取出,然后在设定的内存(通过参数 sort_buffer_size 设定)中进行排序,完成排序之后再次通过行指针信息取出所需的列。
注:该算法是4.1之前只有这种算法,它需要两次访问数据,尤其是第二次读取操作会导致大量的随机I/O操作。不过,这种方法内存开销较小。
2、一次扫描算法(single pass)
该算法一次性将所需的列全部取出,在内存中排序后直接将结果输出。
注:从 MySQL 4.1 版本开始支持该算法。它减少了I/O的次数,效率较高,但是内存开销也较大。如果我们将并不需要的列也取出来,就会极大地浪费排序过程所需要的内存。在 MySQL 4.1 之后的版本中,可以通过设置 max_length_for_sort_data 参数来控制 MySQL 选择第一种排序算法还是第二种。当取出的所有大字段总大小大于max_length_for_sort_data 的设置时,MySQL 就会选择使用第一种排序算法,反之,则会选择第二种。为了尽可能地提高排序性能,我们自然更希望使用第二种排序算法,所以在SQL中仅仅取出需要的列是非常有必要的。
当对连接操作进行排序时,如果ORDER BY仅仅引用第一个表的列,MySQL对该表进行filesort操作,然后进行连接处理,此时,EXPLAIN输出“Using filesort”;否则,MySQL必须将查询的结果集生成一个临时表,在连接完成之后进行filesort操作,此时,EXPLAIN输出“Using temporary;Using filesort”。
后面是几个几个测试结果,有兴趣不怕累的可以看看,哈哈。
测试MySQL版本:5.5.37-log MySQL Community Server (GPL)
创建一个测试表,id是主键字段,(a1, a2) 组成联合索引
~~~
(yejr@imysql.com)> show create table t\G
*************************** 1\. row ***************************
Table: t
Create Table: CREATE TABLE `t` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`a1` int(10) unsigned NOT NULL DEFAULT '0',
`a2` int(10) unsigned NOT NULL DEFAULT '0',
`aa` varchar(20) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx` (`a1`,`a2`)
) ENGINE=InnoDB AUTO_INCREMENT=65 DEFAULT CHARSET=utf8
~~~
填充了64条测试数据
~~~
(yejr@imysql.com)> show table status like 't'\G
*************************** 1\. row ***************************
Name: t
Engine: InnoDB
Version: 10
Row_format: Compact
Rows: 64
Avg_row_length: 256
Data_length: 16384
Max_data_length: 0
Index_length: 16384
Data_free: 0
Auto_increment: 122
Create_time: 2014-09-15 17:17:09
Update_time: NULL
Check_time: NULL
Collation: utf8_general_ci
Checksum: NULL
Create_options:
Comment:
~~~
对 a1、a2 正序排序,同时取a1、a2两个字段,可以直接使用该联合索引取回结果,并且排序完成
#符合规则c
~~~
(yejr@imysql.com)> explain select a1, a2 from t order by a1, a2\G
id: 1
select_type: SIMPLE
table: t
type: index
possible_keys: NULL
key: idx
key_len: 8
ref: NULL
rows: 64
Extra: Using index
~~~
对 a1、a2 倒序排序,同时取a1、a2两个字段,可以直接使用该联合索引取回结果,并且排序完成
由于同时对a1、a2都是倒序排序,因此完全可以用到索引的顺序,只是反向扫描而已
符合规则c
~~~
(yejr@imysql.com)> explain select a1, a2 from t order by a1 desc, a2 desc\G
*************************** 1\. row ***************************
id: 1
select_type: SIMPLE
table: t
type: index
possible_keys: NULL
key: idx
key_len: 8
ref: NULL
rows: 64
Extra: Using index
~~~
对 a1、a2正序排序,只取a1字段,可以直接使用该联合索引取回结果,并且排序完成
匹配规则c
~~~
(yejr@imysql.com)> explain select a1 from t order by a1, a2\G
id: 1
select_type: SIMPLE
table: t
type: index
possible_keys: NULL
key: idx
key_len: 8
ref: NULL
rows: 64
Extra: Using index
~~~
对 a1、a2 正序排序,只取a2字段,可以直接使用该联合索引取回结果,并且排序完成
符合规则c
~~~
(yejr@imysql.com)> explain select a2 from t order by a1, a2 \G
id: 1
select_type: SIMPLE
table: t
type: index
possible_keys: NULL
key: idx
key_len: 8
ref: NULL
rows: 64
Extra: Using index
~~~
只对 a1 正序排序,同时取a1、a2两个字段,可以直接使用该联合索引取回结果,并且排序完成
符合规则c
~~~
(yejr@imysql.com)> explain select a1, a2 from t order by a1\G
id: 1
select_type: SIMPLE
table: t
type: index
possible_keys: NULL
key: idx
key_len: 8
ref: NULL
rows: 64
Extra: Using index
~~~
对 a1 正序排序,对 a2 倒序排序,只取a1字段,可以直接使用该联合索引取回结果,但排序时需要进行filesort排序,不能利用索引直接得到排序结果
这时虽然只读取一个字段,但实际还是扫描了整个索引,并非使用前缀索引
符合规则c、f
~~~
(yejr@imysql.com)> explain select a1 from t order by a1, a2 desc \G
id: 1
select_type: SIMPLE
table: t
type: index
possible_keys: NULL
key: idx
key_len: 8
ref: NULL
rows: 64
Extra: Using index; Using filesort
~~~
只取a1字段,同时只对 a1 字段正序排序,这时可用联合索引取得结果,同时也可以利用前缀索引的原则进行排序
符合规则c
~~~
(yejr@imysql.com)> explain select a1 from t order by a1\G
id: 1
select_type: SIMPLE
table: t
type: index
possible_keys: NULL
key: idx
key_len: 8
ref: NULL
rows: 64
Extra: Using index
~~~
只取a1字段,同时只对 a2 字段正序排序,这时虽然可用联合索引取得结果,但排序时需要进行filesort排序,不能利用索引直接得到排序结果
符合规则c、f
~~~
(yejr@imysql.com)> explain select a1 from t order by a2\G
id: 1
select_type: SIMPLE
table: t
type: index
possible_keys: NULL
key: idx
key_len: 8
ref: NULL
rows: 64
Extra: Using index; Using filesort
~~~
对 a1 正序排序,对a2 倒序排序,只取a1字段,可以直接使用该联合索引取回结果,但排序时需要进行filesort排序,不能利用索引直接得到排序结果
这时虽然只读取一个字段,但实际还是扫描了整个索引,并非使用前缀索引
符合规则c、f
~~~
(yejr@imysql.com)> explain select a1 from t order by a1, a2 desc \G
id: 1
select_type: SIMPLE
table: t
type: index
possible_keys: NULL
key: idx
key_len: 8
ref: NULL
rows: 64
Extra: Using index; Using filesort
~~~
对 a1 正序排序,对a2 倒序排序,只取a2字段,可以直接使用该联合索引取回结果,但排序时需要进行filesort排序,不能利用索引直接得到排序结果
这时虽然只读取一个字段,但实际还是扫描了整个索引,并非使用前缀索引
符合规则c、f
~~~
(yejr@imysql.com)> explain select a2 from t order by a1, a2 desc \G
id: 1
select_type: SIMPLE
table: t
type: index
possible_keys: NULL
key: idx
key_len: 8
ref: NULL
rows: 64
Extra: Using index; Using filesort
~~~
对 a1 正序排序,对a2 倒序排序,只取a2字段,可以直接使用该联合索引取回结果,但排序时需要进行filesort排序,不能利用索引直接得到排序结果
这时虽然只读取一个字段,但实际还是扫描了整个索引,并非使用前缀索引
符合规则c、f
~~~
(yejr@imysql.com)> explain select a1 from t order by a1, a2 \G
id: 1
select_type: SIMPLE
table: t
type: index
possible_keys: NULL
key: idx
key_len: 8
ref: NULL
rows: 64
Extra: Using index
~~~
对 a1 、a2顺序排序,取得主键id字段,可以直接使用该联合索引取回结果并完成排序。
这里需要注意下,二级索引其实是包括主键索引的,因此用idx索引即可取到全部结果。
下面这个SQL也是一样的效果:select a1,a2,id from t order by a1, a2;
符合规则c、h
~~~
(yejr@imysql.com)> explain select id from t order by a1, a2 \G
id: 1
select_type: SIMPLE
table: t
type: index
possible_keys: NULL
key: idx
key_len: 8
ref: NULL
rows: 64
Extra: Using index
~~~
对 a1 正序排序,对a2 倒序排序,取得主键id字段,可以直接使用该联合索引取回结果,但需要进行filesort排序。
符合规则c、f、h
~~~
(yejr@imysql.com)> explain select id from t order by a1, a2 desc \G
id: 1
select_type: SIMPLE
table: t
type: index
possible_keys: NULL
key: idx
key_len: 8
ref: NULL
rows: 64
Extra: Using index; Using filesort
~~~
对 a1 倒序排序,对a2 正序排序,取得主键id字段,可以直接使用该联合索引取回结果,但需要进行filesort排序。
符合规则c、f、h
~~~
(yejr@imysql.com)> explain select id from t order by a1 desc, a2 \G
id: 1
select_type: SIMPLE
table: t
type: index
possible_keys: NULL
key: idx
key_len: 8
ref: NULL
rows: 64
Extra: Using index; Using filesort
~~~
过滤条件a1字段(使用前缀索引扫描,key_len为4),对a2字段进行正序排序,取得主键id字段,可以直接使用联合索引取回结果
符合规则a、c、d、h
~~~
(yejr@imysql.com)> explain select id from t where a1 = 219 order by a2\G
id: 1
select_type: SIMPLE
table: t
type: ref
possible_keys: idx
key: idx
key_len: 4
ref: const
rows: 2
Extra: Using where; Using index
~~~
';
为什么要关闭query cache,如何关闭
最后更新于:2022-04-01 21:02:54
[](https://docs.gechiui.com/gc-content/uploads/sites/kancloud/2015-07-29_55b878aba787b.png)
_备注:插图来自淘宝苏普的博客并保留水印,如果觉得不当还请及时告知 :)_
写在前面:MySQL的query cache大部分情况下其实只是鸡肋而已,建议全面禁用。当然了,或许在你的场景下还是挺好的,还能发挥作用,那就继续使用吧,把本文当做参考就好。
不过,可能有的人人为只需要把 query_cache_size 大小调整为 0 就可以了,可以忽略 query_cache_type 参数的值,反正它也是可以在线调整的。
事实果真如此吗?让我们来实际模拟测试下就知道了。
我们模拟了以下几种场景:
~~~
1、初始化时,同时设置 query_cache_size 和 query_cache_type 的值为 0;
2、初始化时,设置 query_cache_size = 0,但设置 query_cache_type = 1;
3、初始化时,设置 query_cache_size = 0,query_cache_type = 1,但是启动后立刻 修改 query_cache_type = 0
4、初始化时,设置 query_cache_size = 0,query_cache_type = 0,但是启动后立刻 修改 query_cache_type = 1
5、初始化时,设置 query_cache_size = xMB,query_cache_type = 1,但是启动后立刻 修改 query_cache_type = 0
~~~
经过测试,可以得到下面几个重要结论(详细测试过程请见最后):
~~~
1、想要彻底关闭query cache,务必在一开始就设置 query_cache_type = 0,即便是启动后将 query_cache_type 从 1 改成 0,也不行;
2、即便query_cache_size = 0,但 query_cache_type 非 0 的话,在实际环境中,可能会频繁发生 Waiting for query cache lock;
3、一开始就设置 query_cache_type = 0 的话,没有办法在运行 过程中再次动态启用,反过来则可以。也就是说,一开始是启用 query cache 的, 在运行过程中将其关闭,但事实上仍然会发生 Waiting for query cache lock,并没有真正的关闭;
~~~
关于query cache的延伸阅读,请见:
1、我的前同事waterbin帅哥的悲惨经历:[MySQL Troubleshoting:Waiting on query cache mutex](http://blog.csdn.net/dba_waterbin/article/details/9201645 "MySQL Troubleshoting:Waiting on query cache mut")
2、淘宝苏普的旧文:[Query Cache,看上去很美](http://www.orczhou.com/index.php/2009/08/query-cache-1/ "Query Cache,看上去很美")
详细测试过程:
一、测试方法
采用sysbench模拟并发oltp请求:
~~~
sysbench --test=tests/db/oltp.lua --oltp_tables_count=10 --oltp-table-size=100000 --rand-init=on --num-threads=64 --oltp-read-only=off --report-interval=10 --rand-type=uniform --max-time=1800 --max-requests=0 run
~~~
二、具体几种测试模式
1、一直关闭QC(query cache的简写,下同),即 query_cache_size = 0, query_cache_type = 0
测试过程中,一直都没有和query cache lock相关的状态出现,结果tps:2295.34
2、启用QC,但QC size 设置为 0,即:query_cache_size = 0,query_cache_type = 1
测试过程中,一直有 Waiting for query cache lock 状态出现,结果tps:2272.52
3、启用QC,但QC size为0,但启动时立刻关闭QC,即初始化时 query_cache_size = 0,query_cache_type = 1,启动后立刻修改 query_cache_type = 0
测试过程中,也一直有 Waiting for query cache lock 状态出现,结果tps:2311.54
4、关闭QC,但启动后立刻启用QC,即初始化时 query_cache_size = 0,query_cache_type = 0,启动后立刻修改 query_cache_type = 1
这时,会提示报错信息:
失败:ERROR 1651 (HY000): Query cache is disabled; restart the server with query_cache_type=1 to enable it
也就是说,如果一开始就关闭 QC 的话,是没办法在运行过程中动态再启用QC的。
5、启用QC,并设置QC size为256M,即 query_cache_size = 256M,query_cache_type = 1
这种情况下,在测试过程中一直有 Waiting for query cache lock 状态出现,并且结果tps也很差,只有 1395.39(几个案例中最差的一种)
6、启用QC,设置QC size为256M,但启动后立刻关闭QC,即 query_cache_size = 256M,query_cache_type = 1,启动后立刻修改 query_cache_type = 0
这种情况下,在测试过程中也一直有 Waiting for query cache lock 状态出现,结果tps:2295.79(在这个模式下,如果设置 query_cache_type = 2,效果也不佳)
第三种模式下,虽然看起来tps还不错,但毕竟上面只是简单模拟测试,实际情况下如果有频繁的query cache lock的话,tps肯定不会太好看。
因此,总的来说,想要获得较高tps的话,最好还是一开始就关闭QC,不要心存侥幸或者固守陈规。
';
pt-table-checksum工具使用报错一例
最后更新于:2022-04-01 21:02:51

_图片来自Percona官网_
今天同事在用 [percona toolkit](http://www.percona.com/software/percona-toolkit "percona toolkit") 工具中的 [pt-table-checksum](http://www.percona.com/doc/percona-toolkit/2.2/pt-table-checksum.html "pt-table-checksum") 对主从数据库进行校验,提交命令后,一直提示下面的信息:
~~~
Pausing because Threads_running=0
~~~
看字面意思是在提示当前活跃线程数为0,但为什么不继续执行呢。这个提示信息有点含糊其辞,该工具是用Perl写的,因此直接打开看脚本跟踪一下,大概就明白怎么回事了,原来是这个工具有负载保护机制,避免运行时对线上数据库产生影响。
和这个机制相关的参数名是: –max-load,其类型是:Array,用法是一个或多个 variables = value 组成的判断条件,然后根据这个规则判断某些条件是否超标。例如,设定 –max-load=”Threads_running=25″,意思是当前活跃线程数如果超过25,就暂停 checksum 工作,直到活跃线程数低于 25。
因此,在我们这个案例中,想要强制让 table-checksum 继续工作的话,可以设定 –max-load 的值,例如:
~~~
pt-table-checksum --max-load="Threads_running=25" ...其他选项...
~~~
或者
~~~
pt-table-checksum --max-load="Threads_connected=25" ...其他选项...
~~~
前面的选项意思是判断活跃线程数不要超过25个,后面的选项意思是当前打开的线程数不要超过25个。
下面是 pt-table-checksum 帮助手册里的一段话:
> –max-load
> type: Array; default: Threads_running=25; group: Throttle
>
> Examine SHOW GLOBAL STATUS after every chunk, and pause if any status variables are higher than the threshold. The option accepts a comma-sep-
> arated list of MySQL status variables to check for a threshold. An optional “=MAX_VALUE” (or “:MAX_VALUE”) can follow each variable. If not
> given, the tool determines a threshold by examining the current value and increasing it by 20%.
>
> For example, if you want the tool to pause when Threads_connected gets too high, you can specify “Threads_connected”, and the tool will check
> the current value when it starts working and add 20% to that value. If the current value is 100, then the tool will pause when Threads_con-
> nected exceeds 120, and resume working when it is below 120 again. If you want to specify an explicit threshold, such as 110, you can use
> either “Threads_connected:110″ or “Threads_connected=110″.
>
> The purpose of this option is to prevent the tool from adding too much load to the server. If the checksum queries are intrusive, or if they
> cause lock waits, then other queries on the server will tend to block and queue. This will typically cause Threads_running to increase, and the
> tool can detect that by running SHOW GLOBAL STATUS immediately after each checksum query finishes. If you specify a threshold for this vari-
> able, then you can instruct the tool to wait until queries are running normally again. This will not prevent queueing, however; it will only
> give the server a chance to recover from the queueing. If you notice queueing, it is best to decrease the chunk time.
';
MySQL无法启动例一
最后更新于:2022-04-01 21:02:49
## 场景
某个打算用于slave新搭建的实例启动报错,启动过程中报告InnoDB数据页发生损坏。错误日志像下面这样:
> 150330 15:37:44 mysqld_safe Starting mysqld daemon with databases from /data/mysql/mytest_3306
> 2015-03-30 15:37:45 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use –explicit_defaults_for_timestamp server option (see documentation for more details).
> 2015-03-30 15:37:45 5884 [Warning] Using unique option prefix myisam_recover instead of myisam-recover-options is deprecated and will be removed in a future release. Please use the full name instead.
> 2015-03-30 15:37:45 5884 [Note] Plugin ‘FEDERATED’ is disabled.
> 2015-03-30 15:37:45 5884 [Note] InnoDB: Using atomics to ref count buffer pool pages
> 2015-03-30 15:37:45 5884 [Note] InnoDB: The InnoDB memory heap is disabled
> 2015-03-30 15:37:45 5884 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
> 2015-03-30 15:37:45 5884 [Note] InnoDB: Memory barrier is not used
> 2015-03-30 15:37:45 5884 [Note] InnoDB: Compressed tables use zlib 1.2.3
> 2015-03-30 15:37:45 5884 [Note] InnoDB: Using Linux native AIO
> 2015-03-30 15:37:45 5884 [Note] InnoDB: Using CPU crc32 instructions
> 2015-03-30 15:37:45 5884 [Note] InnoDB: Initializing buffer pool, size = 2.0G
> 2015-03-30 15:37:46 5884 [Note] InnoDB: Completed initialization of buffer pool
> 2015-03-30 15:37:47 5884 [Note] InnoDB: Highest supported file format is Barr.
> 2015-03-30 15:37:48 5884 [Warning] InnoDB: Resizing redo log from 3*32768 to 2*16384 pages, LSN=2740249189
> 2015-03-30 15:37:48 5884 [Warning] InnoDB: Starting to delete and rewrite log files.
> 2015-03-30 15:37:48 5884 [Note] InnoDB: Setting log file ./ib_logfile101 size to 256 MB
> InnoDB: Progress in MB: 100 200
> 2015-03-30 15:37:49 5884 [Note] InnoDB: Setting log file ./ib_logfile1 size to 256 MB
> InnoDB: Progress in MB: 100 200
> 2015-03-30 15:37:50 5884 [Note] InnoDB: Renaming log file ./ib_logfile101 to ./ib_logfile0
> 2015-03-30 15:37:50 5884 [Warning] InnoDB: New log files created, LSN=2740249612
> 2015-03-30 15:37:50 5884 [Note] InnoDB: 128 rollback segment(s) are active.
> 2015-03-30 15:37:50 5884 [Note] InnoDB: Waiting for purge to start
> 2015-03-30 15:37:50 5884 [Note] InnoDB: Percona XtraDB (http://www.percona.com) 5.6.21-rel69.0 started; log sequence number 2740249189
> 2015-03-30 15:37:50 5884 [Warning] No existing UUID has been found, so we assume that this is the first time that this server has been started. Generating a new UUID: ab27d3e4-d6af-11e4-8020-c81f66eeffa6.
> 150330 15:36:33 mysqld_safe Starting mysqld daemon with databases from /data/mysql/mytest_3306
> 2015-03-30 15:37:50 5884 [Warning] No existing UUID has been found, so we assume that this is the first time that this server has been started. Generating a new UUID: ab27d3e4-d6af-11e4-8020-c81f66eeffa6.
> 2015-03-30 15:37:50 5884 [Note] RSA private key file not found: /data/mysql/mytest_3306//private_key.pem. Some authentication plugins will not work.
> 2015-03-30 15:37:50 5884 [Note] RSA public key file not found: /data/mysql/mytest_3306//public_key.pem. Some authentication plugins will not work.
> 2015-03-30 15:37:50 5884 [Note] Server hostname (bind-address): ’10.x.x.x'; port: 3306
> 2015-03-30 15:37:50 5884 [Note] – ’10.x.x.x’ resolves to ’10.x.x.x';
> 2015-03-30 15:37:50 5884 [Note] Server socket created on IP: ’10.x.x.x’.
> 2015-03-30 15:37:50 7f4ce4d68700 InnoDB: Error: page 32769 log sequence number 2740254202
> InnoDB: is in the future! Current system log sequence number 2740249622.
> InnoDB: Your database may be corrupt or you may have copied the InnoDB
> InnoDB: tablespace but not the InnoDB log files. See
> InnoDB: http://dev.mysql.com/doc/refman/5.6/en/forcing-innodb-recovery.html
> InnoDB: for more information.
> 2015-03-30 15:37:50 5884 [Note] Event Scheduler: Loaded 0 events
> 2015-03-30 15:37:50 5884 [Note] /opt/Percona-Server-5.6.21-rel69.0-675.Linux.x86_64/bin/mysqld: ready for connections.
> Version: ‘5.6.21-69.0-log’ socket: ‘/data/mysql/mytest_3306/mysql.sock’ port: 3306 Percona Server (GPL), Release 69.0, Revision 675
> 2015-03-30 15:37:58 7f4ce4d68700 InnoDB: Error: page 6327 log sequence number 2740254445
> InnoDB: is in the future! Current system log sequence number 2740251356.
> InnoDB: Your database may be corrupt or you may have copied the InnoDB
> InnoDB: tablespace but not the InnoDB log files. See
> InnoDB: http://dev.mysql.com/doc/refman/5.6/en/forcing-innodb-recovery.html
> InnoDB: for more information.
## 分析
正常情况下,新部署的实例是不太可能出现InnoDB数据页损坏的。经了解,这个实例是采用xtrabackup工具从master备份过来做恢复的。
细心的同学,通过观察上面的日志,应该能从中发现一些蛛丝马迹。有几个地方需要引起注意:
~~~
1、版本是Percona Server 5.6.21;
2、刚启动就把InnoDB的redo log给resize了;
3、刚启动就发现InnoDB的page LSN和redo log中的不匹配;
~~~
之所以提醒大家注意上面的三点,并且把版本信息放在了第一条,是因为从5.6版本开始,InnoDB如如果发现当前的redo log文件大小和预设配置的redo log大小不一致的话,就会自动将其删除重建。
写到这里,相信聪明的你应该已经想到什么了吧,没错,导致这个启动报错的原因是:从master上xtrabackup备份出来的innodb redo log大小和本地配置参数不一致,被删除重建,结果事务恢复失败,提示数据也损坏错误信息。
## 解决
修改slave本地配置文件,把下面几个InnoDB配置选项都修改成和在master上的一样,再次执行恢复启动即可。
~~~
innodb_data_file_path
innodb_log_file_size
innodb_log_files_in_group
innodb_file_per_table
~~~
';
processlist中哪些状态要引起关注
最后更新于:2022-04-01 21:02:47
一般而言,我们在processlist结果中如果经常能看到某些SQL的话,至少可以说明这些SQL的频率很高,通常需要对这些SQL进行进一步优化。
今天我们要说的是,在processlist中,看到哪些运行状态时要引起关注,主要有下面几个:
| 状态 | 建议 |
|--|----|
| copy to tmp table | 执行ALTER TABLE修改表结构时建议:放在凌晨执行或者采用类似pt-osc工具 |
| Copying to tmp table | 拷贝数据到内存中的临时表,常见于GROUP BY操作时建议:创建适当的索引 |
| Copying to tmp table on disk | 临时结果集太大,内存中放不下,需要将内存中的临时表拷贝到磁盘上,形成 `#sql***.MYD`、`#sql***.MYI`(在5.6及更高的版本,临时表可以改成InnoDB引擎了,可以参考选项default_tmp_storage_engine)建议:创建适当的索引,并且适当加大sort_buffer_size/tmp_table_size/max_heap_table_size |
| Creating sort index | 当前的SELECT中需要用到临时表在进行ORDER BY排序建议:创建适当的索引 |
| Creating tmp table | 创建基于内存或磁盘的临时表,当从内存转成磁盘的临时表时,状态会变成:Copying to tmp table on disk建议:创建适当的索引,或者少用UNION、视图(VIEW)、子查询(SUBQUERY)之类的,确实需要用到临时表的时候,可以在session级临时适当调大 tmp_table_size/max_heap_table_size 的值 |
| Reading from net | 表示server端正通过网络读取客户端发送过来的请求建议:减小客户端发送数据包大小,提高网络带宽/质量 |
| Sending data | 从server端发送数据到客户端,也有可能是接收存储引擎层返回的数据,再发送给客户端,数据量很大时尤其经常能看见备注:Sending Data不是网络发送,是从硬盘读取,发送到网络是Writing to net(建议:通过索引或加上LIMIT,减少需要扫描并且发送给客户端的数据量) |
| Sorting result | 正在对结果进行排序,类似Creating sort index,不过是正常表,而不是在内存表中进行排序建议:创建适当的索引 |
| statistics | 进行数据统计以便解析执行计划,如果状态比较经常出现,有可能是磁盘IO性能很差建议:查看当前io性能状态,例如iowait |
| Waiting for global read lock | FLUSH TABLES WITH READ LOCK整等待全局读锁建议:不要对线上业务数据库加上全局读锁,通常是备份引起,可以放在业务低谷期间执行或者放在slave服务器上执行备份 |
| Waiting for tables,Waiting for table flush | FLUSH TABLES, ALTER TABLE, RENAME TABLE, REPAIR TABLE, ANALYZE TABLE, OPTIMIZE TABLE等需要刷新表结构并重新打开建议:不要对线上业务数据库执行这些操作,可以放在业务低谷期间执行 |
| Waiting for lock_type lock | 等待各种类型的锁:• Waiting for event metadata lock• Waiting for global read lock • Waiting for schema metadata lock• Waiting for stored function metadata lock• Waiting for stored procedure metadata lock• Waiting for table level lock• Waiting for table metadata lock• Waiting for trigger metadata lock建议:比较常见的是上面提到的global read lock以及table metadata lock,建议不要对线上业务数据库执行这些操作,可以放在业务低谷期间执行。如果是table level lock,通常是因为还在使用MyISAM引擎表,赶紧转投InnoDB引擎吧,别再老顽固了 |
更多详情可参考官方手册:[8.14.2 General Thread States](http://dev.mysql.com/doc/refman/5.6/en/general-thread-states.html)
';
EXPLAIN结果中哪些信息要引起关注
最后更新于:2022-04-01 21:02:44
我们使用EXPLAIN解析SQL执行计划时,如果有下面几种情况,就需要特别关注下了:
首先看下 type 这列的结果,如果有类型是 ALL 时,表示预计会进行全表扫描(full table scan)。通常全表扫描的代价是比较大的,建议创建适当的索引,通过索引检索避免全表扫描。此外,全索引扫描(full index scan)的代价有时候是比全表扫描还要高的,除非是基于InnoDB表的主键索引扫描。
再来看下 Extra 列的结果,如果有出现 Using temporary 或者 Using filesort 则要多加关注:
Using temporary,表示需要创建临时表以满足需求,通常是因为GROUP BY的列没有索引,或者GROUP BY和ORDER BY的列不一样,也需要创建临时表,建议添加适当的索引。
Using filesort,表示无法利用索引完成排序,也有可能是因为多表连接时,排序字段不是驱动表中的字段,因此也没办法利用索引完成排序,建议添加适当的索引。
Using where,通常是因为全表扫描或全索引扫描时(type 列显示为ALL 或 index),又加上了WHERE条件,建议添加适当的索引。
暂时想到上面几个,如果有遗漏,以后再补充。
其他状态例如:Using index、Using index condition、Using index for group-by 则都还好,不用紧张。
更多详情请看官方文档:[8.8.2 EXPLAIN Output Format](http://dev.mysql.com/doc/refman/5.6/en/explain-output.html#explain-join-types)
';
profiling中要关注哪些信息
最后更新于:2022-04-01 21:02:42
利用MySQL的PROFILE功能,我们可以很方便的查看一个SQL具体的执行代价是怎样的,尤其是可以分析它的最大瓶颈在哪里。目前PROFILE功能可提供除了内存以外的其他资源消耗统计,例如CPU、I/O、CONTEXT、SWAP等。
PROFILE功能只能在SESSION级别使用,还做不到像SQL Server那样可以全局开启,收集一段时间后再关闭,这点有待改进。关于PROFILE的具体用法大家可以查看手册 [13.7.5.31 SHOW PROFILE Syntax](http://dev.mysql.com/doc/refman/5.6/en/show-profile.html),这里不细说。
大部分情况下,PROFILE的结果我们主要关注两列:Status、Duration,前者表示的是PROFILE里的状态,它和PROCESSLIST的状态基本是一致的,后者是该状态的耗时。因此,我们最主要的是关注处于哪个状态耗时最久,这些状态中,哪些可以进一步优化。
和我们之前的一个分享 [[MySQL FAQ]系列 — processlist中哪些状态要引起关注](http://imysql.com/2015/06/10/mysql-faq-processlist-thread-states.shtml "编辑“[MySQL FAQ]系列 — processlist中哪些状态要引起关注”") 类似,PROFILE中,下面几种状态是要尤其关注的,而且大多数通过创建合适的索引就可以完成优化。
| Status | 建议 |
|------|--------|
| System lock | 确认是由于哪个锁引起的,通常是因为MySQL或InnoDB内核级的锁引起的建议:如果耗时较大再关注即可,一般情况下都还好 |
| Sending data | 从server端发送数据到客户端,也有可能是接收存储引擎层返回的数据,再发送给客户端,数据量很大时尤其经常能看见(备注:Sending Data不是网络发送,是从硬盘读取,发送到网络是Writing to net 建议:通过索引或加上LIMIT,减少需要扫描并且发送给客户端的数据量) |
| Sorting result | 正在对结果进行排序,类似Creating sort index,不过是正常表,而不是在内存表中进行排序(建议:创建适当的索引) |
| Table lock | 表级锁,没什么好说的,要么是因为MyISAM引擎表级锁,要么是其他情况显式锁表 |
| create sort index | 当前的SELECT中需要用到临时表在进行ORDER BY排序(建议:创建适当的索引) |
| checking query cache for querychecking privileges on cachedsending cached result to clien storing result in query cache | 和query cache相关的状态,已经多次强烈建议关闭 |
更多状态请移步之前的分享文章 [[MySQL FAQ]系列 — processlist中哪些状态要引起关注](http://imysql.com/2015/06/10/mysql-faq-processlist-thread-states.shtml "编辑“[MySQL FAQ]系列 — processlist中哪些状态要引起关注”") 以及官方文档 [8.14.2 General Thread States](http://dev.mysql.com/doc/refman/5.6/en/general-thread-states.html),如果有未涉及想了解的状态,也请在评论区给我留言,谢谢。
';
什么情况下会用到临时表
最后更新于:2022-04-01 21:02:40
MySQL在以下几种情况会创建临时表:
> 1、UNION查询;
> 2、用到TEMPTABLE算法或者是UNION查询中的视图;
> 3、ORDER BY和GROUP BY的子句不一样时;
> 4、表连接中,ORDER BY的列不是驱动表中的;
> 5、DISTINCT查询并且加上ORDER BY时;
> 6、SQL中用到SQL_SMALL_RESULT选项时;
> 7、FROM中的子查询;
> 8、子查询或者semi-join时创建的表;
EXPLAIN 查看执行计划结果的 Extra 列中,如果包含 [Using Temporary](http://imysql.com/2015/06/14/mysql-faq-what-important-information-in-explain.shtml) 就表示会用到临时表。
当然了,如果临时表中需要存储的数据量超过了上限( [tmp-table-size](https://dev.mysql.com/doc/refman/5.6/en/server-system-variables.html#sysvar_tmp_table_size) 或[max-heap-table-size](https://dev.mysql.com/doc/refman/5.6/en/server-system-variables.html#sysvar_max_heap_table_size) 中取其大者),这时候就需要生成基于磁盘的临时表了。
在以下几种情况下,会创建磁盘临时表:
> 1、数据表中包含BLOB/TEXT列;
> 2、在 GROUP BY 或者 DSTINCT 的列中有超过 512字符 的字符类型列(或者超过 512字节的 二进制类型列,在5.6.15之前只管是否超过512字节);
> 3、在SELECT、UNION、UNION ALL查询中,存在最大长度超过512的列(对于字符串类型是512个字符,对于二进制类型则是512字节);
> 4、执行SHOW COLUMNS/FIELDS、DESCRIBE等SQL命令,因为它们的执行结果用到了BLOB列类型。
从5.7.5开始,新增一个系统选项[internal_tmp_disk_storage_engine](https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html#sysvar_internal_tmp_disk_storage_engine) 可定义磁盘临时表的引擎类型为 InnoDB,而在这以前,只能使用 MyISAM。而在5.6.3以后新增的系统选项 [default_tmp_storage_engine](https://dev.mysql.com/doc/refman/5.6/en/server-system-variables.html#sysvar_default_tmp_storage_engine) 是控制 CREATE TEMPORARY TABLE创建的临时表的引擎类型,在以前默认是MEMORY,不要把这二者混淆了。
见下例:
~~~
mysql> set default_tmp_storage_engine = "InnoDB";
-rw-rw---- 1 mysql mysql 8558 Jul 7 15:22 #sql4b0e_10_0.frm -- InnoDB引擎的临时表
-rw-rw---- 1 mysql mysql 98304 Jul 7 15:22 #sql4b0e_10_0.ibd
-rw-rw---- 1 mysql mysql 8558 Jul 7 15:25 #sql4b0e_10_2.frm
mysql> set default_tmp_storage_engine = "MyISAM";
-rw-rw---- 1 mysql mysql 0 Jul 7 15:25 #sql4b0e_10_2.MYD -- MyISAM引擎的临时表
-rw-rw---- 1 mysql mysql 1024 Jul 7 15:25 #sql4b0e_10_2.MYI
mysql> set default_tmp_storage_engine = "MEMORY";
-rw-rw---- 1 mysql mysql 8558 Jul 7 15:26 #sql4b0e_10_3.frm -- MEMORY引擎的临时表
~~~
延伸阅读:
[[MySQL优化案例]系列 — 频繁创建临时表](http://imysql.com/2009_02_17_mysql_optimize_to_many_temp_table)
[无需过分关注Created_tmp_disk_tables](http://www.imysql.com/2009/07/01/donot_worry_about_tmp_table_on_disk)
[8.4.4 How MySQL Uses Internal Temporary Tables](https://dev.mysql.com/doc/refman/5.6/en/internal-temporary-tables.html)
';
修改my.cnf配置不生效
最后更新于:2022-04-01 21:02:38
## 问题
修改了 my.cnf 配置文件后,却不生效,这是怎么回事?
## 原因
我们注意到,这里只说了修改 my.cnf,并没有说清楚其绝对路径是哪个文件。也就是说,有可能修改的不是正确路径下的my.cnf文件。
在MySQL中,是允许存在多个 my.cnf 配置文件的,有的能对整个系统环境产生影响,例如:/etc/my.cnf。有的则只能影响个别用户,例如:~/.my.cnf。
MySQL读取各个my.cnf配置文件的先后顺序是:
* /etc/my.cnf
* /etc/mysql/my.cnf
* /usr/local/mysql/etc/my.cnf
* ~/.my.cnf
* 其他自定义路径下的my.cnf,例如:/data/mysql/yejr_3306/my.cnf
不管是mysqld服务器端程序,还是mysql客户端程序,都可以采用下面两个参数来自行指定要读取的配置文件路径:
* –defaults-file=#, 只读取指定的文件(不再读取其他配置文件)
* –defaults-extra-file=#, 从其他优先级更高的配置文件中读取全局配置后,再读取指定的配置文件(有些选项可以覆盖掉全局配置从的设定值)
因此,可以看到,如果你修改的是非“著名”目录下的 my.cnf,有可能看起来是不生效的,需要自行指定,或者统一放在 /etc/my.cnf 下,采用多实例的方式来管理即可。
';
使用mysqldump备份时为什么要加上 -q 参数
最后更新于:2022-04-01 21:02:35
[](https://docs.gechiui.com/gc-content/uploads/sites/kancloud/2015-07-29_55b8754987525.png)
写在前面:我们在使用mysqldump备份数据时,请一定记住要加上 -q 参数,后果可能是很严重的,不要给自己挖坑哦。到底为什么呢,且听我慢慢道来!
先来看看 mysqldump –help 中,关于 -q 参数的解释:
~~~
-q, --quick Don't buffer query, dump directly to stdout.
~~~
简言之,就是说加上 -q 后,不会把SELECT出来的结果放在buffer中,而是直接dump到标准输出中,顶多只是buffer当前行结果,正常情况下是不会超过 max_allowed_packet 限制的,它默认情况下是开启的。
如果关闭该参数,则会把SELECT出来的结果放在本地buffer中,然后再输出给客户端,会消耗更多内存。
在mysqldump.c中也能看到二者的对比(现在流行深入源码,虽然我不是专注开发的,找几行源码能力还尚存,用来装B的,大家知道就好,哈哈):
~~~
if (quick)
res=mysql_use_result(sock);
else
res=mysql_store_result(sock);
~~~
有理论,也要有实践不是,我们来看看在实际场景中,加不加 -q 的区别有多大。
| 备份方式 | 部分备份(启用-q) | 部分备份(禁用-q) | 完整备份(启用-q) | 完整备份(禁用-q) |
|-----|------------|------------|------------|--------------|
| 备份总耗时 | 27.882秒 | 22.665秒 | 277.387秒 | 217.074秒 |
| 占用内存(含swap) | 3056KB | 2.5GB | 3048KB | 内存:12GBswap:305MB |
可以看到,如果只是备份小量数据,足以放在空闲内存buffer中的话,禁用 -q 会快一些,但如果是大数据集,没办法完全hold在内存buffer中时,就会产生swap,效率反而更差,真是赔了夫人又折兵。
因此,如果使用mysqldump来备份数据时,建议总是加上 -q 参数,避免发生swap反而影响备份效率。
详细过程(有耐心的可以继续往下看)
1、全量备份:备份时不使用 -q 参数
~~~
mysqldump --quick=false -Smysql.sock -B yejr --tables t_yejr
#先看下一开始时的状态:
Mem: 32863040k total, 29338704k used, 3524336k free, 227632k buffers
Swap: 16777208k total, 23548k used, 16753660k free, 8200416k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
21986 root 20 0 6119m 5.9g 2192 S 20.6 18.9 0:21.69 mysqldump
#再看下备份结束后的状态,内存不够用,产生了swap
Mem: 32863040k total, 32521328k used, 341712k free, 440k buffers
Swap: 16777208k total, 336876k used, 16440332k free, 315192k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
21986 root 20 0 12.3g 12g 656 R 100.0 39.1 2:23.93 mysqldump
#最后看下备份总耗时
real 4m37.387s
user 2m2.731s
sys 0m24.608s
~~~
2、全量备份:备份时启用 -q 参数
~~~
mysqldump -Smysql.sock -B yejr --tables t_yejr
#先看下一开始时的状态:
Mem: 32863040k total, 20157476k used, 12705564k free, 4608k buffers
Swap: 16777208k total, 0k used, 16777208k free, 488296k cached
#再看下备份结束后,可以看到,没有使用到swap
Mem: 32863040k total, 32644496k used, 218544k free, 920k buffers
Swap: 16777208k total, 0k used, 16777208k free, 12618740k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
25234 root 20 0 50880 3048 2192 S 57.6 0.0 2:22.79 mysqldump
#最后看下总耗时统计:
real 3m37.074s
user 2m6.018s
sys 0m17.315s
~~~
3、部分备份:备份时不使用 -q 参数
~~~
mysqldump -w " id<100000 " -Smysql.sock --quick=false -Smysql.sock -B yejr --tables t_yejr
#看下总耗时
real 0m22.665s
user 0m20.458s
sys 0m2.156s
#再看下mysqldump进程消耗的内存,最高时大概使用了2.5G内存
20619 root 20 0 2571m 2.5g 2208 R 99.9 7.8 0:11.63 mysqldump
~~~
4、部分备份:备份时启用 -q 参数
~~~
mysqldump -w " id<100000 " -Smysql.sock -Smysql.sock -B yejr --tables t_yejr
#看下总耗时,并没有慢多少
real 0m27.882s
user 0m22.610s
sys 0m0.670s
#再看下mysqldump进程消耗的内存,只占用了极少量内存
19690 root 20 0 50880 3056 2200 S 73.4 0.0 0:06.01 mysqldump
~~~
';
mysqldump加-w参数备份
最后更新于:2022-04-01 21:02:33
我们在用mysqldump备份数据时,有个选项是 –where / -w,可以指定备份条件,这个选项的解释是:
~~~
-w, --where=name Dump only selected records. Quotes are mandatory
~~~
我们可以做个测试,例如:
~~~
mysqldump --single-transaction -w ' id mydump.sql
~~~
这时候就可以备份出mytable表中 id< 10000 的所有记录了。假设我们还想加一个时间范围条件,例如:
~~~
mysqldump --single-transaction -w " id mydump.sql
~~~
在这里,一定注意单引号和双引号问题,避免出现这种情况:
~~~
mysqldump --single-transaction -w ' id mydump.sql
~~~
这样的话,结果条件会被解析成:
~~~
WHERE id < 10000 and logintime < unix_timestamp(2014-06-01)
~~~
眼尖的同学会发现,时间条件变成了:
~~~
WHERE id < 10000 and logintime < unix_timestamp(2014-06-01)
~~~
也就是变成了:
~~~
unix_timestamp(2007) -- 2014-6-1 = 2007
~~~
这和我们原先的设想大相径庭,因此一定要谨慎。
';
如何将两个表名对调
最后更新于:2022-04-01 21:02:31
## 问题
有位同学问我,在类似pt-osc场景下,需要将两个表名对调,怎么才能确保万无一失呢?
## 分析
估计其他同学就笑了,表名对掉还不简单吗,相互RENAME一下嘛。
但是,我们想要的是同时完成表名对调,如果是先后的对掉,可能会导致有些数据写入失败,那怎么办?
其实也不难,从MySQL手册里就能找到方法,那就是:同时锁定2个表,不允许写入,然后对调表名。
我们通常只锁一个表,那么同时锁两个表应该怎么做呢,可以用下面的方法:
~~~
LOCK TABLES t1 WRITE, t2 WRITE;
ALTER TABLE t1 RENAME TO t3;
ALTER TABLE t2 RENAME TO t1;
ALTER TABLE t3 RENAME TO t2;
UNLOCK TABLES;
~~~
看到了吧,其实很简单,两个表同时加表级写锁,然后用ALTER语法改名就可以了。
废话挺多的,谢谢各位客官耐心看完 :)
';
Spring框架中调用存储过程失败
最后更新于:2022-04-01 21:02:29
Spring框架中,调用存储过程同时还需要show create procedure权限,对于普通用户而言,还要授予 select on mysql.proc 权限才能正常
';
不同的binlog_format会导致哪些SQL不会被记录
最后更新于:2022-04-01 21:02:26
我们都知道binlog_format有三种可选配置:STATEMENT、ROW、MIXED,相应地,基于这三种模式的Replication分别称为SBR(STATEMENT BASED Replication)、RBR、MBR。 同时,我们也知道,MySQL Replication可以支持比较灵活的binlog规则,可以设置某些库、某些表记录或者忽略不记录。
通常地,我们强烈建议不要设置这些规则,默认都记录就好,在Slave上也是如此,默认所有库都进行Replicate,不要设置DO、IGNORE、REWRITE规则。 如果非要设置这些规则的话,可能会导致某些场景下或者某些特定的SQL无法被记录,就需要特别注意了。
我经过比较简单的测试,不同的binlog_format可能会导致某些SQL不被记录的情况总结如下:
[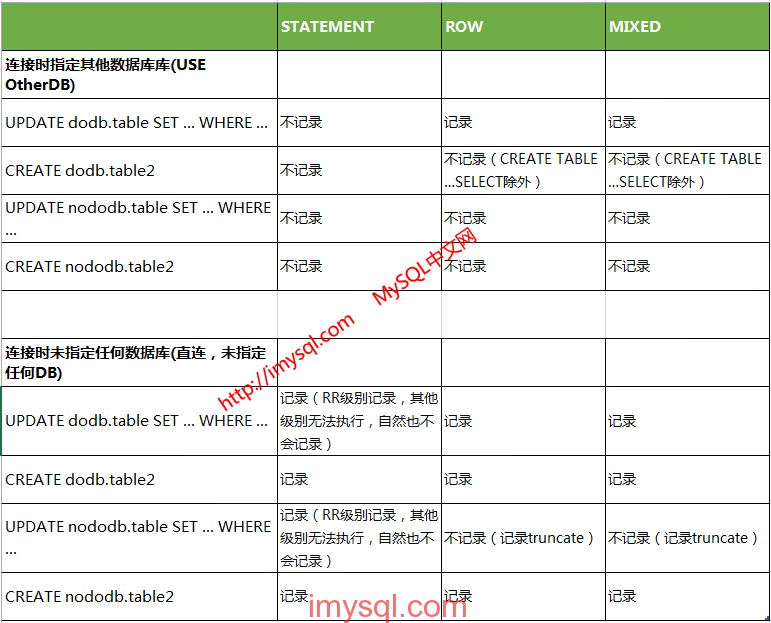](https://docs.gechiui.com/gc-content/uploads/sites/kancloud/2015-07-29_55b8749378beb.png)
上面的测试区分了两种模式,一种是连接时指定了其他数据库,一种是连接时未指定任何数据库,相当于下面的两种方式:
~~~
#假设do/ignore规则中的DB名字叫DoDB/IgnoreDB/RewriteDB的话,OtherDB是规则之外的其他DB
#一种是:连接时指定了do/ignore/rewrite规则之外的其他DB
mysql -h host -u user -p passwd -p port -A OtherDB
#还有一种是:连接时不指定任何DB
mysql -h host -u user -p passwd -p port -A
#tips,加上 -A 是--no-auto-rehash的缩写,其作用是连接后不读取数据库、表、字段信息。与其相反的选项是 --auto-rehash,也就是连接后会读取数据库、表、字段信息,以便自动补齐。
~~~
更多情况请读者自行进行测试吧 :)
';
5.6版本GTID复制异常处理一例
最后更新于:2022-04-01 21:02:24
昨天处理了一个MySQL 5.6版本下开启GTID模式复制异常案例,MASTER上的任何操作都无法在SLAVE上应用,SLAVE的RELAY LOG里有记录,但SLAVE的BINLOG却找不到蛛丝马迹。由于开启了GTID,所以排查起来也简单,只需要在SLAVE上把RELAY LOG和BINLOG分别解析成文本文件,再直接搜索MASTER的UUID,就能找到SLAVE上是否应用了MASTER复制过来的事务。 排查过程中,曾经一度怀疑是因为设置了BINLOG-DO或者IGNORE规则,或者设置了REPLICATION-DO或IGNORE规则,甚至是GTID的严重BUG,但都没发现端倪。直到从 SHOW SLAVE STATUS 里发现下面这个信息:
~~~
[yejr@imysql.com]> show slave status\G
*************************** 1\. row ***************************
Slave_IO_State: Waiting for master to send event
...
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 2539
Relay_Log_File: mysql-relay-bin.000003
Relay_Log_Pos: 1996
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
# 两个线程工作正常
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
#没设置任何规则
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 2539 # 无论binlog file 还是 pos,都和MASTER保持一致,也就是说BINLOG的接收和RELAYR LOG的APPLY都很正常,有条不紊工作着
Relay_Log_Space: 2778
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
...
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
# 没设置忽略某些 server-id 上的BINLOG
Master_Server_Id: 123315
Master_UUID: 35cc99c6-0297-11e4-9916-782bcb2c9453
Master_Info_File: /data/db11_3316/master.info
SQL_Delay: 0 # 没有设置复制延迟策略 SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Master_Retry_Count: 4294967295
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 35cc99c6-0297-11e4-9916-782bcb2c9453:1-451
Executed_Gtid_Set: 35cc99c6-0297-11e4-9916-782bcb2c9453:1-2455:792490-4517929 Auto_Position: 1
~~~
从上面的日志发现什么了没?尤其是这两行:
~~~
Retrieved_Gtid_Set: 35cc99c6-0297-11e4-9916-782bcb2c9453:1-451
Executed_Gtid_Set: 35cc99c6-0297-11e4-9916-782bcb2c9453:1-2455:792490-4517929 Auto_Position: 1
~~~
这下有点明白了吧,意思是:
~~~
1、SLAVE从MASTER上复制了GTID范围是:1-451;
2、SLAVE上执行GTID的范围分为两段,一段是:1-2455,另一段是:792490-4517929;
~~~
尼玛,不应该是连续的嘛,怎么会这么奇葩⊙﹏⊙b,这可如何是好呀,好捉急~~~ 莫急,且容我们慢慢分析为啥GTID从MASTER到SLAVE之后发生了断点,产生了间隙。
正常滴,在MySQL 5.6启用GTID后,部署REPLICATION复制时,可以设定 MASTER_AUTO_POSITION = 1,让 SLAVE 根据 GTID 自动选择适当的事务点进行复制,DBA基本上无需关注和担心主从不一致的问题,还是很让DBA省心的。 在启用 MASTER_AUTO_POSITION = 1 的情况下,正常是不会发生 GTID 中间有个空隙,产生断点的问题发生。除非是下面这种情况:
~~~
1、人工暂停SLAVE进程;
2、MASTER上继续写入数据;
3、MASTER上刷新LOG;
4、MASTER上删除旧BINLOG,只保留最新的BINLOG;
5、SLAVE上启动MASTER,这时候会报错,像下面这样:
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
~~~
针对这种问题的处理方法可以这么做:
~~~
1、关闭MASTER_AUTO_POSITION,即设置 MASTER_AUTO_POSITION = 0;
2、手工CHANGE BINLOG FILE & POS;
~~~
这种情况下,不能再次设置 MASTER_AUTO_POSITION = 1,否则还会再次报错。 还有一种情况会发生 GTID 间隙断点问题,例如这样:
~~~
1、正常配置 REPLICATION 复制,但是设置 MASTER_AUTO_POSITION = 0,也就是人工指定 BINLOG FILE & POS的传统方法;
2、在复制过程中,暂时关闭 SLAVE 进程;
3、手工修改 BINLOG FILE & POS 信息,指向新的 BINLOG FILE & POS 点;
4、启动SLAVE,这时候就会发现 GTID 断点的现象重现了;
~~~
在主从高可用模式下,可能主从间会发生切换,然后再次切换回来,这时候也可能发生上述的断点问题。因此我们建议采用双主来部署高可用切换,基本上可以实现任意来回切换,无需手工指定新的 BINLOG FIEE & POS 信息。
还有最后一种情况,就是在 MASTER 上执行了 RESET MASTER,导致 MASTER 上的 BINLOG FILE & POS 全部重置,SLAVE 上读取到的信息自然也就不一致了。
好了,说了那么多,我们最后来说下如何应对处理 GTID 断点的问题。
方法一:手工修改 BINLOG FILE & POS
~~~
1、关闭SLAVE;
2、手工CHANGE BINLOG FILE & POS,指向MASTER上最新产生的BINLOG FILE & POS,并且设置 MASTER_AUTO_POSITION = 0;
3、启动SLAVE;
~~~
方法二:手工修改 GTID_PURGED 值
~~~
1、关闭 SLAVE;
2、在 SLAVE 上执行 RESET MASTER,重设 SLAVE 上的 BINLOG FILE & POS(如果这个节点用于复制中继,要注意所有binlog是否都被读取完毕,避免数据丢失);
3、在 SLAVE 上执行 SET @@GLOBAL.GTID_PURGED = '35cc99c6-0297-11e4-9916-782bcb2c9453:1-2455';
4、启动 SLAVE;
~~~
这种做法比较费解一点,意思是,我们告诉SLAVE要主动抛弃掉 MASTER 上传输过来的某些区间的事务。在这个例子中,我们抛弃了 1-2455 这个区间,也就是在 GTID 从 2466 开始,又会继续应用 RELAY LOG 了,相比我们最开始的那个信息:
~~~
Retrieved_Gtid_Set: 35cc99c6-0297-11e4-9916-782bcb2c9453:1-451
Executed_Gtid_Set: 35cc99c6-0297-11e4-9916-782bcb2c9453:1-2455:792490-4517929
~~~
我们强制 SLAVE 只忽略 1-2455 这个区间,从 2466 开始继续复制,消除了本来也会被忽略的区间: 792490-4517929,确保新产生的事务都会被继续应用。这个做法可以参考MySQL手册:[Excluding transactions with gtid_purged](https://dev.mysql.com/doc/refman/5.6/en/replication-gtids-failover.html#replication-gtids-failover-gtid-purged "Excluding transactions with gtid_purged")。
还有另外一种费力不讨好的做法,就是在 MASTER 上执行一些没用的空事务,使得 GTID 的序号一直在加大,直到超过 2555 为止,然后在 792490-4517929 这个区间依法炮制一番,但我们非常不推荐采用这种做法,既麻烦又容易误操作。 说了这么多,在 MySQL 5.6及以上版本中,我们强烈建议启用 MASTER_AUTO_POSITION = 1,让 MySQL 自己去做判断,减少一些不必要的问题,并且采用双主(其中一个主设为只读)的方式,方便两个主之间可以随意相互切换,而不必担心数据不一致。
上面过程我采用的MySQL版本:5.6.17-65.0-rel65.0-log Percona Server with XtraDB (GPL), Release rel65.0, Revision 587,实际案例发生的MySQL版本当时忘了记录了,但肯定也是5.6以上的啦,哈哈~~~
';
从MyISAM转到InnoDB需要注意什么
最后更新于:2022-04-01 21:02:22
## 问题
当前,绝大多数业务场景用InnoDB已经完全能搞定了,越来越多的业务从MyISAM转向InnoDB引擎,那么有哪些注意事项呢?
## 分析
当了解完两种引擎的不同之处,很轻松的就能知道有哪些关键点了。
总的来说,从MyISAM转向InnoDB的注意事项有:
~~~
1、MyISAM的主键索引中,可以在非第一列(非第一个字段)使用自增列,而InnoDB的主键索引中包含自增列时,必须在最前面;这个特性在discuz论坛中,被设计用于“抢楼”功能,因此,若有类似的业务,则无法将该表从MyISAM转成InnoDB,需要自行变通实现(我们则是将其改到Redis中实现);
2、不带条件频繁统计全表总记录数时(SELECT COUNT(*) FROM TAB),InnoDB相对较慢,而MyISAM则飞快;不过,如果是基于索引条件的统计,则二者相差不大;
3、InnoDB在5.6以前不支持全文索引,不过这个相信无所谓,没什么人会在MySQL里直接跑全文索引,尤其是对中文的全文索引(前阵子有开发同学提需求直接被我否了),确实有需要的话,可以采用Sphinx、Lucene等其他方案实现;
4、一次性导入大量数据并且后续还要进行加工处理的,可以先导入到MyISAM引擎表中,经过一通加工处理完后,再导入InnoDB表(我曾经在业务中用此方法提高数据批量导入及处理效率);
5、InnoDB不支持LOAD TABLE FROM MASTER语法(不过应该也很少人使用吧);
~~~
从MyISAM转成InnoDB可以享受的好处则有:
~~~
1、完整事务特性支持,以及更高的数据并发存取效率,即更高的TPS;
2、数据库实例异常重启后,InnoDB表能自动修复,而且速度相对更快,而MyISAM需要被触发才能修复,且相对耗时可能多4~5倍甚至更多;
3、更高的数据读取性能,因为InnoDB把数据及索引同时缓存在内存中,而MyISAM只缓存了索引;
4、InnoDB支持外键(不过在MySQL中,应该很少人用到外键);
~~~
两个引擎间的重要区别详情见下:
MyISAM引擎的特点:
~~~
1、堆组织表;
2、不支持事务;
3、数据文件和索引文件分开存储;
4、支持全文索引;
5、主键索引和二级索引完全一样都是B+树的数据结构,只有是否唯一的区别(主键和唯一索引有唯一属性,其他普通索引没有唯一属性。B+树叶子节点存储的都是指向行记录的row pointer);
6、有特殊计数器记录当前记录数;
7、不支持Crash recovery;
8、索引文件很容易损坏;
~~~
InnoDB引擎的特点
~~~
1、索引组织表;
2、支持事务;
3、数据文件和索引文件存储在同一个表空间中;
4、在5.6以前,不支持全文索引;
5、主键和二级索引数据结构一样都是B+树,但叶子节点存储的键值不一样(主键的叶子节点存储整行数据,因此也称为聚集索引;而二级索引的叶子节点存储的是主键的键值)
5、支持Crash recovery;
6、相同数据量时,InnoDB表空间文件大小约为MyISAM引擎的1.5~2倍;
~~~
关于InnoDB、MyISAM两种引擎的对比测试,可以参考Percona的这个对比:[http://www.percona.com/blog/2007/01/08/innodb-vs-myisam-vs-falcon-benchmarks-part-1/](http://www.percona.com/blog/2007/01/08/innodb-vs-myisam-vs-falcon-benchmarks-part-1/)
';