9.1 底层命令 (Plumbing) 和高层命令 (Porcelain)
最后更新于:2022-04-01 00:22:13
本书讲解了使用` checkout, branch, remote` 等共约 30 个 Git 命令。然而由于 Git 一开始被设计成供 VCS 使用的工具集而不是一整套用户友好的 VCS,它还包含了许多底层命令,这些命令用于以 UNIX 风格使用或由脚本调用。这些命令一般被称为 "plumbing" 命令(底层命令),其他的更友好的命令则被称为 "porcelain" 命令(高层命令)。
本书前八章主要专门讨论高层命令。本章将主要讨论底层命令以理解 Git 的内部工作机制、演示 Git 如何及为何要以这种方式工作。这些命令主要不是用来从命令行手工使用的,更多的是用来为其他工具和自定义脚本服务的。
当你在一个新目录或已有目录内执行 `git init` 时,`Git `会创建一个 .git 目录,几乎所有 Git 存储和操作的内容都位于该目录下。如果你要备份或复制一个库,基本上将这一目录拷贝至其他地方就可以了。本章基本上都讨论该目录下的内容。该目录结构如下:
~~~
$ ls
HEAD
branches/
config
description
hooks/
index
info/
objects/
refs/
~~~
该目录下有可能还有其他文件,但这是一个全新的` git init `生成的库,所以默认情况下这些就是你能看到的结构。新版本的 Git 不再使用 branches 目录,`description` 文件仅供 `GitWeb` 程序使用,所以不用关心这些内容。config 文件包含了项目特有的配置选项,info 目录保存了一份不希望在 .gitignore 文件中管理的忽略模式 (ignored patterns) 的全局可执行文件。hooks 目录保存了第七章详细介绍了的客户端或服务端钩子脚本。
另外还有四个重要的文件或目录:`HEAD `及 `index` 文件,`objects `及 refs 目录。这些是 Git 的核心部分。`objects` 目录存储所有数据内容,`refs` 目录存储指向数据 (分支) 的提交对象的指针,HEAD 文件指向当前分支,index 文件保存了暂存区域信息。马上你将详细了解 Git 是如何操纵这些内容的。
9.8 总结
最后更新于:2022-04-01 00:22:11
现在你应该对 Git 可以作什么相当了解了,并且在一定程度上也知道了 Git 是如何实现的。本章覆盖了许多 plumbing 命令 ── 这些命令比较底层,且比你在本书其他部分学到的 porcelain 命令要来得简单。从底层了解 Git 的工作原理可以帮助你更好地理解为何 Git 实现了目前的这些功能,也使你能够针对你的工作流写出自己的工具和脚本。
Git 作为一套 content-addressable 的文件系统,是一个非常强大的工具,而不仅仅只是一个 VCS 供人使用。希望借助于你新学到的 Git 内部原理的知识,你可以实现自己的有趣的应用,并以更高级便利的方式使用 Git。
9.7 维护及数据恢复
最后更新于:2022-04-01 00:22:09
你时不时的需要进行一些清理工作 ── 如减小一个仓库的大小,清理导入的库,或是恢复丢失的数据。本节将描述这类使用场景。
## 维护
Git 会不定时地自动运行称为 "auto gc" 的命令。大部分情况下该命令什么都不处理。不过要是存在太多松散对象 (loose object, 不在 packfile 中的对象) 或 packfile,Git 会进行调用 git gc 命令。 gc 指垃圾收集 (garbage collect),此命令会做很多工作:收集所有松散对象并将它们存入 packfile,合并这些 packfile 进一个大的 packfile,然后将不被任何 commit 引用并且已存在一段时间 (数月) 的对象删除。
可以手工运行 auto gc 命令:
`$ git gc --auto`
再次强调,这个命令一般什么都不干。如果有 7,000 个左右的松散对象或是 50 个以上的 packfile,Git 才会真正调用 gc 命令。可能通过修改配置中的` gc.auto` 和` gc.autopacklimit` 来调整这两个阈值。
gc 还会将所有引用 (references) 并入一个单独文件。假设仓库中包含以下分支和标签:
~~~
$ find .git/refs -type f
.git/refs/heads/experiment
.git/refs/heads/master
.git/refs/tags/v1.0
.git/refs/tags/v1.1
~~~
这时如果运行 git gc, refs 下的所有文件都会消失。Git 会将这些文件挪到 .git/packed-refs 文件中去以提高效率,该文件是这个样子的:
~~~
$ cat .git/packed-refs
pack-refs with: peeled
cac0cab538b970a37ea1e769cbbde608743bc96d refs/heads/experiment
ab1afef80fac8e34258ff41fc1b867c702daa24b refs/heads/master
cac0cab538b970a37ea1e769cbbde608743bc96d refs/tags/v1.0
9585191f37f7b0fb9444f35a9bf50de191beadc2 refs/tags/v1.1
^1a410efbd13591db07496601ebc7a059dd55cfe9
~~~
当更新一个引用时,Git 不会修改这个文件,而是在 refs/heads 下写入一个新文件。当查找一个引用的 SHA 时,Git 首先在 refs 目录下查找,如果未找到则到 `packed-refs` 文件中去查找。因此如果在 refs 目录下找不到一个引用,该引用可能存到 packed-refs 文件中去了。
请留意文件最后以 ^ 开头的那一行。这表示该行上一行的那个标签是一个 annotated 标签,而该行正是那个标签所指向的 commit 。
## 数据恢复
在使用 Git 的过程中,有时会不小心丢失 commit 信息。这一般出现在以下情况下:强制删除了一个分支而后又想重新使用这个分支,hard-reset 了一个分支从而丢弃了分支的部分 commit。如果这真的发生了,有什么办法把丢失的 commit 找回来呢?
下面的示例演示了对 test 仓库主分支进行 hard-reset 到一个老版本的 commit 的操作,然后恢复丢失的 commit 。首先查看一下当前的仓库状态:
~~~
$ git log --pretty=oneline
ab1afef80fac8e34258ff41fc1b867c702daa24b modified repo a bit
484a59275031909e19aadb7c92262719cfcdf19a added repo.rb
1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
~~~
接着将 master 分支移回至中间的一个 commit:
~~~
$ git reset --hard 1a410efbd13591db07496601ebc7a059dd55cfe9
HEAD is now at 1a410ef third commit
$ git log --pretty=oneline
1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
~~~
这样就丢弃了最新的两个 commit ── 包含这两个 commit 的分支不存在了。现在要做的是找出最新的那个 commit 的 SHA,然后添加一个指它它的分支。关键在于找出最新的 commit 的 SHA ── 你不大可能记住了这个 SHA,是吧?
通常最快捷的办法是使用 git reflog 工具。当你 (在一个仓库下) 工作时,Git 会在你每次修改了 HEAD 时悄悄地将改动记录下来。当你提交或修改分支时,reflog 就会更新。git update-ref 命令也可以更新 reflog,这是在本章前面的 "Git References" 部分我们使用该命令而不是手工将 SHA 值写入 ref 文件的理由。任何时间运行 git reflog 命令可以查看当前的状态:
~~~
$ git reflog
1a410ef HEAD@{0}: 1a410efbd13591db07496601ebc7a059dd55cfe9: updating HEAD
ab1afef HEAD@{1}: ab1afef80fac8e34258ff41fc1b867c702daa24b: updating HEAD
~~~
可以看到我们签出的两个 commit ,但没有更多的相关信息。运行 git log -g 会输出 reflog 的正常日志,从而显示更多有用信息:
~~~
$ git log -g
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Reflog: HEAD@{0} (Scott Chacon <schacon@gmail.com>)
Reflog message: updating HEAD
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:22:37 2009 -0700
third commit
commit ab1afef80fac8e34258ff41fc1b867c702daa24b
Reflog: HEAD@{1} (Scott Chacon <schacon@gmail.com>)
Reflog message: updating HEAD
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
modified repo a bit
~~~
看起来弄丢了的 commit 是底下那个,这样在那个 commit 上创建一个新分支就能把它恢复过来。比方说,可以在那个 commit (ab1afef) 上创建一个名为 recover-branch 的分支:
~~~
$ git branch recover-branch ab1afef
$ git log --pretty=oneline recover-branch
ab1afef80fac8e34258ff41fc1b867c702daa24b modified repo a bit
484a59275031909e19aadb7c92262719cfcdf19a added repo.rb
1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
~~~
酷!这样有了一个跟原来 master 一样的 recover-branch 分支,最新的两个 commit 又找回来了。接着,假设引起 commit 丢失的原因并没有记录在 reflog 中 ── 可以通过删除 recover-branch 和 reflog 来模拟这种情况。这样最新的两个 commit 不会被任何东西引用到:
~~~
$ git branch -D recover-branch
$ rm -Rf .git/logs/
~~~
因为 reflog 数据是保存在 .git/logs/ 目录下的,这样就没有 reflog 了。现在要怎样恢复 commit 呢?办法之一是使用 git fsck 工具,该工具会检查仓库的数据完整性。如果指定 --full 选项,该命令显示所有未被其他对象引用 (指向) 的所有对象:
~~~
$ git fsck --full
dangling blob d670460b4b4aece5915caf5c68d12f560a9fe3e4
dangling commit ab1afef80fac8e34258ff41fc1b867c702daa24b
dangling tree aea790b9a58f6cf6f2804eeac9f0abbe9631e4c9
dangling blob 7108f7ecb345ee9d0084193f147cdad4d2998293
~~~
本例中,可以从 dangling commit 找到丢失了的 commit。用相同的方法就可以恢复它,即创建一个指向该 SHA 的分支。
## 移除对象
Git 有许多过人之处,不过有一个功能有时却会带来问题:git clone 会将包含每一个文件的所有历史版本的整个项目下载下来。如果项目包含的仅仅是源代码的话这并没有什么坏处,毕竟 Git 可以非常高效地压缩此类数据。不过如果有人在某个时刻往项目中添加了一个非常大的文件,那们即便他在后来的提交中将此文件删掉了,所有的签出都会下载这个大文件。因为历史记录中引用了这个文件,它会一直存在着。
当你将 Subversion 或 Perforce 仓库转换导入至 Git 时这会成为一个很严重的问题。在此类系统中,(签出时) 不会下载整个仓库历史,所以这种情形不大会有不良后果。如果你从其他系统导入了一个仓库,或是发觉一个仓库的尺寸远超出预计,可以用下面的方法找到并移除大 (尺寸) 对象。
警告:此方法会破坏提交历史。为了移除对一个大文件的引用,从最早包含该引用的 tree 对象开始之后的所有 commit 对象都会被重写。如果在刚导入一个仓库并在其他人在此基础上开始工作之前这么做,那没有什么问题 ── 否则你不得不通知所有协作者 (贡献者) 去衍合你新修改的 commit 。
为了演示这点,往 test 仓库中加入一个大文件,然后在下次提交时将它删除,接着找到并将这个文件从仓库中永久删除。首先,加一个大文件进去:
~~~
$ curl http://kernel.org/pub/software/scm/git/git-1.6.3.1.tar.bz2 > git.tbz2
$ git add git.tbz2
$ git commit -am 'added git tarball'
[master 6df7640] added git tarball
1 files changed, 0 insertions(+), 0 deletions(-)
create mode 100644 git.tbz2
~~~
喔,你并不想往项目中加进一个这么大的 tar 包。最后还是去掉它:
~~~
$ git rm git.tbz2
rm 'git.tbz2'
$ git commit -m 'oops - removed large tarball'
[master da3f30d] oops - removed large tarball
1 files changed, 0 insertions(+), 0 deletions(-)
delete mode 100644 git.tbz2
~~~
对仓库进行 gc 操作,并查看占用了空间:
~~~
$ git gc
Counting objects: 21, done.
Delta compression using 2 threads.
Compressing objects: 100% (16/16), done.
Writing objects: 100% (21/21), done.
Total 21 (delta 3), reused 15 (delta 1)
~~~
可以运行 count-objects 以查看使用了多少空间:
~~~
$ git count-objects -v
count: 4
size: 16
in-pack: 21
packs: 1
size-pack: 2016
prune-packable: 0
garbage: 0
~~~
size-pack 是以千字节为单位表示的 packfiles 的大小,因此已经使用了 2MB 。而在这次提交之前仅用了 2K 左右 ── 显然在这次提交时删除文件并没有真正将其从历史记录中删除。每当有人复制这个仓库去取得这个小项目时,都不得不复制所有 2MB 数据,而这仅仅因为你曾经不小心加了个大文件。当我们来解决这个问题。
首先要找出这个文件。在本例中,你知道是哪个文件。假设你并不知道这一点,要如何找出哪个 (些) 文件占用了这么多的空间?如果运行 git gc,所有对象会存入一个 packfile 文件;运行另一个底层命令 git verify-pack 以识别出大对象,对输出的第三列信息即文件大小进行排序,还可以将输出定向到 tail 命令,因为你只关心排在最后的那几个最大的文件:
~~~
$ git verify-pack -v .git/objects/pack/pack-3f8c0...bb.idx | sort -k 3 -n | tail -3
e3f094f522629ae358806b17daf78246c27c007b blob 1486 734 4667
05408d195263d853f09dca71d55116663690c27c blob 12908 3478 1189
7a9eb2fba2b1811321254ac360970fc169ba2330 blob 2056716 2056872 5401
~~~
最底下那个就是那个大文件:2MB 。要查看这到底是哪个文件,可以使用第 7 章中已经简单使用过的 rev-list 命令。若给 rev-list 命令传入 --objects 选项,它会列出所有 commit SHA 值,blob SHA 值及相应的文件路径。可以这样查看 blob 的文件名:
~~~
$ git rev-list --objects --all | grep 7a9eb2fb
7a9eb2fba2b1811321254ac360970fc169ba2330 git.tbz2
~~~
接下来要将该文件从历史记录的所有 tree 中移除。很容易找出哪些 commit 修改了这个文件:
~~~
$ git log --pretty=oneline --branches -- git.tbz2
da3f30d019005479c99eb4c3406225613985a1db oops - removed large tarball
6df764092f3e7c8f5f94cbe08ee5cf42e92a0289 added git tarball
~~~
必须重写从 6df76 开始的所有 commit 才能将文件从 Git 历史中完全移除。这么做需要用到第 6 章中用过的 filter-branch 命令:
~~~
$ git filter-branch --index-filter \
'git rm --cached --ignore-unmatch git.tbz2' -- 6df7640^..
Rewrite 6df764092f3e7c8f5f94cbe08ee5cf42e92a0289 (1/2)rm 'git.tbz2'
Rewrite da3f30d019005479c99eb4c3406225613985a1db (2/2)
Ref 'refs/heads/master' was rewritten
~~~
--index-filter 选项类似于第 6 章中使用的 --tree-filter 选项,但这里不是传入一个命令去修改磁盘上签出的文件,而是修改暂存区域或索引。不能用 rm file 命令来删除一个特定文件,而是必须用 git rm --cached 来删除它 ── 即从索引而不是磁盘删除它。这样做是出于速度考虑 ── 由于 Git 在运行你的 filter 之前无需将所有版本签出到磁盘上,这个操作会快得多。也可以用 --tree-filter 来完成相同的操作。git rm 的 --ignore-unmatch 选项指定当你试图删除的内容并不存在时不显示错误。最后,因为你清楚问题是从哪个 commit 开始的,使用 filter-branch 重写自 6df7640 这个 commit 开始的所有历史记录。不这么做的话会重写所有历史记录,花费不必要的更多时间。
现在历史记录中已经不包含对那个文件的引用了。不过 reflog 以及运行 filter-branch 时 Git 往 .git/refs/original 添加的一些 refs 中仍有对它的引用,因此需要将这些引用删除并对仓库进行 repack 操作。在进行 repack 前需要将所有对这些 commits 的引用去除:
~~~
$ rm -Rf .git/refs/original
$ rm -Rf .git/logs/
$ git gc
Counting objects: 19, done.
Delta compression using 2 threads.
Compressing objects: 100% (14/14), done.
Writing objects: 100% (19/19), done.
Total 19 (delta 3), reused 16 (delta 1)
~~~
看一下节省了多少空间。
~~~
$ git count-objects -v
count: 8
size: 2040
in-pack: 19
packs: 1
size-pack: 7
prune-packable: 0
garbage: 0
~~~
repack 后仓库的大小减小到了 7K ,远小于之前的 2MB 。从 size 值可以看出大文件对象还在松散对象中,其实并没有消失,不过这没有关系,重要的是在再进行推送或复制,这个对象不会再传送出去。如果真的要完全把这个对象删除,可以运行` git prune --expire` 命令。
9.6 传输协议
最后更新于:2022-04-01 00:22:07
Git 可以以两种主要的方式跨越两个仓库传输数据:基于HTTP协议之上,和 `file://, ssh://, 和 git://` 等智能传输协议。这一节带你快速浏览这两种主要的协议操作过程。
## 哑协议
Git 基于HTTP之上传输通常被称为哑协议,这是因为它在服务端不需要有针对 Git 特有的代码。这个获取过程仅仅是一系列GET请求,客户端可以假定服务端的Git仓库中的布局。让我们以 simplegit 库来看看 http-fetch 的过程:
`$ git clone http://github.com/schacon/simplegit-progit.git`
它做的第1件事情就是获取 info/refs 文件。这个文件是在服务端运行了 `update-server-info` 所生成的,这也解释了为什么在服务端要想使用HTTP传输,必须要开启 `post-receive` 钩子:
~~~
=> GET info/refs
ca82a6dff817ec66f44342007202690a93763949 refs/heads/master
~~~
现在你有一个远端引用和SHA值的列表。下一步是寻找HEAD引用,这样你就知道了在完成后,什么应该被检出到工作目录:
~~~
=> GET HEAD
ref: refs/heads/master
~~~
这说明在完成获取后,需要检出 master 分支。 这时,已经可以开始漫游操作了。因为你的起点是在 info/refs 文件中所提到的 ca82a6 commit 对象,你的开始操作就是获取它:
~~~
=> GET objects/ca/82a6dff817ec66f44342007202690a93763949
(179 bytes of binary data)
~~~
然后你取回了这个对象 - 这在服务端是一个松散格式的对象,你使用的是静态的 HTTP GET 请求获取的。可以使用 zlib 解压缩它,去除其头部,查看它的 commmit 内容:
~~~
$ git cat-file -p ca82a6dff817ec66f44342007202690a93763949
tree cfda3bf379e4f8dba8717dee55aab78aef7f4daf
parent 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
author Scott Chacon <schacon@gmail.com> 1205815931 -0700
committer Scott Chacon <schacon@gmail.com> 1240030591 -0700
changed the version number
~~~
这样,就得到了两个需要进一步获取的对象 - cfda3b 是这个 commit 对象所对应的 tree 对象,和 085bb3 是它的父对象;
~~~
=> GET objects/08/5bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
(179 bytes of data)
~~~
这样就取得了这它的下一步 commit 对象,再抓取 tree 对象:
~~~
=> GET objects/cf/da3bf379e4f8dba8717dee55aab78aef7f4daf
(404 - Not Found)
~~~
Oops - 看起来这个 tree 对象在服务端并不以松散格式对象存在,所以得到了404响应,代表在HTTP服务端没有找到该对象。这有好几个原因 - 这个对象可能在替代仓库里面,或者在打包文件里面, Git 会首先检查任何列出的替代仓库:
~~~
=> GET objects/info/http-alternates
(empty file)
~~~
如果这返回了几个替代仓库列表,那么它会去那些地方检查松散格式对象和文件 - 这是一种在软件分叉之间共享对象以节省磁盘的好方法。然而,在这个例子中,没有替代仓库。所以你所需要的对象肯定在某个打包文件中。要检查服务端有哪些打包格式文件,你需要获取 objects/info/packs 文件,这里面包含有打包文件列表(是的,它也是被 update-server-info 所生成的);
~~~
=> GET objects/info/packs
P pack-816a9b2334da9953e530f27bcac22082a9f5b835.pack
~~~
这里服务端只有一个打包文件,所以你要的对象显然就在里面。但是你可以先检查它的索引文件以确认。这在服务端有多个打包文件时也很有用,因为这样就可以先检查你所需要的对象空间是在哪一个打包文件里面了:
~~~
=> GET objects/pack/pack-816a9b2334da9953e530f27bcac22082a9f5b835.idx
(4k of binary data)
~~~
现在你有了这个打包文件的索引,你可以看看你要的对象是否在里面 - 因为索引文件列出了这个打包文件所包含的所有对象的SHA值,和该对象存在于打包文件中的偏移量,所以你只需要简单地获取整个打包文件:
~~~
=> GET objects/pack/pack-816a9b2334da9953e530f27bcac22082a9f5b835.pack
(13k of binary data)
~~~
现在你也有了这个 tree 对象,你可以继续在 commit 对象上漫游。它们全部都在这个你已经下载到的打包文件里面,所以你不用继续向服务端请求更多下载了。 在这完成之后,由于下载开始时已探明HEAD引用是指向 master 分支, Git 会将它检出到工作目录。
整个过程看起来就像这样:
~~~
$ git clone http://github.com/schacon/simplegit-progit.git
Initialized empty Git repository in /private/tmp/simplegit-progit/.git/
got ca82a6dff817ec66f44342007202690a93763949
walk ca82a6dff817ec66f44342007202690a93763949
got 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
Getting alternates list for http://github.com/schacon/simplegit-progit.git
Getting pack list for http://github.com/schacon/simplegit-progit.git
Getting index for pack 816a9b2334da9953e530f27bcac22082a9f5b835
Getting pack 816a9b2334da9953e530f27bcac22082a9f5b835
which contains cfda3bf379e4f8dba8717dee55aab78aef7f4daf
walk 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
walk a11bef06a3f659402fe7563abf99ad00de2209e6
~~~
## 智能协议
这个HTTP方法是很简单但效率不是很高。使用智能协议是传送数据的更常用的方法。这些协议在远端都有Git智能型进程在服务 - 它可以读出本地数据并计算出客户端所需要的,并生成合适的数据给它,这有两类传输数据的进程:一对用于上传数据和一对用于下载。
## 上传数据
为了上传数据至远端, Git 使用 send-pack 和 receive-pack 进程。这个 send-pack 进程运行在客户端上,它连接至远端运行的 receive-pack 进程。
举例来说,你在你的项目上运行了 git push origin master, 并且 origin 被定义为一个使用SSH协议的URL。 Git 会使用 send-pack 进程,它会启动一个基于SSH的连接到服务器。它尝试像这样透过SSH在服务端运行命令:
~~~
$ ssh -x git@github.com "git-receive-pack 'schacon/simplegit-progit.git'"
005bca82a6dff817ec66f4437202690a93763949 refs/heads/master report-status delete-refs
003e085bb3bcb608e1e84b2432f8ecbe6306e7e7 refs/heads/topic
0000
~~~
这里的 git-receive-pack 命令会立即对它所拥有的每一个引用响应一行 - 在这个例子中,只有 master 分支和它的SHA值。这里第1行也包含了服务端的能力列表(这里是 report-status 和 delete-refs)。
每一行以4字节的十六进制开始,用于指定整行的长度。你看到第1行以005b开始,这在十六进制中表示91,意味着第1行有91字节长。下一行以003e起始,表示有62字节长,所以需要读剩下的62字节。再下一行是0000开始,表示服务器已完成了引用列表过程。
现在它知道了服务端的状态,你的 send-pack 进程会判断哪些 commit 是它所拥有但服务端没有的。针对每个引用,这次推送都会告诉对端的 receive-pack 这个信息。举例说,如果你在更新 master 分支,并且增加 experiment 分支,这个 send-pack 将会是像这样:
~~~
0085ca82a6dff817ec66f44342007202690a93763949 15027957951b64cf874c3557a0f3547bd83b3ff6 refs/heads/master report-status
00670000000000000000000000000000000000000000 cdfdb42577e2506715f8cfeacdbabc092bf63e8d refs/heads/experiment
0000
~~~
这里的全'0'的SHA-1值表示之前没有过这个对象 - 因为你是在添加新的 experiment 引用。如果你在删除一个引用,你会看到相反的: 就是右边是全'0'。
Git 针对每个引用发送这样一行信息,就是旧的SHA值,新的SHA值,和将要更新的引用的名称。第1行还会包含有客户端的能力。下一步,客户端会发送一个所有那些服务端所没有的对象的一个打包文件。最后,服务端以成功(或者失败)来响应:
`000Aunpack ok`
## 下载数据
当你在下载数据时, fetch-pack 和 upload-pack 进程就起作用了。客户端启动 fetch-pack 进程,连接至远端的 upload-pack 进程,以协商后续数据传输过程。
在远端仓库有不同的方式启动 upload-pack 进程。你可以使用与 receive-pack 相同的透过SSH管道的方式,也可以通过 Git 后台来启动这个进程,它默认监听在9418号端口上。这里 fetch-pack 进程在连接后像这样向后台发送数据:
`003fgit-upload-pack schacon/simplegit-progit.git\0host=myserver.com\0`
它也是以4字节指定后续字节长度的方式开始,然后是要运行的命令,和一个空字节,然后是服务端的主机名,再跟随一个最后的空字节。 Git 后台进程会检查这个命令是否可以运行,以及那个仓库是否存在,以及是否具有公开权限。如果所有检查都通过了,它会启动这个 upload-pack 进程并将客户端的请求移交给它。
如果你透过SSH使用获取功能, fetch-pack 会像这样运行:
`$ ssh -x git@github.com "git-upload-pack 'schacon/simplegit-progit.git'"`
不管哪种方式,在 fetch-pack 连接之后, upload-pack 都会以这种形式返回:
~~~
0088ca82a6dff817ec66f44342007202690a93763949 HEAD\0multi_ack thin-pack \
side-band side-band-64k ofs-delta shallow no-progress include-tag
003fca82a6dff817ec66f44342007202690a93763949 refs/heads/master
003e085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7 refs/heads/topic
0000
~~~
这与 `receive-pack` 响应很类似,但是这里指的能力是不同的。而且它还会指出HEAD引用,让客户端可以检查是否是一份克隆。
在这里, `fetch-pack` 进程检查它自己所拥有的对象和所有它需要的对象,通过发送 "want" 和所需对象的SHA值,发送 "have" 和所有它已拥有的对象的SHA值。在列表完成时,再发送 "done" 通知 upload-pack 进程开始发送所需对象的打包文件。这个过程看起来像这样:
~~~
0054want ca82a6dff817ec66f44342007202690a93763949 ofs-delta
0032have 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
0000
0009done
~~~
这是传输协议的一个很基础的例子,在更复杂的例子中,客户端可能会支持 `multi_ack` 或者 `side-band` 能力;但是这个例子中展示了智能协议的基本交互过程。
9.5 The Refspec
最后更新于:2022-04-01 00:22:04
这本书读到这里,你已经使用过一些简单的远程分支到本地引用的映射方式了,这种映射可以更为复杂。 假设你像这样添加了一项远程仓库:
`$ git remote add origin git@github.com:schacon/simplegit-progit.git`
它在你的 .git/config 文件中添加了一节,指定了远程的名称 (origin), 远程仓库的URL地址,和用于获取操作的 Refspec:
~~~
[remote "origin"]
url = git@github.com:schacon/simplegit-progit.git
fetch = +refs/heads/*:refs/remotes/origin/*
~~~
Refspec 的格式是一个可选的 + 号,接着是 <src>:<dst> 的格式,这里 <src> 是远端上的引用格式, <dst> 是将要记录在本地的引用格式。可选的 + 号告诉 Git 在即使不能快速演进的情况下,也去强制更新它。
缺省情况下 refspec 会被 git remote add 命令所自动生成, Git 会获取远端上 refs/heads/ 下面的所有引用,并将它写入到本地的 refs/remotes/origin/. 所以,如果远端上有一个 master 分支,你在本地可以通过下面这种方式来访问它的历史记录:
~~~
$ git log origin/master
$ git log remotes/origin/master
$ git log refs/remotes/origin/master
~~~
它们全是等价的,因为 Git 把它们都扩展成 `refs/remotes/origin/master.`
如果你想让 Git 每次只拉取远程的 master 分支,而不是远程的所有分支,你可以把 fetch 这一行修改成这样:
`fetch = +refs/heads/master:refs/remotes/origin/master`
这是 git fetch 操作对这个远端的缺省 refspec 值。而如果你只想做一次该操作,也可以在命令行上指定这个 refspec. 如可以这样拉取远程的 master 分支到本地的 origin/mymaster 分支:
`$ git fetch origin master:refs/remotes/origin/mymaster`
你也可以在命令行上指定多个 refspec. 像这样可以一次获取远程的多个分支:
~~~
$ git fetch origin master:refs/remotes/origin/mymaster \
topic:refs/remotes/origin/topic
From git@github.com:schacon/simplegit
! [rejected] master -> origin/mymaster (non fast forward)
* [new branch] topic -> origin/topic
~~~
在这个例子中, master 分支因为不是一个可以快速演进的引用而拉取操作被拒绝。你可以在 refspec 之前使用一个 + 号来重载这种行为。
你也可以在配置文件中指定多个 refspec. 如你想在每次获取时都获取 master 和 experiment 分支,就添加两行:
~~~
[remote "origin"]
url = git@github.com:schacon/simplegit-progit.git
fetch = +refs/heads/master:refs/remotes/origin/master
fetch = +refs/heads/experiment:refs/remotes/origin/experiment
~~~
但是这里不能使用部分通配符,像这样就是不合法的:
`fetch = +refs/heads/qa*:refs/remotes/origin/qa*`
但无论如何,你可以使用命名空间来达到这个目的。如你有一个QA组,他们推送一系列分支,你想每次获取 master 分支和QA组的所有分支,你可以使用这样的配置段落:
~~~
[remote "origin"]
url = git@github.com:schacon/simplegit-progit.git
fetch = +refs/heads/master:refs/remotes/origin/master
fetch = +refs/heads/qa/*:refs/remotes/origin/qa/*
~~~
如果你的工作流很复杂,有QA组推送的分支、开发人员推送的分支、和集成人员推送的分支,并且他们在远程分支上协作,你可以采用这种方式为他们创建各自的命名空间。
## 推送 Refspec
采用命名空间的方式确实很棒,但QA组成员第1次是如何将他们的分支推送到 qa/ 空间里面的呢?答案是你可以使用 refspec 来推送。
如果QA组成员想把他们的 master 分支推送到远程的 qa/master 分支上,可以这样运行:
`$ git push origin master:refs/heads/qa/master`
如果他们想让 Git 每次运行 git push origin 时都这样自动推送,他们可以在配置文件中添加 push 值:
~~~
[remote "origin"]
url = git@github.com:schacon/simplegit-progit.git
fetch = +refs/heads/*:refs/remotes/origin/*
push = refs/heads/master:refs/heads/qa/master
~~~
这样,就会让 git push origin 缺省就把本地的 master 分支推送到远程的 qa/master 分支上。
## 删除引用
你也可以使用 refspec 来删除远程的引用,是通过运行这样的命令:
~~~
$ git push origin :topic
~~~
因为` refspec` 的格式是 <src>:<dst>, 通过把` <src>` 部分留空的方式,这个意思是是把远程的 topic 分支变成空,也就是删除它。
9.4 Packfiles
最后更新于:2022-04-01 00:22:02
我们再来看一下 test Git 仓库。目前为止,有 11 个对象 ── 4 个 blob,3 个 tree,3 个 commit 以及一个 tag:
~~~
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/95/85191f37f7b0fb9444f35a9bf50de191beadc2 # tag
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1
~~~
Git 用 zlib 压缩文件内容,因此这些文件并没有占用太多空间,所有文件加起来总共仅用了 925 字节。接下去你会添加一些大文件以演示 Git 的一个很有意思的功能。将你之前用到过的 Grit 库中的 repo.rb 文件加进去 ── 这个源代码文件大小约为 12K:
~~~
$ curl http://github.com/mojombo/grit/raw/master/lib/grit/repo.rb > repo.rb
$ git add repo.rb
$ git commit -m 'added repo.rb'
[master 484a592] added repo.rb
3 files changed, 459 insertions(+), 2 deletions(-)
delete mode 100644 bak/test.txt
create mode 100644 repo.rb
rewrite test.txt (100%)
~~~
如果查看一下生成的 tree,可以看到 repo.rb 文件的 blob 对象的 SHA-1 值:
~~~
$ git cat-file -p master^{tree}
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 9bc1dc421dcd51b4ac296e3e5b6e2a99cf44391e repo.rb
100644 blob e3f094f522629ae358806b17daf78246c27c007b test.txt
~~~
然后可以用 git cat-file 命令查看这个对象有多大:
~~~
$ du -b .git/objects/9b/c1dc421dcd51b4ac296e3e5b6e2a99cf44391e
4102 .git/objects/9b/c1dc421dcd51b4ac296e3e5b6e2a99cf44391e
~~~
稍微修改一下些文件,看会发生些什么:
~~~
$ echo '# testing' >> repo.rb
$ git commit -am 'modified repo a bit'
[master ab1afef] modified repo a bit
1 files changed, 1 insertions(+), 0 deletions(-)
~~~
查看这个 commit 生成的 tree,可以看到一些有趣的东西:
~~~
$ git cat-file -p master^{tree}
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 05408d195263d853f09dca71d55116663690c27c repo.rb
100644 blob e3f094f522629ae358806b17daf78246c27c007b test.txt
~~~
blob 对象与之前的已经不同了。这说明虽然只是往一个 400 行的文件最后加入了一行内容,Git 却用一个全新的对象来保存新的文件内容:
~~~
$ du -b .git/objects/05/408d195263d853f09dca71d55116663690c27c
4109 .git/objects/05/408d195263d853f09dca71d55116663690c27c
~~~
你的磁盘上有了两个几乎完全相同的 12K 的对象。如果 Git 只完整保存其中一个,并保存另一个对象的差异内容,岂不更好?
事实上 Git 可以那样做。Git 往磁盘保存对象时默认使用的格式叫松散对象 (loose object) 格式。Git 时不时地将这些对象打包至一个叫 packfile 的二进制文件以节省空间并提高效率。当仓库中有太多的松散对象,或是手工调用 git gc 命令,或推送至远程服务器时,Git 都会这样做。手工调用 git gc 命令让 Git 将库中对象打包并看会发生些什么:
~~~
$ git gc
Counting objects: 17, done.
Delta compression using 2 threads.
Compressing objects: 100% (13/13), done.
Writing objects: 100% (17/17), done.
Total 17 (delta 1), reused 10 (delta 0)
~~~
查看一下 objects 目录,会发现大部分对象都不在了,与此同时出现了两个新文件:
~~~
$ find .git/objects -type f
.git/objects/71/08f7ecb345ee9d0084193f147cdad4d2998293
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
.git/objects/info/packs
.git/objects/pack/pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.idx
.git/objects/pack/pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.pack
~~~
仍保留着的几个对象是未被任何 commit 引用的 blob ── 在此例中是你之前创建的 "what is up, doc?" 和 "test content" 这两个示例 blob。你从没将他们添加至任何 commit,所以 Git 认为它们是 "悬空" 的,不会将它们打包进 packfile 。
剩下的文件是新创建的 packfile 以及一个索引。packfile 文件包含了刚才从文件系统中移除的所有对象。索引文件包含了 packfile 的偏移信息,这样就可以快速定位任意一个指定对象。有意思的是运行 gc 命令前磁盘上的对象大小约为 12K ,而这个新生成的 packfile 仅为 6K 大小。通过打包对象减少了一半磁盘使用空间。
Git 是如何做到这点的?Git 打包对象时,会查找命名及尺寸相近的文件,并只保存文件不同版本之间的差异内容。可以查看一下 packfile ,观察它是如何节省空间的。git verify-pack 命令用于显示已打包的内容:
~~~
$ git verify-pack -v \
.git/objects/pack/pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.idx
0155eb4229851634a0f03eb265b69f5a2d56f341 tree 71 76 5400
05408d195263d853f09dca71d55116663690c27c blob 12908 3478 874
09f01cea547666f58d6a8d809583841a7c6f0130 tree 106 107 5086
1a410efbd13591db07496601ebc7a059dd55cfe9 commit 225 151 322
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a blob 10 19 5381
3c4e9cd789d88d8d89c1073707c3585e41b0e614 tree 101 105 5211
484a59275031909e19aadb7c92262719cfcdf19a commit 226 153 169
83baae61804e65cc73a7201a7252750c76066a30 blob 10 19 5362
9585191f37f7b0fb9444f35a9bf50de191beadc2 tag 136 127 5476
9bc1dc421dcd51b4ac296e3e5b6e2a99cf44391e blob 7 18 5193 1 \
05408d195263d853f09dca71d55116663690c27c
ab1afef80fac8e34258ff41fc1b867c702daa24b commit 232 157 12
cac0cab538b970a37ea1e769cbbde608743bc96d commit 226 154 473
d8329fc1cc938780ffdd9f94e0d364e0ea74f579 tree 36 46 5316
e3f094f522629ae358806b17daf78246c27c007b blob 1486 734 4352
f8f51d7d8a1760462eca26eebafde32087499533 tree 106 107 749
fa49b077972391ad58037050f2a75f74e3671e92 blob 9 18 856
fdf4fc3344e67ab068f836878b6c4951e3b15f3d commit 177 122 627
chain length = 1: 1 object
pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.pack: ok
~~~
如果你还记得的话,` 9bc1d` 这个 blob 是 repo.rb 文件的第一个版本,这个 blob 引用了` 05408` 这个 blob,即该文件的第二个版本。命令输出内容的第三列显示的是对象大小,可以看到 `05408 `占用了 12K 空间,而 `9bc1d` 仅为 7 字节。非常有趣的是第二个版本才是完整保存文件内容的对象,而第一个版本是以差异方式保存的 ── 这是因为大部分情况下需要快速访问文件的最新版本。
最妙的是可以随时进行重新打包。Git 自动定期对仓库进行重新打包以节省空间。当然也可以手工运行 git gc 命令来这么做。
9.3 Git References
最后更新于:2022-04-01 00:22:00
你可以执行像 git log 1a410e 这样的命令来查看完整的历史,但是这样你就要记得 1a410e 是你最后一次提交,这样才能在提交历史中找到这些对象。你需要一个文件来用一个简单的名字来记录这些 SHA-1 值,这样你就可以用这些指针而不是原来的 SHA-1 值去检索了。
在 Git 中,我们称之为“引用”(references 或者 refs,译者注)。你可以在 .git/refs 目录下面找到这些包含 SHA-1 值的文件。在这个项目里,这个目录还没不包含任何文件,但是包含这样一个简单的结构:
~~~
$ find .git/refs
.git/refs
.git/refs/heads
.git/refs/tags
$ find .git/refs -type f
$
~~~
如果想要创建一个新的引用帮助你记住最后一次提交,技术上你可以这样做:
`$ echo "1a410efbd13591db07496601ebc7a059dd55cfe9" > .git/refs/heads/master`
现在,你就可以在 Git 命令中使用你刚才创建的引用而不是 SHA-1 值:
~~~
$ git log --pretty=oneline master
1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
~~~
当然,我们并不鼓励你直接修改这些引用文件。如果你确实需要更新一个引用,Git 提供了一个安全的命令 update-ref:
`$ git update-ref refs/heads/master 1a410efbd13591db07496601ebc7a059dd55cfe9`
基本上 Git 中的一个分支其实就是一个指向某个工作版本一条 HEAD 记录的指针或引用。你可以用这条命令创建一个指向第二次提交的分支:
`$ git update-ref refs/heads/test cac0ca`
这样你的分支将会只包含那次提交以及之前的工作:
~~~
$ git log --pretty=oneline test
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
~~~
现在,你的 Git 数据库应该看起来像图 9-4 一样。
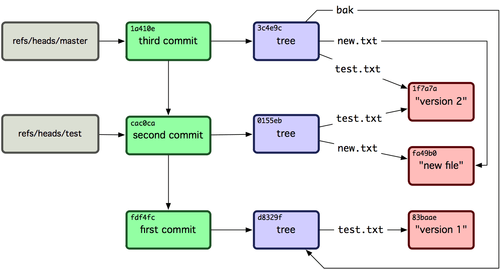
图 9-4. 包含分支引用的 Git 目录对象
每当你执行 git branch (分支名称) 这样的命令,Git 基本上就是执行 update-ref 命令,把你现在所在分支中最后一次提交的 SHA-1 值,添加到你要创建的分支的引用。
## HEAD 标记
现在的问题是,当你执行` git branch` (分支名称) 这条命令的时候,Git 怎么知道最后一次提交的 SHA-1 值呢?答案就是 HEAD 文件。HEAD 文件是一个指向你当前所在分支的引用标识符。这样的引用标识符——它看起来并不像一个普通的引用——其实并不包含 SHA-1 值,而是一个指向另外一个引用的指针。如果你看一下这个文件,通常你将会看到这样的内容:
~~~
$ cat .git/HEAD
ref: refs/heads/master
~~~
如果你执行 git checkout test,Git 就会更新这个文件,看起来像这样:
~~~
$ cat .git/HEAD
ref: refs/heads/test
~~~
当你再执行 `git commit `命令,它就创建了一个 commit 对象,把这个 commit 对象的父级设置为 `HEAD `指向的引用的 SHA-1 值。
你也可以手动编辑这个文件,但是同样有一个更安全的方法可以这样做:symbolic-ref。你可以用下面这条命令读取 HEAD 的值:
~~~
$ git symbolic-ref HEAD
refs/heads/master
~~~
你也可以设置 HEAD 的值:
~~~
$ git symbolic-ref HEAD refs/heads/test
$ cat .git/HEAD
ref: refs/heads/test
~~~
但是你不能设置成 refs 以外的形式:
~~~
$ git symbolic-ref HEAD test
fatal: Refusing to point HEAD outside of refs/
Tags
~~~
你刚刚已经重温过了 Git 的三个主要对象类型,现在这是第四种。Tag 对象非常像一个 commit 对象——包含一个标签,一组数据,一个消息和一个指针。最主要的区别就是 Tag 对象指向一个 commit 而不是一个 tree。它就像是一个分支引用,但是不会变化——永远指向同一个 commit,仅仅是提供一个更加友好的名字。
正如我们在第二章所讨论的,Tag 有两种类型:annotated 和 lightweight 。你可以类似下面这样的命令建立一个 lightweight tag:
`$ git update-ref refs/tags/v1.0 cac0cab538b970a37ea1e769cbbde608743bc96d`
这就是 `lightweight tag` 的全部 —— 一个永远不会发生变化的分支。 annotated tag 要更复杂一点。如果你创建一个 `annotated tag,Git `会创建一个 tag 对象,然后写入一个指向指向它而不是直接指向 commit 的 reference。你可以这样创建一个 `annotated tag`(-a 参数表明这是一个 annotated tag):
`$ git tag -a v1.1 1a410efbd13591db07496601ebc7a059dd55cfe9 -m 'test tag'`
这是所创建对象的 SHA-1 值:
~~~
$ cat .git/refs/tags/v1.1
9585191f37f7b0fb9444f35a9bf50de191beadc2
~~~
现在你可以运行 cat-file 命令检查这个 SHA-1 值:
~~~
$ git cat-file -p 9585191f37f7b0fb9444f35a9bf50de191beadc2
object 1a410efbd13591db07496601ebc7a059dd55cfe9
type commit
tag v1.1
tagger Scott Chacon <schacon@gmail.com> Sat May 23 16:48:58 2009 -0700
test tag
~~~
值得注意的是这个对象指向你所标记的 commit 对象的 SHA-1 值。同时需要注意的是它并不是必须要指向一个 commit 对象;你可以标记任何 Git 对象。例如,在 Git 的源代码里,管理者添加了一个 GPG 公钥(这是一个 blob 对象)对它做了一个标签。你就可以运行:
`$ git cat-file blob junio-gpg-pub`
来查看 Git 源代码仓库中的公钥. Linux kernel 也有一个不是指向 commit 对象的 tag —— 第一个 tag 是在导入源代码的时候创建的,它指向初始 tree (initial tree,译者注)。
## Remotes
你将会看到的第四种 `reference` 是` remote reference`(远程引用,译者注)。如果你添加了一个 remote 然后推送代码过去,Git 会把你最后一次推送到这个 remote 的每个分支的值都记录在 `refs/remotes` 目录下。例如,你可以添加一个叫做 origin 的 remote 然后把你的 master 分支推送上去:
~~~
$ git remote add origin git@github.com:schacon/simplegit-progit.git
$ git push origin master
Counting objects: 11, done.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (7/7), 716 bytes, done.
Total 7 (delta 2), reused 4 (delta 1)
To git@github.com:schacon/simplegit-progit.git
a11bef0..ca82a6d master -> master
~~~
然后查看` refs/remotes/origin/master` 这个文件,你就会发现 origin remote 中的 master 分支就是你最后一次和服务器的通信。
~~~
$ cat .git/refs/remotes/origin/master
ca82a6dff817ec66f44342007202690a93763949
~~~
`Remote` 引用和分支主要区别在于他们是不能被 check out 的。Git 把他们当作是标记了这些分支在服务器上最后状态的一种书签。
9.2 Git 对象
最后更新于:2022-04-01 00:21:57
Git 是一套内容寻址文件系统。很不错。不过这是什么意思呢? 这种说法的意思是,Git 从核心上来看不过是简单地存储键值对(`key-value)`。它允许插入任意类型的内容,并会返回一个键值,通过该键值可以在任何时候再取出该内容。可以通过底层命令 `hash-object `来示范这点,传一些数据给该命令,它会将数据保存在 .git 目录并返回表示这些数据的键值。首先初使化一个 Git 仓库并确认 `objects `目录是空的:
~~~
$ mkdir test
$ cd test
$ git init
Initialized empty Git repository in /tmp/test/.git/
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type f
$
~~~
Git 初始化了 objects 目录,同时在该目录下创建了 pack 和 info 子目录,但是该目录下没有其他常规文件。我们往这个 Git 数据库里存储一些文本:
~~~
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4
~~~
参数` -w` 指示 `hash-object `命令存储 (数据) 对象,若不指定这个参数该命令仅仅返回键值。`--stdin `指定从标准输入设备 (stdin) 来读取内容,若不指定这个参数则需指定一个要存储的文件的路径。该命令输出长度为 40 个字符的校验和。这是个` SHA-1` 哈希值──其值为要存储的数据加上你马上会了解到的一种头信息的校验和。现在可以查看到 Git 已经存储了数据:
~~~
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
~~~
可以在 objects 目录下看到一个文件。这便是 Git 存储数据内容的方式──为每份内容生成一个文件,取得该内容与头信息的 SHA-1 校验和,创建以该校验和前两个字符为名称的子目录,并以 (校验和) 剩下 38 个字符为文件命名 (保存至子目录下)。
通过 cat-file 命令可以将数据内容取回。该命令是查看 Git 对象的瑞士军刀。传入 -p 参数可以让该命令输出数据内容的类型:
~~~
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test content
~~~
可以往 Git 中添加更多内容并取回了。也可以直接添加文件。比方说可以对一个文件进行简单的版本控制。首先,创建一个新文件,并把文件内容存储到数据库中:
~~~
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30
~~~
接着往该文件中写入一些新内容并再次保存:
~~~
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
~~~
数据库中已经将文件的两个新版本连同一开始的内容保存下来了:
~~~
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
~~~
再将文件恢复到第一个版本:
~~~
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1
~~~
或恢复到第二个版本:
~~~
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2
~~~
需要记住的是几个版本的文件 SHA-1 值可能与实际的值不同,其次,存储的并不是文件名而仅仅是文件内容。这种对象类型称为 blob 。通过传递 SHA-1 值给 cat-file -t 命令可以让 Git 返回任何对象的类型:
~~~
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blob
~~~
## tree (树) 对象
接下去来看 tree 对象,tree 对象可以存储文件名,同时也允许存储一组文件。Git 以一种类似 UNIX 文件系统但更简单的方式来存储内容。所有内容以 tree 或 blob 对象存储,其中 tree 对象对应于 UNIX 中的目录,blob 对象则大致对应于 inodes 或文件内容。一个单独的 tree 对象包含一条或多条 tree 记录,每一条记录含有一个指向 blob 或子 tree 对象的 SHA-1 指针,并附有该对象的权限模式 (mode)、类型和文件名信息。以 simplegit 项目为例,最新的 tree 可能是这个样子:
~~~
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
~~~ lib
`master^{tree} `表示 `master` 分支上最新提交指向的 tree 对象。请注意 lib 子目录并非一个 blob 对象,而是一个指向另一个 tree 对象的指针:
~~~
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb
~~~
从概念上来讲,Git 保存的数据如图 9-1 所示。
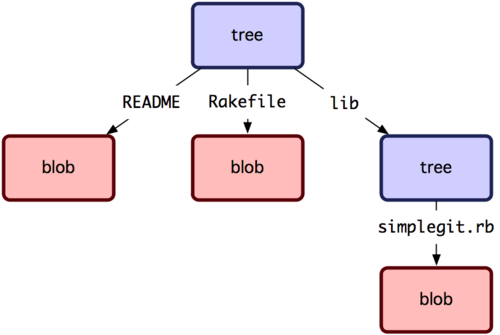
图 9-1. Git 对象模型的简化版
你可以自己创建 tree 。通常 Git 根据你的暂存区域或 index 来创建并写入一个 tree 。因此要创建一个 tree 对象的话首先要通过将一些文件暂存从而创建一个 index 。可以使用 plumbing 命令` update-index `为一个单独文件` ── test.txt `文件的第一个版本 ── 创建一个 index 。通过该命令人为的将` test.txt` 文件的首个版本加入到了一个新的暂存区域中。由于该文件原先并不在暂存区域中 (甚至就连暂存区域也还没被创建出来呢) ,必须传入 --add 参数;由于要添加的文件并不在当前目录下而是在数据库中,必须传入 --cacheinfo 参数。同时指定了文件模式,SHA-1 值和文件名:
~~~
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txt
~~~
在本例中,指定了文件模式为 100644,表明这是一个普通文件。其他可用的模式有:100755 表示可执行文件,120000 表示符号链接。文件模式是从常规的 UNIX 文件模式中参考来的,但是没有那么灵活 ── 上述三种模式仅对 Git 中的文件 (blobs) 有效 (虽然也有其他模式用于目录和子模块)。
现在可以用 write-tree 命令将暂存区域的内容写到一个 tree 对象了。无需 -w 参数 ── 如果目标 tree 不存在,调用` write-tree` 会自动根据 index 状态创建一个 tree 对象。
~~~
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt
~~~
可以这样验证这确实是一个 tree 对象:
~~~
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
tree
~~~
再根据 test.txt 的第二个版本以及一个新文件创建一个新 tree 对象:
~~~
$ echo 'new file' > new.txt
$ git update-index test.txt
$ git update-index --add new.txt
~~~
这时暂存区域中包含了 test.txt 的新版本及一个新文件 new.txt 。创建 (写) 该 tree 对象 (将暂存区域或 index 状态写入到一个 tree 对象),然后瞧瞧它的样子:
~~~
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
~~~
请注意该 tree 对象包含了两个文件记录,且 test.txt 的 SHA 值是早先值的 "第二版" (1f7a7a)。来点更有趣的,你将把第一个 tree 对象作为一个子目录加进该 tree 中。可以用 read-tree 命令将 tree 对象读到暂存区域中去。在这时,通过传一个 --prefix 参数给 read-tree,将一个已有的 tree 对象作为一个子 tree 读到暂存区域中:
~~~
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
~~~
如果从刚写入的新 tree 对象创建一个工作目录,将得到位于工作目录顶级的两个文件和一个名为 bak 的子目录,该子目录包含了 test.txt 文件的第一个版本。可以将 Git 用来包含这些内容的数据想象成如图 9-2 所示的样子。
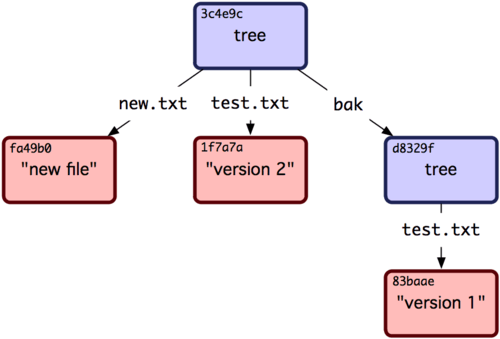
图 9-2. 当前 Git 数据的内容结构
## commit (提交) 对象
你现在有三个 tree 对象,它们指向了你要跟踪的项目的不同快照,可是先前的问题依然存在:必须记往三个 SHA-1 值以获得这些快照。你也没有关于谁、何时以及为何保存了这些快照的信息。commit 对象为你保存了这些基本信息。
要创建一个 commit 对象,使用 commit-tree 命令,指定一个 tree 的 SHA-1,如果有任何前继提交对象,也可以指定。从你写的第一个 tree 开始:
~~~
$ echo 'first commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3d
~~~
通过 cat-file 查看这个新 commit 对象:
~~~
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
first commit
~~~
commit 对象有格式很简单:指明了该时间点项目快照的顶层树对象、作者/提交者信息(从 Git 设置的 user.name 和 user.email中获得)以及当前时间戳、一个空行,以及提交注释信息。
接着再写入另外两个 commit 对象,每一个都指定其之前的那个 commit 对象:
~~~
$ echo 'second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9
~~~
每一个 commit 对象都指向了你创建的树对象快照。出乎意料的是,现在已经有了真实的 Git 历史了,所以如果运行 git log 命令并指定最后那个 commit 对象的 SHA-1 便可以查看历史:
~~~
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
third commit
bak/test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletions(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
first commit
test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
~~~
真棒。你刚刚通过使用低级操作而不是那些普通命令创建了一个 Git 历史。这基本上就是运行 `git add` 和` git commit `命令时 Git 进行的工作 ──保存修改了的文件的 blob,更新索引,创建 tree 对象,最后创建 commit 对象,这些 commit 对象指向了顶层 tree 对象以及先前的 commit 对象。这三类 Git 对象` ── blob,tree` 以及 commit ── 都各自以文件的方式保存在 `.git/objects `目录下。以下所列是目前为止样例中的所有对象,每个对象后面的注释里标明了它们保存的内容:
~~~
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1
~~~
如果你按照以上描述进行了操作,可以得到如图 9-3 所示的对象图。
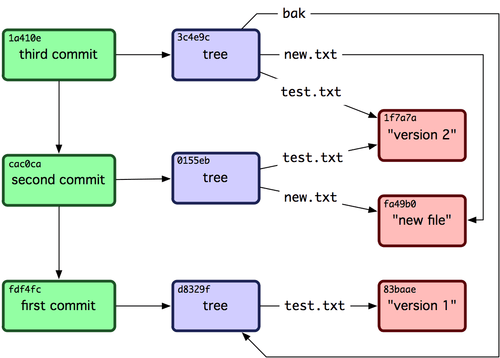
图 9-3. Git 目录下的所有对象
## 对象存储
之前我提到当存储数据内容时,同时会有一个文件头被存储起来。我们花些时间来看看 Git 是如何存储对象的。你将看来如何通过 Ruby 脚本语言存储一个 blob 对象 (这里以字符串 "what is up, doc?" 为例) 。使用 irb 命令进入 Ruby 交互式模式:
~~~
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"
~~~
Git 以对象类型为起始内容构造一个文件头,本例中是一个 blob。然后添加一个空格,接着是数据内容的长度,最后是一个空字节 (null byte):
~~~
>> header = "blob #{content.length}\0"
=> "blob 16\000"
~~~
Git 将文件头与原始数据内容拼接起来,并计算拼接后的新内容的 SHA-1 校验和。可以在 Ruby 中使用 require 语句导入 SHA1 digest 库,然后调用 Digest::SHA1.hexdigest() 方法计算字符串的 SHA-1 值:
~~~
>> store = header + content
=> "blob 16\000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"
~~~
Git 用 zlib 对数据内容进行压缩,在 Ruby 中可以用 zlib 库来实现。首先需要导入该库,然后用` Zlib::Deflate.deflate()` 对数据进行压缩:
~~~
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\234K\312\311OR04c(\317H,Q\310,V(-\320QH\311O\266\a\000_\034\a\235"
~~~
最后将用 zlib 压缩后的内容写入磁盘。需要指定保存对象的路径 (SHA-1 值的头两个字符作为子目录名称,剩余 38 个字符作为文件名保存至该子目录中)。在 Ruby 中,如果子目录不存在可以用 FileUtils.mkdir_p() 函数创建它。接着用 File.open 方法打开文件,并用 write() 方法将之前压缩的内容写入该文件:
~~~
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32
~~~
这就行了 ── 你已经创建了一个正确的 blob 对象。所有的 Git 对象都以这种方式存储,惟一的区别是类型不同 ── 除了字符串 blob,文件头起始内容还可以是` commit` 或 tree 。不过虽然 `blob` 几乎可以是任意内容,commit 和 tree 的数据却是有固定格式的。
9. Git 内部原理
最后更新于:2022-04-01 00:21:55
不管你是从前面的章节直接跳到了本章,还是读完了其余各章一直到这,你都将在本章见识 Git 的内部工作原理和实现方式。我个人发现学习这些内容对于理解 Git 的用处和强大是非常重要的,不过也有人认为这些内容对于初学者来说可能难以理解且过于复杂。正因如此我把这部分内容放在最后一章,你在学习过程中可以先阅读这部分,也可以晚点阅读这部分,这完全取决于你自己。
既然已经读到这了,就让我们开始吧。首先要弄明白一点,从根本上来讲 Git 是一套内容寻址 (content-addressable) 文件系统,在此之上提供了一个 VCS 用户界面。马上你就会学到这意味着什么。
早期的 Git (主要是 1.5 之前版本) 的用户界面要比现在复杂得多,这是因为它更侧重于成为文件系统而不是一套更精致的 VCS 。最近几年改进了 UI 从而使它跟其他任何系统一样清晰易用。即便如此,还是经常会有一些陈腔滥调提到早期 Git 的 UI 复杂又难学。
内容寻址文件系统层相当酷,在本章中我会先讲解这部分。随后你会学到传输机制和最终要使用的各种库管理任务。
8.3 总结
最后更新于:2022-04-01 00:21:53
现在的你应该掌握了在 Subversion 上使用 Git 以及把几乎任何先存仓库无损失的导入为 Git 仓库。下一章将介绍 Git 内部的原始数据格式,从而是使你能亲手锻造其中的每一个字节,如果必要的话。
8.2 迁移到 Git
最后更新于:2022-04-01 00:21:50
如果在其他版本控制系统中保存了某项目的代码而后决定转而使用 Git,那么该项目必须经历某种形式的迁移。本节将介绍 Git 中包含的一些针对常见系统的导入脚本,并将展示编写自定义的导入脚本的方法。
## 导入
你将学习到如何从专业重量级的版本控制系统中导入数据—— Subversion 和 Perforce —— 因为据我所知这二者的用户是(向 Git)转换的主要群体,而且 Git 为此二者附带了高质量的转换工具。
## Subversion
读过前一节有关 git svn 的内容以后,你应该能轻而易举的根据其中的指导来 git svn clone 一个仓库了;然后,停止 Subversion 的使用,向一个新 Git server 推送,并开始使用它。想保留历史记录,所花的时间应该不过就是从 Subversion 服务器拉取数据的时间(可能要等上好一会就是了)。
然而,这样的导入并不完美;而且还要花那么多时间,不如干脆一次把它做对!首当其冲的任务是作者信息。在 Subversion,每个提交者在都在主机上有一个用户名,记录在提交信息中。上节例子中多处显示了 schacon ,比如 blame 的输出以及 git svn log。如果想让这条信息更好的映射到 Git 作者数据里,则需要 从 Subversion 用户名到 Git 作者的一个映射关系。建立一个叫做 user.txt 的文件,用如下格式表示映射关系:
~~~
schacon = Scott Chacon <schacon@geemail.com>
selse = Someo Nelse <selse@geemail.com>
~~~
通过该命令可以获得 SVN 作者的列表:
~~~
$ svn log ^/ --xml | grep -P "^<author" | sort -u | \
perl -pe 's/<author>(.*?)<\/author>/$1 = /' > users.txt
~~~
它将输出 XML 格式的日志——你可以找到作者,建立一个单独的列表,然后从 XML 中抽取出需要的信息。(显而易见,本方法要求主机上安装了grep,sort 和 perl.)然后把输出重定向到 user.txt 文件,然后就可以在每一项的后面添加相应的 Git 用户数据。
为 git svn 提供该文件可以然它更精确的映射作者数据。你还可以在 clone 或者 init后面添加 --no-metadata 来阻止 git svn 包含那些 Subversion 的附加信息。这样 import 命令就变成了:
~~~
$ git svn clone http://my-project.googlecode.com/svn/ \
--authors-file=users.txt --no-metadata -s my_project
~~~
现在 my_project 目录下导入的 Subversion 应该比原来整洁多了。原来的 commit 看上去是这样:
~~~
commit 37efa680e8473b615de980fa935944215428a35a
Author: schacon <schacon@4c93b258-373f-11de-be05-5f7a86268029>
Date: Sun May 3 00:12:22 2009 +0000
fixed install - go to trunk
git-svn-id: https://my-project.googlecode.com/svn/trunk@94 4c93b258-373f-11de-
be05-5f7a86268029
~~~
现在是这样:
~~~
commit 03a8785f44c8ea5cdb0e8834b7c8e6c469be2ff2
Author: Scott Chacon <schacon@geemail.com>
Date: Sun May 3 00:12:22 2009 +0000
fixed install - go to trunk
~~~
不仅作者一项干净了不少,`git-svn-id` 也就此消失了。
你还需要一点 post-import(导入后) 清理工作。最起码的,应该清理一下 git svn 创建的那些怪异的索引结构。首先要移动标签,把它们从奇怪的远程分支变成实际的标签,然后把剩下的分支移动到本地。
要把标签变成合适的 Git 标签,运行
`$ git for-each-ref refs/remotes/tags | cut -d / -f 4- | grep -v @ | while read tagname; do git tag "$tagname" "tags/$tagname"; git branch -r -d "tags/$tagname"; done`
该命令将原本以 tag/ 开头的远程分支的索引变成真正的(轻巧的)标签。
接下来,把 `refs/remotes `下面剩下的索引变成本地分支:
`$ git for-each-ref refs/remotes | cut -d / -f 3- | grep -v @ | while read branchname; do git branch "$branchname" "refs/remotes/$branchname"; git branch -r -d "$branchname"; done`
现在所有的旧分支都变成真正的 Git 分支,所有的旧标签也变成真正的 Git 标签。最后一项工作就是把新建的 Git 服务器添加为远程服务器并且向它推送。下面是新增远程服务器的例子:
`$ git remote add origin git@my-git-server:myrepository.git`
为了让所有的分支和标签都得到上传,我们使用这条命令:
~~~
$ git push origin --all
$ git push origin --tags
~~~
所有的分支和标签现在都应该整齐干净的躺在新的 Git 服务器里了。
## Perforce
你将了解到的下一个被导入的系统是 Perforce. Git 发行的时候同时也附带了一个 Perforce 导入脚本,不过它是包含在源码的 contrib 部分——而不像 git svn 那样默认可用。运行它之前必须获取 Git 的源码,可以在 `git.kernel.org `下载:
~~~
$ git clone git://git.kernel.org/pub/scm/git/git.git
$ cd git/contrib/fast-import
~~~
在这个 fast-import 目录下,应该有一个叫做 `git-p4` 的 `Python` 可执行脚本。主机上必须装有 Python 和 p4 工具该导入才能正常进行。例如,你要从 Perforce 公共代码仓库(译注: Perforce Public Depot,Perforce 官方提供的代码寄存服务)导入 Jam 工程。为了设定客户端,我们要把 P4PORT 环境变量 export 到 Perforce 仓库:
`$ export P4PORT=public.perforce.com:1666`
运行` git-p4 clone `命令将从 `Perforce `服务器导入 Jam 项目,我们需要给出仓库和项目的路径以及导入的目标路径:
~~~
$ git-p4 clone //public/jam/src@all /opt/p4import
Importing from //public/jam/src@all into /opt/p4import
Reinitialized existing Git repository in /opt/p4import/.git/
Import destination: refs/remotes/p4/master
Importing revision 4409 (100%)
~~~
现在去 /opt/p4import 目录运行一下 git log ,就能看到导入的成果:
~~~
$ git log -2
commit 1fd4ec126171790efd2db83548b85b1bbbc07dc2
Author: Perforce staff <support@perforce.com>
Date: Thu Aug 19 10:18:45 2004 -0800
Drop 'rc3' moniker of jam-2.5. Folded rc2 and rc3 RELNOTES into
the main part of the document. Built new tar/zip balls.
Only 16 months later.
[git-p4: depot-paths = "//public/jam/src/": change = 4409]
commit ca8870db541a23ed867f38847eda65bf4363371d
Author: Richard Geiger <rmg@perforce.com>
Date: Tue Apr 22 20:51:34 2003 -0800
Update derived jamgram.c
[git-p4: depot-paths = "//public/jam/src/": change = 3108]
~~~
每一个 commit 里都有一个 git-p4 标识符。这个标识符可以保留,以防以后需要引用 Perforce 的修改版本号。然而,如果想删除这些标识符,现在正是时候——在开启新仓库之前。可以通过` git filter-branch` 来批量删除这些标识符:
~~~
$ git filter-branch --msg-filter '
sed -e "/^\[git-p4:/d"
'
Rewrite 1fd4ec126171790efd2db83548b85b1bbbc07dc2 (123/123)
Ref 'refs/heads/master' was rewritten
~~~
现在运行一下 git log,你会发现这些 commit 的 SHA-1 校验值都发生了改变,而那些 git-p4 字串则从提交信息里消失了:
~~~
$ git log -2
commit 10a16d60cffca14d454a15c6164378f4082bc5b0
Author: Perforce staff <support@perforce.com>
Date: Thu Aug 19 10:18:45 2004 -0800
Drop 'rc3' moniker of jam-2.5. Folded rc2 and rc3 RELNOTES into
the main part of the document. Built new tar/zip balls.
Only 16 months later.
commit 2b6c6db311dd76c34c66ec1c40a49405e6b527b2
Author: Richard Geiger <rmg@perforce.com>
Date: Tue Apr 22 20:51:34 2003 -0800
Update derived jamgram.c
~~~
至此导入已经完成,可以开始向新的 Git 服务器推送了。
## 自定导入脚本
如果先前的系统不是 Subversion 或 Perforce 之一,先上网找一下有没有与之对应的导入脚本——导入 CVS,Clear Case,Visual Source Safe,甚至存档目录的导入脚本已经存在。假如这些工具都不适用,或者使用的工具很少见,抑或你需要导入过程具有更多可制定性,则应该使用 git fast-import。该命令从标准输入读取简单的指令来写入具体的 Git 数据。这样创建 Git 对象比运行纯 Git 命令或者手动写对象要简单的多(更多相关内容见第九章)。通过它,你可以编写一个导入脚本来从导入源读取必要的信息,同时在标准输出直接输出相关指示。你可以运行该脚本并把它的输出管道连接到 git fast-import。
下面演示一下如何编写一个简单的导入脚本。假设你在进行一项工作,并且按时通过把工作目录复制为以时间戳 back_YY_MM_DD 命名的目录来进行备份,现在你需要把它们导入 Git 。目录结构如下:
~~~
$ ls /opt/import_from
back_2009_01_02
back_2009_01_04
back_2009_01_14
back_2009_02_03
current
~~~
为了导入到一个 Git 目录,我们首先回顾一下 Git 储存数据的方式。你可能还记得,Git 本质上是一个 commit 对象的链表,每一个对象指向一个内容的快照。而这里需要做的工作就是告诉 fast-import 内容快照的位置,什么样的 commit 数据指向它们,以及它们的顺序。我们采取一次处理一个快照的策略,为每一个内容目录建立对应的 commit ,每一个 commit 与之前的建立链接。
正如在第七章 "Git 执行策略一例" 一节中一样,我们将使用 Ruby 来编写这个脚本,因为它是我日常使用的语言而且阅读起来简单一些。你可以用任何其他熟悉的语言来重写这个例子——它仅需要把必要的信息打印到标准输出而已。同时,如果你在使用 Windows,这意味着你要特别留意不要在换行的时候引入回车符(译注:`carriage returns,Windows` 换行时加入的符号,通常说的` \r )—— git fast-import` 对仅使用换行符(LF)而非 Windows 的回车符(CRLF)要求非常严格。
首先,进入目标目录并且找到所有子目录,每一个子目录将作为一个快照被导入为一个 commit。我们将依次进入每一个子目录并打印所需的命令来导出它们。脚本的主循环大致是这样:
`last_mark = nil`
~~~
循环遍历所有目录
Dir.chdir(ARGV[0]) do
Dir.glob("*").each do |dir|
next if File.file?(dir)
~~~
~~~
进入目标目录
Dir.chdir(dir) do
last_mark = print_export(dir, last_mark)
end
end
end
~~~
我们在每一个目录里运行 print_export ,它会取出上一个快照的索引和标记并返回本次快照的索引和标记;由此我们就可以正确的把二者连接起来。"标记(mark)" 是 fast-import 中对 commit 标识符的叫法;在创建 commit 的同时,我们逐一赋予一个标记以便以后在把它连接到其他 commit 时使用。因此,在 print_export 方法中要做的第一件事就是根据目录名生成一个标记:
`mark = convert_dir_to_mark(dir)`
实现该函数的方法是建立一个目录的数组序列并使用数组的索引值作为标记,因为标记必须是一个整数。这个方法大致是这样的:
~~~
$marks = []
def convert_dir_to_mark(dir)
if !$marks.include?(dir)
$marks << dir
end
($marks.index(dir) + 1).to_s
end
有了整数来
~~~代表每个 commit,我们现在需要提交附加信息中的日期。由于日期是用目录名表示的,我们就从中解析出来。print_export 文件的下一行将是:
`date = convert_dir_to_date(dir)`
而` convert_dir_to_date` 则定义为
~~~
def convert_dir_to_date(dir)
if dir == 'current'
return Time.now().to_i
else
dir = dir.gsub('back_', '')
(year, month, day) = dir.split('_')
return Time.local(year, month, day).to_i
end
end
~~~
它为每个目录返回一个整型值。提交附加信息里最后一项所需的是提交者数据,我们在一个全局变量中直接定义之:
`$author = 'Scott Chacon <schacon@example.com>'`
我们差不多可以开始为导入脚本输出提交数据了。第一项信息指明我们定义的是一个 commit 对象以及它所在的分支,随后是我们生成的标记,提交者信息以及提交备注,然后是前一个 commit 的索引,如果有的话。代码大致这样:
~~~
# 打印导入所需的信息
puts 'commit refs/heads/master'
puts 'mark :' + mark
puts "committer #{$author} #{date} -0700"
export_data('imported from ' + dir)
puts 'from :' + last_mark if last_mark
~~~
时区(-0700)处于简化目的使用硬编码。如果是从其他版本控制系统导入,则必须以变量的形式指明时区。 提交备注必须以特定格式给出:
`data (size)\n(contents)`
该格式包含了单词 data,所读取数据的大小,一个换行符,最后是数据本身。由于随后指明文件内容的时候要用到相同的格式,我们写一个辅助方法,export_data:
~~~
def export_data(string)
print "data #{string.size}\n#{string}"
end
~~~
唯一剩下的就是每一个快照的内容了。这简单的很,因为它们分别处于一个目录——你可以输出 deleeall 命令,随后是目录中每个文件的内容。Git 会正确的记录每一个快照:
~~~
puts 'deleteall'
Dir.glob("**/*").each do |file|
next if !File.file?(file)
inline_data(file)
end
~~~
注意:由于很多系统把每次修订看作一个 commit 到另一个 commit 的变化量,`fast-import` 也可以依据每次提交获取一个命令来指出哪些文件被添加,删除或者修改过,以及修改的内容。我们将需要计算快照之间的差别并且仅仅给出这项数据,不过该做法要复杂很多——还如不直接把所有数据丢给 Git 然它自己搞清楚。假如前面这个方法更适用于你的数据,参考 fast-import 的 man 帮助页面来了解如何以这种方式提供数据。
列举新文件内容或者指明带有新内容的已修改文件的格式如下:
~~~
M 644 inline path/to/file
data (size)
(file contents)
~~~
这里,644 是权限模式(加入有可执行文件,则需要探测之并设定为 755),而 inline 说明我们在本行结束之后立即列出文件的内容。我们的 inline_data 方法大致是:
~~~
def inline_data(file, code = 'M', mode = '644')
content = File.read(file)
puts "#{code} #{mode} inline #{file}"
export_data(content)
end
~~~
我们重用了前面定义过的 export_data,因为这里和指明提交注释的格式如出一辙。
最后一项工作是返回当前的标记以便下次循环的使用。
## return mark
注意:如果你在用 Windows,一定记得添加一项额外的步骤。前面提过,Windows 使用` CRLF` 作为换行字符而` git fast-import` 只接受 LF。为了绕开这个问题来满足` git fast-import,`你需要让 ruby 用 LF 取代 CRLF:
`$stdout.binmode`
搞定了。现在运行该脚本,你将得到如下内容:
~~~
$ ruby import.rb /opt/import_from
commit refs/heads/master
mark :1
committer Scott Chacon <schacon@geemail.com> 1230883200 -0700
data 29
imported from back_2009_01_02deleteall
M 644 inline file.rb
data 12
version two
commit refs/heads/master
mark :2
committer Scott Chacon <schacon@geemail.com> 1231056000 -0700
data 29
imported from back_2009_01_04from :1
deleteall
M 644 inline file.rb
data 14
version three
M 644 inline new.rb
data 16
new version one
(...)
~~~
要运行导入脚本,在需要导入的目录把该内容用管道定向到 `git fast-import`。你可以建立一个空目录然后运行 git init 作为开头,然后运行该脚本:
~~~
$ git init
Initialized empty Git repository in /opt/import_to/.git/
$ ruby import.rb /opt/import_from | git fast-import
git-fast-import statistics:
---------------------------------------------------------------------
Alloc'd objects: 5000
Total objects: 18 ( 1 duplicates )
blobs : 7 ( 1 duplicates 0 deltas)
trees : 6 ( 0 duplicates 1 deltas)
commits: 5 ( 0 duplicates 0 deltas)
tags : 0 ( 0 duplicates 0 deltas)
Total branches: 1 ( 1 loads )
marks: 1024 ( 5 unique )
atoms: 3
Memory total: 2255 KiB
pools: 2098 KiB
objects: 156 KiB
---------------------------------------------------------------------
pack_report: getpagesize() = 4096
pack_report: core.packedGitWindowSize = 33554432
pack_report: core.packedGitLimit = 268435456
pack_report: pack_used_ctr = 9
pack_report: pack_mmap_calls = 5
pack_report: pack_open_windows = 1 / 1
pack_report: pack_mapped = 1356 / 1356
---------------------------------------------------------------------
~~~
你会发现,在它成功执行完毕以后,会给出一堆有关已完成工作的数据。上例在一个分支导入了5次提交数据,包含了18个对象。现在可以运行 `git log` 来检视新的历史:
~~~
$ git log -2
commit 10bfe7d22ce15ee25b60a824c8982157ca593d41
Author: Scott Chacon <schacon@example.com>
Date: Sun May 3 12:57:39 2009 -0700
imported from current
commit 7e519590de754d079dd73b44d695a42c9d2df452
Author: Scott Chacon <schacon@example.com>
Date: Tue Feb 3 01:00:00 2009 -0700
imported from back_2009_02_03
~~~
就它了——一个干净整洁的 Git 仓库。需要注意的是此时没有任何内容被检出——刚开始当前目录里没有任何文件。要获取它们,你得转到 master 分支的所在:
~~~
$ ls
$ git reset --hard master
HEAD is now at 10bfe7d imported from current
$ ls
file.rb lib
~~~
`fast-import` 还可以做更多——处理不同的文件模式,二进制文件,多重分支与合并,标签,进展标识等等。一些更加复杂的实例可以在 Git 源码的 contib/fast-import 目录里找到;其中较为出众的是前面提过的 git-p4 脚本。
8.1 Git 与 Subversion
最后更新于:2022-04-01 00:21:48
当前,大多数开发中的开源项目以及大量的商业项目都使用 Subversion 来管理源码。作为最流行的开源版本控制系统,Subversion 已经存在了接近十年的时间。它在许多方面与 CVS 十分类似,后者是前者出现之前代码控制世界的霸主。
Git 最为重要的特性之一是名为 git svn 的 Subversion 双向桥接工具。该工具把 Git 变成了 Subversion 服务的客户端,从而让你在本地享受到 Git 所有的功能,而后直接向 Subversion 服务器推送内容,仿佛在本地使用了 Subversion 客户端。也就是说,在其他人忍受古董的同时,你可以在本地享受分支合并,使暂存区域,衍合以及 单项挑拣等等。这是个让 Git 偷偷潜入合作开发环境的好东西,在帮助你的开发同伴们提高效率的同时,它还能帮你劝说团队让整个项目框架转向对 Git 的支持。这个 Subversion 之桥是通向分布式版本控制系统(DVCS, Distributed VCS )世界的神奇隧道。
## git svn
Git 中所有 Subversion 桥接命令的基础是 git svn 。所有的命令都从它开始。相关的命令数目不少,你将通过几个简单的工作流程了解到其中常见的一些。
值得警戒的是,在使用 git svn 的时候,你实际是在与 Subversion 交互,Git 比它要高级复杂的多。尽管可以在本地随意的进行分支和合并,最好还是通过衍合保持线性的提交历史,尽量避免类似与远程 Git 仓库动态交互这样的操作。
避免修改历史再重新推送的做法,也不要同时推送到并行的 Git 仓库来试图与其他 Git 用户合作。Subersion 只能保存单一的线性提交历史,一不小心就会被搞糊涂。合作团队中同时有人用 SVN 和 Git,一定要确保所有人都使用 SVN 服务来协作——这会让生活轻松很多。
### 初始设定
为了展示功能,先要一个具有写权限的 SVN 仓库。如果想尝试这个范例,你必须复制一份其中的测试仓库。比较简单的做法是使用一个名为 svnsync 的工具。较新的 Subversion 版本中都带有该工具,它将数据编码为用于网络传输的格式。
要尝试本例,先在本地新建一个 Subversion 仓库:
~~~
$ mkdir /tmp/test-svn
$ svnadmin create /tmp/test-svn
~~~
然后,允许所有用户修改 `revprop ——` 简单的做法是添加一个总是以 0 作为返回值的` pre-revprop-change` 脚本:
~~~
$ cat /tmp/test-svn/hooks/pre-revprop-change
!/bin/sh
exit 0;
$ chmod +x /tmp/test-svn/hooks/pre-revprop-change
~~~
现在可以调用 svnsync init 加目标仓库,再加源仓库的格式来把该项目同步到本地了:
`$ svnsync init file:///tmp/test-svn http://progit-example.googlecode.com/svn/`
这将建立进行同步所需的属性。可以通过运行以下命令来克隆代码:
~~~
$ svnsync sync file:///tmp/test-svn
Committed revision 1.
Copied properties for revision 1.
Committed revision 2.
Copied properties for revision 2.
Committed revision 3.
...
~~~
别看这个操作只花掉几分钟,要是你想把源仓库复制到另一个远程仓库,而不是本地仓库,那将花掉接近一个小时,尽管项目中只有不到 100 次的提交。 Subversion 每次只复制一次修改,把它推送到另一个仓库里,然后周而复始——惊人的低效,但是我们别无选择。
### 入门
有了可以写入的 `Subversion `仓库以后,就可以尝试一下典型的工作流程了。我们从` git svn clone `命令开始,它会把整个 Subversion 仓库导入到一个本地的 Git 仓库中。提醒一下,这里导入的是一个货真价实的 Subversion 仓库,所以应该把下面的 `file:///tmp/test-svn` 换成你所用的 `Subversion` 仓库的 URL:
~~~
$ git svn clone file:///tmp/test-svn -T trunk -b branches -t tags
Initialized empty Git repository in /Users/schacon/projects/testsvnsync/svn/.git/
r1 = b4e387bc68740b5af56c2a5faf4003ae42bd135c (trunk)
A m4/acx_pthread.m4
A m4/stl_hash.m4
...
r75 = d1957f3b307922124eec6314e15bcda59e3d9610 (trunk)
Found possible branch point: file:///tmp/test-svn/trunk => \
file:///tmp/test-svn /branches/my-calc-branch, 75
Found branch parent: (my-calc-branch) d1957f3b307922124eec6314e15bcda59e3d9610
Following parent with do_switch
Successfully followed parent
r76 = 8624824ecc0badd73f40ea2f01fce51894189b01 (my-calc-branch)
Checked out HEAD:
file:///tmp/test-svn/branches/my-calc-branch r76
~~~
这相当于针对所提供的 URL 运行了两条命令—— git svn init 加上 git svn fetch 。可能会花上一段时间。我们所用的测试项目仅仅包含 75 次提交并且它的代码量不算大,所以只有几分钟而已。不过,Git 仍然需要提取每一个版本,每次一个,再逐个提交。对于一个包含成百上千次提交的项目,花掉的时间则可能是几小时甚至数天。
`-T trunk -b branches -t tags` 告诉 Git 该 Subversion 仓库遵循了基本的分支和标签命名法则。如果你的主干(译注:trunk,相当于非分布式版本控制里的master分支,代表开发的主线),分支或者标签以不同的方式命名,则应做出相应改变。由于该法则的常见性,可以使用 -s 来代替整条命令,它意味着标准布局(s 是 Standard layout 的首字母),也就是前面选项的内容。下面的命令有相同的效果:
`$ git svn clone file:///tmp/test-svn -s`
现在,你有了一个有效的 Git 仓库,包含着导入的分支和标签:
~~~
$ git branch -a
* master
my-calc-branch
tags/2.0.2
tags/release-2.0.1
tags/release-2.0.2
tags/release-2.0.2rc1
trunk
~~~
值得注意的是,该工具分配命名空间时和远程引用的方式不尽相同。克隆普通的 Git 仓库时,可以以 origin/[branch] 的形式获取远程服务器上所有可用的分支——分配到远程服务的名称下。然而 git svn 假定不存在多个远程服务器,所以把所有指向远程服务的引用不加区分的保存下来。可以用 Git 探测命令 show-ref 来查看所有引用的全名。
~~~
$ git show-ref
1cbd4904d9982f386d87f88fce1c24ad7c0f0471 refs/heads/master
aee1ecc26318164f355a883f5d99cff0c852d3c4 refs/remotes/my-calc-branch
03d09b0e2aad427e34a6d50ff147128e76c0e0f5 refs/remotes/tags/2.0.2
50d02cc0adc9da4319eeba0900430ba219b9c376 refs/remotes/tags/release-2.0.1
4caaa711a50c77879a91b8b90380060f672745cb refs/remotes/tags/release-2.0.2
1c4cb508144c513ff1214c3488abe66dcb92916f refs/remotes/tags/release-2.0.2rc1
1cbd4904d9982f386d87f88fce1c24ad7c0f0471 refs/remotes/trunk
~~~
而普通的 Git 仓库应该是这个模样:
~~~
$ git show-ref
83e38c7a0af325a9722f2fdc56b10188806d83a1 refs/heads/master
3e15e38c198baac84223acfc6224bb8b99ff2281 refs/remotes/gitserver/master
0a30dd3b0c795b80212ae723640d4e5d48cabdff refs/remotes/origin/master
25812380387fdd55f916652be4881c6f11600d6f refs/remotes/origin/testing
~~~
这里有两个远程服务器:一个名为 `gitserver` ,具有一个 master分支;另一个叫 `origin`,具有` master` 和 `testing` 两个分支。
注意本例中通过 git svn 导入的远程引用,(Subversion 的)标签是当作远程分支添加的,而不是真正的 Git 标签。导入的 Subversion 仓库仿佛是有一个带有不同分支的 tags 远程服务器。
### 提交到 Subversion
有了可以开展工作的(本地)仓库以后,你可以开始对该项目做出贡献并向上游仓库提交内容了,Git 这时相当于一个 SVN 客户端。假如编辑了一个文件并进行提交,那么这次提交仅存在于本地的 Git 而非 Subversion 服务器上。
~~~
$ git commit -am 'Adding git-svn instructions to the README'
[master 97031e5] Adding git-svn instructions to the README
1 files changed, 1 insertions(+), 1 deletions(-)
~~~
接下来,可以将作出的修改推送到上游。值得注意的是,Subversion 的使用流程也因此改变了——你可以在离线状态下进行多次提交然后一次性的推送到 Subversion 的服务器上。向 Subversion 服务器推送的命令是 `git svn dcommit:`
~~~
$ git svn dcommit
Committing to file:///tmp/test-svn/trunk ...
M README.txt
Committed r79
M README.txt
r79 = 938b1a547c2cc92033b74d32030e86468294a5c8 (trunk)
No changes between current HEAD and refs/remotes/trunk
Resetting to the latest refs/remotes/trunk
~~~
所有在原 Subversion 数据基础上提交的 commit 会一一提交到 Subversion,然后你本地 Git 的 commit 将被重写,加入一个特别标识。这一步很重要,因为它意味着所有 commit 的 SHA-1 指都会发生变化。这也是同时使用 Git 和 Subversion 两种服务作为远程服务不是个好主意的原因之一。检视以下最后一个 commit,你会找到新添加的 git-svn-id (译注:即本段开头所说的特别标识):
~~~
$ git log -1
commit 938b1a547c2cc92033b74d32030e86468294a5c8
Author: schacon <schacon@4c93b258-373f-11de-be05-5f7a86268029>
Date: Sat May 2 22:06:44 2009 +0000
Adding git-svn instructions to the README
git-svn-id: file:///tmp/test-svn/trunk@79 4c93b258-373f-11de-be05-5f7a86268029
~~~
注意看,原本以 97031e5 开头的 SHA-1 校验值在提交完成以后变成了 938b1a5 。如果既要向 Git 远程服务器推送内容,又要推送到 Subversion 远程服务器,则必须先向 Subversion 推送(dcommit),因为该操作会改变所提交的数据内容。
### 拉取最新进展
如果要与其他开发者协作,总有那么一天你推送完毕之后,其他人发现他们推送自己修改的时候(与你推送的内容)产生冲突。这些修改在你合并之前将一直被拒绝。在 git svn 里这种情况形似:
~~~
$ git svn dcommit
Committing to file:///tmp/test-svn/trunk ...
Merge conflict during commit: Your file or directory 'README.txt' is probably \
out-of-date: resource out of date; try updating at /Users/schacon/libexec/git-\
core/git-svn line 482
~~~
为了解决该问题,可以运行 git svn rebase ,它会拉取服务器上所有最新的改变,再次基础上衍合你的修改:
~~~
$ git svn rebase
M README.txt
r80 = ff829ab914e8775c7c025d741beb3d523ee30bc4 (trunk)
First, rewinding head to replay your work on top of it...
Applying: first user change
~~~
现在,你做出的修改都发生在服务器内容之后,所以可以顺利的运行 `dcommit :`
~~~
$ git svn dcommit
Committing to file:///tmp/test-svn/trunk ...
M README.txt
Committed r81
M README.txt
r81 = 456cbe6337abe49154db70106d1836bc1332deed (trunk)
No changes between current HEAD and refs/remotes/trunk
Resetting to the latest refs/remotes/trunk
~~~
需要牢记的一点是,Git 要求我们在推送之前先合并上游仓库中最新的内容,而 git svn 只要求存在冲突的时候才这样做。假如有人向一个文件推送了一些修改,这时你要向另一个文件推送一些修改,那么 dcommit 将正常工作:
~~~
$ git svn dcommit
Committing to file:///tmp/test-svn/trunk ...
M configure.ac
Committed r84
M autogen.sh
r83 = 8aa54a74d452f82eee10076ab2584c1fc424853b (trunk)
M configure.ac
r84 = cdbac939211ccb18aa744e581e46563af5d962d0 (trunk)
W: d2f23b80f67aaaa1f6f5aaef48fce3263ac71a92 and refs/remotes/trunk differ, \
using rebase:
:100755 100755 efa5a59965fbbb5b2b0a12890f1b351bb5493c18 \
015e4c98c482f0fa71e4d5434338014530b37fa6 M autogen.sh
First, rewinding head to replay your work on top of it...
Nothing to do.
~~~
这一点需要牢记,因为它的结果是推送之后项目处于一个不完整存在与任何主机上的状态。如果做出的修改无法兼容但没有产生冲突,则可能造成一些很难确诊的难题。这和使用 Git 服务器是不同的——在 Git 世界里,发布之前,你可以在客户端系统里完整的测试项目的状态,而在 SVN 永远都没法确保提交前后项目的状态完全一样。
即使还没打算进行提交,你也应该用这个命令从 Subversion 服务器拉取最新修改。sit svn fetch 能获取最新的数据,不过 git svn rebase 才会在获取之后在本地进行更新 。
~~~
$ git svn rebase
M generate_descriptor_proto.sh
r82 = bd16df9173e424c6f52c337ab6efa7f7643282f1 (trunk)
First, rewinding head to replay your work on top of it...
Fast-forwarded master to refs/remotes/trunk.
~~~
不时地运行一下 git svn rebase 可以确保你的代码没有过时。不过,运行该命令时需要确保工作目录的整洁。如果在本地做了修改,则必须在运行 git svn rebase 之前或暂存工作,或暂时提交内容——否则,该命令会发现衍合的结果包含着冲突因而终止。
### Git 分支问题
习惯了 Git 的工作流程以后,你可能会创建一些特性分支,完成相关的开发工作,然后合并他们。如果要用 git svn 向 Subversion 推送内容,那么最好是每次用衍合来并入一个单一分支,而不是直接合并。使用衍合的原因是 Subversion 只有一个线性的历史而不像 Git 那样处理合并,所以 git svn 在把快照转换为 Subversion 的 commit 时只能包含第一个祖先。
假设分支历史如下:创建一个 experiment 分支,进行两次提交,然后合并到 master 。在 dcommit 的时候会得到如下输出:
~~~
$ git svn dcommit
Committing to file:///tmp/test-svn/trunk ...
M CHANGES.txt
Committed r85
M CHANGES.txt
r85 = 4bfebeec434d156c36f2bcd18f4e3d97dc3269a2 (trunk)
No changes between current HEAD and refs/remotes/trunk
Resetting to the latest refs/remotes/trunk
COPYING.txt: locally modified
INSTALL.txt: locally modified
M COPYING.txt
M INSTALL.txt
Committed r86
M INSTALL.txt
M COPYING.txt
r86 = 2647f6b86ccfcaad4ec58c520e369ec81f7c283c (trunk)
No changes between current HEAD and refs/remotes/trunk
Resetting to the latest refs/remotes/trunk
~~~
在一个包含了合并历史的分支上使用 dcommit 可以成功运行,不过在 Git 项目的历史中,它没有重写你在 experiment 分支中的两个 commit ——另一方面,这些改变却出现在了 SVN 版本中同一个合并 commit 中。
在别人克隆该项目的时候,只能看到这个合并 commit 包含了所有发生过的修改;他们无法获知修改的作者和时间等提交信息。
### Subversion 分支
Subversion 的分支和 Git 中的不尽相同;避免过多的使用可能是最好方案。不过,用 git svn 创建和提交不同的 Subversion 分支仍是可行的。
#### 创建新的 SVN 分支
要在 Subversion 中建立一个新分支,需要运行 git svn branch [分支名] :
~~~
$ git svn branch opera
Copying file:///tmp/test-svn/trunk at r87 to file:///tmp/test-svn/branches/opera...
Found possible branch point: file:///tmp/test-svn/trunk => \
file:///tmp/test-svn/branches/opera, 87
Found branch parent: (opera) 1f6bfe471083cbca06ac8d4176f7ad4de0d62e5f
Following parent with do_switch
Successfully followed parent
r89 = 9b6fe0b90c5c9adf9165f700897518dbc54a7cbf (opera)
~~~
这相当于在 Subversion 中的 `svn copy trunk branches/opera` 命令,并会对` Subversion` 服务器进行相关操作。值得注意的是它没有检出和转换到那个分支;如果现在进行提交,将提交到服务器上的 trunk, 而非` opera。`
### 切换当前分支
Git 通过搜寻提交历史中 Subversion 分支的头部来决定 dcommit 的目的地——而它应该只有一个,那就是当前分支历史中最近一次包含 git-svn-id 的提交。
如果需要同时在多个分支上提交,可以通过导入 Subversion 上某个其他分支的 commit 来建立以该分支为 dcommit 目的地的本地分支。比如你想拥有一个并行维护的 opera 分支,可以运行
`$ git branch opera remotes/opera`
然后,如果要把 opera 分支并入 trunk (本地的 master 分支),可以使用普通的 git merge。不过最好提供一条描述提交的信息(通过 -m),否则这次合并的记录是 Merge branch opera ,而不是任何有用的东西。
记住,虽然使用了 git merge 来进行这次操作,并且合并过程可能比使用 Subversion 简单一些(因为 Git 会自动找到适合的合并基础),这并不是一次普通的 Git 合并提交。最终它将被推送回 commit 无法包含多个祖先的 Subversion 服务器上;因而在推送之后,它将变成一个包含了所有在其他分支上做出的改变的单一 commit。把一个分支合并到另一个分支以后,你没法像在 Git 中那样轻易的回到那个分支上继续工作。提交时运行的 dcommit 命令擦除了全部有关哪个分支被并入的信息,因而以后的合并基础计算将是不正确的—— dcommit 让 git merge 的结果变得类似于 git merge --squash。不幸的是,我们没有什么好办法来避免该情况—— Subversion 无法储存这个信息,所以在使用它作为服务器的时候你将永远为这个缺陷所困。为了不出现这种问题,在把本地分支(本例中的 opera)并入 trunk 以后应该立即将其删除。
### 对应 Subversion 的命令
git svn 工具集合了若干个与 Subversion 类似的功能,对应的命令可以简化向 Git 的转化过程。下面这些命令能实现 Subversion 的这些功能。
#### SVN 风格的历史
习惯了 Subversion 的人可能想以 SVN 的风格显示历史,运行 git svn log 可以让提交历史显示为 SVN 格式:
~~~
$ git svn log
------------------------------------------------------------------------
r87 | schacon | 2009-05-02 16:07:37 -0700 (Sat, 02 May 2009) | 2 lines
autogen change
------------------------------------------------------------------------
r86 | schacon | 2009-05-02 16:00:21 -0700 (Sat, 02 May 2009) | 2 lines
Merge branch 'experiment'
------------------------------------------------------------------------
r85 | schacon | 2009-05-02 16:00:09 -0700 (Sat, 02 May 2009) | 2 lines
updated the changelog
~~~
关于 git svn log ,有两点需要注意。首先,它可以离线工作,不像 svn log 命令,需要向 Subversion 服务器索取数据。其次,它仅仅显示已经提交到 Subversion 服务器上的` commit`。在本地尚未` dcommit `的 Git 数据不会出现在这里;其他人向 `Subversion` 服务器新提交的数据也不会显示。等于说是显示了最近已知 Subversion 服务器上的状态。
### SVN 日志
类似 git svn log 对 git log 的模拟,svn annotate 的等效命令是 git svn blame [文件名]。其输出如下:
~~~
$ git svn blame README.txt
2 temporal Protocol Buffers - Google's data interchange format
2 temporal Copyright 2008 Google Inc.
2 temporal http://code.google.com/apis/protocolbuffers/
2 temporal
22 temporal C++ Installation - Unix
22 temporal =======================
2 temporal
79 schacon Committing in git-svn.
78 schacon
2 temporal To build and install the C++ Protocol Buffer runtime and the Protocol
2 temporal Buffer compiler (protoc) execute the following:
2 temporal
~~~
同样,它不显示本地的 Git 提交以及 Subversion 上后来更新的内容。
### SVN 服务器信息
还可以使用 git svn info 来获取与运行 svn info 类似的信息:
~~~
$ git svn info
Path: .
URL: https://schacon-test.googlecode.com/svn/trunk
Repository Root: https://schacon-test.googlecode.com/svn
Repository UUID: 4c93b258-373f-11de-be05-5f7a86268029
Revision: 87
Node Kind: directory
Schedule: normal
Last Changed Author: schacon
Last Changed Rev: 87
Last Changed Date: 2009-05-02 16:07:37 -0700 (Sat, 02 May 2009)
~~~
它与 blame 和 log 的相同点在于离线运行以及只更新到最后一次与 Subversion 服务器通信的状态。
### 略 Subversion 之所略
假如克隆了一个包含了 svn:ignore 属性的 Subversion 仓库,就有必要建立对应的 .gitignore 文件来防止意外提交一些不应该提交的文件。git svn 有两个有益于改善该问题的命令。第一个是` git svn create-ignore,`它自动建立对应的 .gitignore 文件,以便下次提交的时候可以包含它。
第二个命令是` git svn show-ignore`,它把需要放进 `.gitignore` 文件中的内容打印到标准输出,方便我们把输出重定向到项目的黑名单文件:
`$ git svn show-ignore > .git/info/exclude`
这样一来,避免了 `.gitignore` 对项目的干扰。如果你是一个 Subversion 团队里唯一的 Git 用户,而其他队友不喜欢项目包含 .gitignore,该方法是你的不二之选。
## Git-Svn 总结
git svn 工具集在当前不得不使用 Subversion 服务器或者开发环境要求使用 Subversion 服务器的时候格外有用。不妨把它看成一个跛脚的 Git,然而,你还是有可能在转换过程中碰到一些困惑你和合作者们的迷题。为了避免麻烦,试着遵守如下守则:
保持一个不包含由` git merge` 生成的` commit `的线性提交历史。将在主线分支外进行的开发通通衍合回主线;避免直接合并。
不要单独建立和使用一个 Git 服务来搞合作。可以为了加速新开发者的克隆进程建立一个,但是不要向它提供任何不包含` git-svn-id `条目的内容。甚至可以添加一个` pre-receive` 挂钩来在每一个提交信息中查找 git-svn-id 并拒绝提交那些不包含它的 commit。
如果遵循这些守则,在` Subversion` 上工作还可以接受。然而,如果能迁徙到真正的` Git` 服务器,则能为团队带来更多好处。
8. Git与其他系统
最后更新于:2022-04-01 00:21:46
世界不是完美的。大多数时候,将所有接触到的项目全部转向 Git 是不可能的。有时我们不得不为某个项目使用其他的版本控制系统(VCS, Version Control System ),其中比较常见的是 Subversion 。你将在本章的第一部分学习使用 `git svn` ,Git 为 Subversion 附带的双向桥接工具。
或许现在你已经在考虑将先前的项目转向 Git 。本章的第二部分将介绍如何将项目迁移到 Git:先介绍从 Subversion 的迁移,然后是 Perforce,最后介绍如何使用自定义的脚本进行非标准的导入。
7.5 总结
最后更新于:2022-04-01 00:21:43
你已经见识过绝大多数通过自定义 Git 客户端和服务端来来适应自己工作流程和项目内容的方式了。无论你创造出了什么样的工作流程,Git 都能用的顺手.
7.4 Git 强制策略实例
最后更新于:2022-04-01 00:21:41
在本节中,我们应用前面学到的知识建立这样一个Git 工作流程:检查提交信息的格式,只接受纯fast-forward内容的推送,并且指定用户只能修改项目中的特定子目录。我们将写一个客户端脚本来提示开发人员他们推送的内容是否会被拒绝,以及一个服务端脚本来实际执行这些策略。
这些脚本使用 Ruby 写成,一半由于它是作者倾向的脚本语言,另外作者觉得它是最接近伪代码的脚本语言;因而即便你不使用 Ruby 也能大致看懂。不过任何其他语言也一样适用。所有 Git 自带的样例脚本都是用 Perl 或 Bash 写的。所以从这些脚本中能找到相当多的这两种语言的挂钩样例。
## 服务端挂钩
所有服务端的工作都在hooks(挂钩)目录的 update(更新)脚本中制定。update 脚本为每一个得到推送的分支运行一次;它接受推送目标的索引,该分支原来指向的位置,以及被推送的新内容。如果推送是通过 SSH 进行的,还可以获取发出此次操作的用户。如果设定所有操作都通过公匙授权的单一帐号(比如"git")进行,就有必要通过一个 shell 包装依据公匙来判断用户的身份,并且设定环境变量来表示该用户的身份。下面假设尝试连接的用户储存在 $USER 环境变量里,我们的 update 脚本首先搜集一切需要的信息:
~~~
!/usr/bin/env ruby
refname = ARGV[0]
oldrev = ARGV[1]
newrev = ARGV[2]
user = ENV['USER']
puts "Enforcing Policies... \n(#{refname}) (#{oldrev[0,6]}) (#{newrev[0,6]})"
~~~
### 指定特殊的提交信息格式
我们的第一项任务是指定每一条提交信息都必须遵循某种特殊的格式。作为演示,假定每一条信息必须包含一条形似 "ref: 1234" 这样的字符串,因为我们需要把每一次提交和项目的问题追踪系统。我们要逐一检查每一条推送上来的提交内容,看看提交信息是否包含这么一个字符串,然后,如果该提交里不包含这个字符串,以非零返回值退出从而拒绝此次推送。
把 $newrev 和 $oldrev 变量的值传给一个叫做 `git rev-list `的 `Git plumbing `命令可以获取所有提交内容的 SHA-1 值列表。`git rev-list `基本类似 `git log `命令,但它默认只输出 SHA-1 值而已,没有其他信息。所以要获取由 SHA 值表示的从一次提交到另一次提交之间的所有 SHA 值,可以运行:
~~~
$ git rev-list 538c33..d14fc7
d14fc7c847ab946ec39590d87783c69b031bdfb7
9f585da4401b0a3999e84113824d15245c13f0be
234071a1be950e2a8d078e6141f5cd20c1e61ad3
dfa04c9ef3d5197182f13fb5b9b1fb7717d2222a
17716ec0f1ff5c77eff40b7fe912f9f6cfd0e475
~~~
截取这些输出内容,循环遍历其中每一个 SHA 值,找出与之对应的提交信息,然后用正则表达式来测试该信息包含的格式话的内容。
下面要搞定如何从所有的提交内容中提取出提交信息。使用另一个叫做 git cat-file 的 Git plumbing 工具可以获得原始的提交数据。我们将在第九章了解到这些 plumbing 工具的细节;现在暂时先看一下这条命令的输出:
~~~
$ git cat-file commit ca82a6
tree cfda3bf379e4f8dba8717dee55aab78aef7f4daf
parent 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
author Scott Chacon <schacon@gmail.com> 1205815931 -0700
committer Scott Chacon <schacon@gmail.com> 1240030591 -0700
changed the version number
~~~
通过 SHA-1 值获得提交内容中的提交信息的一个简单办法是找到提交的第一行,然后取从它往后的所有内容。可以使用 Unix 系统的 sed 命令来实现该效果:
~~~
$ git cat-file commit ca82a6 | sed '1,/^$/d'
changed the version number
~~~
这条咒语从每一个待提交内容里提取提交信息,并且会在提取信息不符合要求的情况下退出。为了退出脚本和拒绝此次推送,返回一个非零值。整个脚本大致如下:
`$regex = /\[ref: (\d+)\]/`
### 指定提交信息格式
~~~
def check_message_format
missed_revs = `git rev-list #{$oldrev}..#{$newrev}`.split("\n")
missed_revs.each do |rev|
message = `git cat-file commit #{rev} | sed '1,/^$/d'`
if !$regex.match(message)
puts "[POLICY] Your message is not formatted correctly"
exit 1
end
end
end
check_message_format
~~~
把这一段放在 update 脚本里,所有包含不符合指定规则的提交都会遭到拒绝。
### 实现基于用户的访问权限控制列表(ACL)系统
假设你需要添加一个使用访问权限控制列表的机制来指定哪些用户对项目的哪些部分有推送权限。某些用户具有全部的访问权,其他人只对某些子目录或者特定的文件具有推送权限。要搞定这一点,所有的规则将被写入一个位于服务器的原始 Git 仓库的 acl 文件。我们让 update 挂钩检阅这些规则,审视推送的提交内容中需要修改的所有文件,然后决定执行推送的用户是否对所有这些文件都有权限。
我们首先要创建这个列表。这里使用的格式和 CVS 的 ACL 机制十分类似:它由若干行构成,第一项内容是 avail 或者 unavail,接着是逗号分隔的规则生效用户列表,最后一项是规则生效的目录(空白表示开放访问)。这些项目由 | 字符隔开。
下例中,我们指定几个管理员,几个对 doc 目录具有权限的文档作者,以及一个对 lib 和 tests 目录具有权限的开发人员,相应的 ACL 文件如下:
~~~
avail|nickh,pjhyett,defunkt,tpw
avail|usinclair,cdickens,ebronte|doc
avail|schacon|lib
avail|schacon|tests
~~~
首先把这些数据读入你编写的数据结构。本例中,为保持简洁,我们暂时只实现 avail 的规则(译注:也就是省略了 unavail 部分)。下面这个方法生成一个关联数组,它的主键是用户名,值是一个该用户有写权限的所有目录组成的数组:
~~~
def get_acl_access_data(acl_file)
# read in ACL data
acl_file = File.read(acl_file).split("\n").reject { |line| line == '' }
access = {}
acl_file.each do |line|
avail, users, path = line.split('|')
next unless avail == 'avail'
users.split(',').each do |user|
access[user] ||= []
access[user] << path
end
end
access
end
~~~
针对之前给出的 ACL 规则文件,这个 get_acl_access_data 方法返回的数据结构如下:
~~~
{"defunkt"=>[nil],
"tpw"=>[nil],
"nickh"=>[nil],
"pjhyett"=>[nil],
"schacon"=>["lib", "tests"],
"cdickens"=>["doc"],
"usinclair"=>["doc"],
"ebronte"=>["doc"]}
~~~
搞定了用户权限的数据,下面需要找出哪些位置将要被提交的内容修改,从而确保试图推送的用户对这些位置有全部的权限。
使用 git log 的 --name-only 选项(在第二章里简单的提过)我们可以轻而易举的找出一次提交里修改的文件:
~~~
$ git log -1 --name-only --pretty=format:'' 9f585d
README
lib/test.rb
~~~
使用 get_acl_access_data 返回的 ACL 结构来一一核对每一次提交修改的文件列表,就能找出该用户是否有权限推送所有的提交内容:
~~~
# 仅允许特定用户修改项目中的特定子目录
def check_directory_perms
access = get_acl_access_data('acl')
# 检查是否有人在向他没有权限的地方推送内容
new_commits = `git rev-list #{$oldrev}..#{$newrev}`.split("\n")
new_commits.each do |rev|
files_modified = `git log -1 --name-only --pretty=format:'' #{rev}`.split("\n")
files_modified.each do |path|
next if path.size == 0
has_file_access = false
access[$user].each do |access_path|
if !access_path || # 用户拥有完全访问权限
(path.index(access_path) == 0) # 或者对此位置有访问权限
has_file_access = true
end
end
if !has_file_access
puts "[POLICY] You do not have access to push to #{path}"
exit 1
end
end
end
end
check_directory_perms
~~~
以上的大部分内容应该都比较容易理解。通过 git rev-list 获取推送到服务器内容的提交列表。然后,针对其中每一项,找出它试图修改的文件然后确保执行推送的用户对这些文件具有权限。一个不太容易理解的 Ruby 技巧是` path.index(access_path) ==0` 这句,它的返回真值如果路径以 `access_path `开头——这是为了确保 `access_path `并不是只在允许的路径之一,而是所有准许全选的目录都在该目录之下。
现在你的用户没法推送带有不正确的提交信息的内容,也不能在准许他们访问范围之外的位置做出修改。
### 只允许 Fast-Forward 类型的推送
剩下的最后一项任务是指定只接受 `fast-forward` 的推送。在 Git 1.6 或者更新版本里,只需要设定 `receive.denyDeletes` 和 `receive.denyNonFastForwards `选项就可以了。但是通过挂钩的实现可以在旧版本的 Git 上工作,并且通过一定的修改它它可以做到只针对某些用户执行,或者更多以后可能用的到的规则。
检查这一项的逻辑是看看提交里是否包含从旧版本里能找到但在新版本里却找不到的内容。如果没有,那这是一次纯 `fast-forward` 的推送;如果有,那我们拒绝此次推送:
~~~
# 只允许纯 fast-forward 推送
def check_fast_forward
missed_refs = `git rev-list #{$newrev}..#{$oldrev}`
missed_ref_count = missed_refs.split("\n").size
if missed_ref_count > 0
puts "[POLICY] Cannot push a non fast-forward reference"
exit 1
end
end
check_fast_forward
~~~
一切都设定好了。如果现在运行` chmod u+x .git/hooks/update `—— 修改包含以上内容文件的权限,然后尝试推送一个包含非 `fast-forward` 类型的索引,会得到一下提示:
~~~
$ git push -f origin master
Counting objects: 5, done.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 323 bytes, done.
Total 3 (delta 1), reused 0 (delta 0)
Unpacking objects: 100% (3/3), done.
Enforcing Policies...
(refs/heads/master) (8338c5) (c5b616)
[POLICY] Cannot push a non fast-forward reference
error: hooks/update exited with error code 1
error: hook declined to update refs/heads/master
To git@gitserver:project.git
! [remote rejected] master -> master (hook declined)
error: failed to push some refs to 'git@gitserver:project.git'
~~~
这里有几个有趣的信息。首先,我们可以看到挂钩运行的起点:
~~~
Enforcing Policies...
(refs/heads/master) (8338c5) (c5b616)
~~~
注意这是从 update 脚本开头输出到标准你输出的。所有从脚本输出的提示都会发送到客户端,这点很重要。
下一个值得注意的部分是错误信息。
~~~
[POLICY] Cannot push a non fast-forward reference
error: hooks/update exited with error code 1
error: hook declined to update refs/heads/master
~~~
第一行是我们的脚本输出的,在往下是 Git 在告诉我们 update 脚本退出时返回了非零值因而推送遭到了拒绝。最后一点:
~~~
To git@gitserver:project.git
! [remote rejected] master -> master (hook declined)
error: failed to push some refs to 'git@gitserver:project.git'
~~~
我们将为每一个被挂钩拒之门外的索引受到一条远程信息,解释它被拒绝是因为一个挂钩的原因。
而且,如果那个 ref 字符串没有包含在任何的提交里,我们将看到前面脚本里输出的错误信息:
`[POLICY] Your message is not formatted correctly`
又或者某人想修改一个自己不具备权限的文件然后推送了一个包含它的提交,他将看到类似的提示。比如,一个文档作者尝试推送一个修改到 lib 目录的提交,他会看到
`[POLICY] You do not have access to push to lib/test.rb`
全在这了。从这里开始,只要 update 脚本存在并且可执行,我们的仓库永远都不会遭到回转或者包含不符合要求信息的提交内容,并且用户都被锁在了沙箱里面。
## 客户端挂钩
这种手段的缺点在于用户推送内容遭到拒绝后几乎无法避免的抱怨。辛辛苦苦写成的代码在最后时刻惨遭拒绝是十分悲剧且具有迷惑性的;更可怜的是他们不得不修改提交历史来解决问题,这怎么也算不上王道。
逃离这种两难境地的法宝是给用户一些客户端的挂钩,在他们作出可能悲剧的事情的时候给以警告。然后呢,用户们就能在提交--问题变得更难修正之前解除隐患。由于挂钩本身不跟随克隆的项目副本分发,所以必须通过其他途径把这些挂钩分发到用户的 .git/hooks 目录并设为可执行文件。虽然可以在相同或单独的项目内 容里加入并分发它们,全自动的解决方案是不存在的。
首先,你应该在每次提交前核查你的提交注释信息,这样你才能确保服务器不会因为不合条件的提交注释信息而拒绝你的更改。为了达到这个目的,你可以增加'commit-msg'挂钩。如果你使用该挂钩来阅读作为第一个参数传递给git的提交注释信息,并且与规定的模式作对比,你就可以使git在提交注释信息不符合条件的情况下,拒绝执行提交。
~~~
#!/usr/bin/env ruby
message_file = ARGV[0]
message = File.read(message_file)
$regex = /\[ref: (\d+)\]/
if !$regex.match(message)
puts "[POLICY] Your message is not formatted correctly"
exit 1
~~~
end
如果这个脚本放在这个位置 (`.git/hooks/commit-msg`) 并且是可执行的, 并且你的提交注释信息不是符合要求的,你会看到:
~~~
$ git commit -am 'test'
[POLICY] Your message is not formatted correctly
~~~
在这个实例中,提交没有成功。然而如果你的提交注释信息是符合要求的,git会允许你提交:
~~~
$ git commit -am 'test [ref: 132]'
[master e05c914] test [ref: 132]
1 files changed, 1 insertions(+), 0 deletions(-)
~~~
接下来我们要保证没有修改到 ACL 允许范围之外的文件。加入你的 .git 目录里有前面使用过的 ACL 文件,那么以下的 pre-commit 脚本将把里面的规定执行起来:
~~~
#!/usr/bin/env ruby
$user = ENV['USER']
# [ insert acl_access_data method from above ]
# 只允许特定用户修改项目重特定子目录的内容
def check_directory_perms
access = get_acl_access_data('.git/acl')
files_modified = `git diff-index --cached --name-only HEAD`.split("\n")
files_modified.each do |path|
next if path.size == 0
has_file_access = false
access[$user].each do |access_path|
if !access_path || (path.index(access_path) == 0)
has_file_access = true
end
if !has_file_access
puts "[POLICY] You do not have access to push to #{path}"
exit 1
end
end
end
check_directory_perms
~~~
这和服务端的脚本几乎一样,除了两个重要区别。第一,ACL 文件的位置不同,因为这个脚本在当前工作目录运行,而非 Git 目录。ACL 文件的目录必须从
`access = get_acl_access_data('acl')`
修改成:
`access = get_acl_access_data('.git/acl')`
另一个重要区别是获取被修改文件列表的方式。在服务端的时候使用了查看提交纪录的方式,可是目前的提交都还没被记录下来呢,所以这个列表只能从暂存区域获取。和原来的
~~~
files_modified = `git log -1 --name-only --pretty=format:'' #{ref}`
~~~
不同,现在要用
~~~
files_modified = `git diff-index --cached --name-only HEAD`
~~~
不同的就只有这两点——除此之外,该脚本完全相同。一个小陷阱在于它假设在本地运行的账户和推送到远程服务端的相同。如果这二者不一样,则需要手动设置一下 $user 变量。
最后一项任务是检查确认推送内容中不包含非` fast-forward` 类型的索引,不过这个需求比较少见。要找出一个非 fast-forward 类型的索引,要么衍合超过某个已经推送过的提交,要么从本地不同分支推送到远程相同的分支上。
既然服务器将给出无法推送非 fast-forward 内容的提示,而且上面的挂钩也能阻止强制的推送,唯一剩下的潜在问题就是衍合一次已经推送过的提交内容。
下面是一个检查这个问题的 pre-rabase 脚本的例子。它获取一个所有即将重写的提交内容的列表,然后检查它们是否在远程的索引里已经存在。一旦发现某个提交可以从远程索引里衍变过来,它就放弃衍合操作:
~~~
!/usr/bin/env ruby
base_branch = ARGV[0]
if ARGV[1]
topic_branch = ARGV[1]
else
topic_branch = "HEAD"
end
target_shas = `git rev-list #{base_branch}..#{topic_branch}`.split("\n")
remote_refs = `git branch -r`.split("\n").map { |r| r.strip }
target_shas.each do |sha|
remote_refs.each do |remote_ref|
shas_pushed = `git rev-list ^#{sha}^@ refs/remotes/#{remote_ref}`
if shas_pushed.split("\n").include?(sha)
puts "[POLICY] Commit #{sha} has already been pushed to #{remote_ref}"
exit 1
end
end
end
~~~
这个脚本利用了一个第六章"修订版本选择"一节中不曾提到的语法。通过这一句可以获得一个所有已经完成推送的提交的列表:
`git rev-list ^#{sha}^@ refs/remotes/#{remote_ref}`
`SHA^@ `语法解析该次提交的所有祖先。这里我们从检查远程最后一次提交能够衍变获得但从所有我们尝试推送的提交的 SHA 值祖先无法衍变获得的提交内容——也就是 `fast-forward` 的内容。
这个解决方案的硬伤在于它有可能很慢而且常常没有必要——只要不用 `-f `来强制推送,服务器会自动给出警告并且拒绝推送内容。然而,这是个不错的练习而且理论上能帮助用户避免一次将来不得不折回来修改的衍合操作。
7.3 Git挂钩
最后更新于:2022-04-01 00:21:39
和其他版本控制系统一样,当某些重要事件发生时,Git 以调用自定义脚本。有两组挂钩:客户端和服务器端。客户端挂钩用于客户端的操作,如提交和合并。服务器端挂钩用于 Git 服务器端的操作,如接收被推送的提交。你可以随意地使用这些挂钩,下面会讲解其中一些。
## 安装一个挂钩
挂钩都被存储在 Git 目录下的hooks子目录中,即大部分项目中的`.git/hooks。` Git 默认会放置一些脚本样本在这个目录中,除了可以作为挂钩使用,这些样本本身是可以独立使用的。所有的样本都是shell脚本,其中一些还包含了Perl的脚本,不过,任何正确命名的可执行脚本都可以正常使用 — 可以用`Ruby`或`Python`,或其他。在Git 1.6版本之后,这些样本名都是以.sample结尾,因此,你必须重新命名。在Git 1.6版本之前,这些样本名都是正确的,但这些样本不是可执行文件。
把一个正确命名且可执行的文件放入 Git 目录下的hooks子目录中,可以激活该挂钩脚本,因此,之后他一直会被 Git 调用。随后会讲解主要的挂钩脚本。
## 客户端挂钩
有许多客户端挂钩,以下把他们分为:提交工作流挂钩、电子邮件工作流挂钩及其他客户端挂钩。
### 提交工作流挂钩
有 4个挂钩被用来处理提交的过程。pre-commit挂钩在键入提交信息前运行,被用来检查即将提交的快照,例如,检查是否有东西被遗漏,确认测试是否运行,以及检查代码。当从该挂钩返回非零值时,Git 放弃此次提交,但可以用git commit --no-verify来忽略。该挂钩可以被用来检查代码错误(运行类似lint的程序),检查尾部空白(默认挂钩是这么做的),检查新方法(译注:程序的函数)的说明。
`prepare-commit-msg`挂钩在提交信息编辑器显示之前,默认信息被创建之后运行。因此,可以有机会在提交作者看到默认信息前进行编辑。该挂钩接收一些选项:拥有提交信息的文件路径,提交类型,如果是一次修订的话,提交的SHA-1校验和。该挂钩对通常的提交来说不是很有用,只在自动产生的默认提交信息的情况下有作用,如提交信息模板、合并、压缩和修订提交等。可以和提交模板配合使用,以编程的方式插入信息。
`commit-msg`挂钩接收一个参数,此参数是包含最近提交信息的临时文件的路径。如果该挂钩脚本以非零退出,Git 放弃提交,因此,可以用来在提交通过前验证项目状态或提交信息。本章上一小节已经展示了使用该挂钩核对提交信息是否符合特定的模式。
`post-commit`挂钩在整个提交过程完成后运行,他不会接收任何参数,但可以运行git log -1 HEAD来获得最后的提交信息。总之,该挂钩是作为通知之类使用的。
提交工作流的客户端挂钩脚本可以在任何工作流中使用,他们经常被用来实施某些策略,但值得注意的是,这些脚本在clone期间不会被传送。可以在服务器端实施策略来拒绝不符合某些策略的推送,但这完全取决于开发者在客户端使用这些脚本的情况。所以,这些脚本对开发者是有用的,由他们自己设置和维护,而且在任何时候都可以覆盖或修改这些脚本。
### E-mail工作流挂钩
有3个可用的客户端挂钩用于e-mail工作流。当运行git am命令时,会调用他们,因此,如果你没有在工作流中用到此命令,可以跳过本节。如果你通过e-mail接收由git format-patch产生的补丁,这些挂钩也许对你有用。
首先运行的是applypatch-msg挂钩,他接收一个参数:包含被建议提交信息的临时文件名。如果该脚本非零退出,Git 放弃此补丁。可以使用这个脚本确认提交信息是否被正确格式化,或让脚本编辑信息以达到标准化。
下一个在git am运行期间调用是pre-applypatch挂钩。该挂钩不接收参数,在补丁被运用之后运行,因此,可以被用来在提交前检查快照。你能用此脚本运行测试,检查工作树。如果有些什么遗漏,或测试没通过,脚本会以非零退出,放弃此次git am的运行,补丁不会被提交。
最后在git am运行期间调用的是post-applypatch挂钩。你可以用他来通知一个小组或获取的补丁的作者,但无法阻止打补丁的过程。
### 其他客户端挂钩
`pre-rebase`挂钩在衍合前运行,脚本以非零退出可以中止衍合的过程。你可以使用这个挂钩来禁止衍合已经推送的提交对象,Git pre-rebase挂钩样本就是这么做的。该样本假定next是你定义的分支名,因此,你可能要修改样本,把next改成你定义过且稳定的分支名。
在`git checkout`成功运行后,post-checkout挂钩会被调用。他可以用来为你的项目环境设置合适的工作目录。例如:放入大的二进制文件、自动产生的文档或其他一切你不想纳入版本控制的文件。
最后,在merge命令成功执行后,post-merge挂钩会被调用。他可以用来在 Git 无法跟踪的工作树中恢复数据,诸如权限数据。该挂钩同样能够验证在 Git 控制之外的文件是否存在,因此,当工作树改变时,你想这些文件可以被复制。
## 服务器端挂钩
除了客户端挂钩,作为系统管理员,你还可以使用两个服务器端的挂钩对项目实施各种类型的策略。这些挂钩脚本可以在提交对象推送到服务器前被调用,也可以在推送到服务器后被调用。推送到服务器前调用的挂钩可以在任何时候以非零退出,拒绝推送,返回错误消息给客户端,还可以如你所愿设置足够复杂的推送策略。
### pre-receive 和 post-receive
处理来自客户端的推送(push)操作时最先执行的脚本就是 pre-receive 。它从标准输入(stdin)获取被推送引用的列表;如果它退出时的返回值不是0,所有推送内容都不会被接受。利用此挂钩脚本可以实现类似保证最新的索引中不包含非fast-forward类型的这类效果;抑或检查执行推送操作的用户拥有创建,删除或者推送的权限或者他是否对将要修改的每一个文件都有访问权限。
### post-receive
挂钩在整个过程完结以后运行,可以用来更新其他系统服务或者通知用户。它接受与 pre-receive 相同的标准输入数据。应用实例包括给某邮件列表发信,通知实时整合数据的服务器,或者更新软件项目的问题追踪系统 —— 甚至可以通过分析提交信息来决定某个问题是否应该被开启,修改或者关闭。该脚本无法组织推送进程,不过客户端在它完成运行之前将保持连接状态;所以在用它作一些消耗时间的操作之前请三思。
### update
`update` 脚本和` pre-receive `脚本十分类似。不同之处在于它会为推送者更新的每一个分支运行一次。假如推送者同时向多个分支推送内容,pre-receive 只运行一次,相比之下 update 则会为每一个更新的分支运行一次。它不会从标准输入读取内容,而是接受三个参数:索引的名字(分支),推送前索引指向的内容的 SHA-1 值,以及用户试图推送内容的 SHA-1 值。如果 update 脚本以退出时返回非零值,只有相应的那一个索引会被拒绝;其余的依然会得到更新。
7.2 Git属性
最后更新于:2022-04-01 00:21:36
一些设置项也能被运用于特定的路径中,这样,Git 以对一个特定的子目录或子文件集运用那些设置项。这些设置项被称为 Git 属性,可以在你目录中的.gitattributes文件内进行设置(通常是你项目的根目录),也可以当你不想让这些属性文件和项目文件一同提交时,在.git/info/attributes进行设置。
使用属性,你可以对个别文件或目录定义不同的合并策略,让 Git 知道怎样比较非文本文件,在你提交或签出前让 Git 过滤内容。你将在这部分了解到能在自己的项目中使用的属性,以及一些实例。
## 二进制文件
你可以用 Git 属性让其知道哪些是二进制文件(以防 Git 没有识别出来),以及指示怎样处理这些文件,这点很酷。例如,一些文本文件是由机器产生的,而且无法比较,而一些二进制文件可以比较 — 你将会了解到怎样让 Git 识别这些文件。
### 识别二进制文件
一些文件看起来像是文本文件,但其实是作为二进制数据被对待。例如,在Mac上的Xcode项目含有一个以.pbxproj结尾的文件,它是由记录设置项的IDE写到磁盘的JSON数据集(纯文本javascript数据类型)。虽然技术上看它是由ASCII字符组成的文本文件,但你并不认为如此,因为它确实是一个轻量级数据库 — 如果有2人改变了它,你通常无法合并和比较内容,只有机器才能进行识别和操作,于是,你想把它当成二进制文件。
让 Git 把所有pbxproj文件当成二进制文件,在.gitattributes文件中设置如下:
`*.pbxproj -crlf -diff`
现在,Git 会尝试转换和修正CRLF(回车换行)问题,也不会当你在项目中运行git show或git diff时,比较不同的内容。在Git 1.6及之后的版本中,可以用一个宏代替-crlf -diff:
`*.pbxproj binary`
### 比较二进制文件
你可以使用 Git 属性来有效地比较两个二进制文件(binary files,译注:指非文本文件)。那么第一步要做的是,告诉 Git 怎么把你的二进制文件转化为纯文本格式,从而让普通的 diff 命令可以进行文本对比。但是,我们怎么把二进制文件转化为文本呢?最好的解决方法是找到一个转换工具帮助我们进行转化。但是,大部分的二进制文件不能表示为可读的文本,例如语音文件就很难转化为文本文件。如果你遇到这些情况,比较简单的解决方法是从这些二进制文件中获取元数据。虽然这些元数据并不能完全描述一个二进制文件,但大多数情况下,都是能够概括文件情况的。
下面,我们将会展示,如何使用转化工具进行二进制文件的比较。
边注:有一些二进制文件虽然包含文字,但是却难以转换。(译注:例如 Word 文档。)在这些情况,你可以尝试使用 strings 工具来获取其中的文字。但如果当这些文档包含 UTF-16 编码,或者其他代码页(codepages),strings 也可能无补于事。strings 在大部分的 Mac 和 Linux 下都有安装。当遇到有二进制文件需要转换的时候,你可以试试这个工具。
## Word文档
这个特性很酷,而且鲜为人知,因此我会结合实例来讲解。首先,要解决的是最令人头疼的问题:对Word文档进行版本控制。很多人对Word文档又恨又爱,如果想对其进行版本控制,你可以把文件加入到 Git 库中,每次修改后提交即可。但这样做没有一点实际意义,因为运行git diff命令后,你只能得到如下的结果:
~~~
$ git diff
diff --git a/chapter1.doc b/chapter1.doc
index 88839c4..4afcb7c 100644
Binary files a/chapter1.doc and b/chapter1.doc differ
~~~
你不能直接比较两个不同版本的Word文件,除非进行手动扫描,不是吗? Git 属性能很好地解决此问题,把下面的行加到.gitattributes文件:
`*.doc diff=word`
当你要看比较结果时,如果文件扩展名是"doc",Git 调用"word"过滤器。什么是"word"过滤器呢?其实就是 Git 使用strings 程序,把Word文档转换成可读的文本文件,之后再进行比较:
`$ git config diff.word.textconv catdoc`
这个命令会在你的 .git/config 文件中增加一节:
~~~
[diff "word"]
textconv = catdoc
~~~
现在如果在两个快照之间比较以.doc结尾的文件,Git 对这些文件运用"word"过滤器,在比较前把Word文件转换成文本文件。
下面展示了一个实例,我把此书的第一章纳入 Git 管理,在一个段落中加入了一些文本后保存,之后运行git diff命令,得到结果如下:
~~~
$ git diff
diff --git a/chapter1.doc b/chapter1.doc
index c1c8a0a..b93c9e4 100644
--- a/chapter1.doc
+++ b/chapter1.doc
@@ -128,7 +128,7 @@ and data size)
Since its birth in 2005, Git has evolved and matured to be easy to use
and yet retain these initial qualities. It’s incredibly fast, it’s
very efficient with large projects, and it has an incredible branching
-system for non-linear development.
+system for non-linear development (See Chapter 3).
~~~
Git 成功且简洁地显示出我增加的文本"(See Chapter 3)"。工作的很完美!
## OpenDocument文本文档
我们用于处理Word文档(*.doc)的方法同样适用于处理`OpenOffice.org`创建的OpenDocument文本文档(*.odt)。
把下面这行添加到.gitattributes文件:
`*.odt diff=odt`
然后在.git/config 文件中设置odt过滤器:
~~~
[diff "odt"]
binary = true
textconv = /usr/local/bin/odt-to-txt
~~~
OpenDocument文档实际上是多个文件(包括一个XML文件和表格、图片等文件)的压缩包。我们需要写一个脚本来提取其中纯文本格式的内容。创建一个文件/usr/local/bin/odt-to-txt(你也可以放到其他目录下),写入下面内容:
~~~
! /usr/bin/env perl
Simplistic OpenDocument Text (.odt) to plain text converter.
Author: Philipp Kempgen
if (! defined($ARGV[0])) {
print STDERR "No filename given!\n";
print STDERR "Usage: $0 filename\n";
exit 1;
}
my $content = '';
open my $fh, '-|', 'unzip', '-qq', '-p', $ARGV[0], 'content.xml' or die $!;
{
local $/ = undef; # slurp mode
$content = <$fh>;
}
close $fh;
$_ = $content;
s/<text:span\b[^>]*>//g; # remove spans
s/<text:h\b[^>]*>/\n\n***** /g; # headers
s/<text:list-item\b[^>]*>\s*<text:p\b[^>]*>/\n -- /g; # list items
s/<text:list\b[^>]*>/\n\n/g; # lists
s/<text:p\b[^>]*>/\n /g; # paragraphs
s/<[^>]+>//g; # remove all XML tags
s/\n{2,}/\n\n/g; # remove multiple blank lines
s/\A\n+//; # remove leading blank lines
print "\n", $_, "\n\n";
~~~
然后把它设为可执行文件
`chmod +x /usr/local/bin/odt-to-txt`
现在git diff命令就可以显示.odt文件的变更了。
## 图像文件
你还能用这个方法比较图像文件。当比较时,对JPEG文件运用一个过滤器,它能提炼出EXIF信息 — 大部分图像格式使用的元数据。如果你下载并安装了exiftool程序,可以用它参照元数据把图像转换成文本。比较的不同结果将会用文本向你展示:
~~~
$ echo '*.png diff=exif' >> .gitattributes
$ git config diff.exif.textconv exiftool
~~~
如果在项目中替换了一个图像文件,运行git diff命令的结果如下:
~~~
diff --git a/image.png b/image.png
index 88839c4..4afcb7c 100644
--- a/image.png
+++ b/image.png
@@ -1,12 +1,12 @@
ExifTool Version Number : 7.74
-File Size : 70 kB
-File Modification Date/Time : 2009:04:17 10:12:35-07:00
+File Size : 94 kB
+File Modification Date/Time : 2009:04:21 07:02:43-07:00
File Type : PNG
MIME Type : image/png
-Image Width : 1058
-Image Height : 889
+Image Width : 1056
+Image Height : 827
Bit Depth : 8
Color Type : RGB with Alpha
~~~
你会发现文件的尺寸大小发生了改变。
## 关键字扩展
使用SVN或CVS的开发人员经常要求关键字扩展。在 Git 中,你无法在一个文件被提交后修改它,因为 Git 会先对该文件计算校验和。然而,你可以在签出时注入文本,在提交前删除它。 Git 属性提供了2种方式这么做。
首先,你能够把blob的SHA-1校验和自动注入文件的$Id$字段。如果在一个或多个文件上设置了此字段,当下次你签出分支的时候,Git 用blob的SHA-1值替换那个字段。注意,这不是提交对象的SHA校验和,而是blob本身的校验和:
~~~
$ echo '*.txt ident' >> .gitattributes
$ echo '$Id$' > test.txt
~~~
下次签出文件时,Git 入了blob的SHA值:
~~~
$ rm test.txt
$ git checkout -- test.txt
$ cat test.txt
$Id: 42812b7653c7b88933f8a9d6cad0ca16714b9bb3 $
~~~
然而,这样的显示结果没有多大的实际意义。这个SHA的值相当地随机,无法区分日期的前后,所以,如果你在CVS或Subversion中用过关键字替换,一定会包含一个日期值。
因此,你能写自己的过滤器,在提交文件到暂存区或签出文件时替换关键字。有2种过滤器,"clean"和"smudge"。在 .gitattributes文件中,你能对特定的路径设置一个过滤器,然后设置处理文件的脚本,这些脚本会在文件签出前("smudge",见图 7-2)和提交到暂存区前("clean",见图7-3)被调用。这些过滤器能够做各种有趣的事。

图7-2. 签出时,"smudge"过滤器被触发。
图7-3. 提交到暂存区时,"clean"过滤器被触发。
这里举一个简单的例子:在暂存前,用indent(缩进)程序过滤所有C源代码。在.gitattributes文件中设置"indent"过滤器过滤*.c文件:
`*.c filter=indent`
然后,通过以下配置,让 Git 知道"indent"过滤器在遇到"smudge"和"clean"时分别该做什么:
~~~
$ git config --global filter.indent.clean indent
$ git config --global filter.indent.smudge cat
~~~
于是,当你暂存*.c文件时,indent程序会被触发,在把它们签出之前,cat程序会被触发。但cat程序在这里没什么实际作用。这样的组合,使C源代码在暂存前被indent程序过滤,非常有效。
另一个例子是类似RCS的$Date$关键字扩展。为了演示,需要一个小脚本,接受文件名参数,得到项目的最新提交日期,最后把日期写入该文件。下面用Ruby脚本来实现:
~~~
! /usr/bin/env ruby
data = STDIN.read
last_date = `git log --pretty=format:"%ad" -1`
puts data.gsub('$Date$', '$Date: ' + last_date.to_s + '$')
~~~
该脚本从git log命令中得到最新提交日期,找到文件中的所有$Date$字符串,最后把该日期填充到$Date$字符串中 — 此脚本很简单,你可以选择你喜欢的编程语言来实现。把该脚本命名为expand_date,放到正确的路径中,之后需要在 Git 中设置一个过滤器(dater),让它在签出文件时调用expand_date,在暂存文件时用Perl清除之:
~~~
$ git config filter.dater.smudge expand_date
$ git config filter.dater.clean 'perl -pe "s/\\\$Date[^\\\$]*\\\$/\\\$Date\\\$/"'
~~~
这个Perl小程序会删除$Date$字符串里多余的字符,恢复$Date$原貌。到目前为止,你的过滤器已经设置完毕,可以开始测试了。打开一个文件,在文件中输入$Date$关键字,然后设置 Git 属性:
~~~
$ echo '# $Date$' > date_test.txt
$ echo 'date*.txt filter=dater' >> .gitattributes
~~~
如果暂存该文件,之后再签出,你会发现关键字被替换了:
~~~
$ git add date_test.txt .gitattributes
$ git commit -m "Testing date expansion in Git"
$ rm date_test.txt
$ git checkout date_test.txt
$ cat date_test.txt
# $Date: Tue Apr 21 07:26:52 2009 -0700$
~~~
虽说这项技术对自定义应用来说很有用,但还是要小心,因为.gitattributes文件会随着项目一起提交,而过滤器(例如:dater)不会,所以,过滤器不会在所有地方都生效。当你在设计这些过滤器时要注意,即使它们无法正常工作,也要让整个项目运作下去。
## 导出仓库
Git属性在导出项目归档时也能发挥作用。
### export-ignore
当产生一个归档时,可以设置 Git 不导出某些文件和目录。如果你不想在归档中包含一个子目录或文件,但想他们纳入项目的版本管理中,你能对应地设置export-ignore属性。
例如,在test/子目录中有一些测试文件,在项目的压缩包中包含他们是没有意义的。因此,可以增加下面这行到 Git 属性文件中:
### test/ export-ignore
现在,当运行 git archive 来创建项目的压缩包时,那个目录不会在归档中出现。
### export-subst
还能对归档做一些简单的关键字替换。在第2章中已经可以看到,可以以`--pretty=format`形式的简码在任何文件中放入`$Format:$` 字符串。例如,如果想在项目中包含一个叫作`LAST_COMMIT`的文件,当运行git archive时,最后提交日期自动地注入进该文件,可以这样设置:
~~~
$ echo 'Last commit date: $Format:%cd$' > LAST_COMMIT
$ echo "LAST_COMMIT export-subst" >> .gitattributes
$ git add LAST_COMMIT .gitattributes
$ git commit -am 'adding LAST_COMMIT file for archives'
~~~
运行git archive后,打开该文件,会发现其内容如下:
~~~
$ cat LAST_COMMIT
Last commit date: $Format:Tue Apr 21 08:38:48 2009 -0700$
~~~
## 合并策略
通过 Git 属性,还能对项目中的特定文件使用不同的合并策略。一个非常有用的选项就是,当一些特定文件发生冲突,Git 会尝试合并他们,而使用你这边的合并。
如果项目的一个分支有歧义或比较特别,但你想从该分支合并,而且需要忽略其中某些文件,这样的合并策略是有用的。例如,你有一个数据库设置文件database.xml,在2个分支中他们是不同的,你想合并一个分支到另一个,而不弄乱该数据库文件,可以设置属性如下:
### database.xml merge=ours
如果合并到另一个分支,database.xml文件不会有合并冲突,显示如下:
~~~
$ git merge topic
Auto-merging database.xml
Merge made by recursive.
~~~
这样,database.xml会保持原样。
7.1 配置 Git
最后更新于:2022-04-01 00:21:34
如第一章所言,用git config配置 Git,要做的第一件事就是设置名字和邮箱地址:
~~~
$ git config --global user.name "John Doe"
$ git config --global user.email johndoe@example.com
~~~
从现在开始,你会了解到一些类似以上但更为有趣的设置选项来自定义 Git。
先过一遍第一章中提到的 Git 配置细节。Git 使用一系列的配置文件来存储你定义的偏好,它首先会查找/etc/gitconfig文件,该文件含有 对系统上所有用户及他们所拥有的仓库都生效的配置值(译注:gitconfig是全局配置文件), 如果传递--system选项给git config命令, Git 会读写这个文件。
接下来 Git 会查找每个用户的~/.gitconfig文件,你能传递--global选项让 Git读写该文件。
最后 Git 会查找由用户定义的各个库中 Git 目录下的配置文件(.git/config),该文件中的值只对属主库有效。 以上阐述的三层配置从一般到特殊层层推进,如果定义的值有冲突,以后面层中定义的为准,例如:在.git/config和/etc/gitconfig的较量中, .git/config取得了胜利。虽然你也可以直接手动编辑这些配置文件,但是运行git config命令将会来得简单些。
## 客户端基本配置
Git 能够识别的配置项被分为了两大类:客户端和服务器端,其中大部分基于你个人工作偏好,属于客户端配置。尽管有数不尽的选项,但我只阐述 其中经常使用或者会对你的工作流产生巨大影响的选项,如果你想观察你当前的 Git 能识别的选项列表,请运行
`$ git config --help`
`git config`的手册页(译注:以man命令的显示方式)非常细致地罗列了所有可用的配置项。
### core.editor
Git默认会调用你的环境变量editor定义的值作为文本编辑器,如果没有定义的话,会调用Vi来创建和编辑提交以及标签信息, 你可以使用core.editor改变默认编辑器:
`$ git config --global core.editor emacs`
现在无论你的环境变量editor被定义成什么,Git 都会调用Emacs编辑信息。
### commit.template
如果把此项指定为你系统上的一个文件,当你提交的时候, Git 会默认使用该文件定义的内容。 例如:你创建了一个模板文件`$HOME/.gitmessage.txt`,它看起来像这样:
~~~
subject line
what happened
[ticket: X]
~~~
设置`commit.template,`当运行`git commit`时, Git 会在你的编辑器中显示以上的内容, 设置`commit.template`如下:
~~~
$ git config --global commit.template $HOME/.gitmessage.txt
$ git commit
~~~
然后当你提交时,在编辑器中显示的提交信息如下:
~~~
subject line
what happened
[ticket: X]
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: lib/test.rb
#
~
~
".git/COMMIT_EDITMSG" 14L, 297C
~~~
如果你有特定的策略要运用在提交信息上,在系统上创建一个模板文件,设置 Git 默认使用它,这样当提交时,你的策略每次都会被运用。
### core.pager
`core.pager`指定 Git 运行诸如log、diff等所使用的分页器,你能设置成用more或者任何你喜欢的分页器(默认用的是less), 当然你也可以什么都不用,设置空字符串:
`$ git config --global core.pager ''`
这样不管命令的输出量多少,都会在一页显示所有内容。
### user.signingkey
如果你要创建经签署的含附注的标签(正如第二章所述),那么把你的GPG签署密钥设置为配置项会更好,设置密钥ID如下:
`$ git config --global user.signingkey <gpg-key-id>`
现在你能够签署标签,从而不必每次运行git tag命令时定义密钥:
`$ git tag -s <tag-name>`
### core.excludesfile
正如第二章所述,你能在项目库的.gitignore文件里头用模式来定义那些无需纳入 Git 管理的文件,这样它们不会出现在未跟踪列表, 也不会在你运行git add后被暂存。然而,如果你想用项目库之外的文件来定义那些需被忽略的文件的话,用core.excludesfile 通知 Git 该文件所处的位置,文件内容和.gitignore类似。
### help.autocorrect
该配置项只在 Git 1.6.1及以上版本有效,假如你在Git 1.6中错打了一条命令,会显示:
~~~
$ git com
git: 'com' is not a git-command. See 'git --help'.
Did you mean this?
commit
~~~
如果你把help.autocorrect设置成1(译注:启动自动修正),那么在只有一个命令被模糊匹配到的情况下,Git 会自动运行该命令。
## Git中的着色
Git能够为输出到你终端的内容着色,以便你可以凭直观进行快速、简单地分析,有许多选项能供你使用以符合你的偏好。
### color.ui
Git会按照你需要自动为大部分的输出加上颜色,你能明确地规定哪些需要着色以及怎样着色,设置color.ui为true来打开所有的默认终端着色。
``$ git config --global color.ui true``
设置好以后,当输出到终端时,Git 会为之加上颜色。其他的参数还有false和`always,false`意味着不为输出着色,而always则表明在任何情况下都要着色,即使 Git 命令被重定向到文件或管道。Git 1.5.5版本引进了此项配置,如果你拥有的版本更老,你必须对颜色有关选项各自进行详细地设置。
你会很少用到`color.ui = always,`在大多数情况下,如果你想在被重定向的输出中插入颜色码,你能传递`--color`标志给 `Git `命令来迫使它这么做,color.ui = true应该是你的首选。
### color.*
想要具体到哪些命令输出需要被着色以及怎样着色或者 Git 的版本很老,你就要用到和具体命令有关的颜色配置选项,它们都被置为true、false或always:
~~~
color.branch
color.diff
color.interactive
color.status
~~~
除此之外,以上每个选项都有子选项,可以被用来覆盖其父设置,以达到为输出的各个部分着色的目的。例如,让diff输出的改变信息以粗体、蓝色前景和黑色背景的形式显示:
`$ git config --global color.diff.meta "blue black bold"`
你能设置的颜色值如:`normal、black、red、green、yellow、blue、magenta、cyan、white,`正如以上例子设置的粗体属性,想要设置字体属性的话,可以选择如:`bold、dim、ul、blink、reverse。`
如果你想配置子选项的话,可以参考git config帮助页。
## 外部的合并与比较工具
虽然 Git 自己实现了diff,而且到目前为止你一直在使用它,但你能够用一个外部的工具替代它,除此以外,你还能用一个图形化的工具来合并和解决冲突从而不必自己手动解决。有一个不错且免费的工具可以被用来做比较和合并工作,它就是P4Merge(译注:Perforce图形化合并工具),我会展示它的安装过程。
P4Merge可以在所有主流平台上运行,现在开始大胆尝试吧。对于向你展示的例子,在Mac和Linux系统上,我会使用路径名,在Windows上,/usr/local/bin应该被改为你环境中的可执行路径。
下载P4Merge:
`http://www.perforce.com/product/components/perforce-visual-merge-and-diff-tools`
首先把你要运行的命令放入外部包装脚本中,我会使用Mac系统上的路径来指定该脚本的位置,在其他系统上,它应该被放置在二进制文件p4merge所在的目录中。创建一个merge包装脚本,名字叫作extMerge,让它带参数调用p4merge二进制文件:
~~~
$ cat /usr/local/bin/extMerge
#!/bin/sh
/Applications/p4merge.app/Contents/MacOS/p4merge $*
~~~
diff包装脚本首先确定传递过来7个参数,随后把其中2个传递给merge包装脚本,默认情况下, Git 传递以下参数给diff:
`path old-file old-hex old-mode new-file new-hex new-mode`
由于你仅仅需要old-file和new-file参数,用diff包装脚本来传递它们吧。
~~~
$ cat /usr/local/bin/extDiff
#!/bin/sh
[ $# -eq 7 ] && /usr/local/bin/extMerge "$2" "$5"
~~~
确认这两个脚本是可执行的:
~~~
$ sudo chmod +x /usr/local/bin/extMerge
$ sudo chmod +x /usr/local/bin/extDiff
~~~
现在来配置使用你自定义的比较和合并工具吧。这需要许多自定义设置:merge.tool通知 Git 使用哪个合并工具;`mergetool.*.cmd`规定命令运行的方式;`mergetool.trustExitCode`会通知 Git 程序的退出是否指示合并操作成功;`diff.external`通知 Git 用什么命令做比较。因此,你能运行以下4条配置命令:
~~~
$ git config --global merge.tool extMerge
$ git config --global mergetool.extMerge.cmd \
'extMerge "$BASE" "$LOCAL" "$REMOTE" "$MERGED"'
$ git config --global mergetool.trustExitCode false
$ git config --global diff.external extDiff
~~~
或者直接编辑`~/.gitconfig`文件如下:
~~~
[merge]
tool = extMerge
[mergetool "extMerge"]
cmd = extMerge \"$BASE\" \"$LOCAL\" \"$REMOTE\" \"$MERGED\"
trustExitCode = false
[diff]
external = extDiff
~~~
设置完毕后,运行diff命令:
`$ git diff 32d1776b1^ 32d1776b1`
命令行居然没有发现diff命令的输出,其实,Git 调用了刚刚设置的P4Merge,它看起来像图7-1这样:
Figure 7-1. P4Merge.
当你设法合并两个分支,结果却有冲突时,运行`git mergetool,Git `会调用P4Merge让你通过图形界面来解决冲突。
设置包装脚本的好处是你能简单地改变diff和merge工具,例如把extDiff和extMerge改成KDiff3,要做的仅仅是编辑extMerge脚本文件:
~~~
$ cat /usr/local/bin/extMerge
#!/bin/sh
/Applications/kdiff3.app/Contents/MacOS/kdiff3 $*
~~~
现在 Git 会使用KDiff3来做比较、合并和解决冲突。
Git预先设置了许多其他的合并和解决冲突的工具,而你不必设置cmd。可以把合并工具设置为:kdiff3、opendiff、tkdiff、meld、xxdiff、emerge、vimdiff、gvimdiff。如果你不想用到KDiff3的所有功能,只是想用它来合并,那么kdiff3正符合你的要求,运行:
`$ git config --global merge.tool kdiff3`
如果运行了以上命令,没有设置extMerge和extDiff文件,Git 会用KDiff3做合并,让通常内设的比较工具来做比较。
## 格式化与空白
格式化与空白是许多开发人员在协作时,特别是在跨平台情况下,遇到的令人头疼的细小问题。由于编辑器的不同或者Windows程序员在跨平台项目中的文件行尾加入了回车换行符,一些细微的空格变化会不经意地进入大家合作的工作或提交的补丁中。不用怕,Git 的一些配置选项会帮助你解决这些问题。
### core.autocrlf
假如你正在Windows上写程序,又或者你正在和其他人合作,他们在Windows上编程,而你却在其他系统上,在这些情况下,你可能会遇到行尾结束符问题。这是因为Windows使用回车和换行两个字符来结束一行,而Mac和Linux只使用换行一个字符。虽然这是小问题,但它会极大地扰乱跨平台协作。
Git可以在你提交时自动地把行结束符CRLF转换成LF,而在签出代码时把LF转换成CRLF。用core.autocrlf来打开此项功能,如果是在Windows系统上,把它设置成true,这样当签出代码时,LF会被转换成CRLF:
`$ git config --global core.autocrlf true`
Linux或Mac系统使用LF作为行结束符,因此你不想 Git 在签出文件时进行自动的转换;当一个以CRLF为行结束符的文件不小心被引入时你肯定想进行修正,把core.autocrlf设置成input来告诉 Git 在提交时把CRLF转换成LF,签出时不转换:
`$ git config --global core.autocrlf input`
这样会在Windows系统上的签出文件中保留CRLF,会在Mac和Linux系统上,包括仓库中保留LF。
如果你是Windows程序员,且正在开发仅运行在Windows上的项目,可以设置false取消此功能,把回车符记录在库中:
`$ git config --global core.autocrlf false`
### core.whitespace
Git预先设置了一些选项来探测和修正空白问题,其4种主要选项中的2个默认被打开,另2个被关闭,你可以自由地打开或关闭它们。
默认被打开的2个选项是`trailing-space`和`space-before-tab,``trailing-space`会查找每行结尾的空格,``space-before-tab`会查找每行开头的制表符前的空格。
默认被关闭的2个选项是`indent-with-non-tab`和`cr-at-eol`,`indent-with-non-tab`会查找8个以上空格(非制表符)开头的行,`cr-at-eol让 Git` 知道行尾回车符是合法的。
设置core.whitespace,按照你的意图来打开或关闭选项,选项以逗号分割。通过逗号分割的链中去掉选项或在选项前加-来关闭,例如,如果你想要打开除了cr-at-eol之外的所有选项:
~~~
$ git config --global core.whitespace \
trailing-space,space-before-tab,indent-with-non-tab
~~~
当你运行git diff命令且为输出着色时,Git 探测到这些问题,因此你也许在提交前能修复它们,当你用git apply打补丁时同样也会从中受益。如果正准备运用的补丁有特别的空白问题,你可以让 Git 发警告:
`$ git apply --whitespace=warn <patch>`
或者让 Git 在打上补丁前自动修正此问题:
`$ git apply --whitespace=fix <patch>`
这些选项也能运用于衍合。如果提交了有空白问题的文件但还没推送到上游,你可以运行带有--whitespace=fix选项的rebase来让Git在重写补丁时自动修正它们。
## 服务器端配置
Git服务器端的配置选项并不多,但仍有一些饶有生趣的选项值得你一看。
### receive.fsckObjects
Git默认情况下不会在推送期间检查所有对象的一致性。虽然会确认每个对象的有效性以及是否仍然匹配SHA-1检验和,但 Git 不会在每次推送时都检查一致性。对于 Git 来说,库或推送的文件越大,这个操作代价就相对越高,每次推送会消耗更多时间,如果想在每次推送时 Git 都检查一致性,设置` receive.fsckObjects` 为true来强迫它这么做:
`$ git config --system receive.fsckObjects true`
现在 Git 会在每次推送生效前检查库的完整性,确保有问题的客户端没有引入破坏性的数据。
### receive.denyNonFastForwards
如果对已经被推送的提交历史做衍合,继而再推送,又或者以其它方式推送一个提交历史至远程分支,且该提交历史没在这个远程分支中,这样的推送会被拒绝。这通常是个很好的禁止策略,但有时你在做衍合并确定要更新远程分支,可以在push命令后加-f标志来强制更新。
要禁用这样的强制更新功能,可以设置~~~
receive.denyNonFastForwards:
~~~
`$ git config --system receive.denyNonFastForwards true`
稍后你会看到,用服务器端的接收钩子也能达到同样的目的。这个方法可以做更细致的控制,例如:禁用特定的用户做强制更新。
### receive.denyDeletes
规避`denyNonFastForwards`策略的方法之一就是用户删除分支,然后推回新的引用。在更新的 Git 版本中(从1.6.1版本开始),把receive.denyDeletes设置为true:
`$ git config --system receive.denyDeletes true`
这样会在推送过程中阻止删除分支和标签 — 没有用户能够这么做。要删除远程分支,必须从服务器手动删除引用文件。通过用户访问控制列表也能这么做,在本章结尾将会介绍这些有趣的方式。
7. 自定义Git
最后更新于:2022-04-01 00:21:32
到目前为止,我阐述了 Git 基本的运作机制和使用方式,介绍了 Git 提供的许多工具来帮助你简单且有效地使用它。 在本章,我将会介绍 Git 的一些重要的配置方法和钩子机制以满足自定义的要求。通过这些工具,它会和你和公司或团队配合得天衣无缝。
6.8 总结
最后更新于:2022-04-01 00:21:30
你已经看到了很多高级的工具,允许你更加精确地操控你的提交和暂存区。当你碰到问题时,你应该可以很容易找出是哪个分支什么时候由谁引入了它们。如果你想在项目中使用子项目,你也已经学会了一些方法来满足这些需求。到此,你应该能够完成日常里你需要用命令行在 Git 下做的大部分事情,并且感到比较顺手。