简述互联网背景下的金融和支付
最后更新于:2022-04-01 11:03:04
互联网金融,本质上是金融,互联网只是手段。金融是什么?资金融通,存款、贷款、证券,都是金融。
### 互联网金融为什么能火?
貌似从2013开始开火的,称之为互联网金融元年。民间借贷,借助于互联网这个工具,开始服务更多的人,满足各种人的借出接入需求。
对于lender来说,比银行的利息高,总比股市的风险小,所以,愿意借钱给资质高、信用好的互联网金融平台。
对于debtor来说,从银行借不到钱,而互联网金融的利息也比地下高利贷低,所以,愿意从任何利息较低的互联网金融平台借钱。
### 互联网金融的风险在哪里?
### 借方借钱不还
谁都怕这个不是。。遇到借钱不还的,特别是企业客户(也就是通常说的B端客户),一借几千万,到时还不出,引起资金链断裂,不能对lender按时履约,只能卷钱跑路了。
所以,和任何金融一样,互联网金融的核心也是风控,风险控制。
对B端的风控能力很难,手段也比较传统。
对C端的风控手段就比较多样,不会过分依赖传统手段(比如银行流水、工资记录、收入证明)等,可以从更互联网的方式进行信审,勾勒出一个人的信用情况。
有哪些手段呢?
曾经听过一个公司的公开讲座,大致罗列了如下方面:
基本情况:比如年龄、籍贯、职业、健康、社保情况
信用历史:过往信用账户还款记录及信用账户历史
行为偏好:在购物、缴费、转账、理财等活动中的偏好及稳定性
人脉关系:好友的身份特征以及跟好友互动程度
通过这些情况,勾勒出一个人的信用评分,决定是否给这个人贷款。
淘宝的“芝麻信用”评分,国外的FICO评分,都是干这个的。
同时,C端个人是多样的,可以有效的分散风险,所以很多互联网金融只作C端,不做B端。
### 贷方恶意挤兑
这个尚好,不像银行,有信用杠杆,有100块钱,利用信用杠杆,可以借出N个100块钱。
互联网金融是没有杠杆的,赚的只是借入借出的差价,很像电子商务,只是商品是钱。
只要利用合同控制贷方的行为,则基本没什么问题,比如:银行的T+1到账期限,不能让大额随借立提。
### 支撑互联网金融的系统有哪些?
**撮合**
把lender和debtor,直接撮合到一起。N <-----> N的形式。
**贷前管理**
lender及其借出款项的管理。
**贷后管理**
debtor及其借入款项、按期划款、催缴的管理。
**信用评估**
风险控制的手段。依靠信息收集和数据模型进行分析计算。
**支付中心**
所有款项的真实流转,记账,对账,都要走支付中心。
**资金托管**
资金托管,寓意是:“不能随便挪作他用,有监管了”,可以说是一种提高自身身价的手段。
**清算结算**
央行只管账户(比如,开个账户,日终时同步到央行即可),不通银行之间的清算结算,当前是被银联垄断的。2015-06-01,这个“银行卡清算”时长被放开,只要符合一定条件,具备一套符合央行标准的清结算系统,就可以进入这个市场,比如,支付宝就具备这个条件。
###支付中心
所有款项的真实流转,记账,对账,都要走支付中心。支付中心,最核心的工作,是一个对交易的“联机处理”的过程。
商户端通过其App发起交易请求开始,进入支付中心的OLTP环节,经过一系列的处理流程,比如:交易预处理、交易检查、风险控制、交易路由(走那个通道的规则)、计入最终的支付通道,支付完成后,记如账务系统。
在这个流转过程中,必须做到不出错,出一次错误,后果都是很严重的。特别是批量,可能就涉及个几百万的款项,难以追回。
### 最大的两个风险点
批量代付,付重:向客人追讨,是很麻烦的,甚至追不回来;这种情况是最危险的,客人本来就是取钱,说明需要钱,我们重复给他,他自然想千方百计推脱,先用着再说了。
批量收款,没有成功,通知客人成功:客人可能会赖着不还;这种情况还好一些,客人本来就是还钱,通过客服的手段,比较能说服客人重新还款。
### 针对风险点的风控手段
除了完整流程、状态控制之外,额外考虑两种最终的风控方法:
1、通过和通道的接口约定,能保证对于同一笔交易单号,可以验重,失败的可以多笔,成功只能有一笔,这是最完美的,能做到100%防重的一道关卡。
2、通道之后的风控手段:实时交易监控,这是一种事后的风控手段。
商业智能系统–公司运营、系统运行等的统计和分析
最后更新于:2022-04-01 11:03:02
### 开篇
商业智能系统,Business Intelligence,BI,数据中心,叫法各异,职责相同,以下统一称为BI系统。
BI负载对于公司的运营效果、系统的运行情况及改版效果,基于数据层面,进行比较客观的统计和分析,为高层管理人员对于公司运营、为产品部门对于网站的设计及改版或算法调整前后效果,提供参考及考量。
BI系统的职责是统计分析相关的,对数据的实时性要求不高,允许一天以上的数据延迟;对于和具体的业务密切相关的、或者实时性要求高的统计分析,则不应该放到BI系统,而是应该放在各自的业务支持系统中去。
BI系统是一个数据系统,用来帮助企业更好地利用数据提高决策质量的技术集合,是从大量的数据中钻取信息与知识的过程。简单讲就是业务、数据、数据价值应用的过程。基础的BI是统计分析,BI的进阶是决策支持,从“之前发生了什么,为什么会发生”,到“现在发生了什么,将来会发生什么”。
### 名词解释
BI:商业智能(Business Intelligence)
ETL: 提取、转换和加载(Extraction-Transformation-Loading)
ODS:操作型数据存储( Operational Data Storage )
DW:数据仓库(Data Warehouse)
DM: 数据集市 (Data Mar) 、 数据挖掘(Data Mining)
OLAP:联机分析处理(Online Analysis Process)
### 系统解决办法
(1)根据统计的需要,进行数据抽取,从业务系统数据库中,抽取到BI数据库
(a)、抽取的过程中,可能是每天定时、每小时定时、触发等方式,具体是要根据具体的场景
(b)、抽取的逻辑,要能保证重复抽取,比如某天数据出现问题时。。。
(c)、抽取的过程,可能涉及一些计算逻辑,比如对于毛利率的计算,需要商品的成本价,对于成本价的获取,可能就有一些逻辑
(d)、数据抽取的办法,可以引入能简化开发工作量的第三方框架,比如dataX
(2)数据收集
(a)、数据置标:根据业务的需要,一些数据需要置标,通过日志进行分析,或者把标记记录到数据库中,比如下单的:source、ref、pos
(b)、网站流量:插码或者分析日志,[http://blog.csdn.net/puma_dong/article/details/38943251#t12](http://blog.csdn.net/puma_dong/article/details/38943251#t12)
(c)、日志分析:收集用户访问路径,停留时间,退出页等
(3)结果呈现
(a)、使用好的JS框架图形化呈现BI报表,比如JQuery插件,但是不推荐ExtJS框架,太过于封装及学习成本的原因
(b)、短信提醒,重要结果的提醒
(4)公式定义
(a)BI的产品定义,对要展示数据内容的明确定义,比如毛利率公式、转化率等。
### 系统功能设置
呈现:
(1)实时数据报表
(2)订单售后相关报表
(3)商品库存相关报表
(4)渠道广告相关报表
(5)网站流量相关报表
数据:
(1)流量统计
(2)数据抽取中间件
### 待续
没有骨架就没有血肉,所谓皮之不存,毛将焉附,想到一点就写下来,后续补充。。。
订单管理系统–多种维度、多种渠道订单管理,自动化处理,及退换货处理
最后更新于:2022-04-01 11:02:59
### 界面
### 项目说明
订单中心,为网站下单提供接口,并基于多种维度提供订单查询,报表、导出功能。
关于订单的售后,放在“客服中心”系统中。
订单中心,负责处理订单流程,及与订单流程紧密相关的各种行为的支持。
所有市场、销售行为,最终目标都是带来订单。
市场行为中的各大网站广告,网站联盟,线下发卡行为 的效果,以及网站中点击各个位置下得单,都会记录在订单表的来源中,并在BI之类系统中进行统计,进行效果分析。
订单的下单方式,记录在订单类型字段中,用来标记是通过网站、手机等渠道下单的。
当前的订单来源,绝大多数都是来源于互联网,这也是互联网极大迅速发展的结果;电子商务之初不是这样的,开始的时候呼叫中心是最大的订单来源。
### 项目功能
计划实现的订单中心功能单元如下:
order-api-server:订单接口,对接其他系统
order-schedule:订单自动化处理任务,比如:转有效、转无效等
order-server:订单管理界面
订单中心相关IT功能的特点是:准确、实时性要求高,涉及的实时款项处理较多,涉及的业务逻辑较多,相对技术含量更少,这是个业务性更强的系统,当然,相对来说,后台相关的系统都是业务性强于技术性。
### 业务逻辑
分单:一般是按照库房+发货点/供应商进行分单,如果不分单,就要有库房之间的调拨,如何在客户体验和配送成本之间达到最佳平衡,是分单需要重点考虑的问题。
促销:各种各样的促销的伴随于订单流转中,下单就分摊到产品折扣中,利于后续的所有流程,因为促销是成本,会有各种核算,SVIP/VIP的折扣也归到这里来维护。
礼品卡/优惠劵:其实也是一种促销方式,其实际业务使用形式,各公司界定不相同。
抹零:方便配送上门收款,同时应尽量避免公司损失。
中间件:订单的自动化处理流程,例如各种根据库存的自动化处理,各种拦截及反拦截,流转过程中对用户友好而亲切的提醒。
中间件之对于于提高效率、减少成本非常关键,所谓“技术驱动”的公司,基本也反映在系统中各处中间件的强大程度吧。
### mybatis-generator
ORM框架采用MyBatis,为了提高开发效率,先根据数据库表单结构自动生成Model和MyBatis相关类,生成命令如下:
java -jar mybatis-generator-core-1.3.1.jar -configfile config_order.xml -overwrite
生成时需要把mybatis-generator-core-1.3.1.jar、mysql-connector-java-5.1.24-bin.jar、config_order.xml放到一个目录下,生成的相关类和XML会放置到CreateResult文件夹下面。
jar下载地址:http://pan.baidu.com/s/1qW98L0C
### 代码说明
前置项目:http://blog.csdn.net/puma_dong/article/details/12391479
最新源码:git clone git@github.com:pumadong/cl-purchase.git
### 问题
高并发场景如何占用库存,比如20台机器负载,在秒杀活动中,几秒可能会秒出上万商品。
推荐系统–揭开推荐的神秘面纱
最后更新于:2022-04-01 11:02:57
### 开篇
先推荐几篇关于推荐的文章,个人感觉对于入门很有实际意义,是IBM的工程师写的,如下:
[探索推荐引擎内部的秘密,第 1 部分: 推荐引擎初探](http://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy1/index.html)
[探索推荐引擎内部的秘密,第 2 部分: 深入推荐引擎相关算法 - 协同过滤](http://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/index.html)
[探索推荐引擎内部的秘密,第 3 部分: 深入推荐引擎相关算法 - 聚类](http://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy3/index.html)
**推荐两本书,如下:**
项亮:《推荐系统实践》
蒋凡:《推荐系统》
### 推荐系统是什么
推荐,就是把你可能喜欢的商品,推到你的面前。构建一个推荐系统,就是构建如何把商品推到你面前的过程。
经常有人说,推荐就是算法,从某种角度来说,这未尝不对。但在接触推荐系统之前,我们还是先不研究算法,一说到算法,可能就以为很高深了,也很唬人,立马产生一种膜拜之感,也就变得神秘起来了。
对于我们没有多少推荐理论支撑的工程师,进入推荐,还是先求入门。我们不缺实践,先通过工作中的实践领会某种推荐方案,再求通过阅读书籍、学习算法加深领会和理解,进而通过不同的推荐方案,以及其效果的客观评估,提高水平和境界。
第一步,当我们真正完完整整的接触到推荐系统,达到一个入门级水平,可以独立构建一个千万级PV网站的推荐系统之后,可能基本的观点会是:
(1)推荐是一个整体的计算过程,在编码中,关于算法的部分所占的工作量可能1%都不到;
(2)每一种推荐方案的选择,都是一种整体的计算过程。
构建一个千万PV级别的推荐系统相对容易,一天的日志不过几百M,计算过程中的数据,单台机器的内存可以存下,当PV达到几亿几十亿时,就需要进行稍微复杂一点的分布式计算了;
推荐的计算方法很多,如何选择,效果难以预料,只有通过横向和纵向多做效果分析,才有意义。
随着理解的加深,境界的提升,知识的更多了解,认知也都会处于不断的调整中。。。
### 推荐的计算过程
### 计算的数据来源
Web访问日志、购买、收藏,这些实际是用户的行为数据;
用户,这是分析的基础数据;
商品,这是分析的基础数据;
### 计划日志的存储格式
如何标记同一个未登陆用户;如何找出未登陆用户和登陆用户是用一个人。
这是很重要的,这是以后日志分析计算的基础。
**示例如下:**
27.189.237.91 - - [27/Jun/2014:15:00:01 +0800] "GET 某个URL HTTP/1.1" 200 75 "前一个URL" "95907011.390482691.1402709325.1403851977.1403852394.7" "95907011.8a8a8aeb385a8c6b013860df24501310" [- - -] [image/webp,*/*;q=0.8] "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36"
以上Web日志URL,95907011.390482691.1402709325.1403851977.1403852394.7 和 95907011.8a8a8aeb385a8c6b013860df24501310 ,使用google analysis的js代码记录的,分别用来标记未登录用户的ID和登录用户的ID。
对于google analysis的js代码的用途,这里衍生一下,实际上,完全可以基于它建立第三方的流量分析系统,流程如下:
(1)需要统计流量的网站进行查码,用来记录cookie等,并触发到服务器端的请求(可以是去请求一个不存在的图片)
(2)当服务器端接收到请求后,会把Head里面的网站访问流量相关信息进行记录,服务器端的程序是一个简单的Servlet即可。
### 计算过程第一步
根据用户行为数据,分析出用户和商品的关系;用户<-->浏览、用户<-->购买、用户<-->收藏等。
### 计算过程的第二步
根据第一步计算的数据,分析中常用的推荐结果,比如根据浏览数据,计算出“看了又看”,根据购买数据,计算出“买了又买”等。
### 计算过程的算法(或者叫规则)
算法,是广义的,数学公式;规则,是小众的,公司自己定义的,复杂自己场景的业务规则,在计算过程的第二步,计算最终的推荐结果时,大部分使用的都是自行定义的业务规则。
以推荐“看了又看”为例,根据一个商品,如何推荐出其他商品呢:
可以就根据这个推荐类型的基本含义,一个商品 ---> 看了这个商品的很多人,又看了 ---> 很多的商品,这就是推荐结果了,但是这个推荐结果有非常非常多,如何推荐呢?
可以推荐购买次数最终的,推荐最新的,推荐两个商品的View人群最相似的......
### 推荐结果的接口提供
这就没有什么了,都是通用的。
### 推荐系统的核心
基于业务的,推荐效果的评价体系;
基于技术的,大数据量时的分布式计算
### 代码说明
**前置项目:**这个相关项目就比较多了,网站、商品、订单,都有相关性。
**最新源码:**git clone git@github.com:pumadong/cl-recommend.git 。
### 推荐的发展
大数据量计算、数据流实时计算、用户行为精准分析、用户聚簇细化、个性化推荐等。
可能更高级别的搜索推荐,还是需要搜索推荐理论的支撑,不同于实现层面的东西,这个可能存在境界层次方面的不同,认知了才知道。。。
### 日志分析扩展和流量统计
对于日志的分析,可以统计网站的流量,但是要过滤掉对JS/CSS/IMG等静态资源的URL,只保留真实有效的访问。
在一个页面的访问过程中,浏览器会向服务器发起很多个请求,把HTML/CSS/IMG/JS等都下载下来,解析成美观的页面,展现给访问者,在这个过程中其实会在NGINX等Web服务器中,记录很多行日志。
关于流量统计,也有很多采用插码的方式,插码这种方式,业界的代码标准是Google的GA,插码的好处是可以统计记录更多信息(超出日志),可以自定义很多事件,收集更多信息。
当前google由于特殊原因国内不能直接访问,但是对于ga代码的统计是没有问题的,访问地址是:http://www.google-analytics.com/ga.js。
比较日志分析和插码两种方式,日志分析是有访问就记录日志,此时页面可能没展示完成访问者就关闭了;插码这种方式,只有执行到插入的JS代码的时候,才会记录流星;也就是前一种强调来过,后一种强调有效访问。
日志分析这种流量分析方式,需要过滤掉爬虫的IP地址;而插码就不需要,因为爬虫只会爬页面内容,并不会执行JS,JS的执行实际是浏览器的JS引擎帮我们做的。
另外,对于第三方的流量分析,则必须是插码,不可能使用日志分析。
官方网址:[https://support.google.com/analytics](https://support.google.com/analytics) 。
搜索系统–基于Solr4.9.0的实现
最后更新于:2022-04-01 11:02:55
### 为什么需要搜索系统
随着商品数量的增长、以及复杂检索的需求,直接从数据库中检索信息,已经不能满足展示机搜索的需求。 比如:
[http://search.jd.com/Search?keyword=%E8%8B%B9%E6%9E%9C&enc=utf-8](http://search.jd.com/Search?keyword=%E8%8B%B9%E6%9E%9C&enc=utf-8)
[http://www.yougou.com/sr/searchKey.sc?keyword=%E5%A5%B3%E9%9E%8B%E5%A4%A9%E7%BE%8E%E6%84%8F](http://www.yougou.com/sr/searchKey.sc?keyword=%E5%A5%B3%E9%9E%8B%E5%A4%A9%E7%BE%8E%E6%84%8F)
这个时候就需要引入搜索系统。
搜索系统当前最常用的框架有:Solr、ElasticSearch,他们都是基于Lucene构建的。
本文演示的搜索系统,使用的框架是:Solr4.9.0,关于Solr框架的使用,可以参阅站点:
[http://lucene.apache.org/solr/](http://lucene.apache.org/solr/)
[http://blog.csdn.net/puma_dong/article/details/38880699](http://blog.csdn.net/puma_dong/article/details/38880699)
补充个概念,倒排索引,我们理解搜索系统的索引是怎么建立的,但是,为什么叫倒排索引呢?[http://www.zhihu.com/question/23202010/answer/23901671](http://www.zhihu.com/question/23202010/answer/23901671)
### 系统说明
### 基本信息
演示对商品信息的全量索引建立、主从配置以及搜索的Dubbo接口提供;
对Solr做了入门型的说明,基本满足基于Solr的搜索的日常应用,对于更多Solr的参数设置,深入研究需要在实践中不断总结进步。
**关于索引,基本内容大致包含如下:**
商品(编码,款号、名称、价格、尺码编号、尺码名称、颜色、价格、折扣、图片链接、销量);
分类(名称、别名、编码、拼音名称);
品牌(编码、中英文名称、别名、拼音名称、首字母拼音名称);
商品的属性项目(属性值);
以及一些用来排序的信息:销量、价格、折扣等;
对于品牌分类等,需要同时记录英文名称;
索引还需要一些管理控制功能,比如脏词屏蔽、扩展词库等;
为了提高建立索引的效率,可能还需要对一些中间结果进行计算,比如:商品的2周销售数量;
注:关于分类的别名、品牌的别名之类,不建议在搜索系统中单独为,建议提需求给商品管理系统。
本项目仅仅是演示的雏形,流程是可用的,单没有完整的信息完整的索引创建、索引接口、及管理控制功能,这个留待以后是否有足够的业余时间。
索引建立的运行方式如下:crontab */10 * * * * /usr/local/cl/create_index.sh &。
### 技术框架
在索引建立项目中,没有使用任何框架,使用最基础的JDK编码,定时任务方式采用crontab,任务流程控制采用linux shell命令。
索引查询接口项目中,依旧是采用dubbo提供接口。
客户端使用Solrj。
中文分词使用IK Analyzer 2012FF_hfl。
### 代码说明
**前置项目:**[http://blog.csdn.net/puma_dong/article/details/9854899](http://blog.csdn.net/puma_dong/article/details/9854899)
**最新源码:**git clone git@github.com:pumadong/cl-search.git 。
图片管理系统–CDN源站图片管理
最后更新于:2022-04-01 11:02:53
### 图片管理系统界面
### 图片浏览
### 图片上传
### 系统说明
这是Java开发的跨域的图片上传、图片删除解决办法;
提供针对商品的图片管理功能:浏览、切图、删除、上传;
这个系统仅仅进行图片在服务器硬盘的相关操作,除了认证、授权之外,和其他系统完全独立;
对于图片上传、图片删除是没有权限控制的;对于5个图片管理功能演示,使用Jasig CAS进行单点登录;
这个系统的目的是部署在作为CDN源站得图片服务器上,管理图片,主要是作为商品系统的图片管理的服务器端。
### 代码说明
**前置项目:**http://blog.csdn.net/puma_dong/article/details/12391479
**最新源码:**git clone git@github.com:pumadong/cl-picture.git 。
权限管理系统–Bootstrap框架/JasigCAS单点登录/Dubbo接口授权
最后更新于:2022-04-01 11:02:50
### 权限管理系统界面
### 部门管理
### 角色管理

### 开发语言及技术框架
**后台:**Java、MySQL、Dubbo、Spring、SpringMVC、MyBatis、Redis、JasigCAS
**前台:**Bootstrap、Jquery(jsTree、jquery.validate、DataTables、Bootstrap Modals、jquery-multi-select )
### 系统特点
1、基于角色的管理,账户不进行单独的权限设置,只通过赋予账户多个角色进行授权。
2、一个权限实际就是一个菜单,通过账户具有的权限,控制对于账户显示哪些菜单。
3、认证和授权分为两个部分:认证是使用JasigCAS实现单点登录,授权是通过Dubbo接口提供。
将来会继续开发对于功能点的权限管理,以及登录日志模块。
关于系统的更多说明,请参阅这里:[https://github.com/pumadong/cl-privilege](https://github.com/pumadong/cl-privilege)
### 代码说明
这已经是第三个版本,放弃了Thrift这个通讯框架,改用Dubbo;对于界面,采用MetroNic这套基于BootStrap和JQuery框架的模板。
**最新源码:**git clone git@github.com:pumadong/cl-privilege.git 。
### 关于Thrift和Dubbo的比较
1、性能方面:Socket>Thrift>Dubbo>Hessian>WebService
2、易用性方面:Dubbo是一个完整的服务治理框架,本身通过Zookeeper提供负载,通过Netty进行基础通讯,易用、管理配置都方便
3、开发效率:Dubbo=WebService=Hessian > Thrift > Socket
Thrift:[http://thrift.apache.org/](http://thrift.apache.org/)
DUBBO:[http://alibaba.github.io/dubbo-doc-static/Home-zh.htm](http://alibaba.github.io/dubbo-doc-static/Home-zh.htm)[](http://code.alibabatech.com/wiki/display/dubbo/Home-zh)
商品管理系统–分类、品牌、属性、商品、价格、图片管理
最后更新于:2022-04-01 11:02:48
# 商品管理系统界面
### 分类管理
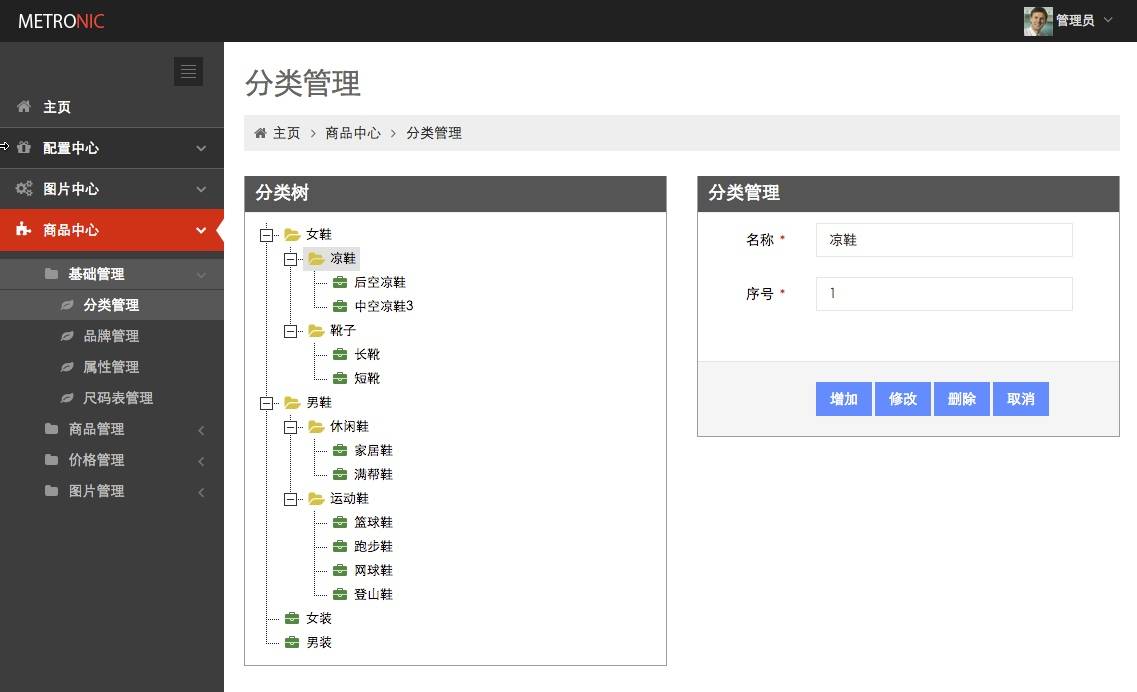
# 系统说明
本系统当前没有实现所有的功能,而是描述了实现思路,设计了主要功能和流程,设计了系统框架,并简要演示了几个功能;可以方便在这个系统基础上进行开发完善即可。后续的功能也会逐渐开发完善。
本系统的开发过程中,为了提高工作效率,使用MyBatisGenerator自动生成最初始的Model、Mapper类及Mapper.Xml,完成最基本的增、删、改、查功能,然后再此基础上进行加工 。
# 业务知识
### 概述
商品中心,是一个核心系统,会和其他系统都有交集,比如:网站、订单、采购、仓储、配送...,所以独立出来,做一个单独的商品中心,有人负责,还是很有必要的。
商品状态:1.新建(待进货)、2.待售(入库后)、3.上架(在售)、4.下架(停售),将来有审核的话用-状态
### 术语
款号:style,一个系列,一般都是供应商或者生产厂家进行编码并提供;
款色编码:供应商或生产厂家对某个系列下某个颜色商品的编码;到色的,级别对应的是系统的商品编码;
商品编码:系统按照一定的规则,对商品进行的规律性更强的编码,这个系统使用8-10位数字;
货品编码:我们把到尺码的商品,定义为货品,这个系统对货品的编码采取商品编码+3位数字的方式;
### 分类和属性绑定
分类和属性绑定,必须先绑定属性项,再绑定属性值,绑定属性项时,必须设置属性的规则(比如是否多远,是否必填,是否网站显示),即这些规则限制都是跟着分类走的;
规则限制以后的行为,不限制既存的数据:比如把一个属性项修改成必填,不代表要把过去的数据都设成必填。
### 数据批量导入
数据的批量导入,比如商品货品批量进入,批量调价等,本系统不使用Excel,建议使用页面上的表格,并间隔时间自动保存,存储格式为JSON,可以多次编辑进行导入。
### 商品标题是否可变
系统本身不做任何限制,但原则上业务会少改动;
### 商品价格
商品表里面会有成本价、卖价、市场价,并随着各种因素调整,支持着商品的销售;
订单里面记录成交价;
采购单里面记录成本价;
一个商品可以对应很多的订单,也可以对应很多采购单。
### 商品的属性项、属性值
对于商品,进行属性项、属性值的维护,目的是可以基于此建立搜索系统,消费者可以基于这些属性项、属性值检索,更准确找到和自己需求匹配的商品
# 代码说明
**前置项目:**http://blog.csdn.net/puma_dong/article/details/12391479
**最新源码:**git clone git@github.com:pumadong/cl-commodity.git
电子商务IT系统-系统框架、机器框架及人员构成
最后更新于:2022-04-01 11:02:46
### 框架选择
### Windows还是Linux
Windows生态相对简单易用,对开发、运维要求较低,可以满足大中型应用;费用不菲,1台机器的授权费用,Windows Server是万级,SqlServer是10万级;
Linux生态框架甚多,学习成本较高,开发、运维要求较高,可以满足大中型、及超大型应用;完全开源免费。
技术上讲一点,比如应用容器:
在Windows下,基本就是使用IIS了,Apache、Nginx 之类基本不适用;IIS 主要使用UI配置;
在Linux下,则一般用 Nginx 作为Web容器,及反向代理;用Tomcat/Jetty之类作为Java容器;使用 web.xml 作为主要的配置文件。
用了 Linux+java 生态,可以逐渐掌握技术的细节,而Windows生态,技术上的进步要慢一些、困难一些。
### CS还是BS
CS有其固有的优势,比如:开发效率会高:做个界面,弄个事件啥的都很快,可以有本地缓存,可以有客户端的多线程处理;
缺点是软件的升级维护相对麻烦;
由于Windows在桌面上的绝对垄断地位,以及Visual Studio开发桌面程序的效率,当前,CS开发基本都是使用.Net框架。
考虑到软件的升级维护,及长远的可扩展性,BS是更好的选择。
场景:
1、基于WindowsCE系列的PDA设备(仓储的手持设备),仓储的打包台部分(性能效率要求极高时);
2、频繁Excel处理的小工具,其实这个可以考虑用Web上的表格输入来实现;
3、其他场景,建议全部是BS。
### 开发语言
这个实在讨论的太多了。
.net开发人员众多,微软紧密集成,服务器基本就是windows了,数据库也基本是sqlserver了;
java开发人员也是众多,框架众多,对架构、运维要求都更高,否则易出问题,服务器基本是linux,数据库基本是oracle,mysql;
ruby on rails,据说开发web快,也有新锐者使用了;
根据公司实际情况选择吧;中小可以.Net,大中小都可以java。
这个选择还有个成本考虑,微软的服务器产品全部都是要钱的:Windows Server上万,SqlServer 上10万;linux系列的产品都是开源免费的,但是人力资本相对就高些。
### SOA框架及系统拆分
SOA框架实际是一种开发方式,让人专注于自己最熟悉的一块,不同系统之间发生的业务交叉,全部采用接口的方式提供,其最大的好处:
是非常有利于系统的性能提升,可以更方便的分库;
专注也能更利于优化和提升;
缺点是我们用不了以前那种查询所有的业务表,用一个大事务来保证一起执行的开发方式了,我们必须对系统的异常情况考虑更多,对关键业务的失败要做回滚处理,编码更多了;
对于大型系统来说,SOA是必然的选择;
对于小系统来说,为了快速开发,开始可能都是单库、查表;随着业务的发展,数据的增大,不可避免的要重构,要分库。
一般公司的框架发展过程(Linux/Java/MySql):
1、系统初创阶段,一般不给我们好好系统设计的时间,很多着急上线,经常会选择最快的方式而忽略系统架构,如果不能选择,这个阶段必须考虑以下部分:MVC、ORM(不要用Hibernate);这个阶段一定不要把需求做庞大,先做主干流程,先上线,后丰满;先出成果起到激励作用,否则迁延日久,士气怠矣。
2、快速发展阶段,拆系统,大约10块,指的是系统个数,不是行政组:
[权限管理系统](http://blog.csdn.net/puma_dong/article/details/12391479)
网站:网站(CMS)
销售中心:[销(订单、促销、退换货、分销)](http://blog.csdn.net/puma_dong/article/details/39272243)
采购中心:[采购管理系统](http://blog.csdn.net/puma_dong/article/details/39013635)
仓储中心:仓储管理系统
用户中心:[会员系统](http://blog.csdn.net/puma_dong/article/details/39505955)、[客服系统](http://blog.csdn.net/puma_dong/article/details/39506157)
商品中心:[商品管理系统](http://blog.csdn.net/puma_dong/article/details/9854899)、[图片管理系统](http://blog.csdn.net/puma_dong/article/details/16835677)
财务中心:结算、收付
搜索推荐:[搜索系统](http://blog.csdn.net/puma_dong/article/details/38942777)、[推荐系统](http://blog.csdn.net/puma_dong/article/details/38943251)
商业智能系统:数据统计分析
3、快速发展阶段,拆服务、加缓存:
各个系统之间数据交换尽量服务化,减少直接的查询本业务之外的数据。引入Dubbo、RabbitMQ、Redis等框架
4、快速发展阶段,拆数据库:
各业务系统数据库完全独立,除了MySql的主从同步之外,引入Otter框架用于数据复制。
5、经过以上的过程,达到完全的SOA化,但是这个过程的演进,实际是多花了非常非常多的时间,2倍?3倍?如果条件允许,尽量还是直接基于SOA框架进行开发,只要框架做好了,仅仅是编码工作而已,最初的开发工作量实际上和那种”原始的、所有系统、数据库都在一起的,唯速度考虑的编程方式“,不会增加很多,但是后期的好处及长远考虑,是值得的。因为,从长远来看,SOA是必须的。
有两篇文章很好,如下:
[http://javatar.iteye.com/blog/1329022](http://javatar.iteye.com/blog/1329022)
[http://javatar.iteye.com/blog/1345073](http://javatar.iteye.com/blog/1345073)
### 是否要读写分离
读写分离对于减小数据库压力是很有帮助的,原则上select只要能访问从库的就一定不要访问主库,因为从库是可以无限扩展的,而主库不容易扩展。
但是主从访问的方式是个选择性问题:
有的给软件开发者一定的自由决定,是连接主库还是从库,这导致了很多不必要的主库连接;
有的公司采取一刀切的方式,统一采用ameba,corba之类的系统连接数据库,只要是select,全部去了从库;这种方式,在一些写完马上查的地方,很容易发生“主从问题”,对代码要求严谨一些;
所以,这是个选择性问题,根据业务场景进行具体的选择,很多场景中:使用主库+缓存的模式,可以很好的解决问题。
### 千万PV需要的服务器规模估计
### 业务系统
| 用途 | 系统 | 物理机数量 | 虚拟机数量 | 备注 |
|-----|-----|-----|-----|-----|
| 网站中心 | 网站主站 | 10 | 0 | |
| | 网站后台 | 0 | 2 | |
| 订单中心 | 网站购物流程 | 0 | 0 | 包含在网站主站之内 |
| | 订单接口 | 3 | 0 | |
| 用户中心 | 网站会员中心 | 0 | 0 | 包含在网站主站之内 |
| | 用户接口 | 2 | 0 | |
| 商品中心 | 商品管理系统 | 0 | 2 | |
| | 图片管理系统及CDN源站 | 1 | 0 | |
| 采购中心 | 采购管理系统 | 0 | 2 | |
| | 采购接口 | 0 | 2 | |
| 仓储中心 | 仓储系统 | 0 | 2 | |
| | 配送系统 | 0 | 2 | |
| | 仓储配送接口 | 3 | 0 | 库存可以通过结构调整记录到商品表中,这里指的是为内部系统提供的接口 |
| 结算中心 | 结算管理系统 | 0 | 2 | |
| 客服中心 | 客服管理系统 | 0 | 2 | |
| 分销中心 | 网盟管理系统 | 0 | 0 | 前期暂缓 |
| 商家中心 | 招商管理系统 | 0 | 0 | 前期暂缓 |
| 搜索 | 搜索推荐系统 | 6 | 0 | 前期可以现有搜索系统,中后期再开发推荐 |
| 机器冗余 | | 1 | 0 | 冗余备用的机器1-2台 |
合计:29台物理机,16台虚拟机。
### 架构支撑
| 用途 | 系统 | 物理机数量 | 虚拟机数量 | 备注 |
|-----|-----|-----|-----|-----|
| Dubbo | Zookeeper集群 | 3 | 0 | |
| 消息 | RabbitMQ高可用 | 2 | 0 | |
| 缓存 | Redis高可用集群 | 2 | 0 | |
| 负载 | HAProxy/LVS | 3 | 0 | |
合计:10台物理机,0台虚拟机。
### 总结
1、系统是UI,接口逻辑,系统要满足的基本是静态PV,要求的是IO能力,不是CPU和内存,接口计算任务会多,要求CPU和内存;压力一般都在接口和数据库;
2、数据库按照业务系统的50%计算,4台虚拟机需要1台物理机计算,总计约需要60台服务器;
3、真实案例:Windows+MSSQL,支撑1000万PV,有人用过约120-150台R410/710服务器,个人感觉比较浪费;
4、我的估算和上面这个真实案例差别很大,实践中,可以根据实际情况,酌情增减;
5、针对3的真实案例,如果全用正版,仅license一项,就要花费几百万费用,才仅仅是一个千万PV的规模;
6、初期就安装SOA框架开发,相对于系统上规模再拆分,可以节省非常多的时间,架构做好了,开发效率并不低,而且,随着系统更大,非常容易扩展;
7、对于初期,可以先按照1/5规模,约12台,上线,逐步扩充。
### 服务器型号
| Dell服务器 | 档次 | 价格 |
|-----|-----|-----|
| 410/420系列 | 低端 | 1-2W |
| 710/720系列 | 中端 | 2-6W |
| 910系列 | 高端 | 6-~W |
Dell官网:http://www.dell.com.cn
### 人员构成
这里不考虑运维、产品、项目、测试部门,只描述研发部门。
### 1、角色定义
技术总监:资深的技术研发管理者,深厚的技术及业务功底;也有公司在这个职位上的人完全不懂技术,可能是产品总监、项目总监暂代。
架构师:技术框架的制定者,技术路线的倡导者,负责解决研发中框架相关的问题。
研发经理:经验丰富的工程师,业务功底,协调能力。
高级工程师:经验丰富的工程师,疑难技术问题的解决者。
工程师:自行协调、并解决问题的人。
初级工程师:能在帮助下解决问题的人。
### 2、人员构成
总监:1
架构师:2
经理:6-8
高级工程师:12-16
工程师:18-24
初级工程师:6-8
总计:五、六十人的规模
### 3、人员素质
不断学习的进取心、及悟性;
隐忍坚持、协作性好;
胜任职位的技术功底;
其实,我个人认为,人员的素质,其实指的是人员的工作素质,和公司本身的文化是非常相关的,甚至可以说,是公司的文化,塑造了职员在这个公司的工作素质。
### 电商IT系统介绍
[1、权限管理系统](http://blog.csdn.net/puma_dong/article/details/12391479)
[2、图片管理系统](http://blog.csdn.net/puma_dong/article/details/16835677)
[3、商品管理系统](http://blog.csdn.net/puma_dong/article/details/9854899)
[4、采购管理系统](http://blog.csdn.net/puma_dong/article/details/39013635)
[5、搜索系统](http://blog.csdn.net/puma_dong/article/details/38942777)
[6、推荐系统](http://blog.csdn.net/puma_dong/article/details/38943251)
[7、订单管理系统](http://blog.csdn.net/puma_dong/article/details/39272243)
[8、客服管理系统](http://blog.csdn.net/puma_dong/article/details/39506157)
[9、会员管理系统](http://blog.csdn.net/puma_dong/article/details/39505955)
[10、商业智能系统](http://blog.csdn.net/puma_dong/article/details/41546423)
以上系统并未完全实现,有些仅仅是功能设想和简单列表功能实现,需要在实际的生产过程中逐渐来补充,抛砖引玉,仅供参考。
电子商务(B2C)IT系统–综述
最后更新于:2022-04-01 11:02:43
### IT系统
### 商品中心
这是最基础的业务系统,和所有其他系统的关联最紧密。
这个系统主要会管理如下内容:
分类、品牌、商品(基本信息、价格信息、图片信息、属性信息)
### 采购中心
买断方式的运营方式中,需要采购管理系统的支持。
这个系统主要会管理如下内容:
合同、采购单、发货单。关于采购的结算管理(押款、预付款、对账单、付款、发票)等,有放在采购中心的,也有放在财务中心的,我个人感觉放在财务中似乎更合适,这样一来,采购中心相对就比较简单了。
### 招商中心
联营方式的运营方式中,需要招商管理系统的支持。
这个系统主要就是一个UI,供应商使用这个系统的过程中,会调用其他系统的接口,控制联营商品的流转。会涉及的相关系统会有:商品中心、订单中心、结算中心等。
### 仓储中心
仓储管理系统,负责在商品的“六进六出”过程中,保证库存在仓库、货位的准确。
六进六出指的是:采购返厂、订单退订、借出返还、调拨、盘盈盘亏、正残转换。
主要的功能大致如下:
基本功能(仓库、货位、条形码),六进六出的单据明细管理,预警功能,报表查询功能。
仓储的研发中,为了保证操作的高效可用,有两个地方建议做成CS的,打包台使用的打包、分拣、出库部分;仓库日常操作使用手持设备。
### 订单中心
订单管理系统,负责订单的流转过程。主要功能大致如下:
订单生成(分单逻辑、促销逻辑)、订单修改、订单退换货。
### 会员中心
会员部分,主要是指的网站的会员中心,以及为客户系统提供关于会员的接口。主要功能大致如下:
会员注册、会员管理(信息、级别、积分)
### 客服中心
个人感觉,应该最大限度的缩小这个系统的功能。
不要代客下单,售后服务也尽量引导用户在网站自行完成。
关于这个系统本身,主要提供的功能:订单查询、修改;退换货办理。
### 网站中心(CMS)
网站系统,直面消费者的终端。主要指:首页、频道页、专题页、单品页、活动页(促销)的展示,及其后台管理,也可称之为CMS。
### 搜索推荐
搜索系统:是基于搜索框架的商品索引建立及复杂查询接口提供,目的是方便检索。
推荐系统:是基于商品信息、用户行为的关联商品推荐,目的是相关性强的推荐商品,提高订单转化率。
### 分销中心
网站联盟、市场活动等分销、广告活动的管理。
### 结算中心
采购返厂的结算、联盟佣金的结算,一切和资金流转相关的系统都在这里。
### 数据中心
或者叫商业智能中心,BI系统,是一个数据系统,从各种维度(比如销售、退换、渠道、广告、流量等)统计分析当前网站的运行状况,并对网站的发展进行一定程度的预测。
### 研发行政组
网站组:网站中心(CMS)、会员中心、分销中心
商品组:商品中心、采购中心、招商中心
仓储组:仓储中心
订单组:订单中心、客服中心
搜索组:搜索推荐、网站的搜索频道(比如search.jd.com)
财务组:结算中心
相对来说,前台相关的,技术更多一些;后台相关的,业务更多一些。总的来说,研发是要懂业务,不懂业务,在很多情况下,就不敢改代码。
研发组,加上架构、DBA、运维、测试,也就是一个技术部了。
前言
最后更新于:2022-04-01 11:02:41
> 原文出处:[电商系统](http://blog.csdn.net/column/details/b2c-it.html)
作者:[puma_dong](http://blog.csdn.net/puma_dong)
**本系列文章经作者授权在看云整理发布,未经作者允许,请勿转载!**
# 电商系统
> 介绍电子商务,特别是B2C相关的业务支撑系统,希望能对电商IT系统的开发,起到一点点的借鉴作用。