(9)编译程序第一个工作阶段-词法分析(NFA和DFA转换) .
最后更新于:2022-04-01 14:41:07
上篇讲述确定有穷自动机和不确定有穷自动机,本篇讲述不确定有穷自动机和确定有穷自动机之间的转换。从百度文库中找到一个示例感觉很合适。
如图所示:
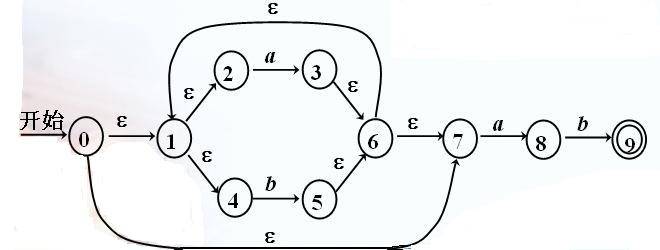
**1.具有ε动作的NFA状态转换表**
<table border="1" cellspacing="0" cellpadding="0"><tbody><tr><td valign="top"><p align="center"><strong><span style="font-size:14px"> </span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px"> a </span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px"> b </span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px"> ε </span></strong></p></td></tr><tr><td valign="top"><p align="center"><strong><span style="font-size:14px">0</span></strong></p></td><td valign="top"><p align="center"><a name="OLE_LINK1"><strong><span style="font-size:14px">Φ</span></strong></a></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">1, 7</span></strong></p></td></tr><tr><td valign="top"><p align="center"><strong><span style="font-size:14px">1</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">2, 4</span></strong></p></td></tr><tr><td valign="top"><p align="center"><strong><span style="font-size:14px">2</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">3</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td></tr><tr><td valign="top"><p align="center"><strong><span style="font-size:14px">3</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">6</span></strong></p></td></tr><tr><td valign="top"><p align="center"><strong><span style="font-size:14px">4</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">5</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td></tr><tr><td valign="top"><p align="center"><strong><span style="font-size:14px">5</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">6</span></strong></p></td></tr><tr><td valign="top"><p align="center"><strong><span style="font-size:14px">6</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">1, 7</span></strong></p></td></tr><tr><td valign="top"><p align="center"><strong><span style="font-size:14px">7</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">8</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td></tr><tr><td valign="top"><p align="center"><strong><span style="font-size:14px">8</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">9</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td></tr><tr><td valign="top"><p align="center"><strong><span style="font-size:14px">9</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td><td valign="top"><p align="center"><strong><span style="font-size:14px">Φ</span></strong></p></td></tr></tbody></table>
**2.分别求ε-closure**
**ε-closure(I)就是状态集I中,任意状态S经过任意的 ε能到达的状态集合。**
~~~
ε-closure(0) = {0,1,2,4,7}
ε-closure(1) = {1,2,4}
ε-closure(2) = {2}
ε-closure(3) = {1,2,3,4,6,7}
ε-closure(4) = {4}
ε-closure(5) = {1,2,4,5,6,7}
ε-closure(6) ={1,2,4,6,7}
ε-closure(7) = {7}
ε-closure(8) = {8}
ε-closure(9) = {9}
~~~
**3.转换算法:**
**move(I,a)是从I中的某一状态经过一条a弧而到达的状态全体。**
~~~
ε-closure(0) ={0,1,2,4,7} = A
ε-closure(move(A,a))=ε-closure({3,8})={1,2,3,4,6,7,8} = B
ε-closure(move(A,b))=ε-closure({5})={1,2,4,5,6,7} = C
ε-closure(move(B,a))=ε-closure({3,8}) = B
ε-closure(move(B,b))=ε-closure({5,9})={1,2,4,5,6,7,9} = D
ε-closure(move(C,a))=ε-closure({3,8}) = B
ε-closure(move(C,b))=ε-closure({5}) = C
ε-closure(move(D,a))=ε-closure({3,8}) = B
ε-closure(move(D,b))=ε-closure({5}) = C
~~~
****
**4.DFA的转换表**
<table border="1" cellspacing="0" cellpadding="0"><tbody><tr><td rowspan="2"><p align="center"><strong><span style="font-size:14px"> 状态 </span></strong></p></td><td width="379" colspan="2"><p align="center"><strong><span style="font-size:14px"> 输入符号 </span></strong></p></td></tr><tr><td><p align="center"><strong><span style="font-size:14px">a</span></strong></p></td><td><p align="center"><strong><span style="font-size:14px">b</span></strong></p></td></tr><tr><td><p align="center"><strong><span style="font-size:14px">A</span></strong></p></td><td><p align="center"><strong><span style="font-size:14px">B</span></strong></p></td><td><p align="center"><strong><span style="font-size:14px">C</span></strong></p></td></tr><tr><td><p align="center"><strong><span style="font-size:14px">B</span></strong></p></td><td><p align="center"><strong><span style="font-size:14px">B</span></strong></p></td><td><p align="center"><strong><span style="font-size:14px">D</span></strong></p></td></tr><tr><td><p align="center"><strong><span style="font-size:14px">C</span></strong></p></td><td><p align="center"><strong><span style="font-size:14px">B</span></strong></p></td><td><p align="center"><strong><span style="font-size:14px">C</span></strong></p></td></tr><tr><td><p align="center"><strong><span style="font-size:14px">D</span></strong></p></td><td><p align="center"><strong><span style="font-size:14px">B</span></strong></p></td><td><p align="center"><strong><span style="font-size:14px">C</span></strong></p></td></tr></tbody></table>
**5.状态转换图**
****
本篇到这里,编译原理入门教程就到这里了,仅仅是编译原理的初学者,请您多多指教哦
愿开心每一天~
(8)编译程序第一个工作阶段-词法分析(有穷自动机)
最后更新于:2022-04-01 14:41:05
上篇我们介绍了词法分析阶段单词的识别工具--正规式。本篇介绍正规式的识别装置--有穷自动机。
之所以称为有穷自动机?我想这和人们把把不同的设计模式起了名字一样,和同样是java代码被称为Servlet一样。人们把抽象的东西起了一个客观的名字。
**有穷自动机:**
能准确的识别正规集,能识别正规文法所定义的语言和正规式表示的集合,也为词法分析程序的自动构造寻找特殊的方法和工具。
分为两类:**确定的有穷自动机**(determinirstic finite automata)和**不确定的有穷自动机**(nondeterministic finite automata)。
确定和不确定的区别在哪里呢?首先分别看看我们的定义。
**确定有穷自动机:**
一个确定的有穷自动机M是一个五元组:M=(K, ∑,f,S,Z)其中,
1)K是一个有穷集,他的每个元素称为一种状态。
2) ∑是一个有穷字母表,他的每个元素称为一个输入符号,所以∑称为输入符号表。
3)f是转换函数,是KX∑-->K 上的映像,例如f(ki,a)=kj这就意味着,当前状态为k,输入字符a后,将转换到下一状态kj,我们把kj称为ki的一个后继状态;
4)S属于K,是**唯一**的一个出态。
5)Z属于K,是一个终态,终态也称为可接受状态或结束状态。
例 如下:
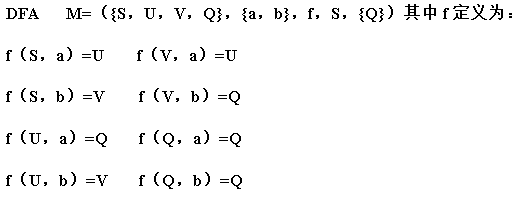
一个DFA可以表示一个状态转换图,如下所示:
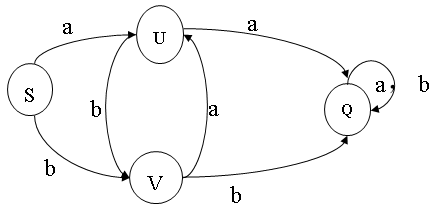
也可以用状态矩阵显示,行表示状态,列表示输入符号,终态在表的右端标1,非终态在表的右边标0。

**不确定有穷自动机:**
与确定有穷自动机不同:
3)是一个子集映像。
4)S属于K是一个非空出态集;
5)Z属于K是一个终态集。
例如:
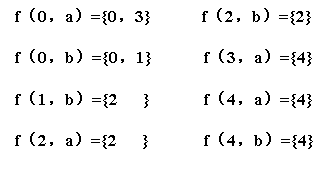
注: 上面的图片中改为 f(0,b)={0}
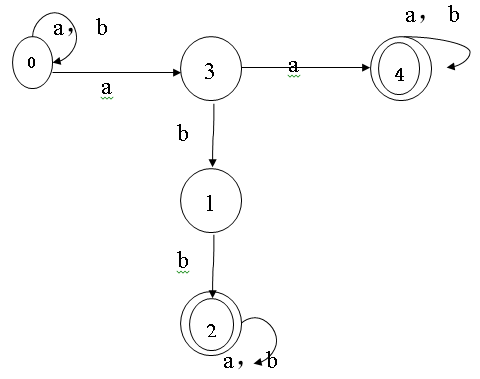
他们有什么不同之处呢?
1)确定有穷自动机状态是唯一的。
2)确定有穷自动机f是单值映射。
确定的有穷自动机就是说当一个状态面对一个输入符号的时候,它所转换到的是一个唯一确定的状态;而不确定的有穷自动机是说当一个状态面对一个输入符号的时候,它所转换到的可能不只一个状态,可以是一个状态集合。这就是两者的主要区别。还有就是DFA的开始状态是唯一的,而NFA的开始状态是一个开始状态集。
我们自己理解,确定和不确定的区别,确定是不怎么变化的,不确定是变化的,无论是变化还是不变化的问题的本质呢?
本篇就介绍到这里,下篇介绍不确定有穷自动机和确定有穷自动机之间的转换和自动机的最小化。
愿开心阅读~~~
(7)编译程序第一个工作阶段-词法分析(正规式)
最后更新于:2022-04-01 14:41:03
上篇讲述了句型的两种类型--自上而下和自下而上,本篇进入编译程序的第一个工作阶段--**词法分析**。
我们在[第二篇](http://blog.csdn.net/lovesummerforever/article/details/9027461)中讲述了关于词法分析的简单介绍,词法分析工作可以独立的一遍,把字符流的源程序变成单词序列,输出在一个中间文件上,这个文件作为下一个工作阶段-词法分析程序的输入而继续编译的过程。
一般情况下降词法程序设计成一个子程序,每当语法分析程序需要一个单词的时候,则调用该子程序。词法分析程序每得到一次调用,便从源程序文件中读入一些字符,直到识别出一个单词。
**那经过第一阶段的加工,我们的词法分析之后,得到什么?**
词法分析的输出:读入源程序,输出单词符号,单词符号包括单词的中类和单词自身的值,例如关键字有 end if 、while、var等;运算符有+ ,*,《=等。
**又有一个问题了,为什么要有这个阶段,将词法分析这个工作分为一个阶段?为什么将编译过程分为词法分析和语法分析?**
笔者认为这就和三层架构一样,系统为什么要分为三层架构?其实这也和我们的生活有关,现代社会不再单靠一个人单打独斗的社会,我们当代的社会人们分工明确,各司其职,社会稳步发展~ 这样提高全社会运转效率。我们的编译程序也是,主要原因有一下三点:
1、使整个编译程序的结构更加简洁、清晰和条理化。
2、编译程序的效率会改进。
3、增强了编译程序的可移植性。
**词法分析开始**:
词法分析开始,第一步当然是要从源程序中读入单词了,我们在文法中描述单词的工具是什么?正规式(也称正则表达式),是用以描述单词符号的方便工具。
**正规式和正规集定义**:

字母表集合内,所含有两个相继的a或两个相继的b组成的串 |
**正规式服从代数规律**:
~~~
1)r|s = s|r
2)r|(s|t) = (r|s)|t
3)(rs)t = r(st)
4)r(s|t)r = sr|tr
5)**ε**r = r r**ε**= r
6)r|r = r
~~~
**正规文法和正规式的转换:**

**例如:**
将r = a(a|d)* 转换为相应的正规文法。
S->a(a|d)* ==> S->aA A->(a|d)* ==>A->(a|d)B A->**ε** ==>B->(a|d)B B->**ε**
**转换结果为:S->aA A->(a|d)B A->**ε** B->(a|d)B B->ε**
**单词的识别工具--正规式,本篇讲述到这里,下一篇讲述正规式的识别装置--有穷自动机。**
**愿开心阅读O(∩_∩)O~~**
(6)句型的分析
最后更新于:2022-04-01 14:41:00
上篇讲述了上下文无关文法的推导以及句子的语法树。
**本篇继续对句型分析**。
**开始教程**:
对于句子而言,语法树是句子的几何表示形式,把句型形象直观的表示出来了,语法树是句型分析结构分析很好的工具。本篇
所说的句型分析是,给定一个符号串,是否为某文法的句型,也就是给定一串字符串,视图按照某文法的规则为该符号构造推导或
推导树,以此识别他是否是该文法的一个**句型**,当符号串全部是由非终结符组成的时候,就可以知道他是否是某个文法的**句子**。
这样根据一个句子得到的树,称为分析树。
句型分析是一个识别输入符号串是否为语法上正确的程序的过程。
我们的分析算法分为:**自上而下和自下而上**两大类。
**自上而下分析算法**:
从文法的开始符出发,反复使用各种产生式,寻找“匹配”于输入符号的推导。
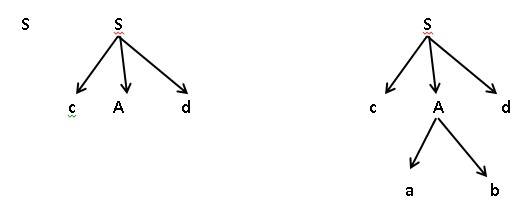
**自下而上的分析算法**:
从输入符号串开始,逐步进行“归约”,直至规归约到文法的开始符号。
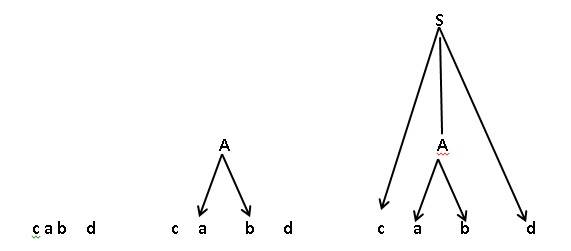
**从语法树的角度来描述这两种**:**自上而下**是从开始开始推导,使语法树的末端正好是输入符号串。
**自下而上**是把输入的符号串作为语法树末端的符号串,自底向上的构造语法树。
句型分析的一些说明:
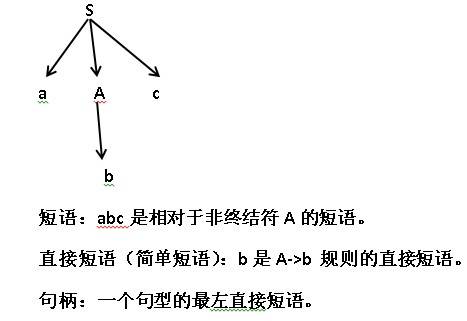
例如:

**文法的一些实用性规则**:
在实用中,我们限制文法不能含有有害规则和多余规则。
**有害规则**:形为U——>U的规则。
**多余规则**:一个句子的归到用不到的规则。
本篇讲述到这里,下一篇讲解词法分析,词法分析的工具--正规式。
愿开心阅读,共同提高(*^__^*) 。
(5)上下文无关文法,及其语法树
最后更新于:2022-04-01 14:40:58
首先我们回顾一下上篇的内容,上篇讲述了四种类型的文法,0型1型2型3型,他们要求的规则越来越严格。
**开始教程**:
本篇着重讲解上下文无关文法及其语法树,因为对于计算机程序来讲,上下文无关文法表达能力足够强,来表达大多数程序语言的语法。
描述一种上下文无关的推导工具:**句型的推导和语法树(推导树)**
给定文法G(VN,VT,P ,S),对于G的任何句型都能构造与之关联的语法树。**这棵树满足下面四个条件**:
① 每个结点都有一个标记,此标记是V的 一个符号。(说的是节点一定是终结符或非终结符)
② 根的标记是S。(说的是树根的标记是开始符号S)
③ 若一结点标记A,至少有一个从它出发的分枝,则A肯定在VN中(说的是如果一个节点有分支的话,这个节点一定是非终结符)
④ 如果标记为A,有n个从它出发的分枝,并且这些分枝的结点的标记(从左到右)为B1, B2,…,Bn,那么A→B1B2,…,Bn一定是P中的一个产生式。(说的是从A出发的叶子节点从左到右排列,一定是P中规则的一个产生式)
例1: 文法G[S]:
S→aAS
A→SbA
A→SS
S→a
A→ba
写出aabbaa句型的推导过程:
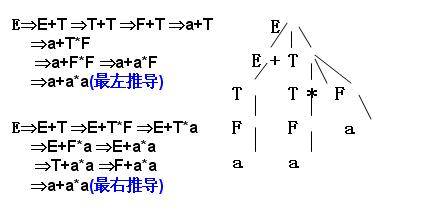
(1)S=>aAS=>aAa=>aSbAa=>aSbbaa=>aabbaa(最右推导)(最右推(2)S=>aAS=>aSbAS=>aabAS=>aabbaS=>aabbaa(最左推导)(最左推导,就是从最左侧的非终结符开始)
例2: G[E]: E→E+T|T
T→T*F|F
F→(E)|a
判断a+a*a 是否是合法的句子,采用最左推导和最右推导
E=>E+T=>T+T=>F+T=>a+T=>a+T*F
=>a+F*F=>a+a*F=>a+a*a(最左推导)
E=>E+T=>E+T*F=>E+T*a=>E+F*a
=>E+a*a=>T+a*a=>F+a*a=>a+a*a(最右推导)
书上规定,**最右推导又称为规范推导,规范推导推导出的句型又称为规范句型**。
**构造上述句型的语法树:**
画出a+a*a句型的语法树
E→E+T|T
T→T*F|F
F→(E)|a
注:上面的例子来自网络。
而一个语法树可以表示可能的不同推导过程,包括最右推导和最左推导。但是一个句型是否对应唯一的一颗语法树呢?一个句型是否只有唯一的一个最左推导(最右推导)?答案是否定的,下面我们讲述二义文法。
看看下面的文法推导树:
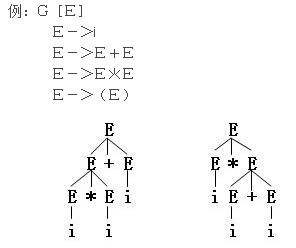
**二义文法的定义**:
若一个文法存在某个句子对应两棵不同的语法树,则称这个文法是二义的,或一个文法有两个不同的最左推导,则称这个文法是二义的。
当然我们不希望程序的某些文法是二义的,希望对程序的每个句子的分析是唯一的。
本篇到此结束,下篇讲述句型的简单分析。
愿开心阅读,一起掌握知识(*^__^*) 。
(4)文法类型
最后更新于:2022-04-01 14:40:56
上篇讲述了文法和语言的概念,什么是文法?相信大家都有所了解了。
本篇讲述文法的类型,**某些类型的文法及其产生的语言得到了细致的研究并被伟大的[乔姆斯基](http://www.baidu.com/s?wd=%E4%B9%94%E5%A7%86%E6%96%AF%E5%9F%BA&rsv_spt=1&issp=1&rsv_bp=0&ie=utf-8&tn=baiduhome_pg&rsv_sug3=1&rsv_sug=0&rsv_sug4=842)单独命名**。乔姆斯基先生能众多规则中进行进一步归纳,对产生式施加不同的限制。而我们只能学习人家乔姆斯基先生研究好的东东,学习这种思考问题的方式。
四种文法之间的关系是将产生式作进一步的限制而定义的:
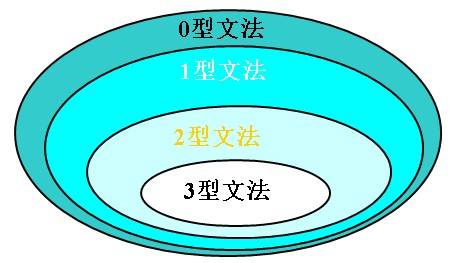
<table border="1" cellspacing="1" cellpadding="1" width="726" style="width:726px; height:171px"><tbody><tr><th scope="col"><span style="font-size:14px">文法类型</span></th><th scope="col"><span style="font-size:14px">规则</span></th><th scope="col"><span style="font-size:14px">示例</span></th></tr></tbody><tbody><tr><th scope="row"><span style="font-size:14px">0型文法</span></th><td><span style="font-size:14px">a->b 产生式左边a至少含有一个非终结符</span></td><td><p><span style="font-size:14px">nA->b</span></p><p><span style="font-size:14px"/> </p></td></tr><tr><th scope="row"><span style="font-size:14px">1型文法</span></th><td><span style="font-size:14px">在0型基础上,a->b 产生式右侧的长度越来越长。|b| >=|a| S->ε 除外。</span></td><td><p><span style="font-size:14px">nA->bSd</span></p><p> </p></td></tr><tr><th scope="row"><span style="font-size:14px">2型文法</span></th><td><span style="font-size:14px">在1型基础上,a->b左侧为一个非终结符。</span></td><td><p><span style="font-size:14px">A->bSd</span></p><p> </p></td></tr><tr><th scope="row"><span style="font-size:14px">3型文法</span></th><td><span style="font-size:14px">在2型基础上,a->b 右侧的形式为:A->cB 或A->c (仅此两种形式)AB为非终结符</span></td><td><p><span style="font-size:14px">A->bS </span></p><p><span style="font-size:14px">A-n</span></p></td></tr></tbody></table>
从0型文法到3型文法,规则越来越严格了。
**0型文法**:可由图灵机识别(关于[图灵机](http://baike.baidu.com/view/117065.htm),百度百科描述很详细了。)
**1型文法**:上下文有关文法。(任何产生规则的左手端和右手端都可以被终结符和非终结符的上下文所围绕,乔姆斯基描述自然语言的一种方式介入的,在自然语言中一个单词是否可以出现在特定的位置要依赖于上下文。)
**2型文法**:上下文无关文法。之所以称为上下文无关文法,是因为在推导式中a->b ,字符a总可以被字符串b自由替换,而无需考虑字符a出现的上下文。
**3型文法**:正规语言,之所人称作正规语言(正则语言),可能是因为3型文法只有两种形式 A->aB A->a ,比较固定,规则明显,所以称为正规语言。(小菜这么想的)
本篇就到这里啦,下篇讲述上下文无关文法及其语法树。
愿开心阅读。(*^__^*)
(3)文法和语言
最后更新于:2022-04-01 14:40:53
**写在开始**:
上篇我们介绍了编译“工厂”的流程,本篇介绍,工厂里的“工具”。
**开始教程**:
语言和文法?语言我们知道,计算机语言,人类的语言,动物的语言,不同国家的语言,不同种族的语言等等。那神马是文法呢?所谓文法,文,文字,法,规则,法则,法律。组合起来就是,文字的规则。每种语言都有自己的文法,不同的语言有不同的文法。例如我们的中文的文法,用一种规则来定义句子的组成,还拿“我是中国人”为例。
我们的个中文句子构造规则:<主语><谓语><宾语><补语><状语>。 而英语的句子构造:S十V主谓结构 S十V十F主系表结构 S十V十O主谓宾结构 S十V十O1十O2主谓双宾结构 S十V十O十C主谓宾补结构说明:S=主语;V=谓语;P=表语;O=宾语;O1=间接宾语;O2=直接宾语;C=宾语补足语。我们可以看出汉语和英语有不同的编排,不同的规则,这就是文法。
**我们这里要说的是编译程序的文法**。
**书中的文法定义**:使用文法作为工具,不仅为了严格地定义句子的结构,也是为了适当条数的规则把语言的全部句子描述出来,可以说文法是以有穷集合刻画无穷集合的工具。
接下来了解一些关于表示文法的一些基本定义:
**一些基本定义**
**符号和符号串**:
正如我们学习的English是由单词和标点符号构成的,单词又是有字母构成的,计算机语言也是如此,也是由字母和数字等一些基本符号构成的,一个源程序就是一个“基本符号串”,所以我们开始了解符号和符号串相关的定义。
**字母表**:
元素的非空有穷集合。不同的语言有他自己不同的字母表,我们的计算机语言字母表就是数字,字母,标点等若干符号了。中文的字母表就是汉字了。
**符号串**:
字母表的符号组成任何又穷序列的符号串。例如字母表A={a,b,c}则由这个字母表组成的符号串包括: {ab,ac,bc,abc,a,b,c}。
有了这些就相当于有了123456,接下来就是一些运算了,符号串的一些运算了。
**连接运算**:
eg:x=bay=nanaxy=banana(很简单,连接在一起)
**方幂运算**:x^0= e ; x^1 = x;.....;(和小学数学的方幂一致)
**两个字母表乘积**:∑1={0,1},∑2={a,b},∑1∑2 ={0a,0b,1a,1b};(小学数学结合运算)
**∑的正闭包**:
∑+=∑∪∑2∪∑3∪∑4∪……
**∑的克林闭包(kleene Closure**)**:
∑*=∑0∪∑+(与正闭包区别哦,这算是新概念)
例如:{0,1}+ = {0,1,00,01,11,000,001,010,011,100,……}
{0,1}* = {ε,0,1,00,01,11,000,001,010,011,100,…}
**我们用这些规则将我们的语言形式化**:
“我是中国人”:名词:: =中国人;代词::=我;动词::=是;
编译程序的文法把计算机语言形式化的定义:A->b ;读作:A定义为b;或把他说成是一条关于A的规则(产生式);
**更加规范的定义**:
文法G的定义:四元组(Vn,Vt,P,S)
Vn:是非终结符集;
Vt:终结符集;
P:表示一种规则(a->b)ab表示终结符和非终结符的集合,但a中至少包括一个非终结符。Vn,Vt,P是非空有穷集合。
S:表示开始符,他是一个非终结符,至少要有一条规则在左侧。
**那什么是终结符和非终结符呢?规则又是怎样?开始符?**
下面来看一个英文句子,以英文句子为例,说说这个过程,幻灯片上的这个例子很适合初学者。
分析句子:The grey wolf will eat the goat .
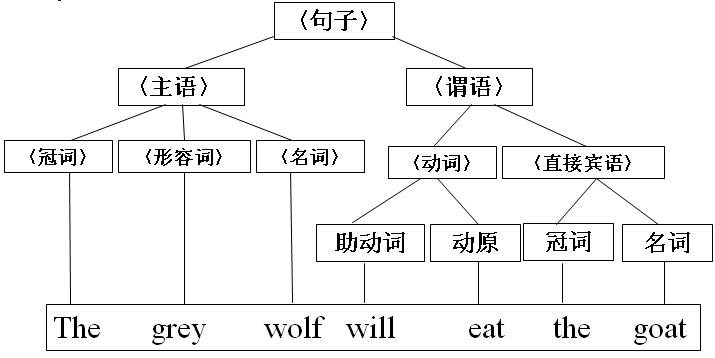
句子的组成规则:

我们如何用文法符号来描述这个归纳的过程呢?这个英文句子怎么形式化的表现出来呢?
这就是为什么我们上述的文法G要用那四个符号来表示了:

因为前人发现重复的地方,想用有穷的地方表达无穷的东西,用这四个方式来表示恰好能将所有的句子归纳。
这是对一个句子的分析,当然如果有一个句子,我们也可以根据这种规则判断是个句子是否符合英文的文法。
**文法描述的语言是该文法一切句子的集合。**
给出几个词,我们能根据文法组成一个句子,可以根据规则产生语言。
给出一个句子,我们把句子的词进行归类,可以判断这个句子是否可被识别。
例如:the grey will eat the goat
the grey wolf will eat wolf
the grey goat will eat the wolf
the grey goat will eat the grey
符合语法语义的句子仅是:
the grey wolf will eat goat
所以文法G的形式定义如上所述
Vt:终结符,我们一般用除了大写字母表示。
Vn:非终结符,我们一般用大写字母表示。
S:一般是开始符号。
P:就表示一种规则啦。
a->b被称为产生式(定义式)
**仙人(前人)给定义的一些说法**:
文法G、、上述定义,cd是Vn和Vt中任意字符,符号串V和W V=caW=db (规则 a->b)则V能直接产生W,则说W是V的直接推导。或说W直接规约到V。
1如果V->W0->W1->W2...->Wn=W (n>0)则称**W规约到V**记作:V ---+- >W (箭头上带一个加号,写的时候不方便。。)
若 1 或V=W则记作V ---*->W (箭头上带一个星号)
**句子句型**:
设G[S]是以文法,如果符号x是从识别符号推到出来的,即有S---*--->x ,则称x是文法G[S]的句型。
若x仅由终结符号组成,则称x为该文法G[S]的句子。
本篇就到这里,讲述了文法的概念--语言的规则,文法的组成,文法的一些基本定义解释。
写在最后:
小菜祝开心阅读,共同提高。(仅是入门教程,更深入的学习遨游到书籍中,能尽快的理解)
(2)编译程序的六个工作流程
最后更新于:2022-04-01 14:40:51
上篇我们介绍了什么是编译程序,简单提到了这个“工厂”工作的六个阶段。本篇介绍一下这六个阶段。
“工厂”导航图(翻译工作的过程):
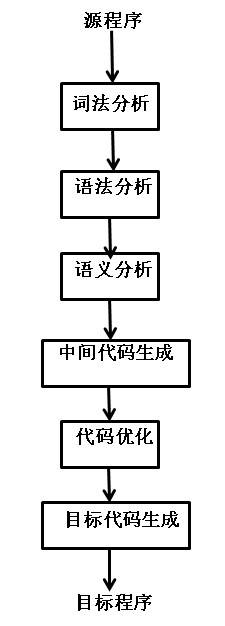
**流水线一--**词法分析:
也就是从左到右一个一个的读入源程序,识别一个单词或符号,并进行归类。类似分析汉语语法,例如,我们输入一句话,我是中国人。然后进行分析,读入我可以识别这个单词,为名词,我就归到名词这类;读入是,我们归到动词这类;读入中字,不能构成一个可识别的东东,接着读入,中国人,为名词类。而在计算机中,例如我们写的某行代码,var sum = first + count*10 ; 进行分类,1保留字:var;标识符:2 sum 3 first 4 count 乘号:5*;
**流水线二--**语法分析:
在词法分析的基础上,将单词序列分解成各类语法短语,如“程序”,“语句”,“表达式”等。例如通过上面的单词“我”“中国人”“是”,可以构成两种形式的语句,我是中国人,中国人是我,都符合<主语><谓语>这样的语法。
**流水线三--**语义分析:
审查源程序是否有语义的错误,当不符合语言规范的时候,程序就会报错。例如上面的“我是中国人”和“中国人是我”两个句子,显然后面的中国人是我就不符合语义了。
**流水线四--**中间代码生成:
在进行了语法和语义的分析工作之后,编译程序将源程序变成了一种内部表示形式,这种内部表示形式叫做中间语言或中间代码。(比较抽象些),个人理解为,生成一种介于源码和机器语言的形式。
**流水线五--**代码优化:
这个阶段是对前阶段的中间代码进行变换或改造,目的是使生成的目标代码更为高效,即节省时间和空间。
**流水线六--**目标代码生成:
也就是把优化后的中间代码变换成指令代码或汇编代码。
这是工作的最后阶段,与硬件系统结构,指令系统相关,涉及到硬件系统功能部件运用、机器指令的选择等等。
编译程序编译性质的语言的翻译程序,而解释程序,相对编译程序简单些,因为解释型语言不需要把源程序翻译成目标代码,也是取分析执行源代码语句,一但一个语句分析结束,就直接运行并显示结果了。
以上简单介绍了编译程序工作的各个阶段。理解不到位之处,请留言哈~
(1)什么是编译程序?
最后更新于:2022-04-01 14:40:48
在软考中些许的接触了编译原理这门课程,只是为了应付考试,就会那点可能考到的东西。这次编译原理老师认真负责的讲解了为期三个月的编译原理,据说是手把手教学,额,可惜我没有怎么去上课,,,自己查找资料自学了一下编译原理。
**写在前面的话**:
编译原理的内容比较多,本篇大概的陈述编译原理是神马东东,我的后续博客会继续细化。仅仅是入门的东西,也是初学者,理解不到位,请您多多指教哦!
**开始教程**:
**编译原理**:初次听到这个词汇,如同见到陌生人这般,一丝畏惧,一丝好奇。
**他对程序员来讲**:第一、学习编译原理可以帮助自己更加深层次的理解程序语言和内部机制。第二、我们学到了一种新的解决问题的方法,从他的各种算法中可以得到启发。(语法分析、语义分析等)一些不同的思想会让你受益终身。第三、让我们更加深入的了解计算机思想,进一步培养计算机思维。第四、表面上的啦,对学习正则表达式有帮助。总之,百利而无一害,大概的懂得一些还是有必要的。
**计算机语言的发展史**:
机器语言--汇编语言--早期高级语言--结构化高级语言--面向对象语言,如同我们的汉语,图画形式--表意符号--甲骨文--象形文字--古代各代的文字--...--现在的文字。语言的发展是越来越高级了,社会也变的越来越文明了。
**编译程序和编译原理**:
就是把高级程序设计语言翻译成计算机汇编语言或机器语言的翻译程序。我们学习的编译原理就是学习如何构造翻译程序,构造翻译程序中的一些思想和原理。就相当于我们现代人穿越到了原始社会,但是原始社会的人不懂得我们的文字啊,我们需要把我们的文字翻译成原始社会人能看懂的文字,但是如何进行翻译呢?我们把翻译的这件事情,单独的交给翻译官(编译程序)来做,而不是每个人都去学如何翻译,这样一个翻译官就解决问题了!OK了!
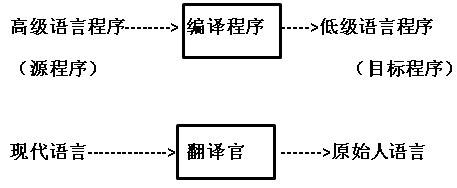
作为翻译官是既要懂现代语言,也需要懂得原始人语言,但是我们的编译程序就没有翻译官那样简单了。是一个复杂的整体过程,而且这个工作时按照阶段来进行的,就像加工一个产品一样,是按照流水线来工作的,而我们的这个工作分成了六个阶段:词法分析、语法分析、语义分析、中间代码生成、代码优化、和目标代码生成六个阶段。
本篇介绍到这里,下篇介绍一下这个六个阶段。
**写在后面的话**:
小菜理解能力有限,我学习编译原理就是这样去思考的,愿读者阅读愉快,开心掌握知识!
前言
最后更新于:2022-04-01 14:40:46
> 原文出处:[编译原理入门教程](http://blog.csdn.net/column/details/bianyiyuanli.html)
作者:[lovesummerforever](http://blog.csdn.net/lovesummerforever)
**本系列文章经作者授权在看云整理发布,未经作者允许,请勿转载!**
# 编译原理入门教程
> 本专栏旨在帮助学习编译原理的初学者迅速入门,并且掌握这门计算机的基础课程。本专栏包括对编译原理的宏观阐释以及对各个阶段的详细讲解,主要内容如下:文法和语言、词法分析、语法分析、中间代码的生成等主要内容。