[python] 专题八.多线程编程之thread和threading
最后更新于:2022-04-01 09:35:52
就个人而言,学了这么多年的课程又写了这么多年的程序,虽然没有涉及到企业级的项目,但还是体会到了有几个知识点是非常重要的,包括:面向对象的思想、如何架构一个项目、设计模式来具体解决问题、应用机器学习和深度学习的方法,当然也包括我这篇文章的内容——多线程和并行化处理数据。
这篇文章主要是参考Wesley J. Chun的《Python核心编程(第二版)》书籍多线程部分,并结合我以前的一些实例进行简单分析。尤其是在大数据、Hadoop\Spark、分布式开发流行的今天,这些基础同样很重要。希望对你有所帮助吧!
PS:推荐大家阅读《Python核心编程》和《Python基础教程》两本书~
强推:[http://www.cnblogs.com/huxi/archive/2010/06/26/1765808.html](http://www.cnblogs.com/huxi/archive/2010/06/26/1765808.html)
##一. 线程和进程的概念
**1.为什么引入多线程编程?**
在多线程(Multithreaded,MT)编程出现之前,电脑程序的运行由一个执行序列组成,执行序列按顺序在主机的中央处理器CPU中运行。即使整个程序由多个相互独立无关的子任务组成,程序都会顺序执行。
由于并行处理可以大幅度地提升整个任务的效率,故引入多线程编程。
多线程中任务具有以下特点:
(1) 这些任务的本质是异步的,需要有多个并发事务;
(2) 各个事务的运行顺序可以是不确定的、随机的、不可预测的。
这样的编程任务可以分成多个执行流,每个流都有一个要完成的目标。再根据不同的应用,这些子任务可能都要计算出一个中间结果,用于合并得到最后的结果。
**2.什么是进程?**
计算机程序只不过是磁盘中可执行的二进制(或其他类型)的数据。它们只有在被读取到内存中,被操作系统调用时才开始它们的生命周期。
进程(亦称为重量级进程)是程序的一次执行。每个进程都有自己的地址空间、内存、数据栈及其他记录其运行轨迹的辅助数据。操作系统管理在其上运行所有的进程,并为这些进程公平分配时间、进程也可以通过[fork](http://www.cnblogs.com/bastard/archive/2012/08/31/2664896.html)和spawn操作来完成其他的任务。
不过进程有自己的内存空间,数据栈等,所以只能使用进程间通讯(interprocess communication, IPC),而不能直接共享信息。
**3.什么是线程?**
线程(亦称为轻量级进程)跟进程有些相似,不同的是:所有的线程运行在同一个进程中,共享相同的运行环境。它们可以被想象成是在主进程或“主线程”中并行运行的“迷你进程”。
线程有开始,顺序执行和结束三部分。它有一个自己的指令指针,记录自己运行到什么地方。线程的运行可能被抢占(中断)或暂时的被挂起(睡眠),让其他线程运行,这叫做让步。
一个进程中的各个线程之间共享同一片数据空间,所以线程之间可以比进程之间更方便地共享数据以及相互通讯。线程一般都是并发执行的,正是由于这种并行和数据共享的机制使得多个任务的合作变成可能。
实际上,在单CPU的系统中,真正的并发是不可能的,每个线程会被安排成每次只运行一小会,然后就把CPU让出来,让其他的线程去运行。在进程的整个运行过程中,每个线程都只做自己的事,在需要的时候跟其他的线程共享运行的结果。
当然,这样的共享并不是完全没有危险的。如果多个线程共同访问同一片数据,则由于数据访问的顺序不同,有可能导致数据结果的不一致的问题,即竞态条件(race condition)。同样,大多数线程库都带有一些列的同步原语,来控制线程的执行和数据的访问。
另一个需要注意的是由于有的函数会在完成之前阻塞住,在没有特别为多线程做修改的情况下,这种“贪婪”的函数会让CPU的时间分配有所倾斜,导致各个线程分配到的运行时间可能不尽相同,不尽公平。
**4.简述进程和线程的区别**
参考下面三篇文章:
[进程和线程关系及区别 - yaosiming2011](http://blog.csdn.net/yaosiming2011/article/details/44280797)
[进程与线程的区别 - flashsky](http://www.cnblogs.com/flashsky/articles/642720.html)
[应届生经典面试题:说说进程与线程的区别与联系 - way_testlife](http://www.cnblogs.com/way_testlife/archive/2011/04/16/2018312.html)
##二. Python线程和全局解释器锁
**1.全局解释器锁(GIL)**
Python代码的执行由Python虚拟机(也叫解释器主循环)来控制。Python在设置之初就考虑到要在主循环中,同时只有一个线程在执行,就像单CPU的系统中运行多个进程那样,内存中可以存放多个程序,但任意时刻,只有一个程序在CPU中运行。同样,虽然Python解释器可以“运行”多个线程,但任意时刻,只有一个线程在解释器中运行。
对Python虚拟机的访问由全局解释器锁(global interpreter lock,GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。在多线程环境中,Python虚拟机按一下方式执行:
(1) 设置GIL
(2) 切换到一个线程去运行
(3) 运行:
a. 指定数量的字节码的指令,或者
b. 线程主动让出控制(可以调用time.sleep(0))
(4) 把线程设置为睡眠状态
(5) 解锁GIL
(6) 再次重复以上所有步骤
在调用外部代码(如C/C++扩展函数)的时候,GIL将会被锁定,直到这个函数结束为止(由于这期间没有Python的字节码被运行,所以不会做线程切换)。编写扩展的程序员可以主动解锁GIL。不过Python开发人员则不用担心在这些情况下你的Python代码会被锁住。
对源代码,解释器主循环和GIL感兴趣的人,可以看看Python/ceval.c文件。
**2.退出线程**
当一个线程结束计算,它就退出了。线程可以调用thread.exit()之类的退出函数,也可以使用Python退出进程的标准方法,如sys.exit()或抛出一个SystemExit异常等。不过,你不可以直接杀掉Kill一个线程。
后面会讲述两个与线程相关的模块,在这两个模块中,该书中不建议使用thread模块。主要原因是当主线程退出的时候,其他所有线程没有被清除就退出了。而threading模块就能确保所有“重要的”子线程都退出后,进程才会结束。
主线程应该是一个好的管理者,它要了解每个线程都要做些什么事,线程都需要什么数据和什么参数,以及在线程结束的时候,它们都提供了什么结果。这样,主线程就可以把各个线程的结果组成一个有意义的最后结果。
在Python2.7交互式解释器中导入**import thread**没有报错即表示线程可用。
**3.没有线程的例子**
使用time.sleep()函数来演示线程的工作,这个例子主要为后面线程做对比。time.sleep()需要一个浮点型的参数,来指定“睡眠”的时间(单位秒)。这就相当于程序的运行会被挂起指定的时间。
代码解释:两个计时器,loop0睡眠4秒,loop1()睡眠2秒,它们是在一个进程或者线程中,顺序地执行loop0()和loop1(),那总运行时间为6秒。有可能启动过程中会再花些时间。
~~~
from time import sleep, ctime
def loop0():
print 'Start loop 0 at:', ctime()
sleep(4)
print 'Loop 0 done at:', ctime()
def loop1():
print 'Start loop 1 at:', ctime()
sleep(2)
print 'Loop 1 done at:', ctime()
def main():
print 'Starting at:', ctime()
loop0()
loop1()
print 'All done at:', ctime()
if __name__ == '__main__':
main()
~~~
代码的运行结果如下图所示,它将和后面的并行代码做对比。
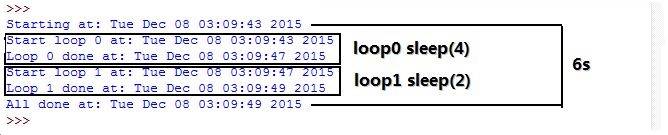
**4.避免使用thread模块**
Python提供了几个用于多线程编程的模块,包括thread、threading和Queue等。
(1) thread模块: 允许程序员创建和管理线程,它提供了基本的线程和锁的支持。
(2) threading模块: 允许程序员创建和管理线程,它提供了更高级别,更强的线程管理的功能。
(3) Queue模块: 允许用户创建一个可用于多个线程间共享数据的队列数据结构。
下面简单分析为什么需要避免使用thread模块?
(1) 首先更高级别的threading模块更为先进,对线程的支持更为完善,而且使用thread模块里的属性有可能会与threading出现冲突。
(2) 其次,低级别的thread模块的同步原语很少(实际只有一个),而threading模块则有很多。
(3) 另一个原因是thread对你的进程什么时候应该结束完全没有控制,当主线程结束时,所有的线程都会被强制结束掉,没有警告也不会有正常的清除工作。而threading模块能确保重要的子线程退出后进程才退出。
当然,为了你更好的理解线程,还是会对thread进行讲解。但是我们只建议那些有经验的专家想访问线程的底层结构时,才使用thread模块。而如果可以,你的第一个线程程序应尽可能使用threading等高级别的模块。
##三. thread模块
**1.基础知识**
首先来看看thread模块都提供了些什么。除了产生线程外,thread模块也提供了基本的同步数据结构锁对象(lock object,也叫原语锁、简单锁、互斥锁、互斥量、二值信号量)。同步原语与线程的管理是密不可分的。
常用的线程模块函数
<table class=" " cellpadding="0" cellspacing="0" style="line-height:26px; padding:0px; margin:0px auto 10px; font-size:12px; border-collapse:collapse; color:rgb(85,85,85); font-family:宋体,'Arial Narrow',arial,serif"><tbody style="padding:0px; margin:0px"><tr style="padding:0px; margin:0px"><td valign="top" width="300" style="border:1px solid rgb(0,0,0); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">模块函数</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:solid solid solid none; border-color:rgb(0,0,0) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="padding:0px; margin:0px"><span style="font-family:宋体; padding:0px; margin:0px"><span style="color:rgb(0,0,0)">描述</span></span></span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:rgb(0,0,0)">start_new_thread(function, args kwargs=None)</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">产生一个新线程,在新线程中用指定的参数和可选的kwargs来调用该函数</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:rgb(0,0,0)">allocate_lock()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">分配一个LockType类型的锁对象</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:rgb(0,0,0)">exit()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">让线程退出</span></p></td></tr></tbody></table>
LockType类型锁对象方
<table class=" " cellpadding="0" cellspacing="0" style="line-height:26px; padding:0px; margin:0px auto 10px; font-size:12px; border-collapse:collapse; color:rgb(85,85,85); font-family:宋体,'Arial Narrow',arial,serif"><tbody style="padding:0px; margin:0px"><tr style="padding:0px; margin:0px"><td valign="top" width="300" style="border:1px solid rgb(0,0,0); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="padding:0px; margin:0px"><span style="color:rgb(0,0,0)"><span style="font-family:宋体; padding:0px; margin:0px">类型锁对象方法</span></span></span></p></td><td valign="top" width="482" style="border-width:1px; border-style:solid solid solid none; border-color:rgb(0,0,0) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="padding:0px; margin:0px"><span style="font-family:宋体; padding:0px; margin:0px"><span style="color:rgb(0,0,0)">描述</span></span></span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:rgb(0,0,0)">acquire(wait=None)</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">尝试获取锁对象</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:rgb(0,0,0)">locked()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">如果获取了锁对象返回True,否则返回False</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:rgb(0,0,0)">release()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">释放锁</span></p></td></tr></tbody></table>
start_new_thread()函数是thread模块的一个关键函数,它的语法和内建的apply()函数一样,其参数为:函数,函数的参数以及可选的关键字的参数。不同的是,函数不是在主线程里运行,而是产生一个新的线程来运行这个函数。
**2.Thread模块实现代码**
现在实现一个线程的代码,与前面没有线程总运行时间为6秒的进行对比。
~~~
import thread
from time import sleep, ctime
def loop0():
print 'Start loop 0 at:', ctime()
sleep(4)
print 'Loop 0 done at:', ctime()
def loop1():
print 'Start loop 1 at:', ctime()
sleep(2)
print 'Loop 1 done at:', ctime()
def main():
try:
print 'Starting at:', ctime()
thread.start_new_thread(loop0, ())
thread.start_new_thread(loop1, ())
sleep(6)
print 'All done at:', ctime()
except Exception,e:
print 'Error:',e
finally:
print 'END\n'
if __name__ == '__main__':
main()
~~~
代码解释:
使用thread模块提供简单的额多线程机制。loop0和loop1并发地被执行(显然,短的那个先结束),总的运行时间为最慢的那个线程的运行时间,而不是所有的线程的运行时间之和。start_new_thread()要求一定要有前两个参数,即使运行的函数不要参数,也要传一个空的元组。
由于采用Python IDLE运行总是报错Runtime,而且已经设置了sleep(6)。运行一个线程勉强能运行,两个线程无论是thread或threading都报错,估计环境配置问题。
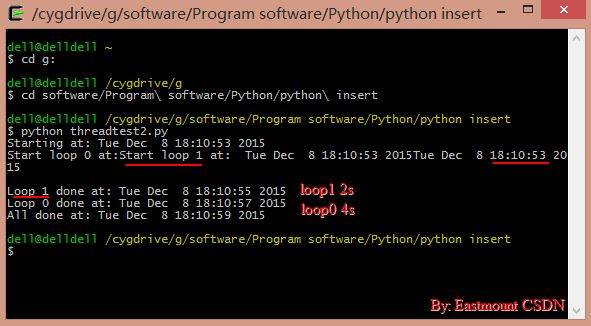
最后采用Cygwin Terminal模拟Linux下运行程序。可以发现loop1和loop0是并发执行的,其中loop1先结束运行2秒,而loop0运行4秒。
同时程序主函数中多了个sleep(6),为什么要加这一句话呢?
因为如果我们没有让主线程停下来,那主线程就会运行下一条语句,显示“All done”,然后就关闭运行着loop0和loop1的两个线程,退出了。
我们没有写让主线程停下来等所有子线程结束后再继续运行的代码,这就是前面所说的需要同步的原因。在这里,我们使用sleep(6)作为同步机制。设置6秒,两个线程一个4秒(53-57),一个2秒(53-55),在主线程等待6秒(53-59)后应该已经结束了。
cygwin需要用到的常见用法包括,也可以安装VIM编辑器:
cd c: 进入 'c:' 目录,空格用'\ '转义字符
pwd 显示工作路径
ls 查看目录中的文件
file test.py 查看文件内容
python test.py 运行python程序
配置方法见:[http://blog.sina.com.cn/s/blog_691ebcfc0101lgme.html](http://blog.sina.com.cn/s/blog_691ebcfc0101lgme.html)
下载地址见:[http://pan.baidu.com/s/1jGYEtro](http://pan.baidu.com/s/1jGYEtro)
**3.线程加锁方法**
那么,有什么好的管理线程的方法呢?而不是在主线程里做个额外的延时6秒操作。因为总的运行时间并不比单线程的代码少;而且使用sleep()函数做线程的同步操作是不可靠的;如果循环的执行时间不能事先确定的话,这可能会造成主线程过早或过晚的退出。
这就需要引入锁的概念。下面代码执行loop函数,与前面代码的区别是不用为线程什么时候结束再做额外的等待了。使用锁之后,可以在两个线程都退出后,马上退出。
~~~
#coding=utf-8
import thread
from time import sleep, ctime
loops = [4,2] #等待时间
#锁序号 等待时间 锁对象
def loop(nloop, nsec, lock):
print 'start loop', nloop, 'at:', ctime()
sleep(nsec)
print 'loop', nloop, 'done at:', ctime()
lock.release() #解锁
def main():
print 'starting at:', ctime()
locks =[]
nloops = range(len(loops)) #以loops数组创建列表并赋值给nloops
for i in nloops:
lock = thread.allocate_lock() #创建锁对象
lock.acquire() #获取锁对象 加锁
locks.append(lock) #追加到locks[]数组中
#执行多线程 (函数名,函数参数)
for i in nloops:
thread.start_new_thread(loop,(i,loops[i],locks[i]))
#循环等待顺序检查每个所都被解锁才停止
for i in nloops:
while locks[i].locked():
pass
print 'all end:', ctime()
if __name__ == '__main__':
main()
~~~
运行结果如下:
Starting at: Tue Dec 8 21:57:56 2015
Start loop 0 at: Tue Dec 8 21:57:56 2015
Start loop 1 at: Tue Dec 8 21:57:56 2015
Loop 1 done at: Tue Dec 8 21:57:58 2015
Loop 0 done at: Tue Dec 8 21:58:00 2015
All end: Tue Dec 8 21:58:00 2015
我们在函数中记录下循环的号码和睡眠的时间,同时每个线程都会被分配一个事先已经获得的锁,在sleep()的时间到了之后就释放相应的锁以通知住线程,这个线程已经结束了。
(1) loops[4, 2]定义睡眠时间 nloops=range(len(loops))创建列表[0, 1] 号码;
(2) 调用thread.allocate_lock()函数创建一个锁的列表,并分别调用各个锁的acquire()函数获得锁对象。获得锁表示“把锁锁上”,并放到锁列表locks中;
(3) 再循环创建线程,调用thread.start_new_thread(loop,(i,loops[i],locks[i]))。参数对应线程循环号、睡眠时间和锁。
(4) 在线程结束时,需要做解锁操作,调用lock.release()函数;
(5) 最后一个循环是坐在那一直等待(达到暂停主线程的目的),直到两个锁都被解锁才继续运行。它是顺序检查每个锁,主线程需不停地对所有锁进行检查直到都释放。
为什么我们不在创建锁的循环里创建线程呢?一方面是想实现线程的同步,所以要让“所有的马同时冲出栅栏”;另外获取锁要花些时间,如果线程退出太快,可能导致还没有获得锁,线程就已经结束了。
最后再强调下,thread模块仅仅了解就行,你应该使用更高级别的threading等。
##四. threading模块
threading模块不仅提供了Thread类,还提供了各种非常好用的同步机制。如下表列出了threading模块里所有的对象。
<table class=" " cellpadding="0" cellspacing="0" style="line-height:26px; padding:0px; margin:0px auto 10px; font-size:12px; border-collapse:collapse; color:rgb(85,85,85); font-family:宋体,'Arial Narrow',arial,serif"><tbody style="padding:0px; margin:0px"><tr style="padding:0px; margin:0px"><td valign="top" width="250" style="border:1px solid; border-color:rgb(0,0,0); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:rgb(0,0,0)">threading模块对象</span></p></td><td valign="top" width="520" style="border:1px solid; border-color:rgb(0,0,0) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="padding:0px; margin:0px"><span style="font-family:宋体; padding:0px; margin:0px"><span style="color:rgb(0,0,0)">描述</span></span></span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">Thread</span></p></td><td valign="top" width="482" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">表示一个线程的执行的对象</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">Lock</span></p></td><td valign="top" width="482" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:rgb(0,0,0)">锁原语对象(跟thread模块里的锁对象相同)</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">RLock</span></p></td><td valign="top" width="482" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">可重入锁对象。使单线程可以再次获得已经获得了的锁(递归锁定)</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">Condition</span></p></td><td valign="top" width="482" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">条件变量对象能让一个线程停下来,等待其他线程满足了某个“条件”。如状态的改变或值的改变</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:rgb(0,0,0)">Event</span></p></td><td valign="top" width="482" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">通用的条件变量。多个线程可以等待某个时间的发生,在事件发生后,所有的线程都被激活</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">Semaphore</span></p></td><td valign="top" width="482" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">为等待锁的线程提供一个类似“等候室”的结构</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:rgb(0,0,0)">BoundedSemaphore</span></p></td><td valign="top" width="482" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">与Semaphore类似,只是它不允许超过初始值</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">Timer</span></p></td><td valign="top" width="482" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">与thread类似,只是它要等待一段时间后才开始运行</span></p></td></tr></tbody></table>
**1.守护线程**
其中thread模块需要避免的一个原因是:它不支持守护线程。当主线程退出时,所有的子线程不论它们是否还在工作,都会被强行退出。有时我们并不期望这种行为,这就引入了守护线程的概念。
Threading模块支持守护线程,它们工作流程如下:守护线程一般是一个等待客户请求的服务器,如果没有客户提出请求,它就在那等着。如果你设定一个线程为守护线程,就表示你在说这个线程是不重要的,在进程退出时,不用等待这个线程退出,正如网络编程中服务器线程运行在一个无限循环中,一般不会退出的。
如果你的主线程要退出的时候,不用等待那些子线程完成,那就设定这些线程的**daemon属性**。即,线程开始(调用thread.start())之前,调用**setDaemon()函数**设定线程的daemon标准(thread.setDaemon(True))就表示这个线程“不重要”。
如果你想要等待子线程完成再退出,那就什么都不用做,或者显示地调用**thread.setDaemon(False)**以保证其daemon标志位False。你可以调用thread.isDaemon()函数来判断其daemon标志的值。
新的子线程会继承其父线程的daemon标志,整个Python会在所有的非守护线程退出后才会结束,即进程中没有非守护线程存在的时候才结束。
**2.Thread类**
threading的Thread类是你主要的运行对象。它有很多thread模块里没有的函数。
<table class=" " cellpadding="0" cellspacing="0" style="line-height:26px; padding:0px; margin:0px auto 10px; font-size:12px; border-collapse:collapse; color:rgb(85,85,85); font-family:宋体,'Arial Narrow',arial,serif"><tbody style="padding:0px; margin:0px"><tr style="padding:0px; margin:0px"><td valign="top" width="250" style="border:1px solid; border-color:rgb(0,0,0); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">函数</span></p></td><td valign="top" width="520" style="border:1px solid; border-color:rgb(0,0,0) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="padding:0px; margin:0px"><span style="font-family:宋体; padding:0px; margin:0px"><span style="color:rgb(0,0,0)">描述</span></span></span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">start()</span></p></td><td valign="top" width="482" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">开始线程的执行</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">run()</span></p></td><td valign="top" width="482" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">定义线程的功能的函数(一般会被子类重写)</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">join(timeout=None)</span></p></td><td valign="top" width="482" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">程序挂起,直到线程结束;如果给了timeout,则最多阻塞timeout秒</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">getName()</span></p></td><td valign="top" width="482" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">返回线程的名字</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">setName(name)</span></p></td><td valign="top" width="482" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">设置线程的名字</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">isAlive()</span></p></td><td valign="top" width="482" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">布尔标志,表示这个线程是否还在运行中</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">isDaemon()</span></p></td><td valign="top" width="482" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">返回线程的daemon标志</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">setDaemon(daemonic)</span></p></td><td valign="top" width="482" style="border:1px solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">把线程的daemon标志设为daemonic(一定要在调用start()函数前调用)</span></p></td></tr></tbody></table>
用Thread类,可以用多种方法来创建线程。现在介绍三种方法,你可以选择自己喜欢或社和自己程序的方法(通常选择最后一个):
(1) 创建一个Thread的实例,传给它一个函数;
(2) 创建一个Thread的实例,传给它一个可调用的类对象;
(3) 从Thread派生出一个子类,创建一个这个子类的实例。
**3.创建Thread实例,传给它一个函数**
这第一个例子使用方法一,把函数及其参数如上面Thread模块的例子一样传进去。主要变化包括:添加了一些Thread对象;在实例化每个Thread对象时,把函数(target)和参数(args)都传进去,得到返回的Thread实例。
实例化一个Thread调用Thread()方法与调用thread.start_new_thread()之间的最大区别是:新的线程不会立即开始。在你创建线程对象,但不想马上开始运行线程的时候,这是一个很有用的同步特性。
threading模块的Thread类有一个join()函数,允许主线程等待线程的结束。
~~~
#coding=utf-8
import threading
from time import sleep, ctime
loops = [4,2] #睡眠时间
def loop(nloop, nsec):
print 'Start loop', nloop, 'at:', ctime()
sleep(nsec)
print 'Loop', nloop, 'done at:', ctime()
def main():
print 'Starting at:', ctime()
threads = []
nloops = range(len(loops)) #列表[0,1]
#创建线程
for i in nloops:
t = threading.Thread(target=loop,args=(i,loops[i]))
threads.append(t)
#开始线程
for i in nloops:
threads[i].start()
#等待所有结束线程
for i in nloops:
threads[i].join()
print 'All end:', ctime()
if __name__ == '__main__':
main()
~~~
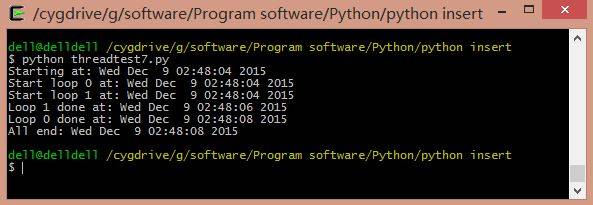
运行结果如下图所示:其中loop0和loop1并行执行,loop1先结束共执行2秒,loop0后结束执行4秒,总共运行时间4秒。注意:此时Start是分行显示了。

所有的线程都创建之后,再一起调用**start()函数启动线程**,而不是创建一个启动一个。而且,不用再管理一堆锁(分配锁、获得锁、释放锁、检查锁的状态等),只要简单地对每个线程调用**join()函数**就可以了。
join()会**等到线程结束**,或者在给了timeout参数的时候,等到超时为止。使用join()比使用一个等待锁释放的无限循环清楚一些(也称“自旋锁”)。
join()的另一个比较重要的方法是它可以**完全不用调用**。一旦线程启动后,就会一直运行,直到线程的函数结束,退出为止。
如果你的主线程除了等线程结束外,还有其他的事情要做(如处理或等待其他的客户请求),那就不用调用join(),只有在你要等待线程结束的时候才要调用join()。
**4.创建一个Thread实例,传给它一个可调用的类对象**
这是第二个方法,与传一个函数很相似,但它是传一个可调用的类的实例供线程启动的时候执行,这是多线程编程的一个更为面向对象的方法。相对于一个或几个函数来说,由于类对象里可以使用类请打的功能,可以保存更多的信息,这种方法更为灵活。
~~~
#coding=utf-8
import threading
from time import sleep, ctime
loops = [4,2] #睡眠时间
class ThreadFunc(object):
def __init__(self, func, args, name=''):
self.name=name
self.func=func
self.args=args
def __call__(self):
apply(self.func, self.args)
def loop(nloop, nsec):
print "Start loop", nloop, 'at:', ctime()
sleep(nsec)
print 'Loop', nloop, 'done at:', ctime()
def main():
print 'Starting at:', ctime()
threads=[]
nloops = range(len(loops)) #列表[0,1]
for i in nloops:
#调用ThreadFunc类实例化的对象,创建所有线程
t = threading.Thread(
target=ThreadFunc(loop, (i,loops[i]), loop.__name__)
)
threads.append(t)
#开始线程
for i in nloops:
threads[i].start()
#等待所有结束线程
for i in nloops:
threads[i].join()
print 'All end:', ctime()
if __name__ == '__main__':
main()
~~~
运行结果如下图所示,传递的是一个可调用的类,而不是一个函数。
创建Thread对象时会实例化一个可调用类ThreadFunc的类对象。这个类保存了函数的参数,函数本身以及函数的名字字符串。
构造器__init__()函数:初始化赋值工作;
特殊函数__call__():由于我们已经有要用的参数,所以就不用再传到Thread()构造器中;由于我们有一个参数的元组,这时要在代码中使用apply()函数。
apply(func [, args [, kwargs ]]) 函数:用于当函数参数已经存在于一个元组或字典中时,间接地调用函数。args是一个包含将要提供给函数的按位置传递的参数的元组。如果省略了args,任何参数都不会被传递,kwargs是一个包含关键字参数的字典。
~~~
def say(a, b):
print a, b
apply(say,("Eastmount", "Python线程"))
# 输出
# Eastmount Python线程
~~~
**5.Thread派生一个子类,创建这个子类的实例**
这是第三个方法,主要是如何子类化Thread类,该方法与第二个方法类似。其中创建子类方法和调用类对象方法的最重要改变是:
(1) MyThread子类的构造器一定要先调用基类的构造器;
(2) 之前特殊函数__call__()在子类中,名字要改为run()。
~~~
#coding=utf-8
import threading
from time import sleep, ctime
loops = [4,2] #睡眠时间
class MyThread(threading.Thread):
def __init__(self, func, args, name=''):
threading.Thread.__init__(self)
self.name=name
self.func=func
self.args=args
def run(self): #run()函数
apply(self.func, self.args)
def loop(nloop, nsec):
print "Start loop", nloop, 'at:', ctime()
sleep(nsec)
print 'Loop', nloop, 'done at:', ctime()
def main():
print 'Starting at:', ctime()
threads=[]
nloops = range(len(loops)) #列表[0,1]
for i in nloops:
#子类MyThread实例化,创建所有线程
t = MyThread(loop, (i,loops[i]), loop.__name__)
threads.append(t)
#开始线程
for i in nloops:
threads[i].start()
#等待所有结束线程
for i in nloops:
threads[i].join()
print 'All end:', ctime()
if __name__ == '__main__':
main()
~~~
运行结果如下图所示:

**6.线程运行斐波那契、阶乘和加和**
需要在MyThread类中加入输出信息,除了使用apply()函数运行斐波那契、接触和加和函数外,还把结果保存到实现的self.res属性中,并创建一个函数getResult()得到结果。换句话说,子类方法更加灵活。
~~~
#coding=utf-8
import threading
from time import sleep, ctime
class MyThread(threading.Thread):
def __init__(self, func, args, name=''):
threading.Thread.__init__(self)
self.name=name
self.func=func
self.args=args
def getResult(self):
return self.res
def run(self): #run()函数
print "Starting", self.name, 'at:', ctime()
self.res = apply(self.func, self.args)
print self.name, 'finished at:', ctime()
~~~
在threadfunc.py文件中调用前面定义的Thread子类,myThread.py中的MyThread类。由于这些函数运行得很快(斐波那契函数运行慢些),使用sleep()函数比较它们的时间。实际工作中不需要添加sleep()函数。
~~~
#coding=utf-8
from myThread import MyThread #myThread.py文件中MyThread类
from time import sleep, ctime
#斐波那契函数
def fib(x):
sleep(0.005)
if x < 2:
return 1
return (fib(x-2) + fib(x-1))
#阶乘函数 factorial calculation
def fac(x):
sleep(0.1)
if x < 2:
return 1
return (x * fac(x-1))
#求和函数
def sum(x):
sleep(0.1)
if x < 2:
return 1
return (x + sum(x-1))
funcs = [fib, fac, sum]
n = 14
def main():
nfuncs = range(len(funcs))
print '***单线程方法***'
for i in nfuncs:
print 'Starting', funcs[i].__name__, 'at:', ctime()
print funcs[i](n)
print 'Finished', funcs[i].__name__, 'at:', ctime()
print '***结束单线程***'
print ' '
print '***多线程方法***'
threads = []
for i in nfuncs:
#调用MyThread类实例化的对象,创建所有线程
t = MyThread(funcs[i], (n,), funcs[i].__name__)
threads.append(t)
#开始线程
for i in nfuncs:
threads[i].start()
#等待所有结束线程
for i in nfuncs:
threads[i].join()
print threads[i].getResult()
print '***结束多线程***'
if __name__ == '__main__':
main()
~~~
运行结果如下图所示,单线程运行10s,多线程运行6s。
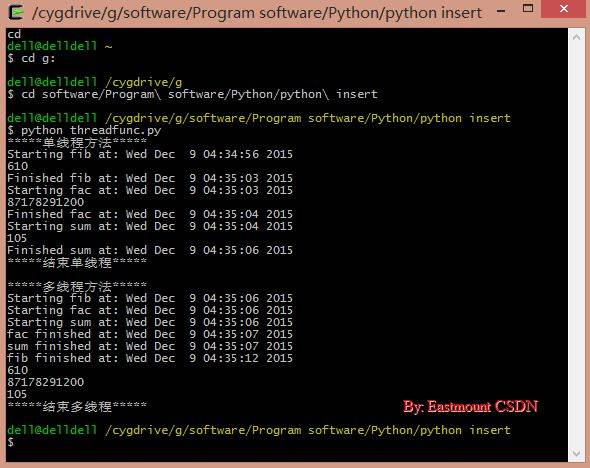
至于Queue模块这里就不再叙述了。
下面介绍除了各种同步对象和线程对象外,threading模块还提供了一些函数。
<table class=" " cellpadding="0" cellspacing="0" style="line-height:26px; padding:0px; margin:0px auto 10px; font-size:12px; border-collapse:collapse; color:rgb(85,85,85); font-family:宋体,'Arial Narrow',arial,serif"><tbody style="padding:0px; margin:0px"><tr style="padding:0px; margin:0px"><td valign="top" width="250" style="border:1px solid rgb(0,0,0); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">函数</span></p></td><td valign="top" width="520" style="border-width:1px; border-style:solid; border-color:rgb(0,0,0) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="padding:0px; margin:0px"><span style="font-family:宋体; padding:0px; margin:0px"><span style="color:rgb(0,0,0)">描述</span></span></span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">activeCount()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">当前活动的线程对象的数量</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">currentThread()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">返回当前线程对象</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">enumerate()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">返回当前活动线程的列表</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">settrace(func)</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">为所有线程设置一个跟踪函数</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">setprofile(func)</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">为所有线程设置一个profile函数</span></p></td></tr></tbody></table>
最后给出一些多线程编程中可能用得到的模块。
<table class=" " cellpadding="0" cellspacing="0" style="line-height:26px; padding:0px; margin:0px auto 10px; font-size:12px; border-collapse:collapse; color:rgb(85,85,85); font-family:宋体,'Arial Narrow',arial,serif"><tbody style="padding:0px; margin:0px"><tr style="padding:0px; margin:0px"><td valign="top" width="250" style="border:1px solid rgb(0,0,0); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:rgb(0,0,0)">模块</span></p></td><td valign="top" width="520" style="border-width:1px; border-style:solid; border-color:rgb(0,0,0) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="padding:0px; margin:0px"><span style="font-family:宋体; padding:0px; margin:0px"><span style="color:rgb(0,0,0)">描述</span></span></span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:rgb(0,0,0)">thread</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">基本的、低级别的线程模块</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">threading</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:rgb(0,0,0)">高级别的线程和同步对象</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">Queue</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">供多线程使用的同步先进先出(FIFO)队列</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">mutex</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">互斥对象</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">SocketServer</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:rgb(0,0,0)">具有线程控制的TCP和UDP管理器<br/></span></p></td></tr></tbody></table>
总之,这篇文章主要是参考《Python核心编程》的,希望文章对你有所帮助~尤其是初学Python编程的,同时为后面我学习多线程的爬虫或分布式爬虫做铺垫。这篇文章花了自己一些时间,写到半夜;写文不易,且看且珍惜吧!勿喷~
(By:Eastmount 2015-12-09 半夜5点 [http://blog.csdn.net/eastmount/](http://blog.csdn.net/eastmount/))
[python] 专题七.网络编程之套接字Socket、TCP和UDP通信实例
最后更新于:2022-04-01 09:35:49
很早以前研究过C#和C++的网络通信,参考我的文章:
[C#网络编程之Tcp实现客户端和服务器聊天](http://blog.csdn.net/eastmount/article/details/9389935)
[C#网络编程之套接字编程基础知识](http://blog.csdn.net/eastmount/article/details/9321153)
[C#网络编程之使用Socket类Send、Receive方法的同步通讯](http://blog.csdn.net/eastmount/article/details/9409935)
Python网络编程也类似。同时最近找工作笔试面试考察Socket套接字、TCP\UDP区别比较多,所以这篇文章主要精简了《Python核心编程(第二版)》第16章内容。内容包括:服务器和客户端架构、套接字Socket、TCP\UDP通信实例和常见笔试考题。
最后希望文章对你有所帮助,如果有不足之处,还请海涵~
##一. 服务器和客户端架构
**1.什么是客户端/服务区架构?**
书中的定义是服务器是一个软件或硬件,用于向一个或多个客户端(客户)提供所需要的“服务”。服务器存在的唯一目的就是等待客户的请求,给这些客户服务,然后再等待其他的请求。而客户连接上(预先已知的)服务器,提出自己的请求,发送必要的数据,然后等待服务器完成请求或说明失败原因的反馈。
服务器不停的处理外来的请求,而客户一次只能提出一个服务的请求,等待结果。再结束这个事务。客户之后可以再提出其他的请求,只是这个请求会被视为另一个不同的事务了。
2.硬件客户端/服务器架构和软件客户端/服务器架构
硬件的客户端/服务器架构,例如打印服务器、文件服务器(客户可以远程把服务器的磁盘映射到自己本体并使用);软件客户端/服务器架构主要是程序的运行、数据收发、升级等,最常见的是Web服务器、数据库服务器。如一台机器存放一些网页或Web应用程序,然后启动服务。其服务器的任务就是接受客户端的请求,把网页发给客户端(如用户计算机上的浏览器),然后再等待下一个客户端请求。
3.客户端/服务器网络编程
在完成服务之前,服务器必须要先完成一些设置。先要先创建一个通讯端点,让服务器能“监听”请求。你可以把我们服务器比作一个公司的接待员或回答公司总线电话的话务员,一旦电话和设备安装完成,话务员也就到位后,服务就开始了。
同样一旦通信端点创建好之后,我们在“监听”的服务器就可以进入它那等待和处理客户请求的无限循环中了。服务器准备好之后,也要通知潜在的客户,让它们知道服务器已经准备好处理服务了,否则没人会提请求的。所以需要把公司电话公开给客户。
而客户端只要创建一个通信端点,建立到服务器的连接,然后客户端就可以提出请求了。请求中也可以包含必要的数据交互。一旦请求处理完成,客户端收到了结果,通信就结束了。这就是客户端和服务器的简单网络通信。
##二. 套接字Socket
1.什么是套接字
套接字是一种具有之前所说的“通信端点”概念的计算网络数据结构。相当于**电话插口**,没它无法通信,这个比喻非常形象。
套接字起源于20世纪70年代加州伯克利分校版本的Unix,即BSDUnix。又称为“伯克利套接字”或“BSD套接字”。最初套接字被设计用在同一台主机上多个应用程序之间的通讯,这被称为进程间通讯或IPC。
套接字分两种:基于文件型和基于网络的
第一个套接字家族为**AF_UNIX**,表示“地址家族:UNIX”。包括Python在内的大多数流行平台上都使用术语“地址家族”及其缩写AF。由于两个进程都运行在同一台机器上,而且这些套接字是基于文件的,所以它们的底层结构是由文件系统来支持的。可以理解为同一台电脑上,文件系统确实是不同的进程都能进行访问的。
第二个套接字家族为**AF_INET**,表示”地址家族:Internet“。还有一种地址家族AF_INET6被用于网际协议IPv6寻址。Python2.5中加入了一种Linux套接字的支持:**AF_NETLINK**(无连接)套接字家族,让用户代码与内核代码之间的IPC可以使用标准BSD套接字接口,这种方法更为精巧和安全。
Python只支持AF_UNIX、AF_NETLINK和AF_INET家族。网络编程关注AF_INET。
如果把套接字比作电话的查看——即通信的最底层结构,那主机与端口就相当于区号和电话号码的一对组合。一个因特网地址由网络通信必须的主机与端口组成。
而且另一端一定要有人接听才行,否则会提示”对不起,您拨打的电话是空号,请查询后再拨“。同样你也可能会遇到如”不能连接该服务器、服务器无法响应“等。合法的端口范围是0~65535,其中小于1024端口号为系统保留端口。
2.面向连接与无连接
面向连接:**通信之前一定要建立一条连接,这种通信方式也被成为”虚电路“或”流套接字“。面向连接的通信方式提供了**顺序的、可靠地、不会重复的数据传输**,而且也不会被加上数据边界。这意味着,每发送一份信息,可能会被拆分成多份,每份都会不多不少地正确到达目的地,然后重新按顺序拼装起来,传给正等待的应用程序。
实现这种连接的主要协议就是**传输控制协议TCP**。要创建TCP套接字就得创建时指定套接字类型为**SOCK_STREAM**。TCP套接字这个类型表示它作为流套接字的特点。由于这些套接字使用网际协议IP来查找网络中的主机,所以这样形成的整个系统,一般会由这两个协议(TCP和IP)组合描述,即TCP/IP。
**无连接:**无需建立连接就可以通讯。但此时,数据到达的顺序、可靠性及不重复性就无法保障了。数据报会保留数据边界,这就表示数据是**整个发送**的,不会像面向连接的协议先拆分成小块。它就相当于邮政服务一样,邮件和包裹不一定按照发送顺序达到,有的甚至可能根本到达不到。而且网络中的报文可能会重复发送。
那么这么多缺点,为什么还要使用它呢?由于面向连接套接字要提供一些保证,需要维护虚电路连接,这都是严重的额外负担。数据报**没有这些负担**,所有它会更”便宜“,通常能提供更好的性能,更适合某些场合,如**现场直播**要求的实时数据讲究快等。
实现这种连接的主要协议是**用户数据报协议UDP**。要创建UDP套接字就得创建时指定套接字类型为**SOCK_DGRAM**。这个名字源于datagram(数据报),这些套接字使用网际协议来查找网络主机,整个系统叫UDP/IP。
3.socket()模块函数
使用socket模块的socket()函数来创建套接字。语法如下:
socket(socket_family, socket_type, protocol=0)
其中socket_family不是AF_VNIX就是AF_INET,socket_type可以是SOCK_STREAM或者SOCK_DGRAM,protocol一般不填,默认值是0。
创建一个TCP/IP套接字的语法如下:
tcpSock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
同样创建一个UDP/IP套接字的语法如下:
udpSock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
由于socket模块中有太多属性,所以使用"from socket import *"语句,把socket模块里面的所有属性都带到命名空间中,大幅缩短代码。调用如下:
tcpSock = socket(AF_INET, SOCK_STREAM)
4.套接字对象方法
下面是最常用的套接字对象方法:
**服务器端套接字函数**
<table class=" " cellpadding="0" cellspacing="0" style="line-height:26px; padding:0px; margin:0px auto 10px; font-size:12px; border-collapse:collapse; color:rgb(85,85,85); font-family:宋体,'Arial Narrow',arial,serif"><tbody style="padding:0px; margin:0px"><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:solid; border-color:rgb(0,0,0); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="padding:0px; margin:0px"><span style="color:#000000">socket<span style="font-family:宋体; padding:0px; margin:0px">类型</span></span></span></p></td><td valign="top" width="482" style="border-width:1px; border-style:solid solid solid none; border-color:rgb(0,0,0) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="padding:0px; margin:0px"><span style="font-family:宋体; padding:0px; margin:0px"><span style="color:#000000">描述</span></span></span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.bind()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体"><span style="color:#000000">绑定地址(主机号 端口号对)到套接字</span></span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.listen()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体"><span style="color:#000000">开始TCP监听</span></span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.accept()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">被动接受TCP客户端连接,(阻塞式)等待连续的到来</span></p></td></tr></tbody></table>
**客户端套接字函数**
<table class=" " cellpadding="0" cellspacing="0" style="line-height:26px; padding:0px; margin:0px auto 10px; font-size:12px; border-collapse:collapse; color:rgb(85,85,85); font-family:宋体,'Arial Narrow',arial,serif"><tbody style="padding:0px; margin:0px"><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:solid; border-color:rgb(0,0,0); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="padding:0px; margin:0px"><span style="color:#000000">socket<span style="font-family:宋体; padding:0px; margin:0px">类型</span></span></span></p></td><td valign="top" width="482" style="border-width:1px; border-style:solid solid solid none; border-color:rgb(0,0,0) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="padding:0px; margin:0px"><span style="font-family:宋体; padding:0px; margin:0px"><span style="color:#000000">描述</span></span></span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.connect()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">主动初始化TCP服务器连接</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.connect_ex()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体"><span style="color:#000000">connect()函数扩展版本,出错时返回出错码而不是跑出异常</span></span></p></td></tr></tbody></table>
**公共用途的套接字函数**
<table class=" " cellpadding="0" cellspacing="0" style="line-height:26px; padding:0px; margin:0px auto 10px; font-size:12px; border-collapse:collapse; color:rgb(85,85,85); font-family:宋体,'Arial Narrow',arial,serif"><tbody style="padding:0px; margin:0px"><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:solid; border-color:rgb(0,0,0); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="padding:0px; margin:0px"><span style="color:#000000">socket<span style="font-family:宋体; padding:0px; margin:0px">类型</span></span></span></p></td><td valign="top" width="482" style="border-width:1px; border-style:solid solid solid none; border-color:rgb(0,0,0) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="padding:0px; margin:0px"><span style="font-family:宋体; padding:0px; margin:0px"><span style="color:#000000">描述</span></span></span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.recv()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">接受TCP数据</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.send()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">发送TCP数据</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.sendall()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">完整发送TCP数据</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.recvfrom()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">接受UDP数据</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.sendto()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">发送UDP数据</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.getpeername()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">连接到当前套接字的远端地址(TCP连接)</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.getsockname()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">获取当前套接字的地址</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.getsockopt()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">返回指定套接字的参数</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.s<span style="line-height:26px">etsockopt</span>()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">设置指定套接字的参数</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.close()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">关闭套接字</span></p></td></tr></tbody></table>
**面向模块的套接字函数**
<table class=" " cellpadding="0" cellspacing="0" style="line-height:26px; padding:0px; margin:0px auto 10px; font-size:12px; border-collapse:collapse; color:rgb(85,85,85); font-family:宋体,'Arial Narrow',arial,serif"><tbody style="padding:0px; margin:0px"><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:solid; border-color:rgb(0,0,0); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="padding:0px; margin:0px"><span style="color:#000000">socket<span style="font-family:宋体; padding:0px; margin:0px">类型</span></span></span></p></td><td valign="top" width="482" style="border-width:1px; border-style:solid solid solid none; border-color:rgb(0,0,0) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="padding:0px; margin:0px"><span style="font-family:宋体; padding:0px; margin:0px"><span style="color:#000000">描述</span></span></span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.setblocking()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">设置套接字的阻塞与非阻塞模式</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.settimeout()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">设置阻塞套接字操作的超时时间</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.gettimeout()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">得到阻塞套接字操作的超时时间</span></p></td></tr></tbody></table>
面向文件的套接字函数
<table class=" " cellpadding="0" cellspacing="0" style="line-height:26px; padding:0px; margin:0px auto 10px; font-size:12px; border-collapse:collapse; color:rgb(85,85,85); font-family:宋体,'Arial Narrow',arial,serif"><tbody style="padding:0px; margin:0px"><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:solid; border-color:rgb(0,0,0); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="padding:0px; margin:0px"><span style="color:#000000">socket<span style="font-family:宋体; padding:0px; margin:0px">类型</span></span></span></p></td><td valign="top" width="482" style="border-width:1px; border-style:solid solid solid none; border-color:rgb(0,0,0) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px; background-color:rgb(242,242,242)"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="padding:0px; margin:0px"><span style="font-family:宋体; padding:0px; margin:0px"><span style="color:#000000">描述</span></span></span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.fileno()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">套接字的文件描述符</span></p></td></tr><tr style="padding:0px; margin:0px"><td valign="top" width="226" style="border-width:1px; border-style:none solid solid; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="color:#000000">s.makefile()</span></p></td><td valign="top" width="482" style="border-width:1px; border-style:none solid solid none; border-color:rgb(221,221,221) rgb(0,0,0) rgb(0,0,0) rgb(221,221,221); padding:0px 7px; margin:0px"><p style="margin-top:0px; margin-bottom:0px; padding-top:0px; padding-bottom:0px; clear:both; height:auto; overflow:hidden"><span style="font-family:宋体; color:#000000">创建一个与套接字关联的文件对象</span></p></td></tr></tbody></table>
提示:在运行网络应用程序时,如果能够使用在不同的电脑上运行服务器和客户端最好不过,它能让你更好理解通信过程,而更多的是方位localhost或127.0.0.1.
## 三. TCP通信实例
**1.服务器 tcpSerSock.py**
核心操作如下:
ss = socket() # 创建服务器套接字
ss.bind() # 地址绑定到套接字上
ss.listen() # 监听连接
inf_loop: # 服务器无限循环
cs = ss.accept() # 接受客户端连接 阻塞式:程序连接之前处于挂起状态
comm_loop: # 通信循环
cs.recv()/cs.send() # 对话 接受与发送数据
cs.close() # 关闭客户端套接字
ss.close() # 关闭服务器套接字 (可选)
~~~
# -*- coding: utf-8 -*-
from socket import *
from time import ctime
HOST = 'localhost' #主机名
PORT = 21567 #端口号
BUFSIZE = 1024 #缓冲区大小1K
ADDR = (HOST,PORT)
tcpSerSock = socket(AF_INET, SOCK_STREAM)
tcpSerSock.bind(ADDR) #绑定地址到套接字
tcpSerSock.listen(5) #监听 最多同时5个连接进来
while True: #无限循环等待连接到来
try:
print 'Waiting for connection ....'
tcpCliSock, addr = tcpSerSock.accept() #被动接受客户端连接
print u'Connected client from : ', addr
while True:
data = tcpCliSock.recv(BUFSIZE) #接受数据
if not data:
break
else:
print 'Client: ',data
tcpCliSock.send('[%s] %s' %(ctime(),data)) #时间戳
except Exception,e:
print 'Error: ',e
tcpSerSock.close() #关闭服务器
~~~
**2.客户端 tcpCliSock.py**
核心操作如下:
cs = socket() # 创建客户端套接字
cs.connect() # 尝试连接服务器
comm_loop: # 通讯循环
cs.send()/cs.recv() # 对话 发送接受数据
cs.close() # 关闭客户端套接字
~~~
# -*- coding: utf-8 -*-
from socket import *
HOST = 'localhost' #主机名
PORT = 21567 #端口号 与服务器一致
BUFSIZE = 1024 #缓冲区大小1K
ADDR = (HOST,PORT)
tcpCliSock = socket(AF_INET, SOCK_STREAM)
tcpCliSock.connect(ADDR) #连接服务器
while True: #无限循环等待连接到来
try:
data = raw_input('>')
if not data:
break
tcpCliSock.send(data) #发送数据
data = tcpCliSock.recv(BUFSIZE) #接受数据
if not data:
break
print 'Server: ', data
except Exception,e:
print 'Error: ',e
tcpCliSock.close() #关闭客户端
~~~
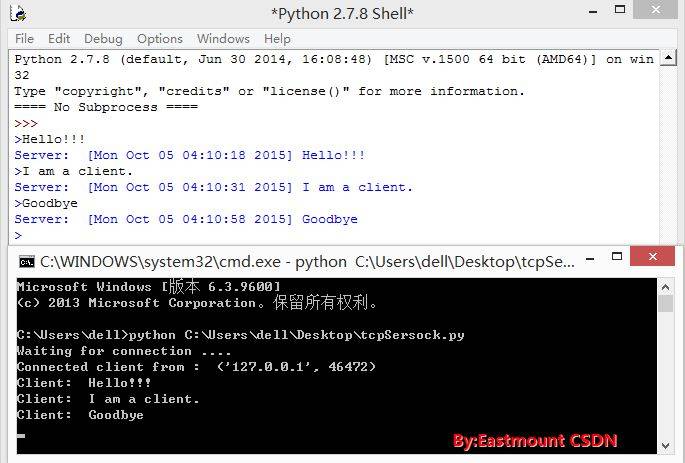
**3.运行结果及注意**
由于服务器被动地无限循环等待连接,所以需要**先运行服务器,再开客户端。**又因为我的Python总会无法响应,所以采用cmd运行服务器Server程序,Python IDLE运行客户端进行通信。运行结果如下图所示:
如果出现错误[Error] Bad file descriptor表示服务器关闭客户端连接了,删除即可
建议:创建线程来处理客户端请求。SocketServer模块是一个基于socket模块的高级别的套接字通信模块,支持新的线程或进程中处理客户端请求。同时建议在退出和调用服务器close()函数时使用try-except语句。
## 四. UDP通信实例
**1.服务器 udpSerSock.py**
核心操作如下:
ss = socket() # 创建服务器套接字
ss.bind() # 绑定服务器套接字
inf_loop: # 服务器无限循环
cs = ss.recvfrom()/ss.sendto()
# 对话 接受与发送数据
ss.close() # 关闭服务器套接字
~~~
# -*- coding: utf-8 -*-
from socket import *
from time import ctime
HOST = '' #主机名
PORT = 21567 #端口号
BUFSIZE = 1024 #缓冲区大小1K
ADDR = (HOST,PORT)
udpSerSock = socket(AF_INET, SOCK_DGRAM)
udpSerSock.bind(ADDR) #绑定地址到套接字
while True: #无限循环等待连接到来
try:
print 'Waiting for message ....'
data, addr = udpSerSock.recvfrom(BUFSIZE) #接受UDP
print 'Get client msg is: ', data
udpSerSock.sendto('[%s] %s' %(ctime(),data), addr) #发送UDP
print 'Received from and returned to: ',addr
except Exception,e:
print 'Error: ',e
udpSerSock.close() #关闭服务器
~~~
**2.客户端 udpCliSock.py**
核心操作如下:
cs = socket() # 创建客户端套接字
inf_loop: # 服务器无限循环
cs.sendto()/cs.recvfrom() # 对话 接受与发送数据
cs.close() # 关闭客户端套接字
~~~
# -*- coding: utf-8 -*-
from socket import *
HOST = 'localhost' #主机名
PORT = 21567 #端口号 与服务器一致
BUFSIZE = 1024 #缓冲区大小1K
ADDR = (HOST,PORT)
udpCliSock = socket(AF_INET, SOCK_DGRAM)
while True: #无限循环等待连接到来
try:
data = raw_input('>')
if not data:
break
udpCliSock.sendto(data, ADDR) #发送数据
data,ADDR = udpCliSock.recvfrom(BUFSIZE) #接受数据
if not data:
break
print 'Server : ', data
except Exception,e:
print 'Error: ',e
udpCliSock.close() #关闭客户端
~~~
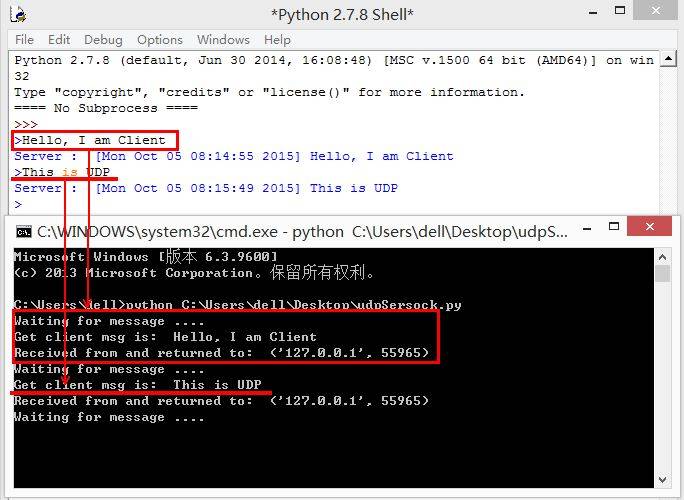
**3.运行结果及注意**
UDP服务器不是面向连接的,所以不需要设置什么东西,直接等待连接就好。同时由于数据报套接字是无连接的,所以无法把客户端连接交给另外的套接字进行后续的通讯,这些服务器只是接受消息,需要的话加时间错后返回一个收到的结果给客户端。
UDP客户端与TCP客户端唯一区别就是不用去UDP服务器建立连接,而是直接把消息发送出去,然后等待服务器回复即可。
运行结果如下图所示:白色为客户端输入消息,黑色为服务器收到消息并回复。当Client输入"Hello, I am Client"时,服务器显示该消息并返回时间戳和收到的信息给客户端。
**总结:**
后面大家自己可以阅读下SocketServer模块,它是标准库中一个高级别的模块,用于简化实现网络客户端和服务器所需的大量样板代码。该模块中已经实现了一些可供使用的类直接调用几块。
Twisted框架是一个完全事件驱动的网络框架。它允许你使用和开发完全异步的网络应用程序和协议。
这些东西我更倾向于分享原理和底层的一些东西吧!同时最近考到的笔试题包括:TCP和UDP的区别、socket其中的参数含义、TCP三次握手及传递的参数、写个socket通讯伪代码。
总之,希望文章对你有所帮助~
(By:Eastmount 2015-10-5 早上8点 [http://blog.csdn.net/eastmount/](http://blog.csdn.net/eastmount/))
[Python学习] 专题六.局部变量、全局变量global、导入模块变量
最后更新于:2022-04-01 09:35:47
定义在函数内的变量有局部作用域,在一个模块中最高级别的变量有全局作用域。本文主要讲述全局变量、局部变量和导入模块变量的方法。
参考:《Python核心编程 (第二版)》
##一. 局部变量
声明适用的程序的范围被称为了声明的作用域。在一个过程中,如果名字在过程的声明之内,它的出现即为过程的局部变量;否则出现即为非局部。例:
~~~
def foo(x):
print 'x = ',x
x = 200
print 'Changed in foo(), x = ',x
x = 100
foo(x)
print 'x = ',x
~~~
输出结果如下:
~~~
>>>
x = 100
Changed in foo(), x = 200
x = 100
~~~
在主块中定义x=100,Python使用函数声明的形参传递x至foo()函数。foo()中把x赋值为200,x是函数的局部变量;所以在函数内改变x的值,主块中定义的x不受影响。
核心笔记:
当搜索一个标识符时,Python先从局部作用域开始搜索。如果在局部作用域内没有找到那个名字,那么一定会在全局域找到这个变量,否则会被抛出NameError异常。
作用域的概念和用于找到变量的名称空间搜索顺序相关。当一个函数执行时,所有在局部命名空间的名字都在局部作用域内;当查找一个变量时,第一个被搜索的名称空间,如果没有找到那个变量,那么就可能找到同名的局部变量。
##二. 全局变量
全局变量的一个特征是除非删除掉,否则它们存活到脚本运行结束,且对于所有的函数,它们的值都是可以被访问的。然而局部变量,就像它们存放的栈,暂时地存在,仅仅只依赖于定义它们的函数现阶段是否处于活动。当一个函数调用出现时,其局部变量就进入声明它们的作用域。在那一刻,一个新的局部变量名为那个对象创建了,一旦函数完成,框架被释放,变量将会离开作用域。
~~~
X = 100
def foo():
global X
print 'foo() x = ',X
X = X + 5
print 'Changed in foo(), x = ',X
def fun():
global X
print 'fun() x = ',X
X = X + 1
print 'Changed in fun(), x = ',X
if __name__ == '__main__':
foo()
fun()
print 'Result x = ',X
~~~
输出结果如下:
~~~
>>>
foo() x = 100
Changed in foo(), x = 105
fun() x = 105
Changed in fun(), x = 106
Result x = 106
~~~
核心笔记:
使用global语句定义全局变量。当使用全局变量同名的局部变量时要小心,如果将全局变量的名字声明在一个函数体内,全局变量的名字能被局部变量给覆盖掉。所以,你应该尽量添加global语句,否则会使得程序的读者不清楚这个变量在哪里定义的。
你可以使用同一个global语句指定多个全局变量。例如global x, y, z。
当我在制作Python爬虫时,需要想函数中传递url,循环爬取每个url页面的InfoBox,此时的文件写入操作就可以有两种方法实现:1.通过传递参数file;2.通过定义全局变量file。
~~~
SOURCE = open("F:\\test.txt",'w')
def writeInfo(i):
global SOURCE
SOURCE.write('number'+str(i)+'\n')
def main():
i=0
while i<50:
writeInfo(i)
print i
i=i+1
else:
print 'End'
SOURCE.close()
main()
~~~
**PS:**在此种用法中,如果我们在函数writeInfo()中不使用global 声明全局变量SOURCE,其实也可以使用,但是此时应该是作为一个内部变量使用,由于没有初始值,因此报错。Python查找变量是顺序是:先局部变量,再全局变量。
~~~
UnboundLocalError: local variable 'SOURCE' referenced before assignment
~~~
##三. 模块导入变量
主要方法是通过在py文件中模块定义好变量,然后通过import导入全局变量并使用。例:
~~~
import global_abc
def foo():
print global_abc.GLOBAL_A
print global_abc.GLOBAL_B
print global_abc.GLOBAL_C
global_abc.GLOBAL_C = global_abc.GLOBAL_C + 200
print global_abc.GLOBAL_C
if __name__ == '__main__':
foo()
print global_abc.GLOBAL_A + ' ' + global_abc.GLOBAL_B
print global_abc.GLOBAL_C
~~~
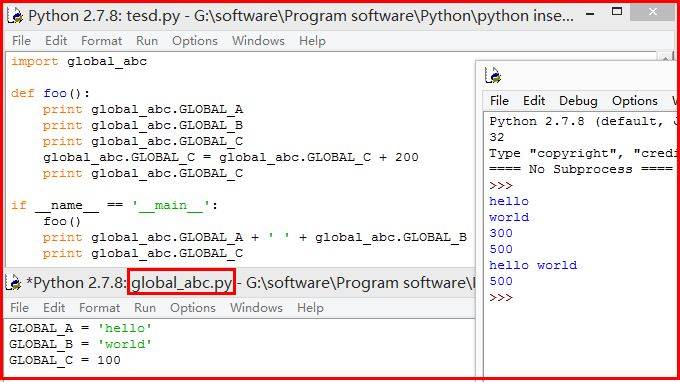
输出如下所示,全局变量结构是可以改变的。
~~~
>>>
hello
world
300
500
hello world
500
~~~
截图如下所示:
**PS:**应该尽量避免使用全局变量。不同的模块都可以自由的访问全局变量,可能会导致全局变量的不可预知性。对全局变量,如果程序员甲修改了_a的值,程序员乙同时也要使用_a,这时可能导致程序中的错误。这种错误是很难发现和更正的。同时,全局变量降低了函数或模块之间的通用性,不同的函数或模块都要依赖于全局变量。同样,全局变量降低了代码的可读性,阅读者可能并不知道调用的某个变量是全局变量,但某些情况不可避免的需要使用它。
最后关于闭包和Lambda(相当于函数)就不再介绍,希望文章对你有所帮助~同时今天也是中秋节,祝所有程序猿和读者中秋节快乐。
(By:Eastmount 2015-9-27 下午4点 [http://blog.csdn.net/eastmount/](http://blog.csdn.net/eastmount/))
[Python] 专题五.列表基础知识 二维list排序、获取下标和处理txt文本实例
最后更新于:2022-04-01 09:35:45
通常测试人员或公司实习人员需要处理一些txt文本内容,而此时使用Python是比较方便的语言。它不光在爬取网上资料上方便,还在NLP自然语言处理方面拥有独到的优势。这篇文章主要简单的介绍使用Python处理txt汉字文字、二维列表排序和获取list下标。希望文章对你有所帮助或提供一些见解~
##一. list二维数组排序
功能:已经通过Python从维基百科中获取了国家的国土面积和排名信息,此时需要获取国土面积并进行排序判断世界排名是否正确。
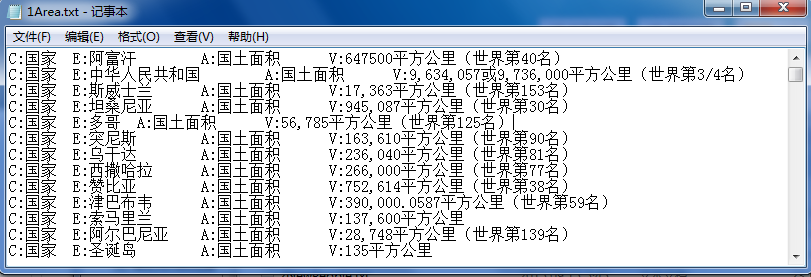
**列表基础知识**
列表类型同字符串一样也是序列式的数据类型,可以通过下标或切片操作来访问某一个或某一块连续的元素。它和字符串不同之处在于:字符串只能由字符组成而且不可变的(不能单独改变它的某个值),而列表是能保留任意数目的Python对象灵活容器。
总之,列表可以包含不同类型的对象(包括用户自定义的对象)作为元素,列表可以添加或删除元素,也可以合并或拆分列表,包括insert、update、remove、sprt、reverse等操作。
**列表排序介绍**
常用列表排序方法包括使用List内建函数list.sort()或序列类型函数sorted(list)排序
~~~
#list.sort(func=None, key=None, reverse=False)
list = [4, 3, 9, 1, 5, 2]
print list
list.sort()
print list
#输出
[4, 3, 9, 1, 5, 2]
[1, 2, 3, 4, 5, 9]
~~~
通过对比下面的代码,可以发现两种方法的区别是:list.sort()改变了原list的顺序,而sorted没有。
~~~
#sorted(list)
list = ['h', 'a', 'p', 'd', 'i', 'b']
print list
print sorted(list)
print list
#输出
['h', 'a', 'p', 'd', 'i', 'b']
['a', 'b', 'd', 'h', 'i', 'p']
['h', 'a', 'p', 'd', 'i', 'b']
~~~
**二维列表排序**
通过lambda表达式实现二维列表排序,并且按照第二个关键字进行排序。[参考](http://blog.chinaunix.net/uid-20775448-id-4222915.html)
~~~
#list.sort(func=None, key=None, reverse=False)
list = [('Tom',4),('Jack',7),('Daly',9),('Mary',1),('God',5),('Yuri',3)]
print list
list.sort(lambda x,y:cmp(x[1],y[1]))
print list
#输出
[('Tom', 4), ('Jack', 7), ('Daly', 9), ('Mary', 1), ('God', 5), ('Yuri', 3)]
[('Mary', 1), ('Yuri', 3), ('Tom', 4), ('God', 5), ('Jack', 7), ('Daly', 9)]
~~~
题目中如果第一个数存储文件中读取的行号,第二个数存储人口数量,此时可对第二个数进行排序。需要注意的是它们一组(1,93)是tuple元组。
~~~
#list.sort(func=None, key=None, reverse=False)
list = [(1,93),(2,71),(3,89),(4,93),(5,85),(6,77)]
print list
list.sort(key=lambda x:x[1])
print list
#输出
[(1, 93), (2, 71), (3, 89), (4, 93), (5, 85), (6, 77)]
[(2, 71), (6, 77), (5, 85), (3, 89), (1, 93), (4, 93)]
~~~
**lambada表达式**
在上述代码中,如果还不知道lambada是什么鬼东西的话?那我就来帮你回顾了。
python允许使用lambda关键字创造匿名函数,它不需要以标准的方式来声明,如def语句。然而作为函数,它们也能有参数。
lambda就是一个表达式,而不是一个代码块。而且这个表达是的定义必须和声明放在同一行,能在lambda中封装有限的逻辑进去,起到一个函数速写的作用。例如:
~~~
#lambda [arg1[, arg2, ..., argN]]:expression
f = lambda x,y,z:x+y+z
num = f(1,2,3)
print 'lambda: ' + str(num)
#等价于
def add(x,y,z):
return x+y+z
num = add(1,2,3)
print 'function: ' + str(num)
#输出
lambda: 6
function: 6
~~~
##二. 处理txt文本
下面是通过txt文件按行读取,并获取面积进行排序。其中核心代码如下:
**读取文件&列表添加**
~~~
source = open("F:\\Student\\1Area.txt",'r')
lines = source.readlines()
L = [] #列表二维 国家行数 人口数
count = 1 #当前国家在文件中第count行
for line in lines:
line = line.rstrip('\n') #去除换行
.... #获取排名和面积
fNum = string.atof(number) #面积
L.append((count,ffNum)) #列表添加
count = count + 1
else:
print 'End While'
source.close()
~~~
**列表排序**
~~~
L.sort(lambda x,y:cmp(x[1],y[1]),reverse = True)
#遍历过程 表示第i名 (文件第x行,面积y平方公里)
#重点 L[i]输出列表 1 (46, 17075200.0) L[i][0]表示元组tuple第一个数 1 46
for i in range(len(L)):
print (i+1), L[i]
~~~
** 获取面积字符串**
~~~
line = line.rstrip('\n') #去除换行
start = line.find(r'V:')
end = line.find(r'平方公里')
number = line[start+2:end]
number = number.replace(',','') #去除','
#输出
line => C:国家 E:中华人民共和国 A:国土面积 V:9,634,057或9,736,000平方公里(世界第3/4名)
number => 9634057或9736000
~~~
最后同时需要处理各种字符串情况,如‘或’、‘万’要乘10000、删除‘[1]’等。更简单的方法是通过正则表达式或获取第一个非数字字符。
运行结果如下所示,排序后的txt和纠错txt:

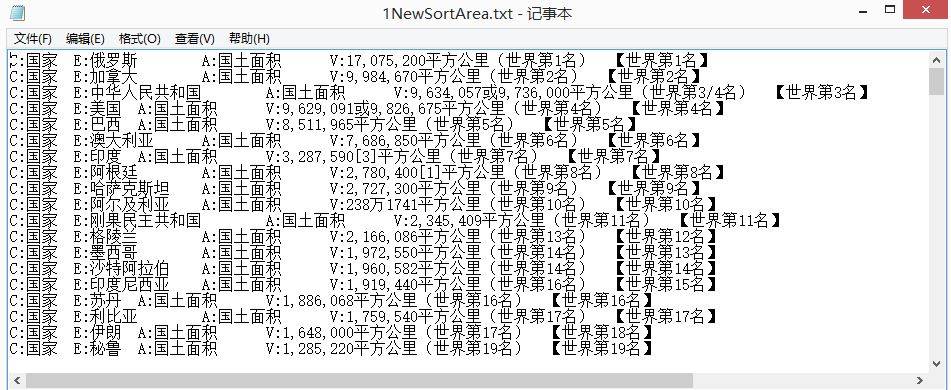
代码如下:
~~~
# coding=utf-8
import time
import re
import os
import string
import sys
source = open("F:\\Student\\1Area.txt",'r')
lines = source.readlines()
count = 1
L = [] #列表二维 国家行数 人口数
'''
第一部分 获取国土面积
'''
print 'Start!!!'
for line in lines:
line = line.rstrip('\n') #去除换行
start = line.find(r'V:')
end = line.find(r'平方公里')
number = line[start+2:end]
number = number.replace(',','') #去除','
fNum = 0.0
if '万' in number:
end = line.find(r'万')
newNum = line[start+2:end]
fNum = string.atof(newNum)*10000
else: #如何优化代码 全局变量
if '/' in number:
end = line.find(r'/')
newNum = line[start+2:end]
newNum = newNum.replace(',','')
fNum = string.atof(newNum)
elif '(' in number:
end = line.find(r'(')
newNum = line[start+2:end]
newNum = newNum.replace(',','')
fNum = string.atof(newNum)
elif '[' in number:
end = line.find(r'[')
newNum = line[start+2:end]
newNum = newNum.replace(',','')
fNum = string.atof(newNum)
elif '或' in number:
end = line.find(r'或')
newNum = line[start+2:end]
newNum = newNum.replace(',','')
fNum = string.atof(newNum)
elif ' ' in number:
end = line.find(r' ')
newNum = line[start+2:end]
newNum = newNum.replace(',','')
fNum = string.atof(newNum)
else:
fNum = string.atof(number)
#print line
#print number
#print fNum
L.append((count,fNum))
count = count + 1
else:
print 'End While'
source.close()
'''
第二部分 从大到小排序
参看 http://blog.chinaunix.net/uid-20775448-id-4222915.html
'''
L.sort(lambda x,y:cmp(x[1],y[1]),reverse = True)
#print L
#遍历过程 表示第i名 (文件第x行,面积y平方公里)
#重点 L[i]输出列表 1 (46, 17075200.0) L[i][0]表示元组tuple第一个数 1 46
for i in range(len(L)):
print (i+1), L[i]
'''
第三部分 读写文件
'''
source = open("F:\\Student\\1Area.txt",'r')
lines = source.readlines()
result = open("F:\\Student\\1NewArea.txt",'w')
count = 1
for line in lines:
line = line.rstrip('\n')
#获取列表L中排名位置pm
pm = 0
for i in range(len(L)):
if count==L[i][0]:
pm = i+1
break
#获取文件中名次
if '世界第' in line:
start = line.find(r'世界第')
end = line.find(r'名')
number = line[start+9:end]
if '/' in number: #防止中国第3/4名
end = line.find(r'/')
number = line[start+9:end]
if '包括海外' in number:
number = '41'
print number,pm,type(number),type(pm)
if string.atoi(number)==pm:
line = line + ' 【排名正确】 【世界第' + str(pm) + '名】'
result.write(line+'\n')
else:
line = line + ' 【排名错误】 【世界第' + str(pm) + '名】'
result.write(line+'\n')
else: #文件中没有排名
line = line + ' 【新加排名】 【世界第' + str(pm) + '名】'
result.write(line+'\n')
count = count + 1
else:
print 'End Sorted'
source.close()
result.close()
'''
第四部分 输出一个排序好的文件 便于观察
'''
source = open("F:\\Student\\1Area.txt",'r')
lines = source.readlines()
result = open("F:\\Student\\1NewSortArea.txt",'w')
#i表示第i名 L[i][0]表示行数
pm = 0
for i in range(len(L)):
pm = L[i][0]
count = 1
for line in lines:
line = line.rstrip('\n')
if count==pm:
line = line + ' 【世界第' + str(i+1) + '名】'
result.write(line+'\n')
break
else:
count = count + 1
else:
print 'End Sorted Second'
source.close()
result.close()
~~~
最后希望文章对你有所帮助,文章主要通过讲述一个实际操作,帮你巩固学习liet列表的二维排序和字符串txt处理。如果文中有错误或不足之处,还请海涵~
(By:Eastmount 2015-9-16 晚上9点 [http://blog.csdn.net/eastmount/](http://blog.csdn.net/eastmount/))
[Python学习] 简单爬取CSDN下载资源信息
最后更新于:2022-04-01 09:35:42
这是一篇Python爬取CSDN下载资源信息的例子,主要是通过urllib2获取CSDN某个人所有资源的资源URL、资源名称、下载次数、分数等信息;写这篇文章的原因是我想获取自己的资源所有的评论信息,但是由于评论采用JS临时加载,所以这篇文章先简单介绍如何人工分析HTML页面爬取信息。
**源代码**
~~~
# coding=utf-8
import urllib
import time
import re
import os
#**************************
#第一步 遍历获取每页对应主题的URL
#http://download.csdn.net/user/eastmount/uploads/1
#http://download.csdn.net/user/eastmount/uploads/8
#**************************
num=1 #记录资源总数 共46个资源
number=1 #记录列表总数1-8
fileurl=open('csdn_url.txt','w+')
fileurl.write('********获取资源URL*******\n\n')
while number<9:
url='http://download.csdn.net/user/eastmount/uploads/' + str(number)
fileurl.write('下载列表URL:'+url+'\n\n')
print unicode('下载列表URL:'+url,'utf-8')
content=urllib.urlopen(url).read()
open('csdn.html','w+').write(content)
#获取包含URL块内容 匹配需要计算</div>个数
start=content.find(r'<div class="list-container mb-bg">')
end=content.find(r'<div class="page_nav">')
cutcontent=content[start:end]
#print cutcontent
#获取块内容中URL
#形如<dt><div><img 图标></div><h3><a href>标题</a></h3></dt>
res_dt = r'<dt>(.*?)</dt>'
m_dt = re.findall(res_dt,cutcontent,re.S|re.M)
for obj in m_dt:
#记录URL数量
print '**********************'
print '第'+str(num)+'个资源'
fileurl.write('**********************\n')
fileurl.write('第'+str(num)+'个资源\n')
num = num +1
#获取具体URL
url_list = re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')", obj)
for url in url_list:
url_load='http://download.csdn.net'+url
print 'URL: '+url_load
fileurl.write('URL: http://download.csdn.net'+url+'\n')
#获取资源标题
#<a href="/detail/eastmount/8757243">MFC显示BMP图片</a>
res_title = r'<a href=.*?>(.*?)</a>'
title = re.findall(res_title,obj,re.S|re.M)
for t in title:
print unicode('Title: ' + t,'utf-8')
fileurl.write('Title: ' + t +'\n')
#**************************
#第二步 遍历具体资源的内容及评论
#http://download.csdn.net/detail/eastmount/8785591
#**************************
#定位指定结构化信息盒Infobox
resources = urllib.urlopen(url_load).read()
open('resource.html','w+').write(resources)
start_res=resources.find(r'<div class="wraper-info">')
end_res=resources.find(r'<div class="enter-link">')
infobox=resources[start_res:end_res]
#获取资源积分、下载次数、资源类型、资源大小(前4个<span></span>)
res_span = r'<span>(.*?)</span>'
m_span = re.findall(res_span,infobox,re.S|re.M)
print '资源积分: '+m_span[0]
fileurl.write('资源积分: ' + m_span[0] +'\n')
print '下载次数: '+m_span[1]
fileurl.write('下载次数: ' + m_span[1] +'\n')
print '资源类型: '+m_span[2]
fileurl.write('资源类型: ' + m_span[2] +'\n')
print '资源大小: '+m_span[3]
fileurl.write('资源大小: ' + m_span[3] +'\n')
#**************************
#第三步 如何获取评论
#http://jeanphix.me/Ghost.py/
#http://segmentfault.com/q/1010000000143340
#http://casperjs.org/
#**************************
else:
fileurl.write('**********************\n\n')
print '**********************\n'
print 'Load Next List\n'
number = number+1 #列表加1
#退出所有循环
else:
fileurl.close()
~~~
显示结果
显示内容包括资源URL、资源标题、资源积分、下载次数、资源类型和资源大小:
比如现在爬取郭霖大神的资源信息,其中页面链接如下:(共7页)
[http://download.csdn.net/user/sinyu890807/uploads/1](http://download.csdn.net/user/sinyu890807/uploads/1)
[http://download.csdn.net/user/sinyu890807/uploads/7](http://download.csdn.net/user/sinyu890807/uploads/7)
简单修改Python源代码URL后,下载页面如下图所示:
运行结果如下图所示:
HTML分析
首先,获取每列中的所有资源的URL和标题,通过分析源代码。
~~~
<dt>
<div class="icon"><img src="/images/minetype/rar.gif" title="rar文件"></div>
<div class="btns"></div>
<h3><a href="/detail/eastmount/8772951">
MFC 图像处理之几何运算 图像平移旋转缩放镜像(源码)</a>
<span class="points">0</span>
</h3>
</dt>
<dd class="meta">上传者:
<a class="user_name" href="/user/eastmount">eastmount</a>
| 上传时间:2015-06-04
| 下载26次
</dd>
<dd class="intro">
该资源主要参考我的博客【数字图像处理】六.MFC空间几何变换之图像平移、镜像、旋转
缩放详解,主要讲述基于VC++6.0 MFC图像处理的应用知识,要通过MFC单文档视图实现显
示BMP图片。
</dd>
<dd class="tag">
<a href="/tag/MFC">MFC</a>
<a href="/tag/%E5%9B%BE%E5%83%8F%E5%A4%84%E7%90%86">图像处理</a><
</dd>
~~~
对应的HTML显示如下图所示:
然后通过URL去到具体的资源获取我自己称为像消息盒的信息:
对应审查元素的信息如下所示,获取<span>0分</span>即可:

最后我想做的事获取评论信息,但是它是通过JS实现的:
~~~
<div class="section-list panel panel-default">
<div class="panel-heading">
<h3 class="panel-title">资源评论</h3>
</div>
<!-- recommand -->
<script language='JavaScript' defer type='text/javascript'
src='/js/comment.js'></script>
<div class="recommand download_comment panel-body" sourceid="8772951"></div>
</div>
~~~
显示的JS页面部分如下:
~~~
var base_url= (window.location.host.substring(0,5)=='local') ? 'http://local.downloadv3.csdn.net' : 'http://download.csdn.net';
base_url = "";
$(document).ready(function(){
CC_Comment.initConfig();
CC_Comment.getContent(1);
});
var CC_Comment =
{
sourceid:0,
initConfig:function()
{
var sid = parseInt($(".download_comment").attr('sourceid'));
if(isNaN(sid) || sid<=0)
{
this.sourceid = 0;
}else
{
this.sourceid = sid;
}
}
....
}
~~~
最后希望文章对你有所帮助吧!下一篇准备分析下Python如何获取JS的评论信息,同时该篇文章可以给你提供一种简单的人工分析页面的例子;也可以获取某个人CSDN资源下载多、分数高的给你挑选。基础知识,仅供参考~
(By:Eastmount 2015-7-21 下午5点 [http://blog.csdn.net/eastmount/](http://blog.csdn.net/eastmount/))
[python学习] 模仿浏览器下载CSDN源文并实现PDF格式备份
最后更新于:2022-04-01 09:35:40
最近突然想给自己的博客备份下,看了两个软件:一个是CSDN博客导出软件,好像现在不能使用了;一个是豆约翰博客备份专家,感觉都太慢,而且不灵活,想单独下一篇文章就比较费时。而且我的毕业论文是基于Python自然语言相关的,所以想结合前面的文章用Python实现简单的功能:
1.通过网络下载本体的博客,包括图片;
2.在通过Python把HTML转换成PDF格式;
3.如果可能,后面可能会写文章对代码采用特定的方式进行处理。
言归正传,直接上代码通过两个方面进行讲解。
##一. 设置消息头下载CSDN文章内容
获取一篇文章Python的代码如下,如韩寒的新浪博客:(文章最后的总结有我以前关于Python爬虫博文链接介绍)
~~~
import urllib
content = urllib.urlopen("http://blog.sina.com.cn/s/blog_4701280b0102eo83.html").read()
open('blog.html','w+').write(content)
~~~
但是很多网站都防止这种获取方式,如CSDN会返回如下html代码:“403 Forbidden错误”:
~~~
<html>
<head><title>403 Forbidden</title></head>
<body bgcolor="white">
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx</center>
</body>
</html>
~~~
此时通过设置消息头或模仿登录,可以伪装成浏览器实现下载。代码如下:
~~~
#coding:utf-8
import urllib
import urllib2
import cookielib
import string
import time
import re
import sys
#定义类实现模拟登陆下载HTML
class GetInfoByBrowser:
#初始化操作
#常见错误:AttributeError: .. instance has no attribute 'opener' 是双下划线
def __init__(self):
socket.setdefaulttimeout(20)
self.headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:28.0) Gecko/20100101 Firefox/28.0'}
self.cookie_support = urllib2.HTTPCookieProcessor(cookielib.CookieJar())
self.opener = urllib2.build_opener(self.cookie_support,urllib2.HTTPHandler)
#定义函数模拟登陆
def openurl(self,url):
urllib2.install_opener(self.opener)
self.opener.addheaders = [("User-agent",self.headers),("Accept","*/*"),('Referer','http://www.google.com')]
try:
result = self.opener.open(url)
content = result.read()
open('openurl.html','w+').write(content)
print content
print 'Open Succeed!!!'
except Exception,e:
print "Exception: ",e
else:
return result
#定义Get请求 添加请求消息头,伪装成浏览器
def geturl(self,get_url):
result = ""
try:
req = urllib2.Request(url = get_url, headers = self.headers)
result = urllib2.urlopen(req).read()
open('geturl.html','w+').write(result)
type = sys.getfilesystemencoding()
print result.decode("UTF-8").encode(type) #防止中文乱码
print 'Get Succeed!!!'
except Exception,e:
print "Exception: ",e
else:
return result
#调用该类获取HTML
print unicode('调用模拟登陆函数openurl:','utf-8')
print unicode('第一种方法 openurl:','utf-8')
getHtml = GetInfoByBrowser()
getHtml.openurl("http://blog.csdn.net/eastmount/article/details/39770543")
print unicode('第二种方法 geturl:','utf-8')
getHtml.geturl("http://blog.csdn.net/eastmount/article/details/39770543")
~~~
运行效果是下载我的文章“[Python学习] 简单网络爬虫抓取博客文章及思想介绍”,两种方法效果一样,其中本体两个文件geturl.html和openurl.html。该方法运行Python定义类、函数、urllib2和cookielib相关知识。
相关类似的优秀文章推荐三篇,其中POST方法类似:
[[Python]一起来写一个Python爬虫工具类whyspider——汪海](http://blog.csdn.net/pleasecallmewhy/article/details/24021695)
[用python 写爬虫,去爬csdn的内容,完美解决 403 Forbidden](http://www.yihaomen.com/article/python/210.htm)
[urllib2.HTTPError: HTTP Error 403: Forbidden](http://blog.csdn.net/my2010sam/article/details/17398807)
##二. 实现HTML转PDF格式备份文章
首先声明:这部分代码实现最终以失败告终,以后可能还会继续研究,一方面由于最近太忙;一方面对Linux的欠缺和对Python的掌握不够,但还是想把这部分写出来,感觉还是有些东西的,可能对你也有所帮助!感觉好遗憾啊~
### 1.转PDF解决方法
通过网上查阅资料,发现最常见的两种调用Python库转PDF的方法:
方法一:调用PDF报表类库Reportlab,它是在线网站转PDF该库不属于Python的标准类库,所以必须手动下载类库包并安装;同时由于涉及到把图片转换为PDF,所以还需要Python imaging library(PIL)类库。
参考文章:[python实现抓取HTML,取出数据,分析,绘出PDF版图形](http://blog.chinaunix.net/xmlrpc.php?r=blog/article&uid=29525990&id=4202841)
方法二:通过调用xhtml2pdf和pisa库实现HTML转PDF
该方法可以实现将静态的HTML转换成PDF格式,其中核心代码如下,将本地的"1.html"静态界面转换为"test.pdf",下面我尝试采取的方法也是该方法。
~~~
# -*- coding: utf-8 -*-
import sx.pisa3 as pisa
data= open('1.htm').read()
result = file('test.pdf', 'wb')
pdf = pisa.CreatePDF(data, result)
result.close()
pisa.startViewer('test.pdf')
~~~
参考文章:[python将html转成PDF的实现代码(包含中文)](http://www.jb51.net/article/34499.htm)
方法三:调用第三方wkhtmltopdf软件实现
该方法并不像Python调用第三方那样有详细代码,很多文章都是基于输入命令实现。下面三篇文章都是关于wkhtmltopdf的实现。
参考文章:[HTML转换成PDF工具:wkhtmltopdf](http://blog.csdn.net/hantiannan/article/details/4597278)
[[php]将html批量转pdf文件的解决方案,研究有感](http://blog.csdn.net/w520hua/article/details/12573697)
[wkhtmltopdf 生成带封面、页眉、页脚、目录的pdf](http://my.oschina.net/bobbob/blog/360946)
### 2.安装PIP及介绍
此时准备介绍通过xhtml2pdf和pisa库实现HTML转PDF的功能,首先需要安装PIP软件。正如[xifeijian大神](http://blog.csdn.net/xifeijian/article/details/12576455)所说:“作为Python爱好者,如果不知道easy_install或者pip中的任何一个的话,那么......”。
easy_insall的作用和perl中的cpan,ruby中的gem类似,都提供了在线一键安装模块的傻瓜方便方式,而pip是easy_install的改进版,提供更好的提示信息,删除package等功能。老版本的python中只有easy_install,没有pip。常见的具体用法如下:
~~~
easy_install的用法:
1) 安装一个包
$ easy_install <package_name>
$ easy_install "<package_name>==<version>"
2) 升级一个包
$ easy_install -U "<package_name>>=<version>"
pip的用法
1) 安装一个包
$ pip install <package_name>
$ pip install <package_name>==<version>
2) 升级一个包 (如果不提供version号,升级到最新版本)
$ pip install --upgrade <package_name>>=<version>
3)删除一个包
$ pip uninstall <package_name>
~~~
**第一步:下载PIP软件**
可以在官网[http://pypi.python.org/pypi/pip#downloads](http://pypi.python.org/pypi/pip#downloads)下载,同时cd切换到PIP目录,在通过python setup.py install安装。而我采用的是下载pip-Win_1.7.exe进行安装,下载地址如下:
[https://sites.google.com/site/pydatalog/python/pip-for-windows](https://sites.google.com/site/pydatalog/python/pip-for-windows)
**第二步:安装PIP软件**
当提示"pip and virtualenvinstalled"表示安装成功,那怎么测试PIP安装成功呢?
**第三步:配置环境变量**
此时在cmd中输入pip指令会提示错误“不是内部或外部命令”,所以需要添加path环境变量。PIP安装完成后,会在Python安装目录下添加python\Scripts目录,即在python安装目录的Scripts目录下,将此目录加入环境变量中即可!过程如下:

**第四步:使用PIP命令**
下面在CMD中使用PIP命令,“pip list outdate”列举Python安装库的版本信息。
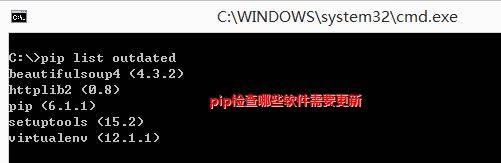
**PIP常用的命令如下所示: (参考[pip安装使用详解](http://www.ttlsa.com/python/how-to-install-and-use-pip-ttlsa/))**
~~~
Usage:
pip <command> [options]
Commands:
install 安装软件.
uninstall 卸载软件.
freeze 按着一定格式输出已安装软件列表
list 列出已安装软件.
show 显示软件详细信息.
search 搜索软件,类似yum里的search.
wheel Build wheels from your requirements.
zip 不推荐. Zip individual packages.
unzip 不推荐. Unzip individual packages.
bundle 不推荐. Create pybundles.
help 当前帮助.
General Options:
-h, --help 显示帮助.
-v, --verbose 更多的输出,最多可以使用3次
-V, --version 现实版本信息然后退出.
-q, --quiet 最少的输出.
--log-file <path> 覆盖的方式记录verbose错误日志,默认文件:/root/.pip/pip.log
--log <path> 不覆盖记录verbose输出的日志.
--proxy <proxy> Specify a proxy in the form [user:passwd@]proxy.server:port.
--timeout <sec> 连接超时时间 (默认15秒).
--exists-action <action> 默认活动当一个路径总是存在: (s)witch, (i)gnore, (w)ipe, (b)ackup.
--cert <path> 证书.
~~~
### 3.安装xhtml2pdf和pisa软件
通过PIP命令安装xhtml2pdf和pisa库。下载地址:
xhtml2pdf 0.0.6:[https://pypi.python.org/pypi/xhtml2pdf/](https://pypi.python.org/pypi/xhtml2pdf/)
pisa 3.0.33:[https://pypi.python.org/pypi/pisa/](https://pypi.python.org/pypi/pisa/)
然后通过下面命令安装:
pip install xhtml2pdf
pip install pisa
参考:
[安装html5转化为pdf的python库pisa 安装matplotlab数据转为图形的python库](http://blog.csdn.net/lifeiaidajia/article/details/10827527)
### 4.失败原因
最初没有安装Pisa库时运行那段HTML转PDF的代码会报错:
~~~
>>>
Traceback (most recent call last):
File "G:/software/Program software/Python/python insert/HtmlToPDF.py", line 12, in <module>
ImportError: No module named sx.pisa3
~~~
在安装完成后不会提示导入库名不存在,但此时HTML转PDF的代码会报错:
~~~
**************************
IMPORT ERROR!
Reportlab Version 2.1+ is needed!
**************************
The following Python packages are required for PISA:
- Reportlab Toolkit >= 2.2 <http://www.reportlab.org/>
- HTML5lib >= 0.11.1 <http://code.google.com/p/html5lib/>
Optional packages:
- pyPDF <http://pybrary.net/pyPdf/>
- PIL <http://www.pythonware.com/products/pil/>
Traceback (most recent call last):
File "G:\software\Program software\Python\python insert\HtmlToPDF.py", line 5, in <module>
import sx.pisa3 as pisa
...
raise ImportError("Reportlab Version 2.1+ is needed!")
ImportError: Reportlab Version 2.1+ is needed!
~~~
其原因是导入"import sx.pisa3 as pisa "时就显示Reportlab版本需要大于2.1以上。而通过代码查看版本为3.1.44。
~~~
>>> import reportlab
>>> print reportlab.Version
3.1.44
>>>
~~~
查看了很多资料都没有解决该问题,其中最典型的是将pisa安装目录下,sx\pisa3\pisa_util.py文件中代码修改:
~~~
if not (reportlab.Version[0] == "2" and reportlab.Version[2] >= "1"):
raise ImportError("Reportlab Version 2.1+ is needed!")
REPORTLAB22 = (reportlab.Version[0] == "2" and reportlab.Version[2] >= "2")
~~~
修改后的代码如下:
~~~
if not (reportlab.Version[:3] >="2.1"):
raise ImportError("Reportlab Version 2.1+ is needed!")
REPORTLAB22 = (reportlab.Version[:3] >="2.1")
~~~
但仍然不能解决该问题,这就导致了我无法验证该代码并实现后面的HTML转换为PDF的功能。参看了很多国外的资料:
[xhtml2pdf ImportError - Django 来自stackoverflow](http://stackoverflow.com/questions/22075485/xhtml2pdf-importerror-django)
[https://github.com/stephenmcd/cartridge/issues/174](https://github.com/stephenmcd/cartridge/issues/174)
[https://groups.google.com/forum/#!topic/xhtml2pdf/mihS51DtZkU](https://groups.google.com/forum/#!topic/xhtml2pdf/mihS51DtZkU)
[http://linux.m2osw.com/xhtml2pdf-generating-error-under-1404](http://linux.m2osw.com/xhtml2pdf-generating-error-under-1404)
##三. 总结
最后简单总结下吧!文章主要想实现从CSDN下载HTML静态网页形式的文章,再通过Python第三方库实现转换成PDF格式的备份文章功能,但由于Pisa无法导入最终失败。你可能非常失望,我也很遗憾。但仍然能从文章中学到一些东西,包括:
1.如何通过Python获取403禁止的内容,写消息头模仿登录,采用geturl和openurl两种方法实现;
2.如何配置PIP,它能让我们更方便的安装第三方库,让你了解些配置过程;
3.让你了解了HTML转PDF的一些思想。
最后推荐下我以前关于Python的爬虫文章,可能会给你提供些想法,虽然比那些开源的软件差很多,但这方面的文章和资源还是比较少的,哪怕给你一点灵感就好。
[[Python学习] 专题一.函数的基础知识](http://blog.csdn.net/eastmount/article/details/39088881)
[[Python学习] 专题二.条件语句和循环语句的基础知识](http://blog.csdn.net/eastmount/article/details/39458521)
[[Python学习] 专题三.字符串的基础知识](http://blog.csdn.net/eastmount/article/details/39599061)
[[Python学习] 简单网络爬虫抓取博客文章及思想介绍](http://blog.csdn.net/eastmount/article/details/39770543)
[[python学习] 简单爬取维基百科程序语言消息盒](http://blog.csdn.net/eastmount/article/details/44342559)
[[python学习] 简单爬取图片网站图库中图片](http://blog.csdn.net/eastmount/article/details/44492787)
[[python知识] 爬虫知识之BeautifulSoup库安装及简单介绍](http://blog.csdn.net/eastmount/article/details/44593165)
[[python+nltk] 自然语言处理简单介绍和NLTK坏境配置及入门知识(一)](http://blog.csdn.net/eastmount/article/details/45079095)
如果你有“Reportlab Version 2.1+ is needed!”好的解决方案可告知我,小弟我感激不尽。潜心学习,研究这方面的功能,最好不是调用第三方库,为自己加油。
最后希望文章对你有所帮助,如果有不足之处或错误的地方,还请海涵~
(By:Eastmount 2015-5-17 凌晨3点 [http://blog.csdn.net/eastmount/](http://blog.csdn.net/eastmount/))
[python+nltk] 自然语言处理简单介绍和NLTK坏境配置及入门知识(一)
最后更新于:2022-04-01 09:35:38
本文主要是总结最近学习的论文、书籍相关知识,主要是Natural Language Pracessing(自然语言处理,简称NLP)和Python挖掘维基百科Infobox等内容的知识。
此篇文章主要参考书籍《Natural Language Processing with Python》Python自然语言处理,希望对大家有所帮助。书籍下载地址:
官方网页版书籍:[http://www.nltk.org/book/](http://www.nltk.org/book/)
CSDN下载地址:[http://download.csdn.net/detail/eastmount/8601705](http://download.csdn.net/detail/eastmount/8601705)
##一. 自然语言处理简单介绍
所谓“自然语言”,是指人们日常交流使用的语言,如英语、印地语随着不断演化,很难用明确的规则来刻画。
从广义上,“自然语言处理”(Natural Language Processing简称NLP)包含所有计算机对自然语言进行的操作,从最简单的通过计数词出现的频率来比较不同的写作风格到最复杂的完全“理解”人所说的话。
基于NLP的技术应用日益广泛,如手机和手持电脑支持输入法联想提示(predictive text)和手写识别、网络搜索引擎能搜到非结构化文本中的信息、机器翻译能把中文文本翻译成西班牙文等。
通过使用Python程序设计语言和自然语言工具包(NLTK,Natural Language Toolkit)的开源函数库,本书包括自然语言处理的实际经验。本书可以自学,也可以作为自然语言处理或计算机语言学课程的教科书,或是人工智能、文本挖掘、语料库语言学课程的补充读物。
本书为什么使用Python呢?
Python是一种简单功能强大的变成语言,非常适合处理语言数据。
作为解释语言,Python便于交互式变成;作为面向对象语言,Python允许数据和方法被方面的封装和重用。作为动态语言,Python允许属性等程序运行时才被添加到对象,允许变量自动类型转换,提高开发效率。Python自带强大的标准库,包括图像编程、数值处理和网络连接等组件。


章节介绍包括:如何使用很短的Python程序分析感兴趣的文本信息(1-3章)、结构化程序设计章节(第4章)、语言处理的主要内容:标注、分类和信息提取(5-7章)、探索分析句子、识别句法结构和构建表示句意的方法(8-10章)、最后一章讲述如何有效管理语言数据(第11章)。
##二. NLTK环境配置
首先安装Python,可在官网[https://www.python.org/](https://www.python.org/)下载。
Python对用户友好的一个方式是你可以在交互式解释器运行你的程序,通过一个简单的交互式开发坏境(Interactive DeveLopment Environment,简称IDLE)的图形接口访问Python解释器。后面配置NLTK就是在IDLE环境下进行。
然后下载NLTK,资料如下:
官网链接:[http://www.nltk.org/](http://www.nltk.org/)
安装步骤:[http://www.nltk.org/install.html](http://www.nltk.org/install.html)
下载地址:[https://pypi.python.org/pypi/nltk](https://pypi.python.org/pypi/nltk)
由于我的电脑是windows系统,安装的步骤如下图所示:
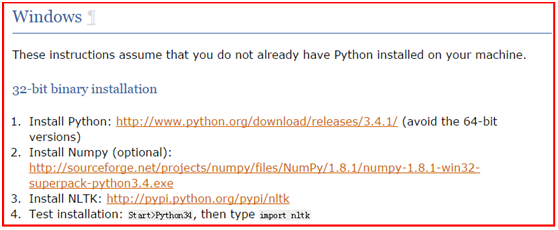
安装NLTK3.0

测试NLTK输入代码:
~~~
>>> import nltk
>>> nltk.download()
~~~
如下图所示:
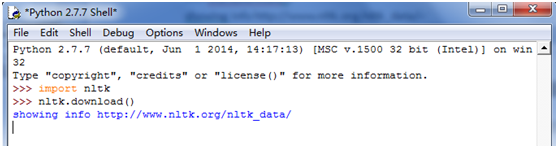
下载NLTK图书集:使用nltk.download()浏览可用的软件包,下载器上的Collections选项卡显示软件包如何被打包分组;选择book标记所在行,获取本书的例子和联系所需的全部数据。可参考[资料](http://www.cnblogs.com/huangcong/archive/2011/08/29/2157437.html)。
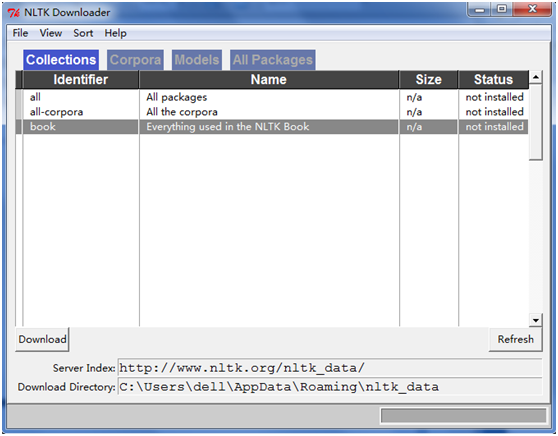
点击”Download“后安装需要一定时间,最后选项book变成”Installed“:

同时如果无法下载,你可以对自己感兴趣的选择双击进行下载:
当数据下载到机器后,你可以使用Python解释器加载其中一些,在Python提示符后输入”from nltk.book import *”告诉解释器从NLTK的book加载所有的文本,输入text1找到相应的文本名字。如下图所示:
此时你的NLTK配置成功。
##三. 自然语言处理常用方法
### 1.concordance函数
功能:搜索文本,在text1中输入函数concordance(),查找《白鲸记》中的词语monstrous。
~~~
>>> text1.concordance("monstrous")
~~~
提示:可以通过快捷键Alt+P获取之前输入的命令,共搜索11个匹配结果。
### 2.similar函数
功能:通过函数similar()可以查询括号中相关词在上下文中相似的词语。词语索引使我们看到此的上下文,如monstrous出现的上下文,如the_pictures和the_size。
~~~
>>> text1.similar("monstrous")
~~~
可以发现与monstrous(丑陋的)相似的大部分都是形容词:curious(好奇的)、impalpable(无形的)、perilous(危险的)、lazy(懒惰的)等。

我的怀疑应该是和上下文语义结构有关,却没有“理解”它具体的词义。如:the Monstrous Pictures、more monstrous stories、a monstrous size。很显然monstrous充当修饰名词的形容词结构——冠词+monstrous+名词。
### 3.common_contexts函数
功能:函数common_contexts允许我们研究两个或两个以上的词共同的上下文,如monstrous和very。
~~~
>>> text2.common_contexts(["monstrous","very"])
a_pretty is_pretty a_lucky am_glad be_glad
~~~
必须用方括号和圆括号把这些词括起来,中间用逗号分隔。个人理解:似乎similar是与之相关的词语,而common_contexts是相似的结构。

### 4.generate函数
功能:通过函数generate()产生一些随机文本自动生成文章。
~~~
>>> text3.generate()
~~~
注意:第一次运行此命令时,由于要搜集词序列的统计信息而执行得比较慢,每次运行它,输出的文本都会不同。虽然文本是随机的,但是它重用了源文本中的词和短语,从而使我们能够感觉到它的风格和内容。
报错:”AttributeError: 'Text' object has noattribute 'generate'“其原因参照StackFlow:

理想输出结果如下:

总结:最后希望这篇入门文章对大家有所帮助,如果有错误或不足之处,亲海涵!后面还会深入的讲解自然语言处理和Python挖掘相关知识;同时包括NLTK的更广泛应用及理解。建议大家购买正版书籍阅读,挺不错的书籍《Python自然语言处理》作者:Steven Bird, Ewan Klein & Edward Loper。
(By:Eastmount 2015-4-16 晚上8点 [http://blog.csdn.net/eastmount/](http://blog.csdn.net/eastmount/))
[python知识] 爬虫知识之BeautifulSoup库安装及简单介绍
最后更新于:2022-04-01 09:35:35
##一. 前言
在前面的几篇文章中我介绍了如何通过Python分析源代码来爬取博客、维基百科InfoBox和图片,其文章链接如下:
[[python学习] 简单爬取维基百科程序语言消息盒](http://blog.csdn.net/eastmount/article/details/44342559)
[[Python学习] 简单网络爬虫抓取博客文章及思想介绍](http://blog.csdn.net/eastmount/article/details/39770543)
[[python学习] 简单爬取图片网站图库中图片](http://blog.csdn.net/eastmount/article/details/44492787)
其中核心代码如下:
~~~
# coding=utf-8
import urllib
import re
#下载静态HTML网页
url='http://www.csdn.net/'
content = urllib.urlopen(url).read()
open('csdn.html','w+').write(content)
#获取标题
title_pat=r'(?<=<title>).*?(?=</title>)'
title_ex=re.compile(title_pat,re.M|re.S)
title_obj=re.search(title_ex, content)
title=title_obj.group()
print title
#获取超链接内容
href = r'<a href=.*?>(.*?)</a>'
m = re.findall(href,content,re.S|re.M)
for text in m:
print unicode(text,'utf-8')
break #只输出一个url
~~~
输出结果如下:
~~~
>>>
CSDN.NET - 全球最大中文IT社区,为IT专业技术人员提供最全面的信息传播和服务平台
登录
>>>
~~~
图片下载的核心代码如下:
~~~
import os
import urllib
class AppURLopener(urllib.FancyURLopener):
version = "Mozilla/5.0"
urllib._urlopener = AppURLopener()
url = "http://creatim.allyes.com.cn/imedia/csdn/20150228/15_41_49_5B9C9E6A.jpg"
filename = os.path.basename(url)
urllib.urlretrieve(url , filename)
~~~
但是上面这种分析HTML来爬取网站内容的方法存在很多弊端,譬如:
1.正则表达式被HTML源码所约束,而不是取决于更抽象的结构;网页结构中很小的改动可能会导致程序的中断。
2.程序需要根据实际HTML源码分析内容,可能会遇到字符实体如&之类的HTML特性,需要指定处理如<span></span>、图标超链接、下标等不同内容。
3.正则表达式并不是完全可读的,更复杂的HTML代码和查询表达式会变得很乱。
正如《Python基础教程(第2版)》采用两种解决方案:第一个是使用Tidy(Python库)的程序和XHTML解析;第二个是使用BeautifulSoup库。
##二. 安装及介绍Beautiful Soup库
Beautiful Soup是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree)。
它提供简单又常用的导航navigating,搜索以及修改剖析树的操作。它可以大大节省你的编程时间。
正如书中所说“那些糟糕的网页不是你写的,你只是试图从中获得一些数据。现在你不用关心HTML是什么样子的,解析器帮你实现”。
下载地址:
[http://www.crummy.com/software/BeautifulSoup/](http://www.crummy.com/software/BeautifulSoup/)
[http://www.crummy.com/software/BeautifulSoup/bs4/download/4.3/](http://www.crummy.com/software/BeautifulSoup/bs4/download/4.3/)
安装过程如下图所示:python setup.py install
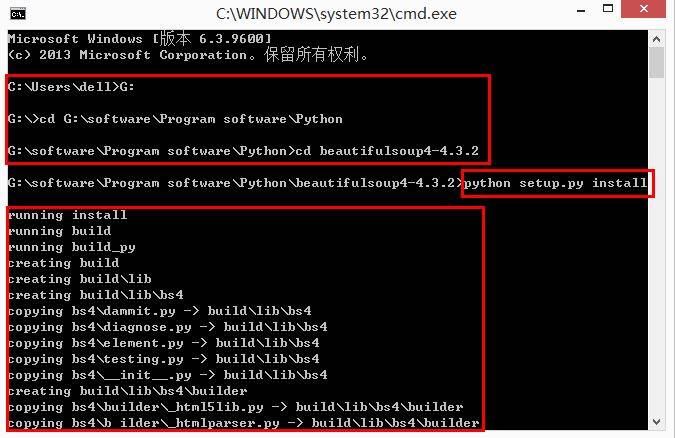
具体使用方法建议参照中文:
[http://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html](http://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html)
其中BeautifulSoup的用法简单讲解下,使用“爱丽丝梦游仙境”的官方例子:
~~~
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#获取BeautifulSoup对象并按标准缩进格式输出
soup = BeautifulSoup(html_doc)
print(soup.prettify())
~~~
输出内容按照标准的缩进格式的结构输出如下:
~~~
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
Elsie
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
;
and they lived at the bottom of a well.
</p>
<p class="story">
...
</p>
</body>
</html>
~~~
下面是BeautifulSoup库简单快速入门介绍:(参考:[官方文档](http://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html))
~~~
'''获取title值'''
print soup.title
# <title>The Dormouse's story</title>
print soup.title.name
# title
print unicode(soup.title.string)
# The Dormouse's story
'''获取<p>值'''
print soup.p
# <p class="title"><b>The Dormouse's story</b></p>
print soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
'''从文档中找到<a>的所有标签链接'''
print soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
for link in soup.find_all('a'):
print(link.get('href'))
# http://example.com/elsie
# http://example.com/lacie
# http://example.com/tillie
print soup.find(id='link3')
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
~~~
如果想获取文章中所有文字内容,代码如下:
~~~
'''从文档中获取所有文字内容'''
print soup.get_text()
# The Dormouse's story
#
# The Dormouse's story
#
# Once upon a time there were three little sisters; and their names were
# Elsie,
# Lacie and
# Tillie;
# and they lived at the bottom of a well.
#
# ...
~~~
同时在这过程中你可能会遇到两个典型的错误提示:
1.ImportError: No module named BeautifulSoup
当你成功安装BeautifulSoup 4库后,“from BeautifulSoup import BeautifulSoup”可能会遇到该错误。

其中的原因是BeautifulSoup 4库改名为bs4,需要使用“from bs4 import BeautifulSoup”导入。
2.TypeError: an integer is required
当你使用“print soup.title.string”获取title的值时,可能会遇到该错误。如下:

它应该是IDLE的BUG,当使用命令行Command没有任何错误。参考:[stackoverflow](http://stackoverflow.com/questions/28849615/why-they-didnt-work-when-i-scrape-the-string-in-html-by-using-beautifulsoup)。同时可以通过下面的代码解决该问题:
print unicode(soup.title.string)
print str(soup.title.string)
##三. Beautiful Soup常用方法介绍
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:Tag、NavigableString、BeautifulSoup、Comment
1.Tag标签
tag对象与XML或HTML文档中的tag相同,它有很多方法和属性。其中最重要的属性name和attribute。用法如下:
~~~
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" id="start"><b>The Dormouse's story</b></p>
"""
soup = BeautifulSoup(html)
tag = soup.p
print tag
# <p class="title" id="start"><b>The Dormouse's story</b></p>
print type(tag)
# <class 'bs4.element.Tag'>
print tag.name
# p 标签名字
print tag['class']
# [u'title']
print tag.attrs
# {u'class': [u'title'], u'id': u'start'}
~~~
使用BeautifulSoup每个tag都有自己的名字,可以通过.name来获取;同样一个tag可能有很多个属性,属性的操作方法与字典相同,可以直接通过“.attrs”获取属性。至于修改、删除操作请参考文档。
2.NavigableString
字符串常被包含在tag内,BeautifulSoup用NavigableString类来包装tag中的字符串。一个NavigableString字符串与Python中的Unicode字符串相同,并且还支持包含在遍历文档树和搜索文档树中的一些特性,通过unicode()方法可以直接将NavigableString对象转换成Unicode字符串。
~~~
print unicode(tag.string)
# The Dormouse's story
print type(tag.string)
# <class 'bs4.element.NavigableString'>
tag.string.replace_with("No longer bold")
print tag
# <p class="title" id="start"><b>No longer bold</b></p>
~~~
这是获取“<p class="title" id="start"><b>The Dormouse's story</b></p>”中tag = soup.p的值,其中tag中包含的字符串不能编辑,但可通过函数replace_with()替换。
NavigableString 对象支持遍历文档树和搜索文档树中定义的大部分属性, 并非全部。尤其是一个字符串不能包含其它内容(tag能够包含字符串或是其它tag),字符串不支持 .contents 或 .string 属性或 find() 方法。
如果想在Beautiful Soup之外使用 NavigableString 对象,需要调用 unicode() 方法,将该对象转换成普通的Unicode字符串,否则就算Beautiful Soup已方法已经执行结束,该对象的输出也会带有对象的引用地址。这样会浪费内存。
3.Beautiful Soup对象
该对象表示的是一个文档的全部内容,大部分时候可以把它当做Tag对象,它支持遍历文档树和搜索文档树中的大部分方法。
注意:因为BeautifulSoup对象并不是真正的HTML或XML的tag,所以它没有name和 attribute属性,但有时查看它的.name属性可以通过BeautifulSoup对象包含的一个值为[document]的特殊实行.name实现——soup.name。
Beautiful Soup中定义的其它类型都可能会出现在XML的文档中:CData , ProcessingInstruction , Declaration , Doctype 。与 Comment 对象类似,这些类都是 NavigableString的子类,只是添加了一些额外的方法的字符串独享。
4.Command注释
Tag、NavigableString、BeautifulSoup几乎覆盖了html和xml中的所有内容,但是还有些特殊对象容易让人担心——注释。Comment对象是一个特殊类型的NavigableString对象。
~~~
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>"
soup = BeautifulSoup(markup)
comment = soup.b.string
print type(comment)
# <class 'bs4.element.Comment'>
print unicode(comment)
# Hey, buddy. Want to buy a used parser?
~~~
介绍完这四个对象后,下面简单介绍遍历文档树和搜索文档树及常用的函数。
5.遍历文档树
一个Tag可能包含多个字符串或其它的Tag,这些都是这个Tag的子节点。BeautifulSoup提供了许多操作和遍历子节点的属性。引用官方文档中爱丽丝例子:
操作文档最简单的方法是告诉你想获取tag的name,如下:
~~~
soup.head
# <head><title>The Dormouse's story</title></head>
soup.title
# <title>The Dormouse's story</title>
soup.body.b
# <b>The Dormouse's story</b>
~~~
注意:通过点取属性的放是只能获得当前名字的第一个Tag,同时可以在文档树的tag中多次调用该方法如soup.body.b获取<body>标签中第一个<b>标签。
如果想得到所有的<a>标签,使用方法find_all(),在前面的Python爬取维基百科等HTML中我们经常用到它+正则表达式的方法。
~~~
soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
~~~
子节点:在分析HTML过程中通常需要分析tag的子节点,而tag的 .contents 属性可以将tag的子节点以列表的方式输出。字符串没有.contents属性,因为字符串没有子节点。
~~~
head_tag = soup.head
head_tag
# <head><title>The Dormouse's story</title></head>
head_tag.contents
[<title>The Dormouse's story</title>]
title_tag = head_tag.contents[0]
title_tag
# <title>The Dormouse's story</title>
title_tag.contents
# [u'The Dormouse's story']
~~~
通过tag的 .children 生成器,可以对tag的子节点进行循环:
~~~
for child in title_tag.children:
print(child)
# The Dormouse's story
~~~
子孙节点:同样 .descendants 属性可以对所有tag的子孙节点进行递归循环:
~~~
for child in head_tag.descendants:
print(child)
# <title>The Dormouse's story</title>
# The Dormouse's story
~~~
父节点:通过 .parent 属性来获取某个元素的父节点.在例子“爱丽丝”的文档中,<head>标签是<title>标签的父节点,换句话就是增加一层标签。
注意:文档的顶层节点比如<html>的父节点是 BeautifulSoup 对象,BeautifulSoup 对象的 .parent 是None。
~~~
title_tag = soup.title
title_tag
# <title>The Dormouse's story</title>
title_tag.parent
# <head><title>The Dormouse's story</title></head>
title_tag.string.parent
# <title>The Dormouse's story</title>
~~~
兄弟节点:因为<b>标签和<c>标签是同一层:他们是同一个元素的子节点,所以<b>和<c>可以被称为兄弟节点。一段文档以标准格式输出时,兄弟节点有相同的缩进级别.在代码中也可以使用这种关系。
~~~
sibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></b></a>")
print(sibling_soup.prettify())
# <html>
# <body>
# <a>
# <b>
# text1
# </b>
# <c>
# text2
# </c>
# </a>
# </body>
# </html>
~~~
在文档树中,使用 .next_sibling 和 .previous_sibling 属性来查询兄弟节点。<b>标签有.next_sibling 属性,但是没有.previous_sibling 属性,因为<b>标签在同级节点中是第一个。同理<c>标签有.previous_sibling 属性,却没有.next_sibling 属性:
~~~
sibling_soup.b.next_sibling
# <c>text2</c>
sibling_soup.c.previous_sibling
# <b>text1</b>
~~~
介绍到这里基本就可以实现我们的BeautifulSoup库爬取网页内容,而网页修改、删除等内容建议大家阅读文档。下一篇文章就再次爬取维基百科的程序语言的内容吧!希望文章对大家有所帮助,如果有错误或不足之处,还请海涵!建议大家阅读官方文档和《Python基础教程》书。
(By:Eastmount 2015-3-25 下午6点 [http://blog.csdn.net/eastmount/](http://blog.csdn.net/eastmount/))**
[python学习] 简单爬取图片网站图库中图片
最后更新于:2022-04-01 09:35:33
最近老师让学习Python与维基百科相关的知识,无聊之中用Python简单做了个爬取“游讯网图库”中的图片,因为每次点击下一张感觉非常浪费时间又繁琐。主要分享的是如何爬取HTML的知识和Python如何下载图片;希望对大家有所帮助,同时发现该网站的图片都挺精美的,建议阅读原网下载图片,支持游讯网不要去破坏它。
通过浏览游讯网发现它的图库URL为,其中全部图片为0_0_1到0_0_75:
[http://pic.yxdown.com/list/0_0_1.html](http://pic.yxdown.com/list/0_0_1.html)
[ http://pic.yxdown.com/list/0_0_75.html](http://pic.yxdown.com/list/0_0_1.html)
同时通过下图可以发现游讯网的1-75页个列表,每页中有很多个主题,每个主题都有相应的多张图片。
源代码如下:
(需在本地创建E:\\Picture3文件夹和Python运行目录创建yxdown文件夹)
~~~
# coding=utf-8
# 声明编码方式 默认编码方式ASCII 参考https://www.python.org/dev/peps/pep-0263/
import urllib
import time
import re
import os
'''
Python下载游迅网图片 BY:Eastmount
'''
'''
**************************
#第一步 遍历获取每页对应主题的URL
#http://pic.yxdown.com/list/0_0_1.html
#http://pic.yxdown.com/list/0_0_75.html
**************************
'''
fileurl=open('yxdown_url.txt','w')
fileurl.write('********获取游讯网图片URL*******\n\n')
#建议num=3 while num<=3一次遍历一个页面所有主题,下次换成num=4 while num<=4而不是1-75
num=3
while num<=3:
temp = 'http://pic.yxdown.com/list/0_0_'+str(num)+'.html'
content = urllib.urlopen(temp).read()
open('yxdown_'+str(num)+'.html','w+').write(content)
print temp
fileurl.write('********第'+str(num)+'页*******\n\n')
#爬取对应主题的URL
#<div class="cbmiddle"></div>中<a target="_blank" href="/html/5533.html" >
count=1 #计算每页1-75中具体网页个数
res_div = r'<div class="cbmiddle">(.*?)</div>'
m_div = re.findall(res_div,content,re.S|re.M)
for line in m_div:
#fileurl.write(line+'\n')
#获取每页所有主题对应的URL并输出
if "_blank" in line: #防止获取列表list/1_0_1.html list/2_0_1.html
#获取主题
fileurl.write('\n\n**********************\n')
title_pat = r'<b class="imgname">(.*?)</b>'
title_ex = re.compile(title_pat,re.M|re.S)
title_obj = re.search(title_ex, line)
title = title_obj.group()
print unicode(title,'utf-8')
fileurl.write(title+'\n')
#获取URL
res_href = r'<a target="_blank" href="(.*?)"'
m_linklist = re.findall(res_href,line)
#print unicode(str(m_linklist),'utf-8')
for link in m_linklist:
fileurl.write(str(link)+'\n') #形如"/html/5533.html"
'''
**************************
#第二步 去到具体图像页面 下载HTML页面
#http://pic.yxdown.com/html/5533.html#p=1
#注意先本地创建yxdown 否则报错No such file or directory
**************************
'''
#下载HTML网页无原图 故加'#p=1'错误
#HTTP Error 400. The request URL is invalid.
html_url = 'http://pic.yxdown.com'+str(link)
print html_url
html_content = urllib.urlopen(html_url).read() #具体网站内容
#可注释它 暂不下载静态HTML
open('yxdown/yxdown_html'+str(count)+'.html','w+').write(html_content)
'''
#第三步 去到图片界面下载图片
#图片的链接地址为http://pic.yxdown.com/html/5530.html#p=1 #p=2
#点击"查看原图"HTML代码如下
#<a href="javascript:;" style=""onclick="return false;">查看原图</a>
#通过JavaScript实现 而且该界面存储所有图片链接<script></script>之间
#获取"original":"http://i-2.yxdown.com/2015/3/18/6381ccc..3158d6ad23e.jpg"
'''
html_script = r'<script>(.*?)</script>'
m_script = re.findall(html_script,html_content,re.S|re.M)
for script in m_script:
res_original = r'"original":"(.*?)"' #原图
m_original = re.findall(res_original,script)
for pic_url in m_original:
print pic_url
fileurl.write(str(pic_url)+'\n')
'''
#第四步 下载图片
#如果浏览器存在验证信息如维基百科 需添加如下代码
class AppURLopener(urllib.FancyURLopener):
version = "Mozilla/5.0"
urllib._urlopener = AppURLopener()
#参考 http://bbs.csdn.net/topics/380203601
#http://www.lylinux.org/python使用多线程下载图片.html
'''
filename = os.path.basename(pic_url) #去掉目录路径,返回文件名
#No such file or directory 需要先创建文件Picture3
urllib.urlretrieve(pic_url, 'E:\\Picture3\\'+filename)
#http://pic.yxdown.com/html/5519.html
#IOError: [Errno socket error] [Errno 10060]
#只输出一个URL 否则输出两个相同的URL
break
#当前页具体内容个数加1
count=count+1
time.sleep(0.1)
else:
print 'no url about content'
time.sleep(1)
num=num+1
else:
print 'Download Over!!!'
~~~
其中下载[http://pic.yxdown.com/list/0_0_1.html](http://pic.yxdown.com/list/0_0_1.html)的图片E:\\Picture文件夹如下:
下载[http://pic.yxdown.com/list/0_0_3.html](http://pic.yxdown.com/list/0_0_1.html)的图片E:\\Picture3文件夹如下:
由于代码注释中有详细的步骤,下面只是简单介绍过程。
1.简单遍历网站,获取每页对应主题的URL。其中每页都有无数个主题,其中主题的格式如下:
~~~
<!-- 第一步 爬取的HTML代码如下 -->
<div class="conbox">
<div class="cbtop">
</div>
<div class="cbmiddle">
<a target="_blank" href="/html/5533.html" class="proimg">
<img src="http://i-2.yxdown.com/2015/3/19/KDE5Mngp/a78649d0-9902-4086-a274-49f9f3015d96.jpg" alt="Miss大小姐驾到!细数《英雄联盟》圈的电竞女神" />
<strong></strong>
<p>
<span>b></b>1836人看过</span>
<em><b></b>10张</em>
</p>
<b class="imgname">Miss大小姐驾到!细数《英雄联盟》圈的电竞女神</b>
</a>
<a target="_blank" href="/html/5533.html" class="plLink"><em>1</em>人评论</a>
</div>
<div class="cbbottom">
</div>
<a target="_blank" class="plBtn" href="/html/5533.html"></a>
</div>
~~~
它是由无数个<div class="conbox"></div>组成,其中我们只需要提取<a target="_blank" href="/html/5533.html" class="proimg">中的href即可,然后通过URL拼接实现到具体的主题页面。其中对应上面的布局如下图所示:


2.去到具体图像页面 下载HTML页面,如:
[http://pic.yxdown.com/html/5533.html#p=1](http://pic.yxdown.com/html/5533.html#p=1)
同时下载本地HTML页面可以注释该句代码。此时需要点击“查看图片”才能下载原图,点击右键只能另存为网站html。
3.我最初打算是是分析“查看原图”的URL来实现下载,其他网站同理是分析“下一页”来实现的。但我发现它是通过JavaScript实现的浏览,即:
<a href="javascript:;" onclick="return false;" id="photoOriginal">查看原图</a>
同时它把所有图片都写在下面代码<script></script>中:
~~~
<script>var images = [
{ "big":"http://i-2.yxdown.com/2015/3/18/KDkwMHgp/6381ccc0-ed65-4422-8671-b3158d6ad23e.jpg",
"thumb":"http://i-2.yxdown.com/2015/3/18/KHgxMjAp/6381ccc0-ed65-4422-8671-b3158d6ad23e.jpg",
"original":"http://i-2.yxdown.com/2015/3/18/6381ccc0-ed65-4422-8671-b3158d6ad23e.jpg",
"title":"","descript":"","id":75109},
{ "big":"http://i-2.yxdown.com/2015/3/18/KDkwMHgp/fec26de9-8727-424a-b272-f2827669a320.jpg",
"thumb":"http://i-2.yxdown.com/2015/3/18/KHgxMjAp/fec26de9-8727-424a-b272-f2827669a320.jpg",
"original":"http://i-2.yxdown.com/2015/3/18/fec26de9-8727-424a-b272-f2827669a320.jpg",
"title":"","descript":"","id":75110},
...
</script>
~~~
其中获取原图-original即可,缩略图-thumb,大图-big,通过正则表达式下载URL:
res_original = r'"original":"(.*?)"' #原图
m_original = re.findall(res_original,script)
4.最后一步就是下载图片,其中我不太会使用线程,只是简单添加了time.sleep(0.1) 函数。下载图片可能会遇到维基百科那种访问受限,需要相应设置,核心代码如下:
~~~
import os
import urllib
class AppURLopener(urllib.FancyURLopener):
version = "Mozilla/5.0"
urllib._urlopener = AppURLopener()
url = "http://i-2.yxdown.com/2015/2/25/c205972d-d858-4dcd-9c8b-8c0f876407f8.jpg"
filename = os.path.basename(url)
urllib.urlretrieve(url , filename)
~~~
同时我也在本地创建文件夹Picture3,并txt记录获取的URL,如下图所示:

最后希望文章对大家有所帮助,简单来说文章就两句话:如何分析源代码通过正则表达式提取指定URL;如何通过Python下载图片。如果文章有不足之处,请海涵!
(By:Eastmount 2015-3-20 下午5点 [http://blog.csdn.net/eastmount/](http://blog.csdn.net/eastmount/))
[python学习] 简单爬取维基百科程序语言消息盒
最后更新于:2022-04-01 09:35:31
文章主要讲述如何通过Python爬取维基百科的消息盒(Infobox),主要是通过正则表达式和urllib实现;后面的文章可能会讲述通过BeautifulSoup实现爬取网页知识。由于这方面的文章还是较少,希望提供一些思想和方法对大家有所帮助。如果有错误或不足之处,欢迎之处;如果你只想知道该篇文章最终代码,建议直接阅读第5部分及运行截图。
##一. 维基百科和Infobox
你可能会疑惑Infobox究竟是个什么东西呢?下面简单介绍。
维基百科作为目前规模最大和增长最快的开放式的在线百科系统,其典型包括两个网状结构:文章网络和分类树(以树为主体的图)。该篇博客主要是对维基百科“程序语言”结构进行分析,下载网页后提取相关消息盒(Infobox)中属性和对应的值。
Infobox是模板(一系列的信息框),通常是成对的标签label和数据data组成。参考:[http://zh.wikipedia.org/wiki/Template:Infobox](http://zh.wikipedia.org/wiki/Template:Infobox)
下图是维基百科“世界政区索引”中“中国”的部分Infobox信息和“程序设计语言列表”的“ACL2”语言的消息盒。

##二. 爬虫实现
###1. python下载html网页
首先需要访问维基百科的“程序设计语言列表”,并简单讲述如何下载静态网页的代码。在维基百科中输入如下URL可以获取所有程序语言列表:
[http://zh.wikipedia.org/wiki/程序设计语言列表](http://zh.wikipedia.org/wiki/程序设计语言列表)
你可以看到从A到Z的各种程序语言,如A#.NET、ActionScript、C++、易语言等,当然可能其中很多语言都没有完善或没有消息盒Infobox。同样如果你想查询世界各个国家的信息,输入URL如下:
[http://zh.wikipedia.org/wiki/世界政区索引](http://zh.wikipedia.org/wiki/世界政区索引)
通过如下代码可以获取静态的html页面:
~~~
# coding=utf-8
import urllib
import time
import re
#第一步 获取维基百科内容
#http://zh.wikipedia.org/wiki/程序设计语言列表
keyname="程序设计语言列表"
temp='http://zh.wikipedia.org/wiki/'+str(keyname)
content = urllib.urlopen(temp).read()
open('wikipedia.html','w+').write(content)
print 'Start Crawling pages!!!'
~~~
获取的本地wikipedia.html界面如下图所示:
##2. 正则表达式获取URL超链
现在需要通过Python正则表达式获取所有语言的超链接URL。
网页中创建超链接需要使用A标记符,结束标记符为</A>.它的最基本属性是href,用于指定超链接的目标,通过href属性指定不同的值,可以创建不同类型的超链接.
~~~
href = '<p><a href="www.csdn.cn" title="csdn">CSDN</a></p>'
link = re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')", href)
print link
~~~
上面是获取网页URL的正则表达式代码,输出结果是:['www.csdn.cn']。
但是获取“程序设计语言列表”中所有语言时,我是通过人工确定起始位置“0-9”和结束位置“参看”进行查找的,代码如下:
~~~
# coding=utf-8
import urllib
import time
import re
#第一步 获取维基百科内容
#http://zh.wikipedia.org/wiki/程序设计语言列表
keyname="程序设计语言列表"
temp='http://zh.wikipedia.org/wiki/'+str(keyname)
content = urllib.urlopen(temp).read()
open('wikipedia.html','w+').write(content)
print 'Start Crawling pages!!!'
#第二步 获取网页中的所有URL
#从原文中"0-9"到"参看"之间是A-Z各个语言的URL
start=content.find(r'0-9')
end=content.find(r'参看')
cutcontent=content[start:end]
link_list = re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')", cutcontent)
fileurl=open('test.txt','w')
for url in link_list:
print url
~~~
输出的结果HTML源码主要包括以下几种形式:
~~~
<a href="#A">A</a>
<a href="/wiki/C%EF%BC%83" title="C#" class="mw-redirect">C#</a>
<a href="/w/index.php?title=..." class="new" title="A Sharp (.NET)(页面不存在)">A# .NET</a>
输出:
#A
/wiki/C%EF%BC%83
/w/index.php?title=A%2B%2B&action=edit&redlink=1.
~~~
此时获取了href中URL,很显然“http://zh.wikipedia.org”加上获取的后缀就是具体的一门语言信息,如:
[http://zh.wikipedia.org/wiki/C#](http://zh.wikipedia.org/wiki/C%E2%99%AF)
[](http://zh.wikipedia.org/wiki/C%E2%99%AF) [http://zh.wikipedia.org/wiki/A_Sharp_(.NET)](http://zh.wikipedia.org/wiki/A_Sharp_(.NET))
它会转换成C%EF%..等形式。而index.php?此种形式表示该页面维基百科未完善,相应的Infobox消息盒也是不存在的。下面就是去到每一个具体的URL获取里面的title信息,同时下载相应的静态URL。
##3. 获取程序语言title信息及下载html
首先通过拼接成完整的URL,在通过open函数下载对应的程序语言html源码至language文件夹下;再通过正则表达式r'(?<=<title>).*?(?=</title>)'可以获取网页的title信息。代码如下:
~~~
# coding=utf-8
import urllib
import time
import re
#第一步 获取维基百科内容
#http://zh.wikipedia.org/wiki/程序设计语言列表
keyname="程序设计语言列表"
temp='http://zh.wikipedia.org/wiki/'+str(keyname)
content = urllib.urlopen(temp).read()
open('wikipedia.html','w+').write(content)
print 'Start Crawling pages!!!'
#第二步 获取网页中的所有URL
#从原文中"0-9"到"参看"之间是A-Z各个语言的URL
start=content.find(r'0-9')
end=content.find(r'参看')
cutcontent=content[start:end]
link_list = re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')", cutcontent)
fileurl=open('test.txt','w')
for url in link_list:
#字符串包含wiki或/w/index.php则正确url 否则A-Z
if url.find('wiki')>=0 or url.find('index.php')>=0:
fileurl.write(url+'\n')
#print url
num=num+1
fileurl.close()
print 'URL Successed! ',num,' urls.'
#第三步 下载每个程序URL静态文件并获取Infobox对应table信息
#国家:http://zh.wikipedia.org/wiki/阿布哈茲
#语言:http://zh.wikipedia.org/wiki/ActionScript
info=open('infobox.txt','w')
info.write('********获取程序语言信息*******\n\n')
j=1
for url in link_list:
if url.find('wiki')>=0 or url.find('index.php')>=0:
#下载静态html
wikiurl='http://zh.wikipedia.org'+str(url)
print wikiurl
language = urllib.urlopen(wikiurl).read()
name=str(j)+' language.html'
#注意 需要创建一个country的文件夹 否则总报错No such file or directory
open(r'language/'+name,'w+').write(language) #写方式打开+没有即创建
#获取title信息
title_pat=r'(?<=<title>).*?(?=</title>)'
title_ex=re.compile(title_pat,re.M|re.S)
title_obj=re.search(title_ex, language) #language对应当前语言HTML所有内容
title=title_obj.group()
#获取内容'C语言 - 维基百科,自由的百科全书' 仅获取语言名
middle=title.find(r'-')
info.write('【程序语言 '+title[:middle]+'】\n')
print title[:middle]
#设置下载数量
j=j+1
time.sleep(1)
if j==20:
break;
else:
print 'Error url!!!'
else:
print 'Download over!!!'
~~~
输出结果如下图所示,其中获取20个程序语言URL的标题输入infobox.txt如下:
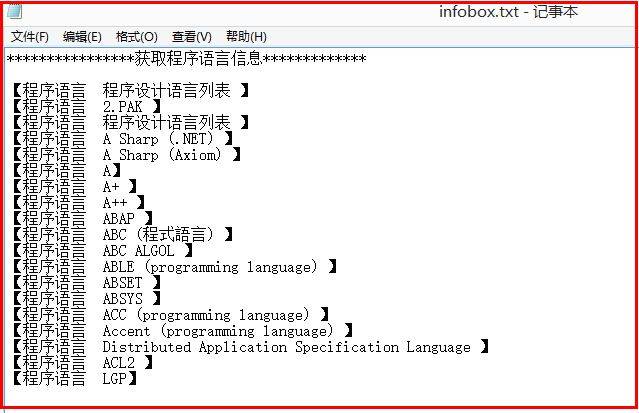
然后是获取每门语言HTML下载至本地的language文件夹下,需要自己创建一个文件夹。其中一门语言代码如下,标题就是下图左上方的ACL2:

##4. 爬取class=Infobox的table信息
获取Infobox的table信息,通过分析源代码发现“程序设计语言列表”的消息盒如下:
~~~
<table class="infobox vevent" ..><tr><th></th><td></td></tr></table>
~~~
而“世界政区索引”的消息盒形式如下:
~~~
<table class="infobox"><tr><td></td></tr></table>
~~~
具体的代码如下所示:
~~~
# coding=utf-8
import urllib
import time
import re
#第一步 获取维基百科内容
#http://zh.wikipedia.org/wiki/程序设计语言列表
keyname="程序设计语言列表"
temp='http://zh.wikipedia.org/wiki/'+str(keyname)
content = urllib.urlopen(temp).read()
open('wikipedia.html','w+').write(content)
print 'Start Crawling pages!!!'
#第二步 获取网页中的所有URL
#从原文中"0-9"到"参看"之间是A-Z各个语言的URL
start=content.find(r'0-9')
end=content.find(r'参看')
cutcontent=content[start:end]
link_list = re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')", cutcontent)
fileurl=open('test.txt','w')
for url in link_list:
#字符串包含wiki或/w/index.php则正确url 否则A-Z
if url.find('wiki')>=0 or url.find('index.php')>=0:
fileurl.write(url+'\n')
#print url
num=num+1
fileurl.close()
print 'URL Successed! ',num,' urls.'
#第三步 下载每个程序URL静态文件并获取Infobox对应table信息
#国家:http://zh.wikipedia.org/wiki/阿布哈茲
#语言:http://zh.wikipedia.org/wiki/ActionScript
info=open('infobox.txt','w')
info.write('********获取程序语言信息*******\n\n')
j=1
for url in link_list:
if url.find('wiki')>=0 or url.find('index.php')>=0:
#下载静态html
wikiurl='http://zh.wikipedia.org'+str(url)
print wikiurl
language = urllib.urlopen(wikiurl).read()
name=str(j)+' language.html'
#注意 需要创建一个country的文件夹 否则总报错No such file or directory
open(r'language/'+name,'w+').write(language) #写方式打开+没有即创建
#获取title信息
title_pat=r'(?<=<title>).*?(?=</title>)'
title_ex=re.compile(title_pat,re.M|re.S)
title_obj=re.search(title_ex, language) #language对应当前语言HTML所有内容
title=title_obj.group()
#获取内容'C语言 - 维基百科,自由的百科全书' 仅获取语言名
middle=title.find(r'-')
info.write('【程序语言 '+title[:middle]+'】\n')
print title[:middle]
#第四步 获取Infobox的内容
#标准方法是通过<table>匹配</table>确认其内容,找与它最近的一个结束符号
#但此处分析源码后取巧<p><b>实现
start=language.find(r'<table class="infobox vevent"') #起点记录查询位置
end=language.find(r'<p><b>'+title[:middle-1]) #减去1个空格
infobox=language[start:end]
print infobox
#设置下载数量
j=j+1
time.sleep(1)
if j==20:
break;
else:
print 'Error url!!!'
else:
print 'Download over!!!'
~~~
“print infobox”输出其中一门语言ActionScript的InfoBox消息盒部分源代码如下:
~~~
<table class="infobox vevent" cellspacing="3" style="border-spacing:3px;width:22em;text-align:left;font-size:small;line-height:1.5em;">
<caption class="summary"><b>ActionScript</b></caption>
<tr>
<th scope="row" style="text-align:left;white-space:nowrap;;;">发行时间</th>
<td style=";;">1998年</td>
</tr>
<tr>
<th scope="row" style="text-align:left;white-space:nowrap;;;">实现者</th>
<td class="organiser" style=";;"><a href="/wiki/Adobe_Systems" title="Adobe Systems">Adobe Systems</a></td>
</tr>
<tr>
<tr>
<th scope="row" style="text-align:left;white-space:nowrap;;;">启发语言</th>
<td style=";;"><a href="/wiki/JavaScript" title="JavaScript">JavaScript</a>、<a href="/wiki/Java" title="Java">Java</a></td>
</tr>
</table>
~~~
##5. 爬取消息盒属性-属性值
爬取格式如下:
~~~
<table>
<tr>
<th>属性</th>
<td></td>
</tr>
</table>
~~~
其中th表示加粗处理,td和th中可能存在属性如title、id、type等值;同时<td></td>之间的内容可能存在<a href=..></a>或<span></span>或<br />等值,都需要处理。下面先讲解正则表达式获取td值的例子:
参考:[http://bbs.csdn.net/topics/390353859?page=1](http://bbs.csdn.net/topics/390353859?page=1)
~~~
<table>
<tr>
<td>序列号</td><td>DEIN3-39CD3-2093J3</td>
<td>日期</td><td>2013年1月22日</td>
<td>售价</td><td>392.70 元</td>
<td>说明</td><td>仅限5用户使用</td>
</tr>
</table>
~~~
Python代码如下:
~~~
s = '''<table>
....
</table>''' #对应上面HTML
res = r'<td>(.*?)</td><td>(.*?)</td>'
m = re.findall(res,s,re.S|re.M)
for line in m:
print unicode(line[0],'utf-8'),unicode(line[1],'utf-8') #unicode防止乱码
#输出结果如下:
#序列号 DEIN3-39CD3-2093J3
#日期 2013年1月22日
#售价 392.70 元
#说明 仅限5用户使用
~~~
如果<td id="">包含该属性则正则表达式为r'<td id=.*?>(.*?)</td>';同样如果不一定是id属性开头,则可以使用正则表达式r'<td .*?>(.*?)</td>'。
最终代码如下:
~~~
# coding=utf-8
import urllib
import time
import re
#第一步 获取维基百科内容
#http://zh.wikipedia.org/wiki/程序设计语言列表
keyname="程序设计语言列表"
temp='http://zh.wikipedia.org/wiki/'+str(keyname)
content = urllib.urlopen(temp).read()
open('wikipedia.html','w+').write(content)
print 'Start Crawling pages!!!'
#第二步 获取网页中的所有URL
#从原文中"0-9"到"参看"之间是A-Z各个语言的URL
start=content.find(r'0-9')
end=content.find(r'参看')
cutcontent=content[start:end]
link_list = re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')", cutcontent)
fileurl=open('test.txt','w')
for url in link_list:
#字符串包含wiki或/w/index.php则正确url 否则A-Z
if url.find('wiki')>=0 or url.find('index.php')>=0:
fileurl.write(url+'\n')
#print url
num=num+1
fileurl.close()
print 'URL Successed! ',num,' urls.'
#第三步 下载每个程序URL静态文件并获取Infobox对应table信息
#国家:http://zh.wikipedia.org/wiki/阿布哈茲
#语言:http://zh.wikipedia.org/wiki/ActionScript
info=open('infobox.txt','w')
info.write('********获取程序语言信息*******\n\n')
j=1
for url in link_list:
if url.find('wiki')>=0 or url.find('index.php')>=0:
#下载静态html
wikiurl='http://zh.wikipedia.org'+str(url)
print wikiurl
language = urllib.urlopen(wikiurl).read()
name=str(j)+' language.html'
#注意 需要创建一个country的文件夹 否则总报错No such file or directory
open(r'language/'+name,'w+').write(language) #写方式打开+没有即创建
#获取title信息
title_pat=r'(?<=<title>).*?(?=</title>)'
title_ex=re.compile(title_pat,re.M|re.S)
title_obj=re.search(title_ex, language) #language对应当前语言HTML所有内容
title=title_obj.group()
#获取内容'C语言 - 维基百科,自由的百科全书' 仅获取语言名
middle=title.find(r'-')
info.write('【程序语言 '+title[:middle]+'】\n')
print title[:middle]
#第四步 获取Infobox的内容
#标准方法是通过<table>匹配</table>确认其内容,找与它最近的一个结束符号
#但此处分析源码后取巧<p><b>实现
start=language.find(r'<table class="infobox vevent"') #起点记录查询位置
end=language.find(r'<p><b>'+title[:middle-1]) #减去1个空格
infobox=language[start:end]
#print infobox
#第五步 获取table中属性-属性值
if "infobox vevent" in language: #防止无Infobox输出多余换行
#获取table中tr值
res_tr = r'<tr>(.*?)</tr>'
m_tr = re.findall(res_tr,infobox,re.S|re.M)
for line in m_tr:
#print unicode(line,'utf-8')
#获取表格第一列th 属性
res_th = r'<th scope=.*?>(.*?)</th>'
m_th = re.findall(res_th,line,re.S|re.M)
for mm in m_th:
#如果获取加粗的th中含超链接则处理
if "href" in mm:
restr = r'<a href=.*?>(.*?)</a>'
h = re.findall(restr,mm,re.S|re.M)
print unicode(h[0],'utf-8')
info.write(h[0]+'\n')
else:
#报错用str()不行 针对两个类型相同的变量
#TypeError: coercing to Unicode: need string or buffer, list found
print unicode(mm,'utf-8') #unicode防止乱
info.write(mm+'\n')
#获取表格第二列td 属性值
res_td = r'<td .*?>(.*?)</td>'
m_td = re.findall(res_td,line,re.S|re.M)
for nn in m_td:
if "href" in nn:
#处理超链接<a href=../rel=..></a>
res_value = r'<a .*?>(.*?)</a>'
m_value = re.findall(res_value,nn,re.S|re.M) #m_td会出现TypeError: expected string or buffer
for value in m_value:
print unicode(value,'utf-8'),
info.write(value+' ')
print ' ' #换行
info.write('\n')
else:
print unicode(nn,'utf-8')
info.write(nn+'\n')
print '\n'
info.write('\n\n')
else:
print 'No Infobox\n'
info.write('No Infobox\n\n\n')
#设置下载数量
j=j+1
time.sleep(1)
if j==40:
break;
else:
print 'Error url!!!'
else:
print 'Download over!!!'
~~~
输出结果是自定义爬取多少门语言,其中Ada编程语言如下图所示:
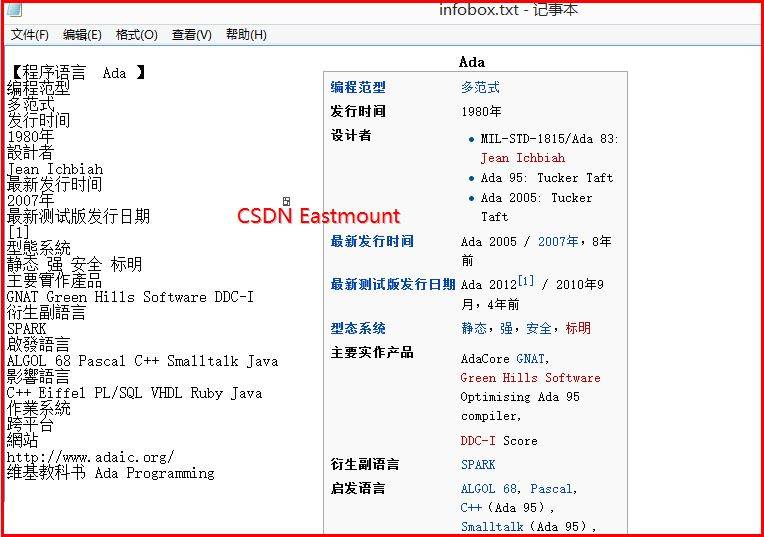
最初我采用的是如下方法,维基百科需要中文繁体,需要人工标注分析HTML再爬取两个尖括号(>...<)之间的内容:
~~~
#启发语言
start=infobox.find(r'啟發語言')
end=infobox.find(r'</tr>',start)
print infobox[start:end]
info.write(infobox[start:end]+'\n')
~~~
当然代码中还存在很多小问题,比如爬取的信息中含<a href>超链接时只能爬取含超链接的信息,而没有超链接的信息被忽略了;如何删除<span class="noprint"></span>或<br/>等信息。但是我希望自己能提供一种爬取网页知识的方法给大家分享,后面可能会讲述如何通过Python实现BeautifulSoup爬取网页知识以及如何爬取图片,很多时候我们在野网站浏览图片都需要不断点击下一张。
(By:Eastmount 2015-3-18 深夜4点 [http://blog.csdn.net/eastmount/](http://blog.csdn.net/eastmount/))
[Python学习] 专题四.文件基础知识
最后更新于:2022-04-01 09:35:28
前面讲述了函数、语句和字符串的基础知识,该篇文章主要讲述文件的基础知识(与其他语言非常类似).
##一. 文件的基本操作
文件是指存储在外部介质(如磁盘)上数据的集合.文件的操作流程为:
打开文件(读方式\写方式)->读写文件(read\readline\readlines\write\writelines)->关闭文件
1.打开文件
调用函数open打开文件,其函数格式为:
~~~
file_obj=open(filename[, mode[, buffering]]) 返回一个文件对象(file object)
— filename文件名(唯一强制参数)
·原始字符串 r'c:\temp\test.txt'
·转移字符串 'c:\\temp\\test.txt'
— mode文件模式
·r 读模式
·w 写模式
·a 追加模式(写在上次后面)
·+ 读/写模式(没有文件即创建,可添加到其他模式中使用)
·b 二进制模式(可添加到其他模式中使用)
— buffering缓冲(可选参数)
·参数=0或False 输入输出I/O是无缓冲的,所有读写操作针对硬盘
·参数=1或True 输入输出I/O是有缓冲的,内存替代硬盘
·参数>1数字代表缓冲区的大小,单位字节.-1或负数代表使用默认缓冲区大小
~~~
注意:当处理二进制文件如声音剪辑或图像时使用'b'二进制模式,可以'rb'读取一个二进制文件.
2.关闭文件
应该牢记使用close方法关闭文件,因为Python可能会缓存(出于效率考虑把数据临时存储某处)写入数据,如果程序突然崩溃,数据根本不会被写入文件,为安全起见,在使用完文件后关闭.如果想确保文件被关闭,应该使用try/finally语句,并且在finally子句中调用close方法.如:
~~~
#Open your file
try:
#Write data to your file
finally:
file.close()
~~~
3.读写文件
调用函数write方法向文件中写入数据,其函数格式为:
~~~
file_obj.write(string) 参数string会被追加到文件中已存部分后面
file_obj.writelines(sequence_of_strings) 仅传递一个参数,列表[ ] 元组() 字典{}
~~~
注意:实用字典时字符串的顺序出现是随机的.
~~~
#使用write()写文件
file_obj=open('test.txt','w')
str1='hello\n'
str2='world\n'
str3='python'
file_obj.write(str1)
file_obj.write(str2)
file_obj.write(str3)
file_obj.close()
#使用writelines()写文件
file_obj=open('test.txt','w')
str1='hello\n'
str2='world\n'
str3='python'
file_obj.writelines([str1,str2,str3])
file_obj.close()
#输出 本地test.txt文件
hello
word
python
~~~
调用函数read方法读取数据,其函数格式为:var=file_obj.read(),其中read全部读取,返回string;readline读取一行,返回string;readlines读取文件所有行,返回a list of string.例:
~~~
#使用read
print 'Use the read'
file_obj=open('test.txt','r')
s=file_obj.read()
print s
file_obj.close
#使用readline
print 'Use the readline'
file_obj=open('test.txt','r')
line1=file_obj.readline()
line1=line1.rstrip('\n')
print 'l1 ',line1
line2=file_obj.readline()
line2=line2.rstrip('\n')
print 'l2 ',line2
line3=file_obj.readline()
line3=line3.rstrip('\n')
print 'l3 ',line3
file_obj.close
#使用readlines
print 'Use the readlines'
file_obj=open('test.txt','r')
li=file_obj.readlines()
print li
file_obj.close
~~~
输出内容如下:
~~~
Use the read
hello
world
python
Use the readline
l1 hello
l2 world
l3 python
Use the readlines
['hello\n', 'world\n', 'python']
~~~
可以发现在使用readline()函数时它返回的结果是'hello\n'字符串,需要使用rstrip去除'\n',否则print输出时总空一行.同时写入文件时使用格式化写入比较方便,如s="xxx%dyyy%s\n"%(28,'csdn').
~~~
#格式化写入
fd=open('format.txt','w')
head="%-8s%-10s%-10s\n"%('Id','Name','Record')
fd.write(head)
item1="%-8d%-10s%-10.2f\n"%(10001,'Eastmount',78.9)
fd.write(item1)
item2="%-8d%-10s%-10.2f\n"%(10002,'CSDN',89.1234)
fd.write(item2)
fd.close()
#输出
Id Name Record
10001 Eastmount 78.90
10002 CSDN 89.12
~~~
##二. 文件与循环
前面介绍了文件的基本操作和使用方法,但是文件操作通常会与循环联系起来,下面介绍while循环和for循环实现文件操作.代码如下:
~~~
#使用while循环
fr=open('test.txt','r')
str=fr.readline()
str=str.rstrip('\n')
while str!="":
print str
str=fr.readline()
str=str.rstrip('\n')
else:
print 'End While'
fr.close
#使用for循环
rfile=open('test.txt','r')
for s in rfile:
s=s.rstrip('\n')
print s
print 'End for'
rfile.close()
~~~
其中for调用迭代器iterator,迭代器提供一种方法顺序访问一个聚合对象中的各个元素,它相当于通过Iter函数获取对象的迭代器,再通过next函数(该方法调用时不需要任何参数)获取下一个值.for可以遍历iterator_obj包括List\String\Tuple\Dict\File.如:
~~~
s='www.csdn.net'
si=iter(s) #生成迭代器
print si.next() #调用next依次获取元素,最后迭代器没有返回值时引发StopIteration异常**
~~~
##三. 总结
该篇文章主要讲述了Python文件基础知识,包括文件的打开、读写、关闭操作、使用循环读写文件及迭代器的知识.希望对大家有所帮助,如果有错误或不足之处,还请海涵!
(By:Eastmount 2014-10-8 中午11点 原创CSDN [http://blog.csdn.net/eastmount/](http://blog.csdn.net/eastmount/)**)
参考资料:
1.51CTO学院 智普教育的python视频 [**http://edu.51cto.com/course/course_id-581.html**](http://edu.51cto.com/course/course_id-581.html)
2.《Python基础教程(第2版)》Magnus Lie Hetland[挪]著
[Python学习] 简单网络爬虫抓取博客文章及思想介绍
最后更新于:2022-04-01 09:35:26
前面一直强调Python运用到网络爬虫方面非常有效,这篇文章也是结合学习的Python视频知识及我研究生数据挖掘方向的知识.从而简单介绍下Python是如何爬去网络数据的,文章知识非常简单,但是也分享给大家,就当简单入门吧!同时只分享知识,希望大家不要去做破坏网络的知识或侵犯别人的原创型文章.主要包括:
1.介绍爬取CSDN自己博客文章的简单思想及过程
2.实现Python源码爬取新浪韩寒博客的316篇文章
## 一.爬虫的简单思想
最近看刘兵的《Web数据挖掘》知道,在研究信息抽取问题时主要采用的是三种方法:
1.手工方法:通过观察网页及源码找出模式,再编写程序抽取目标数据.但该方法无法处理站点数量巨大情形.
2.包装器归纳:它英文名称叫WrapperInduction,即有监督学习方法,是半自动的.该方法从手工标注的网页或数据记录集中学习一组抽取规则,从而抽取具有类似格式的网页数据.
3.自动抽取:它是无监督方法,给定一张或数张网页,自动从中寻找模式或语法实现数据抽取,由于不需要手工标注,故可以处理大量站点和网页的数据抽取工作.
这里使用的Python网络爬虫就是简单的数据抽取程序,后面我也将陆续研究一些Python+数据挖掘的知识并写这类文章.首先我想获取的是自己的所有CSDN的博客(静态.html文件),具体的思想及实现方式如下:
第一步 分析csdn博客的源码
首先需要实现的是通过分析博客源码获取一篇csdn的文章,在使用IE浏览器按F12或Google Chrome浏览器右键"审查元素"可以分析博客的基本信息.在网页中[http://blog.csdn.net/eastmount](http://blog.csdn.net/eastmount)链接了作者所有的博文.
显示的源码格式如下:
其中<diw class="list_item article_item">..</div>表示显示的每一篇博客文章,其中第一篇显示如下:

它的具体html源代码如下:
所以我们只需要获取每页中博客<div class="article_title">中的链接<a href="/eastmount/article/details/39599061">,并增加[http://blog.csdn.net](http://blog.csdn.net)即可.在通过代码:
~~~
import urllib
content = urllib.urlopen("http://blog.csdn.net/eastmount/article/details/39599061").read()
open('test.html','w+').write(content)
~~~
但是CSDN会禁止这样的行为,服务器禁止爬取站点内容到别人的网上去.我们的博客文章经常被其他网站爬取,但并没有申明原创出处,还请尊重原创.它显示的错误"403 Forbidden".
PS:据说模拟正常上网能实现爬取CSDN内容,读者可以自己去研究,作者此处不介绍.参考(已验证):
[**http://www.yihaomen.com/article/python/210.htm**](http://www.yihaomen.com/article/python/210.htm)
[http://www.2cto.com/kf/201405/304829.html](http://www.2cto.com/kf/201405/304829.html)
第二步 获取自己所有的文章
这里只讨论思想,假设我们第一篇文章已经获取成功.下面使用Python的find()从上一个获取成功的位置继续查找下一篇文章链接,即可实现获取第一页的所有文章.它一页显示的是20篇文章,最后一页显示剩下的文章.
那么如何获取其他页的文章呢?
我们可以发现当跳转到不同页时显示的超链接为:
~~~
第1页 http://blog.csdn.net/Eastmount/article/list/1
第2页 http://blog.csdn.net/Eastmount/article/list/2
第3页 http://blog.csdn.net/Eastmount/article/list/3
第4页 http://blog.csdn.net/Eastmount/article/list/4
~~~
这思想就非常简单了,其过程简单如下:
~~~
for(int i=0;i<4;i++) //获取所有页文章
for(int j=0;j<20;j++) //获取一页文章 注意最后一页文章篇数
GetContent(); //获取一篇文章 主要是获取超链接
~~~
同时学习过通过正则表达式,在获取网页内容图片过程中格外方便.如我前面使用C#和正则表达式获取图片的文章:[http://blog.csdn.net/eastmount/article/details/12235521](http://blog.csdn.net/eastmount/article/details/12235521)
## 二.爬取新浪博客
上面介绍了爬虫的简单思想,但是由于一些网站服务器禁止获取站点内容,但是新浪一些博客还能实现.这里参照"51CTO学院 智普教育的python视频"获取新浪韩寒的所有博客.
地址为:[http://blog.sina.com.cn/s/articlelist_1191258123_0_1.html](http://blog.sina.com.cn/s/articlelist_1191258123_0_1.html)
采用同上面一样的方式我们可以获取每个<div class="articleCell SG_j_linedot1">..</div>中包含着一篇文章的超链接,如下图所示:

此时通过Python获取一篇文章的代码如下:
~~~
import urllib
content = urllib.urlopen("http://blog.sina.com.cn/s/blog_4701280b0102eo83.html").read()
open('blog.html','w+').write(content)
~~~
可以显示获取的文章,现在需要获取一篇文章的超链接,即:
<a title="《论电影的七个元素》——关于我对电影的一些看法以及《后会无期》的一些消息" target="_blank" href="**[**http://blog.sina.com.cn/s/blog_4701280b0102eo83.html**](http://blog.sina.com.cn/s/blog_4701280b0102eo83.html)**">《论电影的七个元素》——关于我对电…</a>
在没有讲述正则表达式之前使用Python人工获取超链接http,从文章开头查找第一个"<a title",然后接着找到"href="和".html"即可获取"[http://blog.sina.com.cn/s/blog_4701280b0102eo83.html](http://blog.sina.com.cn/s/blog_4701280b0102eo83.html)".代码如下:
~~~
#<a title=".." target="_blank" href="http://blog.sina...html">..</a>
#coding:utf-8
con = urllib.urlopen("http://blog.sina.com.cn/s/articlelist_1191258123_0_1.html").read()
title = con.find(r'<a title=')
href = con.find(r'href=',title) #从title位置开始搜索
html = con.find(r'.html',href) #从href位置开始搜素最近html
url = con[href+6:html+5] #href="共6位 .html共5位
print 'url:',url
#输出
url: http://blog.sina.com.cn/s/blog_4701280b0102eohi.html
~~~
下面按照前面讲述的思想通过两层循环即可实现获取所有文章,具体代码如下:
~~~
#coding:utf-8
import urllib
import time
page=1
while page<=7:
url=['']*50 #新浪播客每页显示50篇
temp='http://blog.sina.com.cn/s/articlelist_1191258123_0_'+str(page)+'.html'
con =urllib.urlopen(temp).read()
#初始化
i=0
title=con.find(r'<a title=')
href=con.find(r'href=',title)
html = con.find(r'.html',href)
#循环显示文章
while title!=-1 and href!=-1 and html!=-1 and i<50:
url[i]=con[href+6:html+5]
print url[i] #显示文章URL
#下面的从第一篇结束位置开始查找
title=con.find(r'<a title=',html)
href=con.find(r'href=',title)
html = con.find(r'.html',href)
i=i+1
else:
print 'end page=',page
#下载获取文章
j=0
while(j<i): #前面6页为50篇 最后一页为i篇
content=urllib.urlopen(url[j]).read()
open(r'hanhan/'+url[j][-26:],'w+').write(content) #写方式打开 +表示没有即创建
j=j+1
time.sleep(1)
else:
print 'download'
page=page+1
else:
print 'all find end'
~~~
这样我们就把韩寒的316篇新浪博客文章全部爬取成功并能显示每一篇文章,显示如下:
这篇文章主要是简单的介绍了如何使用Python实现爬取网络数据,后面我还将学习一些智能的数据挖掘知识和Python的运用,实现更高效的爬取及获取客户意图和兴趣方面的知识.想实现智能的爬取图片和小说两个软件.
该文章仅提供思想,希望大家尊重别人的原创成果,不要随意爬取别人的文章并没有含原创作者信息的转载!最后希望文章对大家有所帮助,初学Python,如果有错误或不足之处,请海涵!
(By:Eastmount 2014-10-4 中午11点 原创CSDN [http://blog.csdn.net/eastmount/](http://blog.csdn.net/eastmount/))
参考资料:
1.51CTO学院 智普教育的python视频**[**http://edu.51cto.com/course/course_id-581.html**](http://edu.51cto.com/course/course_id-581.html)
2.《Web数据挖掘》刘兵著
[Python学习] 专题三.字符串的基础知识
最后更新于:2022-04-01 09:35:24
在Python中最重要的数据类型包括字符串、列表、元组和字典等.该篇主要讲述Python的字符串基础知识.
##一.字符串基础
字符串指一有序的字符序列集合,用单引号、双引号、三重(单双均可)引号引起来.如:
s1='www.csdn.net' s2="www.csdn.net" s3='''aaabbb'''
其中字符串又包括:
1.转义字符串
像C语言中定义了一些字母前加"\"来表示常见的那些不能显示的ASCII字符,python也有转义字符.如下:
\\-反斜杠符号 \'-单引号 \"-双引号 \ a-响铃 \b-退格(Backspace)
\n-换行 \r-回车 \f-换页 \v-纵向制表符 \t-横向制表符 \e-转义
\000-空 \oyy-八进制数yy代表的字符 \xyy-十进制yy代表的字符
2.raw字符串
Python中原始字符串(raw strings),r关闭转义机制.告诉Python后面是连串,"\"不当转义字符处理.例:
~~~
#转义字符和raw字符
s1="aa\nbb"
print s1
s2=r"aa\nbb"
print s2
#输出
aa
bb
aa\nbb
#raw原始字符串处理磁盘路径
open(r'C:\temp\test.txt','a+')
open('C:\\temp\\test.txt','a+')
~~~
3.unicode字符串
告诉Python是Unicode编码,Unicode(统一码、万国码)是一种在计算机上使用的字符编码.在Unicode之前用的都是ASCII码,Unicode通过使用一个或者多个字节来表示一个字符.Python里面默认所有字面上的字符串都用ASCII编码,可以通过在字符串前面加一个'u'前缀的方式声明Unicode字符串,这个'u'前缀告诉Python后面的字符串要编成Unicode字符串.例:s=u'aa\nbb'
中文处理一直很让人头疼,推荐:[Unicode和Python的中文处理](http://www.cnblogs.com/TsengYuen/archive/2012/05/22/2513290.html)
4.格式化字符串
字符串格式化功能使用字符串格式化操作符%(百分号)实现,在%的左侧放置一个字符串(格式化字符串),而右侧放置希望格式化的值,也可是元组和字典.如果需要在字符串里包括百分号,使用%%.如果右侧是元组的话,则其中每一个元素都会被单独格式化,每个值都对应一个转化说明符.例:
"your age %d,sex %s,record %f"%(28,"Male",78.5)
输出:'your age 28,sex Male,record 78.500000'
它有点类似于C语言的printf("%d",x),其中百分号%相当于C语言的逗号.其中字符串格式化转换类型如下:
d,i 带符号的十进制整数
o 不带符号的八进制
u 不带符号的十进制
x 不带符号的十六进制(小写)
X 不带符号的十六进制(大写)
e,E 科学计数法表示的浮点数(小写,大写)
f,F 十进制浮点数
c 单字符
r 字符串(使用repr转换的任意Python)
s 字符串(使用str转换的任意Python)
g,G 指数大于4或小于精度值和e相同,否则和f相同**
##二.字符串操作
字符串的基础操作包括分割,索引,乘法,判断成员资格,求长度等.
1.+连接操作
~~~
如:s1='csdn' s2='Eastmount' s3=s1+s2
print s1,s2 => 输出:csdn Eastmount
print s3 => 输出:csdnEastmount
~~~
2.重复操作
~~~
如:s1='abc'*5
print s1 => 输出:abcabcabcabcabc
~~~
3.索引s[index]
Python的索引格式string_name[index],可以访问字符串里面的字符成员.
4.切片s[i:j]
Python中切片的基本格式是s[i:j:step],其中step表示切片的方向,起点不写从0开始,终点不写切到最后.如:
~~~
s='abcdefghijk'
sub=s[3:8]
print sub => 输出defgh_
3 78 (起点是3 终点8不取)
~~~
其中当step=-1时表示反方向切片.如:
~~~
s='abcdefghijk'
sub=s[-1:-4:-1]
print sub => 输出kji
~~~
因为最后一个"-1"表示从反方向切片,s[9]='j' s[-2]='j',正方向第一个'a'索引下标值为0,最后一个'k'索引下标值为-1.故'j'为-2,而sub[-1:-4:-1]表示从k(-1位置)切到h(-4位置,但不取该值).故结果为"kji".
如果想完成字符串逆序,s='www.baidu.com',则可s1=[-1::-1]即可.起点为m(-1),无终点表示切到最后.
5.字段宽度和精度
前面讲述的format()函数中涉及到该知识,如'%6.2f'%12.345678 输出"口12.35"其中6表示字段宽度,2表示精度,故补一个空格,同时采用四舍五入的方法结果输出12.35.
同时,零(0)可表示数字将会用0填充,减号(-)用来实现左对齐数值,空白(" ")意味着正数前加上空格,在正负数对其时非常有用,加号表示不管正数还是负数都标识出符号,对齐时也有用.例:
~~~
#字段宽度和精度
num = 12.345678
s1 = '%6.2f'%num
print s1
#补充0
s2 = '%08.2f'%num
print s2
#减号实现左对齐
s3 = '%-8.2f'%num
print s3
#空白
print ('% 5d'%10) + '\n' + ('% 5d'%-10)
#符号
print ('%+5d'%10) + '\n' + ('%+5d'%-10)
#输出
12.35
00012.35
12.35
10
-10
+10
-10
~~~
##三.字符串方法
字符串从string模块中"继承"了很多方法,下面讲解一些常用的方法:
find()
在一个较长的字符串中查找子字符串,它返回子串所在位置的最左端索引,如果没有找到则返回-1.其格式为"S.find(sub [,start [,end]]) -> int",其中该方法可接受可选的起始点和结束点参数.而rfind()从右往左方向查找.
~~~
title = 'Hello Python,Great Python'
length = len(title)
print length
print title.find('Python')
print title.find('Python',10,30)
#输出:
25
6
19
~~~
join()
其格式为"S.join(iterable) -> string",含义为"Return a string which is the concatenation of the strings in the iterable. The separator between elements is S."即用来在队列中添加元素,但队列中元素必须是字符串.它是split方法的逆方法.
~~~
seq = ['1','2','3','4']
sep = '+'
print sep.join(seq) #连接字符串列表 sep表示'+'连接
dirs = '','usr','bin','env'
print '/'.join(dirs)
print 'C:'+'\\'.join(dirs)
#输出
1+2+3+4
/usr/bin/env
C:\usr\bin\env
~~~
split()
字符串分割函数,格式为"S.split([sep [,maxsplit]]) -> list of strings",将字符串分割成序列,如果不提供分割符,程序将会把所有空格作为分隔符.
~~~
#按空格拆分成4个单词,返回list
s = 'please use the Python!'
li = s.split()
print li
print '1+2+3+4+5'.split('+')
#输出
['please', 'use', 'the', 'Python!']
['1', '2', '3', '4', '5']
~~~
strip()
去掉开头和结尾的空格键(两侧且不包含内部),S.strip([chars])可以去除指定字符.而函数lstrip()去除字符串最开始的所有空格,rstrip()去除字符串最尾部的所有空格.
replace()
该方法返回某字符串的所有匹配项均被替换后得到字符串,如文字处理程序中"查找并替换"功能.
translate()
该方法和replace一样,可以替换字符串中某部分,但与前者的区别是translate只处理单个字符,它的优势在于可以同时替换多个,有时候效率比replace高.
如:s='eastmount' s1=s.replace('e','E') => 替换后'Eastmount'
字符串判断方法
isalnum()判断是否都是有效字符(字母+数字),如判断密码帐号,输出Ture\False.
isalpha()判断是否是字母
isdigit()判断是否是数字
islower()判断是否全是小写
isupper()判断是否全是大写
isspace()判断是否是空格(' ')
lower()
该方法返回字符串的小写字母版,在判断用户名不区分大小写时使用.upper()转换为大写,title()函数将字符串转换为标题——所有单词的首字母大写,而其他字母小写,但是它使用的单词划分方法可能会得到不自然的结果.
~~~
s = 'this is a good idea'
s1 = s.upper()
print s1
s2 = s.title()
print s2
#输出
THIS IS A GOOD IDEA
This Is A Good Idea
~~~
PS:我主要是通过《Python基础教程》和"51CTO学院 智普教育的python视频"学习.所以文中引用了很多视频中的知识、书籍知识和自己的知识,感谢那些作者和老师,希望文章对大家有所帮助,才开始学习python知识,如果文章中有错误或不足之处,还请海涵,也希望大家提出意见与君共勉.勿喷~
(By:Eastmount 2014-9-28 中午11点 原创CSDN [http://blog.csdn.net/eastmount/](http://blog.csdn.net/eastmount/))
[Python学习] 专题二.条件语句和循环语句的基础知识
最后更新于:2022-04-01 09:35:22
前面讲述了"**专题一.函数的基础知识**",而这篇文章讲述的Python的条件语句和循环语句的基础知识.主要内容包括:
1.条件语句:包括单分支、双分支和多分支语句,if-elif-else
2.循环语句:while的使用及简单网络刷博器爬虫
3.循环语句:for的使用及遍历列表、元组、文件和字符串**
##前言: 语句块
在讲诉条件语句、循环语句和其他语句之前,先来补充语句块知识.(前面讲函数时已经用到过) 语句块并非一种语句,它是在条件为真(条件语句)时执行或执行多次(循环语句)的一组语句.在代码前放置空格或tab字符来缩进语句即可创建语句块.很多语言特殊单词或字符(如begin或{)来表示一个语句块的开始,用另外的单词或字符(如end或})来表示语句块的结束.
而在Python中使用冒号(:)来标识语句块的开始,块中每一个语句都是缩进的(缩进量相同).当回退到和已经闭合的块一样的缩进量时,就表示当前块已经结束.
##一. 条件语句if
if分支语句表达式基本类型常见的有一下三种:
1.单分支语句
它的基本格式是:
if condition:
statement
statement
需要注意的是Ptthon中if条件语句条件无需圆括号(),条件后面需要添加冒号,它没有花括号{}而是使用TAB实现区分.其中condition条件判断通常有布尔表达式(True|False 0-假|1-真 非0即真)、关系表达式(>= <= == !=)和逻辑运算表达式(and or not).
2.双分支语句
它的基本格式是:
if condition:
statement
statement
else:
statement
statement
3.多分支语句
if多分支由if-elif-else组成,其中elif相当于elseif,同时它可以使用多个if的嵌套.具体代码如下所示:
~~~
#双分支if-else
count = input("please input:")
print 'count=',count
if count>80:
print 'lager than 80'
else:
print 'lower than 80'
print 'End if-else'
#多分支if-elif-else
number = input("please input:")
print 'number=',number
if number>=90:
print 'A'
elif number>=80:
print 'B'
elif number>=70:
print 'C'
elif number>=60:
print 'D'
else:
print 'No pass'
print 'End if-elif-else'
#条件判断
sex = raw_input("plz input your sex:")
if sex=='male' or sex=='m' or sex=='man':
print 'Man'
else:
print 'Woman'
~~~
##二. 循环语句while
while循环语句的基本格式如下:
while condition:
statement
statement
else:
statement
statement
其中判断条件语句condition可以为布尔表达式、关系表达式和逻辑表达式,else可以省略(此处列出为与C语言等区别).举个例子:**
~~~
#循环while计数1+2+..+100
i = 1
s = 0
while i <= 100:
s = s+i
i = i+1
else:
print 'exit while'
print 'sum = ',s
'''
输出结果为:exit while
sum = 5050
'''
~~~
它的输出结果为5050,当时当i加到101时,由于i>100将执行else语句.
需要注意的是Python中使用井号(#)表示行注释,使用三引号('''...''')表示多行注释.区别于C/C++的//行注释和/**/多行注释.
下面讲述一段代码刷博器爬虫,先给出代码再讲解:
~~~
import webbrowser as web
import time
import os
i=0
while i<5:
web.open_new_tab('http://andy111.blog.sohu.com/46684846.html')
i=i+1
time.sleep(0.8)
else:
os.system('taskkill /F /IM iexplore.exe')
print 'close IE'
~~~
在搜狐博客或新浪博客中只要在新窗口打开就会增加浏览访问次数,所以上面的代码主要是通过调用webbrowser浏览器的open_new_tab打开新的窗口,而CSDN不行(估计绑定用户或ip有关).
上面代码中windoes命令taskkill的作用是杀掉应用程序IE浏览器,在DOS中输入"taskkill /F /IM iexplore.exe"可以强行关闭应用程序(chrome.exe或qq.exe),其中/F表示强行终止程序,/IM表示图像.在该程序中主要的作用是清除内存,防止内存消耗太大出现死机现象;但是需要调用import os的system()函数打开,而Linux下用kill命令(kill -pid或killall)终止进程.
代码中time.sleep(seconds)表示"Delay execution for a given number of seconds.",从打开到加载有一定时间.
当你需要大量增加浏览量时可以使用两层循环嵌套,每次打开5个网页在关闭在执行100次,这样你的内存也不会因为消耗太大出现死机现象,也可以使用import random count=random.randint(20,40)产生20到40随机数来执行外层循环.代码比较简单,主要是想通过它介绍些Python的基础知识.但是初次打开IE浏览器会出现打开次数不一致的错误.why?
##三. 循环语句for
该循环语句的基础格式为:
for target in sequences:
statements
target表示变量名,sequences表示序列,常见类型有list(列表)、tuple(元组)、strings(字符串)和files(文件).
Python的for没有体现出循环的次数,不像C语言的for(i=0;i<10;i++)中i循环计数,Python的for指每次从序列sequences里面的数据项取值放到target里,取完即结束,取多少次循环多少次.其中in为成员资格运算符,检查一个值是否在序列中.同样可以使用break和continue跳出循环.
1.字符串循环
~~~
s1 = 'Eastmount of CSDN'
for c in s1:
print c,
~~~
注意:如果在print结尾加上逗号,那么接下来语句会与前一条语句在同一行打印.故上面输出显示一行.
2.列表循环
~~~
list1 = [1,3,4,5,'x',12.5]
i = 0
for val in list1:
print format(i,'2d'),val
i = i+1
else:
print 'out for'
~~~
注意:列表List由一堆数据用逗号间隔,方括号括起,可以是同类型也可以是不同类型.format(i,'2d')相当于输出两位,不足的补空格.当输出0-9时显示"口0",而输出10-99时显示"10"实现对其功能.输出结果如下:
~~~
1 3
2 4
3 5
4 x
5 12.5
out for
~~~
因为迭代(循环另一种说法)某范围的数字是很常用的,所以有个内建的范围函数range供使用.列表中for n in [1,2,3,4,5,6,7,8]相当于listNum=range(1,9).其格式"range(start, stop[, step]) -> list of integers",它的工作方式类似于分片,它包含下限(本例range(1,9)中为1),但不包含上限(本例中9),如果希望下限为0,可以只提供上限如range(4)=[0,1,2,3].
产生1到100的数字range(1,101),输出1到100的奇数range(1,101,2),输出1到100的偶数range(2,101,2).
3.元组循环
~~~
tup = (1,2,3,4,5)
for n in tup:
print n
else:
print 'End for'
~~~
元组tuple每个数据项不可修改,只可读,而序列list[1,2,3,4]可以修改.
4.文件循环
help(file.read)返回一个字符串."read([size]) -> read at most size bytes, returned as a string."
help(file.readlines)返回一个列表."readlines([size]) -> list of strings, each a line from the file."相当于读n行,由n次readline组成,读出的字符串构成列表.
help(file.readline)从某个文件读一行."readline([size]) -> next line from the file, as a string."
~~~
#文件循环遍历三种对比
for n in open('for.py','r').read():
print n,
print 'End'
for n in open('for.py','r').readlines():
print n,
print 'End'
for n in open('for.py','r').readline():
print n,
print 'End'
~~~
输出显示:
~~~
#第一个read()输出:每个字符间有个空格
s 1 = ' E a s t m o u n t o f C S D N '
f o r c i n s 1 :
....
End
#第二个readlines()输出:读取的是一行
s1 = 'Eastmount of CSDN'
for c in s1:
....
End
#第三个readline()输出:读取for.py文件第一行并输出
s 1 = ' E a s t m o u n t o f C S D N '
End
~~~
如果需要文件输出也可以通过下面代码实现,使用w会覆盖而a+是追加功能,后面讲文件详细叙述.
for r in open('test.txt','r').readlines():
open('test.txt','a+').write(c)
PS:我主要是通过《Python基础教程》和"51CTO学院 智普教育的python视频"学习.所以文中引用了很多视频中的知识、书籍知识和自己的知识,感谢那些作者和老师,希望文章对大家有所帮助,才开始学习python知识,如果文章中有错误或不足之处,还请海涵,也希望大家提出意见与君共勉.勿喷~
(By:Eastmount 2014-9-22 夜7点 原创CSDN [http://blog.csdn.net/eastmount/](http://blog.csdn.net/eastmount/)**)
[Python学习] 专题一.函数的基础知识
最后更新于:2022-04-01 09:35:19
最近才开始学习Python语言,但就发现了它很多优势(如语言简洁、网络爬虫方面深有体会).我主要是通过《Python基础教程》和"51CTO学院 智普教育的python视频"学习,在看视频中老师讲述函数知识的时候觉得非常不错,所以就写了第一篇Python学习的文章分享给大家.主要内容:
1.Python安装与基本输入输出,print()函数和raw_input()函数简单用法.
2.我根据视频中学到的知识,讲解函数的基本知识:
(1).系统提供内部函数:字符串函数库、数学函数库、网络编程函数库、OS函数库
(2).第三方提供函数库:讲解如何安装httplib2第三方函数库,再做了个简单的网页爬虫例子
(3).用户自定义函数:讲解无返回类型、有形参、预设值参数等自定义函数
3.同时网络编程中与C#以前学过的进行了简单对比,发现python确实有很多优点,而且很方便强大.
PS:文章中引用了很多视频中的知识、书籍知识和自己的知识,感谢那些作者和老师,希望文章对大家有所帮助,才开始学习python知识,如果文章中有错误或不足之处,还请海涵,也希望大家提出意见与君共勉.勿喷~
##一. Python安装及输入输出函数
python解释器在Linux中可以内置使用安装,windows中需要去**[**www.python.org**](http://www.python.org/)**官网downloads页面下载(如python-2.7.8.amd64.msi),安装Python集成开发环境(Python Integrated Development Environment,IDLE)即可.运行程序输入">>>print 'hello world'"则python解释器会打印输出"hello world"字符串. 如下:
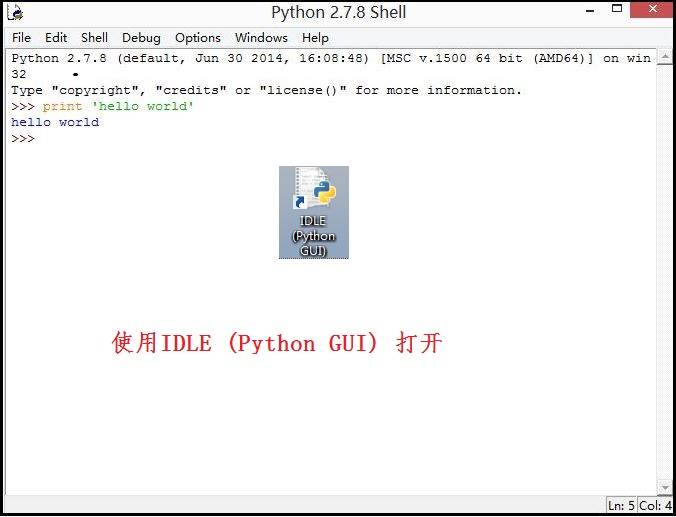
然后讲述Python程序的基本框架是"输入-处理-输出",而输入输出函数如下:
1.print()函数
函数用于输出或打印整型、浮点型、字符串数据至屏幕,如print(3)、print(12.5)、print('H').它输出变量格式"print(x)或printx",而且可以输出多个变量"print x,y,z".并且支持格式化输出数据,调用format()函数,其格式为:
print(format(val,format_modifier)) 其中val表示值,format_modifier表示格式字.
~~~
#简单输出
>>> print(12.5)
12.5
>>> print("eastmount")
eastmount
#输出"123.46",6.2表示输出6位,小数点后精度2位,输出最后一位6是四舍五入的结果
>>> print(format(123.45678,'6.2f'))
123.46
#输出"口口口123",采用右对齐补空格方式输出总共6位
>>> print(format(123.45678,'6.0f'))
123
#输出"123.456780000"小数点后面9位,超出范围会自动补0
>>> print(format(123.45678,'6.9f'))
123.456780000
#输出"34.56%"表示打印百分率
>>> print(format(0.3456,'.2%'))
34.56%
~~~
2.raw_input()函数
内建函数从sys.stdin接受输入,读取输入语句并返回string字符串.输入以换行符结束,通过help(raw_input)可以查找帮助,常见格式为:
s = raw_input([prompt]) 参数[prompt]可选,用于提示用户输入
~~~
#输入函数
>>> str1 = raw_input("please input a string:")
please input a string:I love you
>>> print(str1)
I love you
#查看str1数据类型
>>> type(str1)
<type 'str'>
~~~
注意raw_input()与input()的区别:
(1).input支持合法python表格式"abc",字符串必须用引号括起,否则会报错"NameError: name 'abc' is not defined",而raw_input()任何类型输入都可接受;
(2).raw_input()将所有输入作为字符串,返回string,而input()输入纯数字时具有自己的特性,返回输入的数字类型int或float.举例解释如下:
~~~
#SyntaxError语法错误
>>> str1 = input("input:")
input:abc
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<string>", line 1, in <module>
NameError: name 'abc' is not defined
#正确输入输出
>>> str1 = input("input:")
input:"I love you"
>>> print str1
I love you
#input纯数字 数据类型
>>> weight = input("weight:")
weight:12.5
>>> type(weight)
<type 'float'>
#raw_input 数据类型均为str
>>> age = raw_input("age:")
age:20
>>> type(age)
<type 'str'>
~~~
##二. 函数之系统提供内部函数
python提供的系统内部库函数主要讲述一下四种类型:(引自视频,只简单介绍)
1.字符串函数库
通过help(str)可以查询字符串函数库,其中查询过程中"-More-"输入回车实现滚动信息,输出"q"退出帮助(Quit).字符串函数大家都比较熟悉,无论C\C++\C#\Java都学过很多,而且基本大同小异.如:
islower()函数判断字符串是否大小写,一个大写返回False.前面使用的format()函数、求字符串长度len()函数均属于字符串函数库,help(str.replace)可以查询具体函数用法,该函数用于新字符串替换旧字符串.**
~~~
#判断字符串是否小写
>>> str1 = "Eastmount"
>>> str1.islower()
False
#字符串替换
>>> str2 = 'adfababdfab'
>>> str2.replace('ab','AB')
'adfABABdfAB'
#字符串求长度
>>> print(len(str2))
11
>>>
~~~
2.数学函数库
使用数学函数库时需要注意的是导入库"importmath",该库中函数我们也非常熟悉,如sin()求正弦,cos()求余弦,pow(x,y)计算x的y次幂,如pow(3,4)=3*3*3*3,python中也可以使用3**4表示.help(math)中可以查看详细信息,而且库中定义了两个常数DATA:
e = 2.718281... pi = 3.14159265...
~~~
#导入math库
>>> import math
>>> print math.pi
3.14159265359
#计算sin30度
>>> val = math.sin(math.pi/6)
>>> print val
0.5
#pow函数
>>> math.pow(3,4)
81.0
>>> 3**4
81
>>> help(math.pow)
Help on built-in function pow in module math:
pow(...)
pow(x, y)
Return x**y (x to the power of y).
>>>
~~~
3.网络编程库
系统提供内部库函数中网络编程库,我此处仅仅举个简单例子,socket(套接字网络编程)获取主机ip地址这是非常常见的运用,我将与C#网络编程进行简单对比.后面的博文中将详细讲述python网络编程.
~~~
>>> import socket
>>> baiduip = socket.gethostbyname('www.baidu.com')
>>> print baiduip
61.135.169.125
~~~
其中socket编程很常用,gethostbyname()返回指定主机ip,而C#中获取百度网址的ip地址代码如下所示.代码中可能会出现"警告:Dns.GetHostByName()函数已过时",可替换为IPHostEntry myHost = Dns.GetHostEntry([www.baidu.com](http://www.baidu.com)).输出:
61.135.169.121
61.134.169.125
~~~
//引用新命名空间
using System.Net;
namespace GetIp
{
class Program
{
static void Main(string[] args)
{
//获取DNS主机名的DNS信息
IPHostEntry myHost = Dns.GetHostByName("www.baidu.com");
IPAddress[] address = myHost.AddressList;
for (int index = 0; index < address.Length; index++)
{
Console.WriteLine(address[index]);
}
Console.ReadKey();
}
}
}
~~~
4.操作系统(OS)函数库
操作系统库函数引用"importos",举例获取当前工作路径和先死当前路径下的文件和目录.使用os.system("cls")可以实现清屏功能.安装python目录Lib文件夹下含有很多py库文件供使用.
~~~
>>> import os
#获取当前工作路径
>>> current = os.getcwd()
>>> print current
G:\software\Program software\Python\python insert
#获取当前路径下的文件和目录
>>> dir = os.listdir(current)
>>> print dir
['DLLs', 'Doc', 'h2.txt', 'include', 'Lib', 'libs', 'LICENSE.txt
', 'NEWS.txt', 'python.exe', 'pythonw.exe', 'README.txt', 'tcl', 'Tools']
>>>
~~~
##三. 函数之第三方提供函数库及安装httplib2模块过程
(一).安装第三方函数库httplib2过程
Python中第三方开源项目中提供函数库供我们使用,比如使用httplib2库函数.在Linux中直接使用"easy_installhttplib2"搜索自动安装,Windows下python开发工具IDLE里安装httplib2模块的过程如下(其他模块类似).
1.下载httplib2模块"**[**https://code.google.com/p/httplib2/**](https://code.google.com/p/httplib2/)**"到指定目录,解压压缩包"httplib2_0.8.zip"到某目录下,如果该网址google访问失败,可以到此处下载:
2.配置python运行环境
右键"计算机"->"属性"->在"系统"中选择"高级系统设置"->在"系统属性"中"高级"选择"环境变量"**
在系统环境变量Path后添加python安装目录"G:\software\Program software\Python\python insert"
3.在dos下安装httpLib2
管理员模式运行cmd,利用cd命令进入httplib2_0.8.zip解压目录,输入"python settup.py install",如下图所示安装成功.
4.使用httplib2
如果httplib2库函数没有安装成功,"importhttplib2"会提示错误"ImportError: No module namedhttplib2".否则安装成功,举例如下.看参考更多"[Python - 熟悉httplib2](http://blog.csdn.net/leehark/article/details/7079761#)"
~~~
import httplib2
#获取HTTP对象
h = httplib2.Http()
#发出同步请求并获取内容
resp, content = h.request("http://www.csdn.net/")
#显示返回头信息
print resp
#显示网页相关内容
print content
输出头信息:
{'status': '200', 'content-length': '108963', 'content-location': 'http://www.csdn.net/', .... 'Fri, 05 Sep 2014 20:07:24 GMT', 'content-type': 'text/html; charset=utf-8'}
~~~
(二).简单网页爬虫示例
使用第三方函数库时的具体格式为module_name.method(parametes) 第三方函数名.方法(参数).
讲述一个引用web库,urllib库访问公网上网页,webbrowser库调用浏览器操作,下载csdn官网内容并通过浏览器显示的实例.
~~~
import urllib
import webbrowser as web
url = "http://www.soso.com"
content = urllib.urlopen(url).read()
open("soso.html","w").write(content)
web.open_new_tab("soso.html")
~~~
它会输出True并在浏览器中打开下载的静态网页.引用import webbrowser as web使用web,也可以直接引用,使用时"**module_name.method**"即可.读者可以对比我的C#文章"[C# 网络编程之网页简单下载实现](http://blog.csdn.net/eastmount/article/details/9628443)".
content = urllib.urlopen(url).read()表示打开url并读取赋值open("soso.html","w").write(content)表示在python安装目录写静态soso.html文件web.open_new_tab("soso.html")表示打开该静态文件新标签.
同样可以使用web.open_new_tab('http://www.soso.com')直接在浏览器打开动态网页.效果如下图所示:
##四. 函数之自定义函数
1.无返回值自定义函数
其基本语法格式如下:
def function_name([parameters]):函数名([参数]),其中参数可有可无
(TAB) statement1
(TAB) statement2
...
注意:
(1).自定义函数名后面的冒号(:)不能省略,否则报错"invalid syntax",而且无需像C语言一样加{};
(2).函数里每条语句前都有缩进TAB,否则会报错"There's an error in your programs:expected an indented block",它的功能相当于区分函数里的语句与函数外的语句.
举例:打开IDLE工具->点击栏"File"->New File新建文件->命名为test.py文件,在test文件里添加代码如下.
~~~
def fun1():
print 'Hello world'
print 'by eastmount csdn'
print 'output'
fun1()
def fun2(val1,val2):
print val1
print val2
fun2(8,15)
~~~
保存,在test.py文件里点击Run->Run Module.输出结果如下图所示,其中fun1()函数无形参自定义函数,fun2(val1,val2)是有形参自定义函数,fun2(8,15)为函数的调用,实参8和15.
2.有返回值自定义函数
其基本语法格式如下:
def funtion_name([para1,para2...paraN])
statement1
statement2
....
return value1,value2...valueN
返回值支持一个或多个返回,需要注意的是自定义函数有返回值,主调函数就需要接受值(接受返回的结果).同时在定义变量时可能sum这些可能是关键字(注意颜色),最好使用不是关键字的变量.举例:
~~~
def fun3(n1,n2):
print n1,n2
n = n1 + n2
m = n1 - n2
p = n1 * n2
q = n1 / n2
e = n1 **n2
return n,m,p,q,e
a,b,c,d,e = fun3(2,10)
print 'the result are ',a,b,c,d,e
re = fun3(2,10)
print re
~~~
输出结果如下,其中需要注意的是参数一一对应,在除法中2/10=0,**幂运算2的10次方=1024.而使用re=fun3(2,10)直接输出的结果成为元组,后面会详细讲述,(12,-8,20,0,1024)元组中re[0]存储12,re[1]存储-8,依次~**
~~~
2 10
the result are 12 -8 20 0 1024
2 10
(12, -8, 20, 0, 1024)
~~~
3.自定义函数参数含预定义
预设值的基本格式如下:
def function_name(para1,para2...parai=default1...paran=defaultn)
statement1
statement2
...
return value1,value2...valuen
其中需要注意的是预定义值得参数不能先于无预定义值参数,举个例子讲解.
~~~
def fun4(n1,n2,n3=10):
print n1,n2,n3
n = n1 + n2 + n3
return n
re1 = fun4(2,3)
print 'result1 = ',re1
re2 = fun4(2,3,5)
print 'result2 = ',re2
~~~
输出结果如下图所示,预定义的参数在调用时,实参可以省略,也可以替换默认定义的预定义值.
~~~
2 3 10
result1 = 15
2 3 5
result2 = 10
~~~
其中如果函数定义为def fun4(n3=10,n2,n1)就会报错"non-default argument follows default argument"(没预定义的参数在预定义参数的后面),所以定义函数时需要注意该点.
同时需要注意函数调用时的赋值顺序问题,最好采用一对一复制,也可以函数调用中给出具体形参进行赋值,但需要注意的是在函数调用过程中(使用函数时),有预定义值的参数不能先于无预定义值参数被赋值.
如例子中自定义函数def fun4(n1,n2,n3=10),在调用时可以:
(1).s=fun4(2,3)省略预定义参数,它是一对一赋值,其中n1赋值2、n2赋值3、n3赋值10(预定义)
(2).s=fun4(4,n2=1,n3=12)它也是一对一赋值,而且预定义值n3替换为12
(3).s=fun4(n2=1,n1=4,n3=15)它的顺序与定义函数没有对应,但是调用时给出具体对应也行
下面的情况就会出现所述的"**有预定义值的参数先于无预定义值参数被赋值**"错误:
(1).s=fun4(n3=12,n2=1,4)此时会报错"non-keyword arg after keyword arg",它不能指定n1=4,就是没有指定预定值n1=4在有预定值n3=12,n2=1之后,如果改成s=fun4(4,n2=1,n3=12)或s=fun4(4,n3=12,n2=1)即可.
(2).s=fun4(4,n1=2)此时也会报错"TypeError: fun4() got multiple values for keyword argument 'n1'",它不能指定n1=2&n2=4,而是n1会赋值多个.
所以,最好还是一一对应的调用函数,平时写程序没有这样去刁难自己,对应即可
总结:文章从系统提供的内部函数、第三方提供函数库+简单爬出代码及安装httplib2模块过程和用户自定函数三个方面进行讲述.文章中如果有错误或不足之处,海涵~最后感谢那个视频老师和上述博主、书籍老师及me.
Python 公开课视频链接 [http://edu.51cto.com/course/course_id-527.html](http://edu.51cto.com/course/course_id-527.html)
最后祝大家中秋节快乐!全家团圆,聚聚玩玩.
(By:Eastmount 2014-9-8 夜5点 原创CSDN [http://blog.csdn.net/eastmount/](http://blog.csdn.net/eastmount/)**)
前言
最后更新于:2022-04-01 09:35:17
> 原文出处:[Python学习系列](http://blog.csdn.net/column/details/eastmount-python.html)
作者:[eastmount](http://blog.csdn.net/eastmount)
**本系列文章经作者授权在看云整理发布,未经作者允许,请勿转载!**
# Python学习系列
> 该专栏主要叙述了Python的基础知识,从最简单的函数、字符串、循环语句、文件知识,到使用Python实现网络编程,结合数据挖掘的知识爬取网站内容。不仅仅包含基础知识,还有实际的工程运用知识讲解Python这门语言。