[python学习] 模仿浏览器下载CSDN源文并实现PDF格式备份
最后更新于:2022-04-01 09:35:40
最近突然想给自己的博客备份下,看了两个软件:一个是CSDN博客导出软件,好像现在不能使用了;一个是豆约翰博客备份专家,感觉都太慢,而且不灵活,想单独下一篇文章就比较费时。而且我的毕业论文是基于Python自然语言相关的,所以想结合前面的文章用Python实现简单的功能:
1.通过网络下载本体的博客,包括图片;
2.在通过Python把HTML转换成PDF格式;
3.如果可能,后面可能会写文章对代码采用特定的方式进行处理。
言归正传,直接上代码通过两个方面进行讲解。
##一. 设置消息头下载CSDN文章内容
获取一篇文章Python的代码如下,如韩寒的新浪博客:(文章最后的总结有我以前关于Python爬虫博文链接介绍)
~~~
import urllib
content = urllib.urlopen("http://blog.sina.com.cn/s/blog_4701280b0102eo83.html").read()
open('blog.html','w+').write(content)
~~~
但是很多网站都防止这种获取方式,如CSDN会返回如下html代码:“403 Forbidden错误”:
~~~
<html>
<head><title>403 Forbidden</title></head>
<body bgcolor="white">
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx</center>
</body>
</html>
~~~
此时通过设置消息头或模仿登录,可以伪装成浏览器实现下载。代码如下:
~~~
#coding:utf-8
import urllib
import urllib2
import cookielib
import string
import time
import re
import sys
#定义类实现模拟登陆下载HTML
class GetInfoByBrowser:
#初始化操作
#常见错误:AttributeError: .. instance has no attribute 'opener' 是双下划线
def __init__(self):
socket.setdefaulttimeout(20)
self.headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:28.0) Gecko/20100101 Firefox/28.0'}
self.cookie_support = urllib2.HTTPCookieProcessor(cookielib.CookieJar())
self.opener = urllib2.build_opener(self.cookie_support,urllib2.HTTPHandler)
#定义函数模拟登陆
def openurl(self,url):
urllib2.install_opener(self.opener)
self.opener.addheaders = [("User-agent",self.headers),("Accept","*/*"),('Referer','http://www.google.com')]
try:
result = self.opener.open(url)
content = result.read()
open('openurl.html','w+').write(content)
print content
print 'Open Succeed!!!'
except Exception,e:
print "Exception: ",e
else:
return result
#定义Get请求 添加请求消息头,伪装成浏览器
def geturl(self,get_url):
result = ""
try:
req = urllib2.Request(url = get_url, headers = self.headers)
result = urllib2.urlopen(req).read()
open('geturl.html','w+').write(result)
type = sys.getfilesystemencoding()
print result.decode("UTF-8").encode(type) #防止中文乱码
print 'Get Succeed!!!'
except Exception,e:
print "Exception: ",e
else:
return result
#调用该类获取HTML
print unicode('调用模拟登陆函数openurl:','utf-8')
print unicode('第一种方法 openurl:','utf-8')
getHtml = GetInfoByBrowser()
getHtml.openurl("http://blog.csdn.net/eastmount/article/details/39770543")
print unicode('第二种方法 geturl:','utf-8')
getHtml.geturl("http://blog.csdn.net/eastmount/article/details/39770543")
~~~
运行效果是下载我的文章“[Python学习] 简单网络爬虫抓取博客文章及思想介绍”,两种方法效果一样,其中本体两个文件geturl.html和openurl.html。该方法运行Python定义类、函数、urllib2和cookielib相关知识。
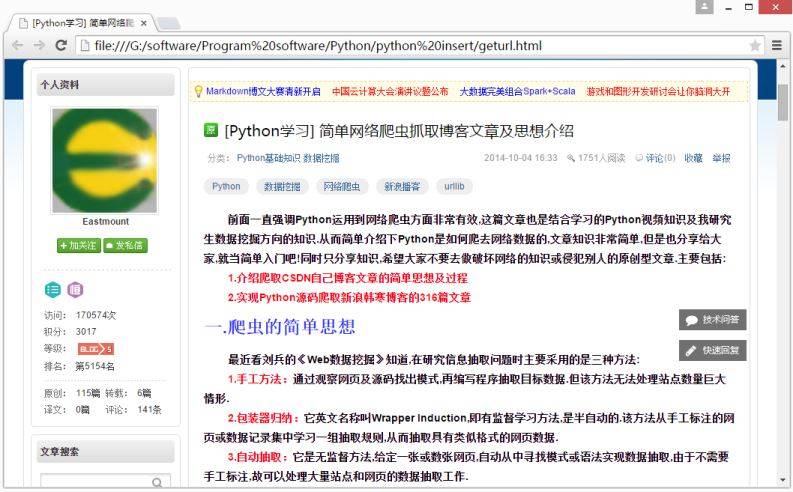
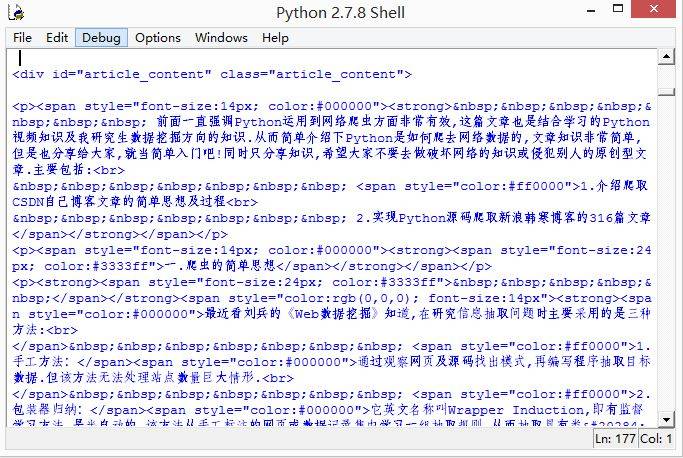
相关类似的优秀文章推荐三篇,其中POST方法类似:
[[Python]一起来写一个Python爬虫工具类whyspider——汪海](http://blog.csdn.net/pleasecallmewhy/article/details/24021695)
[用python 写爬虫,去爬csdn的内容,完美解决 403 Forbidden](http://www.yihaomen.com/article/python/210.htm)
[urllib2.HTTPError: HTTP Error 403: Forbidden](http://blog.csdn.net/my2010sam/article/details/17398807)
##二. 实现HTML转PDF格式备份文章
首先声明:这部分代码实现最终以失败告终,以后可能还会继续研究,一方面由于最近太忙;一方面对Linux的欠缺和对Python的掌握不够,但还是想把这部分写出来,感觉还是有些东西的,可能对你也有所帮助!感觉好遗憾啊~
### 1.转PDF解决方法
通过网上查阅资料,发现最常见的两种调用Python库转PDF的方法:
方法一:调用PDF报表类库Reportlab,它是在线网站转PDF该库不属于Python的标准类库,所以必须手动下载类库包并安装;同时由于涉及到把图片转换为PDF,所以还需要Python imaging library(PIL)类库。
参考文章:[python实现抓取HTML,取出数据,分析,绘出PDF版图形](http://blog.chinaunix.net/xmlrpc.php?r=blog/article&uid=29525990&id=4202841)
方法二:通过调用xhtml2pdf和pisa库实现HTML转PDF
该方法可以实现将静态的HTML转换成PDF格式,其中核心代码如下,将本地的"1.html"静态界面转换为"test.pdf",下面我尝试采取的方法也是该方法。
~~~
# -*- coding: utf-8 -*-
import sx.pisa3 as pisa
data= open('1.htm').read()
result = file('test.pdf', 'wb')
pdf = pisa.CreatePDF(data, result)
result.close()
pisa.startViewer('test.pdf')
~~~
参考文章:[python将html转成PDF的实现代码(包含中文)](http://www.jb51.net/article/34499.htm)
方法三:调用第三方wkhtmltopdf软件实现
该方法并不像Python调用第三方那样有详细代码,很多文章都是基于输入命令实现。下面三篇文章都是关于wkhtmltopdf的实现。
参考文章:[HTML转换成PDF工具:wkhtmltopdf](http://blog.csdn.net/hantiannan/article/details/4597278)
[[php]将html批量转pdf文件的解决方案,研究有感](http://blog.csdn.net/w520hua/article/details/12573697)
[wkhtmltopdf 生成带封面、页眉、页脚、目录的pdf](http://my.oschina.net/bobbob/blog/360946)
### 2.安装PIP及介绍
此时准备介绍通过xhtml2pdf和pisa库实现HTML转PDF的功能,首先需要安装PIP软件。正如[xifeijian大神](http://blog.csdn.net/xifeijian/article/details/12576455)所说:“作为Python爱好者,如果不知道easy_install或者pip中的任何一个的话,那么......”。
easy_insall的作用和perl中的cpan,ruby中的gem类似,都提供了在线一键安装模块的傻瓜方便方式,而pip是easy_install的改进版,提供更好的提示信息,删除package等功能。老版本的python中只有easy_install,没有pip。常见的具体用法如下:
~~~
easy_install的用法:
1) 安装一个包
$ easy_install <package_name>
$ easy_install "<package_name>==<version>"
2) 升级一个包
$ easy_install -U "<package_name>>=<version>"
pip的用法
1) 安装一个包
$ pip install <package_name>
$ pip install <package_name>==<version>
2) 升级一个包 (如果不提供version号,升级到最新版本)
$ pip install --upgrade <package_name>>=<version>
3)删除一个包
$ pip uninstall <package_name>
~~~
**第一步:下载PIP软件**
可以在官网[http://pypi.python.org/pypi/pip#downloads](http://pypi.python.org/pypi/pip#downloads)下载,同时cd切换到PIP目录,在通过python setup.py install安装。而我采用的是下载pip-Win_1.7.exe进行安装,下载地址如下:
[https://sites.google.com/site/pydatalog/python/pip-for-windows](https://sites.google.com/site/pydatalog/python/pip-for-windows)
**第二步:安装PIP软件**
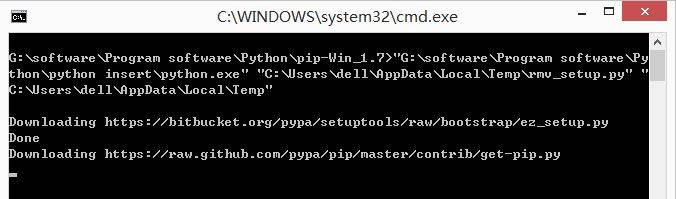
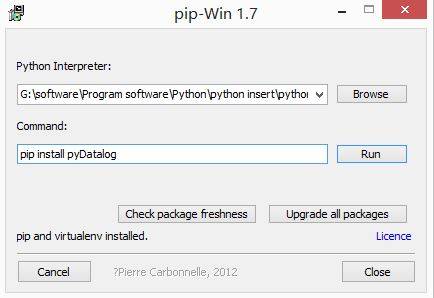
当提示"pip and virtualenvinstalled"表示安装成功,那怎么测试PIP安装成功呢?
**第三步:配置环境变量**
此时在cmd中输入pip指令会提示错误“不是内部或外部命令”,所以需要添加path环境变量。PIP安装完成后,会在Python安装目录下添加python\Scripts目录,即在python安装目录的Scripts目录下,将此目录加入环境变量中即可!过程如下:
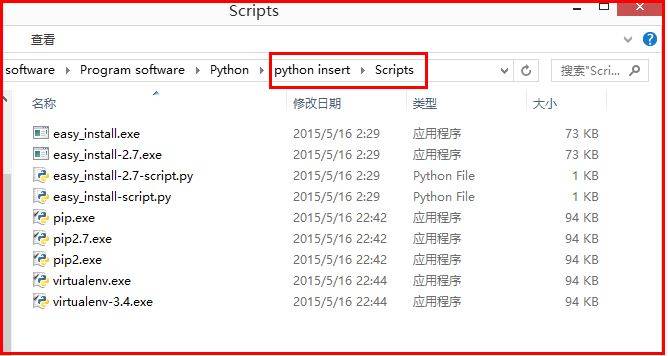

**第四步:使用PIP命令**
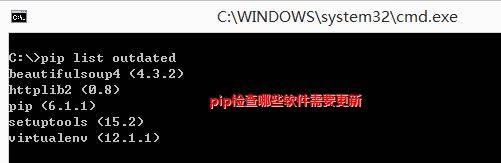
下面在CMD中使用PIP命令,“pip list outdate”列举Python安装库的版本信息。
**PIP常用的命令如下所示: (参考[pip安装使用详解](http://www.ttlsa.com/python/how-to-install-and-use-pip-ttlsa/))**
~~~
Usage:
pip <command> [options]
Commands:
install 安装软件.
uninstall 卸载软件.
freeze 按着一定格式输出已安装软件列表
list 列出已安装软件.
show 显示软件详细信息.
search 搜索软件,类似yum里的search.
wheel Build wheels from your requirements.
zip 不推荐. Zip individual packages.
unzip 不推荐. Unzip individual packages.
bundle 不推荐. Create pybundles.
help 当前帮助.
General Options:
-h, --help 显示帮助.
-v, --verbose 更多的输出,最多可以使用3次
-V, --version 现实版本信息然后退出.
-q, --quiet 最少的输出.
--log-file <path> 覆盖的方式记录verbose错误日志,默认文件:/root/.pip/pip.log
--log <path> 不覆盖记录verbose输出的日志.
--proxy <proxy> Specify a proxy in the form [user:passwd@]proxy.server:port.
--timeout <sec> 连接超时时间 (默认15秒).
--exists-action <action> 默认活动当一个路径总是存在: (s)witch, (i)gnore, (w)ipe, (b)ackup.
--cert <path> 证书.
~~~
### 3.安装xhtml2pdf和pisa软件
通过PIP命令安装xhtml2pdf和pisa库。下载地址:
xhtml2pdf 0.0.6:[https://pypi.python.org/pypi/xhtml2pdf/](https://pypi.python.org/pypi/xhtml2pdf/)
pisa 3.0.33:[https://pypi.python.org/pypi/pisa/](https://pypi.python.org/pypi/pisa/)
然后通过下面命令安装:
pip install xhtml2pdf
pip install pisa
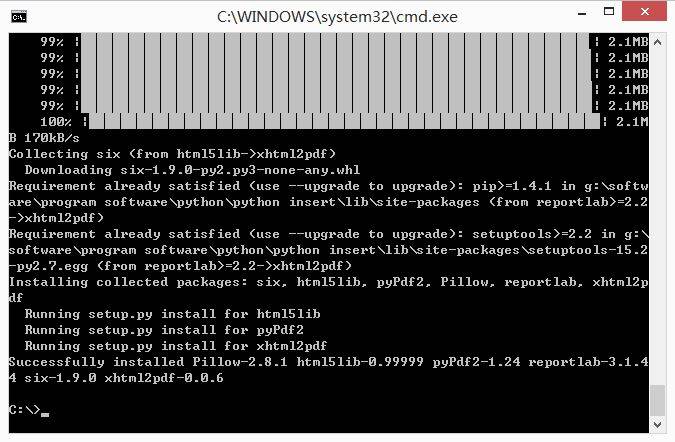
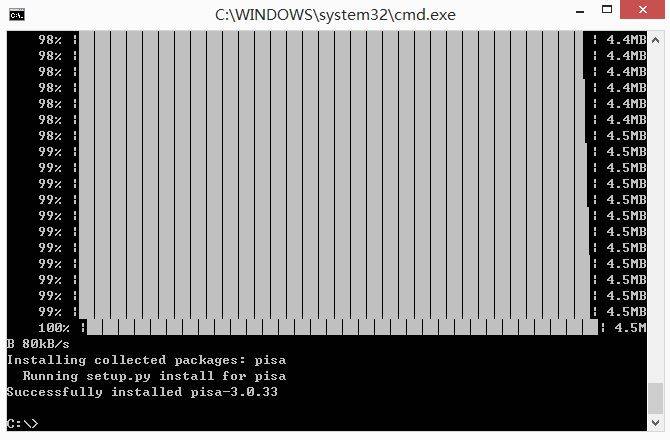
参考:
[安装html5转化为pdf的python库pisa 安装matplotlab数据转为图形的python库](http://blog.csdn.net/lifeiaidajia/article/details/10827527)
### 4.失败原因
最初没有安装Pisa库时运行那段HTML转PDF的代码会报错:
~~~
>>>
Traceback (most recent call last):
File "G:/software/Program software/Python/python insert/HtmlToPDF.py", line 12, in <module>
ImportError: No module named sx.pisa3
~~~
在安装完成后不会提示导入库名不存在,但此时HTML转PDF的代码会报错:
~~~
**************************
IMPORT ERROR!
Reportlab Version 2.1+ is needed!
**************************
The following Python packages are required for PISA:
- Reportlab Toolkit >= 2.2 <http://www.reportlab.org/>
- HTML5lib >= 0.11.1 <http://code.google.com/p/html5lib/>
Optional packages:
- pyPDF <http://pybrary.net/pyPdf/>
- PIL <http://www.pythonware.com/products/pil/>
Traceback (most recent call last):
File "G:\software\Program software\Python\python insert\HtmlToPDF.py", line 5, in <module>
import sx.pisa3 as pisa
...
raise ImportError("Reportlab Version 2.1+ is needed!")
ImportError: Reportlab Version 2.1+ is needed!
~~~
其原因是导入"import sx.pisa3 as pisa "时就显示Reportlab版本需要大于2.1以上。而通过代码查看版本为3.1.44。
~~~
>>> import reportlab
>>> print reportlab.Version
3.1.44
>>>
~~~
查看了很多资料都没有解决该问题,其中最典型的是将pisa安装目录下,sx\pisa3\pisa_util.py文件中代码修改:
~~~
if not (reportlab.Version[0] == "2" and reportlab.Version[2] >= "1"):
raise ImportError("Reportlab Version 2.1+ is needed!")
REPORTLAB22 = (reportlab.Version[0] == "2" and reportlab.Version[2] >= "2")
~~~
修改后的代码如下:
~~~
if not (reportlab.Version[:3] >="2.1"):
raise ImportError("Reportlab Version 2.1+ is needed!")
REPORTLAB22 = (reportlab.Version[:3] >="2.1")
~~~
但仍然不能解决该问题,这就导致了我无法验证该代码并实现后面的HTML转换为PDF的功能。参看了很多国外的资料:
[xhtml2pdf ImportError - Django 来自stackoverflow](http://stackoverflow.com/questions/22075485/xhtml2pdf-importerror-django)
[https://github.com/stephenmcd/cartridge/issues/174](https://github.com/stephenmcd/cartridge/issues/174)
[https://groups.google.com/forum/#!topic/xhtml2pdf/mihS51DtZkU](https://groups.google.com/forum/#!topic/xhtml2pdf/mihS51DtZkU)
[http://linux.m2osw.com/xhtml2pdf-generating-error-under-1404](http://linux.m2osw.com/xhtml2pdf-generating-error-under-1404)
##三. 总结
最后简单总结下吧!文章主要想实现从CSDN下载HTML静态网页形式的文章,再通过Python第三方库实现转换成PDF格式的备份文章功能,但由于Pisa无法导入最终失败。你可能非常失望,我也很遗憾。但仍然能从文章中学到一些东西,包括:
1.如何通过Python获取403禁止的内容,写消息头模仿登录,采用geturl和openurl两种方法实现;
2.如何配置PIP,它能让我们更方便的安装第三方库,让你了解些配置过程;
3.让你了解了HTML转PDF的一些思想。
最后推荐下我以前关于Python的爬虫文章,可能会给你提供些想法,虽然比那些开源的软件差很多,但这方面的文章和资源还是比较少的,哪怕给你一点灵感就好。
[[Python学习] 专题一.函数的基础知识](http://blog.csdn.net/eastmount/article/details/39088881)
[[Python学习] 专题二.条件语句和循环语句的基础知识](http://blog.csdn.net/eastmount/article/details/39458521)
[[Python学习] 专题三.字符串的基础知识](http://blog.csdn.net/eastmount/article/details/39599061)
[[Python学习] 简单网络爬虫抓取博客文章及思想介绍](http://blog.csdn.net/eastmount/article/details/39770543)
[[python学习] 简单爬取维基百科程序语言消息盒](http://blog.csdn.net/eastmount/article/details/44342559)
[[python学习] 简单爬取图片网站图库中图片](http://blog.csdn.net/eastmount/article/details/44492787)
[[python知识] 爬虫知识之BeautifulSoup库安装及简单介绍](http://blog.csdn.net/eastmount/article/details/44593165)
[[python+nltk] 自然语言处理简单介绍和NLTK坏境配置及入门知识(一)](http://blog.csdn.net/eastmount/article/details/45079095)
如果你有“Reportlab Version 2.1+ is needed!”好的解决方案可告知我,小弟我感激不尽。潜心学习,研究这方面的功能,最好不是调用第三方库,为自己加油。
最后希望文章对你有所帮助,如果有不足之处或错误的地方,还请海涵~
(By:Eastmount 2015-5-17 凌晨3点 [http://blog.csdn.net/eastmount/](http://blog.csdn.net/eastmount/))