一入python深似海–Views in Python3.1
最后更新于:2022-04-02 00:35:25
在Python3中,Views(视图)的作用,类似于数据库中视图的一个作用,能够反映所对应对象的变化。就像数据库表变化后,视图查询的结果是变化后的值一样,python中通过Views查询的值也是这样的。
Python3中,dict.keys(),dict.items(),dict.values()返回的是Views,而不是list。可以通过list()函数将Views()转换为list。
下面是一个说明Views作用的例子:
~~~
>>> dishes = {'eggs': 2, 'sausage': 1, 'bacon': 1, 'spam': 500}
>>> keys = dishes.keys()
>>> values = dishes.values()
>>> # iteration
>>> n = 0
>>> for val in values:
... n += val
>>> print(n)
504
>>> # keys and values are iterated over in the same order
>>> list(keys)
['eggs', 'bacon', 'sausage', 'spam']
>>> list(values)
[2, 1, 1, 500]
>>> # view objects are dynamic and reflect dict changes
>>> del dishes['eggs']
>>> del dishes['sausage']
>>> list(keys)
['spam', 'bacon']
>>> # set operations
>>> keys & {'eggs', 'bacon', 'salad'}
{'bacon'}
~~~
';
what\’s new in python 3.0
最后更新于:2022-04-02 00:35:22
官方英文文档:[https://docs.python.org/3/whatsnew/3.0.html](https://docs.python.org/3/whatsnew/3.0.html)
中文翻译版转载地址:[http://www.kankanews.com/ICkengine/archives/70301.shtml](http://www.kankanews.com/ICkengine/archives/70301.shtml)
这篇文章总结了一些与Python2.6相比Python3.0中的新特性.Python3是一个不向后兼容的版本,有了很多的改变,这些对于Python开发者来说是非常重要的,虽然多数人说Python3真正流行起来还需要一段时间,但是Python3确实有了很大的改进,现在也是时间来学习Python3了。在真正理解Python3中的一些变化之后,会发现其实Python3的变化并没有想象的那么多,主要是修复了一些令人讨厌的地方。
一般在每一个发行版源码的Misc/NEWS文件中详细描述了每一个细小的变化。
### 1、常见的障碍
#### 1.1 Print是一个函数
在Python3中print是个函数,这意味着在使用的时候必须带上小括号,并且它是带有参数的。
~~~
old: print "The answer is", 2+2
new: print("The answer is", 2+2)
old: print x, # 末尾加上逗号阻止换行
new: print(x, end="") # 使用空格来代替新的一行
old: print >>sys.staerr, "fatal error"
new: print ("fatal error", file=sys.stderr)
old: print (x, y) # 打印出元组(x, y)
new: print((x, y)) # 同上,在python3中print(x, y)的结果是跟这不同的
~~~
在Python3中还可以定义分隔符,使用参数sep来指定.
~~~
print("There are <", 2+5, ">possibilities", sep="")
~~~
上面代码的结果如下:
~~~
There are <7> possibilities
~~~
注意:
- print()函数不支持Python2.X中print中的“软空格”。在Python2.X中,print “A\n”, “B”的结果是”A\nB\n”;而在Python3中print(“A\n”, “B”)的结果是”A\n B\n”。
- 在刚开始使用Python3的时候,你会发现你经常在交互模式下你还是经常使用老式的语法print x,是时候锻炼你的手指用print(x)来取代它啦。
- 如果你的项目比较大,而又想升级到Python3的时候,不用担心,2to3这个工具会将所有的print语句转换为print()函数。
#### 1.2 使用Views和Iterators代替Lists
- dict的方法dict.keys(),dict.items(),dict.values()不会再返回列表,而是返回一个易读的“views”。这样一来,像这样的语法将不再有用了:k = d.keys();k.sort(),你可以使用k = sorted(d)来代替。sorted(d)在Python2.5及以后的版本中也有用,但是Python3效率更高了。
~~~
d = {'a': 1}
d.keys() # dict_keys(['a'])
d.items() # dict_items([('a', 1)])
d.values() # dict_values([1])
k = d.keys(); k.sort() # AttributeError: 'dict_keys' object has no attribute 'sort'
~~~
- 同样,dict.iterkeys(),dict.iteritems(),dict.itervalues()方法也不再支持。
-
map()和filter()将返回iterators。如果你真的想要得到列表,list(map(…))是一个快速的方法,但是更好的方法是使用列表推导(尤其是原代码使用了lambda表达式的时候),或者重写原来的代码,改为不需要使用列表。特别是map()会给函数带来副作用,正确的方法是改为使用for循环,因为创建一个列表是非常浪费的事情。
-
Python3中的range()函数跟Python2.X的xrange()函数的作用是一样的,这样可以使用任意的数字,Python3中去除了xrange()函数。
-
zip()在Python3中返回的是一个迭代器。
#### 1.3 比较符
Python3简化了比较符。
-
在使用比较符(<,<=,>=,>)时,当相比较的操作数的排序是没有意义的时候将会抛出TypeError异常,因此像1 < ”,0 > None,len <= len这样的语句不再合法了。None < None也会抛出TypeError异常,而不是返回False。你应该明白了,胡乱的比较是没有意义的,相比较的元素必须是能够比较的才行。需要注意的是,==和!=不包括在内,因为不通类型的,无法比较元素总是不等于另一个的。
-
builtin.sorted和list.sort()不再有提供比较函数的cmp参数,只有参数key和reverse。
-
cmp()函数应该当做被去除了,__cmp__()特殊方法也不再支持。在需要的时候使用__lt__,__eg__和__hash__。
#### 1.4 整型数
-
从本质上来说,long重命名了int,因为在内置只有一个名为int的整型,但它基本跟之前的long一样。
-
像1/2这样的语句将返回float,即0.5。使用1//2来获取整型,这也是之前版本所谓的“地板除”。
-
移除了sys.maxint,因为整型数已经没了限制。sys.maxsize可以用来当做一个比任何列表和字符串下标都要大的整型数。
-
repr()中比较大的整型数将不再带有L后缀。
-
八进制数的字面量使用0o720代替了0720。
#### 1.5 Text Vs. Data 代替 Unicode Vs. 8-bit
Python3中改变了二进制数据和Unicode字符串。
-
Python3使用文本和(二进制)数据的理念代替之前的Unicode字符串和8-bit字符串,所有的文本默认是Unicode编码。使用str类型保存文本,使用bytes类型保存数据。当你混淆文本和数据的时候Python3会抛出TypeError的错误。
-
不能再使用u”…”字面量表示unicode文本,而必须使用b”…”字面量表示二进制数据。
-
因为str和bytes不能弄混,所以你必须显式地将他们进行转换。使用str.encode()将str转换为bytes,使用bytes.decode()将bytes转换为str,也可以使用bytes(s, encoding=…)和str(b, encoding=…)。
-
str和bytes都是不可变的类型,有一个分离的可变类型的bytearray可以保存缓存的二进制数据,所有能够接受bytes的API都能够使用bytearray。这些可变的API是基于collections.MutableSequence的。
-
移除了抽象类型basestring,使用str代替。
-
文件默认使用文本类型打开,这也是open()函数默认的。如果要打开二进制文件必须使用b参数,否则会出现错误,而不会默默地提供错误的数据。
-
文件名都使用unicode字符串传入和输出。
-
一些关于系统的API,如os.environ和sys.argv,当系统允许bytes并且不能正常转换为unicode的话,也会出现问题。所以,将系统的LANG设置好是最好的做法。
-
repr()函数不再转义非ASCII字符。
-
代码默认为UTF-8编码。
-
移除了StringIO和cStringIO。加入了io模块,并分别使用io.StringIO和io.BytesIO分别用于text和data。
### 2、语法改变
#### 2.1 新增语法
-
函数变量和返回值[annotations](http://www.python.org/dev/peps/pep-3107/)。
-
[Keyword-only](http://www.python.org/dev/peps/pep-3102/)变量。
-
nonlocal声明。使用nonlocal x可以直接引用一个外部作用域的变量,但不是全局变量。
- 扩展了迭代的解包。
~~~
(a, *rest, b) = range(5)
a # 0
rest # [1,2,3]
b # 4
~~~
- 字典推导。{k: v for k, v in stuff }。
~~~
t = ((1,1), (2,2))
d = {k: v for k, v in t}
d # {1: 1, 2: 2}
~~~
-
集合推导。{x for x in stuff},与set(stuff)效果一样,但是更加灵活。
-
八进制字面量0o720。
-
二进制字面量0b1010,相当于新的内置函数bin()。
-
字节字面量b或者B,相当于新的内置函数bytes()。
#### 2.2 改变的语法
~~~
# old
class C:
__metaclass__ = M
....
# new
class C(metaclass=M):
....
~~~
- 列表推导不再支持[... for var in item1, item2, ...],必须写成[... for var in (item1, item2,...)]。
-
省略号…作为连续表达式可以用于任何地方,之前只能用于分片中。但是必须连续写,之前带空格的. . .不再支持。
#### 2.3 移除的语法
-
移除了元组的解包。不能再写def foo(a, (b, c)): ….,需要写成def foo(a, b_c):b, c = b_c。
-
移除<>,使用!=代替。
-
exec()不能再作为关键词,只能作为一个函数。并且exec()不再支持流变量,如exec(f)需写成exec(f.read())。
-
整型不支持l/L后缀。
-
字符串不支持’u/U’前缀。
-
from module import *只能用在模块级,在函数中不可使用。
-
所有不以.开始的import语句均作为绝对路径的import对待。
- 移除了经典类。
### 3、推荐阅读:
### 使用 2to3 将代码移植到 Python 3
[http://woodpecker.org.cn/diveintopython3/porting-code-to-python-3-with-2to3.html](http://woodpecker.org.cn/diveintopython3/porting-code-to-python-3-with-2to3.html)
Moving from Python 2 to Python 3
[http://ptgmedia.pearsoncmg.com/imprint_downloads/informit/promotions/python/python2python3.pdf](http://ptgmedia.pearsoncmg.com/imprint_downloads/informit/promotions/python/python2python3.pdf)
';
小爬虫
最后更新于:2022-04-02 00:35:20
一个从百度贴吧,爬取图片的例子。
### 包
urllib,urllib2,re
### 函数
page=urllib.urlopen('http://...') 返回一个网页对象
html=page.read() 读取网页的html源码
urllib.urlretrieve() 下载资源到本地
### 代码
~~~
#coding:utf8
import re
import urllib
def getHtml(url):
page=urllib.urlopen(url)
html=page.read()
return html
def getImgUrl(html):
reg=r'src="(.*?\.jpg)"'#?非贪婪匹配,()分组只返回分组结果,外单引号内双引号
imgre=re.compile(reg)#编译正则表达式,加快速度
imglist=re.findall(imgre,html)
return imglist
url="http://tieba.baidu.com/p/3162606526"#贴吧地址
html=getHtml(url)
ImgList=getImgUrl(html)
ImgList= ImgList[1:10]#取前10个下载
print ImgList
x=0
for imgurl in ImgList:
urllib.urlretrieve(imgurl,'%s.jpg' %x)
x+=1
~~~
';
目录遍历
最后更新于:2022-04-02 00:35:18
### 目录遍历
### 包:
os os.path
### 函数:
os.listdir(dirname):列出dirname下的目录和文件
os.getcwd():获得当前工作目录
os.curdir:返回当前目录('.')
os.chdir(dirname):改变工作目录到dirname
os.path.isdir(name):判断name是不是一个目录,name不是目录就返回false
os.path.isfile(name):判断name是不是一个文件,不存在name也返回false
os.path.exists(name):判断是否存在文件或目录name
os.path.getsize(name):获得文件大小,如果name是目录返回0
os.path.abspath(name):获得绝对路径
os.path.normpath(path):规范path字符串形式
os.path.split(name):分割文件名与目录(事实上,如果你完全使用目录,它也会将最后一个目录作为文件名而分离,同时它不会判断文件或目录是否存在)
os.path.splitext():分离文件名与扩展名
os.path.join(path,name):连接目录与文件名或目录
os.path.basename(path):返回文件名
os.path.dirname(path):返回文件路径
### 递归法
~~~
#coding:utf8
import os
def dirList(path,allfile):
filelist=os.listdir(path)
for filename in filelist:
filepath=os.path.join(path,filename)
if os.path.isdir(filepath):
dirList(filepath,allfile)
allfile.append(filepath)
allfile=[]
dirList('D:\\pythonPro\\test',allfile)
print allfile
~~~
### os.walk()法
os.walk(path)返回一个生成器,可以用next()方法,或者for循环访问该生成器的每一个元素。他的每个部分都是一个三元组,('目录x',[目录x下的目录list],[目录x下面的文件list])
~~~
path='D:\\pythonPro\\test'
allfile1=[]
g=os.walk(path)
for root,dirs,files in os.walk(path):
for filename in files:
allfile1.append(os.path.join(root,filename))
for dirname in dirs:
allfile1.append(os.path.join(root,dirname))
print allfile1
~~~
os.walk()方法操作更加方便,实用。
';
python之道
最后更新于:2022-04-02 00:35:16
python社区不乏幽默,先来看“python之道”这首诗。
导入this包:
~~~
import this
~~~
输出是一首诗,这首诗总结了Python的风格,可以指导Python程序员的编程。下面是译文:
~~~
The Zen of Python, by Tim Peters
Python之道
Beautiful is better than ugly.
美观胜于丑陋。
Explicit is better than implicit.
显示胜于隐式。
Simple is better than complex.
简单胜于复杂。
Complex is better than complicated.
复杂胜于过度复杂。
Flat is better than nested.
平面胜于嵌套。
Sparse is better than dense.
稀少胜于稠密。
Readability counts.
可读性需要考虑。
Special cases aren't special enough to break the rules.
即使情况特殊,也不应打破原则,
Although practicality beats purity.
尽管实用胜于纯净。
Errors should never pass silently.
错误不应悄无声息的通过,
Unless explicitly silenced.
除非特意这么做。
In the face of ambiguity, refuse the temptation to guess.
当有混淆时,拒绝猜测(深入的搞明白问题)。
There should be one-- and preferably only one --obvious way to do it.
总有一个,且(理想情况下)只有一个,明显的方法来处理问题。
Although that way may not be obvious at first unless you're Dutch.
尽管那个方法可能并不明显,除非你是荷兰人。(Python的作者Guido是荷兰人,这是在致敬)
Now is better than never.
现在开始胜过永远不开始,
Although never is often better than *right* now.
尽管永远不开始经常比仓促立即开始好。
If the implementation is hard to explain, it's a bad idea.
如果程序实现很难解释,那么它是个坏主意。
If the implementation is easy to explain, it may be a good idea.
如果程序实现很容易解释,那么它可能是个好主意。
Namespaces are one honking great idea -- let's do more of those!
命名空间是个绝好的主意,让我们多利用它。
~~~
**"Python之道"强调美观、简单、可读和实用,拒绝复杂或模糊。**
';
对象的属性
最后更新于:2022-04-02 00:35:13
Python中一切皆是对象,每个对象都可以有多个属性。Python是如何管理这些属性呢?我们来探讨一下。
### 属性的__dict__系统
对象的属性包含两部分:**类属性**和**对象属性**。对象的属性可能来自于其类的定义,叫做类属性。类属性可能来自于类的定义自身,也可能来自父类。一个对象的属性还可能是该对象实例定义的,叫做对象属性。
对象的属性存储在对象的__dict__属性中。__dict__为一个字典,键为属性名,对应的值为属性本身。下面是一个例子。
~~~
class bird(object):
feather = True
class chicken(bird):
fly = False
def __init__(self, age):
self.age = age
summer = chicken(2)
print(bird.__dict__)
print(chicken.__dict__)
print(summer.__dict__)
~~~
对于summer对象,对象的属性包括,类属性:feather/fly/__init__,对象属性:age.
当我们有一个summer对象的时候,分别查询summer对象、chicken类、bird类以及object类的属性,就可以知道summer对象的所有的__dict__,就可以找到通过对象summer可以调用和修改所有的属性了。
### 特性
同一个对象的不同属性之间可以存在依赖关系。当某个属性被修改时,我们希望依赖于该属性的其他属性也同时变化。这时,我们不能通过__dict__的方式来静态的存储属性。Python提供多种即时生成属性的方法。其中一种称为特性。特性是特殊的属性。比如我们为chicken类增加一个特性adult。当对象的age超过1时,adult为True;否则为False:
~~~
class bird(object):
feather = True
class chicken(bird):
fly = False
def __init__(self, age):
self.age = age
def getAdult(self):
if self.age > 1.0: return True
else: return False
adult = property(getAdult) # property is built-in
summer = chicken(2)
print(summer.adult)
summer.age = 0.5
print(summer.adult)
~~~
特性使用内置函数property()来创建。property()最多可以加载四个参数。前三个参数为函数,分别用于查询特性、修改特性、删除特性。最后一个参数为特性的文档,可以为一个字符串,起说明作用。
我们用下一个例子进一步说明:
~~~
class num(object):
def __init__(self, value):
self.value = value
def getNeg(self):
return -self.value
def setNeg(self, value):
self.value = -value
def delNeg(self):
print("value also deleted")
del self.value
neg = property(getNeg, setNeg, delNeg, "I'm negative")
x = num(1.1)
print(x.neg)
x.neg = -22
print(x.value)
print(num.neg.__doc__)
del x.neg
~~~
上面的num为一个数字,而neg为一个特性,用来表示数字的负数。当一个数字确定时,它的负数总是确定的;而当我们修改一个数的负数时,它本身的值也应该变化。这两点由getNeg和setNeg来实现。而delNeg表示的是,如果删除特性neg,那么应该执行的操作是删除属性value。最后一个参数为特性negative的说明文档。
### 使用特殊方法__getattr__
我们可以用__getattr__(self,name)来查询即时生成的属性,当我们查询一个属性时,**如果通过__dict__方法无法找到该属性**,那么Python会调用对象的__getattr__方法,来即时生成该属性。比如:
~~~
class bird(object):
feather = True
class chicken(bird):
fly = False
def __init__(self, age):
self.age = age
def __getattr__(self, name):
if name == 'adult':
if self.age > 1.0: return True
else: return False
else: raise AttributeError(name)
summer = chicken(2)
print(summer.adult)
summer.age = 0.5
print(summer.adult)
print(summer.male)
~~~
每个特性需要有自己的处理函数,而__getattr__可以将所有的即时生成属性放在同一个函数中处理。__getattr__可以根据函数名区别处理不同的属性。比如上面我们查询属性名male的时候,raise AttributeError。
print(summer.adult) __getattr__生成adult属性,print(summer.male)无法生成(__getattr__中没有对应的生成项),抛出异常。
__setattr__(self, name, value)和__delattr__(self, name)可用于修改和删除属性。它们的应用面更广,可用于任意属性。
### 总结
__dict__分层存储属性。每一层的__dict__只存储该层新增的属性。子类不需要重复存储父类中的属性。
即时生成属性是值得了解的概念。在Python开发中,你有可能使用这种方法来更合理的管理对象的属性。
';
tuple和set
最后更新于:2022-04-02 00:35:11
### tuple(元组)
另一种有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改,tuple属于不可变对象。比如同样是列出同学的名字:
~~~
>>> classmates = ('Michael', 'Bob', 'Tracy')
~~~
现在,classmates这个tuple不能变了,它也没有append(),insert()这样的方法。其他获取元素的方法和list是一样的,你可以正常地使用`classmates[0]`,`classmates[-1]`,但不能赋值成另外的元素。
不可变的tuple有什么意义?因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
**只有1个元素的tuple定义时必须加一个逗号**,**,以消除与数学表达式的歧义。
~~~
>>> t = (1,)#not (1)
>>> t
(1,)
~~~
**最后来看一个“可变的”tuple:**
~~~
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'
>>> t[2][1] = 'Y'
>>> t
('a', 'b', ['X', 'Y'])
~~~
这个tuple定义的时候有3个元素,分别是`'a'`,`'b'`和一个list。不是说tuple一旦定义后就不可变了吗?怎么后来又变了?
别急,我们先看看定义的时候tuple包含的3个元素: 当我们把list的元素`'A'`和`'B'`修改为`'X'`和`'Y'`后,tuple变为:
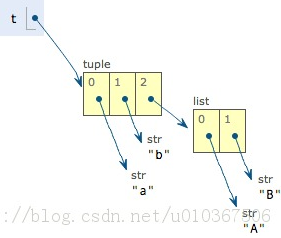

表面上看,tuple的元素确实变了,但其实变的不是tuple的元素,而是list的元素。tuple一开始指向的list并没有改成别的list,所以,**tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。**即指向`'a'`,就不能改成指向`'b'`,指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!
理解了“指向不变”后,要创建一个内容也不变的tuple怎么做?那就必须保证tuple的每一个元素本身也不能变。
### set(集合)
set可以看成数学意义上的无序和无重复元素的集合。
~~~
>>> s = set([1, 1, 2, 2, 3, 3])
>>> s
set([1, 2, 3])
~~~
set操作结合:
通过`add(key)`方法可以添加元素到set中,可以重复添加,但不会有效果:
~~~
>>> s.add(4)
>>> s
set([1, 2, 3, 4])
>>> s.add(4)
>>> s
set([1, 2, 3, 4])
~~~
通过`remove(key)`方法可以删除元素:
~~~
>>> s.remove(4)
>>> s
set([1, 2, 3])
~~~
两个set可以做数学意义上的交集、并集等操作:
~~~
>>> s1 = set([1, 2, 3])
>>> s2 = set([2, 3, 4])
>>> s1 & s2
set([2, 3])
>>> s1 | s2
set([1, 2, 3, 4])
~~~
**set和dict的唯一区别仅在于没有存储对应的value,但是,set的原理和dict一样,所以,同样不可以放入可变对象**,因为无法判断两个可变对象是否相等,也就无法保证set内部“不会有重复元素”。试试把list放入set,看看是否会报错。
';
正则表达式
最后更新于:2022-04-02 00:35:09
字符串是编程时涉及到的最多的一种数据结构,对字符串进行操作的需求几乎无处不在。比如判断一个字符串是否是一个合法的Email地址,虽然可以编程提取@前后的子串,再分别判断是否是单词和域名,但这样做不但麻烦,而且代码难以复用。
正则表达式是一种用来匹配字符串的强有力的武器。它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们juice认为它“匹配”了,否则,该字符串就是不合法的。
所以我们判断一个字符串是否是合法的Email的方法是:
1.创建一个匹配Email的正则表达式;
2.用该正则表达式去匹配用户的输入来判断是否合法。
由于正则表达式也是用字符串表示的,所以,我们要首先了解如何用字符来表述字符。
### 一、匹配单个字符
在正则表达式中,如果直接给出字符,就是精确匹配。
\d可以匹配一个数字
\w可以匹配一个字母或数字
. 可以匹配任意一个字符
如,‘00\d' 可以匹配'007',但无法匹配'00A';
### 二、匹配边长的字符
要匹配变长的字符,在正则表达式中,用 * 表示任意个字符(包括0个),用 + 表示至少一个字符,用 ? 表示0个或1个字符,用 {n} 表示n个字符,用
{n,m} 表示n-m个字符:
如,\d{3}\s+\d{3,8}表示,三个数字,至少一个空格,3-8个数字
### 三、进阶
要做更精确地匹配,可以用 [ ] 表示范围,
比如:
-
`[0-9a-zA-Z\_]`可以匹配一个数字、字母或者下划线;
-
`[0-9a-zA-Z\_]+`可以匹配至少由一个数字、字母或者下划线组成的字符串,比如`'a100'`,`'0_Z'`,`'Py3000'`等等;
-
`[a-zA-Z\_][a-zA-Z\_]*`可以匹配由字母或下划线开头,后接任意个由一个数字、字母或者下划线组成的字符串,也就是Python合法的变量;
-
`[a-zA-Z\_][a-zA-Z\_]{0, 19}`更精确地限制了变量的长度是1-20个字符(前面1个字符+后面最多19个字符)。
`A|B`可以匹配A或B,所以`[P|p]ython`可以匹配`'Python'`或者`'python'`。
`^`表示行的开头,`^\d`表示必须以数字开头。
`$`表示行的结束,`\d$`表示必须以数字结束。
你可能注意到了,`py`也可以匹配`'python'`,但是加上`^py$`就变成了整行匹配,就只能匹配`'py'`了。
### 四、re模块
python提供re模块,包含所有正则表达式的功能。
### 先来看看如何判断正则表达式是否匹配:
~~~
>>> import re
>>> re.match(r'^\d{3}\-\d{3,8}$', '010-12345')
<_sre.SRE_Match object at 0x1026e18b8>
>>> re.match(r'^\d{3}\-\d{3,8}$', '010 12345')
>>>
~~~
`match()`方法判断是否匹配,如果匹配成功,返回一个`Match`对象,否则返回`None`。常见的判断方法就是:
~~~
test = '用户输入的字符串'
if re.match(r'正则表达式', test):
print 'ok'
else:
print 'failed'
~~~
### 搜索子字符串
`search()`方法判断是包含子字符串,如果包含可用group()来查看结果,如果不包含返回None。
~~~
>>> m = re.search('[0-9]','abcd3ef')
>>> print m.group(0)
3
>>> m = re.search('[0-9]','abcdef')
>>> m.group()
~~~
### 替换子串
~~~
str = re.sub(pattern, replacement, string)
# 在string中利用正则变换pattern进行搜索,对于搜索到的字符串,用另一字符串replacement替换。返回替换后的字符串。
~~~
~~~
>>> str=re.sub('[0-9]','u','ab2c1def')
>>> str
'abucudef'
~~~
### 切分字符串
用正则表达式**切分字符串**比用固定的字符更灵活,请看正常的切分代码:
~~~
>>> 'a b c'.split(' ')
['a', 'b', '', '', 'c']
~~~
结果发现,无法识别连续的空格,用正则表达式试试:
~~~
>>> re.split(r'\s+', 'a b c')
['a', 'b', 'c']
~~~
无论多少个空格都可以正常进行分割。加入,试试:
~~~
>>> re.split(r'[\s\,]+', 'a,b, c d')
['a', 'b', 'c', 'd']
~~~
### 分组(提取子串)
除了简单地判断是否匹配之外,正则表达式还有**提取子串的强大功能**。用`()`表示的就是要提取的分组(Group)。
比如:`^(\d{3})-(\d{3,8})$`分别定义了两个组,可以直接从匹配的字符串中提取出区号和本地号码:
~~~
>>> m = re.match(r'^(\d{3})-(\d{3,8})$', '010-12345')
>>> m
<_sre.SRE_Match object at 0x1026fb3e8>
>>> m.group(0)
'010-12345'
>>> m.group(1)
'010'
>>> m.group(2)
'12345'
~~~
如果正则表达式中定义了组,就可以在`Match`对象上用`group()`方法提取出子串来。
注意到`group(0)`永远是原始字符串,`group(1)`、`group(2)`……表示第1、2、……个子串。
### 五、编译
当我们在Python中使用正则表达式时,re模块内部会干两件事情:
1.编译正则表达式,如果正则表达式的字符串本身不合法,会报错;
2.用编译后的正则表达式去匹配字符串。
如果一个正则表达式要重复使用几千次,出于效率的考虑,我们**可以预编译该正则表达式**,接下来重复使用时就不需要编译这个步骤了,直接匹配:
~~~
>>> import re
# 编译:
>>> re_telephone = re.compile(r'^(\d{3})-(\d{3,8})$')
# 使用:
>>> re_telephone.match('010-12345').groups()
('010', '12345')
>>> re_telephone.match('010-8086').groups()
('010', '8086')
~~~
编译后生成Regular Expression对象,由于该对象自己包含了正则表达式,所以调用对应的方法时不用给出正则字符串。
';
变量和对象
最后更新于:2022-04-02 00:35:07
### 一、基本原理
Python中一切都是对象,变量是对象的引用。这是一个普遍的法则。我们举个例子来说,Python是如何来处理的。
~~~
x = 'blue'
y = 'green'
z = x
~~~
当python执行上面第一句的时候,会在heap中首先创建一个str对象,其文本内容为blue,同时还创建一个名为x的对象引用,x引用的就是这个str对象。第二句也是类似;第三条创建了一个名为z的新对象引用,并将其设置为对象引用x所指向的相同对象。如下图的变化。
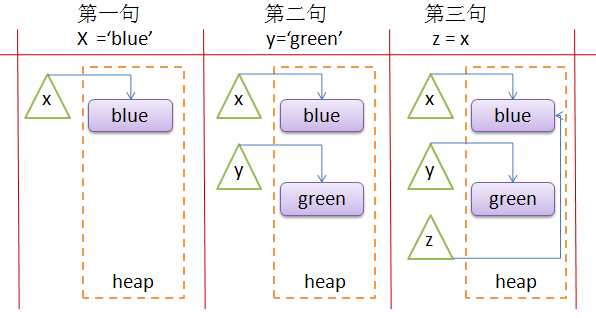
所以看出在Python中赋值操作符号“=”的作用是,将对象引用和内存中的某个对象进行绑定。如果对象已经存在,就进行简单的重新绑定,以便引用“=”右边的对象;如果对象引用尚未存在,就首先创建对象,然后将对象引用和对象进行绑定。
Python使用“动态类型”机制,也就是说,在Python程序中,任何时候可以根据需要,某个对象引用都可以重新绑定到另一个不同的对象上(不要求是相同的类型),这和其他强化型语言如(C++,Java)不太一样,只允许重新绑定相同类型的对象上。在Python中,因为有“动态类型”机制,所以一个对象引用可以执行不同类型的对象适用的方法。当一个对象不存在任何对象引用的时候,就进入了垃圾收集的过程。
查看类型程序:
~~~
import types
type(100)
~~~
~~~
>>> a=100
>>> a/10
10
>>> a[0]
Traceback (most recent call last):
File "", line 1, in
a[0]
TypeError: 'int' object has no attribute '__getitem__'
>>> a='hello'
>>> a[0]
'h'
>>> a/10
Traceback (most recent call last):
File "", line 1, in
a/10
TypeError: unsupported operand type(s) for /: 'str' and 'int'
>>>
~~~
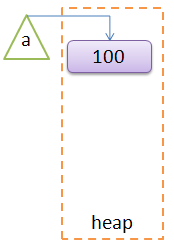
第一句 a = 100
Python会在heap创建一个int对象,其内容为100,同时创建a变量,其值指向heap中的int对象
第二句 a/10
Python适用“动态类型”机制,判断a指向的对象是int型,可以适用/(除法)操作。于是便进行运算产生结果。(它会在heap中在创建一个10.0的对象么?)
第三句 a[0]
Python适用“动态类型”机制,判断a指向的对象是int型,并不适用[](分片)操作。于是就进行报错。
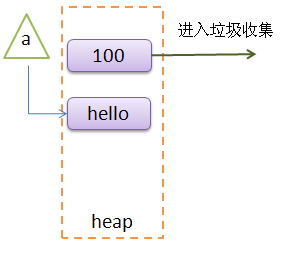
第四句 a = 'hello'
Python会在heap创建一个str对象,其内容为hello,同时改变a变量,使得其值指向heap中的str对象。同时原来的int对象,由于不在存在对象引用,所以就进入了垃圾收集过程。
第五句 a[0]
Python适用“动态类型”机制,判断a指向的对象是str型,可以适用[](分片)操作。于是便进行运算产生结果。
第六句 a/10
Python适用“动态类型”机制,判断a指向的对象是str型,并不适用/(除法)操作。于是就进行报错。
**总之**:在Python中一切都是对象,变量总是存放对象引用。当一个对象没有变量指向它的时候,它便进入了垃圾收集过程。Python的“动态类型”机制,负责检查变量的对象引用适用操作。如果该对象不适用该操作,则会直接报错。一句话”**变量无类型,对象有类型**“
### 二、python的id(),==,is的差别
1. id():获取的是对象在内存中的地址
2. is :比对2个变量的**对象引用**(对象在内存中的地址,即id() 获得的值)**是否相同**。如果相同则返回True,否则返回False。换句话说,就是比对2个变量的对象引用是否指向同一个对象。
3. ==:比对2个变量指向的对象的内容是否相同。
';
浅拷贝与深拷贝
最后更新于:2022-04-02 00:35:04
python中有一个模块copy,deepcopy函数用于深拷贝,copy函数用于浅拷贝。要理解浅拷贝,必须先弄清楚python中的引用。
### 引用
**Python中一切都是对象,变量中存放的是对象的引用**。这是一个普遍的法则。**可以说 Python 没有赋值,只有引用**。如,a=1,变量a只是整数对象1的引用。
####
### 可变对象与不可变对象及其引用
#### 一、不可变对象
不可变对象包括:数字,字符串,元组。
由于Python中的变量存放的是对象引用,所以对于不可变对象而言,尽管对象本身不可变,但变量的对象引用是可变的。运用这样的机制,有时候会让人产生糊涂,似乎可变对象变化了。如下面的代码:
~~~
i=73
i+=2
~~~
这里的‘=’表示引用。

从上面得知,不可变的对象的特征没有变,依然是不可变对象,变的只是创建了新对象,改变了变量的对象引用。
#### 二、可变对象
可变对象包括:列表、字典
其对象的内容是可以变化的。当对象的内容发生变化时,变量的对象引用是不会变化的。如下面的例子。
~~~
m=[5,9]
m+=[6]
~~~
列表m的每个元素均是对象的引用。对象的生成,涉及到对应机制,如整形对象分为大整数对象和小整数对象,生成机制不同,这里不作详细阐述。

### 三、函数的参数传递
函数的参数传递,本质上传递的是引用。
### 拷贝
(1)没有限制条件的分片表达式(L[:])能够复制序列,但此法只能浅层复制。
(2)字典 copy 方法,D.copy() 能够复制字典,但此法只能浅层复制
(3)有些内置函数,例如 list,能够生成拷贝 list(L)
(4)copy 标准库模块能够生成完整拷贝:deepcopy,递归 copy
### 浅拷贝
浅拷贝由copy模块中的copy()函数实现,简单地说,copy.copy 浅拷贝 只拷贝父对象,不会拷贝对象的内部的可变子对象。具体点说就是,**浅拷贝是指拷贝的只是原对象元素的引用,换句话说,浅拷贝产生的对象本身是新的,但是它的内容不是新的,只是对原子对象的一个引用。**
~~~
import copy
aList=[[1,2],3,4]
bList=copy.copy(aList)
print aList
print bList
print id(aList)
print id(bList)
aList[0][0]=5
print aList
print bList
~~~
由id(aList)不等于id(bList),表明浅拷贝产生的对象本身是新的,但是它的子对象(即,那个列表)是对原子对象的一个引用。**那么3,4两个元素呢?这就要讲讲python中的可变对象和不可变对象的引用了。**
但是有点需要特别提醒的,如果对象本身是不可变的,那么浅拷贝时也是引用。
见这个例子:
~~~
import copy
aList=[[1,2],3,4]
bList=copy.copy(aList)
print aList
print bList
print id(aList[1])
print id(bList[1])
aList[2]=5#变量的对象引用改变了而已
aList[0]=[0,1,1]#变量的对象引用改变了而已
print aList
print bList
~~~
总结,即**浅拷贝产生的对象本身是新的,但是它的内容不是新的,**只是对原**子对象**的一个**引用。**
### 深拷贝
浅拷贝由copy模块中的deepcopy()函数实现,简单地说,深拷贝 拷贝对象及其子对象。
一个例子展示引用、深拷贝与浅拷贝的不同。
~~~
import copy
aList=[[1,2],3,4]
bList=aList
cList=copy.copy(aList)
dList=copy.deepcopy(aList)
print aList
print bList
print cList
print dList
print id(aList)
print id(bList)
print id(cList)
print id(dList)
aList.append(5)
aList[0].append('hello')
print aList
print bList
print cList
print dList
~~~
其实我觉得记住这一点就行,**浅拷贝产生的对象本身是新的,但是它的内容不是新的,只是对原**子对象**的一个**引用**。关键是要理解python中引用的含义。**
';
class
最后更新于:2022-04-02 00:35:02
### python class
分为三个部分:class and object(类与对象),inheritance(继承),overload(重载)and override(覆写)。
### class and object
类的定义,实例化,及成员访问,顺便提一下python中类均继承于一个叫object的类。
~~~
class Song(object):#definition
def __init__(self, lyrics):
self.lyrics = lyrics#add attribution
def sing_me_a_song(self):#methods
for line in self.lyrics:
print line
happy_bday = Song(["Happy birthday to you",
"I don't want to get sued",
"So I'll stop right there"])#object1
bulls_on_parade = Song(["They rally around the family",
"With pockets full of shells"])#object2
happy_bday.sing_me_a_song()#call function
bulls_on_parade.sing_me_a_song()
~~~
### inheritance(继承)
python支持继承,与多继承,但是一般不建议用多继承,因为不安全哦!
~~~
class Parent(object):
def implicit(self):
print "PARENT implicit()"
class Child(Parent):
pass
dad = Parent()
son = Child()
dad.implicit()
son.implicit()
~~~
### overload(重载)and override(覆写)
重载(overload)和覆盖(override),在C++,Java,C#等静态类型语言类型语言中,这两个概念同时存在。
python虽然是动态类型语言,但也支持重载和覆盖。
但是与C++不同的是,python通过参数**默认值**来实现函数重载的重要方法。下面将先介绍一个C++中的重载例子,再给出对应的python实现,可以体会一下。
C++函数重载例子:
~~~
void f(string str)//输出字符串str 1次
{
cout<def f(str,times=1):
print str*times
f('sssss')
f('sssss',10)
~~~
覆写
~~~
class Parent(object):
def override(self):
print "PARENT override()"
class Child(Parent):
def override(self):
print "CHILD override()"
dad = Parent()
son = Child()
dad.override()
son.override()
~~~
**super()函数**
**函数被覆写后,如何调用父类的函数呢?**
~~~
class Parent(object):
def altered(self):
print "PARENT altered()"
class Child(Parent):
def altered(self):
print "CHILD, BEFORE PARENT altered()"
super(Child, self).altered()
print "CHILD, AFTER PARENT altered()"
dad = Parent()
son = Child()
dad.altered()
son.altered()
~~~
python中,子类自动调用父类_init_()函数吗?
**答案是否定的,子类需要通过super()函数调用父类的_init_()函数**
~~~
class Child(Parent):
def __init__(self, stuff):
self.stuff = stuff
super(Child, self).__init__()
~~~
';
dict(字典)的一种实现
最后更新于:2022-04-02 00:35:00
下面是python中字典的一种实现,用list数据结构实现字典。具体是这样的:[[(key1,value1),(key2,value2),...],[],[],...]
内部每一个hash地址是一个list,存放hash地址相同的(key,value)对。
### dict代码
~~~
def Map(num_buckets=256):
"""Initializes a Map with the given number of buckets."""
aMap = []
for i in range(0, num_buckets):
aMap.append([])
return aMap
def Map_hash(aMap, key):
"""Given a key this will create a number and then convert it to
and index for the aMap's buckets."""
return hash(key) % len(aMap)
def Map_get_bucket(aMap, key):
"""Given a key, find the bucket where it would go."""
bucket_id = Map_hash(aMap, key)
return aMap[bucket_id]
def Map_get_slot(aMap, key, default=None):
"""Returns the index, key, and value of a slot found in a bucket."""
bucket = Map_get_bucket(aMap, key)
for i, kv in enumerate(bucket):#bucket=[[k1,v1],[k2,v2],...]
k, v = kv
if key == k:
return i, k, v#ex1:i=0,k=k1,v=v1
return -1, key, default
def Map_get(aMap, key, default=None):
"""Gets the value in a bucket for the given key, or the default."""
i, k, v = Map_get_slot(aMap, key, default=default)
return v
def Map_set(aMap, key, value):
"""Sets the key to the value, replacing any existing value."""
bucket = Map_get_bucket(aMap, key)
i, k, v = Map_get_slot(aMap, key)
if v:
bucket[i] = (key, value)#key/value pair
else:
bucket.append((key, value))
def Map_delete(aMap, key):
"""Deletes the given key from the Map."""
bucket = Map_get_bucket(aMap, key)
for i in xrange(len(bucket)):
k, v = bucket[i]
if key == k:
del bucket[i]
break
def Map_list(aMap):
"""Prints out what's in the Map."""
for bucket in aMap:
if bucket:
for k, v in bucket:
print k, v
# The tests that it will work.
jazz = Map()
Map_set(jazz, 'Miles Davis', 'Flamenco Sketches')
# confirms set will replace previous one
Map_set(jazz, 'Miles Davis', 'Kind Of Blue')
Map_set(jazz, 'Duke Ellington', 'Beginning To See The Light')
Map_set(jazz, 'Billy Strayhorn', 'Lush Life')
print "---- List Test ----"
Map_list(jazz)
print "---- Get Test ----"
print Map_get(jazz, 'Miles Davis')
print Map_get(jazz, 'Duke Ellington')
print Map_get(jazz, 'Billy Strayhorn')
print "---- Delete Test ----"
print "**Goodbye Miles"
Map_delete(jazz, "Miles Davis")
Map_list(jazz)
print "**Goodby Duke"
Map_delete(jazz, "Duke Ellington")
Map_list(jazz)
print "**Goodbye Billy"
Map_delete(jazz, "Billy Strayhorn")
Map_list(jazz)
print "**Goodbye Pork Pie Hat"
Map_delete(jazz, "Charles Mingus")
~~~
Map_hash()函数的解释如下:
This deceptively simple function is the core of how a dict (Map) works. What it does is uses the built-in Python hash function to convert a string to a number. Python uses this function for its own dict data structure, and I'm just reusing it. You should fire up a Python console to see how it works. Once I have a number for the key, I then use the % (modulus) operator and thelen(aMap) to get a bucket where this key can go. As you should know, the % (modulus) operator will divide any number and give me the remainder. I can also use this as a way of limiting giant numbers to a fixed smaller set of other numbers. If you don't get this then use Python to explore it.
';
Dict
最后更新于:2022-04-02 00:34:58
### 定义及应用
Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度。
### 定义
~~~
stuff = {'name': 'Zed', 'age': 36, 'height': 6*12+2}#key:value pairs
~~~
### 词典的常用方法
print dic.keys() # 返回dic所有的键
print dic.values() # 返回dic所有的值
print dic.items() # 返回dic所有的元素(键值对)
dic.clear() # 清空dic,dict变为{}
del dic['tom'] # 删除 dic 的‘tom’元素
print(len(dic))
dict.get(key,default=None) 对字典dict 中的键key,返回它对应的值value,如果字典中不存在此键,则返回default 的值(注意,参数default 的默认值为None)
dict.has_key(key) 如果键(key)在字典中存在,返回True,否则返回False. 在Python2.2版本引入in 和not in 后,此方法几乎已废弃不用了,但仍提供一个 可工作的接口。
dict.keys() 返回一个包含字典中键的列表
dict.values() 返回一个包含字典中所有值的列表
### 实例
~~~
# create a mapping of state to abbreviation
states = {
'Oregon': 'OR',
'Florida': 'FL',
'California': 'CA',
'New York': 'NY',
'Michigan': 'MI'
}
# create a basic set of states and some cities in them
cities = {
'CA': 'San Francisco',
'MI': 'Detroit',
'FL': 'Jacksonville'
}
# add some more cities
cities['NY'] = 'New York'
cities['OR'] = 'Portland'
# print out some cities
print '-' * 10
print "NY State has: ", cities['NY']
print "OR State has: ", cities['OR']
# print some states
print '-' * 10
print "Michigan's abbreviation is: ", states['Michigan']
print "Florida's abbreviation is: ", states['Florida']
# do it by using the state then cities dict
print '-' * 10
print "Michigan has: ", cities[states['Michigan']]
print "Florida has: ", cities[states['Florida']]
# print every state abbreviation
print '-' * 10
for state, abbrev in states.items():
print "%s is abbreviated %s" % (state, abbrev)
# print every city in state
print '-' * 10
for abbrev, city in cities.items():
print "%s has the city %s" % (abbrev, city)
# now do both at the same time
print '-' * 10
for state, abbrev in states.items():
print "%s state is abbreviated %s and has city %s" % (
state, abbrev, cities[abbrev])
print '-' * 10
# safely get a abbreviation by state that might not be there
state = states.get('Texas', None)
if not state:
print "Sorry, no Texas."
# get a city with a default value
city = cities.get('TX', 'Does Not Exist')#if exist key=='TX',city=value,or city='Dose Not Exist'
print "The city for the state 'TX' is: %s" % city
~~~
output
~~~
----------
NY State has: New York
OR State has: Portland
----------
Michigan's abbreviation is: MI
Florida's abbreviation is: FL
----------
Michigan has: Detroit
Florida has: Jacksonville
----------
California is abbreviated CA
Michigan is abbreviated MI
New York is abbreviated NY
Florida is abbreviated FL
Oregon is abbreviated OR
----------
FL has the city Jacksonville
CA has the city San Francisco
MI has the city Detroit
OR has the city Portland
NY has the city New York
----------
California state is abbreviated CA and has city San Francisco
Michigan state is abbreviated MI and has city Detroit
New York state is abbreviated NY and has city New York
Florida state is abbreviated FL and has city Jacksonville
Oregon state is abbreviated OR and has city Portland
----------
Sorry, no Texas.
The city for the state 'TX' is: Does Not Exist
~~~
和list比较,dict有以下几个特点:
1. 查找和插入的速度极快,不会随着key的增加而增加;
1. 需要占用大量的内存,内存浪费多。
所以,dict是用空间来换取时间的一种方法。
dict可以用在需要高速查找的很多地方,在Python代码中几乎无处不在,正确使用dict非常重要,**需要牢记的第一条就是dict的key必须是**不可变对象**。这是因为dict根据key来计算value的存储位置,如果每次计算相同的key得出的结果不同,那dict内部就完全混乱了。
';
list
最后更新于:2022-04-02 00:34:55
几个实例展示python中数据结构list的魅力!
### list变量申明
~~~
the_count = [1, 2, 3, 4, 5]
fruits = ['apples', 'oranges', 'pears', 'apricots']
change = [1, 'pennies', 2, 'dimes', 3, 'quarters']
~~~
### 访问list元素
~~~
array= [1,2,5,3,6,8,4]
#其实这里的顺序标识是
(0,1,2,3,4,5,6)
(-7,-6,-5,-4,-3,-2,-1)#有负的下标哦
array[0:]#列出index==0以后的
[1,2,5,3,6,8,4]
array[1:]#列出index==1以后的
[2,5,3,6,8,4]
array[:-1]#列出index==-1之前的
[1,2,5,3,6,8]
array[3:-3]#列出index==3到index==-3之间的,注意不包含index==-3,即左闭右开
[3]
~~~
### list应用
### loops and list
~~~
change = [1, 'pennies', 2, 'dimes', 3, 'quarters']
for i in change:
print "I got %r" % i
~~~
### enumerate
~~~
for i,j in enumerate([[1,2],['o',2],[9,3]]):
k1,k2=j
print i,k1,k2
~~~
output
~~~
0 1 2
1 o 2
2 9 3
~~~
### append/extend/pop/del
append()添加元素至list尾部
~~~
elements=[1,2,3,4,5]
elements.append(6)
~~~
extend()拼接两个list
~~~
list1=[1,2,3,4,5]
list2=[6,7]
elements.extend(list2)
print elements
~~~
pop(int i=-1)删除list中指定下标的元素,并返回该位置上的数,default :删除最后一个
~~~
elements=[1,2,3,4,5]
print elements.pop()#default:delete index==-1,i.e. the last element
print elements
elements=[1,2,3,4,5]
elements.pop(-2)#delete index==-2,i.e. 4
print elements
elements.pop(1)
print elements
~~~
del
~~~
elements=[1,2,3,4,5]
del elements[0]#default:delete index==0,i.e. 1
print elements
elements=[1,2,3,4,5]
del elements[2:4]#delete index==2 and index==3,i.e.3 and 4
print elements
elements=[1,2,3,4,5]
del elements#delete all
elements
~~~
### do things to list
~~~
ten_things = "Apples Oranges Crows Telephone Light Sugar"
print "Wait there's not 10 things in that list, let's fix that."
stuff = ten_things.split(' ')
more_stuff = ["Day", "Night", "Song", "Frisbee", "Corn", "Banana", "Girl", "Boy"]
while len(stuff) != 10:
next_one = more_stuff.pop()
print "Adding: ", next_one
stuff.append(next_one)
print "There's %d items now." % len(stuff)
print "There we go: ", stuff
print "Let's do some things with stuff."
print stuff[1]
print stuff[-1] # whoa! fancy
print stuff.pop()
print ' '.join(stuff) # what? cool!
print '#'.join(stuff[3:5]) # super stellar! outputs:stuff[3]#stuff[4]
~~~
' '.join(things) reads as, "Join things with ' ' between them." Meanwhile, join(' ', things) means, "Call join with ' ' and things。返回一个string.
输出
~~~
Wait there's not 10 things in that list, let's fix that.
Adding: Boy
There's 7 items now.
Adding: Girl
There's 8 items now.
Adding: Banana
There's 9 items now.
Adding: Corn
There's 10 items now.
There we go: ['Apples', 'Oranges', 'Crows', 'Telephone', 'Light', 'Sugar', 'Boy', 'Girl', 'Banana', 'Corn']
Let's do some things with stuff.
Oranges
Corn
Banana
['Apples', 'Oranges', 'Crows', 'Telephone', 'Light', 'Sugar', 'Boy', 'Girl', 'Corn']
Apples Oranges Crows Telephone Light Sugar Boy Girl Corn
Telephone#Light#Sugar
~~~
实验一些list的方法:
n1=[1,2,3,4]
print nl.count(5) # 计数,看总共有多少个5
print nl.index(3) # 查询 nl 的第一个3的下标
nl.append(6) # 在 nl 的最后增添一个新元素6
nl.sort() # 对nl的元素排序
print nl.pop() # 从nl中去除最后一个元素,并将该元素返回。
nl.remove(2) # 从nl中去除第一个2
nl.insert(0,9) # 在下标为0的位置插入9
';
while-loop与for-loop
最后更新于:2022-04-02 00:34:53
### while loops
定义与实例
~~~
i = 0
numbers = []
while i < 6:
print "At the top i is %d" % i
numbers.append(i)
i = i + 1
print "Numbers now: ", numbers
print "At the bottom i is %d" % i
print "The numbers: "
for num in numbers:
print num,
~~~
输出
~~~
At the top i is 0
Numbers now: [0]
At the bottom i is 1
At the top i is 1
Numbers now: [0, 1]
At the bottom i is 2
At the top i is 2
Numbers now: [0, 1, 2]
At the bottom i is 3
At the top i is 3
Numbers now: [0, 1, 2, 3]
At the bottom i is 4
At the top i is 4
Numbers now: [0, 1, 2, 3, 4]
At the bottom i is 5
At the top i is 5
Numbers now: [0, 1, 2, 3, 4, 5]
At the bottom i is 6
The numbers:
0 1 2 3 4 5
~~~
### for loops
定义和实例
~~~
elements = []
# then use the range function to do 0 to 5 counts
for i in range(0, 6):
print "Adding %d to the list." % i
# append is a function that lists understand
elements.append(i)
~~~
### A&Q
**What's the difference between a for-loop**and a **while-loop**?
ans: A for-loop can only iterate (loop) "over" collections of things. A while-loop can do any kind of iteration (looping) you want. However, while-loops are harder to get right and you normally can get many things done with for-loops.
';
range()、list与for
最后更新于:2022-04-02 00:34:51
### range用法
使用python的人都知道range()函数很方便,今天再用到他的时候发现了很多以前看到过但是忘记的细节。
这里记录一下:
再看看list的操作:
';
range(1,5)#代表从1到5(不包含5)[1,2,3,4]range(1,5,2)#代表从1到5,间隔2(不包含5)[1,3]range(5)#代表从0到5(不包含5)[0,1,2,3,4] |
array= [1,2,5,3,6,8,4]#其实这里的顺序标识是[1,2,5,3,6,8,4](0,1,2,3,4,5,6)(-7,-6,-5,-4,-3,-2,-1)array[0:]#列出0以后的[1,2,5,3,6,8,4]array[1:]#列出1以后的[2,5,3,6,8,4]array[:-1]#列出-1之前的[1,2,5,3,6,8]array[3:-3]#列出3到-3之间的[3]
|
split
最后更新于:2022-04-02 00:34:49
下面说说python中字符串处理函数split()的用法
~~~
def break_words(stuff):
"""This function will break up words for us."""
words = stuff.split(' ')#split('.',1) use '.' split one time
return words
def sort_words(words):
"""Sorts the words."""
return sorted(words)
def print_first_word(words):
"""Prints the first word after popping it off."""
word = words.pop(0)
print word
def print_last_word(words):
"""Prints the last word after popping it off."""
word = words.pop(-1)
print word
def sort_sentence(sentence):
"""Takes in a full sentence and returns the sorted words."""
words = break_words(sentence)
return sort_words(words)
def print_first_and_last(sentence):
"""Prints the first and last words of the sentence."""
words = break_words(sentence)
print_first_word(words)
print_last_word(words)
def print_first_and_last_sorted(sentence):
"""Sorts the words then prints the first and last one."""
words = sort_sentence(sentence)
print_first_word(words)
print_last_word(words)
~~~
';
函数与文件
最后更新于:2022-04-02 00:34:46
先上写干货,几个开源网站:
- [github.com](#)
- [launchpad.net](#)
- [gitorious.org](#)
- [sourceforge.net](#)
- [freecode.com](#)
今天介绍一下python函数和文件读写的知识。
### 函数
###
~~~
def print_two(*args):#That tells Python to take all the arguments to the function and then put them in args as a list
arg1,arg2=args
print "arg1: %r, arg2: %r"%(arg1,arg2)
def print_two_again(arg1,arg2):
print "arg: %r,arg: %r"%(arg1,arg2)
def print_one(arg1):
print "arg1: %r" %arg1
def print_none():
print "I got nothin'."
return ;
print_two("zed","shaw")
print_two_again("zed","shaw")
print_one("First!")
print_none()
~~~
~~~
def secret_formula(started):
jelly_beans = started * 500
jars = jelly_beans / 1000
crates = jars / 100
return jelly_beans, jars, crates
start_point = 10000
beans, jars, crates = secret_formula(start_point)
~~~
### 文件读写
**读写取方法:**
**read()** 方法用来直接读取字节到字符串中, 不带参数表示全部读取,参数表示读取多少个字节
**readline()** 方法读取打开文件的一行,如果提供参数表示读取字节数,默认参数是-1,代表行的结尾
**readlines()**方法会读取所有(剩余的)行然后把他们作为一个字符串列表返回。可选参数代表返回的最大字节大小。
**输出方法:**
**write()** 方法表示写入到文件中去
**writelines()** 方法是针对列表的操作,接受一个字符串列表作为参数,写入文件。行结束符不会自动加入。
**核心笔记:**使用输入方法read() 或者 readlines() 从文件中读取行时,python并不会删除行结尾符。
**文件内移动:**
**seek()** 方法,移动文件指针到不同的位置。
**tell()** 显示文件当前指针的位置。
**文件内建属性**
file.name 返回文件名(包含路径)
file.mode 返回文件打开模式
file.closed 返回文件是否已经关闭
file.encoding 返回文件的编码
~~~
input_file=raw_input("input_file: ")
def print_all(f):
print f.read()
def rewind(f):
f.seek(24)#seek 24 characters
def print_a_line(line_count,f):
print line_count,f.readline()
current_file=open(input_file)
print "First let's print the whole file: \n"
print_all(current_file)
print "Now let's rewing,kind of like a tape."
rewind(current_file)
print" Let's print three lines: "
current_line = 1
print_a_line(current_line,current_file)
current_line=current_line+1
print_a_line(current_line,current_file)
current_line=current_line+1
print_a_line(current_line,current_file)
~~~
如果文件是配置文件,可以用下面的代码来调用:
~~~
for line in f.readlines():
print(line.strip()) # 把末尾的'\n'删掉
~~~
更详细的介绍请点击:[http://www.cnblogs.com/NNUF/archive/2013/01/22/2872234.html](http://www.cnblogs.com/NNUF/archive/2013/01/22/2872234.html)
';
最后更新于:2022-04-02 00:34:44
先给大家来个干货^~^,学习Python的一个好网站,[http://learnpythonthehardway.org/book/](http://learnpythonthehardway.org/book/)
### 经典例子
下面是几个老经典的例子喽,刚接触Python的可以敲一敲,看看结果喽!
~~~
my_name='Zed A. Shaw'
my_age=35#not a lie
my_height=74#inches
my_weight=180#1bs
my_eyes='Blue'
my_teeth='white'
my_hair='Brown'
print my_name
print "Let's talk about %r" %my_name
print "He's %d inches tall." %my_height
print "He's %d pounds heavy." %my_weight
print "Actually that's not too heavy."
print "He's got %s eyes and %s hair."%(my_eyes,my_hair)
print "His teeth are usually %s depending on the coffee."%my_teeth
#this line is tricky,try to get it exactly right
print "If I add %d, %d,and %r I get %d."%(my_age,my_height,my_weight,my_age+my_height+my_weight)
~~~
~~~
x="There are %d types of people."%10
binary="binary"
do_not="don't"
y="Those who know %s and those who %s"%(binary,do_not)
print x
print y
print "I said: %r."%x
print "I also said: '%s'."%y
hilarious=False
joke_evaluation="Isn't that joke so funny?! %r"
print joke_evaluation % hilarious
w="This is the left side of..."
e="a string with a right side"
print w+e
~~~
~~~
print "Mary had a little lamb."
print "Its fleece was white as %s."%'snow'
print "Its fleece was white as %r."%'snow'
print "And everywhere that Mary went."
print "."*10 #output . 10 times
end1="c"
end2="h"
end3="e"
end4="e"
end5="s"
end6="e"
#watch that comma at the end.
print end1+end2+end3,
print end4+end5+end6
~~~
~~~
formatter="%r %r %r %r"
print formatter %(1,2,3,4)
print formatter %("one","two","three","four")
print formatter %(True,False,False,True)
print formatter %(formatter,formatter,formatter,formatter)
print formatter %(
"I had this thing.",
"That you could type up right.",
"But it didn't sing.",
"So I said goodnight."
)
~~~
~~~
days="Mon Tue Wed Thu Fri Sat Sun"
months="Jan\nFeb\nMar\nApr\nMay\nJun\nAug"
print "Here are the days:",days
print "Here are the months:",months
print "Here are the months: %r"%months
#That's how %r formatting works;
#it prints it the way you wrote it (or close to it). It's the "raw" format for debugging.
print """
There's something going on here.
whith the three double-quotes.
we'll be able to type as much as we like.
Even 4 lines if we want, or 5, or 6.
"""
~~~
~~~
tabby_cat="\tI'm stabbed in."
persian_cat="I'm split\non a line."
backslash_cat="I'm \\ a \\ cat."
fat_fat="""
I'll do a list:
\t* Cat food
\t* Fishies
\t* Catnip\n\t* Grass
"""
print tabby_cat
print persian_cat
print backslash_cat
print fat_fat
~~~
### %r与%s的区别
我的总结是这么个点: %r与%s的区别
That's how %r formatting works; it prints it the way you wrote it (or close to it). It's the "raw" format for debugging.
**Always remember this: %r is for debugging, %s is for displaying.**
';
前言
最后更新于:2022-04-02 00:34:42
> 原文出处:[一入python深似海](http://blog.csdn.net/column/details/learnpython.html)
作者:[u010367506](http://blog.csdn.net/u010367506)
**本系列文章经作者授权在看云整理发布,未经作者允许,请勿转载!**
# 一入python深似海
> 学习python的点点滴滴,路在脚下,生生不息。
';