模式识别:分类回归决策树CART的研究与实现
最后更新于:2022-04-01 06:47:45
摘 要:本实验的目的是学习和掌握分类回归树算法。CART提供一种通用的树生长框架,它可以实例化为各种各样不同的判定树。CART算法采用一种二分递归分割的技术,将当前的样本集分为两个子样本集,使得生成的决策树的每个非叶子节点都有两个分支。因此,CART算法生成的决策树是结构简洁的二叉树。在MATLAB平台上编写程序,较好地实现了非剪枝完全二叉树的创建、应用以及近似剪枝操作,同时把算法推广到多叉树。
##一、技术论述
**1.非度量方法**
在之前研究的多种模式分类算法中,经常会使用到样本或向量之间距离度量(distance metric)的方法。最典型的是最近邻分类器,距离的概念是这个分类方法的根本思想所在。在神经网络中,如果两个输入向量足够相似,则它们的输出也很相似。总的来说,大多数的模式识别方法在研究这类问题中,由于特征向量是实数数据,因此自然拥有距离的概念。
而在现实世界中,另外一类酚类问题中使用的是“语义数据”(nominal data),又称为“标称数据”或“名义数据”。这些数据往往是离散的,其中没有任何相似性的概念,甚至没有次序的关系。以下给出一个简单的例子:
试用牙齿的信息对鱼和海洋哺乳动物分类。一些鱼的牙齿细小而精致(如巨大的须鲸),这种牙齿用于在海里筛滤出微小的浮游生物来吃;另一些有成排的牙齿(如鲨鱼);一些海洋动物,如海象,有很长的牙齿;而另外一些,如鱿鱼,则根本没有牙齿。这里并没有一个清楚的概念来表示关于牙齿的相似性或距离度量,打个比方,须鲸和海象的牙齿之间并不比鲨鱼和鱿鱼之间更相似。本实验的目的是将以往以实向量形式表示的模式,转变成以非度量(nonmetric)的语义属性来表示的模式。
**2.判定树**
利用一系列的查询回答来判断和分类某模式是一种很自然和直观的做法。有一个问题的提法依赖于前一个问题的回答。这种“问卷表”方式的做法对非度量数据特别有效,因为回答问题时的是“是/否”、“真/假”、“属性值”等并不涉及任何距离测度概念。这些实际问题可以用有向的判定树(decision tree)的形式表示。从结构上看,一棵树的第一个节点又称为根节点,存在于最上方,与其他节点通过分支实现有序的相连。继续上述的构造过程,知道没有后续的叶节点为止,下图给出了一个判定树的实例。
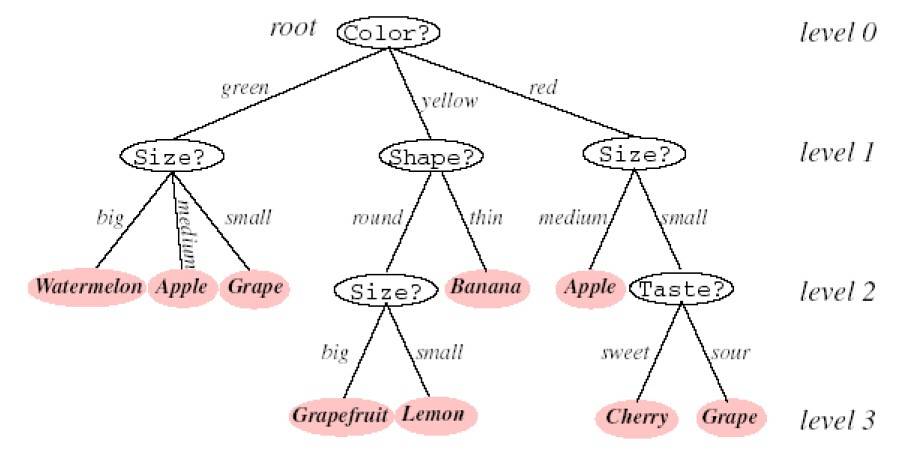
从根节点开始,对模式的某一属性的取值提问。与根节点相连的不同分支,对应这个属性的不同取值,根据不同的结果转向响应的后续子节点。这里需要注意的是树的各分支之间必须是互斥的,且各分支覆盖了整个可能的取值空间。
在把当前到达的节点视为新的根节点,做同样的分支判断。不断继续这一过程直至到达叶节点。每个叶节点都拥有一个相应的类别标记,测试样本被标记为它所到达的叶节点的类别标记。
决策树算法相比其他分类器(如神经网络)的优点之一是,树中所体现的语义信息,容易直接用逻辑表达式表示出。而树分类器的另外一个有点是分类速度快。这是因为树提供了一种很自然的嵌入人类专家的先验知识的机制,在实际中,当问题较为简单且训练样本较少的情况下,这类专家知识往往十分有效。
**3.分类和回归树(CART)算法**
综合以上概念,这里讨论一个问题,即基于训练样本构造或“生成一棵判定树”的问题。假设一个训练样本集D,该训练集拥有类别标记,同时确定了一个用于判定模式的属性集。对于一棵判定树,其任务是把训练样本逐步划分成越来越小的子集,一个理想的情况是每个子集中所有的样本均拥有同种类别标记,树的分类操作也到此结束,这类子集称为“纯”的子集。而一般情况下子集中的类别标记并不唯一,这时需要执行一个操作,要么接受当前有“缺陷”的判决结果,停止继续分类;要么另外选取一个属性进一步生长该树,这一过程是一种递归结构的树的生长过程。
若从数据结构的角度来看,数据表示在每个节点上,要么该节点已经是叶节点(自身已拥有明确的类别标记),要么利用另一种属性,继续分裂出子节点。分类和回归树是仅有的一种通用的树生长算法。CART提供一种通用的框架,使用者可以将其实例化为各种不同的判定树。
**3.1 CART算法的分支数目**
节点处的一次判别称为一个分支,它将训练样本划分成子集。根节点处的分支对应于全部训练样本,气候每一次判决都是一次子集划分过程。一般情况下,节点的分支数目由树的设计者确定,并且在一棵树上可能有不同的值。从一个节点中分出去的分支数目有时称为节点的分支率(branching ratio),这里用B表示。这里需要说明一个事实,即每个判别都可以用二值判别表示出来。由于二叉树具有普适性,而且构造比较方便,因此被广泛采用。
**3.2 CART算法中查询的选取与节点不纯度**
在决策树的设计过程中,一个重点是考虑在每个节点处应该选出测试或查询哪一个属性。我们知道对于数值数据,用判定树的方法得到的分类边界存在着较为自宏观的几何解释;而对于非数值数据,在节点处作查询进而划分数据的过程并没有直接的几何解释。
构造树的过程的一个基本原则是简单。我们期望获得的判定树简单紧凑,只有很少的节点。本着这一目标,应试图寻找这样一个查询T,它能使后继节点数据尽可能的“纯”。这里需要定义“不纯度”的指标。用i(N)表示节点N的“不纯度”,当节点上的模式数据均来自同一类别时,令i(N)=0;若类别标记均匀分布时,i(N)应当比较大。一种最流行的测量称为“熵不纯度”(entropy impurity),又称为信息量不纯度(information impurity):
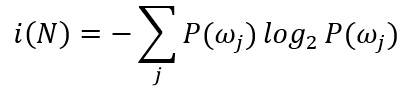
其中P(ωj)是节点N处属于ωj类模式样本数占总样本数的频度。根据熵的特性,如果所有模式的样本都来自同一类别,则不纯度为零,否则则大于零。当且仅当所有类别以等概率出现时,熵值取最大值。以下给出另外几种常用的不纯度定义:
“平方不纯度”,根据当节点样本均来自单一类别时不纯度为0的思想,用以下多项式定义不纯度,该值与两类分布的总体分布方差有关:
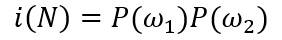
“Gini不纯度”,用于多类分类问题的方差不纯度(也是当节点N的类别标记任意选取时对应的误差率):
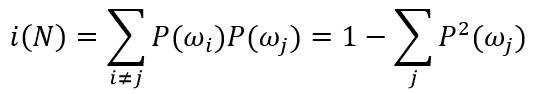
当类别标记等概率时“Gini不纯度”指标的峰度特性比“熵不纯度”要好。
“误分类不纯度”,用于衡量节点N处训练样本分类误差的最小概率:
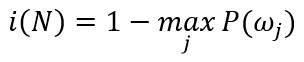
该指标在之前讨论过的不纯度指标中当等概率标记时具有最好的峰值特性。然而由于存在不连续的导数值,因而在连续参数空间搜索最大值时会出现问题。
当给定一种不纯度计算方法,另一个关键问题是:对于一棵树,目前已生长到节点N,要求对该节点作属性查询T,应该如何选择待查询值s?一种思路是选择那个能够使不纯度下降最快的那个查询,不纯度的下降公式可写为:
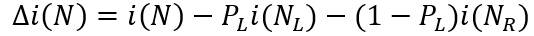
其中N_L和N_R分别表示左右子节点,i(N_L)和i(N_R)是相应的不纯度。P_L是当查询T被采纳时,树由N生长到N_L的概率。若采用熵不纯度指标,则不纯度的下降差就是本次查询所能提供的信息增益。由于二叉树的每次查询仅仅给出是/否的回答,所以每次分支所引起的熵不纯度的下降差不会超过1位。
##二、实验步骤
训练数据:
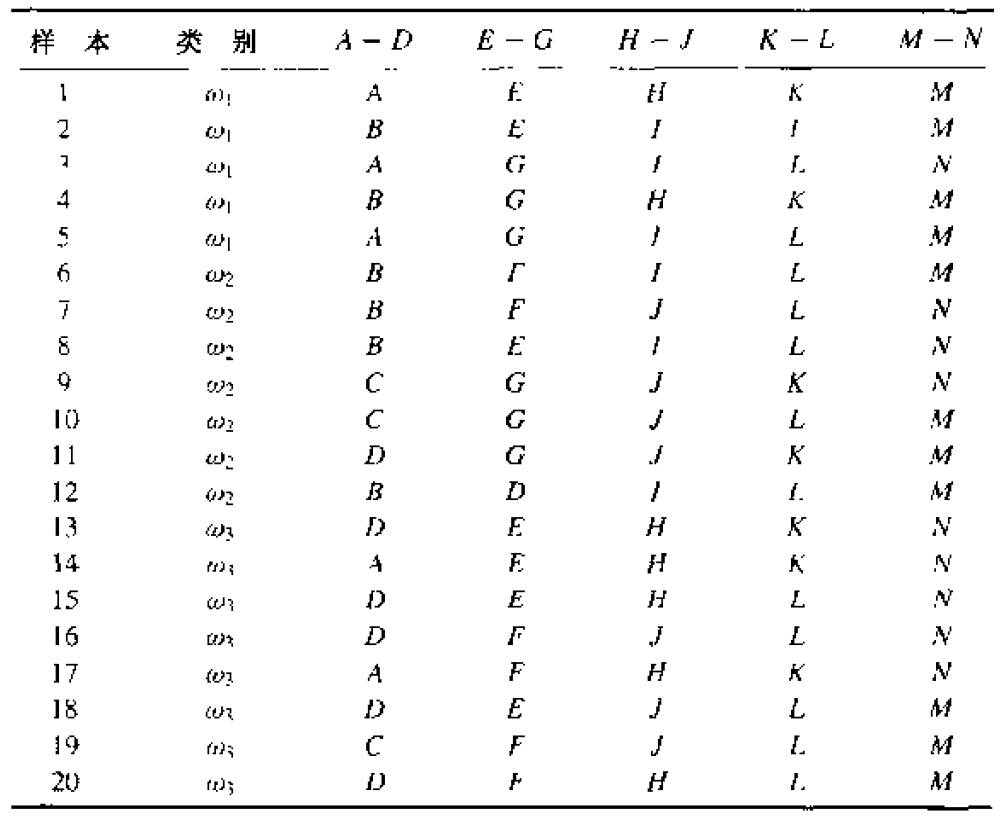
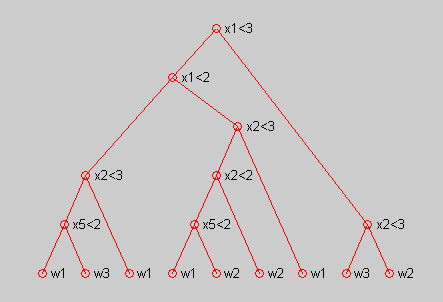
编写一个生成二叉分类树的通用程序,并使用上表中的数据来训练该树,训练过程中使用熵不纯度进行分支。通过过程中的判决条件,使用treeplot函数画出决策二叉树,如下图所示。
用上述程序训练好的非剪枝完全树,分类下列模式:
{A,E,I,L,N},{D,E,J,K,N},{B,F,J,K,M},{C,D,J,L,N}
用上述程序训练好的非剪枝完全树,选择其中的一对叶节点进行剪枝,使剪枝后树的熵不纯度的增量尽可能小。
##三、实验结果
使用未剪枝的树进行分类:

使用剪枝后的树进行分类:

**四、MATLAB代码**
主函数:
~~~
clear all; clc; close all;
%% 数据预处理
% 训练样本
w1 = ['AEHKM'; 'BEILM'; 'AGILN'; 'BGHKM'; 'AGILM'];
w2 = ['BFILM'; 'BFJLN'; 'BEILN'; 'CGJKN'; 'CGJLM'; 'DGJKM'; 'BDILM'];
w3 = ['DEHKN'; 'AEHKN'; 'DEHLN'; 'DFJLN'; 'AFHKN'; 'DEJLM'; 'CFJLM'; 'DFHLM'];
w = [w1; w2; w3];
C = [ones(5,1); 2*ones(7,1); 3*ones(8,1)]; % 分类标签
% 数据范围
Region = ['AD'; 'EG'; 'HJ'; 'KL'; 'MN'];
%测试样本
T1 = 'AEILN';
T2 = 'DEJKN';
T3 = 'BFJKM';
T4 = 'CDJLM';
%字符串矩阵 数据转化为 相应的自然数矩阵,方便后续处理
w = w + 0; % w=abs(w)
Region = abs(Region);
global Tree;
global Flag;
%% 非剪枝完全树
%建立一二叉树并用样本进行训练
Tree = CART_MakeBinaryTree(w, C, Region)
p=[0 1 2 3 4 4 3 2 8 9 10 10 9 8 1 15 15];
treeplot(p)%画出二叉树
%使用该分类树
W1 = CART_UseBinaryTree(Tree,T1)
W2 = CART_UseBinaryTree(Tree,T2)
W3 = CART_UseBinaryTree(Tree,T3)
W4 = CART_UseBinaryTree(Tree,T4)
%% B 剪枝
W1=CART_PruningBinaryTree(Tree,T1)
W2=CART_PruningBinaryTree(Tree,T2)
W3=CART_PruningBinaryTree(Tree,T3)
W4=CART_PruningBinaryTree(Tree,T4)
%% 多叉树分类
%AnyTree=CART_MakeAnyTree(w, C, Region)
%MultiTree=CART_MakeMultiTree(w, C, Region)
~~~
~~~
function Tree = CART_MakeBinarySortTree(Train_Samples, TrainingTargets, Region)
% 基于 熵不纯度 递归地实现 非剪枝完全二叉树
% 输入变量:
% Train_Samples:n个d维训练样本,为(n * d)的矩阵
% TrainingTargets:对应的类别属性,为(n * 1)的矩阵
% Region:特征向量维度顺序下上限,为(d * 2)的矩阵(特征值取离散的自然数区间,左小右大)
% 输出变量:一个基本树形节点 Tree
% 基本树形节点结构
% 一:标签(记录当前节点判定所用的维度,表叶子时为空);
% 二:阈值(记录当前所用维度判定之阈值,叶子节点时表类别);
% 三:左枝(小于等于阈值的待分目标 归于此,表叶子时为空)
% 四:右枝(大于阈值的 归于此,表叶子时为空)
[n,Dim] = size(Train_Samples);
[t,m] = size(Region);
if Dim ~= t || m ~= 2
disp('参数错误,请检查');
return;
end
%检查类别属性是否只有一个属性,若是则当前为叶节点,否则需要继续分
if ( length(unique(TrainingTargets)) == 1)
Tree.Label = [];
Tree.Value = TrainingTargets(1);
% 无左右子节点
Tree.Right = [];
Tree.Left = [];
Tree.Num = n;
return;
end
% 如果两个样本 为两类 直接设置为左右叶子
% 差异最大维度做为查询项目
% 单独处理此类情况,做为一种优化方法应对 后面提到的缺陷
if length(TrainingTargets) == 2
[m,p] = max(abs(Train_Samples(1,:) -Train_Samples(2,:)));
Tree.Label = p;
Tree.Value = ((Train_Samples(1,p) +Train_Samples(2,p))/2);
Tree.Num = n;
BranchRight.Right = [];
BranchRight.Left = [];
BranchRight.Label = [];
BranchRight.Num =1;
BranchLeft.Right = [];
BranchLeft.Left = [];
BranchLeft.Label = [];
BranchLeft.Num =1;
if Train_Samples(1,p) > Tree.Value
BranchRight.Value = TrainingTargets(1);
BranchLeft.Value = TrainingTargets(2);
else
BranchRight.Value = TrainingTargets(2);
BranchLeft.Value = TrainingTargets(1);
end
Tree.Right = BranchRight;
Tree.Left = BranchLeft;
return;
end
%确定节点的标签(当前节点判定所用的维度),熵不纯度下降落差最大的维度当选
%依次计算各个维度当选之后所造成的不纯度之和
%每个维度中可选值中 最大值代表本维度
Dvp=zeros(Dim,2); %记录每个维度中最大的不纯度及相应的阈值
for k=1:Dim
EI=-20*ones(Region(k,2)-Region(k,1)+1,1);
Iei=0;
for m = Region(k,1):Region(k,2)
Iei =Iei +1;
%计算临时分类结果 去右边的记为 1
CpI = Train_Samples(:,k) > m;
SumCpI = sum(CpI);
if SumCpI == n || SumCpI == 0 %分到一边去了,不妥,直接考察下一个
continue;
end
CpI = [not(CpI),CpI];
EIt = zeros(2,1);
%统计预计 新分到左右两枝的类别及相应的比率,然后得出熵不纯度
for j = 1:2
Cpt = TrainingTargets(CpI(:, j));
if ( length(unique(Cpt)) == 1) %应对 hist() 在处理同一元素时所存在的异常问题
Pw = 0;
else
Pw = hist(Cpt,unique(Cpt));
Pw=Pw/length(Cpt); % 被分到该类的比率
Pw=Pw.*log2(Pw);
end
EIt(j) = sum(Pw);
end
Pr = length(Cpt)/n;
EI(Iei) = EIt(1) *(1-Pr) + EIt(2) *Pr;
end
[maxEI, p] = max(EI);
NmaxEI = sum(EI == maxEI);
if NmaxEI > 1 %如果最大值有多个,取中间那一个, 稍微改进了默认地只取第一个最大值的缺陷
t = find(EI == maxEI);
p = round(NmaxEI /2);
p = t(p);
end
Dvp(k,1) = maxEI;
Dvp(k,2) = Region(k,1) +p -1;
end
%更新节点标签和阈值
[maxDv, p] = max(Dvp(:,1));
NmaxDv = sum(Dvp(:,1) == maxDv);
if NmaxDv > 1 %如果最大值有多个,采用取值范围较小的那一个维度属性, 稍微改进了默认地只取第一个最大值的缺陷
t = find(Dvp(:,1) == maxDv);
[D,p] = min(Region(t,2) -Region(t,1));
p = t(p);
end
Tree.Label = p;
Tree.Value = Dvp(p,2);
%将训练样本分成两类,对左右子节点分别形成二叉树,需要进行递归调用
CprI = Train_Samples(:,p) > Dvp(p,2);
CplI = not(CprI);
Tree.Num = n;
Tree.Right = CART_MakeBinarySortTree(Train_Samples(CprI,:), TrainingTargets(CprI), Region);
Tree.Left = CART_MakeBinarySortTree(Train_Samples(CplI,:), TrainingTargets(CplI), Region);
~~~
~~~
% 针对 由函数 CART_MakeBinaryTree()生成的二叉树 Tree,给出 Test 类属 W
function W = CART_UseBinarySortTree(tree, testSamples)
% 当前节点不存在左右子结点时,判定为叶节点并返回其类别属性
if isempty(tree.Right) && isempty(tree.Left)
W = tree.Value;
return;
end
% 非叶节点的判决过程
if testSamples(tree.Label) > tree.Value
W = CART_UseBinarySortTree(tree.Right,testSamples);
else
W = CART_UseBinarySortTree(tree.Left,testSamples);
end
~~~
~~~
function W = CART_PruningBinarySortTree(tree, Samples)
% 针对 由函数 CART_MakeBinaryTree()生成的二叉树 Tree,按样本 Samples 遍历Tree
%如果 发现有与叶子共父节点的长枝条,并且其数量不多于叶子中的样本数,则将其父节点设为叶子,类别属性取多数
%由于程序编写上一时间没能用Matlab语言实现对二叉树的修改,所以没有真实地修剪树,但是起到的修剪之后的效果,
%遇到叶子时,就可以返回其类别属性
TempLift=tree.Left;
TempRight=tree.Right;
LeftEmpty =isempty(TempLift.Right) && isempty(TempLift.Left);
RightEmpty=isempty(TempRight.Right) && isempty(TempRight.Left);
if LeftEmpty && RightEmpty %遇到挂有 两叶子节点,执行剪枝,择多归类
if TempLift.Num > TempRight.Num
W=TempLift.Value;
else
W=TempRight.Value;
end
return;
elseif LeftEmpty || RightEmpty %遇到挂有 一个叶子 和 一个子父节点,比较,择多归类
if LeftEmpty && (TempLift.Num > TempRight.Num /3)
W=TempLift.Value;
return;
elseif RightEmpty && (TempRight.Num > TempLift.Num /3)
W=TempRight.Value;
return;
end
end
if Samples(tree.Label) > tree.Value
if RightEmpty
W = tree.Right.Value;
return;
else
W = CART_PruningBinarySortTree(tree.Right,Samples);
end
else
if LeftEmpty
W = tree.Left.Value;
return;
else
W = CART_PruningBinarySortTree(tree.Left,Samples);
end
end
~~~
参考书籍:Richard O. Duda, Peter E. Hart, David G. Stork 著《模式分类》
模式识别:k-均值聚类算法的研究与实现
最后更新于:2022-04-01 06:47:42
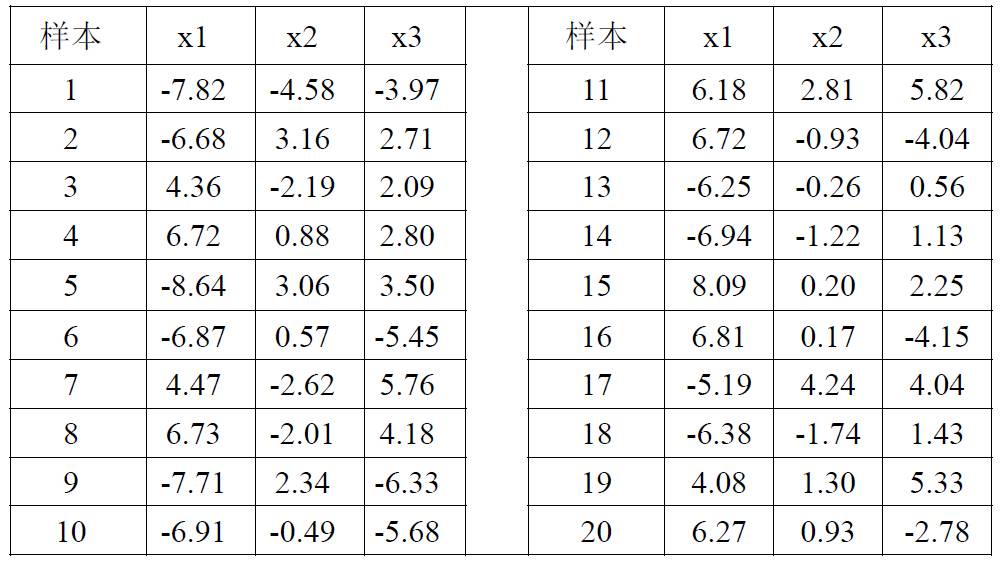
本实验的目的是学习和掌握k-均值聚类算法。k-均值算法是一种经典的无监督聚类和学习算法,它属于迭代优化算法的范畴。本实验在MATLAB平台上,编程实现了k-均值聚类算法,并使用20组三维数据进行测试,比较分类结果。实验中初始聚类中心由人为设定,以便于实验结果的比较与分析。
##一、技术论述
**1.无监督学习和聚类**
在之前设计分类器的时候,通常需要事先对训练样本集的样本进行标定以确定类别归属。这种利用有标记样本集的方法称为“有监督”或“有教师”方法。这一类方法的使用固然十分广泛,也有着很坚实的理论基础,但在实际运用中这类方法经常会遇到以下瓶颈:
1. 收集并标记大量样本集是一件相当费时费力的前期工作;
2. 现实中存在很多应用,其分类模式的性质会随着时间发生变化,单单使用已标记样本无法满足这类情况;
3. 有人希望能逆向解决问题:先用大量未标记的样本集来自动地训练分类器,再人工地标记数据分组的结果,如数据挖掘的大型应用,因为这些应用往往不知道待处理数据的具体情况。
可以看到,无监督学习方法的提出是十分必要的。事实上,在任何一项探索性的工作中,无监督的方法均向我们揭示了观测数据的一些普遍规律。很多无监督方法都可以以独立于数据的方式工作,为后续步骤提供“灵巧的预处理”和“灵巧的特征提取”等有效的前期处理。在无监督的情况下,聚类算法是模式识别研究中著名的一类技术。
**2.分类与聚类的差别**
分类(Classification):对于一个分类器,通常需要你告诉它“这个东西被分为某某类”这样一些例子。通常情况下,一个分类器会从它得到的训练数据中进行学习,从而具备对未知数据进行分类的能力,这种提供训练数据的过程通常叫做有监督学习。
聚类(Clustering):简单地说就是把相似的东西分到一组。聚类的时候,我们并不关心某一类是什么,这里需要实现的目标只是把相似的东西聚到一起。因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了。因此,聚类方法通常并不需要使用训练数据进行学习,因此桔类方法属于无监督学习的范畴。
**3.常见的分类与聚类算法**
所谓分类,就是根据数据样本的特征或属性,划分到已有的类别中。前面使用到的模式分类方法主要有:贝叶斯分类算法(Bayesian classifier) 、PCA主分量分析法、Fisher线性判别分析法、Parzen窗估计法、k-最近邻法(k-nearest neighbor,kNN)、基于支持向量机(SVM)的分类器、人工神经网络(ANN)和决策树分类法等等。
分类作为一种有监督学习方法,要求必须在分类之前明确知道各个类别的必要特征和信息,并且标记所有训练样本都有一个类别与之相对应。但是很多情况下这些条件往往无法满足,尤其是在处理海量数据的时候,数据预处理的代价非常大。
聚类算法中最经典的当属k均值聚类(K-means clustering)算法。该算法又称为“c均值算法”,因为它的目标就是找到c个均值向量作为聚类中心:μ1,μ2,…,μc,实际上k与c是等价的。
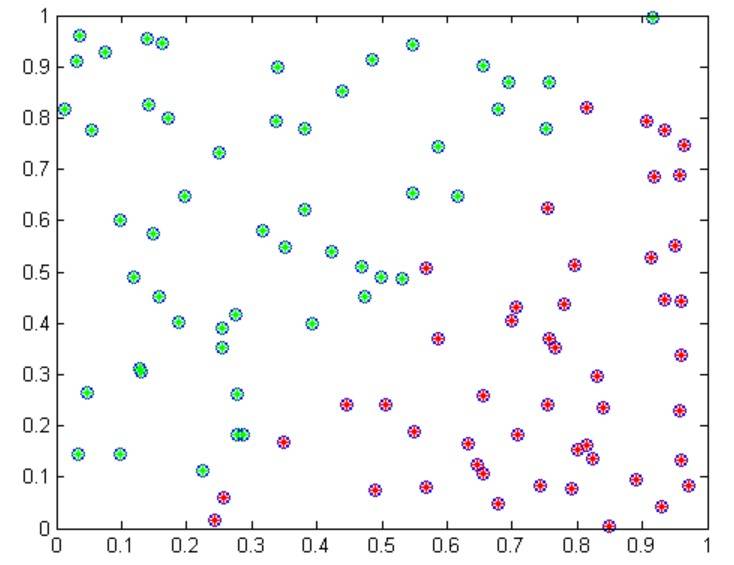
以上是对二维随机样本进行聚类的实例。
**4.聚类任务的基本步骤**
假设所有模式都用一组特征表示,模式被表示为L维的特征矢量。聚类任务需包含以下步骤:
1. **特征选择**。选择特征尽可能与感兴趣的任务相关。特征之间的信息冗余度要尽可能小。
2. **相似性测度**。一个基本的保证是所有选择的特征对相似性测度计算的贡献都是均衡的,没有那一个特征是绝对占优的。
3. **聚类准则**。聚类准则依赖于专家判断的在数据集合内部隐含类的类型解释。聚类准则可以被表示为代价函数和其它类型的规则。
4. **聚类算法**。在确定相似性测度和聚类准则后,这一步就是要选择一个具体的算法方案将数据集合分解为类结构。
5. **结构的有效性**。一旦聚类算法获得了结果,需要采用合适的检验方法检验其正确性。
6. **结果的解释**。应用领域的专家必须结合其它的试验证据和分析解释聚类结果,以便得到正确的结论。
**5.k-均值聚类算法**
k-均值聚类算法的目标是找到k个均值向量或“聚类中心”。算法的实现步骤如下所示,其中n表示模式的数量,c表示类别的数量,通常的做法是从样本中随机取出c个作为初始的聚类中心。当然,初始的聚类中心也可以通过人为来确定:

该算法的计算复杂度为:
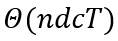
其中d代表样本的维数,T是聚类的迭代次数,一般来说,迭代次数通常远少于样本的数量。
该算法是一种典型的聚类算法,把它归入迭代优化算法的范畴是因为算法规定的c个均值会不断地移动,使得一个平方误差准则函数最小化。在算法的每一步迭代中,每个样本点均被认为是完全属于某一类别。
##二、实验结果讨论
实验所使用的样本:
设计步骤主要包括以下几个部分:
编写程序,实现以上所述的k-均值聚类算法。其中,在算法中样本与聚类中心的距离采用欧氏距离的形式。
类别数目和聚类中心初始值选为以下参数进行实验:
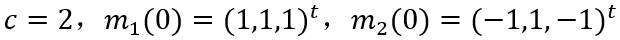
再将类别数目和聚类中心初始值改变为以下参数进行实验。
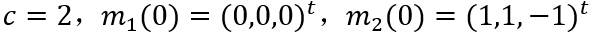
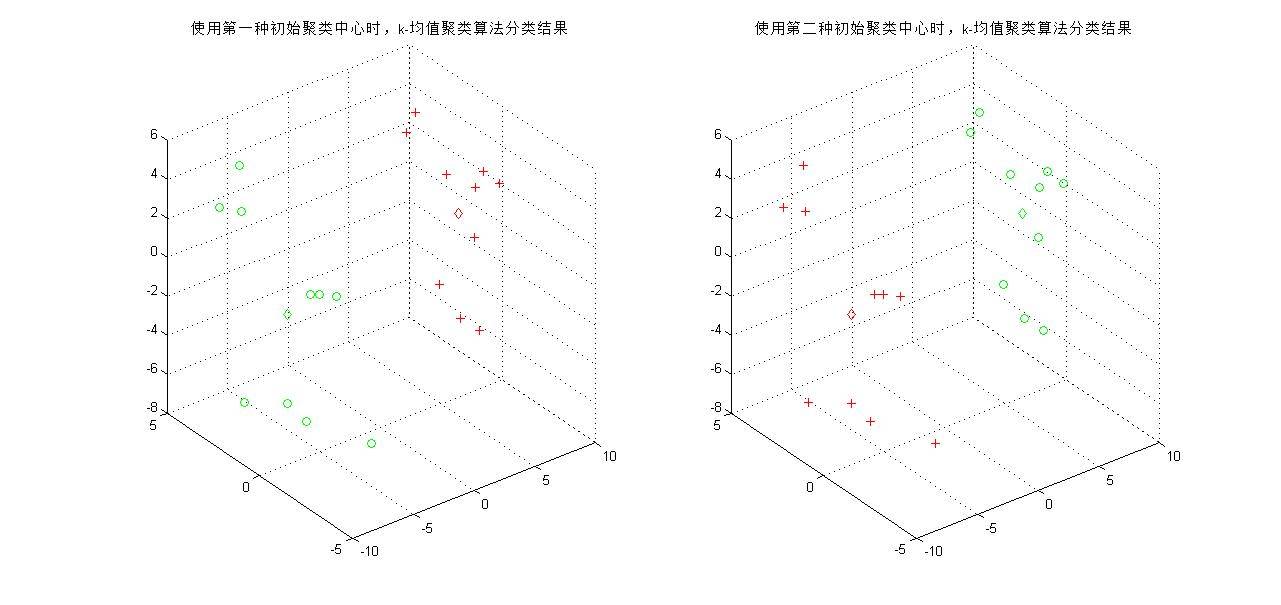
下图得到两次聚类的结果,可以看到当分类类别为2时,初始聚类中心对分类结果影响不大(至少对于样本少的情况是这样的),最终两种情况都能得到一样的最终聚类中心。

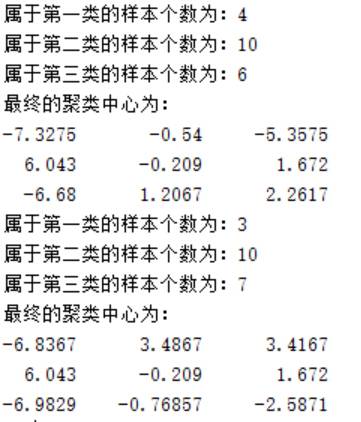
下面测试将样本分为三类的情况。将类别数目和聚类中心初始值选为以下参数进行实验:
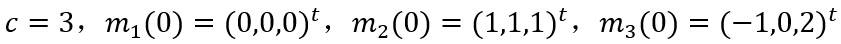
再将类别数目和聚类中心初始值改变为以下参数进行实验:

下图得到两次聚类的结果,可以看到当分类类别为3时,分类复杂度增加,随着聚类中心的移动,对于同一组测试样本可能有不同的划分结果。虽然初始聚类中心的作用只是将样本初步地分为几个区域,但事实上不同的初始中心会给分类结果带来巨大的差异。
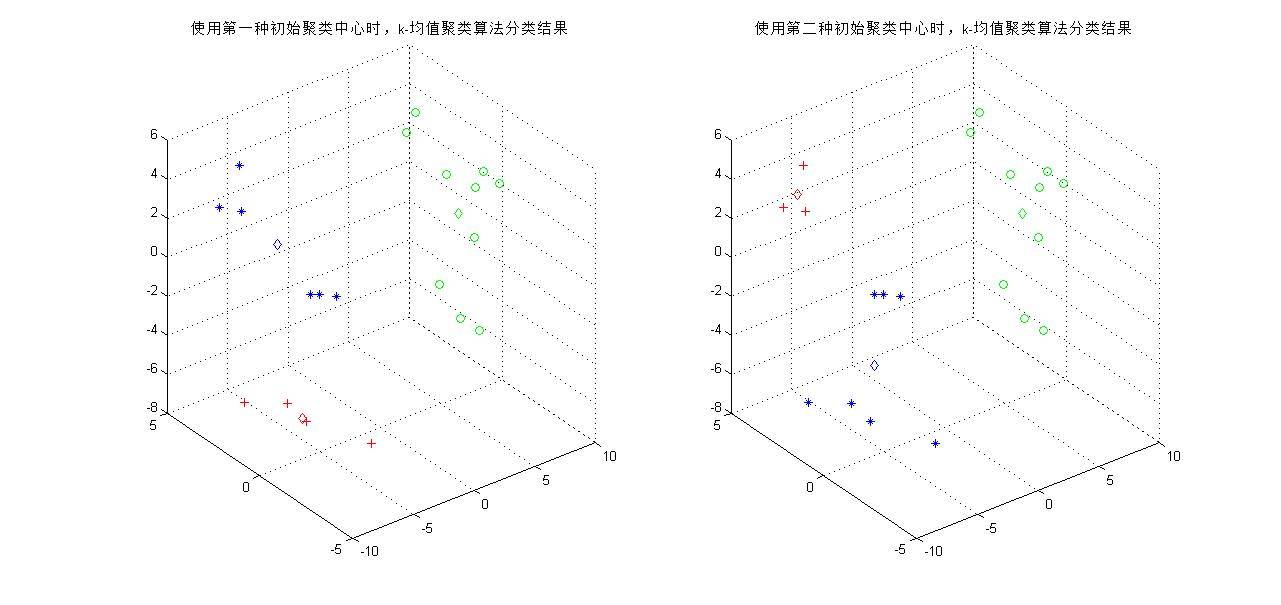
在程序中,使用欧氏距离作为样本到聚类中心的距离,事实上也可以使用其他多种距离度量进行运算,如街区距离(1范数)、棋盘距离(∞范数)等等。
##三、完整代码
~~~
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% k-均值聚类函数
% 输入参数:
% w:需要分类的样本
% k:分类数
% m:初始聚类中心
% iteration:迭代次数
% 中间参数:
% class_id:存放各个样本属于一类的下标
% dist:计算样本到聚类中心的距离
% 输出参数:
% class_result:存放样本的分类结果
% class_num:存放被分到各类的样本个数
% center:迭代结束时的聚类中心
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function [class_result, class_num, center] = kmeans(w, k, m, iteration)
[n,d] = size(w);
class_result = zeros(1,n);
class_num = zeros(1,k);
time = 1;
% 以下步骤计算每个样本到聚类中心的距离
while time < iteration % 迭代次数限制
for i = 1:n
dist = sqrt(sum((repmat(w(i,:), k, 1) - m).^2, 2)); % 欧氏距离
% dist = sum(abs(repmat(x(i,:), k, 1) - nc), 2); % 街区距离
[y,class_id] = min(dist); % 计算样本对三类中哪一类有最小距离并存放在class_id
class_result(i) = class_id;
end
for i = 1:k
% 找到每一类的所有数据,计算平均值,其值作为新的聚类中心
class_id = find(class_result == i);
m(i, :) = mean(w(class_id, :)); % 更新聚类中心
% 统计每一类样本的个数
class_num(i) = length(class_id);
end
time = time + 1;
end
center = m;
~~~
~~~
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 样本分类结果的绘图函数
% 输入参数:
% w:需要分类的样本
% class:聚类后的样本分类结果
% flag:分类类别数
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%function draw(w, class, center)
[flag x] = size(center);
[n, d] = size(w);
% figure;
if flag == 2 % 若将样本分成两类
for i=1:n
if class(i) == 1
plot3(w(i,1),w(i,2),w(i,3),'r+'); % 显示第一类
hold on;
grid on;
elseif class(i) == 2
plot3(w(i,1),w(i,2),w(i,3),'go'); %显示第二类
hold on;
grid on;
end
end
for j = 1:flag
if j == 1
plot3(center(j,1),center(j,2),center(j,3),'rd'); % 聚类中心
elseif j == 2
plot3(center(j,1),center(j,2),center(j,3),'gd'); % 聚类中心
end
end
end
if flag == 3 % 若将样本分成三类
% 显示分类结果
for i = 1:n
if class(i) == 1
plot3(w(i,1),w(i,2),w(i,3),'r+'); % 显示第一类
hold on;
grid on;
elseif class(i) == 2
plot3(w(i,1),w(i,2),w(i,3),'go'); % 显示第二类
hold on;
grid on;
elseif class(i) == 3
plot3(w(i,1),w(i,2),w(i,3),'b*'); % 显示第三类
hold on;
grid on;
end
end
for j = 1:flag
if j == 1
plot3(center(j,1),center(j,2),center(j,3),'rd'); % 聚类中心
elseif j == 2
plot3(center(j,1),center(j,2),center(j,3),'gd'); % 聚类中心
elseif j == 3
plot3(center(j,1),center(j,2),center(j,3),'bd'); % 聚类中心
end
end
end
~~~
~~~
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% k-均值聚类的研究与实现主函数
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
clear all;
close all;
% 测试样本
w = [-7.82 -4.58 -3.97;...
-6.68 3.16 2.71;...
4.36 -2.19 2.09;...
6.72 0.88 2.80;...
-8.64 3.06 3.50;...
-6.87 0.57 -5.45;...
4.47 -2.62 5.76;...
6.73 -2.01 4.18;...
-7.71 2.34 -6.33;...
-6.91 -0.49 -5.68;...
6.18 2.18 5.28;...
6.72 -0.93 -4.04;...
-6.25 -0.26 0.56;...
-6.94 -1.22 1.33;...
8.09 0.20 2.25;...
6.81 0.17 -4.15;...
-5.19 4.24 4.04;...
-6.38 -1.74 1.43;...
4.08 1.30 5.33;...
6.27 0.93 -2.78];
[n, d] = size(w);
% 以下是k均值聚类的参数设定(c = 2时)
k = 2;
m = [1 1 1; -1 1 -1]; % 初始聚类中心
% m = [0 0 0; 1 1 -1]; % 初始聚类中心
iteration = 200; % k均值聚类的迭代次数
% 调用kmeans函数进行聚类
[class, class_num, center] = kmeans(w, k, m, iteration);
% 画出样本分类结果
figure;subplot(121);draw(w, class, center);
title('使用第一种初始聚类中心时,k-均值聚类算法分类结果');
% 显示信息
disp(['属于第一类的样本个数为:',num2str(class_num(1))]);
disp(['属于第二类的样本个数为:',num2str(class_num(2))]);
disp('最终的聚类中心为:');
disp(num2str(center));
% 以下是k均值聚类的参数设定(c = 2时)
k = 2;
% m = [1 1 1; -1 1 -1]; % 初始聚类中心
m = [0 0 0; 1 1 -1]; % 初始聚类中心
iteration = 200; % k均值聚类的迭代次数
% 调用kmeans函数进行聚类
[class, class_num, center] = kmeans(w, k, m, iteration);
% 画出样本分类结果
subplot(122);draw(w, class, center);
title('使用第二种初始聚类中心时,k-均值聚类算法分类结果');
% 显示信息
disp(['属于第一类的样本个数为:',num2str(class_num(1))]);
disp(['属于第二类的样本个数为:',num2str(class_num(2))]);
disp('最终的聚类中心为:');
disp(num2str(center));
% 以下是k均值聚类的参数设定(c = 3时)
k = 3;
m = [0 0 0; 1 1 1; -1 0 2]; % 初始聚类中心
% m = [-0.1 0.0 0.1; 0 -0.1 0.1; -0.1 -0.1 0.1]; % 初始聚类中心
iteration = 200; % k均值聚类的迭代次数
% 调用kmeans函数进行聚类
[class, class_num, center] = kmeans(w, k, m, iteration);
% 画出样本分类结果
figure;subplot(121);draw(w, class, center);
title('使用第一种初始聚类中心时,k-均值聚类算法分类结果');
% 显示信息
disp(['属于第一类的样本个数为:',num2str(class_num(1))]);
disp(['属于第二类的样本个数为:',num2str(class_num(2))]);
disp(['属于第三类的样本个数为:',num2str(class_num(3))]);
disp('最终的聚类中心为:');
disp(num2str(center));
% 以下是k均值聚类的参数设定(c = 3时)
k = 3;
% m = [0 0 0; 1 1 1; -1 0 2]; % 初始聚类中心
m = [-0.1 0.0 0.1; 0 -0.1 0.1; -0.1 -0.1 0.1]; % 初始聚类中心
iteration = 200; % k均值聚类的迭代次数
% 调用kmeans函数进行聚类
[class, class_num, center] = kmeans(w, k, m, iteration);
% 画出样本分类结果
subplot(122);draw(w, class, center);
title('使用第二种初始聚类中心时,k-均值聚类算法分类结果');
% 显示信息
disp(['属于第一类的样本个数为:',num2str(class_num(1))]);
disp(['属于第二类的样本个数为:',num2str(class_num(2))]);
disp(['属于第三类的样本个数为:',num2str(class_num(3))]);
disp('最终的聚类中心为:');
disp(num2str(center));
~~~
模式识别:模拟退火算法的设计与实现
最后更新于:2022-04-01 06:47:40
本节的目的是记录以下学习和掌握模拟退火(Simulated Annealing,简称SA算法)过程。模拟退火算法是一种通用概率算法,用来在一个大的搜寻空间内寻找命题的最优解。这里分别使用随机模拟退火算法和确定性模拟退火算法,在MATLAB平台上进行编程,以寻找一个6-单元全连接网络的能量最小化模型。
参考书籍:Richard O. Duda, Peter E. Hart, David G. Stork 著《模式分类》
##一、技术论述
**1.随机方法**
学习在构造模式分类器中起着中心的作用。一个通常的做法是先假设一个单参数或多参数的模型,然后根据训练样本来估计各参数的取值。当模型相当简单并且低维时,可以采用解析的方法,如求函数导数,来显式求解方程以获得最优参数。如果模型相对复杂一些,则可以通过计算局部的导数而采用梯度下降算法来解,如人工神经网络或其他一些最大似然方法。而对于更复杂的模型,经常会出现许多局部极值,上述方法的效果往往不尽人意。
如果一个问题越复杂,或者先验知识和训练样本越少,我们对能够自动搜索可行解的复杂搜索算法的依赖性就越强,如基于参数搜索的随即方法。一个通常的做法是使搜索朝着预期最优解的区域前进,同时允许一定程度的随机扰动,以发现更好的解。
**2.随机搜索**
这里主要研究在多个候选解中搜索最优解的方法。假设给定多个变量si,i=1,2,…,N,其中每个变量的数值都取两个离散值之一(如-1和1)。优化问题是这样描述的:确定N个si的合适取值,时下述能量函数(又称为代价函数)最小:
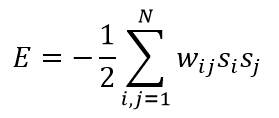
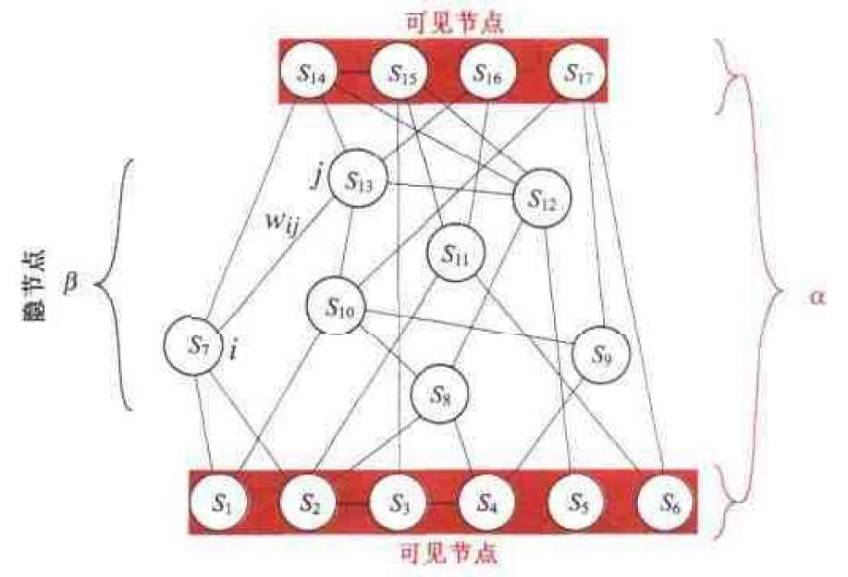
其中w_ij是一个实对称矩阵,取值可正可负,其中令到自身的反馈权为零(即w_ii=0),这是因为非零w_ii只是在能量函数E上增加一个与si无关的常数,不影响问题的本质。这个优化问题可以用网络和节点的方式表示,如下图所示,其中节点之间的链接对应每个权值w_ij。
**3.贪心算法的局限性**
如上所述,对于求解有N个变量si的能量E最小化问题,除非N的取值很小,否则往往无法直接求解,因为其构型数目高达N^2。如果使用贪心算法搜索最优的构型,需要先随机选取每个节点的起始状态,然后顺序考查每个节点从而计算与之相联系的si=1状态和si=-1状态的能量,最后选取能够降低能量的状态迁移。这种判断只用到了直接与之相连的具有非零权值的相邻节点。
这种贪心搜索算法成功找到最优解的可能性很小,因为系统常常会陷入局部能量最小值,或根本就不收敛,因此需要选择其他搜索方法。
**4.模拟退火**
在热力学中,固体的退火过程主要由以下三部分组成:
1. 加温过程。其目的是增强粒子的热运动,使其偏离平衡位置。当温度足够高时,固体将熔解为液体,从而消除系统原先可能存在的非均匀态,使随后进行的冷却过程以某一平衡态为起点。熔解过程实际是系统的熵增过程,系统能量也随温度的升高而增大。
2. 等温过程。物理学的知识告诉我们,对于与周围环境交换热量而温度不变的封闭系统,系统状态的自发变化总是朝自由能减少的方向进行,当自由能达到最小时,系统达到平衡态。
3. 冷却过程。其目的是使粒子的热运动减弱并渐趋有序,系统能量逐渐下降,从而得到低能的晶体结构。
Metropolis等在1953年提出了重要性采样法,即以概率大小接受新状态。具体而言,在温度T时, 由当前状态i产生新状态j,两者的能量分别为Ei和Ej,若Ej小于Ei,则接受新状态j为当前状态;否则,计算概率p(∆E):

若p(∆E)大于[0,1]区间内的随机数,则仍旧接受新状态j为当前状态;若不成立则保留i为当前状态,其中k为玻尔兹曼常数,T为系统温度。上述重要性采样过程通常称为Metropolis准则:
1. 在高温下可接受与当前状态能量差较大的新状态;
2. 而在低温下基本只接受与当前能量差较小的新状态;
3. 且当温度趋于零时,就不能接受比当前状态能量高的新状态。
1983年Kirkpatrick 等意识到组合优化与物理退火的相似性,并受到Metropolis 准则的启迪,提出了模拟退火算法。模拟退火算法是基于Monte Carlo 迭代求解策略的一种随机寻优算法,其出发点是基于物理退火过程与组合优化之间的相似性,模拟退火方法由某一较高初温开始,利用具有概率突跳特性的Metropolis抽样策略在解空间中进行随机搜索,伴随温度的不断下降,重复抽样过程,最终得到问题的全局最优。对比贪心算法,模拟退火算法主要的优势在于它使系统有可能从局部最小处跳出。
对于一个优化问题:
把优化问题的求解过程与统计热力学的热平衡问题进行类比,通过模拟高温物体退火过程的方法,试图找到优化问题的全局最优或近似全局最优解;
允许随着参数的调整,目标函数可以偶尔向能量增加的方向发展(对应于能量有时上升),以利于跳出局部极小的区域,随着假想温度的下降(对应于物体的退火),系统活动性降低,最终稳定在全局最小所在的区域。
**5.两种模拟退火算法**
两种模拟退火算法,即随机模拟退火和和确定性模拟退火算法的实现步骤如下所示:

随机模拟退火算法收敛很慢,部分原因在于其中搜索的全部的构型空间的离散本质,即构型空间是一个N维超立方体。每一次搜索轨迹都只能沿着超立方体的一条边,状态只能落在超立方体的顶点上,因此失去了完整的梯度信息。而梯度信息是可以用超立方体内部的连续状态值提供的。一种更快的方法就是以下的确定性模拟退火算法:

##二、实验结果讨论
构造一个6-单元全连接网络,能量函数使用公式:
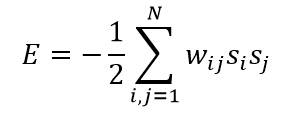
其中网络的连接权值矩阵如下:

设计步骤主要包括以下几个部分:
编写程序[E, s_out] = RandomSimulatedAnnealing(T_max, time_max, c, s, w),实现以上算法1所述的随机模拟退火算法。这里需要设定以下参数: T_max=10,T(m+1) =c*T(m),c=0.9,进行实验,能量随温度下降次数的变化曲线如图2所示(由于模拟退火算法所得到的结果有一定的随机性,因此以下步骤均执行四次算法进行观察),四次所得到的最终构型s如图3所示。
改变参数:初始温度:T_max=5,T(m+1) =c*T(m),c=0.5,进行实验,能量随温度下降次数的变化曲线如图4所示,四次所得到的最终构型s如图5所示。
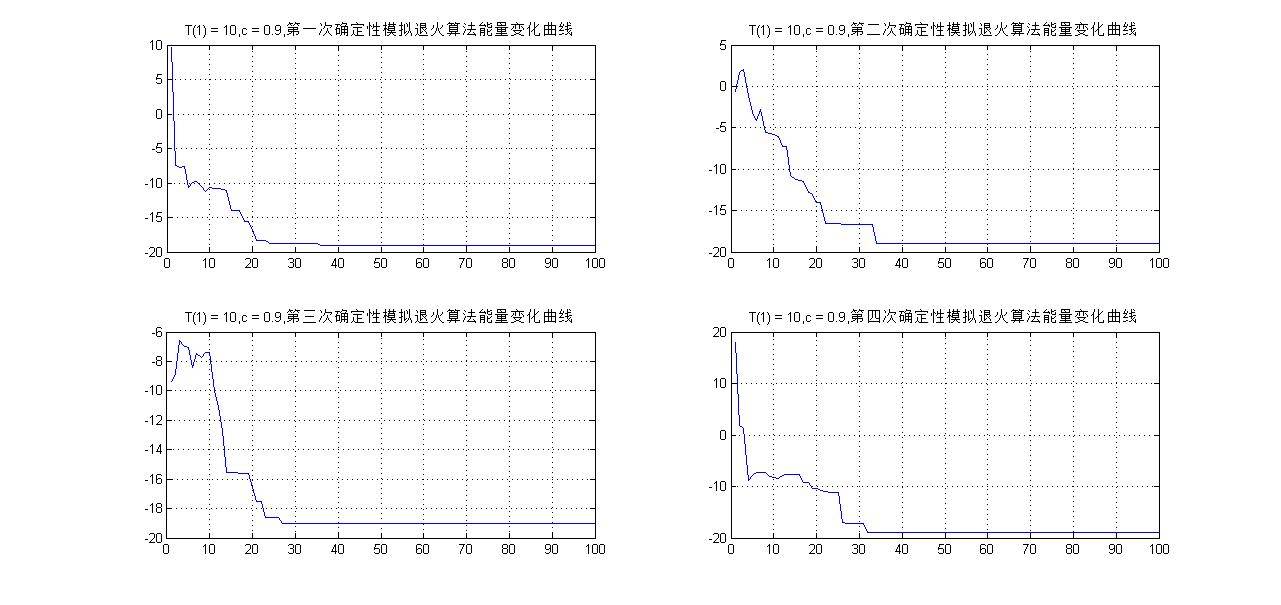
编写程序[E, s_out] = DeterministicAnnealing(T_max, time_max, c, s, w),实现以上算法2所述的确定性模拟退火算法。这里需要设定以下参数: T_max=10,T(m+1) =c*T(m),c=0.9,进行实验,能量随温度下降次数的变化曲线如图6所示,四次所得到的最终构型s如图7所示。
改变参数:初始温度:T_max=5,T(m+1) =c*T(m),c=0.5,进行实验,能量随温度下降次数的变化曲线如图8所示,四次所得到的最终构型s如图9所示。
结论:图2、3给出了多次随机模拟退火算法的运行结果,可以看到构型s不一定完全一样;能量函数E的波形在经过若干次逐渐递减的震荡后基本收敛到全局最小值-19。当改变T(1)=5,c=0.5时,从图4中可观察到能量函数E的波形极速下降,并达到较小的值,中间少了一个温度渐变和震荡调整的过程。
图6、7给出多次确定性模拟退火算法的运行结果,且每次得到的最终构型s均一致;能量函数E的波形在经过平缓递减后收敛到全局最小值-19,不出现随机模拟退火中剧烈震荡的情况。当改变T(1)=5,c=0.5时,从图8中可观察到能量函数E的波形同样呈现出极速下降的态势,并达到较小的值,中间少了一个温度渐变和调整的过程。
综合以上的实验结果,我们发现随机退火和确定性退火均能给出相似的最终解,但对于一些大规模的现实问题,随机模拟退火的运行速度很慢,而相比之下确定性退火算法要快很多,有时可以快2~3个数量级。
另外,初温T(1)和温度下降系数c的选择对算法性能也有很大影响。初温的确定应折衷考虑优化质量和优化效率,常用方法包括以下几种:
* 均匀抽样一组状态,以各状态目标值的方差为初温;
* 随机产生一组状态,确定两两状态间的最大目标值差|∆max|,然后依据差值,利用一定的函数确定初温。譬如T(1)=-∆/ln
p_r,其中p_r为初始接受概率;
* 利用经验公式给出。
模拟退火算法设计中包括三个重要的函数:状态产生函数、状态接受函数、温度更新函数;同时在程序设计时,需遵循内循环终止准则、外循环终止准则。这些环节的设计将决定模拟退火算法的优化性能。
##三、实验结果



##四、简单代码实现
~~~
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 随机模拟退火函数
% 输入参数:
% T_max:初始温度
% time_max:最大迭代次数
% c:温度下降比率
% s:初始构型
% w:权值矩阵
% 输出参数:
% E:能量变化矩阵
% s_out:经过算法计算后的构型
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function [E, s_out] = RandomSimulatedAnnealing(T_max, time_max, c, s, w)
[x, y] = size(s);
time = 1; % 迭代次数
T(time) = T_max; % 初始温度设置
while (time < (time_max + 1)) % (T(time) > T_min)
for i = 1:1000
num = ceil(rand(1) * y); % 选择产生一个1到y之间的随机数
for j = 1:y
e(j) = w(num, j) * s(num) * s(j);
end
Ea(time) = -1 / 2 * sum(e);
Eb(time) = -Ea(time);
if Eb(time) < Ea(time)
s(num) = -s(num);
elseif (exp(-(Eb(time) - Ea(time)) / T(time)) > rand())
s(num) = -s(num);
else
s(num) = s(num);
end
end
% 计算能量E
E(time) = 0;
for it = 1:6
for jt = 1:6
E(time) = E(time) + w(it, jt) * s(it) * s(jt);
end
end
E(time) = E(time) * (-0.5);
s_out(time,:) = s; % 每次形成的构型
time = time + 1;
T(time) = T(time - 1) * c;
end
~~~
~~~
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 确定性模拟退火函数
% 输入参数:
% T_max:初始温度
% time_max:最大迭代次数
% c:温度下降比率
% s:初始构型
% w:权值矩阵
% 中间函数:
% tanh(l / T):响应函数,该函数有一个隐含的重新规格化的作用
% 输出参数:
% E:能量变化矩阵
% s_out:经过算法计算后的构型
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function [E, s_out] = DeterministicAnnealing(T_max, time_max, c, s, w)
[x, y] = size(s);
time = 1; % 迭代次数
T(time) = T_max; % 初始温度设置
while (time < (time_max + 1))
num = ceil(rand(1) * y); % 选择产生一个1到y之间的随机数
for j = 1:y
e(j) = w(num, j) * s(j);
end
l(time) = sum(e);
s(num) = tanh(l(time) / T(time));
% 计算能量E
E(time) = 0;
for it = 1:6
for jt = 1:6
E(time) = E(time) + w(it, jt) * s(it) * s(jt);
end
end
E(time) = E(time) * (-0.5);
s_out(time,:) = s; % 每次形成的构型
time = time + 1;
T(time) = T(time - 1) * c;
end
~~~
~~~
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%模拟退火算法实验
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
clear;
close all;
% 网络的连接权值矩阵
w = [ 0 5 -3 4 4 1;...
5 0 -1 2 -3 1;...
-3 -1 0 2 2 0;...
4 2 2 0 3 -3;...
4 -3 2 3 0 5;...
1 1 0 -3 5 0];
num = 6; % 总共产生6个数
s_in = rand(1,num); % 生成1和-1的随机序列
s_in(s_in > 0.5) = 1;
s_in(s_in < 0.5) = -1;
disp(['初始构型S为:',num2str(s_in)]);
% 以下是随机模拟退火算法
T_max = 10; % 初始温度设置
time_max = 100; % 最大迭代次数
c = 0.9; % 温度变化比率
[E1, s_out1] = RandomSimulatedAnnealing(T_max, time_max, c, s_in, w);
subplot(221),plot(E1);grid on;
title(['T(1) = ',num2str(T_max),',c = ',num2str(c),',随机模拟退火算法能量变化曲线']);
disp(['T(1) = 10,c = 0.9,随机模拟退火算法最终构型S为:',num2str(s_out1(time_max,:))]);
T_max = 5; % 初始温度设置
time_max = 100; % 最大迭代次数
c = 0.5; % 温度变化比率
[E2, s_out2] = RandomSimulatedAnnealing(T_max, time_max, c, s_in, w);
subplot(222),plot(E2);grid on;
title(['T(1) = ',num2str(T_max),',c = ',num2str(c),',随机模拟退火算法能量变化曲线']);
disp(['T(1) = 5,c = 0.5,随机模拟退火算法最终构型S为:',num2str(s_out2(time_max,:))]);
% 以下是确定性模拟退火算法
T_max = 10; % 初始温度设置
time_max = 100; % 最大迭代次数
c = 0.9; % 温度变化比率
[E3, s_out3] = DeterministicAnnealing(T_max, time_max, c, s_in, w);
subplot(223),plot(E3);grid on;
title(['T(1) = ',num2str(T_max),',c = ',num2str(c),',确定性模拟退火算法能量变化曲线']);
disp(['T(1) = 10,c = 0.9,确定性模拟退火算法最终构型S为:',num2str(s_out3(time_max,:))]);
T_max = 5; % 初始温度设置
time_max = 100; % 最大迭代次数
c = 0.5; % 温度变化比率
[E4, s_out4] = DeterministicAnnealing(T_max, time_max, c, s_in, w);
subplot(224),plot(E4);grid on;
title(['T(1) = ',num2str(T_max),',c = ',num2str(c),',确定性模拟退火算法能量变化曲线']);
disp(['T(1) = 5,c = 0.5,确定性模拟退火算法最终构型S为:',num2str(s_out4(time_max,:))]);
~~~
参考链接:[http://www.cnblogs.com/growing/archive/2010/12/16/1908255.html](http://www.cnblogs.com/growing/archive/2010/12/16/1908255.html)
模式识别:三层BP神经网络的设计与实现
最后更新于:2022-04-01 06:47:38
本文的目的是学习和掌握BP神经网络的原理及其学习算法。在MATLAB平台上编程构造一个3-3-1型的singmoid人工神经网络,并使用随机反向传播算法和成批反向传播算法来训练这个网络,这里设置不同的初始权值,研究算法的学习曲线和训练误差。有了以上的理论基础,最后将构造并训练一个3-3-4型的神经网络来分类4个等概率的三维数据集合。
##一、技术论述
**1.神经网络简述**
神经网络是一种可以适应复杂模型的非常灵活的启发式的统计模式识别技术。而反向传播算法是多层神经网络有监督训练中最简单也最一般的方法之一,它是线性LMS算法的自然延伸。
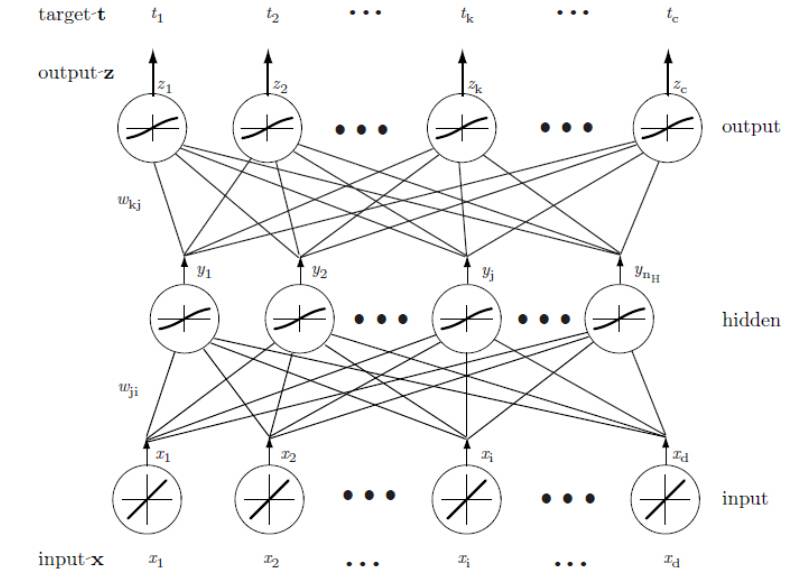
网络基本的学习方法是从一个未训练网络开始,向输入层提供一个训练模式,再通过网络传递信号,并决定输出层的输出值。此处的这些输出都与目标值进行比较;任一差值对应一误差。该误差或准则函数是权值的某种标量函数,它在网络输出与期望输出匹配时达到最小。权值向着减小误差值的方向调整。一个BP神经网络的基本结构如下图所示,图中Wji,Wkj是需要学习的权值矩阵:
**2.三层BP神经网络**
一个三层神经网络是由一个输入层、一个隐含层和一个输出层组成,他们由可修正的权值互连。在这基础上构建的3-3-1神经网络,是由三个输入层、三个隐含层和一个输出层组成。隐含层单元对它的各个输入进行加权求和运算而形成标量的“净激活”。也就是说,净激活是输入信号与隐含层权值的内积。通常可把净激活写成:
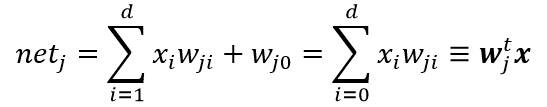
其中x为增广输入特征向量(附加一个特征值x0=1),w为权向量(附加一个值W0)。由上面的图可知,这里的下标i是输入层单元的索引值,j是隐含层单元的索引。Wji表示输入层单元i到隐含层单元j的权值。为了跟神经生物学作类比,这种权或连接被称为“突触”,连接的值叫“突触权”。每一个隐含层单元激发出一个输出分量,这个分量是净激活net的非线性函数f(net),即:

**这里需要重点认识激活函数的作用。激活函数的选择是构建神经网络过程中的重要环节,下面简要介绍常用的激活函数:**
(a)线性函数 ( Liner Function )
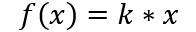
(b) 阈值函数 ( Threshold Function )
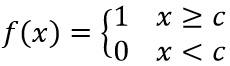
以上激活函数都属于线性函数,下面是两个常用的非线性激活函数:
(c)S形函数 ( Sigmoid Function )
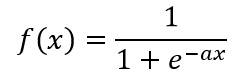
(d) 双极S形函数
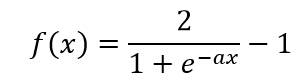
S形函数与双极S形函数的图像如下:
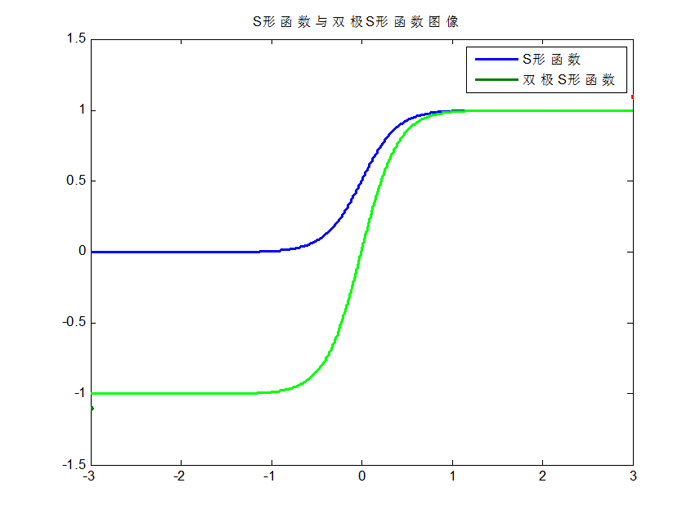
由于S形函数与双极S形函数都是可导的,因此适合用在BP神经网络中。(BP算法要求激活函数可导)
介绍完激活函数,类似的,每个输出单元在隐含层单元信号的基础上,使用类似的方法就可以算出它的净激活如下:

同理,这里的下标k是输出层单元的索引值,nH表示隐含层单元的数目,这里把偏置单元等价于一个输入恒为y0=1的隐含层单元。将输出单元记为zk,这样输出单元对net的非线性函数写为:
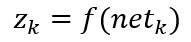
综合以上公式,显然输出zk可以看成是输入特征向量x的函数。当有c个输出单元时,可以这样来考虑此网络:计算c个判别函数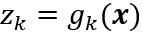,并通过使判别函数最大来将输入信号分类。在只有两种类别的情况下,一般只采用单个输出单元,而用输出值z的符号来标识一个输入模式。
**3.网络学习**
反向传播算法(BP算法)由两部分组成:信息的正向传递与误差的反向传播。在正向传播过程中,输入信息从输入经隐含层逐层计算传向输出层,第一层神经元的状态只影响下一层神经元的状态。如果输出层没有得到期望的输出,则计算输出层的误差变化值,然后转向反向传播,通过网络将误差信号沿原来的连接通路反传回来修改各层神经元的权值直至达到期望目标。
神经网络的学习方法正是依赖以上两个步骤,对于单个模式的学习规则,考虑一个模式的训练误差,先定义为输出端的期望输出值tk(由教师信号给出)和实际输出值zk的差的平方和:
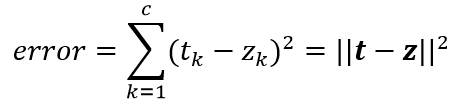
定义目标函数:
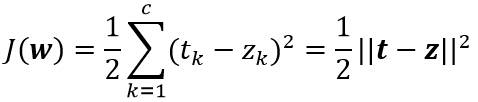
其中t和z是长度为c的目标向量和网络输出向量;w表示神经网络里的所有权值。
反向传播算法学习规则是基于梯度下降算法的。权值首先被初始化为随机值,然后向误差减小的方向调整:
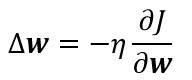
其中η是学习率,表示权值的相对变化尺度。反向传播算法在第m次迭代时的权向量更新公式可写为:
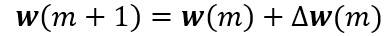
其中m是特定模式的索引。由于误差并不是明显决定于Wjk,这里需要使用链式微分法则:
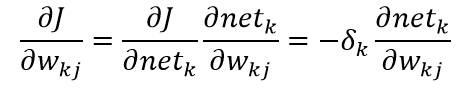
其中单元k的敏感度定义为:
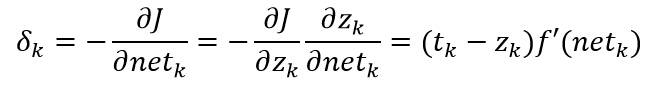
又有:
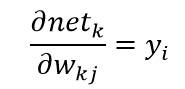
综上所述,隐含层到输出层的权值更新为:
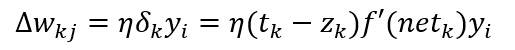
输入层到隐含层的权值学习规则更微妙。再运用链式法则计算:
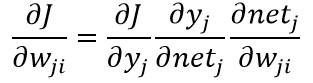
其中:
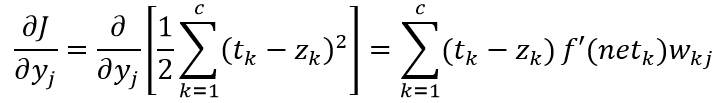
可以用上式来定义隐单元的敏感度:
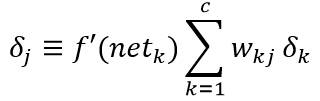
因此,输入层到隐含层的权值的学习规则就是:
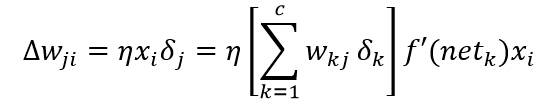
**4.训练协议**
反向传播的随机协议和成批协议如下步骤所示:

在成批训练中,所有的训练模式都先提供一次,然后将对应的权值更新相加,只有这时网络里的实际权值才开始更新。这个过程将一直迭代知道某停止准则满足。

##二、自编函数实现BP网络
以下简单编写了一个3-3-1三层BP神经网络的构建与两种训练方法(写得比较杂乱),以下是基本步骤:
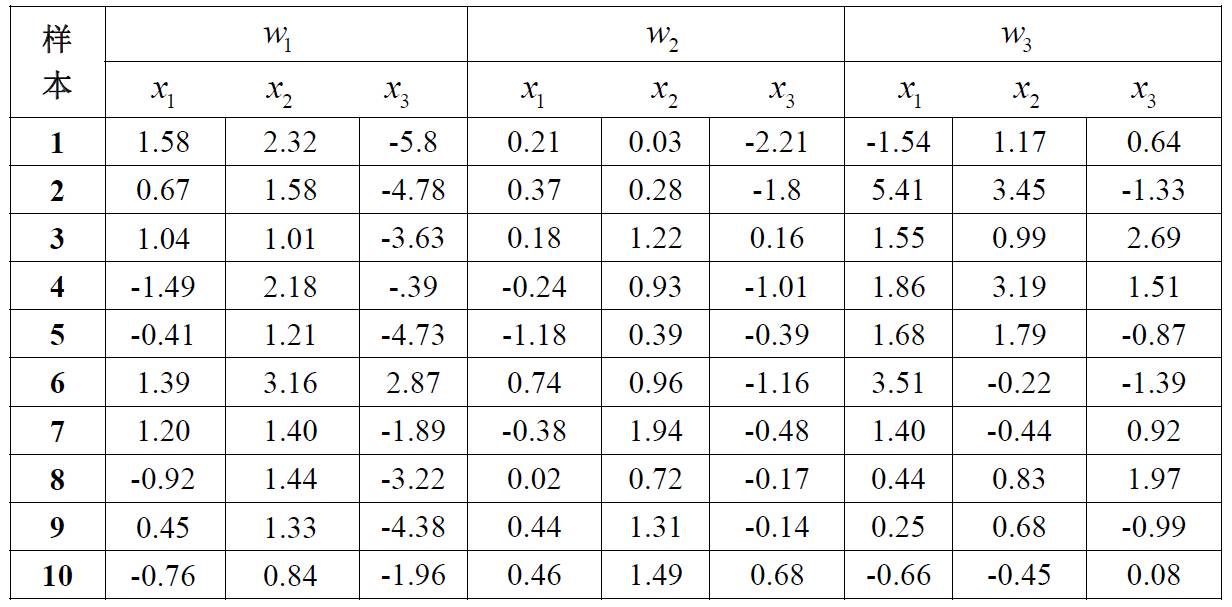
1.构造 3-3-1 型的sigmoid 网络,用以下表格中的w1和w2类的数据进行训练,并对新模式进行分类。利用随机反向传播(算法1),学习率η=0.1,以及sigmoid函数,其中a=1.716,b =2/3,作为其隐单元和输出单元的激活函数。
2.构造三层神经网络,参数包括:输入层、中间层、输出层神经元向量,以及输入层到中间层的权值矩阵,中间层到输出层的权值矩阵,中间层神经元的偏置向量,输出层神经元的偏置向量等。其实质是定义上述变量的一维和二维数组。
3.编写函数[net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb),实现BP网络的前馈输出。为了便于后续的学习算法的实现,该函数的输出变量包含:第j个隐单元对各输入的净激活net_j;第k个输出单元对各输入的净激活net_k;网络中隐藏层的输出y和输出单元的输出向量z。
4.编写函数,实现BP网络的权值修正。其中,神经元函数,及其导数可参考:
神经元函数:
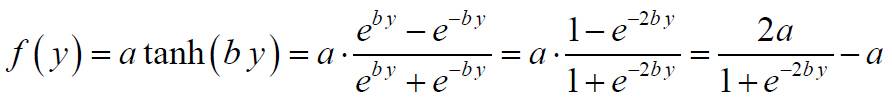
神经元函数导数:
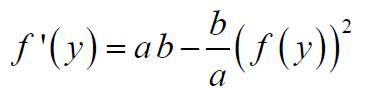
5.编写函数[NewWxy, NewWyz, NewWyb, NewWzb, J] = train(x, t, Wxy, Wyz, Wyb, Wzb),实现算法1和2所述的BP网络的训练算法,输出各权向量的变化量和当前目标函数值J。
~~~
% 函数:计算人工神经网络的各级输出
% 输入参数:
% x:输入层神经元向量(3维)
% Wxy:随机生成的从输入层到隐含层的权值矩阵
% Wyz:随机生成的从隐含层到输出层的权值矩阵
% Wyb:权值偏置向量
% Wzb:权值偏置向量
% 内部变量与公式:
% f(net)=a*tanh(b*net):Sigmoid激活函数
% a:Sigmoid激活函数的参数
% b:Sigmoid激活函数的参数
% 输出参数:
% net_j:第j个隐单元对各输入的净激活
% net_k:第k个输出单元对各输入的净激活
% y:隐含层的输出向量
% z:输出单元的输出向量
function [net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb)
% Sigmoid激活函数的参数
a = 1.716;
b = 2/3;
net_j = Wxy * x' + Wyb;
y = 3.432 ./ (1 + exp(-1.333 * net_j)) - 1.716;% a * tanh(b * net_j); % 隐含层的输出
net_k = Wyz' * y + Wzb;
z = 3.432 ./ (1 + exp(-1.333 * net_k)) - 1.716;%a * tanh(b * net_k); % 输出层结果
~~~
~~~
% 人工神经网络训练函数
% 输入参数:
% x:输入层神经元向量(3维)
% t:教师向量
% Wxy:随机生成的从输入层到隐含层的权值矩阵
% Wyz:随机生成的从隐含层到输出层的权值矩阵
% Wyb:权值偏置向量
% Wzb:权值偏置向量
% 内部变量与公式:
% Error_xy:隐藏层反传回输入层的误差
% Error_yz:输出层反传回隐藏层的误差
% 输出参数:
% NewWxy:更新后的从输入层到隐含层的权值矩阵
% NewWyz:更新后的从隐含层到输出层的权值矩阵
% NewWyb:更新后的权值偏置向量
% NewWzb:更新后的权值偏置向量
function [NewWxy, NewWyz, NewWyb, NewWzb, J] = train(x, t, Wxy, Wyz, Wyb, Wzb)
% 基本参数设定
Eta = 0.01; % 学习因子
% Sigmoid激活函数的参数
a = 1.716;
b = 2/3;
% 计算训练样本经过神经网络后的输出
[net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb);
% 计算当前目标函数值
J = power(norm((t - z),2), 2) / 2;
% 计算输出层反传回隐藏层的敏感度
Error_yz = (t - z) .* (a * b - b / a * z .* z); % zz
% 计算隐藏层反传回输入层的敏感度
Error_xy = Wyz * Error_yz .* (a * b - b / a * y .* y);
% 计算输出层到隐藏层的权值更新量
delta_Wyz = Eta * y * Error_yz';
% 计算隐藏层到输入层的权值更新量
delta_Wxy = Eta * Error_xy * x;
% 更新权值
NewWxy = Wxy + delta_Wxy;
NewWyz = Wyz + delta_Wyz;
NewWyb = Wyb + Eta * Error_xy;
NewWzb = Wzb + Eta * Error_yz;
~~~
~~~
function [delta_Wxy, delta_Wyz, Error_xy, Error_yz, J] = BatchTrain(x, t, Wxy, Wyz, Wyb, Wzb)
% 基本参数设定
Eta = 0.01; % 学习因子
% Sigmoid激活函数的参数
a = 1.716;
b = 2/3;
% 计算训练样本经过神经网络后的输出
[net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb);
% 计算当前目标函数值
J = 1 / 2 * power(norm(t - z), 2);
% 计算输出层反传回隐藏层的误差
Error_yz = (t - z) .* (a * b - b / a * z .* z);
% 计算隐藏层反传回输入层的误差
Error_xy = Wyz * Error_yz .* (a * b - b / a * y .* y);
% 计算输出层到隐藏层的权值更新量
delta_Wyz = Eta * Error_yz * y';
% 计算隐藏层到输入层的权值更新量
delta_Wxy = Eta * Error_xy * x;
~~~
~~~
% clear all;
% close all;
% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% % BP神经网络实验
% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
clear;
close all;
% 训练样本(3类)
w1 = [ 1.58 2.32 -5.8 ;...
0.67 1.58 -4.78;...
1.04 1.01 -3.63;...
-1.49 2.18 -0.39;...
-0.41 1.21 -4.73;...
1.39 3.16 2.87;...
1.20 1.40 -1.89;...
-0.92 1.44 -3.22;...
0.45 1.33 -4.38;...
-0.76 0.84 -1.96];
w2 = [ 0.21 0.03 -2.21;...
0.37 0.28 -1.8 ;...
0.18 1.22 0.16;...
-0.24 0.93 -1.01;...
-1.18 0.39 -0.39;...
0.74 0.96 -1.16;...
-0.38 1.94 -0.48;...
0.02 0.72 -0.17;...
0.44 1.31 -0.14;...
0.46 1.49 0.68];
w3 = [-1.54 1.17 0.64;...
5.41 3.45 -1.33;...
1.55 0.99 2.69;...
1.86 3.19 1.51;...
1.68 1.79 -0.87;...
3.51 -0.22 -1.39;...
1.40 -0.44 0.92;...
0.44 0.83 1.97;...
0.25 0.68 -0.99;...
-0.66 -0.45 0.08];
% 初始化权值(随机初始化)
Wxy = rand(3,3) * 2 - 1;
Wyz = rand(3,1) * 2 - 1;
Wyb = rand(3,1) * 2 - 1;
Wzb = rand() * 2 - 1;
w = [w1; w2];
T = [1 1 1 1 1 1 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]; % 教师向量
% 以下是随机反向传播算法
delta_J = 0.001;
time = 1;
J(time) = 2 * delta_J; % 只是让迭代开始,没什么作用
detJ = 2 * delta_J;
while time < 10000%detJ > delta_J
num = ceil(rand(1) * 20); % 选择产生一个1到20之间的随机数
x = w(num, :); % 任取w中一个模式
t = T(num);
time = time + 1; % 计算迭代次数
[NewWxy, NewWyz, NewWyb, NewWzb, J(time)] = train(x, t, Wxy, Wyz, Wyb, Wzb);
% 更新权值
Wxy = NewWxy;
Wyz = NewWyz;
Wyb = NewWyb;
Wzb = NewWzb;
detJ = abs(J(time) - J(time - 1)); % 前后两次目标函数的差值
end
Jt = J(2:time); % J(1)和J(2)存储了相同的值,从J(2)算起,迭代了(time - 1)次
figure,plot(Jt);grid on;% subplot(1,2,1)
xlabel(['权值为随机时,迭代次数为:',num2str(time - 1),'次']);
for i = 1:20
[net_j,net_k,y,z] = BackPropagation(w(i,:), Wxy, Wyz, Wyb, Wzb);
a(i) = z;
end
% 初始化权值(0.5和-0.5)
Wxy = 0.5 * ones(3,3);
Wyz = -0.5 * ones(3,1);
Wyb = 0.5 * ones(3,1);
Wzb = -0.5;
w = [w1; w2];
T = [1 1 1 1 1 1 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]; % 教师向量
%
% 以下是随机反向传播算法
delta_J = 0.001;
time = 1;
% [net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb);
% J(time) = 1 / 2 * power(norm(t - z), 2);
detJ = 2 * delta_J;
while time < 10000%detJ > delta_J
num = ceil(rand(1) * 20); % 选择产生一个1到20之间的随机数
x = w(num, :); % 任取w中一个模式
t = T(num);
time = time + 1; % 计算迭代次数
[NewWxy, NewWyz, NewWyb, NewWzb, J(time)] = train(x, t, Wxy, Wyz, Wyb, Wzb);
% 更新权值
Wxy = NewWxy;
Wyz = NewWyz;
Wyb = NewWyb;
Wzb = NewWzb;
% detJ = abs(J(time) - J(time - 1)); % 前后两次目标函数的差值
end
Jt = J(2:time); % J(1)和J(2)存储了相同的值,从J(2)算起,迭代了(time - 1)次
figure,plot(Jt);grid on;% subplot(1,2,2),
xlabel(['权值为固定时,迭代次数为:',num2str(time - 1),'次']);
for i = 1:20
[net_j,net_k,y,z] = BackPropagation(w(i,:), Wxy, Wyz, Wyb, Wzb);
b(i) = z;
end
% 以下是成批反向传播算法
Eta = 0.01; % 学习因子
% 初始化权值(随机初始化)
Wxy = rands(3,3);
Wyz = rand(3,1);
Wyb = rand(3,1);
Wzb = rand();
SumDelta_Wxy = zeros(3,3);
SumDelta_Wyz = zeros(3,1);
SumError_xy = zeros(3,1);
SumError_yz = 0;
w = [w1; w2];
T = [1 1 1 1 1 1 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]; % 教师向量
delta_J = 0.001;
time = 1;
J(time) = 2 * delta_J;
detJ = 2 * delta_J;
% [net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb);
% J(time) = delta_J * 2; % 1 / 2 * power(norm(t - z), 2);
while time < 1000 %detJ > delta_J
time = time + 1; % 计算迭代次数
J(time) = 0;
for num = 1:20
x = w(num, :); % 任取w1中一个模式
t = T(num);
[delta_Wxy, delta_Wyz, Error_xy, Error_yz, Jt] = BatchTrain(x, t, Wxy, Wyz, Wyb, Wzb);
SumDelta_Wxy = SumDelta_Wxy + delta_Wxy;
SumDelta_Wyz = SumDelta_Wyz + delta_Wyz';
SumError_xy = SumError_xy + Error_xy;
SumError_yz = SumError_yz + Error_yz;
J(time) = J(time) + Jt;
end
% 更新权值
Wxy = Wxy + SumDelta_Wxy;
Wyz = Wyz + SumDelta_Wyz;
Wyb = Wyb + Eta * SumError_xy;
Wzb = Wzb + Eta * SumError_yz;
detJ = abs(J(time) - J(time - 1)); % 前后两次目标函数的差值
end
Jt = J(1, 2:time); % J(1)和J(2)存储了相同的值,从J(2)算起,迭代了(time - 1)次
figure,plot(Jt);grid on;
xlabel(['权值为随机时,迭代次数为:',num2str(time - 1),'次']);
for i = 1:20
[net_j,net_k,y,z] = BackPropagation(w(i,:), Wxy, Wyz, Wyb, Wzb);
c(i) = z;
end
c
% 以下是成批反向传播算法
Eta = 0.001; % 学习因子
% 初始化权值(0.5和-0.5)
Wxy = 0.5 * ones(3,3);
Wyz = -0.5 * ones(3,1);
Wyb = 0.5 * ones(3,1);
Wzb = -0.5;
SumDelta_Wxy = zeros(3,3);
SumDelta_Wyz = zeros(3,1);
SumError_xy = zeros(3,1);
SumError_yz = 0;
w = [w1; w2];
T = [1 1 1 1 1 1 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]; % 教师向量
delta_J = 0.001;
time = 1;
while time < 1000 % detJ > delta_J
time = time + 1; % 计算迭代次数
J(time) = 0;
for num = 1:20
x = w(num, :); % 任取w1中一个模式
t = T(num);
[delta_Wxy, delta_Wyz, Error_xy, Error_yz, Jt] = BatchTrain(x, t, Wxy, Wyz, Wyb, Wzb);
SumDelta_Wxy = SumDelta_Wxy + delta_Wxy;
SumDelta_Wyz = SumDelta_Wyz + delta_Wyz';
SumError_xy = SumError_xy + Error_xy;
SumError_yz = SumError_yz + Error_yz;
J(time) = J(time) + Jt;
end
% 更新权值
Wxy = Wxy + SumDelta_Wxy;
Wyz = Wyz + SumDelta_Wyz;
Wyb = Wyb + Eta * SumError_xy;
Wzb = Wzb + Eta * SumError_yz;
detJ = abs(J(time) - J(time - 1)); % 前后两次目标函数的差值
end
Jt = J(1, 2:time); % J(1)和J(2)存储了相同的值,从J(2)算起,迭代了(time - 1)次
figure,plot(Jt);grid on;
xlabel(['权值为固定时,迭代次数为:',num2str(time - 1),'次']);
for i = 1:20
[net_j,net_k,y,z] = BackPropagation(w(i,:), Wxy, Wyz, Wyb, Wzb);
d(i) = z;
end
d
~~~
一个目标函数经多次训练后的变化曲线:
##三、调用MATLAB实现BP网络
其实MATLAB中可直接调用函数来构造神经网络,但自己编写程序实现有助于了解整个神经网络的各个细节。 使用Matlab建立前馈神经网络时可以使用到下面3个函数:
~~~
newff :前馈网络创建函数
train:训练一个神经网络
sim:使用网络进行仿真
~~~
关于这3个函数的用法如下:
**1.newff函数**
**(1)newff函数的调用方法**
newff函数参数列表有很多的可选参数,具体可以参考Matlab的帮助文档,这里介绍newff函数的一种简单的形式。
~~~
net = newff(A,... % 一个n*2的矩阵,第i行元素为输入信号xi的最小值和最大值
B,... % 一个k维行向量,其元素为网络中各层节点数
{C},... % 一个k维字符串行向量,每一分量为对应层神经元的激活函数
'trainFun'); % 选用的训练算法
~~~
**(2)常用的激活函数**
常用的激活函数有:
a) 线性函数 (Linear transfer function):f(x) = x。该函数所对应的字符串为’purelin’。
b) 对数S形转移函数( Logarithmic sigmoid transfer function )。该函数所对应的字符串为’logsig’。
c) 双曲正切S形函数 (Hyperbolic tangent sigmoid transfer function ),也就是上面所提到的Sigmoid函数。该函数所对应的字符串为’tansig’。
**注:Matlab的安装目录下的toolbox\nnet\nnet\nntransfer子目录中有所有激活函数的定义说明。**
**(3)常见的训练函数**
traingd:梯度下降BP训练函数(Gradient descent backpropagation)
traingdx:梯度下降自适应学习率训练函数
**(4)一些重要的网络配置参数设置**
~~~
net.trainparam.goal:神经网络训练的目标误差
net.trainparam.show: 显示中间结果的周期
net.trainparam.epochs:最大迭代次数
net.trainParam.lr: 学习率
~~~
**2.神经网络训练函数train**
~~~
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 神经网络训练函数train
% 各参数的含义如下:
% X:网络实际输入
% Y:网络应有输出
% tr:训练跟踪信息
% Y1:网络实际输出
% E:误差矩阵
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
[ net, tr, Y1, E ] = train(net, X, Y )
~~~
**3.sim函数**
~~~
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 各参数的含义如下:
% net:网络
% X:输入给网络的K*N矩阵,其中K为网络输入个数,N为数据样本数
% Y:输出矩阵Q*N,其中Q为神经网络输出单元的个数
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Y = sim(net, X)
~~~
**基于MATLAB自带函数的BP神经网络设计实例**
一个实例参考:[http://blog.csdn.net/gongxq0124/article/details/7681000](http://blog.csdn.net/gongxq0124/article/details/7681000)
参考链接:[http://www.cnblogs.com/heaad/archive/2011/03/07/1976443.html](http://www.cnblogs.com/heaad/archive/2011/03/07/1976443.html)
模式识别:非参数估计法之Parzen窗估计和k最近邻估计
最后更新于:2022-04-01 06:47:35
本实验的目的是学习Parzen窗估计和k最近邻估计方法。在之前的模式识别研究中,我们假设概率密度函数的参数形式已知,即判别函数J(.)的参数是已知的。本节使用非参数化的方法来处理任意形式的概率分布而不必事先考虑概率密度的参数形式。在模式识别中有躲在令人感兴趣的非参数化方法,Parzen窗估计和k最近邻估计就是两种经典的估计法。
参考书籍:《模式分类》
作者:RichardO.Duda,PeterE.Hart,DavidG.Stork
##一、基本原理
**1.非参数化概率密度的估计**
对于未知概率密度函数的估计方法,其核心思想是:一个向量x落在区域R中的概率可表示为:
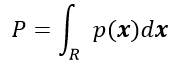
其中,P是概率密度函数p(x)的平滑版本,因此可以通过计算P来估计概率密度函数p(x),假设n个样本x1,x2,…,xn,是根据概率密度函数p(x)独立同分布的抽取得到,这样,有k个样本落在区域R中的概率服从以下分布:

其中k的期望值为:
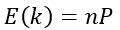
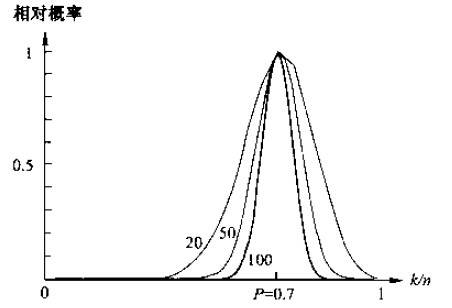
k的分布在均值附近有着非常显著的波峰,因此若样本个数n足够大时,使用k/n作为概率P的一个估计将非常准确。假设p(x)是连续的,且区域R足够小,则有:
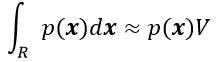
如下图所示,以上公式产生一个特定值的相对概率,当n趋近于无穷大时,曲线的形状逼近一个δ函数,该函数即是真实的概率。公式中的V是区域R所包含的体积。综上所述,可以得到关于概率密度函数p(x)的估计为:
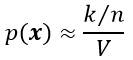
在实际中,为了估计x处的概率密度函数,需要构造包含点x的区域R1,R2,…,Rn。第一个区域使用1个样本,第二个区域使用2个样本,以此类推。记Vn为Rn的体积。kn为落在区间Rn中的样本个数,而pn (x)表示为对p(x)的第n次估计:
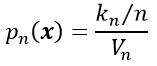
欲满足pn(x)收敛:pn(x)→p(x),需要满足以下三个条件:
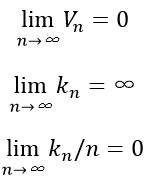
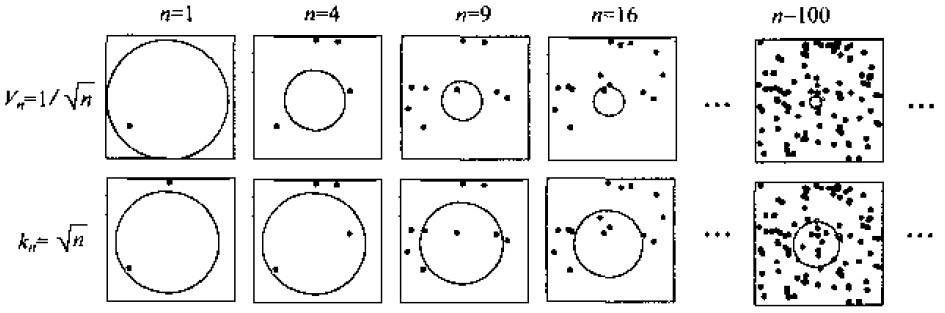
有两种经常采用的获得这种区域序列的途径,如下图所示。其中“Parzen窗方法”就是根据某一个确定的体积函数,比如Vn=1/√n来逐渐收缩一个给定的初始区间。这就要求随机变量kn和kn/n能够保证pn (x)能收敛到p(x)。第二种“k-近邻法”则是先确定kn为n的某个函数,如kn=√n。这样,体积需要逐渐生长,直到最后能包含进x的kn个相邻点。
**2.Parzen窗估计法**
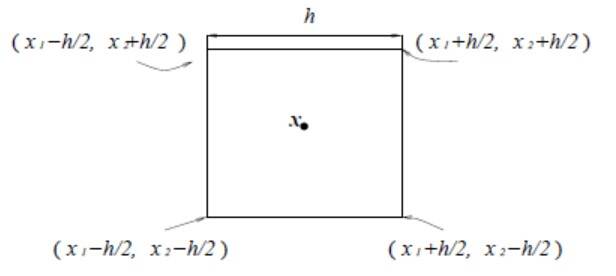
已知测试样本数据x1,x2,…,xn,在不利用有关数据分布的先验知识,对数据分布不附加任何假定的前提下,假设R是以x为中心的超立方体,h为这个超立方体的边长,对于二维情况,方形中有面积V=h^2,在三维情况中立方体体积V=h^3,如下图所示。
根据以下公式,表示x是否落入超立方体区域中:
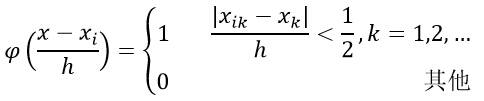
估计它的概率分布:
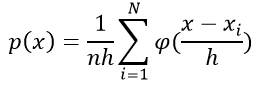
其中n为样本数量,h为选择的窗的长度,φ(.)为核函数,通常采用矩形窗和高斯窗。
**3.k最近邻估计**
在Parzen算法中,窗函数的选择往往是个需要权衡的问题,k-最近邻算法提供了一种解决方法,是一种非常经典的非参数估计法。基本思路是:已知训练样本数据x1,x2,…,xn而估计p(x),以点x为中心,不断扩大体积Vn,直到区域内包含k个样本点为止,其中k是关于n的某一个特定函数,这些样本被称为点x的k个最近邻点。
当涉及到邻点时,通常需要计算观测点间的距离或其他的相似性度量,这些度量能够根据自变量得出。这里我们选用最常见的距离度量方法:欧几里德距离。
最简单的情况是当k=1的情况,这时我们发现观测点就是最近的(最近邻)。一个显著的事实是:这是简单的、直观的、有力的分类方法,尤其当我们的训练集中观测点的数目n很大的时候。可以证明,k最近邻估计的误分概率不高于当知道每个类的精确概率密度函数时误分概率的两倍。
##二、实验基本步骤
**第一部分**,对表格中的数据,进行Parzen 窗估计和设计分类器,本实验的窗函数为一个球形的高斯函数,如下:
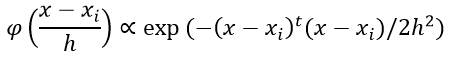
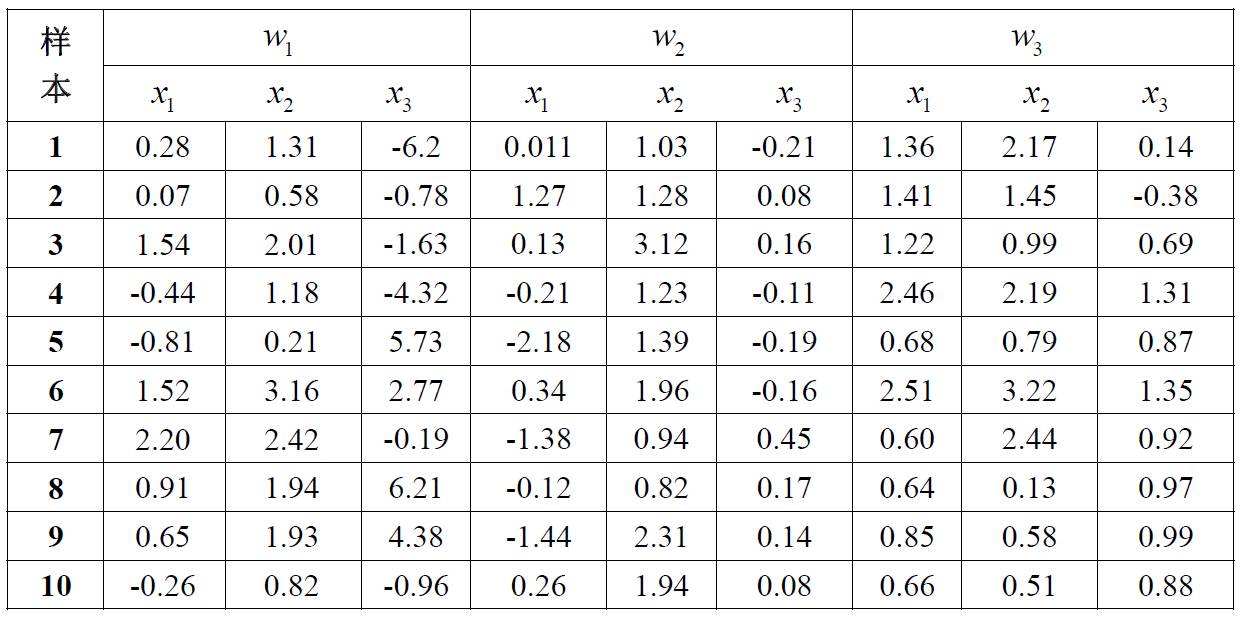
1) 编写程序,使用Parzen 窗估计方法对一个任意的测试样本点x 进行分类。对分类器的训练则使用表格 3中的三维数据。同时,令h =1,分类样本点为(0.5,1.0,0.0),(0.31,1.51,-0.50),(-0.3,0.44,-0.1)进行实验。
2) 可以改变h的值,不同的h将导致不同的概率密度曲线,如下图所示。
h=0.1时:
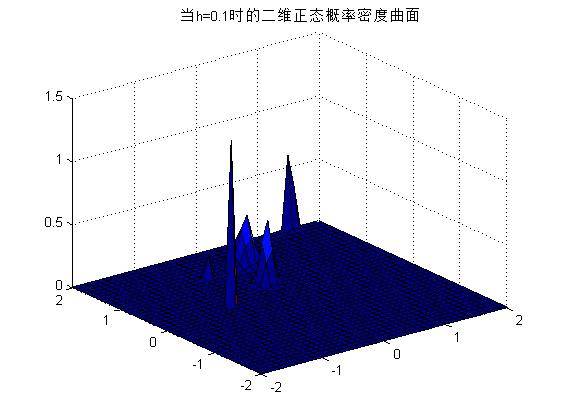
h=0.5时:
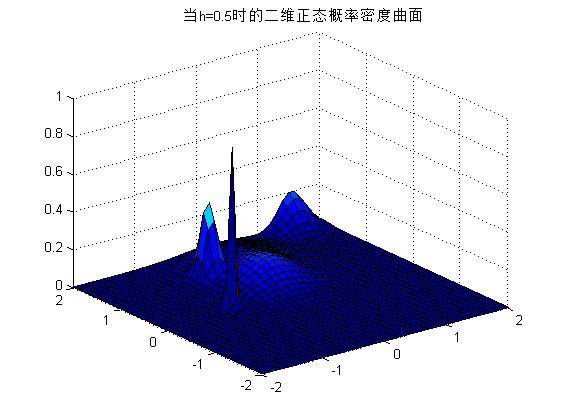
h=1时:

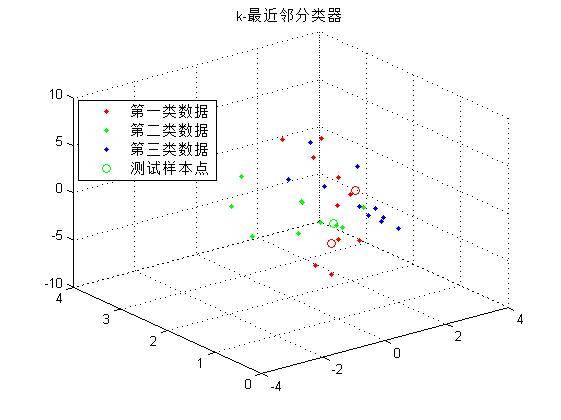
**第二部分**的实验目的是学习和掌握非参数估计:k-近邻概率密度估计方法。对前面表格中的数据进行k-近邻概率密度估计方法和设计分类器。
编写程序,对表格中的3个类别的三维特征,使用k-近邻概率密度估计方法。并且对下列点处的概率密度进行估计:(-0.41,0.82,0.88),(0.14,0.72, 4.1) ,(-0.81,0.61,-0.38)。
实验代码如下:
~~~
% Parzen窗算法
% w:c类训练样本
% x:测试样本
% h:参数
% 输出p:测试样本x落在每个类的概率
function p = Parzen(w,x,h)
[xt,yt,zt] = size(w);
p = zeros(1,zt);
for i = 1:zt
hn = h;
for j = 1:xt
hn = hn / sqrt(j);
p(i) = p(i) + exp(-(x - w(j,:,i))*(x - w(j,:,i))'/ (2 * power(hn,2))) / (hn * sqrt(2*3.14));
end
p(i) = p(i) / xt;
end
~~~
~~~
% k-最近邻算法
% w:c类训练样本
% x:测试样本
% k:参数
function p = kNearestNeighbor(w,k,x)
% w = [w(:,:,1);w(:,:,2);w(:,:,3)];
[xt,yt,zt] = size(w);
wt = [];%zeros(xt*zt, yt);
if nargin==2
p = zeros(1,zt);
for i = 1:xt
for j = 1:xt
dist(j,i) = norm(wt(i,:) - wt(j,:));
end
t(:,i) = sort(dist(:,i));
m(:,i) = find(dist(:,i) <= t(k+1,i)); % 找到k个最近邻的编号
end
end
if nargin==3
for q = 1:zt
wt = [wt; w(:,:,q)];
[xt,yt] = size(wt);
end
for i = 1:xt
dist(i) = norm(x - wt(i,:));
end
t = sort(dist); % 欧氏距离排序
[a,b] = size(t);
m = find(dist <= t(k+1)); % 找到k个最近邻的编号
num1 = length(find(m>0 & m<11));
num2 = length(find(m>10 & m<21));
num3 = length(find(m>20 & m<31));
if yt == 3
plot3(w(:,1,1),w(:,2,1),w(:,3,1), 'r.');
hold on;
grid on;
plot3(w(:,1,2),w(:,2,2),w(:,3,2), 'g.');
plot3(w(:,1,3),w(:,2,3),w(:,3,3), 'b.');
if (num1 > num2) || (num1 > num3)
plot3(x(1,1),x(1,2),x(1,3), 'ro');
disp(['点:[',num2str(x),']属于第一类']);
elseif (num2 > num1) || (num2 > num3)
plot3(x(1,1),x(1,2),x(1,3), 'go');
disp(['点:[',num2str(x),']属于第二类']);
elseif (num3 > num1) || (num3 > num2)
plot3(x(1,1),x(1,2),x(1,3), 'bo');
disp(['点:[',num2str(x),']属于第三类']);
else
disp('无法分类');
end
end
if yt == 2
plot(w(:,1,1),w(:,2,1), 'r.');
hold on;
grid on;
plot(w(:,1,2),w(:,2,2), 'g.');
plot(w(:,1,3),w(:,2,3), 'b.');
if (num1 > num2) || (num1 > num3)
plot(x(1,1),x(1,2), 'ro');
disp(['点:[',num2str(x),']属于第一类']);
elseif (num2 > num1) || (num2 > num3)
plot(x(1,1),x(1,2), 'go');
disp(['点:[',num2str(x),']属于第二类']);
elseif (num3 > num1) || (num3 > num2)
plot(x(1,1),x(1,2), 'bo');
disp(['点:[',num2str(x),']属于第三类']);
else
disp('无法分类');
end
end
end
title('k-最近邻分类器');
legend('第一类数据',...
'第二类数据',...
'第三类数据',...
'测试样本点');
~~~
~~~
clear;
close all;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Parzen窗估计和k最近邻估计
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
w1(:,:,1) = [ 0.28 1.31 -6.2;...
0.07 0.58 -0.78;...
1.54 2.01 -1.63;...
-0.44 1.18 -4.32;...
-0.81 0.21 5.73;...
1.52 3.16 2.77;...
2.20 2.42 -0.19;...
0.91 1.94 6.21;...
0.65 1.93 4.38;...
-0.26 0.82 -0.96];
w1(:,:,2) = [0.011 1.03 -0.21;...
1.27 1.28 0.08;...
0.13 3.12 0.16;...
-0.21 1.23 -0.11;...
-2.18 1.39 -0.19;...
0.34 1.96 -0.16;...
-1.38 0.94 0.45;...
-0.12 0.82 0.17;...
-1.44 2.31 0.14;...
0.26 1.94 0.08];
w1(:,:,3) = [ 1.36 2.17 0.14;...
1.41 1.45 -0.38;...
1.22 0.99 0.69;...
2.46 2.19 1.31;...
0.68 0.79 0.87;...
2.51 3.22 1.35;...
0.60 2.44 0.92;...
0.64 0.13 0.97;...
0.85 0.58 0.99;...
0.66 0.51 0.88];
x(1,:) = [0.5 1 0];
x(2,:) = [0.31 1.51 -0.5];
x(3,:) = [-0.3 0.44 -0.1];
% 验证h的二维数据
w2(:,:,1) = [ 0.28 1.31 ;...
0.07 0.58 ;...
1.54 2.01 ;...
-0.44 1.18 ;...
-0.81 0.21 ;...
1.52 3.16 ;...
2.20 2.42 ;...
0.91 1.94 ;...
0.65 1.93 ;...
-0.26 0.82 ];
w2(:,:,2) = [0.011 1.03 ;...
1.27 1.28 ;...
0.13 3.12 ;...
-0.21 1.23 ;...
-2.18 1.39 ;...
0.34 1.96 ;...
-1.38 0.94 ;...
-0.12 0.82 ;...
-1.44 2.31 ;...
0.26 1.94 ];
w2(:,:,3) = [1.36 2.17 ;...
1.41 1.45 ;...
1.22 0.99 ;...
2.46 2.19 ;...
0.68 0.79 ;...
2.51 3.22 ;...
0.60 2.44 ;...
0.64 0.13 ;...
0.85 0.58 ;...
0.66 0.51 ];
y(1,:) = [0.5 1];
y(2,:) = [0.31 1.51];
y(3,:) = [-0.3 0.44];
h = .1; % 重要参数
p = Parzen(w1,x(1,:),h);
num = find(p == max(p));
disp(['点:[',num2str(x(1,:)),']落在三个类别的概率分别为:',num2str(p)]);
disp(['点:[',num2str(x(1,:)),']落在第',num2str(num),'类']);
% 给定三类二维样本,画出二维正态概率密度曲面图验证h的作用
num =1; % 第num类的二维正态概率密度曲面图,取值为1,2,3
draw(w2,h,num);
str1='当h=';str2=num2str(h);str3='时的二维正态概率密度曲面';
SC = [str1,str2,str3];
title(SC);
% k近邻算法设计的分类器
% x1和y1为测试样本
x1 = [-0.41,0.82,0.88];
x2 = [0.14,0.72, 4.1];
x3 = [-0.81,0.61,-0.38];
y(1,:) = [0.5 1];
y(2,:) = [0.31 1.51];
y(3,:) = [-0.3 0.44];
w = w1;
%w = w1(:,1,3);
k = 5;
kNearestNeighbor(w,k,x1);
kNearestNeighbor(w,k,x2);
kNearestNeighbor(w,k,x3);
~~~
模式识别:感知器的实现
最后更新于:2022-04-01 06:47:33
在之前的模式识别研究中,判别函数J(.)的参数是已知的,即假设概率密度函数的参数形式已知。本节不考虑概率密度函数的确切形式,使用非参数化的方法来求解判别函数。由于线性判别函数具有许多优良的特性,因此这里我们只考虑以下形式的判别函数:它们或者是**x**的各个分量的线性函数,或者是关于以**x**为自变量的某些函数的线性函数。在设计感知器之前,需要明确以下几个基本概念:
##一、判别函数:是指由x的各个分量的线性组合而成的函数:

若样本有c类,则存在c个判别函数,对具有形式的判别函数的一个两类线性分类器来说,要求实现以下判定规则:

方程g(x)=0定义了一个判定面,它把两个类的点分开来,这个平面被称为超平面,如下图所示。

##二、广义线性判别函数
线性判别函数g(x)又可写成以下形式:

其中系数wi是权向量w的分量。通过加入另外的项(w的各对分量之间的乘积),得到二次判别函数:

因为,不失一般性,可以假设。这样,二次判别函数拥有更多的系数来产生复杂的分隔面。此时g(x)=0定义的分隔面是一个二阶曲面。
若继续加入更高次的项,就可以得到多项式判别函数,这可看作对某一判别函数g(x)做级数展开,然后取其截尾逼近,此时广义线性判别函数可写成:

或:

这里y通常被成为“增广特征向量”(augmented feature vector),类似的,a被称为“增广权向量”,分别可写成:

这个从d维x空间到d+1维y空间的映射虽然在数学上几乎没有变化,但十分有用。虽然增加了一个常量,但在x空间上的所有样本间距离在变换后保持不变,得到的y向量都在d维的自空间中,也就是x空间本身。通过这种映射,可以将寻找权向量w和权阈值w0的问题简化为寻找一个简单的权向量a。
##三、样本线性可分
即在特征空间中可以用一个或多个线性分界面正确无误地分开若干类样本;对于两类样本点w1和w2,其样本点集合表示为: ,使用一个判别函数来划分w1和w2,需要用这些样本集合来确定判别函数的权向量**a**,可采用增广样本向量**y**,即存在合适的增广权向量**a**,使得:

则称样本是线性可分的。如下图中第一个图就是线性可分,而第二个图则不可分。所有满足条件的权向量称为解向量。


通常对解区限制:引入余量b,要求解向量满足:

余量b的加入在一定程度上可防止优化算法收敛到解区的边界。
##四、感知器准则函数
这里考虑构造线性不等式 的准则函数的问题,令准则函数J(.)为:

其中Y是被权向量a错分的样本集。当且仅当JP(a*) = min JP(a) = 0 时,a*是解向量。这就是感知器(Perceptron)准则函数。
**1.基本的感知器设计**
感知器准则函数的最小化可以使用梯度下降迭代算法求解:

其中,k为迭代次数,η为调整的步长。即下一次迭代的权向量是把当前时刻的权向量向目标函数的负梯度方向调整一个修正量。

即在每一步迭代时把错分的样本按照某个系数叠加到权向量上。这样就得到了感知算法。
**2.批处理感知器算法**

**3.固定增量感知器算法**
通常情况,一次将所有错误样本进行修正不是效率最高的做法,更常用是每次只修正一个样本或一批样本的固定增量法:

##五、收敛性分析:
只要训练样本集是线性可分的,对于任意的初值 a(1) ,经过有限次迭代运算,算法必定收敛。而当样本线性不可分时,感知器算法无法收敛。
**总结**:感知器是最简单可以“学习”的机器,是解决线性可分的最基本方法。也是很多复杂算法的基础。感知器的算法的推广有很多种,如带裕量的变增量感知器、批处理裕量松弛算法、单样本裕量松弛算法等等。
以下是批处理感知器算法与固定增量感知器算法实现的MATLAB代码,并给出四组数据以供测试:
~~~
% 批处理感知器算法
function BatchPerceptron(w1, w2)
figure;
plot(w1(:,1),w1(:,2),'ro');
hold on;
grid on;
plot(w2(:,1),w2(:,2),'b+');
% 对所有训练样本求增广特征向量y
one = ones(10,1);
y1 = [one w1];
y2 = [one w2];
w12 = [y1; -y2]; % 增广样本规范化
y = zeros(size(w12,1),1); % 错分样本集y初始为零矩阵
% 初始化参数
a = [0 0 0]; % [0 0 0];
Eta = 1;
time = 0; % 收敛步数
while any(y<=0)
for i=1:size(y,1)
y(i) = a * w12(i,:)';
end;
a = a + sum(w12(find(y<=0),:));%修正向量a
time = time + 1;%收敛步数
if (time >= 300)
break;
end
end;
if (time >= 300)
disp('目标函数在规定的最大迭代次数内无法收敛');
disp(['批处理感知器算法的解矢量a为: ',num2str(a)]);
else
disp(['批处理感知器算法收敛时解矢量a为: ',num2str(a)]);
disp(['批处理感知器算法收敛步数k为: ',num2str(time)]);
end
%找到样本在坐标中的集中区域,以便于打印样本坐标图
xmin = min(min(w1(:,1)),min(w2(:,1)));
xmax = max(max(w1(:,1)),max(w2(:,1)));
xindex = xmin-1:(xmax-xmin)/100:xmax+1;
yindex = -a(2)*xindex/a(3)-a(1)/a(3);
plot(xindex,yindex);
title('批处理感知器算法实现两类数据的分类');
~~~
~~~
% 固定增量感知器算法
function FixedIncrementPerceptron(w1, w2)
[n, d] = size(w1);
figure;
plot(w1(:,1),w1(:,2),'ro');
hold on;
grid on;
plot(w2(:,1),w2(:,2),'b+');
% 对所有训练样本求增广特征向量y
one = ones(10,1);
y1 = [one w1];
y2 = [one w2];
w12 = [y1; -y2]; % 增广样本规范化
y = zeros(size(w12,1),1); % 错分样本集y初始为零矩阵
% 初始化参数
a = [0 0 0];
Eta = 1;
% k = 0;
time = 0; % 收敛的步数
yk = zeros(10,3);
y = a * w12';
while sum(y<=0)>0
% for i=1:size(y,1)
% y(i) = a * w12(i,:)';
% end;
y = a * w12';
rej=[];
for i=1:2*n %这个循环计算a(K+1) = a(k) + sum {yj被错误分类} y(j)
if y(i)<=0
a = a + w12(i,:);
rej = [rej i];
end
end
% fprintf('after iter %d, a = %g, %g\n', time, a);
% rej
time = time + 1;
if ((size(rej) == 0) | (time >= 300))
break;
end
end;
if (time >= 300)
disp('目标函数在规定的最大迭代次数内无法收敛');
disp(['固定增量感知器算法的解矢量a为: ',num2str(a)]);
else
disp(['固定增量感知器算法收敛时解矢量a为: ',num2str(a)]);
disp(['固定增量感知器算法收敛步数kt为: ',num2str(time)]);
end
%找到样本在坐标中的集中区域,以便于打印样本坐标图
xmin = min(min(w1(:,1)),min(w2(:,1)));
xmax = max(max(w1(:,1)),max(w2(:,1)));
xindex = xmin-1:(xmax-xmin)/100:xmax+1;
% yindex = -a(2)*xindex/a(3)-a(1)/a(3);
yindex = -a(2)*xindex/a(3) - a(1)/a(3);
plot(xindex,yindex);
title('固定增量感知器算法实现两类数据的分类');
~~~
~~~
close all;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 感知器实验
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
w1 = [ 0.1 1.1;...
6.8 7.1;...
-3.5 -4.1;...
2.0 2.7;...
4.1 2.8;...
3.1 5.0;...
-0.8 -1.3;...
0.9 1.2;...
5.0 6.4;...
3.9 4.0];
w2 = [ 7.1 4.2;...
-1.4 -4.3;...
4.5 0.0;...
6.3 1.6;...
4.2 1.9;...
1.4 -3.2;...
2.4 -4.0;...
2.5 -6.1;...
8.4 3.7;...
4.1 -2.2];
w3 = [-3.0 -2.9;...
0.54 8.7;...
2.9 2.1;...
-0.1 5.2;...
-4.0 2.2;...
-1.3 3.7;...
-3.4 6.2;...
-4.1 3.4;...
-5.1 1.6;...
1.9 5.1];
w4 = [-2.0 -8.4;...
-8.9 0.2;...
-4.2 -7.7;...
-8.5 -3.2;...
-6.7 -4.0;...
-0.5 -9.2;...
-5.3 -6.7;...
-8.7 -6.4;...
-7.1 -9.7;...
-8.0 -6.3];
BatchPerceptron(w1, w2);
FixedIncrementPerceptron(w1, w3);
~~~
模式识别:PCA主分量分析与Fisher线性判别分析
最后更新于:2022-04-01 06:47:31
本实验的目的是学习和掌握PCA主分量分析方法和Fisher线性判别方法。首先了解PCA主分量分析方法的基本概念,理解利用PCA 分析可以对数据集合在特征空间进行平移和旋转。实验的第二部分是学习和掌握Fisher线性判别方法。了解Fisher线性判别方法找的最优方向与非最优方向的差异,将高维分布的数据进行降维,并通过Fisher线性判别方法实现高维数据在一维中分类。
##一、技术论述
**1.统计分析方法中的降维思想**
在模式识别的研究过程中,往往需要对反映事物的多个变量进行大量的观测,收集大量数据以便进行统计分析。多变量大样本为研究者提供了丰富的信息,但也在一定程度上增加了统计分析的运算量。而在多数情况下,变量与变量之间存在着相关性,因而又增加了问题分析的复杂性。如果分别对每个指标进行分析,分析往往是孤立的,而不是综合的。盲目减少数据会损失很多信息,容易产生错误的判决结果。
因此需要找到一个合理的方法,在减少需要分析的信息和保证分析质量两者中取得平衡。前面说到由于各变量间存在一定的相关关系,这使得这种思想成为可能。可以采用特征线性组合的方法减少特征空间中的特征维数。将高维数据投影到较低维空间上。主成分分析(principal component analysis)和Fisher判别分析法是两类有效的线性组合变换方法。
**2.主成分分析PCA**
主成分分析的主要思想是对于原先提出的所有变量,建立尽可能少的新变量,使得这些新变量是两两不相关的,而且这些新变量在反映课题的信息方面尽可能保持原有的信息。主分量分析的目的是通过特征的线性组合降低特征空间的维数。
假设一个由n个样本组成的数据集合,每个样本是一个d维特征矢量:{ x1,x2,…,xn };希望使用一个单一的模式空间的点x0来表示整个样本集合;并希望所选取的模式空间的点x0与数据集合中各个样本点之间的距离都尽可能地小。即:

使均方误差最小的矢量x_0是均值矢量m。样本均值的优点是表达简单,缺点是其不能表达集合中的样本之间的差异,同时样本集合的0维表示可以提供的信息很少。
将样本集合的全部样本向通过均值矢量的一条直线作投影,可以得到样本空间中表示样本集合的一条直线,称之为样本集合的1维表达:
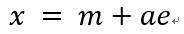
其中,e表示通过均值的直线方向上的单位矢量;a是一个实数标量,表示直线的某一点x距离均值点m的距离。假设使用该直线上的一个点(m+ak*e)来表示样本点xk,则可以构造样本集合的平方误差准则函数:
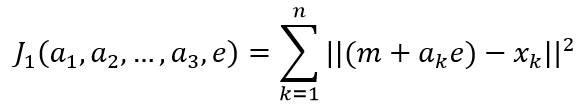
求解准则函数的最优解:
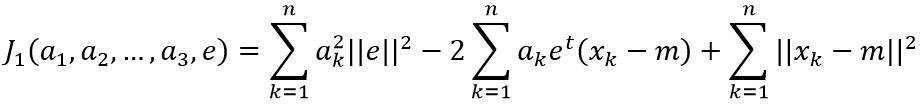
其中||e||=1,对ak求偏导数并使结果为0,可以得到:
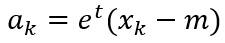
为向量(xk-m)在直线x=m+a*e方向上的投影长度。在PCA中,定义样本集合的散布矩阵为:
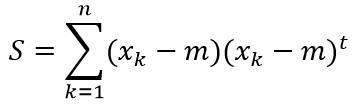
由上述定义可以看出,散布矩阵是样本协方差矩阵的(n-1)倍。最后,寻找最优的直线方向e,使得平方误差准则函数J1值最小。
将上述结论从1维推广到高维,使用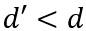维的特征矢量来近似原空间中的d维矢量:
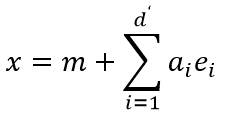
其中,e1,e2,…ed’是散布矩阵S的对应于d’个最大特征值的特征矢量,这些矢量之间相互正交,构成了d’维空间的基矢量。而系数ai是矢量x对应于基ei的系数,称为主分量(Principal Component)。
**3.Fisher线性判别方法**
PCA方法寻找的是用来有效表示同一类样本共同特点的主轴方向,这对于表示同一类数据样本的共同特征是非常有效的。但PCA不适合用于区分不同的样本类。Fisher线性判别分析(FDA)是用于寻找最有效地对不同样本类进行区分的方向。其主要思想是考虑将d维空间中的点投影到一条直线上。通过适当地选择直线的方向,有可能找到能够最大限度地区分各类样本数据点的投影方向。
设一组由n个d维样本组成的数据集合{x1,x2,…,xn},它们分属于两个不同的类ω1和ω2,其中ω1类的样本子集为D_1,包含n1个样本点;ω2类的样本子集为D2,包含n2个样本点。将每一个样本点投影到方向为w的直线上,其中||w||=1,有:
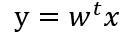
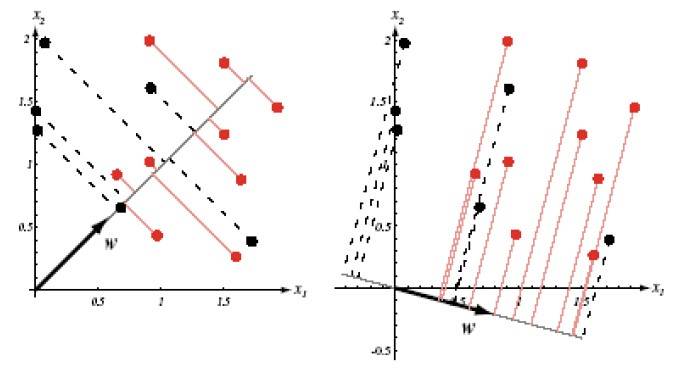
得到n个投影标量y1,y2,…,yn,对应于ω1和ω2,分别属于集合Y1和Y2,下图给出同一组样本点在不同方向投影后可分性不同:
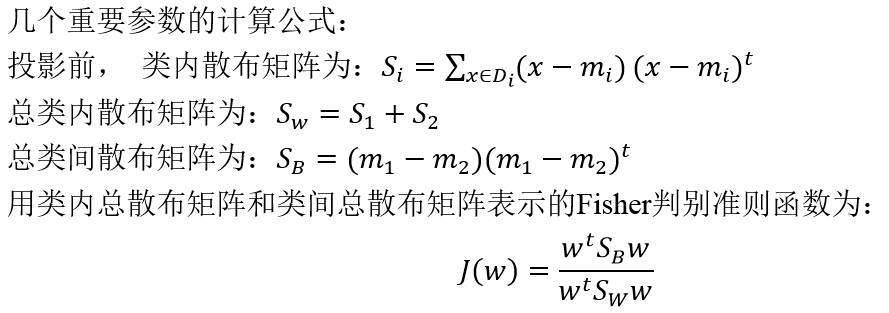
Fisher判别分析的目的就是要找到使得该准则函数J(.)最大化时的直线w。经过推导,J(.)最大化时的w为:
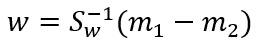
##二、实验结果讨论
第一部分PCA主分量分析部分的实验步骤主要包括以下几个部分:
1)参考实验Proj01-01,对二维高斯分布情况,给定均值矢量和协方差矩阵如下:
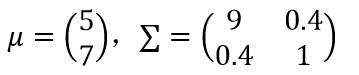
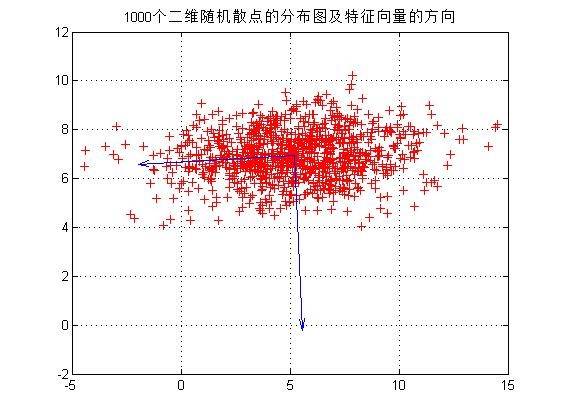
2)生成1000个二维样本矢量的数据集合X。并绘出该样本集合的二维散点图;编写函数[Y,mu_X,scatterMatrix,V,D] = PCA(X),输入:散点矩阵X,输出:Y=D_x (x-m_x) 、mu_X:均值向量、scatterMatrix:散布矩阵、V:特征向量、D:由特征值组成的对角矩阵,计算上述样本集合的均值向量和散布矩阵,计算散布矩阵的特征值和特征向量(可使用MATLAB中的eig函数)。在二维坐标中,以均值向量为中心,画出每一个特征向量方向的直线。将表示特征向量方向的直线叠加在在(1)中的二维散点图上,如下图所示。
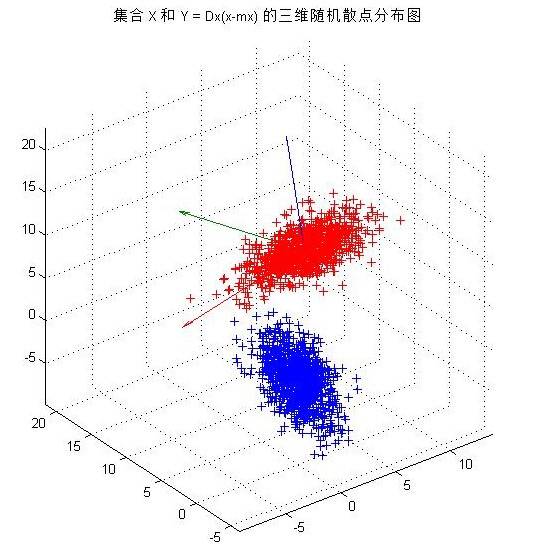
3)假设数据集合X的均值向量为mx,散布矩阵的特征向量矩阵为D_x=[e1 e2],对集合X中的每个向量x进行下面的变换,生成集合Y:Y=Dx (x-mx)。用不同的颜色分别绘出集合X和集合Y的二维散点图,如下图所示。经观察Y是集合X经平移旋转后形成的散点图,且其分布与X正交。

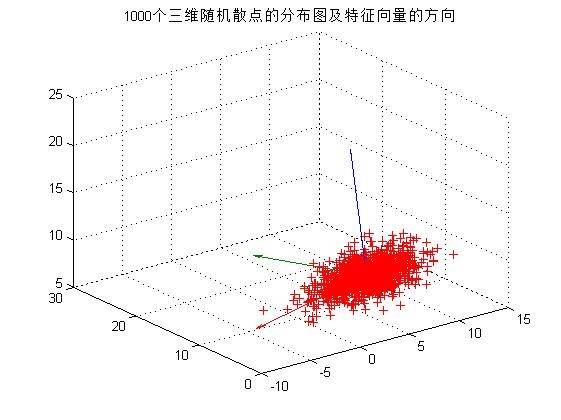
4)在(1)中,对三维高斯分布情况,生成三维样本集合,重复实验(2)和(3),输出图像如下图所示。同二维散点分布的情况相似,三维散点集合Y是集合X经平移旋转后形成的散点图,且其分布与X正交。
**第二部分**是Fisher 线性判别分析,主要了解Fisher线性判别方法找的最优方向与非最优方向的差异,将高维分布数据降维为一维,通过Fisher线性判别方法实现高维数据在一维中分类。本实验的数据见以下表格:
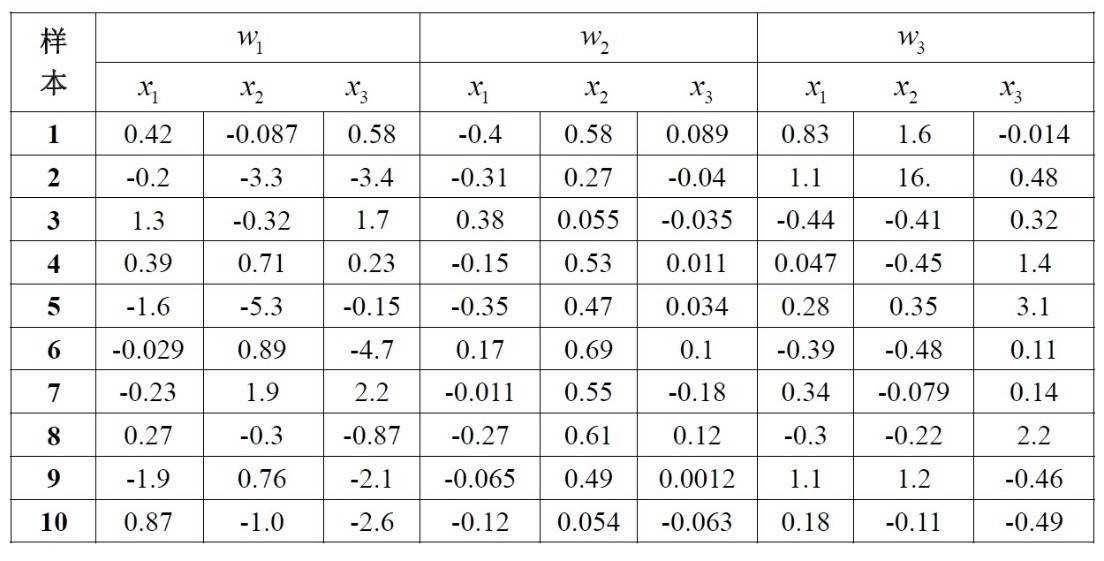
1)编写通用函数fisher(w)实现Fisher线性判别方法。
2)对表格中的类别w2和w3,计算最优方向w并画出表示最优方向w的直线,并且标记出投影后的点在直线上的位置,如下图所示。
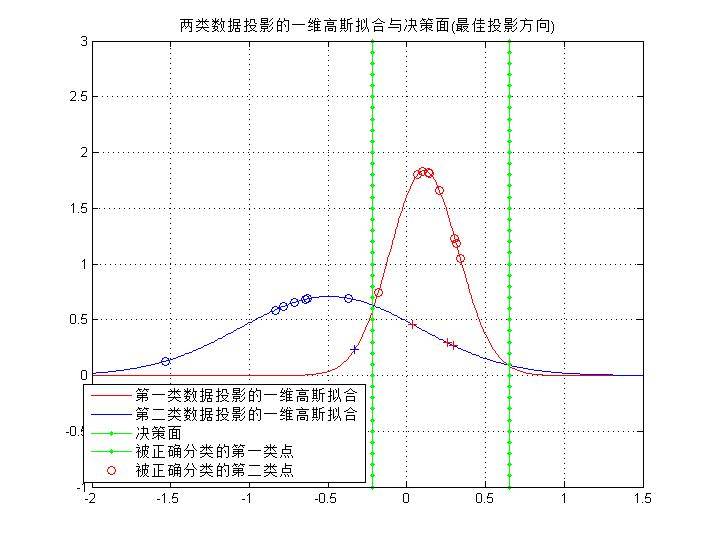
3)在这个子空间中,对每种分布用一维高斯函数拟合,即把投影后的每一类数据看作满足一维高斯分布,求出其均值和方差。并且求出分类决策面(两个一维高斯分布的交点处),如下图所示。
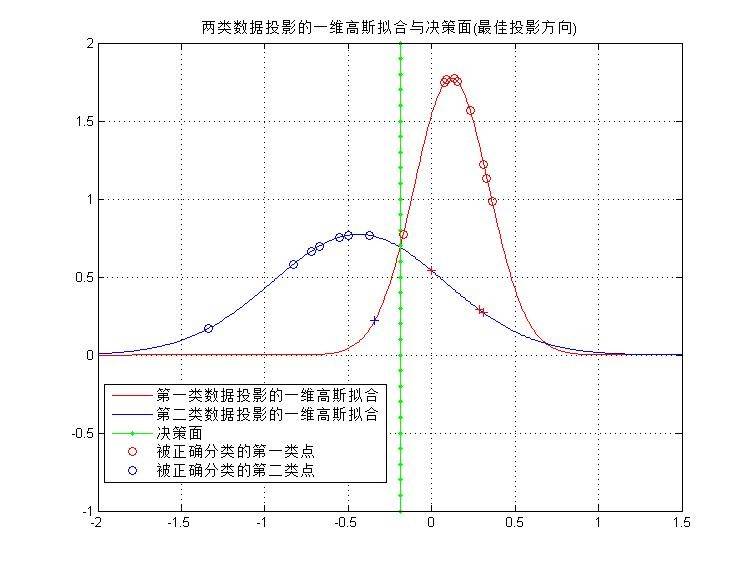
4)计算得到的分类器的训练误差,如图8所示。

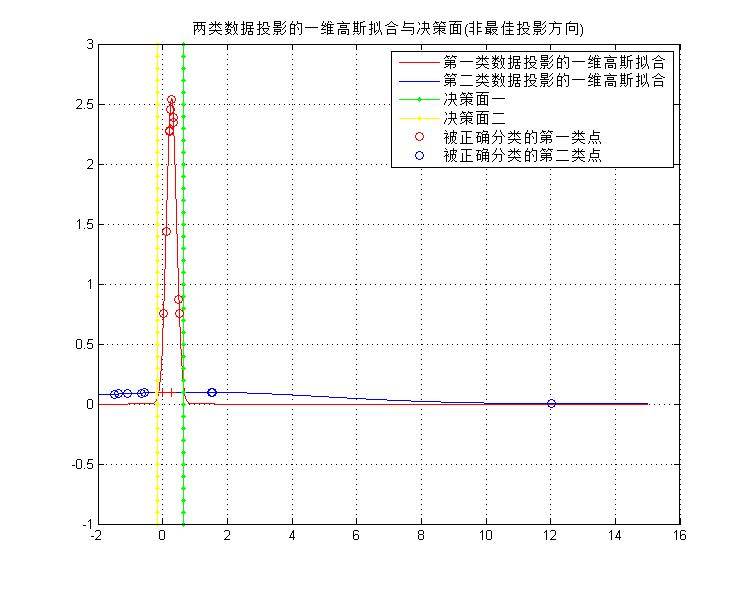
5)为了比较,使用非最优方向w=(1.0,2.0,-1.5)重复(4)(5)两个步骤,在这个非最优子空间中,得到两类数据到非最优方向的投影和训练误差,如下图所示。
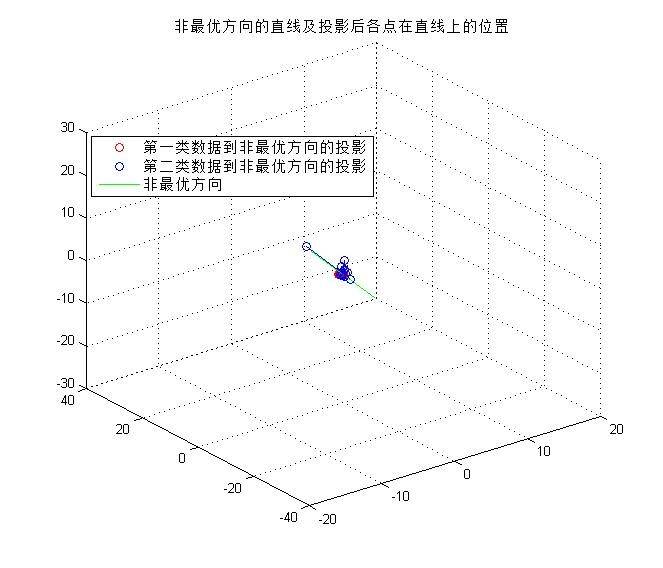

**初步结论:**对比最佳方向与非最佳方向的分类结果,前者的效果不如后者,一个原因是因为训练样本只有两类20个样本,无法体现真实的误差情况。另一个原因是由于样本集中出现了距离样本均值很大的样本点,当使用非最优方向时,拟合后的一维高斯函数方差非常大(如下图所示),对于快速收敛的红色曲线,平坦的蓝色曲线在更多的区域的值要高于红色线。综上所述,需要使用更多的样本点才能准确验证最优方向的分类结果确实是最优。
PCA主分量分析与Fisher线性判别分析涉及大量的数学推理,需要进一步的学习!以下是MATLAB源码:
~~~
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 产生模式类函数
% N:生成散点个数 C:类别个数 d:散点的维数
% mu:各类散点的均值矩阵
% sigma:各类散点的协方差矩阵
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function result = MixGaussian(N, C, d, mu, sigma)
color = {'r.', 'g.', 'm.', 'b.', 'k.', 'y.'}; % 用于存放不同类数据的颜色
% if nargin <= 3 & N < 0 & C < 1 & d < 1
% error('参数太少或参数错误');
% figure;
if d == 1
for i = 1 : C
for j = 1 : N/C
r(j,i) = sqrt(sigma(1,i)) * randn() + mu(1,i);
end
end
elseif d == 2
for i = 1:C
r(:,:,i) = mvnrnd(mu(:,:,i),sigma(:,:,i),round(N/C));
end
%title('N类二维随机散点的分布图');
elseif d == 3
for i = 1:C
r(:,:,i) = mvnrnd(mu(:,:,i),sigma(:,:,i),round(N/C));
end
else disp('维数只能设置为1,2或3');
end
result = r;
~~~
~~~
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% PCA算法函数
% 输入参数:
% X:样本点矩阵
% 输出参数:
% Y = Dx(x-mx)
% mu_X:均值向量
% scatterMatrix:散布矩阵
% V:特征向量
% D:由特征值组成的对角矩阵
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function [Y,mu_X,scatterMatrix,V,D] = PCA(X)
[N,d] = size(X); % N个d维样本
% 计算输入参数的样本均值和散布矩阵
mu_X = sum(X) / N
scatterMatrix = zeros(d,d);
for i = 1:N
scatterMatrix = scatterMatrix + (X(i,:) - mu_X)' * (X(i,:) - mu_X);
end
% 计算散布矩阵的特征值和特征向量
% V为特征向量,它的每一列都是特征向量
% D是特征值构成的对角矩阵
% 这些特征值和特征向量都没有经过排序
[V,D] = eig(scatterMatrix);
% 生成集合Y
for k = 1:N
Y(k,:) = (V * (X(k,:) - mu_X)')';
end
% 画图线
if d == 2
plot(X(:,1),X(:,2),'r+');
grid on;
hold on;
title('1000个二维随机散点的分布图及特征向量的方向');
for j = 1:d
% 画出带有箭头的向量
quiver(mu_X(1), mu_X(2), 8*V(1,j), 8*V(2,j),'b');
hold on;
end
figure,plot(X(:,1),X(:,2),'r+');
hold on;
for j = 1:d
% 画出带有箭头的向量
quiver(mu_X(1), mu_X(2), 8*V(1,j), 8*V(2,j),'b');
hold on;
end
plot(Y(:,1),Y(:,2),'b+');
grid on;
title('集合 X (红色)和 Y = Dx(x-mx) (蓝色)的二维随机散点分布图');
else if d ==3
plot3(X(:,1),X(:,2),X(:,3),'r+');
grid on;
hold on;
% 画出带有箭头的向量
for j = 1:d
quiver3(mu_X(1),mu_X(2),mu_X(3),15*V(1,j), 15*V(2,j), 15*V(3,j));
hold on;
end
title('1000个三维随机散点的分布图及特征向量的方向');
figure,plot3(X(:,1),X(:,2),X(:,3),'r+');
hold on;
% 画出带有箭头的向量
for j = 1:d
quiver3(mu_X(1),mu_X(2),mu_X(3),15*V(1,j), 15*V(2,j), 15*V(3,j));
hold on;
end
plot3(Y(:,1),Y(:,2),Y(:,3),'b+');
grid on;
title('集合 X 和 Y = Dx(x-mx) 的三维随机散点分布图');
end
end
~~~
~~~
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Fisher线性判别方法函数
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function fisher(w)
[x,y,z] = size(w);
for i = 1:z
% wi类的样本均值
mu(:,:,i) = sum(w(:,:,i)) ./ x;
% wi类的协方差矩阵
sigma(:,:,i) = cov(w(:,:,i));
end
% 总类内散布矩阵?
% sw = sigma(:,:,1) + sigma(:,:,2);
s = zeros(y,y,2);
for q = 1:z
for qt = 1:x
s(:,:,q) = s(:,:,q) + (w(qt,:,i) - mu(:,:,q))'*(w(qt,:,i) - mu(:,:,q))
end
end
sw = s(:,:,1) + s(:,:,2);
%投影向量的计算公式,计算最优方向的直线
wk = inv(sw) * (mu(:,:,1)-mu(:,:,2))';% 最优方向的特征向量
% wk = [1; 2; -1.5];% 若不是最优方向
wk = wk/sqrt(sum(wk.^2)); % 特征向量单位化
t1 = zeros(1,3,10);
t2 = zeros(1,3,10);
%计算将样本投影到最佳方向上以后的新坐标
cm1=w(:,1,1)*wk(1)+w(:,2,1)*wk(2)+w(:,3,1)*wk(3);
cm2=w(:,1,2)*wk(1)+w(:,2,2)*wk(2)+w(:,3,2)*wk(3);
new1=[wk(1)*cm1 wk(2)*cm1 wk(3)*cm1];
new2=[wk(1)*cm2 wk(2)*cm2 wk(3)*cm2];
% 投影后的点在直线上的位置
weigh = 2; % 绘制较长的向量
wk = wk * weigh;
plot3([-wk(1),0.5 * wk(1)],[-wk(2),0.5 * wk(2)],[-wk(3),0.5 * wk(3)],'g');
for r = 1:10
plot3(new1(r,1),new1(r,2),new1(r,3),'ro');
plot3([w(r,1,1) new1(r,1)],[w(r,2,1) new1(r,2)],[w(r,3,1) new1(r,3)],'r');
hold on;
plot3(new2(r,1),new2(r,2),new2(r,3),'bo');
plot3([w(r,1,2) new2(r,1)],[w(r,2,2) new2(r,2)],[w(r,3,2) new2(r,3)],'b');
hold on;
end
title('最优方向的直线及投影后各点在直线上的位置');
legend('第一类数据到最优方向的投影',...
'第二类数据到最优方向的投影',...
'最优方向');
% 投影后的标量y1和y2,对应两类数据
wk = wk / weigh;
y1 = wk' * w(:,:,1)';
y2 = wk' * w(:,:,2)';
% 一维高斯拟合
[mu1, sigma1] = normfit(y1);
[mu2, sigma2] = normfit(y2);
x=-2:0.01:1.5;
y1 = normpdf(x,mu1,sigma1);
y2 = normpdf(x,mu2,sigma2);
figure,plot(x,y1,'r');
hold on;
plot(x,y2,'b');
hold on;
% 决策面
if (mu2 > mu1)
xt = mu1:0.01:mu2;
else if (mu2 < mu1)
xt = mu2:0.01:mu1;
end
end
% 产生决策面
y1 = normpdf(xt,mu1,sigma1);
y2 = normpdf(xt,mu2,sigma2);
judge = find(abs(y1-y2) < 0.05);
judge = mu2 + 0.01 * judge(1);
y=-1:0.1:3;
x= judge + 0.*y; % 产生一个和y长度相同的x数组
plot(x,y,'g.-');
hold on;
% % 正确分类的散点个数
right1 = 0;
right2 = 0;
% % 正确率
rightRate1 = 0;
rightRate2 = 0;
for t = 1:10
P1_c1(t) = normpdf(cm1(t), mu1, sigma1);
P2_c1(t) = normpdf(cm1(t), mu2, sigma2);
P1_c2(t) = normpdf(cm2(t), mu1, sigma1);
P2_c2(t) = normpdf(cm2(t), mu2, sigma2);
if (P1_c1(t) > P2_c1(t))
plot(cm1(t),P1_c1(t),'ro');
hold on;
right1 = right1 + 1;
else
plot(cm1(t),P1_c1(t),'b+');
end
if (P2_c2(t) > P1_c2(t))
plot(cm2(t),P2_c2(t),'bo');
hold on;
right2 = right2 + 1;
else
plot(cm2(t),P2_c2(t),'r+');
end
legend('第一类数据投影的一维高斯拟合',...
'第二类数据投影的一维高斯拟合',...
'决策面',...
'被正确分类的第一类点',...
'被正确分类的第二类点');
end
rightRate1 = right1 / 10;
rightRate2 = right2 / 10;
disp(['使用最佳方向时第一类的错分点个数为:',num2str(10 - right1)]);
disp(['使用最佳方向时第一类的分类准确率为:',num2str(rightRate1 * 100),'%']);
disp(['使用最佳方向时第二类的错分点个数为:',num2str(10 - right2)]);
disp(['使用最佳方向时第二类的分类准确率为:',num2str(rightRate2 * 100),'%']);
grid on;
title('两类数据投影的一维高斯拟合与决策面(最佳投影方向)');
~~~
~~~
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% PCA 主分量分析与Fisher 线性判别分析实验主函数
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 生成1000个二维样本矢量的数据集合X,并绘出该样本集合的二维散点图。
N = 1000; % 1000个点
C = 1; % 种类
d = 3; % 维数
% mu = [5 7 ];
% sigma = [9 0.4;0.4 1];
mu = [5 7 9];
sigma = [7 1.2 0.4;1.2 3 0;0.4 0 1];
X = MixGaussian(N, C, d, mu, sigma);
PCA(X);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Fisher 线性判别分析部分
% w1,w2,w3三类散点
w = zeros(10,3,2);
% w(:,:,1) = [ 0.42 -0.087 0.58;...
% -0.2 -3.3 -3.4 ;...
% 1.3 -0.32 1.7 ;...
% 0.39 0.71 0.23;...
% -1.6 -5.3 -0.15;...
% -0.029 0.89 -4.7 ;...
% -0.23 1.9 2.2 ;...
% 0.27 -0.3 -0.87;...
% -1.9 0.76 -2.1 ;...
% 0.87 -1.0 -2.6];
w(:,:,1) = [-0.4 0.58 0.089; ...
-0.31 0.27 -0.04; ...
0.38 0.055 -0.035;...
-0.15 0.53 0.011;...
-0.35 0.47 0.034;...
0.17 0.69 0.1; ...
-0.011 0.55 -0.18; ...
-0.27 0.61 0.12; ...
-0.065 0.49 .0012;...
-0.12 0.054 -0.063];
w(:,:,2) = [ 0.83 1.6 -0.014;...
1.1 16. 0.48; ...
-0.44 -0.41 0.32; ...
0.047 -0.45 1.4; ...
0.28 0.35 3.1; ...
-0.39 -0.48 0.11; ...
0.34 -0.079 0.14; ...
-0.3 -0.22 2.2; ...
1.1 1.2 -0.46; ...
0.18 -0.11 -0.49];
figure,plot3(w(:,1,1),w(:,2,1),w(:,3,1),'ro');
grid on;
hold on;
plot3(w(:,1,2),w(:,2,2),w(:,3,2),'bo');
hold on;
fisher(w);
~~~
模式识别:最大似然估计与贝叶斯估计方法
最后更新于:2022-04-01 06:47:28
之前学习了贝叶斯分类器的构造和使用,其中核心的部分是**得到事件的先验概率并计算出后验概率** ,而事实上在实际使用中,很多时候无法得到这些完整的信息,因此我们需要使用另外一个重要的工具——参数估计。
参数估计是在已知系统模型结构时,用系统的输入和输出数据计算系统模型参数的过程。18世纪末德国数学家C.F.高斯首先提出参数估计的方法,他用最小二乘法计算天体运行的轨道。20世纪60年代,随着电子计算机的普及,参数估计有了飞速的发展。参数估计有多种方法,有最小二乘法、极大似然法、极大验后法、最小风险法和极小化极大熵法等。在一定条件下,后面三个方法都与极大似然法相同。最基本的方法是最小二乘法和极大似然法。这里使用MATLAB实现几种经典的方法并研究其估计特性。
目前理论部分尚在研究当中,无法解释得很清楚,这是一个长期的学习过程。
##一、最大似然估计法
最大似然估计是一种统计方法,它用来求一个样本集的相关概率密度函数的参数。这个方法最早是遗传学家以及统计学家罗纳德•费雪爵士在 1912 年至1922 年间开始使用的。这种方法的基本思想是:当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该使得从模型中抽取该n组样本观测值的概率最大,而不是像最小二乘估计法旨在得到使得模型能最好地拟合样本数据的参数估计量。
最大似然估计的优点主要有:
1\. 随着样本数量的增加,收敛性变好;
2\. 比任何其他的迭代技术都简单,适合实用。
最大四然估计的一般原理:
假设有c个类,且:
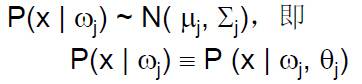
在正态分布时有:
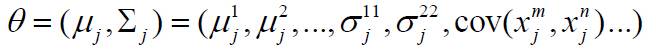
假设数据集合D划分成的类为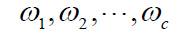
我们可以将数据集合D划分成互不相交的样本子集合,每一个子集合中的样本属于同一类。对每一个数据集合Di ,单独估计自己的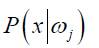 ,这样只需估计其参数即可得到分布函数。
这样,假设集合D包含同一类n个样本, x1, x2,…, xn,且这些样本是独立抽样得到的,则:
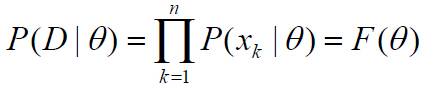
P(D | θ)称为样本集合D的似然函数。**参数θ 的最大似然估计是通过使定义的P(D | θ) 最大化得到的θ的值,使得实际观测到的样本集合具有最大的概率。**在实际中,可以对似然函数进行对数运算,为此定义对数似然函数如下:
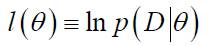
这样有:
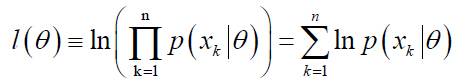
其导数定义为:
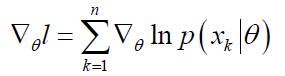
(注:由于自然对数函数是单调增函数,因此对数似然函数和似然函数的极值点的位置相同!)
这里我们要寻找最优解,这是最大似然估计的基本思想。最优解的必要条件是:
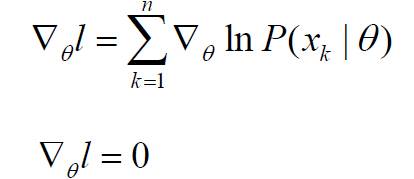
若θ由p个参数组成,则上式代表p个方程组成的方程组。下一步是求取似然函数的极值点:

此时问题可以重新表述为:求对数似然函数的极值点参数θ,使对数似然函数取得最大值:
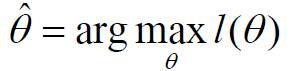
根据以上公式,在样本点服从正态分布,且均值和协方差矩阵未知的情况下,我们可以得到以下两个公式,分别计算估计均值和协方差矩阵。
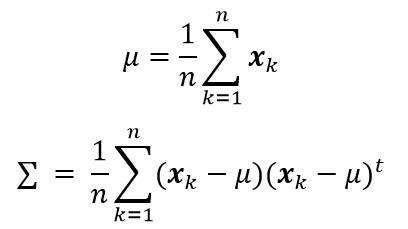
##二、贝叶斯估计法
在最大似然估计中,假设参数θ未知,但事实上它是确定的量。在而在贝叶斯估计法中,参数θ视为一个随机变量。后验概率P(x| D) 的计算是贝叶斯学习的最终目的,其核心问题是给定样本集合D,计算P(θ| D)。方法二和方法三就属于贝叶斯估计法。(公式的推导有待进一步研究)

离散情况:
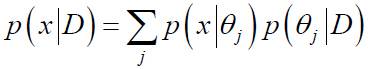
##三、估计方法的公式总结
这里假设样本点服从正态分布,且均值和协方差矩阵未知的情况下,方法一计算估计均值和协方差矩阵:
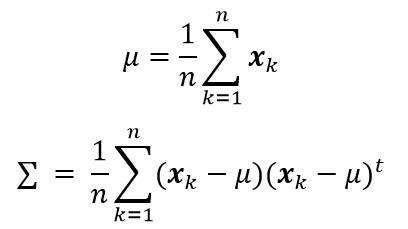
方法二计算估计均值和协方差矩阵:
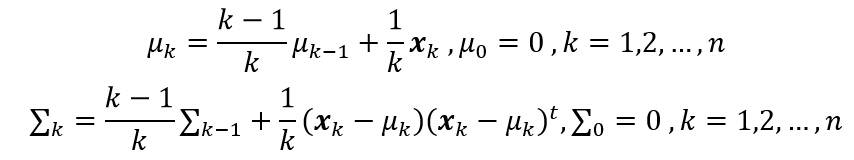
方法三计算估计均值和协方差矩阵:
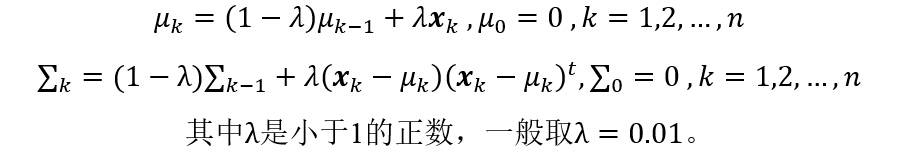
其中,λ 是一个小于1的正数,一般可取λ=0.01。可以看到,**方法二和方法三均使用迭代的方法求解每一步的均值矢量和协方差矩阵。**
##四、估计误差
在方法二、三中,在第k步的估计误差可以由下面的公式计算:
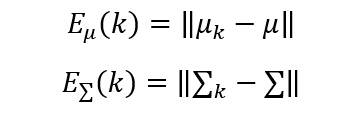
上面的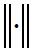是向量和矩阵范数,一般可以取欧氏范数的形式。
##五、实验步骤与讨论
对不同维数下的高斯概率密度模型,用最大似然估计等方法对其参数进行估计。假设有概率密度为高斯分布p(x) ~N(μ,∑)的样本集合S={xk,k = 1,2,…,n},可以使用以上介绍的三种方法进行均值矢量和协方差矩阵的参数估计,实验步骤主要包括以下几个部分:
1)参考:[http://blog.csdn.net/liyuefeilong/article/details/44247589](http://blog.csdn.net/liyuefeilong/article/details/44247589) 中的程序,调用模式类生成函数MixGaussian,要求给定一组均值(均值向量)和方差(协方差矩阵),生成一维、二维或三维的高斯分布的散点,每一组数据集合的样本个数为100。
2)利用上面介绍的方法一、方法二和方法三,分别估计这三组数据的均值(均值向量)和方差(协方差矩阵)。
3)利用上面介绍的误差计算公式,计算方法一、方法二和方法三的估计误差。对于方法二和方法三,计算每一次迭代估计的误差值,并绘制出误差曲线图。
这里生成三维散点图,以下是三种方法的估计结果与误差曲线图:
方法一:
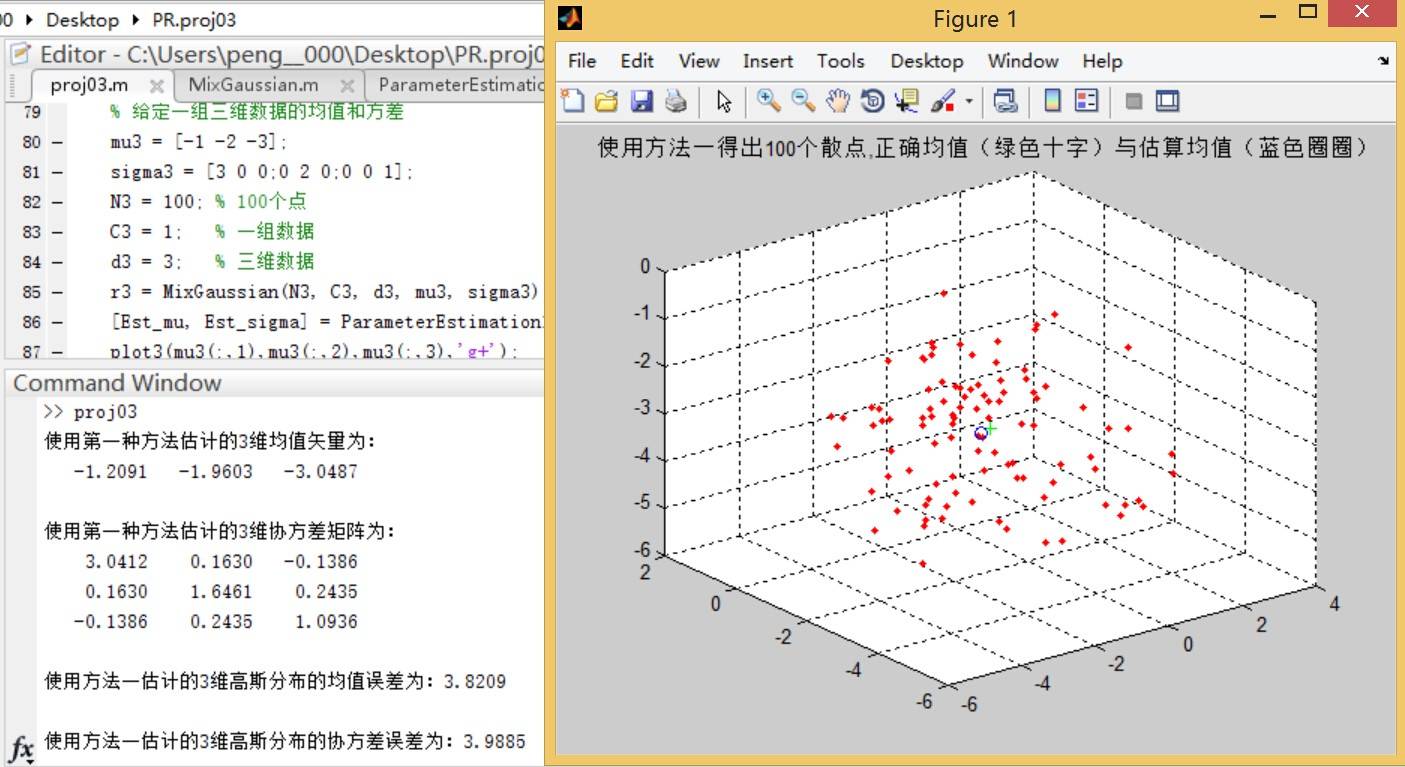
方法二:
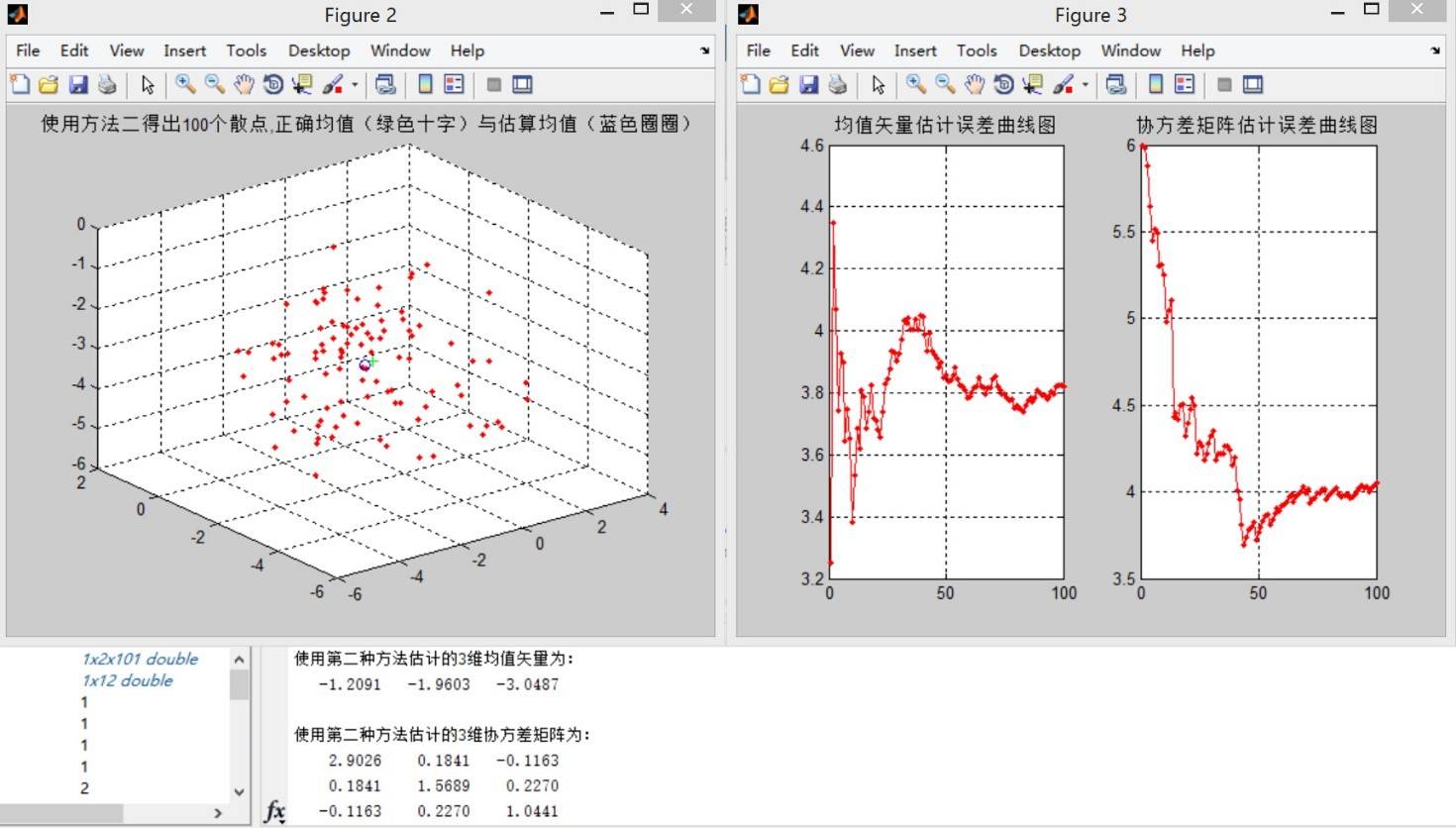
方法三:
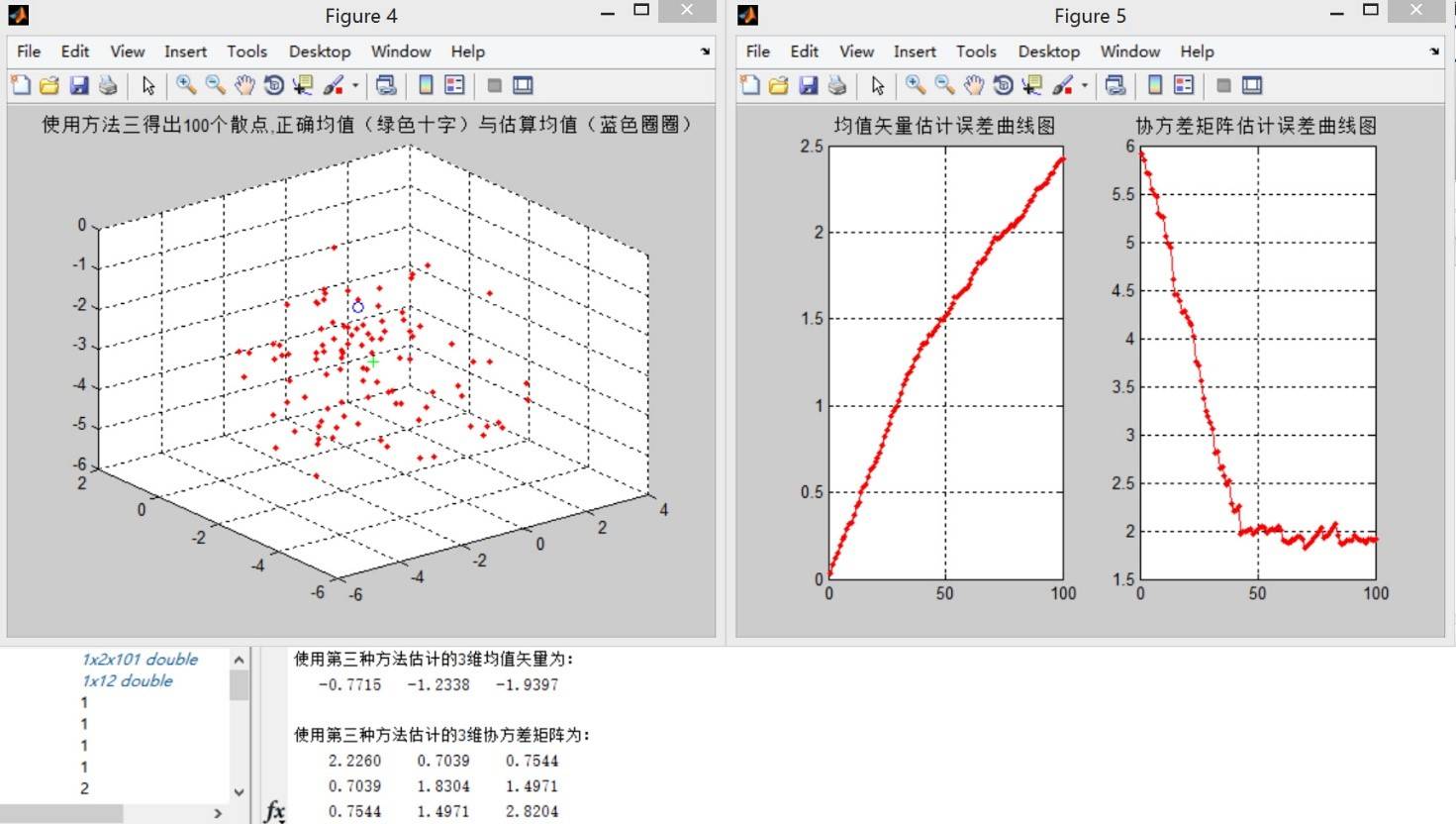
**结论一:** 观察误差曲线图,方法三在估计样本点个数少的时候比方法二的均值误差更小,但方法二的均值误差曲线总体呈单调递减的走势,而方法三正好相反。在观察误差曲线时,无法找出更多可靠的规律。考虑到这里样本点只有100个,因此增加样本点个数进行实验。
4)在(1)中,将每一个数据集合的样本个数变为10000,重新生成数据集合,重复(2) (3)中的实验。
方法一:
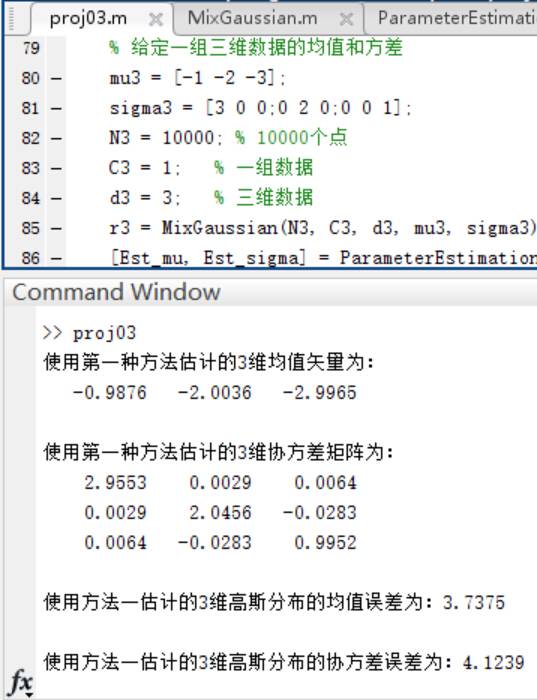
方法二:

方法三:
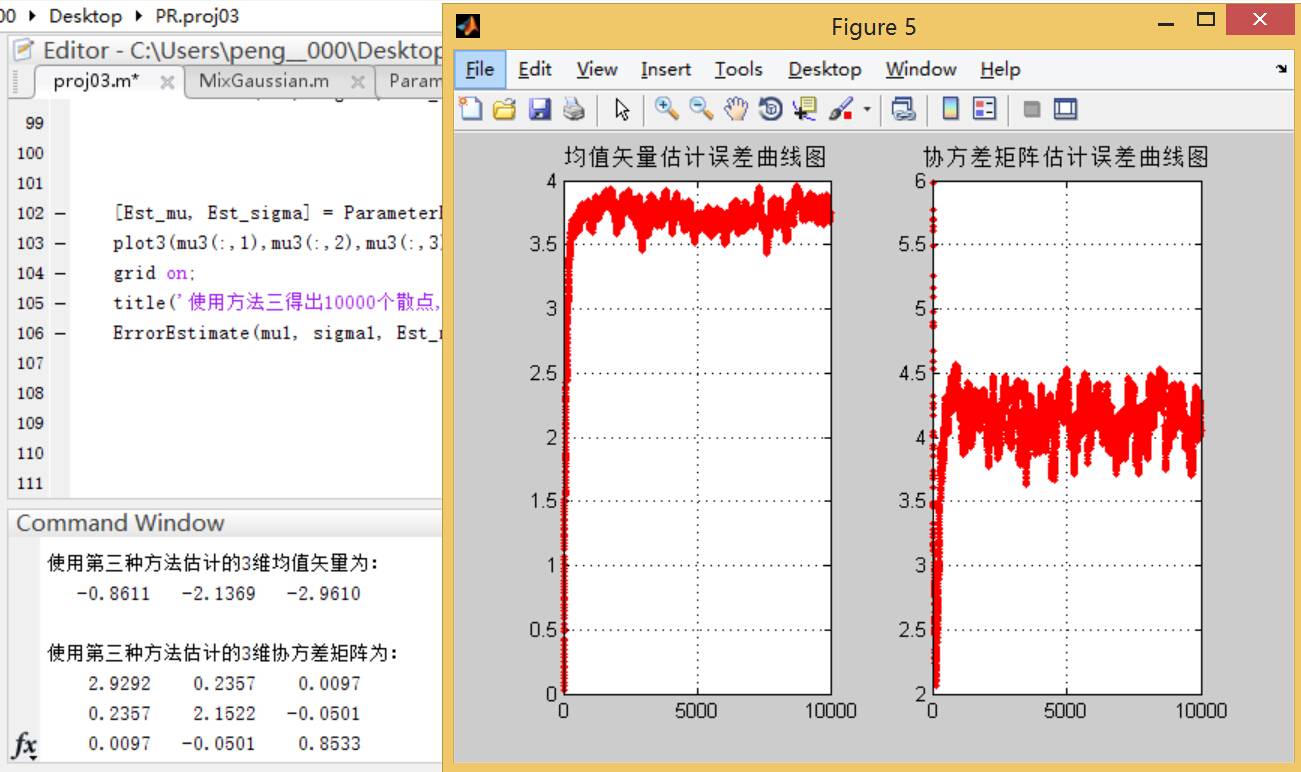
**结论二:**可以看到,使用方法二进行迭代求取均值和协方差矩阵的方法的误差曲线随着样本点数的增多而区域平缓;相比之下,方法三的误差曲线变化幅度较大,而且在样本个数较多的情况下误差要大于方法二。
5)该部分是论证方法三中λ的取值对估计误差的影响。这里选取不同的λ值,重复(2) (3) (4)中的实验,观察结果的异同,并加以解释分析。
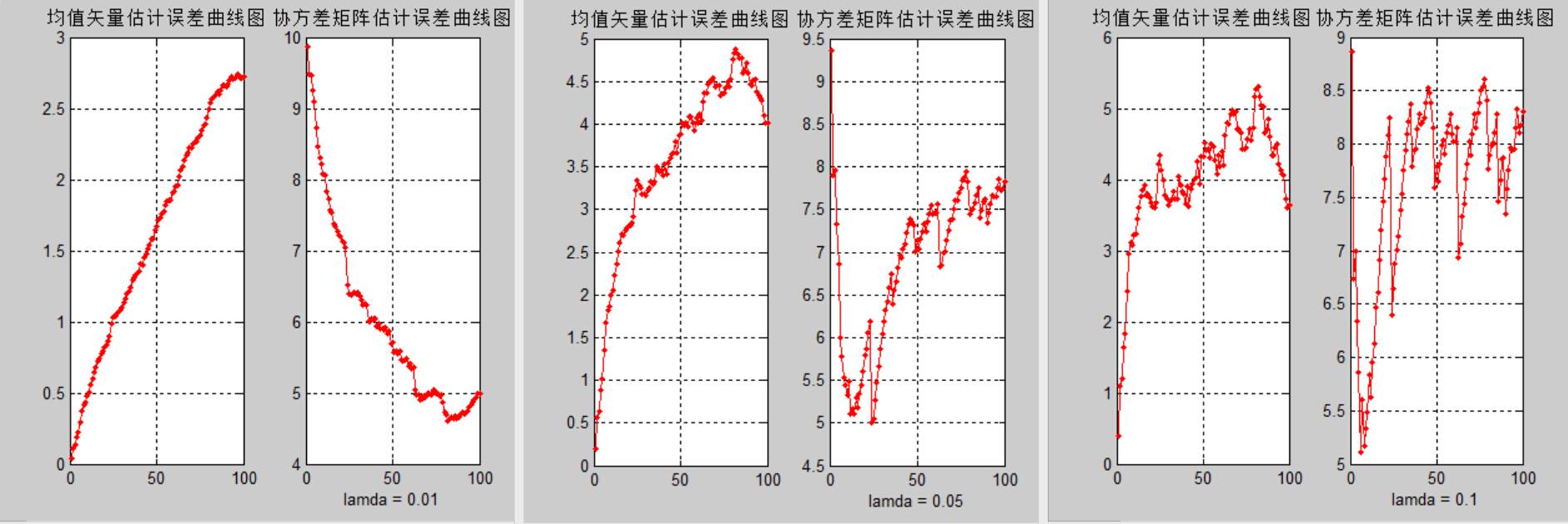
100数据lamda比较:
10000数据lamda比较:
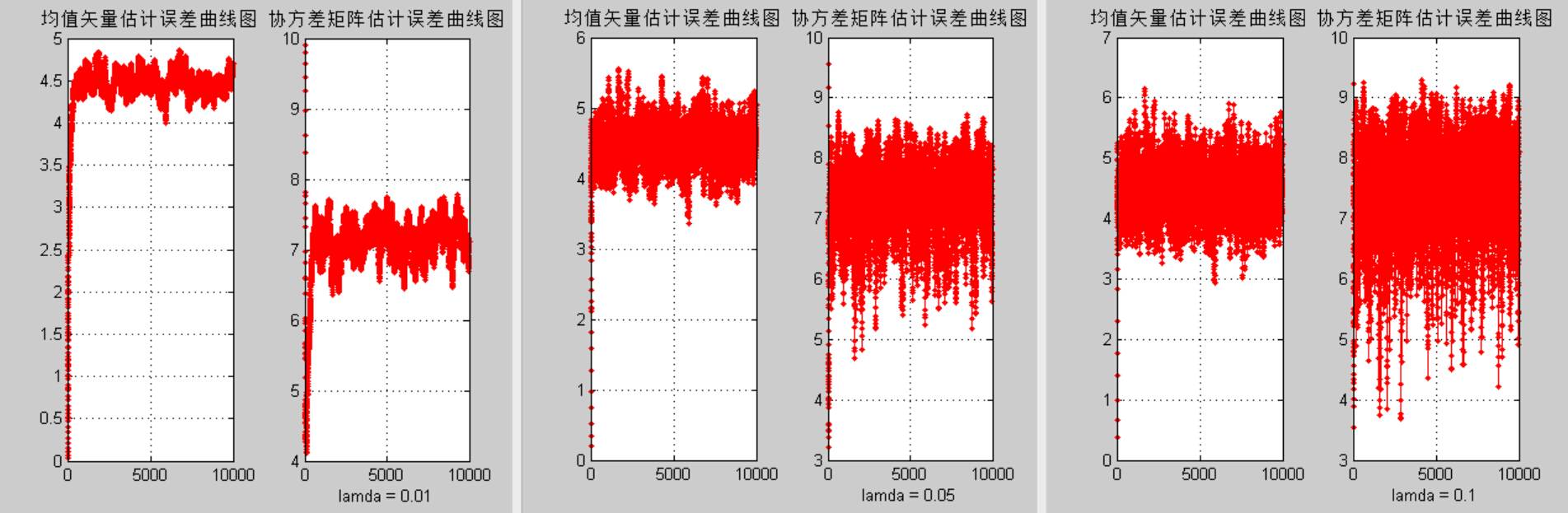
**结论三:**结合输出结果可以发现,方法三中λ的取值对均值矢量估计和协方差矩阵估计的误差有很大影响,过大的λ取值会导致更大的估计误差,因此通常λ取0.01。
**总结:由于实验采用了有限样本估计带来了一定的估计误差,这一误差的影响可以通过增加样本个数的方法来减小。在理论上,贝叶斯估计方法有很强的理论和算法基础,但实际中,最大似然估计算法更加简便,而且设计出的分类器性能几乎与贝叶斯方法得到的结果相差无几。若碰到样本点个数很少时,可以尝试使用方法三进行估计。**
最后给出几个主要函数的定义,只需简单设置参数就可以调用这些函数:
~~~
% 方法一进行参数估计,输出估计均值和协方差矩阵
function [mu,sigma] = ParameterEstimation1(r)
[x,y] = size(r);
% 散点的均值计算
mu = sum(r)/x;
% 散点的协方差矩阵计算
a = 0;
for i = 1:x
a = a + (r(i,:,:) - mu)' * (r(i,:,:) - mu);
end
sigma = a/x;
disp(['使用第一种方法估计的',num2str(y),'维均值矢量为:']);
disp(mu);
disp(['使用第一种方法估计的',num2str(y),'维协方差矩阵为:']);
disp(sigma);
if y == 1
k=-3:0.1:x;
x=mu + 0.*k; % 产生一个和y长度相同的x数组
plot(x,k,'g-');
else if y == 2
figure;
plot(r(:,1),r(:,2),'r.');
hold on;
plot(mu(1,1),mu(1,2),'bo');
else if y == 3
figure;
plot3(r(:,1),r(:,2),r(:,3),'r.');
hold on;
plot3(mu(1,1),mu(1,2),mu(1,3),'bo');
end
end
end
title('使用方法一得出散点图与估算均值(蓝色圈圈)');
~~~
~~~
% 方法二进行参数估计,输出估计均值和协方差矩阵
function [mu,sigma] = ParameterEstimation2(r)
[x,y] = size(r);
% 套用公式前均值和协方差矩阵的初值
mu = zeros(1,y);
sigma = zeros(y,y);
for i = 1:x
mu(:,:,i+1) = mu(:,:,i)*(i-1)/i + r(i,:)/i;
sigma(:,:,i+1) = sigma(:,:,i)*(i-1)/i + (r(i,:) - mu(:,:,i+1))' * (r(i,:) - mu(:,:,i+1)) ./i;
end
disp(['使用第二种方法估计的',num2str(y),'维均值矢量为:']);
disp(mu(1,:,x+1));
disp(['使用第二种方法估计的',num2str(y),'维协方差矩阵为:']);
disp(sigma(:,:,x+1));
if y == 1
k=-3:0.1:x;
x=mu(1,1,x+1) + 0.*k; % 产生一个和y长度相同的x数组
plot(x,k,'g-');
else if y == 2
figure;
plot(r(:,1),r(:,2),'r.');
hold on;
plot(mu(1,1,x+1),mu(1,2,x+1),'bo');
else if y == 3
figure;
plot3(r(:,1),r(:,2),r(:,3),'r.');
hold on;
plot3(mu(1,1,x+1),mu(1,2,x+1),mu(1,3,x+1),'bo');
end
end
end
title('使用方法二得出散点图与估算均值(蓝色圈圈)');
~~~
~~~
% 方法三进行参数估计,输出估计均值和协方差矩阵
% 输入不同维度的高斯概率密度模型,估计均值和协方差矩阵
% lamda为方法三中的调节参数,默认为0.01
function [mu,sigma] = ParameterEstimation3(r, lamda)
% lamda的缺省值为0.01
default_lamda = 0.01;
% 如果只输入r而没有设定lamda,则lamda选用默认值
if nargin == 1
lamda = default_lamda;
end
[x,y] = size(r);
% 套用公式前均值和协方差矩阵的初值
mu = zeros(1,y);
sigma = zeros(y,y);
for i = 1:x
mu(:,:,i+1) = mu(:,:,i)*(1 - lamda) + r(i,:) * lamda;
sigma(:,:,i+1) = sigma(:,:,i)*(1 - lamda) + (r(i,:) - mu(:,:,i+1))' * (r(i,:) - mu(:,:,i+1)) .*lamda;
end
disp(['使用第三种方法估计的',num2str(y),'维均值矢量为:']);
disp(mu(1,:,x+1));
disp(['使用第三种方法估计的',num2str(y),'维协方差矩阵为:']);
disp(sigma(:,:,x+1));
if y == 1
k=-3:0.1:x;
x=mu(1,1,x+1) + 0.*k; % 产生一个和y长度相同的x数组
plot(x,k,'g-');
else if y == 2
figure;
plot(r(:,1),r(:,2),'r.');
hold on;
plot(mu(1,1,x+1),mu(1,2,x+1),'bo');
else if y == 3
figure;
plot3(r(:,1),r(:,2),r(:,3),'r.');
hold on;
plot3(mu(1,1,x+1),mu(1,2,x+1),mu(1,3,x+1),'bo');
end
end
end
title('使用方法三得出散点图与估算均值(蓝色圈圈)');
~~~
~~~
% 误差估计函数
function ErrorEstimate(mu, sigma, Est_mu, Est_sigma)
[x,y,z] = size(Est_mu);
if z == 1
Emu = norm((Est_mu - mu),2);
Esigma = norm((Est_sigma - sigma),2);
fprintf(['使用方法一估计的',num2str(y),'维高斯分布的均值误差为:',num2str(Emu),'\n']);
fprintf(['\n使用方法一估计的',num2str(y),'维高斯分布的协方差误差为:',num2str(Esigma),'\n\n']);
else
for i = 1:z-1
Emu(i) = norm((Est_mu(:,:,i+1) - mu),2);
Esigma(i) = norm((Est_sigma(:,:,i+1) - sigma),2);
end
x = 1:1:z-1;
figure;
subplot(1,2,1);
plot(x,Emu,'r.-');
title('均值矢量估计误差曲线图');
grid on;
subplot(1,2,2),plot(x,Esigma,'r.-');
title('协方差矩阵估计误差曲线图');
grid on;
end
~~~
MATLAB实现贝叶斯分类器
最后更新于:2022-04-01 06:47:26
***贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。也就是说,贝叶斯分类器是最小错误率意义上的优化,它遵循“多数占优”这一基本原则。***
##一、分类器的基本概念
经过了一个阶段的模式识别学习,对于模式和模式类的概念有一个基本的了解,并尝试使用MATLAB实现一些模式类的生成。而接下来如何对这些模式进行分类成为了学习的第二个重点。这就需要用到分类器。
表述模式分类器的方式有很多种,其中用的最多的是一种判别函数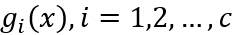的形式,如果对于所有的j≠i,有:
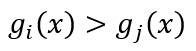
则此分类器将这个特征向量x判为ωi类。因此,此分类器可视为计算c个判别函数并选取与最大判别值对应的类别的网络或机器。一种分类器的网络结构如下图所示:
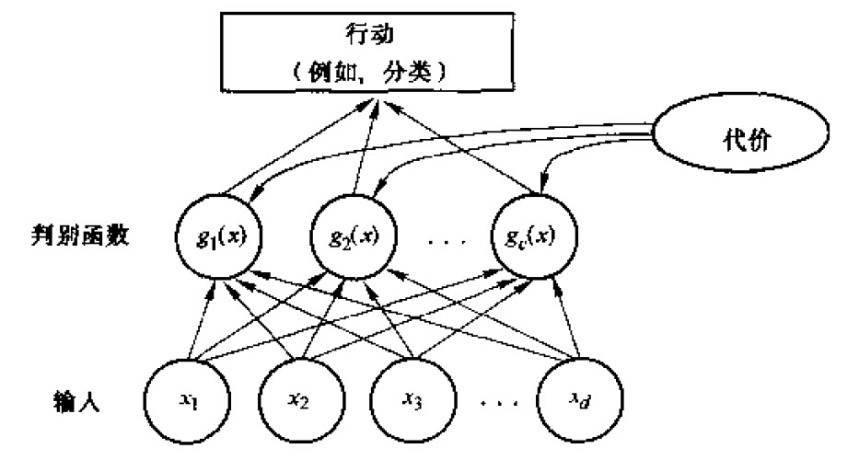
##二、贝叶斯分类器
一个贝叶斯分类器可以简单自然地表示成以上网络结构。贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。在具有模式的完整统计知识条件下,按照贝叶斯决策理论进行设计的一种最优分类器。分类器是对每一个输入模式赋予一个类别名称的软件或硬件装置,而贝叶斯分类器是各种分类器中分类错误概率最小或者在预先给定代价的情况下平均风险最小的分类器。它的设计方法是一种最基本的统计分类方法。
对于贝叶斯分类器,其判别函数的选择并不是唯一的,我们可以将所有的判别函数乘上相同的正常数或者加上一个相同的常量而不影响其判决结果;在更一般的情况下,如果将每一个gi (x)替换成f(gi (x)),其中f(∙)是一个单调递增函数,其分类的效果不变。特别在对于最小误差率分类,选择下列任何一种函数都可以得到相同的分类结果,但是其中一些比另一些计算更为简便:
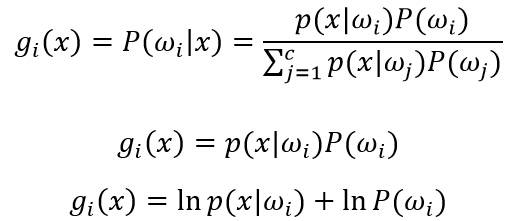
一个典型的模式识别系统是由特征提取和模式分类两个阶段组成的,而其中模式分类器(Classifier)的性能直接影响整个识别系统的性能。 因此有必要探讨一下如何评价分类器的性能,这是一个长期探索的过程。分类器性能评价方法见:[http://blog.csdn.net/liyuefeilong/article/details/44604001](http://blog.csdn.net/liyuefeilong/article/details/44604001)
##三、基本的Bayes分类器实现
这里将在MATLAB中实现一个可以对两类模式样本进行分类的贝叶斯分类器,假设两个模式类的分布均为高斯分布。模式类1的均值矢量m1 = (1, 3),协方差矩阵为S1 =(1.5, 0; 0, 1);模式类2的均值矢量m2 = (3, 1),协方差矩阵为S2 =(1, 0.5; 0.5, 2),两类的先验概率p1 = p2 = 1/2。详细的操作包含以下四个部分:
1.首先,编写一个函数,其功能是为若干个模式类生成指定数目的随机样本,这里为两个模式类各生成100个随机样本,并在一幅图中画出这些样本的二维散点图;
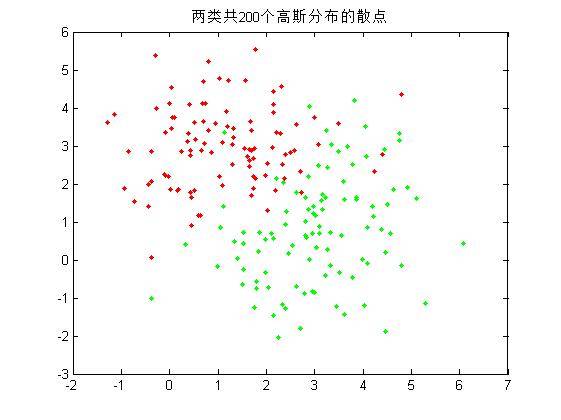
2.由于每个随机样本均含有两个特征分量,这里先仅仅使用模式集合的其中**一个特征分量**作为分类特征,对第一步中的200个样本进行分类,统计正确分类的百分比,并在二维图上用不同的颜色画出正确分类和错分的样本;(**注:绿色点代表生成第一类的散点,红色代表第二类;绿色圆圈代表被分到第一类的散点,红色代表被分到第二类的散点!** 因此,里外颜色不一样的点即被错分的样本。)
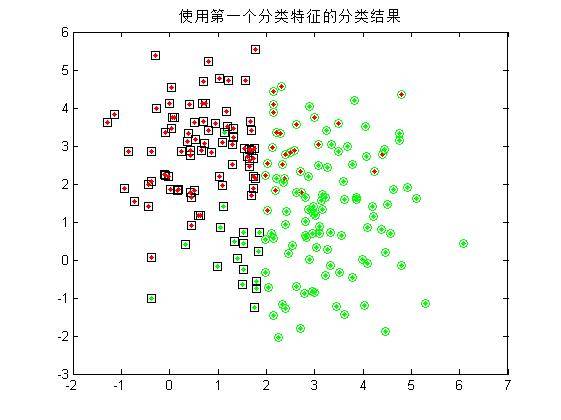
3.仅用模式的第二个特征分量作为分类特征,重复第二步的操作;
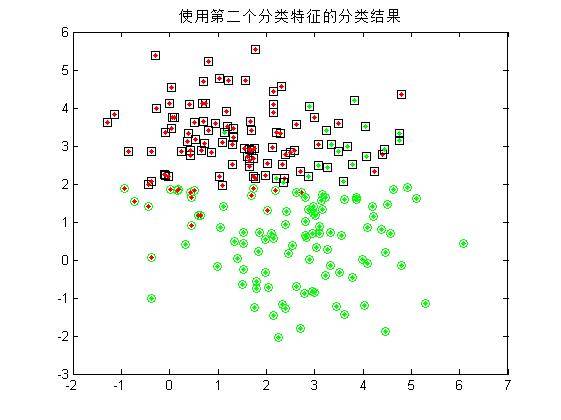
4.同时用模式的两个分量作为分类特征,对200个样本进行分类,统计正确分类百分比,并在二维图上用不同的颜色画出正确分类和错分的样本;
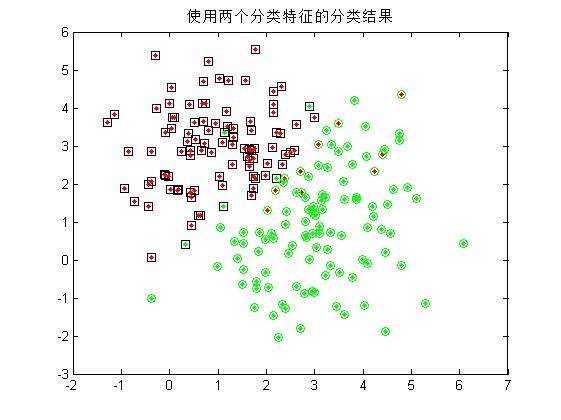
正确率:
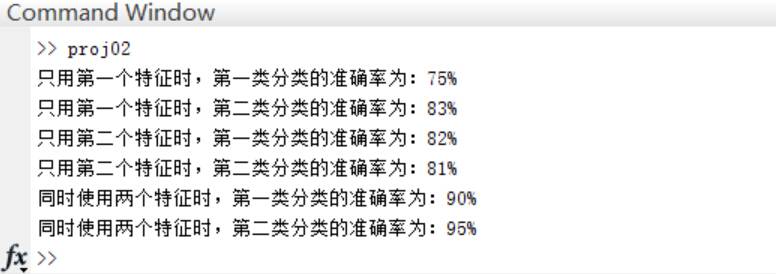
可以看到,单单使用一个分类特征进行分类时,错误率较高(多次试验均无法得出较好的分类结果),而增加分类特征的个数是提高正确率的有效手段,当然,这会给算法带来额外的时间代价。
##四、进一步的Bayes分类器
假设分类数据均满足高斯分布的情况下,设计一个判别分类器,实验目的是为了初步了解和设计一个分类器。
1.编写一个高斯型的Bayes判别函数GuassianBayesModel( mu,sigma,p,X ),该函数输入为:一给定正态分布的均值mu、协方差矩阵sigma,先验概率p以及模式样本矢量X,输出判别函数的值,其代码如下:
2.以下表格给出了三类样本各10个样本点,假设每一类均为正态分布,三个类别的先验概率相等均为P(w1)=P(w2 )=P(w3 )=1/3。计算每一类样本的均值矢量和协方差矩阵,为这三个类别设计一个分类器。
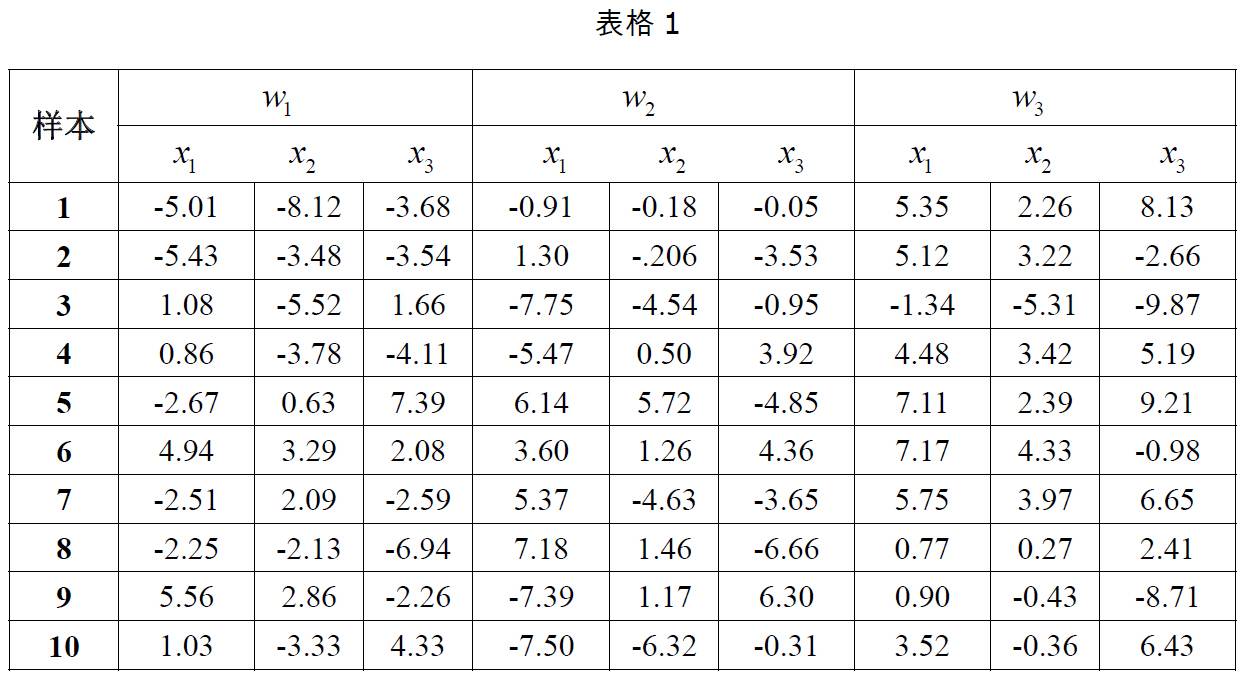
3.用第二步中设计的分类器对以下测试点进行分类:(1,2,1),(5,3,2),(0,0,0),并且利用以下公式求出各个测试点与各个类别均值之间的Mahalanobis距离。以下是来自百度百科的关于马氏距离的解释:

马氏距离计算公式:
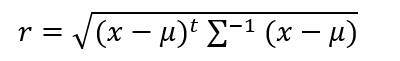
更具体的见: [http://baike.baidu.com/link?url=Pcos75ou28q7IukueePCNqf8N7xZifuXOTrwzeWpJULgVrRnytB9Gji6IEhEzlK6q4eTLvx45TAJdXVd7Lnn2q](http://baike.baidu.com/link?url=Pcos75ou28q7IukueePCNqf8N7xZifuXOTrwzeWpJULgVrRnytB9Gji6IEhEzlK6q4eTLvx45TAJdXVd7Lnn2q)
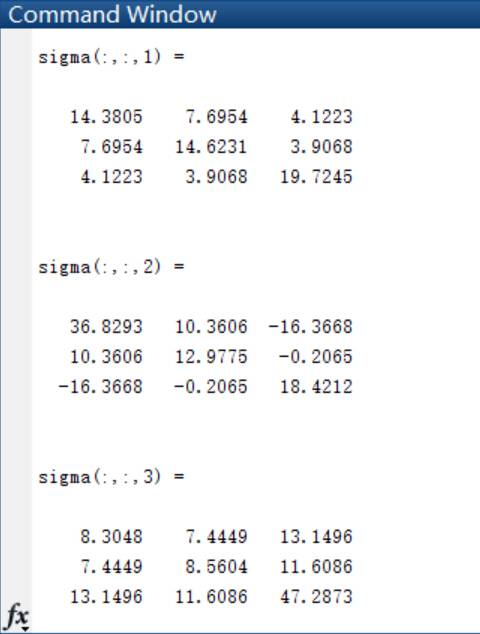
4.如果P(w1)=0.8, P(w2 )=P(w3 )=0.1,再进行第二步和第三步实验。实验的结果如下:
首先是得出三类样本点各自的均值和协方差矩阵:

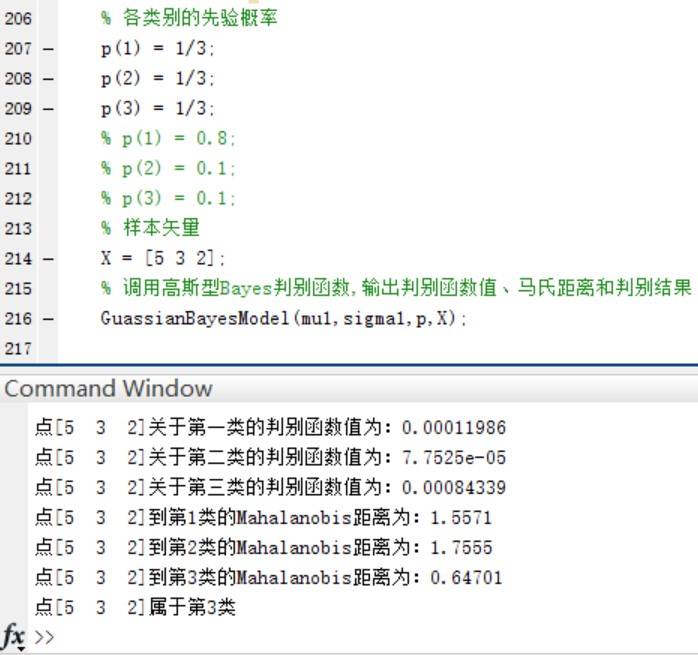
在三个类别的先验概率均为P(w1)=P(w2 )=P(w3 )=1/3时,使用函数进行分类并给出分类结果和各个测试点与各个类别均值之间的Mahalanobis距离。

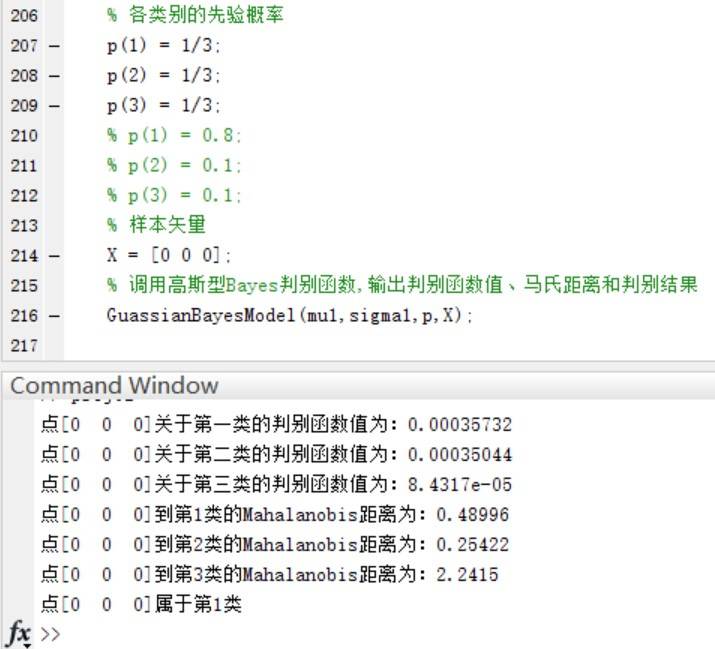
验证当三个类别的先验概率不相等时,同样使用函数进行分类并给出分类结果和各个测试点与各个类别均值之间的Mahalanobis距离。
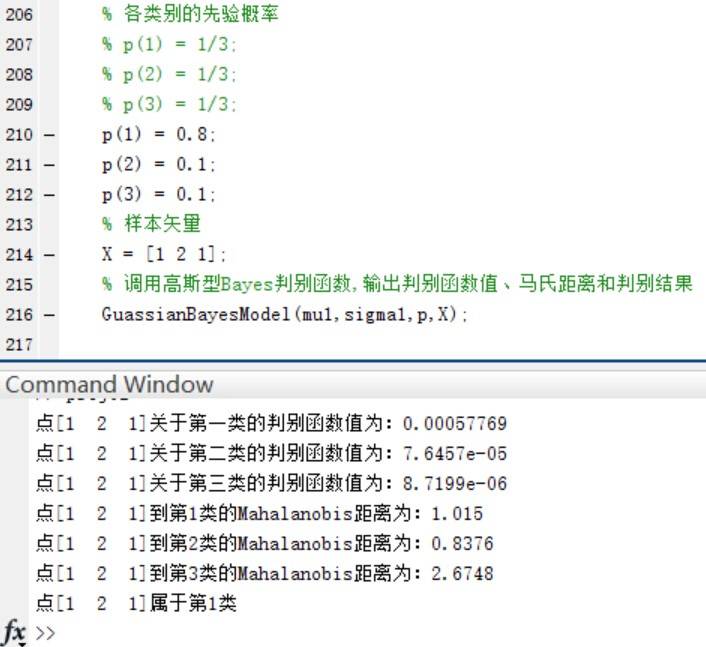


可以看到,在Mahalanobis距离不变的情况下,不同的先验概率对高斯型Bayes分类器的分类结果影响很大~ **事实上,最优判决将偏向于先验概率较大的类别。**
完整的代码如下由两个函数和主要的执行流程组成:
~~~
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 产生模式类函数
% N:生成散点个数 C:类别个数 d:散点的维数
% mu:各类散点的均值矩阵
% sigma:各类散点的协方差矩阵
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function result = MixGaussian(N, C, d, mu, sigma)
color = {'r.', 'g.', 'm.', 'b.', 'k.', 'y.'}; % 用于存放不同类数据的颜色
% if nargin <= 3 & N < 0 & C < 1 & d < 1
% error('参数太少或参数错误');
if d == 1
for i = 1 : C
for j = 1 : N/C
r(j,i) = sqrt(sigma(1,i)) * randn() + mu(1,i);
end
X = round(mu(1,i)-5);
Y = round(mu(1,i) + sqrt(sigma(1,i))+5);
b = hist(r(:,i), X:Y);
subplot(1,C,i),bar(X:Y, b,'b');
title('三类一维随机点的分布直方图');
grid on
end
elseif d == 2
for i = 1:C
r(:,:,i) = mvnrnd(mu(:,:,i),sigma(:,:,i),round(N/C));
plot(r(:,1,i),r(:,2,i),char(color(i)));
hold on;
end
elseif d == 3
for i = 1:C
r(:,:,i) = mvnrnd(mu(:,:,i),sigma(:,:,i),round(N/C));
plot3(r(:,1,i),r(:,2,i),r(:,3,i),char(color(i)));
hold on;
end
else disp('维数只能设置为1,2或3');
end
result = r;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 高斯型Bayes判别函数
% mu:输入正态分布的均值
% sigma:输入正态分布的协方差矩阵
% p:输入各类的先验概率
% X:输入样本矢量
% 输出判别函数值、马氏距离和判别结果
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function GuassianBayesModel( mu,sigma,p,X )
% 构建判别函数
% 计算点到每个类的Mahalanobis距离
for i = 1:3;
P(i) = mvnpdf(X, mu(:,:,i), sigma(:,:,i)) * p(i);
r(i) = sqrt((X - mu(:,:,i)) * inv(sigma(:,:,i)) * (X - mu(:,:,i))');
end
% 判断样本属于哪个类的概率最高
% 并显示点到每个类的Mahalanobis距离
maxP = max(P);
style = find(P == maxP);
disp(['点[',num2str(X),']关于第一类的判别函数值为:',num2str(P(1))]);
disp(['点[',num2str(X),']关于第二类的判别函数值为:',num2str(P(2))]);
disp(['点[',num2str(X),']关于第三类的判别函数值为:',num2str(P(3))]);
disp(['点[',num2str(X),']到第1类的Mahalanobis距离为:',num2str(r(1))]);
disp(['点[',num2str(X),']到第2类的Mahalanobis距离为:',num2str(r(2))]);
disp(['点[',num2str(X),']到第3类的Mahalanobis距离为:',num2str(r(3))]);
disp(['点[',num2str(X),']属于第',num2str(style),'类']);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%贝叶斯分类器实验主函数
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 生成两类各100个散点样本
mu(:,:,1) = [1 3];
sigma(:,:,1) = [1.5 0; 0 1];
p1 = 1/2;
mu(:,:,2) = [3 1];
sigma(:,:,2) = [1 0.5; 0.5 2];
p2 = 1/2;
% 生成200个二维散点,平分为两类,每类100个
aa = MixGaussian(200, 2, 2, mu, sigma);
title('两类共200个高斯分布的散点');
% 只x分量作为分类特征的分类情况
figure;
% 正确分类的散点个数
right1 = 0;
right2 = 0;
% 正确率
rightRate1 = 0;
rightRate2 = 0;
for i = 1:100
x = aa(i,1,1);
plot(aa(:,1,1),aa(:,2,1),'r.');
% 计算后验概率
P1 = normpdf(x, 1, sqrt(1.5));
P2 = normpdf(x, 3, sqrt(1));
if P1 > P2
plot(aa(i,1,1),aa(i,2,1),'ks');
hold on;
right1 = right1 + 1;% 统计正确个数
elseif P1 < P2
plot(aa(i,1,1),aa(i,2,1),'go');
hold on;
end
end
rightRate1 = right1 / 100; % 正确率
for i = 1:100
x = aa(i,1,2);
plot(aa(:,1,2),aa(:,2,2),'g.');
% 计算后验概率
P1 = normpdf(x, 1, sqrt(1.5));
P2 = normpdf(x, 3, sqrt(1));
if P1 > P2
plot(aa(i,1,2),aa(i,2,2),'ks');
hold on;
elseif P1 < P2
plot(aa(i,1,2),aa(i,2,2),'go');
hold on;
right2 = right2 + 1; % 统计正确个数
end
end
rightRate2 = right2 / 100;
title('使用第一个分类特征的分类结果');
disp(['只用第一个特征时,第一类分类的准确率为:',num2str(rightRate1*100),'%']);
disp(['只用第一个特征时,第二类分类的准确率为:',num2str(rightRate2*100),'%']);
% 只使用y分量的分类特征的分类情况
figure;
% 正确分类的散点个数
right1 = 0;
right2 = 0;
% 正确率
rightRate1 = 0;
rightRate2 = 0;
for i = 1:100
y = aa(i,2,1);
plot(aa(:,1,1),aa(:,2,1),'r.');
% 计算后验概率
P1 = normpdf(y, 3, sqrt(1));
P2 = normpdf(y, 1, sqrt(2));
if P1 > P2
plot(aa(i,1,1),aa(i,2,1),'ks');
hold on;
right1 = right1 + 1; % 统计正确个数
elseif P1 < P2
plot(aa(i,1,1),aa(i,2,1),'go');
hold on;
end
end
rightRate1 = right1 / 100; % 正确率
for i = 1:100
y = aa(i,2,2);
plot(aa(:,1,2),aa(:,2,2),'g.');
% 计算后验概率
P1 = normpdf(y, 3, sqrt(1));
P2 = normpdf(y, 1, sqrt(2));
if P1 > P2
plot(aa(i,1,2),aa(i,2,2),'ks');
hold on;
elseif P1 < P2
plot(aa(i,1,2),aa(i,2,2),'go');
hold on;
right2 = right2 + 1; % 统计正确个数
end
end
rightRate2 = right2 / 100; % 正确率
title('使用第二个分类特征的分类结果');
disp(['只用第二个特征时,第一类分类的准确率为:',num2str(rightRate1*100),'%']);
disp(['只用第二个特征时,第二类分类的准确率为:',num2str(rightRate2*100),'%']);
% 同时使用两个分类特征的分类情况
figure;
% 正确分类的散点个数
right1 = 0;
right2 = 0;
% 正确率
rightRate1 = 0;
rightRate2 = 0;
for i = 1:100
x = aa(i,1,1);
y = aa(i,2,1);
plot(aa(:,1,1),aa(:,2,1),'r.');
% 计算后验概率
P1 = mvnpdf([x,y], mu(:,:,1), sigma(:,:,1));
P2 = mvnpdf([x,y], mu(:,:,2), sigma(:,:,2));
if P1 > P2
plot(aa(i,1,1),aa(i,2,1),'ks');
hold on;
right1 = right1 + 1;
else if P1 < P2
plot(aa(i,1,1),aa(i,2,1),'go');
hold on;
end
end
end
rightRate1 = right1 / 100;
for i = 1:100
x = aa(i,1,2);
y = aa(i,2,2);
plot(aa(:,1,2),aa(:,2,2),'g.');
% 计算后验概率
P1 = mvnpdf([x,y], mu(:,:,1), sigma(:,:,1));
P2 = mvnpdf([x,y], mu(:,:,2), sigma(:,:,2));
if P1 > P2
plot(aa(i,1,2),aa(i,2,2),'ks');
hold on;
else if P1 < P2
plot(aa(i,1,2),aa(i,2,2),'go');
hold on;
right2 = right2 + 1;
end
end
end
rightRate2 = right2 / 100;
title('使用两个分类特征的分类结果');
disp(['同时使用两个特征时,第一类分类的准确率为:',num2str(rightRate1*100),'%']);
disp(['同时使用两个特征时,第二类分类的准确率为:',num2str(rightRate2*100),'%']);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 进一步的Bayes分类器
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% w1,w2,w3三类散点
w = zeros(10,3,3);
w(:,:,1) = [-5.01 -8.12 -3.68;...
-5.43 -3.48 -3.54;...
1.08 -5.52 1.66;...
0.86 -3.78 -4.11;...
-2.67 0.63 7.39;...
4.94 3.29 2.08;...
-2.51 2.09 -2.59;...
-2.25 -2.13 -6.94;...
5.56 2.86 -2.26;...
1.03 -3.33 4.33];
w(:,:,2) = [-0.91 -0.18 -0.05;...
1.30 -.206 -3.53;...
-7.75 -4.54 -0.95;...
-5.47 0.50 3.92;...
6.14 5.72 -4.85;...
3.60 1.26 4.36;...
5.37 -4.63 -3.65;...
7.18 1.46 -6.66;...
-7.39 1.17 6.30;...
-7.50 -6.32 -0.31];
w(:,:,3) = [ 5.35 2.26 8.13;...
5.12 3.22 -2.66;...
-1.34 -5.31 -9.87;...
4.48 3.42 5.19;...
7.11 2.39 9.21;...
7.17 4.33 -0.98;...
5.75 3.97 6.65;...
0.77 0.27 2.41;...
0.90 -0.43 -8.71;...
3.52 -0.36 6.43];
% 均值
mu1(:,:,1) = sum(w(:,:,1)) ./ 10;
mu1(:,:,2) = sum(w(:,:,2)) ./ 10;
mu1(:,:,3) = sum(w(:,:,3)) ./ 10;
% 协方差矩阵
sigma1(:,:,1) = cov(w(:,:,1));
sigma1(:,:,2) = cov(w(:,:,2));
sigma1(:,:,3) = cov(w(:,:,3));
% 各类别的先验概率
% p(1) = 1/3;
% p(2) = 1/3;
% p(3) = 1/3;
p(1) = 0.8;
p(2) = 0.1;
p(3) = 0.1;
% 样本矢量
X = [1 0 0];
% 调用高斯型Bayes判别函数,输出判别函数值、马氏距离和判别结果
GuassianBayesModel(mu1,sigma1,p,X);
~~~
模式识别:分类器的性能评价
最后更新于:2022-04-01 06:47:24
>最近开始了模式识别的学习,对模式和模式类的概念有一个基本的了解,并使用MATLAB实现一些模式类的生成。而接下来如何对这些模式进行分类成为了学习的第二个重点。我们都知道,一个典型的模式识别系统是由特征提取和模式分类两个阶段组成的,而其中模式分类器(Classifier)的性能直接影响整个识别系统的性能。 >因此有必要探讨一下如何评价分类器的性能,这是一个长期探索的过程.
##一、敏感性和特异性
以下例子假定x是一个连续随机变量,对于类别状态 和 的x的概率密度函数如图所示:
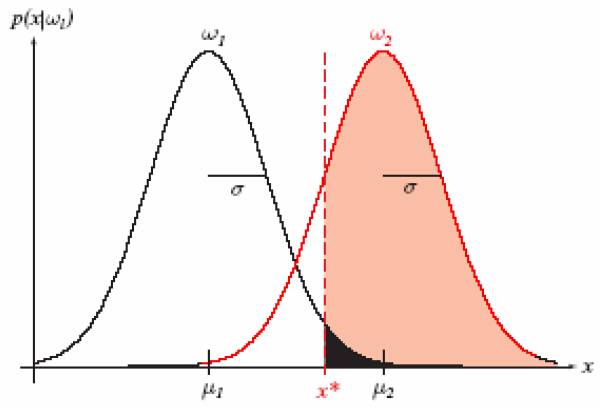
这里假设先验概率已知,对于一个二分类问题,可以定义以下四个统计值:

可以将实例分成正类(Positive)或负类(Negative)。这样会出现四种分类结果:
TP(True Positive):正确的正例,一个实例是正类并且也被判定成正类;
FN(False Negative):错误的反例,漏报,本为正类但判定为假类;
FP(False Positive):错误的正例,误报,本为假类但判定为正类;
TN(True Negative):正确的反例,一个实例是假类并且也被判定成假类;
根据以上四种情况,引出以下公式:
敏感性,又称真正类率(true positive rate ,TPR),它表示了分类器所识别出的正实例占所有正实例的比例。计算公式为:
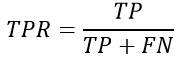
特异性,又称负正类率(False positive rate, FPR),它表示的是分类器错认为正类的负实例占所有负实例的比例。计算公式为:
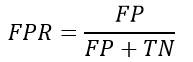
除此之外,还有真负类率(True Negative Rate,TNR),计算公式为:
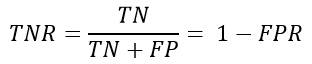
负负类率?(False Negative Rate,FNR),计算公式为:
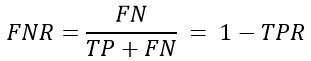
这两个公式用于F score性能评价。
##二、ROC曲线
接收机工作特征曲线 (receiver operating characteristic curve,简称ROC曲线),又称为感受性曲线(sensitivity curve)。ROC曲线是根据一系列不同的二分类方式,将TPR定义为X轴,将FPR定义为Y轴而绘制的曲线。曲线下面积越大,分类的准确性就越高。在ROC曲线上,最靠近坐标图左上方的点为灵敏性和特异性均较高的临界值。
ROC曲线上各点反映着相同的感受性,它们都是对同一信号刺激的反应,只不过是在几种不同的判定标准下所得的结果而已。接受者操作特性曲线就是以虚报概率为横轴,击中概率为纵轴所组成的坐标图,和被试在特定刺激条件下由于采用不同的判断标准得出的不同结果画出的曲线。
ROC曲线最初源于20世纪70年代的信号检测理论,它反映了FPR与TPR之间权衡的情况,通俗地来说,即在TPR随着FPR递增的情况下,谁增长得更快,快多少的问题。TPR增长得越快,曲线越往上屈,AUC就越大,反映了模型的分类性能就越好。当正负样本不平衡时,这种模型评价方式比起一般的精确度评价方式的好处尤其显著。一个典型的ROC曲线下图所示:
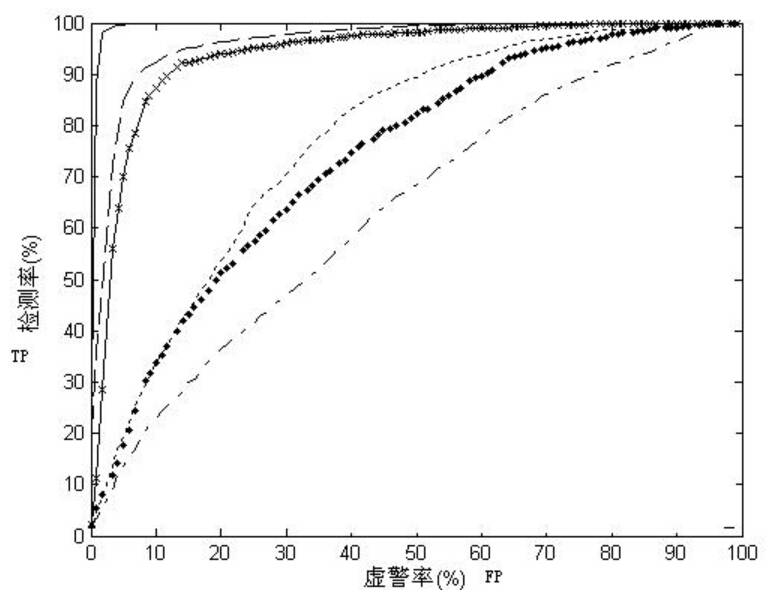
更多关于ROC曲线的经典例子可参考:[http://blog.csdn.net/abcjennifer/article/details/7359370](http://blog.csdn.net/abcjennifer/article/details/7359370)
##三、混淆矩阵
混淆矩阵(Confusion matrix),在人工智能领域中,就是用于总结有监督学习的分类结果的矩阵。沿着主对角线上的项表示正确分类的总数,其他非主对角线的项表示分类的错误数,如下表所示。二分问题存在“错误接受”和“错误拒绝”两种不同类型的错误。若将二分问题的混淆矩阵归一化,就是一个关于0和1二值的离散变量的联合分布概率。对于二分类问题来说,混淆矩阵可以用下面的形式表示:
##四、F score
由于分类准确率有时并不能很好地突出样本集的特点以及判断一个分类器的性能,对于二分类问题,可以使用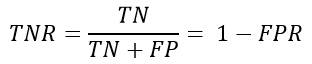 和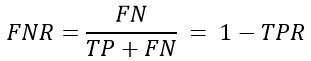 这两个参数来评价分类器的性能。F Score的定义可参照一篇名为:Mining Comparative Sentences and Relations的论文。其中TNR和FNR分别用precision, recall来代替。
一般认为,F评分越高则分类器对于正样本是分类效果越好。需要注意的是,TNR和FNR会互相影响,因此,单独使用一个参数来评价分类器的性能,并不能全面的评价一个分类器。。
模式识别:利用MATLAB生成模式类
最后更新于:2022-04-01 06:47:21
最近开始了模式识别的学习,在此之前需要对模式和模式类的概念有一个了解,这里使用MATLAB实现一些模式类的生成。在此之前,引用百科上对于模式识别和模式类的定义,也算加深以下了解:
>模式识别(Pattern Recognition):人类在日常生活的每个环节,从事着模式识别的活动。可以说每个有正常思维的人,在他没有入睡时都在进行模式识别的活动。坐公共汽车找汽车站,骑车判别可行进道路,对观察到的现象作出判断,对听到的声音作出反应,判断东西的好与坏以及水果的成熟与否等等都是人们判断是非,判别事物的过程。但是对模式识别这个词就显得陌生而难以理解了。确切地说,模式识别在这里是针对让计算机来判断事物而提出的,如检测病理切片中是否有癌细胞,文字识别,话语识别,图像中物体识别等等。该学科研究的内容是使机器能做以前只能由人类才能做的事,具备人所具有的、对各种事物与现象进行分析、描述与判断的部分能力。
模式类与模式,或者模式与样本在集合论中是子集与元素之间的关系。当用一定的度量来衡量两个样本,而找不出它们之间的差别时,它们在这种度量条件下属于同一个等价类。这就是说它们属于同一子集,是一个模式,或一个模式类。而不同的模式类之间应该是可以区分的,它们之间应有明确的界线。但是对实际样本来说,有时又往往不能对它们进行确切的划分,即在所使用的度量关系中,分属不同的类别的样本却表现出相同的属性,因而无法确凿无误地对它们进行区分。例如在癌症初期,癌细胞与正常细胞的界线是含糊的,除非医术有>了进一步发展,能找到更准确有效的分类方法。
下面是练习:
在Matlab 中提供了很多产生随机数和随机向量的函数,以及计算随机函数的概率密度值的函数。下面是几个较常用的函数:
rand() 生成均匀分布随机数
randn() 生成高斯分布随机数
mvnrnd() 生成多元高斯分布的随机向量矩阵
mvnpdf() 计算多元高斯分布的概率密度函数值
在阅读了上述函数的MATLAB在线帮助后,完成下面的程序实现,分为三个练习:
练习一:在一维区间[10,70]中,生成1000个均匀分布的随机数,然后统计并绘制这些数的直方图;在二维区间[1,5]☓[20,30]中,生成5000 个均匀分布的二维随机点,并绘制出它们的二维散点图;在三维区间[10,50]☓[30,60]☓[10,15]中,生成10000 个均匀分布的三维随机点量,并绘制出它们的三维散点图。
~~~
% rand()生成区间[10,70]的1000个随机数
% 并显示直方图
for i = 1:1000
a(i) = rand() * 60 + 10;
end
b = hist(a, 10:70);
figure,bar(10:70, b, 'g');
grid on
title('rand()产生1000个[10,70]的随机数直方图');
for k = 1:5000
TwoDimension(k,1) = rand() * 4 + 1;
TwoDimension(k,2) = rand() * 10 + 20;
end
figure,plot(TwoDimension(:,1), TwoDimension(:,2), '*');
xlim([0 6]);
ylim([10 40]);
grid on
title('在[1,5]*[20,30]中产生5000个均匀分布的二维随机点');
for j = 1:10000
ThreeDimension(j,1) = rand() * 40 + 10;
ThreeDimension(j,2) = rand() * 30 + 30;
ThreeDimension(j,3) = rand() * 5 + 10;
end
figure,scatter3(ThreeDimension(:,1),ThreeDimension(:,2),ThreeDimension(:,3),'r');
xlim([0 60]);
ylim([20 70]);
zlim([0 20]);
grid on;
title('产生10000个均匀分布的三维随机点');
~~~
输出一维、二维和三维随机点生成效果(边界限定参照要求):
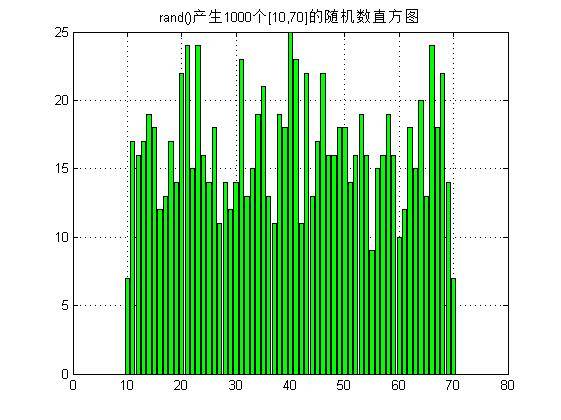
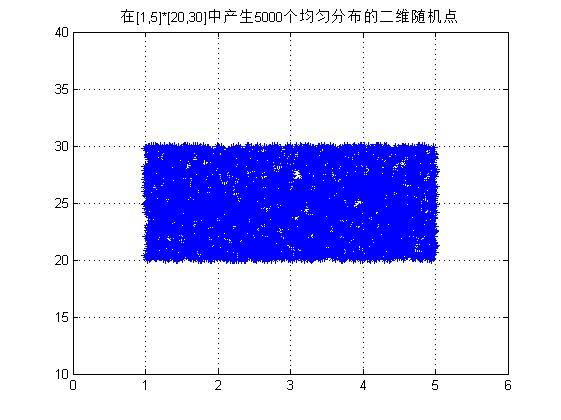
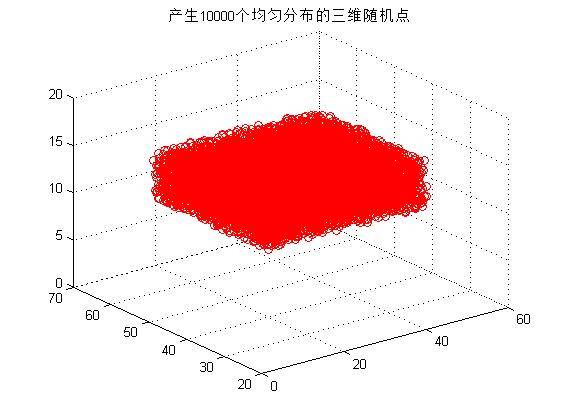
下面是在练习一基础上的扩展:利用均匀分布的随机数函数,编写可以生成具有三角分布、以及梯形分布的随机数的函数。用它们生成一定数量的样本数据,并绘制数据分布图。
~~~
% 产生5000个随机点,然后根据公式剔除三角形外的点
n = 5000;
x = rand(n,2) * 2;
% 变量名 = @(输入参数列表)运算表达式
fx = @(x)(x < 1).*(2*x)+(x >= 1).*(4-2*x);
g=0:0.2:2;
y=fx(g);
% 绘制边界直线,设定直线粗细
figure,plot(g,y,'r-','linewidth',3);
hold on
% 判断元素在y轴上的值是否超出三角形的边界
% 对边界外的点标记为一个值
for t = 1:n
if x(t,2) > fx(x(t,1))
x(t,:) = [0, 0];
end
end
% 扫描标定的值并删除这些元素,剩下边界内的元素
for t = n:-1:1
if x(t,:) == [0, 0]
x(t,:) = [];
end
end
plot(x(:,1),x(:,2),'o');
title('若干个三角分布的随机点');
% 绘制随机点分布直方图
[f, y] = hist(x(:,1), g);
figure,bar(y,f,1);
title('随机点分布直方图');
% 产生5000个随机点,然后根据公式剔除梯形外的点
n = 5000;
x = rand(n,2) * 3;
% 变量名 = @(输入参数列表)运算表达式
fx = @(x)(x <= 1).*(3*x)+( x > 1 & x <= 2).*3 + (x > 2).*(9-3*x);
g=0:0.1:3;
y=fx(g);
% 绘制边界直线,设定直线粗细
figure,plot(g,y,'r-','linewidth',3);
hold on
% 判断元素在y轴上的值是否超出梯形的边界
% 对边界外的点标记为一个值
for t = 1:n
if x(t,2) > fx(x(t,1))
x(t,:) = [0, 0];
end
end
% 扫描标定的值并删除这些元素,剩下边界内的元素
for t = n:-1:1
if x(t,:) == [0, 0]
x(t,:) = [];
end
end
plot(x(:,1),x(:,2),'o');
title('若干个梯形分布的随机点');
% 绘制随机点分布直方图
[f, y] = hist(x(:,1), g);
figure,bar(y,f,1);
title('随机点分布直方图');
~~~
输出三角分布和梯形分布的随机点结果、直方图:


练习二:生成两组各1000个具有不同均值和方差的一维高斯分布的随机数,然后统计并绘制这些点的直方图;生成三组各1000 个具有不同均值矢量和协方差矩阵的二维随机矢量,并绘制出它们的二维散点图;生成五组各1000个具有不同均值矢量和协方差矩阵的三维随机矢量,并绘制出它们的三维散点图。进一步,绘制上述三维随机矢量数据集合的二维投影散点图。可以指定模式向量的其中两个分量,将集合中每个向量的这两个分量提取出来构成一个2维模式子分量的向量集合,然后在二维平面上画出该子分量集合的二维散点图。
~~~
% 使用randn()两组1000个随机数
% 并显示直方图
% 产生一个随机分布的指定均值和方差的矩阵:将randn产生的结果乘以标准差,然后加上期望均值即可。
for i = 1:1000
Gaussian(i,1) = sqrt(1) * randn() + 5;
Gaussian(i,2) = sqrt(2) * randn() + 10;
end
G1 = hist(Gaussian(:,1), 0:20);
G2 = hist(Gaussian(:,2), 0:20);
figure,subplot(1,2,1),bar(0:20, G1, 'g');
grid on
title('均值为5,方差为1的高斯分布随机数直方图');
subplot(1,2,2),bar(0:20, G2, 'g');
grid on
title('均值为10,方差为2的高斯分布随机数直方图');
% mvnrnd(mu,sigma,n)
% 产生二维正态随机数,mu为期望向量,sigma为协方差矩阵,n为规模。
mu = [2 2];
sigma = [1 0; 0 2];
r = mvnrnd(mu,sigma,1000);
figure,plot(r(:,1),r(:,2),'r+');
hold on;
mu = [7 10];
sigma = [ 3 0; 0 3];
r2 = mvnrnd(mu,sigma,1000);
plot(r2(:,1),r2(:,2),'b*')
hold on;
mu = [15 20];
sigma = [ 2 0; 0 2];
r3 = mvnrnd(mu,sigma,1000);
plot(r3(:,1),r3(:,2),'go')
grid on;
title('三组高斯二维随机矢量散点图');
% 产生五组不同的三维高斯随机矢量
mu1 = [2 2 2];
sigma1 = [1 0 0; 0 2 0; 0 0 3];
r1 = mvnrnd(mu1,sigma1,1000);
mu2 = [6 0 -4];
sigma2 = [1 0 0; 0 2 0; 0 0 3];
r2 = mvnrnd(mu2,sigma2,1000);
mu3 = [-9 7 0];
sigma3 = [1 0 0; 0 2 0; 0 0 3];
r3 = mvnrnd(mu3,sigma3,1000);
mu4 = [0 15 -2];
sigma4 = [1 0 0; 0 2 0; 0 0 3];
r4 = mvnrnd(mu4,sigma4,1000);
mu5 = [-12 12 -12];
sigma5 = [1 0 0; 0 2 0; 0 0 3];
r5 = mvnrnd(mu5,sigma5,1000);
figure,plot3(r1(:,1),r1(:,2),r1(:,3),'r+',...
r2(:,1),r2(:,2),r2(:,3),'g+',...
r3(:,1),r3(:,2),r3(:,3),'b+',...
r4(:,1),r4(:,2),r4(:,3),'m+',...
r5(:,1),r5(:,2),r5(:,3),'k+');
grid on
title('五组不同的三维高斯随机矢量');
% 绘制三维随机矢量的二维投影散点图
figure,plot(r1(:,2),r1(:,3),'r+',...
r2(:,2),r2(:,3),'g+',...
r3(:,2),r3(:,3),'b+',...
r4(:,2),r4(:,3),'m+',...
r5(:,2),r5(:,3),'k+');
grid on
title('三维高斯随机矢量的二维投影,取第2、3维');
~~~
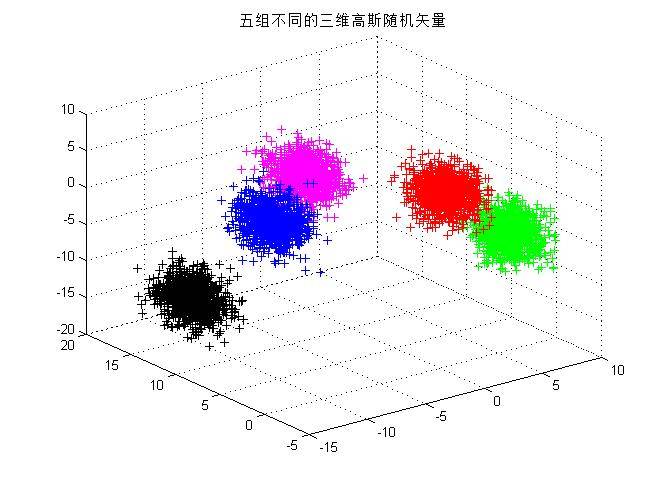

练习三:确定一个二维的均值矢量和协方差矩阵,然后利用matlab 中的meshgrid 函数生成一个二维网格,利用mvnpdf 函数计算在每个网格点上的概率密度函数值,并绘制出这些函数值的三维曲面图。
~~~
% 用meshgird,mvnpdf等函数绘制三维网格图
mu = [0 0];
SIGMA = [1 0; 0 1];
[X,Y] = meshgrid(-5:0.2:5, -5:0.2:5); %在XOY面上,产生网格
p = mvnpdf([X(:),Y(:)],mu,SIGMA); % 求取联合概率密度,相当于Z轴
p = reshape(p,size(X)); % 将Z值对应到相应的坐标上
mesh(X,Y,p); % 绘制
title('三维正态分布图曲面图');
~~~
扩展实验2,编写一个生成N 个d 维向量的混合高斯类数据集的函数。其中,生成的数据集中共有N个模式向量,它们分成c 类。各个类对应的样本数分别为Ni,i = 1, 2, …, c,服从N(mi,Si),i = 1, 2, …, c 的高斯分布, mi,Si 分别是第i 类的均值向量和协方差矩阵。取不同的值,在二维空间和三维空间中生成数据,并绘制出散点图进行验证。这里我们创建一个函数实现这个功能MixGaussian():
~~~
% 随机点个数N ,类别C ,维度d ,均值mu, 方差sigma
function result = MixGaussian(N, C, d, mu, sigma)
color = {'r.', 'g.', 'm.', 'b.', 'k.', 'y.'}; % 用于存放不同类数据的颜色
% if nargin <= 3 & N < 0 & C < 1 & d < 1
% error('参数太少或参数错误');
if d == 1
for i = 1 : C
for j = 1 : N/C
r(j,i) = sqrt(sigma(1,i)) * randn() + mu(1,i);
end
X = round(mu(1,i)-5);
Y = round(mu(1,i) + sqrt(sigma(1,i))+5);
b = hist(r(:,i), X:Y);
subplot(1,C,i),bar(X:Y, b,'b');
title('三类一维随机点的分布直方图');
grid on
end
elseif d == 2
for i = 1:C
r(:,:,i) = mvnrnd(mu(:,:,i),sigma(:,:,i),round(N/C));
plot(r(:,1,i),r(:,2,i),char(color(i)));
hold on;
end
elseif d == 3
for i = 1:C
r(:,:,i) = mvnrnd(mu(:,:,i),sigma(:,:,i),round(N/C));
plot3(r(:,1,i),r(:,2,i),r(:,3,i),char(color(i)));
hold on;
end
else disp('维数只能设置为1,2或3');
end
result = r;
~~~
效果如下,根据输入的维度、方差、均值等参数的不同均可以输出模式类:
扩展实验3,编写一个绘制由c类共N个d 维模式向量构成的多模式类集合的二维投影绘图函数。其中,模式的类别标记已知,不同类别的模式绘制时用不同的颜色表示。其中,d维模式的2维子空间,简单来说就是由d 维模式矢量中的其中2个分量构成向量空间,在作图时以这两个分量做为坐标量,这里定义一个函数TwoDProject()。
~~~
% 输入数据,输出二维投影,X,Y为坐标轴选择
function TwoDProject(data, X, Y)
color = {'r.', 'g.', 'm.', 'b.', 'k.', 'y.'}; % 用于存放不同类数据的颜色
figure;
[a,b,c] = size(data);
if X == 1 && Y == 2
for i = 1:c
plot(data(:,X,i),data(:,Y,i),char(color(i)));
hold on;
end
elseif X == 1 && Y == 3
for i = 1:c
plot(data(:,X,i),data(:,Y,i),char(color(i)));
hold on;
end
elseif X == 2 && Y == 3
for i = 1:c
plot(data(:,X,i),data(:,Y,i),char(color(i)));
hold on;
end
else
disp('维数设置错误');
end
grid on;
title('多维随机点的二维投影图');
~~~
以上完整代码可在此处下载:[http://download.csdn.net/detail/liyuefeilong/8499915](http://download.csdn.net/detail/liyuefeilong/8499915)
前言
最后更新于:2022-04-01 06:47:19
> 原文出处:[模式分类理论与方法专栏文章](http://blog.csdn.net/column/details/prandmethod.html)
> 作者:[谢浩鹏](http://blog.csdn.net/liyuefeilong)
**本系列文章经作者授权在看云整理发布,未经作者允许,请勿转载!**
# 模式分类理论与方法
> 模式识别是指对表征事物或现象的各种形式的(数值的、文字的和逻辑关系的)信息进行处理和分析,以对事物或现象进行描述、辨认、分类和解释的过程,是信息科学和人工智能的重要组成部分。