模式识别:最大似然估计与贝叶斯估计方法
最后更新于:2022-04-01 06:47:28
之前学习了贝叶斯分类器的构造和使用,其中核心的部分是**得到事件的先验概率并计算出后验概率** ,而事实上在实际使用中,很多时候无法得到这些完整的信息,因此我们需要使用另外一个重要的工具——参数估计。
参数估计是在已知系统模型结构时,用系统的输入和输出数据计算系统模型参数的过程。18世纪末德国数学家C.F.高斯首先提出参数估计的方法,他用最小二乘法计算天体运行的轨道。20世纪60年代,随着电子计算机的普及,参数估计有了飞速的发展。参数估计有多种方法,有最小二乘法、极大似然法、极大验后法、最小风险法和极小化极大熵法等。在一定条件下,后面三个方法都与极大似然法相同。最基本的方法是最小二乘法和极大似然法。这里使用MATLAB实现几种经典的方法并研究其估计特性。
目前理论部分尚在研究当中,无法解释得很清楚,这是一个长期的学习过程。
##一、最大似然估计法
最大似然估计是一种统计方法,它用来求一个样本集的相关概率密度函数的参数。这个方法最早是遗传学家以及统计学家罗纳德•费雪爵士在 1912 年至1922 年间开始使用的。这种方法的基本思想是:当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该使得从模型中抽取该n组样本观测值的概率最大,而不是像最小二乘估计法旨在得到使得模型能最好地拟合样本数据的参数估计量。
最大似然估计的优点主要有:
1\. 随着样本数量的增加,收敛性变好;
2\. 比任何其他的迭代技术都简单,适合实用。
最大四然估计的一般原理:
假设有c个类,且:
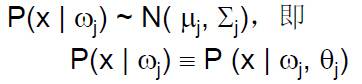
在正态分布时有:
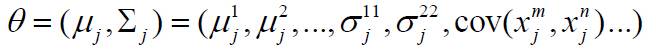
假设数据集合D划分成的类为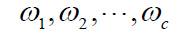
我们可以将数据集合D划分成互不相交的样本子集合,每一个子集合中的样本属于同一类。对每一个数据集合Di ,单独估计自己的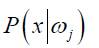 ,这样只需估计其参数即可得到分布函数。
这样,假设集合D包含同一类n个样本, x1, x2,…, xn,且这些样本是独立抽样得到的,则:
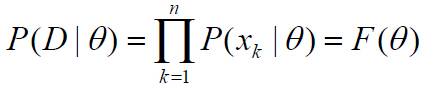
P(D | θ)称为样本集合D的似然函数。**参数θ 的最大似然估计是通过使定义的P(D | θ) 最大化得到的θ的值,使得实际观测到的样本集合具有最大的概率。**在实际中,可以对似然函数进行对数运算,为此定义对数似然函数如下:
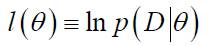
这样有:
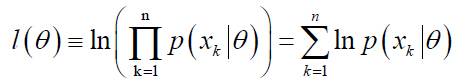
其导数定义为:
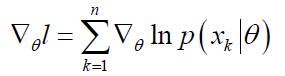
(注:由于自然对数函数是单调增函数,因此对数似然函数和似然函数的极值点的位置相同!)
这里我们要寻找最优解,这是最大似然估计的基本思想。最优解的必要条件是:
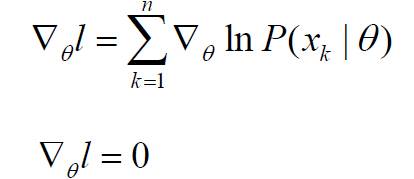
若θ由p个参数组成,则上式代表p个方程组成的方程组。下一步是求取似然函数的极值点:

此时问题可以重新表述为:求对数似然函数的极值点参数θ,使对数似然函数取得最大值:
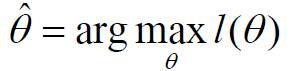
根据以上公式,在样本点服从正态分布,且均值和协方差矩阵未知的情况下,我们可以得到以下两个公式,分别计算估计均值和协方差矩阵。
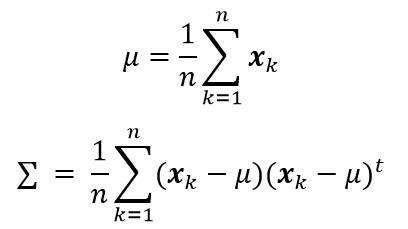
##二、贝叶斯估计法
在最大似然估计中,假设参数θ未知,但事实上它是确定的量。在而在贝叶斯估计法中,参数θ视为一个随机变量。后验概率P(x| D) 的计算是贝叶斯学习的最终目的,其核心问题是给定样本集合D,计算P(θ| D)。方法二和方法三就属于贝叶斯估计法。(公式的推导有待进一步研究)

离散情况:
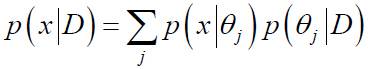
##三、估计方法的公式总结
这里假设样本点服从正态分布,且均值和协方差矩阵未知的情况下,方法一计算估计均值和协方差矩阵:
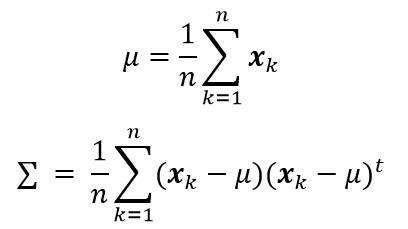
方法二计算估计均值和协方差矩阵:
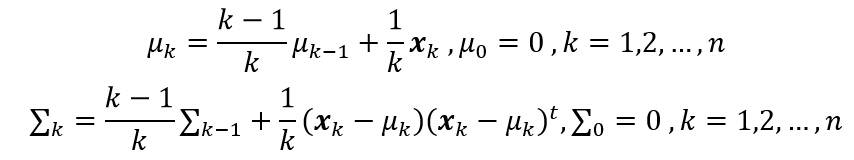
方法三计算估计均值和协方差矩阵:
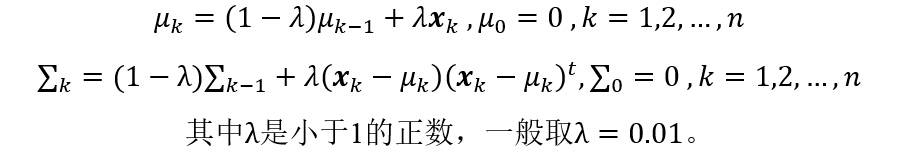
其中,λ 是一个小于1的正数,一般可取λ=0.01。可以看到,**方法二和方法三均使用迭代的方法求解每一步的均值矢量和协方差矩阵。**
##四、估计误差
在方法二、三中,在第k步的估计误差可以由下面的公式计算:
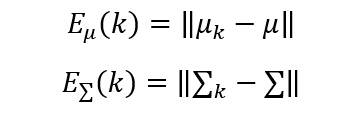
上面的是向量和矩阵范数,一般可以取欧氏范数的形式。
##五、实验步骤与讨论
对不同维数下的高斯概率密度模型,用最大似然估计等方法对其参数进行估计。假设有概率密度为高斯分布p(x) ~N(μ,∑)的样本集合S={xk,k = 1,2,…,n},可以使用以上介绍的三种方法进行均值矢量和协方差矩阵的参数估计,实验步骤主要包括以下几个部分:
1)参考:[http://blog.csdn.net/liyuefeilong/article/details/44247589](http://blog.csdn.net/liyuefeilong/article/details/44247589) 中的程序,调用模式类生成函数MixGaussian,要求给定一组均值(均值向量)和方差(协方差矩阵),生成一维、二维或三维的高斯分布的散点,每一组数据集合的样本个数为100。
2)利用上面介绍的方法一、方法二和方法三,分别估计这三组数据的均值(均值向量)和方差(协方差矩阵)。
3)利用上面介绍的误差计算公式,计算方法一、方法二和方法三的估计误差。对于方法二和方法三,计算每一次迭代估计的误差值,并绘制出误差曲线图。
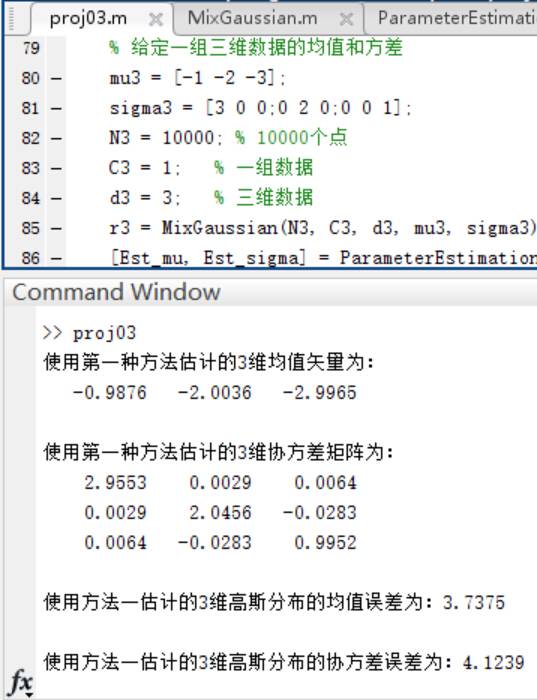
这里生成三维散点图,以下是三种方法的估计结果与误差曲线图:
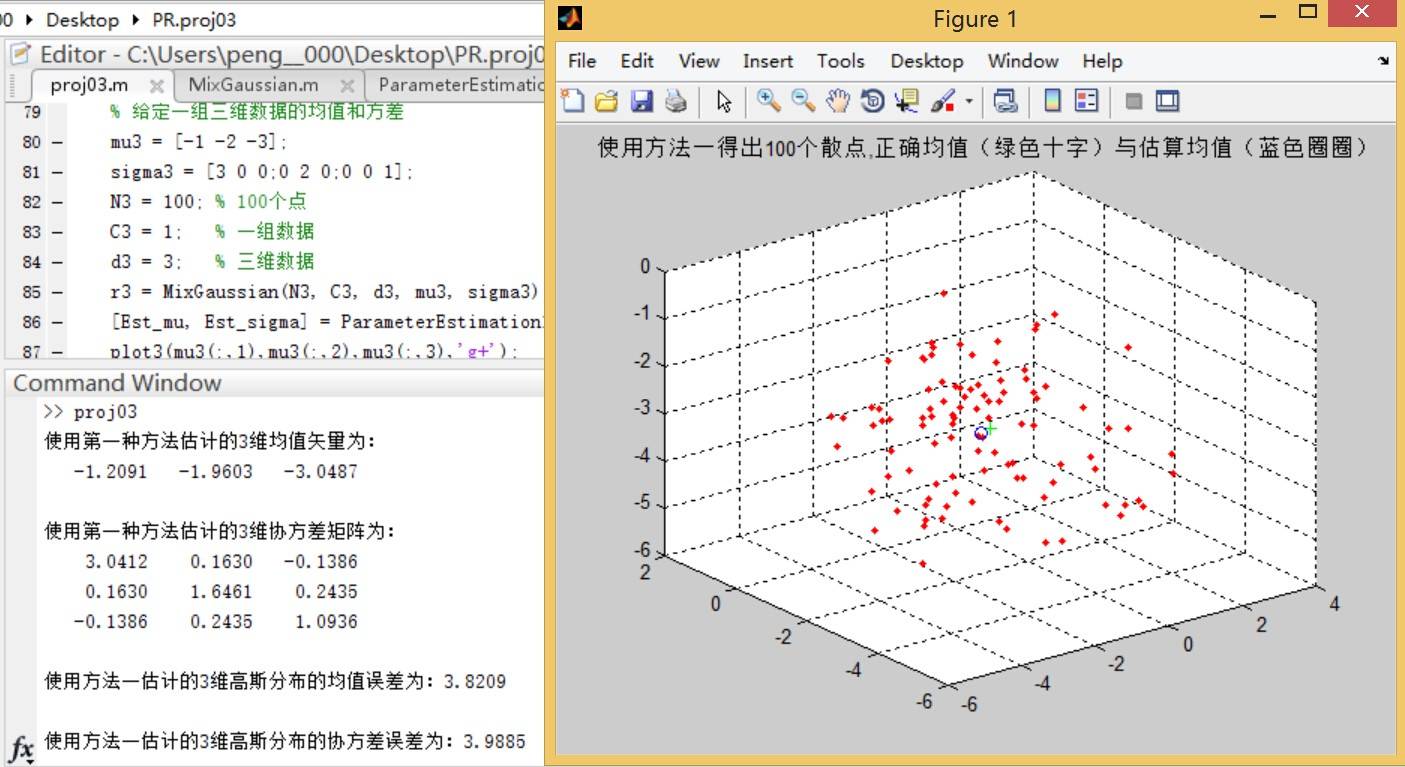
方法一:
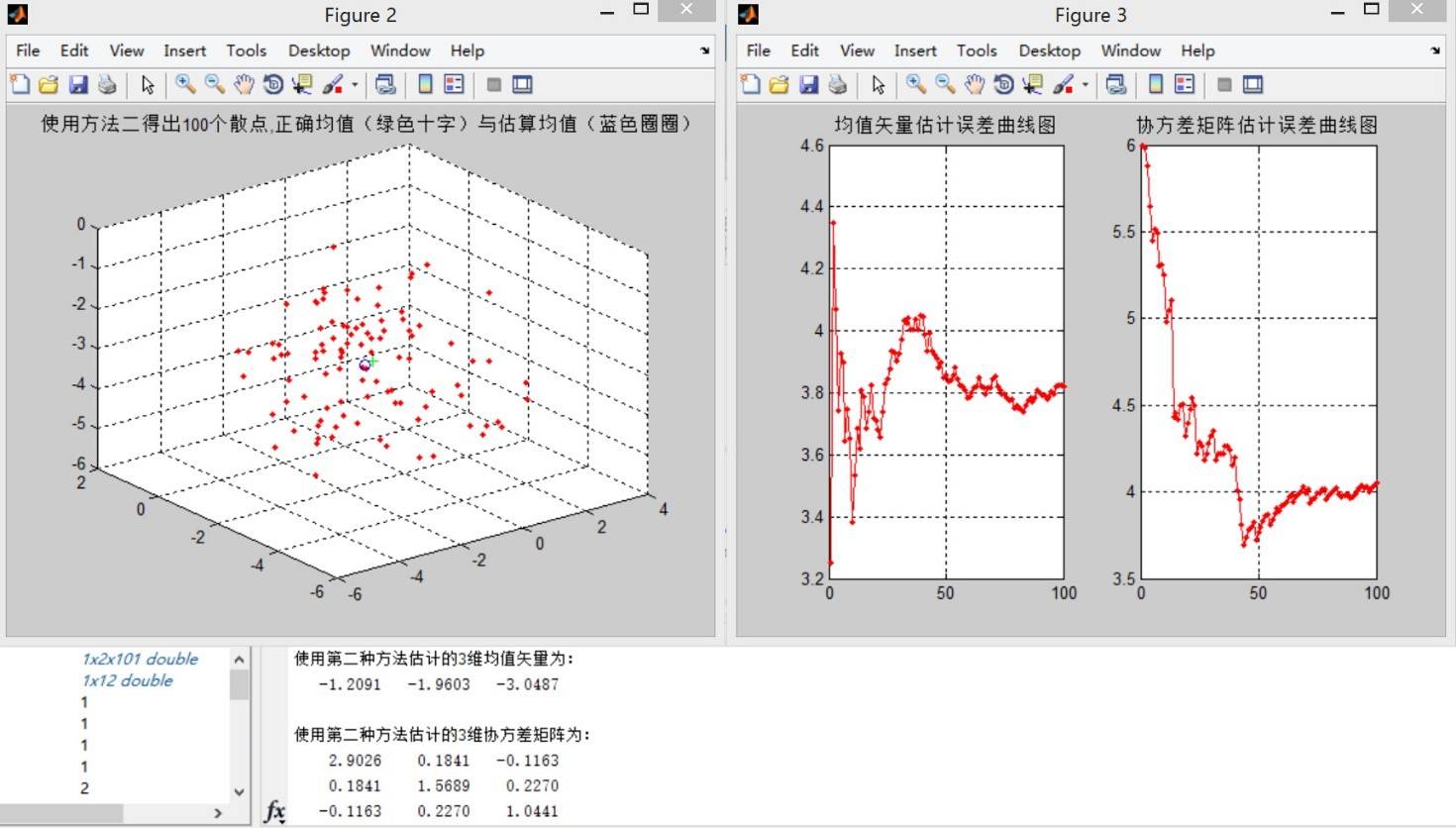
方法二:
方法三:
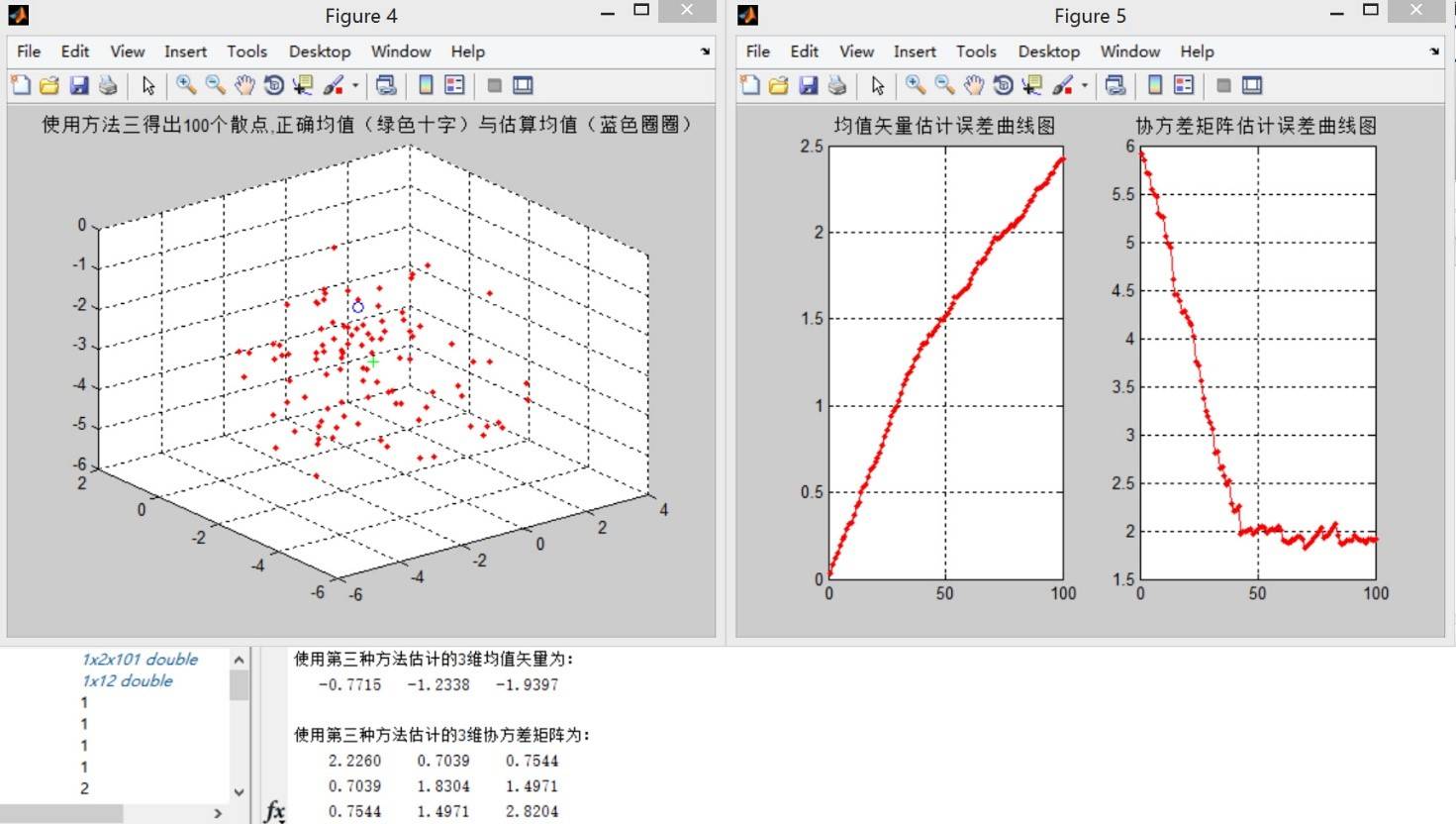
**结论一:** 观察误差曲线图,方法三在估计样本点个数少的时候比方法二的均值误差更小,但方法二的均值误差曲线总体呈单调递减的走势,而方法三正好相反。在观察误差曲线时,无法找出更多可靠的规律。考虑到这里样本点只有100个,因此增加样本点个数进行实验。
4)在(1)中,将每一个数据集合的样本个数变为10000,重新生成数据集合,重复(2) (3)中的实验。
方法一:
方法二:

方法三:
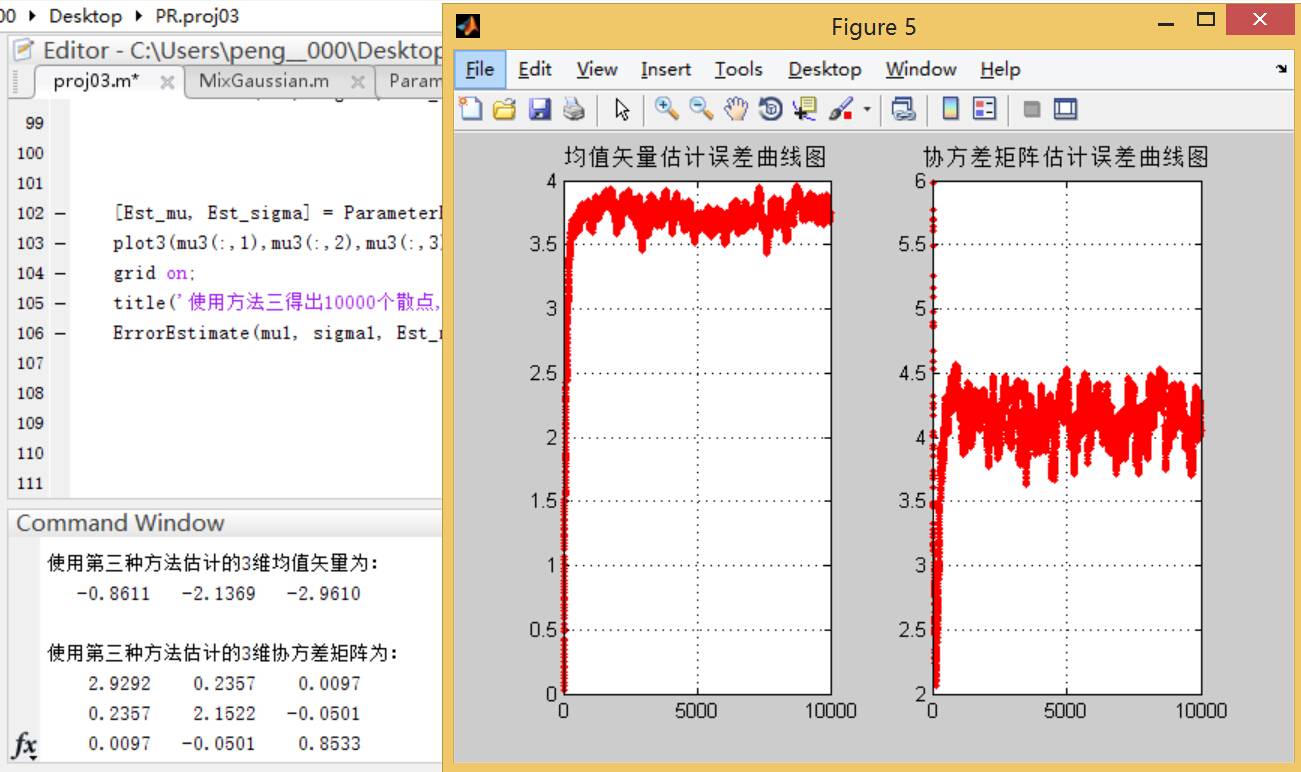
**结论二:**可以看到,使用方法二进行迭代求取均值和协方差矩阵的方法的误差曲线随着样本点数的增多而区域平缓;相比之下,方法三的误差曲线变化幅度较大,而且在样本个数较多的情况下误差要大于方法二。
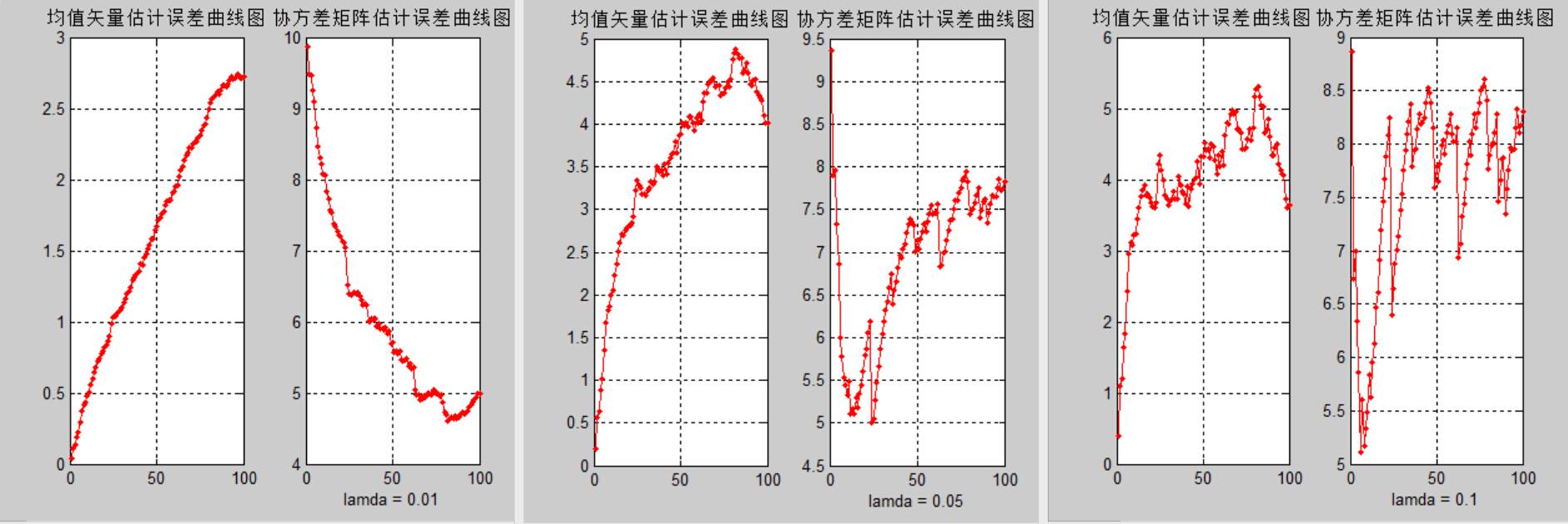
5)该部分是论证方法三中λ的取值对估计误差的影响。这里选取不同的λ值,重复(2) (3) (4)中的实验,观察结果的异同,并加以解释分析。
100数据lamda比较:
10000数据lamda比较:
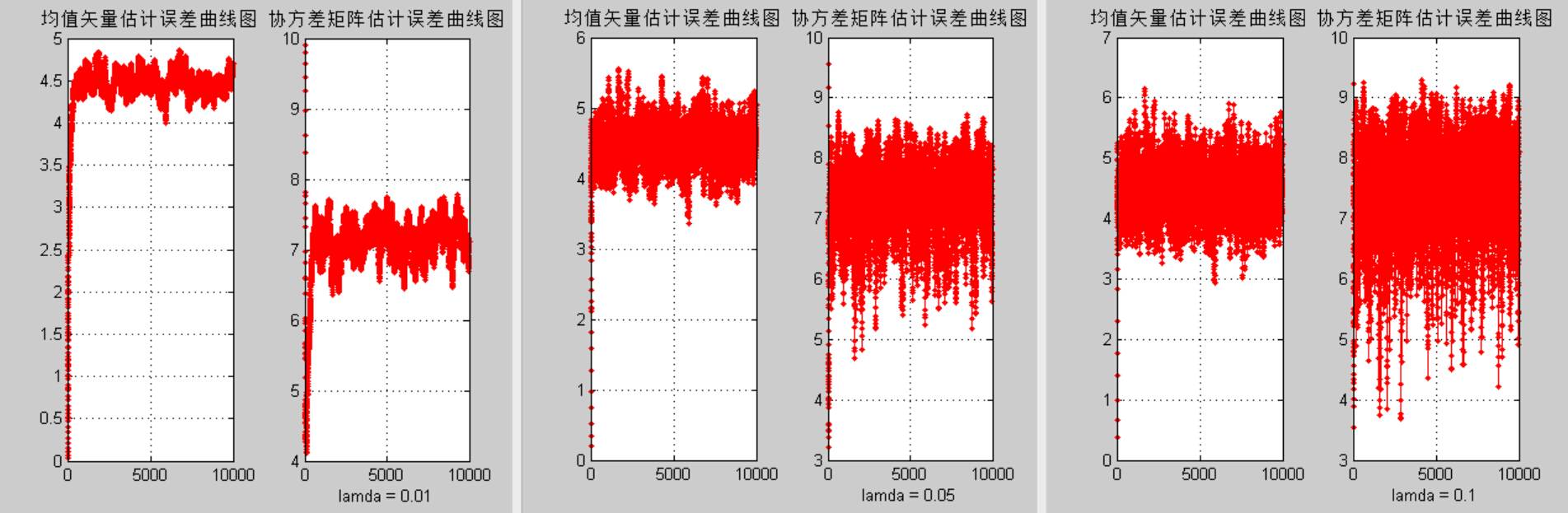
**结论三:**结合输出结果可以发现,方法三中λ的取值对均值矢量估计和协方差矩阵估计的误差有很大影响,过大的λ取值会导致更大的估计误差,因此通常λ取0.01。
**总结:由于实验采用了有限样本估计带来了一定的估计误差,这一误差的影响可以通过增加样本个数的方法来减小。在理论上,贝叶斯估计方法有很强的理论和算法基础,但实际中,最大似然估计算法更加简便,而且设计出的分类器性能几乎与贝叶斯方法得到的结果相差无几。若碰到样本点个数很少时,可以尝试使用方法三进行估计。**
最后给出几个主要函数的定义,只需简单设置参数就可以调用这些函数:
~~~
% 方法一进行参数估计,输出估计均值和协方差矩阵
function [mu,sigma] = ParameterEstimation1(r)
[x,y] = size(r);
% 散点的均值计算
mu = sum(r)/x;
% 散点的协方差矩阵计算
a = 0;
for i = 1:x
a = a + (r(i,:,:) - mu)' * (r(i,:,:) - mu);
end
sigma = a/x;
disp(['使用第一种方法估计的',num2str(y),'维均值矢量为:']);
disp(mu);
disp(['使用第一种方法估计的',num2str(y),'维协方差矩阵为:']);
disp(sigma);
if y == 1
k=-3:0.1:x;
x=mu + 0.*k; % 产生一个和y长度相同的x数组
plot(x,k,'g-');
else if y == 2
figure;
plot(r(:,1),r(:,2),'r.');
hold on;
plot(mu(1,1),mu(1,2),'bo');
else if y == 3
figure;
plot3(r(:,1),r(:,2),r(:,3),'r.');
hold on;
plot3(mu(1,1),mu(1,2),mu(1,3),'bo');
end
end
end
title('使用方法一得出散点图与估算均值(蓝色圈圈)');
~~~
~~~
% 方法二进行参数估计,输出估计均值和协方差矩阵
function [mu,sigma] = ParameterEstimation2(r)
[x,y] = size(r);
% 套用公式前均值和协方差矩阵的初值
mu = zeros(1,y);
sigma = zeros(y,y);
for i = 1:x
mu(:,:,i+1) = mu(:,:,i)*(i-1)/i + r(i,:)/i;
sigma(:,:,i+1) = sigma(:,:,i)*(i-1)/i + (r(i,:) - mu(:,:,i+1))' * (r(i,:) - mu(:,:,i+1)) ./i;
end
disp(['使用第二种方法估计的',num2str(y),'维均值矢量为:']);
disp(mu(1,:,x+1));
disp(['使用第二种方法估计的',num2str(y),'维协方差矩阵为:']);
disp(sigma(:,:,x+1));
if y == 1
k=-3:0.1:x;
x=mu(1,1,x+1) + 0.*k; % 产生一个和y长度相同的x数组
plot(x,k,'g-');
else if y == 2
figure;
plot(r(:,1),r(:,2),'r.');
hold on;
plot(mu(1,1,x+1),mu(1,2,x+1),'bo');
else if y == 3
figure;
plot3(r(:,1),r(:,2),r(:,3),'r.');
hold on;
plot3(mu(1,1,x+1),mu(1,2,x+1),mu(1,3,x+1),'bo');
end
end
end
title('使用方法二得出散点图与估算均值(蓝色圈圈)');
~~~
~~~
% 方法三进行参数估计,输出估计均值和协方差矩阵
% 输入不同维度的高斯概率密度模型,估计均值和协方差矩阵
% lamda为方法三中的调节参数,默认为0.01
function [mu,sigma] = ParameterEstimation3(r, lamda)
% lamda的缺省值为0.01
default_lamda = 0.01;
% 如果只输入r而没有设定lamda,则lamda选用默认值
if nargin == 1
lamda = default_lamda;
end
[x,y] = size(r);
% 套用公式前均值和协方差矩阵的初值
mu = zeros(1,y);
sigma = zeros(y,y);
for i = 1:x
mu(:,:,i+1) = mu(:,:,i)*(1 - lamda) + r(i,:) * lamda;
sigma(:,:,i+1) = sigma(:,:,i)*(1 - lamda) + (r(i,:) - mu(:,:,i+1))' * (r(i,:) - mu(:,:,i+1)) .*lamda;
end
disp(['使用第三种方法估计的',num2str(y),'维均值矢量为:']);
disp(mu(1,:,x+1));
disp(['使用第三种方法估计的',num2str(y),'维协方差矩阵为:']);
disp(sigma(:,:,x+1));
if y == 1
k=-3:0.1:x;
x=mu(1,1,x+1) + 0.*k; % 产生一个和y长度相同的x数组
plot(x,k,'g-');
else if y == 2
figure;
plot(r(:,1),r(:,2),'r.');
hold on;
plot(mu(1,1,x+1),mu(1,2,x+1),'bo');
else if y == 3
figure;
plot3(r(:,1),r(:,2),r(:,3),'r.');
hold on;
plot3(mu(1,1,x+1),mu(1,2,x+1),mu(1,3,x+1),'bo');
end
end
end
title('使用方法三得出散点图与估算均值(蓝色圈圈)');
~~~
~~~
% 误差估计函数
function ErrorEstimate(mu, sigma, Est_mu, Est_sigma)
[x,y,z] = size(Est_mu);
if z == 1
Emu = norm((Est_mu - mu),2);
Esigma = norm((Est_sigma - sigma),2);
fprintf(['使用方法一估计的',num2str(y),'维高斯分布的均值误差为:',num2str(Emu),'\n']);
fprintf(['\n使用方法一估计的',num2str(y),'维高斯分布的协方差误差为:',num2str(Esigma),'\n\n']);
else
for i = 1:z-1
Emu(i) = norm((Est_mu(:,:,i+1) - mu),2);
Esigma(i) = norm((Est_sigma(:,:,i+1) - sigma),2);
end
x = 1:1:z-1;
figure;
subplot(1,2,1);
plot(x,Emu,'r.-');
title('均值矢量估计误差曲线图');
grid on;
subplot(1,2,2),plot(x,Esigma,'r.-');
title('协方差矩阵估计误差曲线图');
grid on;
end
~~~