pytho内置函数大全
最后更新于:2022-04-01 23:52:47
[TOC]
# abs() 函数
> abs() 函数返回数字的绝对值。
~~~
abs(-45) : 45
abs(100.12) : 100.12
abs(119L) : 119
~~~
# divmod() 函数
> divmod() 函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。
```
>>>divmod(7, 2)
(3, 1)
>>> divmod(8, 2)
(4, 0)
>>> divmod(1+2j,1+0.5j)
((1+0j), 1.5j)
```
# input() 函数
```
Python3.x 中 input() 函数接受一个标准输入数据,返回为 string 类型。
Python2.x 中 input() 相等于eval(raw\_input(prompt)),用来获取控制台的输入。
raw\_input() 将所有输入作为字符串看待,返回字符串类型。而 input() 在对待纯数字输入时具有自己的特性,它返回所输入的数字的类型( int, float )。
```
# open() 函数
> open() 函数用于打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。
# staticmethod() 函数
> staticmethod 返回函数的静态方法。
> 该方法不强制要求传递参数,如下声明一个静态方法:
~~~
class C(object):
@staticmethod
def f(arg1, arg2, ...):
...
~~~
以上实例声明了静态方法 f,类可以不用实例化就可以调用该方法 C.f(),当然也可以实例化后调用 C().f()。
# all() 函数
> all() 函数用于判断给定的可迭代参数 iterable 中的所有元素是否都为 TRUE,如果是返回 True,否则返回 False。
> 元素除了是 0、空、FALSE 外都算 TRUE。
```
>>>all(['a', 'b', 'c', 'd']) # 列表list,元素都不为空或0 True
>>> all(['a', 'b', '', 'd']) # 列表list,存在一个为空的元素 False
>>> all([0, 1,2, 3]) # 列表list,存在一个为0的元素 False
>>> all(('a', 'b', 'c', 'd')) # 元组tuple,元素都不为空或0 True
>>> all(('a', 'b', '', 'd')) # 元组tuple,存在一个为空的元素 False
>>> all((0, 1, 2, 3)) # 元组tuple,存在一个为0的元素 False
>>> all([]) # 空列表 True
>>> all(()) # 空元组 True
```
# enumerate() 函数
> enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
Python 2.3. 以上版本可用,2.6 添加 start 参数。
~~~
enumerate(sequence, [start=0])
~~~
* sequence -- 一个序列、迭代器或其他支持迭代对象。
* start -- 下标起始位置。
```
>>>seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons)) [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1)) # 下标从 1 开始 [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
```
# int() 函数
> int() 函数用于将一个字符串或数字转换为整型。
~~~
class int(x, base=10)
~~~
* x -- 字符串或数字。
* base -- 进制数,默认十进制。
# ord() 函数
> ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。
# str() 函数
> str() 函数将对象转化为适于人阅读的形式。
# any() 函数
> any() 函数用于判断给定的可迭代参数 iterable 是否全部为 False,则返回 False,如果有一个为 True,则返回 True。
元素除了是 0、空、FALSE 外都算 TRUE。
# eval() 函数
> eval() 函数用来执行一个字符串表达式,并返回表达式的值。
~~~
eval(expression[, globals[, locals]])
~~~
* expression -- 表达式。
* globals -- 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
* locals -- 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
```
>>>x = 7
>>> eval( '3 * x' )
21
>>> eval('pow(2,2)')
4
>>> eval('2 + 2')
4
>>> n=81
>>> eval("n + 4")
85
```
# isinstance() 函数
> isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
```
isinstance() 与 type() 区别:
* type() 不会认为子类是一种父类类型,不考虑继承关系。
* isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
```
# pow() 函数
> **pow()**方法返回 xy(x的y次方) 的值。
以下是 math 模块 pow() 方法的语法:
~~~
import math
math.pow( x, y )
~~~
内置的 pow() 方法
~~~
pow(x, y[, z])
~~~
函数是计算x的y次方,如果z在存在,则再对结果进行取模,其结果等效于pow(x,y) %z
**注意:**pow() 通过内置的方法直接调用,内置方法会把参数作为整型,而 math 模块则会把参数转换为 float。
# sum() 函数
> **sum()**方法对系列进行求和计算。
以下是 sum() 方法的语法:
~~~
sum(iterable[, start])
~~~
* iterable -- 可迭代对象,如:列表、元组、集合。
* start -- 指定相加的参数,如果没有设置这个值,默认为0。
```
>>>sum([0,1,2])
3
>>> sum((2, 3, 4), 1 # 元组计算总和后再加 1
10
```
# basestring() 函数
> **basestring()**方法是 str 和 unicode 的超类(父类),也是抽象类,因此不能被调用和实例化,但可以被用来判断一个对象是否为 str 或者 unicode 的实例,isinstance(obj, basestring) 等价于 isinstance(obj, (str, unicode))。
```
>>>isinstance("Hello world", str)
True
>>>isinstance("Hello world", basestring)
True
```
# execfile() 函数
> execfile() 函数可以用来执行一个文件。
~~~
execfile(filename[, globals[, locals]])
~~~
* filename -- 文件名。
* globals -- 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
* locals -- 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
# issubclass() 函数
> **issubclass()**方法用于判断参数 class 是否是类型参数 classinfo 的子类。
~~~
issubclass(class, classinfo)
~~~
* class -- 类。
* classinfo -- 类。
如果 class 是 classinfo 的子类返回 True,否则返回 False。
# print() 函数
> **print()**方法用于打印输出,最常见的一个函数。
~~~
print(*objects, sep=' ', end='\n', file=sys.stdout)
~~~
* objects -- 复数,表示可以一次输出多个对象。输出多个对象时,需要用 , 分隔。
* sep -- 用来间隔多个对象,默认值是一个空格。
* end -- 用来设定以什么结尾。默认值是换行符 \\n,我们可以换成其他字符串。
* file -- 要写入的文件对象。
# super() 函数
> **super()**函数是用于调用父类(超类)的一个方法。
super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题。
MRO 就是类的方法解析顺序表, 其实也就是继承父类方法时的顺序表。
# bin() 函数
> **bin()**返回一个整数 int 或者长整数 long int 的二进制表示。
# file() 函数
> **file()**函数用于创建一个 file 对象,它有一个别名叫[open()](http://www.runoob.com/python/pytho-func-open),更形象一些,它们是内置函数。参数是以字符串的形式传递的。
~~~
file(name[, mode[, buffering]])
~~~
* name -- 文件名
* mode -- 打开模式
* buffering -- 0 表示不缓冲,如果为 1 表示进行行缓冲,大于 1 为缓冲区大小。
# iter() 函数
> **iter()**函数用来生成迭代器。
~~~
iter(object[, sentinel])
~~~
* object -- 支持迭代的集合对象。
* sentinel -- 如果传递了第二个参数,则参数 object 必须是一个可调用的对象(如,函数),此时,iter 创建了一个迭代器对象,每次调用这个迭代器对象的\_\_next\_\_()方法时,都会调用 object。
# property() 函数
> **property()**函数的作用是在新式类中返回属性值。
~~~
class property([fget[, fset[, fdel[, doc]]]])
~~~
* fget -- 获取属性值的函数
* fset -- 设置属性值的函数
* fdel -- 删除属性值函数
* doc -- 属性描述信息
# Tuple(元组) tuple()方法
Python 元组 tuple() 函数将列表转换为元组。
~~~
tuple( seq )
~~~
* seq -- 要转换为元组的序列。
# bool() 函数
> **bool()**函数用于将给定参数转换为布尔类型,如果没有参数,返回 False。
bool 是 int 的子类。
~~~
class bool([x])
~~~
* x -- 要进行转换的参数。
# filter() 函数
> **filter()**函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
~~~
filter(function, iterable)
~~~
* function -- 判断函数。
* iterable -- 可迭代对象。
# len()方法
> Python len() 方法返回对象(字符、列表、元组等)长度或项目个数。
~~~
len( s )
~~~
* s -- 对象。
# range() 函数用法
> range() 函数可创建一个整数列表,一般用在 for 循环中。
~~~
range(start, stop[, step])
~~~
* start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
* stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是\[0, 1, 2, 3, 4\]没有5
* step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
# type() 函数
> type() 函数如果你只有第一个参数则返回对象的类型,三个参数返回新的类型对象。
isinstance() 与 type() 区别:
* type() 不会认为子类是一种父类类型,不考虑继承关系。
* isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。
~~~
type(object)
type(name, bases, dict)
~~~
* name -- 类的名称。
* bases -- 基类的元组。
* dict -- 字典,类内定义的命名空间变量。
# bytearray() 函数
> **bytearray()**方法返回一个新字节数组。这个数组里的元素是可变的,并且每个元素的值范围: 0 <= x < 256。
~~~
class bytearray([source[, encoding[, errors]]])
~~~
* 如果 source 为整数,则返回一个长度为 source 的初始化数组;
* 如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
* 如果 source 为可迭代类型,则元素必须为\[0 ,255\] 中的整数;
* 如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
* 如果没有输入任何参数,默认就是初始化数组为0个元素。
# float() 函数
> **float()**函数用于将整数和字符串转换成浮点数。
# list()方法
> list() 方法用于将元组转换为列表。
**注:**元组与列表是非常类似的,区别在于元组的元素值不能修改,元组是放在括号中,列表是放于方括号中。
~~~
list( tup )
~~~
* tup -- 要转换为列表的元组。
# raw_input() 函数
raw\_input() 用来获取控制台的输入。
raw\_input() 将所有输入作为字符串看待,返回字符串类型。
> 注意:input() 和 raw\_input() 这两个函数均能接收 字符串 ,但 raw\_input() 直接读取控制台的输入(任何类型的输入它都可以接收)。而对于 input() ,它希望能够读取一个合法的 python 表达式,即你输入字符串的时候必须使用引号将它括起来,否则它会引发一个 SyntaxError 。
>
> 除非对 input() 有特别需要,否则一般情况下我们都是推荐使用 raw\_input() 来与用户交互。
>
> 注意:python3 里 input() 默认接收到的是 str 类型。
# unichr() 函数
> unichr() 函数 和 chr()函数功能基本一样, 只不过是返回 unicode 的字符。
# callable() 函数
**callable()**函数用于检查一个对象是否是可调用的。如果返回 True,object 仍然可能调用失败;但如果返回 False,调用对象 object 绝对不会成功。
对于函数、方法、lambda 函式、 类以及实现了\_\_call\_\_方法的类实例, 它都返回 True。
# format 格式化函数
新增了一种格式化字符串的函数str.format(),它增强了字符串格式化的功能。
基本语法是通过{}和:来代替以前的%。
format 函数可以接受不限个参数,位置可以不按顺序。
# locals() 函数
> **locals()**函数会以字典类型返回当前位置的全部局部变量。
对于函数, 方法, lambda 函式, 类, 以及实现了 \_\_call\_\_ 方法的类实例, 它都返回 True。
# reduce()函数
> **reduce()**函数会对参数序列中元素进行累积。
函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
~~~
reduce(function, iterable[, initializer])
~~~
* function -- 函数,有两个参数
* iterable -- 可迭代对象
* initializer -- 可选,初始参数
# unicode()
';
python初始
最后更新于:2022-04-01 23:52:44
# :-: python初识
[TOC]
## **数据类型**
1.整数
2.浮点数
3.字符串
4.布尔型
5.空值
注释使用 #
## **变量**
变量名必须是大小写英文、数字和下划线的组合,且不能用数字开头
## **字符串**
字符串可以用`''`或者`""`括起来表示。
如果字符串本身包含`'`怎么办?比如我们要表示字符串` I'm OK `,这时,可以用`" "`括起来表示:
~~~
"I'm OK"
~~~
如果字符串既包含`'`又包含`"`
这个时候,就需要对字符串的某些特殊字符进行“转义”,Python字符串用`\`进行转义。
要表示字符串 `Bob said "I'm OK".`
~~~
'Bob said \"I\'m OK\".'
~~~
常用的转义字符还有:
~~~
\n 表示换行
\t 表示一个制表符
\\ 表示 \ 字符本身
~~~
## **Python中raw字符串与多行字符串**
如果一个字符串包含很多需要转义的字符,对每一个字符都进行转义会很麻烦。为了避免这种情况,我们可以在字符串前面加个前缀`r`,表示这是一个 raw 字符串,里面的字符就不需要转义了。例如:
~~~
r'\(~_~)/ \(~_~)/'
~~~
但是`r'...'`表示法不能表示多行字符串,也不能表示包含`'`和`"`的字符串
如果要表示多行字符串,可以用`'''...'''`表示
~~~
'''Line 1
Line 2
Line 3'''
~~~
上面这个字符串的表示方法和下面的是完全一样的:
```
'Line 1\\nLine 2\\nLine 3'
```
还可以在多行字符串前面添加`r`,把这个多行字符串也变成一个raw字符串:
~~~
r'''Python is created by "Guido".
It is free and easy to learn.
Let's start learn Python in imooc!'''
~~~
## **Python中Unicode字符串**
Python在后来添加了对Unicode的支持,以Unicode表示的字符串用u'...'表示,比如:
~~~
print u'中文'
中文
~~~
Unicode字符串除了多了一个`u`之外,与普通字符串没啥区别,转义字符和多行表示法仍然有效
**多行:**
~~~
u'''第一行
第二行'''
~~~
**raw+多行:**
~~~
ur'''Python的Unicode字符串支持"中文",
"日文",
"韩文"等多种语言'''
~~~
如果中文字符串在Python环境下遇到 UnicodeDecodeError,这是因为.py文件保存的格式有问题。可以在第一行添加注释
~~~
# -*- coding: utf-8 -*-
~~~
## **Python中整数和浮点数**
Python支持对整数和浮点数直接进行四则混合运算,运算规则和数学上的四则运算规则完全一致。
基本的运算:
~~~
1 + 2 + 3 # ==> 6
4 * 5 - 6 # ==> 14
7.5 / 8 + 2.1 # ==> 3.0375
~~~
使用括号可以提升优先级,这和数学运算完全一致,注意只能使用小括号,但是括号可以嵌套很多层:
~~~
(1 + 2) * 3 # ==> 9
(2.2 + 3.3) / (1.5 * (9 - 0.3)) # ==> 0.42145593869731807
~~~
和数学运算不同的地方是,Python的整数运算结果仍然是整数,浮点数运算结果仍然是浮点数:
~~~
1 + 2 # ==> 整数 3
1.0 + 2.0 # ==> 浮点数 3.0
~~~
但是整数和浮点数混合运算的结果就变成浮点数了:
~~~
1 + 2.0 # ==> 浮点数 3.0
~~~
> 为什么要区分整数运算和浮点数运算呢?这是因为整数运算的结果永远是精确的,而浮点数运算的结果不一定精确,因为计算机内存再大,也无法精确表示出无限循环小数,比如`0.1`换成二进制表示就是无限循环小数。
那整数的除法运算遇到除不尽的时候,结果难道不是浮点数吗?我们来试一下:
~~~
11 / 4 # ==> 2
~~~
令很多初学者惊讶的是,Python的整数除法,即使除不尽,结果仍然是整数,余数直接被扔掉。不过,Python提供了一个求余的运算 % 可以计算余数:
~~~
11 % 4 # ==> 3
~~~
如果我们要计算 11 / 4 的精确结果,按照“整数和浮点数混合运算的结果是浮点数”的法则,把两个数中的一个变成浮点数再运算就没问题了:
~~~
11.0 / 4 # ==> 2.75
~~~
## **Python中布尔类型**
**与运算**:只有两个布尔值都为 True 时,计算结果才为 True。
~~~
True and True # ==> True
True and False # ==> False
False and True # ==> False
False and False # ==> False
~~~
**或运算**:只要有一个布尔值为 True,计算结果就是 True。
~~~
True or True # ==> True
True or False # ==> True
False or True # ==> True
False or False # ==> False
~~~
**非运算**:把True变为False,或者把False变为True:
~~~
not True # ==> False
not False # ==> True
~~~
Python把`0`、`空字符串''`和`None`看成 False,其他数值和非空字符串都看成True
~~~
a = True
print a and 'a=T' or 'a=F'
~~~
计算结果不是布尔类型,而是字符串 'a=T'
## **Python创建list**
Python内置的一种数据类型是列表:`list`。list是一种有序的集合,可以随时添加和删除其中的元素。
~~~
>>> ['Michael', 'Bob', 'Tracy']
['Michael', 'Bob', 'Tracy']
~~~
list是数学意义上的有序集合,也就是说,list中的元素是按照顺序排列的。
构造list非常简单,按照上面的代码,直接用`[ ]`把list的所有元素都括起来,就是一个list对象。通常,我们会把list赋值给一个变量,这样,就可以通过变量来引用list:
~~~
>>> classmates = ['Michael', 'Bob', 'Tracy']
>>> classmates # 打印classmates变量的内容
['Michael', 'Bob', 'Tracy']
~~~
由于Python是动态语言,所以list中包含的元素并不要求都必须是同一种数据类型,我们完全可以在list中包含各种数据:
~~~
>>> L = ['Michael', 100, True]
~~~
一个元素也没有的list,就是空list:
~~~
>>> empty_list = []
~~~
## **Python之倒序访问list**
~~~
>>> L = ['Adam', 'Lisa', 'Bart']
~~~
~~~
>>> print L[-1]
Bart
~~~
倒数第二用 -2 表示,倒数第三用 -3 表示,倒数第四用 -4 表示
~~~
>>> print L[-2]
Lisa
>>> print L[-3]
Adam
>>> print L[-4]
Traceback (most recent call last):
File "", line 1, in
IndexError: list index out of range
~~~
## **Python之添加新元素**
**append()**总是把新的元素添加到 list 的尾部。
~~~
>>> L = ['Adam', 'Lisa', 'Bart']
>>> L.append('Paul')
>>> print L
['Adam', 'Lisa', 'Bart', 'Paul']
~~~
用list的`insert()`方法,它接受两个参数,第一个参数是索引号,第二个参数是待添加的新元素:
~~~
>>> L = ['Adam', 'Lisa', 'Bart']
>>> L.insert(0, 'Paul')
>>> print L
['Paul', 'Adam', 'Lisa', 'Bart']
~~~
**L.insert(0, 'Paul')**的意思是,'Paul'将被添加到索引为 0 的位置上(也就是第一个),而原来索引为 0 的Adam同学,以及后面的所有同学,都自动向后移动一位。
## **Python从list删除元素**
~~~
>>> L = ['Adam', 'Lisa', 'Bart', 'Paul']
>>> L.pop()
'Paul'
>>> print L
['Adam', 'Lisa', 'Bart']
~~~
**pop()**方法总是删掉list的最后一个元素,并且它还返回这个元素,所以我们执行 L.pop() 后,会打印出 'Paul'。
要把Paul踢出list,我们就必须先定位Paul的位置。由于Paul的索引是2,因此,用`pop(2)`把Paul删掉:
~~~
>>> L.pop(2)
'Paul'
>>> print L
['Adam', 'Lisa', 'Bart']
~~~
## **Python之创建tuple**
tuple是另一种有序的列表,中文翻译为“ 元组 ”。tuple 和 list 非常类似,但是,tuple一旦创建完毕,就不能修改了。
~~~
>>> t = ('Adam', 'Lisa', 'Bart')
~~~
创建tuple和创建list唯一不同之处是用`( )`替代了`[ ]`。
现在,这个`t`就不能改变了,tuple没有 append()方法,也没有insert()和pop()方法。所以,新同学没法直接往 tuple 中添加,老同学想退出 tuple 也不行。
获取 tuple 元素的方式和 list 是一模一样的,我们可以正常使用 t\[0\],t\[-1\]等索引方式访问元素,但是不能赋值成别的元素
## **Python之创建单元素tuple**
正是因为用()定义单元素的tuple有歧义,所以 Python 规定,单元素 tuple 要多加一个逗号“,”
~~~
>>> t = (1,)
>>> print t
(1,)
~~~
多元素 tuple 加不加这个额外的“,”效果是一样的
~~~
>>> t = (1, 2, 3,)
>>> print t
(1, 2, 3)
~~~
## **Python之“可变”的tuple**
前面我们看到了tuple一旦创建就不能修改。现在,我们来看一个“可变”的tuple:
~~~
>>> t = ('a', 'b', ['A', 'B'])
~~~
**注意**到 t 有 3 个元素:**'a','b'**和一个list:**\['A', 'B'\]**。list作为一个整体是tuple的第3个元素。list对象可以通过 t\[2\] 拿到:
~~~
>>> L = t[2]
~~~
## **Python之if语句**
~~~
age = 20
if age >= 18:
print 'your age is', age
print 'adult'
print 'END'
~~~
> **注意:** Python代码的缩进规则。具有相同缩进的代码被视为代码块,上面的3,4行 print 语句就构成一个代码块(但不包括第5行的print)。如果 if 语句判断为 True,就会执行这个代码块。
> 缩进请严格按照Python的习惯写法:4个空格,不要使用Tab,更不要混合Tab和空格,否则很容易造成因为缩进引起的语法错误。
> **注意**: if 语句后接表达式,然后用`:`表示代码块开始。
> 如果你在Python交互环境下敲代码,还要特别留意缩进,并且退出缩进需要多敲一行回车:
## **Python之 if-else**
当 if 语句判断表达式的结果为True时,就会执行 if 包含的代码块:
~~~
if age >= 18:
print 'adult'
~~~
~~~
if not age >= 18:
print 'teenager'
~~~
~~~
if age >= 18:
print 'adult'
else:
print 'teenager'
~~~
## **Python之 if-elif-else**
~~~
if age >= 18:
print 'adult'
else:
if age >= 6:
print 'teenager'
else:
if age >= 3:
print 'kid'
else:
print 'baby'
~~~
## **Python之 for循环**
list或tuple可以表示一个有序集合。如果我们想依次访问一个list中的每一个元素呢?比如 list:
~~~
L = ['Adam', 'Lisa', 'Bart']
for name in L:
print name
~~~
> **注意: ** name 这个变量是在 for 循环中定义的,意思是,依次取出list中的每一个元素,并把元素赋值给 name,然后执行for循环体(就是缩进的代码块)。
## **Python之 while循环**
和 for 循环不同的另一种循环是while循环,while 循环不会迭代 list 或 tuple 的元素,而是根据表达式判断循环是否结束。
比如要从 0 开始打印不大于 N 的整数:
~~~
N = 10
x = 0
while x < N:
print x
x = x + 1
~~~
while循环每次先判断 x < N,如果为True,则执行循环体的代码块,否则,退出循环。
在循环体内,x = x + 1会让x不断增加,最终因为x < N不成立而退出循环。
如果没有这一个语句,**while循环在判断 x < N 时总是为True**,就会无限循环下去,变成死循环,所以要特别留意while循环的退出条件
## **Python之 break退出循环**
用 for 循环或者 while 循环时,如果要在循环体内直接退出循环,可以使用 break 语句。
比如计算1至100的整数和,我们用while来实现:
~~~
sum = 0
x = 1
while True:
sum = sum + x
x = x + 1
if x > 100:
break
print sum
~~~
## **Python之 continue继续循环**
在循环过程中,可以用break退出当前循环,还可以用continue跳过后续循环代码,继续下一次循环。
假设我们已经写好了利用for循环计算平均分的代码:
~~~
L = [75, 98, 59, 81, 66, 43, 69, 85]
sum = 0.0
n = 0
for x in L:
sum = sum + x
n = n + 1
print sum / n
~~~
现在老师只想统计及格分数的平均分,就要把 x < 60 的分数剔除掉,这时,利用 continue,可以做到当 x < 60的时候,不继续执行循环体的后续代码,直接进入下一次循环:
~~~
for x in L:
if x < 60:
continue
sum = sum + x
n = n + 1
~~~
## **Python之 多重循环**
~~~
for x in ['A', 'B', 'C']:
for y in ['1', '2', '3']:
print x + y
~~~
## **Python之什么是dict**
Python的 dict 就是专门干这件事的。用 **dict **表示**“名字”-“成绩”**的查找表如下:
~~~
d = {
'Adam': 95,
'Lisa': 85,
'Bart': 59
}
~~~
我们把**名字称为key**,对应的**成绩称为value**,dict就是通过**key**来查找**value**。
花括号{}表示这是一个dict,然后按照**key: value**, 写出来即可。最后一个 key: value 的逗号可以省略。
由于dict也是集合,len() 函数可以计算任意集合的大小:
~~~
>>> len(d)
3
~~~
## **Python之访问dict**
可以简单地使用d\[key\]的形式来查找对应的 value,这和 list 很像,不同之处是,**list 必须使用索引返回对应的元素,而dict使用key:**
**注意:**通过 key 访问 dict 的value,只要 key 存在,dict就返回对应的value。如果key不存在,会直接报错:KeyError。
要避免 KeyError 发生,有两个办法:
**一是先判断一下 key 是否存在,用 in 操作符:**
~~~
if 'Paul' in d:
print d['Paul']
~~~
**二是使用dict本身提供的一个 get 方法,在Key不存在的时候,返回None:**
~~~
>>> print d.get('Bart')
59
>>> print d.get('Paul')
None
~~~
## **Python中dict的特点**
**dict的第一个特点是查找速度快,无论dict有10个元素还是10万个元素,查找速度都一样**。而list的查找速度随着元素增加而逐渐下降。
不过dict的查找速度快不是没有代价的,**dict的缺点是占用内存大,还会浪费很多内容**,list正好相反,占用内存小,但是查找速度慢。
由于dict是按 key 查找,所以,在一个dict中,key不能重复。
**dict的第二个特点就是存储的key-value序对是没有顺序的**
**dict的第三个特点是作为 key 的元素必须不可变**
## **Python更新dict**
dict是可变的,也就是说,我们可以随时往dict中添加新的 key-value。比如已有dict:
~~~
d = {
'Adam': 95,
'Lisa': 85,
'Bart': 59
}
~~~
要把新同学'Paul'的成绩 72 加进去,用赋值语句:
~~~
>>> d['Paul'] = 72
~~~
如果 key 已经存在,则赋值会用新的 value 替换掉原来的 value:
## **Python之 遍历dict**
由于dict也是一个集合,所以,遍历dict和遍历list类似,都可以通过 for 循环实现。
直接使用for循环可以遍历 dict 的 key:
~~~
>>> d = { 'Adam': 95, 'Lisa': 85, 'Bart': 59 }
>>> for key in d:
... print key
...
Lisa
Adam
Bart
~~~
## **Python中什么是set**
**dict的作用是建立一组 key 和一组 value 的映射关系,dict的key是不能重复的。**
有的时候,我们只想要 dict 的 key,不关心 key 对应的 value,目的就是保证这个集合的元素不会重复,这时,set就派上用场了。
**set 持有一系列元素,这一点和 list 很像,但是set的元素没有重复,而且是无序的,这点和 dict 的 key很像。**
创建 set 的方式是调用 set() 并传入一个 list,list的元素将作为set的元素:
~~~
>>> s = set(['A', 'B', 'C'])
~~~
~~~
>>> print s
set(['A', 'C', 'B'])
~~~
**请注意**,上述打印的形式类似 list, 但它不是 list,仔细看还可以发现,打印的顺序和原始 list 的顺序有可能是不同的,因为set内部存储的元素是**无序**的。
因为set不能包含重复的元素,所以,当我们传入包含重复元素的 list 会怎么样呢?
~~~
>>> s = set(['A', 'B', 'C', 'C'])
>>> print s
set(['A', 'C', 'B'])
>>> len(s)
3
~~~
## **Python之 访问set**
由于**set存储的是无序集合**,所以我们没法通过索引来访问。
访问 set中的某个元素实际上就是判断一个元素是否在set中。
~~~
>>> s = set(['Adam', 'Lisa', 'Bart', 'Paul'])
~~~
我们可以用 in 操作符判断
~~~
>>> 'Bart' in s
True
~~~
~~~
>>> 'Bill' in s
False
~~~
~~~
>>> 'bart' in s
False
~~~
看来大小写很重要,'Bart' 和 'bart'被认为是两个不同的元素
## **Python之 set的特点**
**set的内部结构和dict很像,唯一区别是不存储value**,因此,判断一个元素是否在set中速度很快。
**set存储的元素和dict的key类似,必须是不变对象**,因此,任何可变对象是不能放入set中的。
最后,set存储的元素也是没有顺序的。
set的这些特点,可以应用在哪些地方呢?
星期一到星期日可以用字符串'MON', 'TUE', ... 'SUN'表示。
假设我们让用户输入星期一至星期日的某天,如何判断用户的输入是否是一个有效的星期呢?
可以用**if 语句**判断,但这样做非常繁琐:
~~~
x = '???' # 用户输入的字符串
if x!= 'MON' and x!= 'TUE' and x!= 'WED' ... and x!= 'SUN':
print 'input error'
else:
print 'input ok'
~~~
**注意:**if 语句中的...表示没有列出的其它星期名称,测试时,请输入完整。
如果事先创建好一个set,包含'MON' ~ 'SUN':
~~~
weekdays = set(['MON', 'TUE', 'WED', 'THU', 'FRI', 'SAT', 'SUN'])
~~~
再判断输入是否有效,只需要判断该字符串是否在set中:
~~~
x = '???' # 用户输入的字符串
if x in weekdays:
print 'input ok'
else:
print 'input error'
~~~
## **Python之 遍历set**
由于 set 也是一个集合,所以,遍历 set 和遍历 list 类似,都可以通过 for 循环实现。
直接使用 for 循环可以遍历 set 的元素:
~~~
>>> s = set(['Adam', 'Lisa', 'Bart'])
>>> for name in s:
... print name
...
Lisa
Adam
Bart
~~~
**注意: **观察 for 循环在遍历set时,元素的顺序和list的顺序很可能是不同的,而且不同的机器上运行的结果也可能不同。
## **Python之 更新set**
由于**set存储的是一组不重复的无序元素**,因此,更新set主要做两件事:
**一是把新的元素添加到set中,二是把已有元素从set中删除。**
添加元素时,用set的add()方法:
~~~
>>> s = set([1, 2, 3])
>>> s.add(4)
>>> print s
set([1, 2, 3, 4])
~~~
如果添加的元素已经存在于set中,add()不会报错,但是不会加进去了:
~~~
>>> s = set([1, 2, 3])
>>> s.add(3)
>>> print s
set([1, 2, 3])
~~~
删除set中的元素时,用set的remove()方法:
~~~
>>> s = set([1, 2, 3, 4])
>>> s.remove(4)
>>> print s
set([1, 2, 3])
~~~
如果删除的元素不存在set中,remove()会报错:
~~~
>>> s = set([1, 2, 3])
>>> s.remove(4)
Traceback (most recent call last):
File "", line 1, in
KeyError: 4
~~~
所以用add()可以直接添加,而remove()前需要判断。
## **Python之调用函数**
Python内置了很多有用的函数,我们可以直接调用。
要调用一个函数,需要知道**函数**的**名称**和**参数**,比如求绝对值的函数 abs,它接收一个参数。
~~~
可以直接从Python的官方网站查看文档:
http://docs.python.org/2/library/functions.html#abs
~~~
也可以在交互式命令行通过help(abs) 查看abs函数的帮助信息。
调用 **abs **函数:
~~~
>>> abs(100)
100
>>> abs(-20)
20
>>> abs(12.34)
12.34
~~~
调用函数的时候,如果传入的参数数量不对,会报**TypeError**的错误,并且Python会明确地告诉你:abs()有且仅有1个参数,但给出了两个:
~~~
>>> abs(1, 2)
Traceback (most recent call last):
File "", line 1, in
TypeError: abs() takes exactly one argument (2 given)
~~~
如果传入的参数数量是对的,但参数类型不能被函数所接受,也会报**TypeError**的错误,并且给出错误信息:str是错误的参数类型:
~~~
>>> abs('a')
Traceback (most recent call last):
File "", line 1, in
TypeError: bad operand type for abs(): 'str'
~~~
而比较函数 cmp(x, y) 就需要两个参数,如果**xy**,返回**1**:
~~~
>>> cmp(1, 2)
-1
>>> cmp(2, 1)
1
>>> cmp(3, 3)
0
~~~
Python内置的常用函数还包括数据类型转换函数,比如 int()函数可以把其他数据类型转换为整数:
~~~
>>> int('123')
123
>>> int(12.34)
12
~~~
str()函数把其他类型转换成 str:
~~~
>>> str(123)
'123'
>>> str(1.23)
'1.23'
~~~
## **Python之编写函数**
在Python中,定义一个函数要使用**def**语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用 return语句返回。
我们以自定义一个求绝对值的 my\_abs 函数为例:
~~~
def my_abs(x):
if x >= 0:
return x
else:
return -x
~~~
**请注意**,函数体内部的语句在执行时,一旦执行到return时,函数就执行完毕,并将结果返回。因此,函数内部通过条件判断和循环可以实现非常复杂的逻辑。
如果没有return语句,函数执行完毕后也会返回结果,只是结果为 None。
return None可以简写为return。
## **Python函数之返回多值**
**\# math**包提供了**sin()**和 **cos()**函数,我们先用import引用它:
~~~
import math
def move(x, y, step, angle):
nx = x + step * math.cos(angle)
ny = y - step * math.sin(angle)
return nx, ny
~~~
这样我们就可以同时获得返回值:
~~~
>>> x, y = move(100, 100, 60, math.pi / 6)
>>> print x, y
151.961524227 70.0
~~~
但其实这只是一种假象,Python函数返回的仍然是单一值:
~~~
>>> r = move(100, 100, 60, math.pi / 6)
>>> print r
(151.96152422706632, 70.0)
~~~
用print打印返回结果,原来返回值是一个**tuple**!
但是,在语法上,返回一个tuple可以省略括号,而多个变量可以同时接收一个tuple,按位置赋给对应的值,所以,**Python的函数**返回多值其实就是**返回一个tuple**,但写起来更方便。
## **Python之递归函数**
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
举个例子,我们来计算阶乘**n! = 1 \* 2 \* 3 \* ... \* n**,用函数 **fact(n)**表示,可以看出:
~~~
fact(n) = n! = 1 * 2 * 3 * ... * (n-1) * n = (n-1)! * n = fact(n-1) * n
~~~
所以,**fact(n)**可以表示为**n \* fact(n-1)**,只有n=1时需要特殊处理。
于是,fact(n)用递归的方式写出来就是:
~~~
def fact(n):
if n==1:
return 1
return n * fact(n - 1)
~~~
递归函数的优点是定义简单,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰
使用递归函数需要注意防止栈溢出。在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。可以试试计算 fact(10000)。
## **Python之定义默认参数**
例如Python自带的**int()**函数,其实就有两个参数,我们既可以传一个参数,又可以传两个参数:
~~~
>>> int('123')
123
>>> int('123', 8)
83
~~~
int()函数的第二个参数是转换进制,如果不传,默认是十进制 (base=10),如果传了,就用传入的参数。
可见,**函数的默认参数的作用是简化调用**,你只需要把必须的参数传进去。但是在需要的时候,又可以传入额外的参数来覆盖默认参数值。
我们来定义一个计算 x 的N次方的函数:
~~~
def power(x, n):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
~~~
假设计算平方的次数最多,我们就可以把 n 的默认值设定为 2:
~~~
def power(x, n=2):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
~~~
这样一来,计算平方就不需要传入两个参数了:
~~~
>>> power(5)
25
~~~
由于函数的参数按从左到右的顺序匹配,所以**默认参数只能定义在必需参数的后面:**
## **Python之定义可变参数**
如果想让一个函数能接受任意个参数,我们就可以定义一个可变参数:
~~~
def fn(*args):
print args
~~~
可变参数的名字前面有个 **\* **号,我们可以传入0个、1个或多个参数给可变参数:
~~~
>>> fn()
()
>>> fn('a')
('a',)
>>> fn('a', 'b')
('a', 'b')
>>> fn('a', 'b', 'c')
('a', 'b', 'c')
~~~
可变参数也不是很神秘,Python解释器会把传入的一组参数组装成一个tuple传递给可变参数,因此,在函数内部,直接把变量args看成一个 tuple 就好了。
定义可变参数的目的也是为了简化调用。假设我们要计算任意个数的平均值,就可以定义一个可变参数:
~~~
def average(*args):
...
~~~
这样,在调用的时候,可以这样写:
~~~
>>> average()
0
>>> average(1, 2)
1.5
>>> average(1, 2, 2, 3, 4)
2.4
~~~
## **对list进行切片**
取一个list的部分元素是非常常见的操作。比如,一个list如下:
~~~
>>> L = ['Adam', 'Lisa', 'Bart', 'Paul']
~~~
取前3个元素,应该怎么做?
笨办法:
~~~
>>> [L[0], L[1], L[2]]
['Adam', 'Lisa', 'Bart']
~~~
之所以是笨办法是因为扩展一下,取前N个元素就没辙了。
取前N个元素,也就是索引为0-(N-1)的元素,可以用循环:
~~~
>>> r = []
>>> n = 3
>>> for i in range(n):
... r.append(L[i])
...
>>> r
['Adam', 'Lisa', 'Bart']
~~~
对这种经常取指定索引范围的操作,用循环十分繁琐,因此,Python提供了切片(Slice)操作符,能大大简化这种操作。
对应上面的问题,取前3个元素,用一行代码就可以完成切片:
~~~
>>> L[0:3]
['Adam', 'Lisa', 'Bart']
~~~
L\[0:3\]表示,从索引0开始取,直到索引3为止,但不包括索引3。即索引0,1,2,正好是3个元素。
如果第一个索引是0,还可以省略:
~~~
>>> L[:3]
['Adam', 'Lisa', 'Bart']
~~~
也可以从索引1开始,取出2个元素出来:
~~~
>>> L[1:3]
['Lisa', 'Bart']
~~~
只用一个**:**,表示从头到尾:
~~~
>>> L[:]
['Adam', 'Lisa', 'Bart', 'Paul']
~~~
因此,L\[:\]实际上复制出了一个新list。
切片操作还可以指定第三个参数:
~~~
>>> L[::2]
['Adam', 'Bart']
~~~
第三个参数表示每N个取一个,上面的 L\[::2\] 会每两个元素取出一个来,也就是隔一个取一个。
把list换成tuple,切片操作完全相同,只是切片的结果也变成了tuple。
## **倒序切片**
对于list,既然Python支持L\[-1\]取倒数第一个元素,那么它同样支持倒数切片,试试:
~~~
>>> L = ['Adam', 'Lisa', 'Bart', 'Paul']
>>> L[-2:]
['Bart', 'Paul']
>>> L[:-2]
['Adam', 'Lisa']
>>> L[-3:-1]
['Lisa', 'Bart']
>>> L[-4:-1:2]
['Adam', 'Bart']
~~~
记住倒数第一个元素的索引是-1。倒序切片包含起始索引,不包含结束索引。
## **对字符串切片**
字符串 'xxx'和 Unicode字符串 u'xxx'也可以看成是一种list,每个元素就是一个字符。因此,字符串也可以用切片操作,只是操作结果仍是字符串:
~~~
>>> 'ABCDEFG'[:3]
'ABC'
>>> 'ABCDEFG'[-3:]
'EFG'
>>> 'ABCDEFG'[::2]
'ACEG'
~~~
在很多编程语言中,针对字符串提供了很多各种截取函数,其实目的就是对字符串切片。Python没有针对字符串的截取函数,只需要切片一个操作就可以完成,非常简单。
## **什么是迭代**
在Python中,如果给定一个**list**或**tuple**,我们可以通过for循环来遍历这个list或tuple,这种遍历我们成为迭代(Iteration)。
在Python中,迭代是通过 for ... in 来完成的,而很多语言比如C或者Java,迭代list是通过下标完成的,比如Java代码:
~~~
for (i=0; i>> L = ['Adam', 'Lisa', 'Bart', 'Paul']
>>> for index, name in enumerate(L):
... print index, '-', name
...
0 - Adam
1 - Lisa
2 - Bart
3 - Paul
~~~
使用 enumerate() 函数,我们可以在for循环中同时绑定索引index和元素name。但是,这不是 enumerate() 的特殊语法。实际上,enumerate() 函数把:
~~~
['Adam', 'Lisa', 'Bart', 'Paul']
~~~
变成了类似:
~~~
[(0, 'Adam'), (1, 'Lisa'), (2, 'Bart'), (3, 'Paul')]
~~~
因此,迭代的每一个元素实际上是一个tuple:
~~~
for t in enumerate(L):
index = t[0]
name = t[1]
print index, '-', name
~~~
如果我们知道每个tuple元素都包含两个元素,for循环又可以进一步简写为:
~~~
for index, name in enumerate(L):
print index, '-', name
~~~
这样不但代码更简单,而且还少了两条赋值语句。
可见,索引迭代也不是真的按索引访问,而是由 enumerate() 函数自动把每个元素变成 (index, element) 这样的tuple,再迭代,就同时获得了索引和元素本身。
## **迭代dict的value**
我们已经了解了**dict对象**本身就是可**迭代对象**,用 for 循环直接迭代 dict,可以每次拿到dict的一个key。
如果我们希望迭代 dict 对象的value,应该怎么做?
dict 对象有一个**values() 方法**,这个方法把dict转换成一个包含所有value的list,这样,我们迭代的就是 dict的每一个 value:
~~~
d = { 'Adam': 95, 'Lisa': 85, 'Bart': 59 }
print d.values()
# [85, 95, 59]
for v in d.values():
print v
# 85
# 95
# 59
~~~
如果仔细阅读Python的文档,还可以发现,dict除了**values()**方法外,还有一个**itervalues()**方法,用**itervalues()**方法替代**values()**方法,迭代效果完全一样:
~~~
d = { 'Adam': 95, 'Lisa': 85, 'Bart': 59 }
print d.itervalues()
#
for v in d.itervalues():
print v
# 85
# 95
# 59
~~~
**那这两个方法有何不同之处呢?**
1.**values()**方法实际上把一个 dict 转换成了包含 value 的list。
2\. 但是**itervalues()**方法不会转换,它会在迭代过程中依次从 dict 中取出 value,所以 itervalues() 方法比 values() 方法节省了生成 list 所需的内存。
3. 打印 itervalues() 发现它返回一个 对象,这说明在Python中,**for 循环可作用的迭代对象远不止 list,tuple,str,unicode,dict等**,任何可迭代对象都可以作用于for循环,而内部如何迭代我们通常并不用关心。
**如果一个对象说自己可迭代,那我们就直接用 for 循环去迭代它,可见,迭代是一种抽象的数据操作,它不对迭代对象内部的数据有任何要求。**
## **迭代dict的key和value**
我们了解了如何**迭代 dict**的**key**和**value**,那么,在一个 for 循环中,能否同时迭代 key和value?答案是肯定的。
首先,我们看看 dict 对象的**items()**方法返回的值:
~~~
>>> d = { 'Adam': 95, 'Lisa': 85, 'Bart': 59 }
>>> print d.items()
[('Lisa', 85), ('Adam', 95), ('Bart', 59)]
~~~
可以看到,items() 方法把dict对象转换成了包含tuple的list,我们对这个list进行迭代,可以同时获得key和value:
~~~
>>> for key, value in d.items():
... print key, ':', value
...
Lisa : 85
Adam : 95
Bart : 59
~~~
和 values() 有一个 itervalues() 类似,**items()**也有一个对应的**iteritems()**,iteritems() 不把dict转换成list,而是在迭代过程中不断给出 tuple,所以, iteritems() 不占用额外的内存。
## **生成列表**
要生成list \[1, 2, 3, 4, 5, 6, 7, 8, 9, 10\],我们可以用range(1, 11):
~~~
>>> range(1, 11)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
~~~
但如果要生成\[1x1, 2x2, 3x3, ..., 10x10\]怎么做?方法一是循环:
~~~
>>> L = []
>>> for x in range(1, 11):
... L.append(x * x)
...
>>> L
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
~~~
但是循环太繁琐,而列表生成式则可以用一行语句代替循环生成上面的list:
~~~
>>> [x * x for x in range(1, 11)]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
~~~
这种写法就是Python特有的列表生成式。利用列表生成式,可以以非常简洁的代码生成 list。
写列表生成式时,把要生成的元素 x \* x 放到前面,后面跟 for 循环,就可以把list创建出来,十分有用,多写几次,很快就可以熟悉这种语法。
## **复杂表达式**
使用**for循环**的迭代不仅可以迭代普通的list,还可以迭代dict。
假设有如下的dict:
~~~
d = { 'Adam': 95, 'Lisa': 85, 'Bart': 59 }
~~~
完全可以通过一个复杂的列表生成式把它变成一个 HTML 表格:
~~~
tds = ['%s %s '
print '
'
~~~
**注:**字符串可以通过%进行格式化,用指定的参数替代%s。字符串的join()方法可以把一个 list 拼接成一个字符串。
把打印出来的结果保存为一个html文件,就可以在浏览器中看到效果了:
~~~
~~~
[](http://img.mukewang.com/540fcd2a0001ff4600940104.jpg)
## **条件过滤**
列表生成式的 **for 循环后面还可以加上 if 判断**。例如:
~~~
>>> [x * x for x in range(1, 11)]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
~~~
如果我们只想要偶数的平方,不改动 range()的情况下,可以加上 if 来筛选:
~~~
>>> [x * x for x in range(1, 11) if x % 2 == 0]
[4, 16, 36, 64, 100]
~~~
有了 if 条件,只有 if 判断为 True 的时候,才把循环的当前元素添加到列表中。
## **多层表达式**
for循环可以嵌套,因此,在列表生成式中,也可以用多层for循环来生成列表。
对于字符串 'ABC' 和 '123',可以使用两层循环,生成全排列:
~~~
>>> [m + n for m in 'ABC' for n in '123']
['A1', 'A2', 'A3', 'B1', 'B2', 'B3', 'C1', 'C2', 'C3']
~~~
翻译成循环代码就像下面这样:
~~~
L = []
for m in 'ABC':
for n in '123':
L.append(m + n)
~~~
';
| Name | Score |
|---|---|
| Name | Score |
|---|---|
| Lisa | 85 |
| Adam | 95 |
| Bart | 59 |
python学习
最后更新于:2022-04-01 23:52:42
[python初始](python%E5%88%9D%E5%A7%8B.md)
[pytho内置函数大全](pytho%E8%BF%9B%E9%98%B6.md)
';
Webpack
最后更新于:2022-04-01 23:52:39
[TOC]
# Webpack
';
Vue-cli
最后更新于:2022-04-01 23:52:37
[Toc]
# Vue-cli 全解
## Vue-cli,开始
一、安装vue-cli
安装vue-cli的前提是你已经安装了npm,安装npm你可以直接下载node的安装包进行安装。你可以在命令行工具里输入npm -v 检测你是否安装了npm和版本情况。出现版本号说明你已经安装了npm和node,我这里的npm版本为3.10.10。如果该命令不可以使用,需要安装node软件包,根据你的系统版本选择下载安装就可以了。
下载地址:http://nodejs.cn/download/
npm没有问题,接下来我们可以用npm 命令安装vue-cli了,在命令行输入下面的命令:
npm install vue-cli -g
1
npm install vue-cli -g
-g :代表全局安装。如果你安装时报错,一般是网络问题,你可以尝试用cnpm来进行安装。安装完成后,可以用vue -V来进行查看 vue-cli的版本号。注意这里的V是大写的。我这里版本号是2.8.1.
如果vue -V的命令管用了,说明已经顺利的把vue-cli安装到我们的计算机里了。
二、初始化项目
**一直转圈圈怎么办**
一、遇到这一步,一般都是在等去网上找了下也没有人发出解决方法,现在无私为大家解决一下,先取消该下载,重新打开 ,利用淘宝镜像先下载 webpack 包
下载命令:
```
$ cmpm install --save-dev webpack
```
下载成功,我们用vue init命令来初始化项目,具体看一下这条命令的使用方法。
```
$ vue init
```
二、使用--offline安装webpack
去网上下载webpack模板
放在
```
C:\Users\用户名称\.vue-templates
```
里然后在项目位置使用
```
vue init webpack 项目名
```
init:表示我要用vue-cli来初始化项目
:表示模板名称,vue-cli官方为我们提供了5种模板,
webpack-一个全面的webpack+vue-loader的模板,功能包括热加载,linting,检测和CSS扩展。
webpack-simple-一个简单webpack+vue-loader的模板,不包含其他功能,让你快速的搭建vue的开发环境。
browserify-一个全面的Browserify+vueify 的模板,功能包括热加载,linting,单元检测。
browserify-simple-一个简单Browserify+vueify的模板,不包含其他功能,让你快速的搭建vue的开发环境。
simple-一个最简单的单页应用模板。
:标识项目名称,这个你可以根据自己的项目来起名字。
在实际开发中,一般我们都会使用webpack这个模板,那我们这里也安装这个模板,在命令行输入以下命令:
```
vue init webpack vuecliTest
```
输入命令后,会询问我们几个简单的选项,我们根据自己的需要进行填写就可以了。
Project name :项目名称 ,如果不需要更改直接回车就可以了。注意:这里不能使用大写,所以我把名称改成了vueclitest
Project description:项目描述,默认为A Vue.js project,直接回车,不用编写。
Author:作者,如果你有配置git的作者,他会读取。
Install vue-router? 是否安装vue的路由插件,我们这里需要安装,所以选择Y
Use ESLint to lint your code? 是否用ESLint来限制你的代码错误和风格。我们这里不需要输入n,如果你是大型团队开发,最好是进行配置。
setup unit tests with Karma + Mocha? 是否需要安装单元测试工具Karma+Mocha,我们这里不需要,所以输入n。
Setup e2e tests with Nightwatch?是否安装e2e来进行用户行为模拟测试,我们这里不需要,所以输入n。
命令行出现上面的文字,说明我们已经初始化好了第一步。命令行提示我们现在可以作的三件事情。
1、cd vuecliTest 进入我们的vue项目目录。
2、npm install 安装我们的项目依赖包,也就是安装package.json里的包,如果你网速不好,你也可以使用cnpm来安装。
3、npm run dev 开发模式下运行我们的程序。给我们自动构建了开发用的服务器环境和在浏览器中打开,并实时监视我们的代码更改,即时呈现给我们。
出现这个页面,说明我们的初始化已经成功,现在可以快乐的玩耍了。
# Vue webpack打包的时候iviewui的字体不显示问题
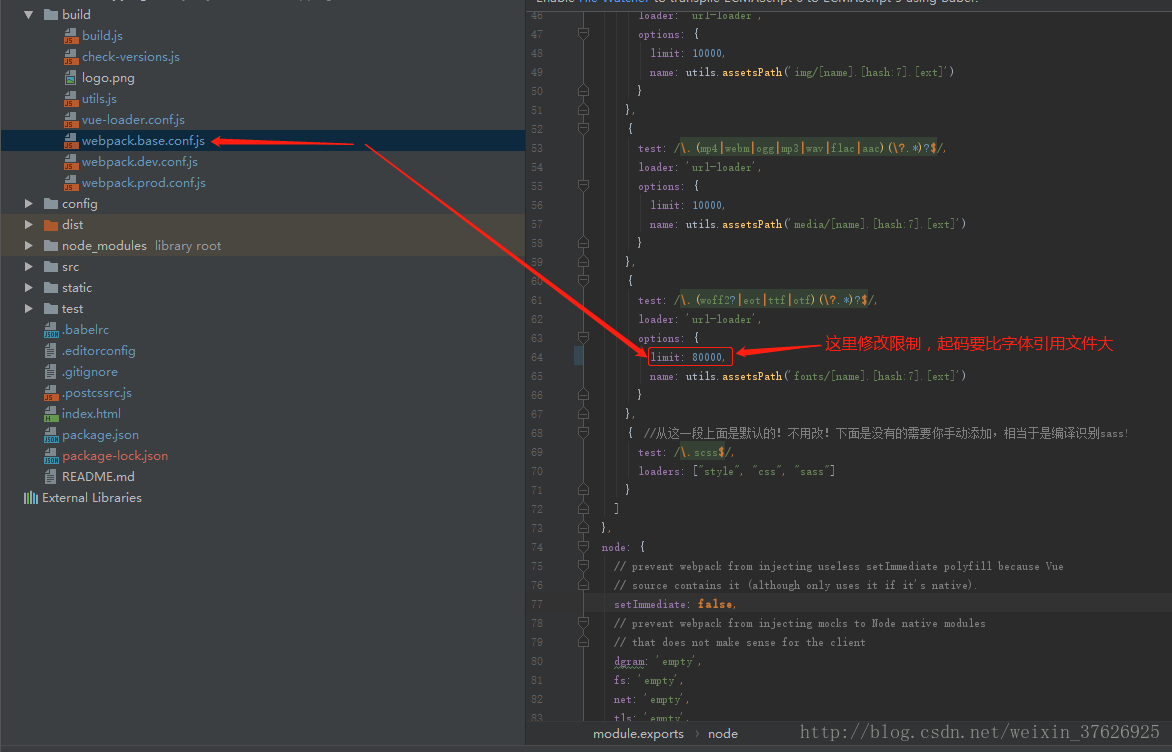
修改字体权重
';
从零开始学Vue
最后更新于:2022-04-01 23:52:35
[Toc]
# VUE学习笔记(内部指令)
## VUE安装方法
1. 去官网 cn.vuejs.org 下载vue.js 和vue.min.js
2. 新建文件夹vue,在vue目录下新建assset文件夹和example文件夹和index.html文件
3. assets文件主要放js和css文件
4. example放一些案例
5. index.html放一些备忘内容
6. 使用VScode编辑内容,点击查看集成终端选择cmd
7. 建立live-server服务
8. cnpm install -g live-server
9. 安装完成后 live-server 启动本地服务
10. 结束本地服务以后,npm init 一下项目
11. 一直确定,会创建一个package.json文件
## 第一个helloword程序
example/helloword.html
```
Helloword
Vue.js实例
``` 在终端中输入live-server 启动服务器点击**Hello World实例**即可看到效果 ## v-if v-else v-show 指令 1. v-if: v-if:是vue 的一个内部指令,指令用在我们的html中。 v-if用来判断是否加载html的DOM,比如我们模拟一个用户登录状态,在用户登录后现实用户名称。 关键代码: ```Helloword
```
这里我们在vue的data里定义了isLogin的值,当它为true时,网页就会显示:你好:像素狮,如果为false时,就显示请登录后操作。
2. v-show :
调整css中display属性,DOM已经加载,只是CSS控制没有显示出来。
```
1. 模板写法 ```
{{item}}
```
2. js写法
```
var app=new Vue({
el:'#app',
data:{
items:[20,23,18,65,32,19,54,56,41]
}
})
```
3. 完整代码
```
V-for 案例
```
这是一个最基础的循环,先在js里定义了items数组,然后在模板中用v-for循环出来,需要注意的是,**你需要那个html标签循环,v-for就写在那个上边。**
二、排序
我们已经顺利的输出了我们定义的数组,但是我需要在输出之前给数组排个序,那我们就用到了Vue的 **computed:** 属性。
```
computed:{
sortItems:function(){
return this.items.sort();
}
}
```
**如果不重新声明报错**我们在computed里新声明了一个对象sortItems,如果不重新声明会污染原来的数据源,这是Vue不允许的,所以你要重新声明一个对象。
**不是成功的排序需要自己封装函数并使用**
**真正的数字排序** ``` //真正的数字排序 function sortNumber(a,b){ return a-b } ``` 用法: ``` computed:{ sortItems:function(){ return this.items.sort(sortNumber); } } ``` 三、对象循环输出 我们上边循环的都是数组,那我们来看一个对象类型的循环是如何输出的。 我们先定义个数组,数组里边是对象数据 ``` students:[ {name:'像素狮',age:'24'}, {name:'小明',age:'26'}, {name:'小张',age:'30'}, {name:'小华',age:'20'}, {name:'Tim',age:'15'}, ] ``` 在模板中输出 ```y)?1:0));
});
}
```
有了数组的排序方法,在computed中进行调用排序
```
sortStudent:function(){
return sortByKey(this.students,'age');
}
```
**注意:** vue低版本中 data里面的items和computed里面可以一样,但是高版本,是不允许相同名称。有很多小伙伴踩到了这个坑,这里提醒学习的小伙伴,根据自己版本的不同,请修改代码。
## v-text & v-html
我们已经会在html中输出data中的值了,我们已经用的是{{xxx}},这种情况是有弊端的,就是当我们网速很慢或者javascript出错时,会暴露我们的{{xxx}}。Vue给我们提供的v-text,就是解决这个问题的。我们来看代码:
```
{{ message }}=
``` 如果在javascript中写有html标签,用v-text是输出不出来的,这时候我们就需要用v-html标签了。 ``` ``` 双大括号会将数据解释为纯文本,而非HTML。为了输出真正的HTML,你就需要使用v-html 指令。 需要注意的是:在生产环境中动态渲染HTML是非常危险的,因为容易导致**XSS攻击**。所以只能在可信的内容上使用**v-html**,永远不要在用户提交和可操作的网页上使用。 ```v-text&v-html
v-on实例
```
javascript代码:
```
var app=new Vue({
el:'#app',
data:{
message:'hello Vue!'
}
})
```
二、修饰符
- **lazy**:取代 imput 监听 change 事件。(v-model.lazy:懒加载失去焦点后加载)
- **number**:输入字符串转为数字。(v-model.number)
- **trim**:输入去掉首尾空格。(v-model.trim)
三、文本区域加入数据绑定
```
```
四、多选按钮绑定一个值
```
![]() ```也是一个标签,我们绑定```
```也是一个标签,我们绑定```![]() ```上的src进行动态赋值。
html文件:
```
```上的src进行动态赋值。
html文件:
```
![]() ```
在html中我们用v-bind:src=”imgSrc”的动态绑定了src的值,这个值是在vue构造器里的data属性中找到的。
js文件:
```
var app=new Vue({
el:'#app',
data:{
imgSrc:'http://baidu.com/wp-content/uploads/2017/02/vue01-2.jpg'
}
})
```
我们在data对象在中增加了imgSrc属性来供html调用。
v-bind 缩写
```
```
绑定CSS样式
在工作中我们经常使用v-bind来绑定css样式:
在绑定CSS样式是,绑定的值必须在vue中的data属性中进行声明。
1、直接绑定class样式
```
```
在html中我们用v-bind:src=”imgSrc”的动态绑定了src的值,这个值是在vue构造器里的data属性中找到的。
js文件:
```
var app=new Vue({
el:'#app',
data:{
imgSrc:'http://baidu.com/wp-content/uploads/2017/02/vue01-2.jpg'
}
})
```
我们在data对象在中增加了imgSrc属性来供html调用。
v-bind 缩写
```
```
绑定CSS样式
在工作中我们经常使用v-bind来绑定css样式:
在绑定CSS样式是,绑定的值必须在vue中的data属性中进行声明。
1、直接绑定class样式
```
v-bind实例
``` ## 其他内部指令(v-pre & v-cloak & v-once) v-pre指令 在模板中跳过vue的编译,直接输出原始值。就是在标签中加入v-pre就不会输出vue中的data值了。 ```v-pre&v-cloak&v-once实例
```
总结:
我们学习了Vue中的指令,这也是Vue中最容易理解的部分,以前我也只是使用Vue,通过这个课程的制作,我也对Vue指令有了全面和更深刻的了解。对于小伙伴们的学习,我想说的是,你看完视频后一定要动手去敲写代码,这样你才能理解并记住,接下来我们将讲解Vue的全局API。
# 全局API
## Vue.directive 自定义指令
一、什么是全局API?
全局API并不在构造器里,而是先声明全局变量或者直接在Vue上定义一些新功能,Vue内置了一些全局API,比如我们今天要学习的指令Vue.directive。说的简单些就是,在构造器外部用Vue提供给我们的API函数来定义新的功能。
二、Vue.directive自定义指令
三、自定义指令中传递的三个参数
el: 指令所绑定的元素,可以用来直接操作DOM。
binding: 一个对象,包含指令的很多信息。
vnode: Vue编译生成的虚拟节点。
四、自定义指令的生命周期
自定义指令有五个生命周期(也叫钩子函数),分别是 **bind,inserted,update,componentUpdated,unbind**
**bind:** 只调用一次,指令第一次绑定到元素时调用,用这个钩子函数可以定义一个绑定时执行一次的初始化动作。
**inserted:** 被绑定元素插入父节点时调用(父节点存在即可调用,不必存在于document中)。
**update:** 被绑定于元素所在的模板更新时调用,而无论绑定值是否变化。通过比较更新前后的绑定值,可以忽略不必要的模板更新。
**componentUpdated:** 被绑定元素所在模板完成一次更新周期时调用。
**unbind:** 只调用一次,指令与元素解绑时调用。
bind:function(){//被绑定
console.log('1 - bind');
},
inserted:function(){//绑定到节点
console.log('2 - inserted');
},
update:function(){//组件更新
console.log('3 - update');
},
componentUpdated:function(){//组件更新完成
console.log('4 - componentUpdated');
},
unbind:function(){//解绑
console.log('1 - bind');
}
## Vue.extend构造器的延伸
一、什么是Vue.extend?
Vue.extend 返回的是一个“扩展实例构造器”,也就是预设了部分选项的Vue实例构造器。经常服务于Vue.component用来生成组件,可以简单理解为当在模板中遇到该组件名称作为标签的自定义元素时,会自动调用“扩展实例构造器”来生产组件实例,并挂载到自定义元素上。
由于我们还没有学习Vue的**自定义组件**,所以我们先看跟组件无关的用途。
二、自定义无参数标签
我们想象一个需求,需求是这样的,要在博客页面多处显示作者的网名,并在网名上直接有链接地址。我们希望在html中只需要写就是管用的。我们来看一下全部代码:
```
vue.extend-扩展实例构造器
Vue.set 全局操作
```
这时我们的界面是不会自动跟新数组的,我们需要用Vue.set(app.arr,1,’ddd’)来设置改变,vue才会给我们自动更新,这就是Vue.set存在的意义。
## Vue的生命周期(钩子函数)
Vue一共有10个生命周期函数,我们可以利用这些函数在vue的每个阶段都进行操作数据或者改变内容。
```
构造器的声明周期
component-1
component-1
component-1组件实例
component-1组件实例
component-2
component-3
component-4
PropsData Option Demo
Computed Option 计算选项
methods Option
methods Option
Watch选项监控数据
```
## Mixins 混入选项操作
Mixins一般有两种用途:
1、在你已经写好了构造器后,需要增加方法或者临时的活动时使用的方法,这时用混入会减少源代码的污染。
2、很多地方都会用到的公用方法,用混入的方法可以减少代码量,实现代码重用。
一、Mixins的基本用法
我们现在有个数字点击递增的程序,假设已经完成了,这时我们希望每次数据变化时都能够在控制台打印出提示:“数据发生变化”.
代码实现过程:
```
Mixins Option Demo
```
二、mixins的调用顺序
从执行的先后顺序来说,都是混入的先执行,然后构造器里的再执行,需要注意的是,这并不是方法的覆盖,而是被执行了两边。
在上边的代码的构造器里我们也加入了updated的钩子函数:
```
updated:function(){
console.log("构造器里的updated方法。")
},
```
这时控制台输出的顺序是:
```
mixins数据放生变化,变化成2.
构造器里的updated方法。
```
PS:当混入方法和构造器的方法重名时,混入的方法无法展现,也就是不起作用。
三、全局API混入方式
我们也可以定义全局的混入,这样在需要这段代码的地方直接引入js,就可以拥有这个功能了。我们来看一下全局混入的方法:
```
Vue.mixin({
updated:function(){
console.log('我是全局被混入的');
}
})
```
PS:全局混入的执行顺序要前于混入和构造器里的方法。
## Extends Option 扩展选项
通过外部增加对象的形式,对构造器进行扩展。它和我们上节课讲的混入非常的类似。
一、extends我们来看一个扩展的实例。
```
Extends Optin Demo
Early Examples Demo
Examples Method Demo
{{pxsData.Url}}
{{pxsData.netName}}
{{pxsData.skill}}
```
2、在组件模板中用slot
{{pxsData.Url}}
{{pxsData.netName}}
{{pxsData.skill}}
```
';
Helloword
{{message}}
```
index.html
```
Vue2.0实例
``` 在终端中输入live-server 启动服务器点击**Hello World实例**即可看到效果 ## v-if v-else v-show 指令 1. v-if: v-if:是vue 的一个内部指令,指令用在我们的html中。 v-if用来判断是否加载html的DOM,比如我们模拟一个用户登录状态,在用户登录后现实用户名称。 关键代码: ```
你好,像素狮!
```
```
v-if&v-else&v-show
你好,像素狮!
请登录后操作
你好,像素狮!
你好:像素狮
```
3. v-if 和v-show的区别:
- v-if: 判断是否加载,可以减轻服务器的压力,在需要时加载。
- v-show:调整css dispaly属性,可以使客户端操作更加流畅。
**v-else要放在v-if后面要不然无效**
## v-for指令 :解决模板循环问题
v-for指令是循环渲染一组data中的数组,v-for 指令需要以 item in items 形式的特殊语法,items 是源数据数组并且item是数组元素迭代的别名。
一、基本用法:1. 模板写法 ```
v-for指令用法
- {{item}}
**真正的数字排序** ``` //真正的数字排序 function sortNumber(a,b){ return a-b } ``` 用法: ``` computed:{ sortItems:function(){ return this.items.sort(sortNumber); } } ``` 三、对象循环输出 我们上边循环的都是数组,那我们来看一个对象类型的循环是如何输出的。 我们先定义个数组,数组里边是对象数据 ``` students:[ {name:'像素狮',age:'24'}, {name:'小明',age:'26'}, {name:'小张',age:'30'}, {name:'小华',age:'20'}, {name:'Tim',age:'15'}, ] ``` 在模板中输出 ```
- {{student.name}} - {{student.age}}
- {{index}}:{{student.name}} - {{student.age}}
``` 如果在javascript中写有html标签,用v-text是输出不出来的,这时候我们就需要用v-html标签了。 ``` ``` 双大括号会将数据解释为纯文本,而非HTML。为了输出真正的HTML,你就需要使用v-html 指令。 需要注意的是:在生产环境中动态渲染HTML是非常危险的,因为容易导致**XSS攻击**。所以只能在可信的内容上使用**v-html**,永远不要在用户提交和可操作的网页上使用。 ```
v-text&v-html实例
{{message}}=
```
## v-on:绑定事件监听器
v-on 就是监听事件,可以用v-on指令监听DOM事件来触发一些javascript代码。
一、使用绑定事件监听器,编写一个加分减分的程序。
```
v-on实例
本场比赛得分:{{fenshu}}
```
我们的 **v-on** 还有一种简单的写法,就是用 **@** 代替。
```
```
我们除了绑定click之外,我们还可以绑定其它事件,比如键盘回车事件v-on:keyup.enter,现在我们增加一个输入框,然后绑定回车事件,回车后把文本框里的值加到我们的count上。
```
onEnter:function(){
this.count=this.count+parseInt(this.secondCount);
}
```
因为文本框的数字会默认转变成字符串,所以我们需要用parseInt()函数进行整数转换。
## v-model指令★
v-model指令,我理解为绑定数据源。就是把数据绑定在特定的表单元素上,可以很容易的实现双向数据绑定。
一、我们来看一个最简单的双向数据绑定代码:
html文件:
```
原始文本信息:{{message}}
文本框
v-model:
多选按钮绑定一个值
``` 五、多选绑定一个数组 ```多选绑定一个数组
{{web_Names}}
``` 六、单选按钮绑定数据 ```单选按钮绑定
{{sex}}
``` ## v-bind 指令 v-bind是处理HTML中的标签**属性**的,例如 ``````就是一个标签,```1、绑定classA
```
2、绑定classA并进行判断,在isOK为true时显示样式,在isOk为false时不显示样式。
```
2、绑定class中的判断
```
3、绑定class中的数组
```
3、绑定class中的数组
```
4、绑定class中使用三元表达式判断
```
4、绑定class中的三元表达式判断
```
5、绑定style
```
5、绑定style
```
6、用对象绑定style样式
```
6、用对象绑定style样式
```
```
var app=new Vue({
el:'#app',
data:{
styleObject:{
fontSize:'24px',
color:'green'
}
}
})
```
7. 本节源码
```
v-bind实例
``` ## 其他内部指令(v-pre & v-cloak & v-once) v-pre指令 在模板中跳过vue的编译,直接输出原始值。就是在标签中加入v-pre就不会输出vue中的data值了。 ```
{{message}}
```
这时并不会输出我们的message值,而是直接在网页中显示{{message}}
v-cloak指令
在vue渲染完指定的整个DOM后才进行显示。它必须和CSS样式一起使用,
```
[v-cloak] {
display: none;
}
```
```
{{ message }}
```
v-once指令
在第一次DOM时进行渲染,渲染完成后视为静态内容,跳出以后的渲染过程。
```
第一次绑定的值:{{message}}
```
源码
```
v-pre&v-cloak&v-once实例
{{message}}
渲染完成后,才显示!
{{message}}
{{message}}
vue.extend-扩展实例构造器
Vue.set 全局操作
- {{aa}}
构造器的声明周期
{{message}}
```
## Template 制作模版
一、直接写在选项里的模板
直接在构造器里的template选项后边编写。这种写法比较直观,但是如果模板html代码太多,不建议这么写。
javascript代码:
```
var app=new Vue({
el:'#app',
data:{
message:'hello Vue!'
},
template:`
我是选项模板
` }) ``` 这里需要注意的是模板的标识不是单引号和双引号,而是,就是Tab上面的键。 二、写在标签里的模板 这种写法更像是在写HTML代码,就算不会写Vue的人,也可以制作页面。 ```我是template标签模板
``` 三、写在 ``` 这节课我们学习了Template的三种写法,以后学习到vue-cli的时候还会学到一种xxx.vue的写法。 ## Component 初识组件★★★ component组件是Vue学习的重点、重点、重点,重要的事情说三遍。所以你必须学好Vue component。其实组件就是制作自定义的标签,这些标签在HTML中是没有的。比如:component-1
component-1
component-1组件实例
component-1组件实例
component-2
Panda from {{ here }}.
`,
props:['fromHere']
}
}
})
```
**因为这里有坑,所以还是少用-为好。**
三、在构造器里向组件中传值
把构造器中data的值传递给组件,我们只要进行绑定就可以了。就是我们第一季学的v-bind:xxx.
我们直接看代码:
Html文件:
```
Panda from {{ here }}.
`,
props:['here']
}
}
})
```
## Component 父子组件关系
在实际开发中我们经常会遇到在一个自定义组件中要使用其他自定义组件,这就需要一个父子组件关系。
一、构造器外部写局部注册组件
上面上课我们都把局部组件的编写放到了构造器内部,如果组件代码量很大,会影响构造器的可读性,造成拖拉和错误。
我们把组件编写的代码放到构造器外部或者说单独文件。
我们需要先声明一个对象,对象里就是组件的内容。
```
var jspang = {
template:`Panda from China!
`
}
```
声明好对象后在构造器里引用就可以了。
```
components:{
"jspang":jspang
}
```
html中引用
```
component-3
I'm componentA
`
}
var componentB={
template:`I'm componentB
`
}
var componentC={
template:`I'm componentC
`
}
```
2.我们在构造器的components选项里加入这三个组件。
```
components:{
"componentA":componentA,
"componentB":componentB,
"componentC":componentC,
}
```
3.我们在html里插入component标签,并绑定who数据,根据who的值不同,调用不同的组件。
```
component-4
PropsData Option Demo
{{message}}-{{a}}
`, data:function(){ return { message:'Hello,I am Header' } }, props:['a'] }); new header_a({propsData:{a:1}}).$mount('header'); ``` 总结:propsData在实际开发中我们使用的并不多,我们在后边会学到Vuex的应用,他的作用就是在单页应用中保持状态和数据的。 ## computed Option 计算选项 computed 的作用主要是对原数据进行改造输出。改造输出:包括格式的编辑,大小写转换,顺序重排,添加符号……。 一、格式化输出结果: 我们先来做个读出价格的例子:我们读书的原始数据是price:100 但是我们输出给用户的样子是(¥100元)。 主要的javascript代码: ``` computed:{ newPrice:function(){ return this.price='¥' + this.price + '元'; } } ``` 全部代码: ```Computed Option 计算选项
{{newPrice}}
```
现在输出的结果就是:¥100元。
二、用计算属性反转数组
例如:我们得到了一个新闻列表的数组,它的顺序是安装新闻时间的顺序正序排列的,也就是早反生的新闻排在前面。这是反人类的,我们需要给他反转。这时我们就可以用到我们的计算属性了。
没有排序的新闻列表,是安装日期正序排列的。
```
var newsList=[
{title:'香港或就“装甲车被扣”事件追责 起诉涉事运输公司',date:'2017/3/10'},
{title:'日本第二大准航母服役 外媒:针对中国潜艇',date:'2017/3/12'},
{title:'中国北方将有明显雨雪降温天气 南方阴雨持续',date:'2017/3/13'},
{title:'起底“最短命副市长”:不到40天落马,全家被查',date:'2017/3/23'},]
```
我们希望输出的结果:
起底“最短命副市长”:不到40天落马,全家被查-2017/3/23
中国北方将有明显雨雪降温天气 南方阴雨持续-2017/3/13
日本第二大准航母服役 外媒:针对中国潜艇-2017/3/12
香港或就“装甲车被扣”事件追责 起诉涉事运输公司-2017/3/10
我们的在computed里的javascript代码:我们用js原生方法给数组作了反转。
```
computed:{
reverseNews:function(){
return this.newsList.reverse();
}
}
```
总结:computed 属性是非常有用,在输出数据前可以轻松的改变数据。所以说这节课的代码必须要多敲几遍,加深印象。
## Methods Option方法选项
在以前的学习中,已经大量的使用了构造器里的methods选项,但是并没有仔细和系统的讲解过,这节课我们用点时间把methods这个选项涉及的东西都讲一讲。
```
methods Option
{{ a }}
```
一、methods中参数的传递
使用方法和正常的javascript传递参数的方法一样,分为两部:
1、在methods的方法中进行声明,比如我们给add方法加上一个num参数,就要写出add:function(num){}.
2、调用方法时直接传递,比如我们要传递2这个参数,我们在button上就直接可以写。.
现在知道了加参数的方法,看一段完整的代码,代码中给add添加了num参数,并在按钮上调用传递了。
```
methods Option
{{ a }}
```
这时,再点击按钮是每次加2个数字。
二、methods中的$event参数
传递的$event参数都是关于你点击鼠标的一些事件和属性。我们先看看传递的方法。
传递: 。
我们这时候可以打印一下,看看event到底是个怎样的对象。你会发现,它包含了大部分鼠标事件的属性。
三、native 给组件绑定构造器里的原生事件。
在实际开发中经常需要把某个按钮封装成组件,然后反复使用,如何让组件调用构造器里的方法,而不是组件里的方法。就需要用到我们的.native修饰器了。
现在我们把我们的add按钮封装成组件:
声明btn对象:
```
var btn={
template:``
}
```
在构造器里声明:
```
components:{
"btn":btn
}
```
用.native修饰器来调用构造器里的add方法
```
Watch选项监控数据
今日温度: {{wendu}} 度
穿衣建议:{{chuanyi}}
Mixins Option Demo
num:{{ num }}
Extends Optin Demo
{{message}}
```
二、delimiters 选项
因为这节课内容比较少,所以我们把要讲的最后一个选项一起讲了。delimiters的作用是改变我们插值的符号。Vue默认的插值是双大括号{{}}。但有时我们会有需求更改这个插值的形式。
```
delimiters:['${','}']
```
现在我们的插值形式就变成了${}。
# 实例和内置组件
## 实例入门-实例属性
一、Vue和Jquery.js一起使用
1、下载并引入jquery框架
下载可以去官网进行下载,我这里使用的版本是3.1.1,下载好后在需要的页面引入就可以了。当然你还有很多其它的方法引入jquery,只要可以顺利引入就可以了。
```
```
试着作一个案例,在DOM被挂载后修改里边的内容。
```
Early Examples Demo
{{message}}
```
现在页面显示是:我是jQuery,而不是hello Vue了。
二、实例调用自定义方法
在Vue的构造器里我们写一个add方法,然后我们用实例的方法调用它。
构造器里的add方法:
```
methods:{
add:function(){
console.log("调用了Add方法");
}
}
```
实例调用:
```
app.add();
```
PS:我们有可能把app.add()的括号忘记或省略,这时候我们得到的就是方法的字符串,但是并没有执行,所以必须要加上括号。
## 实例方法
一、$mount方法
$mount方法是用来挂载我们的扩展的,我们先来复习一下扩展的写法。
这里我们作了jspang的扩展,然后用$mount的方法把jspang挂载到DOM上,我们也生成了一个Vue的实例,直接看代码。
```
Examples Method Demo
{{message}}
```
这段代码我们在学习extends的时候已经写过一次,这里就不作过多解释了。
二、$destroy() 卸载方法
用$destroy()进行卸载。
我写了一个button按钮,点击后卸载整个挂载。
html:
```
```
javascript
```
function destroy(){
vm.$destroy();
}
```
PS:$destroy()后边必须要有括号,没有括号是无用的。
三、$forceUpdate() 更新方法
```
vm.$forceUpdate()
```
四、$nextTick() 数据修改方法
当Vue构造器里的data值被修改完成后会调用这个方法,也相当于一个钩子函数吧,和构造器里的updated生命周期很像。
```
function tick(){
vm.message="update message info ";
vm.$nextTick(function(){
console.log('message更新完后我被调用了');
})
}
```
五、安装Vue的控制台调试工具。
每个人的安装方法不同,不作太多的介绍,可能需要你科学上网。
## 实例事件
实例事件就是在构造器外部写一个调用构造器内部的方法。这样写的好处是可以通过这种写法在构造器外部调用构造器内部的数据。
我们还是写一个点击按钮,持续加1的例子。
一、$on 在构造器外部添加事件。
```
app.$on('reduce',function(){
console.log('执行了reduce()');
this.num--;
});
```
$on接收两个参数,第一个参数是调用时的事件名称,第二个参数是一个匿名方法。
如果按钮在作用域外部,可以利用$emit来执行。
```
//外部调用内部事件
function reduce(){
app.$emit('reduce');
}
```
二、$once执行一次的事件
```
app.$once('reduceOnce',function(){
console.log('只执行一次的方法');
this.num--;
});
```
三、$off关闭事件
```
//关闭事件
function off(){
app.$off('reduce');
}
```
## 内置组件 -slot讲解
slot是标签的内容扩展,也就是说你用slot就可以在自定义组件时传递给组件内容,组件接收内容并输出。
先来定义一个站酷地址:
站酷名称:
技术类型:
站酷地址:
站酷名称:
技术类型:
slot
站酷地址:
站酷名称:
技术类型:
VUE避坑指南
最后更新于:2022-04-01 23:52:33
[TOC]
# Vue.js学习笔记
## 学习前言
目前比较流行的有三个前端框架
1、Vue.js
2、react.js和ReactNative
3、Angular.js
三者有各自的优缺点
首先说说Vue.js:轻量级,适合中小项目,开发快,上手也快。缺点就是生态圈有点小, 但是随着发展,这一点正在逐步改善。
其次就是React,比Vue早出现,生态圈广泛,在移动端方面和旗下ReactNative互通屹立于移动端开发。接着就是Angular.js适合大型项目,分支比较多,出现时间早,学习成本比较大。
## 详细的安装步骤
如下:
一、安装node.js
说明:安装node.js的windows版本后,会自动安装好node以及包管理工具npm,我们后续的安装将依赖npm工具。
node.js的官方地址为:https://nodejs.org/en/download/,如下图所示:
根据自己电脑的具体配置,选择你要下载的安装包,作者选择的是windows 64bit。
下载完毕,按照windows一般应用程序,一路next就可以安装成功,建议不要安装在系统盘(如C:)。
二、设置global和cache路径
说明:设置路径能够把通过npm安装的模块集中在一起,便于管理。
1、在nodejs的安装目录下,新建node_global和node_cache两个文件夹,作者的安装目录为“D:\Program Files\nodejs\”
2、设置global和cache
npm config set prefix "D:\Program Files\nodejs\node_global"
和
npm config set cache "D:\Program Files\nodejs\node_cache"
设置成功后,后续用命令npm install XXX -g安装以后模块就在D:\Program Files\nodejs\node_global\node_modules里
三、安装cnpm
说明:由于许多npm包都是在国外,我们这里用到淘宝的镜像服务器,来对我们依赖的module进行安装,因此首先安装“中国的npm”——cnpm
参考网址如下:http://npm.taobao.org/
安装命令为:
npm install -g cnpm --registry=https://registry.npm.taobao.org
四、设置环境变量(非常重要)
说明:设置环境变量可以使得住任意目录下都可以使用cnpm、vue等命令,而不需要输入全路径
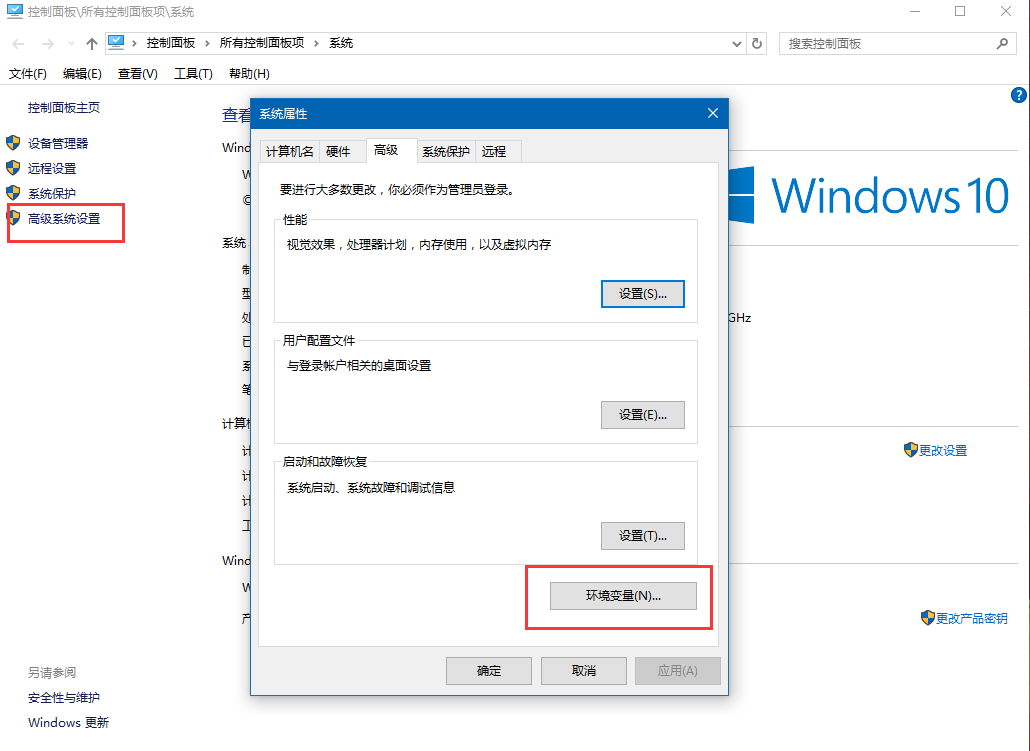
1、鼠标右键"此电脑",选择“属性”菜单,在弹出的“系统”对话框中左侧选择“高级系统设置”,弹出“系统属性”对话框。
2、点击环境变量弹出下列对话框:
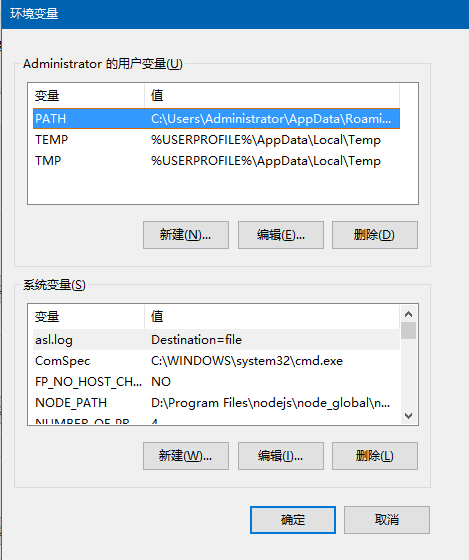
3、修改用户变量PATH:
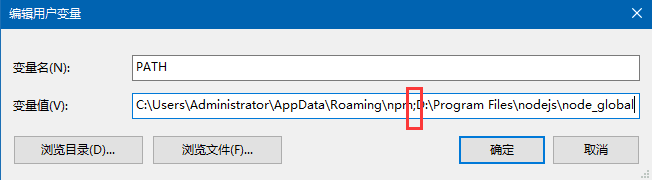
选中PATH,点击编辑,在已有的变量后面,加入英文的";",然后把“D:\Program Files\nodejs\node_global”加到后面
4、新增系统变量NODE_PATH:
在下面的系统变量中点击新建,弹出下框,把变量值设置成“D:\Program Files\nodejs\node_global\node_modules”
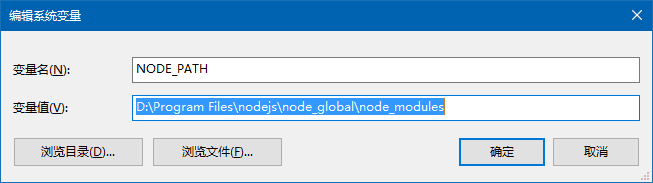
第四第五步,要先进入你要安装的项目文件夹下
四、用cnpm安装vue(打开nodejs\node_global 要在这个目录下用cnpm安装)
cnpm install vue -g
五、安装vue命令行工具
cnpm install vue-cli -g
六、创建工程
1、用cd命令来到你将要新建工程的目录,如“C:\Users\Administrator\Desktop\birdhelper>”
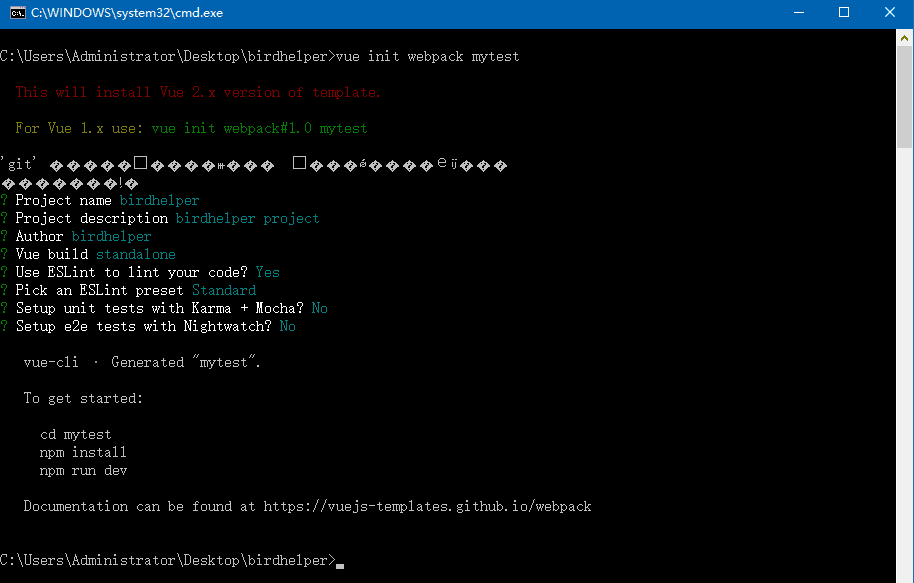
创建一个基于 webpack 模板的新项目,工程名为birdhelper。
1、vue init webpack mytest,具体步骤如下图所示:
2、初始化完成后的目录结构如下:
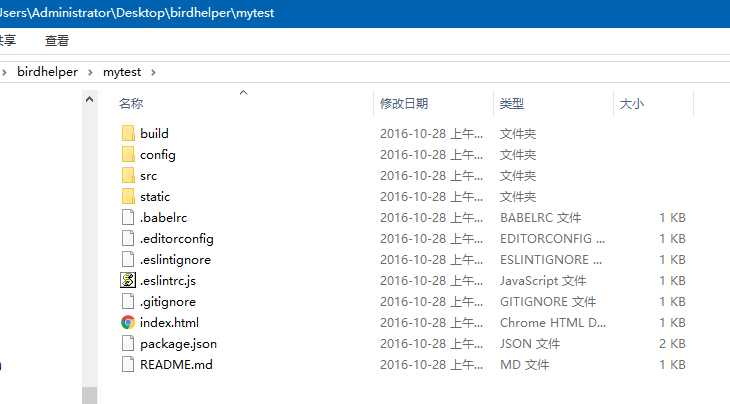
3、定位到mytest的工程目录下
cd mytest
4、安装该工程依赖的模块,这些模块将被安装在:mytest\node_module目录下,node_module文件夹会被新建,而且根据package.json的配置下载该项目的modules
cnpm install
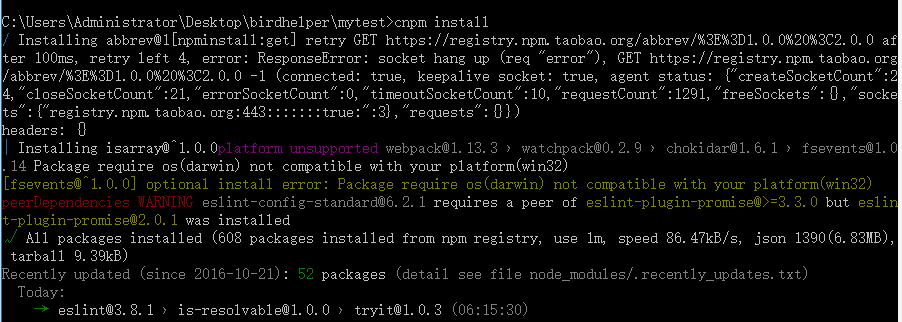
5、运行该项目,测试一下该项目是否能够正常工作,这种方式是用nodejs来启动。
cnpm run dev

## 服务器端构建
有时我们的服务器并不一定是node,也许是IIS,这样我们就需要把工程构建出来,与IIS集成。
构建该项目的命令如下
cnpm run build
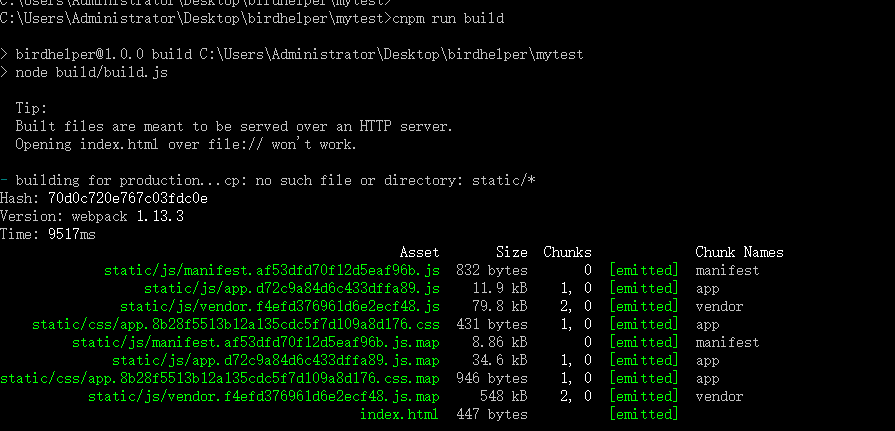
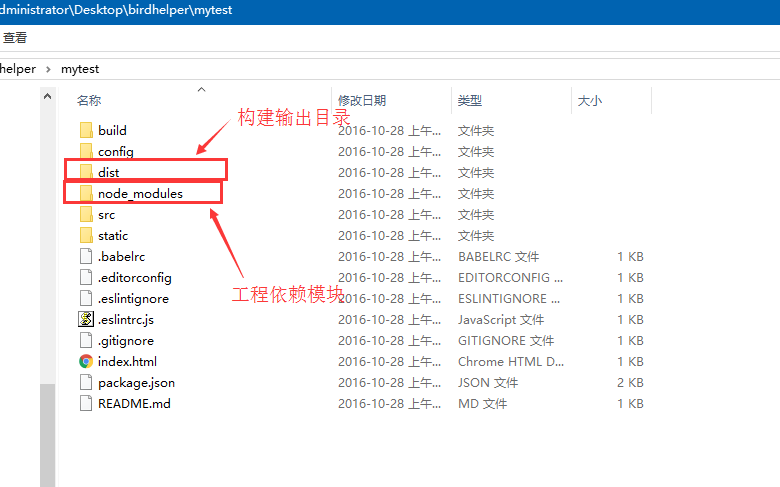
将dist文件夹拷贝出来,放到IIS的发布目录,在浏览器中输入IIS设置的本机ip和端口进行访问即可。Good Luck, guys!
至此,我们已经在win10下搭建成功了vue,并能和iis服务器进行集成。为.net框架开发web应用带来了棒棒的vue。
如果你从GitHub上新下载了一个项目,项目中可能会缺少一个名为node_modules的文件夹,要想让它运行,必须
1.进入项目文件下
2.npm install
3.npm run build
4.npm install npm-cli
5.npm run dev
下次再运行的时候,只需进入项目,再npm run dev即可
';
iOS开发笔记 – 上线流程
最后更新于:2022-04-01 23:52:30
引入简书:http://www.jianshu.com/p/b600c16308f4
# iOS开发笔记 - 上线流程
>

> 在开始讲述上线流程之前,我们假设你已经拥有了Apple ID,但是还没有成为付费的开发者,我们就从申请成为付费开发者开始。
>

图1. 用浏览器打开苹果开发者网站
* * * * *
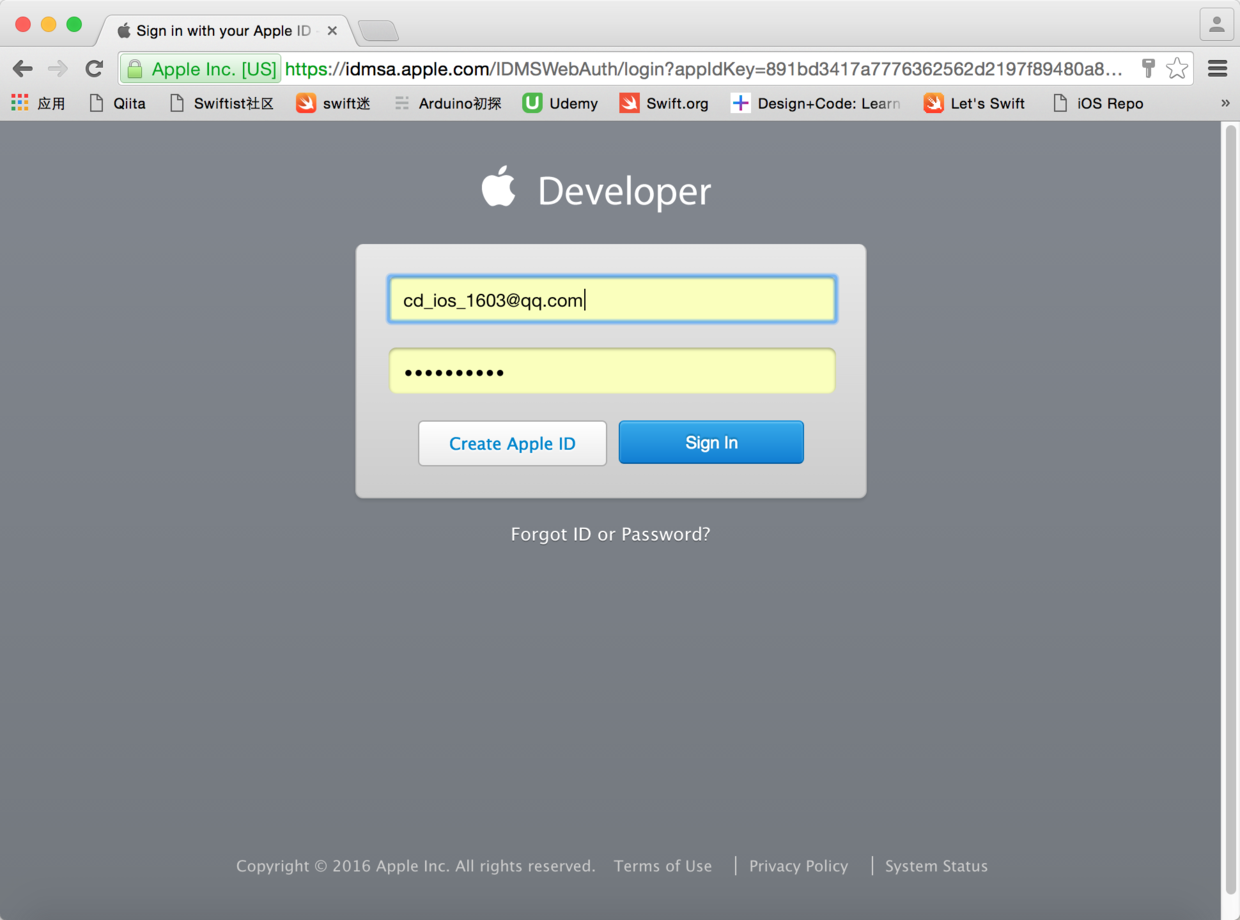
图2. 使用Apple ID登录开发者网站
* * * * *
> 注意,如果你是第一次使用你的Apple ID登入苹果开发者网站,你会看到如下所示的页面,这个时候你需要同意“苹果开发者协议”,并提交你的请求,这个时候你的Apple ID就已经成为一个开发者ID了。
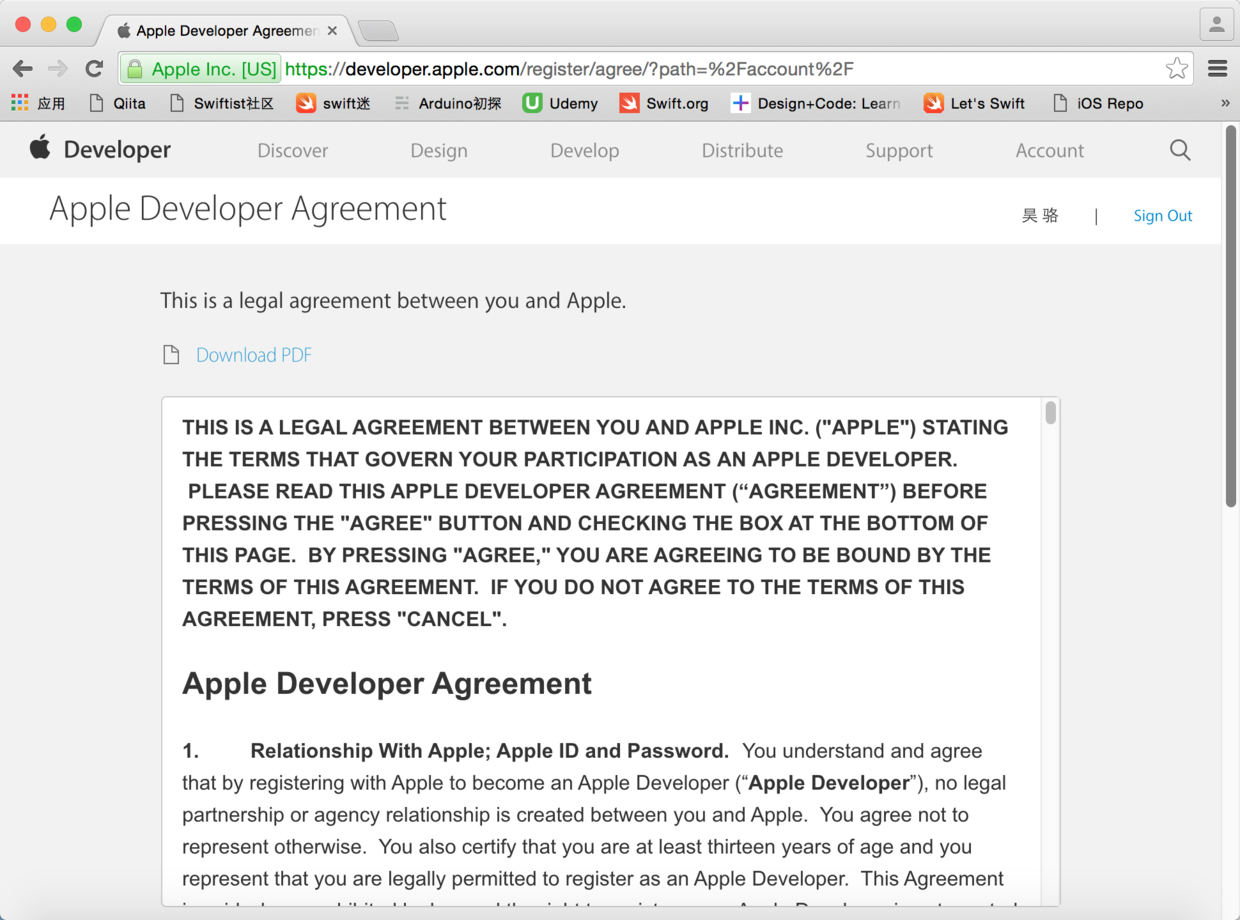
图3. 苹果开发者协议页面
* * * * *
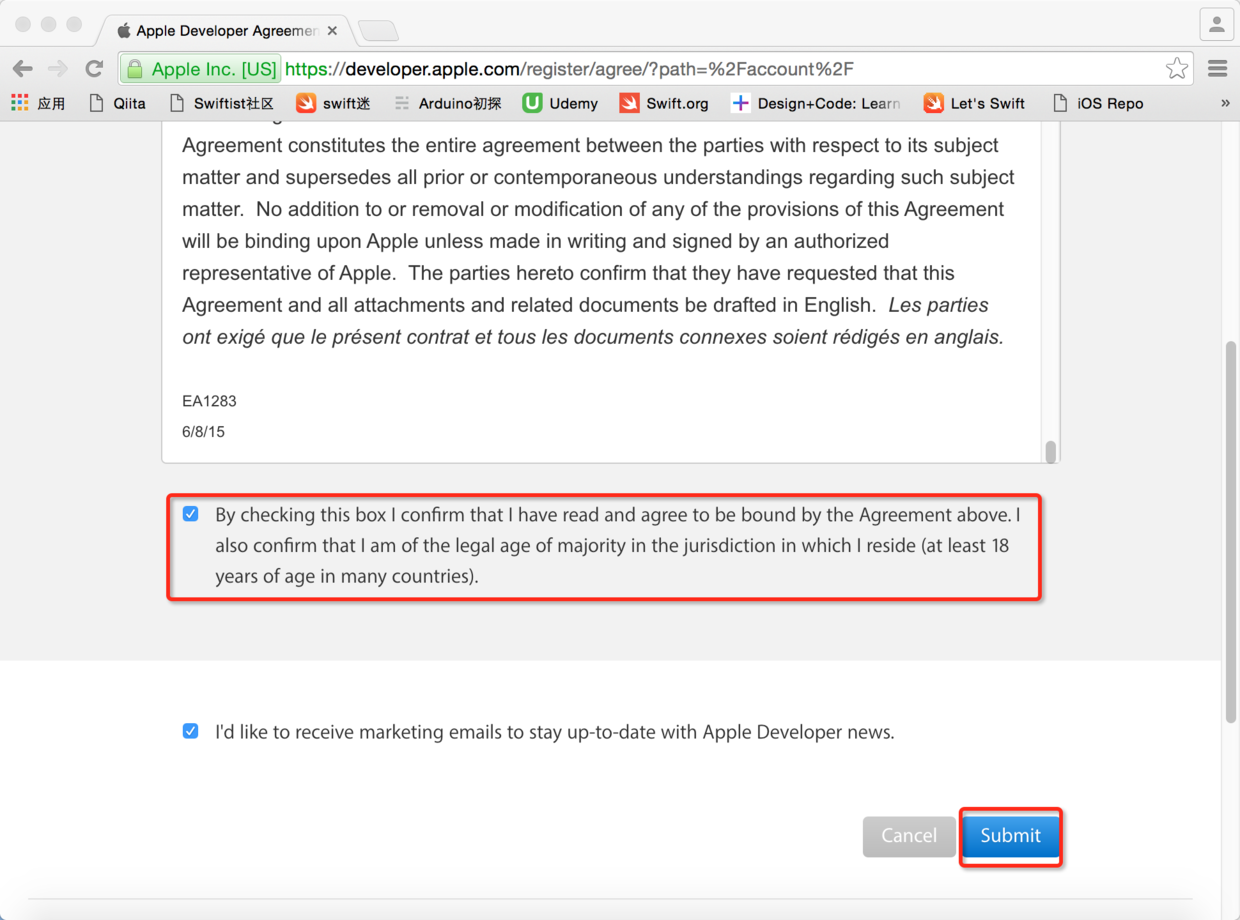
图4. 同意苹果开发者协议并提交申请
* * * * *
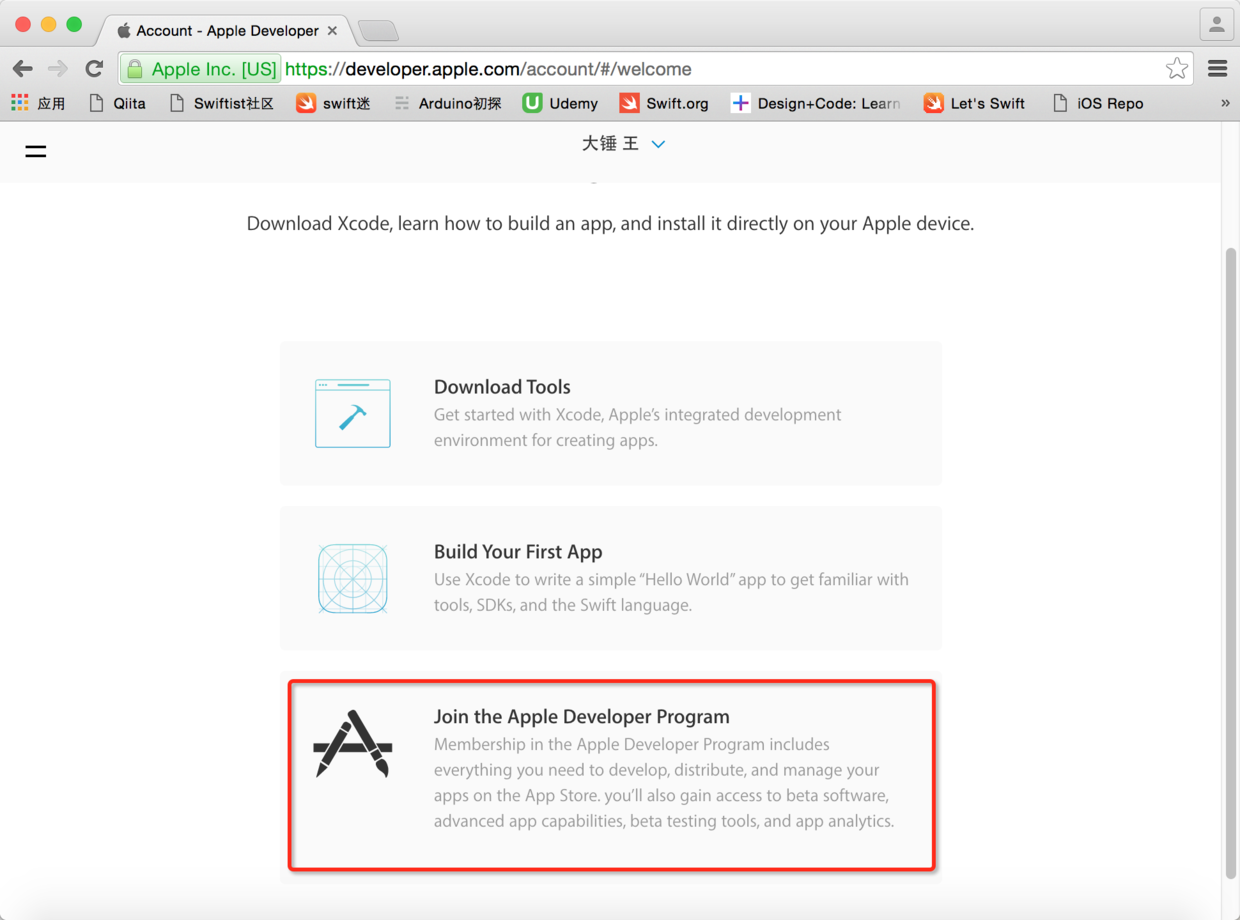
图5. 加入苹果开发计划
* * * * *
接下来的页面中你会发现一个注册的按钮,点击它就可以申请成为付费的开发者了。
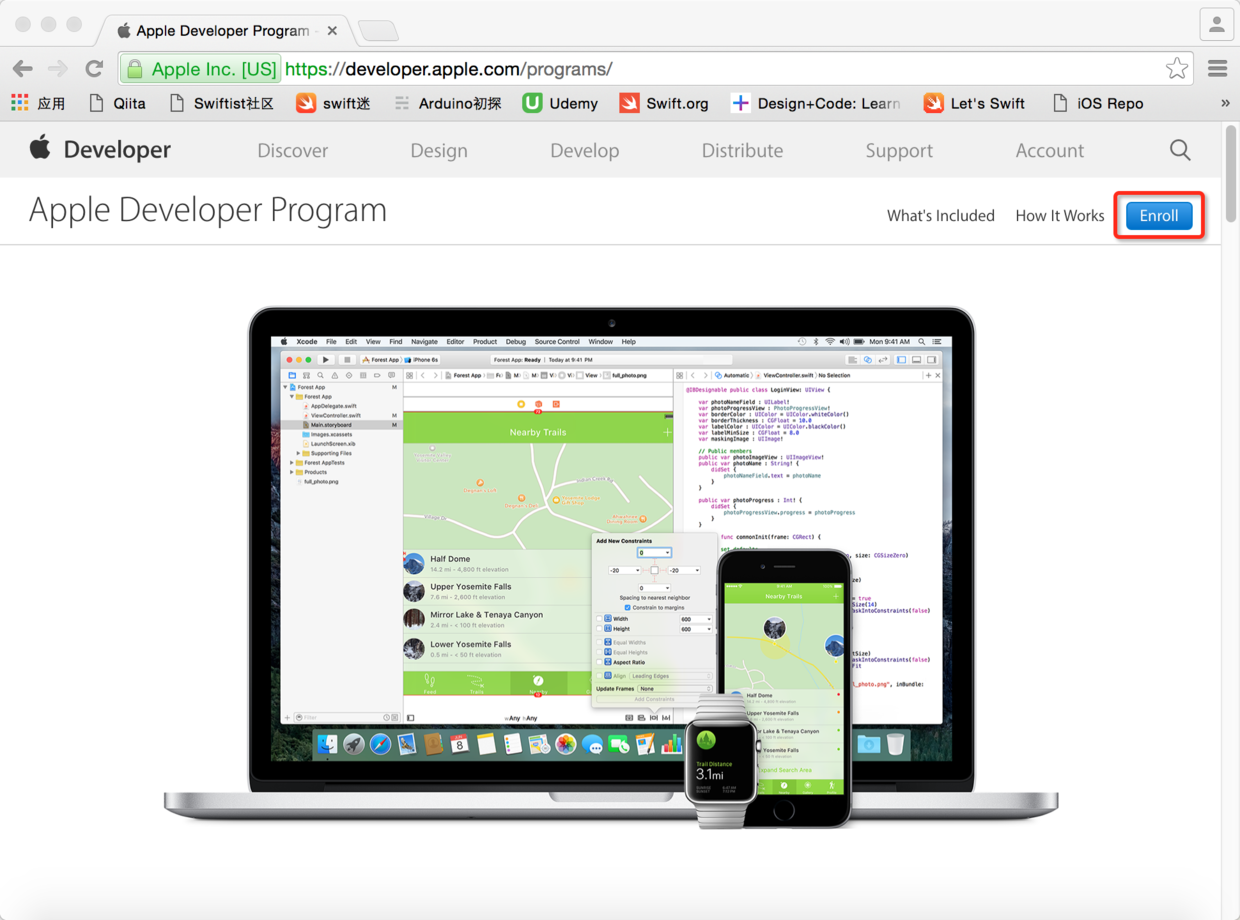
图6. 点击注册按钮
* * * * *
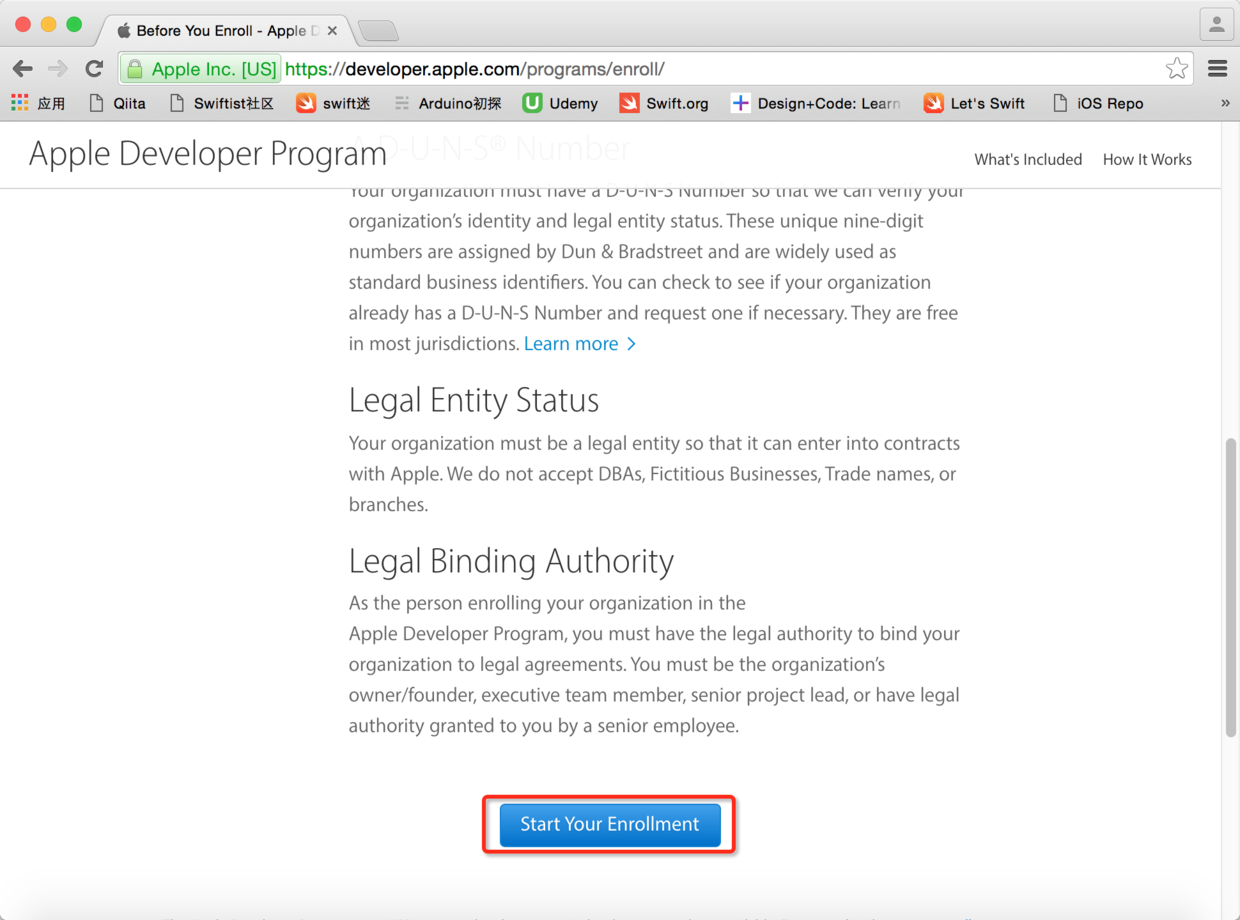
图7. 点击开始注册
* * * * *
在接下来的页面中选择开发者类型后就可以继续了。
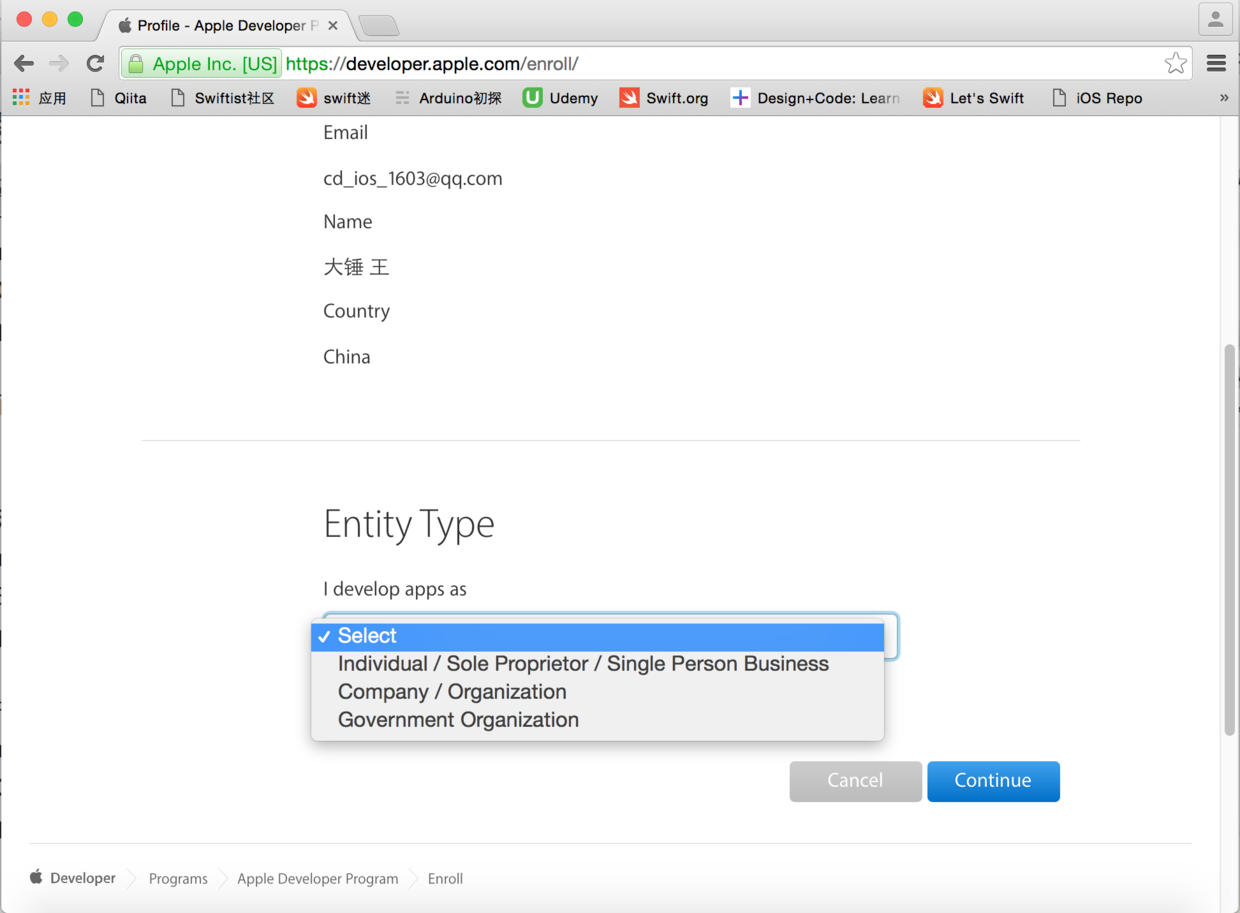
图8. 选择开发者类型并继续
* * * * *
> 注意:个人开发者需要每年支付99美元的费用,而企业开发者需要每年支付299美元的费用。
> 接下来需要填写一大堆的注册信息,而且需要本土语言和英语两种版本,然后还得再次同意一个你不太愿意阅读但是必须得同意的协议。点击“Continue”后会进入下一个页面,如果刚才的信息无误,就再次点击“Continue”按钮进入准备支付的页面。
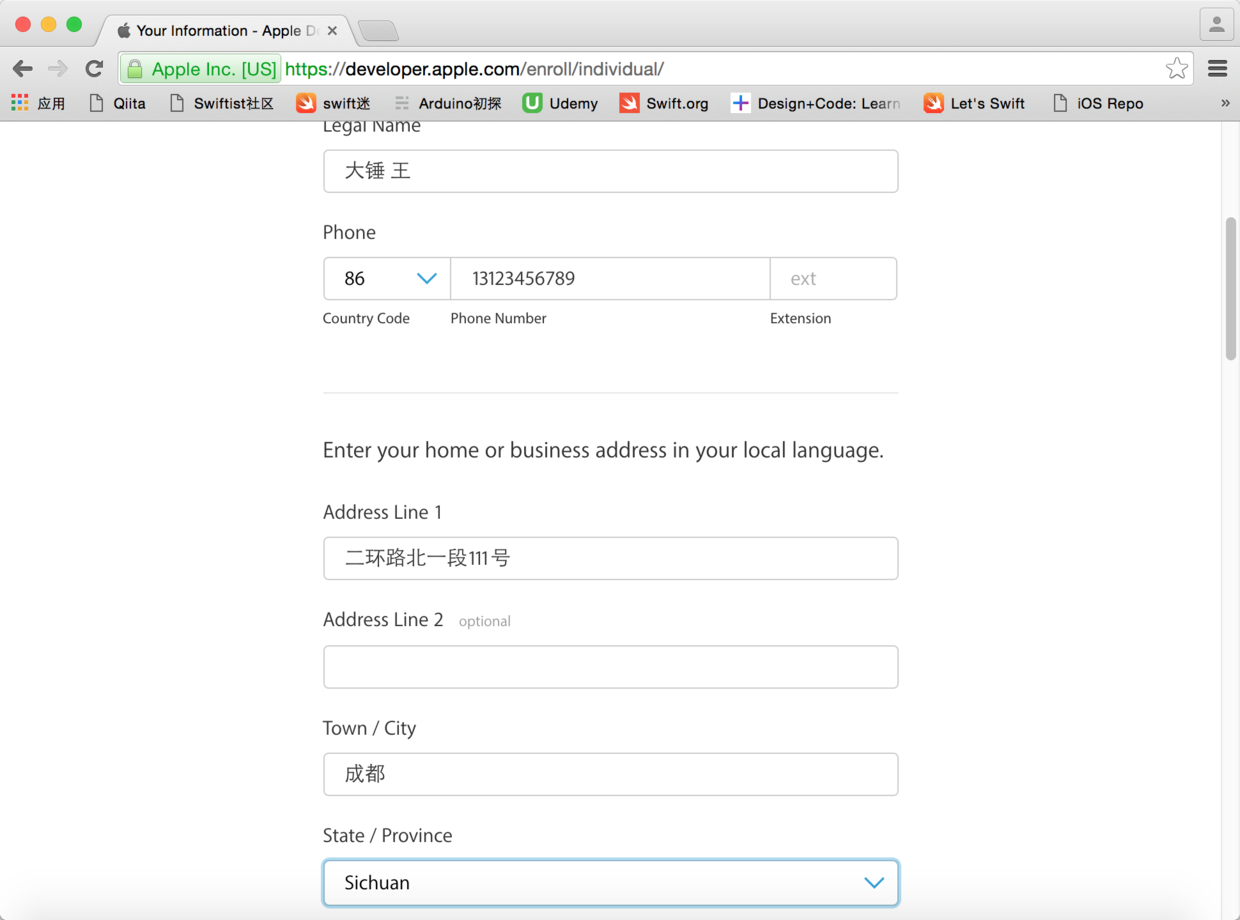
图9. 填写注册信息
* * * * *
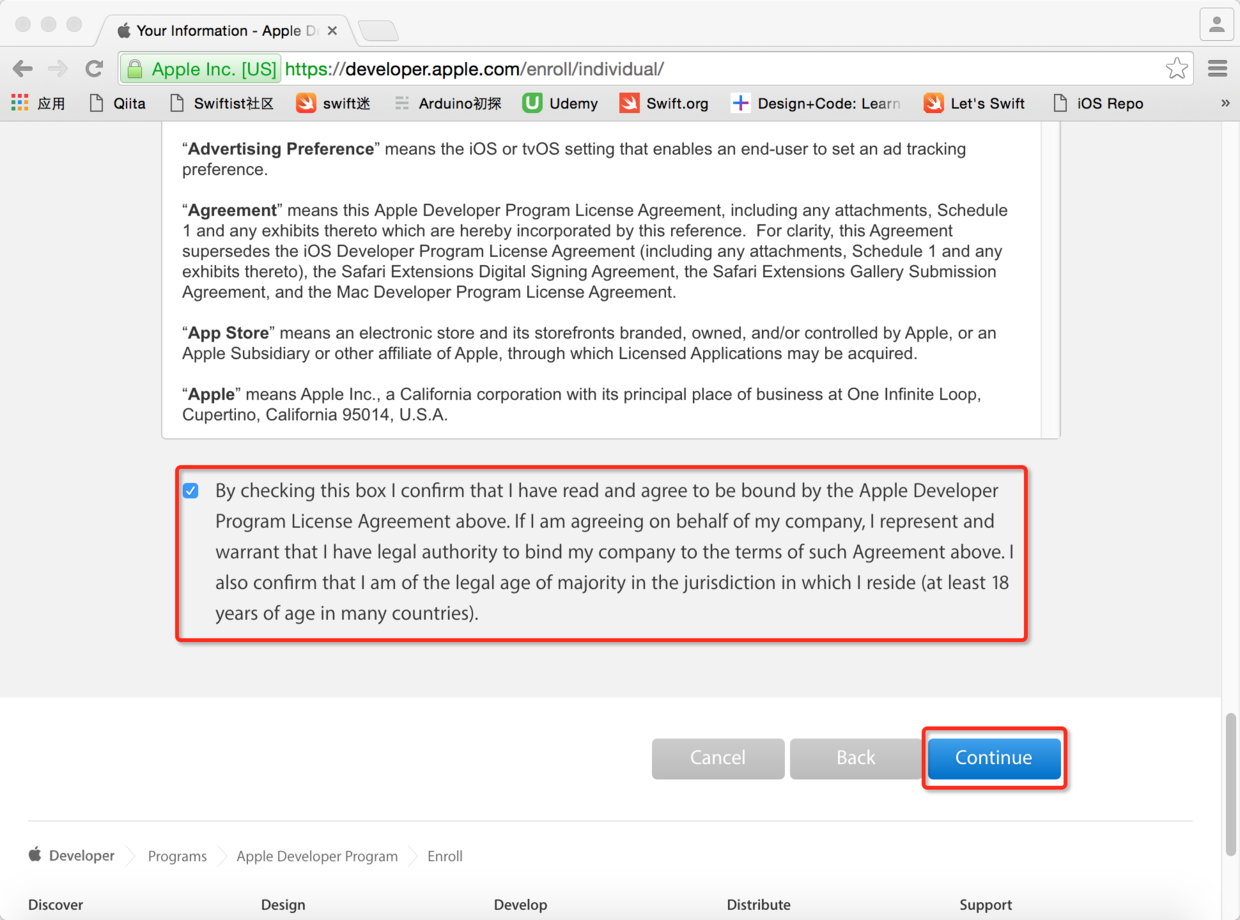
图10. 同意协议并且继续
* * * * *
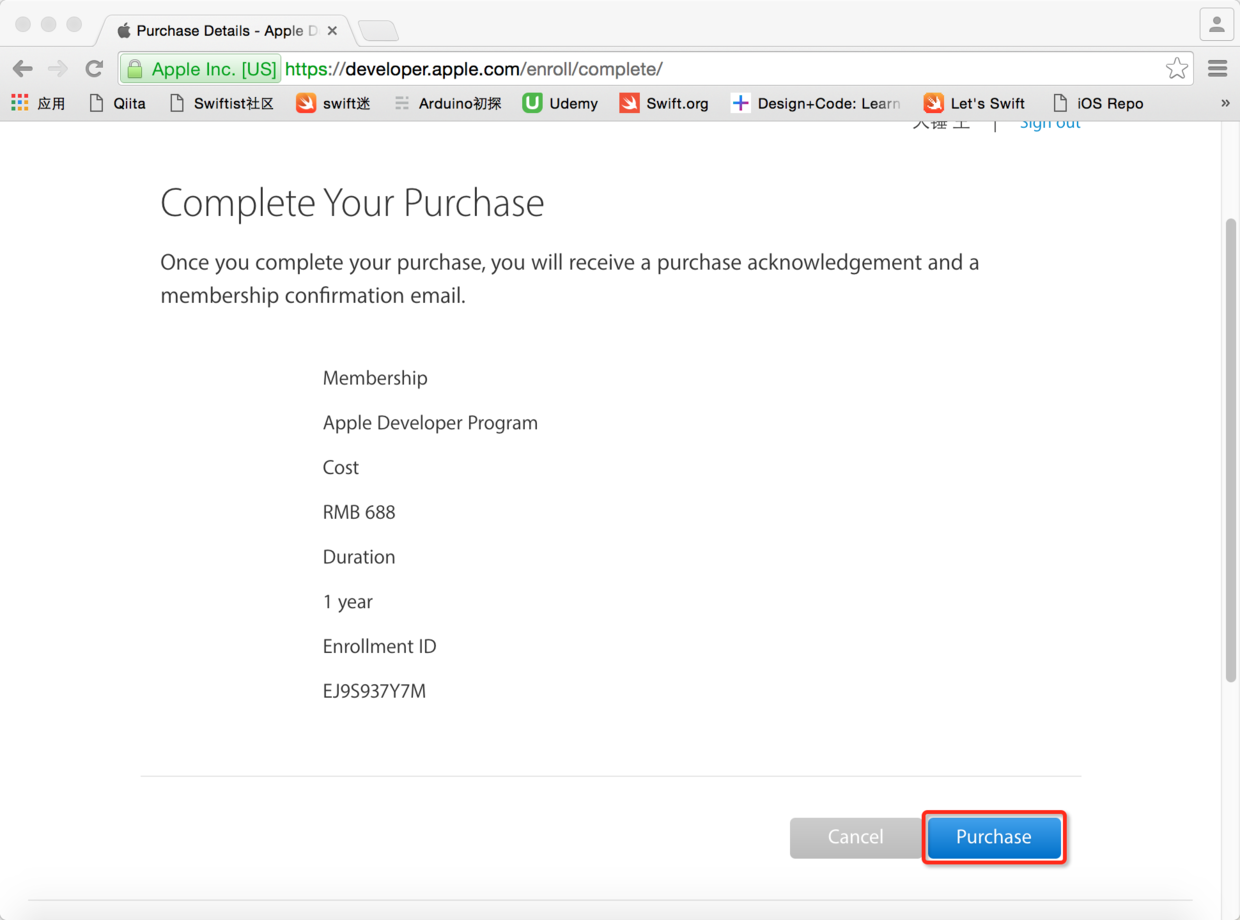
图11. 点击支付按钮
* * * * *
> 接下来还得登录一次,然后终于可以把钱付给Apple了,真是不容易啊,不过你还得有Visa信用卡或者是MasterCard。
>
图12. 再次登录
* * * * *
图13. 填写付费信息的页面
* * * * *
> 剩下的步骤你就按照网页上的提示操作就可以了,国内的很多银行在进行境外支付时可能会给你来电话确认支付授权,所以上面填写的信用卡信息以及账单联系人信息必须匹配,否则基本上会支付失败,即便你通过网上银行开通了境外支付。在上面的页面中还需要填写发票信息,如果需要机打发票的话这里的信息就不要填错了哈。
> 支付成功后,苹果会在48小时内对订单进行处理,然后你可能会收到邮件要求到指定的页面上传身份证照片。如果遇到任何问题,你可以拨打苹果开发的售后服务电话,号码是4006701855。成为开发者后再次登录,就会看到如下所示的页面。

图14. 成为付费开发者后重新登录
* * * * *
图15. 付费开发者登录后的界面
* * * * *
> 上图中点击红框的链接可以进入创建证书、应用ID和Profiles文件的页面;点击篮框的链接可以进入管理自己的App的页面。
图16. 创建证书的页面
* * * * *
> 点击上面页面中左侧的证书,并在右侧点击“+”就可以创建证书。
>
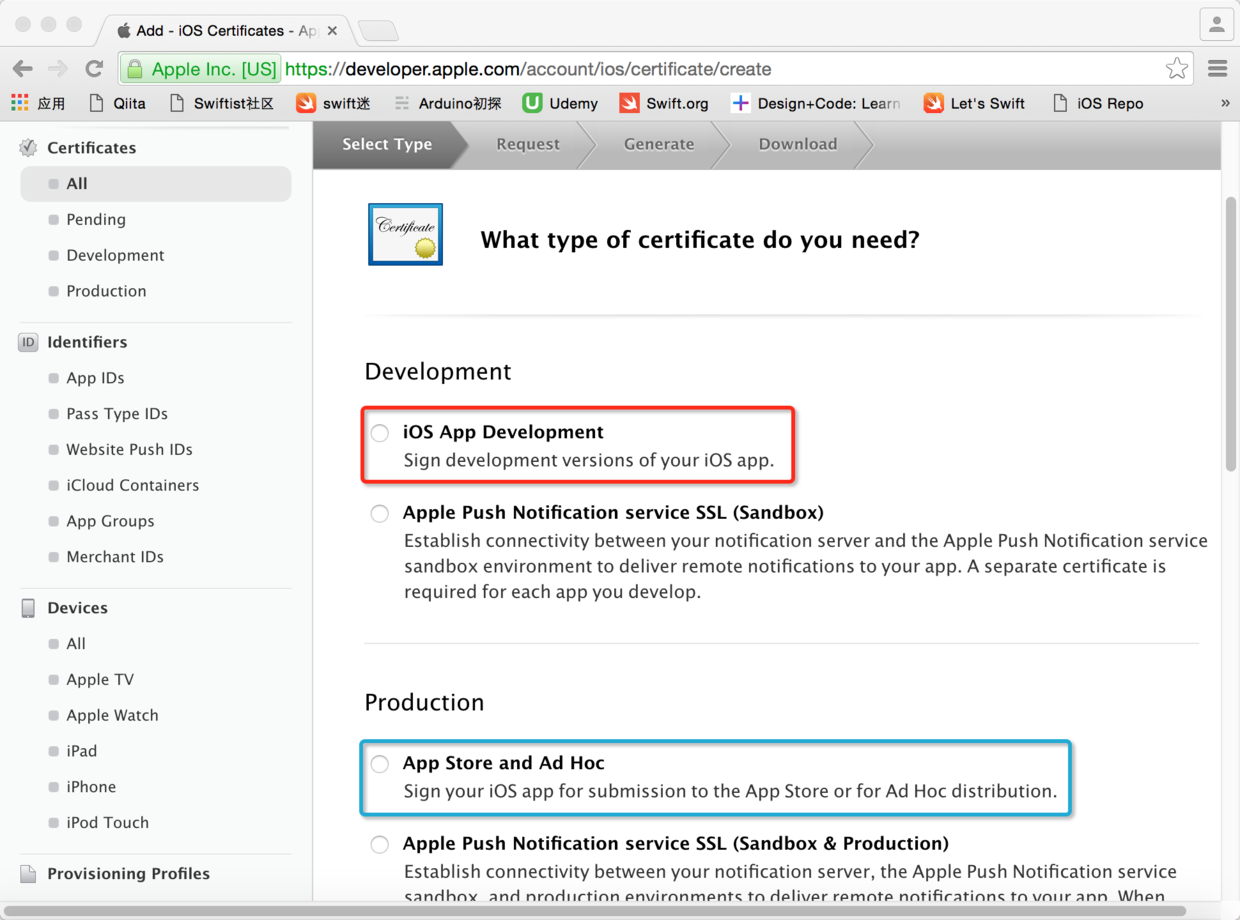
图17. 选择证书类型的页面
> 在上面的页面中选中红框中的选项可以创建开发证书,主要用于真机测试;选中蓝框中的选项可以创建产品证书,用于应用上线到App Store或小范围发布。我们下面要演示完整的项目上线流程,因此在这里选择蓝框中的选项“App Store and Ad Hoc”并点击“Continue”按钮继续。
> 接下来的页面会提示你创建证书需要一个证书签名请求文件,因此我们需要在自己的Mac系统上使用“钥匙串访问”应用创建一个证书签名请求文件
* * * * *
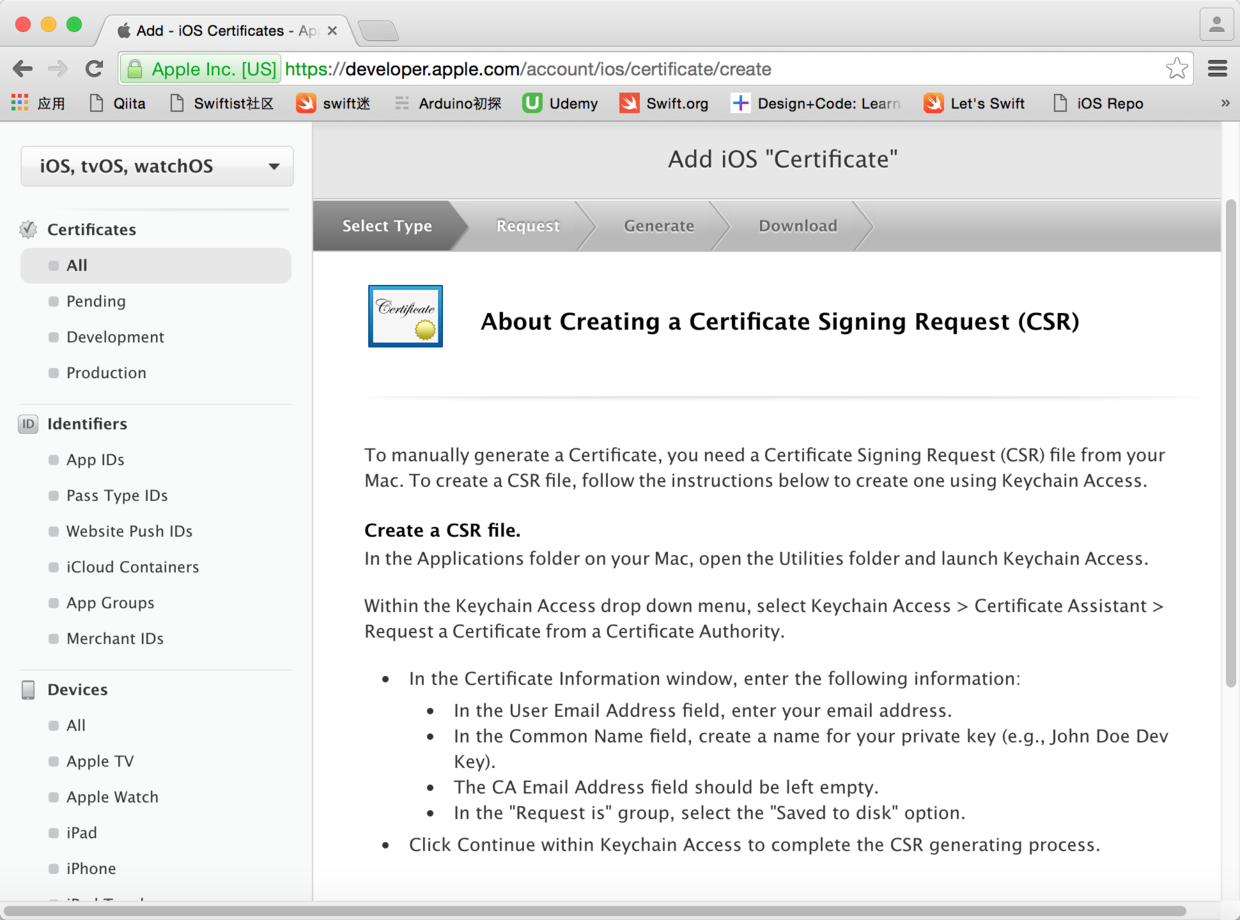
图18. 提示创建证书签名请求的页面
* * * * *

图19. 通过Launchpad打开“钥匙串访问”应用
* * * * *
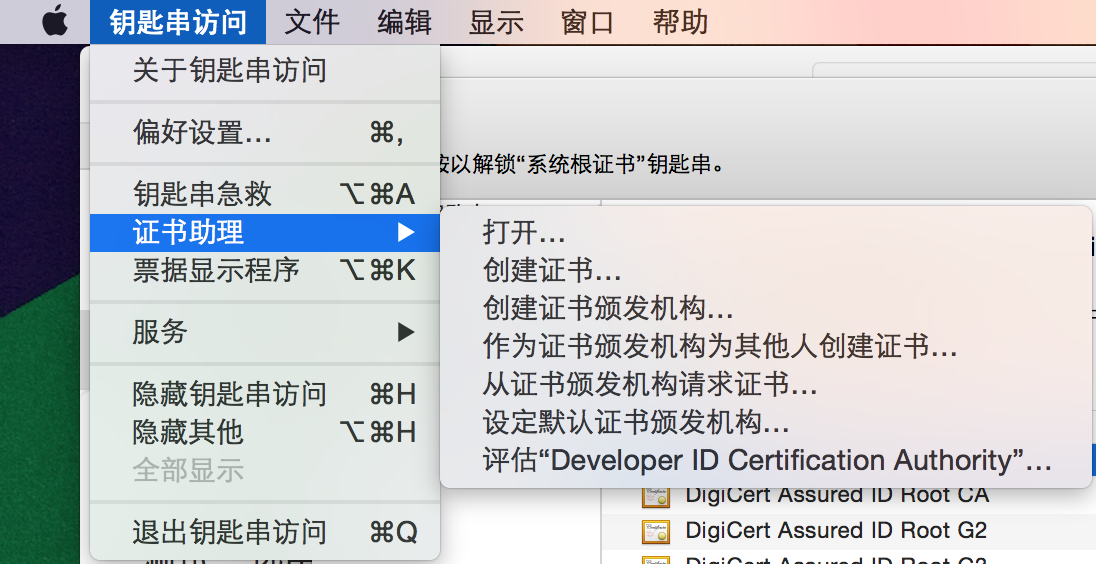
图20. 通过“证书助理”创建证书签名请求
> 注意:在上面的界面中要选中“从证书颁发机构请求证书…”菜单项才能打开如下所示的界面。
>

图21. 将证书签名请求文件保存到桌面
* * * * *
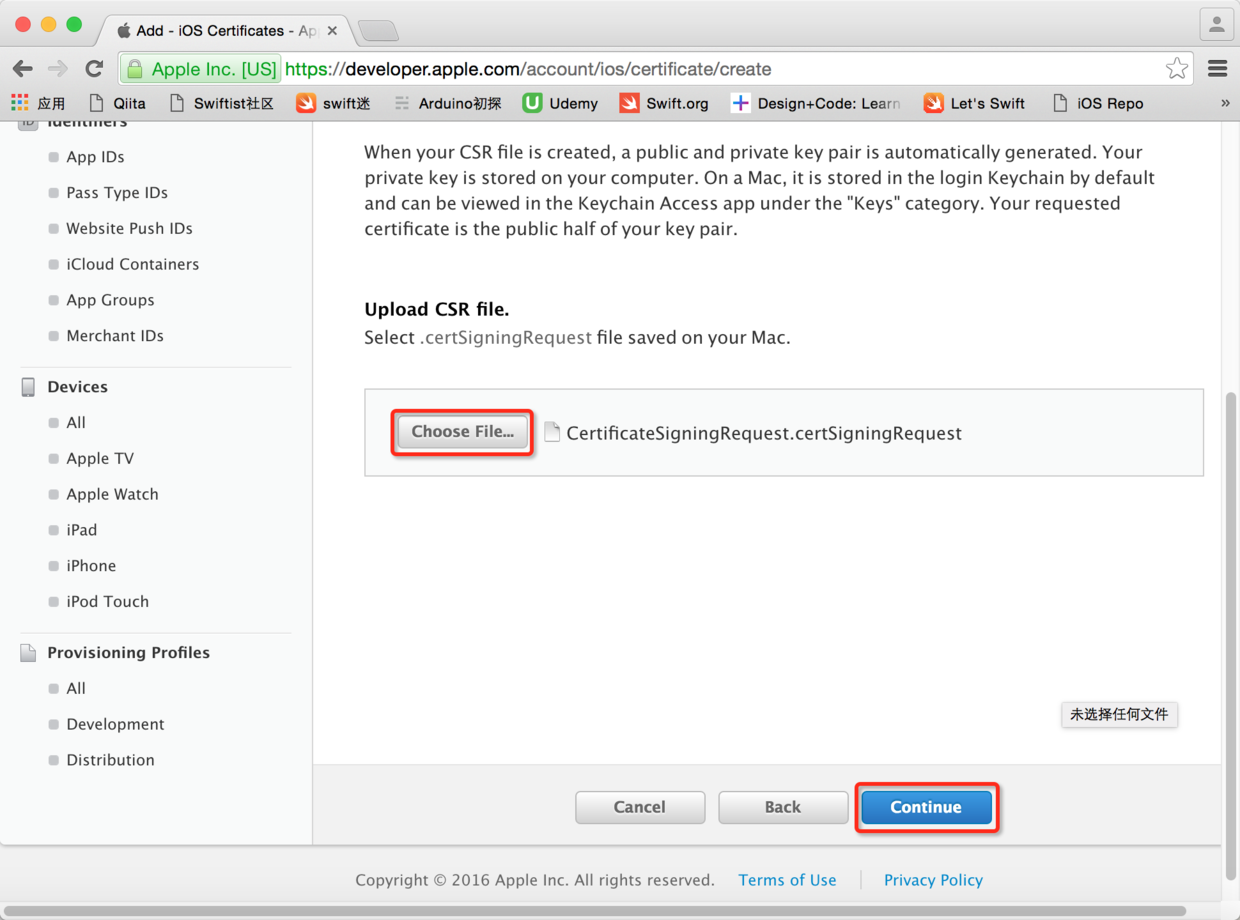
图22. 选择证书签名请求文件并继续
* * * * *
> 接下来可以将生成的证书下载到下来并双击添加到“钥匙串”中。
>
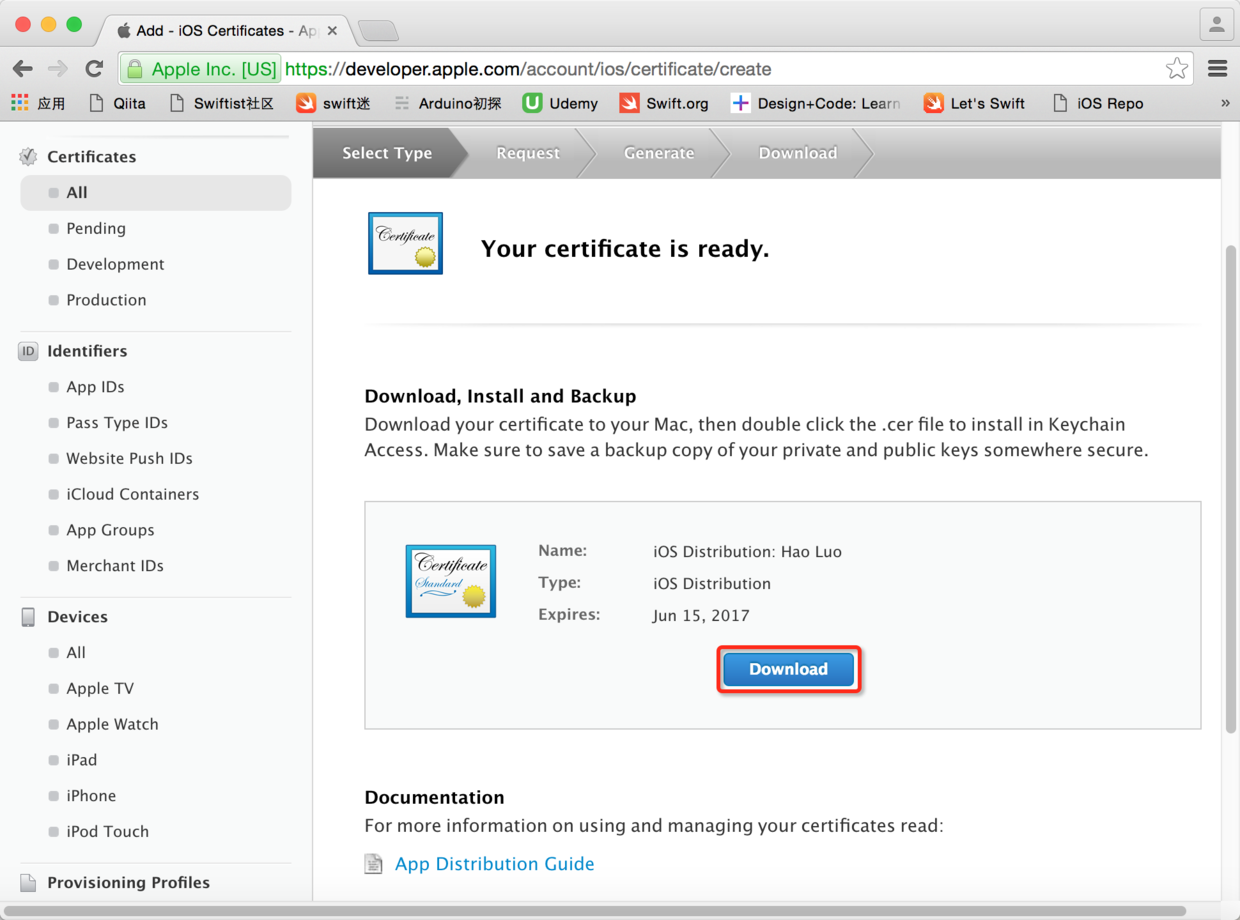
图23. 下载创建好的证书
* * * * *
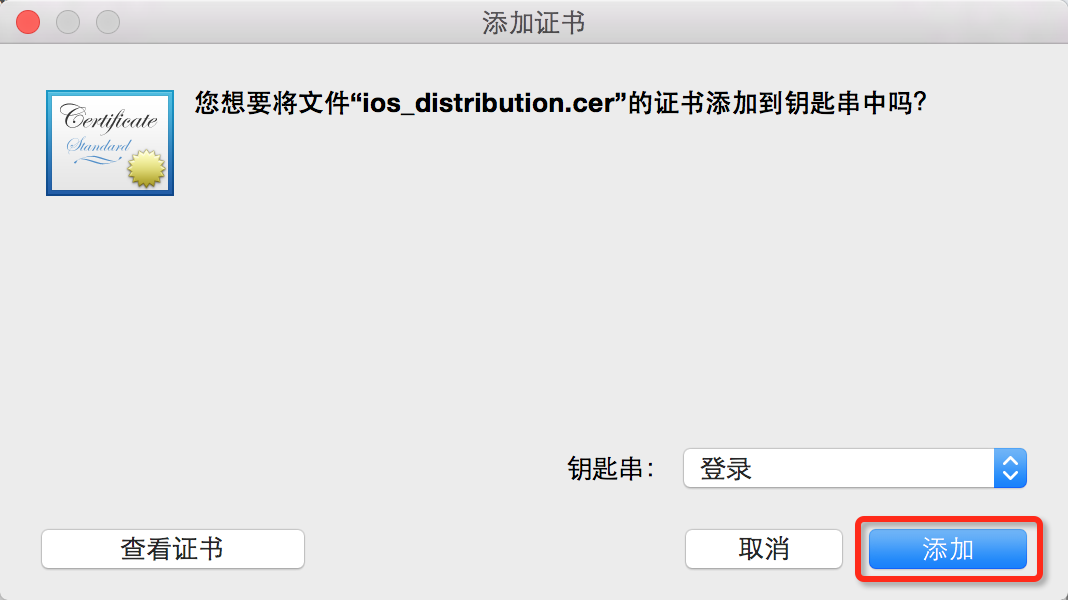
图24. 将证书添加到钥匙串中
* * * * *
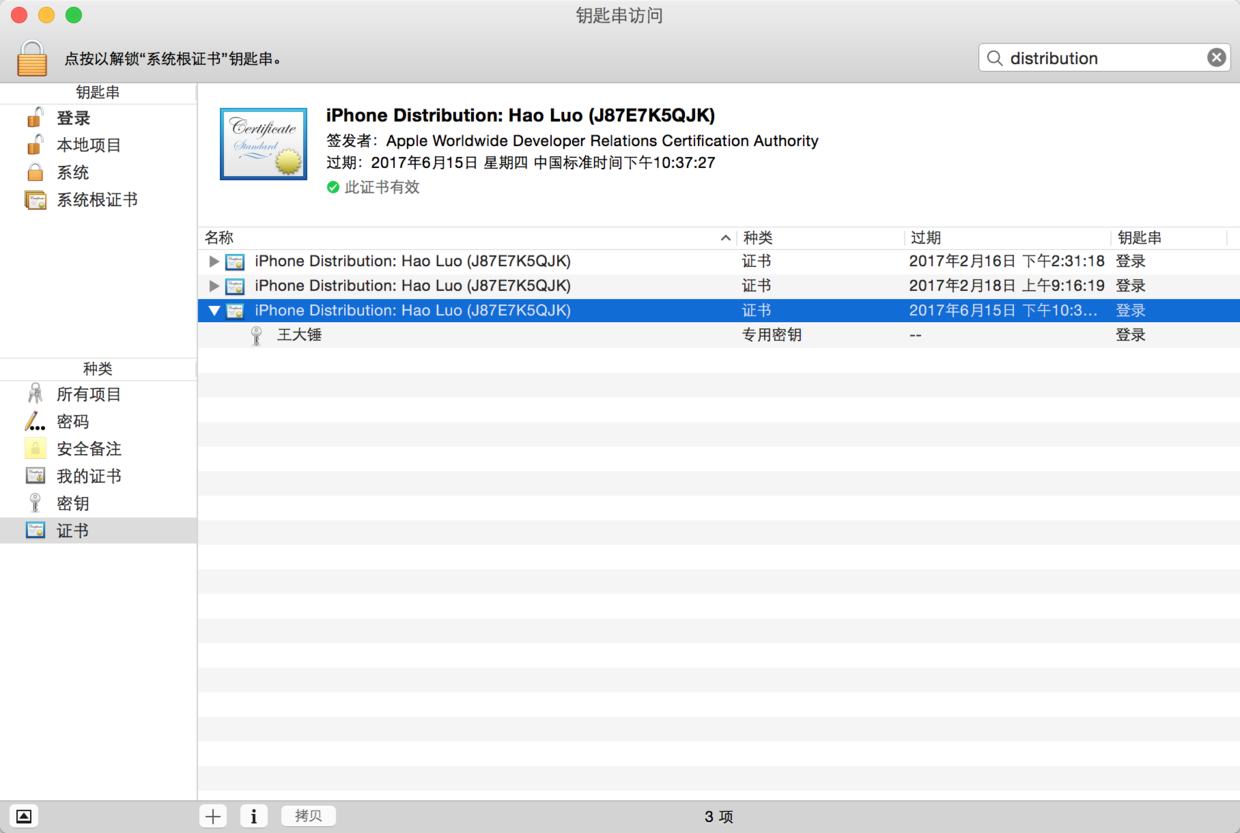
图25. 在“钥匙串”中查看证书
* * * * *
> 接下来选中页面左侧的“Identifiers”并点击右侧的“+”来注册要上线的应用程序ID
>
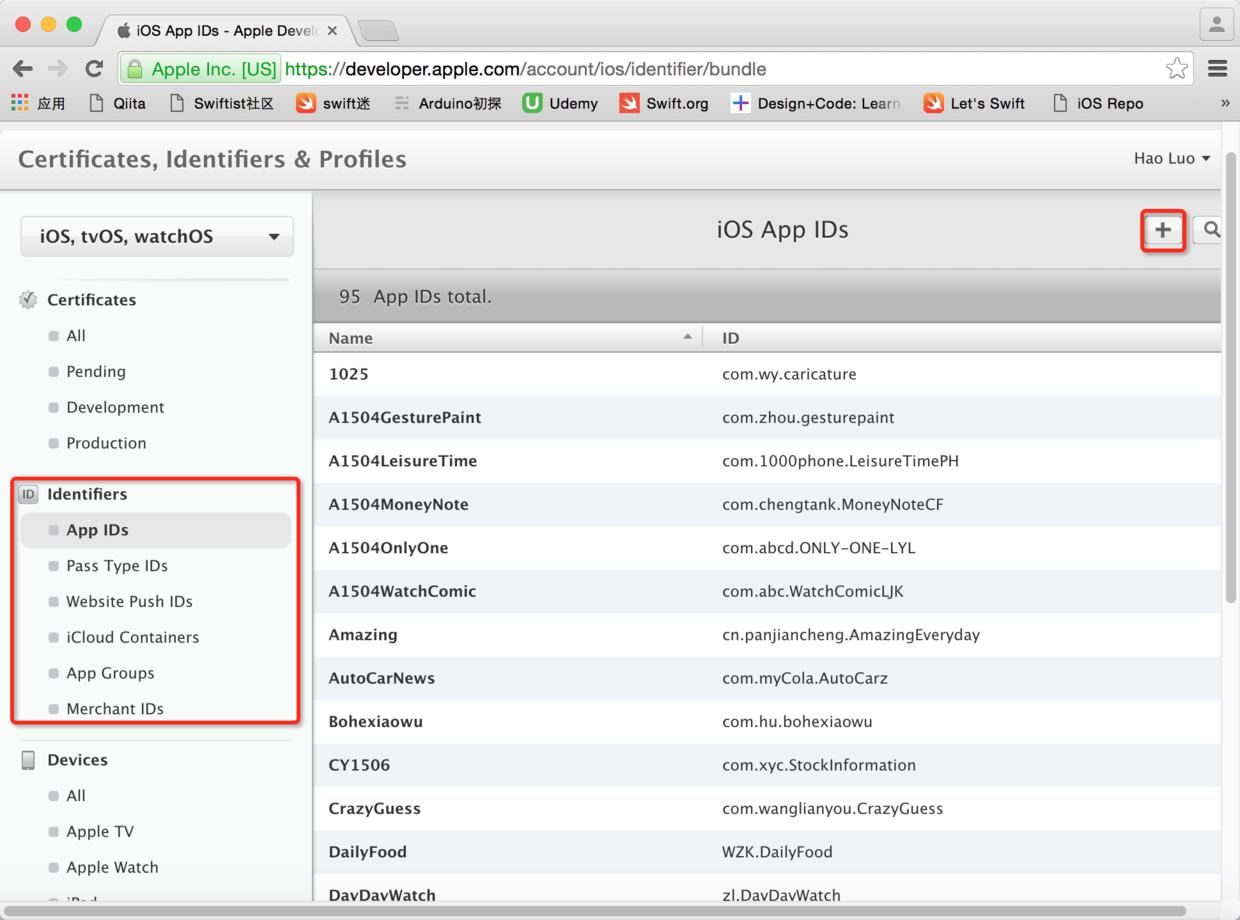
图26. 注册应用的ID
* * * * *
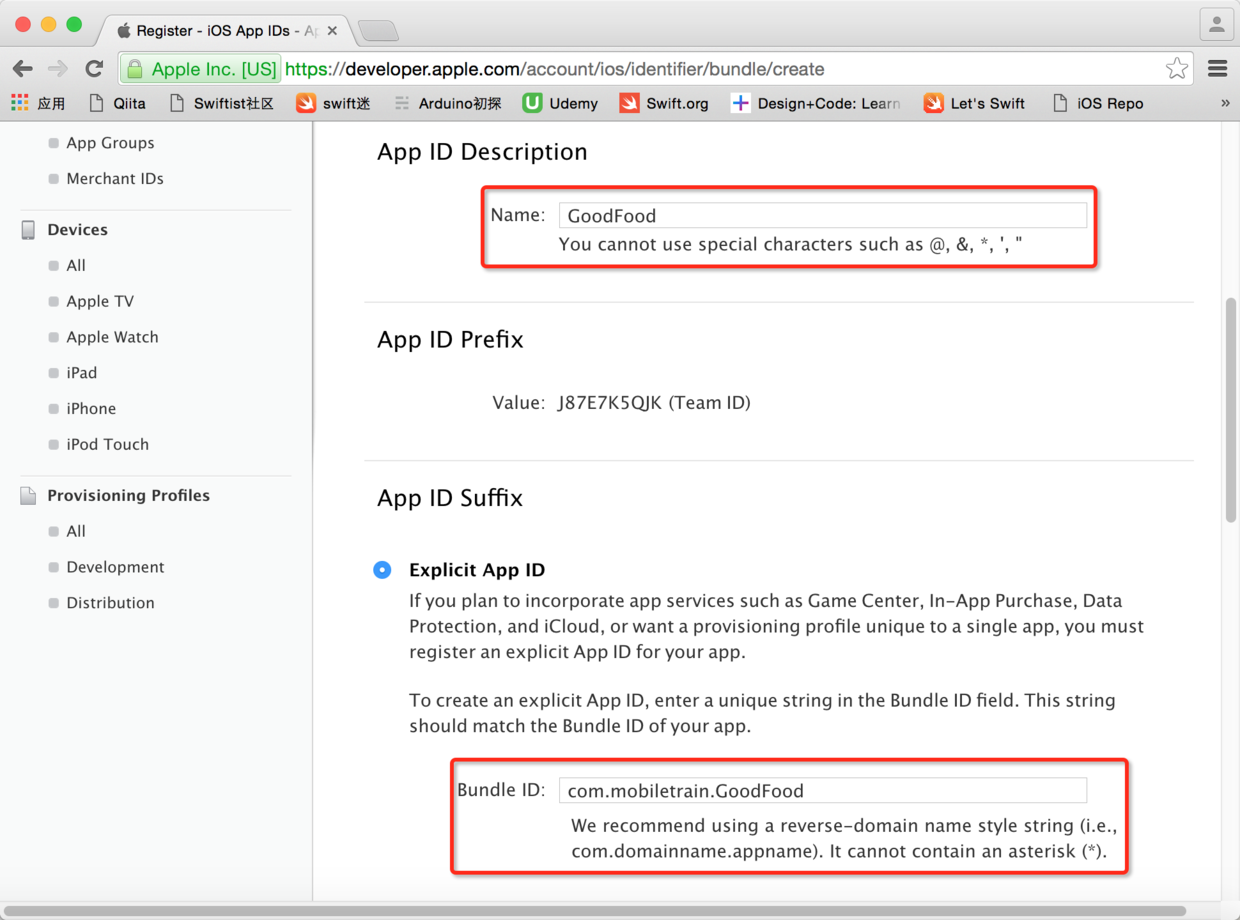
图27. 填写应用ID的名称和Bundle ID
* * * * *
~~~
注意:上面的Bundle ID应该跟Xcode中项目的Bundle ID保持完全一致,此处最好确认一下Xcode中的Bundle ID,如下所示。
~~~
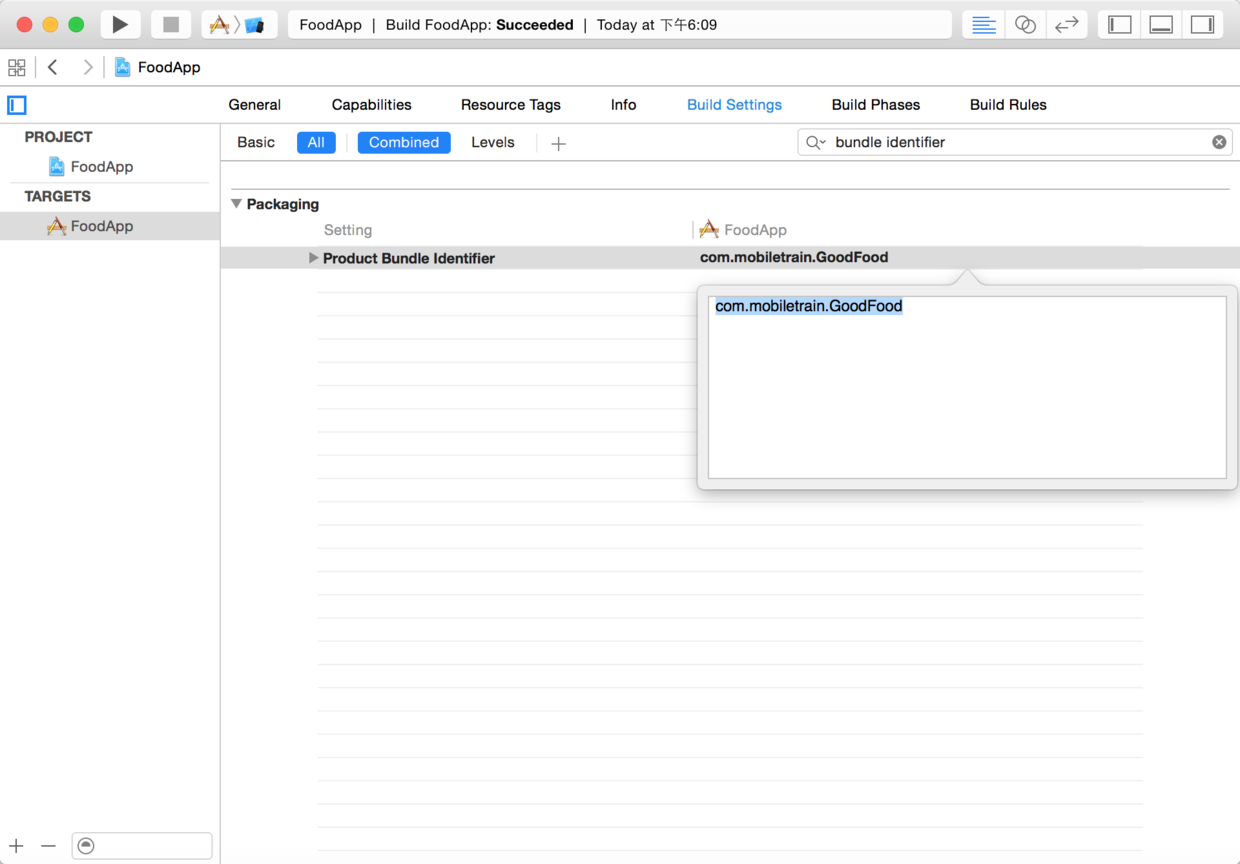
图28. 在Xcode中查看或修改项目的Bundle Identifier
* * * * *
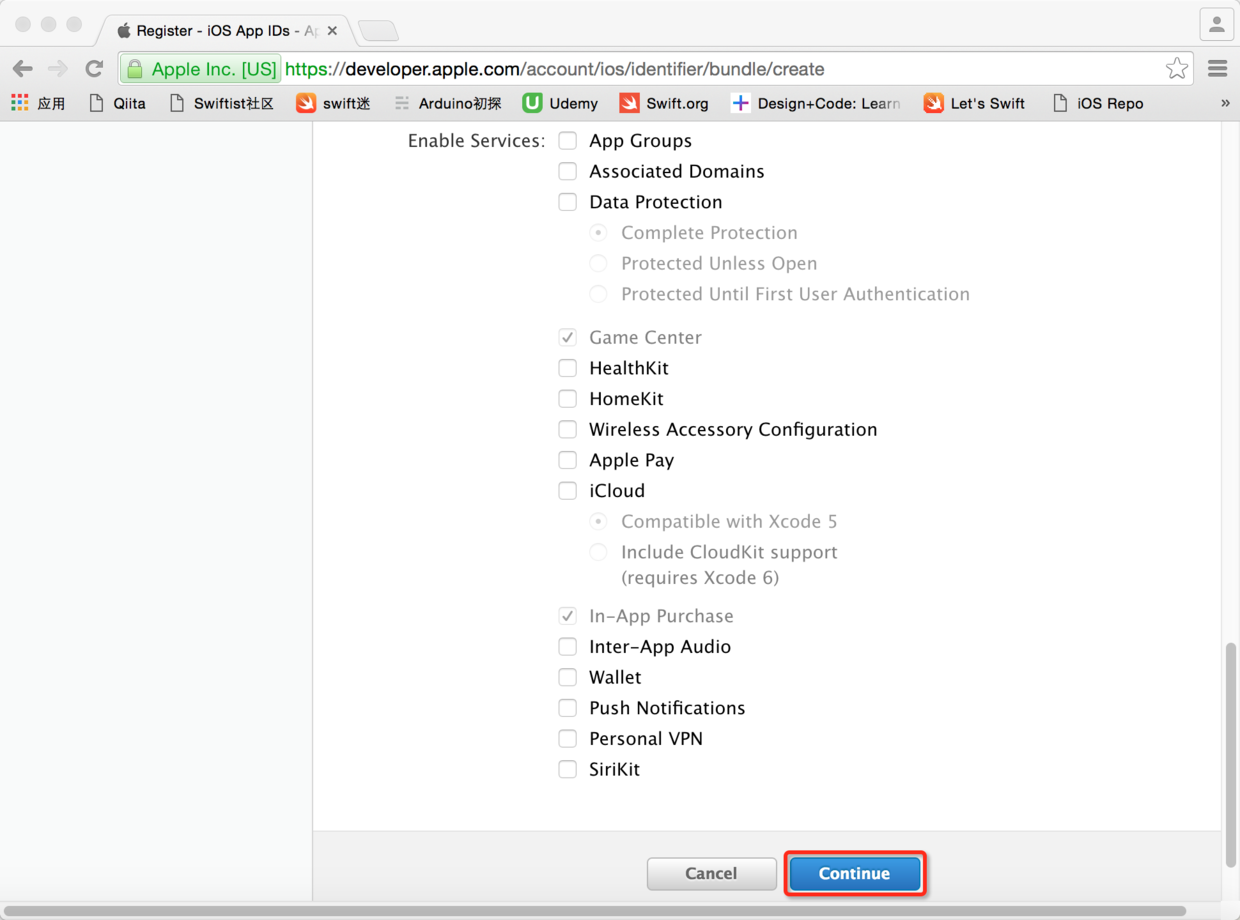
图29. 可以对项目使用的服务进行设置并继续
* * * * *
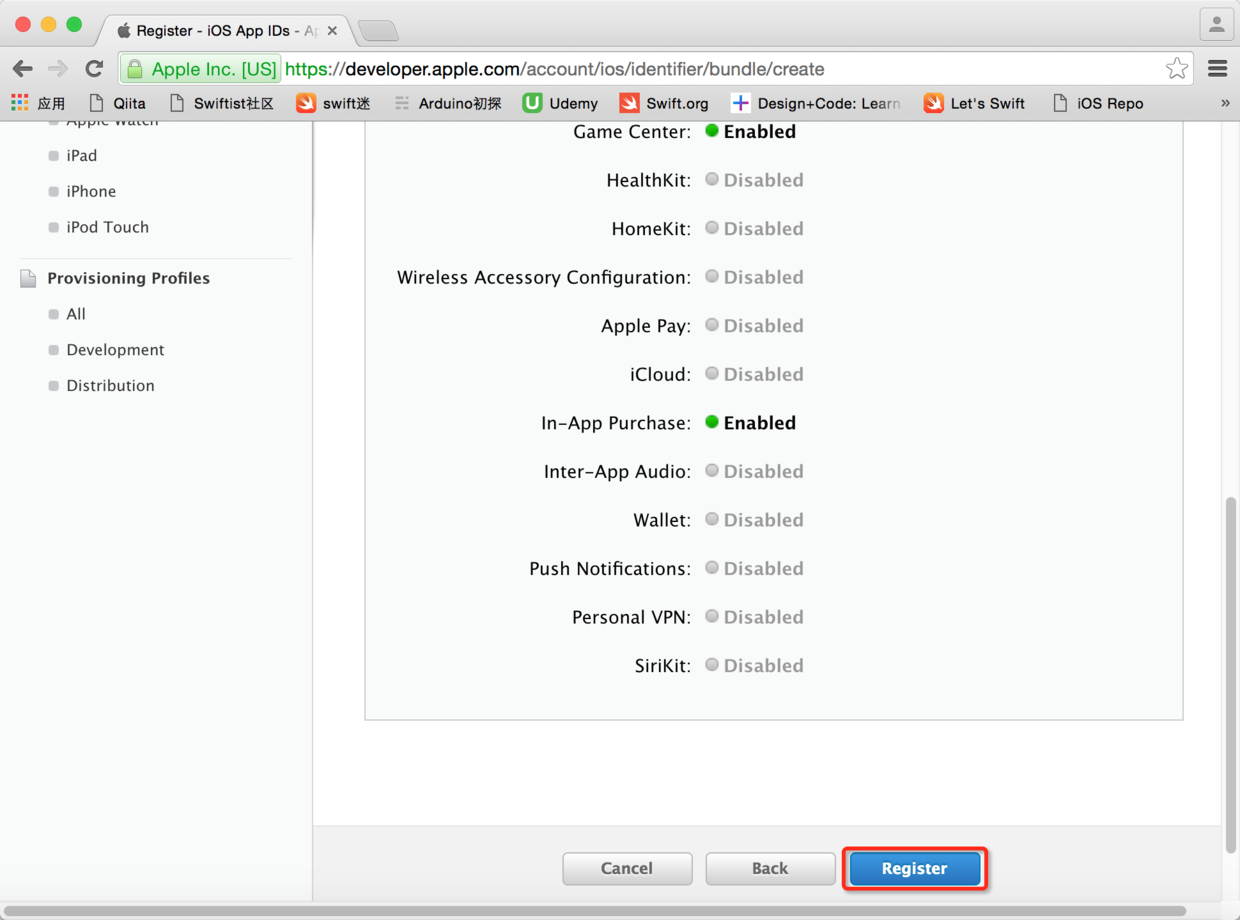
图30. 完成应用ID注册
* * * * *
> 上面一步完成后还要点击“Done”按钮,然后就可以在“App IDs”中看到所有注册过的应用程序的Bundle ID。接下来就可以用证书和注册的应用程序ID来生成“Provisioning Profiles”,你可以把这个文件理解为一个配置文件(后文中将“Provisioning Profile”统称为“配置文件”),有了这个文件才能对你的项目代码用证书进行签名并完成上线的操作。
* * * * *
图31. 查看Provisioning Profiles

* * * * *
点击页面右上方的“+”开始创建“配置文件”。

图32. 创建新的“配置文件”
* * * * *
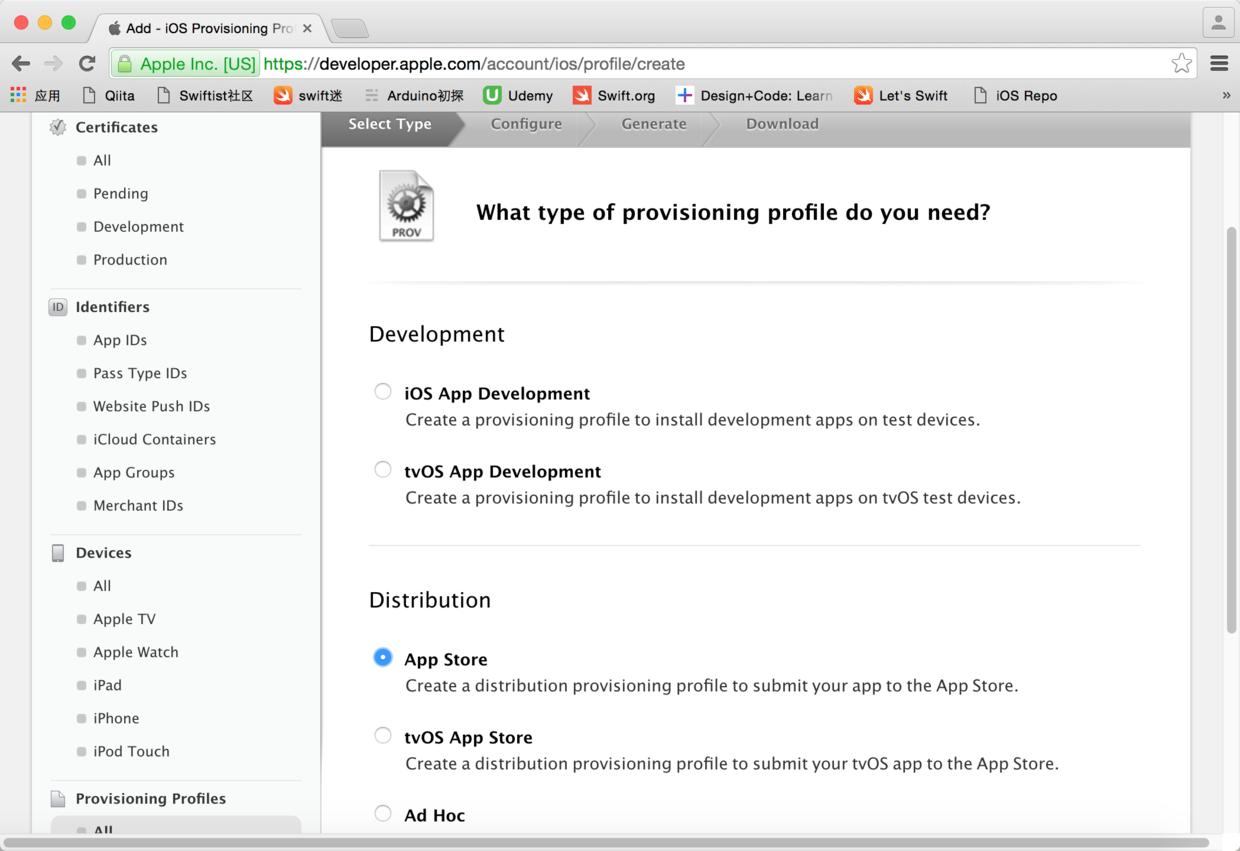
图33. 选择“配置文件”的类型
* * * * *
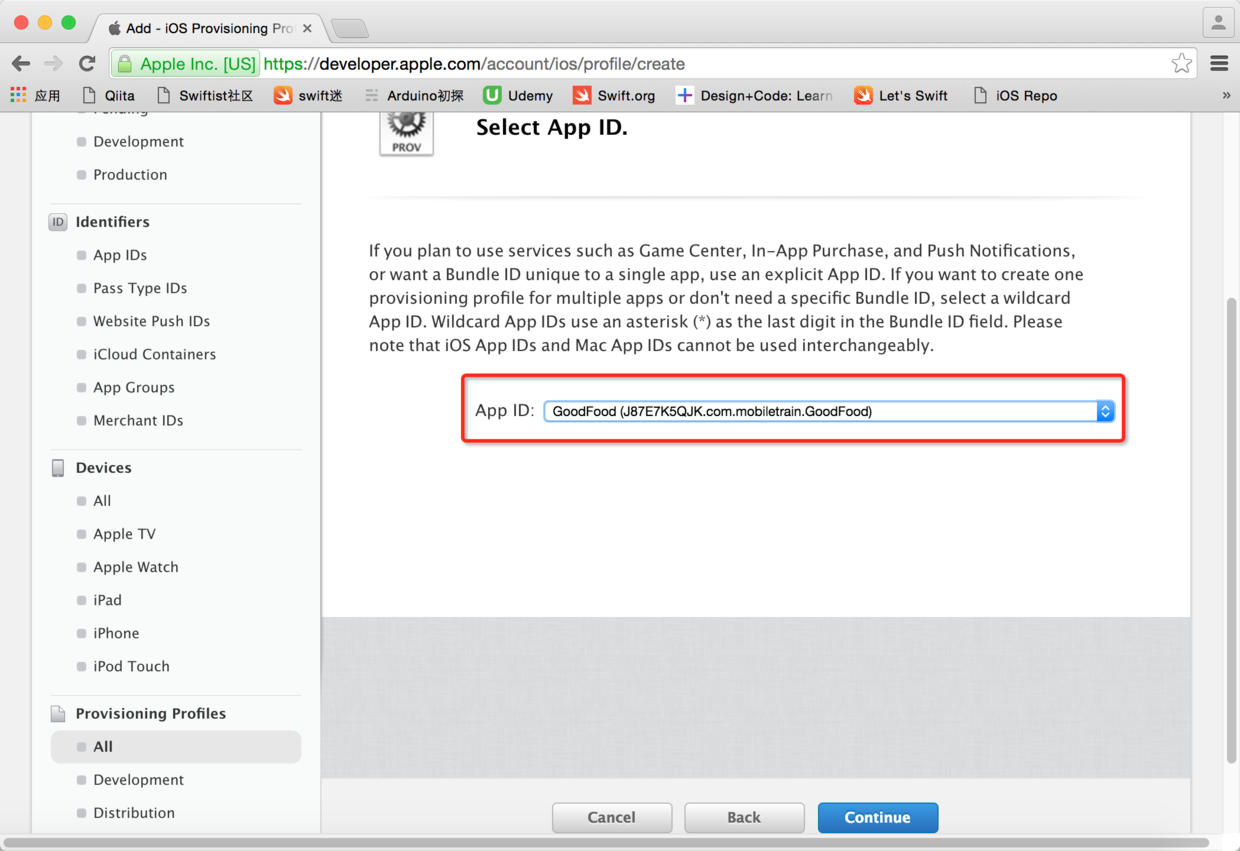
图34. 选择应用程序ID
* * * * *
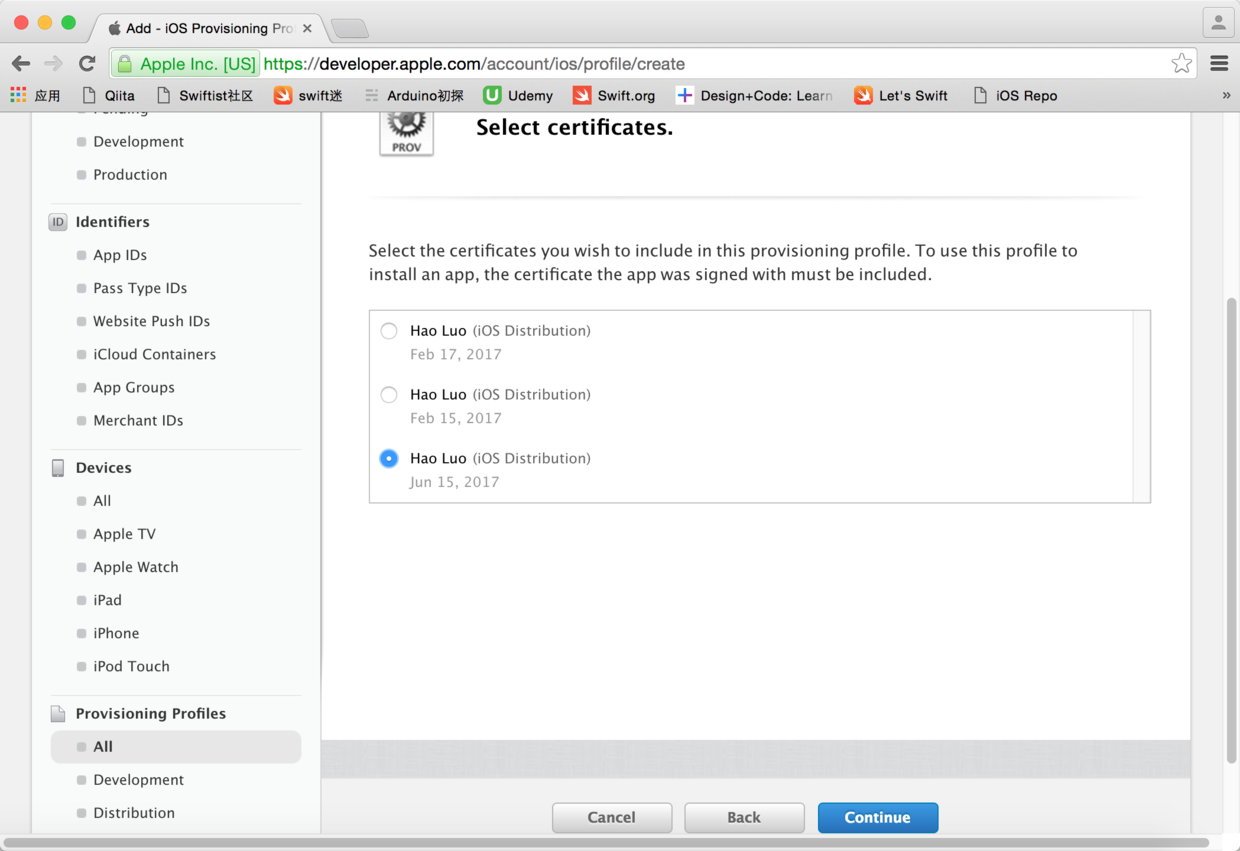
图35. 选择使用的证书
* * * * *
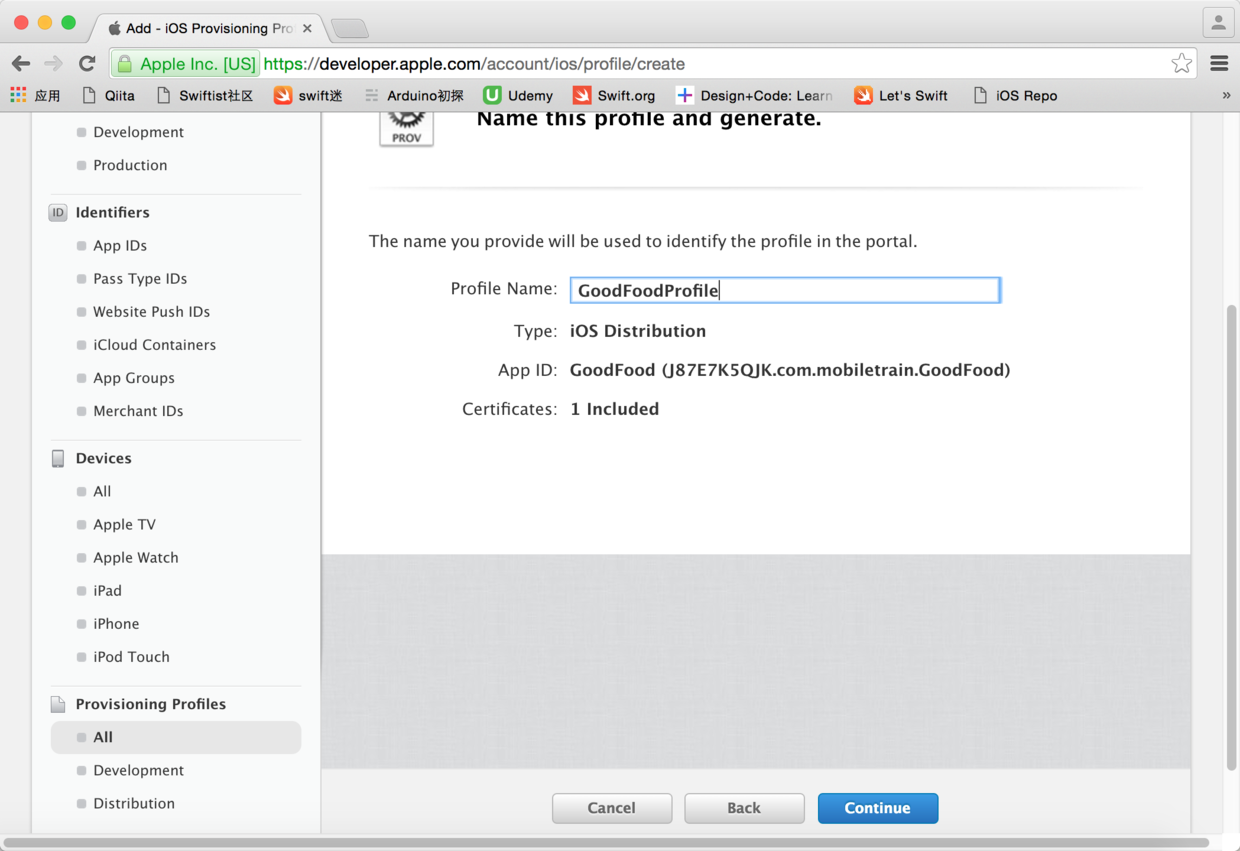
图36. 给“配置文件”命名
* * * * *

图37. 下载“配置文件”并点击“完成”按钮
* * * * *
> 下载好的配置文件可以双击添加到Xcode中,待会就可以使用这个配置文件来完成项目的上线不过现在我们暂时放下这件事情,回到开发者中心,进入“iTunes Connect”。
>

图38. 回到开发者中心
* * * * *
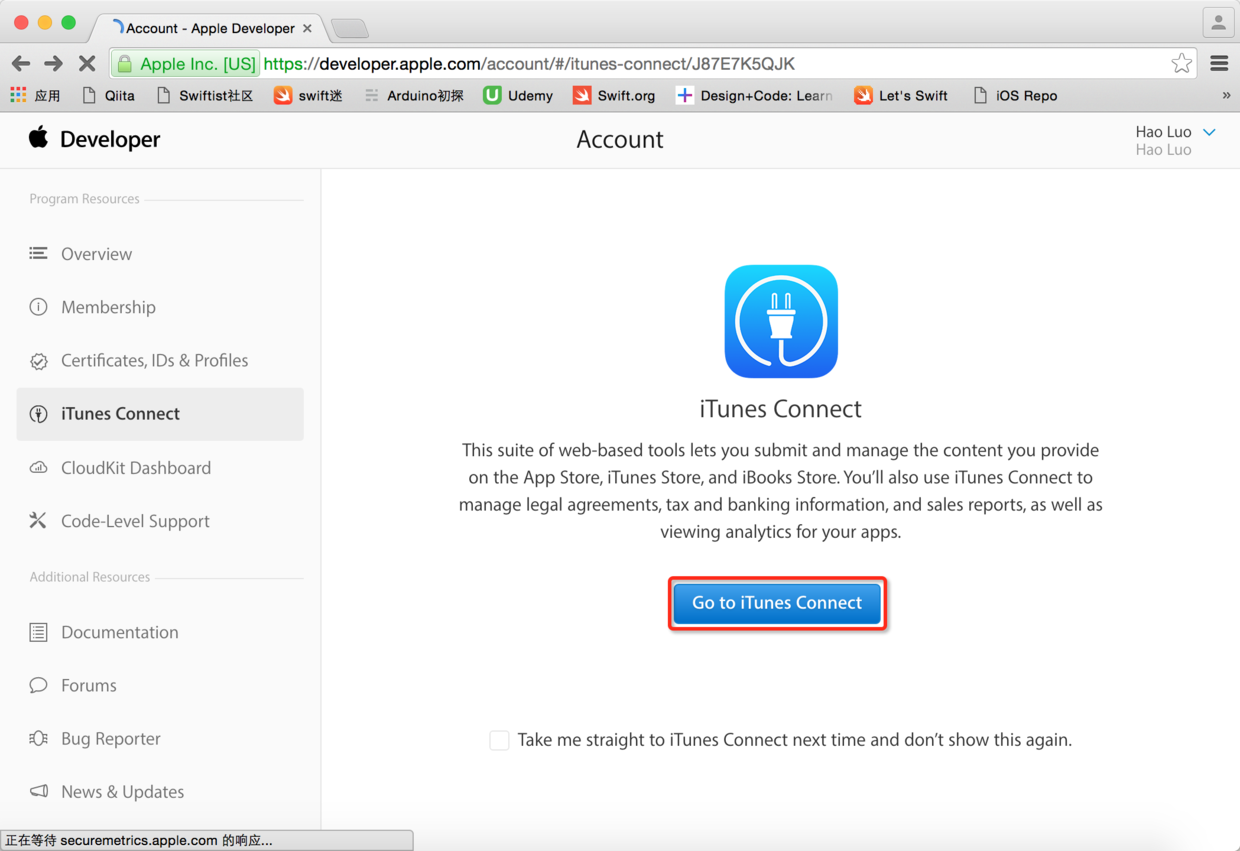
图39. 进入iTunes Connect
* * * * *

图40. 管理App
* * * * *
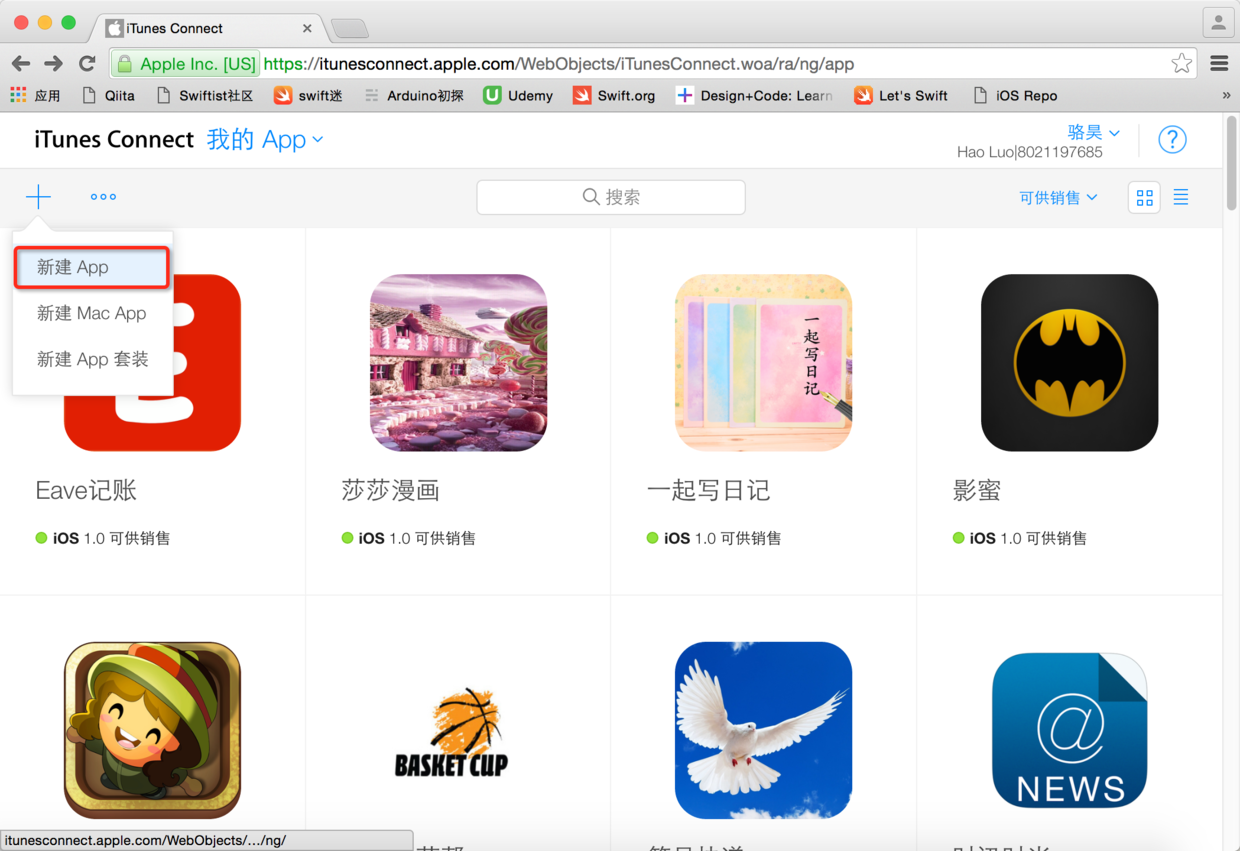
图41. 新建App
* * * * *
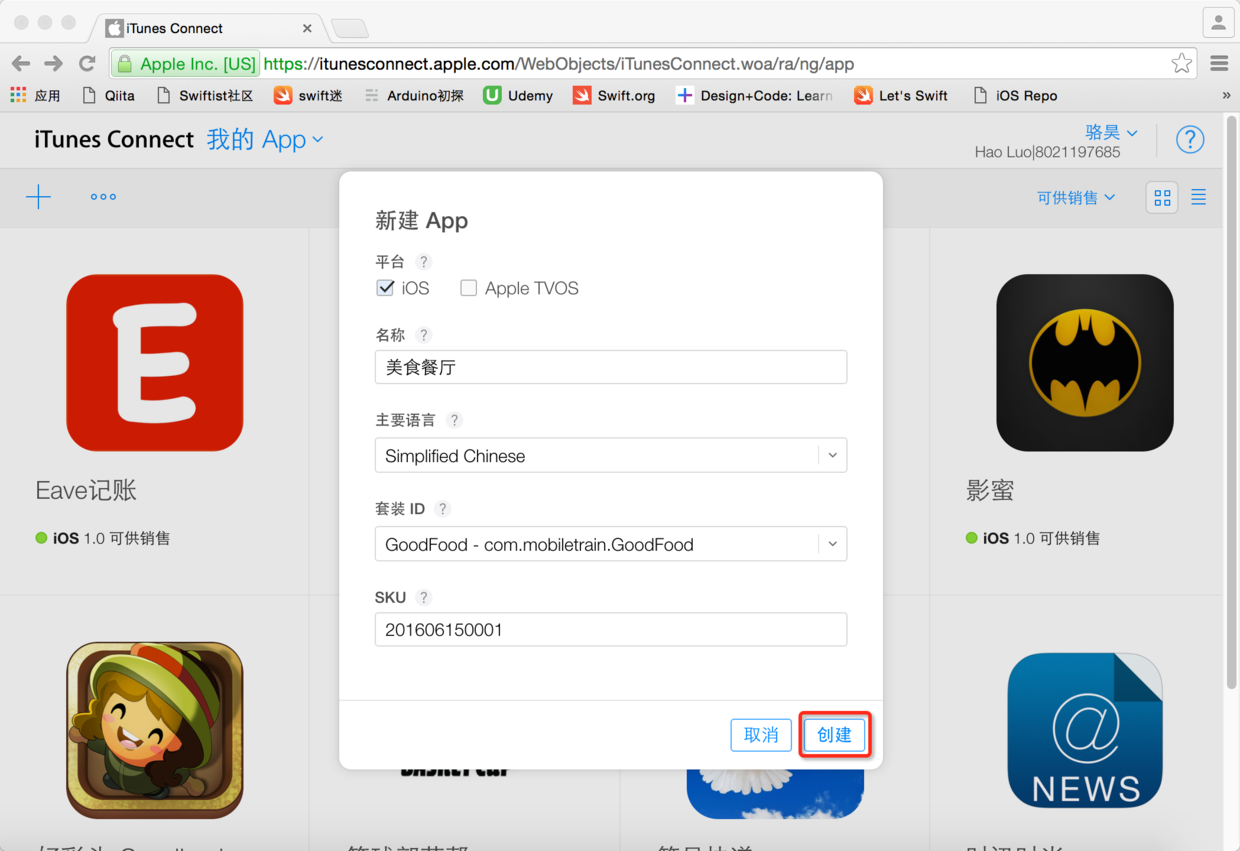
图42. 填写App相关信息
* * * * *
~~~
说明:上图中“名称”是你的应用在App Store中显示的名字;“套装ID”是Xcode中项目的Bundle Identifier;“SKU”可以填写当天日期外加一个编号即可,这是你为你的应用指定的一个标识符。
~~~
接下来的页面中可以指定应用的类别。
图43. 指定应用程序类别并存储
* * * * *

图44. 点击“1.0准备提交”填写App相关信息
* * * * *

图45. 添加App预览和屏幕快照
* * * * *
图46. 编写应用描述和关键词
* * * * *
图47. 设置应用图标并编辑应用分级
* * * * *
~~~
注意:应用图标必须提供1024*1024的图片且图片不能设置alpha通道(透明度);应用分级是为了确定应用使用群体的年龄段,如下图所示。
~~~
图48. 编辑应用分级

图49. 设置完图标和应用分级后的效果
* * * * *
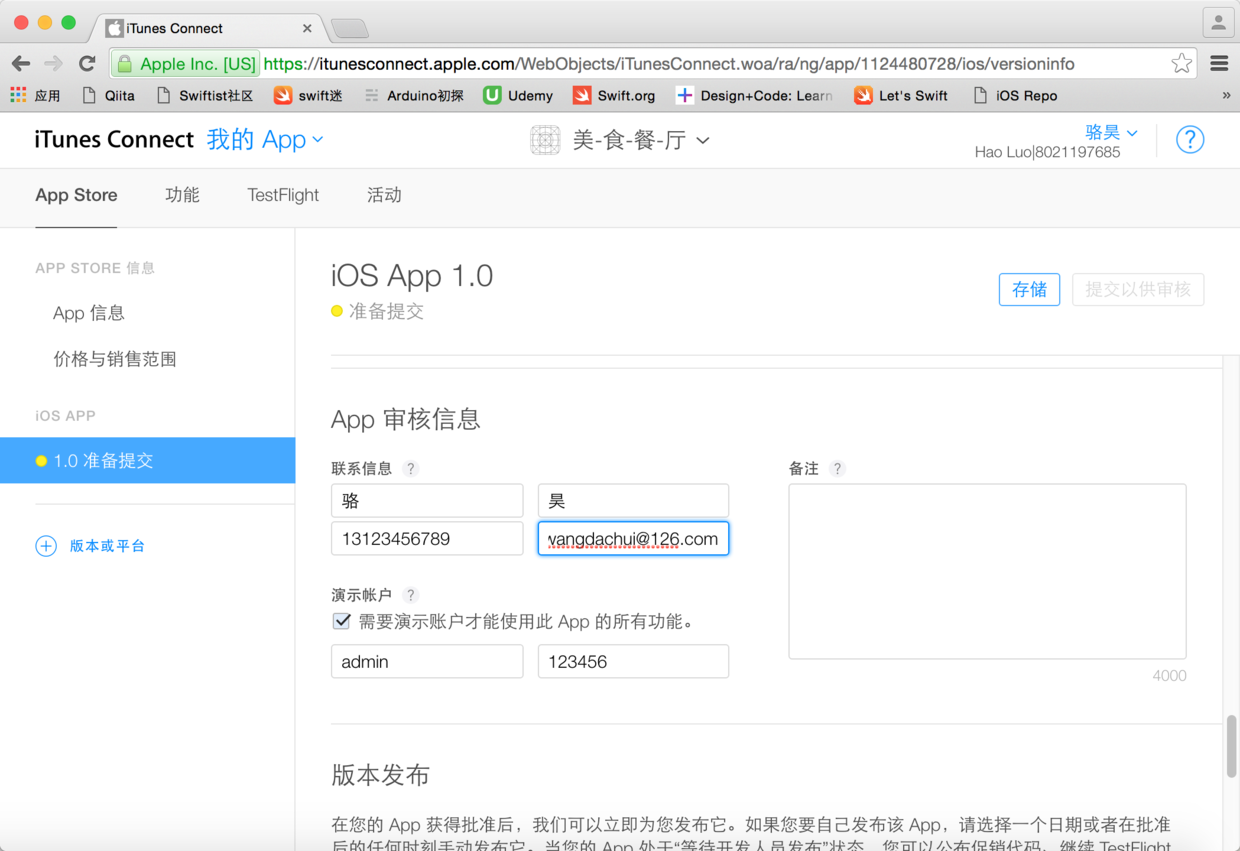
图50. 提供联系人信息和演示账号
* * * * *
~~~
说明:如果你的应用中有需要登录后才能使用的功能那么就必须提供一个演示账号以供审核应用时使用。
~~~
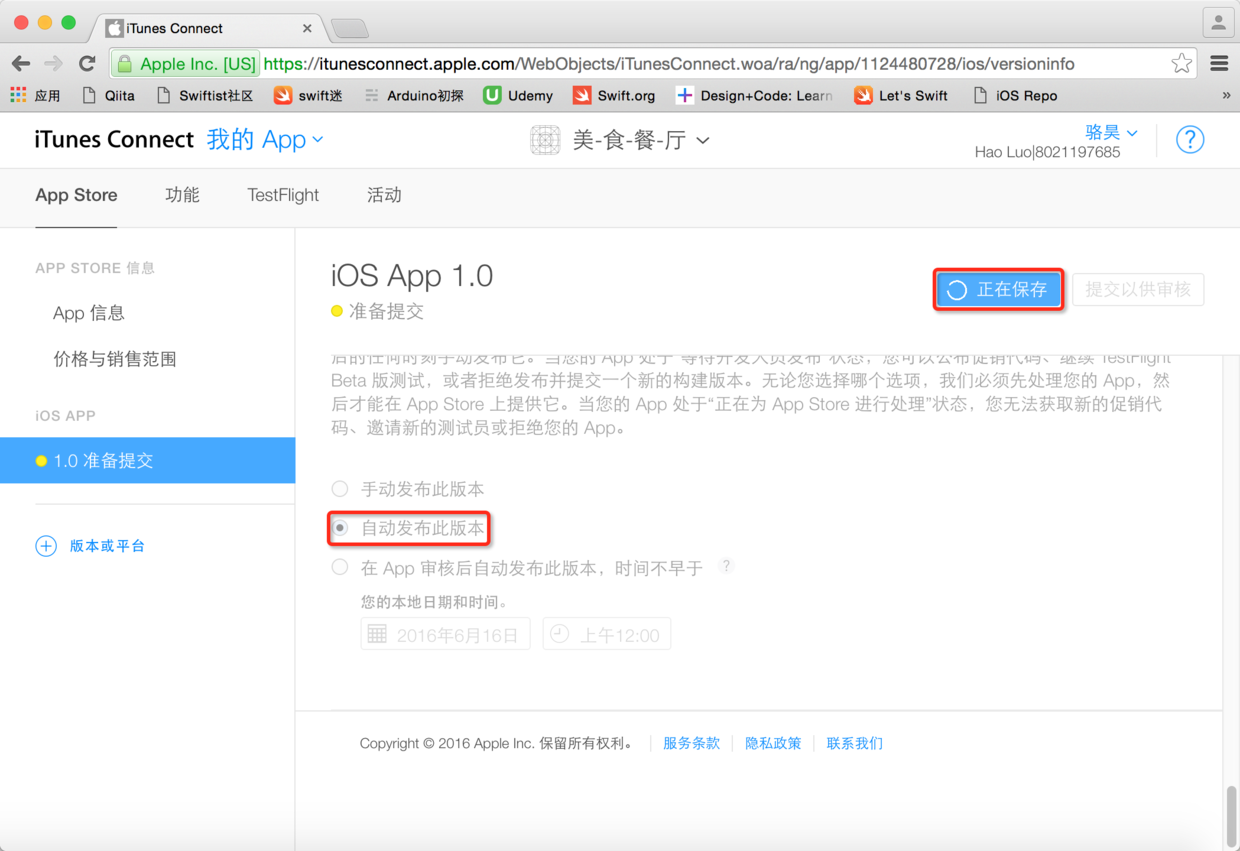
图51. 选择发布方式并保存应用信息
> 接下来就要回到Xcode提交应用程序的代码以供审核,如下图所示我们可以在项目的“Build Settings”中设置代码签名和“配置文件”,可以在上面的工具栏中选中“Generic iOS Device”,然后用“Product”菜单中的“Clean”菜单项对项目做一次清理,再用“Archive”菜单项来对项目进行打包操作。需要提醒的是,如果代码签名出现问题,可以通过如下图所示的“Fix issue”按钮进行联网修复。
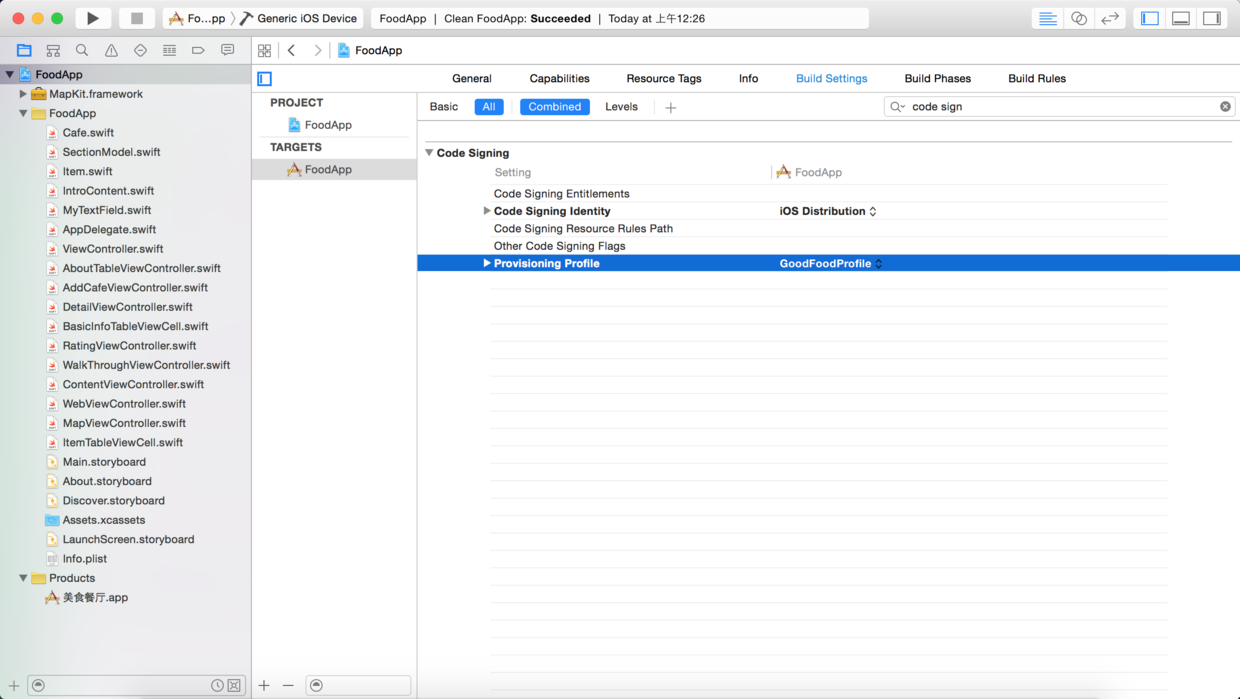
图52. Xcode中设置代码签名和“配置文件”
* * * * *
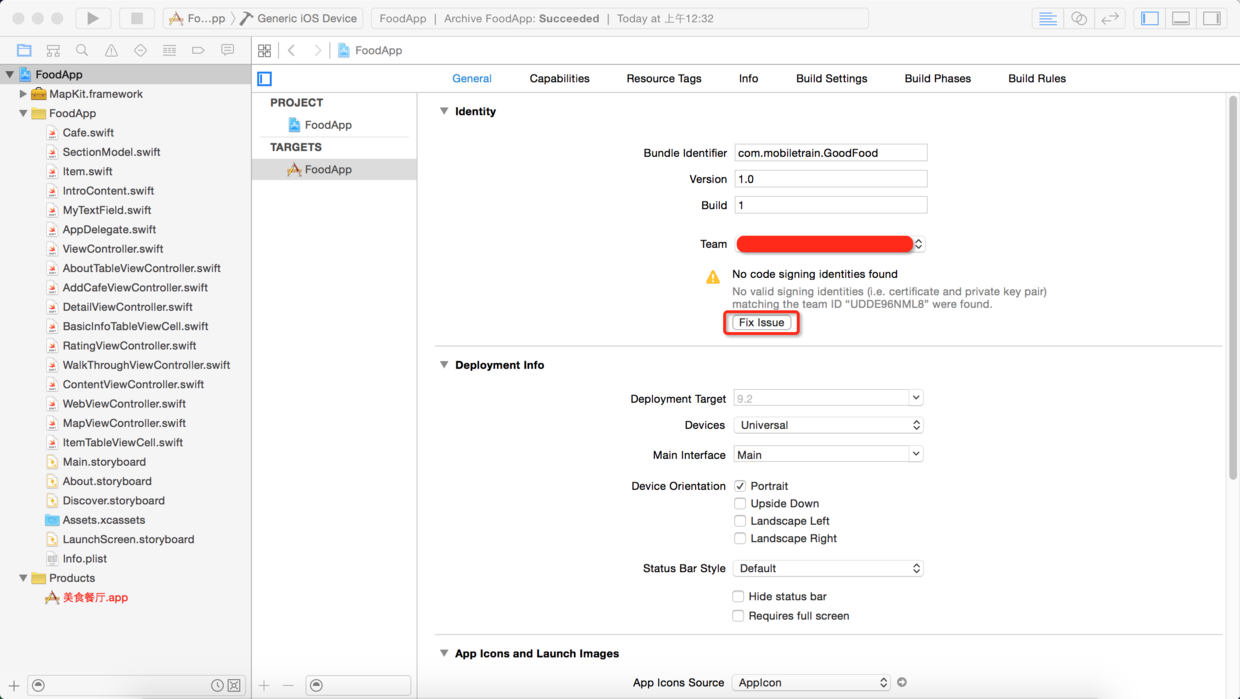
图53. 联网修复代码签名问题
* * * * *
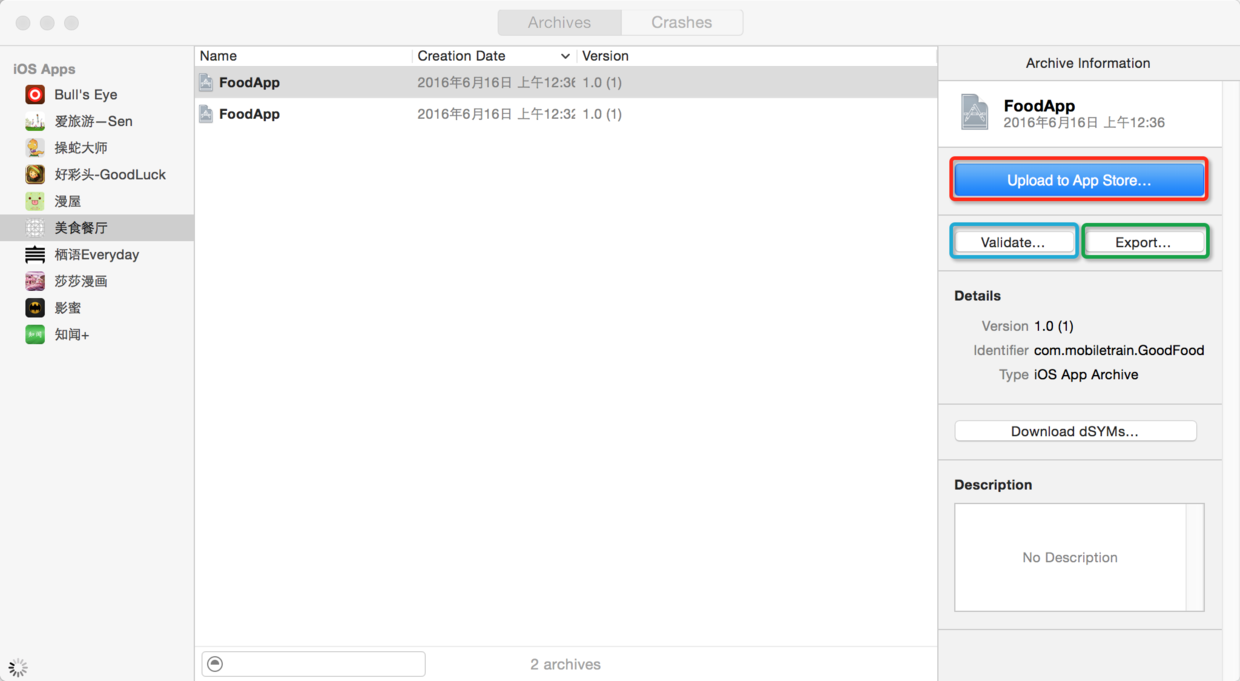
图54. 通过“Product”菜单的“Archive”菜单项启动打包上传工具
* * * * *
> 点击上图红框中的按钮可以上传项目到App Store;点击蓝框中的按钮可以对项目进行验证;点击绿框中的按钮可以将项目导出成ipa文件。
>
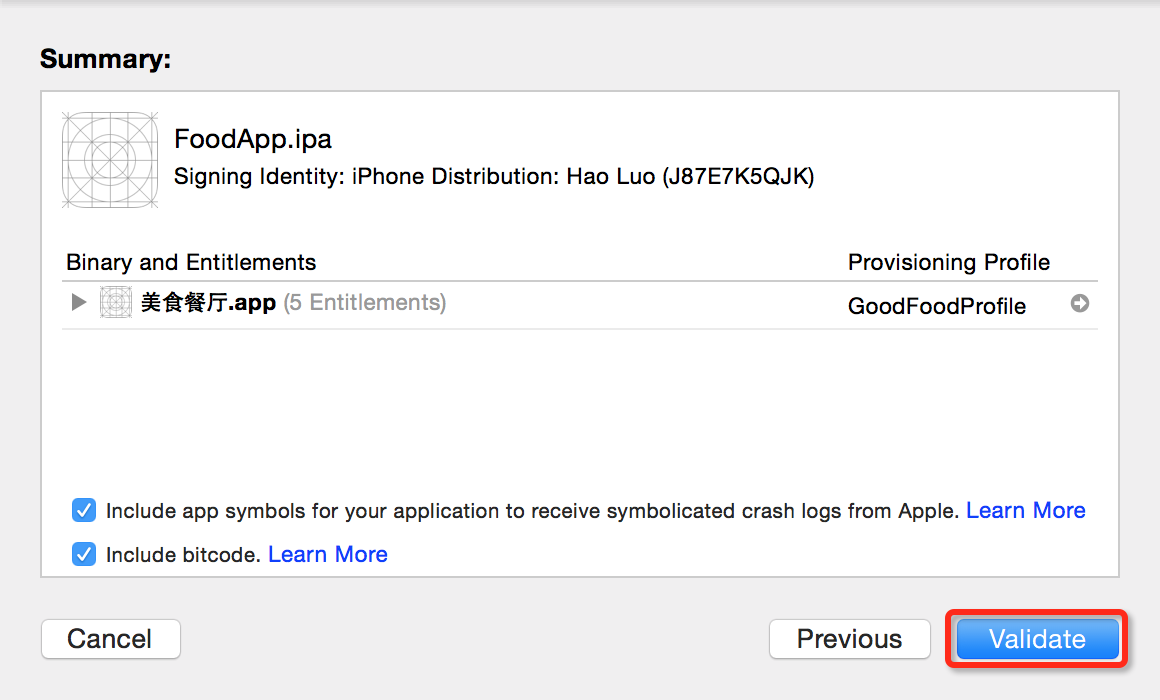
图55. 验证项目界面
* * * * *
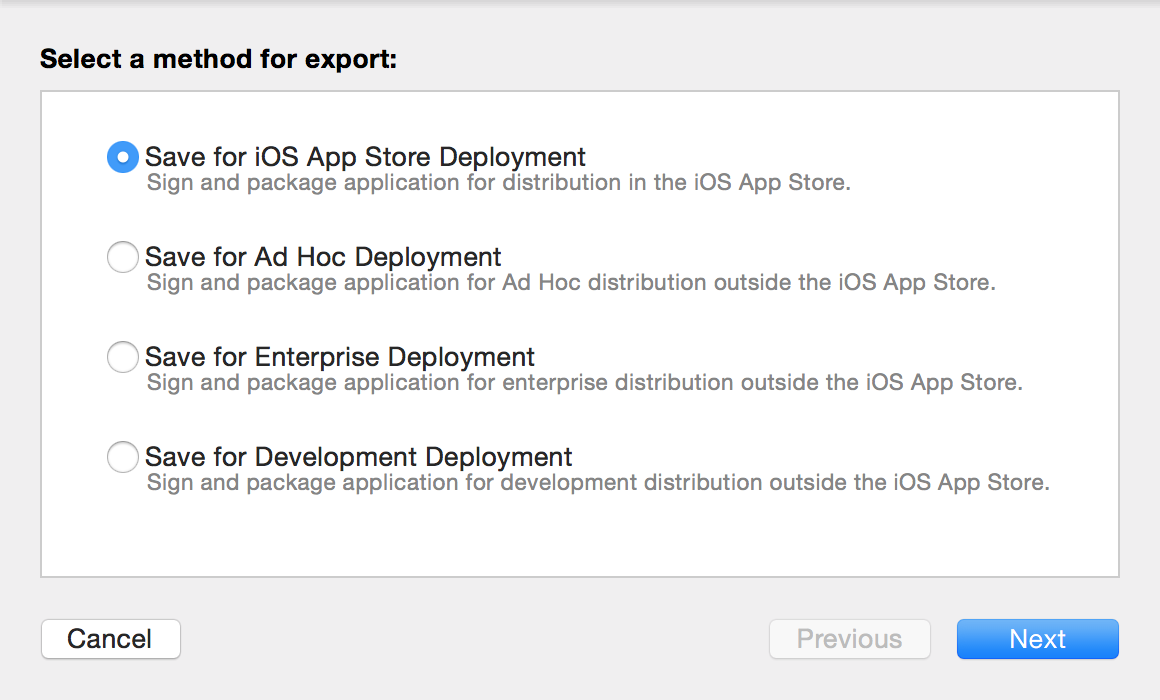
图56. 导出项目的界面
* * * * *
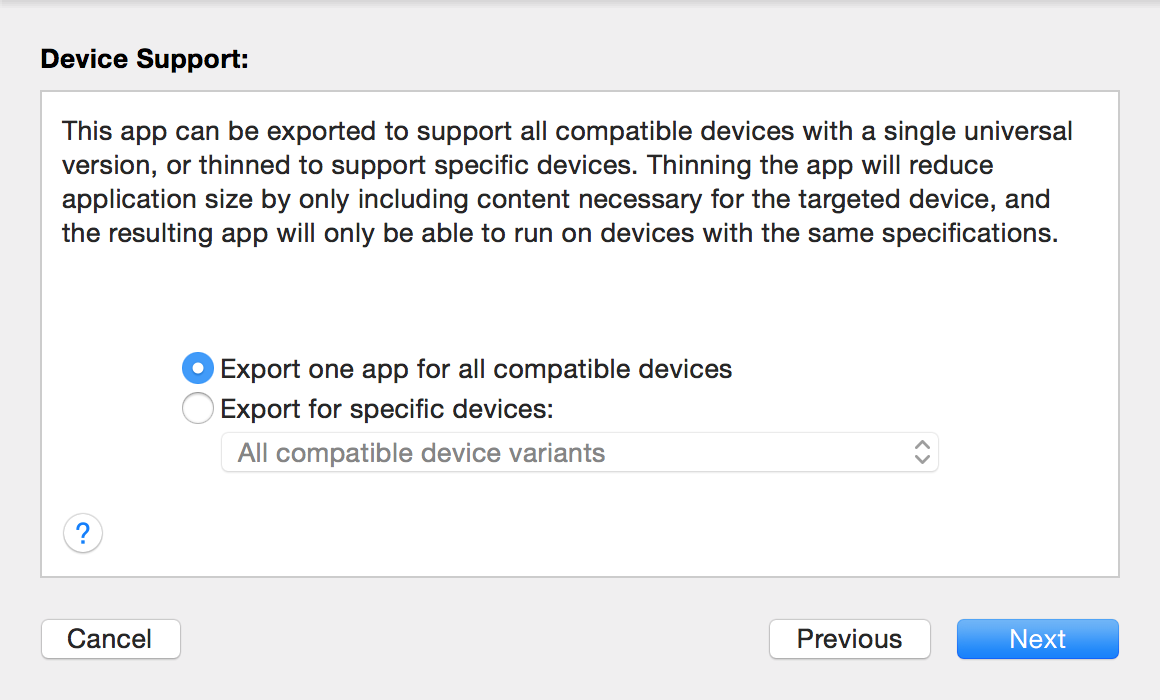
图57. 选择导出的目标设备
* * * * *
导出成功后会看到如下图所示的文件。

图58. 导出后生成的ipa文件
* * * * *
> 可以使用类似于蒲公英这样的内测分发工具将ipa文件上传生成一个二维码,这样可以让所有的测试机通过扫描二维码安装该应用来进行内测,如下图所示。
>

图59. 蒲公英界面
* * * * *
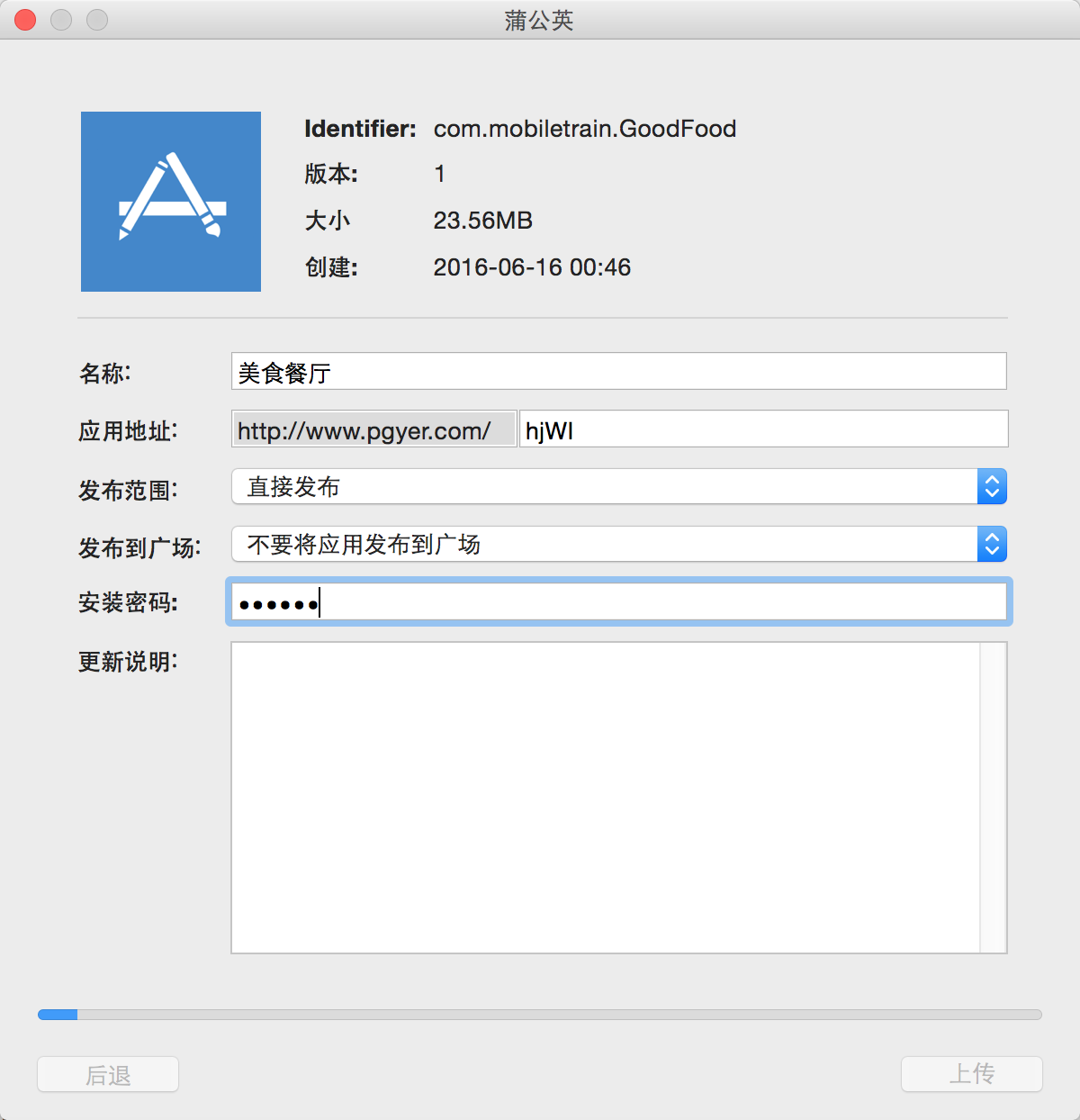
图60. 上传ipa文件并生成二维码
* * * * *
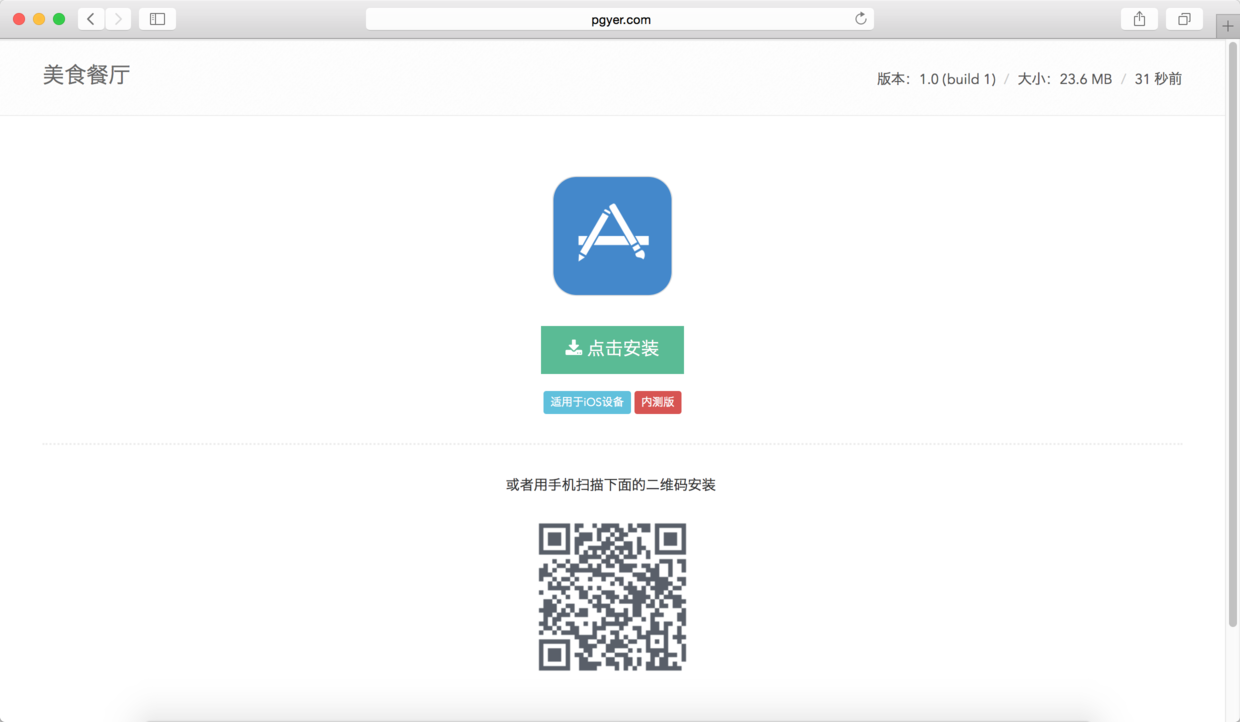
图61. 上传成功后打开应用对应的页面
* * * * *
> 经过严格的内测后,是时候将应用上传到App Store啦。
>

图62. 点击“Upload”上传到App Store
* * * * *
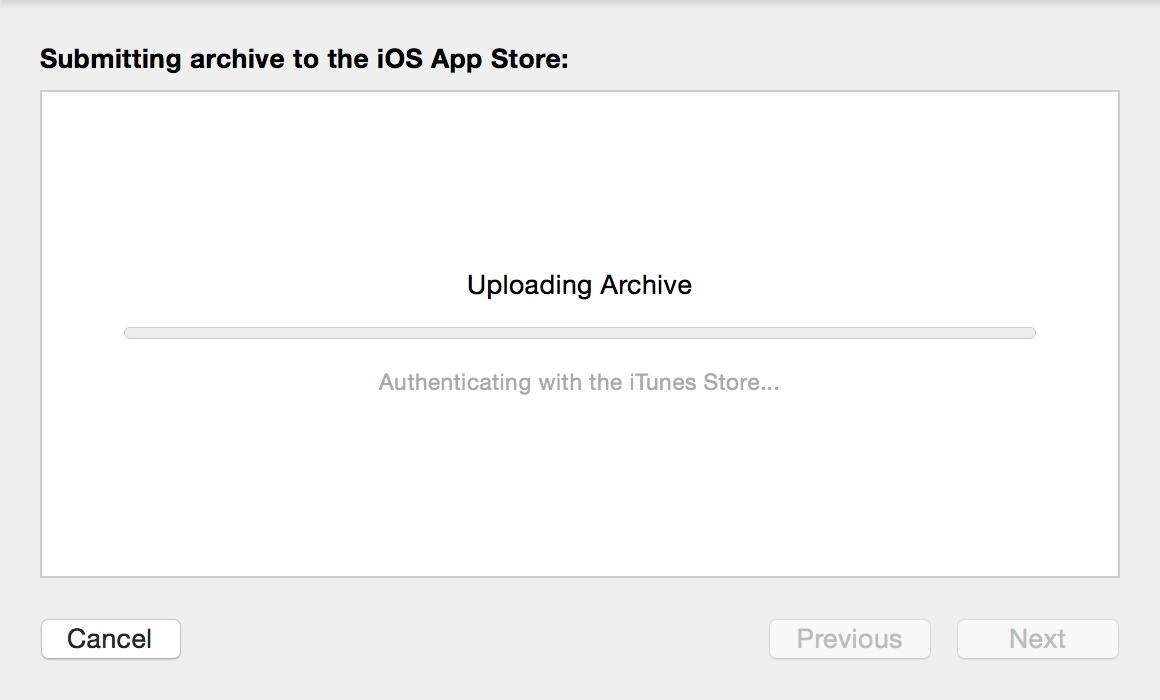
图63. 正在上传应用到App Store
* * * * *
~~~
这个过程可能会比较漫长,你可以放轻松一些,冲一杯咖啡奖励一下自己然后等待上传的结果。
感觉怎么样,是不是觉得上线一个项目还真不容易。这就对了,因为成年人的生活中本来就没有容易二字。
~~~
';
Mysql 复制 (主从复制)
最后更新于:2022-04-01 23:52:28
# :-: **Mysql 5.7 复制**
[TOC]
## 主从复制基本知识了解
1. Mysql复制为 **异步** 复制
2. 主从复制原理 Master 主库 Slave 从库
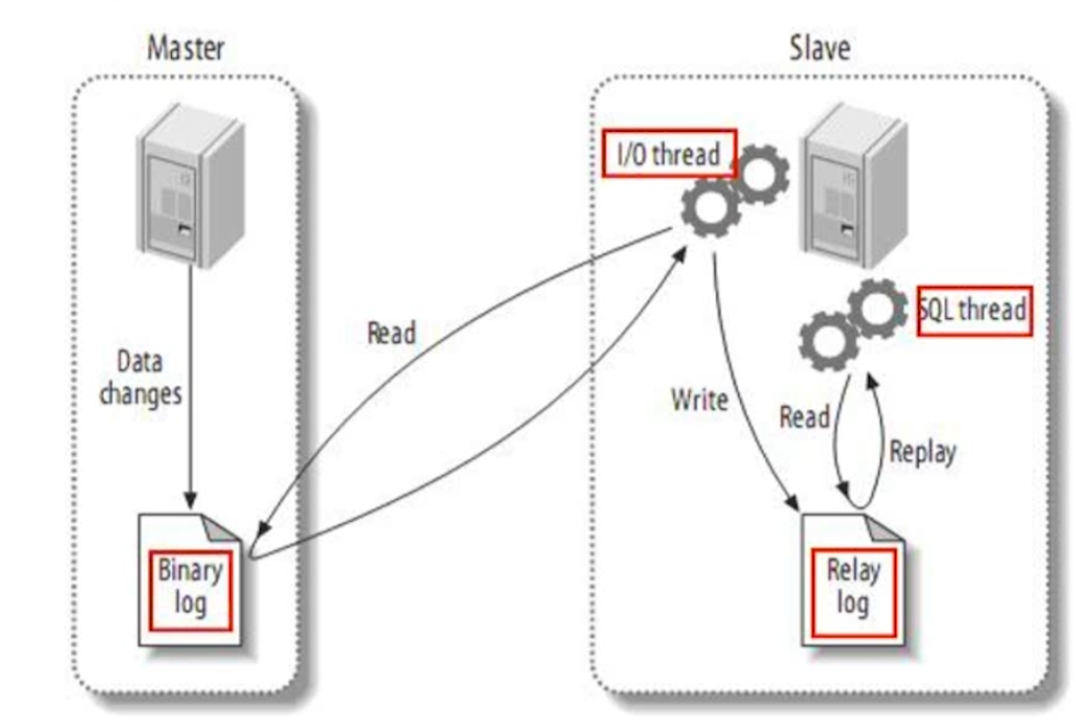
3. TPS 并发读写数 一般在 几百上下/s 也有部分可以达到 几千上下/s
4. 一般主从之间 避免延迟导致的数据 **延迟性** 可使用 **假一致性** (必要的时候 从主库读取实时数据 不必要的用户 依旧读取从库数据)
5. Mysql复制 基于**BinLog**日志
> 日志存在三种格式
> * Statement:BinLog中存储SQL语句,存储日志量最小
> * Row:存储event数据,存储量大,但是不能直接的进行读取
> * Mixed:介于两者之间的存储方式,对不确定的操作使用Row记录,如果每天数据操作量很大,产生日志较多,可以考虑Mixed格式。
> 注意:一般主从复制 不适用Statement日志格式,避免影响主从数据不一致。
6. 
--binglog-do-db : 同步数据库
--binglog-ignore-db : 不同步数据库
7. 
8. Mysql 复制类型
>* [ √ ] 基于二进制日志复制 (Mysql5.5之前唯一支持的复制类型)
>* [ √ ] 使用GTID(全局事务标识符)完成基于事务的复制
9. Mysql 支持半同步复制。
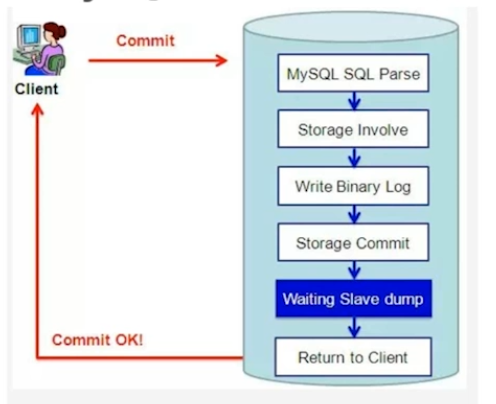 5.6
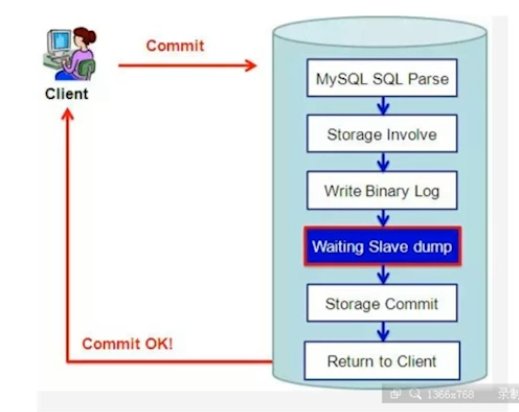 5.7
*****
## 主从复制搭建 (主从均为Linux服务器)
>### 一、创建复制用户 (主库)
```
——不推荐使用——
IP:192.168.1.100 或 192.168.1.%匹配整个1网段
grant replication slave on *.* to '用户名'@'从库IP' identified by '密码';
——推荐——
先创建用户
create user '用户名'@'从库IP' identified by '密码';
授权用户
grant replication slave on *.* to 用户名@'从库IP';
```
>### 二、使用mysqldump导出数据(主库)
```
进入到需要导出的文件位置中
例如 导出到 /tmp/下
mysqldump --single-transaction --master-data=2 --triggers --routines --all-databases -uroot -p> all.sql
按照提示输入密码
```
> ### 三、将导出sql文件传入 从库 中(主库)
```
scp all.sql root@192.168.2.202:/tmp/
```
>### 四、查看all.sql中的MASTER_LOG_FILE、MASTER_LOG_POS(从库)
```
more all.sql
查看 CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=154;
MASTER_LOG_FILE
MASTER_LOG_POS
将两个值记录下来
```
>### 五、从库配置
```
此处用户密码 使用 主库create生成的用户密码
mysql>change master to marset_host='主库IP',
>master_user = '用户',
>master_password='密码',
>master_log_file=上面查看的 MASTER_LOG_FILE值,
>master_log_pos=上面查看的 MASTER_LOG_POS值;
```
>### 六、开启slave
```
start slave;
```
>### 七、 查看slave status
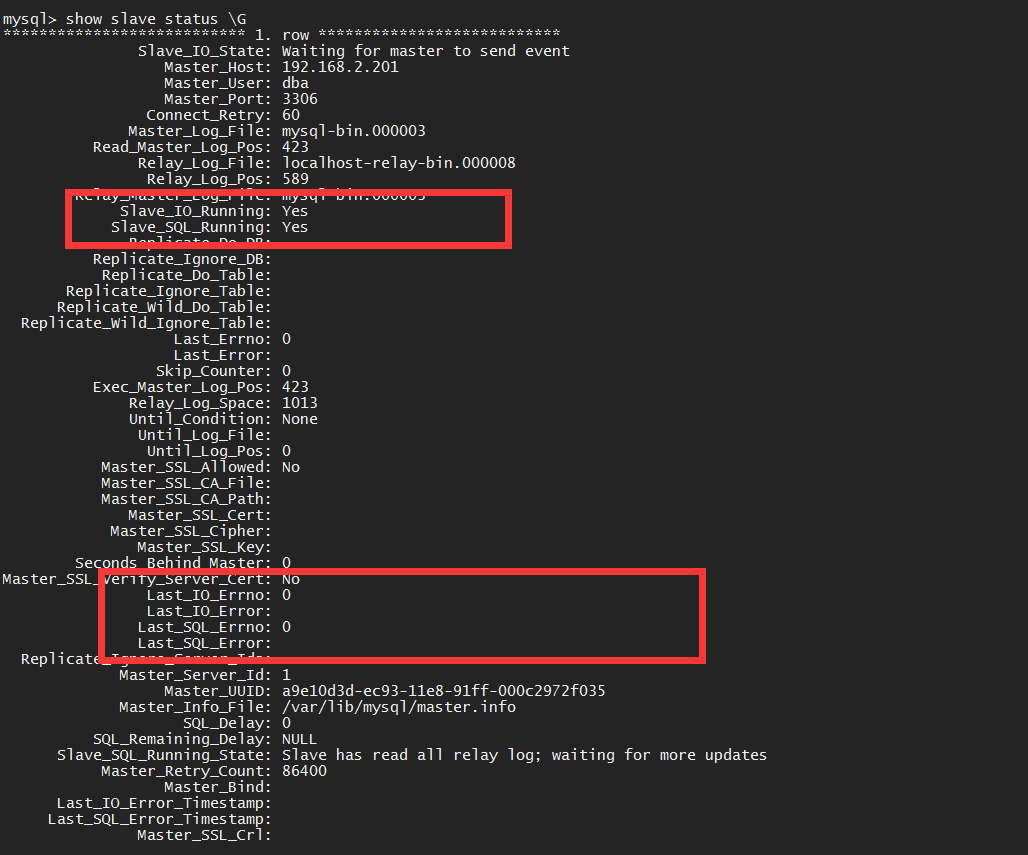
```
show slave status \G;
Slave_IO_Running: No
Slave_SQL_Running: Yes
查看 slave链接状态 都为yes时 连接成功
连接失败时 查看此信息
Last_IO_Errno: 1593
Last_IO_Error: Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work.
```
> **中间可能会因为个人的环境问题 有一些报错,相信大家都可以动手解决掉,解决问题的同时,学习到更广面的知识**
*****
## 扩展知识
>### 主动延时复制
在从库中进入MySQL 进行设置 主动延时复制
**设置延时操作时 先关闭slave服务**
`mysql> change master to master_delay=3600;`
> 设置完成之后,输入一下命令查询
`mysql> use performance_schema;
`
`mysql> show tables;`
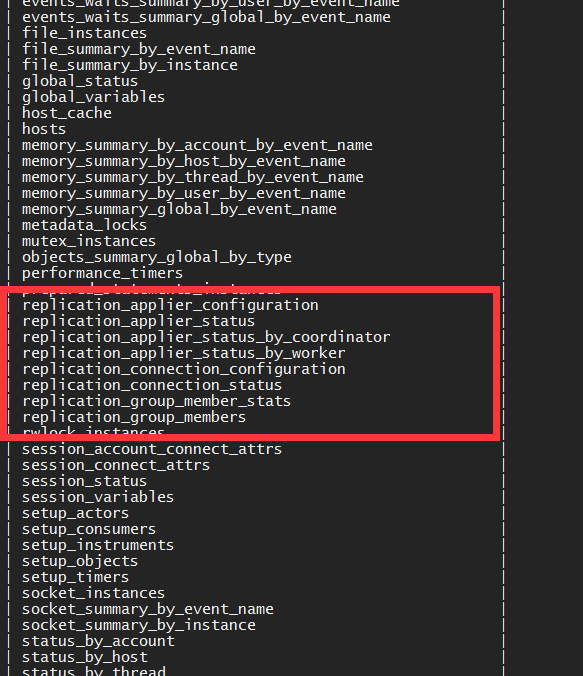
> replication_***开头的表 都是主从配置的视图表
`mysql>select * from replication_applier_configuration ;`

CHANNEL_NAME : 复制链路名称,MySQL支持多链路复制,可以存在一条空字符串的channel_name,当存在多条复制链路时链路的channel_name都不能一样。
DESIRED_DELAY:主从复制延迟,该字段用来配置当主进行操作之后延迟多少秒后才被复制到slave节点。
`mysql>select * from replication_applier_status`;

SERVICE_STATE:复制状态
REMAINING_DELAY:下次主从同步时间
多线程复制视图表
replication_applier_status_by_coordinator
replication_applier_status_by_worker
主从同步配置信息
replication_connection_configuration
链接状态
replication_connection_status
## 基于日志复制 在线转换为 基于事务的复制

**基于事务的复制 对于数据的完整性 更加安全 推荐使用 基于事务的复制**
*****
### 转换分为九个步骤


### 以下为实际操作代码块
#### 查看版本信息
`mysql> show variables like 'version';
`
#### 查看服务器gtid_mode
`mysql> show variables like 'gtid_mode';`
#### 设置gtid_consistency (主库和从库)
`mysql> set @@global.enforce_gtid_consistency=warn;
`
#### 查看当前的错误日志配置 查询日志位置
`mysql> show variables like 'log_error';`
查看错误日志 确定没有报错的情况下
#### 再次设置gtid_consistency (主库和从库)
`
mysql> set @@global.enforce_gtid_consistency=on;
`
> gtid_mode 四种值 只能按顺序设置
> off 关闭
> off_permissive 关闭准备
> on_permissive 启动准备
> on 启动
#### 修改gtid_mode(主库和从库)
`mysql> set @@global.gtid_mode = off_permissive;
`
`mysql> set @@global.gtid_mode = on_permissive;
`
#### 查看是否有匿名复制(日志复制)
为空即可
`mysql> show status like 'ongoing_anonymounse_transcation_count';`
#### 确认没有匿名复制之后继续修改gtid_mode(主库和从库)
`mysql> set @@global.gtid_mode = on;
`
然后查看一下gtid_mode
`mysql> show variables like 'gtid_mode';`
#### 重启slave(从库)
`mysql> stop slave`
`mysql> change master to master_auro_position=1;`
`mysql> start slave`
';
mysql优化
最后更新于:2022-04-01 23:52:26
# :-: mysql优化 -- 收集完善中ing
1. IN、OR 子句常会使用工作表,使索引失效。如果不产生大量重复值,可以考虑把子句拆开。拆开的子 句中应该包含索引。
2. 只要能满足你的需求,应尽可能使用更小的数据类型:例如使用 MEDIUMINT 代替 INT
3. 尽量把所有的列设置为 NOT NULL,如果你要保存 NULL,手动去设置它,而不是把它设为默认值。
4. 尽量少用 VARCHAR、TEXT、BLOB 类型
5. 如果你的数据只有你所知的少量的几个。最好使用 ENUM 类型
6. 任何对列的操作都将导致表扫描,它包括数据库教程函数、计算表达式等等,查询时要尽可能将操作移 至等号右边。
7.
';
MySql主从搭建
最后更新于:2022-04-01 23:52:24
:-: **MySql主从搭建 Windows**
> ## 在MySQL5.7新版本中 不推荐修改my.cnf或者my.ini
[主从搭建原文跳转--亲测可用](https://blog.csdn.net/pz_winner/article/details/78296085)
> 主库master
找到 mysql中的 my.ini 文件 寻找 [mysqld] 一般在末尾
添加如下代码
```
[mysqld]
port = 3306
;数据库ID号, 为1时表示为Master,其中master_id必须为1到232–1之间的一个正整数值;
server-id = 1
;启用二进制日志;
log-bin = mysql-bin
;需要同步的二进制数据库名;
binlog-do-db = test
;不同步的二进制数据库名,如果不设置可以将其注释掉;
;binlog-ignore-db = information_schema
;binlog-ignore-db = mysql
;binlog-ignore-db = personalsite
;binlog-ignore-db = test
;设定生成的log文件名;
log-bin = "binLog"
;把更新的记录写到二进制文件中;
log-slave-updates
```
**如果有 Navicat 数据库管理工具 直接在主库添加一个用户组 **
**我的用户为 **
**用户名称:slave**
**主机地址:从库地址**
**密码:********
**权限:file、reload、replication Slave、super**
> 也可使用命令
**> 注意:创建用户时,不推荐之间grant生成用户 ;应该先create创建用户 然后 grant授权用户**
```
创建用户
——不推荐使用——
IP:192.168.1.100 或 192.168.1.%匹配整个1网段
grant replication slave on *.* to '用户名'@'从库IP' identified by '密码';
——推荐——
先创建用户
create user '用户名'@'从库IP' identified by '密码';
授权用户
grant replication slave on *.* to 用户名@'从库IP';
```
```
mysql> GRANT REPLICATION SLAVE,RELOAD,SUPER,FILE ON *.*
TO {mysql_backup主库地址}@'%'
IDENTIFIED BY '{密码}';
```
**注:命令执行完成之后要刷新用户组**
```
mysql> flush privileges;
```
****
****
> 从库
去 my.ini 文件中
```
[mysqld]
port = 3306
server-id=2
log-bin=mysql-bin
relay-log=relay-bin
relay-log-index=relay-bin-index
replicate-do-db=test
```
> server_id是必须的,而且唯一。slave没有必要开启二进制日志,但是在一些情况下,必须设置,例如,如果slave为其它slave的master,必须设置bin_log。在这里,我们开启了二进制日志,而且显示的命名(默认名称为hostname,但是,如果hostname改变则会出现问题)。
relay_log配置中继日志,log_slave_updates表示slave将复制事件写进自己的二进制日志(后面会看到它的用处)。
有些人开启了slave的二进制日志,却没有设置log_slave_updates,然后查看slave的数据是否改变,这是一种错误的配置。所以,尽量使用read_only,它防止改变数据(除了特殊的线程)。但是,read_only并是很实用,特别是那些需要在slave上创建表的应用。
> 停止从库
```
mysql> stop slave;
```
> 链接主库
```
mysql> CHANGE MASTER TO master_host = '127.0.0.1',
master_user = 'mysql_backup',
master_password = '123456',
# master_log_file = 'mysql-bin.000008',
# master_log_pos = 120;
```
**注意:加#的参数在上图的show master status \G;中找 去主库中执行此命令**
> 启动从库
```
Start slave
```
> 查看从库状态
```
Show slave status
```
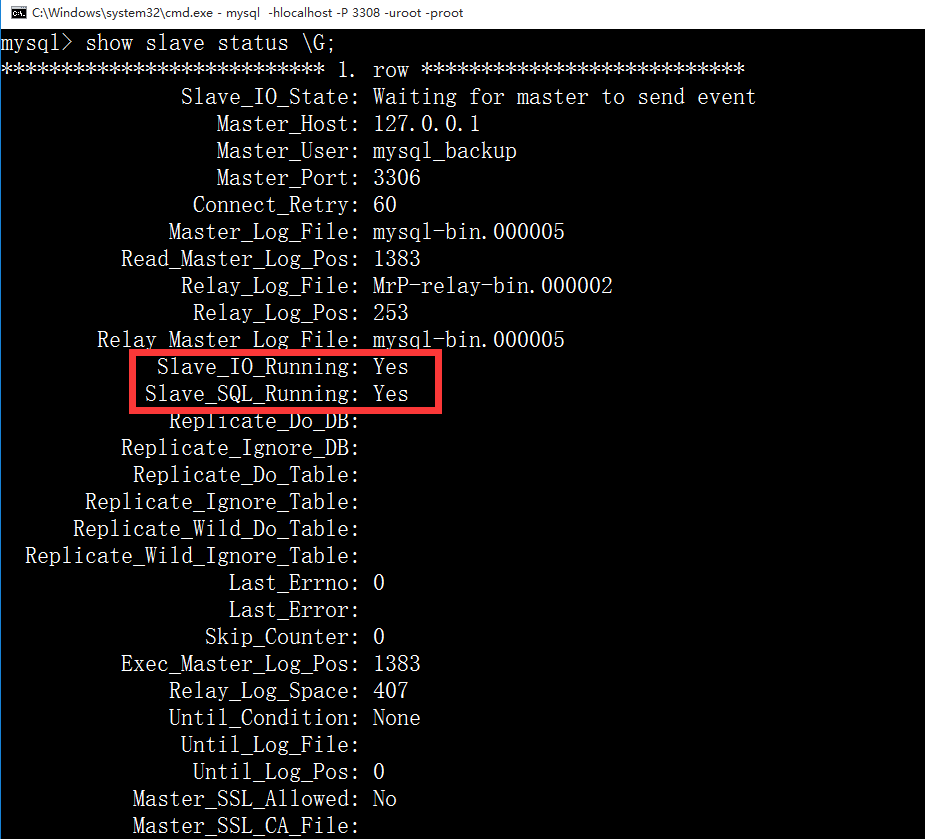
显示都为yes 就搭建成功了
';
MySql监控工具–mytop
最后更新于:2022-04-01 23:52:21
# MYSQL监控工具--mytop
> mysql可以说如今最为流行的数据库了,虽然现在nosql的风头正盛。但我想很多公司重要的业务数据不会用nosql去跑。而在这些方面mysql似乎的使用更盛(开源免费,让我花钱去买oracle,我想我是不会买的)。君不见taobao、腾讯、facebook这些牛X的IT公司们都自己去修改mysql,将核心业务数据运行在mysql之下。
>
> 而平时要对mysql的运行性能进行监控的话工具也非常多。强大复杂的有 oracle官方提供的mysql 企业监控器(当然是收费的),当然开源的配置nagios、cacti上运行的mysql-monitor插件也不少。而想要实时的观察的话,也有mytop、mycheckpoint(绘图显示)、mtop(托管在sourceforge,从04年至今没见更新了。还有一个mongodb 的监控工具也要mtop,托管在github)等等。
>
* * * * *
* * * * *
## 点击[这里](http://blog.csdn.net/u011871037/article/details/52608831)查看详细描述
> Linux 有个非常有用的
top 命令,可以查看操作系统的性能状态,mytop 命令类似 top 命令,界面结构也类似,只是 mytop 显示的是 mysql 的状态信息,例如我们非常关心的
QPS 指标
使用说明
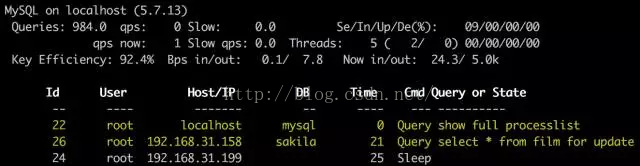
mytop 的结果信息主要分为上下两个部分,上面是各项指标,下面是线程列表
第1行很简单,就是版本信息
第2行是整体信息

Queries 服务器处理过的query总数
qps 每秒处理的query数量的平均值
Slow 慢查询总数
Se/In/Up/De(%) Select,Insert,Update,Delete 各自的占比
第3行是实时信息,本刷新周期内的信息统计,刷新周期是在配置文件中指定

qps now 本周期内的每秒处理query的数量
Slow qps 本周期内的每秒慢查询数量
Threads 当前连接线程数量,后面括号内的第一个数字是active状态的线程数量,第二个数字是在线程缓存中的数量
最后一列是本周期内的 Select,Insert,Update,Delete 各自的占比

Key Efficiency 表示有多少key是从缓存中读取,而不是从磁盘读取的
Bps in/out 表示mysql平均的流入流出数据量
Now in/out
是本周期内的流入流出数据量
剩下的就是线程信息列表

列出了当前的mysql线程,根据idle状态时间排序,通过
o 键可以选择升序或降序
列表中显示出各线程的详细信息,例如 线程ID、用户名、客户端的地址、连接的数据库名称、详细查询语句
会发现 "show full processlist" 一直都在,因为 mytop 会使用这个语句收集 mysql 信息
辅助命令
mytop 提供了一些有用的命令,在运行界面按下相应按键即可
例如按下
?,会进入帮助界面
其他示例:
按键 h 可以根据客户端地址进行过滤
按键
s 可以根据用户名进行过滤
按键
k 可以杀死某个线程
按键
m 进入QPS模式,只是动态显示QPS数量
安装配置
安装
以 centos7 为例,执行以下几个命令即可
rpm -ivh http://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-8.noarch.rpm
yum install yum-plugin-protectbase.noarch -y
yum install mytop -y
配置
vi /root/.mytop
写入如下内容:
host=localhost
user=root
pass=111111
db=mysql
port=3306
socket=/tmp/mysql.sock
delay=5
batchmode=0
color=1
idle=1
保存退出
其中就是mysql的连接信息和基本配置
pass是密码,如果感觉不安全,可以不指定,在执行 mytop 命令时再输入,执行方式:mytop --prompt
delay 指定 mytop 多长时间刷新一次,也就是前面所说的刷新周期
安装配置完成后,执行
mytop 命令就可以了
';
mysql缓存
最后更新于:2022-04-01 23:52:19
# MYSQL 缓存
> 1> 开启缓存方法
windows下是my.ini,linux下是my.cnf
~~~
query_cache_type = 1
query_cache_size = 600000
~~~
需要重启mysql生效;
在mysql命令行输入
~~~
show variables like "%query_cache%"
~~~
## MYSQL缓存详情解读
### 查看query cache相关设置的命令
### 查看query cache工作状态
### 等等
请点击[这里](http://www.chenglin.name/mysql/306.html)查看具体相信内容
';
mysql部分
最后更新于:2022-04-01 23:52:17
[mysql缓存](mysql%E7%BC%93%E5%AD%98.md)
[MySql监控工具--mytop](MySql%E7%9B%91%E6%8E%A7%E5%B7%A5%E5%85%B7--mytop.md)
[MySql主从搭建](MySql%E4%B8%BB%E4%BB%8E%E6%90%AD%E5%BB%BA.md)
[mysql优化](mysql%E4%BC%98%E5%8C%96.md)
[Mysql 复制 (主从复制)](Mysql%E5%A4%8D%E5%88%B6%EF%BC%88%E4%B8%BB%E4%BB%8E%E5%A4%8D%E5%88%B6%EF%BC%89.md)
';
(服务器访问文件404解决办法)IIS 之 添加MIME扩展类型及常用的MIME类型列表
最后更新于:2022-04-01 23:52:14
经常用IIS作为下载服务器的时候有时传上去的文件比如 example.mp4 文件名上传后,但是用http打开的时候确显示为 404 文件不存在。其实是IIS对文件的一种保护,不在IIS指定的MIME类型里的文件不会被操作。
常见的有 mp4 / flv / iso / 7z / apk 等扩展名的文件, iis 本身是没有指定MIME类型的,这类文件默认在IIS里是不能下载的,如确需下载,则需手动添加对应的 MIME 类型。
方法如下:
1. 打开IIS,在右侧找到 MIME类型
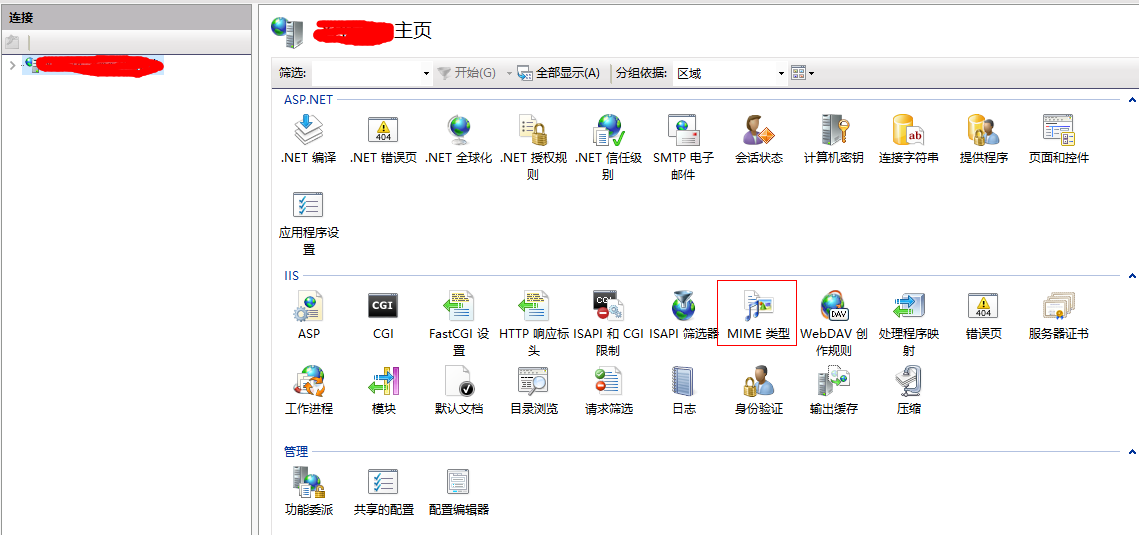
比如我们需要IIS支持 MP4 文件下载可以这么设置:(这里我们对IIS全局进行设置、如果只针对某一个站点可以直接设置站点的)
2. 选中指定网站→在右侧找到 MIME类型 → 双击进入已有类型页 → 点击最右侧添加
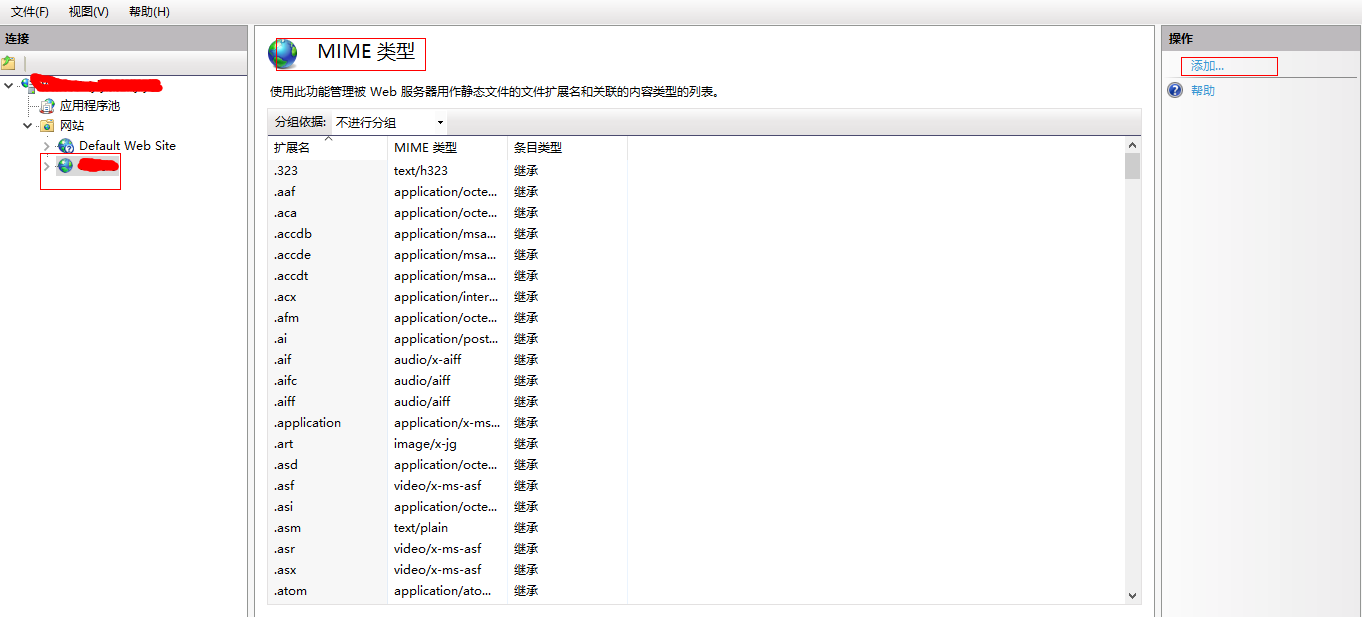
3. 在弹出的 MIME类型框上 扩展名 MP4 MIME类型为: application/octet-stream
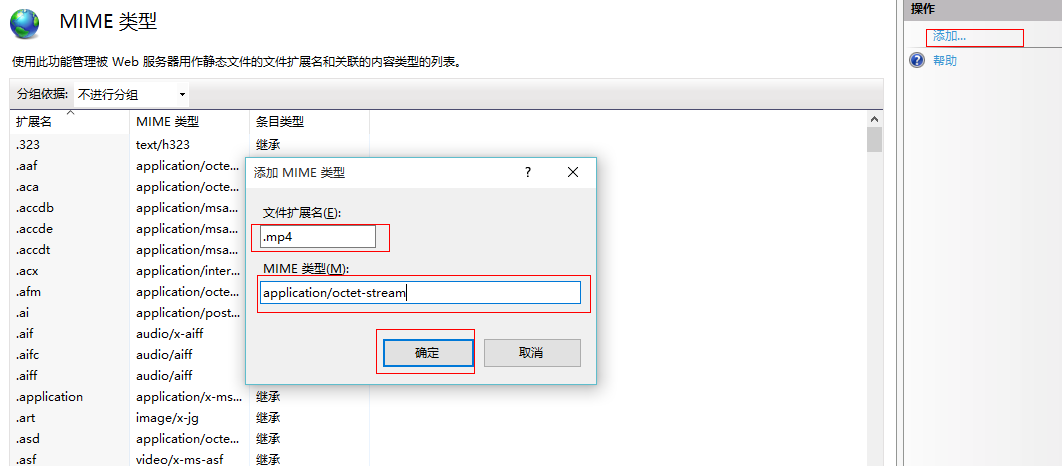
这样IIS就可以支持 MP4下载了。
下面列出一些常用的 扩展名的 MIME类型。
如果不知道MIME类型 可以写通用的: application/octet-stream
还有一些规律如果是文本类的让IE可以直接打开的 MIME 可以为 text/扩展名
如果是音频打开的时候让windows自动播放的可以用 audio/扩展名
* * * * *
~~~
扩展名类型/子类型
application/octet-stream
323 text/h323
acx application/internet-property-stream
ai application/postscript
aif audio/x-aiff
aifc audio/x-aiff
aiff audio/x-aiff
asf video/x-ms-asf
asr video/x-ms-asf
asx video/x-ms-asf
au audio/basic
avi video/x-msvideo
axs application/olescript
bas text/plain
bcpio application/x-bcpio
bin application/octet-stream
bmp image/bmp
c text/plain
cat application/vnd.ms-pkiseccat
cdf application/x-cdf
cer application/x-x509-ca-cert
class application/octet-stream
clp application/x-msclip
cmx image/x-cmx
cod image/cis-cod
cpio application/x-cpio
crd application/x-mscardfile
crl application/pkix-crl
crt application/x-x509-ca-cert
csh application/x-csh
css text/css
dcr application/x-director
der application/x-x509-ca-cert
dir application/x-director
dll application/x-msdownload
dms application/octet-stream
doc application/msword
dot application/msword
dvi application/x-dvi
dxr application/x-director
eps application/postscript
etx text/x-setext
evy application/envoy
exe application/octet-stream
fif application/fractals
flr x-world/x-vrml
gif image/gif
gtar application/x-gtar
gz application/x-gzip
h text/plain
hdf application/x-hdf
hlp application/winhlp
hqx application/mac-binhex40
hta application/hta
htc text/x-component
htm text/html
html text/html
htt text/webviewhtml
ico image/x-icon
ief image/ief
iii application/x-iphone
ins application/x-internet-signup
isp application/x-internet-signup
jfif image/pipeg
jpe image/jpeg
jpeg image/jpeg
jpg image/jpeg
js application/x-javascript
latex application/x-latex
lha application/octet-stream
lsf video/x-la-asf
lsx video/x-la-asf
lzh application/octet-stream
m13 application/x-msmediaview
m14 application/x-msmediaview
m3u audio/x-mpegurl
man application/x-troff-man
mdb application/x-msaccess
me application/x-troff-me
mht message/rfc822
mhtml message/rfc822
mid audio/mid
mny application/x-msmoney
mov video/Quicktime
movie video/x-sgi-movie
mp2 video/mpeg
mp3 audio/mpeg
mpa video/mpeg
mpe video/mpeg
mpeg video/mpeg
mpg video/mpeg
mpp application/vnd.ms-project
mpv2 video/mpeg
ms application/x-troff-ms
mvb application/x-msmediaview
nws message/rfc822
oda application/oda
p10 application/pkcs10
p12 application/x-pkcs12
p7b application/x-pkcs7-certificates
p7c application/x-pkcs7-mime
p7m application/x-pkcs7-mime
p7r application/x-pkcs7-certreqresp
p7s application/x-pkcs7-signature
pbm image/x-portable-bitmap
pdf application/pdf
pfx application/x-pkcs12
pgm image/x-portable-graymap
pko application/ynd.ms-pkipko
pma application/x-perfmon
pmc application/x-perfmon
pml application/x-perfmon
pmr application/x-perfmon
pmw application/x-perfmon
pnm image/x-portable-anymap
pot, application/vnd.ms-powerpoint
ppm image/x-portable-pixmap
pps application/vnd.ms-powerpoint
ppt application/vnd.ms-powerpoint
prf application/pics-rules
ps application/postscript
pub application/x-mspublisher
qt video/quicktime
ra audio/x-pn-realaudio
ram audio/x-pn-realaudio
ras image/x-cmu-raster
rgb image/x-rgb
rmi audio/mid
roff application/x-troff
rtf application/rtf
rtx text/richtext
scd application/x-msschedule
sct text/scriptlet
setpay application/set-payment-initiation
setreg application/set-registration-initiation
sh application/x-sh
shar application/x-shar
sit application/x-stuffit
snd audio/basic
spc application/x-pkcs7-certificates
spl application/futuresplash
src application/x-wais-source
sst application/vnd.ms-pkicertstore
stl application/vnd.ms-pkistl
stm text/html
svg image/svg+xml
sv4cpio application/x-sv4cpio
sv4crc application/x-sv4crc
swf application/x-shockwave-flash
t application/x-troff
tar application/x-tar
tcl application/x-tcl
tex application/x-tex
texi application/x-texinfo
texinfo application/x-texinfo
tgz application/x-compressed
tif image/tiff
tiff image/tiff
tr application/x-troff
trm application/x-msterminal
tsv text/tab-separated-values
txt text/plain
再添几个常用的
apk application/vnd.android.package-archive
MRP文件(国内普遍的手机)
.mrp application/octet-stream
IPA文件(IPHONE)
.ipa application/iphone-package-archive
.deb application/x-debian-package-archive
APK文件(安卓系统)
.apk application/vnd.android.package-archive
CAB文件(Windows Mobile)
.cab application/vnd.cab-com-archive
XAP文件(Windows Phone 7)
.xap application/x-silverlight-app
SIS文件(symbian平台/S60V1)
.sis application/vnd.symbian.install-archive *(下有)
SISX文件(symbian平台/S60V3/V5)
.sisx application/vnd.symbian.epoc/x-sisx-app
~~~
';
tpshop的nginx 服务器配置方法
最后更新于:2022-04-01 23:52:12
这里造成注意第1个location和第2个location,都要加
第3个location中的,根据不同服务器的.sock加载不同的内容,本服务是这个、
~~~
fastcgi_pass unix:/dev/shm/php-cgi.sock;
~~~
在官方给的加的是这个
~~~
fastcgi_pass unix:/tmp/php-cgi.sock;
~~~
很多情况打不开都是因为它的路径不正确而引起的!
~~~
server {
listen 80;
server_name (域名名称 eq:/data/wwwroot/banmutian.sxctkj.cc);
#access_log /data/wwwlogs/banmutian.sxctkj.cc_nginx.log combined;
index index.html index.htm index.php;
root (项目路径 eq:/data/wwwroot/banmutian.sxctkj.cc) ;
location / {
index index.htm index.html index.php;
if (!-e $request_filename){
rewrite ^/(.*)$ /index.php?s=$1 last;
break;
}
}
location ~ /.*\.php/ {
rewrite ^(.*?/?)(.*\.php)(.*)$ /$2?s=$3 last;
break;
}
location ~ \.php {
fastcgi_pass unix:/dev/shm/php-cgi.sock;
fastcgi_index index.php;
include fastcgi_params;
set $real_script_name $fastcgi_script_name;
if ($fastcgi_script_name ~ "^(.+?\.php)(/.+)$") {
set $real_script_name $1;
#set $path_info $2;
}
fastcgi_param SCRIPT_FILENAME $document_root$real_script_name;
fastcgi_param SCRIPT_NAME $real_script_name;
#fastcgi_param PATH_INFO $path_info;
}
}
~~~
';
linux 安装搭建服务器配置及nginx配置
最后更新于:2022-04-01 23:52:10
> 转载
https://oneinstack.com/install/
';
服务器
最后更新于:2022-04-01 23:52:08
[linux 安装搭建服务器配置及nginx配置](%E5%AE%89%E8%A3%85%E6%90%AD%E5%BB%BA%E6%9C%8D%E5%8A%A1%E5%99%A8.md)
[tpshop的nginx 服务器配置方法](tpshop%E7%9A%84nginx%E6%9C%8D%E5%8A%A1%E5%99%A8%E9%85%8D%E7%BD%AE%E6%96%B9%E6%B3%95.md)
[(服务器访问文件404解决办法)IIS 之 添加MIME扩展类型及常用的MIME类型列表](%EF%BC%88%E6%9C%8D%E5%8A%A1%E5%99%A8%E8%AE%BF%E9%97%AE%E6%96%87%E4%BB%B6404%E8%A7%A3%E5%86%B3%E5%8A%9E%E6%B3%95%EF%BC%89IIS%E4%B9%8B%E6%B7%BB%E5%8A%A0MIME%E6%89%A9%E5%B1%95%E7%B1%BB%E5%9E%8B%E5%8F%8A%E5%B8%B8%E7%94%A8%E7%9A%84MIME%E7%B1%BB%E5%9E%8B%E5%88%97%E8%A1%A8.md)
';
PHPstrom软件
最后更新于:2022-04-01 23:52:05
# 在PHPSTROM汉化时,左侧的Structure(函数结构)不显示时,有可能是汉化包的问题
**请使用此文件汉化:**http://pan.baidu.com/s/1cw6Ytw
> 破解方法:在License sever框中填写http://idea.qinxi1992.cn/(注意最后的一个"/"一定要写),然后点击注册就可以了。
';
getmarkman高效的设计稿标注、测量工具
最后更新于:2022-04-01 23:52:03
# **getmarkman** 高效的设计稿标注、测量工具
下载地址:http://getmarkman.com/

**快速做出设计稿** 详情请看官网
';