打包文件
最后更新于:2022-04-01 01:01:04
这一章将详细描述打包文件(packfile)和打包文件索引(packfile index)的格式。
## 打包文件索引
首先, 我们来看一下打包文件索引, 基本上它只是一系列指向打包文件内位置的书签。
打包文件索引有两个版本. 版本1的格式用于Git 1.6版本之前, 版本2的格式用于Git 1.6及以后的版本. 但是版本2可以被Git 1.5.2及以上的Git读取, 同时也被后向移植(backport)到了1.4.4.5版本。
版本2包含了每个对象的CRC校验值, 因此在重打包的过程中, 压缩过的对象可以直接进行包间拷贝(from pack to pack)而不用担心数据损坏. 版本2的打包文件索引同时亦支持大于4G的打包文件。
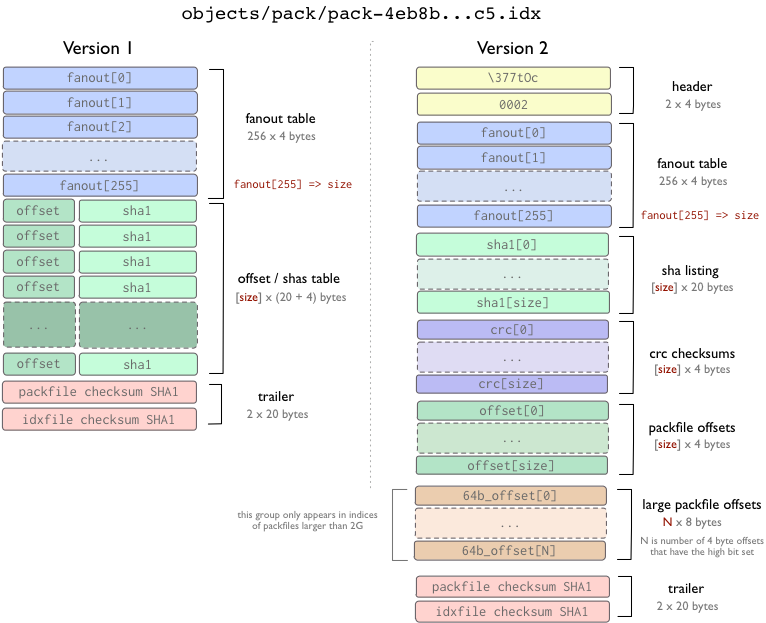
在两个版本格式中, fanout(展开)表用于更快地查找某特定的SHA值在索引文件中的位置. offset/sha1表使用SHA1值进行排序(以便于对这个表进行二分搜索), fanout表用一种特殊的方法指向offset/sha1表(因此后一个表中包含某一特定字节开头的所有Hash的那一部分可以被轻易找到, 而不必经过二分搜索的8次迭代)。
在第1版中, offset(偏移)和SHA值存在在同一位置. 但是在第2版中, SHA值, CRC值和offset被放在不同的表中. 两个版本的文件最后都是索引文件以及指向的打包文件的CRC校验值。
很重要的一点是, 要从打包文件中提取(extract)出一个对象, 索引文件_不是_必不可少的. 索引文件的作用是帮助用户_快速地_从打包文件中提取对象. 那些"上传打包"(upload-pack)和"取回打包"(receive-pack)程序(译注: 实现push和fetch协议的程序)使用打包文件格式(packfile format)去传输对象, 但是没有使用索引 - 索引可以在上传或者取回打包文件之后通过扫描打包文件重新建立。
## 打包文件格式
打包文件格式是很简单的. 它有一个头部(header)和一系列打包过的对象(每个都有自己的header和body), 还有一个校验尾部(trailer). 前4个字节是字符串'PACK', 它用于确保你找到了打包文件的起始位置. 紧接着是4个字节的打包文件版本号, 之后的4个字节指出了此文件中入口(entry)的个数. 你可以用下面Ruby程序读出打包文件的头部:
~~~
def read_pack_header
sig = @session.recv(4)
ver = @session.recv(4).unpack("N")[0]
entries = @session.recv(4).unpack("N")[0]
[sig, ver, entries]
end
~~~
头部之后是一系列按照SHA值排序的打包对象, 每一个打包对象包含了头部和内容. 打包文件的尾部是该文件中所有(已排序)SHA值的SHA1校验值(20字节长)(译注: 即按照排序好的顺序进行迭代SHA1运算)。

对象头部(object header)由1个或以上的字节按序组成, 它指出了后面所跟数据的类型及展开后的尺寸. 头部的每一个字节有7位用于数据, 第1位用于说明头部是否还有后续字节. 如果第1位是'1', 你需要再读入1个字节(译注: 即下一字节仍属于头部), 否则下一字节就是数据. 第一个字节的前3位指定了数据的类型, 具体含义参见下表。
(3个位可以组合成为8个数. 在当前的使用中, 0(000)是'未定义', 5(101)目前未被使用.)
这里我们举一个由两个字节组成的头部的例子. 第1个字节的前3位说明了数据的类型是提交(commit), 余下的4位和第2个字节的7位组成的数字是144, 说明数据展开后的长度是144字节。
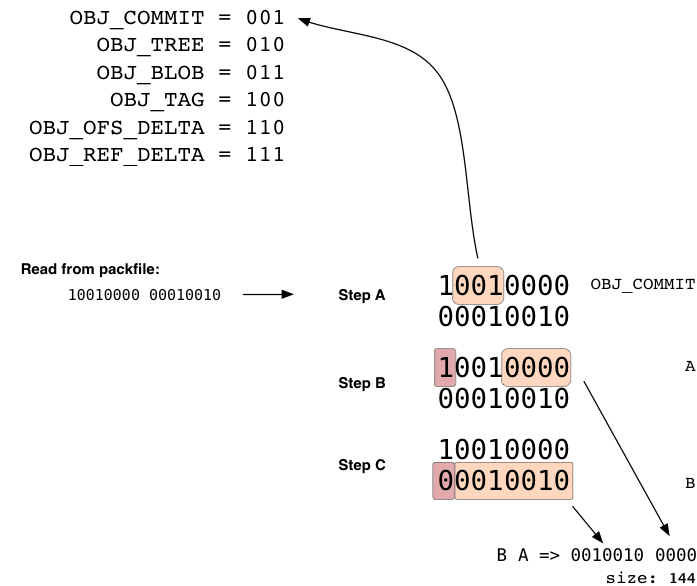
值得注意的一点是, 对象头部中包含的'尺寸'不是后面跟着的数据的长度, 而是数据_展开之后_的长度. 因此, 打包索引文件中的偏移是很有用的, 有了它你不必展开每一个对象就可以得到下一个头部的起始位置。
对于非delta对象, 数据部分就只是zlib压缩后的数据流. 对于那两种delta对象, 数据部分包含了它所依赖的基对象(base object)以及用于重构对象的delta(差异)数据. 数据的前20个字节称为`ref-delta`, 它是基对象SHA值的前20个字节. `ofs-delta`存储了基对象在同一打包文件中的偏移。 任何情况下, 有两个约束必须严格遵守:
* delta对象和基对象必须位于同一打包文件;
* delta对象和基对象的类型必须一致(即tree对tree, blob对blob, 等等).