附录 A. 字符编码
最后更新于:2022-04-01 22:02:25
# 附录 A. 字符编码
**目录**
+ [1\. ASCII码](apas01.html)
+ [2\. Unicode和UTF-8](apas02.html)
+ [3\. 在Linux C编程中使用Unicode和UTF-8](apas03.html)
## 1. ASCII码
ASCII码的取值范围是0~127,可以用7个bit表示。C语言中`char`型变量的大小规定为一字节,如果存放ASCII码则只用到低7位,高位为0。以下是ASCII码表:
**图 A.1. ASCII码表**
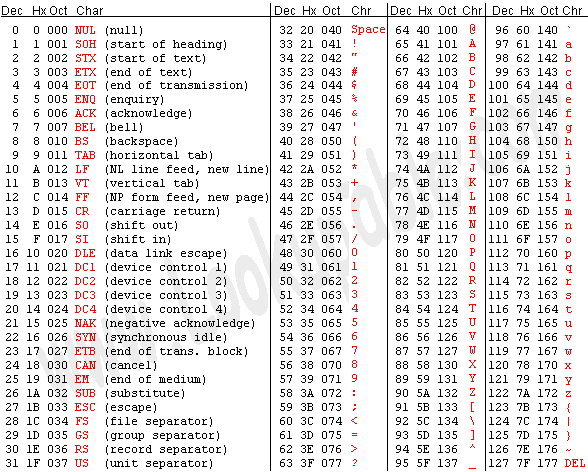
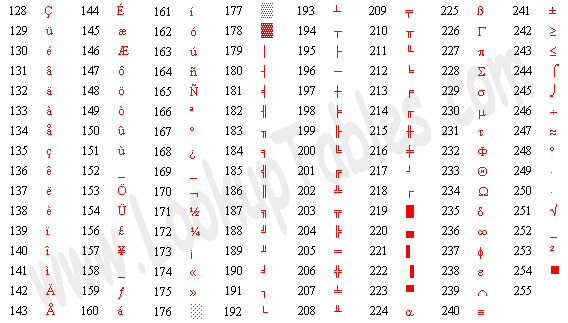
绝大多数计算机的一个字节是8位,取值范围是0~255,而ASCII码并没有规定编号为128~255的字符,为了能表示更多字符,各厂商制定了很多种ASCII码的扩展规范。注意,虽然通常把这些规范称为扩展ASCII码(Extended ASCII),但其实它们并不属于ASCII码标准。例如以下这种扩展ASCII码由IBM制定,在字符终端下被广泛采用,其中包含了很多表格边线字符用来画界面。
**图 A.2. IBM的扩展ASCII码表**
在图形界面中最广泛使用的扩展ASCII码是ISO-8859-1,也称为Latin-1,其中包含欧洲各国语言中最常用的非英文字母,但毕竟只有128个字符,某些语言中的某些字母没有包含。如下表所示。
**图 A.3. ISO-8859-1**

编号为128~159的是一些控制字符,在上表中没有列出。
## 2. Unicode和UTF-8
为了统一全世界各国语言文字和专业领域符号(例如数学符号、乐谱符号)的编码,ISO制定了ISO 10646标准,也称为UCS(Universal Character Set)。UCS编码的长度是31位,可以表示231个字符。如果两个字符编码的高位相同,只有低16位不同,则它们属于一个平面(Plane),所以一个平面由216个字符组成。目前常用的大部分字符都位于第一个平面(编码范围是U-00000000~U-0000FFFD),称为BMP(Basic Multilingual Plane)或Plane 0,为了向后兼容,其中编号为0~256的字符和Latin-1相同。UCS编码通常用U-xxxxxxxx这种形式表示,而BMP的编码通常用U+xxxx这种形式表示,其中x是十六进制数字。在ISO制定UCS的同时,另一个由厂商联合组织也在着手制定这样的编码,称为Unicode,后来两家联手制定统一的编码,但各自发布各自的标准文档,所以UCS编码和Unicode码是相同的。
有了字符编码,另一个问题就是这样的编码在计算机中怎么表示。现在已经不可能用一个字节表示一个字符了,最直接的想法就是用四个字节表示一个字符,这种表示方法称为UCS-4或UTF-32,UTF是Unicode Transformation Format的缩写。一方面这样比较浪费存储空间,由于常用字符都集中在BMP,高位的两个字节通常是0,如果只用ASCII码或Latin-1,高位的三个字节都是0。另一种比较节省存储空间的办法是用两个字节表示一个字符,称为UCS-2或UTF-16,这样只能表示BMP中的字符,但BMP中有一些扩展字符,可以用两个这样的扩展字符表示其它平面的字符,称为Surrogate Pair。无论是UTF-32还是UTF-16都有一个更严重的问题是和C语言不兼容,在C语言中0字节表示字符串结尾,库函数`strlen`、`strcpy`等等都依赖于这一点,如果字符串用UTF-32存储,其中有很多0字节并不表示字符串结尾,这就乱套了。
UNIX之父Ken Thompson提出的UTF-8编码很好地解决了这些问题,现在得到广泛应用。UTF-8具有以下性质:
* 编码为U+0000~U+007F的字符只占一个字节,就是0x00~0x7F,和ASCII码兼容。
* 编码大于U+007F的字符用2~6个字节表示,每个字节的最高位都是1,而ASCII码的最高位都是0,因此非ASCII码字符的表示中不会出现ASCII码字节(也就不会出现0字节)。
* 用于表示非ASCII码字符的多字节序列中,第一个字节的取值范围是0xC0~0xFD,根据它可以判断后面有多少个字节也属于当前字符的编码。后面每个字节的取值范围都是0x80~0xBF,见下面的详细说明。
* UCS定义的所有231个字符都可以用UTF-8编码表示出来。
* UTF-8编码最长6个字节,BMP字符的UTF-8编码最长三个字节。
* 0xFE和0xFF这两个字节在UTF-8编码中不会出现。
具体来说,UTF-8编码有以下几种格式:
U-00000000 – U-0000007F: 0xxxxxxx
U-00000080 – U-000007FF: 110xxxxx 10xxxxxx
U-00000800 – U-0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx
U-00010000 – U-001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
U-00200000 – U-03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
U-04000000 – U-7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
第一个字节要么最高位是0(ASCII字节),要么最高两位都是1,最高位之后1的个数决定后面有多少个字节也属于当前字符编码,例如111110xx,最高位之后还有四个1,表示后面有四个字节也属于当前字符的编码。后面每个字节的最高两位都是10,可以和第一个字节区分开。这样的设计有利于误码同步,例如在网络传输过程中丢失了几个字节,很容易判断当前字符是不完整的,也很容易找到下一个字符从哪里开始,结果顶多丢掉一两个字符,而不会导致后面的编码解释全部混乱了。上面的格式中标为x的位就是UCS编码,最后一种6字节的格式中x位有31个,可以表示31位的UCS编码,UTF-8就像一列火车,第一个字节是车头,后面每个字节是车厢,其中承载的货物是UCS编码。UTF-8规定承载的UCS编码以大端表示,也就是说第一个字节中的x是UCS编码的高位,后面字节中的x是UCS编码的低位。
例如U+00A9(©字符)的二进制是10101001,编码成UTF-8是11000010 10101001(0xC2 0xA9),但不能编码成11100000 10000010 10101001,UTF-8规定每个字符只能用尽可能少的字节来编码。
## 3. 在Linux C编程中使用Unicode和UTF-8
目前各种Linux发行版都支持UTF-8编码,当前系统的语言和字符编码设置保存在一些环境变量中,可以通过`locale`命令查看:
```
$ locale
LANG=en_US.UTF-8
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=
```
常用汉字也都位于BMP中,所以一个汉字的存储通常占3个字节。例如编辑一个C程序:
```
#include
int main(void)
{
printf("你好\n");
return 0;
}
```
源文件是以UTF-8编码存储的:
```
$ od -tc nihao.c
0000000 # i n c l u d e < s t d i o .
0000020 h > \n \n i n t m a i n ( v o i
0000040 d ) \n { \n \t p r i n t f ( " 344 275
0000060 240 345 245 275 \ n " ) ; \n \t r e t u r
0000100 n 0 ; \n } \n
0000107
```
其中八进制的`344 375 240`(十六进制`e4 bd a0`)就是“你”的UTF-8编码,八进制的`345 245 275`(十六进制`e5 a5 bd`)就是“好”。把它编译成目标文件,`"你好\n"`这个字符串就成了这样一串字节:`e4 bd a0 e5 a5 bd 0a 00`,汉字在其中仍然是UTF-8编码的,一个汉字占3个字节,这种字符在C语言中称为多字节字符(Multibyte Character)。运行这个程序相当于把这一串字节`write`到当前终端的设备文件。如果当前终端的驱动程序能够识别UTF-8编码就能打印出汉字,如果当前终端的驱动程序不能识别UTF-8编码(比如一般的字符终端)就打印不出汉字。也就是说,像这种程序,识别汉字的工作既不是由C编译器做的也不是由`libc`做的,C编译器原封不动地把源文件中的UTF-8编码复制到目标文件中,`libc`只是当作以0结尾的字符串原封不动地`write`给内核,识别汉字的工作是由终端的驱动程序做的。
但是仅有这种程度的汉字支持是不够的,有时候我们需要在C程序中操作字符串里的字符,比如求字符串`"你好\n"`中有几个汉字或字符,用`strlen`就不灵了,因为`strlen`只看结尾的0字节而不管字符串里存的是什么,求出来的是字节数7。为了在程序中操作Unicode字符,C语言定义了宽字符(Wide Character)类型`wchar_t`和一些库函数。在字符常量或字符串字面值前面加一个L就表示宽字符常量或宽字符串,例如定义`wchar_t c = L'你';`,变量`c`的值就是汉字“你”的31位UCS编码,而`L"你好\n"`就相当于`{L'你', L'好', L'\n', 0}`,`wcslen`函数就可以取宽字符串中的字符个数。看下面的程序:
```
#include
#include
int main(void)
{
if (!setlocale(LC_CTYPE, "")) {
fprintf(stderr, "Can't set the specified locale! "
"Check LANG, LC_CTYPE, LC_ALL.\n");
return 1;
}
printf("%ls", L"你好\n");
return 0;
}
```
宽字符串`L"你好\n"`在源代码中当然还是存成UTF-8编码的,但编译器会把它变成4个UCS编码`0x00004f60 0x0000597d 0x0000000a 0x00000000`保存在目标文件中,按小端存储就是`60 4f 00 00 7d 59 00 00 0a 00 00 00 00 00 00 00`,用`od`命令查看目标文件应该能找到这些字节。
```
$ gcc hihao.c
$ od -tx1 a.out
```
`printf`的`%ls`转换说明表示把后面的参数按宽字符串解释,不是见到0字节就结束,而是见到UCS编码为0的字符才结束,但是要`write`到终端仍然需要以多字节编码输出,这样终端驱动程序才能识别,所以`printf`在内部把宽字符串转换成多字节字符串再`write`出去。事实上,C标准并没有规定多字节字符必须以UTF-8编码,也可以使用其它的多字节编码,在运行时根据环境变量确定当前系统的编码,所以在程序开头需要调用`setlocale`获取当前系统的编码设置,如果当前系统是UTF-8的,`printf`就把UCS编码转换成UTF-8编码的多字节字符串再`write`出去。一般来说,程序在做内部计算时通常以宽字符编码,如果要存盘或者输出给别的程序,或者通过网络发给别的程序,则采用多字节编码。
关于Unicode和UTF-8本节只介绍了最基本的概念,部分内容出自[[Unicode FAQ]](bi01.html#bibli.unicodefaq "UTF-8 and Unicode FAQ, http://www.cl.cam.ac.uk/~mgk25/unicode.html"),读者可进一步参考这篇文章。
';