优酷土豆2012.9.12校园招聘会笔试题
最后更新于:2022-04-01 21:43:58
**选择题**
1、已知中国人的血型分布约为A型:30%,B型:20%,O型:40%,AB型:10%,则任选一批中国人作为用户调研对象,希望他们中至少有一个是B型血的可能性不低于90%,那么最少需要选多少人?
A、7 B、9 C、11 D、13
2、广告系统为了做地理位置定向,将IPV4分割为627672个区间,并标识了地理位置信息,区间之间无重叠,用二分查找将IP地址映射到地理位置信息,请问在最坏的情况下,需要查找多少次?
A、17 B、18 C、19 D、20
3、有四只老鼠一块出去偷食物(每个都偷了),回来时,族长问它们都偷了什么,老鼠A说:我们每个都偷了奶酪。老鼠B说:我只偷了一颗樱桃。老鼠C说:我没偷奶酪。老鼠D说:有些人没偷奶酪。族长观察了一下,发现它们当中只有一只老鼠说了实话,那么是哪只老鼠说了实话?
A、老鼠A B、老鼠B C、老鼠C D、老鼠D
4、到商店里买200的商品返还100的优惠券(可以在本商店代替现金)。如果使用优惠券买东西不能获得新的优惠券,那么买200返100优惠券,实际上省多少?
A、50%
B、66.7%
C、75%
D、33.3%
5、在数据库逻辑设计中,当将E-R图转换为关系模式时,下面的做法哪一个不正确?
A、一个实体类型转换为一个关系模式
B、一个联系类型转换为一个关系模式
C、由实体类型转换成的关系模式的主键是该实体类型的主键
D、由联系类型转换成的关系模式的属性是与该联系类型相关的诸实体类型的属性的全体
6、一家人有两个孩子,性别未知,现在打电话给其中一个孩子得知是女孩,问另一个孩子也是女孩的概率是多少?
A、1/4 B、1/2 C、1/3 D、1/5
7、关于非空二叉树的性质,下面哪个结论不正确(D)
A、有两个节点的节点一定比没有子节点的节点少一个 n0 = n2 + 1
B、根节点所在的层数为第0层,则第i层最多有2^i个节点
C、若知道二叉树的前序遍历序列和中序遍历序列,则一定可以推出后序遍历序列。
D、堆一定是一个完全二叉树
8、快速排序的平均时间复杂度和最坏时间复杂度是()
A、O(n^2), O(n^2)
B、O(n^2), O(nlgn)
C、O(nlgn) , O(nlgn)
D、O(nlgn) , O(n^2)
9、有一串数字 6 7 4 2 8 1 6 (),请问括号中的数字最可能是()
A、6 B、7 C、8 D、9
10、下面哪项不是链表优于数组的特点?
A、方便删除 B、方便插入 C、长度可变 D、存储空间小
11、给定声明 const char * const * pp; 下属操作或说明正确的是()
A、pp++
B、(*pp)++
C、(**pp) = 'c';
D、以上都不对
12、有下列代码正确的是()
~~~
std::string name1 = "youku";
const char* name2 = "youku";
char name3[] = {'y','o','u','k','u'};
size_t l1 = name1.size();
size_t l2 = strlen(name2);
size_t l3 = sizeof(name2);
size_t l4 = sizeof(name3);
size_t l5 = strlen(name3);
~~~
A、l1 = 5 l2 = 5 l3 = 4 l4 = 5 l5 = 不确定
B、l1 = 5 l2 = 5 l3 = 5 l4 = 5 l5 = 不确定
C、l1 = 5 l2 = 6 l3 = 5 l4 = 5 l5 = 5
D、l1 = 5 l2 = 6 l3 = 5 l4 = 5 l5 = 6
13、Test执行后的输出是:
~~~
void Test()
{
class B
{
public:
B(void)
{
cout<<"B\t";
}
~B(void)
{
cout<<"~B\t";
}
};
struct C
{
C(void)
{
cout<<"C\t";
}
~C(void)
{
cout<<"~C\t";
}
};
struct D : B
{
D()
{
cout<<"D\t";
}
~D()
{
cout<<"~D\t";
}
private:
C c;
};
D d;
}
~~~
A、B C D ~D ~ C ~B
B、D C B ~B ~C ~D
C、C D B ~B ~D ~C
D、C ~C D ~D B ~B
14、下列四种排序中(D)的空间复杂度最大
A、快速排序 B、冒泡排序 C、希尔排序 D、堆
15、设一棵二叉树的深度为k,则该二叉树最多有(D)个节点。
A、2k-1 B、2^k C、2^(k-1) D、2^k-1
16、下面函数的功能是()
~~~
int fun(char *x)
{
char *y = x;
while(*y++);
return (y-x-1);
}
~~~
A、求字符串的长度
B、比较两个字符串的大小
C、将字符串x复制到字符串y
D、将字符串x连接到字符串y后面
17、k为int类型,以下while循环执行()次。
~~~
unsigned int k = 20;
while(k >= 0)
--k;
~~~
A、20次 B、一次也不执行 C、死循环 D、21次
18、关于Cookie 和 Session的概念哪一个是对的
A、Cookie 存储在客户端,但过期时间设置在服务器上
B、Session 存储在客户端,但过期时间设置在服务器上
C、Cookie 中可以存储ASCII空格‘ ’,而Session中不行
D、Cookie可以设置生效的路径,而 Session则不能
19、以下关于链式存储结构的叙述中哪一条是不正确的?
A、结点除自身信息外还包括指针域,因此存储密度小于顺序存储结构
B、逻辑上相邻的结点物理上不必邻接
C、可以通过计算直接确定第i个结点的存储地址
D、插入、删除运算操作方便,不必移动结点
20、32位机器上,定义 int **a[3][4],这个数组占多大的空间()
A、64 B、12 C、48 D、128
**填空题**
1、设数组定义为a[60][70],每个元素占2个存储单元,数组按照列优先存储,元素a[0][0]的地址为1024,那么元素a[32][58]的地址为(8048)
2、在一个娱乐节目上,主持人提供有三扇门(假设为A、B、C),只有1扇门后面有奖品,另两扇门后面是空的,而主持人知道具体哪扇门后有奖品。首先,当你选择了一扇门之后(假设A),主持人会把剩下两扇门中的一扇没有奖品的门打开(假设打开的空门为B),现在你有一次机会决定是否要交换重新选择,如果你坚持选择A,你中奖的概率是(1/3),如果你交换选择C,你中奖的概率是(2/3) [http://en.wikipedia.org/wiki/Monty_Hall_problem](http://en.wikipedia.org/wiki/Monty_Hall_problem)
假设你选择的1门,而主持人打开的是3门,则奖品在2门后面的概率是
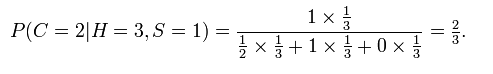
3、一棵深度为h的满二叉树,其最末一层共有(2^h)个节点(根节点深度为0)
4、下面程序的运行结果为(1 3 2)
~~~
void foo(int *a , int *b)
{
*a = *a + *b;
*b = *a - *b;
*a = *a - *b;
}
void main()
{
int a = 1 , b = 2 , c = 3;
foo(&a , &b);
foo(&b , &c);
foo(&c , &a);
printf("%d %d %d\n",a,b,c);
}
~~~
5、4个结点可以构造出(14)个不同的二叉树 Catalan数
6、设有n个无序的记录关键字,则直接插入排序的时间复杂度为(O(n^2)),快速排序的平均时间复杂度为(O(nlgn))
7、设一组初始记录关键字序列为(20,18,22,16,30,19),则以20为中轴的一趟快速排序结果为(19,18,16,20,30,22)
8、C语言的函数参数传递方式有传递 值 和 传递 地址
9、分配在堆上和栈上的内存,哪一个需要手动进行内存释放? 堆上的内存
**问答题:**
一、有一个单向循环链表队列,从头开始报数,当报到m或者m的倍数的元素出列,根据出列的先后顺序重新组成单向循环链表。
函数原型: void reorder(Node **head , int m)
二、优酷是中国第一的视频网站,每天有上亿的视频被观看,现在公司请研发人员找出最热门的视频。
该问题的输入可以简化为一个字符串文件,每一行都表示一个视频id,然后要找出出现次数最多的前100个视频id,将其输出,同时输出该视频的出现次数。
1、假设每天的视频播放次数为3亿次,被观看的视频数量为一百万个,每个视频ID的长度为20个字节,限定使用的内存为1G。请先描述做法,再写代码。
2、假设每个月的视频播放次数为100亿次,被观看的视频数量为1亿个,每个视频ID的长度为20个字节,一台机器被限定使用的内存为1G。
那么想找这个月被播放次数最多的前100个视频,应该怎么做?请描述清楚可能的办法。
解析:海量数据的处理。无法一次性装入内存,可先hash之分为多个文件处理,堆或者Trie树统计次数,求出每个文件中的Top 100。归并之求出总的top 100。
对于第二问:还可以hadoop mapReduce处理之。
首先统计每个视频被观看次数,得到键值对,其中id为视频id,cnt为视频被观看次数。
以cnt作为关键字建立最小堆。遍历所有键值对,若堆的size小于100,则将键值对直接插入堆,否则比较键值对和堆顶元素大小,若cnt大于堆顶元素的cnt,则弹 出堆顶元素并将键值对插入堆。
对于第一问,由于id个数较少,统计部分可直接使用stl的map容器。
对于第二问,由于id个数太大,直接hash内存不够,需要mapReduce。
三、给你一个由n-1个整数组成的未排序的序列,其元素都是1到n中的不同的整数。请写出一个寻找序列中缺失整数的线性时间算法。
异或运算就可以解决了
';
Google2012.9.24校园招聘会笔试题
最后更新于:2022-04-01 21:43:56






代码:
~~~
//转载请标明出处,原文地址:http://blog.csdn.net/hackbuteer1/article/details/8017703
bool IsPrime(int n)
{
int i;
if(n < 2)
return false;
else if(2 == n)
return true;
if((n&1) == 0) //n%2 == 0
return false;
for(i = 3 ; i*i <= n ; i += 2) //只考虑奇数
{
if(n % i == 0)
return false;
}
return true;
}
/*
考虑到所有大于4的质数,被6除的余数只能是1或者5
比如接下来的5,7,11,13,17,19都满足
所以,我们可以特殊化先判断2和3
但后面的问题就出现了,因为并非简单的递增,从5开始是+2,+4,+2,+4,....这样递增的
这样的话,循环应该怎么写呢?
首先,我们定义一个步长变量step,循环大概是这样 for (i = 5; i <= s; i += step)
那么,就是每次循环,让step从2变4,或者从4变2
于是,可以这么写:
*/
bool IsPrime2(int n)
{
int i, step = 4;
if(n < 2)
return false;
else if(2 == n || 3 == n)
return true;
if((n&1) == 0) //n%2 == 0
return false;
if(n%3 == 0) //n%3 == 0
return false;
for(i = 5 ; i*i <= n ; i += step)
{
if(n % i == 0)
return false;
step ^= 6;
}
return true;
}
void print_prime(int n)
{
int i , num = 0;
for(i = 0 ; ; ++i)
{
if(IsPrime2(i))
{
printf("%d " , i);
++num;
if(num == n)
break;
}
}
printf("\n");
}
~~~

代码:
~~~
//转载请标明出处,原文地址:http://blog.csdn.net/hackbuteer1/article/details/8017703
void myswap(int a , int b , int* array)
{
int temp = array[a];
array[a] = array[b];
array[b] = temp;
}
//利用0和其它数交换位置进行排序
void swap_sort(int* array , int len)
{
int i , j;
for(i = 0 ; i < len ; ++i) //因为只能交换0和其他数,所以先把0找出来
{
if(0 == array[i])
{
if(i) //如果元素0不再数组的第一个位置
myswap(0 , i , array);
break;
}
}
for(i = 1 ; i < len ; ++i) //因为是0至N-1的数,所以N就放在第N的位置处
{
if(i != array[i]) //这个很重要,如果i刚好在i处,就不用交换了,否则会出错
{
for(j = i + 1 ; j < len ; ++j)
{
if(i == array[j])
{
myswap(0 , j , array); //把0换到j处,此时j处是0
myswap(j , i , array); //把j处的0换到i处,此时i处是0
myswap(0 , i , array); //把i处的0换到0处
}
}//for
}
}//for
}
~~~

代码:
~~~
//转载请标明出处,原文地址:http://blog.csdn.net/hackbuteer1/article/details/8017703
int mymin(int a , int b , int c)
{
int temp = (a < b ? a : b);
return temp < c ? temp : c;
}
int min_edit_dic(char* source , char* target)
{
int i , j , edit , ans;
int lena , lenb;
lena = strlen(source);
lenb = strlen(target);
int**distance = new int*[lena + 1];
for(i = 0 ; i < lena + 1 ; ++i)
distance[i] = new int[lenb + 1];
distance[0][0] = 0;
for(i = 1 ; i < lena + 1 ; ++i)
distance[i][0] = i;
for(j = 1 ; j < lenb + 1 ; ++j)
distance[0][j] = j;
for(i = 1 ; i < lena + 1 ; ++i)
{
for(j = 1 ; j < lenb + 1 ; ++j)
{
if(source[i - 1] == target[j - 1])
edit = 0;
else
edit = 1;
distance[i][j] = mymin(distance[i - 1][j] + 1 , distance[i][j - 1] + 1 , distance[i - 1][j - 1] + edit);
//distance[i - 1][j] + 1 插入字符
//distance[i][j - 1] + 1 删除字符
//distance[i - 1][j - 1] + edit 是否需要替换
}
}
ans = distance[lena][lenb];
for(i = 0 ; i < lena + 1 ; ++i)
delete[] distance[i];
delete[] distance;
return ans;
}
~~~
';
搜狗2012.9.23校园招聘会笔试题
最后更新于:2022-04-01 21:43:54
转载请标明出处,原文地址:[http://blog.csdn.net/hackbuteer1/article/details/8016173](http://blog.csdn.net/hackbuteer1/article/details/8016173)
C/C++类
1、以下程序的输出是(12)
~~~
class Base
{
public:
Base(int j) : i(j) { }
virtual ~Base() { }
void func1()
{
i *= 10;
func2();
}
int getValue()
{
return i;
}
protected:
virtual void func2()
{
i++;
}
protected:
int i;
};
class Child : public Base
{
public:
Child(int j) : Base(j) { }
void func1()
{
i *= 100;
func2();
}
protected:
void func2()
{
i += 2;
}
};
int main(void)
{
Base *pb = new Child(1);
pb->func1();
cout<getValue()<类型的对象,可以放到std::vector>容器中
B、std::shared_ptr类型的对象,可以放到std::vector>容器中
C、对于复杂类型T的对象tObj,++tObj和tObj++的执行效率相比,前者更高
D、采用new操作符创建对象时,如果没有足够内存空间而导致创建失败,则new操作符会返回NULL
A中auto是给别人东西而自己没有了。所以不符合vector的要求。而B可以。C不解释。new在失败后抛出标准异常std::bad_alloc而不是返回NULL。
9、有如下几个类和函数定义,选项中描述正确的是:【多选】(B)
~~~
class A
{
public:
virtual void foo() { }
};
class B
{
public:
virtual void foo() { }
};
class C : public A , public B
{
public:
virtual void foo() { }
};
void bar1(A *pa)
{
B *pc = dynamic_cast(pa);
}
void bar2(A *pa)
{
B *pc = static_cast(pa);
}
void bar3()
{
C c;
A *pa = &c;
B *pb = static_cast(static_cast(pa));
}
~~~
A、bar1无法通过编译
B、bar2无法通过编译
C、bar3无法通过编译
D、bar1可以正常运行,但是采用了错误的cast方法
选B。dynamic_cast是在运行时遍历继承树,所以,在编译时不会报错。但是因为A和B没啥关系,所以运行时报错(所以A和D都是错误的)。static_cast:编译器隐式执行的任何类型转换都可由它显示完成。其中对于:(1)基本类型。如可以将int转换为double(编译器会执行隐式转换),但是不能将int*用它转换到double*(没有此隐式转换)。(2)对于用户自定义类型,如果两个类无关,则会出错(所以B正确),如果存在继承关系,则可以在基类和派生类之间进行任何转型,在编译期间不会出错。所以bar3可以通过编译(C选项是错误的)。
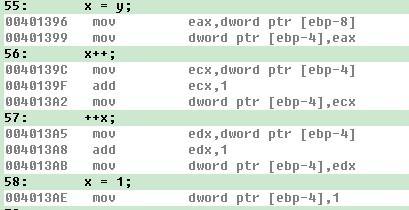
10、在Intel CPU上,以下多线程对int型变量x的操作,哪几个不是原子操作,假定变量的地址都是对齐的。【多选】(ABC)
A、x = y B、x++ C、++x D、x = 1
看下在VC++6.0下的汇编命令即可:从图可以看出本题只有D选项才是原子操作。
11、一般情况下,下面哪些操作会执行失败?【多选】(BCD)
~~~
class A
{
public:
string a;
void f1()
{
printf("Hello World");
}
void f2()
{
a = "Hello World";
printf("%s",a.c_str());
}
virtual void f3()
{
printf("Hello World");
}
virtual void f4()
{
a = "Hello World";
printf("%s",a.c_str());
}
};
~~~
A、A *aptr = NULL; aptr->f1();
B、A *aptr = NULL; aptr->f2();
C、A *aptr = NULL; aptr->f3();
D、A *aptr = NULL; aptr->f4();
至于A为什么正确,因为A没有使用任何成员变量,而成员函数是不属于对象的,所以A正确。其实,A* aptr = NULL;aptr->f5();也是正确的,因为静态成员也是不属于任何对象的。至于BCD,在B中使用了成员变量,而成员变量只能存在于对象,C有虚表指针,所以也只存在于对象中。D就更是一样了。但是,如果在Class A中没有写public,那么就全都是private,以至于所有的选项都将会失败。
12、C++下,下面哪些template实例化使用,会引起编译错误?【多选】(CEF)
~~~
template class stack;
void fi(stack); //A
class Ex
{
stack &rs; //B
stack si; //C
};
int main(void)
{
stack *sc; //D
fi(*sc); //E
int i = sizeof(stack); //F
return 0;
}
~~~
选C E F; 请注意stack和fi都只是声明不是定义。我还以为在此处申明后,会在其他地方定义呢,坑爹啊。
由于stack只是声明,所以C是错误的,stack不能定义对象。E也是一样,stack只是申明,所以不能执行拷贝构造函数,至于F,由于stack只是声明,不知道stack的大小,所以错误。如果stack定义了,将全是正确的。
13、以下哪个说法正确()
~~~
int func()
{
char b[2]={0};
strcpy(b,"aaa");
}
~~~
A、Debug版崩溃,Release版正常
B、Debug版正常,Release版崩溃
C、Debug版崩溃,Release版崩溃
D、Debug版正常,Release版正常
选A。因为在Debug中有ASSERT断言保护,所以要崩溃,而在Release中就会删掉ASSERT,所以会出现正常运行。但是不推荐如此做,因为这样会覆盖不属于自己的内存,这是搭上了程序崩溃的列车。
数据结构类
37、每份考卷都有一个8位二进制序列号,当且仅当一个序列号含有偶数个1时,它才是有效的。例如:00000000 01010011 都是有效的序列号,而11111110不是,那么有效的序列号共有(128)个。
38、对初始状态为递增序列的数组按递增顺序排序,最省时间的是插入排序算法,最费时间的算法(B)
A、堆排序 B、快速排序 C、插入排序 D、归并排序
39、下图为一个二叉树,请选出以下不是遍历二叉树产生的顺序序列的选项【多选】(BD)
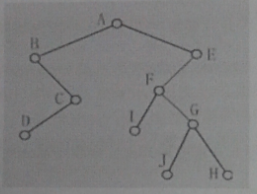
A、ABCDEFIGJH
B、BDCAIJGHFE
C、BDCAIFJGHE
D、DCBJHGIFEA
40、在有序双向链表中定位删除一个元素的平均时间复杂度为()
A、O(1) B、O(N) C、O(logN) D、O(N*logN)
41、将10阶对称矩阵压缩存储到一维数组A中,则数组A的长度最少为()
A、100 B、40 C、55 D、80
42、将数组a[]作为循环队列SQ的存储空间,f为队头指示,r为队尾指示,则执行出队操作的语句为(B)
A、f = f+1 B、f = (f+1)%m C、r = (r+1)%m D、f = (f+1)%(m+1)
43、以下哪种操作最适合先进行排序处理?
A、找最大、最小值 B、计算算出平均值 C、找中间值 D、找出现次数最多的值
44、设有一个二维数组A[m][n],假设A[0][0]存放位置在644(10),A[2][2]存放位置在676(10),每个元元素占一个空间,问A[3][3]存放在什么位置?(C)脚注(10)表示用10进制表示
A、688 B、678 C、692 D、696
45、使用下列二维图形变换矩阵A=T*a,将产生的变换结果为(D)
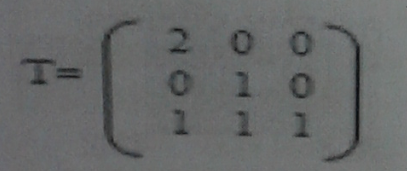
A、图形放大2倍
B、图形放大2倍,同时沿X、Y坐标轴方向各移动一个单位
C、沿X坐标轴方向各移动2个单位
D、沿X坐标轴放大2倍,同时沿X、Y坐标轴方向各移动一个单位
46、体育课的铃声响了,同学们都陆续地奔向操场,按老师的要求从高到矮站成一排。每个同学按顺序来到操场时,都从排尾走向排头,找到第一个比自己高的同学,并站到他的后面,这种站队的方法类似于()算法。
A、快速排序 B、插入排序 C、冒泡排序 D、归并排序
47、处理a.html文件时,以下哪行伪代码可能导致内存越界或者抛出异常(B)
int totalBlank = 0;
int blankNum = 0;
int taglen = page.taglst.size();
A for(int i = 1; i < taglen-1; ++i)
{
//check blank
B while(page.taglst[i] == "
" && i < taglen) { C ++totalBlank; D ++i; } E if(totalBlank > 10) F blankNum += totalBlank; G totalBlank = 0; } 注意:以下代码中taglen是html文件中存在元素的个数,a.html中taglen的值是15,page.taglst[i]取的是a.html中的元素,例如page.taglst[1]的值是 a.html的文件如下: ~~~test
~~~ 48、对一个有向图而言,如果每个节点都存在到达其他任何节点的路径,那么就称它是强连通的。例如,右图就是一个强连通图,事实上,在删掉哪几条边后,它依然是强连通的。(A)  A、a B、b C、c D、d 100、一种计算机,其有如下原子功能: 1、赋值 a=b 2、+1操作,++a; a+1; 3、循环,但是只支持按次数的循环 for(变量名){/*循环里面对变量的修改不影响循环次数*/} 4、只能处理0和正整数 5、函数调用 fun(参数列表) 请用伪代码的形式分别在这个计算机上编程实现变量的加法、减法、乘法。 ~~~ fun_add(a , b) { } fun_multi(a , b) { } fun_minus(a , b) { } ~~~ 问题的关键在于如何实现自减一操作。 本来让-1自增n次即可实现n的自减的,但系统偏偏又不支持负数。 ~~~ fun_add(a , b) { result = a; for(b) ++result; return result; } fun_muti(a , b) { result = 0; for(b) result = fun_add(result , a); return result; } dec(int n) { temp = 0; result = 0; for(n) { result = temp; //result永远比temp少1,巧妙地减少了一次自增 ++temp; } return result; } /* 上面的dec这段函数代码执行后,result的值将变为n-1。注意到这段代码在自增时是如何巧妙地延迟了一步的。 现在,我们相当于有了自减一的函数dec。实现a-b只需要令a自减b次即可 */ fun_minus(a , b) { result = a; for(b) result = dec(result); } ~~~ 101、实现一个队链表排序的算法,C/C++可以使用std::list,Java使用LinkedList
要求先描述算法,然后再实现,算法效率尽可能高效。
主要考察链表的归并排序。
要点:需要使用快、慢指针的方法,找到链表的的中间节点,然后进行二路归并排序
~~~
typedef struct LNode
{
int data;
struct LNode *next;
}LNode , *LinkList;
// 对两个有序的链表进行递归的归并
LinkList MergeList_recursive(LinkList head1 , LinkList head2)
{
LinkList result;
if(head1 == NULL)
return head2;
if(head2 == NULL)
return head1;
if(head1->data < head2->data)
{
result = head1;
result->next = MergeList_recursive(head1->next , head2);
}
else
{
result = head2;
result->next = MergeList_recursive(head1 , head2->next);
}
return result;
}
// 对两个有序的链表进行非递归的归并
LinkList MergeList(LinkList head1 , LinkList head2)
{
LinkList head , result = NULL;
if(head1 == NULL)
return head2;
if(head2 == NULL)
return head1;
while(head1 && head2)
{
if(head1->data < head2->data)
{
if(result == NULL)
{
head = result = head1;
head1 = head1->next;
}
else
{
result->next = head1;
result = head1;
head1 = head1->next;
}
}
else
{
if(result == NULL)
{
head = result = head2;
head2 = head2->next;
}
else
{
result->next = head2;
result = head2;
head2 = head2->next;
}
}
}
if(head1)
result->next = head1;
if(head2)
result->next = head2;
return head;
}
// 归并排序,参数为要排序的链表的头结点,函数返回值为排序后的链表的头结点
LinkList MergeSort(LinkList head)
{
if(head == NULL)
return NULL;
LinkList r_head , slow , fast;
r_head = slow = fast = head;
// 找链表中间节点的两种方法
/*
while(fast->next != NULL)
{
if(fast->next->next != NULL)
{
slow = slow->next;
fast = fast->next->next;
}
else
fast = fast->next;
}*/
while(fast->next != NULL && fast->next->next != NULL)
{
slow = slow->next;
fast = fast->next->next;
}
if(slow->next == NULL) // 链表中只有一个节点
return r_head;
fast = slow->next;
slow->next = NULL;
slow = head;
// 函数MergeList是对两个有序链表进行归并,返回值是归并后的链表的头结点
//r_head = MergeList_recursive(MergeSort(slow) , MergeSort(fast));
r_head = MergeList(MergeSort(slow) , MergeSort(fast));
return r_head;
}
~~~
转载请标明出处,原文地址:[http://blog.csdn.net/hackbuteer1/article/details/8016173](http://blog.csdn.net/hackbuteer1/article/details/8016173)
';
" && i < taglen) { C ++totalBlank; D ++i; } E if(totalBlank > 10) F blankNum += totalBlank; G totalBlank = 0; } 注意:以下代码中taglen是html文件中存在元素的个数,a.html中taglen的值是15,page.taglst[i]取的是a.html中的元素,例如page.taglst[1]的值是 a.html的文件如下: ~~~
aaaaaaa
~~~ 48、对一个有向图而言,如果每个节点都存在到达其他任何节点的路径,那么就称它是强连通的。例如,右图就是一个强连通图,事实上,在删掉哪几条边后,它依然是强连通的。(A)  A、a B、b C、c D、d 100、一种计算机,其有如下原子功能: 1、赋值 a=b 2、+1操作,++a; a+1; 3、循环,但是只支持按次数的循环 for(变量名){/*循环里面对变量的修改不影响循环次数*/} 4、只能处理0和正整数 5、函数调用 fun(参数列表) 请用伪代码的形式分别在这个计算机上编程实现变量的加法、减法、乘法。 ~~~ fun_add(a , b) { } fun_multi(a , b) { } fun_minus(a , b) { } ~~~ 问题的关键在于如何实现自减一操作。 本来让-1自增n次即可实现n的自减的,但系统偏偏又不支持负数。 ~~~ fun_add(a , b) { result = a; for(b) ++result; return result; } fun_muti(a , b) { result = 0; for(b) result = fun_add(result , a); return result; } dec(int n) { temp = 0; result = 0; for(n) { result = temp; //result永远比temp少1,巧妙地减少了一次自增 ++temp; } return result; } /* 上面的dec这段函数代码执行后,result的值将变为n-1。注意到这段代码在自增时是如何巧妙地延迟了一步的。 现在,我们相当于有了自减一的函数dec。实现a-b只需要令a自减b次即可 */ fun_minus(a , b) { result = a; for(b) result = dec(result); } ~~~ 101、实现一个队链表排序的算法,C/C++可以使用std::list
搜狐2012.9.15校园招聘会笔试题
最后更新于:2022-04-01 21:43:51
一、不定项选择题
1、以下程序的打印结果是()
~~~
#include
using namespace std;
void swap_int(int a , int b)
{
int temp = a;
a = b;
b = temp;
}
void swap_str(char* a , char* b)
{
char* temp = a;
a = b;
b = temp;
}
int main(void)
{
int a = 10;
int b = 5;
char* str_a = "hello world";
char* str_b = "world hello";
swap_int(a , b);
swap_str(str_a , str_b);
printf("%d %d %s %s\n", a , b , str_a , str_b);
return 0;
}
~~~
A、10 5 hello world world hello B、10 5 world hello hello world
C、5 10 hello world world hello D、5 10 hello world world hello
2、以下程序打印的两个字符分别是(A)
~~~
typedef struct object object;
struct object
{
char data[3];
};
int main(void)
{
object obj_array[3] = { {'a','b','c'},
{'d','e','f'},
{'g','h','i'} };
object* cur = obj_array;
printf("%c %c\n", *(char*)((char *)(cur)+2) , *(char*)(cur+2));
return 0;
}
~~~
A、c g B、b d C、g g D、g c
3、C/C++语言:请问在64位平台机器下 sizeof(string_a) , sizeof(string_b)大小分别是(A)
~~~
char *string_a = (char *)malloc(100*sizeof(char));
char string_b[100];
~~~
A、8 100 B、100 8 C、100 100 D、8 8
4、假设二叉排序树的定义是:1、若它的左子树不为空,则左子树所有节点均小于它的根节点的值;2、若右子树不为空,则右子树所有节点的值均大于根节点的值;3、它的左右子树也分别为二叉排序树。下列哪种遍历之后得到一个递增有序数列(B)
A、前序遍历 B、中序遍历 C、后序遍历 D、广度遍历
5、往一个栈顺序push下列元素:ABCDE,其pop可能的顺序,下列不正确的是(C)
A、BACDE B、ACDBE C、AEBCD D、AEDCB
6、1100|1010 , 1001^1001 , 1001&1100分别为(A)
A、1110 0000 1000 B、1000 1001 1000
C、1110 1001 0101 D、1000 1001 1000
7、二叉树是一种树形结构,每个节点至多有两颗子树,下列一定是二叉树的是(AC)
A、红黑树 B、B树 C、AVL树 D、B+树
8、int A[2][3] = {1,2,3,4,5,6}; , 则A[1][0]和*(*(A+1)+1)的值分别是(A)
A、4 5 B、4 3 C、3 5 D、3 4
9、序列16 14 10 8 7 9 3 2 4 1的说法下面哪一个正确(A)
A、大顶堆 B、小顶堆 C、不是堆 D、二叉排序树
10、输入若已经是排好序的,下列排序算法最快的是(A)
A、插入排序 B、Shell排序 C、合并排序 D、快速排序
11、一种既有利于短作业又兼顾长期作业的调度方式是(D)
A、先来先服务 B、均衡调度 C、最短作业优先 D、最高响应比优先
12、同一进程下的线程可以共享(B)
A、stack B、data section C、register set D、thread ID
13、系统中的“颠簸”是由(B)引起的。
A、内存容量不足 B、缺页率高 C、交换信息量大 D、缺页率反馈模型不正确
14、8瓶酒一瓶有毒,用人测试。每次测试结果8小时后才会得出,而你只有8个小时的时间。问最少需要(B)人测试?
A、2 B、3 C、4 D、6
是3个人,如果你学过数的2进制编码,就容易说了:
8瓶酒的编码如下:
0: 000
1: 001
2: 010
3: 011
4: 100
5: 101
6: 110
7: 111
3个人分别喝3个位上为1的编码,所以:
第一个:1,3,5,7
第二个:2,3,6,7
第三个:4,5,6,7
把中毒的人的位填1的二进制数,就是毒酒的编号。
15、下列关于网络编程错误的是(AB)
A、TCP建立和关闭连接都只需要三次握手
B、UDP是可靠服务
C、主动关闭的一端会出现TIME_WAIT状态
D、服务端编程会调用listen(),客户端也可以调用bind()
16、进程间通讯有哪几种形式(ABCD)
A、Socket
B、Pipe
C、Shared memory
D、Signal
17、TCP/UDP下面正确的是(AC)
A、TCP provide connection-oriented,byte-stream service;
B、Both TCP and UDP provide reliability service;
C、TCP also provides flow control;
D、Both TCP and UDP provide retransmission mechanism;
18、分布式系统设计包括(ABCDE)
A、容错,design for fault
B、多数据中心的数据一致性
C、数据/服务可靠性
D、可扩展性
E、要满足ACID特性
19、10个不同的球,放入3个不同的桶内,共有(C)种方法。 3^10
A、1000 B、720 C、59049 D、360
20、87的100次幂除以7的余数是多少(D)
A、1 B、2 C、3 D、4
二、简答题:
1、
(1)请描述进程和线程的区别?
(2)多线程程序有什么优点、缺点?
(2)多进程程序有什么优点、缺点?与多线程相比,有何区别?
2、编程题:
写代码,反转一个单链表,分别以迭代和递归的形式来实现
~~~
typedef struct node LinkNode;
struct node
{
int data;
LinkNode* next;
};
~~~
// 返回新链表头节点
LinkNode *reverse_link(LinkNode *head)
LinkNode *reverse_link_recursive(LinkNode *head)
~~~
// 返回新链表头节点
LinkNode *reverse_link(LinkNode *head)
{
if(head == NULL)
return NULL;
LinkNode *prev , *curr , *reverse_head , *temp;
prev = NULL , curr = head;
while(curr->next)
{
temp = curr->next;
curr->next = prev;
prev = curr;
curr = temp;
}
curr->next = prev;
reverse_head = curr;
return reverse_head;
}
LinkNode *reverse_link_recursive(LinkNode *head)
{
if(head == NULL)
return NULL;
LinkNode *curr , *reverse_head , *temp;
if(head->next == NULL) // 链表中只有一个节点,逆转后的头指针不变
return head;
else
{
curr = head;
temp = head->next; // temp为(a2,...an)的头指针
reverse_head = reverse_link_recursive(temp); // 逆转链表(a2,...an),并返回逆转后的头指针
temp->next = curr; // 将a1链接在a2之后
curr->next = NULL;
}
return reverse_head; // (a2,...an)逆转链表的头指针即为(a1,a2,...an)逆转链表的头指针
}
~~~
3、给一个数组,元素都是整数(有正数也有负数),寻找连续的元素相加之和为最大的序列。
如:1、-2、3、5、-4、6 连续序列3、5、-4、6的和最大。
如元素全为负数,则最大的和为0,即一个也没有选。
/*
array[] 输入数组
n 数组元素个数
返回最大序列和
*/
int find_max_sum(int array[] , int n)
~~~
int find_max_sum(int array[] , int n)
{
int i , max , sum;
sum = max = array[0];
for(i = 1 ; i < n ; ++i)
{
if(sum < 0)
sum = array[i];
else
sum += array[i];
if(sum > max)
max = sum;
}
if(max < 0)
max = 0;
return max;
}
~~~
三、设计题
1、设计一个图片存储系统:假设有一个相册系统,每个用户不限制上传的图片数目,每张相片压缩后都在1M以内,需求如下:
(1)文件数量太大,采用传统的文件系统存储导致目录系统非常臃肿,访问速度变得缓慢;
(2)单机存储容量已经远远不能承载所有的文件;
(3)上传之后,用户只有读取操作和删除操作,不支持修改,整个系统读写比例10:1
思路:可以使用分布式的文件系统,觉得hadoop的HDFS很符合要求,这是hadoop对googleGDFS的实现。
';
海量数据随机抽样问题(蓄水池问题)
最后更新于:2022-04-01 21:43:49
随机抽样问题表示如下:
要求从N个元素中随机的抽取k个元素,其中N无法确定。
这种应用的场景一般是数据流的情况下,由于数据只能被读取一次,而且数据量很大,并不能全部保存,因此数据量N是无法在抽样开始时确定的;但又要保持随机性,于是有了这个问题。所以搜索网站有时候会问这样的问题。
这里的核心问题就是“随机”,怎么才能是随机的抽取元素呢?我们设想,买彩票的时候,由于所有彩票的中奖概率都是一样的,所以我们才是“随机的”买彩票。那么要使抽取数据也随机,必须使每一个数据被抽样出来的概率都一样。
【解决】
解决方案就是蓄水库抽样(reservoid sampling)。主要思想就是保持一个集合(这个集合中的每个数字出现),作为蓄水池,依次遍历所有数据的时候以一定概率替换这个蓄水池中的数字。
其伪代码如下:
~~~
Init : a reservoir with the size: k
for i= k+1 to N
M=random(1, i);
if( M < k)
SWAP the Mth value and ith value
end for
~~~
解释一下:程序的开始就是把前k个元素都放到水库中,然后对之后的第i个元素,以k/i的概率替换掉这个水库中的某一个元素。
下面来具体证明一下:每个水库中的元素出现概率都是相等的。
【证明】
(1)初始情况。出现在水库中的k个元素的出现概率都是一致的,都是1。这个很显然。
(2)第一步。第一步就是指,处理第k+1个元素的情况。分两种情况:元素全部都没有被替换;其中某个元素被第k+1个元素替换掉。
我们先看情况2:第k+1个元素被选中的概率是k/(k+1)(根据公式k/i),所以这个新元素在水库中出现的概率就一定是k/(k+1)(不管它替换掉哪个元素,反正肯定它是以这个概率出现在水库中)。下面来看水库中剩余的元素出现的概率,也就是1-P(这个元素被替换掉的概率)。水库中任意一个元素被替换掉的概率是:(k/k+1)*(1/k)=1/(k+1),意即首先要第k+1个元素被选中,然后自己在集合的k个元素中被选中。那它出现的概率就是1-1/(k+1)=k/(k+1)。可以看出来,旧元素和新元素出现的概率是相等的。
情况1:当元素全部都没有替换掉的时候,每个元素的出现概率肯定是一样的,这很显然。但具体是多少呢?就是1-P(第k+1个元素被选中)=1-k/(k+1)=1/(k+1)。
(3)归纳法:重复上面的过程,只要证明第i步到第i+1步,所有元素出现的概率是相等的即可。
看到一个问题:怎样随机从N个元素中选择一个元素,你依次遍历每个元素,但不知道N多大。
将N个元素用[1、2、...、N]编号。如果在知道N的大小,我们可以从[1、N]中随机选择一个数作为选择对象。
但是现在不知道N的大小,要使每一个元素被取的概率相等(随机)。这个概念叫蓄水池抽样。
Solution:以1/i的概率取第i个元素。
证明:数学归纳法。当i=1时:第1个元素以1/1=1的概率被取,符合条件。
设i=k时符合条件,即前k个元素都以1/k的概率被取。
则i=k+1时:对于第k+1个元素,被取概率为1/(k+1),符合条件。
对于前k个元素,每个元素被取的概率=被取并且没被第k+1个元素替换的概率=(1/k)*(1−1/(k+1))=1/(k+1)符合条件。
综上所述:得证。
将问题扩展:给你一个长度为N的链表。N很大,但你不知道N有多大。你的任务是从这N个元素中随机取出k个元素。你只能遍历这个链表一次。你的算法必须保证取出的元素恰好有k个,且它们是完全随机的(出现概率均等)。
这次与上面唯一的不同是:总共需要取k个元素。仿照即可得出解决方案。
Solution:以1的概率取前k个元素,从i=k+1开始,以k/i的概率取第i个元素,若被取,以均等的概率替换先前被取的k个元素。
证明:同样数学归纳法。当i=k+1时:第k+1个元素以k/k+1概率被取,前k个元素被取的概率=1 - 被第k+1个元素替换的概率=1−k/(k+1)*1/k=k/(k+1) 符合条件。
设i=p时符合条件,即前p个元素都以k/p的概率被取。
则i=p+1时:对第p+1个元素,被取概率为k/(p+1)符合条件。
对于前p个元素,每个元素被取的概率=被取并且没有被第p+1个元素替换的概率=
k/p*((1−k/(p+1))+k/(p+1)*(1−1/k))=k/p+1同样符合条件。
综上所述:得证。
另外还有一种方法:给每个元素随机生成一个固定区间(如[0,1])的权重。用一个大小为k的堆来选取权重较大的k个元素。仿照也可解决最开始的取1个的问题。
';
后缀数组求最长重复子串
最后更新于:2022-04-01 21:43:47
问题描述
给定一个字符串,求出其最长重复子串
例如:abcdabcd
最长重复子串是 abcd,最长重复子串可以重叠
例如:abcdabcda,这时最长重复子串是 abcda,中间的 a 是被重叠的。
直观的解法是,首先检测长度为 n - 1 的字符串情况,如果不存在重复则检测 n - 2, 一直递减下去,直到 1 。
这种方法的时间复杂度是 O(N * N * N),其中包括三部分,长度纬度、根据长度检测的字符串数目、字符串检测。
改进的方法是利用后缀数组
后缀数组是一种数据结构,对一个字符串生成相应的后缀数组后,然后再排序,排完序依次检测相邻的两个字符串的开头公共部分。
这样的时间复杂度为:生成后缀数组 O(N),排序 O(NlogN*N) 最后面的 N 是因为字符串比较也是 O(N)
依次检测相邻的两个字符串 O(N * N),总的时间复杂度是 O(N^2*logN),优于第一种方法的 O(N^3)
对于类似从给定的文本中,查找其中最长的重复子字符串的问题,可以采用“后缀数组”来高效地完成此任务。后缀数组使用文本本身和n个附加指针(与文本数组相应的指针数组)来表示输入文本中的n个字符的每个子字符串。
首先,如果输入字符串存储在c[0..n-1]中,那么就可以使用类似于下面的代码比较每对子字符串:
~~~
int main(void)
{
int i , j , thislen , maxlen = -1;
......
......
......
for(i = 0 ; i < n ; ++i )
{
for(j = i+1 ; j < n ; ++j )
{
if((thislen = comlen(&c[i] , &c[j])) > maxlen)
{
maxlen = thislen;
maxi = i;
maxj = j;
}
}
}
......
......
......
return 0;
}
~~~
当作为comlen函数参数的两个字符串长度相等时,该函数便返回这个长度值,从第一个字符开始:
~~~
int comlen( char *p, char *q )
{
int i = 0;
while( *p && (*p++ == *q++) )
++i;
return i;
}
~~~
由于该算法查看所有的字符串对,所以它的时间和n的平方成正比。下面便是使用“后缀数组”的解决办法。
如果程序至多可以处理MAXN个字符,这些字符被存储在数组c中:
~~~
#define MAXCHAR 5000 //最长处理5000个字符
char c[MAXCHAR], *a[MAXCHAR];
~~~
在读取输入时,首先初始化a,这样,每个元素就都指向输入字符串中的相应字符:
~~~
n = 0;
while( (ch=getchar())!='\n' )
{
a[n] = &c[n];
c[n++] = ch;
}
c[n]='\0'; // 将数组c中的最后一个元素设为空字符,以终止所有字符串
~~~
这样,元素a[0]指向整个字符串,下一个元素指向以第二个字符开始的数组的后缀,等等。如若输入字符串为"banana",该数组将表示这些后缀:
a[0]:banana
a[1]:anana
a[2]:nana
a[3]:ana
a[4]:na
a[5]:a
由于数组a中的指针分别指向字符串中的每个后缀,所以将数组a命名为"后缀数组"
第二、对后缀数组进行快速排序,以将后缀相近的(变位词)子串集中在一起
qsort(a, n, sizeof(char*), pstrcmp)后
a[0]:a
a[1]:ana
a[2]:anana
a[3]:banana
a[4]:na
a[5]:nana
第三、使用以下comlen函数对数组进行扫描比较邻接元素,以找出最长重复的字符串:
~~~
for(i = 0 ; i < n-1 ; ++i )
{
temp=comlen( a[i], a[i+1] );
if( temp>maxlen )
{
maxlen=temp;
maxi=i;
}
}
printf("%.*s\n",maxlen, a[maxi]);
~~~
完整的实现代码如下:
~~~
#include
using namespace std;
#define MAXCHAR 5000 //最长处理5000个字符
char c[MAXCHAR], *a[MAXCHAR];
int comlen( char *p, char *q )
{
int i = 0;
while( *p && (*p++ == *q++) )
++i;
return i;
}
int pstrcmp( const void *p1, const void *p2 )
{
return strcmp( *(char* const *)p1, *(char* const*)p2 );
}
int main(void)
{
char ch;
int n=0;
int i, temp;
int maxlen=0, maxi=0;
printf("Please input your string:\n");
n = 0;
while( (ch=getchar())!='\n' )
{
a[n] = &c[n];
c[n++] = ch;
}
c[n]='\0'; // 将数组c中的最后一个元素设为空字符,以终止所有字符串
qsort( a, n, sizeof(char*), pstrcmp );
for(i = 0 ; i < n-1 ; ++i )
{
temp=comlen( a[i], a[i+1] );
if( temp>maxlen )
{
maxlen=temp;
maxi=i;
}
}
printf("%.*s\n",maxlen, a[maxi]);
return 0;
}
~~~
方法二:KMP
通过使用next数组的特性,同样可以求最长重复子串,不过时间复杂度有点高挖。。
~~~
#include
using namespace std;
const int MAX = 100000;
int next[MAX];
char str[MAX];
void GetNext(char *t)
{
int len = strlen(t);
next[0] = -1;
int i = 0 , j = -1;
while(i < len)
{
if(j == -1 || t[i] == t[j])
{
i++;
j++;
if(t[i] != t[j])
next[i] = j;
else
next[i] = next[j];
}
else
j = next[j];
}
}
int main(void)
{
int i , j , index , len;
cout<<"Please input your string:"<>str;
char *s = str;
len = 0;
for(i = 0 ; *s != '\0' ; s++ , ++i)
{
GetNext(s);
for(j = 1 ; j <= strlen(s) ; ++j)
{
if(next[j] > len)
{
len = next[j];
index = i + j; //index是第一个最长重复串在str中的位置
}
}
}
if(len > 0)
{
for(i = index - len ; i < index ; ++i)
cout<
#include
-
using namespace std;
//思路:用一个数组保存字符出现的次数。用i和j进行遍历整个字符串。
//当某个字符没有出现过,次数+1;出现字符已经出现过,次数+1,找到这个字符前面出现的位置的下一个位置,设为i
//并将之前的那些字符次数都-1。继续遍历,直到'\0'
int find(char str[],char *output)
{
int i = 0 , j = 0;
int cnt[26] = {0};
int res = 0 , temp = 0;
char *out = output;
int final;
while(str[j] != '\0')
{
if(cnt[str[j]-'a'] == 0)
{
cnt[str[j]-'a']++;
}
else
{
cnt[str[j]-'a']++;
while(str[i] != str[j])
{
cnt[str[i]-'a']--;
i++;
}
cnt[str[i]-'a']--;
i++;
}
j++;
temp = j-i;
if(temp > res)
{
res = temp;
final = i;
}
}
//结果保存在output里面
for(i = 0 ; i < res ; ++i)
*out++ = str[final++];
*out = '\0';
return res;
}
int main(void)
{
char a[] = "abcdefg";
char b[100];
int max = find(a,b);
cout<
Trie树详解及其应用
最后更新于:2022-04-01 21:43:45
**一、知识简介**
最近在看字符串算法了,其中字典树、AC自动机和后缀树的应用是最广泛的了,下面将会重点介绍下这几个算法的应用。
字典树(Trie)可以保存一些字符串->值的对应关系。基本上,它跟 Java 的 HashMap 功能相同,都是 key-value 映射,只不过 Trie 的 key 只能是字符串。
Trie 的强大之处就在于它的时间复杂度。它的插入和查询时间复杂度都为 O(k) ,其中 k 为 key 的长度,与 Trie 中保存了多少个元素无关。Hash 表号称是 O(1) 的,但在计算 hash 的时候就肯定会是 O(k) ,而且还有碰撞之类的问题;Trie 的缺点是空间消耗很高。
至于Trie树的实现,可以用数组,也可以用指针动态分配,我做题时为了方便就用了数组,静态分配空间。
Trie树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
Trie树的基本性质可以归纳为:
(1)根节点不包含字符,除根节点意外每个节点只包含一个字符。
(2)从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
(3)每个节点的所有子节点包含的字符串不相同。
Trie树有一些特性:
1)根节点不包含字符,除根节点外每一个节点都只包含一个字符。
2)从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
3)每个节点的所有子节点包含的字符都不相同。
4)如果字符的种数为n,则每个结点的出度为n,这也是空间换时间的体现,浪费了很多的空间。
5)插入查找的复杂度为O(n),n为字符串长度。
基本思想(以字母树为例):
1、插入过程
对于一个单词,从根开始,沿着单词的各个字母所对应的树中的节点分支向下走,直到单词遍历完,将最后的节点标记为红色,表示该单词已插入Trie树。
2、查询过程
同样的,从根开始按照单词的字母顺序向下遍历trie树,一旦发现某个节点标记不存在或者单词遍历完成而最后的节点未标记为红色,则表示该单词不存在,若最后的节点标记为红色,表示该单词存在。
二、字典树的数据结构:
利用串构建一个字典树,这个字典树保存了串的公共前缀信息,因此可以降低查询操作的复杂度。
下面以英文单词构建的字典树为例,这棵Trie树中每个结点包括26个孩子结点,因为总共有26个英文字母(假设单词都是小写字母组成)。
则可声明包含Trie树的结点信息的结构体:
~~~
typedef struct Trie_node
{
int count; // 统计单词前缀出现的次数
struct Trie_node* next[26]; // 指向各个子树的指针
bool exist; // 标记该结点处是否构成单词
}TrieNode , *Trie;
~~~
其中next是一个指针数组,存放着指向各个孩子结点的指针。
如给出字符串"abc","ab","bd","dda",根据该字符串序列构建一棵Trie树。则构建的树如下:
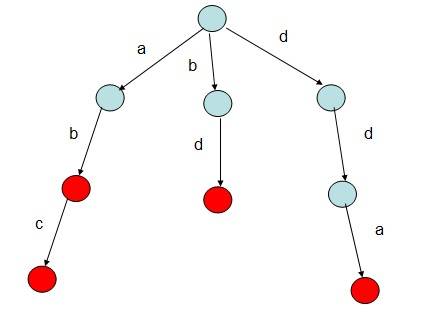
Trie树的根结点不包含任何信息,第一个字符串为"abc",第一个字母为'a',因此根结点中数组next下标为'a'-97的值不为NULL,其他同理,构建的Trie树如图所示,红色结点表示在该处可以构成一个单词。很显然,如果要查找单词"abc"是否存在,查找长度则为O(len),len为要查找的字符串的长度。而若采用一般的逐个匹配查找,则查找长度为O(len*n),n为字符串的个数。显然基于Trie树的查找效率要高很多。
如上图中:Trie树中存在的就是abc、ab、bd、dda四个单词。在实际的问题中可以将标记颜色的标志位改为数量count等其他符合题目要求的变量。
已知n个由小写字母构成的平均长度为10的单词,判断其中是否存在某个串为另一个串的前缀子串。下面对比3种方法:
1、 最容易想到的:即从字符串集中从头往后搜,看每个字符串是否为字符串集中某个字符串的前缀,复杂度为O(n^2)。
2、 使用hash:我们用hash存下所有字符串的所有的前缀子串。建立存有子串hash的复杂度为O(n*len)。查询的复杂度为O(n)* O(1)= O(n)。
3、 使用Trie:因为当查询如字符串abc是否为某个字符串的前缀时,显然以b、c、d....等不是以a开头的字符串就不用查找了,这样迅速缩小查找的范围和提高查找的针对性。所以建立Trie的复杂度为O(n*len),而建立+查询在trie中是可以同时执行的,建立的过程也就可以成为查询的过程,hash就不能实现这个功能。所以总的复杂度为O(n*len),实际查询的复杂度只是O(len)。
**三、Trie树的操作**
在Trie树中主要有3个操作,插入、查找和删除。一般情况下Trie树中很少存在删除单独某个结点的情况,因此只考虑删除整棵树。
1、插入
假设存在字符串str,Trie树的根结点为root。i=0,p=root。
1)取str[i],判断p->next[str[i]-97]是否为空,若为空,则建立结点temp,并将p->next[str[i]-97]指向temp,然后p指向temp;
若不为空,则p=p->next[str[i]-97];
2)i++,继续取str[i],循环1)中的操作,直到遇到结束符'\0',此时将当前结点p中的 exist置为true。
2、查找
假设要查找的字符串为str,Trie树的根结点为root,i=0,p=root
1)取str[i],判断判断p->next[str[i]-97]是否为空,若为空,则返回false;若不为空,则p=p->next[str[i]-97],继续取字符。
2)重复1)中的操作直到遇到结束符'\0',若当前结点p不为空并且 exist 为true,则返回true,否则返回false。
3、删除
删除可以以递归的形式进行删除。
前缀查询的典型应用:
[http://acm.hdu.edu.cn/showproblem.php?pid=1251](http://acm.hdu.edu.cn/showproblem.php?pid=1251)
~~~
#include
#include
using namespace std;
typedef struct Trie_node
{
int count; // 统计单词前缀出现的次数
struct Trie_node* next[26]; // 指向各个子树的指针
bool exist; // 标记该结点处是否构成单词
}TrieNode , *Trie;
TrieNode* createTrieNode()
{
TrieNode* node = (TrieNode *)malloc(sizeof(TrieNode));
node->count = 0;
node->exist = false;
memset(node->next , 0 , sizeof(node->next)); // 初始化为空指针
return node;
}
void Trie_insert(Trie root, char* word)
{
Trie node = root;
char *p = word;
int id;
while( *p )
{
id = *p - 'a';
if(node->next[id] == NULL)
{
node->next[id] = createTrieNode();
}
node = node->next[id]; // 每插入一步,相当于有一个新串经过,指针向下移动
++p;
node->count += 1; // 这行代码用于统计每个单词前缀出现的次数(也包括统计每个单词出现的次数)
}
node->exist = true; // 单词结束的地方标记此处可以构成一个单词
}
int Trie_search(Trie root, char* word)
{
Trie node = root;
char *p = word;
int id;
while( *p )
{
id = *p - 'a';
node = node->next[id];
++p;
if(node == NULL)
return 0;
}
return node->count;
}
int main(void)
{
Trie root = createTrieNode(); // 初始化字典树的根节点
char str[12] ;
bool flag = false;
while(gets(str))
{
if(flag)
printf("%d\n",Trie_search(root , str));
else
{
if(strlen(str) != 0)
{
Trie_insert(root , str);
}
else
flag = true;
}
}
return 0;
}
~~~
字典树的查找
[http://acm.hdu.edu.cn/showproblem.php?pid=1075](http://acm.hdu.edu.cn/showproblem.php?pid=1075)
~~~
#include
#include
using namespace std;
typedef struct Trie_node
{
int count; // 统计单词前缀出现的次数
struct Trie_node* next[26]; // 指向各个子树的指针
bool exist; // 标记该结点处是否构成单词
char trans[11]; // 翻译
}TrieNode , *Trie;
TrieNode* createTrieNode()
{
TrieNode* node = (TrieNode *)malloc(sizeof(TrieNode));
node->count = 0;
node->exist = false;
memset(node->next , 0 , sizeof(node->next)); // 初始化为空指针
return node;
}
void Trie_insert(Trie root, char* word , char* trans)
{
Trie node = root;
char *p = word;
int id;
while( *p )
{
id = *p - 'a';
if(node->next[id] == NULL)
{
node->next[id] = createTrieNode();
}
node = node->next[id]; // 每插入一步,相当于有一个新串经过,指针向下移动
++p;
node->count += 1; // 这行代码用于统计每个单词前缀出现的次数(也包括统计每个单词出现的次数)
}
node->exist = true; // 单词结束的地方标记此处可以构成一个单词
strcpy(node->trans , trans);
}
char* Trie_search(Trie root, char* word)
{
Trie node = root;
char *p = word;
int id;
while( *p )
{
id = *p - 'a';
node = node->next[id];
++p;
if(node == NULL)
return 0;
}
if(node->exist) // 查找成功
return node->trans;
else // 查找失败
return NULL;
}
int main(void)
{
Trie root = createTrieNode(); // 初始化字典树的根节点
char str1[3003] , str2[3003] , str[3003] , *p;
int i , k;
scanf("%s",str1);
while(scanf("%s",str1) && strcmp(str1 , "END") != 0)
{
scanf("%s",str2);
Trie_insert(root , str2 , str1);
}
getchar();
gets(str1);
k = 0;
while(gets(str1))
{
if(strcmp(str1 , "END") == 0)
break;
for(i = 0 ; str1[i] != '\0' ; ++i)
{
if(str1[i] >= 'a' && str1[i] <= 'z')
{
str[k++] = str1[i];
}
else
{
str[k] = '\0';
p = Trie_search(root , str);
if(p)
printf("%s", p);
else
printf("%s", str);
k = 0;
printf("%c", str1[i]);
}
}
printf("\n");
}
return 0;
}
~~~
';
各大IT公司校园招聘程序猿笔试、面试题集锦
最后更新于:2022-04-01 21:43:42
# 百度一面
1、给定一个字符串比如“abcdef”,要求写个函数编程“defabc”,位数是可变的。这个比较简单,我用的是strcpy和memcpy,然后他问有什么优化的办法,我就不知道了。
2、socket过程就是socket的server和client整个流程写下来,这个还是没啥问题的。
3、数据结构二叉树的遍历,给了个二叉树,前序、中序、后序写出来,这个没什么难度。
[http://blog.csdn.net/hackbuteer1/article/details/6583988](http://blog.csdn.net/hackbuteer1/article/details/6583988)
4、树的层次遍历,这个开始真忘了,想了半天才想起来用队列。然后他又让我详细写出入队出队的过程,总之还是搞定了。
5、两圆相切转圏问题——一个小圆半径是1厘米,一个大圆半径是5厘米,小圆沿着大圆转圈,请问要转几圈可以转完大圈?这个问题在行测题做过,就是公转自转的问题,不管大小圆半径是多少,外切转圏要转R/r+1圏,外切转圏转R/r-1圈。
# 百度二面
1、二叉树的前序遍历的递归和非递归的可执行程序
[http://blog.csdn.net/hackbuteer1/article/details/6583988](http://blog.csdn.net/hackbuteer1/article/details/6583988)
2、写出快速排序的实现代码,一个是字符串拼接函数的实现strcat(),还有大数相乘,都是基本题。
3、归并排序的实现。
[http://blog.csdn.net/hackbuteer1/article/details/6568913](http://blog.csdn.net/hackbuteer1/article/details/6568913)
4、文件按a~z编号,aa~az,ba~bz...za...zz...aaa...aaz,aba~abz...这样的方法进行编号。给定任意一个编号,输出文件是第几个文件。并写出测试方法。简单,把编号看成26进制,这题就是一个十进制和26进制的进制转换问题了。
5、编程:两个链表,按升序排序,合并后仍按升序,不准用递归,并求复杂度
# 百度电面:
1、谈谈你对数据库中索引的理解
2、现在普通关系数据库用得数据结构是什么类型的数据结构
3、索引的优点和缺点
4、session、cookie和cache的区别是什么
5、如果有几千个session,怎么提高效率?
6、session是存储在什么地方,以什么形式存储的?
# 新浪技术部笔试题
#
一、数据结构和算法
1、简述什么是hashtable,如何解决hash冲突
2、什么叫二叉树,满二叉树,完全二叉树
4、数组和链表有什么区别,分别用在什么场合
二、操作系统
1、什么叫虚拟内存
2、块设备和字符设备有什么区别
3、进程和线程的区别
4、简述TCP网关连接交互细节
三、Lunix
1、写出10个常用的linux命令和参数
2、如何查看磁盘剩余空间 df -h1
3、如何查看端口是否被占用
4、如何查看某个进程所占用的内存 用ps命令查看进程的内存
四、程序题(具体题目记不太清了)
1、用两个线程实现1-100的输出
2、把一个文件夹中所有01结尾的文件前十行内容输出
# 思科一面:
#
1、C++和Java最大的区别是什么?
2、static、extern、global的作用?(再一次出现了static,上镜率真高挖~)
[http://blog.csdn.net/hackbuteer1/article/details/7487694](http://blog.csdn.net/hackbuteer1/article/details/7487694)
3、inline内联函数是否占用运行时间?
思科二面:
1、进程和线程有什么区别?
2、进程的调度算法,把记得的全说出来
3、页面的替换算法都有哪些?
4、用户态和内核态的区别?
5、平面上N个点 没两个点都确定一条直线 求出斜率最大 那条直线所通过 两个点 斜率不存在 情况不考虑 时间效率越高越好
解法:先把N个点按x排序。
斜率k最大值为max(斜率(point[i],point[i+1])) 0<=ib->c->d->e->f-g,翻转后变为:b->a->d->c->f->e->g
6、求正整数n所有可能的和式的组合(如;4=1+1+1+1、1+1+2、1+3、2+1+1、2+2)
1、实现一个atoi函数==>'注意正负号的判定'
2、翻转一个句子,其中单词是正序的==>两次旋转
3、二叉树两个结点中的最小公共子结点==>求长度,长度之差,远的先走,再一起走
4、三角阵中从第一行到最后一行(给出搜索方向的限制)找一个连续的最大和==>广度优先搜索√
5、实现一个STL中的vector中的尽量多的方法。
6、字符串移动(字符串为*号和26个字母的任意组合,把*号都移动到最左侧,把字母移到最右侧并保持相对顺序不变),要求时间和空间复杂度最小。
~~~
/**
**author :hackbuteer
**date :2012-10-03
**/
void Arrange(char *str , int n)
{
int i , k = n-1;
for(i = n - 1 ; i >= 0 ; --i)
{
if(str[i] != '*')
{
if(str[k] == '*')
{
str[k] = str[i];
str[i] = '*';
}
--k;
}
}
}
~~~
7、说说outer join、inner join、left join、right join的区别是什么?
内连接:进行连接的两个表对应的相匹配的字段完全相同的连接。join
外连接又分为左外连接和右外连接。
左连接即LEFT OUTER JOIN:
两个表进行左连接时会返回左边表中的所有的行和右边表中与之相匹配的列值没有相匹配的用空值代替。
右连接即RIGHT OUTER JOIN:
两个表进行右连接时会返回右边表中的所有的行和左边表中与之相匹配的列值没有相匹配的用空值代替。
我们建立两张表,students、class并插入测试数据
students
---------------------------
id name classId
1 name1 1
2 name2 null
3 name3 2
---------------------------
class
-----------------------
id name
1 class1
2 class2
3 class3
-----------------------
实验结果如下:
mysql> select s.name,c.name from students s join class c where s.classId=c.id ; (注:inner join和join一样)
+-------+-------+
| name | class |
+-------+-------+
| name1 | 1 |
| name3 | 2 |
+-------+-------+
2 rows in set
mysql> select s.name,c.name from students s left join class c on s.classId=c.id ; (left join 和 left outer join 一样)
+-------+-------+
| name | class |
+-------+-------+
| name1 | 1 |
| name2 | NULL |
| name3 | 2 |
+-------+-------+
3 rows in set
mysql> select s.name,c.name from students s right join class c on s.classId=c.id ; (right join 和 right outer join 一样)
+-------+-------+
| name | class |
+-------+-------+
| name1 | 1 |
| name3 | 2 |
| NULL | 3 |
+-------+-------+
3 rows in set
';
C/C++笔试题目大全
最后更新于:2022-04-01 21:43:40
1、以下程序的运行结果是()
~~~
int main(void)
{
printf("%s , %5.3s\n","computer","computer");
return 0;
}
~~~
A、computer , puter B、computer , com
C、computer , computer D、computer , compu.ter
2、以下程序的功能是()
~~~
#include
int main(void)
{
FILE *fp;
long int n;
fp = fopen("wj.txt","rb");
fseek(fp , 0 , SEEK_END);
n = ftell(fp);
fclose(fp);
printf("%ld",n);
}
~~~
A、计算文件wj.txt内容的字节数
B、计算文件wj.txt的终止地址
C、计算文件wj.txt的起始地址
D、将文件指针定位到文件末尾
3、若输入B,则以下程序运行后的输出结果是()
~~~
int main(void)
{
char grade;
scanf("%c",&grade);
switch(grade)
{
case 'A':
printf(">=85");
case 'B':
case 'C':
printf(">=60");
case 'D':
printf("<60");
default:
printf("error.");
}
}
~~~
A、error.
B、>=60
C、>=85
D、>=60<60error.
4、以下程序的输出结果是()
~~~
int power(int x , int y);
int main(void)
{
float a = 2.6 , b = 3.4;
int p;
p = power((int)a , (int)b);
printf("%d\n",p);
return 0;
}
int power(int x , int y)
{
int i , p = 1;
for(i = y ; i > 0 ; i--)
p *= x;
return p;
}
~~~
A、27 B、9 C、8 D、81
5、以下程序段的输出结果是()
~~~
int p = 1234;
printf("%2d\n",p);
~~~
A、12 B、34 C、1234 D、提示出错、无结果
6、以下程序运行后的输出结果是()
~~~
int main(void)
{
int a;
char c = 10;
float f = 100.0;
double x;
a = f /= c *= (x=6.5);
printf("%d %d %3.1f %3.1f\n",a,c,f,x);
return 0;
}
~~~
A、1 65 1 6.5
B、1 65 1.5 6.5
C、1 65 1.0 6.5
D、2 65 1.5 6.5
7、以下程序的运行结果是()(主要考察运算符的优先级)
~~~
int main(void)
{
int x , y , z;
x = 0 , y = 1 , z = 3;
x = ++y <= x || x+y != z;
printf("%d,%d\n",x , y);
return 0;
}
~~~
A、1 ,2 B、1 , 1 C、0,2 D、0,1
8、以下语句的输出结果是()(主要考察逗号表达式)
~~~
int main(void)
{
int x = 10 , y = 3 , z;
printf("%d\n",z = (x%y , x/y));
return 0;
}
~~~
A、4 B、0 C、3 D、1
逗号表达式的一般形式:
表达式1,表达式2,表达式3......表达式n
它的值为表达式n的值。
括号表达式要求按顺序逐一计算各个子表达式,并以最后一个子表达式的值作为括号表达式的结果,最后将该结果赋给变量。
printf("%d %d %d",(a,b,c),b,c);
则(a,b,c)是一个逗号表达式,它的值等于c的值。括号内的逗号不是参数间的分隔符而是逗号运算符。括号中的内容是一个整体,作为printf函数的第一个参数。
9、设有语句 char a = '\72'; 则变量a()
A、包含2个字符 B、说明不合法
C、包含1个字符 D、包含3个字符
10、已知数据表A中每个元素距其最终位置不远,为节省时间,应该采用的算法是()
A、直接选择排序
B、堆排序
C、快速排序
D、直接插入排序
11、以下程序段的运行结果是()
~~~
int main(void)
{
char aa[][3] = {'a','b','c','d','e','f'};
char (*p)[3] = aa;
p++;
printf("%c\n",**p);
return 0;
}
~~~
A、b B、a C、c D、d
12、在C语言中,下列()是合法的标示符。
A、4x B、1P234
C、COUNT D、short
13、C语言中的标识符只能有字母、数字和下划线三种字符组成,且第一个字符()
A、必须为字母
B、必须为字母或下划线
C、必须不是字母或下划线
D、必须为下划线
14、下面程序的输出是()
~~~
int main(void)
{
enum team { my , your = 9 , his , her = his + 3};
printf("%d %d %d %d\n",my , your , his , her);
return 0;
}
~~~
A、0 9 10 13 B、0 8 11 12
C、0 8 10 12 D、0 8 12 9
15、以下程序
~~~
int main(int argc, char**argv)
{
int n = 0 , i;
for(i = 1 ; i < argc ; i++)
n = n * 10 + *argv[i]-'0';
printf("%d\n",n);
return 0;
}
~~~
经编译链接生成可执行文件tt.exe,若运行时输入以下命令行 tt 12 345 678,则程序运行的输出结果是()
A、136 B、12345 C、12345678 D、12
解析:主函数的第一个参数argc为整型参数,记下从命令行输入参数的个数;第二个参数argv是一个字符型的指针数组,它的每一个元素分别指向命令行输入的各字符串。在本例中argc的值为4,argv[0]指向字符串“tt”,argv[1]指向字符串“12”,argv[2]指向字符串“345”, argv[3]指向字符串“678”。程序中,通过一个for循环,遍历了后面的三个参数字符串,每次将n自乘10,然后累加argv[i]-‘0’,即第i个参数字符串的首字符减去‘0’。 一个数字字符减去‘0’字符,即可得到这个数字字符的实际数值,因此三次循环的结果是让n的值变为136,故本题应该选择A。
16、若已定义:int a[9],*p = a; 并在以后的语句中未改变p的值,不能表示a[1]地址的表达式是()
A、++p B、a+1 C、p+1 D、a++
17、若执行下面的程序时,从键盘上输入5,则输出是()
~~~
int main(int argc, char**argv)
{
int x;
scanf("%d",&x);
if(x++ > 5)
printf("%d\n",x);
else
printf("%d\n",x--);
return 0;
}
~~~
A、7 B、4 C、6 D、5
18、已知有如下的变量定义,那么第二行的表达式的值是多少()(主要考察运算符的优先级)
~~~
int main(void)
{
int x = 3 , y = 4 , z = 5;
!(x + y) + z-1 && y + z/2;
return 0;
}
~~~
A、6 B、2 C、0 D、1
19、下列运算符函数中,肯定不属于类Value的成员函数是()
A、Value operator/(Value);
B、Value operator-(Value,Value);
C、Value operator+(Value);
D、Value operator*(int);
20、以下关于函数模板和模板函数的描述中,错误的是()
A、函数模板是定义重载函数的一种工具
B、模板函数在编译时不生成可执行代码
C、函数模板是一组函数的样板
D、模板函数是函数模板的一个实例
21、以下关于文件操作的描述中,不正确的是()
A、关闭文件的目的之一是释放内存中的文件对象
B、关闭文件的目的之一是保证将输出的数据写入硬盘文件
C、文件读写过程中,程序将直接与磁盘文件进行数据交换
D、打开文件的目的是使文件对象与磁盘文件建立联系
22、在重载一运算符时,若运算符函数的形参表中没有参数,则不可能的情况是()
A、该运算符函数是类的友元函数
B、该运算符函数有一个隐含的参数this
C、该运算符函数是类的成员函数
D、该运算符是一个单目运算符
23、下列哪一个是析构函数的特征()
A、析构函数定义只能在类体内
B、一个类中只能定义一个析构函数
C、析构函数名与类名不同
D、析构函数可以有一个或多个参数
24、数据流程图(DFD图)是()
A、软件概要设计的工具
B、软件详细设计的工具
C、结构化方法的需求分析工具
D、面向对象方法的需求分析工具
25、执行 int a = ( 1 , 3 , 11); int b = a; 后,b的值是多少?
A、11
B、1
C、3
D、15
E、{ 1 , 3 , 11}
26、设a=1,b=2,则(a++)+b 和 a+++b 这两个表达式的值分别是()
A、4 , 4
B、3 , 4
C、4 , 3
D、3 , 3
27、如果A类型是B类型的子类型,则A类型必然适应于B类型
A、错 B、对
28、条件语句不能作为多路分支语句。
A、对 B、错
29、下列while循环的次数是()
~~~
void main()
{
while(int i = 0)
i--;
}
~~~
A、无限
B、0
C、1
D、5
30、关于纯虚函数,下列表述正确的是()
A、派生类必须实现基类的纯虚函数
B、纯虚函数的声明总是以”=0“结束
C、纯虚函数是给出实现版本(即无函数体定义)的虚函数
D、含有纯虚函数的类一定是派生类
31、下列静态数据成员的特性中,()是错误的
A、引用静态数据成员时,要在静态数据成员名前加<类名>和作用域运算符
B、说明静态数据成员时前边要加关键字static来修饰
C、静态数据成员在类体外进行初始化
D、静态数据成员不是所有对象所共有的
32、关键词explicit的作用是什么?
A、它使一个默认构造函数的声明变为强制性的
B、它可以使一个变量存在主内存中而不是处理器的缓存中
C、它可以防止单参数的构造函数被用于隐式转换
33、下列输出字符‘A’的方法中,()是错误的
A、char A = 'A'; cout<
using namespace std;
class MyClass
{
public:
MyClass(int i = 0)
{
cout<
using namespace std;
class A
{
public:
A(int i )
{
cout<<"A ";
}
~A() { }
};
class B
{
public:
B(int j )
{
cout<<"B ";
}
~B() { }
};
class C
{
public:
C(int k )
{
cout<<"C ";
}
~C() { cout<<"~C "; }
};
class D : public C
{
public:
D(int i , int j , int k ) : a(i) , b(j) , C(k)
{
cout<<"D ";
}
~D() { cout<<"~D "; }
private:
B b;
A a;
};
int main()
{
C *pc = new D(1 , 2 , 3);
delete pc;
return 0;
}
~~~
A、A B C D ~D
B、A B C D ~C
C、C B A D ~D
**D、C B A D ~C**
42、关于运算符重载,下列说法正确的是()
A、重载时,运算符的结合性可以改变
B、重载时,运算符的优先级可以改变
C、重载时,运算符的功能可以改变
D、重载时,运算符的操作数个数可以改变
43、下面哪一个不是由标准模板库提供的合法的哈希表?
A、hash_multiset
B、hash_table
C、hash_set
D、hash_multimap
E、hash_map
44、int x = 2 , y = 3 , z = 4; 则表达式!x+y>z的值为()
A、1
B、FALSE
C、TRUE
D、0
45、下面的程序段的输出结果是()
~~~
void main()
{
char *x = "abcd";
x += 2;
cout<score的结果是()
~~~
struct node
{
int num;
float score;
}stu[2]={101,91.5,102,92.5} , *p = stu;
~~~
A、102
B、91.5
C、92.5
D、101
81、以下程序的输出结果是()
~~~
#define f(X) X*X
void main()
{
int a = 6 , b = 2 , c;
c = f(a)/f(b);
printf("%d\n",c);
}
~~~
A、18
B、9
C、36
D、6
82、如果a = 1 , b = 2 c = 3 , d = 4,则条件表达式abook,line#,His.age
D、print,_3d,oodb,aBc
88、若执行fopen()发生错误,函数的返回值是()
A、地址值
B、NULL
C、EOF
D、1
89、若调用一个函数,且此函数中无return语句,则正确的说法是()
A、能返回一个用户所希望的函数值
B、返回一个不确定的值
C、返回若干个系统默认值
D、没有返回值
90、长度相同但格式不同的2种浮点数,假设前者阶码长、尾数短,后者阶码短、尾数长,其它的规定均相同,则它们可表示的数的范围和精度为()
A、前者可表示的数的范围大且精度高
B、两者可表示的数的范围和精度相同
C、前者可表示的数的范围大但精度低
D、后者可表示的数的范围大且精度高
91、单继承情况下,派生类中对基类成员的访问也会出现二义性
A、错 B、对
92、关系数据库模型是以下哪种方式组织数据结构
A、二维表
B、网状
C、文本
D、树状
93、()命令可以查看视图的创建语句
A、SHOW VIEW
B、SHOW CREATE VIEW
C、SELECT VIEW
D、DISPLAY VIEW
94、正则表达式中的*代表的是()
A、0个或多个匹配
B、1个或多个匹配
C、0
95、预处理过程是编译过程之后、连接过程之前进行的
A、对 B、错
96、下面程序的输出结果是()
~~~
int main(void)
{
char x = 0xFF;
printf("%d\n",x--);
return 0;
}
~~~
A、-1 B、0 C、255 D、256
printf("%d \n",x--)函数参数首先传递的是x--这个,但是它是先返回值才减小,因此x传递过去时候仍然是0xff。
0xff当作为无符号数的时候,数字为255,作为带符号数时候,是-1。char类型是带符号的,因此是-1。
97、下面程序的输出结果是()
~~~
int main(void)
{
printf("%d\n",12&012);
return 0;
}
~~~
A、12 B、0 C、8 D、-1
012=1010;(C语言中数字前缀0表示八进制)
012是8进制数,它的值为10,二进制是0000 1010
12是十进制,它的二进制是0000 1100
两个数相与(&),得到0000 1000,即8
';
百度最新面试题集锦
最后更新于:2022-04-01 21:43:38
转载请标明出处,原文地址:[http://blog.csdn.net/hackbuteer1/article/details/7348968](http://blog.csdn.net/hackbuteer1/article/details/7348968)
1、实现一个函数,对一个正整数n,算得到1需要的最少操作次数。操作规则为:如果n为偶数,将其除以2;如果n为奇数,可以加1或减1;一直处理下去。
例子:
func(7) = 4,可以证明最少需要4次运算
n = 7
n-1 6
n/2 3
n-1 2
n/2 1
要求:实现函数(实现尽可能高效) int func(unsign int n);n为输入,返回最小的运算次数。给出思路(文字描述),完成代码,并分析你算法的时间复杂度。
答:
~~~
int func(unsigned int n)
{
if(n == 1)
return 0;
if(n % 2 == 0)
return 1 + func(n/2);
int x = func(n + 1);
int y = func(n - 1);
if(x > y)
return y+1;
else
return x+1;
}
~~~
假设n表示成二进制有x bit,可以看出计算复杂度为O(2^x),也就是O(n)。
将n转换到二进制空间来看(比如7为111,6为110):
- 如果最后一位是0,则对应于偶数,直接进行除2操作。
- 如果最后一位是1,情况则有些复杂。
**如果最后几位是???01,则有可能为???001,???1111101。在第一种情况下,显然应该-1;在第二种情况下-1和+1最终需要的步数相同。所以在???01的情况下,应该选择-1操作。
**如果最后几位是???011,则有可能为???0011,???11111011。在第一种情况下,+1和-1最终需要的步数相同;在第二种情况下+1步数更少些。所以在???011的情况下,应该选择+1操作。
**如果最后有更多的连续1,也应该选择+1操作。
如果最后剩下的各位都是1,则有11时应该选择-1;111时+1和-1相同;1111时应选择+1;大于四个1时也应该选择+1;
~~~
int func(unsigned int n)
{
if(n == 1)
return 0;
if(n % 2 == 0)
return 1 + func(n/2);
if(n == 3)
return 2;
if(n&2)
return 1 + func(n+1);
else
return 1 + func(n-1);
}
~~~
由以上的分析可知,奇数的时候加1或减1,完全取决于二进制的后两位,如果后两位是10、00那么肯定是偶数,选择除以2,如果后两位是01、11,那么选择结果会不一样的,如果是***01,那么选择减1,如果是***11,那么选择加1,特殊情况是就是n是3的时候,选择减1操作。
非递归代码如下:
~~~
// 非递归写法
int func(int n)
{
int count = 0;
while(n > 1)
{
if(n % 2 == 0)
n >>= 1;
else if(n == 3)
n--;
else
{
if(n&2) // 二进制是****11时
n++;
else // 二进制是****01时
n--;
}
count++;
}
return count;
}
~~~
另外一种写法如下:
~~~
// 非递归写法
int func(int n)
{
int count = 0;
while(n > 1)
{
if(n % 2 == 0) // n % 4等于0或2
n >>= 1;
else if(n == 3)
n--;
else
n += (n % 4 - 2); // n % 4等于1或3
count++;
}
return count;
}
~~~
2、找到满足条件的数组
给定函数d(n)=n+n的各位之和,n为正整数,如d(78)=78+7+8=93。这样这个函数可以看成一个生成器,如93可以看成由78生成。
定义数A:数A找不到一个数B可以由d(B)=A,即A不能由其他数生成。现在要写程序,找出1至10000里的所有符合数A定义的数。
回答:
申请一个长度为10000的bool数组,每个元素代表对应的值是否可以有其它数生成。开始时将数组中的值都初始化为false。
由于大于10000的数的生成数必定大于10000,所以我们只需遍历1到10000中的数,计算生成数,并将bool数组中对应的值设置为true,表示这个数可以有其它数生成。
最后bool数组中值为false的位置对应的整数就是不能由其它数生成的。
3、一个大的含有50M个URL的记录,一个小的含有500个URL的记录,找出两个记录里相同的URL。
回答:
首先使用包含500个url的文件创建一个hash_set。
然后遍历50M的url记录,如果url在hash_set中,则输出此url并从hash_set中删除这个url。
所有输出的url就是两个记录里相同的url。
4、海量日志数据,提取出某日访问百度次数最多的那个IP。
回答:
如果日志文件足够的大,大到不能完全加载到内存中的话。
那么可以考虑分而治之的策略,按照IP地址的hash(IP)%1024值,将海量日志存储到1024个小文件中。每个小文件最多包含4M个IP地址。
对于每个小文件,可以构建一个IP作为key,出现次数作为value的hash_map,并记录当前出现次数最多的1个IP地址。
有了1024个小文件中的出现次数最多的IP,我们就可以轻松得到总体上出现次数最多的IP。
5、有10个文件,每个文件1G,每个文件的每一行都存放的是用户的query,每个文件的query都可能重复。如何按照query的频度排序?
回答:
1)读取10个文件,按照hash(query)%10的结果将query写到对应的文件中。这样我们就有了10个大小约为1G的文件。任意一个query只会出现在某个文件中。
2)对于1)中获得的10个文件,分别进行如下操作
-利用hash_map(query,query_count)来统计每个query出现的次数。
-利用堆排序算法对query按照出现次数进行排序。
-将排序好的query输出的文件中。
这样我们就获得了10个文件,每个文件中都是按频率排序好的query。
3)对2)中获得的10个文件进行归并排序,并将最终结果输出到文件中。
6、蚂蚁爬杆问题
有一根27厘米长的细木杆,在第3厘米,7厘米,11厘米,17厘米,23厘米这五个位置上各有一只蚂蚁,木杆很细,不能同时通过两只蚂蚁,开始时,蚂蚁的头朝向左还是右是任意的,他们只会朝前走或掉头,但不会后退,当两只蚂蚁相遇后,蚂蚁会同时掉头朝反方向走,假设蚂蚁们每秒钟可以走1厘米的距离。求所有蚂蚁都离开木杆的最小时间和最大时间。
答案:
两只蚂蚁相遇后,各自掉头朝相反方向走。如果我们不考虑每个蚂蚁的具体身份,这和两只蚂蚁相遇后,打个招呼继续向前走没有什么区别。
所有蚂蚁都离开木杆的最小时间为
max(min(3,27-3),min(7,27-7), min(11,27-11), min(17,27-17),min(23,27-23))=11
所有蚂蚁都离开木杆的最大时间为
max(max(3,27-3),max(7,27-7), max(11,27-11), max(17,27-17),max(23,27-23))=24
7、当在浏览器中输入一个url后回车,后台发生了什么?比如输入url后,你看到了百度的首页,那么这一切是如何发生的呢?
回答:
简单来说有以下步骤:
1、查找域名对应的IP地址。这一步会依次查找浏览器缓存,系统缓存,路由器缓存,ISPDNS缓存,根域名服务器。
2、向IP对应的服务器发送请求。
3、服务器响应请求,发回网页内容。
4、浏览器解析网页内容。
当然,由于网页可能有重定向,或者嵌入了图片,AJAX,其它子网页等等,这4个步骤可能反复进行多次才能将最终页面展示给用户。
8、判断两棵树是否相等,请实现两棵树是否相等的比较,相等返回1,否则返回其他值,并说明算法复杂度。
数据结构为:
~~~
typedef struct TreeNode
{
char c;
TreeNode *leftchild;
TreeNode *rightchild;
}TreeNode;
~~~
函数接口为:int CompTree(TreeNode* tree1,TreeNode* tree2);
注:A、B两棵树相等当且仅当RootA->c==RootB-->c,而且A和B的左右子树相等或者左右互换相等。
递归方法:
~~~
bool CompTree(TreeNode *tree1, TreeNode *tree2)
{
if(tree1 == NULL && tree2 == NULL)
return true;
if(tree1 == NULL || tree2 == NULL)
return false;
if(tree1->c != tree2->c)
return false;
if( (CompTree(tree1->leftchild, tree2->leftchild) && CompTree(tree1->rightchild, tree2->rightchild)) || CompTree(tree1->leftchild, tree2->rightchild) && CompTree(tree1->rightchild, tree2->leftchild))
return true;
}
~~~
时间复杂度:
在树的第0层,有1个节点,我们会进行1次函数调用;
在树的第1层,有2个节点,我们可能会进行4次函数调用;
在树的第2层,有4个节点,我们可能会进行16次函数调用;
....
在树的第x层,有2^x个节点,我们可能会进行(2^x)^2次函数调用;
所以假设总节点数为n,则算法的复杂度为O(n^2)。
**腾讯面试题:求一个论坛的在线人数,假设有一个论坛,其注册ID有两亿个,每个ID从登陆到退出会向一个日志文件中记下登陆时间和退出时间,要求写一个算法统计一天中论坛的用户在线分布,取样粒度为秒。**
回答:
一天总共有3600*24=86400秒。
定义一个长度为86400的整数数组intdelta[86400],每个整数对应这一秒的人数变化值,可能为正也可能为负。开始时将数组元素都初始化为0。
然后依次读入每个用户的登录时间和退出时间,将与登录时间对应的整数值加1,将与退出时间对应的整数值减1。
这样处理一遍后数组中存储了每秒中的人数变化情况。
定义另外一个长度为86400的整数数组intonline_num[86400],每个整数对应这一秒的论坛在线人数。
假设一天开始时论坛在线人数为0,则第1秒的人数online_num[0]=delta[0]。第n+1秒的人数online_num[n]=online_num[n-1]+delta[n]。
这样我们就获得了一天中任意时间的在线人数。
9、三个警察和三个囚徒的过河问题
三个警察和三个囚徒共同旅行。一条河挡住了去路,河边有一条船,但是每次只能载2人。存在如下的危险:无论在河的哪边,当囚徒人数多于警察的人数时,将有警察被囚徒杀死。问题:请问如何确定渡河方案,才能保证6人安全无损的过河。
答案:第一次:两囚徒同过,回一囚徒
第二次:两囚徒同过,回一囚徒
第三次:两警察同过,回一囚徒一警察(此时对岸还剩下一囚徒一警察,是安全状态)
第四次:两警察同过,回一囚徒(此时对岸有3个警察,是安全状态)
第五次:两囚徒同过,回一囚徒
第六次:两囚徒同过;over
10、从300万字符串中找到最热门的10条
搜索的输入信息是一个字符串,统计300万输入信息中的最热门的前10条,我们每次输入的一个字符串为不超过255byte,内存使用只有1G。请描述思想,写出算法(c语言),空间和时间复杂度。
答案:
300万个字符串最多(假设没有重复,都是最大长度)占用内存3M*1K/4=0.75G。所以可以将所有字符串都存放在内存中进行处理。
可以使用key为字符串(事实上是字符串的hash值),值为字符串出现次数的hash来统计每个每个字符串出现的次数。并用一个长度为10的数组/链表来存储目前出现次数最多的10个字符串。
这样空间和时间的复杂度都是O(n)。
11、如何找出字典中的兄弟单词。给定一个单词a,如果通过交换单词中字母的顺序可以得到另外的单词b,那么定义b是a的兄弟单词。现在给定一个字典,用户输入一个单词,如何根据字典找出这个单词有多少个兄弟单词?
答案:
使用hash_map和链表。
首先定义一个key,使得兄弟单词有相同的key,不是兄弟的单词有不同的key。例如,将单词按字母从小到大重新排序后作为其key,比如bad的key为abd,good的key为dgoo。
使用链表将所有兄弟单词串在一起,hash_map的key为单词的key,value为链表的起始地址。
开始时,先遍历字典,将每个单词都按照key加入到对应的链表当中。当需要找兄弟单词时,只需求取这个单词的key,然后到hash_map中找到对应的链表即可。
这样创建hash_map时时间复杂度为O(n),查找兄弟单词时时间复杂度是O(1)。
12、找出数组中出现次数超过一半的数,现在有一个数组,已知一个数出现的次数超过了一半,请用O(n)的复杂度的算法找出这个数。
答案1:
创建一个hash_map,key为数组中的数,value为此数出现的次数。遍历一遍数组,用hash_map统计每个数出现的次数,并用两个值存储目前出现次数最多的数和对应出现的次数。
这样可以做到O(n)的时间复杂度和O(n)的空间复杂度,满足题目的要求。
但是没有利用“一个数出现的次数超过了一半”这个特点。也许算法还有提高的空间。
答案2:
使用两个变量A和B,其中A存储某个数组中的数,B用来计数。开始时将B初始化为0。
遍历数组,如果B=0,则令A等于当前数,令B等于1;如果当前数与A相同,则B=B+1;如果当前数与A不同,则令B=B-1。遍历结束时,A中的数就是要找的数。
这个算法的时间复杂度是O(n),空间复杂度为O(1)。
13、找出被修改过的数字
n个空间(其中n<1M),存放a到a+n-1的数,位置随机且数字不重复,a为正且未知。现在第一个空间的数被误设置为-1。已经知道被修改的数不是最小的。请找出被修改的数字是多少。
例如:n=6,a=2,原始的串为5,3,7,6,2,4。现在被别人修改为-1,3,7,6,2,4。现在希望找到5。
回答:
由于修改的数不是最小的,所以遍历第二个空间到最后一个空间可以得到a的值。
a到a+n-1这n个数的和是total=na+(n-1)n/2。
将第二个至最后一个空间的数累加获得sub_total。
那么被修改的数就是total-sub_total。
14、设计DNS服务器中cache的数据结构。
要求设计一个DNS的Cache结构,要求能够满足每秒5000以上的查询,满足IP数据的快速插入,查询的速度要快。(题目还给出了一系列的数据,比如:站点数总共为5000万,IP地址有1000万,等等)
回答:
DNS服务器实现域名到IP地址的转换。
每个域名的平均长度为25个字节(估计值),每个IP为4个字节,所以Cache的每个条目需要大概30个字节。
总共50M个条目,所以需要1.5G个字节的空间。可以放置在内存中。(考虑到每秒5000次操作的限制,也只能放在内存中。)
可以考虑的数据结构包括hash_map,字典树,红黑树等等。
15、找出给定字符串对应的序号。
序列Seq=[a,b,…z,aa,ab…az,ba,bb,…bz,…,za,zb,…zz,aaa,…]类似与excel的排列,任意给出一个字符串s=[a-z]+(由a-z字符组成的任意长度字符串),请问s是序列Seq的第几个。
回答:
注意到每满26个就会向前进一位,类似一个26进制的问题。
比如ab,则位置为26*1+2;
比如za,则位置为26*26+1;
比如abc,则位置为26*26*1+26*2+3;
16、找出第k大的数字所在的位置。写一段程序,找出数组中第k大小的数,输出数所在的位置。例如{2,4,3,4,7}中,第一大的数是7,位置在4。第二大、第三大的数都是4,位置在1、3随便输出哪一个均可。
答案:
先找到第k大的数字,然后再遍历一遍数组找到它的位置。所以题目的难点在于如何最高效的找到第k大的数。
我们可以通过快速排序,堆排序等高效的排序算法对数组进行排序,然后找到第k大的数字。这样总体复杂度为O(NlogN)。
我们还可以通过二分的思想,找到第k大的数字,而不必对整个数组排序。从数组中随机选一个数t,通过让这个数和其它数比较,我们可以将整个数组分成了两部分并且满足,{x,xx,...,t}<{y,yy,...}。
在将数组分成两个数组的过程中,我们还可以记录每个子数组的大小。这样我们就可以确定第k大的数字在哪个子数组中。
然后我们继续对包含第k大数字的子数组进行同样的划分,直到找到第k大的数字为止。
平均来说,由于每次划分都会使子数组缩小到原来1/2,所以整个过程的复杂度为O(N)。
17、给40亿个不重复的unsigned int的整数,没排过序的,然后再给几个数,如何快速判断这几个数是否在那40亿个数当中?
答案:
unsigned int的取值范围是0到2^32-1。我们可以申请连续的2^32/8=512M的内存,用每一个bit对应一个unsigned int数字。首先将512M内存都初始化为0,然后每处理一个数字就将其对应的bit设置为1。当需要查询时,直接找到对应bit,看其值是0还是1即可。
18、在一个文件中有10G个整数,乱序排列,要求找出中位数。内存限制为2G。
回答:
不妨假设10G个整数是64bit的。
2G内存可以存放256M个64bit整数。
我们可以将64bit的整数空间平均分成256M个取值范围,用2G的内存对每个取值范围内出现整数个数进行统计。这样遍历一边10G整数后,我们便知道中数在那个范围内出现,以及这个范围内总共出现了多少个整数。
如果中数所在范围出现的整数比较少,我们就可以对这个范围内的整数进行排序,找到中数。如果这个范围内出现的整数比较多,我们还可以采用同样的方法将此范围再次分成多个更小的范围(256M=2^28,所以最多需要3次就可以将此范围缩小到1,也就找到了中数)。
19、时分秒针在一天之类重合多少次?(24小时)
2次
而时针和分针重合了22次。
20、将多个集合合并成没有交集的集合。
给定一个字符串的集合,格式如:{aaabbbccc},{bbbddd},{eeefff},{ggg},{dddhhh}要求将其中交集不为空的集合合并,要求合并完成后的集合之间无交集,例如上例应输出{aaabbbcccdddhhh},{eeefff},{ggg}。
(1)请描述你解决这个问题的思路;
(2)请给出主要的处理流程,算法,以及算法的复杂度
(3)请描述可能的改进。
回答:
集合使用hash_set来表示,这样合并时间复杂度比较低。
1、给每个集合编号为0,1,2,3...
2、创建一个hash_map,key为字符串,value为一个链表,链表节点为字符串所在集合的编号。遍历所有的集合,将字符串和对应的集合编号插入到hash_map中去。
3、创建一个长度等于集合个数的int数组,表示集合间的合并关系。例如,下标为5的元素值为3,表示将下标为5的集合合并到下标为3的集合中去。开始时将所有值都初始化为-1,表示集合间没有互相合并。在集合合并的过程中,我们将所有的字符串都合并到编号较小的集合中去。
遍历第二步中生成的hash_map,对于每个value中的链表,首先找到最小的集合编号(有些集合已经被合并过,需要顺着合并关系数组找到合并后的集合编号),然后将链表中所有编号的集合都合并到编号最小的集合中(通过更改合并关系数组)。
4、现在合并关系数组中值为-1的集合即为最终的集合,它的元素来源于所有直接或间接指向它的集合。
算法的复杂度为O(n),其中n为所有集合中的元素个数。
题目中的例子:
0:{aaabbbccc}
1:{bbbddd}
2:{eeefff}
3:{ggg}
4:{dddhhh}
生成的hash_map,和处理完每个值后的合并关系数组分别为
aaa:0。[-1,-1,-1,-1,-1]
bbb:0,1。[-1,0,-1,-1,-1]
ccc:0。[-1,0,-1,-1,-1]
ddd:1,4。[-1,0,-1,-1,0]
eee:2。[-1,0,-1,-1,0]
fff:2。[-1,0,-1,-1,0]
ggg:3。[-1,0,-1,-1,0]
hhh:4。[-1,0,-1,-1,0]
所以合并完后有三个集合,第0,1,4个集合合并到了一起,
21、平面内有11个点,由它们连成48条不同的直,由这些点可连成多少个三角形?
解析:
首先你要分析,平面中有11个点,如果这些点中任意三点都没有共线的,那么一共应该有C(11,2)=55, 可是,题目中说可以连接成48条直线,那么这11个点中必定有多点共线的情况。 55-48=7,从7来分析:
假设有一组三个点共线,那么可以组成的直线在55的基础上应该减去C(3,2)-1=2 2*3=6≠7,因此,可以断定不仅有三点共线的,也可能有四个点共线的可能。
假设有一组四个点共线,那么可以组成的直线在55的基础上应该减去C(4,2)-1=5
(备注,五个点共线的可能不存在,因为,C(5,2)-1=9>7,故不可能有五条直线共线。)
因此,三点共线少2条,4点共线少5条,只有一个4点共线,一个3点共线才能满足条件,其余情况不能满足少了7条直线。
那么,这11个点能组成的三角形的个数为,C(11,3)-C(3,3)-C(4,3)=165-1-4=160 (备注,三个点共线不能组成三角形)
转载请标明出处,原文地址:[http://blog.csdn.net/hackbuteer1/article/details/7348968](http://blog.csdn.net/hackbuteer1/article/details/7348968)
';
微策略2011校园招聘笔试题(找出数组中两个只出现一次的数字)
最后更新于:2022-04-01 21:43:36
1、8*8的棋盘上面放着64个不同价值的礼物,每个小的棋盘上面放置一个礼物(礼物的价值大于0),一个人初始位置在棋盘的左上角,每次他只能向下或向右移动一步,并拿走对应棋盘上的礼物,结束位置在棋盘的右下角,请设计一个算法使其能够获得最大价值的礼物。
~~~
//经典的动态规划
//dp[i][j] 表示到棋盘位置(i,j)上可以得到的最大礼物值
//dp[i][j] = max( dp[i][j-1] , dp[i-1][j] ) + value[i][j] (0= 0; r--)
{
for(int c = col-1 ; c >= 0; c--)
{
for(int l = 0 ; l <= limit; l++)
{
if(l >= matrix[r][c])
{
int max = 0;
if(r != row-1 && dp[r+1][c][l-matrix[r][c]]>max)
max = dp[r+1][c][l-matrix[r][c]];
if(c != col-1 && dp[r][c+1][l-matrix[r][c]]>max)
max = dp[r][c+1][l-matrix[r][c]];
if(max == 0 && !(r == row-1 && c == col-1))
dp[r][c][l] = 0;
else
dp[r][c][l] = max + matrix[r][c];
}
}
}
}
return dp[0][0][limit];
}
~~~
或者
~~~
int hash[row][col][limit];
int getMaxLessLimit()
{
memset(hash,0,sizeof(hash));
hash[0][0][matrix[0][0]] = 1;
for(int i = 0 ; i < row ; i++)
{
for(int j = 0 ; j < col ; j++)
{
for(int k = 0 ; k <= limit ; k++)
{
if(k >= matrix[i][j])
{
if(i >= 1 && hash[i-1][j][k-matrix[i][j]])
hash[i][j][k] = 1;
if(j >= 1 && hash[i][j-1][k-matrix[i][j]])
hash[i][j][k] = 1;
}
}
}
}
int ans = 0;
for(int k = limit; k >= 0; k--)
{
if(hash[row-1][col-1][k] && k>ans)
ans = k;
}
return ans;
}
~~~
2、有两个字符串s1和s2,其长度分别为l1和l2,将字符串s1插入到字符串s2中,可以插入到字符串s2的第一个字符的前面或者最后一个字符的后面,对于任意两个字符串s1和s2,判断s1插入到s2中后是否能够构成回文串。。
3、已知有m个顶点,相邻的两个顶点之间有一条边相连接,首尾顶点也有一条边连接,这样就构成了一个圆环。
现在有一个二维数组M[][],M[i][j]=1时,表明第i和j个节点之间有条边存在,M[i][j]=0时,表明第i和j个节点之间没有边存在,其中 M[i][i]=0,M[i][j]=M[j][i],输入为一个二维数组M[][]和顶点的个数n,试着判断该图中是否存在两个圆环,且两个圆环彼此之间没有公共点。试着实现下面这个函数:
bool IsTwoCircle(int **M,int n)
{
......
}
4、给定如下的n*n的数字矩阵,每行从左到右是严格递增, 每列的数据也是严格递增
1 3 7 15 16
2 5 8 18 19
4 6 9 22 23
10 13 17 24 28
20 21 25 26 33
现在要求设计一个算法, 给定一个数k 判断出k是否在这个矩阵中。 描述算法并且给出时间复杂度(不考虑载入矩阵的消耗)
**方法一**
从右上角开始(从左下角开始也是一样的),然后每步往左或往下走。
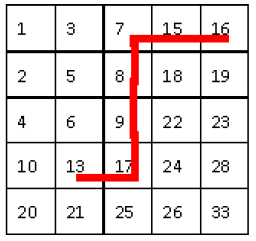
这样每步都能扔掉一行或者一列,最坏的情况是被查找的元素位于另一个对角,需要2N步,因此这个算法是o(n)的,而且代码简洁直接。
~~~
bool stepWise(int mat[][N] , int key , int &row , int &col)
{
if(key < mat[0][0] || key > mat[N-1][N-1])
return false;
row = 0;
col = N-1;
while(row < N && col >= 0)
{
if(mat[row][col] == key ) //查找成功
return true;
else if(mat[row][col] < key )
++row;
else
--col;
}
return false;
}
~~~
**方法二(分治法)**
首先,我们注意到矩阵中的元素总是把整个矩阵分成四个更小的矩阵。例如,中间的元素9把整个矩阵分成如下图所示的四块。由于四个小矩阵也是行列有序的,问题自然而然地划分为四个子问题。每次我们都能排除掉四个中的一个子问题。假如我们的查找目标是21,21>9,于是我们可以立即排除掉9左上方的那块,因为那个象限的元素都小于或等于9。
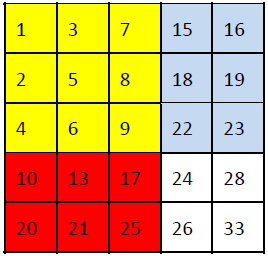
以下是这种二维二分的代码,矩阵的维度使用l、u、r、d刻画的,其中l和u表示左上角的列和行,r和d表示右下角的列和行。
~~~
bool quadPart(int mat[][N] , int key , int l , int u , int r , int d , int &row , int &col)
{
if(l > r || u > d)
return false;
if(key < mat[u][l] || key > mat[d][r])
return false;
int mid_col = (l+r)>>1;
int mid_row = (u+d)>>1;
if(mat[mid_row][mid_col] == key) //查找成功
{
row = mid_row;
col = mid_col;
return true;
}
else if(l == r && u == d)
return false;
if(mat[mid_row][mid_col] > key)
{ // 分别在右上角、左上角、左下角中查找
return quadPart(mat , key , mid_col+1 , u , r , mid_row , row , col) ||
quadPart(mat , key , l , mid_row+1 , mid_col , d , row , col) ||
quadPart(mat , key , l , u , mid_col , mid_row , row , col) ;
}
else
{ // 分别在右上角、左下角、右下角中查找
return quadPart(mat , key , mid_col+1 , u , r , mid_row , row , col) ||
quadPart(mat , key , l , mid_row+1 , mid_col , d , row , col) ||
quadPart(mat , key , mid_col+1 , mid_row+1 , r , d , row , col) ;
}
}
bool quadPart(int mat[][N] , int key , int &row , int &col)
{
return bool quadPart(mat , key , 0 , 0 , N-1 , N-1 , row , col);
}
~~~
5、设 一个64位整型n,各个bit位是1的个数为a个. 比如7, 2进制就是 111, 所以a为3。
现在给出m个数, 求各个a的值。要求代码实现。
思路:如果可以直接用stl的bitset。算法可用移位和&1来做。还有一个更好的算法是直接位与(x-1)直到它为0。
~~~
while(n)
{
n = n & (n-1);
++count;
}
~~~
6、有N+2个数,N个数出现了偶数次,2个数出现了奇数次(这两个数不相等),问用O(1)的空间复杂度,找出这两个数,不需要知道具体位置,只需要知道这两个值。
求解:如果只有一个数出现过奇数次,这个就比较好求解了,直接将数组中的元素进行异或,异或的结果就是只出现过奇数次的那个数。
但是题目中有2个数出现了奇数次?,求解方法如下:
假设这两个数为a,b,将数组中所有元素异或结果x=a^b,判断x中位为1的位数(注:因为a!=b,所以x!=0,我们只需知道某一个位为1的位数k,例如0010 1100,我们可取k=2或者3,或者5),然后将x与数组中第k位为1的数进行异或,异或结果就是a,b中一个,然后用x异或,就可以求出另外一个。
为什么呢?因为x中第k位为1表示a或b中有一个数的第k位也为1,假设为a,我们将x与数组中第k位为1的数进行异或时,也就是将x与a外加上其他第k位为1的出现过偶数次的数进行异或,化简即为x与a异或,结果是b。
代码如下:
~~~
void getNum(int a[],int length)
{
int s = 0;//保存异或结果
for(int i=0;i>1;
k++;
}
for(int i=0;i>k)&1) //将s与数组中第k位为1的数进行异或,求得其中一个数
{
//cout<
using namespace std;
int lowbit(int x)
{
return x & ~(x - 1);
}
void Find2(int seq[], int n, int& a, int& b)
{
int i, xors = 0;
for(i = 0; i < n; i++)
xors ^= seq[i];
int diff = lowbit(xors);
a = 0,b = 0;
for(i = 0; i < n; i++)
{
if( diff&seq[i] ) //与运算,表示数组中与异或结果位为1的位数相同
a ^= seq[i];
else
b ^= seq[i];
}
}
//三个数两两的异或后lowbit有两个相同,一个不同,可以分为两组
void Find3(int seq[], int n, int& a, int& b, int& c)
{
int i, xors = 0;
for(i = 0; i < n; i++)
xors ^= seq[i];
int flips = 0;
for(i = 0; i < n; i++) //因为出现偶数次的seq[i]和xors的异或,异或结果不改变
flips ^= lowbit(xors ^ seq[i]);
//表示的是:flips=lowbit(a^b)^lowbit(a^c)^lowbit(b^c)
//flips = lowbit(flips); 这个是多余的
//三个数两两异或后lowbit有两个相同,一个不同,可以分为两组
//所以flips的值为:lowbit(a^b) 或 lowbit(a^c) 或 lowbit(b^c)
//得到三个数中的一个
a = 0;
for(i = 0; i < n; i++)
{
if(lowbit(seq[i] ^ xors) == flips) //找出三个数两两异或后的lowbit与另外两个lowbit不同的那个数
a ^= seq[i];
}
//找出后,与数组中最后一个值交换,利用Find2,找出剩余的两个
for(i = 0; i < n; i++)
{
if(a == seq[i])
{
int temp = seq[i];
seq[i] = seq[n - 1];
seq[n - 1] = temp;
}
}
//利用Find2,找出剩余的两个
Find2(seq, n - 1, b, c);
}
//假设数组中只有2、3、5三个数,2与3异或后为001,2与5异或后为111,3与5异或后为110,
//则flips的值为lowbit(110)= 2 ,当异或结果xors与2异或的时候,得到的就是3与5异或的结果110,其lowbit值等于flips,所以最先找出来的是三个数中的第一个数:2
int main(void)
{
int seq[]={ 2,3,3,2,4,6,4,10,9,8,8 };
int a,b,c;
Find3(seq, 11, a, b, c);
cout<
';
百度2011.10.16校园招聘会笔试题
最后更新于:2022-04-01 21:43:33
**一、算法设计**
1、设rand(s,t)返回[s,t]之间的随机小数,利用该函数在一个半径为R的圆内找随机n个点,并给出时间复杂度分析。
思路:这个使用数学中的极坐标来解决,先调用[s1,t1]随机产生一个数r,归一化后乘以半径,得到R*(r-s1)/(t1-s1),然后在调用[s2,t2]随机产生一个数a,归一化后得到角度:360*(a-s2)/(t2-s2)
2、为分析用户行为,系统常需存储用户的一些query,但因query非常多,故系统不能全存,设系统每天只存m个query,现设计一个算法,对用户请求的query进行随机选择m个,请给一个方案,使得每个query被抽中的概率相等,并分析之,注意:不到最后一刻,并不知用户的总请求量。
思路:如果用户查询的数量小于m,那么直接就存起来。如果用户查询的数量大于m,假设为m+i,那么在1-----m+i之间随机产生一个数,如果选择的是前面m条查询进行存取,那么概率为m/(m+i),如果选择的是后面i条记录中的查询,那么用这个记录来替换前面m条查询记录的概率为m/(m+i)*(1-1/m)=(m-1)/(m+i),当查询记录量很大的时候,m/(m+i)== (m-1)/(m+i),所以每个query被抽中的概率是相等的。
3、C++ STL中vector的相关问题:
(1)、调用push_back时,其内部的内存分配是如何进行的?
(2)、调用clear时,内部是如何具体实现的?若想将其内存释放,该如何操作?
vector的工作原理是系统预先分配一块CAPACITY大小的空间,当插入的数据超过这个空间的时候,这块空间会让某种方式扩展,但是你删除数据的时候,它却不会缩小。
vector为了防止大量分配连续内存的开销,保持一块默认的尺寸的内存,clear只是清数据了,未清内存,因为vector的capacity容量未变化,系统维护一个的默认值。
有什么方法可以释放掉vector中占用的全部内存呢?
标准的解决方法如下
~~~
template < class T >
void ClearVector( vector< T >& vt )
{
vector< T > vtTemp;
veTemp.swap( vt );
}
~~~
事实上,vector根本就不管内存,它只是负责向内存管理框架acquire/release内存,内存管理框架如果发现内存不够了,就malloc,但是当vector释放资源的时候(比如destruct), stl根本就不调用free以减少内存,因为内存分配在stl的底层:stl假定如果你需要更多的资源就代表你以后也可能需要这么多资源(你的list, hashmap也是用这些内存),所以就没必要不停地malloc/free。如果是这个逻辑的话这可能是个trade-off
一般的STL内存管理器allocator都是用内存池来管理内存的,所以某个容器申请内存或释放内存都只是影响到内存池的剩余内存量,而不是真的把内存归还给系统。这样做一是为了避免内存碎片,二是提高了内存申请和释放的效率——不用每次都在系统内存里寻找一番。
**二、系统设计**
正常用户端每分钟最多发一个请求至服务端,服务端需做一个异常客户端行为的过滤系统,设服务器在某一刻收到客户端A的一个请求,则1分钟内的客户端任何其它请求都需要被过滤,现知每一客户端都有一个IPv6地址可作为其ID,客户端个数太多,以至于无法全部放到单台服务器的内存hash表中,现需简单设计一个系统,使用支持高效的过滤,可使用多台机器,但要求使用的机器越少越好,请将关键的设计和思想用图表和代码表现出来。
**三、求一个全排列函数:**
如p([1,2,3])输出:
[123]、[132]、[213]、[231]、[321]、[312]
求一个组合函数。
方法1:依次从字符串中取出一个字符作为最终排列的第一个字符,对剩余字符组成的字符串生成全排列,最终结果为取出的字符和剩余子串全排列的组合。
~~~
#include
#include
using namespace std;
void permute1(string prefix, string str)
{
if(str.length() == 0)
cout << prefix << endl;
else
{
for(int i = 0; i < str.length(); i++)
permute1(prefix+str[i], str.substr(0,i)+str.substr(i+1,str.length()));
}
}
void permute1(string s)
{
permute1("",s);
}
int main(void)
{
//method1, unable to remove duplicate permutations.
permute1("abc");
return 0;
}
~~~
优点:该方法易于理解,但无法移除重复的排列,如:s="ABA",会生成两个“AAB”。
方法2:利用交换的思想,具体见实例,但该方法不如方法1容易理解。
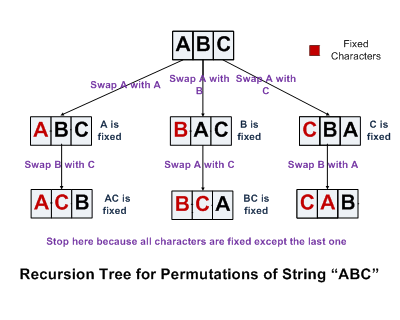
我们以三个字符abc为例来分析一下求字符串排列的过程。首先我们固定第一个字符a,求后面两个字符bc的排列。当两个字符bc的排列求好之后,我们把第一个字符a和后面的b交换,得到bac,接着我们固定第一个字符b,求后面两个字符ac的排列。现在是把c放到第一位置的时候了。记住前面我们已经把原先的第一个字符a和后面的b做了交换,为了保证这次c仍然是和原先处在第一位置的a交换,我们在拿c和第一个字符交换之前,先要把b和a交换回来。在交换b和a之后,再拿c和处在第一位置的a进行交换,得到cba。我们再次固定第一个字符c,求后面两个字符b、a的排列。
既然我们已经知道怎么求三个字符的排列,那么固定第一个字符之后求后面两个字符的排列,就是典型的递归思路了。
基于前面的分析,我们可以得到如下的参考代码:
~~~
void Permutation(char* pStr, char* pBegin)
{
assert(pStr && pBegin);
//if(!pStr || !pBegin)
//return ;
if(*pBegin == '\0')
printf("%s\n",pStr);
else
{
char temp;
for(char* pCh = pBegin; *pCh != '\0'; pCh++)
{
if(pCh != pBegin && *pCh == *pBegin) //为避免生成重复排列,当不同位置的字符相同时不再交换
continue;
temp = *pCh;
*pCh = *pBegin;
*pBegin = temp;
Permutation(pStr, pBegin+1);
temp = *pCh;
*pCh = *pBegin;
*pBegin = temp;
}
}
}
int main(void)
{
char str[] = "aba";
Permutation(str,str);
return 0;
}
~~~
如p([1,2,3])输出:
[1]、[2]、[3]、[1,2]、[2,3]、[1,3]、[1,2,3]
这两问可以用伪代码。
';
网易游戏2011.10.15校园招聘会笔试题
最后更新于:2022-04-01 21:43:31
1、对于一个内存地址是32位、内存页是8KB的系统。0X0005F123这个地址的页号与页内偏移分别是多少。
页面大小是8KB,那么页内偏移量是从0x0000(0)~ 0x1FFF(2的13次方 - 1)。0x5F123/8K=2E,余数是1123;则页号是47页,页内偏移量应该是0X00001123。
2、如果X大于0并小于65536,用移位法计算X乘以255的值为: **(X<<8)-X**
**X<<8-X是不对的,因为移位运算符的优先级没有减号的优先级高,首先计算8-X为0,X左移0位还是8。**
3、一个包含n个节点的四叉树,每个节点都有四个指向孩子节点的指针,这4n个指针中有 **3n+1** 个空指针。
4、以下两个语句的区别是:第一个动态申请的空间里面的值是随机值,第二个进行了初始化,里面的值为0
~~~
int *p1 = new int[10];
int *p2 = new int[10]();
~~~
5、计算机在内存中存储数据时使用了大、小端模式,请分别写出A=0X123456在不同情况下的首字节是,大端模式:0X12 小端模式:0X56 X86结构的计算机使用 **小端** 模式。
一般来说,大部分用户的操作系统(如windows, FreeBsd,Linux)是小端模式的。少部分,如MAC OS,是大端模式 的。
6、在游戏设计中,经常会根据不同的游戏状态调用不同的函数,我们可以通过函数指针来实现这一功能,请声明一个参数为int *,返回值为int的函数指针:
int (*fun)(int *)
7、下面程序运行后的结果为:to test something
~~~
char str[] = "glad to test something";
char *p = str;
p++;
int *p1 = static_cast(p);
p1++;
p = static_cast(p1);
printf("result is %s\n",p);
~~~
8、在一冒险游戏里,你见到一个宝箱,身上有N把钥匙,其中一把可以打开宝箱,假如没有任何提示,随机尝试,问:
(1)恰好第K次(1=
using namespace std;
const int lmax=10000;
int c1[lmax+1],c2[lmax+1];
int main(void)
{
int m,n,i,j,k,a[110];
//计算的方法还是模拟手动运算,一个括号一个括号的计算,从前往后
while (cin>>m && m)
{
n=0;
for(i = 0; i < m; i++)
{
scanf("%d",&a[i]);
n += a[i];
}
n += 5; //有可能无法表示的那个数比所有纸币面额的总和还要大
for(i = 0; i <= n; i++)
{
c1[i] = 0;
c2[i] = 0;
}
for(i = 0; i < 2*a[0]; i += a[0]) //母函数的表达式中第一个括号内的各项系数
c1[i] = 1;
//第一层循环是一共有 n 个小括号,而刚才已经算过一个了,所以是从2 到 n
// i 就是代表的母函数中第几个大括号中的表达式
for(i = 2; i <= m; i++)
{
for(j = 0; j <= n; j++) //j 就是指的已经计算出的各项的系数
{
for (k = 0; k < 2*a[i-1]; k += a[i-1]) //k 就是指将要计算的那个括号中的项
{
c2[j+k] += c1[j]; //合并同类项,他们的系数要加在一起,所以是加法
}
}
for(j = 0; j <= n; j++) // 刷新一下数据,继续下一次计算,就是下一个括号里面的每一项
{
c1[j] = c2[j];
c2[j] = 0;
}
}
for(i = 1; i <= n; i++)
{
if(c1[i] == 0)
{
cout<
';
输入
输出
5
1 2 3 9 100
7
5
1 2 4 9 100
8
5
1 2 4 7 100
15
腾讯2011.10.15校园招聘会笔试题
最后更新于:2022-04-01 21:43:29
转载请标明出处,原文地址:[http://blog.csdn.net/hackbuteer1/article/details/6878287](http://blog.csdn.net/hackbuteer1/article/details/6878287)
1、下面的排序算法中,初始数据集的排列顺序对算法的性能无影响的是(**B**)
A、插入排序 **B、堆排序** C、冒泡排序 D、快速排序
2、以下关于Cache的叙述中,正确的是(**B**)
A、CPU中的Cache容量应大于CPU之外的Cache容量
**B、Cache的设计思想是在合理成本下提高命中率**
C、Cache的设计目标是容量尽可能与主存容量相等
D、在容量确定的情况下,替换算法的时间复杂度是影响Cache命中率的关键因素
3、数据存储在磁盘上的排列方式会影响I/O服务的性能,一个圆环的磁道上有10个物理块,10个数据记录R1------R10存放在这个磁道上,记录的安排顺序如下表所示:
假设磁盘的旋转速度为20ms/周,磁盘当前处在R1的开头处,若系统顺序扫描后将数据放入单缓冲区内,处理数据的时间为4ms(然后再读取下个记录),则处理这10个记录的最长时间为(**C**)
A、180ms B、200ms C、204ms D、220ms
2+4+((2+4)+2*8)*9=204
4、随着IP网络的发展,为了节省可分配的注册IP地址,有一些地址被拿出来用于私有IP地址,以下不属于私有IP地址范围的是(**C**)
A、10.6.207.84 B、172.23.30.28 **C、172.32.50.80** D、192.168.1.100
私有IP地址共有三个范围段:
A: 10.0.0.0~10.255.255.255 /8 B: 172.16.0.0~172.31.255.255 /12 C: 192.168.0.0~192.168.255.255 /16
5、下列关于一个类的静态成员的描述中,不正确的是(**D**)
A、该类的对象共享其静态成员变量的值 B、静态成员变量可被该类的所有方法访问
C、该类的静态方法只能访问该类的静态成员变量 **D、该类的静态数据成员变量的值不可修改**
6、已知一个线性表(38,25,74,63,52,48),假定采用散列函数h(key) = key%7计算散列地址,并散列存储在散列表A【0....6】中,若采用线性探测方法解决冲突,则在该散列表上进行等概率成功查找的平均查找长度为(**C**)
A、1.5 B、1.7 **C、2.0** D、2.3
依次进行取模运算求出哈希地址:
74应该放在下标为4的位置,由于25已经放在这个地方,所以74往后移动,放在了下标为5的位置上了。
由于是等概率查找,所以结果为:1/6*(1+3+1+1+2+4)= 2.0
7、表达式“X=A+B*(C--D)/E”的后缀表示形式可以为(**C**)
A、XAB+CDE/-*= B、XA+BC-DE/*= **C、XABCD-*E/+=** D、XABCDE+*/=
8、(**B**)设计模式将抽象部分与它的实现部分相分离。
A、Singleton(单例) **B、 Bridge(桥接)**
C、 Composite(组合) D、 Facade(外观)
9、下面程序的输出结果为多少?
~~~
void Func(char str_arg[100])
{
printf("%d\n",sizeof(str_arg));
}
int main(void)
{
char str[]="Hello";
printf("%d\n",sizeof(str));
printf("%d\n",strlen(str));
char *p = str;
printf("%d\n",sizeof(p));
Func(str);
}
~~~
输出结果为:6 5 4 4
对字符串进行sizeof操作的时候,会把字符串的结束符“\0”计算进去的,进行strlen操作求字符串的长度的时候,不计算\0的。
数组作为函数参数传递的时候,已经退化为指针了,Func函数的参数str_arg只是表示一个指针,那个100不起任何作用的。
10、C++将父类的析构函数定义为虚函数,下列正确的是哪个?
A、释放父类指针时能正确释放子类对象
B、释放子类指针时能正确释放父类对象
C、这样做是错误的
D、以上全错
C++的多态肯定是使用父类的指针指向子类的对象,所以肯定是释放子类的对象,如果不使用虚函数的话,父类的指针就只能够释放父类的对象。
11、下列哪一个不属于关系数据库的特点?
A、数据冗余度小
B、数据独立性高
C、数据共享性好
D、多用户访问
12、下面程序的输出结果为多少?
~~~
void Func(char str_arg[2])
{
int m = sizeof(str_arg); //指针的大小为4
int n = strlen(str_arg); //对数组求长度,str_arg后面的那个2没有任何意义,数组已经退化为指针了
printf("%d\n",m);
printf("%d\n",n);
}
int main(void)
{
char str[]="Hello";
Func(str);
}
~~~
输出结果为: 4 5
strlen只是对传递给Func函数的那个字符串求长度,跟str_arg中的那个2是没有任何关系的,即使把2改为200也是不影响输出结果的。。
13、typedef char *String_t; 和 #define String_d char * 这两句在使用上有什么区别?
答:typedef char *String_t 定义了一个新的类型别名,有类型检查。而#define String_d char * 只是做了个简单的替换,无类型检查,前者在编译的时候处理,后者在预编译的时候处理。
同时定义多个变量的时候有区别,主要区别在于这种使用方式String_t a,b; String_d c,d; a,b ,c都是char*类型,而d为char类型
由于typedef还要做类型检查。。#define没有。。所以typedef比#define安全。。
14、到商店里买200的商品返还100优惠券(可以在本商店代替现金)。请问实际上折扣是多少?
15、题目:已知rand7() 可以产生 1~7 的7个数(均匀概率),利用rand7() 产生rand10() 1~10(均匀概率)
记住这道题重点是:均匀概率
~~~
//rand7 产生的数概率是一样的,即1~7出现概率一样,由于我们对结果做了一定的筛选只能通过 1~5,而1~5出现的概率也是一样的,又由于范围为1~5 所以 temp1 出现 1~5的概率 为1/5 ,同理 后面的 出现 temp2 的概率为 1/2
//首先temp1出现在1~5的概率为1/5,而temp2出现 1~2 的概率为1/2,也就是说 5*(temp2-1) 出现5或0的概率为1/2,所以假如你要得到1~5的数的话 那么 5*(temp2-1) 必须0,所以因为你要保证 5*(temp2-1)=0,这个概率只有1/2,再加上 你前面指定1~5 的概率 为1/5 ,所以结果为 1/5*1/2=1/10
int rand10()
{
int temp1;
int temp2;
do
{
temp1 = rand7();
}while(temp1>5);
do
{
temp2 = rand7();
}while(temp2>2);
return temp1+5*(temp2-1);
}
~~~
16、给定能随机生成整数1到5的函数,写出能随机生成整数1到7的函数。
17、对一个正整数作如下操作:如果是偶数则除以2,如果是奇数则加1,如此进行直到1时操作停止,求经过9次操作变为1的数有多少个?
第9次操作:结果1由2产生。1个被操作数
8:结果2只能由4产生。1个被操作数
7:结果4由8、3产生。2个
6:结果8由16、7产生;结果3由6产生。共3个
5:结果16由32、15产生;结果7由14产生;结果6由12、5产生。共5个…
每次操作,偶数(2除外)都由该数减1和该数的2倍得来,奇数只由该数的2倍得来
各次操作的操作对象个数为:1,1,2,3,5,8,13,21,34,…
本题可以通过所给的变换规律,由易到难,确定操作可变为1的数组成斐波拉契数列,再根据所发现的规律求出经过9次操作变为1的数的个数。
18、OFFSETOF(s, m)的宏定义,s是结构类型,m是s的成员,求m在s中的偏移量。
~~~
#define OFFSETOF(s,m) ((int)&(((s*)0)->m))
~~~
用地址零作为起始地址,强制转换成结构体类型,然后取出成员的地址,转换成int类型,就可以得到偏移量了。
算法编程题:
1、给定一个字符串,求出其最长的重复子串。
思路:使用后缀数组,对一个字符串生成相应的后缀数组后,然后再排序,排完序依次检测相邻的两个字符串的开头公共部分。
这样的时间复杂度为:
生成后缀数组 O(N)
排序 O(NlogN*N) 最后面的 N 是因为字符串比较也是 O(N)
依次检测相邻的两个字符串 O(N * N)
总的时间复杂度是 O(N^2*logN),
转载请标明出处,原文地址:[http://blog.csdn.net/hackbuteer1/article/details/6878287](http://blog.csdn.net/hackbuteer1/article/details/6878287)
';
物理块 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
逻辑记录 | R1 | R2 | R3 | R4 | R5 | R6 | R7 | R8 | R9 | R10 |
A | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
记录 | 63 | 48 |
| 38 | 25 | 74 | 52 |
查找次数 | 1 | 3 |
| 1 | 1 | 2 | 4 |
淘宝2011.9.21校园招聘会笔试题
最后更新于:2022-04-01 21:43:26
转载请标明出处,原文地址:[http://blog.csdn.net/hackbuteer1/article/details/6823329](http://blog.csdn.net/hackbuteer1/article/details/6823329)
**一、单选题**
1、我们有很多瓶无色的液体,其中有一瓶是毒药,其它都是蒸馏水,实验的小白鼠喝了以后会在5分钟后死亡,而喝到蒸馏水的小白鼠则一切正常。现在有5只小白鼠,请问一下,我们用这五只小白鼠,5分钟的时间,能够检测多少瓶液体的成分(C)
A、5瓶 B、6瓶 **C、31瓶** D、32瓶
2、若某链表最常用的操作是在最后一个结点之后插入一个结点和删除最后一个结点,则采用()存储方式最节省时间?
A、单链表 B、带头结点的非循环双链表 **C、带头节点的双循环链表** D、循环链表
3、如果需要对磁盘上的1000W条记录构建索引,你认为下面哪种数据结构来存储索引最合适?()
A、Hash Table B、AVL-Tree **C、B-Tree** D、List
4、可用来检测一个web服务器是否正常工作的命令是()
A、ping B、tracert **C、telnet** D、ftp
只有C可以测试Web主机的网页服务器是否工作正常,假设该服务器的网页服务器使用的是默认端口,则可以使用命令telnet hostname 80 来测试其是否工作。
5、下面哪个操作是Windows独有的I/O技术()
A、Select B、Poll **C、IOCP** D、Epoll
6、IPV6地址包含了()位
A、16 B、32 C、64 **D、128**
7、数据库里建索引常用的数据结构是()
A、链表 B、队列 **C、树** D、哈希表
8、在公司局域网上ping www.taobao.com没有涉及到的网络协议是()
A、ARP B、DNS **C、TCP** D、ICMP
DNS是将域名[www.taobao.com](http://www.taobao.com/)映射成主机的IP地址,ARP是将IP地址映射成物理地址,ICMP是报文控制协议,由路由器发送给执行ping命令的主机,而一个ping命令并不会建立一条TCP连接,故没有涉及TCP协议。
**二、填空题**
1、http属于(应用层)协议,ICMP属于(网络层)协议。
2、深度为k的完全二叉树至少有(2^(k-1))个结点,至多有(2^k-1)个结点。
3、字节为6位的二进制有符号整数,其最小值是(-32)。
4、设有28盏灯,拟公用一个电源,则至少需有4插头的接线板数(9)个。
第一个板4个口,此后每增加1个板会消耗1个原来的口,总的只增加3个口,故N个接线板能提供 1+3*N个电源口。
**三、综合题**
1、有一颗结构如下的树,对其做镜像反转后如下,请写出能实现该功能的代码。注意:请勿对该树做任何假设,它不一定是平衡树,也不一定有序。
1 1
/ | \ / | \
2 3 4 4 3 2
/|\ /\ | | / \ / | \
6 5 7 8 9 10 10 9 8 7 5 6
答:以孩子、兄弟的存储结构来存储这棵树,使之成为一颗二叉树,然后对二叉树进行链表的转换。
~~~
typedef struct TreeNode
{
int data;
struct TreeNode *firstchild;
struct TreeNode *nextsibling;
}TreeNode,*Tree;
void MirrorTree(Tree root)
{
if(!root)
return ;
if(root->firstchild)
{
Tree p=root->firstchild;
Tree cur=p->nextsibling;
p->nextsibling=NULL;
while(cur)
{
Tree curnext=cur->nextsibling;
cur->nextsibling=p;
if(p->firstchild)
MirrorTree(p);
p=cur;
cur=curnext;
}
root->firstchild=p;
}
}
int main(void)
{
TreeNode *root=(TreeNode *)malloc(sizeof(TreeNode));
Init();
MirrorTree(root);
OutPut();
}
~~~
2、假设某个网站每天有超过10亿次的页面访问量,出于安全考虑,网站会记录访问客户端访问的ip地址和对应的时间,如果现在已经记录了1000亿条数据,想统计一个指定时间段内的区域ip地址访问量,那么这些数据应该按照何种方式来组织,才能尽快满足上面的统计需求呢,设计完方案后,并指出该方案的优缺点,比如在什么情况下,可能会非常慢?
答:用B+树来组织,非叶子节点存储(某个时间点,页面访问量),叶子节点是访问的IP地址。这个方案的优点是查询某个时间段内的IP访问量很快,但是要统计某个IP的访问次数或是上次访问时间就不得不遍历整个树的叶子节点。答:
或者可以建立二级索引,分别是时间和地点来建立索引。
**四、附加题**
1、写出C语言的地址对齐宏ALIGN(PALGNBYTES),其中P是要对齐的地址,ALIGNBYTES是要对齐的字节数(2的N次方),比如说:ALIGN(13,16)=16
~~~
ALIGN(P,ALIGNBYTES) ( (void*)( ((unsigned long)P+ALIGNBYTES-1)&~(ALIGNBYTES-1) ) )
~~~
2、在高性能服务器的代码中经常会看到类似这样的代码:
~~~
typedef union
{
erts_smp_rwmtx_t rwmtx;
byte cache_line_align_[ERTS_ALC_CACHE_LINE_ALIGN_SIZE(sizeof(erts_smp_rwmtx_t))];
}erts_meta_main_tab_lock_t;
erts_meta_main_tab_lock_t main_tab_lock[16];
~~~
请问其中用来填充的cache_line_align的作用是?
3、在现代web服务系统的设计中,为了减轻源站的压力,通常采用分布式缓存技术,其原理如下图所示,前端的分配器将针对不同内容的用户请求分配给不同的缓存服务器向用户提供服务。
分配器
/ | \
缓存 缓存 ...缓存
服务器1 服务器2 ...服务器n
1)请问如何设置分配策略,可以保证充分利用每个缓存服务器的存储空间(每个内容只在一个缓存服务器有副本)
2)当部分缓存服务器故障,或是因为系统扩容,导致缓存服务器的数量动态减少或增加时,你的分配策略是否可以保证较小的缓存文件重分配的开销,如果不能,如何改进?
3)当各个缓存服务器的存储空间存在差异时(如有4个缓存服务器,存储空间比为4:9:15:7),如何改进你的策略,按照如上的比例将内容调度到缓存服务器?
转载请标明出处,原文地址:[http://blog.csdn.net/hackbuteer1/article/details/6823329](http://blog.csdn.net/hackbuteer1/article/details/6823329)
';
网新恒天2011.9.21招聘会笔试题
最后更新于:2022-04-01 21:43:24
1、下列哪种数据类型不能用作switch的表达式变量(C)
A、byte B、char C、long D、enum
2、在图采用邻接表存储时,求最小生成树的 Prim 算法的时间复杂度为( **B** )。
A、 O(n) B、**O(n+e)** C、 O(n2) D、O(n3)
3、在图采用邻接矩阵存储时,求最小生成树的 Prim 算法的时间复杂度为( **C** )。
A、 O(n) B、 O(n+e) C、 O(n2) D、O(n3)
4、树的后根遍历序列等同于该树对应的二叉树的( B ).
A、先序序列 B、中序序列 C、后序序列
5、“Abc汉字”的长度为(**C**)
A、5 B、6 C、7 D、8
~~~
int main(void)
{
char str[]="Abc汉字";
cout<
';
淘宝网 校园招聘 技术人员笔试题
最后更新于:2022-04-01 21:43:22
**通用试题部分:**
**选择题**
1、在按层次遍历二叉树的算法中, 需要借助的辅组数据结构是
A、队列
B、栈
C、线性表
D、有序表
2、所谓指令周期是指
A、取指令和取操作数的时间
B、执行指令和存储操作结果的时间
C、取操作数和执行指令的时间
D、取指令和执行指令的时间
3、 调用一成员函数时, 使用动态联编的情况是
A、通过对象调用一虚函数
B、通过指针或引用调用一虚函数
C、通过对象调用静态函数
D、通过指针或应用调用一静态函数
4、配置管理能起到以下哪些作用
A、版本管理
B、变更管理
C、需求管理
D、测试管理
**简答题**
我们在开发中经常强调要面向接口编程(又称契约式编程), 请问采用接口有什么优点呢, 接口和抽象类又有什么区别呢? 分别使用在哪些场景?
**编程题**(不区分编程语言)
完成一段代码, 代码有三个线程, 主线程由Main进入, 启动一个生产者线程和一个消费者线程, 生产者线程随机产生整数, 并且把这个整数放入一个List中, 消费者从List中取出数据进行显示
**综合设计题**
现由于业务要求, 需要对每日的积分进出帐与支付宝的现金进出帐进行对账. 帐务数据每天约100万条纪录, 现采用按时段生成帐务文件, 帐务文件通过http协议下载. 在次日凌晨下载帐务文件, 与本地的进出明细帐务做逐条核对.
问题 1: 如何保证每个时段的文件都下载了?
问题 2: 如何保证通过http下载的文件都是完整的?
问题 3: 现将本地帐务也生成文件, 帐务文件格式为: "交易号, 进帐金额, 出帐金额"三个字段用逗号分隔. 支付宝帐务文件格式完全相同, 请设计对账流程, 并实现对账算法的主要思路.
**C++开发/搜索引擎开发/数学算法开发**
1、以下程序运行后的输出结果是
~~~
void main()
{
int p[7]={11, 13, 14, 15, 16, 17, 18};
int i=0, j=0;
while(i<7 && p[i]%2==1)
j+=p[i++];
printf("%d\n",j);
}
~~~
输出结果是:24
2、列举出STL中常用的容器,并指出下列场景中分别应该使用哪种容器?
从文件中循环读取一系列不重复的英文单词放入容器中, 并在放入的同时进行排序, 并提供检索特定的单词是否存在于容器中的功能.
从文件中循环读取一系列数目不定的可重复的英文单词放入容器中, 要求读取并放置完后, 能够删除中间单词, 并且能够按以前的顺序再输出到另外的文件中.
从文件中循环读取一系列数目固定的可重复的英文单词放入容器中, 要求提供访问第n个单词的功能.
从文件中循环读取一系列数目不定的大量重复的英文单词放入容器, 要求统计每个单词出现的次数, 并能够检索特定的单词的出现次数.
3、若有以下说明和语句, int c[4][5], (*p)[5]; p=c; 如何使用p而不用c来表示c[2][3]这个元素, 答案中不能出现[]操作符。
答案**:*(*(p+2)+3)**
~~~
int main(void)
{
int c[4][5]={1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20};
int (*p)[5];
p=c;
printf("%d\n",*(*(p+2)+3));
return 0;
}
~~~
4、拷贝构造函数在什么时候被调用, 请写出示例代码
5、有以下定义和语句
int a[3][2]={1,2,3,4,5,6,},*p[3];
p[0]=a[1];
则*(p[0]+1)所代表的数组元素是
~~~
void main()
{
int a[3][2]={1,2,3,4,5,6,},*p[3]; //p先和[]结合,所以是一个数组,数组的元素是int型指针
p[0]=a[1]; //p[0]指向a数组第二行的首地址
printf("%d\n",*(p[0]+1)); //输出a数组第二行第二列的元素:4
}
~~~
6、有以下程序, 程序运行后的输出结果是
~~~
void main()
{
char str[][10]={"China", "Beijing"}, *p=str[0];
printf("%s\n",p+10);
}
~~~
输出为:Beijing
**软件测试**
1、 [语句分析, 本懒虫不打了]
2、HTTP1.1协议中规定便是正常响应的状态代码是
A、400 **B、200** C、 100 D、0
3、单链表的每个结点中包括一个指针link, 它指向该结点的后继结点. 现要将指针q指向的新结点插入到指针p指向的单结点之后, 下面的操作序列中哪一个是真确的?
A、q:=p^.link; p^.link:=q^.link
B、p^.link:=q^.link; q:=p^.link
C、 q^.link:=p^.link; p^.link:=q
D、p^.link:=q; q^.link:=p^.link
4、[逻辑判断题]
5、给出以下定义, 则正确的叙述为
char x[]="abcdefg";
char y[]={'a','b','c','d','e','f','g'};
A、数组X和数组Y等价
B、数组X和数组Y长度相同
C、数组X的长度大于数组Y的长度
D、数组X的长度小于数组Y的长度
printf("%d\n",sizeof(x)); 输出8
printf("%d\n",sizeof(y)); 输出7
因为x数组是字符串数组,后面还有结束符:“\0”,所以长度为:8
而y数组就是普通的字符数组,没有“\0”结束符的,所以长度为:7
6、 下列程序的返回值是多少:
~~~
int countx=0;
int x=17373;
int f()
{
while(x)
{
countx++;
x=x&(x-1);
}
return countx;
}
~~~
countx的值记录的就是x的二进制中1的个数,把x的二进制写出来,数一下其中有多少个1就可以了。。
**数据库开发**
1、本地管理表空间和字典管理表空间的特点,ASSM有什么特点。
2、日志的作用是什么?
答:日志文件是用来记录你所对数据库的操作信息的 例如对数据库的操作等引起的问题 日记文件都有记载下来 。 如果数据库有问题的时候可以去看那个日记文件来分析出错的原因。
3、如果系统现在需要在一个很大的表上创建一个索引, 你会考虑哪些因素, 如何做以尽量减小对应用的影响。
**专业试题部分
Java开发**
1. 请列出Test执行时的输出结果
A. 编译不通过
B. SSA
C. SSS
D. SAA
Test代码如下:
~~~
class A{
public void printValue(){
System.out.print("A");
}
}
class S extends A{
public void printValue(){
System.out.print("S");
}
}
public class Test {
public static void main(String[] args){
S s=new S();
s.printValue();
A as=(A)s;
as.printValue();
as=new A();
as.printValue();
}
}
~~~
2. String compare:
A
~~~
String s1="java";
String s2="java";
(1) s1==s2 (2) s1.equals(s2)
Result: (1) (2)
~~~
B
~~~
String s="ja";
String s1=s+"va";
String s2="java";
(1) s1==s2 (2) s1.equals(s2)
Result: (1) (2)
~~~
3. True or False: Readers have methods that can read and return floats and doubles.
A. True
B. False
4. 在//point x处的哪些声明是句法上合法的(多选)
~~~
class Person{
private int a;
public int change(int m){
return m;
}
}
public class Teacher extends Person {
public int b;
public static void main(String arg[]){
Person p=new Person();
Teacher t=new Teacher();
int i;
//point x
}
}
~~~
A. i=m; B. i=t.b; C. i=p.a; D. i=p.change(30);
5. Given the following code, what will be the output?
~~~
class Value{
public int i=5;
}
public class Test_1 {
public static void main(String argv[]){
Test_1 t=new Test_1();
t.first();
}
public void first(){
int i=5;
Value v=new Value();
v.i=25;
second(v,i);
System.out.print(v.i);
}
public void second(Value v, int i){
i=0;
v.i=20;
Value val=new Value();
v=val;
System.out.print(v.i+" "+i);
}
}
~~~
A. 15 0 20
B. 15 0 15
C. 20 0 20
D. 0 15 20
6. 下面哪一个interface的定义是错误的?
A.
~~~
interface interface1 extends interface2, interface3{
void undo(int i);
void process();
}
~~~
B.
~~~
interface interface1{
public void undo(int i);
}
~~~
C.
~~~
interface interface1{
String aa;
}
~~~
D.
~~~
interface interface1{
private String var;
process(){};
}
~~~
**前端开发**
1. Google Chrome浏览器对CSS的支持度和下面哪个浏览器基本一致:
A. IE7 B. Firefox 3.1 C. Opera 9.5 D. Safari 3.1
2. 下面这段javascript代码,
var msg='hello';
for (var i=0; i<10; i++){
var msg='hello'+i*2+i;
}
alert(msg);
最后一句alert的输出结果是:
A. hello B. hello189 C. hello30 D. hello27
3. 下面哪个Hack属性, IE7浏览器不能识别:
A. @color:red B. *color:red; C. _color:red; D. +color:red;
4. 请问在javascript程序中, alert(undefined==null)的输出结果是:
A. undefined B. null C. true D. false
5. 根据下图, 请您用符合Web语义的(X)HTML代码书写结构[此题目图片懒得搞了, 反正这题也很简单, 省略]
6. 请手写一段javascript程序, 对数组[5, 1000, 6, 3, 8, 123, -12]按从小到大进行排序, 如果你有多种解法, 请阐述各种解法的思路及其优缺点.(仅需用代码实现一种算法, 其他解法用文字阐述思路即可)
**网络系统运维**
1、 在Linux系统中, 为找到文件try_grep含有以a字母为行开头的内容, 可以使用命令:
A、grep -E #$ try_grep
B、grep -E #a try_grep
C、grep -E ^$ try_grep
D、grep -E ^a try_grep
^M 以M开头的行,^表示开始的意思
M$ 以M结尾的行,$表示结束的意思
2、在Linux系统中, 检查硬盘空间使用情况应该使用什么命令?
**A、df** B、 du C、fd D、free
3、 ping命令使用的协议是:
**A、ICMP** B、IMAP C、POP D、 SNMP
4、以下设备中哪种最适合做网站负载均衡设备(Load Balance):
A、二层交换机 B、 路由器 C、四层交换机 D、 防火墙
5、查看当前主机的网关配置地址是多少, 请将地址写入到./ga.txt中。
6、修改当前目录下的smb.conf, 将当前/etc目录共享出去。
';
程序员有趣的面试智力题
最后更新于:2022-04-01 21:43:20
转载请标明出处,原文地址:[http://blog.csdn.net/hackbuteer1/article/details/6726419](http://blog.csdn.net/hackbuteer1/article/details/6726419)
偶然间在网上看到几个原来没见过的面试智力题,有几个题目在国内流传相当广,什么n个人怎么分饼最公平,屋里的三个灯泡分别由哪个开关控制,三架飞机环游世界,用火柴和两根绳子测量45分钟之类的题目,火星得已经可以考古了,这里就不再说了。
1、考虑一个双人游戏。游戏在一个圆桌上进行。每个游戏者都有足够多的硬币。他们需要在桌子上轮流放置硬币,每次必需且只能放置一枚硬币,要求硬币完全置于桌面内(不能有一部分悬在桌子外面),并且不能与原来放过的硬币重叠。谁没有地方放置新的硬币,谁就输了。游戏的先行者还是后行者有必胜策略?这种策略是什么?
答案:先行者在桌子中心放置一枚硬币,以后的硬币总是放在与后行者刚才放的地方相对称的位置。这样,只要后行者能放,先行者一定也有地方放。先行者必胜。
2、 用线性时间和常数附加空间将一篇文章的单词(不是字符)倒序。
答案:先将整篇文章的所有字符逆序(从两头起不断交换位置相对称的字符);然后用同样的办法将每个单词内部的字符逆序。这样,整篇文章的单词顺序颠倒了,但单词本身又被转回来了。
3、 用线性时间和常数附加空间将一个长度为n的字符串向左循环移动m位(例如,"abcdefg"移动3位就变成了"defgabc")。
答案:把字符串切成长为m和n-m的两半。将这两个部分分别逆序,再对整个字符串逆序。
4、一个矩形蛋糕,蛋糕内部有一块矩形的空洞。只用一刀,如何将蛋糕切成大小相等的两块?
答案:注意到平分矩形面积的线都经过矩形的中心。过大矩形和空心矩形各自的中心画一条线,这条线显然把两个矩形都分成了一半,它们的差当然也是相等的。
5、 一块矩形的巧克力,初始时由N x M个小块组成。每一次你只能把一块巧克力掰成两个小矩形。最少需要几次才能把它们掰成N x M块1x1的小巧克力?
答案:N x M - 1次显然足够了。这个数目也是必需的,因为每掰一次后当前巧克力的块数只能增加一,把巧克力分成N x M块当然需要至少掰N x M - 1次。
6、如何快速找出一个32位整数的二进制表达里有多少个"1"?用关于"1"的个数的线性时间?
答案1(关于数字位数线性):for(n=0; b; b >>= 1) if (b & 1) n++;
答案2(关于"1"的个数线性):for(n=0; b; n++) b &= b-1;
7、 一个大小为N的数组,所有数都是不超过N-1的正整数。用O(N)的时间找出重复的那个数(假设只有一个)。一个大小为N的数组,所有数都是不超过N+1的正整数。用O(N)的时间找出没有出现过的那个数(假设只有一个)。
答案:计算数组中的所有数的和,再计算出从1到N-1的所有数的和,两者之差即为重复的那个数。计算数组中的所有数的和,再计算出从1到N+1的所有数的和,两者之差即为缺少的那个数。
8、 给出一行C语言表达式,判断给定的整数是否是一个2的幂。
答案:(b & (b-1)) == 0
9、地球上有多少个点,使得从该点出发向南走一英里,向东走一英里,再向北走一英里之后恰好回到了起点?
答案:“北极点”是一个传统的答案,其实这个问题还有其它的答案。事实上,满足要求的点有无穷多个。所有距离南极点1 + 1/(2π)英里的地方都是满足要求的,向南走一英里后到达距离南极点1/(2π)的地方,向东走一英里后正好绕行纬度圈一周,再向北走原路返回到起点。事实上,这仍然不是满足要求的全部点。距离南极点1 + 1/(2kπ)的地方都是可以的,其中k可以是任意一个正整数。
10、A、B两人分别在两座岛上。B生病了,A有B所需要的药。C有一艘小船和一个可以上锁的箱子。C愿意在A和B之间运东西,但东西只能放在箱子里。只要箱子没被上锁,C都会偷走箱子里的东西,不管箱子里有什么。如果A和B各自有一把锁和只能开自己那把锁的钥匙,A应该如何把东西安全递交给B?
答案:A把药放进箱子,用自己的锁把箱子锁上。B拿到箱子后,再在箱子上加一把自己的锁。箱子运回A后,A取下自己的锁。箱子再运到B手中时,B取下自己的锁,获得药物。
11、 一对夫妇邀请N-1对夫妇参加聚会(因此聚会上总共有2N人)。每个人都和所有自己不认识的人握了一次手。然后,男主人问其余所有人(共2N-1个人)各自都握了几次手,得到的答案全部都不一样。假设每个人都认识自己的配偶,那么女主人握了几次手?
答案:握手次数只可能是从0到2N-2这2N-1个数。除去男主人外,一共有2N-1个人,因此每个数恰好出现了一次。其中有一个人(0)没有握手,有一个人(2N-2)和所有其它的夫妇都握了手。这两个人肯定是一对夫妻,否则后者将和前者握手(从而前者的握手次数不再是0)。除去这对夫妻外,有一个人(1)只与(2N-2)握过手,有一个人(2N-3)和除了(0)以外的其它夫妇都握了手。这两个人肯定是一对夫妻,否则后者将和前者握手(从而前者的握手次数不再是1)。以此类推,直到握过N-2次手的人和握过N次手的人配成一对。此时,除了男主人及其配偶以外,其余所有人都已经配对。根据排除法,最后剩下来的那个握手次数为N-1的人就是女主人了。
12、两个机器人,初始时位于数轴上的不同位置。给这两个机器人输入一段相同的程序,使得这两个机器人保证可以相遇。程序只能包含“左移n个单位”、“右移n个单位”,条件判断语句If,循环语句while,以及两个返回Boolean值的函数“在自己的起点处”和“在对方的起点处”。你不能使用其它的变量和计数器。
答案:两个机器人同时开始以单位速度右移,直到一个机器人走到另外一个机器人的起点处。然后,该机器人以双倍速度追赶对方。程序如下。
~~~
while(!at_other_robots_start) {
move_right 1
}
while(true) {
move_right 2
}
~~~
13、 如果叫你从下面两种游戏中选择一种,你选择哪一种?为什么?
a. 写下一句话。如果这句话为真,你将获得10美元;如果这句话为假,你获得的金钱将少于10美元或多于10美元(但不能恰好为10美元)。
b. 写下一句话。不管这句话的真假,你都会得到多于10美元的钱。
答案:选择第一种游戏,并写下“我既不会得到10美元,也不会得到10000000美元”。
14、你在一幢100层大楼下,有21根电线线头标有数字1..21。这些电线一直延伸到大楼楼顶,楼顶的线头处标有字母A..U。你不知道下面的数字和上面的字母的对应关系。你有一个电池,一个灯泡,和许多很短的电线。如何只上下楼一次就能确定电线线头的对应关系?
答案:在下面把2,3连在一起,把4到6全连在一起,把7到10全连在一起,等等,这样你就把电线分成了6个“等价类”,大小分别为1, 2, 3, 4, 5, 6。然后到楼顶,测出哪根线和其它所有电线都不相连,哪些线和另外一根相连,哪些线和另外两根相连,等等,从而确定出字母A..U各属于哪个等价类。现在,把每个等价类中的第一个字母连在一起,形成一个大小为6的新等价类;再把后5个等价类中的第二个字母连在一起,形成一个大小为5的新等价类;以此类推。回到楼下,把新的等价类区别出来。这样,你就知道了每个数字对应了哪一个原等价类的第几个字母,从而解决问题。
15、某种药方要求非常严格,你每天需要同时服用A、B两种药片各一颗,不能多也不能少。这种药非常贵,你不希望有任何一点的浪费。一天,你打开装药片A的药瓶,倒出一粒药片放在手心;然后打开另一个药瓶,但不小心倒出了两粒药片。现在,你手心上有一颗药片A,两颗药片B,并且你无法区别哪个是A,哪个是B。你如何才能严格遵循药方服用药片,并且不能有任何的浪费?
答案:把手上的三片药各自切成两半,分成两堆摆放。再取出一粒药片A,也把它切成两半,然后在每一堆里加上半片的A。现在,每一堆药片恰好包含两个半片的A和两个半片的B。一天服用其中一堆即可。
16、 你在一个飞船上,飞船上的计算机有n个处理器。突然,飞船受到外星激光武器的攻击,一些处理器被损坏了。你知道有超过一半的处理器仍然是好的。你可以向一个处理器询问另一个处理器是好的还是坏的。一个好的处理器总是说真话,一个坏的处理器总是说假话。用n-2次询问找出一个好的处理器。
答案:给处理器从1到n标号。用符号a->b表示向标号为a的处理器询问处理器b是不是好的。首先问1->2,如果1说不是,就把他们俩都去掉(去掉了一个好的和一个坏的,则剩下的处理器中好的仍然过半),然后从3->4开始继续发问。如果1说2是好的,就继续问2->3,3->4,……直到某一次j说j+1是坏的,把j和j+1去掉,然后问j-1 -> j+2;或者从j+2 -> j+3开始发问,如果前面已经没有j-1了(之前已经被去掉过了)。注意到你始终维护着这样一个“链”,前面的每一个处理器都说后面那个是好的。这条链里的所有处理器要么都是好的,要么都是坏的。当这条链越来越长,剩下的处理器越来越少时,总有一个时候这条链超过了剩下的处理器的一半,此时可以肯定这条链里的所有处理器都是好的。或者,越来越多的处理器都被去掉了,链的长度依旧为0,而最后只剩下一个或两个处理器没被问过,那他们一定就是好的了。另外注意到,第一个处理器的好坏从来没被问过,仔细想想你会发现最后一个处理器的好坏也不可能被问到(一旦链长超过剩余处理器的一半,或者最后没被去掉的就只剩这一个了时,你就不问了),因此询问次数不会超过n-2。
17、一个圆盘被涂上了黑白二色,两种颜色各占一个半圆。圆盘以一个未知的速度、按一个未知的方向旋转。你有一种特殊的相机可以让你即时观察到圆上的一个点的颜色。你需要多少个相机才能确定圆盘旋转的方向?
答案:你可以把两个相机放在圆盘上相近的两点,然后观察哪个点先变色。事实上,只需要一个相机就够了。控制相机绕圆盘中心顺时针移动,观察颜色多久变一次;然后让相机以相同的速度逆时针绕着圆盘中心移动,再次观察变色的频率。可以断定,变色频率较慢的那一次,相机的转动方向是和圆盘相同的。
18、有25匹马,速度都不同,但每匹马的速度都是定值。现在只有5条赛道,无法计时,即每赛一场最多只能知道5匹马的相对快慢。问最少赛几场可以找出25匹马中速度最快的前3名?(**百度**2008年面试题)
每匹马都至少要有一次参赛的机会,所以25匹马分成5组,一开始的这5场比赛是免不了的。接下来要找冠军也很容易,每一组的冠军在一起赛一场就行了(第6场)。最后就是要找第2和第3名。我们按照第6场比赛中得到的名次依次把它们在前5场比赛中所在的组命名为A、B、C、D、E。即:A组的冠军是第6场的第1名,B组的冠军是第6场的第2名……每一组的5匹马按照他们已经赛出的成绩从快到慢编号:
A组:1,**2,3**,4,5
B组:**1,2**,3,4,5
C组:**1,**2,3,4,5
D组:1,2,3,4,5
E组:1,2,3,4,5
从现在所得到的信息,我们可以知道哪些马已经被排除在3名以外。只要已经能确定有3匹或3匹以上的马比这匹马快,那么它就已经被淘汰了。可以看到,只有上表中粗体蓝色的那5匹马才有可能为2、3名的。即:A组的2、3名;B组的1、2名,C组的第1名。取这5匹马进行第7场比赛,第7场比赛的前两名就是25匹马中的2、3名。故一共最少要赛7场。
这道题有一些变体,比如64匹马找前4名。方法是一样的,在得出第1名以后寻找后3名的候选竞争者就可以了。
19、IBM笔试题:一普查员问一女人,“你有多少个孩子,他们多少岁?”
女人回答:“我有三个孩子,他们的岁数相乘是36,岁数相加就等于旁边屋的门牌号码。“普查员立刻走到旁边屋,看了一看,回来说:“我还需要多少资料。”女人回答:“我现在很忙,我最大的孩子正在楼上睡觉。”普查员说:”谢谢,我己知道了。”
问题:那三个孩子的岁数是多少。
36 = 1 × 2 × 2 × 3 × 3
所有的可能为
1,1,36;sum = 38
1,2,18;sum = 21
1,3,12;sum = 16
1,4,9;sum = 14
1,6,6;sum = 13
2,2,9;sum = 13
2,3,6;sum = 11
3,3,4;sum = 10
由于普查员知道了年龄和之后还是不能确定每个孩子的年龄,所以可能性为
1,6,6;sum = 13
2,2,9;sum = 13
由于最大(暗含只有一个最大)的孩子在睡觉,所以只可能是
2,2,9;sum = 13
20、有7克、2克砝码各一个,天平一只,如何只用这些物品三次将140克的盐分成50、90克各一份?
答:第一步:把140克盐分成两等份,每份70克。
第二步:把天平一边放上2+7克砝码,另一边放盐,这样就得到9克和61克分开的盐。
第三步:将9克盐和2克砝码放在天平一边,另一边放盐,这样就得到11克和50克。于是50和90就分开了。
21、有三筐水果,一筐装的全是苹果,第二筐装的全是橘子,第三筐是橘子与苹果混在一起。筐上的标签都是骗人的,(比如,如果标签写的是橘子,那么可以肯定筐里不会只有橘子,可能还有苹果)你的任务是拿出其中一筐,从里面只拿一只水果,然后正确写出三筐水果的标签。
答:从贴有苹果和橘子标签的筐中拿出一个水果,如果是苹果,说明这个筐中全是苹果,那么贴苹果标签的筐里装的全是桔子,则贴有桔子标签的筐中装的苹果和桔子;如果拿出的一个水果是桔子,说明这个筐中全是桔子,那么贴桔子标签的筐里装的全是苹果,贴苹果标签的筐里装的是苹果和桔子。
22、题目如下:
0 1 2 3 4 5 6 7 8 9
_ _ _ _ _ _ _ _ _ _
在横线上填写数字,使之符合要求。
要求如下:对应的数字下填入的数,代表上面的数在下面出现的次数,比如3下面是1,代表3要在下面出现一次。
**正确答案是:0 1 2 3 4 5 6 7 8 9
6 2 1 0 0 0 1 0 0 0**
我的思路是:因为第二行的数字是第一行的数在下面出现的次数,下面10个格子,总共10次。。。所以第2排数字之和为10。
首先从0入手,先填9,肯定不可能,9下面要是1,只剩8个位填0,不够填8,8下面要填1,1要至少填2,后面不用再想,因为已经剩下7个位置,不够填0……如此类推。到0下面填6的时候就得到我上面的答案了。。
其实可以推出这个题目的两个关键条件:
1、第2排数字之和为10。
2、两排数字上下相乘之和也是10!
满足这两个条件的就是答案,下面来编写程序实现!
~~~
//原始数值: 0,1,2,3,4,5,6,7,8,9
//出现次数: 6,2,1,0,0,0,1,0,0,0
#include "iostream"
using namespace std;
#define len 10
class NumberTB
{
private:
int top[len];
int bottom[len];
bool success;
public:
NumberTB();
int *getBottom();
void setNextBottom();
int getFrequecy(int num);
};
NumberTB::NumberTB()
{
success = false;
//format top
for(int i = 0; i < len; i++)
{
top[i] = i;
}
}
int *NumberTB::getBottom()
{
int i = 0;
while(!success)
{
i++;
setNextBottom();
}
return bottom;
}
//set next bottom
void NumberTB::setNextBottom()
{
bool reB = true;
for(int i = 0; i < len; i++)
{
int frequecy = getFrequecy(i);
if(bottom[i] != frequecy)
{
bottom[i] = frequecy;
reB = false;
}
}
success = reB;
}
//get frequency in bottom
int NumberTB::getFrequecy(int num) //此处的num 即指上排的数i
{
int count = 0;
for(int i = 0; i < len; i++)
{
if(bottom[i] == num)
count++;
}
return count; //cout 即对应frequecy
}
int main(void)
{
int i;
NumberTB nTB;
int *result = nTB.getBottom();
cout<<"原始数值:";
for(i=0;i<10;i++)
cout<
';
前言
最后更新于:2022-04-01 21:43:17
> 原文出处:[IT公司笔试题集锦](http://blog.csdn.net/column/details/offer.html)
作者:[hackbuteer1](http://blog.csdn.net/hackbuteer1)
**本系列文章经作者授权在看云整理发布,未经作者允许,请勿转载!**
# IT公司笔试题集锦
> 汇集各大IT公司最新、最全面的笔试、面试题。。
';