百度2011.10.16校园招聘会笔试题
最后更新于:2022-04-01 21:43:33
**一、算法设计**
1、设rand(s,t)返回[s,t]之间的随机小数,利用该函数在一个半径为R的圆内找随机n个点,并给出时间复杂度分析。
思路:这个使用数学中的极坐标来解决,先调用[s1,t1]随机产生一个数r,归一化后乘以半径,得到R*(r-s1)/(t1-s1),然后在调用[s2,t2]随机产生一个数a,归一化后得到角度:360*(a-s2)/(t2-s2)
2、为分析用户行为,系统常需存储用户的一些query,但因query非常多,故系统不能全存,设系统每天只存m个query,现设计一个算法,对用户请求的query进行随机选择m个,请给一个方案,使得每个query被抽中的概率相等,并分析之,注意:不到最后一刻,并不知用户的总请求量。
思路:如果用户查询的数量小于m,那么直接就存起来。如果用户查询的数量大于m,假设为m+i,那么在1-----m+i之间随机产生一个数,如果选择的是前面m条查询进行存取,那么概率为m/(m+i),如果选择的是后面i条记录中的查询,那么用这个记录来替换前面m条查询记录的概率为m/(m+i)*(1-1/m)=(m-1)/(m+i),当查询记录量很大的时候,m/(m+i)== (m-1)/(m+i),所以每个query被抽中的概率是相等的。
3、C++ STL中vector的相关问题:
(1)、调用push_back时,其内部的内存分配是如何进行的?
(2)、调用clear时,内部是如何具体实现的?若想将其内存释放,该如何操作?
vector的工作原理是系统预先分配一块CAPACITY大小的空间,当插入的数据超过这个空间的时候,这块空间会让某种方式扩展,但是你删除数据的时候,它却不会缩小。
vector为了防止大量分配连续内存的开销,保持一块默认的尺寸的内存,clear只是清数据了,未清内存,因为vector的capacity容量未变化,系统维护一个的默认值。
有什么方法可以释放掉vector中占用的全部内存呢?
标准的解决方法如下
~~~
template < class T >
void ClearVector( vector< T >& vt )
{
vector< T > vtTemp;
veTemp.swap( vt );
}
~~~
事实上,vector根本就不管内存,它只是负责向内存管理框架acquire/release内存,内存管理框架如果发现内存不够了,就malloc,但是当vector释放资源的时候(比如destruct), stl根本就不调用free以减少内存,因为内存分配在stl的底层:stl假定如果你需要更多的资源就代表你以后也可能需要这么多资源(你的list, hashmap也是用这些内存),所以就没必要不停地malloc/free。如果是这个逻辑的话这可能是个trade-off
一般的STL内存管理器allocator都是用内存池来管理内存的,所以某个容器申请内存或释放内存都只是影响到内存池的剩余内存量,而不是真的把内存归还给系统。这样做一是为了避免内存碎片,二是提高了内存申请和释放的效率——不用每次都在系统内存里寻找一番。
**二、系统设计**
正常用户端每分钟最多发一个请求至服务端,服务端需做一个异常客户端行为的过滤系统,设服务器在某一刻收到客户端A的一个请求,则1分钟内的客户端任何其它请求都需要被过滤,现知每一客户端都有一个IPv6地址可作为其ID,客户端个数太多,以至于无法全部放到单台服务器的内存hash表中,现需简单设计一个系统,使用支持高效的过滤,可使用多台机器,但要求使用的机器越少越好,请将关键的设计和思想用图表和代码表现出来。
**三、求一个全排列函数:**
如p([1,2,3])输出:
[123]、[132]、[213]、[231]、[321]、[312]
求一个组合函数。
方法1:依次从字符串中取出一个字符作为最终排列的第一个字符,对剩余字符组成的字符串生成全排列,最终结果为取出的字符和剩余子串全排列的组合。
~~~
#include
#include
using namespace std;
void permute1(string prefix, string str)
{
if(str.length() == 0)
cout << prefix << endl;
else
{
for(int i = 0; i < str.length(); i++)
permute1(prefix+str[i], str.substr(0,i)+str.substr(i+1,str.length()));
}
}
void permute1(string s)
{
permute1("",s);
}
int main(void)
{
//method1, unable to remove duplicate permutations.
permute1("abc");
return 0;
}
~~~
优点:该方法易于理解,但无法移除重复的排列,如:s="ABA",会生成两个“AAB”。
方法2:利用交换的思想,具体见实例,但该方法不如方法1容易理解。
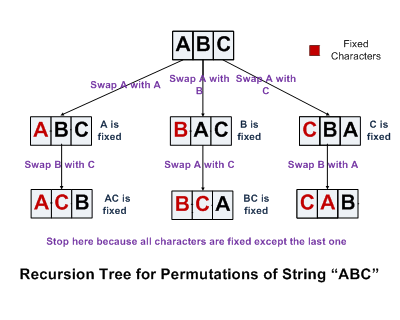
我们以三个字符abc为例来分析一下求字符串排列的过程。首先我们固定第一个字符a,求后面两个字符bc的排列。当两个字符bc的排列求好之后,我们把第一个字符a和后面的b交换,得到bac,接着我们固定第一个字符b,求后面两个字符ac的排列。现在是把c放到第一位置的时候了。记住前面我们已经把原先的第一个字符a和后面的b做了交换,为了保证这次c仍然是和原先处在第一位置的a交换,我们在拿c和第一个字符交换之前,先要把b和a交换回来。在交换b和a之后,再拿c和处在第一位置的a进行交换,得到cba。我们再次固定第一个字符c,求后面两个字符b、a的排列。
既然我们已经知道怎么求三个字符的排列,那么固定第一个字符之后求后面两个字符的排列,就是典型的递归思路了。
基于前面的分析,我们可以得到如下的参考代码:
~~~
void Permutation(char* pStr, char* pBegin)
{
assert(pStr && pBegin);
//if(!pStr || !pBegin)
//return ;
if(*pBegin == '\0')
printf("%s\n",pStr);
else
{
char temp;
for(char* pCh = pBegin; *pCh != '\0'; pCh++)
{
if(pCh != pBegin && *pCh == *pBegin) //为避免生成重复排列,当不同位置的字符相同时不再交换
continue;
temp = *pCh;
*pCh = *pBegin;
*pBegin = temp;
Permutation(pStr, pBegin+1);
temp = *pCh;
*pCh = *pBegin;
*pBegin = temp;
}
}
}
int main(void)
{
char str[] = "aba";
Permutation(str,str);
return 0;
}
~~~
如p([1,2,3])输出:
[1]、[2]、[3]、[1,2]、[2,3]、[1,3]、[1,2,3]
这两问可以用伪代码。
';