【java】微博爬虫(二):如何抓取HTML页面及HttpClient使用
最后更新于:2022-04-01 23:02:29
##一、写在前面
上篇文章以网易微博爬虫为例,给出了一个很简单的微博爬虫的爬取过程,大概说明了网络爬虫其实也就这么回事,或许初次看到这个例子觉得有些复杂,不过没有关系,上篇文章给的例子只是让大家对爬虫过程有所了解。接下来的系列里,将一步一步地剖析每个过程。
爬虫总体流程在上篇文章已经说得很清楚了,没有看过的朋友可以去看下:[【网络爬虫】[java]微博爬虫(一):网易微博爬虫(自定义关键字爬取微博信息数据)](http://blog.csdn.net/dianacody/article/details/39584977)
现在再回顾下爬虫过程:
step1: 通过请求url得到html的string,用httpClient-4.3.1工具,同时设置socket超时和连接超时connectTimeout,本文将详解此步骤。
step2: 对于上步得到的html,验证是否为合法HTML,判断是否为有效搜索页面,因为有些请求的html页面不存在。
step3: 把html这个string存放到本地,写入txt文件;
step4: 从txt文件解析微博数据:userid,timestamp……解析过程才是重点,对于不同网页结构的分析及特征提取,将在系列三中详细讲解。
step5: 解析出来的数据放入txt和xml中,这里主要jsoup解析html,dom4j工具读写xml,将在系列四中讲解。
然后在系列五中会给出一些防止被墙的方法,使用代理IP访问或解析本地IP数据库(前提是你有存放的IP数据库),后面再说。
##二、HttpClient工具包
搞过web开发的朋友对这个应该很熟悉了,不需要再多说,这是个很基本的工具包,一个代码级Http客户端工具,可以使用其模拟浏览器向http服务器发送请求。HttpClient是HttpComponents(简称hc)项目其中的一部分,可以直接下载组件。使用HttpClient还需要HttpCore,后者包括Http请求与Http响应代码封装。它使客户端发送http请求变得容易,同时也会更加深入理解http协议。
在这里可以下载HttpComponents组件:[http://hc.apache.org/](http://hc.apache.org/),下载后目录结构:

首先要注意的有以下几点:
1.httpclient**链接后释放**问题很重要,就跟用database connection要释放资源一样。
2.https网站使用ssl加密传输,证书导入要注意。
3.对于**http协议**要有基本的了解,比如http的200,301,302,400,404,500等返回代码时什么意思(这个是最基本的),还有cookie和session机制(这个在之后的python爬虫系列三“模拟登录”的方法需要抓取数据包分析,主要就是看cookie这些东西,要学会分析数据包)
4.httpclient的redirect(重定向)状态默认是自动的,这在很大程度上给开发者很大的方便(如一些授权获得的cookie),但有时需要手动设置,比如有时会遇到CircularRedictException异常,出现这样的情况是因为返回的头文件中location值指向之前重复地址(端口号可以不同),导致可能会出现死循环递归重定向,此时可以手动关闭:method.setFollowRedirects(false)。
5.模拟浏览器登录,这个对于爬虫来说相当重要,有的网站会先判别用户的请求是否来自浏览器,如果不是直接拒绝访问,这个直接伪装成浏览器访问就好了,好用httpclient抓取信息时在头部加入一些信息:header.put(“User-Agent”, “Mozilla/5.0 (Windows NT 6.1)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36)”);
6.当post请求提交数据时要改变默认编码,不然提交上去的数据会出现乱码。重写postMethod的setContentCharSet()方法就可以了。
下面给几个例子:
(1)发post请求访问本地应用并根据传递参数不同返回不同结果
~~~
public void post() {
//创建默认httpClient实例
CloseableHttpClient httpclient = HttpClients.createDefault();
//创建httpPost
HttpPost httppost = new HttpPost("http://localhost:8088/weibo/Ajax/service.action");
//创建参数队列
List formparams = new ArrayList();
formparams.add(new BasicKeyValue("name", "alice"));
UrlEncodeFormEntity uefEntity;
try {
uefEntity = new UrlEncodeFormEntity(formparams, "utf-8");
httppost.setEntity(uefEntity);
System.out.println("executing request " + httppost.getURI());
CloseableHttpResponse response = httpclient.execute(httppost);
try {
HttpEntity entity = response.getEntity();
if(entity != null) {
System.out.println("Response content: " + EntityUtils.toString(entity, "utf-8"));
}
} finally {
response.close();
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//关闭连接,释放资源
try {
httpclient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
~~~
(2)发get请求
~~~
public void get() {
CloseableHttpClient httpclient = HttpClients.createDefault();
try {
//创建httpget
HttpGet httpget = new HttpGet("http://www.baidu.com");
System.out.println("executing request " + httpget.getURI());
//执行get请求
CloseableHttpResponse response = httpclient.execute(httpget);
try {
//获取响应实体
HttpEntity entity = response.getEntity();
//响应状态
System.out.println(response.getStatusLine());
if(entity != null) {
//响应内容长度
System.out.println("response length: " + entity.getContentLength());
//响应内容
System.out.println("response content: " + EntityUtils.toString(entity));
}
} finally {
response.close();
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//关闭链接,释放资源
try {
httpclient.close();
} catch(IOException e) {
e.printStackTrace();
}
}
}
~~~
(3)设置header
比如在百度搜索”httpclient”关键字,百度一下,发送请求,chrome里按F12开发者工具,在Network选项卡查看分析数据包,可以看到数据包相关信息,比如这里请求头Request Header里的信息。
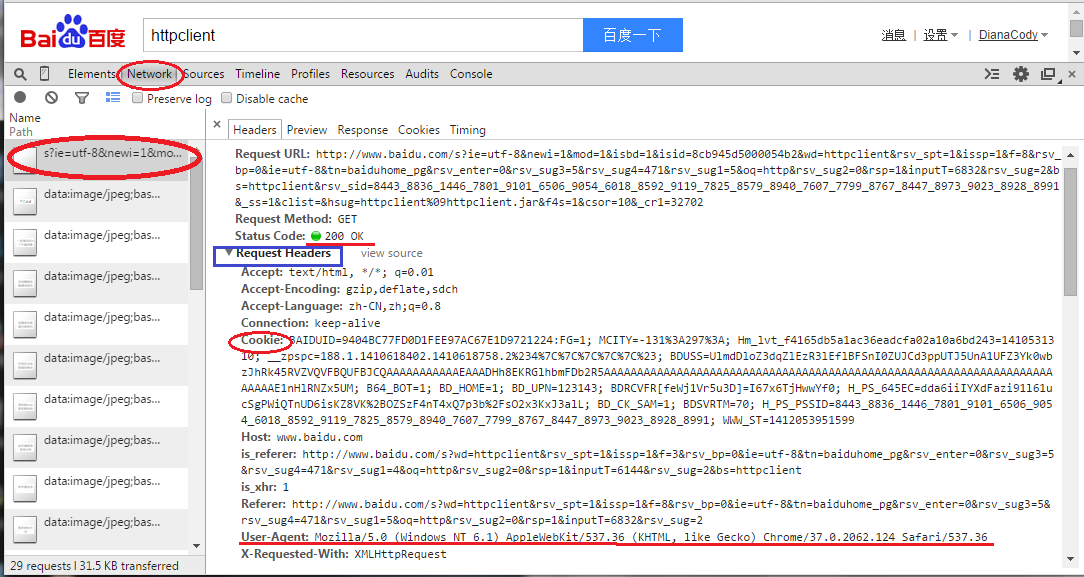
有时需要**模拟浏览器登录**,把header设置一下就OK,照着这里改吧。
~~~
public void header() {
HttpClient httpClient = new DefaultHttpClient();
try {
HttpGet httpget = new HttpGet("http://www.baidu.com");
httpget.setHeader("Accept", "text/html, */*; q=0.01");
httpget.setHeader("Accept-Encoding", "gzip, deflate,sdch");
httpget.setHeader("Accept-Language", "zh-CN,zh;q=0.8");
httpget.setHeader("Connection", "keep-alive");
httpget.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36)");
HttpResponse response = httpClient.execute(httpget);
HttpEntity entity = response.getEntity();
System.out.println(response.getStatusLine()); //状态码
if(entity != null) {
System.out.println(entity.getContentLength());
System.out.println(entity.getContent());
}
} catch (Exception e) {
e.printStackTrace();
}
}
~~~
##三、通过url得到html页面
前面说了这么多,都是些准备工作主要是HttpClient的一些基本使用,其实还有很多,网上其他资料更详细,也不是这里要讲的重点。下面来看如何通过url来得到html页面,其实方法已经在上一篇文章中说过了:[【网络爬虫】[java]微博爬虫(一):网易微博爬虫(自定义关键字爬取微博信息数据)](http://blog.csdn.net/dianacody/article/details/39584977)
新浪微博和网易微博:**(这里尤其要注意地址及参数!)**
新浪微博搜索话题地址:http://s.weibo.com/weibo/苹果手机&nodup=1&page=50
网易微博搜索话题地址:http://t.163.com/tag/苹果手机
这里参数&nodup和参数&page=50,表示从搜索结果返回的前50个html页面,从第50个页面开始爬取。也可以修改参数的值,爬取的页面个数不同。
在这里写了三个方法,分别设置用户cookie、默认一般的方法、代理IP方法,基本思路差不多,主要是在RequestConfig和CloseableHttpClient的custom()可以自定义配置。
~~~
/**
* @note 三种连接url并获取html的方法(有一般方法,自定义cookie方法,代理IP方法)
* @author DianaCody
* @since 2014-09-26 16:03
*
*/
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.net.URISyntaxException;
import java.text.ParseException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpHost;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.config.CookieSpecs;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.config.Registry;
import org.apache.http.config.RegistryBuilder;
import org.apache.http.cookie.Cookie;
import org.apache.http.cookie.CookieOrigin;
import org.apache.http.cookie.CookieSpec;
import org.apache.http.cookie.CookieSpecProvider;
import org.apache.http.cookie.MalformedCookieException;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.impl.conn.DefaultProxyRoutePlanner;
import org.apache.http.impl.cookie.BestMatchSpecFactory;
import org.apache.http.impl.cookie.BrowserCompatSpec;
import org.apache.http.impl.cookie.BrowserCompatSpecFactory;
import org.apache.http.protocol.HttpContext;
import org.apache.http.util.EntityUtils;
public class HTML {
/**默认方法 */
public String[] getHTML(String url) throws ClientProtocolException, IOException {
String[] html = new String[2];
html[1] = "null";
RequestConfig requestConfig = RequestConfig.custom()
.setSocketTimeout(5000) //socket超时
.setConnectTimeout(5000) //connect超时
.build();
CloseableHttpClient httpClient = HttpClients.custom()
.setDefaultRequestConfig(requestConfig)
.build();
HttpGet httpGet = new HttpGet(url);
try {
CloseableHttpResponse response = httpClient.execute(httpGet);
html[0] = String.valueOf(response.getStatusLine().getStatusCode());
html[1] = EntityUtils.toString(response.getEntity(), "utf-8");
//System.out.println(html);
} catch (IOException e) {
System.out.println("----------Connection timeout--------");
}
return html;
}
/**cookie方法的getHTMl() 设置cookie策略,防止cookie rejected问题,拒绝写入cookie --重载,3参数:url, hostName, port */
public String getHTML(String url, String hostName, int port) throws URISyntaxException, ClientProtocolException, IOException {
//采用用户自定义的cookie策略
HttpHost proxy = new HttpHost(hostName, port);
DefaultProxyRoutePlanner routePlanner = new DefaultProxyRoutePlanner(proxy);
CookieSpecProvider cookieSpecProvider = new CookieSpecProvider() {
public CookieSpec create(HttpContext context) {
return new BrowserCompatSpec() {
@Override
public void validate(Cookie cookie, CookieOrigin origin) throws MalformedCookieException {
//Oh, I am easy...
}
};
}
};
Registry r = RegistryBuilder
. create()
.register(CookieSpecs.BEST_MATCH, new BestMatchSpecFactory())
.register(CookieSpecs.BROWSER_COMPATIBILITY, new BrowserCompatSpecFactory())
.register("easy", cookieSpecProvider)
.build();
RequestConfig requestConfig = RequestConfig.custom()
.setCookieSpec("easy")
.setSocketTimeout(5000) //socket超时
.setConnectTimeout(5000) //connect超时
.build();
CloseableHttpClient httpClient = HttpClients.custom()
.setDefaultCookieSpecRegistry(r)
.setRoutePlanner(routePlanner)
.build();
HttpGet httpGet = new HttpGet(url);
httpGet.setConfig(requestConfig);
String html = "null"; //用于验证是否正常取到html
try {
CloseableHttpResponse response = httpClient.execute(httpGet);
html = EntityUtils.toString(response.getEntity(), "utf-8");
} catch (IOException e) {
System.out.println("----Connection timeout----");
}
return html;
}
/**proxy代理IP方法 */
public String getHTMLbyProxy(String targetUrl, String hostName, int port) throws ClientProtocolException, IOException {
HttpHost proxy = new HttpHost(hostName, port);
String html = "null";
DefaultProxyRoutePlanner routePlanner = new DefaultProxyRoutePlanner(proxy);
RequestConfig requestConfig = RequestConfig.custom()
.setSocketTimeout(5000) //socket超时
.setConnectTimeout(5000) //connect超时
.build();
CloseableHttpClient httpClient = HttpClients.custom()
.setRoutePlanner(routePlanner)
.setDefaultRequestConfig(requestConfig)
.build();
HttpGet httpGet = new HttpGet(targetUrl);
try {
CloseableHttpResponse response = httpClient.execute(httpGet);
int statusCode = response.getStatusLine().getStatusCode();
if(statusCode == HttpStatus.SC_OK) { //状态码200: OK
html = EntityUtils.toString(response.getEntity(), "gb2312");
}
response.close();
//System.out.println(html); //打印返回的html
} catch (IOException e) {
System.out.println("----Connection timeout----");
}
return html;
}
}
~~~
##四、验证是否存在HTML页面
有时请求的html不存在,比如在上篇文章中提到的情况一样,这里加个判断函数。
~~~
private boolean isExistHTML(String html) throws InterruptedException {
boolean isExist = false;
Pattern pNoResult = Pattern.compile("\\\\u6ca1\\\\u6709\\\\u627e\\\\u5230\\\\u76f8"
+ "\\\\u5173\\\\u7684\\\\u5fae\\\\u535a\\\\u5462\\\\uff0c\\\\u6362\\\\u4e2a"
+ "\\\\u5173\\\\u952e\\\\u8bcd\\\\u8bd5\\\\u5427\\\\uff01"); //没有找到相关的微博呢,换个关键词试试吧!(html页面上的信息)
Matcher mNoResult = pNoResult.matcher(html);
if(!mNoResult.find()) {
isExist = true;
}
return isExist;
}
~~~
##五、爬取微博返回的HTML字符串
把所有html写到本地txt文件里。
~~~
/**把所有html写到本地txt文件存储 */
public static void writeHTML2txt(String html, int num) throws IOException {
String savePath = "e:/weibo/weibohtml/" + num + ".txt";
File f = new File(savePath);
FileWriter fw = new FileWriter(f);
BufferedWriter bw = new BufferedWriter(fw);
bw.write(html);
bw.close();
}
~~~
爬下来的html:
来看下每个html页面,头部一些数据:

微博正文数据信息,是个json格式,包含一些信息:

至于如何解析提取关键数据,在下篇文章中再写。
原创文章,转载请注明出处:[http://blog.csdn.net/dianacody/article/details/39695285](http://blog.csdn.net/dianacody/article/details/39695285)
';