【python】网络爬虫(二):网易微博爬虫软件开发实例(附软件源码)
最后更新于:2022-04-01 23:02:40
对于urllib2的学习,这里先推荐一个教程《IronPython In Action》,上面有很多简明例子,并且也有很详尽的原理解释:[http://www.voidspace.org.uk/python/articles/urllib2.shtml](http://www.voidspace.org.uk/python/articles/urllib2.shtml)
最基本的爬虫,主要就是两个函数的使用urllib2.urlopen()和re.compile()。
##一、网页抓取简单例子
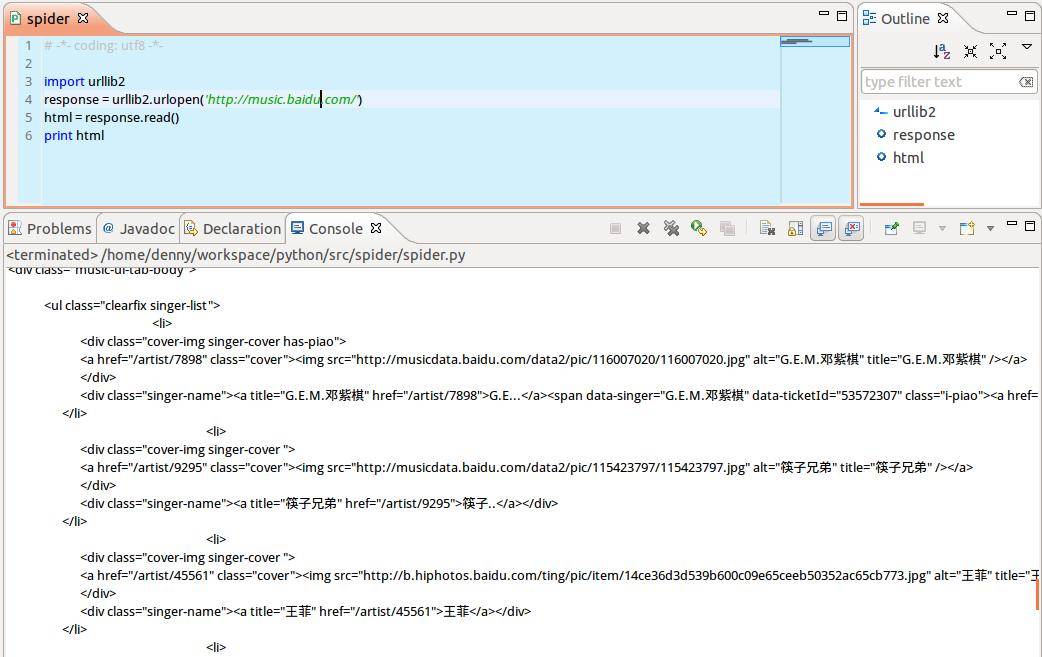
先来看一个最简单的例子,以百度音乐页面为例,访问返回页面html的string形式,程序如下:
~~~
# -*- coding: utf8 -*-
import urllib2
response = urllib2.urlopen('http://music.baidu.com')
html = response.read()
print html
~~~
这个例子主要说下urllib2.open()函数,其作用是:用一个request对象来映射发出的http请求(这里的请求头不一定是http,还可以是ftp:或file:等),http基于请求和应答机制,即客户端提出请求request,服务端应答response。
urllib2用你请求的地址创建一个request对象,调用urlopen并将结果返回作为response对象,并且可以用.read()来读取response对象的内容。所以上面的程序也可以这么写:
~~~
# -*- coding: utf8 -*-
import urllib2
request = urllib2.Request(‘http://music.baidu.com’)
response = urllib2.urlopen(request)
html = response.read()
print html
~~~
##二、网易微博爬虫实例
仍旧以之前的微博爬虫为例,抓取新浪微博一个话题下所有页面,并以html文件形式储存在本地,路径为当前工程目录。url=http://s.weibo.com/wb/苹果手机&nodup=1&page=20
源码如下:
~~~
# -*- coding:utf-8 -*-
'''
#=====================================================
# FileName: sina_html.py
# Desc: download html pages from sina_weibo and save to local files
# Author: DianaCody
# Version: 1.0
# Since: 2014-09-27 15:20:21
#=====================================================
'''
import string, urllib2
# sina tweet's url = 'http://s.weibo.com/wb/topic&nodup=1&page=20'
def writeHtml(url, start_page, end_page):
for i in range(start_page, end_page+1):
FileName = string.zfill(i, 3)
HtmlPath = FileName + '.html'
print 'Downloading No.' + str(i) + ' page and save as ' + FileName + '.html...'
f = open(HtmlPath, 'w+')
html = urllib2.urlopen(url + str(i)).read()
f.write(html)
f.close()
def crawler():
url = 'http://s.weibo.com/wb/iPhone&nodup=1&page='
s_page = 1;
e_page = 10;
print 'Now begin to download html pages...'
writeHtml(url, s_page, e_page)
if __name__ == '__main__':
crawler()
~~~
程序运行完毕后,html页面存放在当前工程目录下,在左侧Package Explorer里刷新一下,可以看到抓回来的html页面,这里先抓了10个页面,打开一个看看:
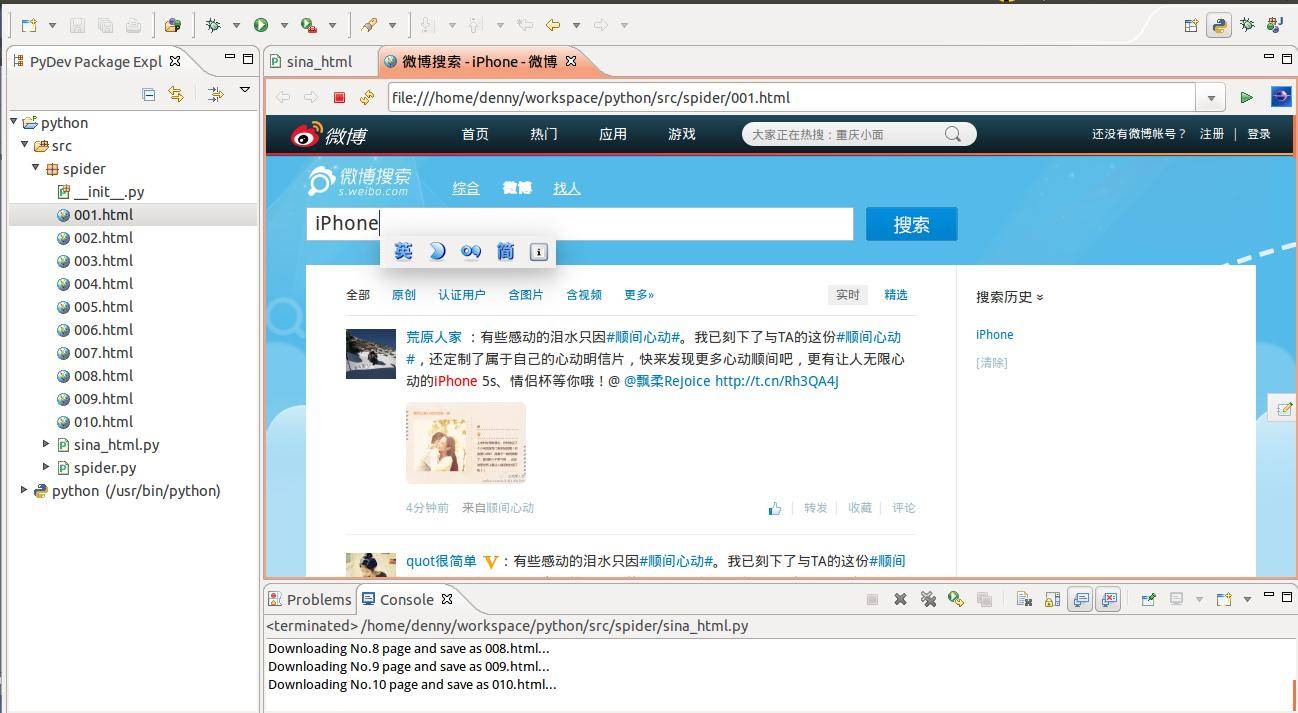
html页面的源码:
剩下的就是正则解析提取字段了,主要用到python的re模块。
##三、网易微博爬虫软件开发(python版)
上面只是给出了基本爬取过程,后期加上正则解析提取微博文本数据,中文字符编码处理等等,下面给出这个爬虫软件。(已转换为可执行exe程序)
完整源码:
~~~
# -*- coding:utf-8 -*-
'''
#=====================================================
# FileName: tweet163_crawler.py
# Desc: download html pages from 163 tweet and save to local files
# Author: DianaCody
# Version: 1.0
# Since: 2014-09-27 15:20:21
#=====================================================
'''
import string
import urllib2
import re
import chardet
# sina tweet's url = 'http://s.weibo.com/wb/topic&nodup=1&page=20'
# 163 tweet's url = 'http://t.163.com/tag/topic&nodup=1&page=20'
def writeHtml(url, start_page, end_page):
for i in range(start_page, end_page+1):
FileName = string.zfill(i, 3)
HtmlPath = FileName + '.html'
print 'Downloading No.' + str(i) + ' page and save as ' + FileName + '.html...'
f = open(HtmlPath, 'w+')
html = urllib2.urlopen(url + str(i)).read()
f.write(html)
f.close()
def crawler(key, s_page, e_page):
url = 'http://t.163.com/tag/'+ key +'&nodup=1&page='
print 'Now begin to download html pages...'
writeHtml(url, s_page, e_page)
def regex():
start_page = 1
end_page = 9
for i in range(start_page, end_page):
HtmlPath = '00'+str(i)+'.html'
page = open(HtmlPath).read()
# set encode format
charset = chardet.detect(page)
charset = charset['encoding']
if charset!='utf-8' and charset!='UTF-8':
page = page.decode('gb2312', 'ignore').encode("utf-8")
unicodePage = page.decode('utf-8')
pattern = re.compile('"content":\s".*?",', re.DOTALL)
contents = pattern.findall(unicodePage)
for content in contents:
print content
if __name__ == '__main__':
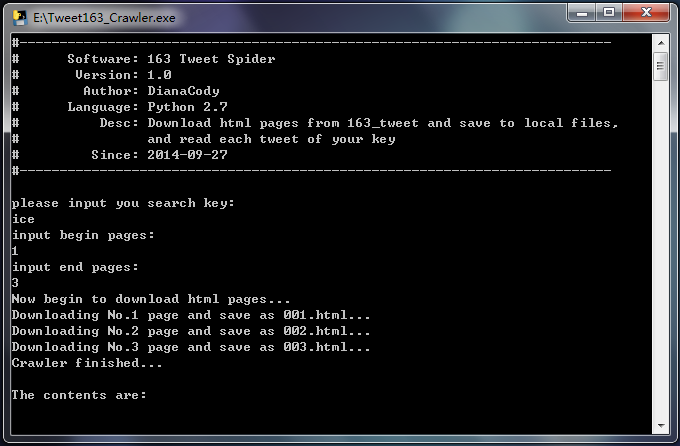
key = str(raw_input(u'please input you search key: \n'))
begin_page = int(raw_input(u'input begin pages:\n'))
end_page = int(raw_input(u'input end pages:\n'))
crawler(key, begin_page, end_page)
print'Crawler finished... \n'
print'The contents are: '
regex()
raw_input()
~~~
**实现自定义输入关键词,指定要爬取的页面数据,根据关键词提取页面中的微博信息数据。**
- 自定义搜索关键字
- 自定义爬取页面数目
- 非登录,爬取当天微博信息数据存储于本地文件
- 解析微博页面获取微博文本内容信息
- 软件为exe程序,无python环境也可运行
1.软件功能
实时爬取微博信息数据,数据源 [http://t.163.com/tag/searchword/](http://t.163.com/tag/yourkey/)
2.软件演示
1.自定义关键词、抓取页面数量
2.爬取结果显示微博文本内容
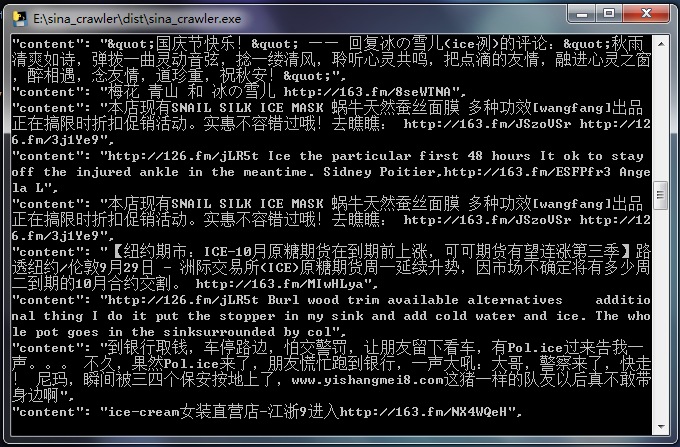
3.软件下载
软件已经放到github,地址 [https://github.com/DianaCody/Spider_python](https://github.com/DianaCody/Spider_python/tree/master/Tweet163_Crawler/release)/。
软件地址: [https://github.com/DianaCody/Spider_python/tree/master/Tweet163_Crawler/release](https://github.com/DianaCody/Spider_python/tree/master/Tweet163_Crawler/release)
exe的软件也可以在这里下载:[点击下载](http://download.csdn.net/detail/dianacody/7659093)
[http://download.csdn.net/detail/dianacody/8001441](http://download.csdn.net/detail/dianacody/8001441)
原创文章,转载请注明出处:[http://blog.csdn.net/dianacody/article/details/39741413](http://blog.csdn.net/dianacody/article/details/39741413)
';