第 23 章 使用 ATN 分析句子
最后更新于:2022-04-01 02:45:48
## 第 23 章 使用 ATN 分析句子
这一章将介绍这样一种技术,它把非确定性分析器(parser) 实现成一种嵌入式的语言。其中,第一部分将会解释什么是 ATN 分析器,以及它们是如何表示语法规则的。第二部分会给出一个 ATN 编译器,这个编译器将会使用在前一章定义的非确定性操作符。最后的几个小节则会展示一个小型的 ATN 语法,然后看看它在实际中是如何分析一段样本代码的。
### 23.1 背景知识
扩充转移网络(ATN),是 Bill Woods 在 1970 年提出的一种分析器。在那之后,ATN 在自然语言分析领域中作为一种形式化方法,被广为使用。只消一个小时,你就能写出一个能分析有意义的英语句子的 ATN 语法。出于这个原因,人们常常在初次见识 ATN 之后,就会为之着迷。
在 1970 年代,一部分研究者认为 ATN 有朝一日有可能会成为真正感觉有智能的程序的一部分。尽管时至今日,还持有这一观点的人寥寥可数,不过 ATN 的地位是不可磨灭的。它虽然没有你分析英语句子那么在行,但是它仍然能分析数量可观的各种句子。
如果你恪守下面的四个限制条件,ATN 就能大显神通:
1. 仅限用于语义上有限制的领域,比如说作为某个特定的数据库前端。
2. 不能给它过于困难的输入。比如说,请不要认为它们能像人一样能理解非常没有语法的句子。
3. 它们仅仅适用于英语,或者其他单词的顺序决定其语法结构的语言。比如说,ATN 就很可能无法被用来分析那种有屈折变化的语言,如拉丁语。
> 译者注:屈折语言(inected language),是语言学中的概念,指因为单词的变格造成语句本身结构和意思的变化。汉语和英语主要依靠单词的顺序来确定其语法结构,而屈折语言则主要根据单词的屈折变化(inection) 来表现句子中的语法关系,比如说拉丁语和德语。虽然英语不是屈折语言,但是它里面还是保留着一些形式的屈折变化。比如我们常见的人称代词的"格" 的变化,主格的he 和宾格的him,属格的his。它们的词根相同,但是词尾的变化导致了词性和意思的变化,但是其在句子中的位置仍是决定其意义的主要因素。
1. 不要认为它们总是能正常工作。如果一个应用程序里,只要求它在 90% 的情况下正常工作就足够了,那么 ATN 是可以胜任的。倘若要求它不能出丝毫的差错,那么就不应该考虑用它。
尽管有种种限制,ATN 还是能在很多地方派上用场。最典型的应用案例是用做数据库的前端。如果你给这种数据库系统配备一个用ATN 驱动的接口,用户查询的时候就不用再构造特定格式的请求,只要用一种形式受限的英语提问就可以了。
### 23.2 形式化
要理解 ATN 的工作机制,我们首先要回忆一下它的全名:
> 扩充转移网络(Augmented Transition Network)。
所谓转移网络,是指由有向路径连接起来的一组节点,从根本上可以把它看作一种流程图。其中一个节点被指定为起始节点,而部分其他节点则被作为终结节点。每条路径上都带有测试条件,只有对应的条件被满足的时候,状态才能经由这条路径转移到新的节点。首先,输入是一个序列,并有一个指向当前单词的指针。根据路径进行状态转移会使指针相应地前进。使用转移网络分析句子的过程,就是找到从起始节点走到某个终止节点的路径的过程,在这个过程中,所有的转移条件都要满足。
ATN 在这个模型的基础上另加入了两个特性:
1. ATN 带有寄存器。寄存器是有名字的 slot,它可以被用来保存分析过程中所需的有关信息。转移路径除了能进行条件判断之外,还会设置和修改寄存器中的内容。
2. ATN 的结构可以是递归的。转移路径可以这样要求:
> 如果要通过这条路径,分析过程必须能通过某个子网络。
而终结节点则使用寄存器中累积得到信息来建立列表结构并返回它,这种返回结果的方式和函数返回值的方式非常像。实际上,除了它具有的非确定性之外,ATN 的行为方式和函数式编程语言很相似。
[示例代码 23.1] 中定义的 ATN 几乎是最简单的ATN 了。它能分析形如 "Spotruns"("电视广告插播中") 的名词--动词型句子。这种 ATN 的网络表示如[示例代码 23.2] 所示。
~~~
(defnode s
(cat noun s2
(setr subj *)))
(defnode s2
(cat verb s3
(setr v *)))
(defnode s3
(up '(sentence
(subject ,(getr subj))
(verb ,(getr v)))))
~~~
[示例代码 23.1]: 一个微型ATN
~~~
noun verb pop
S S2 S3
~~~
[示例代码 23.2]: 微型ATN 的图示
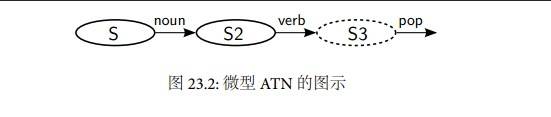
当 ATN 分析输入序列 (spot runs) 时,它是如何工作的呢?
第一个节点有一条出路径(outgoingarc),或者说一条类型路径(cat),这条路径指向节点s2。这事实上是表示:如果当前单词是个名词的话,你就可以通过我;如果你通过我的话,你必须把当前单词(即*) 保存在subj 寄存器中。因而,当离开这个节点时,subj 的内容就变成了spot。
总是有个指针指向当前的单词。在开始的时候,它指向句子的第一个单词。在经过cat 路径的时候,指针会往前移动一个单词。因此,在我们到达s2 节点的时候,当前节点会变成第二个单词,即runs 。第二条路径线和第一条一样,不同之处在于它要求的是个动词。它发现了runs ,并把它保存在寄存器v 里面,然后状态就走到了s3。
在最后一个节点s3 上,只有一个pop 路径(或称为终止路径)。(有pop 路径的节点的外围线是虚线)。由于我们正好在把输入序列读完的时候通过了pop 路径,所以我们进行的句子分析是成功的。Pop 路径返回的是一个反引用表达式:
~~~
(sentence (subject spot)
(verb runs))
~~~
一个 ATN 是与它所要分析语言的语法相对应的。一个用来分析英语的 ATN,如果规模适中的话,那么它会有一个用来分析句子的主网络,以及用来分析名词短语、介词短语,以及修饰词组等语法元素的多个子网络。让我们想一想含有介词短语的名词短语,其中,介词短语也是有可能含有名词短语的,并且这种结构可能会无穷无尽地延续下去。显而易见,要处理下面这种结构的句子,必须要能支持递归:
~~~
"the key on the table in the hall of the house on the hill"
~~~
### 23.3 非确定性
尽管我们在这个简单的例子里面没有看出来,但是 ATN 的确是非确定性的。一个节点可以有多个出路径,而特定的输入可以同时满足一个以上的出路径的条件。举个例子,一个像样的 ATN 应该既能分析祈使句也能分析陈述句。所以第一个节点要有向外的 cat 路径,与名词(用于陈述句)和动词(用于祈使句)。
要是句子开头的单词是 "time" 呢?"time" 既是名词又是动词。分析器如何知道该选哪条路径呢?如果 ATN 是以不确定的方式运行的,那就意味着用户可以认为分析器总是会猜到正确的那条路径线。如果有路径线会让分析过程走进死胡同,那么它们是不会被选中的。
实际上,分析器是无法预见未来的。它只是在无路可走,或者读完了输入还没能结束分析时,通过回溯的方式来表现出老是猜中的表象。不过所有这些回溯的机制是自动嵌入在 ATN 编译器产生的代码里面的。所以,在编写 ATN 时,我们可以认为分析器能够猜出来应该选择哪一条路径通过。
就像许多 (也许是绝大多数) 使用非确定性算法的程序所做的那样,ATN 一样,使用的也是深度优先搜索。
如果曾有过分析英语的经验,就能很快了解到,任何句子都有大把的合法分析结果,但是它们中的绝大多数都是没有意义的。在传统的单处理器电脑上,一样可以迅速得到较好的分析结果。我们不是一下子算出所有的分析结果,而只是得出最有可能的那个。如果分析结果是合理的,那么我们就用不着再去搜索其他的分析方式了;否则我们还可以调用 fail 继续搜寻更多其它的方式。
为了控制生成分析结果的先后顺序,程序员需要借助某种办法来控 制choose 尝试各待选项的顺序。深度优先实现并不是唯一一种控制搜索顺序的办法。除非选择是随机的,否则任意一种实现都会按照其特定的顺序进行选择。不过,ATN 和 Prolog 一样,深度优先实现是其内化了的实现方式。在 ATN 中,出路径被选中的顺序就是它们当初被定义的顺序。使用这样的设计,程序员就可以根据优先级来排列转换路径线的定义了。
### 23.4 一个ATN 编译器
一般来说,一个基于 ATN 的分析器由三个部分组成:ATN 本身,用来遍历这个ATN 的解释器,还有一个可以用于查询的词典。
举个例子,借助词典我们就可以知道 "run" 是个动词。说到词典,那是另一个话题了,我们在这里会使用一个比较初级的手工编制的词典。我们也不用在网络解释器上费心,因为我们会把 ATN 直接翻译成 Lisp 代码。在这里要介绍的程序被称为 ATN 编译器的原因是,这个程序能把整个的 ATN 变成对应的代码。节点会成为函数,而转换路径则会变成函数里的代码块。
第 6 章介绍了把函数作为表达方式的用法。这种编程习惯常常能让程序的运行速度更快。在这里,这意味着会免去在运行时解析网络的开销。而这样处理的缺点在于,如果出了问题的话,分析原因的线索就会更少了,特别是如果你用的 Common Lisp 实现没有提 供function-lambda-expression 的时候。
[示例代码 23.3] 中包含了所有用来把 ATN 节点转换为 Lisp 代码的源程序。其中 defnode 宏被用来定义节点。它本身生成的代码很有限,就是一个 choose ,用来在每个转换路径产生的表达式中进行选择。节点函数有两个参数,分别是 pos 和 regs:
> pos 的值是当前的输入指针(一个整数),而regs 是当前的寄存器组(为一个关联表的列表)。
宏 defnode 定义了一个宏,这个宏的名字和对应的节点相同。节点s 将会被定义成宏 s 。这种习惯做法让转换路径知道如何引用它们的目标节点 它们只要调用和节点同名的宏就可以了。这同时也意味着,你在给节点取名的时候应该避免和已有的函数或者宏重名,否则这些函数或宏会被重定义。 译者注:见CLHS 中 FunctionFUNCTION-LAMBDA-EXPRESSION 一节。
~~~
(defmacro defnode (name &rest arcs)
'(=defun ,name (pos regs) (choose ,@arcs)))
(defmacro down (sub next &rest cmds)
'(=bind (* pos regs) (,sub pos (cons nil regs))
(,next pos ,(compile-cmds cmds))))
(defmacro cat (cat next &rest cmds)
'(if (= (length *sent*) pos)
(fail)
(let ((* (nth pos *sent*)))
(if (member ',cat (types *))
(,next (1+ pos) ,(compile-cmds cmds))
(fail)))))
(defmacro jump (next &rest cmds)
'(,next pos ,(compile-cmds cmds)))
(defun compile-cmds (cmds)
(if (null cmds)
'regs
'(,@(car cmds) ,(compile-cmds (cdr cmds)))))
(defmacro up (expr)
'(let ((* (nth pos *sent*)))
(=values ,expr pos (cdr regs))))
(defmacro getr (key &optional (regs 'regs))
'(let ((result (cdr (assoc ',key (car ,regs)))))
(if (cdr result) result (car result))))
(defmacro set-register (key val regs)
'(cons (cons (cons ,key ,val) (car ,regs))
(cdr ,regs)))
(defmacro setr (key val regs)
'(set-register ',key (list ,val) ,regs))
(defmacro pushr (key val regs)
'(set-register ',key
(cons ,val (cdr (assoc ',key (car ,regs))))
,regs))
~~~
[示例代码 23.3]: 节点和路径的编译
调试ATN 时,需要借助某种 trace 工具。由于节点成为了函数,所以就用不着自己实现 trace 了。我们可以利用内建的 Lisp 函数 trace 。如同第 20.2 节提到的,只要用 =defun 定义节点,就意味着我们可以通过告诉 Lisp (trace =mods)来对节点 mods 的分析过程进行 trace。
节点函数体里面的转移路径就是宏调用,而宏调用返回的代码被嵌入在 defnode 生成的节点函数中。因此,每个节点的出路径都被表示为对应的代码,分析器每碰到一个节点,都会通过执行 choose 使用非确定性的机制来对这些代码择一执行。比如下面这个有几条出路径的节点
~~~
(defnode foo
<arc 1>
<arc 2>)
~~~
就会被变换成如下形式的函数定义:
~~~
(=defun foo (pos regs)
(choose
<translation of arc 1>
<translation of arc 2>))
(defnode s
(down np s/subj
(setr mood 'decl)
(setr subj *))
(cat v v
(setr mood 'imp)
(setr subj '(np (pron you)))
(setr aux nil)
(setr v *)))
~~~
被宏展开成:
~~~
(=defun s(pos regs)
(choose
(=bind (* pos regs) (np pos (cons nil regs))
(s/subj pos
(setr mood 'decl
(setr subj * regs))))
(if (= (length *sent*) pos)
(fail)
(let ((* (nth pos *sent*)))
(if (member 'v (types *))
(v (1+ pos)
(setr mood 'imp
(setr subj '(np (pron you))
(setr aux nil
(setr v * regs)))))
(fail))))))
~~~
[示例代码 23.4]: 节点函数的宏展开
[示例代码 23.4] 显示了[示例代码 23.11] 中作为 ATN 例子里第一个节点的宏展开前后的模样。当节点函数(如s) 在运行时被调用时,会非确定性地选择一条转移路径通过。pos 参数将会是在输入句子中的当前位置,而regs 则是现有的寄存器数据。
就像在我们最初的那个例子中见到的,cat 路径要求当前的输入单词在语法上属于某个类型。在cat 路径的函数体中,符号* 将会被绑定到当前的输入单词上。
由down 定义的 push 路径,则要求对子网络的调用能成功返回。这些路径函数接受两个目标节点作为参数,它们分别是:子网络目标节点sub ,和当前网络的下个节点,即next 。注意到,虽然为cat 路径生成的代码只是调用了网络中的下一个节点,但是为push 路径生成的代码使用的是=bind 。在继续转移到push 路径指向的节点前,程序必须成功地从子网络返回。在regs 被传入子网络前,一组新的空寄存器(nil) 被cons 到它的前面。在其他类型的转移路径的函数体中,符号* 将会被绑定到输入的当前单词上,不过在push 路径中,* 则是被绑定到从子网络返回的表达式上。
jump 路径就像发生了短路一样。分析器直接跳到了目标节点,不需要进行条件测试,同时输入指针没有向前移动。
最后一种转移路径是pop 路径,这种转移路径由up 定义。pop 路径是比较不常见的,原因在于它们没有目标节点。
就像Lisp 的return 类似,return 把程序带到的不是一个子函数,而是主调函数,而pop 路径指向的不是一个新节点,而是把程序带回"调用方" 的push 路径。pop 路径的=values "返回" 的是最近的一个push 路径的=bind 。
但是如第23.2 节所述,这产生的结果和一个普通的Lisp return 还不一样,=bind 的函数体已经被包在一个续延里了,并且被作为参数顺着之后的转移路径一直传下去,直到pop 路径的=values 把"返回" 值作为参数调用这个续延。
第22 章描述的两个版本的非确定性choose,分别是:一个快速的choose (第 22.3 节),虽然它无法保证在搜索空间里有环的情况下能正常终止;以及一个较慢的true-choose (第 22.6 节),它能在有环的情况下仍然正常工作。当然,在一个ATN 同样有可能存在环,不过只要在每个环里至少有一个转移路径能推进输入指针,那么分析器迟早都会走到句子末尾。问题是出在那种不会推进输入指针的那种环上。这里我们有两个方案:
1. 使用较慢的、真正的非确定性选择操作符(**附注**给出了其深度优先版本)。
2. 使用快速的 choose ,同时指出:如果定义的网络含有只需要顺着 jump 路径就能遍历的环,那么这个定义是错误的。
在[示例代码 23.3] 采用的是第二个方案。
[示例代码 23.3] 中的最后四个定义定义了用来读取和设置转移路径函数体中寄存器的宏。在这个程序里,寄存器组是用关联表来表示的。ATN 所使用的并不是寄存器组,而是一系列寄存器组。当分析器进入一个子网络时,它获得了一组新的空寄存器,这组寄存器被压在了已有寄存器组的上面。因此,无论何时,所有寄存器构成的集合都是作为一个关联表的列表存在的。
这些预先定义好的寄存器操作符的操作对象都是当前,或者说是最上面的那一组寄存器:getr 读一个寄存器;setr 设置寄存器;而 pushr 把一个值加入寄存器。setr和pushr 都使用了更基本的寄存器操作宏:set-register。注意到,寄存器不需要事先声明。不管传给 set-register 的是什么名字,它都会用这个名字新建一个寄存器。
这些寄存器操作符都是完全非破坏性的。"Cons,cons,cons",set-register 念念有词。这拖慢了操作符运行的速度,同时也产生了大量无用的垃圾。不过,正如第20.1 节解释的,如果程序某一部分构造了一个续延,那么就不应该破坏性地修改在这个部分用到的对象。一个正在运行的线程中的对象有可能被另一个正被挂起的线程共享。在本例中,在一个分析过程中发现的寄存器会与许多其他分析过程共享数据结构。如果速度成了问题,我们可以把寄存器保存在vector 里面,而不是关联表里,并且把用过的vector 回收到一个公用的vector 池中。
push、cat 和jump 路径都可以包含表达式体。通常情况下,这些表达式只不过会是一些setr 罢了。通过对它们的表达式体调用compile-cmds ,这些几类转移路径的展开函数会把一系列setr 串在一起,成为一个单独的表达式:
~~~
> (compile-cmds '((setr a b) (setr c d)))
(SETR A B (SETR C D REGS))
~~~
每个表达式把它后面的那个表达式作为它的最后一个参数安插到自己的参数列表中,不过最后一个表达式除外,它就是regs 。因此转移路径的函数体中的一系列表达式就会被转换成一个单独的表达式,这个表达式将会返回新的那些寄存器。
这个办法让用户能在转移路径的函数体里安插任意的Lisp 代码,只要把这些Lisp 代码用一个progn 包起来就可以了。举例来说:
~~~
> (compile-cmds '((setr a b)
(progn (princ "ek!"))
(setr c d)))
(SETR A B (PROGN (PRINC "ek!") (SETR C D REGS)))
~~~
我们有意让转移路径的函数体中的代码能访问到部分变量。被分析的句子将被放到全局的*sent* 里。还有两个词法变量也将是可见的,它们是:pos ,它保存着当前的输入指针;以及regs ,它被用来存放当前的所有寄存器。这是又一个有意地利用变量捕捉的实例。如果期望让用户不能引用这些变量,可以考虑把它们换成生成符号。
译者注:原文为 getr ,根据上下文应为setr。
宏 with-parses 是在[示例代码 23.5] 中定义的,它让我们有个办法能调用ATN。要调用它,我们应该传给它起始节点的名字、一个需要分析的表达式,以及一个代码体。这段代码告诉with-parses 应该如何处理返回的分析结果。表面上,with-parses 的功能和dolist 这种操作符差不多。实际上,在它内部进行的并不是简单的叠代操作,而是回溯搜索。每次成功的分析动作都会引起对with-parses 表达式中的代码体的一次求值。在代码体中,符号parse 将会绑定到当前的分析结果上。with-parses 表达式会返回@ ,因为这正是fail 在穷途末路时的返回值。
~~~
(defmacro with-parses (node sent &body body)
(with-gensyms (pos regs)
'(progn
(setq *sent* ,sent)
(setq *paths* nil)
(=bind (parse ,pos ,regs) (,node 0 '(nil))
(if (= ,pos (length *sent*))
(progn ,@body (fail))
(fail))))))
~~~
[示例代码 23.5]: toplevel 宏
在进一步研究表达能力更强的ATN 之前,让我们先看一下之前定义的一个微型ATN 产生的分析结果。
ATN 编译器([示例代码 23.3]) 产生的代码会调用types ,通过它了解单词的在语法上所担当的角色,所以我们需要先给它下个定义:
~~~
(defun types (w)
(cdr (assoc w '((spot noun) (runs verb)))))
~~~
现在我们只要把起始节点作为第一个参数传给with-parses ,并调用它:
~~~
> (with-parses s '(spot runs)
(format t "Parsing: ~A~%" parse))
Parsing: (SENTENCE (SUBJECT SPOT) (VERB RUNS))
@
~~~
### 23.5 一个 ATN 的例子
既然我们把ATN 编译器从头到尾都说清楚了,接下来可以找个例子小试牛刀了。为了让 ATN 的分析器能处理的句子的类型更多些,你需要把 ATN 网络,而不是 ATN 编译器弄得更复杂一些。这里展示的编译器之所以还只是个玩具,其原因是因为它的速度比较慢,而不是它在处理能力上的局限性。
分析器的处理能力(与处理速度相区别) 源自于它的语法,由于这里篇幅的限制,所以我们不得不用一个玩具版本来说明问题。从[示例代码 23.8] 到[示例代码 23.11] 定义了[示例代码 23.6] 中所示的ATN(或者说一组ATN)。这个网络的规模正好足够大,使得它能在分析那句经典的分析素材"Timeieslikeanarrow" 时,能够得出多种分析结果。
如果要分析更复杂的输入的话,我们就需要一个稍大的词典。函数types ([示例代码 23.7]) 提供了一个最基本的词典。它里面定义了一个由22 个词组成的词汇库,同时把每个词都和一个列表相关联,列表由一个或多个单词对应的语法角色构成。
ATN 也是由ATN 本身连接而成的。在本例中,我们的ATN 部件中最小的一个是[示例代码 23.8] 中的ATN。它分析的是修饰语的字符串,在这里,指的就是名词的字符串。mods 是第一个节点,它接受一个名词。第二个节点是mods/n ,它会去寻找更多的名词或者返回一个分析结果。
第2.4 节介绍了把程序写成函数式风格能让程序更易于测试的缘由:
1. 在函数式程序中,可以单独地测试程序的组成部件。
2. 在Lisp 中,可以在toplevel 的循环里交互地测试函数。
s/subj NP v v NP s v s/obj
~~~
pron
pron
det MODS noun NP
np np/det np/mod np/n np/pp
prep NP
pp pp/prep pp/np
noun
mods mods/n noun
~~~
[示例代码 23.6]: 一个规模更大的ATN
~~~
(defun types (word)
(case word
((do does did) '(aux v))
((time times) '(n v))
((fly flies) '(n v))
((like) '(v prep))
((liked likes) '(v))
((a an the) '(det))
((arrow arrows) '(n))
((i you he she him her it) '(pron))))
~~~
[示例代码 23.7]: 象征性的词典
~~~
(defnode mods
(cat n mods/n
(setr mods *)))
(defnode mods/n
(cat n mods/n
(pushr mods *))
(up '(n-group ,(getr mods))))
~~~
[示例代码 23.8]: 修饰词字符串的子网络
这两条原因合在一起,成为了我们能进行交互式开发的理由:当我们用Lisp 写函数式程序的时候,我们就
可以每写一部分代码,就测试它们。
ATN 和函数式程序非常相像,从它的实现上看,ATN 宏展开成了函数式的程序。这个相似点使得交互式的开发方式也一样适用于ATN 的开发。我们可以把任意一个节点作为起点来测试ATN,只要把节点的名字作为with-parses 的第一个参数传入:
~~~
> (with-parses mods '(time arrow)
(format t "Parsing: ~A~%" parse))
Parsing: (N-GROUP (ARROW TIME))
(defnode np
(cat det np/det
(setr det *))
(jump np/det
(setr det nil))
(cat pron pron
(setr n *)))
(defnode pron
(up '(np (pronoun ,(getr n)))))
(defnode np/det
(down mods np/mods
(setr mods *))
(jump np/mods
(setr mods nil)))
(defnode np/mods
(cat n np/n
(setr n *)))
(defnode np/n
(up '(np (det ,(getr det))
(modifiers ,(getr mods))
(noun ,(getr n))))
(down pp np/pp
(setr pp *)))
(defnode np/pp
(up '(np (det ,(getr det))
(modifiers ,(getr mods))
(noun ,(getr n))
,(getr pp))))
~~~
[示例代码 23.9]: 名词短语子网络
接下来的两个网络需要放在一起讨论,因为它们之间是互相递归调用的。[示例代码 23.9] 中定义的网络被用来分析名词短语,它从节点np 开始。在[示例代码 23.10] 中定义的网络则被用来分析介词短语。名词短语有可能含有介词短语,反之亦然。所以它们两个各自有一个push 路径,分别调用另一个网络。
名词短语网络中有六个节点。其中,第一个节点np 有三个选择。如果它读到了一个代词,那么它就可以转移到节点pron ,这会让它弹出这个网络:
~~~
> (with-parses np '(it)
(format t "Parsing: ~A~%" parse))
Parsing: (NP (PRONOUN IT))
@
~~~
另外两个转移路径都指向了节点np/det :一条路径读入一个限定词(比如说"the"),而另一条路径则直接跳转,不从输入读取任何词。在节点np/det ,两条出路径都通向np/mods ;np/det 可以选择push 到子网络mods ,以此来找出修饰词的字串,或者直接jump。节点np/mods 读入一个名词,然后转移到np/n 。这个节点要么弹出结果,要么进入介词短语网络,看看能不能碰到个介词短语。最后的节点,即np/pp ,弹出结果。
分析不同类型的名词短语所走过分析路径也各不相同。下面是两个名词短语网络的分析结果:
~~~
> (with-parses np '(arrows)
(pprint parse))
(NP (DET NIL)
(MODIFIERS NIL)
~~~
220 第23 章 使用ATN 分析句子
~~~
(NOUN ARROWS))
~~~
@
> (with-parses np '(a time fly like him) (pprint parse)) (NP (DET A) (MODIFIERS (N-GROUP TIME)) (NOUN FLY) (PP (PREP LIKE) (OBJ (NP (PRONOUN HIM))))) @
第一次分析在最后jump 到np/det ,再jump 到np/mods 读入一个名词,然后pop 到np/n ,从而成功结束。
第二次的尝试过程中没有jump 过,它首先为了匹配一个修饰词字符串push 进一个子网络,然后为了介词短语也进入了一个子网络。这应该是分析器的通病,我们的分析器也不例外:有些在句法上没有问题的表述在语义上却毫无意义,以致于人都没有办法看出它们的句法结构。这里,名词短语"atimeylikehim" 和"aLisphackerlikehim" 的形式就是一样的。
~~~
(defnode pp
(cat prep pp/prep
(setr prep *)))
(defnode pp/prep
(down np pp/np
(setr op *)))
(defnode pp/np
(up '(pp (prep ,(getr prep))
(obj ,(getr op)))))
~~~
[示例代码 23.10]: 介词短语子网络
万事俱备,只欠东风。现在我们缺的就是一个能识别整句结构的网络了。[示例代码 23.11] 中的网络同时能分析祈使句和陈述句。按照习惯,起始节点被叫做s。第一个节点首先从一个名词短语开始。第二条出路径读入一个动词。当句子在句法结构上有歧义时,两条转移路径都可能被满足,最终得到两个或更多的分析结果,如[示例代码 23.12] 所示。第一个分析结果和"Island nations like a navy" 类似,而第二个和"Find someone like a policeman" 是同一种。对于"Timeieslikeanarrow",更复杂的ATN 能找出六种以上的分析结果。
在这一章给出ATN 编译器的目的更多的在于展示如何提炼出一个ATN 思路的精髓,而不是实现一个产品级的软件。如果进行一些很明显的改进,代码的效率就能显著提升。当速度很重要的时候,用闭包来模拟非确定性这个思路从整体上说,也许就太慢了。但是如果速度不是关键问题,用本章介绍的这种编程技术可以写出十分简洁明了的程序。
~~~
(defnode s
(down np s/subj
(setr mood 'decl)
(setr subj *))
(cat v v
(setr mood 'imp)
(setr subj '(np (pron you)))
(setr aux nil)
(setr v *)))
(defnode s/subj
(cat v v
(setr aux nil)
(setr v *)))
(defnode v
(up '(s (mood ,(getr mood))
(subj ,(getr subj))
(vcl (aux ,(getr aux))
(v ,(getr v)))))
(down np s/obj
(setr obj *)))
(defnode s/obj
(up '(s (mood ,(getr mood))
(subj ,(getr subj))
(vcl (aux ,(getr aux))
(v ,(getr v)))
(obj ,(getr obj)))))
~~~
[示例代码 23.11]: 句子网络
~~~
> (with-parses s '(time flies like an arrow)
(pprint parse))
(S (MOOD DECL)
(SUBJ (NP (DET NIL)
(MODIFIERS (N-GROUP TIME))
(NOUN FLIES)))
(VCL (AUX NIL)
(V LIKE))
(OBJ (NP (DET AN)
(MODIFIERS NIL)
(NOUN ARROW))))
(MOOD IMP)
(SUBJ (NP (PRON YOU)))
(VCL (AUX NIL)
(V TIME))
(OBJ (NP (DET NIL)
(MODIFIERS NIL)
(NOUN FLIES)
(PP (PREP LIKE)
(OBJ (NP (DET AN)
(MODIFIERS NIL)
(NOUN ARROW)))))))
~~~
@
[示例代码 23.12]: 一个句子的两种分析方式