编者注 – 再见 Kenny
最后更新于:2022-04-01 06:53:13
# 编者注 - 再见 Kenny
通过 [Michael Desmond](https://msdn.microsoft.com/zh-cn/magazine/mt149362?author=Michael+Desmond) |2015 年 12 月

他们说三人先后死去会产生的操作。已此处 MSDN 杂志 》,其中我们已经看到三个大的更改到我们的专栏作家团队过去一个月的示例。
在 11 月,我们欢迎 Mark Michaelis 在板上作为作者我们新的基本.NET 专栏重点介绍 C# 和.NET Framework 开发的问题和难题时就启动操作。然后我们学到了该新型应用程序的专栏作家 Rachel Appel 已返回在 Microsoft 工作,并将不再拥有时间认真编写其列。Frank La Vigne — Microsoft 技术推广专家和他自己就偶尔 MSDN 杂志 》 作者 — 将 helming 年 1 月期刊中启动的新型应用程序。
在我们 trifecta 第三个 shakeup? Kenny Kerr,长时间运行 Windows 与 c + + 列,并且一直致力于 MSDN 杂志追溯到 2004 年,专家的作者正在作为专栏作家结束任职。如 Appel,Kerr 接受了在 Microsoft,加入 Windows 工程团队帮助为标准 c + + 生成新的 Windows 运行时语言投射的位置。
具有已 Kerr manning 重要 flank 此处 MSDN 杂志 》,提供专家覆盖范围的 c + + 编程。虽然大部分代表性的读者致力于 C# 开发 (完全 70%标识 C# 中为在我们最新读者调查其主要的编程语言),c + + 仍有 10%的 MSDN 杂志 》 的订阅服务器的主要语言。这使得它的第二个最活跃编程语言在读取器之间。
多年来,Kerr 写入了某些最广泛读取列在杂志中。他的块,"演变的线程和 I/O 在 Windows"([msdn.com/magazine/jj883951](http://msdn.com/magazine/jj883951)),请在 2013 年 1 月是我们已发布在过去五年中,根据第一个月流量的第五个最查看的列。两个其他列,《 现代 c + + 库的 DirectX 编程 》 ([msdn.com/magazine/dn201741](http://msdn.com/magazine/dn201741)) 和"使用正则表达式与现代 c + +"([msdn.com/magazine/dn519920](http://msdn.com/magazine/dn519920)),12 和 14,其分别放置,超出的时间段内的多个 450 总已发布列。对于到最多 10%的读取器将非常有吸引力的列不算坏。
Kerr 的最喜爱的 MSDN 杂志 》 文章,但是,并非他列之一。这是他为 MSDN 杂志 2014年特刊编写了在 Visual Studio 2015 和 Microsoft Azure,"Visual c + + 2015年将现代 c + + 为 Windows API"功能 ([msdn.com/magazine/dn879357](http://msdn.com/magazine/dn879357))。根据他曾编写过 for Microsoft Implements 类模板,它是 Kerr 的单大多数访问篇文章追溯到 2009年。
"实现是完全使用现代 c + + 元编程技术,而不是由 ATL 推广的传统宏繁重方法中实现 IUnknown 和 IInspectable 是可变参数类模板,"Kerr 说。"它是第一次我必须编写任何有用的可变参数模板,并证明是相当新颖且非常有效。它是而巧合的是在现代 c + + 为 Windows 运行库中的基本元编程构造之一。"
您可以告诉我们要在此处的四周错过 Kerr? 也是有一点到报表的好消息: Kerr 规划,以返回到我们的刊物编写偶尔 c + + 主题功能。如 Kerr 将其放,我们的读者不是从他的文章中受益的唯一对象。
"没有为我真正了解一些技术、 语言或技术而不是尝试对其进行解释给其他人只是没有更好的方法,"Kerr 说。"我希望开发人员享受到我的内容,但我怀疑我获得了最大好处。"
恰恰相反。我们已经荣幸您在此处输入这么长时间。
* * *
Michael Desmond *是 MSDN 杂志主编*
别让我打开话匣子 – 重构高等教育
最后更新于:2022-04-01 06:53:11
# 别让我打开话匣子 - 重构高等教育
通过 [David Platt](https://msdn.microsoft.com/zh-cn/magazine/mt149362?author=David+Platt) |2015 年 12 月

我已向学生季度的世纪现在,从开始于 1991 年 C 中的 16 位 Windows SDK 已教学软件开发主题内容已经过这些年来不断地发展演变,Win32、 COM、 Microsoft.NET Framework、 Microsoft Azure 等。但我教学的方法,以及我的同事之前, 将一直处于主要相比并无变化很好的经济衰退期从开发预算中剪切七年前,培训时的第一项。该经济沉重这迫使我们重新评估我们现有的方法,不仅能行业中的我们整个角色。
教授软件开发的最初发送以特定顺序的特定事实上居中的程序员: 第一次调用此函数,然后调用一个。RegisterWindowClass。CreateWindow。和我居最喜欢 CoMarshalInterThreadInterfaceInStream。我的学生都满意的实时教师选取这些复本 1000 页手动外的,因为替代方法阅读整件事情本身。
但是,由于此数据传输是几乎完全单向,技术发展为学生并不需要以实时的人无法告诉它。视频,例如从 Microsoft 虚拟学院或 Pluralsight,可满足很多此函数以更低的成本。这种适合于实时指令调整电影规模比实时表演更好的方法。
良好的、 有效的教育仍需要实时教师,但在不同放置做不同的事情。我们不广播"什么"如何做"我们习惯。相反,我们要保留"为什么,"我们昂贵联系人小时,"如何这与其他东西上,"或者,"下一步做从这里,"以及曾经风靡一时"WTF 那?"
因此,我已更改我的指令进行实时的类。很少显示函数调用到了这一空白一通用组。它是有关帮助我的学员将拼接到其业务逻辑的新的技术详细信息 — 嗯,让我们看一下您的代码,应在其中模块边界以及为什么? 我们应该有何种类型的测试? 我们应如何解决出我们的用户以及他们的需要? 它是完全不同类型的培训和学习。
我有许多人都跟在使这一转变。哈佛医疗学院发出类似调整其课程中,从本年度新生开始。今天的未来的医生不受"sage 上-a-阶段"spouting,"先生们,以下是 12 cranial 紧张: Olfactory、 光纤、 Oculomotor...[等]。" 相反,学生记住从类外部的说明性视频,这些基本情况。教授然后花联系时间在他们通过分析真实的问题,如: "病人的左的页眉,就像 Mr.此时表达有疑问,请并不会向下中会出现。哪些 cranial 勇气要查看第一次,以及为什么? 如何将启动执行该操作? 还有什么您看,以及为什么? 史密斯先生,显得困惑。当然还没有忘记您 cranial 紧张,您是否已经? 毫秒 Jones 请帮帮他。" 您可以阅读在整篇文章 [bit.ly/1S7UR2G](http://bit.ly/1S7UR2G)。
顺便说一下,这篇文章指出"视频是介于 5 到 8 个分钟之间...因为学生的关注范围不会持续很久了。" 未,您会感到恐慌尽量它带来的? 我想知道是否我们极客如今有长或更短的关注范围。
我在我的用户体验类中使用的实际操作模型。不是如何实现此功能或一个 (颜色渐变,比如)。这个数字大约是决定的内容应该以使用户更加开心、 也更高效实现。除非客户端具有一个实际的设计项目以在这些课程实验期间处理的我很少讲授的内部类。我鼓励我公共类,以使其自己的项目中的学生,如果它们不这样做,我为他们分配一个。
正如我在我第一次的别让我打开专栏 ([msdn.com/magazine/ee309884](http://msdn.com/magazine/ee309884)),一种错误的计算机程序要求其用户变得更像是一台计算机。但最好程序使用的计算机进行良好,清除供人们不要仅人类可以跟踪哪些计算机。
教育需要以类似的方式,而逐步演化且最佳的人工教师已开始认识到这一点。它是一回事放入学生的 h e a d 特定事实。它是一个完全不同的事项,更令人满意的事情,为了帮助他们将这一事实工作。
* * *
David S.Platt *讲授在哈佛大学拓展学院以及世界各地的公司的.NET 编程。他著有 11 本编程书籍,包括“Why Software Sucks”(Addison-Wesley Professional,2006)和“Introducing Microsoft .NET”(Microsoft Press,2002 年)。Microsoft 在 2002 年授予他“软件传奇人物”称号。他想知道是不是应该绑住女儿的两根手指,以便她学习用八进制计数。您可以通过 [rollthunder.com](http://rollthunder.com/) 与他联系。*
新式应用 – 需要了解的 Windows 10 应用开发概念
最后更新于:2022-04-01 06:53:08
# 新式应用 - 需要了解的 Windows 10 应用开发概念
作者 [Rachel Appel](https://msdn.microsoft.com/zh-cn/magazine/mt149362?author=Rachel+Appel) | 2015 年 12 月
我想分享一些关于 Windows 10 应用开发的看法,以帮助您了解和更高效地使用它。不过,本文涉及的一些功能适用于一般用户,让开发者了解这些功能绝对是一个好主意,这样可以让开发者从用户的角度了解所构建的软件具有的好处。
## Visual Studio 2015
大多数 Microsoft 开发者使用的 IDE 是 Visual Studio。您首先注意到的一些 Visual Studio 2015 变更包括:经过简化的全新安装程序,以及使用多个帐户登录的功能。对于许多作为顾问和全职员工的开发者(需要白天使用公司网络,晚上在应用商店上发布应用)来说,这真是太棒了。
Visual Studio 安装中包含大量可用的第三方工具。Xamarin 开箱即用,认真执行跨平台开发只需使用这一个软件。不过,您必须通过选择选项,将它添加到安装中。除了 C# (Xamarin) 之外,您还可以通过选择选项来安装适用于 Android 的 Java,以及适用于 iOS 和 Android 的基于 C 的语言。
通常,对于 Visual Studio 版本和授权,几乎需要获得博士学位,才能理解或记住功能和版本的对应关系。幸运的是,您可以访问 [bit.ly/1COm2fP](http://bit.ly/1COm2fP),详细了解和比较 Visual Studio 2015 产品和服务。
每版新发布的 Visual Studio 都会带来全新的一组模板。现在,在 ASP.NET 中,模板使用依赖关系注入(通过整个 ASP.NET MVC 6 应用可用)启用松散耦合的网站构建。在 Microsoft 官方商城中部署的应用主要侧重于通用 Windows 平台 (UWP) 应用概念,这让开发者能够使用基本通用代码构建应用,通用代码适用于运行应用的所有 Windows 操作系统和设备。使用 C#、Visual Basic、JavaScript 或 C++ 可以创建 UWP 应用。在此专栏的后面部分,我将详细介绍 UWP 应用。
## 在全新的 Edge 浏览器上启用 Edge
最显而易见且最常谈及的 Windows 变更之一是 Edge 浏览器,其带来了平稳、快速的浏览体验。在使用 Edge(即使很短一段时间)后,您就会相当明显地发现,这不是父辈们使用的 Internet Explorer。首先,它对浏览体验进行了数千项改进 ([bit.ly/1G49Cwe](http://bit.ly/%c3%82%c2%ad1G49Cwe))。最显而易见的改变是 Edge 流畅的界面(包含许多可自定义内容的起始页)以及整体外观。图 1 展示了 Windows 10 上 Edge 浏览器中的 MSDN 杂志主页。
图 1:提供时尚、平稳的浏览体验的 Edge 浏览器
Edge 浏览器的首要任务始终都是提供互操作性。
每个浏览器都需要一个或多个引擎来处理构成目前网页的 HTML、CSS 和 JavaScript。因此,Edge 团队设计了全新的 HTML 处理引擎(名为 EdgeHTML)。互操作性带来了诸多好处,包括方便您在无缝开发跨平台 Web 应用的同时,创建在各种设备和外形规格上完美显示的 HTML。此团队已在 EdgeHTML 中实现了 45 项新 HTML 标准 ([bit.ly/1G49Cwe](http://bit.ly/1G49Cwe))。
您会发现 Internet Explorer 中使用的同一 Chakra 引擎。Chakra 运行速度极快且性能良好,因此最好保留它并进行一些微调。它的极快速度归功于多项因素,主要因素是一项称为图形处理单元 (GPU) 卸载的技术。Chakra 卸载,或发送脚本至 GPU 进行处理。也就是说,脚本在 GPU 上运行,与此同时 HTML 及“好友”在通常执行处理的 CPU 上运行。在 Internet Explorer 团队实现了此功能之后,其他浏览器也很快开始实现它。您可以查看 Windows 博客 ([bit.ly/1X0Npt0](http://bit.ly/1X0Npt0)),详细了解 Edge 中的 Chakra 性能。
您可以浏览 Edge 开发者指南 ([bit.ly/1jwFYec](http://bit.ly/1jwFYec)),此指南出于有效使用考虑,对 F12 工具的重大变化进行了完整分类列举。一些新增的精彩功能包括设置 XHR 断点,以及在 DOM 资源管理器中查看网页。
## 通用 Windows 平台
智能手机和平板电脑的 Web 流量巨大,不过也有许多用户使用桌面设备浏览 Web。现在,网站和应用必须绝对支持多种设备和外形规格。
Windows 10 是真正的通用 Windows 操作系统系列。现在,对于所有 Windows 10 设备,您都可以只构建和维护一个基本代码、一个包,并能向一个应用商店只提交一次。也就是说,这包括一切设备,从手机、平板电脑和笔记本电脑到台式机、超极本和服务器。只要您说得出名字,UWP 应用就可以在上面运行。
## Windows 通知为我提供消息
谁不喜欢手机、计算机及其他设备可以提醒您所有事项呢(无论对您是否重要)? 您邻居的朋友的姐妹 36 岁生日? 好的,知道了! 现在,您可以提醒用户与您应用相关的各种事项。前提是用户允许这样做。一些用户会关闭通知功能。对于不喜欢这些提醒的用户,他们可以在系统设置中开启“有关 Windows 的提示”,以及全系统范围内或应用特定的通知。
您的应用通知配备有全新的操作中心,它的图标位于屏幕右下角的 Windows 通知区域内(亦称为“系统托盘”)。单击通知图标可调出新式浮出控件窗口,其中包含兼容触摸功能的磁贴(位于等待处理的消息列表下)。当然,如果用户允许,您应用的通知也会显示在通知区域中。
创建通知的代码本质上仍与之前相同,通知的显示位置及其整体外观均由 Windows 控制。当然,您可以从许多预定义通知模板中选择一个,从而在某种程度上自定义外观。选择如此之多,找到一个满足您需求的模板应该没有问题:
~~~
ToastTemplateType toastTemplate = ToastTemplateType.ToastImageAndText01;
XmlDocument toastXml =
ToastNotificationManager.GetTemplateContent(toastTemplate);
~~~
有关详细信息,请参阅 MSDN 库中的“使用磁贴、锁屏提醒和 Toast 通知 (XAML)”一文 ([bit.ly/1LPogJw](http://bit.ly/1LPogJw))。
## 与 Cortana 对话
Windows Phone 让全世界认识了 Cortana。Cortana 是 Microsoft 语音数字助理,允许您使用语音命令执行各种任务,如安排约会时间、查询路线和提取最新的新闻和天气。Cortana 可以协助您完成许多日常活动。如此宝贵而有益的软件有资格使用 SDK;Windows 10 中新增了许多功能,如背景语音命令和连续听写。您甚至可以使用语音 SDK 启用文本到语音转换 (TTS)。使用语音命令和语音识别技术是构建较高质量的产品(不仅具有可见 UI)的绝佳方式。
若要构建启用语音的 Windows 应用,请创建和注册语音定义文件 (.vcd),其中列出了您应用中可用的命令、字词和短语,就像您在旧版 Windows 和 Visual Studio 中一样操作。然后,您可以使用 C#、JavaScript 或所需的其他语言编写您的应用,并让 Cortana 将命令转换成口头形式。代码相当简单(如图 2 中所示),其中替代了 OnActivated 事件来检测发出的是哪个命令,以便应用可以执行操作。
图 2:.vcd 文件的内容和随附的 C# 代码
~~~
<?xml version="1.0" encoding="utf-8"?>
<VoiceCommands xmlns="http://schemas.microsoft.com/voicecommands/1.0">
<CommandSet xml:lang="en-us">
<CommandPrefix> Options </CommandPrefix>
<Example> Show Options</Example>
<Command Name="showOptions">
<Example> Show options </Example>
<ListenFor> [Show] {optionViews} </ListenFor>
<Feedback> Showing {optionViews} </Feedback>
<Navigate Target="/options.xaml"/>
</Command>
<PhraseList Label="optionViews">
<Item> today's specials </Item>
<Item> best sellers </Item>
</PhraseList>
</CommandSet>
<!-- Other CommandSets for other languages -->
</VoiceCommands>
protected override void OnActivated(IActivatedEventArgs args)
{
if (args.Kind ==
Windows.ApplicationModel.Activation.ActivationKind.VoiceCommand)
{
var commandArgs =
args as Windows.ApplicationModel.Activation.VoiceCommandActivatedEventArgs;
Windows.Media.SpeechRecognition.SpeechRecognitionResult
speechRecognitionResult =
commandArgs.Result;
string voiceCommandName = speechRecognitionResult.RulePath[0];
string textSpoken = speechRecognitionResult.Text;
string navigationTarget =
speechRecognitionResult.SemanticInterpretation.
Properties["NavigationTarget"][0];
switch (voiceCommandName)
{
case "showOptions":
// EventReminder(textSpoken, navigationTarget);
break;
// default:
// There is no match for the voice command name
}
}
}
~~~
## Windows 应用商店
全新的 Windows 应用商店为所有人都提供其想要的。对于企业,Windows 应用商店允许管理员为员工展示应用。他们甚至可以分发 Windows 应用商店中的精选应用,从而部署专用业务线应用。此外,采购订单现在是一种已被接受的付款方式。在 Windows 10 中,应用商店现在提供订阅作为额外的货币化选项。
作为应用商店更新的一部分,Windows 10 Microsoft 广告 SDK 目前支持视频广告。一些营销专家表示,视频和多媒体比文字更能提高销售率,那么现在您可以在您的应用中验证这一假说了。幸运的是,由于 Microsoft 宣布了安装跟踪这一新功能,因此您就有办法这么做了。
## 连续体
不过,所有这些 UWP 应用开发都不仅仅局限于跨设备体验。Windows 10 上的 Continuum 可检测您何时想在多功能设备上切换使用模式。以 Francine Flyer 为例,此用户在飞机上使用 Surface 的桌面模式完成了一些工作,现在想看电影。Francine Flyer 只需拆离键盘,即可轻松地在桌面设备和平板电脑模式之间切换。Windows 会通知并询问她是否想要切换到更加兼容触摸功能的模式。Flyer 点按“是”,此时 Windows 进入兼容触摸功能的模式,然后她就可以享受电影了,没有碍手碍脚的键盘或鼠标。如您所见,Continuum 适用于 Surface、混合或变形本笔记本电脑/平板电脑以及任意种类的多功能设备。即使笔记本电脑的触摸屏没有变形本功能,用户仍可在切换模式时受益。受益于 Continuum 的不仅仅局限于大型设备。当用户在手机上连接无线键盘、鼠标和屏幕时,借助适用于手机的 Continuum,用户可以像使用桌面应用一样使用您的应用。周围有这么多与平板手机一样大小的设备,Continuum 当然会得到妥善利用。
## 全新的“开始”(菜单)
绝对最显而易见但可能最具争议的变更是 Windows“开始”菜单。可以说,在计算机发展史中确实有几个 UI“麻烦制造者”,Windows“开始”菜单当然就是其中一个。每当有 Windows 新版本推出,喜欢和不喜欢“开始”菜单变更的人数各占一半。当 Windows 8 中引入新式体验后,新设计得到很多人的称赞,但也有许多人坚持拥护经典的范式并抵制变更。现在,在 Windows 10 中,“开始”菜单发生了一些非常显著的变化。
就目前来看,将磁贴移到“开始”菜单是优于之前的设计(再加上桌面和起始页之间的工作流略有波动)。将此与 Continuum 结合,我们现在就有了增强优化的“开始”菜单,起始页只出现在应有的位置上(在诸如平板电脑、手机之类的触控设备上)。如果您更喜欢键盘快捷方式,请注意 Windows 键盘键已经推出了一段时间。您可以开始键入您应用的名称或想要执行的操作,然后 Windows 会查找相应的应用或执行您希望的操作。
## 调整为自适应用户体验
从概念上讲,在 Windows 操作系统系列上进行的自适应开发与 Web 响应式设计类似。不过,自适应开发以整个设备系列为目标,而响应式开发则以屏幕尺寸范围为目标。在过去几年中,跟上市场上不同设备的爆发式发展节奏是不可能的。有些软件是针对购买新的智能手机的用户,但却引发了分析瘫痪。您能想象如果需要开发适用于所有这些设备的软件是怎样一种境况吗? 幸运的是,Windows 10 可以确定在运行时托管应用的设备或用户如何使用应用,然后相应地调整用户体验。也就是说,诸如浮出控件或其他控件之类的元素可以自动重设大小,或应用更大或更小的字体,具体视分辨率而定。在设计自适应解决方案之前,请务必查阅 MSDN 库中的“适用于通用 Windows 平台 (UWP) 应用的初级设备”一文 ([bit.ly/1MpspVh](http://bit.ly/1MpspVh))。
## 一个 Windows 平台
Windows 10 的一大精选功能是 UWP 应用的出现。UWP 应用是一种您只需使用一种基本代码,即可在所有 Windows 操作系统中部署的应用。 通常,此策略只对后端和逻辑起作用;不过,对于构建 UI,这也是一个更平稳的流程。那是因为,与其定位不同的操作系统和编写同一 UI 代码的多个版本,您不如定位整个设备系列,这样可以减少构建 UI 的麻烦。不过,如果您只想定位一个特定的操作系统,则可以这样做。否则,您需要构造的 UI,使其在设备系列适应 Continuum 的最小和最大尺寸范围内出色运行。XAML 以及 Windows JavaScript 库 (WinJS) 中发生了多项 API 和控件变更。特别是,XAML 带来了新的日历控件,以及用于放置日历的新自适应面板控件。
作为开发者,您可以利用 Visual Studio 中的单一解决方案来处理,因为我们将基础的基本代码称为“一个 Windows 平台”。借助这一解决方案模型,自适应控件和技术使用很少的代码或不使用代码,就可以调整为适应各种设备系列。
## 总结
Windows 一直在重塑用户体验环境,以满足用户的需求。您可以在您的应用中构建许多新的精彩功能,如 API 和控件变更。语音是输入也很容易被忽视,所以对于您的下一个应用,别忘了考虑一下 Cortana。从 Windows 应用商店到 Visual Studio,Windows 10 致力于提供平稳的开发和用户体验。
* * *
Rachel Appel *是一位顾问、作家、导师和前 Microsoft 员工,在 IT 行业有 20 多年的经验。她常在 Visual Studio Live!、DevConnections、MIX 等顶级行业大会上发言。她的专业是开发侧重于 Microsoft 系列开发技术和开放式 Web 并且符合业务和技术需要的解决方案。有关 Appel 的详细信息,请访问她的网站 [rachelappel.com](http://rachelappel.com/)。*
必备 .NET – 设计 C# 7
最后更新于:2022-04-01 06:53:06
# 必备 .NET - 设计 C# 7
作者 [Mark Michaelis](https://msdn.microsoft.com/zh-cn/magazine/mt149362?author=Mark+Michaelis) | 2015 年 12 月

当您阅读本文时,C# 7 设计团队已讨论、规划、实验和计划了大约一年之久。在本期中,我将介绍他们一直在探讨的一些观点示例。
在查看时,请注意目前这些仍是要在 C# 7 中体现的观点。虽然一些观点只是经过了团队讨论阶段,但另一些观点已进入了实验实现阶段。无论如何,所有这些概念均尚未最终敲定;很多观点可能会夭折;甚至是那些已经进入后期阶段的观点也可能会在最终确定语言的最后几个阶段被推翻。
## 声明可以为 null 和不可以为 null 的引用类型
C# 7 讨论中涌现的一些最重要的观点也许与进一步改进 null 的处理方式有关,类似于 C# 6.0 的 null 条件运算符。其中最简单的一项改进可能是,在执行编译器或分析器验证(访问可以为 null 的类型实例)之前,先检查类型实际上是否是不可以为 null 的类型。
如果需要不可以为 null 的引用类型,且您能够完全避免 null,会怎样? 此观点旨在声明引用类型是会允许 null (string?),还是会避免 null (string!)。从理论上讲,甚至可以假定新代码中的所有引用类型声明默认情况下都不可以为 null。然而,正如与我合著“必备 C# 6.0”一书的作者 Eric Lippert 所指出的,确保在编译时引用类型永远不为 null 极为困难 ([bit.ly/1Rd5ekS](http://bit.ly/1Rd5ekS))。即便如此,还是可以确定类型可能为 null且尚未取消引用的的情况,而无需检查是否是不可以为 null 的类型。或者,也可能发生以下情况:类型可能被分配为 null,尽管声明意图是分配不可以为 null 的类型。
为了扩大受益范围,设计团队正在讨论能否对参数使用不可以为 null 的类型声明,以便自动生成 null 检查(尽管这可能会成为一项可选决定,以避免任何非预期的性能降低,除非可以在编译时这样做)。
(讽刺的是,C# 2.0 添加了可以为 null 的值类型,因为在很多情况下(如从数据库中检索的数据),有必要让整数包含 null 值。现在,在 C# 7 中,设计团队正在考虑支持相反的引用类型。)
对于不可以为 null 的类型(例如,string! 文本)的引用类型支持,另一个有趣考虑是公共中间语言 (CIL) 中的实现情况。两个最常用的方案是将它映射到 NonNullable 类型语法,或者像在 [Nullable] 字符串文本中一样利用属性。后者是目前的首选方法。
## 元组
元组是设计团队考虑为 C# 7 添加的另一项功能。此主题已在早期语言版本中多次被提出,但仍未予以落实。根据此观点,可以在集合中声明类型,这样声明中就能包含多个值;同样地,方法也可以返回多个值。若要理解此概念,请查看下面的示例代码:
~~~
public class Person
{
public readonly (string firstName, int lastName) Names; // a tuple
public Person((string FirstName, string LastName)) names, int Age)
{
Names = names;
}
}
~~~
如列表所示,借助元组支持,您可以将类型声明为元组,其中包含两个或多个值。可以在使用数据类型的所有情景(包括字段、参数、变量声明或方法返回)中利用此功能。例如,下面的代码片段会从方法中返回元组:
~~~
public (string FirstName, string LastName) GetNames(string! fullName)
{
string[] names = fullName.Split(" ", 2);
return (names[0], names[1]);
}
public void Main()
{
// ...
(string first, string last) = GetNames("Inigo Montoya");
// ...
}
~~~
在此列表中,有返回元组的方法,以及 GetNames 结果被分配到的第一个和最后一个变量声明。请注意,此分配是基于元组内的顺序(而不是接收变量的名称)。想想我们目前使用的一些替代方法(如数组、集合、自定义类型或输出参数),元组确实具有吸引力。
可以将许多选项与元组结合使用。下面介绍了一些审议选项:
* 元组可以有命名或未命名的属性,如下所示:
~~~
var name = ("Inigo", "Montoya")
~~~
和:
~~~
var name = (first: "John", last: "Doe")
~~~
* 结果可以是匿名类型或显式变量,如下所示:
~~~
var name = (first: "John", last: "Doe")
~~~
或:
~~~
(string first, string last) = GetNames("Inigo Montoya")
~~~
* 您可以将数组转换成元组,如下所示:
~~~
var names = new[]{ "Inigo", "Montoya" }
~~~
* 您可以按名称访问各个元组项,如下所示:
~~~
Console.WriteLine($”My name is { names.first } { names.last }.”);
~~~
* 可以推断未明确指定的数据类型(大体上遵循匿名类型使用的相同方法)
尽管元组还有很多复杂之处,但在大多数情况下,元组遵循的是语言内架构完善的结构,所以它们可以强有力地支持 C# 7 中的功能。
## 模式匹配
模式匹配也是 C# 7 设计团队经常讨论的主题。或许,关于模式匹配的一种更易理解的呈现是,在 case 语句中支持表达式模式(而不仅仅是常量)的扩展 switch(和 if)语句。(若要与扩展 case 语句对应,switch 表达式类型不能局限于拥有对应的常量值的类型)。借助模式匹配,您可以查询模式的 switch 表达式。例如,您能够查询 switch 表达式是特定的类型、具有特定成员的类型,还是匹配特定“模式”或表达式的类型。例如,假设 obj 可能是 Point 类型,并且其 x 值大于 2:
~~~
object obj;
// ...
switch(obj) {
case 42:
// ...
case Color.Red:
// ...
case string s:
// ...
case Point(int x, 42) where (Y > 42):
// ...
case Point(490, 42): // fine
// ...
default:
// ...
}
~~~
有趣的是,当给定的表达式作为 case 语句时,也有必要允许表达式作为 goto case 语句上的自变量。
为了支持 Point 类型的 case 语句,Point 上必须有一些处理模式匹配的成员类型。在此示例中,需要可提取两个 int 类型的自变量的成员。例如,成员:
~~~
public static bool operator is (Point self out int x, out int y) {...}
~~~
请注意,如果没有 where 表达式,case Point(490, 42) 可能永远无法达到,进而会导致编译器发出错误或警告。
switch 语句的限制因素之一是,它不返回值,而是执行代码块。模式匹配的新增功能可以支持返回值的 switchexpression,如下所示:
~~~
string text = match (e) { pattern => expression; ... ; default => expression }
~~~
同样,is 运算符可支持模式匹配,不仅允许进行类型检查,还支持就类型上是否存在特定成员进行更通用的查询。
## 记录
作为 C# 6.0 中考虑添加的简化“构造函数”声明语法(但最终遭到拒绝)的延续,支持在类定义中嵌入构造函数声明,我们将这种概念称为“记录”。 例如,假设声明如下:
~~~
class Person(string Name, int Age);
~~~
此简单语句会自动生成以下内容:
* 构造函数:
~~~
public Person(string Name, int Age)
{
this.Name = Name;
this.Age = Age;
}
~~~
* 只读属性,从而创建不可变类型
* 等同性实现(如 GetHashCode、等于、运算符 ==、运算符 != 等)
* ToString 的默认实现
* “is”运算符的模式匹配支持
尽管会生成大量代码(考虑到仅仅一个很短的代码行就创建了它的全部),但我们希望可以为手动编码(本质上是样本实现)提供相应的重要快捷方式。此外,所有代码都可以被视为显式实现中的“默认”代码,其中的任意内容将具有优先权,并阻止生成相同的成员。
与记录有关的一个更棘手的问题是,如何处理序列化。相当典型的做法大概是将记录用作数据传输对象 (DTO),但仍不明确如何(若有措施)支持此类记录的序列化。
与记录相关的是,支持 with 表达式。借助 with 表达式,您可以根据现有对象对新对象进行实例化。以 person 对象声明为例,您可以通过以下 with 表达式新建一个实例:
~~~
Person inigo = new Person("Inigo Montoya", 42);
Person humperdink = inigo with { Name = "Prince Humperdink" };
~~~
生成的与 with 表达式对应的代码如下所示:
~~~
Person humperdink = new Person(Name: "Prince Humperdink", Age: inigo.42 );
~~~
不过,另一建议是与其依赖 with 表达式的构造函数签名,更可取的做法是将它转换成 with 方法的调用,如下所示:
~~~
Person humperdink = inigo.With(Name: "Prince Humperdink", Age: inigo.42);
~~~
## 异步流
为了加强 C# 7 中的异步支持,处理异步序列的概念非常新奇。以 IAsyncEnumerable 为例,它的属性为 Current 且方法为 Task MoveNextAsync。您可以使用 foreach 循环访问 IAsyncEnumerable 实例,并让编译器负责异步调用流中的每个成员,即执行 await 以确定序列(可能是信道)中是否有要处理的另一元素。对此,还有很多需要评估的注意事项;其中最不需要注意的是,所有返回 IAsyncEnumerable 的 LINQ 标准查询运算符可能会出现的 LINQ 膨胀。此外,如何公开 CancellationToken 支持和 Task.ConfigureAwait 仍不确定。
## 命令行上的 C#
我热衷于研究 Windows PowerShell 如何让 Microsoft .NET Framework 可用于命令行接口 (CLI),我特别感兴趣的一个方面(也许是我最喜欢的一项审议功能)是支持在命令行上使用 C#;通常将这个概念称为支持读取、求值、打印、循环 (REPL)。正如人们所希望的一样,REPL 支持会随附 C# 脚本功能,这在不繁琐的简单方案中不需要使用所有常见形式(如类声明)。没有编译步骤,REPL 会需要新指令来引用程序集和 NuGet 包,以及导入其他文件。目前正在讨论中的方案会支持:
* 用于引用其他程序集或 NuGet 包的 #r。变体是 #r!,它甚至允许访问内部成员,尽管有一些约束。(这适用于您有要访问的程序集的源代码的情况。)
* 用于添加整个目录的 #l(与 F# 类似)。
* 用于导入其他 C# 脚本文件的 #load,方法与您在项目中添加脚本文件几乎相同,不同之处在于现在顺序很重要。(请注意,可能不支持导入 .cs 文件,因为不允许在 C# 脚本中使用命名空间。)
* 在执行的同时开启性能诊断的 #time。
您可以期待即将与 Visual Studio 2015 Update 1 一同发布的首版 C# REPL(以及支持相同功能集的已更新交互式窗口)。有关更多信息,请访问 [Itl.tc/CSREPL](http://itl.tc/CSREPL),以及查看我下个月的专栏。
## 总结
虽然有准备了一年的材料,但若要探究设计团队的所有工作,我们还有其他太多信息需要了解。即使是我介绍的那些观点,您也还是需要考虑其他许多详细信息(注意事项和优势)。不过,我希望您现在已经了解设计团队一直在探讨的观点,以及他们正如何寻求改进已经非常出色的 C# 语言。如果您想直接查阅 C# 7 设计说明,并提供您自己的反馈意见,则可以跳转到 [bit.ly/CSharp7DesignNotes](http://bit.ly/CSharp7DesignNotes) 进行讨论。
* * *
Mark Michaelis *是 IntelliTect 的创始人,担任首席技术架构师和培训师。在近二十年的时间里,他一直是 Microsoft MVP,并且自 2007 年以来一直担任 Microsoft 区域总监。Michaelis 还是多个 Microsoft 软件设计评审团队(包括 C#、Microsoft Azure、SharePoint 和 Visual Studio ALM)的成员。他在开发者会议上发表了演讲,并撰写了大量书籍,包括最新的“必备 C# 6.0(第 5 版)”([itl.tc/EssentialCSharp](http://itl.tc/%c3%82%c2%adEssentialCSharp))。可通过他的 Facebook [facebook.com/Mark.Michaelis](http://facebook.com/Mark.Michaelis)、博客[IntelliTect.com/Mark](http://intellitect.com/Mark)、Twitter @markmichaelis 或电子邮件 [mark@IntelliTect.com](mailto:mark@IntelliTect.com) 与他取得联系。*
Microsoft Azure – Azure、Web API 和 Redis 如何有助于加快数据交付
最后更新于:2022-04-01 06:53:04
# Microsoft Azure - Azure、Web API 和 Redis 如何有助于加快数据交付
通过 [Johnny Webb](https://msdn.microsoft.com/zh-cn/magazine/mt149362?author=Johnny+Webb), ,[Sean Iannuzzi](https://msdn.microsoft.com/zh-cn/magazine/mt149362?author=Sean+Iannuzzi) |2015 年 12 月
在今天的 worldof 实时营销、 死亡的旋转圆,经常伴随等待加载或搜索查询以填充的页面真正意味着销售的死亡。随着越来越多的数据记录的创建、 存储和分析,生成的丰富,实时数据洞察力增长不断更具挑战性。问题就是如何选择适当的技术工具和体系结构,以便最好地筛选数以百万计的数据记录并交付更好的客户体验的即时结果。
本文将探讨我们在其中帮助实现 Redis 和 Web API 的客户端最新的用例。我们将讨论我们实现的方法,我们遇到的难题和如何我们最终实现的性能要求。
## 业务挑战
几个月前,财富 100 强多样的保险和金融服务组织接近 Harte 衷心感谢,一家全球性市场营销公司,使用的新计划。该公司希望在线的保险报价过程提供更好、 更丰富的客户体验。若要执行此操作,它需要以启用对客户的策略数据的快速、 积极主动的访问。
目标是以使客户能够查看和选择一个或多个保险策略是通过 Internet 自助服务或代理面向应用程序。从根本上讲,这将导致更高版本的业务价值、 提高了客户满意度、 更快的报价单绑定速率和改进的代理授权过程。为了使这成为现实,在报价过程中进行处理时所需的客户的存储的详细信息和数据匹配,并且主动,提供几乎即时的方式。
客户端的数据库包含超过 50 万条记录,这意味着与任何传统数据库这种性质的请求通常会需要多长时间加载。我们已任务提供支持此较大的数据源上执行查询并将结果传送到几毫秒的时间的使用者的 Web 服务。
对于此任务中,我们计算的 Redis 和 Web API 的实现。总体的度量值因素是:
* 事务请求
* 对象的请求
* 每秒的响应
* 数据的总带宽
* 总吞吐量的站点
## 实现过程: 我们是如何做到了
构建 Web 服务来公开数据,要求提供特定功能的组件的多个层。随着 Web 服务的需求的发展,支持这些层的基础结构必须修改并快速缩放。和可伸缩性是必需的但同样重要的是可用性,并必须始终被视为为了让使用者满意。此外,还必须监视和使用特定的身份验证协议,以确保受保护的数据并将数据与最大性能安全地传递包装公开的终结点。为了满足这些要求对于我们的解决方案,我们就利用了 Microsoft Azure。在 Azure 中,我们部署了资源包括虚拟机、 Web 应用程序、 虚拟网络、 资源组的组合和可用性集来构建一个完备、 高质量的解决方案。
## 数据层
由于我们的解决方案的大部分都生成使用 Microsoft 堆栈,因此我们在大多数情况下利用 Microsoft SQL Server 一点非常有意义。但是,此解决方案的 SLA 要求在具有超过 50 万条记录的数据集上指定的服务响应时间是小于 1 秒,每个请求,以每小时,大约 6000 请求的速率。类似于 SQL Server 的传统数据库将数据存储到磁盘和 IOPS 的瓶颈,因为我们无法保证每个查询将通过这一要求。若要进一步复杂化了,我们已公开所需的数据子集属于传统的数据库包含千吉字节的不相关的数据。为此,我们开始评估可能快速支持大型数据集的解决方案。即,当我们发现 Redis。
Redis 是内存中数据结构存储,支持多个数据类型。关键的服务器要求包括 Linux 分发,足够的 RAM 来封装你的数据和实现数据持久性足够的磁盘空间。Redis 也可配置为群集中,但这是更适合于具有千吉字节的数据的解决方案。由于我们的数据集是小于 50 GB,所以我们决定使其保持简单并且设置了单一的主/从配置。若要托管此配置,我们在虚拟网络内的两个 CentOS 7.1 虚拟机在 Azure 上创建。每个虚拟机包含为 56 GB 内存、 静态 IP 地址和 SSH 终结点使用 AES256 加密。由于这两个 Vm 共享提供的一组,Azure 将提供 99.95 %sla 保证正常运行时间。另一个好处,我们创建的所有资源被都附加到资源组创建专为此解决方案,使我们能够监视和管理在每月的基础上计费。在几分钟内,我们的虚拟机已部署并对我们可用。
站着我们的 Redis 服务器是简单和造诣颇也在一小时内。在下载并安装到我们新创建的服务器上的最新稳定版本之后, 我首先想知道我们修改了配置文件以允许 Redis 所调用的仅限追加的文件 (说明) 持久性。简单地说,这意味着发送到我们的实例的每个命令会存储到磁盘。如果要重新启动服务器,所有则重新执行命令,将服务器还原到其原始状态。若要消除臃肿的说明,BGREWRITEAOF 命令,将触发有时,重写命令重新生成内存中的当前数据集所需的最短序列的文件。此外,我们配置了 50 GB,创建一个缓冲区,并且如果加载的数据过多占用了所有的系统内存会阻止 Redis 的最大内存用途。这一点,如果我们的解决方案曾经需要更多内存,我们可以轻松地调整 VM 使用 Azure 门户的大小和更新配置更高版本。接下来,我们配置了要确认创建的数据复制到主机的从属服务器实例。如果主实例变得不可用,从设备实例会准备好为客户端提供服务。最后,我们重新启动 Redis 服务器进行配置后,才会生效。下面是我们使用的配置:
~~~
appendonly yes
maxmemory 50000000000
slaveof 10.0.0.x 6379
# cluster-enabled no
~~~
## 数据加载和基准测试
我们需要从我们的传统数据库加载到 Redis 的数据包含大约 4 GB 的客户的元数据。此元数据是每日更新,因此我们需要创建一个进程定期将其转换成 Redis 数据类型和大容量加载它以使我们的解决方案保持最新。若要执行此操作,我们创建自动化的过程以提取到 Redis 协议格式的文件中的每日更改集,并传输到使用可用的 SSH 终结点的主服务器。在主实例中,我们创建了 bash 脚本,以进行大容量加载文件使用管道模式。若要强调,管道模式是解决方案的因为我们很快就在 5 分钟内加载 28 万条记录我们的关键元素。请注意,但是,该管道模式下尚不可用群集实现兼容。在我们最初的原型设计阶段,我们发现,将 28 万条记录加载到群集需要花费大量时间因为记录已单独传输。这是在我们的决策,以保持简单的主/从实现的设计中一个重要的因素。管道模式命令和响应的单个实例如下所示:
~~~
$ cat data.txt | redis-cli –pipe
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 1000000
~~~
在管道模式下执行之后, 响应指示接收到多少个错误和答复。我们分析的脚本中此响应、 存档的文件和电子邮件通知发送给相应的技术团队。对于每个错误,技术无法评估提取并快速确定需要重新加载任何数据。在完成后的日常处理脚本,我们计算速度达到我们使用 Redis 基准检验实用程序的实现。图 1 显示我们的解决方案,它会满足我们的 SLA 要求 reassuring 我们的性能结果。
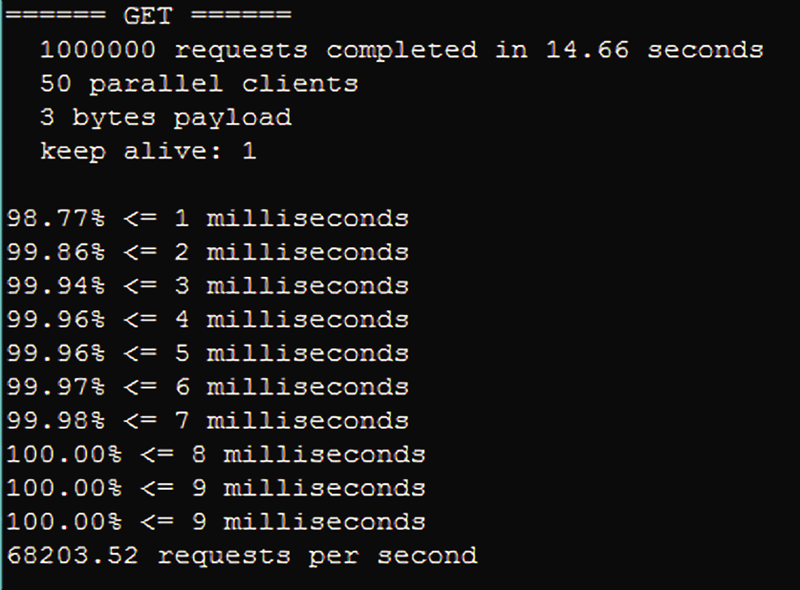
图 1 Redis 基准
## 服务层
它非常重要,我们的客户端是我们的解决方案的唯一消耗者。幸运的是,Azure 可简化此任务使用访问控制服务使我们能够创建 OAuth 提供程序专用于我们的解决方案。实现后,我们的服务所需的每个请求,使用新令牌在 5 分钟后重新生成特定的令牌。同时也请注意,该令牌应始终保持不变到期前。请求新令牌为每个服务调用将实质上是妨碍您的解决方案或者,更糟糕的是,使其无法访问如果超过指定由 Azure 的请求限制。我们强烈建议任何人利用读取 Azure 的文档,然后再在生产环境中实现此功能。
有多个 C# Redis 客户端,但我们使用 StackExchange.Redis,因为我们认为它是最流行且成熟。因为所有的数据存储在组中,我们使用 LRANGE 命令来查询数据。若要防止每个查询的重新连接,使用 StackExchange.Redis 的连接将在一个单独模式中管理。中的示例 图 2 演示我们如何检索数据。
图 2 连接到 Redis 和检索数据
~~~
private static Lazy<ConnectionMultiplexer> lazyConnection =
new Lazy<ConnectionMultiplexer>(() => {
return ConnectionMultiplexer.Connect(
ConfigurationManager.AppSettings[Constants.AppSettings.RedisConnection]);
});
public static ConnectionMultiplexer Connection
{
get
{
return lazyConnection.Value;
}
}
public async static Task<MemberResponse> MemberLookup(MemberRequest request)
{
MemberResponse response = new MemberResponse();
try
{
if (request != null && request.customer != null && request.customer.Count() > 0)
{
foreach (var customer in request.customer)
{
Customer c = customer;
RedisKey key = GetLookupKey(c);
IDatabase db = Connection.GetDatabase();
c.policies = await db.ListRangeAsync(key, 0, -1, CommandFlags.None);
response.customer.Add(c);
}
response.success = true;
}
else
{
response.exceptions = new List<ServiceException>();
response.exceptions.Add(Classes.ErrorCodes.Code_101_CustomerRequired);
response.success = false;
}
}
catch (Exception ex)
{
response.exceptions = new List<ServiceException>();
response.exceptions.Add(Classes.ErrorCodes.Code_100_InternalError);
response.success = false;
Logging.LogException(ex);
}
response.executedOn =
Utils.FormatEST(DateTime.UtcNow).ToString(Constants.DateTimeFormat);
return response;
}
~~~
若要承载我们在 Azure 中的解决方案,我们创建了一个 Web 应用程序。为获得最佳性能非常重要,我们部署 Web 应用程序到 Redis 实例所在的同一区域。一旦部署该应用程序后,我们创建 VNET 连接到我们 Redis 虚拟网络,允许服务以获取对数据的直接访问权限。此连接中进行了演示 图 3。
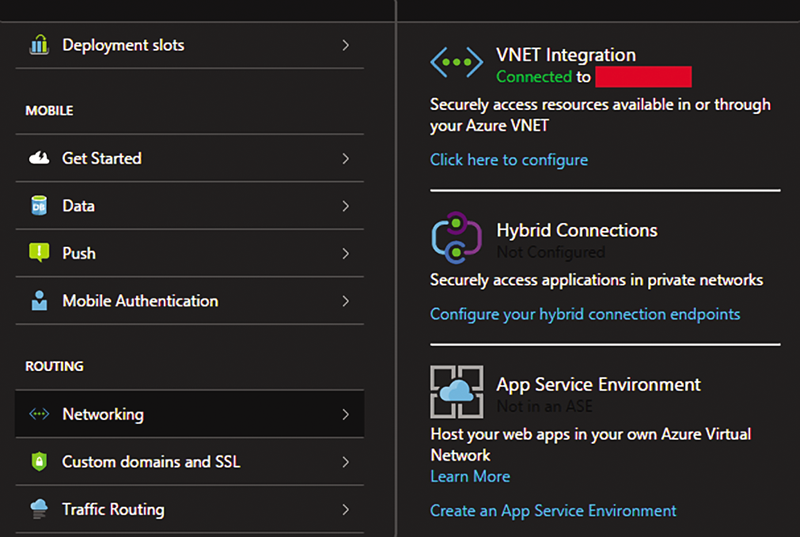
图 3 VNET 集成连接
配置此 Web 应用扩展到基于 CPU 使用情况的 10 个实例。因为我们的解决方案的流量很多种,Web 应用程序才可缩放在必要时。一层额外的安全,SSL 证书被应用到应用程序,以及 IP 筛选专门为我们的客户端。尽管应用程序被配置为自动缩放,但它不自动故障转移。为了最大化到我们的客户端的解决方案的可用性,我们创建的主 Web 应用程序中,克隆,但放在不同的区域。这两个应用程序已添加到 Azure Traffic Manager,后者我们利用进行自动故障转移。
最后,我们购买自定义域,并创建一个指向完成我们的实现我们流量管理器 URL 的 CNAME 记录。若要监视的每日我们的解决方案的性能,我们已购买 New Relic 直接从 Azure 应用商店的实例。通过使用 New Relic 中,我们无法快速确定需要改进,以及服务器的可用性的方面。
## 总结
通过将此解决方案部署到 Azure,我们学到了如何使不同的技术堆栈配合快速以提供一个功能强大、 成功的解决方案。尽管将解决方案部署到 Azure 不会清除服务器维护,如果您按照位置中的模式,则必须成功。根据您的解决方案的平均持续时间,您可以保存对硬件成本的所有解决方案都迁移到云。
实现结束时,平均响应时间为 25 毫秒为 50 个并发用户。根据这些结果,响应时间是每 15 添加的并发用户的扩展大约 10 毫秒。
* * *
Sean Iannuzzi *是 Harte 衷心感谢 h e a d 的技术,已在发挥着关键作用中的大量的社交网络,大数据的技术和业务前景之间的隔阂 20 多年来,本技术行业中数据库解决方案,云计算、 电子商务和今天的财务应用程序。Iannuzzi 具有与 50 多个独特的技术平台的体验、 已取得了很多技术的奖励认证和专门从事推动技术指导和解决方案来帮助实现业务目标。*
Johnny Webb *是 Harte 衷心感谢的软件架构师和已经实施了尖端技术为人所熟知的客户端使用过去十年中的高质量解决方案。他的专业知识包括完整的软件开发生命周期,以及 Microsoft.NET Framework 中,软件体系结构、 云计算,Web 开发、 移动开发、 API 开发、 SQL 数据库和 NoSQL 数据库。*
孜孜不倦的程序员 – 如何成为 MEAN: 快速输入
最后更新于:2022-04-01 06:53:01
# 孜孜不倦的程序员 - 如何成为 MEAN: 快速输入
通过 [Ted Neward](https://msdn.microsoft.com/zh-cn/magazine/mt149362?author=Ted+Neward) |2015 年 12 月

欢迎回来,"Nodeists。"(我已建立的为那些定期使用 Node.js endearment 半官方词。如果您不喜欢它,将一封电子邮件或使用更好的建议 tweet 拖至,应谨记我其他两个的观点是"Noderati"或"Nodeferatu。")
在上一期中,大小已达到应用程序的 Web API 终结点获取的人员 (我的资源为此应用程序; 集合窗体中包含一些输出功能,我似乎要构建某种类型的用户数据库) 或者通过给定的 URL 的一部分为任意"id"的各个人员。就可以开始处理输入 — 能够将新的用户放到系统中,从系统中移除用户,并更新现有人员。在某些方面,这些是"只是"新的 URL 终结点应用程序,但有一些新技巧,我想谈一谈此过程。
我前面提到的最后一次,那些有兴趣查看最新版本-和-的最大编写此系列的一部分的可访问 Microsoft Azure 网站的代码,它持有此序列的代码 (msdn mean.azurewebsites.net) 的最新。很可能文本在此处使用在站点上,提供发布计划是什么是同步的但如果任何内容,该网站就会领先于什么在这里,它为读者提供的展望迎接下一步。
谈到的最后一列,截至上一期的代码可以在数据库中,显示现有人员但其中没有修改说明,否则还。因为这通常是联机的任何系统的关键部分,让我们添加到"R"以完成出 CRUD"CUD"。
## 另一个 Bites 灰尘...
若要实现第一次也是最容易 CRUD 中的"D": 删除。设置 Express 中的路由需要仅使用代码,而非 get 使用上一次删除:
~~~
app.delete('/persons/:personId', deletePerson);
~~~
还记得我的上一篇专栏,": personId"是一个参数,将出现在关联的函数 (deletePerson) 中的 Express"必需"(请求) 对象和拾取也描述了最新时间、 personId 中间件函数,以便您可以知道要从系统中删除人员。
说到 deletePerson,实现相对来说比较简单,使用 lodash remove 方法在内存中数据库中搜索和删除所述的个人 (请参阅 图 1)。
图 1 使用 Lodash Remove 方法
~~~
var deletePerson = function(req, res) {
if (req.person) {
debug("Removing", req.person.firstName, req.person.lastName);
_.remove(personData, function(it) {
it.id === req.person.id;
});
debug("personData=", personData);
var response = { message: "Deleted successfully" };
res.status(200).jsonp(response);
}
else {
var response = { message: "Unrecognized person identifier"};
res.status(404).jsonp(response);
}
};
~~~
PersonId 中间件将选取: personId (无论它的值)、 在数据库中找到适当的 person 对象和放置,为人对传入的请求 ("请求") 对象属性,因此如果没有 req.person,这意味着没有人会通过该 ID 在数据库中找。当您发送响应时,但是,而不是将结果到 JSON 转换是通过内置的 JSON.stringify 方法,从先前的文章中,使用 jsonp 方法将数据转换为 JSON 格式的 — 或者,若要更准确,被广泛认为可以向浏览器发送 JSON 返回的上级 (和更安全) 的方式为 JSONP (且填充 JSON) 格式。请注意该方法如何调用"链";这意味着您可以使用一个 fluent 代码行组成此人已成功,删除一条消息或 404,人的标识无法识别的消息的 JSON 响应一起发回的任一 200。
## 获取向我的数据库
接下来,应该到数据库可能支持放置的人。同样,这是非常简单的路由: Web API 的拥护者按传统方法,建议使用发布到的资源集合 URL (/ 人员) 的方式,将插入到数据库,那么做,如:
~~~
app.post('/persons', insertPerson);
~~~
不特别令人兴奋。但是,新的小问题就会显现出来: 为了插入到系统的人员,您将需要挑选 person 数据从传入的请求的 JSON。做到这一点的一种方法是获取整个请求正文使用 req.body 参数,但再从左到适用于存储对象分析 JSON 的繁重 (和略有危险) 的任务。相反,这其中 Node.js 社区立足于库中,其广泛集合并且果然,没有好的库有,解决了该问题,称为正文分析器。安装它 ("npm 安装正文的解析程序"作为 package.json 的相同目录中),然后可以引用它,并告知速成版应用程序对象来使用它:
~~~
// Load modules
var express = require('express'),
bodyParser = require('body-parser'),
debug = require('debug')('app'),
_ = require("lodash");
// Create express instance
var app = express();
app.use(bodyParser.json());
~~~
回想一下这个问题的讨论之前大约: personId,有关如何快速允许您创建以作为管道的一部分无提示方式执行少量工作的中间件函数? 这正是正文分析器库的作用,它将安装大量"挂钩"(for lack of 更好的词) 处理中各种形式的请求正文。在这里,你要让它来分析 JSON,但它也可以支持 URL 编码、 分析所有内容为特大字符串 (使其成为更轻松地分析 CSV,例如),或到 Node.js 缓冲区抓取"原始"的所有内容 (大概是因为传入的数据是某种形式的二进制文件)。因为我们关心稍后再试大部分处理 json 中,只需使用该就足够了。
InsertPerson 函数,则实际上确实 anticlimactic:
~~~
var insertPerson = function(req, res) {
var person = req.body;
debug("Received", person);
person.id = personData.length + 1;
personData.push(person);
res.status(200).jsonp(person);
};
~~~
(好了,唯一 id 生成代码无法使用了大量工作,但请记住的目标是最终使用 MongoDB,因此,让我们不会花大量时间考虑。)
在从 insertPerson 返回时,该代码发送回完整 Person 对象刚插入,包括其新的 id 字段;这不是一个完全标准约定,但在我自己的代码中我发现它很有帮助。这种方式客户端时注意到任何其他验证/更正/服务器的一侧的增加的已提交的实体,如 id 字段在此情况下。
## 如何发布三个?
顺便说一下,有关这种方式 (而不是更传统的 Web 应用程序) 构建 Web API 值得关注的部分之一是,一些简单的戏法,用于执行应急测试对您不适用。例如,如何您快速测试以查看 insertPerson 函数的工作? 当然,还有大量的支持自动执行在 Node.js 中测试和随后在将来的专栏中,但现在,是最容易使用任一浏览器插件 (如 Chrome Postman) 或者,因忠实的命令行风扇 cURL 免费软件实用程序随附预先安装在 OS X 和大多数 Linux 上图像。您不喜欢其中任何一个,是否存在许多其他所有的复杂性,从临时到自动化的整个整个范围内拉伸包括一个我的收藏夹,Runscope ([runscope.com](http://runscope.com/)),以进行的内容全天候运行自动测试 API 终结点,一个基于云的系统。
无论您使用什么,如果您不喜欢它,移动速度快,因为实际上有数千个所以。
## 与邻居保持为最新
最后,应用程序需要支持更新的人员已经在该数据库。在许多方面,这是组成的复杂程度 (在数据库中查找适当的人员) 的删除和插入 (分析传入 JSON),但已安装的中间件可处理的大部分程序,如中所示 图 2。
图 2 更新数据库中已人
~~~
var updatePerson = function(req, res) {
if (req.person) {
var originalPerson = req.person;
var incomingPerson = req.body;
var newPerson = _.merge(originalPerson, incomingPerson);
res.status(200).jsonp(newPerson);
}
else {
res.status(404).jsonp({ message: "Unrecognized person identifier" });
}
};
// ...
app.put('/persons/:personId', updatePerson);
~~~
中的关键所在 图 2 是 lodash 方法合并,枚举整个第二个参数的属性使用,或者会覆盖具有相同名称的第一个参数的属性,否则将在其添加。它是复制的第二个放在第一个属性,而不销毁并重新创建的第一个对象 (这很重要,这种情况下,因为第一个对象是 personData 数组,用作我们的临时数据库中) 的简单方法。
对于一些好奇的人,则返回 true 的分支的 if 语句无法压缩下移到一行代码:
~~~
var updatePerson = function(req, res) {
if (req.person) {
res.status(200).jsonp(_.merge(req.person, req.body));
}
else {
res.status(404).jsonp({ message: "Unrecognized person identifier" });
}
};
~~~
… 但是这是否是可读更多或更少是由您来决定。
## 总结
对于所期望的人,开始在本系列文章的第二部分的生命周期的 app.js 文件现在是完全 100 行代码 (其中包含有关半打行注释),并且现在支持完整的 CRUD Web API 对内存中数据库。这不是一个世纪相当于在文本编辑器中的错误。但还有多事情需要做: 系统需要摆脱使用内存中数据库向使用 MongoDB,并为此而不会破坏所有已在使用此高度那里 prized Web API 的客户端必须是测试。没有人希望获得其进行测试,又一遍地手工,因此接下来的步骤是将添加自动的测试,以确保转换到 MongoDB 是无缝且简单从客户端的角度来看。同时...祝您编码愉快 !
* * *
Ted Neward *是 iTrellis,基于西雅图的 polytechnology 咨询公司的 CTO。他曾写过 100 多篇文章,是一个 F # MVP、 INETA 发言人,并且具有编写或与他人合著过十几本书。与他联系。[ted@tedneward.com](mailto:ted@tedneward.com) 如果您感兴趣他参与使用你的团队,或阅读他的博客 [tedneward.com](http://tedneward.com/)。*
Xamarin – 使用 Xamarin.Forms 构建跨平台用户体验
最后更新于:2022-04-01 06:52:59
# Xamarin - 使用 Xamarin.Forms 构建跨平台用户体验
通过 [Keith Pijanowski](https://msdn.microsoft.com/zh-cn/magazine/mt149362?author=Keith+Pijanowski) |2015 年 12 月 | [获取代码](http://download.microsoft.com/download/D/5/4/D54647CC-A404-4374-B7EF-E469FB5136B9/Code_Pijanowski.Xamarin.1215.zip)
如果您已决定使用 Xamarin 进行试验,则您已决定启动令人兴奋之旅。与其他开发工具,它将您绑定到单个平台,Xamarin 为四个不同的平台,可以访问。借助 Xamarin,您可用于您的 C# 技能编写适用于 iOS、 Android、 Windows Phone 和 Mac OS X 应用程序。请务必注意 Xamarin 提供了完全本机体验。获取本机性能,完成在所有平台和本机 UI 上的 API 访问。本文将重点介绍三个移动平台支持的 Xamarin: iOS、 Android 和 Windows Phone。
使用 Xamarin 的优势是令人兴奋,原因有多种。原因之一是使用平台 Xamarin 是它们充满乐趣。Xamarin 是了解在同时使用 C# 技能的更多详细信息中的所有这些平台的天堂。而无需在多个工作区 (Xcode、 Android Studio/Eclipse 和 Visual Studio) 中工作的多种语言 (C#、 Java 和目标的 C/Swift),您可以在一个熟悉的环境 (Visual Studio) 使用一种语言 (C#) 进行工作。
也有几个使用 Xamarin 开发应用程序的财务优点。借助 Xamarin,您可以创建一个单一的解决方案可以呈现 iOS、 Android、 Windows Phone 上的应用程序的版本和设置这些平台表示显著的成本节约和工作效率提升之间重用 OS x。 代码重用和技能。当涉及到从中获利您的应用程序时,基本的经济性决定,增加了潜在客户创建更多的机会,为获取更多付费客户。总体来说,Xamarin 所支持的三个移动平台在全球范围内表示 98%以上的所有移动设备。
最后,如果您是构建移动企业业务线 (LOB) 应用程序,然后让创建相关的所有平台的解决方案的功能意味着,员工可能使用他们自己的设备进行工作。
## 传统的 Xamarin 方法
传统 Xamarin 解决方案,它支持所有三个移动平台由作为最低保护措施的四个项目组成 — 可移植类库 (PCL) 和每个平台的特定于平台的项目。PCL (或共享的代码项目) 包含模型、 数据访问代码和业务逻辑。PCL 中的代码可以引用,并可以重复使用从其他项目。但是,Pcl 包含任何 UI 代码。UI 代码都保留在特定于平台的项目。也很重要注意的是传统的 Xamarin 旨在提供本机编程环境以及它们所代表的平台的功能奇偶校验。你可以在 OBJECTIVE-C、 Swift 或 Java 实现的所有内容可以在 C# 中使用 Xamarin 和 Visual Studio。您想要访问在 iOS、 Android 和 Windows Phone 可以; 上的任何 APIXamarin 具有 100%本机 API 访问权限。此代码也是特定于平台的项目中。
在传统的 Xamarin 方法将允许您在共享大量的代码时,没有一种方法来共享更多的代码。
## 输入 Xamarin.Forms
Xamarin.Forms 进一步推送信封的情况下,仍谈到可重用性。具体而言,Xamarin.Forms 同时还允许跨平台重用的 UI 逻辑提供传统方法所有的优点。Xamarin.Forms 解决方案仍然结构化方式与传统的 Xamarin 相同,但是,PCL 现在可以包含用户界面代码。有关项目设置和房子映像和其他资源,则跨平台的不同,仍需要特定于平台的项目。
它也就的不足为奇 Xamarin 的人员也会尝试执行此操作。即使 iOS、 Android 和 Windows Phone 的目的是不同的体系结构设计师,并且在不同屋顶下长大,还有大量其 Ui 的通用性。用户一次查看一页内容。此外,许多控件在平台之间很相似。示例、 文本框、 下压按钮、 单选按钮、 标签,列表视图和图像控件是相对相同的跨平台。总的来说,Xamarin.Forms 附带了 40 控件、 七个布局和五种页面类型用于构建本机 Ux。
Xamarin.Forms 采用的编程模型是 XAML / C#。页面、 布局和控件可以使用 XAML 中与在 Windows Phone 项目中创建的页更相同的方式指定。也可以完全在代码中创建页面、 布局和控件。这两种方法将在本文中所示。
当使用 Xamarin.Forms 什么可能会比较棘手是设计和实现用户界面,可以将组织应用程序的功能和内容。这必须在最大化代码重用在生成的应用程序很自然要使用每个平台上的相同时间一种方法中完成。为此,Xamarin 提供了五种页面类型来提供常见 UI 方案: 用于显示基本内容,则内容页用于提供导航功能; 导航页用于创建具有跨顶部或底部的屏幕; 选项卡页的选项卡式的页面跨两个窗格的信息; 提供高级的数据和详细信息数据的母版-详细信息页和用于创建水平滚动内容的页面的轮播页。本文将演示每种方案的 Xamarin.Forms 解决方案,通过讨论每个五种页面类型。页面布局和 Xamarin.Forms 附带的 UI 控件也会显示此过程。
## 显示内容
在屏幕上显示的基本内容是通过内容页。图 1 显示用于捕获用户反馈的页面的 XAML。
图 1 的内容页面的 XAML
~~~
<?xml version="1.0" encoding="UTF-8"?>
<ContentPage xmlns="http://xamarin.com/schemas/2014/forms"
xmlns:x="http://schemas.microsoft.com/winfx/2009/XAML"
x:Class="XamarinFormsTestHarness.FeedbackPage"
Title="Feedback">
<StackLayout Padding="10,10,10,10">
<Label Text="Name:" FontAttributes="None" FontSize="Medium" TextColor="#3498DB"/>
<Entry Text="{Binding Name}" Placeholder="First and Last" Keyboard="Default"/>
<Label Text="Email:" FontSize="Medium" TextColor="#3498DB" />
<Entry Text="{Binding Email}" Placeholder="name@company.com" Keyboard="Email" />
<Label Text="Feedback:" TextColor="#3498DB" FontSize="Medium"/>
<Editor Text="{Binding Text}" HeightRequest="200" BackgroundColor="Gray"/>
<Button x:Name="ButtonSubmitFeedback" Text="Submit"
BackgroundColor="#3498DB"
TextColor="White"
Command="{Binding SaveFeedbackCommand}"/>
</StackLayout>
</ContentPage>
~~~
中的 XAML 图 1 使用堆栈布局来组织标签、 项、 编辑器和按钮等基本控件。作为 Xamarin.Forms 本机功能的示例,在 iOS 上一项呈现为 UITextField、 EditText 为 Android 和文本框中为 Windows Phone。
需要注意的一点说明: Xamarin XAML 是不同于 Windows Phone XAML。不能使用从 Windows Phone 页面的 XAML,并将其放到 Xamarin 内容页。例如,如果您习惯于使用边距和填充属性对您的控件的位置进行细微调整,则您将不高兴,若要了解这些属性不可用许多 Xamarin.Forms 控件中。此外,许多控件和它们的属性具有与它们对应的 Windows Phone 相比不同的名称。这些差异可能看起来像一种新产品的症状。在许多情况下这可能是为 true,但还请记住 Xamarin 并非仅针对 Windows Phone 开发人员。Xamarin 旨在提供了用于所有背景的移动开发人员环境。如果某个控件以它在 Window Phone 不名为相同,可能会使用 Xamarin 的名称是来自于 Android 或 iOS 的名称。
内容页是用于所有其他页类型的构造块。轮播页面、 选项卡式页面、 导航页和母版详细信息页面使用内容页来生成其 Ux。
## 母版详细信息方案
母版详细信息方案都是在移动应用程序中很常见。因此,Xamarin 生成特定的页面类型来处理此情况。母版详细信息页上可用的应用程序功能或应用程序数据进行组织。例如,管理客户和订单的应用程序,客户的列表可以显示在主页面。一旦在用户触摸特定客户,则可以在详细信息页显示该客户的所有订单。母版详细信息页面也用于显示应用程序的菜单选项。在此方案中,主页面显示应用程序中可用的功能列表和每个详细信息页会提供相应的功能。图 2 显示了使用作为适用性应用程序的主菜单的母版详细信息页的构造函数代码。图 3 演示如何在主机页面全部呈现在每个平台。主页面全部呈现在 iOS 和 Android 作为从屏幕的左边算幻灯片中的弹出菜单。在 Windows Phone 上它将呈现为一个完整的页。当用户按某个选项时,它们都会转到合适的页面。
图 2 母版详细信息页的代码
~~~
using System;
using Xamarin.Forms;
namespace XamarinFormsTestHarness
{
public class MasterDetailControlPage : MasterDetailPage
{
public MasterDetailControlPage()
{
MenuPage menuPage = new MenuPage();
menuPage.MenuListView.ItemSelected += (sender, e) =>
MenuSelected(e.SelectedItem as MenuItem);
// The Detail page must be set or the page will crash when rendered.
this.Master = menuPage;
this.Detail = new NavigationPage(new FeedbackPage());
this.IsPresented = true;
}
...
}
}
~~~
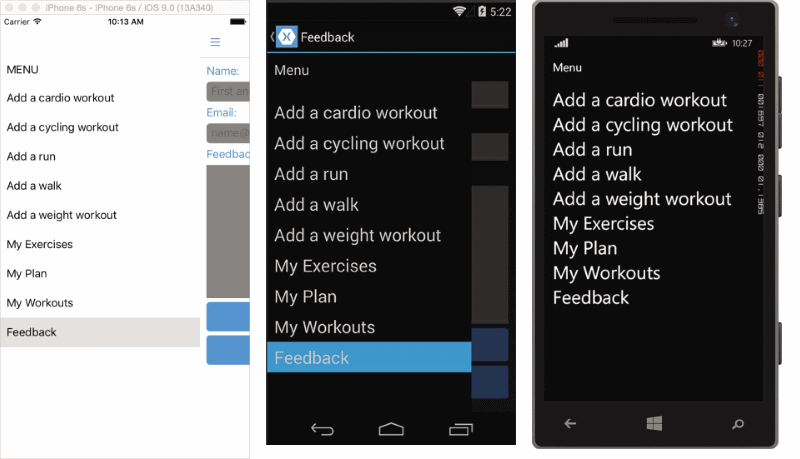
在 iOS 上 (左)、 Android (中心) 和 Windows Phone (右) 呈现的图 3 母版详细信息页
有很多值得注意的代码中的相关事实 图 2 以使其易于理解。首先,母版详细信息页实际上是一个控制器。它不包含主机的 UX 页或任何详细信息页。这些页面并在单独的文件。其工作就是显示的正确页面,基于用户的请求。在 图 3 主页面是一个名为 MenuPage 的内容页。MenuPage 会实例化并将母版详细信息页的属性设置到 Master。为简洁起见,此处显示并不 MenuPage 的 XAML。它可以找到本文附带的代码下载中。中显示的母版详细信息页面 图 2 也不包含任何详细信息页的用户体验。它们也在单独的文件中。实例化和设置到母版详细信息页的详细信息属性,当用户选择菜单选项的详细信息页。
母版详细信息页这两个主构造函数中设置页和详细信息页。在最初显示是否未设置这两个属性时,将 bomb 母版详细信息页。
它还是必须了解 IsPresented 属性。此属性指示是否为主页显示给用户。如果设置为 True 则主页面,显示。如果设置为 False,则将显示当前的详细信息页。
Windows Phone 将整个 Master 页上为单个页面视图的体验。换而言之,当用户导航到详细信息视图时 Windows Phone 并不将其视为标准页面导航。当用户点击后退按钮上的详细信息视图时,用户将进入到母版详细信息页的初始导航之前所示的页面。这是用户体验较差,因为用户很可能想要被带回母版的母版详细信息页面的视图。要解决这个问题 Xamarin.Forms 允许 OnBackButtonPressed 事件中被重写。由于所有 Windows Phone 和 Android 设备都有一个后退按钮,将在 Windows Phone 和 Android 上调用此事件。如果您的应用程序在 iOS 上运行,因为 iOS 没有后退按钮,则不会调用此事件。在 iOS 中用户可以通过点击母版页图标导航回母板页,必须先将其显示在左上方的所有详细信息页。务必要始终设置主文件夹页的 icon 属性,否则用户将被限制在其中一个没有办法回到主页面与应用程序的详细信息页上。
## 应用程序导航
导航页上管理适用于 iOS 和 Android 的页面导航。NavigationPages 是推送/弹出导航。将新的页推送到堆栈的顶部,然后将其弹出。跟踪所有导航都的 Windows Phone 操作系统,并且所有 Windows Phone 设备上都安装硬件后退键。因此,用户始终可以返回到上一屏幕。因此,在 Windows Phone 上导航页上不起作用。
适用于 iOS 和 Android 导航页会提供较页顶部的链接的形式显示当前页的标题和标题的前一页的用户体验。根页将只包含页的标题。如果用户期望触控前一页的标题它们是带回前一页。
使用导航页上的最简单方法是在代码中对其实例化并将一个页面传递到其构造函数。下面的代码行用于创建中的详细信息页 图 2:
~~~
this.Detail = new NavigationPage(displayPage);
~~~
导航页是在 iOS 上尤其重要,因为它在运行没有硬件的设备后退按钮。而无需导航页上提供的功能,用户不具有能够在 iOS 上返回一页。
## 选项卡
选项卡式页面的 UI 将呈现为显示在屏幕顶部或底部显示的选项卡列表。在 iOS 上选项卡的列表显示在该屏幕的底部,详细信息区域上方。如果有多个选项卡不能容纳在屏幕上,iOS 呈现将提供一个"更多"选项卡在屏幕上提供访问权限,无法容纳的选项。在 Android 上标签显示在下方的详细信息区域在屏幕的顶部。如果该集合为太大,无法在屏幕上显示,用户可以水平滚动选项卡的集合。在 Windows Phone 上选项卡式页上呈现为透视页。
有两种方法来创建选项卡式的页。首先,应用程序开发人员可以内容页面对象设置到选项卡式的页面的 Children 属性,如中所示 图 4。为每一项的 Children 集合转换,将创建一个选项卡。每一页的标题和图标属性用于创建的选项卡。当每个选项卡将具有不同的外观,并且每个选项卡中的数据不同,此方法很有用。图 5 演示如何从选项卡式的页面 图 4 呈现在每个平台上。
图 4 使用 Children 属性创建选项卡式的页面
~~~
using Xamarin.Forms;
namespace XamarinFormsTestHarness
{
class TabbedControlPage : TabbedPage
{
public TabbedControlPage()
{
this.Title = "My Workouts";
this.Children.Add(new ThisWeek());
this.Children.Add(new LastWeek());
this.Children.Add(new ThisMonth());
this.Children.Add(new LastMonth());
this.Children.Add(new All());
}
}
}
~~~
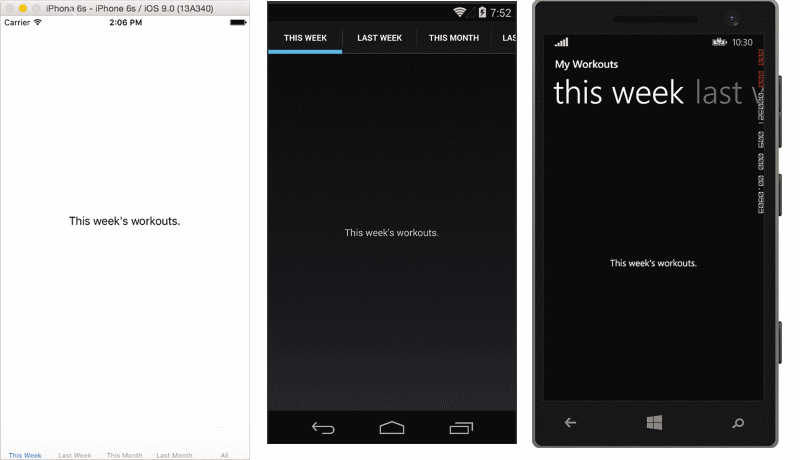
图 5 选项卡式页面呈现在 iOS 上 (左)、 Android (中心) 和 Windows Phone (右)
若要创建选项卡式的页面的另一种方法是将分配到该选项卡式的页面的 ItemsSource 属性从同一个类实例化的对象的列表。将创建此列表中的每个对象的一个选项卡。然后必须将 DataTemplate 设置到选项卡式的页面的 ItemTemplate 属性。必须使用数据绑定来从 ItemSource 属性中的相应对象中获取数据的内容页面从创建 DataTemplate。请务必将此内容页面的 title 属性绑定到绑定的对象中的属性。Title 属性将用于创建选项卡标签。此内容页面的其余部分可能用于将绑定到其他属性的绑定对象中。此方法是最适合于每个选项卡会显示不同的数据相同的用户体验的选项卡式页面。
## 传送带
轮播页的用户界面使用户可以刷从端到端屏幕以显示不同页的内容。Windows Phone 开发人员会将识别轮播页上,为全景图。轮播页包含 Children 属性选项卡式页面一样。若要创建轮播页,设置到轮播页上的子属性的内容页面对象。每个内容页将呈现为内容的屏幕。轮播页中不使用每个内容页面的 Title 属性。(这是在每个标题用作选项卡标题的选项卡式页面。) 因此,如果对于每个屏幕,你需要一个标签,您将需要手动为内容页面内容的一部分实现这一方案。图 6 显示此页上的每个平台的呈现方式。请注意,在 iOS 和 Android 上没有任何可见线索,通知用户的其他内容的左侧或右侧的当前视图。Windows Phone 实现这一点显示页面标题的一部分。出于此原因,使用要小心轮播在 iOS 和 Android。用户可能会错过您的应用程序中的重要内容。
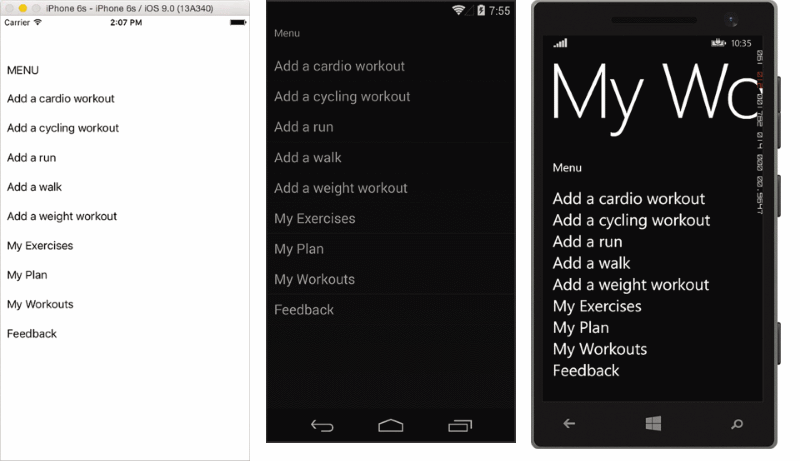
图 6 轮播呈现页面在 iOS 上 (左)、 Android (中心) 和 Windows Phone (右)
## 为三个平台设计
如果您熟悉使用所有三个平台然后此时您可能已发现每个 Xamarin.Forms 页面类型表示具有所需的平台之一中的 UI 方案和创造性地然后中与其他两个实现。例如,需要提供到以前的页面的链接的导航页面以在 iOS 上提供后退键功能,因为 iOS 没有后退键。导航页还呈现了在 Android 上以类似的方式因为即使 Android 具有后退键中具有指向当前页的页首以前访问过的网页的链接是在 Android 上的常用 UI 结构。
同样,在 iOS 和 Android 上经常使用的选项卡。因此,Xamarin.Forms 需要在工具箱中具有此 UI 结构。在 Windows Phone 上选项卡将呈现为透视页,它是操作系统的基本组成部分。
母版详细信息页会提供弹出面板,有时在 iOS 和 Android 使用。
最后,Windows Phone 具有全景图页的概念。全景图页面最适合用作应用程序的主页。全景图页面的目的是提供应用程序的高级视图。设计良好的全景图页就像杂志的封面。它使用户快速浏览一下在包含的内容。如果是以极具吸引力的方式,全景图会将用户进一步拉入应用程序。水平轻扫屏幕的内容之间的想法并不 iOS 和 Android 中常见的情形。因此,必须小心 Xamarin.Forms 应用程序中使用轮播页面时。
Xamarin.Forms 作为平台的发展演变,很可能添加类型的详细页面。Xamarin 开发人员必须设计责任看一看每种页面类型,并确定是否有对其应用程序以之为目标的所有平台而言非常重要。
## 总结
Xamarin 提供两种主要方法构建共享代码的本机应用程序: 传统的 Xamarin 和 Xamarin.Forms。选择正确的方法取决于您的构建。
如果您的应用程序需要每个平台上的专用的交互和利用了许多特定于平台的 Api,使用传统的 Xamarin 方法。传统的 Xamarin 还提供了构建 Ui 自定义的每个平台的能力。
Xamarin.Forms 是一个完整的框架,构建本机应用程序使用单一、 共享代码库。请考虑 Xamarin.Forms,如果您是原型,构建数据输入应用程序或您的应用程序所要求的一些特定于平台的功能。Xamarin.Forms 规则也适用于项目共享代码所在比为每个平台的自定义 UI 更重要。
* * *
Keith Pijanowski *是工程师、 企业家和商人。他在软件行业有 20 多年的经验,就职的公司既有初创公司也有大型公司,从编写代码到业务拓展均有涉猎。与他联系。 [keithpij@msn.com](mailto:keithpij@msn.com) 或在 Twitter 上:[@keithpij](https://twitter.com/@keithpij)。*
测试运行 – 面向 .NET 开发者的 Spark 简介
最后更新于:2022-04-01 06:52:57
# 测试运行 - 面向 .NET 开发者的 Spark 简介
作者 [James McCaffrey](https://msdn.microsoft.com/zh-cn/magazine/mt149362?author=James+McCaffrey) | 2015 年 12 月

Spark 是一种适用于大数据的开放源代码计算框架,且越来越流行,特别是在机器学习方案中。在本文中,我将介绍如何在运行 Windows 操作系统的计算机上安装 Spark,并将从 .NET 开发者的角度介绍 Spark 的基本功能。
了解本文所述观点的最佳方式是查看图 1 中的交互会话演示。从采用管理模式运行的 Windows 命令行界面中,我通过发出 spark-shell 命令,创建了 Spark 环境。
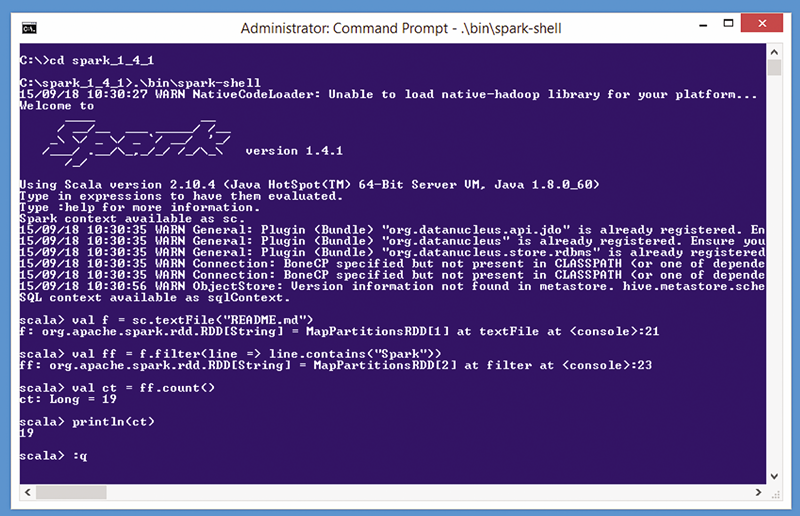
图 1:Spark 的运作方式
spark-shell 命令会创建在 shell 中运行的 Scala 解释器,进而发出 Scala 提示 (scala>)。Scala 是一种基于 Java 的脚本语言。我们还可以通过其他方法与 Spark 交互,但最常用的方法还是使用 Scala 解释器,原因之一是 Spark 框架主要通过 Scala 进行编写。您还可以使用 Python 语言命令或编写 Java 程序,与 Spark 进行交互。
请注意图 1 中的多条警告消息。当您运行 Spark 时,这些消息很常见,因为 Spark 有许多可选组件会生成警告(如果未找到的话)。通常情况下,对于简单方案,可以忽略警告消息。
演示会话中输入的第一个命令是:
~~~
scala> val f = sc.textFile("README.md")
~~~
这可以大致理解为:“将 README.md 文件的内容存储到名为 f 的不可变 RDD 对象中。” Scala 对象可声明为 val 或 var。声明为 val 的对象不可变且无法更改。
Scala 解释器内置名为 sc 的 Spark 上下文对象,用于使用 Spark 功能。textFile 函数将文本文件的内容加载到名为“弹性分布数据集 (RDD)”的 Spark 数据结构中。RDD 是 Spark 中主要使用的编程抽象。您可以将 RDD 看成是存储在多台计算机的 RAM 上的 .NET 集合。
文本文件 README.md(.md 扩展名代表 markdown 文档)位于 Spark 根目录“C:\spark_1_4_1”中。如果您的目标文件位于其他位置,则您可以提供完整路径(如“C:\\Data\\ReadMeToo.txt”)。
演示会话中输入的第二个命令是:
~~~
scala> val ff = f.filter(line => line.contains("Spark"))
~~~
这可以理解为:“仅将对象 f 中含有‘Spark’一词的多行内容存储到名为 ff 的不可变 RDD 对象中。” 筛选器函数接受所谓的闭合。您可以将闭合看成是匿名函数。在这里,闭合接受名为 line 的虚拟字符串输入参数,并在 line 中含有“Spark”时返回 true(反之,则会返回 false)。
由于“line”仅仅是参数名称,因此我可以在闭合中使用其他任何名称,例如:
~~~
ln => ln.contains("Spark")
~~~
由于 Spark 区分大小写,因此以下命令会生成错误:
~~~
ln => ln.Contains("Spark")
~~~
Scala 具有一些函数编程语言特征,所以可以撰写多个命令。例如,前两个命令可以合并成一个命令:
~~~
val ff = sc.textFile("README.md").filter(line => lne.contains("Spark"))
~~~
演示会话中最后输入的三个命令是:
~~~
scala> val ct = ff.count()
scala> println(ct)
scala> :q
~~~
计数函数返回 RDD 中的项目数,在此示例中,即返回 README.md 文件中包含 Spark 一词的行数。行数有 19 行。若要退出 Spark Scala 会话,您可以键入 :q 命令。
## 在 Windows 计算机上安装 Spark
在 Windows 计算机上安装 Spark 主要分为四步。第一步,安装 Java 开发工具包 (JDK) 和 Java Runtime Environment (JRE)。第二步,安装 Scala 语言。第三步,安装 Spark 框架。第四步,配置主机系统变量。
Spark 分发的格式为压缩的 .tar,因此您需要使用实用工具解压 Spark 文件。我建议您在开始前先安装开放源代码的 7-Zip 程序。
尽管并不是所有 Windows 操作系统版本都正式支持 Spark 及其组件,但我已经在运行 Windows 7、8、10、Server 2008 和 2012 的计算机上成功安装了 Spark。图 1 中的演示就是在 Windows 8.1 计算机上运行。
您可以运行自解压可执行文件(通过 Internet 搜索即可找到)来安装 JDK。我使用的版本是 jdk-8u60-windows-x64.exe。
如果您安装的是 64 位版本 JDK,则默认安装目录是 C:\Program Files\Java\jdkx.x.x_xx\(如图 2 所示)。我建议您不要更改默认位置。
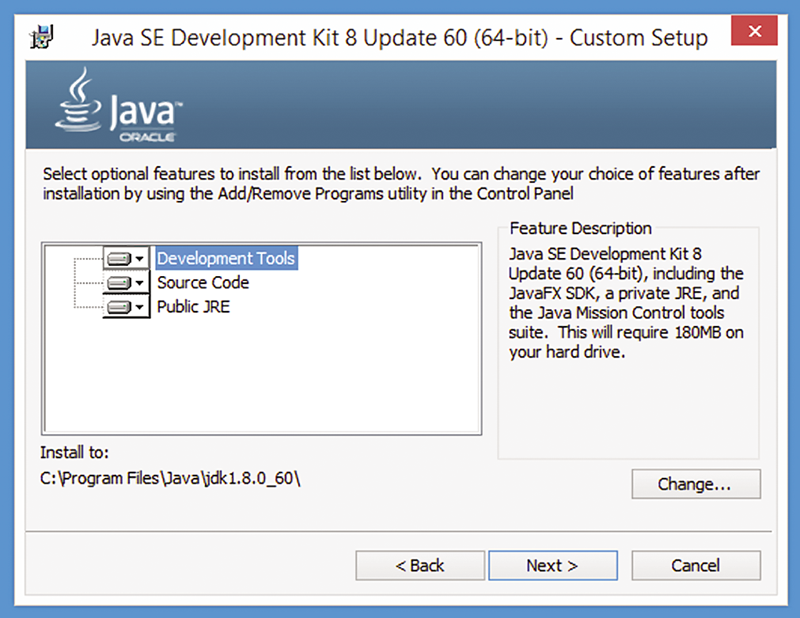
图 2:默认 JDK 位置
安装 JDK 的同时也会安装相关的 JRE。安装完成后,默认的 Java 父目录会同时包含 JDK 目录和相关的 JRE 目录(如图 3 所示)。
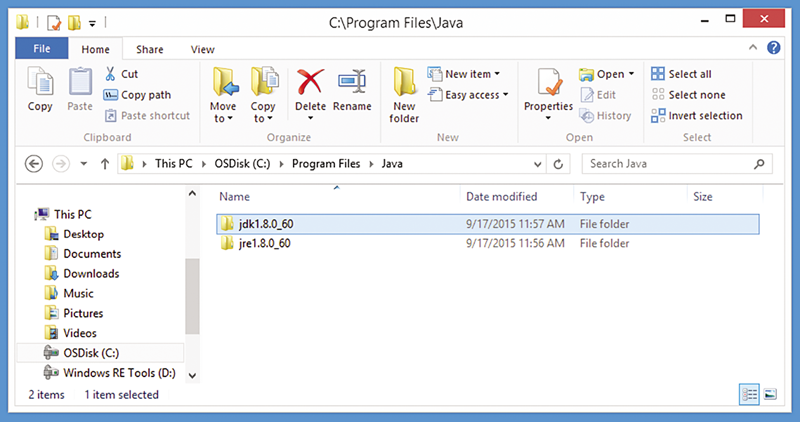
图 3:安装至 C:\Program Files\Java\ 的 Java JDK 和 JRE
请注意,您的计算机上可能有一个 Java 目录,其中包含的一个或多个 32 位 JRE 目录位于 C:\Program Files (x86) 中。计算机上同时包含 32 位和 64 位版本的 JRE 是没有问题的,但我建议您仅使用 64 位版本的 Java JDK。
## 安装 Scala
下一步是安装 Scala 语言,但在安装前,您必须先前往 Spark 下载站点(本文的下一部分将予以介绍),然后确定要安装的 Scala 版本。Scala 版本必须与您将在下一步中安装的 Spark 版本兼容。
很遗憾,关于 Scala-Spark 版本兼容性的信息非常少。当我安装 Spark 组件时(距离您阅读本文已过去相当一段时间),Spark 的当前版本是 1.5.0,但我找不到任何信息可说明哪个 Scala 版本与此版本的 Spark 兼容。因此,我以旧版 Spark ( 1.4.1) 为目标,在开发者讨论网站上找到了一些信息,这些信息表明第 2.10.4 版 Scala 可能与第 1.4.1 版 Spark 兼容。
安装 Scala 很容易。安装流程仅涉及运行 .msi 安装程序文件。
Scala 安装向导会逐步指导您完成整个流程。有趣的是,Scala 的默认安装目录位于 32 位目录 C:\Program Files (x86)\ 中,而不是位于 64 位目录 C:\Program Files\ 中(请参阅图 4)。
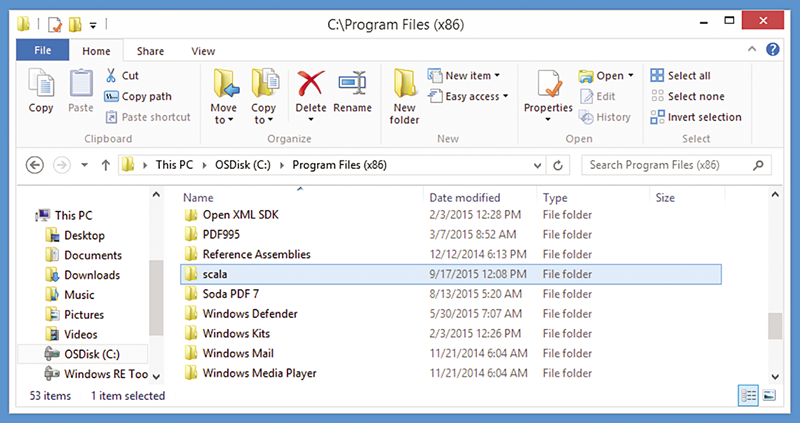
图 4:Scala 安装至 C:\Program Files (x86)\scala\
如果您打算通过编写 Java 程序(而不是使用 Scala 命令)与 Spark 交互,您需要另外安装一项名为 Scala Simple Build Tool (SBT) 的工具。通过编译的 Java 程序与 Spark 进行交互比使用交互 Scala 困难得多。
## 安装 Spark
下一步是安装 Spark 框架。不过,首先,请确保您拥有可解压 .tar 格式文件的实用工具(如 7-Zip)。Spark 安装流程需手动操作,即您需要将压缩文件夹下载到本地计算机中,解压压缩文件,然后将文件复制到根目录中。也就是说,如果您希望卸载 Spark,只需删除 Spark 文件即可。
Spark 站点网址为 spark.apache.org。在下载页上,您可以选择版本和包类型。Spark 是一种计算框架,需要使用分布式文件系统 (DFS)。迄今为止,Spark 框架最常用的 DFS 是 Hadoop 分布式文件系统 (HDFS)。出于测试和实验目的(如图 1 中的演示会话),您可以在没有 DFS 的系统上安装 Spark。在这种情况下,Spark 会使用本地文件系统。
如果您之前没有解压过 .tar 文件,则可能会对这个过程感到些许困惑,因为您通常需要解压两次。首先,将 .tar 文件(我的文件命名为 spark-1.4.1-bin-hadoop2.6.tar)下载到任意临时目录(我使用的是 C:\Temp)。接下来,右键单击 .tar 文件,然后从上下文菜单中选择“解压文件”,将它解压到临时目录内的新目录。
首次解压过程会新建一个不含文件扩展名的压缩文件(我的是 spark-1.4.1-bin-hadoop2.6)。接下来,右键单击这个新建的文件,然后从上下文菜单中再次选择“解压文件”,将它解压到其他目录。第二次解压会生成 Spark 框架文件。
为 Spark 框架文件创建一个目录。通用约定是创建名为 C:\spark_x_x_x 的目录,其中 x 值表示版本。根据此约定,我创建了 C:\spark_1_4_1 目录,并将解压的文件复制到此目录中(如图 5 所示)。
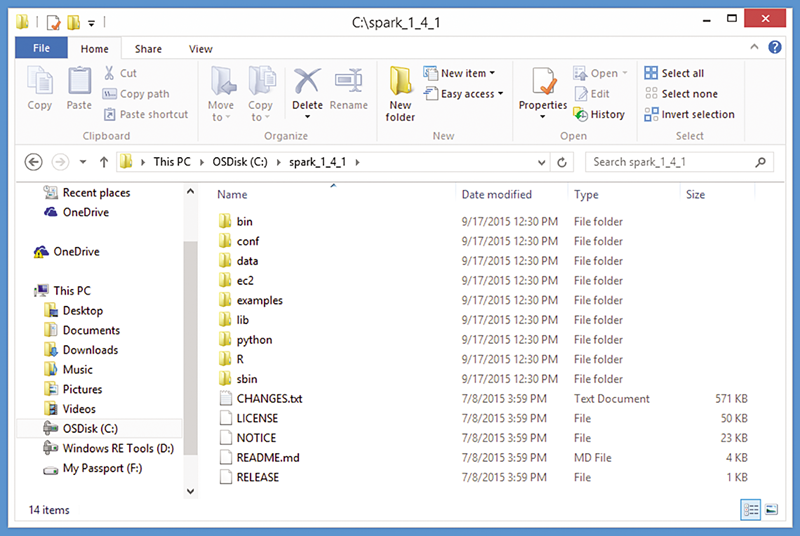
图 5:手动将解压的 Spark 文件复制到 C:\spark_x_x_x\
## 配置计算机
在安装 Java、Scala 和 Spark 之后,最后一步是配置主机。此过程涉及下载 Windows 所需的特殊实用工具文件、设置三个用户定义的系统环境变量、设置系统 Path 变量,以及视需要选择修改 Spark 配置文件。
若要在 Windows 上运行 Spark,本地目录(名为 C:\hadoop)中必须有特殊的实用工具文件(名为 winutils.exe)。通过 Internet 搜索,您可以在多处找到此文件。我创建了目录 C:\hadoop,然后在[http://public-repo-1.hortonworks.com/hdp-win-alpha/winutils.exe](http://http/public-repo-1.hortonworks.com/hdp-win-alpha/winutils.exe) 找到了 winutils.exe 的副本,并将此文件下载到所创建的目录中。
接下来,创建和设置三个用户定义的系统环境变量,并修改系统 Path 变量。转到“控制面板 | 系统 | 高级系统设置 | 高级 | 环境变量”。在“用户变量”部分中,新建三个具有下列名称和值的变量:
~~~
JAVA_HOME C:\Program Files\Java\jdk1.8.0_60
SCALA_HOME C:\Program Files (x86)\scala
HADOOP_HOME C:\hadoop
~~~
然后,在“系统变量”中,添加 Spark 二进制文件的位置 (C:\spark_1_4_1\bin),编辑 Path 变量。请谨慎操作,您一定不想在 Path 变量中丢失任何值。请注意,Scala 安装进程已经为您添加了 Scala 二进制文件的位置(请参阅图 6)。
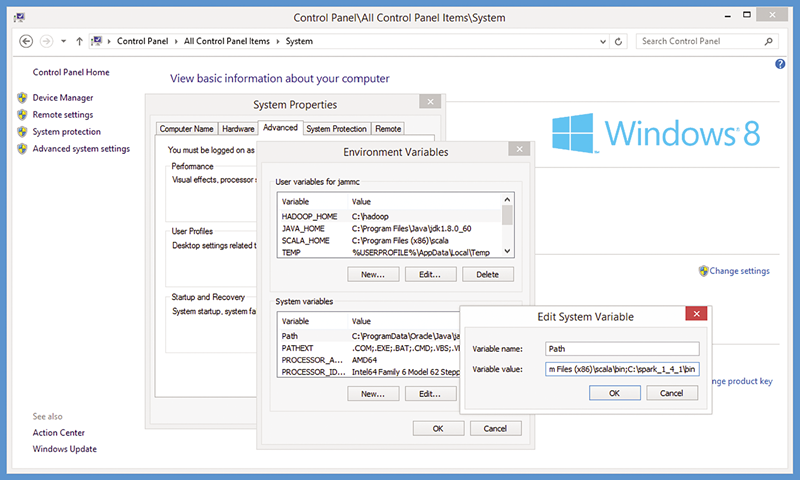
图 6:配置系统
在您设置系统变量后,我建议您修改 Spark 配置文件。转到根目录 C:\spark_1_4_1\config,然后复制 log4j.properties.template 文件。通过删除 .template 扩展名来重命名此副本。编辑 log4j.rootCategory=INFO 和 log4j.rootCategory=WARN 之间的第一个配置条目。
即,默认情况下,Spark 会发出各种各样的信息性消息。将日志记录级别从 INFO 更改为 WARN 会大大地减少消息的数量,并且可以方便您更有条不紊地与 Spark 交互。
## Spark 的 Hello World 示例
分布式计算示例 Hello World 旨在计算数据源中的不同字词数量。图 7 展示了使用 Spark 的字数统计示例。
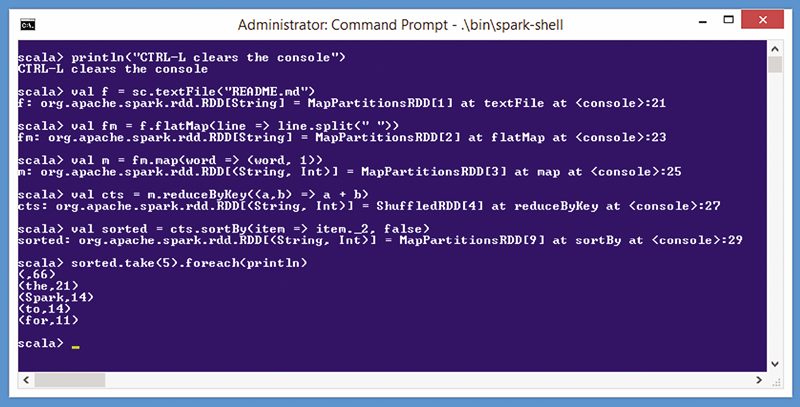
图 7:使用 Spark 的字数统计示例
Scala shell 有时被称为读取、求值、打印、循环 (REPL) shell。您可以按 CTRL+L 来清除 Scala REPL。如上文所解释,图 7 中的第一个命令将 README.md 文件的内容加载到名为 f 的 RDD 中。在实际情况中,您的数据源可以是跨数百台计算机分布的大型文件,也可以位于分布式数据库(如 Cassandra)中。
下一个命令是:
~~~
scala> val fm = f.flatMap(line => line.split(" "))
~~~
flatMap 函数调用在空白空格字符处对 f RDD 对象中的每一行进行拆分,生成的 RDD 对象 fm 会包含一个集合,其中有文件中的所有字词。从开发者的角度来看,您可以将 fm 看成是 .NET List 集合。
下一个命令是:
~~~
scala> val m = fm.map(word => (word, 1))
~~~
映射函数会创建一个保留项目对的 RDD 对象,其中每对都包含一个字词和整数值 1。如果您发出 m.take(5) 命令,则可以看得更清楚。您会看到 README.md 文件中的前五个字词,以及每个字词旁边的值 1。从开发者的角度来看,m 大致是一个 List 集合,其中每个 Pair 对象都包含一个字符串和一个整数。字符串(README.md 中的一个字词)是键,而整数则是值,但与 Microsoft .NET Framework 中的许多键值对不同的是,Spark 中允许重复的键值。保留键值对的 RDD 对象有时被称为 RDD 对,以便于与普通的 RDD 区分开来。
下一个命令是:
~~~
scala> val cts = m.reduceByKey((a,b) => a + b)
~~~
reduceByKey 函数通过添加与相等键值相关联的整数值,在对象 m 中合并各个项目。如果您运行 cts.take(10),则会看到 README.md 中的 10 个字词,后跟每个字词在此文件中的出现次数。您可能还会注意到,对象 cts 中的字词并没有特定的排列顺序。
reduceByKey 函数接受闭合。您可以使用替代的 Scala 快捷符号:
~~~
scala> val cts = m.reduceByKey(_ + _)
~~~
下划线是参数通配符,所以语法可以解析为“添加任意两个收到的值”。
请注意,此字数统计示例先使用映射函数,然后使用 reduceByKey 函数。这就是 MapReduce 范例。
下一个命令是:
~~~
scala> val sorted =
cts.sortBy(item => item._2, false)
~~~
此命令根据项目的第二个值(整数计数),对 cts RDD 中的项目进行排序。自变量 false 表示按降序排序,即从最高计数到最低计数。排序命令的 Scala 快捷语法形式是:
~~~
scala> val sorted = cts.sortBy(_._2, false)
~~~
因为 Scala 具有很多函数语言特征,并且使用很多符号(而不是关键字),因此编写的 Scala 代码会非常不直观。
Hello World 示例中的最后一个命令用于显示结果:
~~~
scala> sorted.take(5).foreach(println)
~~~
可解释为:“提取名为 sorted 的 RDD 对象中的前五个对象,并对此集合进行循环访问,同时对每个项目应用 println 函数。” 结果是:
~~~
(,66)
(the,21)
(Spark,14)
(to,14)
(for,11)
~~~
也就是说,README.md 中出现了 66 次空/null 字词,“the”一词出现了 21 次,“Spark”一词出现了 14 次等。
## 总结
如果您想在 Windows 计算机上试用 Spark,请参阅本文,其中提供的信息旨在帮助您快速掌握如何开始使用和运行 Spark。Spark 是一项相对较新的技术(2009 年始于加州大学柏克莱分校),但在过去的几个月中,对 Spark 感兴趣的人明显增多,至少我的同事们就非常感兴趣。
在 2014 年的大数据处理框架争夺战中,Spark 创造了新的性能记录,很轻松地就打破了 Hadoop 系统在前一年创造的记录。Spark 具有出色的性能,因此非常适合与机器学习系统结合使用。Spark 支持名为 MLib 的机器学习算法开放源代码库。
* * *
Dr.James McCaffrey *供职于华盛顿地区雷蒙德市沃什湾的 Microsoft Research。他参与过多个 Microsoft 产品的工作,包括 Internet Explorer 和 Bing。Scripto可通过 [jammc@microsoft.com](mailto:jammc@microsoft.com) 与 McCaffrey 取得联系。*
游戏开发 – Babylon.js: 构建 Web 基本游戏
最后更新于:2022-04-01 06:52:54
# 游戏开发 - Babylon.js: 构建 Web 基本游戏
作者 [Raanan Weber](https://msdn.microsoft.com/zh-cn/magazine/mt149362?author=Raanan+Weber) | 2015 年 12 月 | [获取代码](http://download.microsoft.com/download/D/5/4/D54647CC-A404-4374-B7EF-E469FB5136B9/Code_Weber.Babylon.1215.zip)
Babylon.js 是一款基于 WebGL 的 3D 引擎,主要以游戏开发和易用性为主。作为 3D 引擎,它包含的工具可用于创建和显示网格,以及在空间中设置纹理,并能添加光源和照相机。由于是以游戏为主,因此 Babylon.js 还具有常规 3D 引擎不需要的一些额外功能。它提供了对碰撞检测、场景重力、面向游戏的照相机(例如,跟踪移动对象的跟随照相机),以及对 Oculus Rift 和其他虚拟现实 (VR) 设备的本地支持。它具有物理引擎插件系统、本地音频支持、基于用户输入的操作管理器等。在本教程中,我将介绍所有这些功能。
## 关于本教程
在本教程中,我将开发一个简单的保龄球游戏。我将创建一个保龄球球道,添加 10 个保龄球瓶和一个保龄球,并提供掷球功能。我的游戏当然不会发布,但我会用它来向您展示如何使用 Babylon.js 提供的工具开发游戏。在开发期间,我会刻意避免使用任何外部工具。我将只使用 JavaScript 代码创建对象、照相机、纹理等。
在本教程中,我将使用最新的稳定版本 Babylon.js 2.1。David Catuhe 和 Babylon 开发团队正在尝试尽可能保持框架的后向兼容性,因此,我只能假设本教程适用于今后发布的版本(至少在下一主要版本发布之前)。我使用的是 Visual Studio 2015 Community Edition,但您也可以根据需要使用任意 IDE。
本教程分为两个部分。在本文中,我将概述 Babylon.js 的构建基块。我将创建网格、设置纹理、添加照相机和光源,并启用简单的用户交互。在第二部分中,我将添加碰撞和物理特性、音频、用户操作和特殊的照相机类型,从而展现 Babylon.js 的真正闪光之处。
## 入门: 新建 Babylon.js 项目
简单的 Babylon.js 项目是一个静态网站。由于我使用的是 Visual Studio,因此我将使用嵌入 Visual Studio 的本地 IIS 服务器来托管这些静态文件。Visual Studio 没有静态网站模板,所以需要采用不同的方法。
首先,新建一个空白解决方案。打开 Visual Studio,然后转到“文件 | 新建 | 项目”。选择左窗格中的“其他项目类型”,然后选择“空白解决方案”(如图 1 所示)。为解决方案命名(我命名的是“BabylonBowling”),然后单击“确定”。
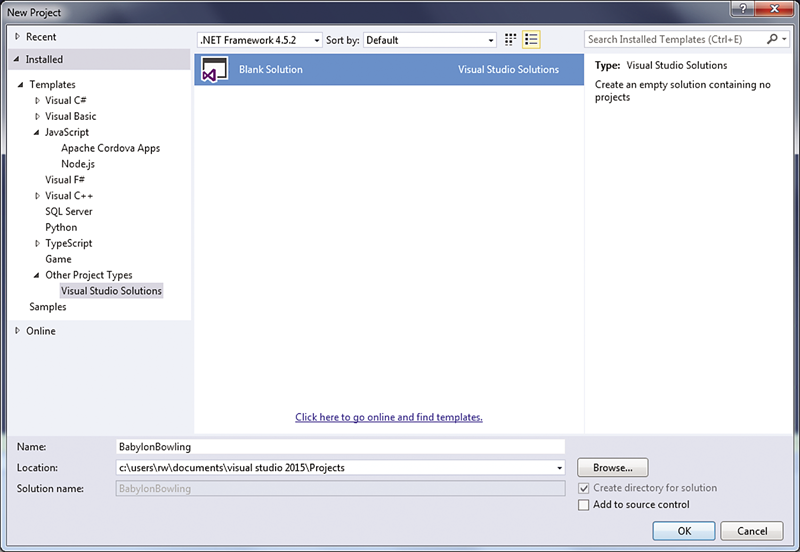
图 1:在 Visual Studio 中新建空白解决方案
若要新建静态网站,您首先需要新建一个托管目录。右键单击空解决方案,然后单击“在文件资源管理器中打开文件夹”(如图 2 所示)。

图 2:在文件资源管理器中打开解决方案文件夹
为 BabylonBowling 项目新建一个目录,然后关闭文件资源管理器。
右键单击解决方案,然后选择“添加 | 现有网站”。选择新创建的文件夹(务必选择刚创建的文件夹,而不是解决方案的文件夹),然后单击“打开”。此时,您应该有一个空白网站作为此解决方案的唯一项目了。
创建项目后,您需要添加框架和框架依赖项。有几种方法可以做到这一点。最简单的方法是使用 NuGet 包管理器。
右键单击项目,然后选择“管理 NuGet 包”。单击搜索字段(键盘快捷方式为 Ctrl+E),然后键入 babylon。此时,您会看到一个窗口(如图 3 所示)。选择“BabylonJS”。请确保选定版本是 2.1(或最新的稳定版本),然后单击“安装”。在弹出的“预览”窗口(若有)中,单击“确定”,然后 Babylon.js 会安装至您的空项目中(包括演示场景)。
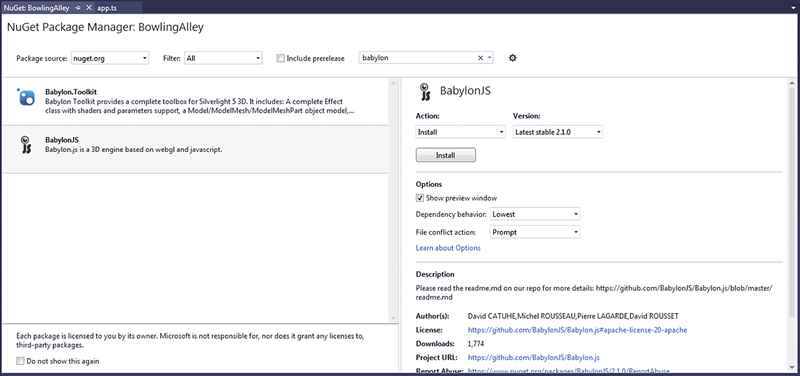
图 3:使用 NuGet 包管理器添加 Babylon.js
如果您将 npm 用作包管理器,则可以使用下列命令安装 Babylon.js:
~~~
npm install babylonjs
~~~
在安装包后,您应该会在脚本文件夹中看到下列文件:
* babylon.js:Babylon.js 的简化版本
* babylon.max.js:Babylon.js 的调试版本
* Oimo.js:Oimo JS 物理引擎,本教程的第二部分中将会用到
* poly2tri.js:可选的三边转换库 ([github.com/r3mi/poly2tri.js](http://github.com/r3mi/poly2tri.js))
* hand-minified.js:指针事件填充代码;在使用 npm 时缺失,因此使用下列命令进行安装:
~~~
npm install handjs
~~~
NuGet 安装程序也会创建 index.html 文件和 index.js 文件。
NuGet 包中的错误会在 web.config 中添加不需要的行。请双击此文件,并删除图 4 中突出显示的行(在我的解决方案中,为第 9 行),直至修复完成。

图 4:从 web.config 中删除突出显示的行
您现在可以测试项目了。使用 Ctrl+Shift+W 或通过单击顶部导航栏的“运行”按钮,在您的默认浏览器中打开项目。如果您看到图 5 中显示的 3D 宇宙飞船,则表明您的项目已准备就绪。

图 5:Babylon 默认宇宙飞船
如果您使用的是其他 IDE,只需按 Babylon.js 文档页中的“创建基本场景”教程执行操作,即可达到当前状态。如果您没有使用 NuGet,我仍然建议您使用 npm 安装依赖项。有关此教程,请访问[bit.ly/1MXT6WP](http://bit.ly/1MXT6WP)。
若要从头开始,请删除 index.js 中的 createScene 函数。
## 构建基块
我首先将介绍的两个元素是引擎和场景。
引擎是负责与低级 WebGL API 通信的对象(WebGL 1 以 OpenGL ES2 为基础,语法非常相似)。引擎提供了更易于理解的较高级 API,这样您就不必编写低级 WebGL 代码了。这对开发者来说也是透明的。除了初始项目设置之外,我根本不会直接使用引擎。虽然使用此引擎可以完成特定的较低级功能,但我不会涉及这一点。
引擎需要两个参数才能初始化。第一个参数是用于绘制的画布。画布是 index.html 中已有的 HTML 元素。第二个参数是抗锯齿状态(开或关)。
打开当前的空白 index.js,然后添加下列代码行:
~~~
function init() {
var engine = initEngine();
}
function initEngine() {
// Get the canvas element from index.html
var canvas = document.getElementById("renderCanvas");
// Initialize the BABYLON 3D engine
var engine = new BABYLON.Engine(canvas, true);
return engine;
}
~~~
在开发期间,我将使用 init 函数为每一步添加新功能。我创建的每个元素都会有自己的函数。
为了更好地了解场景代表什么,请将场景看成是包含不同网页的网站。一个网页中包含文本、图像、事件监听器以及呈现一个网页所需的其他所有资源。加载不同的网页就是加载不同的资源。
如同一个网页,场景包含显示一个 3D“网页”所需的资源。 此场景可能非常大,包含大量资源(网格、照相机、光、用户操作等)。不过,若要从一个网页移到另一个网页,我建议使用新场景。场景也负责呈现它自己的资源,并将所需的信息传达给引擎。保龄球游戏只需要一个场景。不过,如果我计划添加新等级或奖分游戏,那么我会使用新场景创建它们。
若要初始化场景,只需要我创建的引擎。在 index.js 中添加以下代码:
~~~
function createScene(engine) {
var scene = new BABYLON.Scene(engine);
// Register a render loop to repeatedly render the scene
engine.runRenderLoop(function () {
scene.render();
});
}
~~~
首先,我将创建场景对象。接下来的代码行是我与引擎的唯一交互。它们会指示引擎,每当呈现循环运行时,呈现此特定场景。
将以下代码行添加到 init 函数的末尾,以真正创建场景:
~~~
var scene = createScene(engine);
~~~
在继续前,我还需要执行两项操作。当您重设浏览器窗口大小时,画布也会重设大小。引擎还必须重设其内部宽度和高度,以使场景比例正确。就在返回引擎前,向 initEngine 函数添加下列代码行;声明会使场景比例正确。
~~~
// Watch for browser/canvas resize events
window.addEventListener("resize", function () {
engine.resize();
});
~~~
第二项操作是,将 index.html 更改为使用新的 init 函数。打开 index.html,然后查找包含 createScene 调用的脚本标记。将 createScene 更改为 init,然后保存 index.html 并关闭。
此场景的调试层极为高级,可方便您调试正在呈现的场景。它显示正在呈现的网格数以及当前的每秒帧数 (FPS)。借助它,您可以关闭纹理和阴影等功能,并能轻松找到丢失的网格。开启调试层非常简单:
~~~
scene.debugLayer.show();
~~~
开启后,您便能自行调试场景。
此时,我已有引擎和场景,我可以开始添加照相机、光源和网格来创建我的保龄球馆场景了。
## 相机
Babylon.js 提供很多类型的照相机,每个都有自己的特定用途。在为游戏选择照相机之前,让我们先回顾一下最常见的类型:
* 自由照相机是一种由第一人称拍摄的照相机。使用键盘上的箭头键,可以自由地在整个场景中移动它,并能使用鼠标设置方向。还可以视需要选择启用重力和碰撞检测。
* 弧形旋转照相机用于围绕特定的目标旋转。使用鼠标、键盘或触摸事件,用户可以全方位地查看对象。
* 触控照相机是一种使用触摸事件作为输入的自由照相机。它适合所有的移动平台。
* 跟随照相机自动跟踪特定目标。
Babylon.js 对 WebVR 和设备方向照相机提供本地支持。也就是说,您很容易就可以将此类设备列为 Oculus Rift 或 Google Cardboard。
第 2.1 版中引入的新概念让每种类型的照相机都支持 3D。也就是说,每种类型的照相机都可以设置为适应 Oculus Rift 式立体视图和红蓝眼镜(3D 立体)。图 6 展示了使用非立体照相机呈现的宇宙飞船场景,图 7 展示了使用立体照相机呈现的场景。

图 6:非 3D 立体照相机

图 7:立体照相机
对于我的保龄球游戏,我将使用两种类型的照相机。第一种是玩家的主要照相机,用于设置保龄球的掷出位置。这就体现了自由照相机的确切用途。我还想添加不同的视图,即当球在球道中时,我想跟随它直到其撞击到保龄球瓶。
首先,我将添加自由照相机。createFreeCamera 函数将场景视作一个变量:
~~~
function createFreeCamera(scene) {
var camera = new BABYLON.FreeCamera(
"player camera", BABYLON.Vector3.Zero(), scene);
return camera;
}
~~~
我在场景的 0,0,0 位置处创建了照相机位置。稍后,我将把此函数扩展(必要时)为进一步配置照相机。
当然,别忘了最后将它添加到 init 函数中:
~~~
...
// Create the main player camera
var camera = createFreeCamera(scene);
// Attach the control from the canvas' user input
camera.attachControl(engine.getRenderingCanvas());
// Set the camera to be the main active camera
scene.activeCamera = camera;
~~~
attachControl 函数注册特定照相机所需的本地 JavaScript 事件监听器(如鼠标、触摸或键盘输入的事件监听器)。设置场景的活动照相机可以指示场景,此照相机应该用于呈现。
在启用掷球后,我将在第二部分中添加第二种照相机。
## 创建球道
保龄球球道是一种相对简单的几何结构。我将先设置一些常量作为保龄球球道的实际尺寸(以米为单位)。我以米为单位是因为使用的是物理引擎(我将在本文的第二部分中予以解释)。
您可以在项目文件中看到常量。为了计算这些值,我参考了网上关于保龄球球道的可用信息。
在设置这些常量后,我就可以开始创建构成保龄球球道的网格了。图 8 展示了我的 (2D) 规划。我将先创建网格。然后,我会设置网格纹理(即指定材料)。
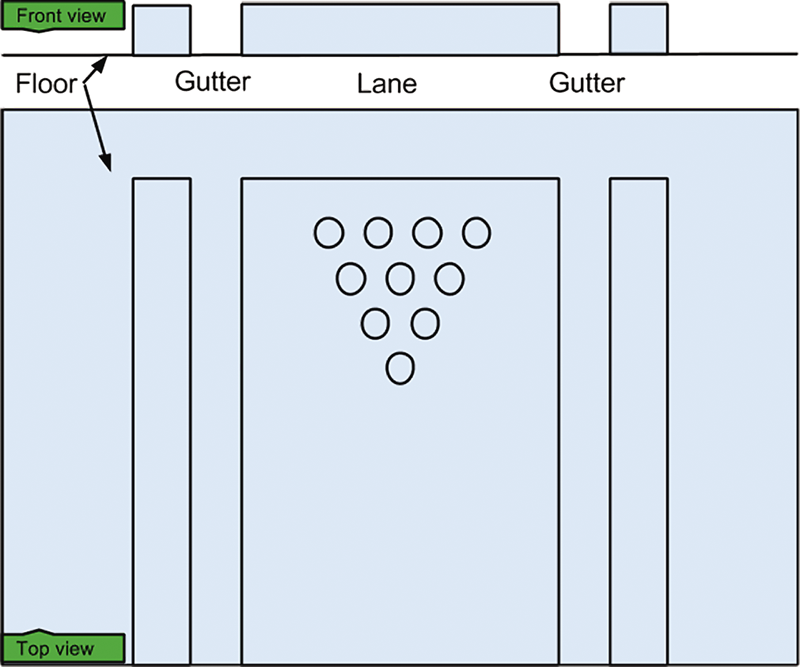
图 8:保龄球球道场景的 2D 规划
首先,我将为场景创建全场地板:
~~~
function createFloor(scene) {
var floor = BABYLON.Mesh.CreateGround("floor", 100, 100, 1, scene, false);
return floor;
}
~~~
这会创建一块简单的 100x100 米地板。使用 Babylon.js 内部函数创建的所有网格都集中位于场景的 0,0,0 位置处。有三个重要的变量用于转换网格并在场景中正确定位网格:
* mesh.position 是网格在空间中的位置的矢量
* mesh.scaling 是网格在每个轴中的比例系数
* mesh.rotation 是每个轴的旋转欧拉角(以弧度为单位);如果您更愿意使用四元(我知道我是这样),则可以改用 mesh.rotationQuaternion
在向 init 函数添加函数并启动场景后,我注意到一个有趣的现象,即我根本看不到我所添加的地板! 原因是照相机和地板两者均创建于空间的同一点 (0,0,0)。由于地面是完全平坦的,因此只有从高空(或低空)审视才会在屏幕上看到它。回到 createCamera 函数中的照相机初始化,我将第二个变量(照相机的初始位置)更改为一个新矢量。现在,照相机离地面有 1.7 个单位(在此示例中,单位为米):
~~~
var camera = new BABYLON.FreeCamera(
"cam", new BABYLON.Vector3(0,1.7,0), scene);
~~~
如果您现在启动场景,则会看到地板拉伸超过屏幕的一半(如图 9 所示)。

图 9:向场景添加地板
尝试使用箭头和鼠标进行移动,以掌握如何控制自由照相机。
您会注意到地板是全黑的。就缺少光! 我将添加新的函数 createLight(稍后我将会扩展)。
~~~
function createLight(scene) {
var light = new BABYLON.DirectionalLight(
"dir01", new BABYLON.Vector3(-0.5, -1, -0.5), scene);
// Set a position in order to enable shadows later
light.position = new BABYLON.Vector3(20, 40, 20);
return light;
}
~~~
别忘了将以下代码行添加到 init 函数中:
~~~
var light = createLight(scene);
~~~
Babylon.js 提供四种类型的光:
* 半球光: 环境光,用地面颜色(正面向下的像素)、天空颜色(正面向上的像素)和反射颜色预定义。
* 点光: 从一个点向所有方向发射的光(如阳光)。
* 投射光: 从名称我们就可以看出,这是从一个点以特定发射半径向特定方向发射的光。此类光可以产生阴影。
* 定向光: 从任意位置向特定方向发射的光。虽然阳光可以为点光,但定向光可以更好地模拟阳光。此类光也可以产生阴影,我的示例中使用的就是这种光。
现在,地板将变成白色。Babylon.js 向尚未分配材料的每个网格分配默认的白色材料。
球道本身就是一个盒子,“躺”在我刚刚创建的地板上:
~~~
function createLane(scene) {
var lane = BABYLON.Mesh.CreateBox("lane", 1, scene, false);
lane.scaling = new BABYLON.Vector3(
laneWidth, laneHeight, totalLaneLength);
lane.position.y = laneHeight / 2; // New position due to mesh centering
lane.position.z = totalLaneLength / 2;
return lane;
}
~~~
再强调一次,别忘了将此函数添加到 init 中。
您可以看到我是如何使用缩放参数的。我创建了一个大小为 1x1x1 的盒子,然后将它的缩放设置更改为适应我预定义的常量。
使用同样的技术,我创建了两个盒子,它们将用作我球道两边的球槽(若以错误的方向掷出,则球会落入此槽)。您可以自己尝试创建看看,也可以查看随附的项目,看我是如何创建的。
## 保龄球瓶和球
现在就差保龄球瓶和球了。为了创建保龄球瓶,我将使用圆柱体,只需将一个圆柱体倍增多次即可(确切地说,是 10 次)。在 Babylon.js 中,我们将这样倍增的对象称为实例。实例就是网格的精确副本(在空间中的转换除外)。也就是说,不能更改实例的几何图形和纹理,但可以更改实例的位置、缩放和旋转。我个人从未在场景中使用过原始对象;如果我想要 10 个保龄球瓶,我将会创建 1 个保龄球瓶并禁用它,然后在 10 个预定义位置上创建 10 个保龄球瓶实例:
~~~
function createPins(scene) {
// Create the main pin
var mainPin = BABYLON.Mesh.CreateCylinder(
"pin", pinHeight, pinDiameter / 2, pinDiameter, 6, 1, scene);
// Disable it so it won't show
mainPin.setEnabled(false);
return pinPositions.map(function (positionInSpace, idx) {
var pin = new BABYLON.InstancedMesh("pin-" + idx, mainPin);
pin.position = positionInSpace;
return pin;
});
}
~~~
此函数中缺少的变量可以在项目文件中找到,包括 pinPositions(包含所有 10 个保龄球瓶的全局位置的数组)。
现在就差保龄球了。保龄球是一种简单的球体,上有 3 个方便手指插入的孔。为了创建此球体,我将使用 Babylon.js 提供的 CreateSphere 函数:
~~~
var sphere = BABYLON.Mesh.CreateSphere("sphere", 12, 0.22, scene);
~~~
现在,我需要钻孔。为此,我将使用已集成到 Babylon.js 中的构造实体几何 (CSG) 功能。借助此功能,我可以向现有网格添加网格或从中去掉网格,或者可以向另一个几何体添加几何体或从中去掉几何体(如果能这样,就更好了)。也就是说,如果两个网格相交,我可以从中“去掉”一个网格,获得另一个经过更改的网格。在我的示例中,我想在一个球体中创建三个圆孔。圆柱体就完全适合。
首先,我将创建用于第一个孔的圆柱体:
~~~
var cylinder = BABYLON.Mesh.CreateCylinder(
"cylinder", 0.15, 0.02, 0.02, 8, 1, scene, false);
~~~
接下来,我将把圆柱体的位置更改为与球体相交:
~~~
cylinder.position.y += 0.15;
~~~
然后,我将创建 CSG 对象,并使用它们从球体中去掉圆柱体:
~~~
var sphereCSG = BABYLON.CSG.FromMesh(sphere);
var cylinderCSG = BABYLON.CSG.FromMesh(cylinder);
sphereCSG.subtractInPlace(cylinderCSG);
var ball = sphereCSG.toMesh("test", sphere.material, scene, false);
~~~
图 10 展示了球体和圆柱体,紧靠着的是使用 CSG 创建的保龄球。

图 10:创建保龄球
图 11 和 [babylonjs-playground.com/#BIG0J](http://babylonjs-playground.com/#BIG0J) 上的园地均展示了从头开始创建保龄球的全部代码。
图 11:使用 CSG 创建保龄球
~~~
// The original sphere, from which the ball will be made
var sphere = BABYLON.Mesh.CreateSphere("sphere", 10.0, 10.0, scene);
sphere.material = new BABYLON.StandardMaterial("sphereMat", scene);
// Create pivot-parent-boxes to rotate the cylinders correctly
var box1 = BABYLON.Mesh.CreateBox("parentBox", 1, scene);
var box2 = box1.clone("parentBox");
var box3 = box1.clone("parentBox");
// Set rotation to each parent box
box2.rotate(BABYLON.Axis.X, 0.3);
box3.rotate(BABYLON.Axis.Z, 0.3);
box1.rotate(new BABYLON.Vector3(0.5, 0, 0.5), -0.2);
[box1, box2, box3].forEach(function (boxMesh) {
// Compute the world matrix so the CSG will get the rotation correctly
boxMesh.computeWorldMatrix(true);
// Make the boxes invisible
boxMesh.isVisible = false;
});
// Create the 3 cylinders
var cylinder1 = BABYLON.Mesh.CreateCylinder(
"cylinder", 4, 1, 1, 30, 1, scene, false);
cylinder1.position.y += 4;
cylinder1.parent = box1;
var cylinder2 = cylinder1.clone("cylinder", box2);
var cylinder3 = cylinder1.clone("cylinder", box3);
// Create the sphere's CSG object
var sphereCSG = BABYLON.CSG.FromMesh(sphere);
// Subtract all cylinders from the sphere's CSG object
[cylinder1, cylinder2, cylinder3].forEach(function (cylinderMesh) {
sphereCSG.subtractInPlace(BABYLON.CSG.FromMesh(cylinderMesh));
});
// Create a new mesh from the sphere CSG
var ball = sphereCSG.toMesh("bowling ball", sphere.material, scene, false);
~~~
## 纹理
我创建的全部网格均分配有默认的白色材料。为了使场景更具吸引力,我应该添加其他材料。标准 Babylon.js 材料(默认着色器)有很多定义,我不会在此进行介绍。(若要详细了解默认 Babylon.js 着色器,您可以试用 [materialeditor.raananweber.com](http://materialeditor.raananweber.com/) 上的 BabylonJS 材料编辑器。) 不过,我将介绍我是如何设置球道和保龄球的纹理的。
为了设置保龄球的纹理,我将使用另一项精彩的 Babylon.js 功能,即过程化纹理。过程化纹理不是使用 2D 图像的标准纹理,而是以编程方式创建的纹理(由 GPU(而不是 CPU)生成),能够对场景的效果产生积极影响。Babylon 提供多种类型的过程化纹理(木质、砖块、火、云、草等)。我将要使用的是大理石纹理。
在创建保龄球的网格后,添加以下代码行会让保龄球变成绿色的大理石球(如图 12 所示):
~~~
var marbleMaterial = new BABYLON.StandardMaterial("ball", scene);
var marbleTexture = new BABYLON.MarbleProceduralTexture(
"marble", 512, scene);
marbleTexture.numberOfTilesHeight = 2;
marbleTexture.numberOfTilesWidth = 2;
marbleMaterial.ambientTexture = marbleTexture;
// Set the diffuse color to the wanted ball's color (green)
marbleMaterial.diffuseColor = BABYLON.Color3.Green();
ball.material = marbleMaterial;
~~~

图 12:应用于保龄球的大理石纹理
可以使用标准材料的漫射纹理,向球道添加木质纹理。不过,这不是我要谈论球道材料的原因所在。如果您看过真实的保龄球球道,则会注意到球道上面有多组点和一组箭头或三角形。为了模拟这样的球道,我可以创建一个非常大的纹理,其上包含所有这些元素,但这样做可能会影响性能(由于纹理非常大)或降低图像质量。
我也可以使用贴花纸,这是 Babylon.js 2.1 中引入的一项新功能。借助贴花纸,您可以在已设置纹理的网格之上“绘制”图形。例如,贴花纸可用于模拟墙上的枪孔,或在保龄球球道上添加装饰(如我的示例所示)。由于贴花纸是网格,因此使用标准材料设置纹理。图 13 展示了我是如何添加边线的,图 14 展示了在我添加贴花纸后保龄球球道的外观,以及在我将过程化纹理(砖块和草)用作材料后地板和球槽的外观。
图 13:添加边线贴花纸
~~~
// Set the decal's position
var foulLinePosition = new BABYLON.Vector3(0, laneHeight, foulLaneDistance);
var decalSize = new BABYLON.Vector3(1,1,1);
// Create the decal (name, the mesh to add it to, position, up vector and the size)
var foulLine = BABYLON.Mesh.CreateDecal("foulLine", lane, foulLinePosition, BABYLON.Vector3.Up(), decalSize);
// Set the rendering group so it will render after the lane
foulLine.renderingGroupId = 1;
// Set the material
var foulMaterial = new BABYLON.StandardMaterial("foulMat", scene);
foulMaterial.diffuseTexture =
new BABYLON.Texture("Assets/dots2-w-line.png", scene);
foulMaterial.diffuseTexture.hasAlpha = true;
foulLine.material = foulMaterial;
// If the action manager wasn't initialized, create a new one
scene.actionManager = new BABYLON.ActionManager(scene);
// Register an action to generate a new color each time I press "c"
scene.actionManager.registerAction(new BABYLON.ExecuteCodeAction({
trigger: BABYLON.ActionManager.OnKeyUpTrigger, parameter: "c" },
// The function to execute every time "c" is pressed"
function () {
ball.material.diffuseColor =
new BABYLON.Color3(Math.random(), Math.random(), Math.random());
}
));
~~~

图 14:添加了贴花纸的球道
## 用户输入 - Babylon.js 操作管理器
作为功能齐全的游戏引擎,Babylon.js 提供了一种与用户输入进行交互的简单方式。假设我想使用 C 键更改保龄球的颜色。每次按下 C,我都想为保龄球设置一种随机颜色:
~~~
// If the action manager wasn't initialized, create a new one
scene.actionManager = new BABYLON.ActionManager(scene);
// Register an action to generate a new color each time I press C
scene.actionManager.registerAction(
new BABYLON.ExecuteCodeAction({ trigger:
BABYLON.ActionManager.OnKeyUpTrigger, parameter: "c" },
// The function to execute every time C is pressed
function () {
ball.material.diffuseColor =
new BABYLON.Color3(Math.random(), Math.random(), Math.random());
}
));
~~~
Babylon.js 操作管理器是一款功能强大的工具,可用于根据触发器控制操作。触发器可以是鼠标移动或单击、网格相交或键盘输入。有很多触发器和操作可供选择。请访问 Babylon.js 教程站点 ([bit.ly/1MEkNRo](http://bit.ly/1MEkNRo)),了解全部触发器和操作。
我将使用操作管理器控制保龄球并重置场景。我将在本教程的第 2 部分中添加这些操作。
## 使用外部资源
我已使用 Babylon.js 的内部函数创建了所需的网格。大多数情况下,这是不够的。Babylon.js 提供了很多网格(从球体和盒子到复杂的带状物),但创建复杂的模型是很难的,如人、Web 版 Doom 中的武器或 Space Invaders 克隆中的宇宙飞船。
Babylon.js 为很多知名的 3D 工具(如 Blender 和 3D-Studio)提供了导出程序插件。您也可以从出色的 Clara.io 中导出您的模型,然后下载 .babylon 文件。
Babylon.js 使用自己的文件格式,这种格式可以包含整个场景,包括网格、照相机、光、动画、几何体和其他信息。因此,如果您愿意,可以将 Blender 仅用于模拟整个场景。您还可以导入单个网格。
不过,这并不在本教程的范围之内。对于本文,我只想展示如何只使用 Babylon.js 创建简单的游戏。
## 下一步是什么?
我已跳过 Babylon.js 中集成的许多功能。它具有大量功能,我强烈建议您查看园地 ([babylonjs-playground.com](http://babylonjs-playground.com/))、文档页 ([doc.babylonjs.com](http://doc.babylonjs.com/)) 和 Babylon.js 主页 ([babylonjs.com](http://babylonjs.com/)),看看如何开创无限可能。如果您觉得本教程的任何部分比较难懂,请联系我或十分活跃的 Babylon.js HTML5 游戏开发论坛 ([bit.ly/1GmUyzq](http://bit.ly/1GmUyzq)) 上的任何一位 Babylon.js 大神。
在下一篇文章中,我将创建实际的游戏,即添加物理特性和碰撞检测、掷球功能、音频等。
* * *
Raanan Weber *既是一名 IT 顾问、完整堆栈开发者,也是一名丈夫和父亲。空闲时,他为 Babylon.js 和其他开放源代码项目献计献策。您可以阅读他的博客 ([blog.raananweber.com](http://blog.raananweber.com/))。*
数据点 – Aurelia 与 DocumentDB 结合: 结合之旅(第 2 部分)
最后更新于:2022-04-01 06:52:52
# 数据点 - Aurelia 与 DocumentDB 结合: 结合之旅(第 2 部分)
通过 [Julie Lerman](https://msdn.microsoft.com/zh-cn/magazine/mt149362?author=Julie+Lerman) |2015 年 12 月 | [获取代码](http://download.microsoft.com/download/D/5/4/D54647CC-A404-4374-B7EF-E469FB5136B9/Code_Lerman.DataPoints1215.zip)

新的 JavaScript 框架、 Aurelia 和 NoSQL 文档数据库服务,Azure DocumentDB 是最近捕获我感兴趣的两个不同的技术。在 6 月,我探讨了较高层面的 DocumentDB ([msdn.com/magazine/mt147238](http://msdn.com/magazine/mt147238))。然后,在 9 月份,我玩游戏与 Aurelia 中的数据绑定 ([msdn.com/magazine/mt422580](http://msdn.com/magazine/mt422580))。通过这两种技术仍好奇,我认为我希望将这两个组合在一起,作为应用程序和 DocumentDB 的前端 Aurelia 用作数据存储区。虽然我的好奇心给我带来了一定的优势 (持久性),我有限的经验与这两种新技术,以及 JavaScript 框架一般情况下,设置我沿多个这样的困境之中尝试地结合使用。没有人最初执行之前此组合的事实后情况已变得更糟 — 至少不公开。我在 11 月的专栏中记录这些失败的尝试 ([msdn.com/magazine/mt620011](http://msdn.com/magazine/mt620011)),则这两篇系列文章的第一个。所选的要跳过的一条浅显路径是使用我包装与 DocumentDB 来代替我在我第一 Aurelia 篇文章中从事 Web API 进行交互的现有 Web API。在其中没有挑战性因所做选择此选项,并因此不内容相当有趣。
我最后来到决定使用另一种服务器端解决方案: Node.js。没有使用 DocumentDB Node.js SDK 和一个不同的前端的现有示例。我仔细检查并共享我学到什么与您在我在 11 月的专栏的第二部分中。然后我将有关重新从 9 月列中,我专家的示例创建这次使用作为从 Aurelia 前端到 DocumentDB 我充当中介的 Node.js。各种错误很多,而且它们远远超出与数据相关的问题了。我必须支持从 Aurelia 核心团队的成员,尤其是从 Patrick Walters 加载 ([github.com/pwkad](http://github.com/pwkad)),用户不仅可以帮助您确认我已充分利用 Aurelia 功能,但也会间接迫使我进一步 hone 到我的 Git 技能。我将关注这里是涉及访问、 更新和将数据绑定解决方案的各个部分。附带了随附的可下载示例的自述文件说明了如何设置您自己 DocumentDB 并导入此解决方案的数据。它还说明了如何设置运行该示例的要求。
## 解决方案体系结构
首先,让我们看一看此解决方案的整体体系结构,如中所示 图 1。
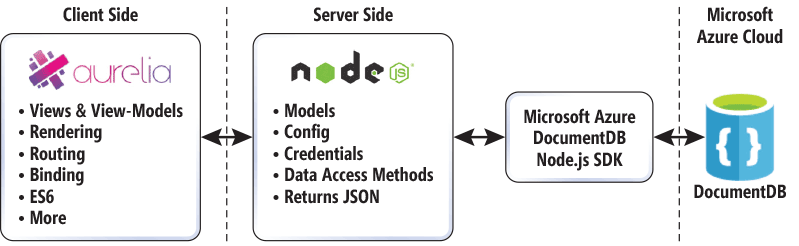
图 1 此解决方案的整体结构
Aurelia 是客户端框架,因此就在这里只是为了处理客户端的要求,如呈现的 HTML,取决于视图和视图模型配对,以及路由、 数据绑定和其他相关任务。(请注意所有客户端代码可以在浏览器,如 Internet Explorer 和 Chrome 中可用的开发人员工具中进行调试。) 在解决方案的路径中,所有客户端代码是在公共/应用程序/src 文件夹中,服务器端代码时的根文件夹中。当运行该 Web 站点时,客户端文件编译通过 Aurelia 以确保浏览器兼容性,且分发到一个名为"dist."文件夹 这些文件是发送到客户端获取的内容。
服务器端代码应熟悉如果您曾在 Microsoft.NET Framework (更接近于我自己背景) 中的 Web 开发。在.NET 环境中,从 web 窗体、 控制器和其他逻辑代码隐藏是传统上编译为 Dll 存在于服务器。当然,大部分内容更改与 ASP.NET 5 (其中我现在感觉更准备好,谢谢到处理此特定项目)。我的 Aurelia 项目还包含服务器端代码,但即便是这样,通过 Node.js 的 JavaScript 代码。此代码不编译为 DLL,但仍保留在其自己单独的文件。更重要的是,它不会下推至客户端并因此不容易公开 (这是,当然,总是非常依赖于安全措施)。如我所述最后一次,他们希望将停留在服务器的代码的推动原因是我需要一种方法来存储我的凭据用于与 DocumentDB 交互。因为我想要试用 Node.js 路径,上述 SDK 进行对话,与 DocumentDB 容易得多。我必须依靠有关如何使用 SDK 的一些基本知识的原始 DocumentDB 节点示例是一个巨大帮助。
我的服务器端代码 (其中我将称它为我的 API) 由四个关键要素组成:
* 可以轻松地找到充当路由器以确保我的 API 函数 api.js 文件。
* 我的核心模块、 ninjas.js,其中包含的 API 函数: getNinjas getNinja 和 updateDetails。
* 控制器类中,执行与 DocumentDb 交互的 DocDbDao (由这些 API 函数调用)。
* 知道如何确保相关数据库和集合的 DocumentDb 实用程序文件存在。
## 绑定客户端、 服务器和云
在我早期 Aurelia 示例中,要获取所有 ninjas 的方法进行直接的 HTTP 调用到.NET 和实体框架进行交互与 SQL Server 数据库使用的 ASP.NET Web API:
~~~
retrieveNinjas() {
return this.http.createRequest
("/ninjas/?page=" + this.currentPage + "&pageSize=100&query=" +
this.searchEntry)
.asGet().send().then(response => {
this.ninjas = response.content;
});
}
~~~
已将结果传递给客户端一侧视图和视图模型 (ninjaList.js 和 ninjaList.html),会输出中显示的页面对 图 2。

图 2 中我 Aurelia 的网站的专家列表
在新的解决方案中,这种方法,重命名为 getNinjas,现在我的服务器端 Node.js API 调用。我使用更高级的 httpClient.fetch ([bit.ly/1M8EmnY](http://bit.ly/1M8EmnY)) 而不是 httpClient 这次进行调用:
~~~
getNinjas(params){
return this.httpClient.fetch(`/ninjas?q=${params}`)
.then(response => response.json())
.then(ninjas => this.ninjas = ninjas);
}
~~~
我已配置在其他地方 httpClient 须知的基 URL。
请注意,我提取的方法调用包括术语 ninjas 的 URI。但是,这不指在服务器端 API 中我 ninjas.js。这可能是 /foo — 只是将我的服务器端路由器的解析的随机的引用。我的服务器端路由器 (它使用明确的、 不 Aurelia,因为 Aurelia 只处理客户端) 指定对 api/ninjas 的调用将路由到 ninjas 模块 getNinjas 函数。下面是从 api.js 定义此代码:
~~~
router.get('/api/ninjas', function (request, response) {
ninjas.getNinjas(req, res);
});
~~~
现在我 getNinjas 函数 (图 3) 使用字符串插值 (mzl.la/1fhuSIg) 以生成一个字符串来表示用于查询 DocumentDB、 SQL 然后询问用户要执行查询并返回结果的控制器。如果名称属性的筛选器已请求在 UI 中,我将追加到查询的 WHERE 子句。主查询投影只我需要将相关属性页上,包括此 id。(有关在 DocumentDB 投影查询的详细信息请参阅 [documentdb.com/sql/demo](http://documentdb.com/sql/demo)。) 查询传递到 docDbDao 控制器的查找方法。Find 方法,这是我在本系列的第一部分所述的原始相比并无变化,使用 Node.js SDK 以及 config.js 中存储的凭据来查询 ninjas 的数据库。然后,getNinjas 接受这些结果,并将它们返回到请求它们的客户端。请注意,尽管对 DocumentDB 的调用不作为 JSON 返回结果,但我仍然需要显式使用 response.json 函数将返回的结果传递。这会提醒调用方,则结果是 JSON 格式。
图 3 在 ninjas.js 服务器端模块 getNinjas 函数
~~~
getNinjas: function (request, response) {
var self = this;
var q = '';
if (request.query.q != "undefined" && req.query.q > "") {
q= `WHERE CONTAINS(ninja.Name,'${req.query.q}')`;
}
var querySpec = {
query:
`SELECT ninja.id, ninja.Name,ninja.ServedInOniwaban,
ninja.DateOfBirth FROM ninja ${q}`
};
self.docDbDao.find(querySpec, function (err, items) {
if (err) {
// TODO: err handling
} else {
response.json(items);
}
})
},
~~~
## 编辑请求的客户端的响应
正如您可以看到在 图 2, ,就可以通过单击铅笔图标编辑专家。下面是我都构建在页标记中的链接:
~~~
<a href="#/ninjas/${ninja.id}" class=
"btn btn-default btn-sm">
<span class="glyphicon glyphicon-pencil" />
</a>
~~~
通过单击我的第一行,其 ID 恰好是"1",编辑图标中,我将获得此 URL:
~~~
http://localhost:9000/app/#/ninjas/1
~~~
在 app.js 的客户端上使用 Aurelia 路由功能,我已指定在请求此 URL 模式时,它应然后调用编辑模块,id 中给编辑视图模型的激活方法作为参数传递,指示通配符 (* Id):
~~~
{ route: 'ninjas/*Id', moduleId: 'edit', title:'Edit Ninja' },
~~~
编辑是指与 edit.html 视图成对出现的客户端 edit.js 模块。然后,我编辑的模块的激活函数名为 retrieveNinja,传入的请求 Id 本模块中调用其他函数:
~~~
retrieveNinja(id) {
return this.httpClient.fetch(`/ninjas/${id}`)
.then(response => response.json())
.then(ninja => this.ninja = ninja);
}
~~~
## 将编辑请求传递到服务器端 API
同样,我使用 httpClient.fetch 请求 api/ninjas / [id] (在我事例 api/ninjas/1) 从 API。服务器端路由器说,这种模式的请求到达时,它应将路由到 ninjas 模块 getNinja 函数。下面是什么该路由将如下所示:
~~~
router.get('/api/ninjas/:id', function(request, response) {
ninjas.getNinja(request, response);
});
~~~
GetNinja 方法然后另一个向发出请求 docDbDao 控制器上,这次是打开 getItem 函数,可从 DocumentDb 获取专家数据。结果是我的 DocumentDB 数据库中存储的 JSON 文档中所示 图 4:
图 4 文档我请求,存储在 DocumentDb Ninjas 收藏
~~~
{
"id": "1",
"Name": "Kacy Catanzaro",
"ServedInOniwaban": false,
"Clan": "American Ninja Warriors",
"Equipment": [
{
"EquipmentName": "Muscles",
"EquipmentType": "Tool"
},
{
"EquipmentName": "Spunk",
"EquipmentType": "Tool"
}
],
"DateOfBirth": "1/14/1990",
"DateCreated": "2015-08-10T20:35:09.7600000",
"DateModified": 1444152912328
}
~~~
## 将结果传递回客户端
此 JSON 对象返回给 ninjas.getNinja 函数,然后将其返回给调用方,在此情况下 edit.js 模块在客户端。然后,Aurelia 将 edit.js 绑定到 edit.html 模板,并将输出一个页面,它设计用于显示此关系图中。
编辑视图允许用户修改的数据的四个部分: 专家的名称和出生日期 (这两个字符串),clan (下拉列表) 和专家是否 Oniwaban 中提供服务。Clan 下拉列表中使用一种特殊的 Web 组件调用的自定义元素。自定义元素规范的 Aurelia 实现是唯一的。因为我正在使用该功能来绑定数据,并且这是一个数据列,我将向您展示如何执行该操作。
## 数据绑定与 Aurelia 自定义元素
类似于其他视图和视图模型对 Aurelia 中的,自定义元素标记的视图和视图模型的逻辑组成。图 5 显示的第三个文件涉及 clans.js,它提供 clans 的列表。
图 5 Clans.js
~~~
export function getClans(){
var clans = [], propertyName;
for(propertyName in clansObject) {
if (clansObject.hasOwnProperty(propertyName)) {
clans.push({ code: clansObject[propertyName], name: propertyName });
}
}
return clans;
}
var clansObject = {
"American Ninja Warriors": "anj",
"Vermont Clan": "vc",
"Turtles": "t"
};
~~~
此元素 (dropdown.html) 的视图使用的启动"选择"元素,我仍将视为一个下拉列表:
~~~
<template>
<select value.bind="selectedClan">
<option repeat.for="clan of clans" model.bind="clan.name">${clan.name}</option>
</select>
</template>
~~~
请注意 value.bind 和 repeat.for,它应是如果您阅读我以前的专栏,在数据绑定与 Aurelia 所熟悉。在 select 元素内的选项将绑定到 clans.js 中定义的 clan 模型,然后显示 clan 名称。我 Clans 对象非常简单,因为具有名称和代码中 (这是在此示例中额外),我可以简单地使用 value.bind 存在。但是,我将坚持使用 model.bind,因为它是一种更好的我记住模式。
Dropdown.js 模块连线具有 clans,标记中所示 图 6。
图 6 自定义元素中 Dropdown.js 的模型代码
~~~
import $ from 'jquery';
import {getClans} from '../clans';
import {bindable} from 'aurelia-framework';
export class Dropdown {
@bindable selectedClan;
attached() {
$(this.dropdown).dropdown();
}
constructor() {
this.clans = getClans();
}
}
~~~
此外,自定义元素就可以让我在我的编辑视图使用很多简单标记:
~~~
<dropdown selected-clan.two-way="ninja.Clan"></dropdown>
~~~
请注意,我正在使用以下两个 Aurelia 特定功能。首先,我的属性称为 selectedClan 在视图模型,但选择 clan 在标记中。Aurelia 约定,基于 HTML 的必要性属性来为小写,是使所有自定义属性的导出名称小写和断字,因此其结果应为驼峰式大小写字母的开始位置的连字符。其次,而不 value.bind,我显式使用双向绑定,此处这样 clan 将重新绑定到专家所选内容更改时。
更重要的是,我可以非常轻松地重复使用我在其他视图中的自定义元素。在本例中,它只需提供可读性,因此,多个可维护性。但在大型应用程序,重复使用的标记和逻辑是很大的收益。
## 将编辑推回 DocumentDB
我的标记是读取关系图中的设备的两个参数,并显示它们。为了简洁起见,我将编辑另一天将设备的数据。
现在工作的最后一位是将备份的更改传递给 API 并将它们发送到 DocumentDB。这会触发与保存按钮。
保存按钮的标记使用另一个 Aurelia 范例,click.delegate—which 使用 JavaScript 事件委托,从而使我能够委托给存储操作 edit.js 中定义的函数。
保存工作中, 所示 图 7, ,创建一个新对象,ninjaRoot,使用从 getNinja,这是在其中定义的专家属性相关的属性,然后绑定到标记中,这样就允许用户从浏览器进行更新。
图 7 ninjas.save 函数
~~~
save() {
this.ninjaRoot = {
Id: this.ninja.id,
ServedInOniwaban: this.ninja.ServedInOniwaban,
Clan: this.ninja.Clan,
Name: this.ninja.Name,
DateOfBirth: this.ninja.DateOfBirth
};
return this.httpClient.fetch('/updateDetails', {
method: 'post',
body: json(this.ninjaRoot)
}).then(response => {this.router.navigate('ninjaList');
});
}
~~~
保存然后使用现在应该很熟悉 httpClient.fetch 请求调用 udpateDetails API URL,然后将传入的 ninjaRoot 对象作为正文。此外,请注意,我指定的这作为 post 方法,不具有 get。API 路由器告知 Node.js 可将路由到 ninjas 模块的 updateDetails 方法。
~~~
router.post('/api/updateDetails', function(request,response){
ninjas.updateDetails(request,response);
});
~~~
现在让我们看一下 ninjas.js 中的服务器端 updateDetails 方法:
~~~
updateDetails: function (request,response) {
var self = this;
var ninja = request.body;
self.docDbDao.updateItem(ninja, function (err) {
if (err) {
throw (err);
} else {
response.send(200);
}
})
},
~~~
我提取存储在请求正文和专家变量,然后将该变量传递到控制器的 updateItem 方法的集 ninjaRoot。作为 图 8 所示,我修改 updateItem 有点以来第一部分我的文章以适应我专家的类型。
图 8 updateItem 方法中 docDbDao 控制器使用说到 DocumentDB Node.js SDK
~~~
updateItem: function (item, callback) {
var self = this;
self.getItem(item.Id, function (err, doc) {
if (err) {
callback(err);
} else {
doc.Clan=item.Clan;
doc.Name=item.Name;
doc.ServedInOniwaban=item.ServedInOniwaban;
doc.DateOfBirth=item.DateOfBirth;
doc.DateModified=Date.now();
self.client.replaceDocument(doc._self, doc, function (err, replaced) {
if (err) {
callback(err);
} else {
callback(null, replaced);
}
});
}
});
},
~~~
UpdateItem 文档使用 id 从数据库进行检索、 更新该文档的相关属性,然后使用 SDK DocumentDBClient.replaceDocument 方法将更改推送到我的 Azure DocumentDB 数据库。回调提醒我的操作已完成。通过 updateDetails 方法,它将返回到调用该 API 的客户端模块返回 200 响应代码,然后记下该回调。如果您回顾一下 save 方法的客户端,您会注意到其回调将路由到 ninjaList。因此更新已成功发布,是显示给用户的 ninjas 的原始列表页。向专家刚刚已更改的任何编辑都将在该列表中可见。
## 我们是否 Ninjas 尚未?
此解决方案将使我的困难和死胡同原来的虚空到。在我的核心目标能够 Aurelia 交谈 DocumentDB 数据库时,我还想要使用这些技术来利用它们带来的好处。这意味着无需理解这么多世界物流的 JavaScript、 管理节点安装,请使用 Visual Studio Code 第一次由于它可以进行调试 Node.js 和甚至更多地了解 DocumentDB。尽管有可能想要在甚至像我这样一个简单的示例中执行操作的许多其他课题,本文应为您提供的操作的运行方式从一端到另一个基本的了解。
请记住的重要一点是,DocumentDB — 像任何 NoSQL 数据库 — 适用于大容量数据。它是不经济有效的小小位的数据,如我在我的示例中使用。不过,若要浏览的功能与数据库连接和交互数据时,大量的数据不是必需的因此五个对象 sufficed。
* * *
Julie Lerman *是 Microsoft MVP、.NET 导师和顾问,住在佛蒙特州的山区。您可以在全球的用户组和会议中看到她对数据访问和其他 .NET 主题的演示。她的博客网址 [thedatafarm.com /blog](http://thedatafarm.com/blog) 和代码优先和 DbContext 版,均出自 O'Reilly Media 以及是 《 Programming Entity Framework 》 的作者。请关注她的 Twitter: [@julielerman](https://twitter.com/@julielerman) 并查看其 Pluralsight 课程,网址 [juliel.me /ps-videos](http://juliel.me/PS-Videos)。*
Microsoft Azure – Azure Service Fabric 和微服务体系结构
最后更新于:2022-04-01 06:52:50
# Microsoft Azure - Azure Service Fabric 和微服务体系结构
作者 [Cesar de la Torre](https://msdn.microsoft.com/zh-cn/magazine/mt149362?author=Cesar+de+la+Torre)、[Kunal Deep Singh](https://msdn.microsoft.com/zh-cn/magazine/mt149362?author=Kunal+Deep+Singh)、[Vaclav Turecek](https://msdn.microsoft.com/zh-cn/magazine/mt149362?author=Vaclav+Turecek) | 2015 年 12 月
微服务是目前的流行语。虽然关于此主题的演示文稿和会议演讲有很多,但许多开发者仍对此感到困惑。我们经常会听到有人提出这样的疑问: “这不就是另一种面向服务的体系结构 (SOA) 或域驱动设计 (DDD) 方法吗?”
当然,微服务方法中使用的许多技术都是源自开发者的 SOA 和 DDD 体验。您可以将微服务看成是“处理得当的 SOA”,具有自治服务、界定上下文模式和事件驱动等原则和模式(均以 SOA 和 DDD 为根源)。
在本文中,我们将介绍微服务理论和实现。我们将先对微服务进行简单介绍,然后转向实际运用方面,介绍如何使用 Azure Service Fabric 构建和部署微服务。最后,我们将说明为什么此平台非常适合构建微服务。
顾名思义,微服务体系结构是一种将服务器应用程序构建为一组小型服务的方法,每个服务都按自己的进程运行,并通过 HTTP 和 WebSocket 等协议相互通信。每个微服务都在特定的界定上下文(每服务)中实现特定的端到端域和业务功能,并且必须由自动机制进行自主开发和独立部署。最后,每个服务都应该拥有自己的相关域数据模型和域逻辑,并能使用不同的数据存储技术(SQL 和非 SQL),对每个微服务使用不同的编程语言。
微服务示例包括协议网关、用户配置文件、购物车、库存处理、购买子系统、付款处理以及队列和缓存。
为什么要使用微服务? 一言以蔽之,就是因为灵活性。从长远来看,微服务能够将应用程序设计为基于许多可独立部署且能制定具体发布规划的服务,从而可以在复杂的可高度扩展大型系统中实现极高的可维护性。
微服务的另外一大优势是,可以独立扩展。您可以扩展特定的微服务,而无需一次性扩展庞大的应用程序块整体。这样一来,可以单独扩展需要更多处理能力或网络带宽以支撑需求的功能区域,而不用扩展应用程序中实际并不需要更多处理能力或网络带宽的其他区域。
通过构建精细的微服务应用程序,您可以持续集成和开发,并能加速在应用程序中实现新功能。通过精细分解应用程序,您还可以单独运行和测试微服务,并能在保持微服务之间的严格协定的同时独立发展微服务。只要您不破坏协定或接口,就可以在后台更改任何微服务实现,并能添加新功能,而不破坏其他依赖微服务。
使用微服务方法,根本宗旨就是借助灵活更改和快速迭代实现高效率,因为您可以更改复杂的可扩展大型应用程序的特定一小部分(如图 1 所示)。
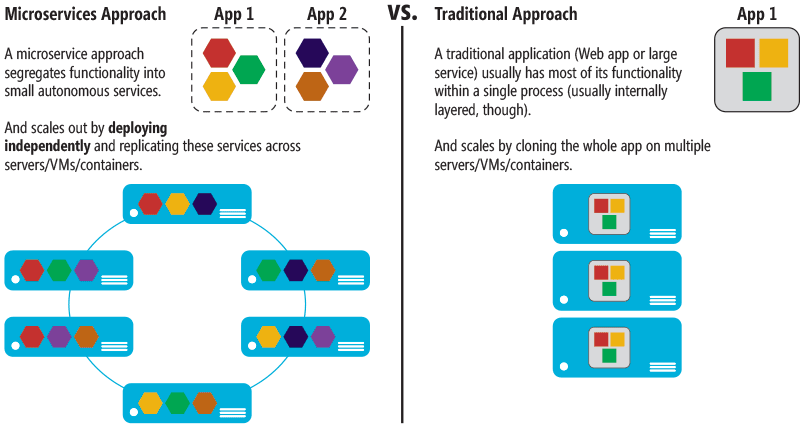
图 1:微服务方法与传统服务器应用程序方法的对比
## 每个微服务的数据主权
这种方法遵循的一项重要规则是,每个微服务都必须拥有自己的域数据和逻辑(在自治生命周期内),且每个微服务都必须独立部署。这实际上与完整的应用程序拥有自己的逻辑和数据别无二致。
也就是说,使用此方法,域的概念模型因子系统或微服务而异。以企业应用程序为例,其中客户关系管理 (CRM) 应用程序、交易购买子系统和客户支持子系统各自调用唯一客户实体属性和数据,并采用不同的界定上下文。
此原则与 DDD 中的原则类似,即每个界定上下文(可与子系统/服务相比的模式)必须拥有自己的域模型(数据和逻辑)。每个 DDD 界定上下文均与不同的微服务相关联。
另一方面,许多应用程序中使用的传统(或整体)方法是对整个应用程序及其所有内部子系统使用一个集中数据库(通常是规范化 SQL 数据库),如图 2 所示。这种方法起初看来比较简单,似乎能够在不同的子系统中重复使用实体,从而保持所有对象的一致性。但实际上,您最终会得到为许多不同的子系统提供服务的大型表格,其中包括大多数情况下并不需要的属性和列。这相当于在进行短途徒步旅行、一天自驾游和学习地理知识时使用同一张自然地图。
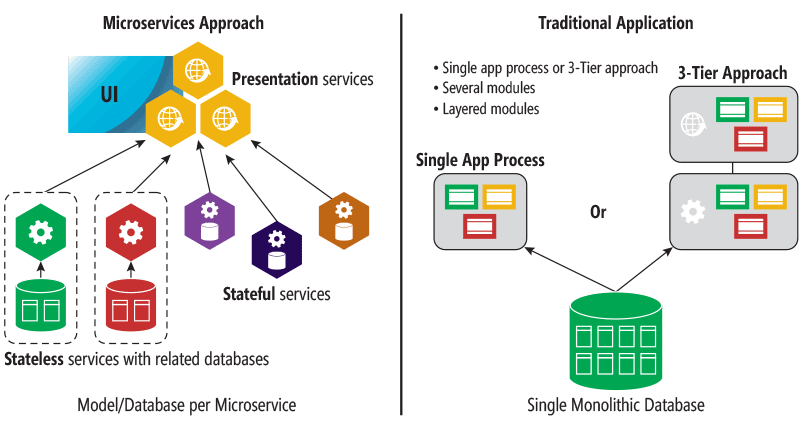
图 2:数据主权比较: 微服务与整体
## 微服务无状态还是有状态?
如前所述,每个微服务都必须拥有自己的域模型。对于无状态微服务,数据库是外部的,并采用 SQL Server 等关系选项,或 MongoDB 或 Azure Document DB 等 NoSQL 选项。进一步探究发现,服务本身可以是有状态的,也就是说数据驻留在同一微服务中。此类数据不仅可以存在于同一服务器中,还可以存在于同一微服务进程中、内存中、硬盘驱动器中,并能复制到其他节点。
无状态是非常有效的方法,比有状态微服务更易于实现,因为无状态类似于传统的已知模式。不过,无状态微服务会导致进程和数据源之间出现延迟,同时还会在通过其他缓存和队列提高性能时呈现更多移动对象。结果就是,您最终会得到包含许多层级的复杂体系结构。
另一方面,有状态微服务在高级方案中脱颖而出,因为域逻辑和数据之间没有延迟。繁重的数据处理、游戏后端、数据库即服务和其他低延迟方案都受益于有状态服务,因为它能启用本地状态以提高访问速度。
缺点是, 有状态服务会增加复杂性,加大了扩展难度。对于跨有状态微服务副本的数据复制、数据分区等问题,必须实施通常在外部数据库边界内实现的功能。而这正是 Service Fabric 最有帮助的一个地方,即简化有状态微服务的开发和生命周期。
## Azure Service Fabric 的优点
微服务方法的任何优点都伴随着缺点。如果您亲自操作,则会发现分布式计算和复杂的微服务部署很难管理。Service Fabric 提供了一种体系,方便您以卓有成效的方式创建、部署、运行和管理微服务。
什么是 Service Fabric? 它是一种分布式系统平台,用于构建面向云的可高度扩展且易于管理的可靠应用程序。Service Fabric 可应对开发和管理云应用程序的巨大挑战。通过使用 Service Fabric,开发者和管理员无需解决复杂的基础结构问题,只需专注于实现要求非常高的任务关键型工作负载即可,因为他们知道应用程序既可扩展,又可管理,而且还十分可靠。Service Fabric 代表 Microsoft 的下一代中间件平台,用于构建和管理这些企业级第 1 级云扩展服务。
Service Fabric 是一种通用的部署环境;您可以部署基于任意语言(Microsoft .NET Framework、Node.js、Java 和 C++)或数据库运行时(如 MongoDB)的所有可执行文件。
因此,请务必明确一点,Azure Service Fabric 并不局限于面向微服务的应用程序。您还可以使用它来托管和部署传统应用程序(Web 应用或服务),并收获许多与可扩展性、负载平衡和快速部署相关的好处。不过,Azure Service Fabric 仍是从零开始构建的全新平台,专为超大规模和基于微服务的系统而设计(如图 3 所示)。

图 3:Microsoft Azure Service Fabric
下面介绍了 Service Fabric 的一些优点:
* 在 Azure、本地或任意云中运行。Service Fabric 的一个非常重要的特征是,您不仅可以在 Azure 上运行它,还可以在本地、您自己的裸机服务器或虚拟机 (VM) 上运行它,甚至能在其他第三方托管云中运行它。并没有与特定的云绑定。您甚至可以在 Amazon Web Services (AWS) 中运行 Service Fabric 群集。
* 支持 Windows 或 Linux。目前(2015 年底),Service Fabric 支持 Windows,但它还将支持 Linux 和容器(Windows 图像和 Docker 图像)。
* 已经过全面审查。几年来,Microsoft 一直在使用 Service Fabric 为其许多云产品提供强力支持。
Service Fabric 的产生是因为需要在 Microsoft 内构建大规模服务。使用 SQL Server 等产品并将它们构建为云中可用的服务(Azure SQL 数据库),同时保持灵活性、可靠性、可扩展性和成本效益性,就需要能有效满足所有这些需求的分布式技术。虽然可满足这些复杂方案需求的核心技术已在构建,但 SQL Server 显然不是唯一取得此类重大突破的产品。Skype for Business 等产品不得不解决类似问题,以便在成为基于微服务的应用程序的道路上取得发展。面对这些挑战,Service Fabric 这一应用程序平台应运而生,已广泛用于 Microsoft 的许多大规模服务,这些服务具有不同的体系结构和大规模运行需求。InTune、DocumentDB 以及 Cortana 和 Skype for Business 的后端都是在 Service Fabric 上运行的服务。
凭借在任务关键型系统方面的经验,Microsoft 设计出一种平台,能够自发了解可用的基础结构资源和可扩展的应用程序的需求。它启用了自动更新的自愈行为,这对以超大规模交付高度可用的持久性服务至关重要。Microsoft 现在将这一“久经沙场”的技术向所有人推出。
## Azure Service Fabric 编程模型
Service Fabric 提供以下两种简略框架来构建服务:Reliable Services API 和 Reliable Actors API。虽然这两种框架均在同一 Service Fabric 核心的基础上构建而成,但在并发、分区和通信方面,它们在简洁性和灵活性之间的取舍不同(如图 4 所示)。了解这两种模型的工作方式非常有用。这样,您便能选择更适合您的服务的框架。在许多应用程序方案中,您可以使用混合方法,并对特定微服务使用执行组件,同时对大量执行组件生成的聚合数据使用 Reliable Services。因此,可靠的服务可以在许多常见方案中安排执行组件服务。
图 4:比较 Service Fabric 编程模型
| Reliable Actor API | Reliable Services API |
|--------|--------|--------|
| 您的方案涉及许多独立的小单元/状态对象和逻辑(具有说服力的示例包括,实际物联网对象或游戏后端方案) | 您需要跨多个实体类型和组件维护逻辑和查询 |
| 您要处理大量单线程对象,同时仍能进行扩展并保持一致性 | 您使用可靠的集合(如 .NET 的可靠字典和队列)来存储和管理您的状态/实体 |
| 您想让框架管理状态的并发和粒度 | 您想控制状态的粒度和并发 |
| 您想让 Service Fabric 为您管理通信实现 | 您想选定、管理和实现通信协议(Web API、WebSocket 和 Windows Communication Foundation 等) |
| 您想让 Service Fabric 管理有状态执行组件服务的分区架构,以便对您保持透明 | 您想控制有状态服务的分区架构 |
## 使用 Azure Service Fabric 构建无状态微服务
Azure Service Fabric 中的微服务可以是您想在服务器中创建的几乎所有进程,无论语言是 .NET Framework、Node.js、Java 还是 C++。目前,仅 Service Fabric API 的 .NET 和 C++ 库可用。因此,您需要在 .NET Framework 或 C++ 中实现微服务,以便实现低级别实现。
如上文所述,无状态微服务是指存在进程(如前端服务或业务逻辑服务),但确实没有状态暂留的服务,或出现的状态在进程结束时丢失且不需要同步、复制、暂留或高可用性的服务。可能存在相关的外部状态,但暂留在外部存储中,如 Azure SQL 数据库、Azure 存储空间、Azure DocumentDB 或其他任何第三方存储引擎(关系或 NoSQL)。因此,任何现有服务(如在云服务上运行的 ASP.NET Web API 服务、辅助角色或 Azure Web 应用)都会轻松地迁移到 Service Fabric 无状态服务中。
若要设置开发环境,您需要使用 Service Fabric SDK 来运行不是仿真器的本地部署群集,但运行位数与 Azure 中一样。此外,Visual Studio 2015 工具集成还可以让开发和调试变得更加轻松。
在本地计算机中部署和调试服务前,您需要先创建节点群集。为此,您可以运行名为 DevClusterSetup.ps1 的 Windows PowerShell 脚本,如文档页“准备开发环境”([bit.ly/1Mfi0LB](http://bit.ly/1Mfi0LB)) 中的“安装和启动本地群集”部分所述。您可以参阅此页,逐步了解整个设置流程。
无状态服务基类 - 所有无状态 Service Fabric 服务类都必须源自 Microsoft.ServiceFabric.Services.StatelessService 类。此类提供与 Service Fabric 群集和执行环境相关的 API 方法和上下文,并挂钩到您服务的生命周期。
无论您的服务是有状态还是无状态,Reliable Services 均提供简单的生命周期,以便您能够快速插入代码并开始操作。实际上,您只需实现一个或两个方法(通常是 RunAsync 和 CreateServiceReplicaListeners)就能启动并运行 Service Fabric 服务,我们将在深入探讨通信协议时介绍这两种方法。
请注意,图 5 中展示了 RunAsync。在这里,您的服务可以在后台“正常运行”。提供的取消令牌是应停止工作的信号。
图 5:Azure Service Fabric 中无状态服务的基本结构
~~~
using Microsoft.ServiceFabric.Services;
namespace MyApp.MyStatelessService
{
public class MyStatelessService : StatelessService
{
//... Service implementation
protected override async Task RunAsync(CancellationToken cancellationToken)
{
int iterations = 0;
while (!cancellationToken.IsCancellationRequested)
{
ServiceEventSource.Current.ServiceMessage(this, "Working-{0}",
iterations++);
// Place to write your own background logic.
// Example: Logic doing any polling task.
// Logic here would be similar to what you usually implement in
// Azure Worker Roles, Azure WebJobs or a traditional Windows Service.
await Task.Delay(TimeSpan.FromSeconds(1), cancellationToken);
}
}
}
}
~~~
Azure Service Fabric Reliable Services 中的通信协议 - Azure Service Fabric Reliable Services 提供可插入通信模型。您可以使用所选择的传输协议,如带 ASP.NET Web API 的 HTTP、WebSocket、Windows Communication Foundation 和自定义 TCP 协议等。
您可以在服务中为选定通信协议实现自己的代码,也可以使用 Service Fabric 随附的任意通信堆栈(如 ServiceCommunicationListener/ServiceProxy,这是 Service Fabric 中由 Reliable Services 框架提供的默认通信堆栈)。您还可以将包含其他通信堆栈的独立 NuGet 包插入 Service Fabric 中。
在 Service Fabric 微服务中使用 ASP.NET Web API - 如上文所述,借助 Service Fabric,您可以决定所需的服务通信方式,但在 .NET Framework 中创建 HTTP 服务的最常用方法之一是使用 ASP.NET Web API。
Service Fabric 中的 Web API 是您了解和钟爱的同一 ASP.NET Web API。您可以使用控制器 HttpRoutes,并能以相同的方法构建 REST 服务,即使用 MapHttpRoute 或您想将其映射到 Http 路由的方法上的属性。使用 Service Fabric 时的不同之处在于托管 Web API 应用程序的方式。首先要考虑到,您无法在 Azure Service Fabric 中使用 IIS,因为它只能使用跨群集复制的普通进程,所以您必须在代码中自托管 HTTP 侦听器。为了对 Web API 服务执行此操作,您有以下两种选择:
* 使用 ASP.NET 5 Web API(代码名称“Project K”),在您的 Service Fabric 微服务进程中自托管 HTTP 侦听器。
* 使用 OWIN/Katana 和 ASP.NET 4.x Web API,在您的 Service Fabric 微服务进程中自托管 HTTP 侦听器。
在 Azure Service Fabric 之上运行 ASP.NET 5 最适合构建微服务,因为如上文所述,Service Fabric 允许您将任意数量的服务部署到每个节点/VM,同时对每个群集实现较高的微服务密度。此外,当 Service Fabric 最终在未来提供 .NET Core 5 和 CoreCLR 支持(在 ASP.NET 5 下)时,高密度功能还会变得更强。最好能实现超高密度的微服务,因为 .NET Core 5 是轻型框架,与完整的 .NET 4.x Framework 相比,它占用的内存非常少。
使用 MVC 型 Web Apps 和 Service Fabric 微服务 - ASP.NET MVC 是一种很常用的框架,用于构建传统网站,但您无法结合使用“旧的”MVC 框架(MVC 5 或更低版本)和 Service Fabric。这是因为在 Service Fabric 中,您需要在进程中自托管 HTTP 侦听器,并且 OWIN/Katana 不受 ASP.NET 4.x MVC 支持(仅受 ASP.NET 4.x Web API 支持)。 因此,在 Service Fabric 服务上实现 MVC 型Web 应用程序的选项如下所示:
* 在 ASP.NET 5 中使用 MVC 6,在您的 Service Fabric 微服务进程中自托管 HTTP 侦听器。它支持 MVC,因为在 ASP.NET 5 中,Web API 和 MVC 已合并,实际上两者是具有相同控制器的同一框架(不依赖 IIS)。只要 ASP.NET 5 已发布以供生产,这就将是首选选项。
* 使用带 OWIN/Katana 的 ASP.NET 4.x Web API 在您的 Service Fabric 微服务进程中自托管 HTTP 侦听器,通过 Web API 控制器模拟 MVC 控制器,并使用 HTML/JavaScript 输出,而不是常规的 Web API 内容 (JSON/XML)。[bit.ly/1UMdKIf](http://bit.ly/1UMdKIf) 上的文档页说明了如何实现这一技术。
## 使用 ASP.NET 4.x Web API 和 OWIN/Katana 实现自托管
对于此方法,您以前经常使用的 Web API 应用程序并未发生改变。这与您以前可能编写过的 Web API 应用程序并无二致,您应该能够立即移动大部分的应用程序代码。如果您一直在 IIS 上进行托管,则应用程序托管方式可能与您以前常用的托管方式略有差异。
服务类中的 CreateServiceReplicaListeners 方法 - 在这里,服务可以定义要使用的通信堆栈。通信堆栈(如 Web API)用于定义服务的侦听终结点,以及这些显示的消息如何与剩余的服务代码进行交互。
回到上文图 4 中提及的服务类,我现在只需添加名为 CreateServiceReplicaListeners 的新方法,即可指定至少一个我想使用的通信堆栈。在此示例中,就是 Web API 使用的 OwinCommunicationListener(如图 6 所示)。
图 6:向无状态服务类添加 CreateServiceReplicaListeners 方法
~~~
using Microsoft.ServiceFabric.Services;
namespace MyApp.MyStatelessService
{
public class MyStatelessService : StatelessService
{
//... Service implementation.
protected override async Task RunAsync(CancellationToken cancellationToken)
{
// Place to write your own background logic here.
// ...
}
protected override IEnumerable<ServiceReplicaListener>
CreateServiceReplicaListeners()
{
return new List<ServiceReplicaListener>()
{
new ServiceReplicaListener(parameters =>
new OwinCommunicationListener(
"api", new Startup()))
};
}
}
}
~~~
必须强调的是,您可以向服务添加多个通信侦听器。
OwinCommunicationListener 类是您将跨所有微服务重复使用的样本代码。您可以类似方式插入其他协议(WCF、WebSocket 等)。
如果您要创建 Web API 微服务,您仍可以使用带有典型代码的控制器,此代码与您在实现 Web API 服务时经常使用的代码并无二致,如以下代码所示:
~~~
// Typical Web API Service class implementation
public class CustomerController : ApiController
{
//// Example - GET /customers/MSFT
[HttpGet]
[Route("customers/{customerKey}", Name = "GetCustomer")]
public async Task<IHttpActionResult> GetCustomer(string customerKey)
{
// ... Stateless method implementation.
}
}
~~~
由于本文是 Azure Service Fabric 和微服务的端到端概述,因此我们不会进一步逐步介绍如何在 Service Fabric 微服务中实现 OWIN。GitHub 上提供了一个简单示例 ([bit.ly/1OW5Bmj](http://bit.ly/1OW5Bmj)),可供您下载和分析, 即 Web API 和 Service Fabric HelloWorld 示例 (ASP.NET 4.x)。
## 使用 ASP.NET 5 Web API 实现自托管
在 Azure Service Fabric 之上运行 ASP.NET 5 最适合构建微服务,因为 Service Fabric 允许您将任意数量的服务部署到每个节点/VM,同时对每个群集实现较高的微服务密度。ASP.NET 5 还提供了以下精彩功能:
* 灵活的托管: 您现在可以在 IIS 或您自己的进程中托管您的 ASP.NET 5 应用程序。在您自己的进程中托管应用程序是 Azure Service Fabric 中的基本托管方式。
* Web API、MVC 和网页: 所有这些合并在一起,简化了概念的数目。
* 全面的并行支持: ASP.NET 5 应用程序现在可以安装在计算机上,而不会影响计算机上其他任何可能使用不同 .NET Framework 版本的应用程序。这是一项重要的 IT 管理功能。
* 跨平台支持: ASP.NET 5 可在 Windows、Mac OS X 和 Linux 上运行,并受到这些操作系统支持。
* 云就绪: 诊断、会话状态、缓存和配置等功能既可以在本地运行,也可以在云(如 Azure)中运行,而无需进行任何更改。
展望未来,当 Service Fabric 最终提供 .NET Core 5 和 CoreCLR 支持时,高密度功能还会变得更强。
虽然对 .NET Core 和 CoreCLR 的支持仍需通过 Service Fabric 实现,但如果此类支持上线,则受益明显。在 .NET Core 5 之上运行 ASP.NET 5 可提供轻型 .NET Framework 和 CoreCLR 运行时,与传统的 .NET 4.x 相比,它占用的内存非常少。这样的组合会形成极高的微服务密度,如图 7 中的“微服务 B”面板所示。
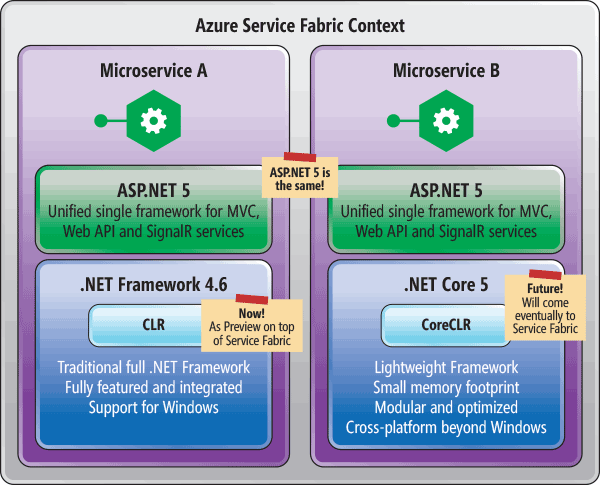
图 7:比较在 Service Fabric 上下文中在 CLR 与 CoreCLR 上运行 ASP.NET 5
虽然 .NET Core 5 和 CoreCLR 支持在将来才能提供,但企业现在就可以做好准备,即在 Service Fabric 的 .NET 4.x 之上开发 ASP.NET 5 服务。这样,可以在将来更轻松地迁移到 CoreCLR。
## 操作和部署超大规模微服务
Service Fabric 非常适合构建和运行超大规模生产微服务还有其他原因,即它提供操作和部署管理。您可以专注于微服务开发,并让 Service Fabric 在后台提供所有复杂的体系。
如果您希望降低基础结构成本,那么较高的微服务密度将大有助益。Service Fabric 群集包括一个由许多 VM/服务器(以及将来的容器)组成的池,这些 VM/服务器在群集中称为“节点”。在每个节点中,Service Fabric 自动部署多个服务,因此,您可以在整个群集中实现超高的微服务密度,具体视每个服务器/VM 的性能而定。
在 Azure Service Fabric 中,您可以在每个计算机或 VM 上运行数百个服务实例。这会大大降低您的总拥有成本 (TCO)。对于相同数量的服务,您需要的硬件变少了。因此,在比较 Azure Service Fabric 和 Azure 云服务且限制为对每个服务使用一个 VM 时,高密度就是非常重要的区分因素。如果您曾将微服务部署为 Web 角色或辅助角色,则您可能向一个微服务分配了太多的资源,导致部署和管理速度降低。例如,在图 8 中,您可以看到示例以 Azure Web 角色或辅助角色的形式,对每个服务实例使用一个 VM(颜色表示服务类型,而每个形状或框则表示不同的 VM 和服务实例)。如果您希望实现较高的微服务密度,那么这种方法将不起作用,除非您使用小型 VM。不过,由于存在限制,因此与 Azue Service Fabric 相比,您无法在两个部署中实现相同的高密度级别。
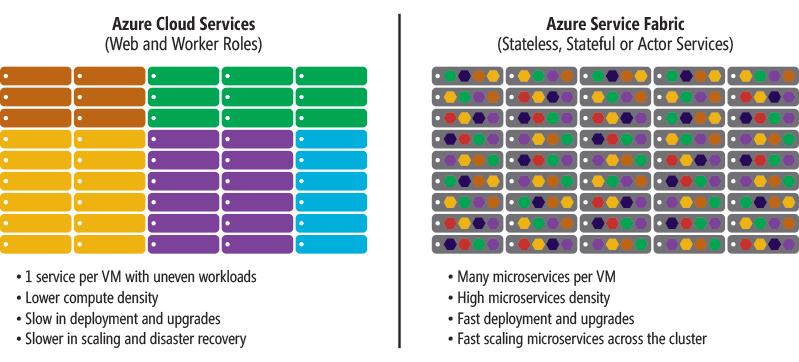
图 8:服务密度比较 - Azure 云服务与 Service Fabric
相比之下,在 Service Fabric 中,您可以对每个节点部署任意数量的微服务,因此服务密度将更加高效,并且成本也会降低。您可以对每个群集部署数十个、数百个或者甚至数千个 VM/服务器,并对每个节点/VM 部署数十个或数百个微服务实例和副本。由于每个微服务只是一个进程,因此部署和扩展比对每个服务新建一个 VM 要快很多,Azure 云服务也是如此。
在 Azure 云中创建群集 - 在部署微服务之前,您需要在 Azure 或本地服务器中创建节点群集。在 Azure 云(类似于您的生产环境或过渡环境)中创建群集时,您可以直接使用 Azure 门户或 Azure 资源管理器 (ARM)。在图 9 中,您可以看到我们使用 Azure 门户在 Azure 订阅中创建的 Service Fabric 群集。从本质上看,群集创建进程是以 Azure ARM 和 Azure 资源组为基础。在此示例中,我们创建了包含五个节点/VM 的群集,这些节点/VM 也位于 Azure 资源组中。
图 9:Azure 门户中的 Service Fabric 群集
将应用程序/服务部署到群集 - 在启动并运行节点/VM 的群集后,您便可以部署服务。在向生产群集部署时,您通常可以使用 Windows PowerShell 脚本将您的应用/服务部署到 Azure 中的群集;不过,对于过渡环境/测试环境,您还可以直接从 Visual Studio 部署。
在使用 Visual Studio 2015 向开发 PC 上的本地群集部署时,您通常可以右键单击 Service Fabric 应用程序项目并选择“部署”,从而直接从 IDE 进行部署。您还可以使用 Windows PowerShell 向笔记本电脑中的开发群集部署,因为在开发群集中运行的 Service Fabric 位数与在基于 Azure 云的群集中运行的 Service Fabric 位数相同。
部署的日常操作和可管理性是确保服务长期顺利运行所必需的,应用程序生命周期管理功能已内置到 Service Fabric 中,将基于微服务的方法纳入考虑。Service Fabric 中可用的操作和管理功能包括快速部署、在应用程序升级期间不停机、服务的运行状况监视以及群集增加和减少。支持在升级期间不停机,因为 Service Fabric 中的升级技术提供滚动升级和自动运行状况检查的内置组合,用于检测和回退升级中可破坏应用程序稳定性的更改。可通过 Windows Powershell 命令管理 Service Fabric 群集和应用程序,同时提供 CLI 和脚本的所有功能,并支持包括 Visual Studio 在内的视觉工具以提高易用性。
滚动升级分阶段执行。在每个阶段,升级应用于群集中的一部分节点(称为“升级域”)。因此,在整个升级期间应用程序仍可用。您还可以使用功能强大的版本控制和并行支持,以便部署同一微服务的 v1 和 v2 版本。Service Fabric 会重定向到其中一种版本,具体视客户端的请求而定。有关更多详细信息,请查看 [bit.ly/1kSupz8](http://bit.ly/1kSupz8) 上的文档。
在 PC 上的本地开发群集中调试服务时,即使服务进程在您启动调试前已经运行,Visual Studio 也能简化调试过程。IDE 自动附加到所有与您的项目相关的微服务进程中,以便您可以轻松入门,并在 Service Fabric 微服务代码中使用常规断点。只需在代码中设置断点,然后点击 F5 即可。您无需了解需要将 Visual Studio 附加到什么进程。
Service Fabric 资源管理器 - Service Fabric 资源管理器(如图 10 所示)是一种由群集提供的基于 Web 的工具,可用于直观地显示已部署应用程序的状态、检查各个节点的内容,以及执行各种管理操作。资源管理器工具由支持 Service Fabric REST API 的相同 HTTP 网关服务提供,可通过导航至 http://:19007/Explorer 获取此工具。在使用本地群集的情况下,此 URL 为 http://localhost:19007/Explorer。
图 10:Service Fabric 资源管理器
有关 Service Fabric 资源管理器的更多详细信息,请阅读文档页“使用 Service Fabric 资源管理器直观显示群集”([bit.ly/1MUNyad](http://bit.ly/1MUNyad))。
Service Fabric 平台提供一系列功能,以便您能够专注于应用程序开发,而不用担心实现复杂的运行状况和可升级系统。其中:
扩展无状态服务 - Service Fabric 业务流程引擎可以跨更多计算机自动扩展您的 Web 应用,无论新节点何时添加到群集中。创建无状态服务的实例时,您可以指定要创建的实例数量。Service Fabric 会相应地将此数量的实例置于群集的节点上,以确保不在任何一个节点上创建多个实例。您还可以将实例计数指定为“-1”,从而指示 Service Fabric 在每个节点上始终创建一个实例。这样一来,无论您何时添加节点以扩展群集,都可以保证在新节点上创建无状态服务的实例。
自动资源平衡 - Service Fabric 提供服务资源平衡(或服务业务流程)功能,用于了解群集中可利用的资源总量(类似于从 VM 进行计算)。它会根据定义的策略和约束自动移动微服务,以便最大程度地优化已创建的服务跨 VM 的分布方式(请参阅图 11)。这侧重于优化成本和性能。
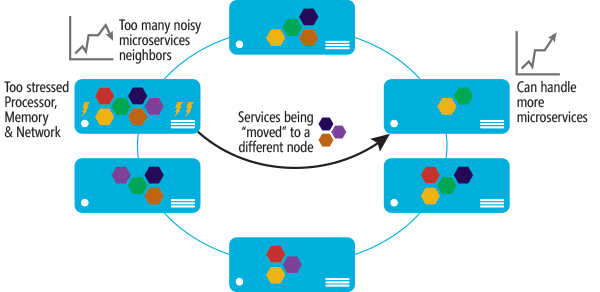
图 11:显示跨节点服务分发的群集和自动资源平衡
内置故障转移和复制 - 任何数据中心或公有云中的计算机都容易发生计划外硬件故障。为了防止出现这种情况,Service Fabric 提供了内置故障转移和复制功能。也就是说,尽管出现硬件问题,服务的可用性也不会受到影响。这是可以实现的,因为 Service Fabric 能够跨计算机和故障域运行和管理每个服务的多个实例。
位置约束 - 您可以指示群集执行下面这样的操作:不要将前端微服务作为中间层微服务置于同一计算机/节点中,以避免在相同节点中并置某些类型的微服务。做到这一点,可以最大限度地减少已知冲突,或确保优先访问某些微服务的资源。
请求的负载平衡 - 不要与自动资源平衡混淆,请求的负载平衡不是由 Service Fabric 处理,而是由 Azure 负载平衡器或 Service Fabric 外部的其他平台进行处理。
运行状况 - 您可以监视和诊断系统。还在应用程序升级期间使用,以提供安全检查,从而在升级会破坏稳定性的情况下回退升级。有关详细信息,请参阅文档页“Service Fabric 运行状况监视简介”([bit.ly/1jSvmHB](http://bit.ly/1jSvmHB))。
## Azure Service Fabric 中的有状态微服务
支持有状态服务是 Azure Service Fabric 的一个重要组成部分,令人非常满意。这也是相当复杂且涉及面非常广的问题,探讨有状态服务不在本文的讨论范围内,但我们将会简单地介绍一下什么是有状态服务。请在今后几期中,关注重点介绍 Service Fabric 这一领域的后续文章。
Service Fabric 中的有状态微服务并置计算和数据,并将状态置于微服务本身之中(位于内存中且暂留在本地磁盘上)。状态的可靠性是通过在其他节点/VM 上进行数据本地暂留和复制而实现的。一般来说,每个数据分区都有多个与其相关联的副本服务。每个副本都可以在不同的节点/VM 中进行部署,以在主要副本不可用时提供高可用性。这就类似于 Azure SQL 数据库如何使用数据库副本,因为它是基于 Azure Service Fabric。
在复杂的可扩展应用程序中,与需要使用外部缓存和队列的传统三层体系结构相比,有状态服务简化了体系结构,并减少了组件数量。使用有状态服务,传统外部缓存的优点现在为有状态服务所固有。此外,不需要外部队列,因为我们可以在 Service Fabric 微服务中实现内部队列。
使用有状态服务,它可以自动创建热备份方案,以便从出现硬件故障后主要服务中断的同一点处选取操作。服务必须扩展多次才能继续满足不断扩增的用户群的需求,同时需要向运行环境添加硬件。Service Fabric 使用分区等功能,这样构建的服务就可以自动分布在新硬件上,而无需用户干预。
有状态 Azure Reliable Services 提供许多功能,包括数据分区支持、副本支持和首项选择、副本服务命名以及服务地址发现(来自网关服务)。借助事务,它还提供状态更改的并发和粒度管理,可以保持一致的状态复制,并使用可靠的已分发键/值集合(可靠字典和可靠队列)。值得庆幸的是,Service Fabric 为您处理这些主题中讨论的复杂问题和细节,以便您可以专注于编写应用程序。
## Azure Service Fabric 中的 Reliable Actors 服务
Azure Service Fabric Reliable Actors 是 Service Fabric 的执行组件编程模型。它提供异步单线程的执行组件模型。执行组件表示状态和计算单元。在某些方面,它类似于 Microsoft Research 创建的开放源代码软件项目“Orleans”。重要的是,Service Fabric Reliable Actors API 基于 Service Fabric 提供的基础结构。
为物联网 (IoT) 设备实现执行组件实例是执行组件服务用途的典型示例。采用 C# 类形式的车辆执行组件类型会封装 IoT 车辆域逻辑及其实际状态(如 GPS 坐标和其他数据)。然后,我们可能会有数百万个执行组件对象或实例采用此类的形式,分布在群集中的许多节点上。
当然,执行组件并不局限于实际 IoT 对象,它们可以用于任意主题,只不过“实际 IoT 对象”是一个极好的教学方案。
执行组件分布在整个群集中以实现非常高的可扩展性和可用性,并被视为每个群集 VM 中的内存对象。它们还暂离在本地磁盘上,并通过群集进行复制。
执行组件是用于封装状态和行为的独立单线程对象。每个执行组件都是一个具有执行组件类型的实例,类似于如下所示的 .NET 代码:
~~~
// Actor definition (State+Behaviour) to run in the back end.
// Object instances of this Actor class will be running transparently
// in the service back end.
public class VehicleActor : Actor<Vehicle>, IVehicleActor
{
public void UpdateGpsPosition(GpsCoordinates coord)
{
// Update coordinates and trigger any data processing
// through the State property on the base class Actor<TState>.
this.State.Position= coord;
}
}
~~~
接下来,以下代码展示了通过代理对象使用执行组件的示例客户端代码:
~~~
// Client .NET code
ActorId actorId = ActorId.NewId();
string applicationName = "fabric:/IoTVehiclesActorApp";
IVehicleActor vehicleActorProxy =
ActorProxy.Create<IVehicleActor>(actorId, applicationName);
vehicleActorProxy.UpdateGpsPosition(new GpsCoordinates(40.748440, -73.984559));
~~~
所有通信基础结构在后台是由 Service Fabric Reliable Actors 框架负责。
您可能会有数百万个 VehicleActor 对象跨许多不同的节点/VM 在您的群集上运行,Service Fabric 会负责相应的体系,包括作为数百万个执行组件的分布和平衡位置的分区和副本。
Actors 客户端 API 提供执行组件实例和执行组件客户端之间的通信。为了与执行组件通信,客户端会创建用于实现执行组件接口的执行组件代理对象。客户端通过在代理对象上调用方法,与执行组件进行交互。
对于执行组件适用的方案,它极大地简化了微服务实现,尤其是与有状态 Reliable Services 相比时。使用有状态 Reliable Services 时,您虽然拥有更多的控制,但需要实现许多与分区数据、分区寻址、副本等相关的体系。如果您不需要精细控制,则可以使用 Reliable Actors 避免额外工作量。
## 总结
微服务体系结构离不开以下组成部分:分散式方法、符合标准的体系结构和设计流程、Azure Service Fabric 等新技术、团队动力变更以便向小型开发团队方向发展,以及对每个微服务应用的灵活原则。
* * *
Cesar de la Torre *是 Microsoft 高级项目经理,居住在美国华盛顿州雷蒙德市。他的研究兴趣包括通过以下方法进行 Microsoft Azure 和 .NET 开发:微服务体系结构、域驱动的设计以及面向服务的移动应用开发。*
Kunal Deep Singh *是 Microsoft Azure Service Fabric 团队的高级项目经理。在 Azure 推出之前,他致力于发布 Windows Phone、Silverlight 的多个版本,并且是 Xbox 主题的游戏开发者。他居住在美国华盛顿州西雅图市。*
Vaclav Turecek *是 Microsoft 高级项目经理。他致力于与极有天赋的团队一起工作,将 Azure Service Fabric 打造成为最强大的下一代平台即服务。*
新员工 – 放长钱钓大鱼
最后更新于:2022-04-01 06:52:47
# 新员工 - 放长钱钓大鱼
通过 [Krishnan Rangachari](https://msdn.microsoft.com/zh-cn/magazine/mt149362?author=Krishnan+Rangachari) |2015 年 12 月
在我职业生涯早期我尝试 compulsively 查找我"激情。" 首先,此激情进行编码,直到新奇 wore 并负责增长具有挑战性。我将此情况来表示我激情安排在其他位置。在今后几年我切换角色、 公司和行业重复,有时来回。我阅读大量书籍,介绍的职业生涯,所用的个性测试中,为职业生涯 counselors 分支并采访了不间断。
我将启动新作业、 分为喜欢上了它,最后我将最后找到我的波澜,然后 (最终) 便开始觉得无聊,再将切换。
现在想来,我已进行了 discomfort 可以保持不变,不通过其传递一个阶段的问题。我意识到,我重复周期必须只有一个通用标准 (me),而且无论我固定的我最终不高兴再次。我已"激情您成功。" 我想象职业生涯没有困难和结束的乐趣,一个工作场所和当现实冲突令我的幻想,我将 bolt!
如果我想我要让我每天心情愉快的环境中的更改,我避免承担全部责任我自己的未来。例如,我相信,通过切换到一家初创公司,我会提高社交人生旅途,因为我本来会更年轻的同事和开发更多友谊,这。唉,这是我为了避免正在致力于我自己社交担心的一种方法。而不有困难我字符能够从容,我已却说我就职的公司!
目前,而不是查找从命中"做我喜欢之后,"我遵守中我已经存在的可能性。查找我的激情不一次性事件,也不是一个工作或一个职业事件 — 它是自行开发的终身进程"热爱我执行哪些操作。"
我曾赋予自己随着时间的推移具有不同的职业生涯和作业的权限。当我看到我的职业生涯选择作为只能完成极端任务,使 it-或-中断的 it 时间时,我士气分担自己,零留出了错误。在工作,我设置不专注于自己的唯目标 — 说,我的客户和同事用作 — 我是在独立于任何角色或行业。如果我进行任何更改此过程中,我将不接受失败;我只不断增加。
## 热情重载
在我的第一个作业的一个,我快速烧坏的工作,为 60 到 80 小时周。我参与过我,我无法仅通过完全退出恢复此类、 麻木。如我正文已尝试恢复从多年的加班的强度,多余的 helpless unproductivity 疑云中的月数。
我已定义自己的我自己假设它意味着要真正程序员。我听说过启动高层人员不会这么回家 ぱ ず 和工程师,负责将忽略其簇,只能以实现总计 IPOs 几年后。我看到任何小于这种承诺为失败。
随着时间推移,我不打算作为我唯一 savior 工作通过修复筋疲力尽。今天,我转到精神上整顿培养爱好、 self-development 上课、 开发密切的关系、 日志、 导师、 获取参赛,花时间填写性质、 采取 naps,仔细考虑一下这个、 读取和 hike。每个这些填充本身起作用的需求无法满足。
我还介绍于早期的指标 (例如,获取在亲人因为什么而怒气冲冲、 出分区或向下的感觉) 作为提醒我稍作休息"gentleness。" 我最初认为难为情中负责自己-离开工作时间、 无效的周末或晚上,或删除从我的电话工作 IM — 因为我已由不参与 self-care 这么多同事括起来。
正如我所见产生积极的 — 让你高枕无忧和乐趣,促销和奖励,生产效率 — 我意识到玩长的游戏中,而不仅仅是工作,但我的生活中的所有区域。当我自己负责,并避免筋疲力尽时,我将只重新充电,因此我可以进行更好、 更一致的发布内容 — 工作、 家人和朋友下, 一步的六个数十年时间,而不仅仅是针对接下来的六个月。
* * *
Krishnan Rangachari *是技术行业作为的职业生涯指导。他是最年轻以往的 UC Berkeley 的学生。在 age 18,他加入了 Microsoft 職,并按年龄 20,他成为速度最快提升员工在他的除法中。Rangachari 工作资深的开发和产品角色中的许多技术公司。请访问 [radicalshifts.com](http://radicalshifts.com/) 若要获取其可用的职业生涯成功工具包。*
Visual Studio – 用于 Web 开发的新式工具: Grunt 和 Gulp
最后更新于:2022-04-01 06:52:45
# Visual Studio - 用于 Web 开发的新式工具: Grunt 和 Gulp
作者 [Adam Tuliper](https://msdn.microsoft.com/zh-cn/magazine/mt149362?author=Adam+Tuliper) | 2015 年 12 月
现代 Web 开发者可以使用的工具有很多。JavaScript 任务运行程序 Grunt 和 Gulp 是目前 Web 项目中最常用的两种工具。如果您从未使用 JavaScript 运行任务,或者您习惯使用普通的 Visual Studio 进行 Web 开发,则会觉得这是个陌生概念,但您有充分的理由试一试。JavaScript 任务运行程序在浏览器外部工作,通常在命令行处使用 Node.js。这样,您便可以轻松运行前端开发相关任务,包括缩小、串联多个文件、确定脚本相关性并按正确顺序向 HTML 页面插入脚本引用、创建单元测试工具、处理前端生成脚本(如 TypeScript 或 CoffeeScript 等)。
## 使用哪一个?Grunt 还是 Gulp?
主要是根据个人和项目偏好来选择任务运行程序,除非您想使用的插件只支持特定的任务运行程序。两者的主要区别在于,Grunt 是由 JSON 配置设置驱动,并且每个 Grunt 任务通常必须创建中间文件将结果传递给其他任务;而 Gulp 则是由可执行的 JavaScript 代码驱动(也就是说,不只是由 JSON 驱动),并能将一个任务的结果流式传输到下一个任务,而无需使用临时文件。Gulp 是冉冉升起的新星,因此,您会发现许多新项目都在使用它。Grunt 依然受到许多众所周知的程序(例如,用它来生成 jQuery 的 jQuery)支持。Grunt 和 Gulp 均通过插件工作,这些插件是您安装用来处理特定任务的模块。可用插件的生态系统十分庞大。通常情况下,您会发现任务包同时支持 Grunt 和 Gulp,这再次说明使用哪一个任务运行程序完全是您的个人选择。
## 安装和使用 Grunt
Grunt 和 Gulp 的安装程序是节点包管理器 (npm),我曾在 10 月发表的文章 ([msdn.com/magazine/mt573714](http://msdn.com/magazine/mt573714)) 中简单介绍过它。Grunt 的安装命令实际分为两个部分。第一部分是 Grunt 命令行接口的一次性安装。第二部分是将 Grunt 安装至项目文件夹。通过这两部分安装,您可以在系统中使用 Grunt 的多个版本,并从任意路径使用 Grunt 命令行接口。
~~~
#only do this once to globally install the grunt command line runner
npm install –g grunt-cli
#run within your project folder one time to create package.json
#this file will track your installed npm dependencies
#like grunt and the grunt plug-ins, similar to bower.json (see the last article)
npm init
#install grunt as a dev dependency into your project (again see last article)
#we will still need a gruntfile.js though to configure grunt
npm install grunt –save-dev
~~~
## Grunt 配置
Grunt 配置文件只是具有包装器函数的 JavaScript 文件,其中包含配置、插件加载和任务定义(如图 1所示)。
图 1:Grunt 配置文件
~~~
module.exports = function (grunt) {
// Where does uglify come from? Installing it via:
// npm install grunt-contrib-uglify --save-dev
grunt.initConfig({
uglify: {
my_target: {
files: {
'dest/output.min.js': '*.js'
}
}
}
});
// Warning: make sure you load your tasks from the
// packages you've installed!
grunt.loadNpmTasks('grunt-contrib-uglify');
// When running Grunt at cmd line with no params,
// you need a default task registered, so use uglify
grunt.registerTask('default', ['uglify']);
// You can include custom code right inside your own task,
// as well as use the above plug-ins
grunt.registerTask('customtask', function () {
console.log("\r\nRunning a custom task");
});
};
~~~
只需调用以下内容,即可在命令行处运行图 1 中的任务:
~~~
#no params means choose the 'default' task (which happens to be uglify)
grunt
#or you can specify a particular task by name
grunt customtask
~~~
然后,您会在 wwwroot/output-min.js 处获得丑化(缩小)的串联结果。如果您已使用 ASP.NET 缩小和捆绑,则会发现此过程的不同之处,即它不是只能用于运行应用或编译,您可以为任务选择其他更多选项(如丑化)。在我看来,我认为此工作流更加简洁明了、易于理解。
您可以使用 Grunt 将任务串联在一起,让它们彼此依赖。这些任务会同步运行,所以必须先完成一个任务,才能移至下一个任务。
~~~
#Specify uglify must run first and then concat. Because grunt works off
#temp files, many tasks will need to wait until a prior one is done
grunt.registerTask('default', ['uglify', 'concat']);
~~~
## 安装和使用 Gulp
Gulp 的安装与 Grunt 类似。我将更详细地介绍 Gulp,但请注意,您可以使用任一任务运行程序执行类似的操作,我只是不想太过重复罢了。Gulp 可以进行全局安装,以便您能在系统上从任意路径使用它;也可以进行本地安装,安装至特定项目版本的项目文件夹中。如果全局安装的 Gulp 发现本地项目中安装的 Gulp,则前者会将控制权移交给后者,从而遵循 Gulp 的项目版本。
~~~
#Only do this once to globally install gulp
npm install –g gulp
#Run within your project folder one time to create package.json
#this file will track your installed npm dependencies
#like gulp and the gulp plug-ins
npm init
#Install gulp as a dev dependency into your project
#we will still need a gulpfile.js to configure gulp
npm install gulp --save-dev
~~~
## Gulp 配置和 API
Gulp 和 Grunt 配置的差异显著。gulpfile.js 配置文件通常具有图 2 中所示的结构,包含插件加载和任务定义的“要求”。请注意,我在这里使用的不是 JSON 配置设置;相反,任务是由代码驱动。
图 2:Gulp 配置文件
~~~
// All the 'requires' to load your
// various plug-ins and gulp itself
var gulp = require('gulp');
var concat = require('gulp-concat');
// A custom task, run via: gulp customtask
gulp.task('customtask', function(){
// Some custom task
});
// Define a default task, run simply via: gulp
gulp.task('default', function () {
gulp.src('./lib/scripts/*.js')
.pipe(concat('all-scripts.js'))
.pipe(gulp.dest('./wwwroot/scripts'));
});
~~~
Gulp 通过以下多个密钥 API 和概念工作:src、dest、管道、任务和 glob。gulp.src API 指示 Gulp 开启哪些文件进行处理,然后这些文件通常会通过管道传送到其他一些函数,而不是所创建的临时文件。这就是与 Grunt 的关键差别。下面展示了一些无需通过管道传送结果的 gulp.src 基本示例,我将对此进行简单介绍。此 API 调用将所谓的 glob 作为参数进行提取。一般来说,glob 是您可以进入的模式(类似于正则表达式)。例如,指定一个或多个文件的路径(若要详细了解 glob,请访问[github.com/isaacs/node-glob](http://github.com/isaacs/node-glob)):
~~~
#Tell gulp about some files to work with
gulp.src('./input1.js');
#This will represent every html file in the wwwroot folder
gulp.src('./wwwroot/*.html')
#You can specify multiple expressions
gulp.src(['./app/**/*.js', './app/*.css']
~~~
如您所想,dest(目标)API 指定目标并提取 glob。由于 glob 能够灵活定义路径,因此您可以输出各个文件或输出到文件夹中:
~~~
#Tell dest you'll be using a file as your output
gulp.dest ('./myfile.js');
#Or maybe you'll write out results to a folder
gulp.dest ('./wwwroot');
~~~
Gulp 中的任务就是您编写用来执行特定操作的代码。任务格式十分简单,但任务的使用方式有多种。最直接的方式是使用默认任务以及一个或多个其他任务:
~~~
gulp.task('customtask', function(){
// Some custom task to ex. read files, add headers, concat
});
gulp.task('default', function () {
// Some default task that runs when you call gulp with no params
});
~~~
任务可以并行执行,也可以彼此依赖。如果您不关心顺序,就可以将它们串联在一起,如下所示:
~~~
gulp.task('default', ['concatjs', 'compileLess'], function(){});
~~~
此示例定义了默认任务,只单独运行各个任务,以串联 JavaScript 文件和编译 LESS 文件(假设此处命名的任务中包含代码)。如果要求规定必须先完成一个任务,然后再执行另一个任务,那么您需要让任务彼此依赖,然后再运行多个任务。在以下代码中,默认任务先等待串联完成,进而等待丑化完成:
~~~
gulp.task('default', ['concat']);
gulp.task('concat', ['uglify'], function(){
// Concat
});
gulp.task('uglify', function(){
// Uglify
});
~~~
管道 API 使用 Node.js 流 API 通过管道将一个函数的结果传送到另一个函数。工作流通常为:读取 src,通过管道发送给任务,通过管道将结果发送到目标。这一完整的 gulpfile.js 示例读取 /scripts 中的所有 JavaScript 文件,将它们串联到一个文件中,然后将输出写入另一个文件夹:
~~~
// Define plug-ins – must first run: npm install gulp-concat --save-dev
var gulp = require('gulp');
var concat = require('gulp-concat');
gulp.task('default', function () {
#Get all .js files in /scripts, pipe to concatenate, and write to folder
gulp.src('./lib/scripts/*.js')
.pipe(concat('all-scripts.js'))
.pipe(gulp.dest('./wwwroot/scripts'));
}
~~~
下面讲一个现实生活中的示例。您经常想串联文件和/或在源代码文件中添加信息标头。只需几步操作,即可轻松完成。您可以向网站的根添加几个文件(此任务也全都通过代码完成,请参阅 gulp-header 文档)。首先,创建名为 copyright.txt 的文件,其中包含要添加的标头,如下所示:
~~~
/*
MyWebSite Version <%= version %>
https://twitter.com/adamtuliper
Copyright 2015, licensing, etc
*/
~~~
接下来,创建名为 version.txt 的文件,其中包含当前版本号(也有可以实现版本号递增的插件,如 gulp-bump 和 grunt-bump):
~~~
1.0.0
~~~
此时,在项目根中安装 gulp-header 和 gulp-concat 插件:
~~~
npm install gulp-concat gulp-header --save-dev
~~~
您也可以将它们手动添加到 package.json 文件中,并且允许 Visual Studio 为您执行包还原。
最后,您只需使用 gulpfile.js 指示 Gulp 要执行的操作(如图 3 所示)。如果您不想将所有脚本串联在一起,只想向每个文件添加标头,则只需注释禁止管道(串联)行即可。非常简单,是不是?
图 3:Gulpfile.js
~~~
var gulp = require('gulp');
var fs = require('fs');
var concat = require("gulp-concat");
var header = require("gulp-header");
// Read *.js, concat to one file, write headers, output to /processed
gulp.task('concat-header', function () {
var appVersion = fs.readFileSync('version.txt');
var copyright =fs.readFileSync('copyright.txt');
gulp.src('./scripts/*.js')
.pipe(concat('all-scripts.js'))
.pipe(header(copyright, {version: appVersion}))
.pipe(gulp.dest('./scripts/processed'));
});
~~~
然后,您只需通过以下命令运行此任务即可。瞧,您已经串联了所有 .js 文件,添加了自定义标头,并将输出写入了 ./scripts/processed 文件夹:
~~~
gulp concat-header
~~~
## 任务运行程序资源管理器
Visual Studio 通过任务运行程序资源管理器为 Gulp 和 Grunt 提供支持。Visual Studio 2015 中包含此资源管理器(作为一项 Visual Studio 扩展)。您可以在“查看 | 其他 Windows | 任务运行程序资源管理器”中找到它。任务运行程序资源管理器非常棒,因为它会检测项目中是否有 gulpfile.js 或 gruntfile.js,解析任务,然后提供 UI 执行所发现的任务(如图 4 所示)。此外,当项目中发生预定义操作时,您可以定义要运行的任务。接下来,我将介绍这一点,因为 ASP.NET 5 在它的默认模板中使用此功能。只需右键单击任务进行执行,或者将它与特定操作绑定(例如,对项目 Open 执行任务)。
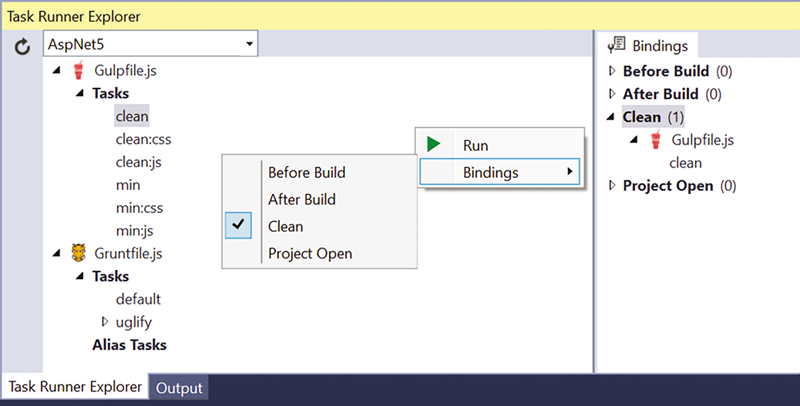
图 4:同时显示 Grunt 和 Gulp 任务及选项的任务运行程序资源管理器
如图 5 所示,当您使用 Gulp 看不到想要突出显示的 Grunt 任务时,Grunt 提供可用选项,特别是强制选项(用于忽略警告)和详述选项(左上角的 F 和 V)。这些只是传递到 Grunt 命令行的参数。任务运行程序资源管理器的主要优点是,可以显示传递到 Grunt 和 Gulp 命令行的命令(在任务输出窗口中),这就让后台运行情况不再神秘。

图 5:其他 Grunt 选项和命令行
## Gulp 和 ASP.NET 5
Visual Studio 2015 中的 ASP.NET 5 模板使用 Gulp,这些模板将 Gulp 安装到项目的 node_components 文件夹,可供项目随时使用。您当然仍能在 ASP.NET 5 项目中使用 Grunt;只需务必按照以下方式将它安装到项目中即可:通过 npm,或将它添加到 devDependencies 内的 packages.json 中,并允许 Visual Studio 的自动包还原功能运转起来。我想强调的是: 您可以通过命令行或在 Visual Studio 内部(以您的偏好为准)做到这一切。
截至本文撰写之时,当前的 ASP.NET 5 模板包含多个任务,可缩小和串联 .css 和 .js 文件。在旧版 ASP.NET 中,这些任务是在运行时通过已编译的代码进行处理,但这并不是完成此类任务的理想位置和时间。如图 6 所示,命名为 clean 和 min 的任务调用它们的 css 和 js 方法,以便缩小这些文件或清理之前缩小的文件。
图 6:ASP.NET 5 预览模板中开箱即用的任务
再例如,下面的 Gruntfile.js 行展示了如何同时运行多个任务:
~~~
gulp.task("clean", ["clean:js", "clean:css"]);
~~~
您可以视需要选择将 Grunt 和 Gulp 任务绑定到 Visual Studio 中的 4 个不同操作。使用 MSBuild 时,惯常做法是定义预生成和生成后的命令行,以便执行各种任务。借助任务运行程序资源管理器,您可以定义“生成前”、“生成后”、“清理”和“项目 Open”事件来执行这些任务。这样做只会向 gulpfile.js 或 gruntfile.js 文件添加注释,并不影响执行,但会被任务运行程序资源管理器查找。若要了解 ASP.NET 5 gulpfile.js 中的“清理”绑定关系,请查看文件顶部的这一行内容:
~~~
// <binding Clean='clean' />
~~~
这就是跟踪事件所需完成的一切。
## 总结
Grunt 和 Gulp 都非常适合添加到您的 Web 工具库中。两种任务运行程序均受到大力支持,且可用插件的生态环境十分庞大。每个 Web 项目都能受益于这两种任务运行程序。有关详细信息,请务必查阅以下内容:
* Grunt“入门”文档 ([bit.ly/1dvvDWq](http://bit.ly/1dvvDWq))
* Gulp 方案 ([bit.ly/1L8SkUC](http://bit.ly/1L8SkUC))
* 包管理和工作流自动化: 计算机包管理器 ([bit.ly/1FLwGW8](http://bit.ly/1FLwGW8))
* Node.js 主控模块和包 ([bit.ly/1N8UKon](http://bit.ly/1N8UKon))
* Adam 的修理厂 ([bit.ly/1NSAYxK](http://bit.ly/1NSAYxK))
* * *
Adam Tuliper *是生活在阳光明媚的南加州的一位 Microsoft 资深技术传播者。他是 Web 开发者、游戏开发者、Pluralsight 作者以及全面技术的爱好者。通过 Twitter [@AdamTuliper](https://twitter.com/@AdamTuliper) 或“Adam 的修理厂”博客 ([bit.ly/1NSAYxK](http://bit.ly/1NSAYxK)) 与他取得联系。*
介绍
最后更新于:2022-04-01 06:52:43
> 原文出处:https://msdn.microsoft.com/zh-cn/magazine/mt595745.aspx
## MSDN 杂志 12月 2015
