测试运行 – 面向 .NET 开发者的 Spark 简介
最后更新于:2022-04-01 06:52:57
# 测试运行 - 面向 .NET 开发者的 Spark 简介
作者 [James McCaffrey](https://msdn.microsoft.com/zh-cn/magazine/mt149362?author=James+McCaffrey) | 2015 年 12 月

Spark 是一种适用于大数据的开放源代码计算框架,且越来越流行,特别是在机器学习方案中。在本文中,我将介绍如何在运行 Windows 操作系统的计算机上安装 Spark,并将从 .NET 开发者的角度介绍 Spark 的基本功能。
了解本文所述观点的最佳方式是查看图 1 中的交互会话演示。从采用管理模式运行的 Windows 命令行界面中,我通过发出 spark-shell 命令,创建了 Spark 环境。
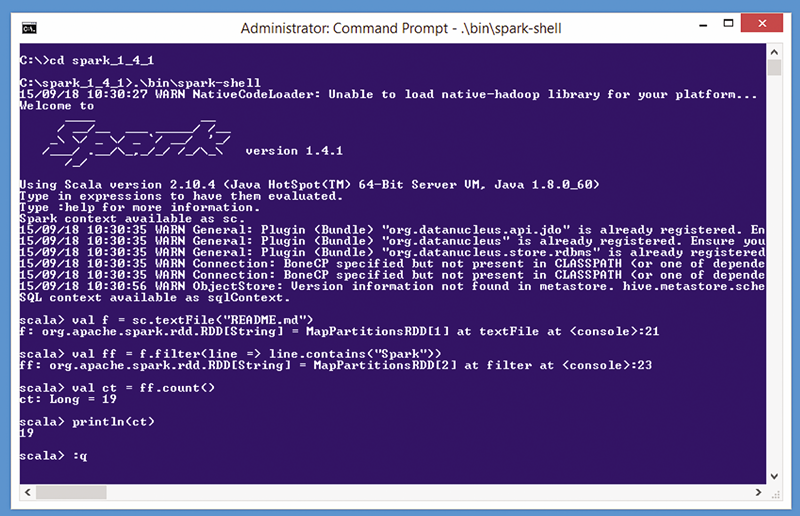
图 1:Spark 的运作方式
spark-shell 命令会创建在 shell 中运行的 Scala 解释器,进而发出 Scala 提示 (scala>)。Scala 是一种基于 Java 的脚本语言。我们还可以通过其他方法与 Spark 交互,但最常用的方法还是使用 Scala 解释器,原因之一是 Spark 框架主要通过 Scala 进行编写。您还可以使用 Python 语言命令或编写 Java 程序,与 Spark 进行交互。
请注意图 1 中的多条警告消息。当您运行 Spark 时,这些消息很常见,因为 Spark 有许多可选组件会生成警告(如果未找到的话)。通常情况下,对于简单方案,可以忽略警告消息。
演示会话中输入的第一个命令是:
~~~
scala> val f = sc.textFile("README.md")
~~~
这可以大致理解为:“将 README.md 文件的内容存储到名为 f 的不可变 RDD 对象中。” Scala 对象可声明为 val 或 var。声明为 val 的对象不可变且无法更改。
Scala 解释器内置名为 sc 的 Spark 上下文对象,用于使用 Spark 功能。textFile 函数将文本文件的内容加载到名为“弹性分布数据集 (RDD)”的 Spark 数据结构中。RDD 是 Spark 中主要使用的编程抽象。您可以将 RDD 看成是存储在多台计算机的 RAM 上的 .NET 集合。
文本文件 README.md(.md 扩展名代表 markdown 文档)位于 Spark 根目录“C:\spark_1_4_1”中。如果您的目标文件位于其他位置,则您可以提供完整路径(如“C:\\Data\\ReadMeToo.txt”)。
演示会话中输入的第二个命令是:
~~~
scala> val ff = f.filter(line => line.contains("Spark"))
~~~
这可以理解为:“仅将对象 f 中含有‘Spark’一词的多行内容存储到名为 ff 的不可变 RDD 对象中。” 筛选器函数接受所谓的闭合。您可以将闭合看成是匿名函数。在这里,闭合接受名为 line 的虚拟字符串输入参数,并在 line 中含有“Spark”时返回 true(反之,则会返回 false)。
由于“line”仅仅是参数名称,因此我可以在闭合中使用其他任何名称,例如:
~~~
ln => ln.contains("Spark")
~~~
由于 Spark 区分大小写,因此以下命令会生成错误:
~~~
ln => ln.Contains("Spark")
~~~
Scala 具有一些函数编程语言特征,所以可以撰写多个命令。例如,前两个命令可以合并成一个命令:
~~~
val ff = sc.textFile("README.md").filter(line => lne.contains("Spark"))
~~~
演示会话中最后输入的三个命令是:
~~~
scala> val ct = ff.count()
scala> println(ct)
scala> :q
~~~
计数函数返回 RDD 中的项目数,在此示例中,即返回 README.md 文件中包含 Spark 一词的行数。行数有 19 行。若要退出 Spark Scala 会话,您可以键入 :q 命令。
## 在 Windows 计算机上安装 Spark
在 Windows 计算机上安装 Spark 主要分为四步。第一步,安装 Java 开发工具包 (JDK) 和 Java Runtime Environment (JRE)。第二步,安装 Scala 语言。第三步,安装 Spark 框架。第四步,配置主机系统变量。
Spark 分发的格式为压缩的 .tar,因此您需要使用实用工具解压 Spark 文件。我建议您在开始前先安装开放源代码的 7-Zip 程序。
尽管并不是所有 Windows 操作系统版本都正式支持 Spark 及其组件,但我已经在运行 Windows 7、8、10、Server 2008 和 2012 的计算机上成功安装了 Spark。图 1 中的演示就是在 Windows 8.1 计算机上运行。
您可以运行自解压可执行文件(通过 Internet 搜索即可找到)来安装 JDK。我使用的版本是 jdk-8u60-windows-x64.exe。
如果您安装的是 64 位版本 JDK,则默认安装目录是 C:\Program Files\Java\jdkx.x.x_xx\(如图 2 所示)。我建议您不要更改默认位置。
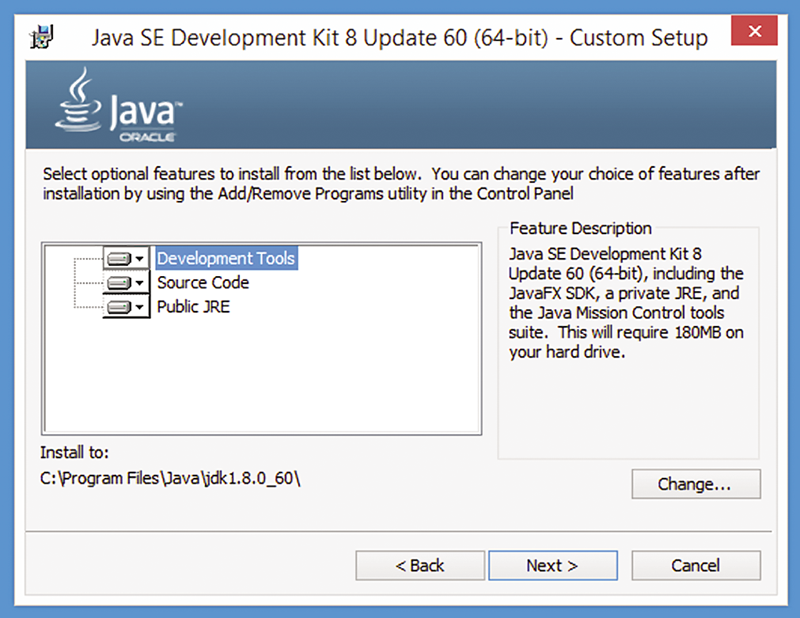
图 2:默认 JDK 位置
安装 JDK 的同时也会安装相关的 JRE。安装完成后,默认的 Java 父目录会同时包含 JDK 目录和相关的 JRE 目录(如图 3 所示)。
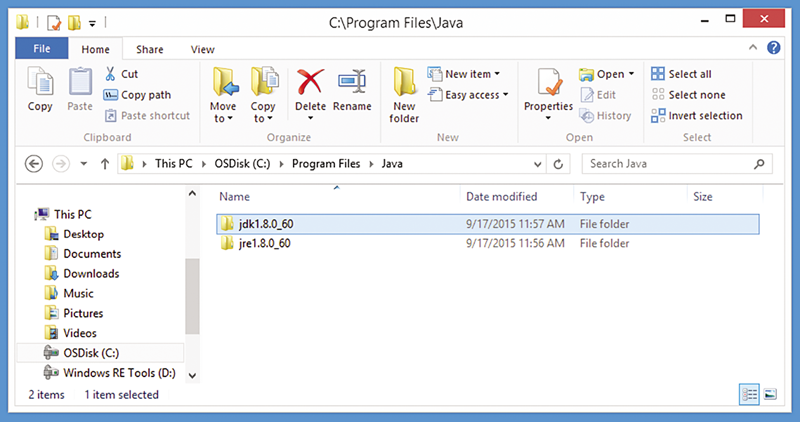
图 3:安装至 C:\Program Files\Java\ 的 Java JDK 和 JRE
请注意,您的计算机上可能有一个 Java 目录,其中包含的一个或多个 32 位 JRE 目录位于 C:\Program Files (x86) 中。计算机上同时包含 32 位和 64 位版本的 JRE 是没有问题的,但我建议您仅使用 64 位版本的 Java JDK。
## 安装 Scala
下一步是安装 Scala 语言,但在安装前,您必须先前往 Spark 下载站点(本文的下一部分将予以介绍),然后确定要安装的 Scala 版本。Scala 版本必须与您将在下一步中安装的 Spark 版本兼容。
很遗憾,关于 Scala-Spark 版本兼容性的信息非常少。当我安装 Spark 组件时(距离您阅读本文已过去相当一段时间),Spark 的当前版本是 1.5.0,但我找不到任何信息可说明哪个 Scala 版本与此版本的 Spark 兼容。因此,我以旧版 Spark ( 1.4.1) 为目标,在开发者讨论网站上找到了一些信息,这些信息表明第 2.10.4 版 Scala 可能与第 1.4.1 版 Spark 兼容。
安装 Scala 很容易。安装流程仅涉及运行 .msi 安装程序文件。
Scala 安装向导会逐步指导您完成整个流程。有趣的是,Scala 的默认安装目录位于 32 位目录 C:\Program Files (x86)\ 中,而不是位于 64 位目录 C:\Program Files\ 中(请参阅图 4)。
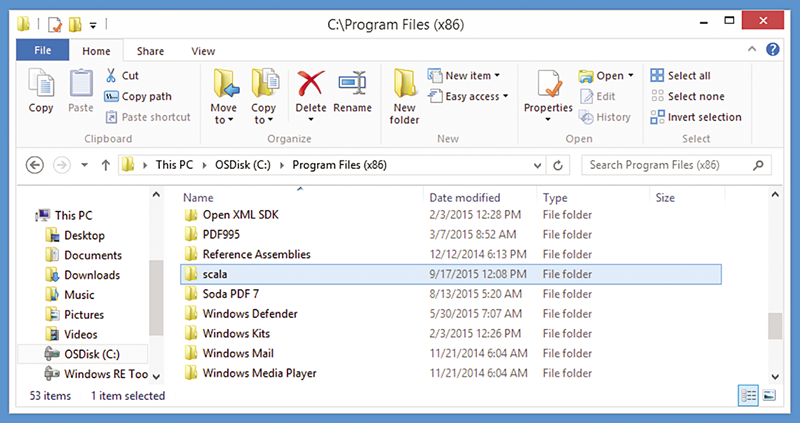
图 4:Scala 安装至 C:\Program Files (x86)\scala\
如果您打算通过编写 Java 程序(而不是使用 Scala 命令)与 Spark 交互,您需要另外安装一项名为 Scala Simple Build Tool (SBT) 的工具。通过编译的 Java 程序与 Spark 进行交互比使用交互 Scala 困难得多。
## 安装 Spark
下一步是安装 Spark 框架。不过,首先,请确保您拥有可解压 .tar 格式文件的实用工具(如 7-Zip)。Spark 安装流程需手动操作,即您需要将压缩文件夹下载到本地计算机中,解压压缩文件,然后将文件复制到根目录中。也就是说,如果您希望卸载 Spark,只需删除 Spark 文件即可。
Spark 站点网址为 spark.apache.org。在下载页上,您可以选择版本和包类型。Spark 是一种计算框架,需要使用分布式文件系统 (DFS)。迄今为止,Spark 框架最常用的 DFS 是 Hadoop 分布式文件系统 (HDFS)。出于测试和实验目的(如图 1 中的演示会话),您可以在没有 DFS 的系统上安装 Spark。在这种情况下,Spark 会使用本地文件系统。
如果您之前没有解压过 .tar 文件,则可能会对这个过程感到些许困惑,因为您通常需要解压两次。首先,将 .tar 文件(我的文件命名为 spark-1.4.1-bin-hadoop2.6.tar)下载到任意临时目录(我使用的是 C:\Temp)。接下来,右键单击 .tar 文件,然后从上下文菜单中选择“解压文件”,将它解压到临时目录内的新目录。
首次解压过程会新建一个不含文件扩展名的压缩文件(我的是 spark-1.4.1-bin-hadoop2.6)。接下来,右键单击这个新建的文件,然后从上下文菜单中再次选择“解压文件”,将它解压到其他目录。第二次解压会生成 Spark 框架文件。
为 Spark 框架文件创建一个目录。通用约定是创建名为 C:\spark_x_x_x 的目录,其中 x 值表示版本。根据此约定,我创建了 C:\spark_1_4_1 目录,并将解压的文件复制到此目录中(如图 5 所示)。
图 5:手动将解压的 Spark 文件复制到 C:\spark_x_x_x\
## 配置计算机
在安装 Java、Scala 和 Spark 之后,最后一步是配置主机。此过程涉及下载 Windows 所需的特殊实用工具文件、设置三个用户定义的系统环境变量、设置系统 Path 变量,以及视需要选择修改 Spark 配置文件。
若要在 Windows 上运行 Spark,本地目录(名为 C:\hadoop)中必须有特殊的实用工具文件(名为 winutils.exe)。通过 Internet 搜索,您可以在多处找到此文件。我创建了目录 C:\hadoop,然后在[http://public-repo-1.hortonworks.com/hdp-win-alpha/winutils.exe](http://http/public-repo-1.hortonworks.com/hdp-win-alpha/winutils.exe) 找到了 winutils.exe 的副本,并将此文件下载到所创建的目录中。
接下来,创建和设置三个用户定义的系统环境变量,并修改系统 Path 变量。转到“控制面板 | 系统 | 高级系统设置 | 高级 | 环境变量”。在“用户变量”部分中,新建三个具有下列名称和值的变量:
~~~
JAVA_HOME C:\Program Files\Java\jdk1.8.0_60
SCALA_HOME C:\Program Files (x86)\scala
HADOOP_HOME C:\hadoop
~~~
然后,在“系统变量”中,添加 Spark 二进制文件的位置 (C:\spark_1_4_1\bin),编辑 Path 变量。请谨慎操作,您一定不想在 Path 变量中丢失任何值。请注意,Scala 安装进程已经为您添加了 Scala 二进制文件的位置(请参阅图 6)。
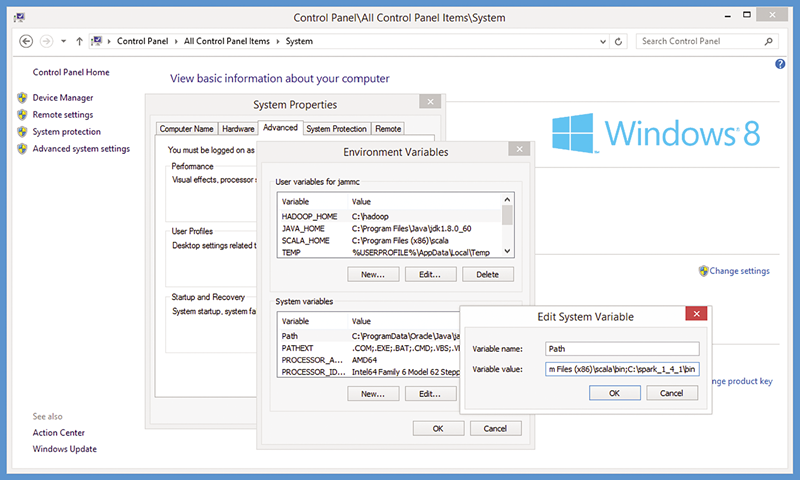
图 6:配置系统
在您设置系统变量后,我建议您修改 Spark 配置文件。转到根目录 C:\spark_1_4_1\config,然后复制 log4j.properties.template 文件。通过删除 .template 扩展名来重命名此副本。编辑 log4j.rootCategory=INFO 和 log4j.rootCategory=WARN 之间的第一个配置条目。
即,默认情况下,Spark 会发出各种各样的信息性消息。将日志记录级别从 INFO 更改为 WARN 会大大地减少消息的数量,并且可以方便您更有条不紊地与 Spark 交互。
## Spark 的 Hello World 示例
分布式计算示例 Hello World 旨在计算数据源中的不同字词数量。图 7 展示了使用 Spark 的字数统计示例。
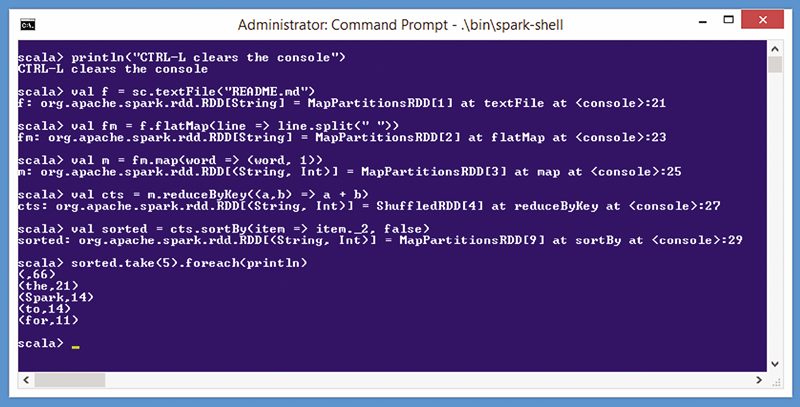
图 7:使用 Spark 的字数统计示例
Scala shell 有时被称为读取、求值、打印、循环 (REPL) shell。您可以按 CTRL+L 来清除 Scala REPL。如上文所解释,图 7 中的第一个命令将 README.md 文件的内容加载到名为 f 的 RDD 中。在实际情况中,您的数据源可以是跨数百台计算机分布的大型文件,也可以位于分布式数据库(如 Cassandra)中。
下一个命令是:
~~~
scala> val fm = f.flatMap(line => line.split(" "))
~~~
flatMap 函数调用在空白空格字符处对 f RDD 对象中的每一行进行拆分,生成的 RDD 对象 fm 会包含一个集合,其中有文件中的所有字词。从开发者的角度来看,您可以将 fm 看成是 .NET List 集合。
下一个命令是:
~~~
scala> val m = fm.map(word => (word, 1))
~~~
映射函数会创建一个保留项目对的 RDD 对象,其中每对都包含一个字词和整数值 1。如果您发出 m.take(5) 命令,则可以看得更清楚。您会看到 README.md 文件中的前五个字词,以及每个字词旁边的值 1。从开发者的角度来看,m 大致是一个 List 集合,其中每个 Pair 对象都包含一个字符串和一个整数。字符串(README.md 中的一个字词)是键,而整数则是值,但与 Microsoft .NET Framework 中的许多键值对不同的是,Spark 中允许重复的键值。保留键值对的 RDD 对象有时被称为 RDD 对,以便于与普通的 RDD 区分开来。
下一个命令是:
~~~
scala> val cts = m.reduceByKey((a,b) => a + b)
~~~
reduceByKey 函数通过添加与相等键值相关联的整数值,在对象 m 中合并各个项目。如果您运行 cts.take(10),则会看到 README.md 中的 10 个字词,后跟每个字词在此文件中的出现次数。您可能还会注意到,对象 cts 中的字词并没有特定的排列顺序。
reduceByKey 函数接受闭合。您可以使用替代的 Scala 快捷符号:
~~~
scala> val cts = m.reduceByKey(_ + _)
~~~
下划线是参数通配符,所以语法可以解析为“添加任意两个收到的值”。
请注意,此字数统计示例先使用映射函数,然后使用 reduceByKey 函数。这就是 MapReduce 范例。
下一个命令是:
~~~
scala> val sorted =
cts.sortBy(item => item._2, false)
~~~
此命令根据项目的第二个值(整数计数),对 cts RDD 中的项目进行排序。自变量 false 表示按降序排序,即从最高计数到最低计数。排序命令的 Scala 快捷语法形式是:
~~~
scala> val sorted = cts.sortBy(_._2, false)
~~~
因为 Scala 具有很多函数语言特征,并且使用很多符号(而不是关键字),因此编写的 Scala 代码会非常不直观。
Hello World 示例中的最后一个命令用于显示结果:
~~~
scala> sorted.take(5).foreach(println)
~~~
可解释为:“提取名为 sorted 的 RDD 对象中的前五个对象,并对此集合进行循环访问,同时对每个项目应用 println 函数。” 结果是:
~~~
(,66)
(the,21)
(Spark,14)
(to,14)
(for,11)
~~~
也就是说,README.md 中出现了 66 次空/null 字词,“the”一词出现了 21 次,“Spark”一词出现了 14 次等。
## 总结
如果您想在 Windows 计算机上试用 Spark,请参阅本文,其中提供的信息旨在帮助您快速掌握如何开始使用和运行 Spark。Spark 是一项相对较新的技术(2009 年始于加州大学柏克莱分校),但在过去的几个月中,对 Spark 感兴趣的人明显增多,至少我的同事们就非常感兴趣。
在 2014 年的大数据处理框架争夺战中,Spark 创造了新的性能记录,很轻松地就打破了 Hadoop 系统在前一年创造的记录。Spark 具有出色的性能,因此非常适合与机器学习系统结合使用。Spark 支持名为 MLib 的机器学习算法开放源代码库。
* * *
Dr.James McCaffrey *供职于华盛顿地区雷蒙德市沃什湾的 Microsoft Research。他参与过多个 Microsoft 产品的工作,包括 Internet Explorer 和 Bing。Scripto可通过 [jammc@microsoft.com](mailto:jammc@microsoft.com) 与 McCaffrey 取得联系。*