第11章-散列表
最后更新于:2022-04-01 07:35:33
# 一、概念
### 1.综述
散表表仅支持INSERT、SEARCH、DELETE操作。
把关键字k映射到槽h(k)上的过程称为散列。
多个关键字映射到同一个数组下标位置称为碰撞。
好的散列函数应使每个关键字都等可能地散列到m个槽位中
### 2.散表函数
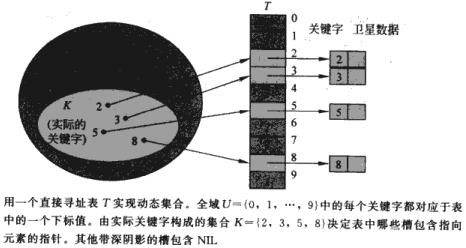
(1)若函数为h(k)=k,就是直接寻址表
(2)除法散列法:h(k) = k mod m
(3)乘法散列法:h(k) = m * (k * A mod 1) (0<A<1)
(4)全域散列:从一组仔细设计的散列函数中随机地选择一个。(即使对同一个输入,每次也都不一样,平均性态较好)
3.冲突解决策略
(1)链接法
(2)开放寻址法
a.线性探测:h(k, i) = (h'(k) + i) mod m
b.二次探测:h(k, i) = (h'(k) + c1*i + c2 *i^2) mod m
c.双重散列:h(k, i) = (h1(k) + i * h2(k)) mod m
(3)完全散列:设计一个较小的二次散列表
# 二、代码
代码中用到了函数指针,函数指针的用法参考[函数指针总结](http://blog.csdn.net/mishifangxiangdefeng/article/details/7209060)
~~~
//Hash.h
#include <iostream>
using namespace std;
int m, NIL = 0;
//11.4 开放寻址法
typedef int (*Probing)(int k, int i);
int h(int k)
{
return k % m;
}
int h2(int k)
{
return 1 + k % (m-1);
}
//线性探测
int Linear_Probing(int k, int i)
{
return (h(k) + i) % m;
}
//二次探测
int Quadratic_Probint(int k, int i)
{
int c1 = 1, c2 = 3;
return (h(k) + c1 * i + c2 * i * i) % m;
}
//双重探测
int Double_Probint(int k, int i)
{
return (h(k) + i * h2(k)) % m;
}
int Hash_Insert(int *T, int k, Probing p)
{
int i = 0, j;
do{
j = p(k, i);
if(T[j] == NIL)
{
T[j] = k;
return j;
}
i++;
}
while(i != m);
cout<<"error:hash table overflow"<<endl;
}
int Hash_Search(int *T, int k, Probing p)
{
int i = 0, j;
while(1)
{
j = p(k, i);
if(T[j] == NIL || i == m)
break;
if(T[j] == k)
return j;
i++;
}
}
~~~
# 三、习题
### 11.1 直接寻址表
~~~
11.1-1
O(m),最坏情况时,集合中只有一个最小关键字
11.1-2
如果插入x,就把向量的第x位置为1
如果删除x,就把向量的第x位置为0
11.1-3
当存在关键字为key的卫星数据时,T[key]指向其中一个关键字为key的卫星数据。若不存在,T[key]指向空。
每一个卫星数据用一个结点表示,结点中有三个域,分别是:关键字key,卫星数据data,指向下一个所有相同关键字的卫星数据的指针next
DIRECT-ADDRESS-SEARCH(T, k)
return T[k];
DIRECT-ADDRESS-INSERT(T, x)
if T[key[x]] = NULL
then T[key[x]] <- x
else next[x] <- next[T[key[x]]]
next[T[key[x]]] <- x
~~~
11.1-4 见[算法导论-11.1-4](http://blog.csdn.net/mishifangxiangdefeng/article/details/7709567)
用一个栈来存储实际插入的数据,插入时栈向上扩展一个空间,删除时,用栈顶元素补充被删除元素的位置,栈向下回收一个空间,方法类似于P127-11.3-4.
这个非常大的数组中不直接存放数据,而是存放数据在Stack中的位置。
对于一个元素p,如果H[p] < 栈中总元素的个数 && p = Stack[H[p]],就是存入,否则就是不存在
### 11.2 散列表
11.2-3
所有操作的时间都是O(n/2),n是一个链表的长度
11.2-4 见[算法导论-11.2-4](http://blog.csdn.net/mishifangxiangdefeng/article/details/7712094)
插入操作时,从自由链表中取出一个空闲slot,填入关键字x,修改指针,链表相应的队列中,具体可以分为以下几种情况:
(1)x所属的slot未被占用,则
step1:把这个slot从自由链表中移出
step2:填入关键字x
step3:修改指针,在这种情况下其next和pre都置为-1
(2)x所属的slot已经被占用,令占用这个slot的关键是y,y也属于这个slot,则
step1:从自由链表中取出一个空闲的slot,这个slot肯定不是x所属的slot,只是拿过来用
step2:填入关键字x
step3:修改指针,把slot链表入到“以x所属的slot为头结点的队列”中
(3)x所属的slot已经被占用,令占用这个slot的关键是y,y不属于这个slot,通过(2)可知,这个情况是有可能的
step1:从自由链表中取出一个空闲的slot,这个slot肯定不是x所属的slot,也不是y所属的slot,只是拿过来用
step2:在新slot中填入关键字y,修改指针,让y使用这个新slot,而把原来的slot空出来还给x
step3:在x所属的slot中填入关键字x
step4:修改“x所属的slot”指针,类似(1)-step3
删除操作时,令待删除的关键字是x,释放x所占用的slot,具体可以分为以下几种情况
(1)x所占用的slot正是x所属的slot,且slot->next=-1,即所有关键字中只有x属于这个slot,x被删除后,slot就空闲了
step1:释放slot到自由链表中
(2)x所占用的slot正是x所属的slot,但还有别的关键字中只有x属于这个slot,应该优先使用关键所属于的slot,而释放“不自己关键字的、临时拿过来用的”slat
step1:从以slot为头结点的队列中另选一个slot2,slot2的关键字属于slot而不属于slot2,只是因为slot被占用,所以才用slot2
step2:把slot2的内容填入slot
step3:修改指针,让slot代替slot2存在于队列中,不同的是slot还是队列头
step4:释放slot2到自由链表中
(3)x所占用的slot不是x所属的slot,这个种情况下,这个slot一定不是队列头,还有别的关键字存在于队列中,并且占用了x所属的slot
step1:把x所占用的slot从“以x所属的slot为头的队列”中移出
step2:释放slot到自由链表中
查找操作,如果理解了插入和删除,查找操作就比较简单了,令待查找的关键字是x,也可分为几种情况
(1)x所属的slot未被占用,即不存在与x相同slot的关键字,当然也不存在x了
(2)x所属的slot被占用了,但它所存的关键不属于这个slot,与(1)相同,不存在与x相同slot的关键字
(3)x所属的slot被占用了,且它所存的关键属于这个slot,即存在与x相同slot的关键字,只是不知这个关键字是不是x,需要进一步查找
### 11.3 散列函数
11.3-1
从散列表中的第h(k)个表中搜索关键字为k的一项
11.3-2
每处理字符串中的一个字符,就取一次模
11.3-4
~~~
#include <cmath>
int main()
{
int n;
while(cin>>n)
{
double A = (sqrt(5.0)-1) / 2;
double t1 = A * n;
int t2 = (int)t1;
double t3 = t1 - t2;
int t4 = t3 * 1000;
cout<<t4<<endl;
}
}
~~~
h(61) = 700
h(62) = 318
h(63) = 936
h(64) = 554
h(65) = 172
### 11.4 开放寻址法
11.4-1
线性探测:22 88 0 0 4 15 28 17 59 31 10
二次探测:22 0 88 17 4 0 28 59 15 31 10
双重探测:22 0 59 17 4 15 28 88 0 31 10
代码如下:代码中用到了函数指针,函数指针的用法参考[函数指针总结](http://blog.csdn.net/mishifangxiangdefeng/article/details/7209060)
~~~
#include <iostream>
#include <string>
#include "Hash.h"
using namespace std;
void Print(int *T)
{
int i;
for(i = 0; i < m; i++)
cout<<T[i]<<' ';
cout<<endl;
}
int main()
{
string str;
int i, j;
m = 11;
int T[11], A[9] = {10, 22, 31, 4, 15, 28, 17, 88, 59};
Probing P[3] = {Linear_Probing, Quadratic_Probint, Double_Probint};
for(i = 0; i < 3; i++)
{
memset(T, 0, sizeof(T));
for(j = 0; j < 9; j++)
Hash_Insert(T, A[j], P[i]);
Print(T);
}
return 0;
}
~~~
11.4-2
删除一个元素后,将这个位置置为DELETED,在插入操作中,L3改为if T[j] = NIL or T[j] = DELETED
~~~
#define DELETED -1
int Hash_Insert(int *T, int k, Probing p)
{
int i = 0, j;
do{
j = p(k, i);
if(T[j] == NIL || T[j] == DELETED)
{
T[j] = k;
return j;
}
i++;
}
while(i != m);
cout<<"error:hash table overflow"<<endl;
}
void Hash_Delete(int *T, int k, Probing p)
{
int j = Hash_Search(T, k, p);
if(j != NIL)
T[j] = DELETED;
}
~~~