前端与后台
最后更新于:2022-04-01 14:31:26
[TOC]
> 前端 Front-end 和后端 Back-end 是描述进程开始和结束的通用词汇。前端作用于采集输入信息,后端进行处理。
这种说法给人一种很模糊的感觉,但是他说得又很对,它负责视觉展示。在 MVC 结构或者 MVP 中,负责视觉显示的部分只有 View 层,而今天大多数所谓的 View 层已经超越了 View 层。前端是一个很神奇的概念,但是而今的前端已经发生了很大的变化。你引入了 Backbone、Angluar,你的架构变成了 MVP、MVVM。尽管发生了一些架构上的变化,但是项目的开发并没有因此而发生变化。这其中涉及到了一些职责的问题,如果某一个层级中有太多的职责,那么它是不是加重了一些人的负担?
后台在过去的岁月里起着很重要的作用,当然在未来也是。就最几年的解耦趋势来看,它在变得更小,变成一系列的服务。并向前台提供很多 RESTful API,看上去有点像提供一些辅助性的工作。
因此在这一章里,我们将讲述详细介绍:
1. 后台语言与选型
2. 前端框架与选型
3. 前端一致化,后台服务化的趋势
4. 前后端通讯
## 后台语言选择
如何选择一门好的后台语言似乎是大家都很感兴趣的问题?大概只是因为他们想要在一开始的时候去学一门很实用的语言——至少会经常用到,而不是学好就被遗弃了。或者它不会因为一门新的语言的出现而消亡。
### JavaScript
在现在看来,JavaScript 似乎是一个性价比非常高的语言。只要是 Web 就会有前端,只要有前端就需要有 JavaScript。与此同时 Node.js 在后台中的地位已经愈发重要了。
对于 JavaScript 来说,它可以做很多类型的应用。这些应用都是基于浏览器来运行的,有:
* Electron + Node.js + JavaScript 做桌面应用
* Ionic + JavaScript 做移动应用
* Node.js + JavaScript 网站前后台
* JavaScript + Tessl 做硬件
So,这是一门很有应用前景的语言。
### Python
Python 诞生得比较早,其语言特性——做事情只有一件方法,也决定了这门语言很简单。在 ThoughtWorks University 的学习过程中,接触了一些外国小伙伴,这是大多数人学习的第一门语言。
Python 在我看来和 JavaScript 是相当划算的语言,除了它不能在前端运行,带来了一点劣势。Python 是一门简洁的语言,而且有大量的数学、科学工具,这意味着在不远的将来它会发挥更大的作用。我喜欢在我的各种小项目上用 Python,如果不是因为我对前端及数据可视化更感兴趣,那么Python 就是我的第一语言了。
### Java
除此呢,我相信 Java 在目前来说也是一个不错的选择。
在学校的时候,一点儿也不喜欢 Java。后来才发现,我从 Java 上学到的东西比其他语言上学得还多。如果 Oracle 不毁坏 Java,那么他会继续存活很久。我可以用 JavaScript 造出各种我想要的东西,但是通常我无法保证他们是优雅的实现。过去人们在 Java 上花费了很多的时间,或在架构上,或在语言上,或在模式上。由于这些投入,都给了人们很多的启发。这些都可以用于新的语言,新的设计,毕竟没有什么技术是独立于旧的技术产生出来的。
### PHP
PHP 呢,据说是这个『世界上最好的语言』,我服务器上运行着几个不同的 WordPress 实例。对于这门语言,我还是相当放心的。并且这门语言由于上手简单,同时国内有大量的程序员已经掌握好了这门语言。不得不提及的是 WordPress 已经占领了 CMS 市场超过一半的份额,并且它也占领了全球网站的四分之一。还有 Facebook,这个世界上最大的 PHP 站点也在使用这门语言。
### 其他
个人感觉 Go 也不错,虽然没怎么用,但是性能应该是相当可以的。
Ruby、Scala,对于写代码的人来说,这是非常不错的语言。但是如果是团队合作时,就有待商榷。
## MVC
人们在不断地反思这其中复杂的过程,整理了一些好的架构模式,其中不得不提到的是我司 Martin Fowler 的《企业应用架构模式》。该书中文译版出版的时候是2004年,那时对于系统的分层是
| 层次 | 职责 |
| --- | --- |
| 表现层 | 提供服务、显示信息、用户请求、HTTP请求和命令行调用。 |
| 领域层 | 逻辑处理,系统中真正的核心。 |
| 数据层 | 与数据库、消息系统、事物管理器和其他软件包通讯。 |
化身于当时最流行的 Spring,就是 MVC。人们有了 iBatis 这样的数据持久层框架,即 ORM,对象关系映射。于是,你的 package 就会有这样的几个文件夹:
~~~
|____mappers
|____model
|____service
|____utils
|____controller
~~~
在 mappers 这一层,我们所做的莫过于如下所示的数据库相关查询:
~~~
@Insert(
"INSERT INTO users(username, password, enabled) " +
"VALUES (#{userName}, #{passwordHash}, #{enabled})"
)
@Options(keyProperty = "id", keyColumn = "id", useGeneratedKeys = true)
void insert(User user);
~~~
model 文件夹和 mappers 文件夹都是数据层的一部分,只是两者间的职责不同,如:
~~~
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
~~~
而他们最后都需要在 Controller,又或者称为 ModelAndView 中处理:
~~~
@RequestMapping(value = {"/disableUser"}, method = RequestMethod.POST)
public ModelAndView processUserDisable(HttpServletRequest request, ModelMap model) {
String userName = request.getParameter("userName");
User user = userService.getByUsername(userName);
userService.disable(user);
Map<String,User> map = new HashMap<String,User>();
Map <User,String> usersWithRoles= userService.getAllUsersWithRole();
model.put("usersWithRoles",usersWithRoles);
return new ModelAndView("redirect:users",map);
}
~~~
在多数时候,Controller 不应该直接与数据层的一部分,而将业务逻辑放在 Controller 层又是一种错误,这时就有了 Service 层,如下图:
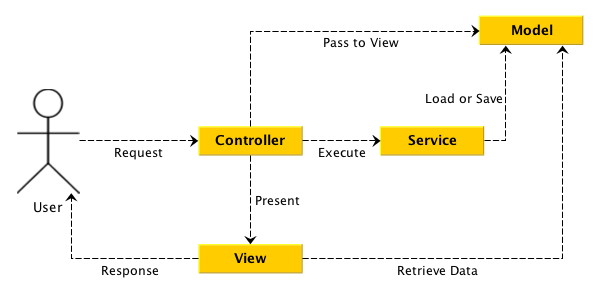
Service MVC
Domain(业务)是一个相当复杂的层级,这里是业务的核心。一个合理的 Controller 只应该做自己应该做的事,它不应该处理业务相关的代码:
我们在 Controller 层应该做的事是:
1. 处理请求的参数
2. 渲染和重定向
3. 选择 Model 和 Service
4. 处理 Session 和 Cookies
业务是善变的,昨天我们可能还在和对手竞争谁先推出新功能,但是今天可能已经合并了。我们很难预见业务变化,但是我们应该能预见 Controller 是不容易变化的。在一些设计里面,这种模式就是 Command 模式。
### Model
> 模型用于封装与应用程序的业务逻辑相关的数据以及对数据的处理方法。
它是介于数据与控制器之间的层级,拥有对数据直接访问的权力——增删改查(CRUD)。Web 应用中,数据通常是由数据库来存储,有时也会用搜索引擎来存储
因此在实现这个层级与数据库交付时,可以使用 SQL 语句,也可以使用 ORM 框架。
SQL(Structured Query Language,即结构化查询语言), 语句是数据库的查询语言
ORM(Object Relational Mapping),即对象关系映射,主要是将数据库中的关系数据映射称为程序中的对象。
### View
View 层在 Web 应用中,一般是使用模板引擎装载对应 HTML。如下所示的是一段 JSP 代码:
~~~
<html>
<head><title>First JSP</title></head>
<body>
<%
double num = Math.random();
if (num > 0.95) {
%>
<h2>You'll have a luck day!</h2><p>(<%= num %>)</p>
<%
} else {
%>
<h2>Well, life goes on ... </h2><p>(<%= num %>)</p>
<%
}
%>
<a href="<%= request.getRequestURI() %>"><h3>Try Again</h3></a>
</body>
</html>
~~~
上面的 JSP 代码在经过程序解析、处理后,会变成相对应的 HTML。而我们可以发现在这里的 View 层不仅仅只有模板的作用,我们会发现这里的 View 层还计划了部分的逻辑。我们可以在后面细细看这些问题,对于前端的 View 层来说,他可能是这样的:
~~~
<div class="information pure-g">
{{#.}}
<div class="pure-u-1 ">
<div class="l-box">
<h3 class="information-head"><a href="#/blog/{{slug}}" alt="{{title}}">{{title}}</a></h3>
<p>
发布时间:<span>{{created}}</span>
<p>
{{{content}}}
</p>
</p>
</div>
</div>
{{/.}}
</div>
~~~
在这里的 View 层只是单纯的一个显示作用,这也是我们推荐的做法。业务逻辑应该尽可能的放置于业务层。
### Controller
> 控制器层起到不同层面间的组织作用,用于控制应用程序的流程。
### 更多
在前后端解耦合的系统中,通常系统的架构模式就变成了 MVP,又或者是 MVVM。
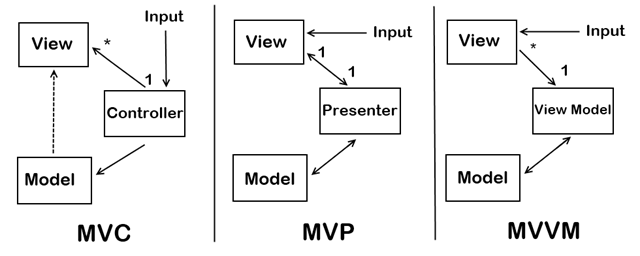
MVC、MVVM、MVP 对比
三者间很大的不同在于层级间的通讯模型、使用场景。
#### MVP
> MVP 是从经典的模式 MVC 演变而来,它们的基本思想有相通的地方:Controller/Presenter 负责逻辑的处理,Model 提供数据,View 负责显示。
#### MVVM
MVVM 是 Model-View-ViewModel 的简写。相比于MVC悠久的历史来说,MVVM 是一个相当新的架构,它最早于2005年被由的 WPF 和Silverlight 的架构师 John Gossman 提出,并且应用在微软的软件开发中。而 MVC 已经被提出了二十多年了,可见两者出现的年代差别有多大。
MVVM 在使用当中,通常还会利用双向绑定技术,使得 Model 变化时,ViewModel 会自动更新,而 ViewModel 变化时,View 也会自动变化。所以,MVVM 模式有些时候又被称作:model-view-binder 模式。
## 后台即服务
> BaaS(Backend as a Service)是一种新型的云服务,旨在为移动和 Web 应用提供后端云服务,包括云端数据/文件存储、账户管理、消息推送、社交媒体整合等。
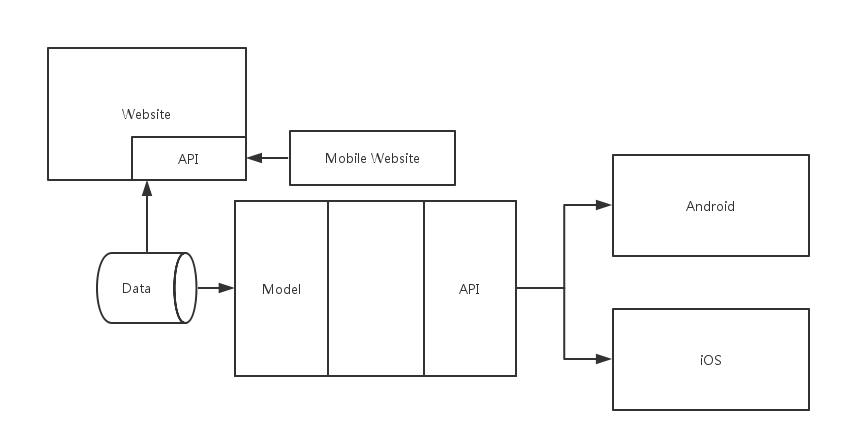
产生这种服务的主要原因之一是因为移动应用的流行。在移动应用中,我们实际上只需要一个 API 接口来连接数据库,并作一些相应的业务逻辑处理。对于不同的应用产商来说,他们打造 API 的方式可能稍有不同,然而他们都只是将后台作为一个服务。
在一些更特殊的例子里,即有网页版和移动应用端,他们也开始使用同一个 API。前端作为一个单页面的应用,或者有后台渲染的应用。其架构如下图所示:

Backend As A Service
### API 演进史
在早期的工作中,我们会发现我们会将大量的业务逻辑放置到 View 层——如迭代出某个结果。
而在今天,当我们有大量的逻辑一致时,我们怎么办,重复实现三次?
如下所示是笔者之前重构的系统的一个架构缩略图:
重复逻辑的系统架构
上面系统产生的主要原因是:技术本身的演进所造成的,并非是系统在一开始没有考虑到这个问题。

API 演进史
从早期到现在的互联网公司都有这样的问题,也会有同样的过程:
第一阶段: 因为创始人对于某个领域的看好,他们就创建了这样的一个桌面网站。这个时间点,大概可以在2000年左右。
第二阶段: 前“智能手机”出现了,人们需要开发移动版本的网站来适用用户的需要。这时由于当时的开发环境,以及技术条件所限,当时的网站只会是桌面模板的简化。这时还没有普及 Ajax 请求、SPA 这些事物。
第三阶段: 手机应用的制作开始流行起来了。由于需要制作手机应用,人们就需要在网站上创建 API。由于当时的业务或者项目需求,这个 API 是直接耦合在系统中的。
第四阶段: 由于手机性能的不断提高,并且移动网络速度不断提升,人们便开始在手机上制作单页面应用。
由于他们使用的是相同业务逻辑、代码逻辑相同而**技术栈不同**的代码,当有一个新的需求出现时,他们需要重复多次实现,如下图所示:

重复业务逻辑的系统架构
随后——也就是今天,各种新的解决方案出现了,如 React、混合应用、原生 + Web 的混合式应用、他们的目的就是解决上述的问题。不过,这些解决方案只是为了解决在前端中可能出现的问题,详细的内容可以见《前端演进史》。
而人们也借此机会在统一后台——因为我们可以借助于混合应用或混合式应用(即原生 + 内嵌 WebView,可以同时解决性能和跨平台问题)统一移动端,借助于响应式设计的理念可以统一桌面、平板和手机端。
因此,我们需要的就只是这样的一个 API:
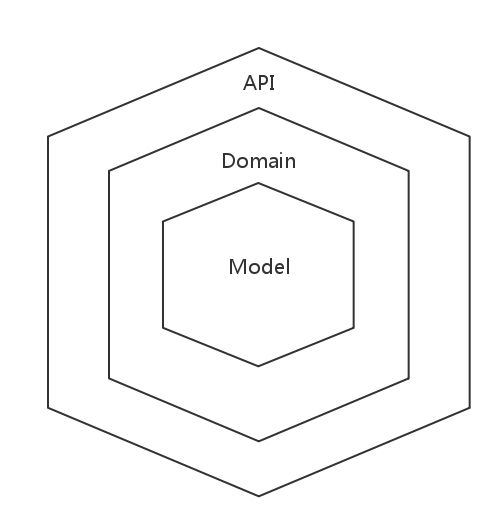
One API
### 后台即服务
现在,让我们来看看一个采用后台即服务的网站架构会是怎样的?
## 数据持久化
信息源于数据,我们在网站上看到的内容都应该是属于信息的范畴。这些信息是应用从数据库中根据业务需求查找、过滤出来的数据。
数据通常以文件的形式存储,毕竟文件是存储信息的基本单位。只是由于业务本身对于 Create、Update、Query、Index 等有不同的组合需求就引发了不同的数据存储软件。
如上章所说,View 层直接从 Model 层取数据,无遗也会暴露数据的模型。作为一个前端开发人员,我们对数据的操作有三种类型:
1. 数据库。由于 Node.js 在最近几年里发展迅猛,越来越多的开发者选择使用 Node.js 作为后台语言。这与传统的 Model 层并无多大不同,要么直接操作数据库,要么间接操作数据库。即使在 NoSQL 数据库中也是如此。
2. 搜索引擎。对于以查询为主的领域来说,搜索引擎是一个更好的选择,而搜索引擎又不好直接向 View 层暴露接口。这和招聘信息一样,都在暴露公司的技术栈。
3. RESTful。RESTful 相当于是 CRUD 的衍生,只是传输介质变了。
4. LocalStorage。LocalStorage 算是另外一种方式的 CRUD。
说了这么多都是废话,他们都是可以用类 CRUD 的方式操作。
### 文件存储
通常来说,以这种方式存储最常见的方式是 log(日志),如 Nginx 的 access.log。像这样的文件就需要一些专业的软件,如 GoAccess、又或者是 Hadoop、Spark 来做对应的事。
在数据库出现之前,人们都是使用文件来存储数据的。数据以文件为单位存储在硬盘上,并且这些文件不容易一起管理、修改等等。如下图所示的是我早期存储文件的一种方式:
~~~
├── 3.12
│ ├── cover.png
│ └── favicon.ico
└── 3.13
└── template.tex
~~~
每天我们都会修改、查看大量的不同类型的文件。而由于工作繁忙,我们可能没有办法一一地去分类这些文件。有时选择的便是,优先先按日期把文件一划分,接着再在随后的日子里归档。而这种存储方式大量的依赖于人来索引的工作,在很多时候往往显得不是很靠谱。并且当我们将数据存储进去后,往往很难进行修改。大量的 Log 文件就需要专门的工作来分析和使用,依赖于人来解析这些日志往往显得不是很靠谱。这时我们就需要一些重量级的工具,如用 Logstash、ElasticSearch、Kibana 来处理 Nginx 访问日志。
而对于那些非专业人员来说,使用 Excel 这样的工具往往显得比较方便。他们不需要去操作数据库,也不需要专业的知识来处理这些知识。只是从某种意义上来说,Excel 应该归属于数据库的范畴。
### 数据库
当我们开始一个 Web 应用的时候,如创建一个用户管理系统的时候,我们就需要不断由于经常对文件进行查询、修改、插入和删除等操作。不仅仅如此,我们还需要定义数据之前的关系,如这个用户对应这个密码。在一些更复杂的情况下,我们还需要寻找中这些用户对应的一些操作数据等等。如果我们还是这些工作交给文件来处理,那么我们便是在向自己挖坑。
> 数据库,简单来说可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据运行新增、截取、更新、删除等操作。
在操作库的时候,我们会使用到一名为 SQL(英语:Structural Query Language,中文: 结构化查询语言)的领域特定语言来对数据进行操作。
> SQL 是高级的非过程化编程语言,它允许用户在高层数据结构上工作。它不要求用户指定对数据的存放方法,也不需要用户了解其具体的数据存放方式。
数据库里存储着大量的数据,在我们对系统建模的时候,也在决定系统的基础模型。
#### ORM
在传统 SQL 数据库中,我们可能会依赖于 ORM,也可能会自己写 SQL。在使用 ORM 框架时,我们需要先定义 Model,如下是 Node.js 的 ORM 框架 Sequelize 的一个示例:
~~~
var User = sequelize.define('user', {
firstName: {
type: Sequelize.STRING,
field: 'first_name'
},
lastName: {
type: Sequelize.STRING
}
}, {
freezeTableName: true
});
User.sync({force: true}).then(function () {
// Table created
return User.create({
firstName: 'John',
lastName: 'Hancock'
});
});
~~~
上面定义的 Model,在程序初始化的时候将会创建相应的数据库字段。并且会创建一个 firstName 为 ‘John’,lastName 为 ‘Hancock’ 的用户。而这个过程中,我们并不需要操作数据库。
像如 MongoDB 这类的数据库,也是存在数据模型,但说的却是嵌入子文档。在业务量大的情况下,数据库在考验公司的技术能力,想想便觉得 Amazon RDS 挺好的。
### 搜索引擎
尽管百科上对于搜索引擎的定义是这样的:
> 搜索引擎指自动从因特网搜集信息,经过一定整理以后,提供给用户进行查询的系统。
但是这样说往得不是非常准确。因为有相当多的网站采用了搜索引擎作为基础的存储服务架构,而且他们并非自动从互联网上搜索信息。搜索引擎应该分成三个部分来组成:
1. 索引服务
2. 搜索服务
3. 索引数据
索引服务便是用于将数据存储到索引数据中,而搜索服务正是搜索引擎存在的意义。对于查询条件复杂的网站来说,采用搜索引擎就意味着减少了非常多的繁琐数据处理事务。在一些架构中,人们用数据库存储数据,并使用工具来将数据注入到搜索引擎中。
从架构上来说,使用搜索引擎的优点是:分离存储、查询部分。从开发上来说,它可以让我们更关注于业务本身的价值,而不是去实现这样一个搜索逻辑。
如下图所示的 Lucene 应用的架构:
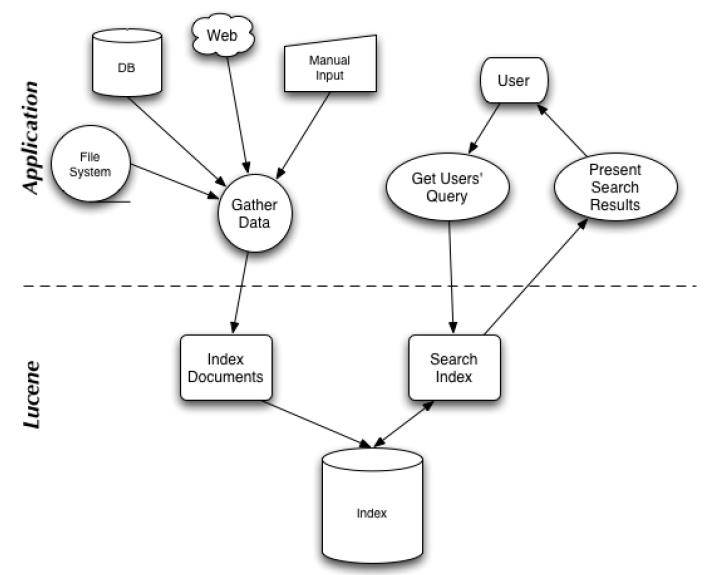
Lucene 应用架构
可以从图中看到系统明显被划分成两部分:
1. Index Documents。索引文档部分,将用于存储数据到文件系统中。
2. Search Index。搜索部分,用于查询相应的数据。
## 前端框架选择
选择前端框架似乎是一件很难的事,然而这件事情并不是看上去那么难。只是有时候你只想追随潮流,或者因为你在技术选型受到一些影响。但是总的来说,选择一个框架并不是一件很难的事。同时也不是一件非常重要的事,因为框架本身是相通的。如果我们不尽量去解耦系统,那么选择什么框架也都是一样的。
### Angular
AngularJS 对于后端人员写前端代码来说,是一个非常不错的选择。Angular 框架采用并扩展了传统 HTML,通过双向的数据绑定来适应动态内容,双向的数据绑定允许模型和视图之间的自动同步。
并且类似于 Ionic 这样的混合框架,也将 Ionic 带到了移动应用的领域。
### React
React 似乎很受市场欢迎,各种各样的新知识——虚拟 DOM、JSX、Component 等等。React 只是我们在上面章节里说到的 View 层,而这个 View 层需要辅以其他框架才能完成更多的工作。
并且 React 还有一个不错的杀手锏——React Native,虽然这个框架还在有条不紊地挖坑中,但是这真的是太爽了。以后我们只需要一次开发就可以多处运行了,再也没有比这更爽的事情发生了。
### Vue
Vue.js 是一个轻量级的前端框架。它是一个更加灵活开放的解决方案。它允许你以希望的方式组织应用程序,你可以将它嵌入一个现有页面而不一定要做成一个庞大的单页应用。
### jQuery 系
jQuery 还是一个不错的选择,不仅仅对于学习来说,而且对于工作来说也是如此。如果你们不是新起一个项目或者重构旧的项目,那么必然你是没有多少机会去超越 DOM。而如果这时候尝试去这样做会付出一定的代价,如我在前端演进史所说的那样——晚点做出选择,可能会好一点。
因为谁说 jQuery 不会去解放 DOM,React 带来的一些新的思想可能就比不上它的缺点。除此,jQuery 耕织几年的生态系统也是不可忽略。
#### Backbone + Zepto + Mustache
这是前几年(今年2016)的一个技术方向,今天似乎已经不太常见了。在这种模式下,人们使用 Backbone 来做一些路由、模型、视图、集合方面的工作,而由 jQuery 的兼容者 Zepto 来负责对 DOM 的处理,而 Mustache 在这里则充当模板系统的工作。
## 前台与后台交互
在我们把后台服务化后,前端跨平台化之前,我们还需要了解前台和后台之间怎么通讯。从现有的一些技术上来看,Ajax 和 WebSocket 是比较受欢迎的。
### Ajax
AJAX 即 “Asynchronous JavaScript And XML”(异步 JavaScript 和 XML),是指一种创建交互式网页应用的网页开发技术。这个功能在之前的很多年来一直被 Web 开发者所忽视,直到 Gmail、Google Suggest 和 Google Maps 的出现,才使人们开始意识到其重要性。通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。传统的网页如果需要更新内容,必须重载整个网页页面。

Ajax 请求
说起 Ajax,我们就需要用 JavaScript 向服务器发送一个 HTTP 请求。这个过程要从 XMLHttpRequest 开始说起,它是一个 JavaScript 对象。它最初由微软设计,随后被 Mozilla、Apple 和 Google 采纳。如今,该对象已经被 W3C 组织标准化。
如下的所示的是一个 Ajax 请求的示例代码:
~~~
var xhr = new XMLHttpRequest();
xhr.onreadystatechange = function() {
if (xhr.readyState == XMLHttpRequest.DONE) {
alert(xhr.responseText);
}
}
xhr.open('GET', 'http://example.com', true);
xhr.send(null);
~~~
我们只需要简单的创建一个请求对象实例,打开一个 URL,然后发送这个请求。当传输完毕后,结果的 HTTP 状态以及返回的响应内容也可以从请求对象中获取。
而这个返回的内容可以是多种格式,如 XML 和 JSON,但是从近年的趋势来看,XML 基本上已经很少看到了。这里我们以 JSON 为主,来简单地介绍一下返回数据的解析。
### JSON
> JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于 ECMAScript 的一个子集。 JSON采用完全独立于语言的文本格式,但是也使用了类似于 C 语言家族的习惯(包括 C、C++、C#、Java、JavaScript、Perl、Python等)。这些特性使 JSON 成为理想的数据交换语言。易于人阅读和编写,同时也易于机器解析和生成(一般用于提升网络传输速率)。
#### XML VS JSON
JSON 格式的数据具有以下的一些特点:
* 容易阅读
* 解析速度更快
* 占用空间更少
如下所示的是一个简单的对比过程:
~~~
myJSON = {"age" : 12, "name" : "Danielle"}
~~~
如果我们要取出上面数值中的age,那么我们只需要这样做:
~~~
anObject = JSON.parse(myJSON);
anObject.age === 12 // True
~~~
同样的,对于 XML 来说,我们有下面的格式:
~~~
<person>
<age>12</age>
<name>Danielle</name>
</person>
~~~
而如果我们要取出上面数据中的age的值,他将是这样的:
~~~
myObject = parseThatXMLPlease();
thePeople = myObject.getChildren("person");
thePerson = thePeople[0];
thePerson.getChildren("age")[0].value() == "12" // True
~~~
对比一下,我们可以发现XML的数据不仅仅解析上比较麻烦,而且还繁琐。
#### JSON WEB Tokens
> JSON Web Token (JWT) 是一种基于 token 的认证方案。
在人们大规模地开始 Web 应用的时候,我们在授权的时候遇到了一些问题,而这些问题不是 Cookie 所能解决的。Cookie 存在一些明显的问题:不能支持跨域、并且不是无状态的、不能使用CDN、与系统耦合等等。除了解决上面的问题,它还可以提高性能等等。基于 Session 的授权机制需要服务端来保存这个状态,而使用 JWT 则可以跳过这个问题,并且使我们设计出来的 API 满足 RESTful 规范。即,我们 API 的状态应该是没有状态的。因此人们提出了 JWT 来解决这一系列的问题。
通过 JWT 我们可以更方便地写出适用于前端应用的认证方案,如登陆、注册这些功能。当我们使用 JWT 来实现我们的注册、登陆功能时,我们在登陆的时候将向我们的服务器发送我们的用户名和密码,服务器验证后将生成对应的 Token。在下次我们进行页面操作的时候,如访问 /Dashboard 时,发出的 HTTP 请求的 Header 中会包含这个 Token。服务器在接收到请求后,将对这个 Token 进行验证并判断这个 Token 是否已经过期了。

JWT 流程
需要注意的一点是:在使用 JWT 的时候也需要注意安全问题,在允许的情况下应该使用 HTTPS 协议。
### WebSocket
在一些网站上为了实现推送技术,都采用了轮询的技术。即在特定的的时间间隔里,由浏览器对服务器发出 HTTP 请求,然后浏览器便可以从服务器获取最新的消息。如下图所示的是 Google Chrome 申请开发者账号时发出的对应的请求:
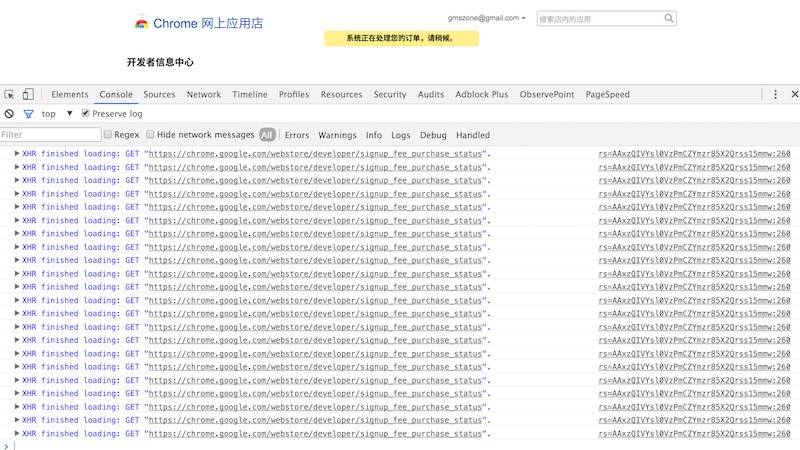
Chrome Ajax 轮询
从上图中我们可以看到,Chrome 的前台正在不断地向后台查询 API 的结果。由于浏览器需要不断的向服务器发出请求,而 HTTP 的 Header 是非常长的,即使是一个很小的数据也会占用大量的带宽和服务器资源。为了解决这个问题,HTML5 推出了一种在单个 TCP 连接上进行全双工通讯的协议WebSocket。
WebSocket 可以让客户端和服务器之间存在持久的连接,而且双方都可以随时开始发送数据。