上线
最后更新于:2022-04-01 14:31:30
[TOC]
作为一个开发人员,我们也需要去了解如何配置服务器。不仅仅因为它可以帮助我们更好地理解 Web 开发,而且有时候很多 Bug 都是因为服务器环境引起的——如臭名昭著地编码问题。
* 一些简单的 Ops 技能。
* 了解服务器的相关软件
* 搭建运行 Web 应用的服务器
* 自动化部署应用
为了即时的完成工作,你是不是放弃了很多东西,比如质量? 测试是很重要的一个环节,不仅可以为我们保证代码的质量,而且还可以为我们以后的重构提供基础条件。
作为一个在敏捷团队里工作的开发人员,初次意识到在国内大部分的开发人员是不写测试的时候,我还是有点诧异。
尽管没有写测试可以在初期走得很快,但是在后期就会遇到一堆麻烦事。传统的思维下,我们会认为一个人会在一家公司工作很久。而这件事在最近几年里变化得特别快,特别是在信息技术高速发展的今天。人们可以从不同的地方得到哪里缺人,从一个地方到另外一个地方也变得异常的快,这就意味着人员流动是常态。
而代码尽管还在,但是却会随着人员流动而出现更多的问题。这时如果代码是有有效的测试,那么则可以帮助系统更好地被理解。
## 隔离与运行环境
为了将我们的应用部署到服务器上,我们需要为其配置一个运行环境。从底层到顶层有这样的运行环境及容器:
1. 隔离硬件:虚拟机
2. 隔离操作系统:容器虚拟化
3. 隔离底层:Servlet 容器
4. 隔离依赖版本:虚拟环境
5. 隔离运行环境:语言虚拟机
6. 隔离语言:DSL
实现上这是一个请求的处理过程,一个 HTTP 请求会先到达你的主机。如果你的主机上运行着多个虚拟机实例,那么请求就会来到这个虚拟机上。又或者是如果你是在 Docker 这一类容器里运行你的程序的话,那么也会先到达 Docker。随后这个请求就会交由 HTTP 服务器来处理,如 Apache、Nginx,这些 HTTP 服务器再将这些请求交由对应的应用或脚本来处理。随后将交由语言底层的指令来处理。
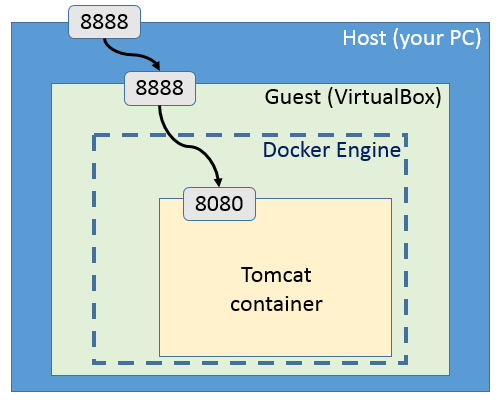
Docker Tomcat
不同的环境有不同的选择,当然也可以结合在一起。不过,从理论上来说在最外层还是应该有一个真机的,但是我想大家都有这个明确的概念,就不多解释了。
### 隔离硬件:虚拟机
在虚拟机技术出现之前,为了运行不同用户的应用程序,人们需要不同的物理机才能实现这样的需求。对于 Web 应用程序来说,有的用户的网站访问量少消耗的系统资源也少,有的用户的网站访问量大消耗的系统资源也多。虽然有不同的服务器类型可以选择,然而对于多数的访问少的用户来说他们需要支付同样的费用。这听上去相当的不合理,并且也浪费了大量的资源。并且对于系统管理员来说,管理这些系统也不是一件容易的事。在过去硬件技术革新特别快,让操作系统运行在不同的机器上也不是一件容易的事。
> 虚拟机(Virtual Machine)指通过软件模拟的具有完整硬件系统功能的、运行在一个完全隔离环境中的完整计算机系统。
这是一个很有意思的技术,它可以让我们在一个主机上同时运行几个不同的操作系统。我们可以为这几个操作系统使用不同的硬件,在这之上的应用可以使用不同的技术栈来运行,并且从理论上互相不影响。其架构如下图所示:
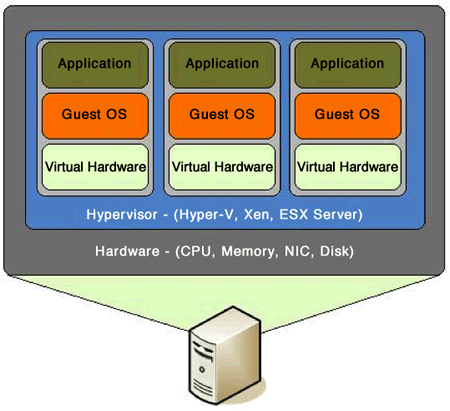
虚拟机
借助于虚拟机技术,当我们需要更多的资源的时候,创建一个新的虚拟机就行了。同时,由于这些虚拟机上运行的是同样的操作系统,并且可以使用相同的配置,我们只需要编写一些脚本就可以实现其自动化。当我们的物联机发生问题时,我们也可以很快将虚拟机迁移或恢复到另外的宿主机。
### 隔离操作系统:容器虚拟化
对于大部分的开发团队来说,直接开发基于虚拟机的自动化工具不是一件容易的事,并且他从使用成本上来说比较高。这时候我们就需要一些更轻量级的工具容器——它可以提供轻量级的虚拟化,以便隔离进程和资源,而且不需要提供指令解释机制以及全虚拟化的其他复杂性。并且,它从启动速度上来说更快。
#### LXC
在介绍 Docker 之前,我们还是稍微提一下 LXC。因为在过去我有一些使用 LXC 的经历,让我觉得 LXC 很赞。
> LXC,其名称来自 Linux 软件容器(Linux Containers)的缩写,一种操作系统层虚拟化(Operating system–level virtualization)技术,为 Linux 内核容器功能的一个用户空间接口。它将应用软件系统打包成一个软件容器(Container),内含应用软件本身的代码,以及所需要的操作系统核心和库。通过统一的名字空间和共用 API 来分配不同软件容器的可用硬件资源,创造出应用程序的独立沙箱运行环境,使得 Linux 用户可以容易的创建和管理系统或应用容器。
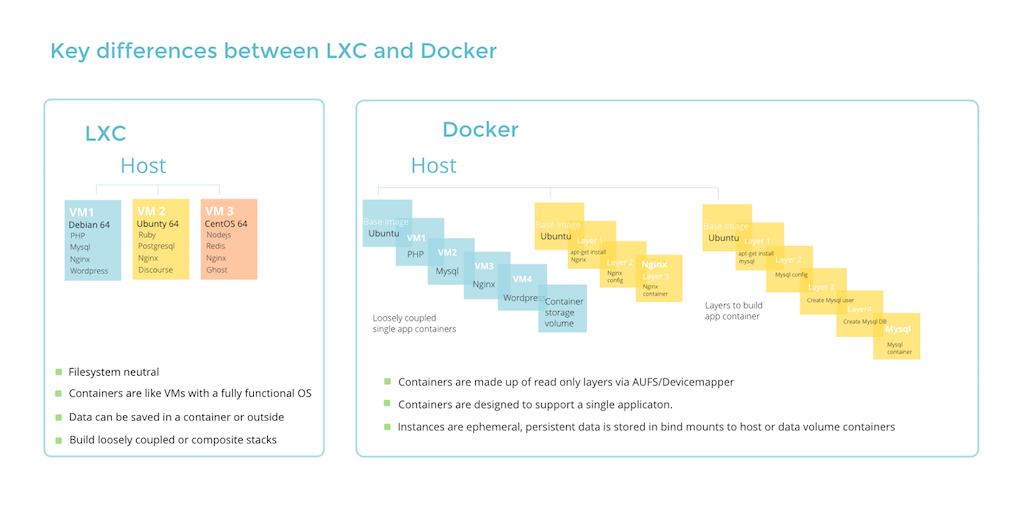
我们可以将之以上面说到的虚拟机作一个简单的对比,其架构图如下所示:
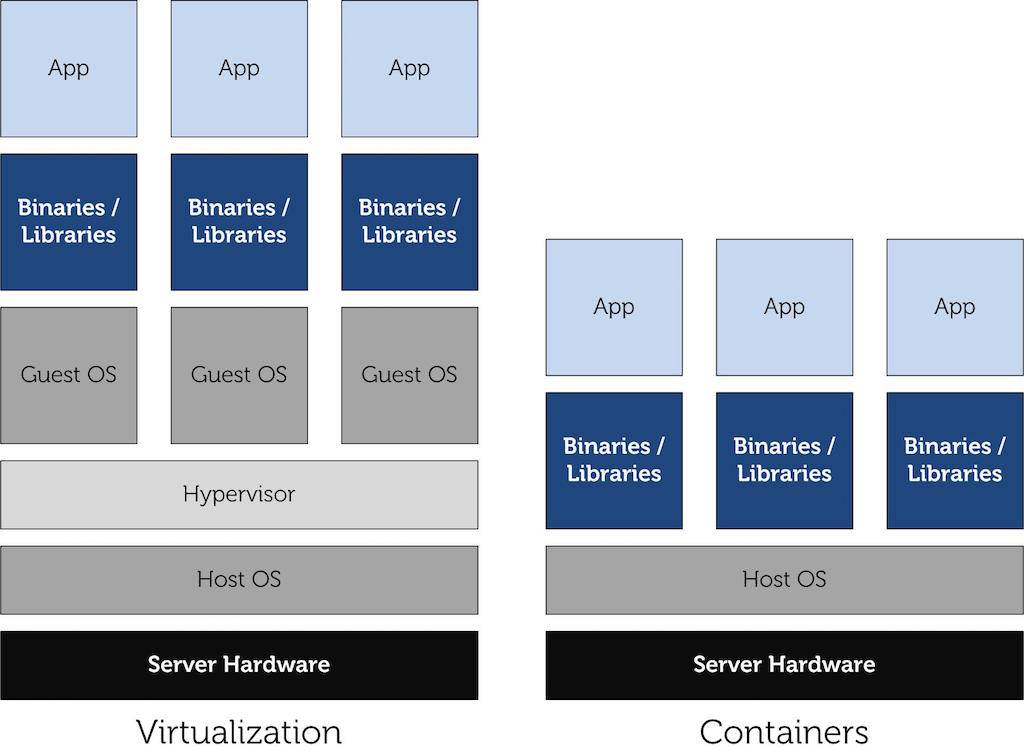
LXC vs VM
我们会发现虚拟机中多了一层 Hypervisor——运行在物理服务器和操作系统之间,它可以让多个操作系统和应用共享一套基础物理硬件。这一层级可以协调访问服务器上的所有物理设备和虚拟机,然而由于这一层级的存在,它也将消耗更多的能量。据爱立信研究院和阿尔托大学发表的论文表示:Docker、LXC 与 Xen、KVM 在完成相同的工作时要少消耗10%的能耗。
LXC 主要是利用 cgroups 与 namespace 的功能,来向提供应用软件一个独立的操作系统运行环境。cgroups(即Control Groups)是 Linux 内核提供的一种可以限制、记录、隔离进程组所使用的物理资源的机制。而由 namespace 来责任隔离控制。
与虚拟机相比,LXC 隔离性方面有所不足,这就意味着在实现可移植部署会遇到一些困难。这时候,我们就需要 Docker 来提供一个抽象层,并提供一个管理机制。
#### Docker
> Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。Docker 可以自动化打包和部署任何应用、创建一个轻量级私有 PaaS 云、搭建开发测试环境、部署可扩展的 Web 应用等。
构建出 Docker 的 Container 是一个很有意思的过程。在这一个过程中,首先我们需要一个 base images,这个基础镜像不仅包含了一个基础系统,如 Ubuntu、Debian。他还包含了一系列的模块,如初始化进程、SSH 服务、syslog-ng 等等的一些工具。由上面原内容构建了一个基础镜像,随后的修改都将于这个镜像,我们可以用它生成新的镜像,一层层的往上叠加。而用户的进程运行在 writeable 的 layer 中。
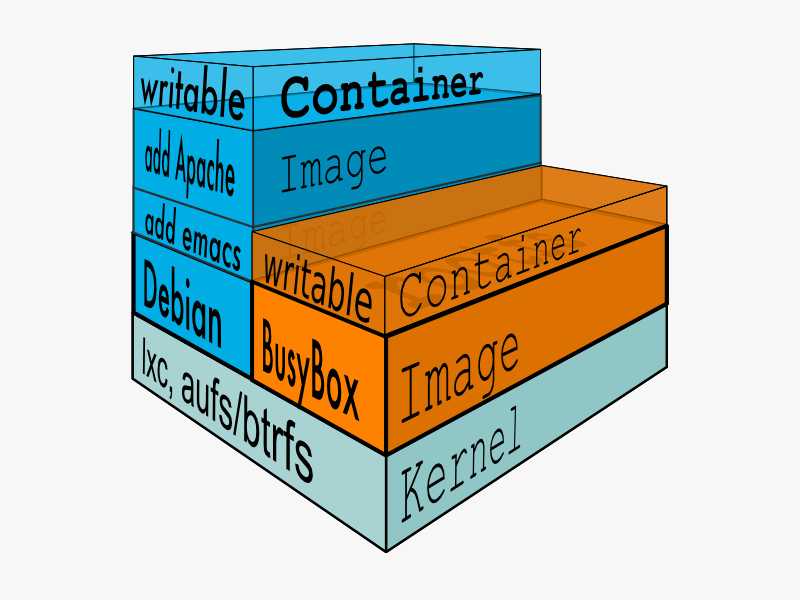
Docker Container
从上图中我们还可以发现一点: Docker 容器是建立在 Aufs 基础上的。AUFS 是一种 Union File System,它可以把不同的目录挂载到同一个虚拟文件系统下。它的目的就是为了实现上图的增量递增的过程,同时又不会影响原有的目录。即如下的流程如下:
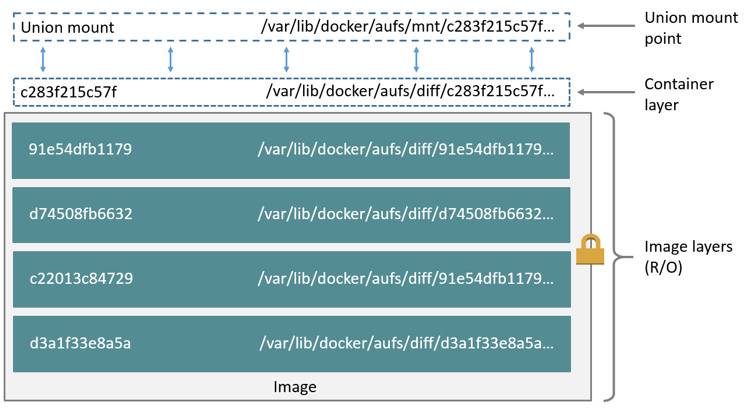
AUFS 层
其增量的过程和我们使用 Git 的过程中有点像,除了在最开始的时候会有一个镜像层。随后我们的修改都可以保存下来,并且当下次我们提交修改的时候,我们也可以在旧有的提交上运行。
因此,Docker 与 LXC 的差距就如下如图所示:
LXC 与 Docker
LXC 时每个虚拟机只能是一个虚拟机,而 Docker 则是一系列的虚拟机。
### 隔离底层:Servlet 容器
在上面的例子里我们已经隔离开了操作系统的因素,接着我们还需要解决操作系统、开发环境引起的差异。早期开发 Web 应用时,人们使用 CGI 技术,它可以让一个客户端,从网页浏览器向执行在网络服务器上的程序请求数据。并且 CGI 程序可以用任何脚本语言或者是完全独立编程语言实现,只要这个语言可以在这个系统上运行。而这样的脚本语言在多数情况下是依赖于系统环境的,特别是针对于 C++ 这一类的编译语言来说,在不同的操作系统中都需要重新编译。
而 Java 的 Servlet 则是另外一种有趣的存在,它是一种**独立于平台和协议**的服务器端的 Java 应用程序,可以生成动态的 Web 页面。
#### Tomcat
在开发 Java Web 应用的过程中,我们在开发环境使用 Jetty 来运行我们的服务,而在生产环境使用 Tomcat 来运行。他们都是 Servlet 容器,可以在其上面运行着同一个 Servlet 应用。Servlet 是指由 Java 编写的服务器端程序,它们是为响应 Web 应用程序上下文中的 HTTP 请求而设计的。它是应用服务器中位于组件和平台之间的接口集合。
Tomcat 服务器是一个免费的开放源代码的 Web 应用服务器。它运行时占用的系统资源小,扩展性好,支持负载平衡与邮件服务等开发应用系统常用的功能。除此,它还是一个 Servlet 和 JSP 容器,独立的 Servlet 容器是 Tomcat 的默认模式。其架构如下图所示:
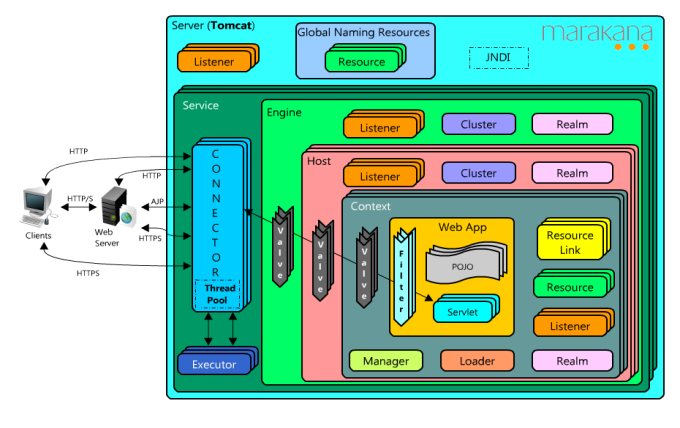
Tomcat架构
Servlet 被部署在应用服务器中,并由容器来控制其生命周期。在运行时由 Web 服务器软件处理一般请求,并把 Servlet 调用传递给“容器”来处理。并且 Tomcat 也会负责对一些静态资源的处理。
### 隔离依赖版本:虚拟环境
对于 Java 这一类的编译语言来说,不存在太多语言运行带来的问题。而对于动态语言来说就存在这样的问题,如 Ruby、Python、Node.js 等等,这一个问题主要集中于开发环境。当然如果你在一个服务器上运行着几个不同的应用来说,也会存在这样的问题。这一类的工具在 Python 里有 VirtualEnv,在 Ruby 里有 RVM、Rbenv,在 Node.js 里有 NVM。
下图是使用 VirtualEnv 时的不同几个应用的架构图:
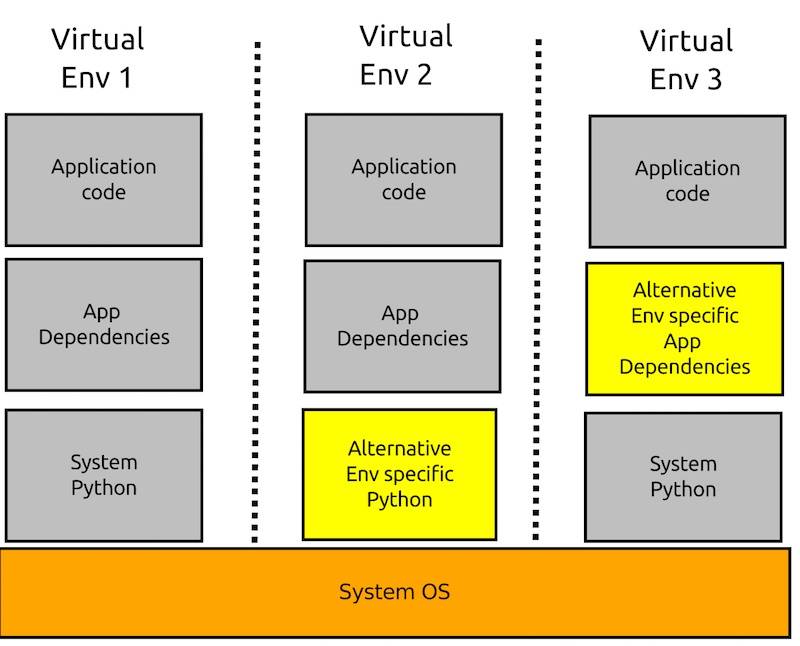
VirtualEnv
如下所示,在不同的虚拟环境里,我们可以使用不同的依赖库。在这上面构建不同的应用,也可以使用不同的 Python 版本来构建系统。通常来说,这一类的工具主要用于本地的开发环境。
### 隔离运行环境:语言虚拟机
最后一个要介绍的可能就是更加抽象的,但是也是更加实用的一个,JVM 就是这方面的一个代表。在我们的编程生涯里,我们很容易就会遇到跨平台问题——即我们在我们的开发机器上开发的软件,在我们的产品环境的机器上就没有办法运行。特别是当我们使用 Mac OS 或者 Windows 机器上开发了我们的应用,然后我们需要在 Linux 系统上运行,就会遇到各种问题。并且当我们使用了一个需要重新编译的库时,这种问题就更加麻烦。
如下图所示的是 JVM 的架构示意图
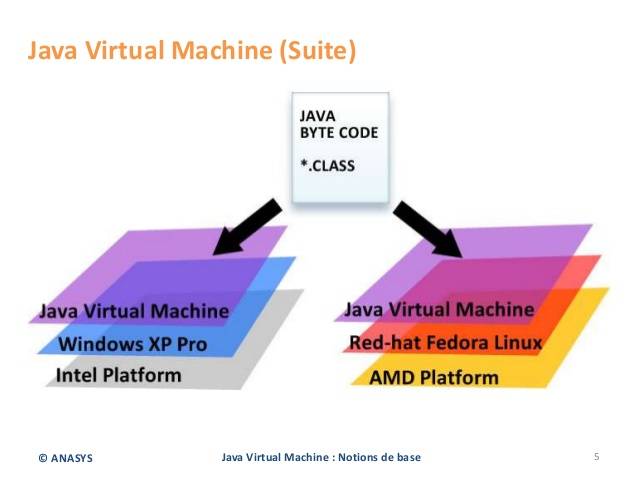
JVM
JVM 是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。它可以实现“编写一次,到处运行”。
换句话来说,它在底层实现了环境隔离,它屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 Java 虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。
基于此,只要其他编程语言的编译器能生成正确 Java bytecode 文件,这个语言也能实现在 JVM 上运行。如下图所示的是基于 JVM 的 Jython 语言的架构图:

Jython
其底层是基于 JVM,而编写时则是用 Python 语言,并且他可以使用 Java 的模块来编程。
常见拥有同样架构的工具,还有 MySQL,如下图是所示的是 MySQL 的架构图:
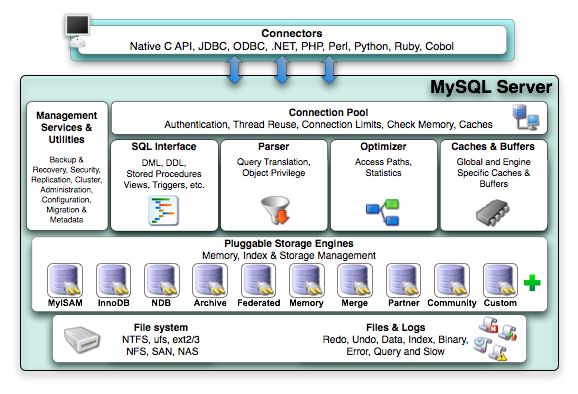
MySQL
MySQL 在最顶层提供了一个名为 SQL 的查询语言,这个查询语言只能用于查询数据库,然而它却是一种更高级的用法。它不像通用目的语言那样目标范围涵盖一切软件问题,而是专门针对某一特定问题的计算机语言,即领域特定语言。
### 隔离语言:DSL
这是一门特别有意思也特别值得期待的技术,但是实现它并不是一件容易的事。
作为讨论隔离环境的一部分,我们只看外部 DSL。内部 DSL 与外部 DSL 最大的区别在于:外部 DSL 近似于创建了一种新的语法和语义的全新语言。如下图所示是两中 DSL 的一种对比:
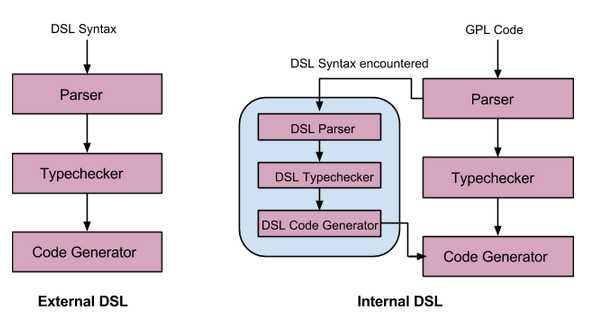
内部 DSL 和外部 DSL
在这样的外部 DSL 里,我们有自己的语法、自己的解析器、类型检测器等等。最简单且最常用的 DSL 就是 Markdown,如下图所示:
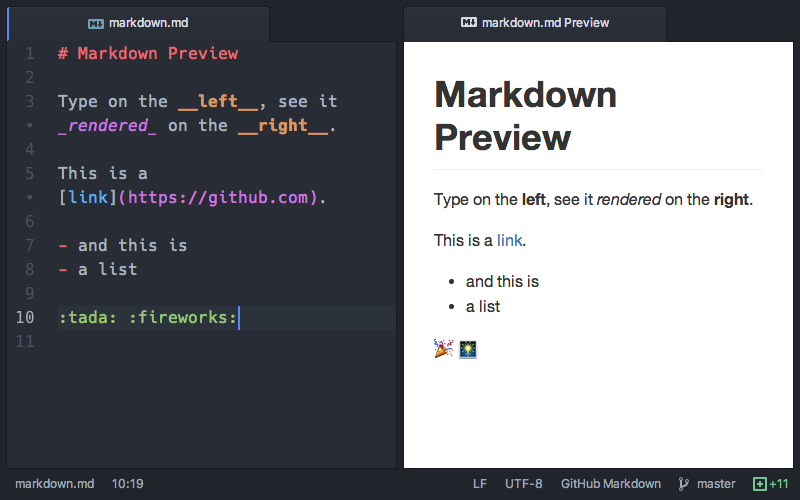
Markdown
如果我们可以将我们的业务逻辑写成 DSL,那么我们就不需要担心底层语言的变动过多地影响原有的业务逻辑。换句话说,这相当于创建了我们自己的语言隔离环境,我们不需要思考用何种语言来实用我们的业务。
## LNMP 架构
> LNMP 是一个基于 CentOS/Debian 编写的 Nginx、PHP、MySQL、phpMyAdmin、eAccelerator 一键安装包。可以在 VPS、独立主机上轻松的安装 LNMP 生产环境。
由于在前面我们已经介绍过了数据库和编程语言,这里我们就只介绍 LN 两项
### GNU/Linux
GNU 工程创始于一九八四年,旨在开发一个完整 GNU 系统。GNU这个名字是“GNU’s Not Unix!”的递归首字母缩写词。“GNU” 的发音为 g’noo,只有一个音节,发音很像 “grew”,但需要把其中的 r 音替换为 n 音。类 Unix 操作系统是由一系列应用程序、系统库和开发工具构成的 软件集合 , 并加上用于资源分配和硬件管理的内核。
Linux 是一种自由和开放源码的类 UNIX 操作系统内核。目前存在着许多不同的 Linux 发行版,可安装在各种各样的电脑硬件设备,从手机、平板电脑、路由器和影音游戏控制台,到桌上型电脑,大型电脑和超级电脑。Linux 是一个领先的操作系统内核,**世界上运算最快的10台超级电脑运行的都是基于 Linux 内核的操作系统**。
Linux 操作系统也是自由软件和开放源代码发展中最著名的例子。只要遵循 GNU 通用公共许可证,任何人和机构都可以自由地使用 Linux 的所有底层源代码,也可以自由地修改和再发布。**严格来讲,Linux 这个词本身只表示 Linux 内核,但在实际上人们已经习惯了用 Linux 来形容整个基于 Linux 内核,并且使用 GNU 工程各种工具和数据库的操作系统(也被称为 GNU/Linux)**。通常情况下,Linux 被打包成供桌上型电脑和服务器使用的 Linux 发行版本。一些流行的主流 Linux 发行版本,包括 Debian(及其衍生版本 Ubuntu),Fedora 和 openSUSE 等。 Linux 得名于电脑业余爱好者 Linus Torvalds。
### HTTP 服务器
> Web 服务器一般指网站服务器,是指驻留于因特网上某种类型计算机的程序,可以向浏览器等 Web 客户端提供文档,也可以放置网站文件,让全世界浏览;可以放置数据文件,让全世界下载。
目前最主流的三个 Web 服务器是 Apache、Nginx、IIS。
#### Apache
Apache 是世界使用排名第一的 Web 服务器软件。它可以运行在几乎所有广泛使用的计算机平台上,由于其跨平台和安全性被广泛使用,是最流行的Web 服务器端软件之一。它快速、可靠并且可通过简单的 API 扩充,将 Perl/Python 等解释器编译到服务器中。
#### Nginx
Nginx 是一款轻量级的 Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,并在一个 BSD-like 协议下发行。由俄罗斯的程序设计师 Igor Sysoev 所开发,供俄国大型的入口网站及搜索引擎 Rambler(俄文:Рамблер)使用。其特点是占有内存少,并发能力强,事实上 Nginx 的并发能力确实在同类型的网页服务器中表现较好,中国大陆使用 Nginx 网站用户有:百度、新浪、网易、腾讯等。
#### IIS
Internet Information Services(IIS,互联网信息服务),是由微软公司提供的基于运行 Microsoft Windows 的互联网基本服务。最初是Windows NT 版本的可选包,随后内置在 Windows 2000、Windows XP Professional 和 Windows Server 2003 一起发行,但在 Windows XP Home 版本上并没有 IIS。
#### 代理服务器
> 代理服务器(Proxy Server)是一种重要的服务器安全功能,它的工作主要在开放系统互联(OSI)模型的会话层,从而起到防火墙的作用。代理服务器大多被用来连接 INTERNET(国际互联网)和 Local Area Network(局域网)。
## Web 缓存
Web 缓存是显著提高 Web 站点的性能最有效的方法之一。主要有:
* 数据库端缓存
* 应用层缓存
* 前端缓存
* 客户端缓存
不同的缓存类型适用于不同的环境下使用。
### 数据库端缓存
这个可以用以“空间换时间”来说。比如建一个表来存储另外一个表某个类型的数据的总条数,在每次更新数据的时候同时更新数据表和统计条数的表。在需要获取某个类型的数据的条数的时候,就不需要 select count 去查询,直接查询统计表就可以了,这样可以提高查询的速度和数据库的性能。
### 应用层缓存
应用层缓存这块跟开发人员关系最大,也是平时经常接触的。
* 缓存数据库的查询结果,减少数据的压力。这个在大型网站是必须做的。
* 缓存磁盘文件的数据。比如常用的数据可以放到内存,不用每次都去读取磁盘,特别是密集计算的程序,比如中文分词的词库。
* 缓存某个耗时的计算操作,比如数据统计。
应用层缓存的架构也可以分几种:
* 嵌入式,也就是缓存和应用在同一个机器。比如单机的文件缓存,java 中用 hashMap 来缓存数据等等。这种缓存速度快,没有网络消耗。
* 分布式缓存,把缓存的数据独立到不同的机器,通过网络来请求数据,比如常用的 memcache 就是这一类。
分布式缓存一般可以分为几种:
* 按应用切分数据到不同的缓存服务器,这是一种比较简单和实用的方式。
* 按照某种规则(hash,路由等等)把数据存储到不同的缓存服务器
* 代理模式,应用在获取数据的时候都由代理透明的处理,缓存机制有代理服务器来处理
### 前端缓存
我们这里说的前端缓存可以理解为一般使用的 cdn 技术,利用 squid 等做前端缓冲技术,主要还是针对静态文件类型,比如图片、css、js、html 等静态文件。
### 客户端缓存
浏览器端的缓存,可以让用户请求一次之后,下一次不在从服务器端请求数据,直接从本地缓存读取,可以减轻服务器负担也可以加快用户的访问速度。
### HTML5 离线缓存
application cahce 是将大部分图片资源、js、css 等静态资源放在 manifest 文件配置中。当页面打开时通过 manifest 文件来读取本地文件或是请求服务器文件。
离线访问对基于网络的应用而言越来越重要。虽然所有浏览器都有缓存机制,但它们并不可靠,也不一定总能起到预期的作用。HTML5 使用 ApplicationCache 接口可以解决由离线带来的部分难题。前提是你需要访问的 Web 页面至少被在线访问过一次。
## 可配置
让我们写的 Web 应用可配置是一项很有挑战性,也很实用的技能。
起先,我们在本地开发的时候为本地创建了一套环境,也创建了本地的配置。接着我们需要将我们的包部署到测试环境,也生成了测试环境的相应配置。这其中如果有其他的环境,我们也需要创建相应的环境。最后,我们还需要为产品环境创建全新的配置。
下图是 Druapl 框架的部署流:

Drupal Deployment Flow
在不同的环境下,他们使用不同的 Content。这些 Content 的内容不仅仅可以是一些系统相当的配置,也可以是一些不同环境下的 UI 等等。而在这其中也会涉及到一些比较复杂的知识,下面只是做一些简单的介绍。
### 环境配置
最常见的例子就是我们需要在不同的环境有不同的配置。大原则就是我们不能直接使用产品的环境测试,因此我们就需要为不同的环境配置不同的数据库:
* 开发环境。即开发者用于开发的环境,大部分的数据都是由我们自己注入的,在开发的过程中我们也会添加一些数据。
* 集成测试环境/测试环境。和开发环境一样,这些数据也是由我们注入的,而这些数据主要是为于测试目的。当我们的应用出现Bug的时候,我们可能就需要添加新的测试及其测试数据。
* 模拟环境(Stageing)。在软件最终发布前,开发或者设计人员对软件进行调整后可以及时预览改变的测试环境,这个环境更接近于产品最终发布后的运行环境。因此,这个环境的数据一般来说就是产品环境的一些旧数据——可能是几个月前,几年前的数据。
* 产品环境。即线上环境,都是真实的用户数据。
因此从理论上来说,我们就需要4~5个不同的数据库配置。而这些不同的数据库配置并不代表着他们使用的是相同的数据库。我们可以在本地环境使用 SQLite,而在我们的产品环境使用 MySQL。不过,最好的情况是我们应该使用同一个配置。这样当出现问题的时候,我们也很容易排查、
而除了数据库配置之外,我们还有一些其他配置。因此针对于不同的环境的配置最好独立地写在不同的文件里。并且这些配置最好可以以文件名来区分,如针对于开发环境,就是`dev.config.js`,针对于测试环境就是 `test.config.js`。
因此,为了实现不同的环境使用不同的配置,我们就需要有一个变更控制。如果我们只有相应的配置,而没有对应的运行机制那就有问题了。
### 运行机制
当我们的应用程序在服务器上运行得好好的时候,我们可能就不想因为修改配置而去重启机器,这时候我们就需要配置热加载。即我们修改配置后,不需要重启服务即可以使用新的配置。对应的还有一种,便是我们需要重启机器才能实现配置。
无论是哪种方式都需要修改配置来实现。而在我们使用的过程中热加载可能需要消耗一些系统资源,因为我们的系统需要不断地读取配置的状态并对其进行判断。并且如果我们的应用运行在多个机器上的时候,我们可能需要一个个的上支个性。而如果我们是冷启动的话,我们就可以考虑使用自动部署的方式来完成。
对应的,我们也需要在我们的代码中实现判断这些配置的逻辑。
### 功能开关
当我们上线了我们的新功能的时候,这时候如果有个 Bug,那么我们是下线么?要知道这个版本里面包含了很多的 Bug 修复。如果在这个设计这个新功能的时候,我们有一个可配置和 Toogle,那么我们就不需要下线了。只需要切的这个toggle,就可以解决问题了。
对于有多套环境的开发来说,如果我们针对不同的环境都有不同的配置,那么这个灵活的开发会帮助我们更好的开发。
#### Feature Toggle
它是一种允许控制线上功能开启或者关闭的方式,通常会采取配置文件的方式来控制。其过程如下图所示:
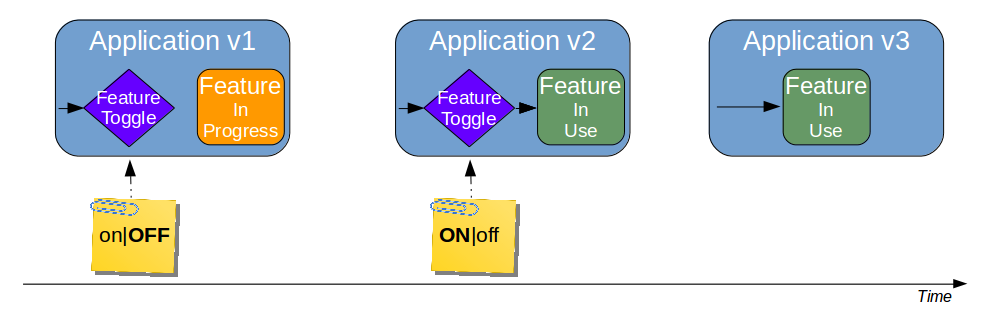
Feature Toggle
当我们需要 A 功能的时候,我们就只需要把 A 功能的开关打开。当我们需要 B 功能,而不需要 A 功能的时候,我们就可以把相应的功能关掉。像在 Java 里的 Spring 框架,就可以用 PropertyPlaceHolder 来做相似的事。使用 bean 文件创建一个 properties
~~~
<util:properties id="myProps" location="WEB-INF/config/prop.properties"/>
~~~
然后向注入这个值:
~~~
@Value("#{myProps['message']}")
~~~
我们就可以直接判断这个值是否是真,从而显示这个内容。
~~~
<spring:eval expression="@myProps.message" var="messageToggle"/>
<c:if test="${messageToggle eq true}">
message
</c:if>
~~~
这是一种很实用,而且很有趣的技术。
参考书籍:**《配置管理最佳实践》**
## 自动化部署
优化我们开发流程有一个很重要的步骤就是:让部署自动化。通过部署自动化,我们可以大大缩减我们的开发周期,加快软件交付流程。下图是一个自动化部署的流程图:
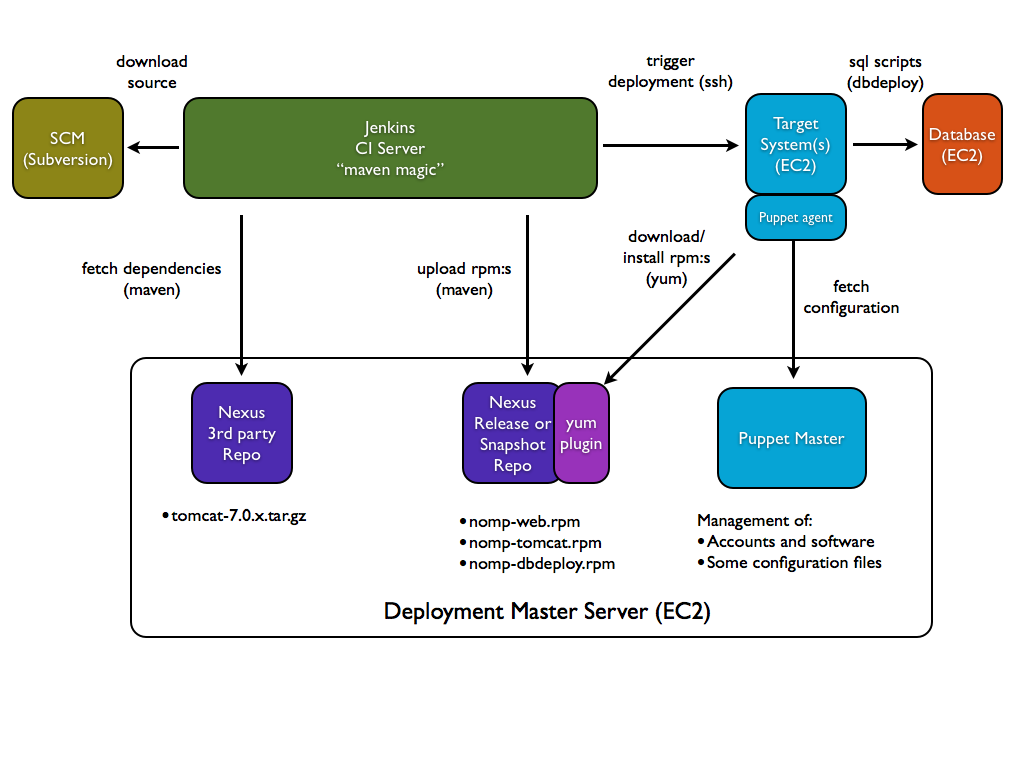
自动化部署
从下图中我们可以得到下面的五个步骤:
* 获取源码
* 获取依赖
* 构建软件包
* 生成/上传安装包
* 目标平台安装/配置
这个过程可能和之前的 Web 项目构建过程差不多,然而却多了好几步。
在前面的章节里,我们已经使用了版本管理系统来管理我们的源码。因此,在这里对于获取源码的介绍就比较简单了——我们只需要在我们的 CI(持续集成)服务器上使用 `git clone` 这一类的方法来获取我们的源码即可。
### 依赖与包仓库
获取完源码后,我们就需要开始下载软件包依赖。无论是 Python、Ruby、Java,还是 JavaScript 都需要这样的一个过程。软件开发已经从大教堂式的开发走向了集市——开源软件改变了这一切。

大教堂与集市
过去我们需要大系统的内部构建我们使用的依赖,现在我们更多地借助于外部的库来实现这些功能。这也意味着,如果在这一个节点里出现了意外——软件被删除,那么这个系统将陷入瘫痪的状态。如之前在 NPM 圈发生了“一个 17 行的模块引发的血案”——即 left-pad 工具模块被作者从 NPM 上撤下,所有直接或者间接依赖这个模块的 NPM 的软件包都挂掉了。因为我们依赖于公有的包服务,所以系统便严重依赖于外部条件。
这时候一种简单、有效的方案就是搭建自己的包服务。如使用 Java 技术栈的项目,就会使用 Nexus 搭建自己的 Maven 私有服务。我们的软件依赖包将会依赖于我们自己的服务,此时会产生的主要问题可能就是:我们的软件包不是最新的。但是对于追求稳定的项目来说,这个并不是必须的需求,反而这也是一个优势。
### 构建软件包
在一些编译型语言里,在我们运行包测试后,我们将会得到一个软件包。如 Jar 包,它是 Java 中所特有一种压缩文档。Jar 包无法直接安装使用,虽然我们可以直接运行这个 Jar 包,但是我们需要通过一些手段将这个 Jar 包拷贝到我们的服务器上,然后运行。在特定的时候,我们还需要修改配置才能完成我们的工作。
因此,使用 RPM 或者 DEB 包会是一种更好的选择。RPM 全称是 Red Hat Package Manager(Red Hat包管理器),它工作于 Red Hat Linux 以及其它 Linux 和 UNIX 系统,可被任何人使用。如下图是 RPM 包的构建过程:
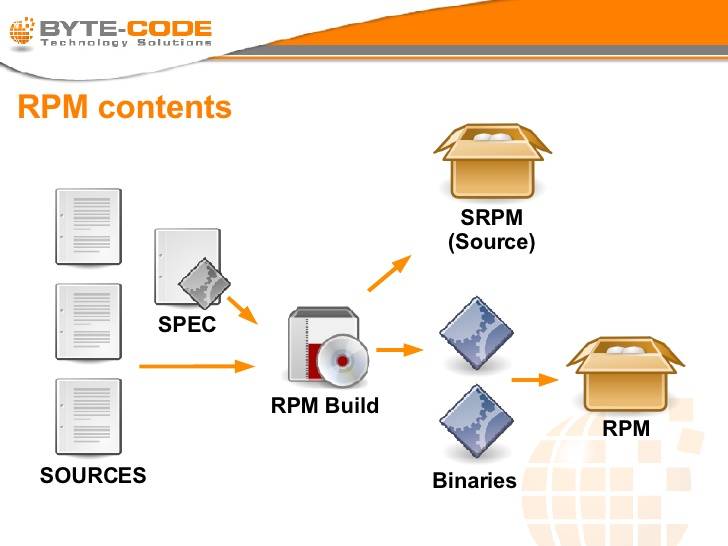
RPM Build Process
要构建一个标准的 RPM 包,我们需要创建 .spec文件,这个文件包含软件打包的全部信息——如包的 Summary、Name、Version、Copyright、Vendor 等等。在产生完这一个配置文件后,执行 rpmbuild 命令,系统会按照步骤生成目标 RPM 包。
### 上传和安装软件包
生成对应的软件包后,我们就可以将其上传到 Koji 上,它是 Fedora 社区的编译系统。如下图所示:
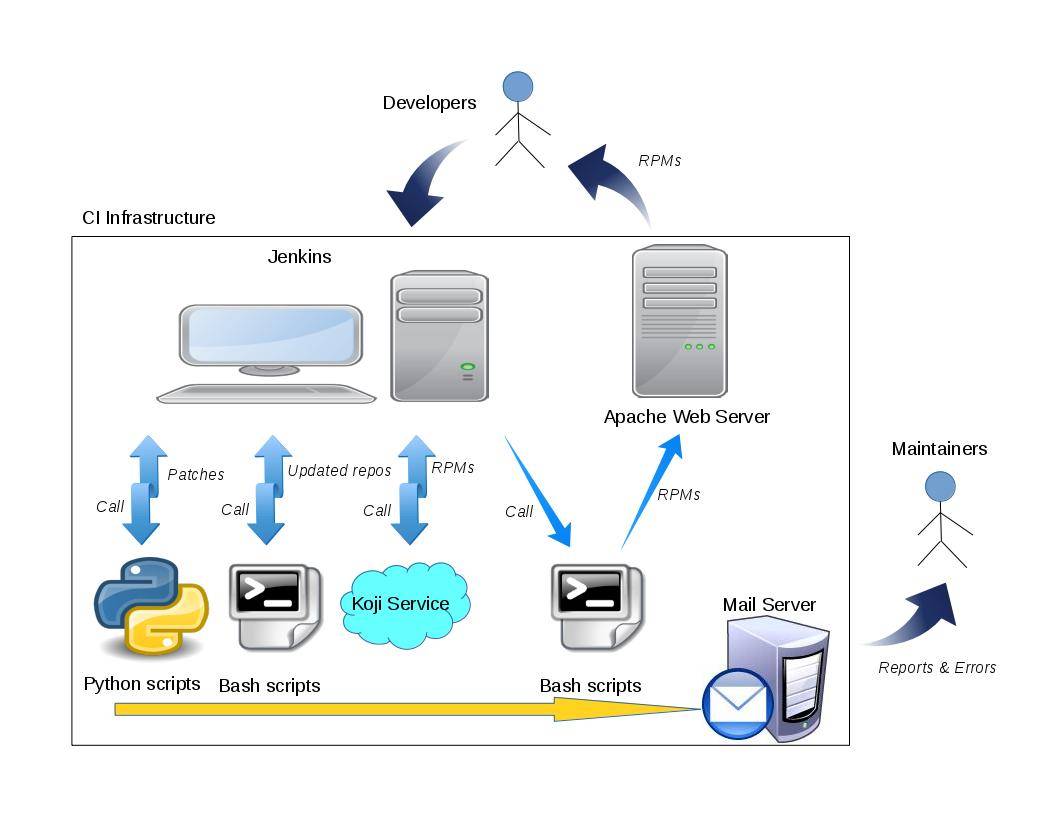
RPM Build Process
如果我们已经对我们的所有目标操作系统配置过,即配置好了软件源,那么我们就可以直接在我们的服务器上使用包管理工具安装,如`yum install`。