14—innodb的旧式记录结构
最后更新于:2022-04-01 16:05:07
在上一篇里,bingxi和alex聊了关于簇页管理。Innodb的记录分为新旧两种格式,在本篇里,bingxi和alex会讨论下innodb的旧式记录结构。
对应的文件为:
D:/mysql-5.1.7-beta/storage/innobase/rem/rem0rec.c
D:/mysql-5.1.7-beta/storage/innobase/include/rem0rec.h
D:/mysql-5.1.7-beta/storage/innobase/include/rem0rec.ic
## 1)innodb旧式结构组成
Bingxi:“alex,mysql存储的最基本的结构是记录。B树的内结点和叶结点都是由记录组成。实际存储的内容如下:
内容1:存放字段偏移量,用于指明字段的偏移量。长度为字段数*1或者字段数*2
内容2:长度为6,存放记录的控制信息。
内容3:存放实际的内容(记录指针指向内容3的开始处)
Alex,你在代码中看下控制信息相关的6个字节的定义。
”
Alex:“好的,我们看下rem0rec.ic的中旧式记录的控制结构的定义。
/* Offsets of the bit-fields in an old-style record. NOTE! In the table the
most significant bytes and bits are written below less significant.
(1) byte offset (2) bit usage within byte
downward from
origin -> 1 8 bits pointer to next record
2 8 bits pointer to next record
3 1 bit short flag
7 bits number of fields
4 3 bits number of fields
5 bits heap number
5 8 bits heap number
6 4 bits n_owned
4 bits info bits
*/
这个定义是从右往左的,如果转化为从左往右,则如下图所示:

因此,我们继续看代码,假设我们已经得到一个记录指针p,那么我们如何获得对应的控制信息。
~~~
/**********************************************************
The following function is used to get the number of fields
in an old-style record. */
UNIV_INLINE
ulint
rec_get_n_fields_old(
/*=================*/
/* out: number of data fields */
rec_t* rec)/* in: physical record */
{
ulintret;
ut_ad(rec);
//在这里设置断点
ret = rec_get_bit_field_2(rec, REC_OLD_N_FIELDS,
REC_OLD_N_FIELDS_MASK, REC_OLD_N_FIELDS_SHIFT);
ut_ad(ret <= REC_MAX_N_FIELDS);
ut_ad(ret > 0);
return(ret);
}
设置断点,可以看到rec在此次终端时的值为0x0119808c,打开内存监控输入该地址。
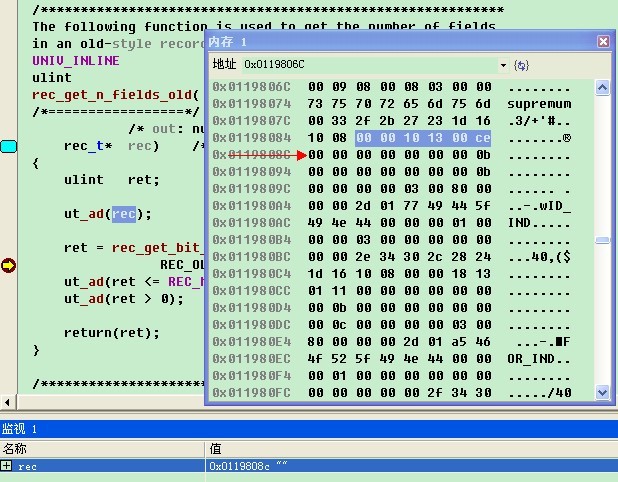
从指针向前数出6个字节,这六个字节是
00 00 10 13 00 ce
根据前面的推算,可以得知如下信息:
4bits info:全为0,也就是表该字段有效
4bits n_owned: 值为0
13bits heap_no: 值为2
10bits n_fiels: 值为9
1bit 1bytes_offs_flag: 值为1,因此1个字节可以表示一个偏移
16bits next 16 bits: 值为0xce
带这这些信息,我们来验证代码,按F11进入rec_get_bit_field_2函数。
/**********************************************************
Gets a bit field from within 2 bytes. */
UNIV_INLINE
ulint
rec_get_bit_field_2(
/*================*/
rec_t* rec, /* in: pointer to record origin */
ulintoffs, /* in: offset from the origin down */
ulintmask, /* in: mask used to filter bits */
ulintshift) /* in: shift right applied after masking */
{
ut_ad(rec);
//在本例中
//rec为0x0119808c
//offs为4
//mask为0x000007fe即,0000 0111 1111 1110
//shift为1
//步骤1:将指针-4,也就是图1中字节3的起始位置,通过与mask的与操作,将与n_fields相关的10个字节“与”出来,将结果右移一位,就得到记录数
return((mach_read_from_2(rec - offs) & mask) >> shift);
}
~~~
继续往下执行,得到返回值9。获取控制信息其他字节的方法类似。
我们接着往下看字段偏移量的类型,在这6个控制信息之前存放的是字段偏移量,也就是相对于记录指针的偏移量。
我们继续进行调试,在rec_1_get_field_start_offs函数设置断点,可以看到rec的值为0x011ac122。
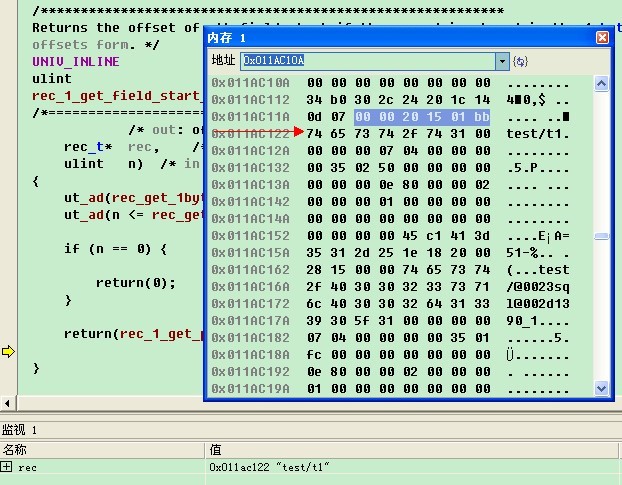
根据控制信息可以知道该记录的字段数为10个。这10个偏移量如下:
34 b0 30 2c 24 20 1c 14 0d 07
这些偏移量是反向存储的,实际上对应的各字段的长度为:
字段0:7
字段1:6 (0d-07=6)
字段2:7 (14-0d=7)
字段3:8 (1c-14=8)
字段4:4 (20-1c=4)
字段5:4 (24-20=4)
字段6:8 (2c-24=8)
字段7:4 (30-2c=4)
字段8::0 (b0的最高位为1,表示该字段为null,b0去掉最高位的0,同样是30)
字段9: 4 (34-30=4)
因此,字段1存储的7是第一个字段的偏移量么?也就是第一个字段开始值是p+7?那么p+0是什么?ok,很明显字段从0开始编码。看下面的代码。
~~~
/**********************************************************
Returns the offset of nth field start if the record is stored in the 1-byte
offsets form. */
UNIV_INLINE
ulint
rec_1_get_field_start_offs(
/*=======================*/
/* out: offset of the start of the field */
rec_t* rec, /* in: record */
ulintn) /* in: field index */
{
ut_ad(rec_get_1byte_offs_flag(rec));
ut_ad(n <= rec_get_n_fields_old(rec));
//步骤1:如果是获得第0个字段的起始地址,那么就是0
if (n == 0) {
return(0);
}
//步骤2:否则调用函数rec_1_get_prev_field_end_info
// rec_1_get_prev_field_end_info的实现为:
// mach_read_from_1(rec - (REC_N_OLD_EXTRA_BYTES + n))
//因此在本例中,假设n为1,则返回7
//假设n为2,则返回13。
return(rec_1_get_prev_field_end_info(rec, n)
& ~REC_1BYTE_SQL_NULL_MASK);
}
~~~
这段代码中出现了宏REC_1BYTE_SQL_NULL_MASK,是因为偏移量的最高为表示是否为null。
当偏移量是1字节时,最高位为0,则是非NULL,为1,则该字段是null。其他的7bit用于表示偏移量,因此可以表示的最大偏移量为127。
当偏移量为2字节时,最高位为0,则是非null,为1,则该字段是null,次最高位用于表示是否字段存储在同一页。
经过重组,本例的记录进行梳理如下:
34 b0 30 2c 24 20 1c 14 0d 07
00 00 20 15 01 bb //6个字节的控制信息
74 65 73 74 2f 74 31 //test/t1 字段0:7字节
00 00 00 00 07 04 //字段1:6字节
00 00 00 00 35 02 50 //字段2:7字节
00 00 00 00 00 00 00 0e //字段3:8字节
80 00 00 02 //字段4:4字节
00 00 00 01 //字段5:4字节
00 00 00 00 //字段6:8字节
00 00 00 00 00 00 00 00 //字段7:4字节
//字段8:null
00 00 00 00 //字段9:4字节
建议将文件中的旧式记录的函数都阅读下。Bingxi,你知道旧式记录用于什么地方么?而新式的又用在什么地方?
”
Bingxi:“默认情况下,5.1.7版本中,数据字典使用还是旧式记录,而用户自己创建的innodb表使用的是新式存储结构。在下一篇里,我们聊下新式记录格式。”
Alex:“ok”