第二十一章 基于prometheus自定指标HPA弹性伸缩
最后更新于:2022-04-02 05:07:25
# HPA 自定义监控指标弹性伸缩
## 架构图

## 使用helm 在CCE 部署rabbitmq-exporter
安装helm
```
wget https://get.helm.sh/helm-v3.3.4-linux-amd64.tar.gz
tart -zxvf helm-v3.3.4-linux-amd64.tar.gz
mv linux-amd64/helm /usr/local/bin/helm
helm version
WARNING: Kubernetes configuration file is group-readable. This is insecure. Location: /root/.kube/config
WARNING: Kubernetes configuration file is world-readable. This is insecure. Location: /root/.kube/config
version.BuildInfo{Version:"v3.3.4", GitCommit:"a61ce5633af99708171414353ed49547cf05013d", GitTreeState:"clean", GoVersion:"go1.14.9"}
You have new mail in /var/spool/mail/root
```
部署rabbitmq-exporter
```
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install prom-rabbit prometheus-community/prometheus-rabbitmq-exporter --set "rabbitmq.url=http://rabbitserver:15672" --set "rabbitmq.user=XXXt" --set "rabbitmq.password=XXXXX" --namespace=monitoring
```
验证部署是否成功
```
kubectl get pod,svc -n monitoring
```

编辑prometheus configmap ,添加 job_name ,rabbitmq-exporter 监控指标存入prometheus。注意target 为上图rabbitmq-exporter service 服务地址。
```
kind: ConfigMap
apiVersion: v1
metadata:
name: prometheus
namespace: monitoring
selfLink: /api/v1/namespaces/monitoring/configmaps/prometheus
uid: 036a2fbf-3718-4372-a138-672c62898048
resourceVersion: '3126060'
creationTimestamp: '2021-08-26T02:58:45Z'
labels:
app: prometheus
chart: prometheus-2.21.11
component: server
heritage: Tiller
release: cceaddon-prometheus
annotations:
description: ''
managedFields:
- manager: Go-http-client
operation: Update
apiVersion: v1
time: '2021-08-28T02:53:49Z'
fieldsType: FieldsV1
fieldsV1:
'f:data':
.: {}
'f:prometheus.yml': {}
'f:metadata':
'f:annotations':
.: {}
'f:description': {}
'f:labels':
.: {}
'f:app': {}
'f:chart': {}
'f:component': {}
'f:heritage': {}
'f:release': {}
data:
prometheus.yml: |-
global:
evaluation_interval: 1m
scrape_interval: 15s
scrape_timeout: 10s
alerting:
alertmanagers:
- scheme: https
tls_config:
insecure_skip_verify: true
static_configs:
- targets:
-
alert_relabel_configs:
- source_labels: [kubernetes_pod]
action: replace
target_label: pod
regex: (.+)
- source_labels: [pod_name]
action: replace
target_label: pod
regex: (.+)
rule_files:
- /etc/prometheus/rules/*/*.yaml
scrape_configs:
- bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
job_name: kubernetes-cadvisor
kubernetes_sd_configs:
- role: node
relabel_configs:
- replacement: kubernetes.default.svc:443
target_label: __address__
- regex: (.+)
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
source_labels:
- __meta_kubernetes_node_name
target_label: __metrics_path__
- target_label: cluster
replacement: f4486e8b-00dc-11ec-a6bf-0255ac1000cf
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
- job_name: kubernetes-nodes
kubernetes_sd_configs:
- role: node
relabel_configs:
- regex: (.+)
replacement: $1:9100
source_labels:
- __meta_kubernetes_node_name
target_label: __address__
- target_label: cluster
replacement: f4486e8b-00dc-11ec-a6bf-0255ac1000cf
- target_label: node
source_labels: [instance]
- job_name: kubernetes-service-endpoints
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- target_label: cluster
replacement: f4486e8b-00dc-11ec-a6bf-0255ac1000cf
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_service
- honor_labels: false
job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
- target_label: cluster
replacement: f4486e8b-00dc-11ec-a6bf-0255ac1000cf
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: drop
regex: cceaddon-prometheus-node-exporter-(.+)
source_labels:
- __meta_kubernetes_pod_name
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scheme
target_label: __scheme__
metric_relabel_configs:
- source_labels: [ __name__ ]
regex: 'kube_node_labels'
action: drop
tls_config:
insecure_skip_verify: true
- job_name: 'istio-mesh'
metrics_path: /stats/prometheus
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_container_port_name]
action: keep
regex: http-envoy-prom
metric_relabel_configs:
- target_label: cluster
replacement: f4486e8b-00dc-11ec-a6bf-0255ac1000cf
- source_labels: [__name__]
action: keep
regex: istio.*
- job_name: 'rabbitmq-exporter'
static_configs:
- targets: ['prom-rabbit-exporter-prometheus-rabbitmq-exporter:9419']
metric_relabel_configs:
- target_label: namespace
replacement: default
```
使用prometheus 控制平台验证 target :rabbitmq-exporter 部署是否成功

验证rabbitmq_queue_messages 消息队列数值

## 构建自定义metric
### 修改 adapter-config,自定查询规则。新增字段
> externalRules
```
kind: ConfigMap
apiVersion: v1
metadata:
name: adapter-config
namespace: monitoring
selfLink: /api/v1/namespaces/monitoring/configmaps/adapter-config
uid: 9b559a81-b0f0-483f-ab4a-65df6073efcd
resourceVersion: '3131912'
creationTimestamp: '2021-08-26T02:58:45Z'
labels:
release: cceaddon-prometheus
managedFields:
- manager: Go-http-client
operation: Update
apiVersion: v1
time: '2021-08-26T02:58:45Z'
fieldsType: FieldsV1
fieldsV1:
'f:data':
.: {}
'f:config.yaml': {}
'f:metadata':
'f:labels':
.: {}
'f:release': {}
data:
config.yaml: |-
rules:
- seriesQuery: '{__name__=~"^container_.*",container_name!="POD",namespace!="",pod_name!=""}'
seriesFilters: []
resources:
overrides:
namespace:
resource: namespace
pod_name:
resource: pod
name:
matches: ^container_(.*)_seconds_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>,container_name!="POD"}[1m])) by (<<.GroupBy>>)
- seriesQuery: '{__name__=~"^container_.*",container_name!="POD",namespace!="",pod_name!=""}'
seriesFilters:
- isNot: ^container_.*_seconds_total$
resources:
overrides:
namespace:
resource: namespace
pod_name:
resource: pod
name:
matches: ^container_(.*)_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>,container_name!="POD"}[1m])) by (<<.GroupBy>>)
- seriesQuery: '{__name__=~"^container_.*",container_name!="POD",namespace!="",pod_name!=""}'
seriesFilters:
- isNot: ^container_.*_total$
resources:
overrides:
namespace:
resource: namespace
pod_name:
resource: pod
name:
matches: ^container_(.*)$
as: ""
metricsQuery: sum(<<.Series>>{<<.LabelMatchers>>,container_name!="POD"}) by (<<.GroupBy>>)
- seriesQuery: '{namespace!="",__name__!~"^container_.*"}'
seriesFilters:
- isNot: .*_total$
resources:
template: <<.Resource>>
name:
matches: ""
as: ""
metricsQuery: sum(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>)
- seriesQuery: '{namespace!="",__name__!~"^container_.*"}'
seriesFilters:
- isNot: .*_seconds_total
resources:
template: <<.Resource>>
name:
matches: ^(.*)_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
- seriesQuery: '{namespace!="",__name__!~"^container_.*"}'
seriesFilters: []
resources:
template: <<.Resource>>
name:
matches: ^(.*)_seconds_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
- seriesQuery: '{kubernetes_namespace!="",__name__!~"^container_.*"}'
seriesFilters:
- isNot: .*_total$
resources:
overrides:
kubernetes_namespace:
resource: namespace
kubernetes_pod:
resource: pod
name:
matches: ""
as: ""
metricsQuery: sum(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>)
- seriesQuery: '{kubernetes_namespace!="",__name__!~"^container_.*"}'
seriesFilters:
- isNot: .*_seconds_total
resources:
overrides:
kubernetes_namespace:
resource: namespace
kubernetes_pod:
resource: pod
name:
matches: ^(.*)_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
- seriesQuery: '{kubernetes_namespace!="",kubernetes_service!=""}'
seriesFilters:
- isNot: .*_seconds_total
resources:
overrides:
kubernetes_namespace:
resource: namespace
kubernetes_service:
resource: service
name:
matches: ^(.*)_total$
as: ""
metricsQuery: (avg(sum(rate(<<.Series>>{}[5m])) by (kubernetes_service, instance)) by (kubernetes_service))
- seriesQuery: '{kubernetes_namespace!="",__name__!~"^container_.*"}'
seriesFilters: []
resources:
overrides:
kubernetes_namespace:
resource: namespace
kubernetes_pod:
resource: pod
name:
matches: ^(.*)_seconds_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
resourceRules:
cpu:
containerQuery: sum(rate(container_cpu_usage_seconds_total{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)
nodeQuery: sum(rate(container_cpu_usage_seconds_total{<<.LabelMatchers>>, id='/'}[1m])) by (<<.GroupBy>>)
resources:
overrides:
instance:
resource: node
namespace:
resource: namespace
pod_name:
resource: pod
containerLabel: container_name
memory:
containerQuery: sum(container_memory_working_set_bytes{<<.LabelMatchers>>}) by (<<.GroupBy>>)
nodeQuery: sum(container_memory_working_set_bytes{<<.LabelMatchers>>,id='/'}) by (<<.GroupBy>>)
resources:
overrides:
instance:
resource: node
namespace:
resource: namespace
pod_name:
resource: pod
containerLabel: container_name
window: 1m
externalRules:
- seriesQuery: '{__name__=~"^rabbitmq_.*",queue="input.service.run_intelligent_classification"}'
resources:
template: <<.Resource>>
name:
matches: ""
as: ""
metricsQuery: 'max(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>)'
```
自定义custom-metrics-apiserver k8s apiserver ,创建k8s-api.yml
```
apiVersion: apiregistration.k8s.io/v1beta1
kind: APIService
metadata:
name: v1beta1.external.metrics.k8s.io
spec:
service:
name: custom-metrics-apiserver
namespace: monitoring
group: external.metrics.k8s.io
version: v1beta1
insecureSkipTLSVerify: true
groupPriorityMinimum: 100
versionPriority: 100
```
验证rabbitmq_queue_messages 指标, 是否能从metric-server 查询。
```
# kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/default/rabbitmq_queue_messages"
{"kind":"ExternalMetricValueList","apiVersion":"external.metrics.k8s.io/v1beta1","metadata":{"selfLink":"/apis/external.metrics.k8s.io/v1beta1/namespaces/default/rabbitmq_queue_messages"},"items":[{"metricName":"rabbitmq_queue_messages","metricLabels":{},"timestamp":"2021-08-28T10:37:16Z","value":"32847"}]}
```
编辑hpa-controller-custom-metrics clusterrolebinding权限,修改namespace
```
kubectl edit clusterrolebinding -oyaml hpa-controller-custom-metrics
```
```
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
creationTimestamp: "2021-08-26T02:58:45Z"
labels:
release: cceaddon-prometheus
name: hpa-controller-custom-metrics
resourceVersion: "3147794"
selfLink: /apis/rbac.authorization.k8s.io/v1/clusterrolebindings/hpa-controller-custom-metrics
uid: d7ab1332-e54f-42ad-bb51-0b0c5db4f386
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: custom-metrics-server-resources
subjects:
- kind: ServiceAccount
name: horizontal-pod-autoscaler
namespace: kube-system # monitering修改为kube-system
```
编辑 custom-metrics-server-resources ,clusterrole 新增apiGroups : external.metrics.k8s.io
```
kubectl edit clusterrole custom-metrics-server-resources
```
```
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
creationTimestamp: "2021-08-26T02:58:45Z"
labels:
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
release: cceaddon-prometheus
name: custom-metrics-server-resources
resourceVersion: "3140104"
selfLink: /apis/rbac.authorization.k8s.io/v1/clusterroles/custom-metrics-server-resources
uid: 5fb1a3d6-6da2-4197-a039-55f7770cca3e
rules:
- apiGroups:
- custom.metrics.k8s.io
- external.metrics.k8s.io # 新增external组
resources:
- '*'
verbs:
- '*'
```
部署nginx deployment服务,并创建HPA 策略。
```
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: scale-nginx
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ngin
minReplicas: 1 # 最小副本数
maxReplicas: 5 # 最大副本数
metrics:
- type: External
external:
metricName: rabbitmq_queue_messages # 自定义监控服务名称
targetValue: 1000 # 消息队列大于1000,nginx服务开始扩容
```
HPA RBAC 权限报错
```
[root@alg-ty-69070 ~]# kubectl get hpa -oyaml scale
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
annotations:
autoscaling.alpha.kubernetes.io/conditions: '[{"type":"AbleToScale","status":"True","lastTransitionTime":"2021-08-28T08:48:11Z","reason":"SucceededGetScale","message":"the
HPA controller was able to get the target''s current scale"},{"type":"ScalingActive","status":"False","lastTransitionTime":"2021-08-28T08:48:11Z","reason":"FailedGetExternalMetric","message":"the
HPA was unable to compute the replica count: unable to get external metric default/rabbitmq_queue_messages/nil:
unable to fetch metrics from external metrics API: rabbitmq_queue_messages.external.metrics.k8s.io
is forbidden: User \"system:serviceaccount:kube-system:horizontal-pod-autoscaler\"
cannot list resource \"rabbitmq_queue_messages\" in API group \"external.metrics.k8s.io\"
in the namespace \"default\""}]'
autoscaling.alpha.kubernetes.io/metrics: '[{"type":"External","external":{"metricName":"rabbitmq_queue_messages","targetValue":"1k"}}]'
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"autoscaling/v2beta1","kind":"HorizontalPodAutoscaler","metadata":{"annotations":{},"name":"scale","namespace":"default"},"spec":{"maxReplicas":10,"metrics":[{"external":{"metricName":"rabbitmq_queue_messages","targetValue":1000},"type":"External"}],"minReplicas":1,"scaleTargetRef":{"apiVersion":"apps/v1","kind":"Deployment","name":"alg-ty-es"}}}
creationTimestamp: "2021-08-28T08:47:56Z"
managedFields:
- apiVersion: autoscaling/v2beta1
fieldsType: FieldsV1
fieldsV1:
f:metadata:
f:annotations:
.: {}
f:kubectl.kubernetes.io/last-applied-configuration: {}
f:spec:
f:maxReplicas: {}
f:metrics: {}
f:minReplicas: {}
f:scaleTargetRef:
f:apiVersion: {}
f:kind: {}
f:name: {}
manager: kubectl-client-side-apply
operation: Update
time: "2021-08-28T08:47:56Z"
```
';
第二十章 基于jenkins的CI/CD(二)
最后更新于:2022-04-02 05:07:22
上节课我们实现了在Kubernetes环境中动态生成Jenkins Slave 的方法,这节课我们来给大家讲解下如何在 Jenkins 中来部署一个 Kubernetes 应用。
## Jenkins Pipeline 介绍
要实现在 Jenkins 中的构建工作,可以有多种方式,我们这里采用比较常用的 Pipeline 这种方式。Pipeline,简单来说,就是一套运行在 Jenkins 上的工作流框架,将原来独立运行于单个或者多个节点的任务连接起来,实现单个任务难以完成的复杂流程编排和可视化的工作。
Jenkins Pipeline 有几个核心概念:
* Node:节点,一个 Node 就是一个 Jenkins 节点,Master 或者 Agent,是执行 Step 的具体运行环境,比如我们之前动态运行的 Jenkins Slave 就是一个 Node 节点
* Stage:阶段,一个 Pipeline 可以划分为若干个 Stage,每个 Stage 代表一组操作,比如:Build、Test、Deploy,Stage 是一个逻辑分组的概念,可以跨多个 Node
* Step:步骤,Step 是最基本的操作单元,可以是打印一句话,也可以是构建一个 Docker 镜像,由各类 Jenkins 插件提供,比如命令:sh ‘make’,就相当于我们平时 shell 终端中执行 make 命令一样。
那么我们如何创建 Jenkins Pipline 呢?
* Pipeline 脚本是由 Groovy 语言实现的,但是我们没必要单独去学习 Groovy,当然你会的话最好
* Pipeline 支持两种语法:Declarative(声明式)和 Scripted Pipeline(脚本式)语法
* Pipeline 也有两种创建方法:可以直接在 Jenkins 的 Web UI 界面中输入脚本;也可以通过创建一个 Jenkinsfile 脚本文件放入项目源码库中
* 一般我们都推荐在 Jenkins 中直接从源代码控制(SCMD)中直接载入 Jenkinsfile Pipeline 这种方法
### 创建一个简单的 Pipeline
我们这里来给大家快速创建一个简单的 Pipeline,直接在 Jenkins 的 Web UI 界面中输入脚本运行。
* 新建 Job:在 Web UI 中点击 New Item -> 输入名称:pipeline-demo -> 选择下面的 Pipeline -> 点击 OK
* 配置:在最下方的 Pipeline 区域输入如下 Script 脚本,然后点击保存。 shell node { stage('Clone') { echo "1.Clone Stage" } stage('Test') { echo "2.Test Stage" } stage('Build') { echo "3.Build Stage" } stage('Deploy') { echo "4. Deploy Stage" } }
* 构建:点击左侧区域的 Build Now,可以看到 Job 开始构建了
隔一会儿,构建完成,可以点击左侧区域的 Console Output,我们就可以看到如下输出信息:

### 在 Slave 中构建任务
上面我们创建了一个简单的 Pipeline 任务,但是我们可以看到这个任务并没有在 Jenkins 的 Slave 中运行,那么如何让我们的任务跑在 Slave 中呢?还记得上节课我们在添加 Slave Pod 的时候,一定要记住添加的 label 吗?没错,我们就需要用到这个 label,我们重新编辑上面创建的 Pipeline 脚本,给 node 添加一个 label 属性,如下:
node('haimaxy-jnlp') {
stage('Clone') {
echo "1.Clone Stage"
}
stage('Test') {
echo "2.Test Stage"
}
stage('Build') {
echo "3.Build Stage"
}
stage('Deploy') {
echo "4. Deploy Stage"
}
}
我们这里只是给 node 添加了一个 haimaxy-jnlp 这样的一个label,然后我们保存,构建之前查看下 kubernetes 集群中的 Pod:
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
jenkins-7c85b6f4bd-rfqgv 1/1 Running 4 6d
然后重新触发立刻构建:
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
jenkins-7c85b6f4bd-rfqgv 1/1 Running 4 6d
jnlp-0hrrz 1/1 Running 0 23s
我们发现多了一个名叫jnlp-0hrrz的 Pod 正在运行,隔一会儿这个 Pod 就不再了:
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
jenkins-7c85b6f4bd-rfqgv 1/1 Running 4 6d
这也证明我们的 Job 构建完成了,同样回到 Jenkins 的 Web UI 界面中查看 Console Output,可以看到如下的信息:

是不是也证明我们当前的任务在跑在上面动态生成的这个 Pod 中,也符合我们的预期。我们回到 Job 的主界面,也可以看到大家可能比较熟悉的 Stage View 界面:
[https://blog.qikqiak.com/img/posts/pipeline-demo3.png](https://blog.qikqiak.com/img/posts/pipeline-demo3.png)
### 部署 Kubernetes 应用
上面我们已经知道了如何在 Jenkins Slave 中构建任务了,那么如何来部署一个原生的 Kubernetes 应用呢? 要部署 Kubernetes 应用,我们就得对我们之前部署应用的流程要非常熟悉才行,我们之前的流程是怎样的:
1. 编写代码
2. 测试
3. 编写 Dockerfile
4. 构建打包 Docker 镜像
5. 推送 Docker 镜像到仓库
6. 编写 Kubernetes YAML 文件
7. 更改 YAML 文件中 Docker 镜像 TAG
8. 利用 kubectl 工具部署应用
我们之前在 Kubernetes 环境中部署一个原生应用的流程应该基本上是上面这些流程吧?现在我们就需要把上面这些流程放入 Jenkins 中来自动帮我们完成(当然编码除外),从测试到更新 YAML 文件属于 CI 流程,后面部署属于 CD 的流程。如果按照我们上面的示例,我们现在要来编写一个 Pipeline 的脚本,应该怎么编写呢?
node('haimaxy-jnlp') {
stage('Clone') {
echo "1.Clone Stage"
}
stage('Test') {
echo "2.Test Stage"
}
stage('Build') {
echo "3.Build Docker Image Stage"
}
stage('Push') {
echo "4.Push Docker Image Stage"
}
stage('YAML') {
echo "5. Change YAML File Stage"
}
stage('Deploy') {
echo "6. Deploy Stage"
}
}
这里我们来将一个简单 golang 程序,部署到 kubernetes 环境中,代码链接:https://github.com/cnych/jenkins-demo。如果按照之前的示例,我们是不是应该像这样来编写 Pipeline 脚本:
* 第一步,clone 代码,这个没得说吧
* 第二步,进行测试,如果测试通过了才继续下面的任务
* 第三步,由于 Dockerfile 基本上都是放入源码中进行管理的,所以我们这里就是直接构建 Docker 镜像了
* 第四步,镜像打包完成,就应该推送到镜像仓库中吧
* 第五步,镜像推送完成,是不是需要更改 YAML 文件中的镜像 TAG 为这次镜像的 TAG
* 第六步,万事俱备,只差最后一步,使用 kubectl 命令行工具进行部署了
到这里我们的整个 CI/CD 的流程是不是就都完成了。
接下来我们就来对每一步具体要做的事情进行详细描述就行了:
### 第一步,Clone 代码
stage('Clone') {
echo "1.Clone Stage"
git url: "https://github.com/cnych/jenkins-demo.git"
}
### 第二步,测试
由于我们这里比较简单,忽略该步骤即可.
### 第三步,构建镜像
stage('Build') {
echo "3.Build Docker Image Stage"
sh "docker build -t cnych/jenkins-demo:${build_tag} ."
}
我们平时构建的时候是不是都是直接使用docker build命令进行构建就行了,那么这个地方呢?我们上节课给大家提供的 Slave Pod 的镜像里面是不是采用的 Docker In Docker 的方式,也就是说我们也可以直接在 Slave 中使用 docker build 命令,所以我们这里直接使用 sh 直接执行 docker build 命令即可,但是镜像的 tag 呢?如果我们使用镜像 tag,则每次都是 latest 的 tag,这对于以后的排查或者回滚之类的工作会带来很大麻烦,我们这里采用和git commit的记录为镜像的 tag,这里有一个好处就是镜像的 tag 可以和 git 提交记录对应起来,也方便日后对应查看。但是由于这个 tag 不只是我们这一个 stage 需要使用,下一个推送镜像是不是也需要,所以这里我们把这个 tag 编写成一个公共的参数,把它放在 Clone 这个 stage 中,这样一来我们前两个 stage 就变成了下面这个样子:
stage('Clone') {
echo "1.Clone Stage"
git url: "https://github.com/cnych/jenkins-demo.git"
script {
build_tag = sh(returnStdout: true, script: 'git rev-parse --short HEAD').trim()
}
}
stage('Build') {
echo "3.Build Docker Image Stage"
sh "docker build -t cnych/jenkins-demo:${build_tag} ."
}
第四步,推送镜像
镜像构建完成了,现在我们就需要将此处构建的镜像推送到镜像仓库中去,当然如果你有私有镜像仓库也可以,我们这里还没有自己搭建私有的仓库,所以直接使用 docker hub 即可。
我们知道 docker hub 是公共的镜像仓库,任何人都可以获取上面的镜像,但是要往上推送镜像我们就需要用到一个帐号了,所以我们需要提前注册一个 docker hub 的帐号,记住用户名和密码,我们这里需要使用。正常来说我们在本地推送 docker 镜像的时候,是不是需要使用docker login命令,然后输入用户名和密码,认证通过后,就可以使用docker push命令来推送本地的镜像到 docker hub 上面去了,如果是这样的话,我们这里的 Pipeline 是不是就该这样写了:
stage('Push') {
echo "4.Push Docker Image Stage"
sh "docker login -u cnych -p xxxxx"
sh "docker push cnych/jenkins-demo:${build_tag}"
}
如果我们只是在 Jenkins 的 Web UI 界面中来完成这个任务的话,我们这里的 Pipeline 是可以这样写的,但是我们是不是推荐使用 Jenkinsfile 的形式放入源码中进行版本管理,这样的话我们直接把 docker 仓库的用户名和密码暴露给别人这样很显然是非常非常不安全的,更何况我们这里使用的是 github 的公共代码仓库,所有人都可以直接看到我们的源码,所以我们应该用一种方式来隐藏用户名和密码这种私密信息,幸运的是 Jenkins 为我们提供了解决方法。
在首页点击 Credentials -> Stores scoped to Jenkins 下面的 Jenkins -> Global credentials (unrestricted) -> 左侧的 Add Credentials:添加一个 Username with password 类型的认证信息,如下:

Add Credentials 输入 docker hub 的用户名和密码,ID 部分我们输入dockerHub,注意,这个值非常重要,在后面 Pipeline 的脚本中我们需要使用到这个 ID 值。
有了上面的 docker hub 的用户名和密码的认证信息,现在我们可以在 Pipeline 中使用这里的用户名和密码了:
stage('Push') {
echo "4.Push Docker Image Stage"
withCredentials([usernamePassword(credentialsId: 'dockerHub', passwordVariable: 'dockerHubPassword', usernameVariable: 'dockerHubUser')]) {
sh "docker login -u ${dockerHubUser} -p ${dockerHubPassword}"
sh "docker push cnych/jenkins-demo:${build_tag}"
}
}
注意我们这里在 stage 中使用了一个新的函数withCredentials,其中有一个credentialsId值就是我们刚刚创建的 ID 值,然后我们就可以在脚本中直接使用这里两个变量值来直接替换掉之前的登录 docker hub 的用户名和密码,现在是不是就很安全了,我只是传递进去了两个变量而已,别人并不知道我的真正用户名和密码,只有我们自己的 Jenkins 平台上添加的才知道。
### 第五步,更改 YAML
上面我们已经完成了镜像的打包、推送的工作,接下来我们是不是应该更新 Kubernetes 系统中应用的镜像版本了,当然为了方便维护,我们都是用 YAML 文件的形式来编写应用部署规则,比如我们这里的 YAML 文件:(k8s.yaml)
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: jenkins-demo
spec:
template:
metadata:
labels:
app: jenkins-demo
spec:
containers:
- image: cnych/jenkins-demo:
imagePullPolicy: IfNotPresent
name: jenkins-demo
对于 Kubernetes 比较熟悉的同学,对上面这个 YAML 文件一定不会陌生,我们使用一个 Deployment 资源对象来管理 Pod,该 Pod 使用的就是我们上面推送的镜像,唯一不同的地方是 Docker 镜像的 tag 不是我们平常见的具体的 tag,而是一个 的标识,实际上如果我们将这个标识替换成上面的 Docker 镜像的 tag,是不是就是最终我们本次构建需要使用到的镜像?怎么替换呢?其实也很简单,我们使用一个sed命令就可以实现了:
stage('YAML') {
echo "5. Change YAML File Stage"
sh "sed -i 's//${build_tag}/' k8s.yaml"
}
上面的 sed 命令就是将 k8s.yaml 文件中的 标识给替换成变量 build_tag 的值。
第六步,部署
Kubernetes 应用的 YAML 文件已经更改完成了,之前我们手动的环境下,是不是直接使用 kubectl apply 命令就可以直接更新应用了啊?当然我们这里只是写入到了 Pipeline 里面,思路都是一样的:
stage('Deploy') {
echo "6. Deploy Stage"
sh "kubectl apply -f k8s.yaml"
}
这样到这里我们的整个流程就算完成了。
### 人工确认
理论上来说我们上面的6个步骤其实已经完成了,但是一般在我们的实际项目实践过程中,可能还需要一些人工干预的步骤,这是为什么呢?比如我们提交了一次代码,测试也通过了,镜像也打包上传了,但是这个版本并不一定就是要立刻上线到生产环境的,对吧,我们可能需要将该版本先发布到测试环境、QA 环境、或者预览环境之类的,总之直接就发布到线上环境去还是挺少见的,所以我们需要增加人工确认的环节,一般都是在 CD 的环节才需要人工干预,比如我们这里的最后两步,我们就可以在前面加上确认,比如:
stage('YAML') {
echo "5. Change YAML File Stage"
def userInput = input(
id: 'userInput',
message: 'Choose a deploy environment',
parameters: [
[
$class: 'ChoiceParameterDefinition',
choices: "Dev\nQA\nProd",
name: 'Env'
]
]
)
echo "This is a deploy step to ${userInput.Env}"
sh "sed -i 's//${build_tag}/' k8s.yaml"
}
我们这里使用了 input 关键字,里面使用一个 Choice 的列表来让用户进行选择,然后在我们选择了部署环境后,我们当然也可以针对不同的环境再做一些操作,比如可以给不同环境的 YAML 文件部署到不同的 namespace 下面去,增加不同的标签等等操作:
stage('Deploy') {
echo "6. Deploy Stage"
if (userInput.Env == "Dev") {
// deploy dev stuff
} else if (userInput.Env == "QA"){
// deploy qa stuff
} else {
// deploy prod stuff
}
sh "kubectl apply -f k8s.yaml"
}
由于这一步也属于部署的范畴,所以我们可以将最后两步都合并成一步,我们最终的 Pipeline 脚本如下:
node('haimaxy-jnlp') {
stage('Clone') {
echo "1.Clone Stage"
git url: "https://github.com/cnych/jenkins-demo.git"
script {
build_tag = sh(returnStdout: true, script: 'git rev-parse --short HEAD').trim()
}
}
stage('Test') {
echo "2.Test Stage"
}
stage('Build') {
echo "3.Build Docker Image Stage"
sh "docker build -t cnych/jenkins-demo:${build_tag} ."
}
stage('Push') {
echo "4.Push Docker Image Stage"
withCredentials([usernamePassword(credentialsId: 'dockerHub', passwordVariable: 'dockerHubPassword', usernameVariable: 'dockerHubUser')]) {
sh "docker login -u ${dockerHubUser} -p ${dockerHubPassword}"
sh "docker push cnych/jenkins-demo:${build_tag}"
}
}
stage('Deploy') {
echo "5. Deploy Stage"
def userInput = input(
id: 'userInput',
message: 'Choose a deploy environment',
parameters: [
[
$class: 'ChoiceParameterDefinition',
choices: "Dev\nQA\nProd",
name: 'Env'
]
]
)
echo "This is a deploy step to ${userInput}"
sh "sed -i 's//${build_tag}/' k8s.yaml"
if (userInput == "Dev") {
// deploy dev stuff
} else if (userInput == "QA"){
// deploy qa stuff
} else {
// deploy prod stuff
}
sh "kubectl apply -f k8s.yaml"
}
}
现在我们在 Jenkins Web UI 中重新配置 jenkins-demo 这个任务,将上面的脚本粘贴到 Script 区域,重新保存,然后点击左侧的 Build Now,触发构建,然后过一会儿我们就可以看到 Stage View 界面出现了暂停的情况:

pipeline demo5 这就是我们上面 Deploy 阶段加入了人工确认的步骤,所以这个时候构建暂停了,需要我们人为的确认下,比如我们这里选择 QA,然后点击 Proceed,就可以继续往下走了,然后构建就成功了,我们在 Stage View 的 Deploy 这个阶段可以看到如下的一些日志信息:

打印出来了 QA,和我们刚刚的选择是一致的,现在我们去 Kubernetes 集群中观察下部署的应用:
$ kubectl get deployment -n kube-ops
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
jenkins 1 1 1 1 7d
jenkins-demo 1 1 1 0 1m
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
jenkins-7c85b6f4bd-rfqgv 1/1 Running 4 7d
jenkins-demo-f6f4f646b-2zdrq 0/1 Completed 4 1m
$ kubectl logs jenkins-demo-f6f4f646b-2zdrq -n kube-ops
Hello, Kubernetes!I'm from Jenkins CI!
我们可以看到我们的应用已经正确的部署到了 Kubernetes 的集群环境中了
参照以上的方法 我们简单的使用了pipeline完成了一个应用的部署功能,对于使用pipeline 有一定基础要求。在此提供一个shell 脚本,实现一个CI/CD 流程。
#!/bin/bash
# Filename: k8s-deploy_v0.1.sh
# Description: jenkins CI/CD 持续发布脚本
# Author: yi.hu
# Email: 345270016@qq.com
# Revision: 1.0
# Date: 2018-08-10
# Note: prd
# zookeeper基础服务,依照环境实际地址配置
init() {
local lowerEnv="$(echo ${AppEnv} | tr '[:upper:]' 'lower')"
case "${lowerEnv}" in
dev)
CFG_ADDR="10.34.11.186:4181"
DR_CFG_ZOOKEEPER_ENV_URL="10.34.11.186:4181"
;;
demo)
CFG_ADDR="10.34.11.186:4181"
DR_CFG_ZOOKEEPER_ENV_URL="10.34.11.186:4181"
;;
*)
echo "Not support AppEnv: ${AppEnv}"
exit 1
;;
esac
}
# 初始化变量
AppId=$(echo ${AppOrg}_${AppEnv}_${AppName} |sed 's/[^a-zA-Z0-9_-]//g' | tr "[:lower:]" "[:upper:]")
CFG_LABEL=${CfgLabelBaseNode}/${AppId}
CFG_ADDR=${CFG_ADDR}
# 登录harbor 仓库
docker_login () {
docker login ${DOCKER_REGISTRY} -u${User} -p${PassWord}
}
# 编译代码,制作镜像
build() {
echo $ACTION
if [ "x${ACTION}" == "xDEPLOY" ] || [ "x${ACTION}" == "xPRE_DEPLOY" ]; then
echo "Test harbor registry: ${DOCKER_REGISTRY}"
#curl -X GET --connect-timeout 30 -I ${DOCKER_REGISTRY}/v2/ 2>/dev/null | grep 'HTTP/1.1 200 OK' > /dev/null
curl --connect-timeout 30 -I ${DOCKER_REGISTRY}/api/projects 2>/dev/null | grep 'HTTP/1.1 200 OK' > /dev/null
echo "Check image EXIST or NOT: ${ToImage}"
#Image_Check=$(echo ${ToImage} | sed 's/\([^/]\+\)\([^:]\+\):/\1\/v2\2\/manifests\//')
ImageCheck_Harbor=$(echo ${ToImage} | sed 's/\([^/]\+\)\([^:]\+\):/\1\/api\/repositories\2\/tags\//')
Responed_Code=$(curl -u${User}:${PassWord} -so /dev/null -w '%{response_code}' ${ImageCheck_Harbor} || true)
if [ "${NoCache}" == "true" ] || [ "x${Responed_Code}" != "x200" ] ; then
if [ "x${BuildCmd}" == "x" ]; then
echo "Generating Dockerfile"
echo "FROM ${FromImage}" > Dockerfile
cat >> Dockerfile <<- EOF
${Dockerfile}
EOF
echo "$( Dockerfile <<- EOF
FROM ${FromImage}
MAINTAINER devops
ADD ${CodeBasename} \${AppCode}
EOF
echo "$( ${WORKSPACE}/${AppName}-deploy.yaml <<- EOF
#####################################################
#
# ${ACTION} Deployment
#
#####################################################
apiVersion: apps/v1beta2 # for versions before 1.8.0 use apps/v1beta1
kind: Deployment
metadata:
name: ${AppName}
namespace: ${NameSpace}
labels:
app: ${AppName}
version: ${GitBranch}
AppEnv: ${AppEnv}
spec:
replicas: ${Replicas}
selector:
matchLabels:
app: ${AppName}
template:
metadata:
labels:
app: ${AppName}
spec:
containers:
- name: ${AppName}
image: ${ToImage}
ports:
- containerPort: ${ContainerPort}
livenessProbe:
httpGet:
path: ${HealthCheckURL}
port: ${ContainerPort}
initialDelaySeconds: 90
timeoutSeconds: 5
periodSeconds: 5
readinessProbe:
httpGet:
path: ${HealthCheckURL}
port: ${ContainerPort}
initialDelaySeconds: 5
timeoutSeconds: 5
periodSeconds: 5
# configmap env
env:
- name: CFG_LABEL
value: ${CFG_LABEL}
- name: CFG_ADDR
valueFrom:
configMapKeyRef:
name: ${ConfigMap}
key: CFG_ADDR
- name: DR_CFG_ZOOKEEPER_ENV_URL
valueFrom:
configMapKeyRef:
name: ${ConfigMap}
key: DR_CFG_ZOOKEEPER_ENV_URL
- name: CFG_FILES
valueFrom:
configMapKeyRef:
name: ${ConfigMap}
key: CFG_FILES
# configMap volume
volumeMounts:
- name: applogs
mountPath: /volume_logs/
volumes:
- name: applogs
hostPath:
path: /opt/app_logs/${AppName}
imagePullSecrets:
- name: ${ImagePullSecrets}
---
apiVersion: v1
kind: Service
metadata:
name: ${AppName}
namespace: ${NameSpace}
labels:
app: ${AppName}
spec:
ports:
- port: ${ContainerPort}
targetPort: ${ContainerPort}
selector:
app: ${AppName}
---
kind: ConfigMap
apiVersion: v1
metadata:
name: ${ConfigMap}
namespace: ${NameSpace}
data:
CFG_ADDR: ${CFG_ADDR}
DR_CFG_ZOOKEEPER_ENV_URL: ${DR_CFG_ZOOKEEPER_ENV_URL}
CFG_FILES: ${Cfs_Files}
EOF
# 执行部署
deploy
# 打印配置
cat ${WORKSPACE}/${AppName}-deploy.yaml
';
第十九章 基于 Jenkins 的 CI/CD(一)
最后更新于:2022-04-02 05:07:20
# 基于Jenkins 的CI/CD(一)
## 介绍
本文将讨论和探索两个令人惊奇和相当有趣的技术。一个是Jenkins,一个流行的持续集成/发布的工具,另一个是Kubernetes,一个流行的容器编排引擎。
持续构建与发布是我们日常工作中必不可少的一个步骤,目前大多公司都采用 Jenkins 集群来搭建符合需求的 CI/CD 流程,然而传统的 Jenkins Slave 一主多从方式会存在一些痛点,比如:主 Master 发生单点故障时,整个流程都不可用了;每个 Slave 的配置环境不一样,来完成不同语言的编译打包等操作,但是这些差异化的配置导致管理起来非常不方便,维护起来也是比较费劲;资源分配不均衡,有的 Slave 要运行的 job 出现排队等待,而有的 Slave 处于空闲状态;最后资源有浪费,每台 Slave 可能是实体机或者 VM,当 Slave 处于空闲状态时,也不会完全释放掉资源。
提到基于Kubernete的CI/CD,可以使用的工具有很多,比如Jenkins、Gitlab CI已经新兴的drone之类的,我们这里会使用大家最为熟悉的Jenins来做CI/CD的工具。
## 优点
Jenkins 安装完成了,接下来我们不用急着就去使用,我们要了解下在 Kubernetes 环境下面使用 Jenkins 有什么好处。
我们知道持续构建与发布是我们日常工作中必不可少的一个步骤,目前大多公司都采用 Jenkins 集群来搭建符合需求的 CI/CD 流程,然而传统的 Jenkins Slave 一主多从方式会存在一些痛点,比如:
* 主 Master 发生单点故障时,整个流程都不可用了
* 每个 Slave 的配置环境不一样,来完成不同语言的编译打包等操作,但是这些差异化的配置导致管理起来非常不方便,维护起来也是比较费劲
* 资源分配不均衡,有的 Slave 要运行的 job 出现排队等待,而有的 Slave 处于空闲状态
* 资源有浪费,每台 Slave 可能是物理机或者虚拟机,当 Slave 处于空闲状态时,也不会完全释放掉资源。
正因为上面的这些种种痛点,我们渴望一种更高效更可靠的方式来完成这个 CI/CD 流程,而 Docker 虚拟化容器技术能很好的解决这个痛点,又特别是在 Kubernetes 集群环境下面能够更好来解决上面的问题,下图是基于 Kubernetes 搭建 Jenkins 集群的简单示意图

从图上可以看到 Jenkins Master 和 Jenkins Slave 以 Pod 形式运行在 Kubernetes 集群的 Node 上,Master 运行在其中一个节点,并且将其配置数据存储到一个 Volume 上去,Slave 运行在各个节点上,并且它不是一直处于运行状态,它会按照需求动态的创建并自动删除。
这种方式的工作流程大致为:当 Jenkins Master 接受到 Build 请求时,会根据配置的 Label 动态创建一个运行在 Pod 中的 Jenkins Slave 并注册到 Master 上,当运行完 Job 后,这个 Slave 会被注销并且这个 Pod 也会自动删除,恢复到最初状态。
那么我们使用这种方式带来了哪些好处呢?
* 服务高可用,当 Jenkins Master 出现故障时,Kubernetes 会自动创建一个新的 Jenkins Master 容器,并且将 Volume 分配给新创建的容器,保证数据不丢失,从而达到集群服务高可用。
* 动态伸缩,合理使用资源,每次运行 Job 时,会自动创建一个 Jenkins Slave,Job 完成后,Slave 自动注销并删除容器,资源自动释放,而且 Kubernetes 会根据每个资源的使用情况,动态分配 Slave 到空闲的节点上创建,降低出现因某节点资源利用率高,还排队等待在该节点的情况。
* 扩展性好,当 Kubernetes 集群的资源严重不足而导致 Job 排队等待时,可以很容易的添加一个 Kubernetes Node 到集群中,从而实现扩展。
是不是以前我们面临的种种问题在 Kubernetes 集群环境下面是不是都没有了啊?看上去非常完美。
### 安装
听我们课程的大部分同学应该都或多或少的听说过Jenkins,我们这里就不再去详细讲述什么是 Jenkins 了,直接进入正题,后面我们会单独的关于 Jenkins 的学习课程,想更加深入学习的同学也可以关注下。既然要基于Kubernetes来做CI/CD,当然我们这里需要将 Jenkins 安装到 Kubernetes 集群当中,新建一个 Deployment:(jenkins-deployment.yaml)
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: jenkins2
namespace: kube-ops
spec:
template:
metadata:
labels:
app: jenkins2
spec:
terminationGracePeriodSeconds: 10
serviceAccountName: jenkins2
containers:
- name: jenkins
image: jenkins/jenkins:lts
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
name: web
protocol: TCP
- containerPort: 50000
name: agent
protocol: TCP
resources:
limits:
cpu: 2000m
memory: 4Gi
requests:
cpu: 1000m
memory: 2Gi
livenessProbe:
httpGet:
path: /login
port: 8080
initialDelaySeconds: 60
timeoutSeconds: 5
failureThreshold: 12
readinessProbe:
httpGet:
path: /login
port: 8080
initialDelaySeconds: 60
timeoutSeconds: 5
failureThreshold: 12
volumeMounts:
- name: jenkinshome
subPath: jenkins2
mountPath: /var/jenkins_home
env:
- name: LIMITS_MEMORY
valueFrom:
resourceFieldRef:
resource: limits.memory
divisor: 1Mi
- name: JAVA_OPTS
value: -Xmx$(LIMITS_MEMORY)m -XshowSettings:vm -Dhudson.slaves.NodeProvisioner.initialDelay=0 -Dhudson.slaves.NodeProvisioner.MARGIN=50 -Dhudson.slaves.NodeProvisioner.MARGIN0=0.85 -Duser.timezone=Asia/Shanghai
securityContext:
fsGroup: 1000
volumes:
- name: jenkinshome
persistentVolumeClaim:
claimName: opspvc
---
apiVersion: v1
kind: Service
metadata:
name: jenkins2
namespace: kube-ops
labels:
app: jenkins2
spec:
selector:
app: jenkins2
ports:
- name: web
port: 8080
targetPort: web
- name: agent
port: 50000
targetPort: agent
为了方便演示,我们把本节课所有的对象资源都放置在一个名为 kube-ops 的 namespace 下面,所以我们需要添加创建一个 namespace:
kubectl create namespace kube-ops
我们这里使用一个名为 jenkins/jenkins:lts 的镜像,这是 jenkins 官方的 Docker 镜像,然后也有一些环境变量,当然我们也可以根据自己的需求来定制一个镜像,比如我们可以将一些插件打包在自定义的镜像当中,可以参考文档:https://github.com/jenkinsci/docker,我们这里使用默认的官方镜像就行,另外一个还需要注意的是我们将容器的 /var/jenkins_home 目录挂载到了一个名为 opspvc 的 PVC 对象上面,所以我们同样还得提前创建一个对应的 PVC 对象,当然我们也可以使用我们前面的 StorageClass 对象来自动创建:(jenkins-pvc.yaml)
apiVersion: v1
kind: PersistentVolume
metadata:
name: opspv
spec:
capacity:
storage: 200Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Delete
nfs:
server: 10.34.11.12
path: /opt/nfs
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: opspvc
namespace: kube-ops
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 200Gi
创建需要用到的 PVC 对象
$ kubectl create -f jenkins-pvc.yaml
另外我们这里还需要使用到一个拥有相关权限的 serviceAccount:jenkins2,我们这里只是给 jenkins 赋予了一些必要的权限,当然如果你对 serviceAccount 的权限不是很熟悉的话,我们给这个 sa 绑定一个 cluster-admin 的集群角色权限也是可以的,当然这样具有一定的安全风险:(jenkins-rbac.yaml)
apiVersion: v1
kind: ServiceAccount
metadata:
name: jenkins2
namespace: kube-ops
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: jenkins2
namespace: kube-ops
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["create","delete","get","list","patch","update","watch"]
- apiGroups: [""]
resources: ["pods/exec"]
verbs: ["create","delete","get","list","patch","update","watch"]
- apiGroups: [""]
resources: ["pods/log"]
verbs: ["get","list","watch"]
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: jenkins2
namespace: kube-ops
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: jenkins2
subjects:
- kind: ServiceAccount
name: jenkins2
namespace: kube-ops
创建 rbac 相关的资源对象:
$ kubectl create -f jenkins-rbac.yaml
最后为了方便我们测试,我们这里通过 ingress的形式来访问Jenkins 的 web 服务,Jenkins 服务端口为8080,50000 端口为agent,这个端口主要是用于 Jenkins 的 master 和 slave 之间通信使用的。(jenkins-ingress.yaml)
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: jenkins-ingress
namespace: kube-ops
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: jenkins-k8s.jiedai361.com
http:
paths:
- backend:
serviceName: jenkins2
servicePort: 8080
一切准备的资源准备好过后,我们直接创建 Jenkins 服务:
kubectl create -f jenkins-deployment.yaml
最后创建ingress 路由服务
kubectl apply -f jenkins-ingress.yaml
创建完成后,要去拉取镜像可能需要等待一会儿,然后我们查看下 Pod 的状态:
# kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
jenkins2-58df5d8fdc-w9xqh 1/1 Running 0 7d
等到服务启动成功后,我们就可以根据ingress 服务域名(jenkins-k8s.jiedai361.com)就可以访问 jenkins 服务了,可以根据提示信息进行安装配置即可:

初始化的密码我们可以在 jenkins 的容器的日志中进行查看,也可以直接在 nfs 的共享数据目录中查看
cat /opt/nfs/jenkins2/secret/initAdminPassword
然后选择安装推荐的插件即可。

安装完成后添加管理员帐号即可进入到 jenkins 主界面: jenkins home

## 配置
接下来我们就需要来配置 Jenkins,让他能够动态的生成 Slave 的 Pod
jenkins依赖插件清单
- kubernetes
- managed scripts
**第1步**. 我们需要安装kubernetes plugin, 点击 Manage Jenkins -> Manage Plugins -> Available -> Kubernetes plugin 勾选安装即可。 kubernetes plugin

**第2步**. 安装完毕后,点击 Manage Jenkins —> Configure System —> (拖到最下方)Add a new cloud —> 选择 Kubernetes,然后填写 Kubernetes 和 Jenkins 配置信息。

注意 namespace,我们这里填 kube-ops,然后点击Test Connection,如果出现 Connection test successful 的提示信息证明 Jenkins 已经可以和 Kubernetes 系统正常通信了,然后下方的 Jenkins URL 地址:http://jenkins2.kube-ops.svc.cluster.local:8080,这里的格式为:服务名.namespace.svc.cluster.local:8080,根据上面创建的jenkins 的服务名填写,我这里是之前创建的名为jenkins,如果是用上面我们创建的就应该是jenkins2
**第3步.** 配置 Pod Template,其实就是配置 Jenkins Slave 运行的 Pod 模板,命名空间我们同样是用 kube-ops,Labels 这里也非常重要,对于后面执行 Job 的时候需要用到该值,然后我们这里使用的是 cnych/jenkins:jnlp 这个镜像,这个镜像是在官方的 jnlp 镜像基础上定制的,加入了 kubectl 等一些实用的工具。

另外需要注意我们这里需要在下面挂载一个主机目录,一个是 /var/run/docker.sock,该文件是用于 Pod 中的容器能够共享宿主机的 Docker,这就是大家说的 docker in docker 的方式,Docker 二进制文件我们已经打包到上面的镜像中了。如果在slave agent中想要访问kubernetes 集群中其他资源,我们还需要绑定之前创建的Service Account 账号:jenkins2

另外还有几个参数需要注意,如下图中的Time in minutes to retain slave when idle,这个参数表示的意思是当处于空闲状态的时候保留 Slave Pod 多长时间,这个参数最好我们保存默认就行了,如果你设置过大的话,Job 任务执行完成后,对应的 Slave Pod 就不会立即被销毁删除。
到这里我们的 Kubernetes Plugin 插件就算配置完成了。
## 测试
Kubernetes 插件的配置工作完成了,接下来我们就来添加一个 Job 任务,看是否能够在 Slave Pod 中执行,任务执行完成后看 Pod 是否会被销毁
在 Jenkins 首页点击create new jobs,创建一个测试的任务,输入任务名称,然后我们选择 Freestyle project 类型的任务: jenkins demo

注意在下面的 Label Expression 这里要填入haimaxy-jnlp,就是前面我们配置的 Slave Pod 中的 Label,这两个地方必须保持一致

然后往下拉,在 Build 区域选择Execute shell

然后输入我们测试命令
echo "测试 Kubernetes 动态生成 jenkins slave"
echo "==============docker in docker==========="
docker info
echo "=============kubectl============="
kubectl get pods -n kube-system
最后点击保存

现在我们直接在页面点击做成的 Build now 触发构建即可,然后观察 Kubernetes 集群中 Pod 的变化
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
jenkins2-7c85b6f4bd-rfqgv 1/1 Running 3 1d
jnlp-hfmvd 0/1 ContainerCreating 0 7s
同样也可以查看到对应的控制台信息:

到这里证明我们的任务已经构建完成,然后这个时候我们再去集群查看我们的 Pod 列表,发现 kube-ops 这个 namespace 下面已经没有之前的 Slave 这个 Pod 了。
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
jenkins2-7c85b6f4bd-rfqgv 1/1 Running 3 1d
到这里我们就完成了使用 Kubernetes 动态生成 Jenkins Slave 的方法。下节课我们来给大家介绍下怎么在 Jenkins 中来发布我们的 Kubernetes 应用
';
第十八章 在kubernetes 使用ceph
最后更新于:2022-04-02 05:07:18
部署环境依赖:如果使用kubeadmin方式部署K8S。因为apiserver 使用docker方式。默认镜像不带有ceph-common 客户端驱动。通过部署rbd-provisioner,手动加载驱动方式解决此问题。
* * * * *
创建一个rbd-provisioner.yaml 驱动:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: rbd-provisioner
namespace: monitoring
spec:
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: rbd-provisioner
spec:
containers:
- name: rbd-provisioner
image: "quay.io/external_storage/rbd-provisioner:latest"
env:
- name: PROVISIONER_NAME
value: ceph.com/rbd
args: ["-master=http://10.18.19.98:8080", "-id=rbd-provisioner"]
### 生成 Ceph secret
使用 Ceph 管理员提供给你的 ceph.client.admin.keyring 文件,我们将它放在了 /etc/ceph 目录下,用来生成 secret。
grep key /etc/ceph/ceph.client.admin.keyring |awk '{printf "%s", $NF}'|base64
### 创建 Ceph secret
apiVersion: v1
kind: Secret
metadata:
name: ceph-secret
namespace: monitoring
type: "kubernetes.io/rbd"
data:
key: QVFCZU54dFlkMVNvRUJBQUlMTUVXMldSS29mdWhlamNKaC8yRXc9PQ==
### 创建 StorageClass
二进制部署方式参考,ceph-class.yaml 文件内容为:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: prometheus-ceph
namespace: noah
provisioner: ceph.com/rbd
parameters:
monitors: 10.18.19.91:6789
adminId: admin
adminSecretName: ceph-secret
adminSecretNamespace: monitoring
userSecretName: ceph-secret
pool: prometheus #建立自己的RBD存储池
userId: admin
调用rbd-provisioner, 参考以下内容
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: kong-cassandra-fast
namespace: monitoring
provisioner: ceph.com/rbd #调用rbd-provisione
parameters:
monitors: 10.18.19.91:6789
adminId: admin
adminSecretName: ceph-secret
adminSecretNamespace: monitoring
userSecretName: ceph-secret
pool: prometheus
userId: admin
### 列出所有的pool
ceph osd lspools
### 列出pool中的所有镜像
rbd ls prometheus
### 创建pool
ceph osd pool create prometheus 128 128
配置 prometheus,添加ceph class
配置文件如下:
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: prometheus-core
namespace: monitoring
labels:
app: prometheus
component: core
version: v1
spec:
serviceName: prometheus-core
replicas: 1
template:
metadata:
labels:
app: prometheus
component: core
spec:
serviceAccountName: prometheus-k8s
containers:
- name: prometheus
image: prom/prometheus:v1.7.0
args:
- '-storage.local.retention=336h'
- '-storage.local.memory-chunks=1048576'
- '-config.file=/etc/prometheus/prometheus.yaml'
- '-alertmanager.url=http://alertmanager:9093/'
ports:
- name: webui
containerPort: 9090
resources:
requests:
cpu: 2
memory: 2Gi
limits:
cpu: 2
memory: 2Gi
volumeMounts:
- name: config-volume
mountPath: /etc/prometheus
- name: rules-volume
mountPath: /etc/prometheus-rules
- name: data
mountPath: /prometheus/data
volumes:
- name: config-volume
configMap:
name: prometheus-core
- name: rules-volume
configMap:
name: prometheus-rules
volumeClaimTemplates:
- metadata:
name: data
annotations:
volume.beta.kubernetes.io/storage-class: "ceph-aliyun"
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 50Gi
';
第十七章 kubernetes 从1.7 到1.8升级记录
最后更新于:2022-04-02 05:07:16
Kubernetes 1.9已经发布,可以开始考虑将团队线上环境的Kubernetes集群从1.7升级到1.8了。 本文记录了在测试环境中的演练过程。
从 [github release](https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG.md) 页面,下载最新版本。
# 准备
当前Kubernetes 1.8的小版本是1.8.7。 在升级之前一定要多读几遍官方的升级须知Kubernetes 1.8 - Action Required Before Upgrading。其中和我们相关的:
- 从Kubernetes 1.8开始如果Node上开启了swap,kubelet会启动失败。所以如果服务器是专门用作k8s Node节点的话需要将系统的swap关闭。因为我们测试环境中k8s的Node上还部署了一些遗留服务,为了稳定性,这里不会关闭Swap,需要kubelet加上启动参数--fail-swap-on=false。这个需要在我们的ansible role中做更新。
- CronJob API进入beta阶段,现在的版本是v1beta1,但v2alpha1在Kubernetes 1.8中仍然可用。可以在完成集群的升级后,将集群中部署的CronJob统一修改到v1beta1。最后才可以移除apiserver的--runtime-config=batch/v2alpha1=true。
- rbac/v1alpha1, settings/v1alpha1, and scheduling/v1alpha1 APIs在Kubernetes 1.8中默认被禁用。
- 在Kubernetes 1.8中工作负载API版本升级到了apps/v1beta2,可以在集群升级到1.8后对集群中部署的DaemonSet,Deployment,ReplicaSet做修改。
### 使用ansible升级Kubernetes核心组件
接下来尝试使用ansible将Kubernetes的核心组件从1.7升级到1.8。 直接使用二进制包覆盖原有路径。
ansible kube-node -m unarchive -a 'src=/root/k8s/k8s-v1.8.7/kubernetes-server-linux-amd64.tar.gz dest=/usr/local/'
### 生产使用建议关闭 swap
Kubernetes 1.8开始要求关闭系统的Swap,如果不关闭,默认配置下kubelet将无法启动。可以通过kubelet的启动参数--fail-swap-on=false更改这个限制。 我们这里关闭系统的Swap:
swapoff -a
修改 /etc/fstab 文件,注释掉 SWAP 的自动挂载,使用free -m确认swap已经关闭。
swappiness参数调整,修改/etc/sysctl.d/k8s.conf添加下面一行:
vm.swappiness=0
### 重启kubelet服务
systemctl restart kubelet.service
### 检查node 是否升级成功
[root@cd-k8s-master k8s-v1.8.7]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
172.16.200.206 Ready 121d v1.8.7
172.16.200.209 Ready 171d v1.8.7
172.16.200.216 Ready 126d v1.8.7
';
第十六章 使用helm 应用部署工具
最后更新于:2022-04-02 05:07:13
# 简化Kubernetes应用部署工具-Helm简介
微服务和容器化给复杂应用部署与管理带来了极大的挑战。Helm是目前Kubernetes服务编排领域的唯一开源子项目,做为Kubernetes应用的一个包管理工具,可理解为Kubernetes的apt-get / yum,由Deis 公司发起,该公司已经被微软收购。Helm通过软件打包的形式,支持发布的版本管理和控制,很大程度上简化了Kubernetes应用部署和管理的复杂性。
随着业务容器化与向微服务架构转变,通过分解巨大的单体应用为多个服务的方式,分解了单体应用的复杂性,使每个微服务都可以独立部署和扩展,实现了敏捷开发和快速迭代和部署。但任何事情都有两面性,虽然微服务给我们带来了很多便利,但由于应用被拆分成多个组件,导致服务数量大幅增加,对于Kubernetest编排来说,每个组件有自己的资源文件,并且可以独立的部署与伸缩,这给采用Kubernetes做应用编排带来了诸多挑战:
1. 管理、编辑与更新大量的K8s配置文件
1. 部署一个含有大量配置文件的复杂K8s应用
1. 分享和复用K8s配置和应用
1. 参数化配置模板支持多个环境
1. 管理应用的发布:回滚、diff和查看发布历史
1. 控制一个部署周期中的某一些环节
1. 发布后的验证
Helm把Kubernetes资源(比如deployments、services或 ingress等) 打包到一个chart中,而chart被保存到chart仓库。通过chart仓库可用来存储和分享chart。Helm使发布可配置,支持发布应用配置的版本管理,简化了Kubernetes部署应用的版本控制、打包、发布、删除、更新等操作。
本文简单介绍了Helm的用途、架构与实现。
## Helm产生原因
Helm基本架构如下:

# helm 安装
完本文后您应该可以自己创建chart,并创建自己的私有chart仓库。
Helm是一个kubernetes应用的包管理工具,用来管理charts——预先配置好的安装包资源,有点类似于Ubuntu的APT和CentOS中的yum。
Helm chart是用来封装kubernetes原生应用程序的yaml文件,可以在你部署应用的时候自定义应用程序的一些metadata,便与应用程序的分发。
Helm和charts的主要作用:
- 应用程序封装
- 版本管理
- 依赖检查
- 便于应用程序分发
本文同时归档到kubernetes-handbook。
安装Helm
前提要求
- Kubernetes1.5以上版本
- 集群可访问到的镜像仓库
- 执行helm命令的主机可以访问到kubernetes集群
安装步骤
首先需要安装helm客户端
curl https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get > get_helm.shchmod 700 get_helm.sh./get_helm.sh
创建tiller的serviceaccount和clusterrolebinding
kubectl create serviceaccount --namespace kube-system tiller
kubectl create clusterrolebinding tiller-cluster-rule --clusterrole=cluster-admin --serviceaccount=kube-system:tiller
然后安装helm服务端tiller
helm init -i harbor-demo.dianrong.com/k8s/kubernetes-helm-tiller:v2.7.0 --service-account tiller
我们使用-i指定自己的镜像,因为官方的镜像因为某些原因无法拉取。
为应用程序设置serviceAccount:
kubectl patch deploy --namespace kube-system tiller-deploy -p '{"spec":{"template":{"spec":{"serviceAccount":"tiller"}}}}'
检查是否安装成功:
$ kubectl -n kube-system get pods|grep tiller
tiller-deploy-3243657295-4dg28 1/1 Running 0 8m
# helm version
Client: &version.Version{SemVer:"v2.7.0", GitCommit:"08c1144f5eb3e3b636d9775617287cc26e53dba4", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.7.0", GitCommit:"08c1144f5eb3e3b636d9775617287cc26e53dba4", GitTreeState:"clean"}
> 注意检查是否安装socat依赖 :yum install socat
### 创建自己的chart
我们创建一个名为mychart的chart,看一看chart的文件结构。
# helm create mychart
# tree mychart/
mychart/
├── charts
├── Chart.yaml
├── templates
│ ├── deployment.yaml
│ ├── _helpers.tpl
│ ├── ingress.yaml
│ ├── NOTES.txt
│ └── service.yaml
└── values.yaml
2 directories, 7 files
模板
Templates目录下是yaml文件的模板,遵循Go template语法。使用过Hugo的静态网站生成工具的人应该对此很熟悉。
我们查看下deployment.yaml文件的内容。
# cat mychart/templates/deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: {{ template "mychart.fullname" . }}
labels:
app: {{ template "mychart.name" . }}
chart: {{ .Chart.Name }}-{{ .Chart.Version | replace "+" "_" }}
release: {{ .Release.Name }}
heritage: {{ .Release.Service }}
spec:
replicas: {{ .Values.replicaCount }}
template:
metadata:
labels:
app: {{ template "mychart.name" . }}
release: {{ .Release.Name }}
spec:
containers:
- name: {{ .Chart.Name }}
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"
imagePullPolicy: {{ .Values.image.pullPolicy }}
ports:
- containerPort: {{ .Values.service.internalPort }}
livenessProbe:
httpGet:
path: /
port: {{ .Values.service.internalPort }}
readinessProbe:
httpGet:
path: /
port: {{ .Values.service.internalPort }}
resources:
{{ toYaml .Values.resources | indent 12 }}
{{- if .Values.nodeSelector }}
nodeSelector:
{{ toYaml .Values.nodeSelector | indent 8 }}
{{- end }}
这是该应用的Deployment的yaml配置文件,其中的双大括号包扩起来的部分是Go template,其中的Values是在values.yaml文件中定义的:
cat mychart/values.yaml
# Default values for mychart.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
replicaCount: 1
image:
repository: nginx
tag: 1.9
pullPolicy: IfNotPresent
service:
name: nginx
type: ClusterIP
externalPort: 80
internalPort: 80
ingress:
enabled: false
# Used to create an Ingress record.
hosts:
- chart-example.local
annotations:
# kubernetes.io/ingress.class: nginx
# kubernetes.io/tls-acme: "true"
tls:
# Secrets must be manually created in the namespace.
# - secretName: chart-example-tls
# hosts:
# - chart-example.local
resources:
# We usually recommend not to specify default resources and to leave this as a conscious
# choice for the user. This also increases chances charts run on environments with little
# resources, such as Minikube. If you do want to specify resources, uncomment the following
# lines, adjust them as necessary, and remove the curly braces after 'resources:'.
limits:
cpu: 100m
memory: 128Mi
requests:
cpu: 100m
memory: 128Mi
比如在Deployment.yaml中定义的容器镜像image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"其中的:
- .Values.image.repository就是nginx
- .Values.image.tag就是stable
以上两个变量值是在create chart的时候自动生成的默认值。
我们将默认的镜像地址和tag改成我们自己的镜像sz-pg-oam-docker-hub-001.tendcloud.com/library/nginx:1.9。
### 检查配置和模板是否有效
当使用kubernetes部署应用的时候实际上讲templates渲染成最终的kubernetes能够识别的yaml格式。
helm install --dry-run --debug -n string
命令来验证chart配置。该输出中包含了模板的变量配置与最终渲染的yaml文件。
# helm install --dry-run --debug mychart/ --name test
[debug] Created tunnel using local port: '45443'
[debug] SERVER: "localhost:45443"
[debug] Original chart version: ""
[debug] CHART PATH: /root/k8s/helm/mychart
NAME: test
REVISION: 1
RELEASED: Fri Nov 3 13:37:44 2017
CHART: mychart-0.1.0
USER-SUPPLIED VALUES:
{}
COMPUTED VALUES:
image:
pullPolicy: IfNotPresent
repository: nginx
tag: 1.9
ingress:
annotations: null
enabled: false
hosts:
- chart-example.local
tls: null
replicaCount: 1
resources:
limits:
cpu: 100m
memory: 128Mi
requests:
cpu: 100m
memory: 128Mi
service:
externalPort: 80
internalPort: 80
name: nginx
type: ClusterIP
HOOKS:
MANIFEST:
---
# Source: mychart/templates/service.yaml
apiVersion: v1
kind: Service
metadata:
name: test-mychart
labels:
app: mychart
chart: mychart-0.1.0
release: test
heritage: Tiller
spec:
type: ClusterIP
ports:
- port: 80
targetPort: 80
protocol: TCP
name: nginx
selector:
app: mychart
release: test
---
# Source: mychart/templates/deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: test-mychart
labels:
app: mychart
chart: mychart-0.1.0
release: test
heritage: Tiller
spec:
replicas: 1
template:
metadata:
labels:
app: mychart
release: test
spec:
containers:
- name: mychart
image: "nginx:1.9"
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: /
port: 80
readinessProbe:
httpGet:
path: /
port: 80
resources:
limits:
cpu: 100m
memory: 128Mi
requests:
cpu: 100m
memory: 128Mi
我们可以看到Deployment和Service的名字前半截由两个随机的单词组成,最后才是我们在values.yaml中配置的值。
### 部署到kubernetes
在mychart目录下执行下面的命令将nginx部署到kubernetes集群上。
# helm install . --name test
NAME: test
LAST DEPLOYED: Fri Nov 3 14:30:19 2017
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
test-mychart ClusterIP 10.254.242.188 80/TCP 0s
==> v1beta1/Deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
test-mychart 1 0 0 0 0s
NOTES:
1. Get the application URL by running these commands:
export POD_NAME=$(kubectl get pods --namespace default -l "app=mychart,release=test" -o jsonpath="{.items[0].metadata.name}")
echo "Visit http://127.0.0.1:8080 to use your application"
kubectl port-forward $POD_NAME 8080:80
现在nginx已经部署到kubernetes集群上,本地执行提示中的命令在本地主机上访问到nginx实例。
export POD_NAME=$(kubectl get pods --namespace default -l "app=eating-hound-mychart" -o jsonpath="{.items[0].metadata.name}")
echo "Visit http://127.0.0.1:8080 to use your application"
kubectl port-forward $POD_NAME 8080:80
在本地访问http://127.0.0.1:8080即可访问到nginx。
查看部署的relaese
# helm list
NAME REVISION UPDATED STATUS CHART NAMESPACE
peeking-yak 1 Fri Nov 3 15:01:20 2017 DEPLOYED mychart-0.1.0 default
删除部署的release
$ helm delete eating-houndrelease "eating-hound" deleted
打包分享
我们可以修改Chart.yaml中的helm chart配置信息,然后使用下列命令将chart打包成一个压缩文件。
helm package .
打包出mychart-0.1.0.tgz文件。
';
第十五章 使用Prometheus监控Kubernetes集群和应用
最后更新于:2022-04-02 05:07:11
实战 | 使用Prometheus监控Kubernetes集群和应用
====================================
### 一、环境准备
----------------
必要的环境:
* Kubernetes集群,版本1.4以上
* 相关镜像准备:
* gcr.io/google_containers/kube-state-metrics:v0.5.0
* prom/prometheus:v1.7.0
* prom/node-exporter:v0.14.0
* giantswarm/tiny-tools
* dockermuenster/caddy:0.9.3
* grafana/grafana:4.2.0
* quay.io/prometheus/alertmanager:v0.7.1
访问专属harbor下载所有镜像,harbor地址如下:
`http://harbor.ttlinux.com.cn/harbor/sign-in`
* 将上述镜像下载到本地后,使用`docker load`命令加载到*Kubernetes*每台Node节点上。
### 二、Prometheus介绍
---------------------
*Prometheus*由SoundCloud开源的监控系统,它与*Kubernetes*是**CNCF**组织最初的两个项目,
*Prometheus*很大程度上受到了*Google*的*Borgmon*系统启发,与传统的监控方式不同,*Prometheus*使用**拉(Pull)**的方式。
*Prometheus*是一个监控系统,它不仅仅包含了时间序列数据库,还有全套的抓取、检索、绘图、报警的功能。
下图是*Prometheus*的架构图:
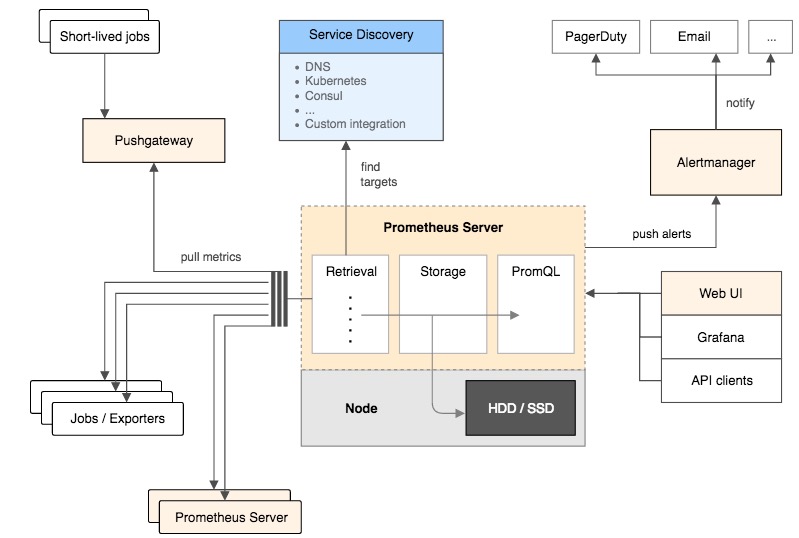
更多细节请访问[*Prometheus*官方网站](https://prometheus.io/docs/introduction/overview/)
### 三、监控组件安装
----------------------
下载*Prometheus*的部署文件:[prometheus配置文件下载](https://gitee.com/huyipow/k8s-deploy.git),使用`kubectl`命令创建*Prometheus*各个组件:
```bash
kubectl create -f manifests-all.yaml
```
执行完成后,*Kubernetes*集群中会出现一个新的*Namespace*: "monitoring",里面有很多组件:
```bash
kubectl get pods,svc,deployment,job,daemonset,ingress --namespace=monitoring
NAME READY STATUS RESTARTS AGE
po/alertmanager-3874563995-fqvet 1/1 Running 1 1d
po/grafana-core-741762473-exne3 1/1 Running 1 2d
po/kube-state-metrics-1381605391-hiqti 1/1 Running 1 1d
po/kube-state-metrics-1381605391-j11e6 1/1 Running 1 2d
po/node-directory-size-metrics-0abcp 2/2 Running 2 16d
po/node-directory-size-metrics-6xmzk 2/2 Running 2 16d
po/node-directory-size-metrics-d5cka 2/2 Running 2 16d
po/node-directory-size-metrics-ojo1x 2/2 Running 2 16d
po/node-directory-size-metrics-rdvn8 2/2 Running 2 16d
po/node-directory-size-metrics-tfqox 2/2 Running 2 16d
po/node-directory-size-metrics-wkec1 2/2 Running 2 16d
po/prometheus-core-4080573952-vu2dg 1/1 Running 49 1d
po/prometheus-node-exporter-1dnvp 1/1 Running 1 16d
po/prometheus-node-exporter-64763 1/1 Running 1 16d
po/prometheus-node-exporter-6h6u0 1/1 Running 1 16d
po/prometheus-node-exporter-i29ic 1/1 Running 1 16d
po/prometheus-node-exporter-i6mvh 1/1 Running 1 16d
po/prometheus-node-exporter-lxqou 1/1 Running 1 16d
po/prometheus-node-exporter-n1n8y 1/1 Running 1 16d
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/alertmanager 192.168.3.247 9093/TCP 16d
svc/grafana 192.168.3.89 3000/TCP 16d
svc/kube-state-metrics 192.168.3.78 8080/TCP 16d
svc/prometheus 192.168.3.174 9090/TCP 16d
svc/prometheus-node-exporter None 9100/TCP 16d
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/alertmanager 1 1 1 1 16d
deploy/grafana-core 1 1 1 1 16d
deploy/kube-state-metrics 2 2 2 2 16d
deploy/prometheus-core 1 1 1 1 16d
NAME DESIRED SUCCESSFUL AGE
jobs/grafana-import-dashboards 1 1 16d
NAME DESIRED CURRENT NODE-SELECTOR AGE
ds/node-directory-size-metrics 7 7 16d
ds/prometheus-node-exporter 7 7 16d
NAME HOSTS ADDRESS PORTS AGE
ing/grafana grafana.yeepay.com 80 16d
```
*manifests-all.yaml*文件中使用30161和30162的*Nodeport*端口作为*Grafana*和*Prometheus* Web界面的访问端口。
### 四、监控初始化
----------------------------------
#### 1、 登录*Grafana*
---------------------
通过[http://${Your_API_SERVER_IP}:30161/]()登录*Grafana*,默认的用户名和密码都是*admin*,登录如下图所示:

#### 2、添加数据源
-------------------
点击左上角图标,找到*DataSource*选项,添加数据源:

#### 3、添加*Prometheus*的数据源
--------------------
将*Prometheus*的作为数据源的相关参数如下图所示:

点击*Save & Test*按钮,保存数据源。
#### 五、监控*Kubernetes*集群
---------------
#### 1、导入模板文件:
--------------------
点击左上角*Grafana*的图标,选在*Dashboard*选项:

点击*Import*导入监控模板:

可以从[这里](https://grafana.com/dashboards)下载各种监控模板,然后使用*Upload*到*Grafana*:

#### 2、Kubernetes集群监控实例
------------

下载此监控模板:[kubernetes-cluster-monitoring-via-prometheus_rev2.json](grafana/kubernetes-cluster-monitoring-via-prometheus_rev2.json)
#### 3、Deployment级别监控实例
------------------

下载此监控模板:[deployment-metrics_rev1.json](grafana/deployment-metrics_rev1.json)
#### 4、Pod级别资源监控实例
-----------------

下载此监控模板:[pod-metrics_rev2.json](grafana/pod-metrics_rev2.json)
#### 5、App级别的资源、请求量监控实例
--------------

下载此监控模板:[kubernetes-apps_rev1.json](grafana/kubernetes-apps_rev1.json)
';
第十四章 部署nginx ingress
最后更新于:2022-04-02 05:07:09
# 如何访问K8S中的服务

# Ingress 介绍
Kubernetes 暴露服务的方式目前只有三种:LoadBlancer Service、NodePort Service、Ingress;前两种估计都应该很熟悉,具体的可以参考下 [这篇文](https://mritd.me/2016/12/06/try-traefik-on-kubernetes//)章;下面详细的唠一下这个 Ingress
# Ingress 是个什么玩意
可能从大致印象上 Ingress 就是能利用 Nginx、Haproxy 啥的负载均衡器暴露集群内服务的工具;那么问题来了,集群内服务想要暴露出去面临着几个问题:
- #### Pod 漂移问题
众所周知 Kubernetes 具有强大的副本控制能力,能保证在任意副本(Pod)挂掉时自动从其他机器启动一个新的,还可以动态扩容等,总之一句话,这个 Pod 可能在任何时刻出现在任何节点上,也可能在任何时刻死在任何节点上;那么自然随着 Pod 的创建和销毁,Pod IP 肯定会动态变化;那么如何把这个动态的 Pod IP 暴露出去?这里借助于 Kubernetes 的 Service 机制,Service 可以以标签的形式选定一组带有指定标签的 Pod,并监控和自动负载他们的 Pod IP,那么我们向外暴露只暴露 Service IP 就行了;这就是 NodePort 模式:即在每个节点上开起一个端口,然后转发到内部 Service IP 上,如下图所示

- #### 端口管理问题
采用 NodePort 方式暴露服务面临一个坑爹的问题是,服务一旦多起来,NodePort 在每个节点上开启的端口会及其庞大,而且难以维护;这时候引出的思考问题是 “能不能使用 Nginx 啥的只监听一个端口,比如 80,然后按照域名向后转发?” 这思路很好,简单的实现就是使用 DaemonSet 在每个 node 上监听 80,然后写好规则,因为 Nginx 外面绑定了宿主机 80 端口(就像 NodePort),本身又在集群内,那么向后直接转发到相应 Service IP 就行了,如下图所示

- #### 域名分配及动态更新问题
从上面的思路,采用 Nginx 似乎已经解决了问题,但是其实这里面有一个很大缺陷:每次有新服务加入怎么改 Nginx 配置?总不能手动改或者来个 Rolling Update 前端 Nginx Pod 吧?这时候 “伟大而又正直勇敢的” Ingress 登场,如果不算上面的 Nginx,Ingress 只有两大组件:Ingress Controller 和 Ingress
Ingress 这个玩意,简单的理解就是 你原来要改 Nginx 配置,然后配置各种域名对应哪个 Service,现在把这个动作抽象出来,变成一个 Ingress 对象,你可以用 yml 创建,每次不要去改 Nginx 了,直接改 yml 然后创建/更新就行了;那么问题来了:”Nginx 咋整?”
Ingress Controller 这东西就是解决 “Nginx 咋整” 的;Ingress Controoler 通过与 Kubernetes API 交互,动态的去感知集群中 Ingress 规则变化,然后读取他,按照他自己模板生成一段 Nginx 配置,再写到 Nginx Pod 里,最后 reload 一下,工作流程如下图

当然在实际应用中,最新版本 Kubernetes 已经将 Nginx 与 Ingress Controller 合并为一个组件,所以 Nginx 无需单独部署,只需要部署 Ingress Controller 即可。
# 怼一个 Nginx Ingress
上面啰嗦了那么多,只是为了讲明白 Ingress 的各种理论概念,下面实际部署很简单
### 配置 ingress RBAC
cat nginx-ingress-controller-rbac.yml
#apiVersion: v1
#kind: Namespace
#metadata:
# name: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: nginx-ingress-serviceaccount
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: nginx-ingress-clusterrole
rules:
- apiGroups:
- ""
resources:
- configmaps
- endpoints
- nodes
- pods
- secrets
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- apiGroups:
- ""
resources:
- services
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- apiGroups:
- "extensions"
resources:
- ingresses/status
verbs:
- update
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: Role
metadata:
name: nginx-ingress-role
namespace: kube-system
rules:
- apiGroups:
- ""
resources:
- configmaps
- pods
- secrets
- namespaces
verbs:
- get
- apiGroups:
- ""
resources:
- configmaps
resourceNames:
# Defaults to "-"
# Here: "-"
# This has to be adapted if you change either parameter
# when launching the nginx-ingress-controller.
- "ingress-controller-leader-nginx"
verbs:
- get
- update
- apiGroups:
- ""
resources:
- configmaps
verbs:
- create
- apiGroups:
- ""
resources:
- endpoints
verbs:
- get
- create
- update
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: nginx-ingress-role-nisa-binding
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: nginx-ingress-role
subjects:
- kind: ServiceAccount
name: nginx-ingress-serviceaccount
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: nginx-ingress-clusterrole-nisa-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: nginx-ingress-clusterrole
subjects:
- kind: ServiceAccount
name: nginx-ingress-serviceaccount
namespace: kube-system
### 部署默认后端
我们知道 前端的 Nginx 最终要负载到后端 service 上,那么如果访问不存在的域名咋整?官方给出的建议是部署一个 默认后端,对于未知请求全部负载到这个默认后端上;这个后端啥也不干,就是返回 404,部署如下
kubectl create -f default-backend.yaml
这个 default-backend.yaml 文件可以在 github [Ingress 仓库](https://github.com/kubernetes/ingress-nginx/tree/master) 找到. 针对官方配置 我们单独添加了 nodeselector 指定,绑定LB地址 以方便DNS 做解析。
cat default-backend.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: default-http-backend
labels:
k8s-app: default-http-backend
namespace: kube-system
spec:
replicas: 1
template:
metadata:
labels:
k8s-app: default-http-backend
spec:
terminationGracePeriodSeconds: 60
containers:
- name: default-http-backend
# Any image is permissable as long as:
# 1. It serves a 404 page at /
# 2. It serves 200 on a /healthz endpoint
image: harbor-demo.dianrong.com/kubernetes/defaultbackend:1.0
livenessProbe:
httpGet:
path: /healthz
port: 8080
scheme: HTTP
initialDelaySeconds: 30
timeoutSeconds: 5
ports:
- containerPort: 8080
resources:
limits:
cpu: 10m
memory: 20Mi
requests:
cpu: 10m
memory: 20Mi
nodeSelector:
kubernetes.io/hostname: 172.16.200.209
---
apiVersion: v1
kind: Service
metadata:
name: default-http-backend
namespace: kube-system
labels:
k8s-app: default-http-backend
spec:
ports:
- port: 80
targetPort: 8080
selector:
k8s-app: default-http-backend
### 部署 Ingress Controller
部署完了后端就得把最重要的组件 Nginx+Ingres Controller(官方统一称为 Ingress Controller) 部署上
kubectl create -f nginx-ingress-controller.yaml
注意: 官方的 Ingress Controller 有个坑,默认注释了hostNetwork 工作方式。以防止端口的在宿主机的冲突。没有绑定到宿主机 80 端口,也就是说前端 Nginx 没有监听宿主机 80 端口(这还玩个卵啊);所以需要把配置搞下来自己加一下 hostNetwork
cat nginx-ingress-controller.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-ingress-controller
labels:
k8s-app: nginx-ingress-controller
namespace: kube-system
spec:
replicas: 1
template:
metadata:
labels:
k8s-app: nginx-ingress-controller
spec:
# hostNetwork makes it possible to use ipv6 and to preserve the source IP correctly regardless of docker configuration
# however, it is not a hard dependency of the nginx-ingress-controller itself and it may cause issues if port 10254 already is taken on the host
# that said, since hostPort is broken on CNI (https://github.com/kubernetes/kubernetes/issues/31307) we have to use hostNetwork where CNI is used
# like with kubeadm
# hostNetwork: true
terminationGracePeriodSeconds: 60
hostNetwork: true
serviceAccountName: nginx-ingress-serviceaccount
containers:
- image: harbor-demo.dianrong.com/kubernetes/nginx-ingress-controller:0.9.0-beta.1
name: nginx-ingress-controller
readinessProbe:
httpGet:
path: /healthz
port: 10254
scheme: HTTP
livenessProbe:
httpGet:
path: /healthz
port: 10254
scheme: HTTP
initialDelaySeconds: 10
timeoutSeconds: 1
ports:
- containerPort: 80
hostPort: 80
- containerPort: 443
hostPort: 443
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
args:
- /nginx-ingress-controller
- --default-backend-service=$(POD_NAMESPACE)/default-http-backend
# - --default-ssl-certificate=$(POD_NAMESPACE)/ingress-secret
nodeSelector:
kubernetes.io/hostname: 172.16.200.102
### 部署 Ingress
从上面可以知道 Ingress 就是个规则,指定哪个域名转发到哪个 Service,所以说首先我们得有个 Service,当然 Service 去哪找这里就不管了;这里默认为已经有了两个可用的 Service,以下以 Dashboard 为例
先写一个 Ingress 文件,语法格式啥的请参考 官方文档,由于我的 Dashboard 都在kube-system 这个命名空间,所以要指定 namespace.
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: dashboard-ingress
namespace: kube-system
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: fox-dashboard.dianrong.com
http:
paths:
- backend:
serviceName: kubernetes-dashboard
servicePort: 80
装逼成功截图如下

### 部署 Ingress TLS
上面已经搞定了 Ingress,下面就顺便把 TLS 怼上;官方给出的样例很简单,大致步骤就两步:创建一个含有证书的 secret、在 Ingress 开启证书;但是我不得不喷一下,文档就提那么一嘴,大坑一堆,比如多域名配置,TLS功能的启动都没。启用tls 需要在 nginx-ingress-controller添加参数,上面的controller以配置好。
--default-ssl-certificate=$(POD_NAMESPACE)/ingress-secret
### 证书格式转换
创建secret 需要使用你的证书文件,官方要求证书的编码需要使用base64。转换方法如下:
证书转换pem 格式:
openssl x509 -inform DER -in cert/doamin.crt -outform PEM -out cert/domain.pem
证书编码转换base64
cat domain.crt | base64 > domain.crt.base64
### 创建 secret ,需要使用base64 编码格式证书。
cat ingress-secret.yml
apiVersion: v1
data:
tls.crt: LS0tLS1CRU
tls.key: LS0tLS1CRU
kind: Secret
metadata:
name: ingress-secret
namespace: kube-system
type: Opaque
其实这个配置比如证书转码啥的没必要手动去做,可以直接使用下面的命令创建,kubectl 将自动为我们完整格式的转换。
kubectl create secret tls ingress-secret --key certs/ttlinux.com.cn-key.pem --cert certs/ttlinux.com.cn.pem
### 重新部署 Ingress
生成完成后需要在 Ingress 中开启 TLS,Ingress 修改后如下
cat dashboard-ingress.yml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: dashboard-ingress
namespace: kube-system
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
tls:
- hosts:
- fox-dashboard.dianrong.com
secretName: ingress-secret
rules:
- host: fox-dashboard.dianrong.com
http:
paths:
- backend:
serviceName: kubernetes-dashboard
servicePort: 80
注意:一个 Ingress 只能使用一个 secret(secretName 段只能有一个),也就是说只能用一个证书,更直白的说就是如果你在一个 Ingress 中配置了多个域名,那么使用 TLS 的话必须保证证书支持该 Ingress 下所有域名;并且这个 secretName 一定要放在上面域名列表最后位置,否则会报错 did not find expected key 无法创建;同时上面的 hosts 段下域名必须跟下面的 rules 中完全匹配
更需要注意一点:之所以这里单独开一段就是因为有大坑;Kubernetes Ingress 默认情况下,当你不配置证书时,会默认给你一个 TLS 证书的,也就是说你 Ingress 中配置错了,比如写了2个 secretName、或者 hosts 段中缺了某个域名,那么对于写了多个 secretName 的情况,所有域名全会走默认证书;对于 hosts 缺了某个域名的情况,缺失的域名将会走默认证书,部署时一定要验证一下证书,不能 “有了就行”;更新 Ingress 证书可能需要等一段时间才会生效
最后重新部署一下即可
kubectl delete -f dashboard-ingress.yml
kubectl create -f dashboard-ingress.yml
部署 TLS 后 80 端口会自动重定向到 443,最终访问截图如下

### ingress 高级用法

- lvs 反向代理到 物理nginx。完成https拆包,继承nginx所有功能
- nginx 反向代理到ingress-control。 ingress-control 有两种部署方式 。
- ingress-control 使用nodePort 方式暴漏服务
- ingress-control 使用hostNetwork 方式暴漏服务
#### 总结分析
1. ingress-control 在自己的所属的namespace=ingress, 是可以夸不同namespace提供反向代理服.
1. 如果需要提供夸NS 访问ingress,先给 ingress-control创建RBAC .
1. ingress-control 使用hostnetwork 模式 性能比使用service nodePort 性能好很多。因为hostnetwork 是直接获取pod 的IP?

';
第十三章 Kubernetes中的角色访问控制机制(RBAC)支持
最后更新于:2022-04-02 05:07:06
## RBAC Support in Kubernetes
Kubernetes 中的 RBAC 支持
> PS:在Kubernetes1.6版本中新增角色访问控制机制(Role-Based Access,RBAC)让集群管理员可以针对特定使用者或服务账号的角色,进行更精确的资源访问控制。在RBAC中,权限与角色相关联,用户通过成为适当角色的成员而得到这些角色的权限。这就极大地简化了权限的管理。在一个组织中,角色是为了完成各种工作而创造,用户则依据它的责任和资格来被指派相应的角色,用户可以很容易地从一个角色被指派到另一个角色。
>
## RBAC vs ABAC
鉴权的作用是,决定一个用户是否有权使用 Kubernetes API 做某些事情。它除了会影响 kubectl 等组件之外,还会对一些运行在集群内部并对集群进行操作的软件产生作用,例如使用了 Kubernetes 插件的 Jenkins,或者是利用 Kubernetes API 进行软件部署的 Helm。ABAC 和 RBAC 都能够对访问策略进行配置。
ABAC(Attribute Based Access Control)本来是不错的概念,但是在 Kubernetes 中的实现比较难于管理和理解(怪我咯),而且需要对 Master 所在节点的 SSH 和文件系统权限,而且要使得对授权的变更成功生效,还需要重新启动 API Server。
而 RBAC 的授权策略可以利用 kubectl 或者 Kubernetes API 直接进行配置。RBAC 可以授权给用户,让用户有权进行授权管理,这样就可以无需接触节点,直接进行授权管理。RBAC 在 Kubernetes 中被映射为 API 资源和操作。
因为 Kubernetes 社区的投入和偏好,相对于 ABAC 而言,RBAC 是更好的选择。
## 基础概念
需要理解 RBAC 一些基础的概念和思路,RBAC 是让用户能够访问 Kubernetes API 资源的授权方式。
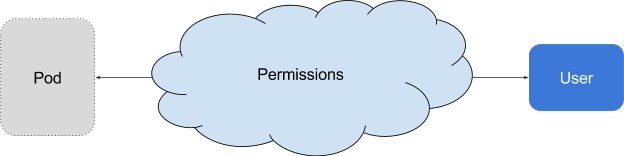
在 RBAC 中定义了两个对象,用于描述在用户和资源之间的连接权限。
## Role and ClusterRole
在 RBAC API 中,Role 表示一组规则权限,权限只会增加(累加权限),不存在一个资源一开始就有很多权限而通过 RBAC 对其进行减少的操作;Role 可以定义在一个 namespace 中,如果想要跨 namespace 则可以创建 ClusterRole。
### 角色
角色是一系列的权限的集合,例如一个角色可以包含读取 Pod 的权限和列出 Pod 的权限, ClusterRole 跟 Role 类似,但是可以在集群中到处使用.
**Role 只能用于授予对单个命名空间中的资源访问权限**, 以下是一个对默认命名空间中 Pods 具有访问权限的样例:
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""] # "" indicates the core API group
resources: ["pods"]
verbs: ["get", "watch", "list"]
ClusterRole 具有与 Role 相同的权限角色控制能力,不同的是 ClusterRole 是集群级别的,ClusterRole 可以用于:
- 集群级别的资源控制(例如 node 访问权限)
- 非资源型 endpoints(例如 /healthz 访问)
- 所有命名空间资源控制(例如 pods)
以下是 ClusterRole 授权某个特定命名空间或全部命名空间(取决于绑定方式)访问 secrets 的样例
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
# "namespace" omitted since ClusterRoles are not namespaced
name: secret-reader
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get", "watch", "list"]
### RoleBinding and ClusterRoleBinding
RoloBinding 可以将角色中定义的权限授予用户或用户组,RoleBinding 包含一组权限列表(subjects),**权限列表中包含有不同形式的待授予权限资源类型(users, groups, or service accounts)**;RoloBinding 同样包含对被 Bind 的 Role 引用;RoleBinding 适用于某个命名空间内授权,而 ClusterRoleBinding 适用于集群范围内的授权。
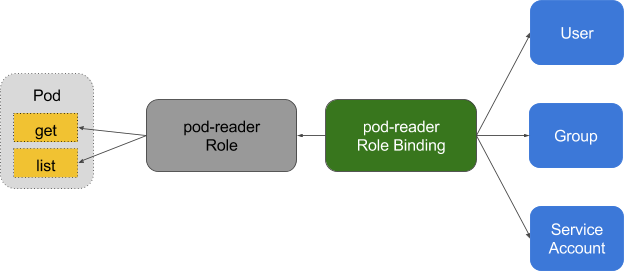
RoleBinding 可以在同一命名空间中引用对应的 Role,以下 RoleBinding 样例将 default 命名空间的 pod-reader Role 授予 jane 用户,此后 jane 用户在 default 命名空间中将具有 pod-reader 的权限
# This role binding allows "jane" to read pods in the "default" namespace.
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: read-pods
namespace: default
subjects:
- kind: User
name: jane
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io
**RoleBinding 同样可以引用 ClusterRole 来对当前 namespace 内用户、用户组或 ServiceAccount 进行授权,这种操作允许集群管理员在整个集群内定义一些通用的 ClusterRole,然后在不同的 namespace 中使用 RoleBinding 来引用**
例如,以下 RoleBinding 引用了一个 ClusterRole,这个 ClusterRole 具有整个集群内对 secrets 的访问权限;但是其授权用户 dave 只能访问 development 空间中的 secrets(因为 RoleBinding 定义在 development 命名空间)
# This role binding allows "dave" to read secrets in the "development" namespace.
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: read-secrets
namespace: development # This only grants permissions within the "development" namespace.
subjects:
- kind: User
name: dave
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.io
最后,使用 ClusterRoleBinding 可以对整个集群中的所有命名空间资源权限进行授权;以下 ClusterRoleBinding 样例展示了授权 manager 组内所有用户在全部命名空间中对 secrets 进行访问
# This cluster role binding allows anyone in the "manager" group to read secrets in any namespace.
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: read-secrets-global
subjects:
- kind: Group
name: manager
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.io
## Referring to Resources
Kubernetes 集群内一些资源一般以其名称字符串来表示,这些字符串一般会在 API 的 URL 地址中出现;同时某些资源也会包含子资源,例如 logs 资源就属于 pods 的子资源,API 中 URL 样例如下
GET /api/v1/namespaces/{namespace}/pods/{name}/log
**如果要在 RBAC 授权模型中控制这些子资源的访问权限,可以通过 / 分隔符来实现**,以下是一个定义 pods 资资源 logs 访问权限的 Role 定义样例
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
namespace: default
name: pod-and-pod-logs-reader
rules:
- apiGroups: [""]
resources: ["pods", "pods/log"]
verbs: ["get", "list"]
具体的资源引用可以通过 resourceNames 来定义,当指定 get、delete、update、patch 四个动词时,可以控制对其目标资源的相应动作;以下为限制一个 subject 对名称为 my-configmap 的 configmap 只能具有 get 和 update 权限的样例
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
namespace: default
name: configmap-updater
rules:
- apiGroups: [""]
resources: ["configmap"]
resourceNames: ["my-configmap"]
verbs: ["update", "get"]
**值得注意的是,当设定了 resourceNames 后,verbs 动词不能指定为 list、watch、create 和 deletecollection;因为这个具体的资源名称不在上面四个动词限定的请求 URL 地址中匹配到,最终会因为 URL 地址不匹配导致 Role 无法创建成功**
## Referring to Subjects
RoleBinding 和 ClusterRoleBinding 可以将 Role 绑定到 Subjects;Subjects 可以是 groups、users 或者 service accounts。
Subjects 中 Users 使用字符串表示,它可以是一个普通的名字字符串,如 “alice”;也可以是 email 格式的邮箱地址,如 “bob@example.com”;甚至是一组字符串形式的数字 ID。Users 的格式必须满足集群管理员配置的验证模块,RBAC 授权系统中没有对其做任何格式限定;但是 Users 的前缀 system: 是系统保留的,集群管理员应该确保普通用户不会使用这个前缀格式
Kubernetes 的 Group 信息目前由 Authenticator 模块提供,Groups 书写格式与 Users 相同,都为一个字符串,并且没有特定的格式要求;同样 system: 前缀为系统保留
具有 system:serviceaccount: 前缀的用户名和 system:serviceaccounts: 前缀的组为 Service Accounts
### Role Binding Examples
以下示例仅展示 RoleBinding 的 subjects 部分
指定一个名字为 alice@example.com 的用户
subjects:
- kind: User
name: "alice@example.com"
apiGroup: rbac.authorization.k8s.io
指定一个名字为 frontend-admins 的组
subjects:
- kind: Group
name: "frontend-admins"
apiGroup: rbac.authorization.k8s.io
指定 kube-system namespace 中默认的 Service Account
subjects:
- kind: ServiceAccount
name: default
namespace: kube-system
指定在 qa namespace 中全部的 Service Account
subjects:
- kind: Group
name: system:serviceaccounts:qa
apiGroup: rbac.authorization.k8s.io
指定全部 namspace 中的全部 Service Account
subjects:
- kind: Group
name: system:serviceaccounts
apiGroup: rbac.authorization.k8s.io
指定全部的 authenticated 用户(1.5+)
subjects:
- kind: Group
name: system:authenticated
apiGroup: rbac.authorization.k8s.io
指定全部的 unauthenticated 用户(1.5+)
subjects:
- kind: Group
name: system:unauthenticated
apiGroup: rbac.authorization.k8s.io
指定全部用户
subjects:
- kind: Group
name: system:authenticated
apiGroup: rbac.authorization.k8s.io
- kind: Group
name: system:unauthenticated
apiGroup: rbac.authorization.k8s.io
';
第十二章 K8S服务组件之kube-dns&Dashboard
最后更新于:2022-04-02 05:07:04
## 实现原理
- kubedns容器的功能:
- 接入SkyDNS,为dnsmasq提供查询服务
- 替换etcd容器,使用树形结构在内存中保存DNS记录
- 通过K8S API监视Service资源变化并更新DNS记录
- 服务10053端口
- 会检查两个容器的健康状态。
- dnsmasq容器的功能:
- Dnsmasq是一款小巧的DNS配置工具
- 在kube-dns插件中的作用
- 通过kubedns容器获取DNS规则,在集群中提供DNS查询服务
- 提供DNS缓存,提高查询性能
- 降低kubedns容器的压力、提高稳定性
- 在kube-dns插件的编排文件中可以看到,dnsmasq通过参数–server=127.0.0.1#10053指定upstream为kubedns。
- exec-healthz容器的功能:
- 在kube-dns插件中提供健康检查功能
- 会对两个容器都进行健康检查,更加完善。
#### 备注:kube-dns组件 [github 下载地址](https://github.com/kubernetes/kubernetes)
### 创建kubedns-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: kube-dns
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: EnsureExists
### 对比 kubedns-dns-controller 配置文件修改
diff kubedns-controller.yaml.sed /root/kubernetes/k8s-deploy/mainifest/dns/kubedns-controller.yaml
58c58
< image: gcr.io/google_containers/k8s-dns-kube-dns-amd64:1.14.5
---
> image: gcr.io/google_containers/k8s-dns-kube-dns-amd64:1.14.4
88c88
< - --domain=$DNS_DOMAIN.
---
> - --domain=cluster.local.
109c109
< image: gcr.io/google_containers/k8s-dns-dnsmasq-nanny-amd64:1.14.5
---
> image: gcr.io/google_containers/k8s-dns-dnsmasq-nanny-amd64:1.14.4
128c128
< - --server=/$DNS_DOMAIN/127.0.0.1#10053
---
> - --server=/cluster.local/127.0.0.1#10053
147c147
< image: gcr.io/google_containers/k8s-dns-sidecar-amd64:1.14.5
---
> image: gcr.io/google_containers/k8s-dns-sidecar-amd64:1.14.4
160,161c160,161
< - --probe=kubedns,127.0.0.1:10053,kubernetes.default.svc.$DNS_DOMAIN,5,A
< - --probe=dnsmasq,127.0.0.1:53,kubernetes.default.svc.$DNS_DOMAIN,5,A
---
> - --probe=kubedns,127.0.0.1:10053,kubernetes.default.svc.cluster.local,5,A
> - --probe=dnsmasq,127.0.0.1:53,kubernetes.default.svc.cluster.local,5,A
### 创建kubedns-dns-controller
# Should keep target in cluster/addons/dns-horizontal-autoscaler/dns-horizontal-autoscaler.yaml
# in sync with this file.
# Warning: This is a file generated from the base underscore template file: kubedns-controller.yaml.base
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: kube-dns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
# replicas: not specified here:
# 1. In order to make Addon Manager do not reconcile this replicas parameter.
# 2. Default is 1.
# 3. Will be tuned in real time if DNS horizontal auto-scaling is turned on.
strategy:
rollingUpdate:
maxSurge: 10%
maxUnavailable: 0
selector:
matchLabels:
k8s-app: kube-dns
template:
metadata:
labels:
k8s-app: kube-dns
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
volumes:
- name: kube-dns-config
configMap:
name: kube-dns
optional: true
containers:
- name: kubedns
image: gcr.io/google_containers/k8s-dns-kube-dns-amd64:1.14.4
resources:
# TODO: Set memory limits when we've profiled the container for large
# clusters, then set request = limit to keep this container in
# guaranteed class. Currently, this container falls into the
# "burstable" category so the kubelet doesn't backoff from restarting it.
limits:
memory: 170Mi
requests:
cpu: 100m
memory: 70Mi
livenessProbe:
httpGet:
path: /healthcheck/kubedns
port: 10054
scheme: HTTP
initialDelaySeconds: 60
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
readinessProbe:
httpGet:
path: /readiness
port: 8081
scheme: HTTP
# we poll on pod startup for the Kubernetes master service and
# only setup the /readiness HTTP server once that's available.
initialDelaySeconds: 3
timeoutSeconds: 5
args:
- --domain=cluster.local.
- --dns-port=10053
- --config-dir=/kube-dns-config
- --v=2
env:
- name: PROMETHEUS_PORT
value: "10055"
ports:
- containerPort: 10053
name: dns-local
protocol: UDP
- containerPort: 10053
name: dns-tcp-local
protocol: TCP
- containerPort: 10055
name: metrics
protocol: TCP
volumeMounts:
- name: kube-dns-config
mountPath: /kube-dns-config
- name: dnsmasq
image: gcr.io/google_containers/k8s-dns-dnsmasq-nanny-amd64:1.14.4
livenessProbe:
httpGet:
path: /healthcheck/dnsmasq
port: 10054
scheme: HTTP
initialDelaySeconds: 60
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
args:
- -v=2
- -logtostderr
- -configDir=/etc/k8s/dns/dnsmasq-nanny
- -restartDnsmasq=true
- --
- -k
- --cache-size=1000
- --log-facility=-
- --server=/cluster.local/127.0.0.1#10053
- --server=/in-addr.arpa/127.0.0.1#10053
- --server=/ip6.arpa/127.0.0.1#10053
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
# see: https://github.com/kubernetes/kubernetes/issues/29055 for details
resources:
requests:
cpu: 150m
memory: 20Mi
volumeMounts:
- name: kube-dns-config
mountPath: /etc/k8s/dns/dnsmasq-nanny
- name: sidecar
image: gcr.io/google_containers/k8s-dns-sidecar-amd64:1.14.4
livenessProbe:
httpGet:
path: /metrics
port: 10054
scheme: HTTP
initialDelaySeconds: 60
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
args:
- --v=2
- --logtostderr
- --probe=kubedns,127.0.0.1:10053,kubernetes.default.svc.cluster.local,5,A
- --probe=dnsmasq,127.0.0.1:53,kubernetes.default.svc.cluster.local,5,A
ports:
- containerPort: 10054
name: metrics
protocol: TCP
resources:
requests:
memory: 20Mi
cpu: 10m
dnsPolicy: Default # Don't use cluster DNS.
serviceAccountName: kube-dns
### 创建 kubedns-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "KubeDNS"
spec:
selector:
k8s-app: kube-dns
clusterIP: 10.254.0.2
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCP
### 创建 kubedns-sa.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-dns
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
## 部署dns-horizontal-autoscaler
创建 dns-horizontal-autoscaler-rbac.yaml
kind: ServiceAccount
apiVersion: v1
metadata:
name: kube-dns-autoscaler
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: system:kube-dns-autoscaler
labels:
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["list"]
- apiGroups: [""]
resources: ["replicationcontrollers/scale"]
verbs: ["get", "update"]
- apiGroups: ["extensions"]
resources: ["deployments/scale", "replicasets/scale"]
verbs: ["get", "update"]
# Remove the configmaps rule once below issue is fixed:
# kubernetes-incubator/cluster-proportional-autoscaler#16
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["get", "create"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: system:kube-dns-autoscaler
labels:
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: kube-dns-autoscaler
namespace: kube-system
roleRef:
kind: ClusterRole
name: system:kube-dns-autoscaler
apiGroup: rbac.authorization.k8s.io
创建 dns-horizontal-autoscaler.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: kube-dns-autoscaler
namespace: kube-system
labels:
k8s-app: kube-dns-autoscaler
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
template:
metadata:
labels:
k8s-app: kube-dns-autoscaler
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
containers:
- name: autoscaler
image: gcr.io/google_containers/cluster-proportional-autoscaler-amd64:1.1.2-r2
resources:
requests:
cpu: "20m"
memory: "10Mi"
command:
- /cluster-proportional-autoscaler
- --namespace=kube-system
- --configmap=kube-dns-autoscaler
# Should keep target in sync with cluster/addons/dns/kubedns-controller.yaml.base
- --target=Deployment/kube-dns
# When cluster is using large nodes(with more cores), "coresPerReplica" should dominate.
# If using small nodes, "nodesPerReplica" should dominate.
- --default-params={"linear":{"coresPerReplica":256,"nodesPerReplica":16,"preventSinglePointFailure":true}}
- --logtostderr=true
- --v=2
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
serviceAccountName: kube-dns-autoscaler
# 创建 dashboard-rbac
apiVersion: v1
kind: ServiceAccount
metadata:
name: dashboard
namespace: kube-system
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: dashboard
subjects:
- kind: ServiceAccount
name: dashboard
namespace: kube-system
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
### 创建 dashboard-controller
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: kubernetes-dashboard
namespace: kube-system
labels:
k8s-app: kubernetes-dashboard
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
selector:
matchLabels:
k8s-app: kubernetes-dashboard
template:
metadata:
labels:
k8s-app: kubernetes-dashboard
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
containers:
- name: kubernetes-dashboard
image: gcr.io/google_containers/kubernetes-dashboard-amd64:v1.6.1
resources:
# keep request = limit to keep this container in guaranteed class
limits:
cpu: 100m
memory: 300Mi
requests:
cpu: 100m
memory: 100Mi
ports:
- containerPort: 9090
args:
- --apiserver-host=http://172.16.200.100:8080
livenessProbe:
httpGet:
path: /
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
### 创建 dashboard-service
apiVersion: v1
kind: Service
metadata:
name: kubernetes-dashboard
namespace: kube-system
labels:
k8s-app: kubernetes-dashboard
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
type: NodePort
selector:
k8s-app: kubernetes-dashboard
ports:
- port: 80
targetPort: 9090
';
第十一章 kubernetes之pod 调度
最后更新于:2022-04-02 05:07:02
# kubernetes pod 调度
### 简述
Kubernetes调度器根据特定的算法与策略将pod调度到工作节点上。在默认情况下,Kubernetes调度器可以满足绝大多数需求,例如调度pod到资源充足的节点上运行,或调度pod分散到不同节点使集群节点资源均衡等。但一些特殊的场景,默认调度算法策略并不能满足实际需求,例如使用者期望按需将某些pod调度到特定硬件节点(数据库服务部署到SSD硬盘机器、CPU/内存密集型服务部署到高配CPU/内存服务器),或就近部署交互频繁的pod(例如同一机器、同一机房、或同一网段等)。
Kubernetes中的调度策略主要分为全局调度与运行时调度2种。其中全局调度策略在调度器启动时配置,而运行时调度策略主要包括选择节点(nodeSelector),节点亲和性(nodeAffinity),pod亲和与反亲和性(podAffinity与podAntiAffinity)。Node Affinity、podAffinity/AntiAffinity以及后文即将介绍的污点(Taints)与容忍(tolerations)等特性,在Kuberntes1.6中均处于Beta阶段。
node 添加标签
kubectl label nodes 172.16.200.101 disktype=ssd
查看node 节点标签(label)
kubectl get node --show-labels
删除一个label
kubectl label node 172.16.200.101 disktype-
修改一个label
# kubectl label node 172.16.200.101 disktype=scsi --overwrite
### 选择节点(nodeselector)
apiVersion: v1
kind: ReplicationController
metadata:
name: redis-master
labels:
name: redis-master
spec:
replicas: 1
selector:
name: redis-master
template:
metadata:
labels:
name: redis-master
spec:
containers:
- name: master
image: kubeguide/redis-master
ports:
- containerPort: 6379
nodeSelector:
disktype: ssd
## 亲和性(Affinity)与非亲和性(anti-affinity)
前面提及的nodeSelector,其仅以一种非常简单的方式、即label强制限制pod调度到指定节点。而亲和性(Affinity)与非亲和性(anti-affinity)则更加灵活的指定pod调度到预期节点上,相比nodeSelector,Affinity与anti-affinity优势体现在:
- 表述语法更加多样化,不再仅受限于强制约束与匹配。
- 调度规则不再是强制约束(hard),取而代之的是软限(soft)或偏好(preference)。
- 指定pod可以和哪些pod部署在同一个/不同拓扑结构下。
亲和性主要分为3种类型:node affinity与inter-pod affinity/anti-affinity,下文会进行详细说明。
### 节点亲和性(Node affinity)
Node affinity在Kubernetes 1.2做为alpha引入,其涵盖了nodeSelector功能,主要分为requiredDuringSchedulingIgnoredDuringExecution与preferredDuringSchedulingIgnoredDuringExecution 2种类型。前者可认为一种强制限制,如果 Node 的标签发生了变化导致其没有符合 Pod 的调度要求节点,那么pod调度就会失败。而后者可认为理解为软限或偏好,同样如果 Node 的标签发生了变化导致其不再符合 pod 的调度要求,pod 依然会调度运行。
Node affinity举例
设置节点label:
kubectl label node 172.16.200.100 cpu=high
kubectl label node 172.16.200.101 cpu=mid
kubectl label node 172.16.200.102 cpu=low
部署pod的预期是到CPU高配的机器上(cpu=high)。
查看满足条件节点:
kubectl get nodes -l 'cpu=high'
redis-master.yaml 文件内容如下
apiVersion: v1
kind: ReplicationController
metadata:
name: redis-master
labels:
name: redis-master
spec:
replicas: 1
selector:
name: redis-master
template:
metadata:
labels:
name: redis-master
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: cpu
operator: In
values:
- high
containers:
- name: master
image: kubeguide/redis-master
ports:
- containerPort: 6379
检查结果符合预期,pod nginx成功部署到非master节点且CPU高配的机器上。
# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
redis-master-lbz9f 1/1 Running 0 11s 10.24.77.4 172.16.200.100
### pod亲和性(Inter-pod affinity)与反亲和性(anti-affinity)
inter-pod affinity与anti-affinity由Kubernetes 1.4引入,当前处于beta阶段,其中podAffinity用于调度pod可以和哪些pod部署在同一拓扑结构之下。而podAntiAffinity相反,其用于规定pod不可以和哪些pod部署在同一拓扑结构下。通过pod affinity与anti-affinity来解决pod和pod之间的关系。
与Node affinity类似,pod affinity与anti-affinity同样分为requiredDuringSchedulingIgnoredDuringExecution and preferredDuringSchedulingIgnoredDuringExecution等2种类型,前者被认为是强制约束,而后者后者可认为理解软限(soft)或偏好(preference)。
pod affinity与anti-affinity举例
本示例中假设部署场景为:期望redis-slave服务与redis-master服务就近部署,而不希望与frontend服务部署同一拓扑结构上。
redis-slave yaml文件部分内容:
apiVersion: v1
kind: ReplicationController
metadata:
name: redis-slave
spec:
replicas: 2
selector:
name: redis-slave
template:
metadata:
name: redis-slave
labels:
name: redis-slave
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: name
operator: In
values:
- redis-master
topologyKey: kubernetes.io/hostname
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: name
operator: In
values:
- frontend
topologyKey: beta.kubernetes.io/os
containers:
- name: redis-slave
image: kubeguide/guestbook-redis-slave
env:
- name: GET_HOSTS_FROM
value: env
ports:
- containerPort: 6379
查看部署结果,redis-slave服务与redis-master部署到了同一台机器,而frontend被部署在其他机器上。
# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
frontend-4nmkz 1/1 Running 0 4m 10.24.51.5 172.16.200.101
frontend-xmjsr 1/1 Running 0 4m 10.24.77.5 172.16.200.100
redis-master-lbz9f 1/1 Running 0 41m 10.24.77.4 172.16.200.100
redis-slave-t9tw4 1/1 Running 3 1m 10.24.77.7 172.16.200.100
redis-slave-zvcrg 1/1 Running 3 1m 10.24.77.6 172.16.200.100
### 亲和性/反亲和性调度策略比较
调度策略 | 匹配标签 | 操作符 | 拓扑域支持 | 调度目标
---|---|---|---|---
nodeAffinity | 主机|In, NotIn, Exists, DoesNotExist, Gt, Lt | 否| pod到指定主机
podAffinity |Pod |In, NotIn, Exists, DoesNotExist| 是 | pod与指定pod同一拓扑域
PodAntiAffinity|Pod| In, NotIn, Exists, DoesNotExist |是|pod与指定pod非同一拓扑域
';
第十章 在kubernetes 部署第一个应用
最后更新于:2022-04-02 05:07:00
# 实例结构
* * * * *

# 创建redis-master-controller.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: redis-master
labels:
name: redis-master
spec:
replicas: 1
selector:
name: redis-master
template:
metadata:
labels:
name: redis-master
spec:
containers:
- name: master
image: kubeguide/redis-master
ports:
- containerPort: 6379
发布到kubernetes集群,自动创建pod
kubectl create -f redis-master-controller.yaml
kubectl get rc
kubectl get pods
# 创建redis-master-service.yaml
apiVersion: v1
kind: Service
metadata:
name: redis-master
labels:
name: redis-master
spec:
ports:
- port: 6379
targetPort: 6379
selector:
name: redis-master
创建service
kubectl create -f redis-master-service.yaml
kubectl get services
# 创建redis-slave-controller.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: redis-slave
spec:
replicas: 2
selector:
name: redis-slave
template:
metadata:
name: redis-slave
labels:
name: redis-slave
spec:
containers:
- name: redis-slave
image: kubeguide/guestbook-redis-slave
env:
- name: GET_HOSTS_FROM
value: env
ports:
- containerPort: 6379
创建 redis-slave
kubectl create -f redis-slave-controller.yaml
kubectl get rc
kubectl get pods
# 创建redis-slave-service.yaml
apiVersion: v1
kind: Service
metadata:
name: redis-slave
labels:
name: redis-slave
spec:
ports:
- port: 6379
selector:
name: redis-slave
创建 redis-slave service
kubectl create -f redis-slave-service.yaml
kubectl get services
# 创建frontend-controller.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: frontend
labels:
name: frontend
spec:
replicas: 3
selector:
name: frontend
template:
metadata:
labels:
name: frontend
spec:
containers:
- name: frontend
image: kubeguide/guestbook-php-frontend
env:
- name: GET_HOSTS_FROM
value: env
ports:
- containerPort: 80
创建
kubectl create -f frontend-controller.yaml
kubectl get rc
kubectl get pods
# 创建frontend-service.yaml
apiVersion: v1
kind: Service
metadata:
name: frontend
labels:
name: frontend
spec:
type: NodePort
ports:
- port: 80
nodePort: 30001
selector:
name: frontend
创建
kubectl create -f frontend-service.yaml
kubectl get services
';
第九章 kubectl 操作示例
最后更新于:2022-04-02 05:06:57
### 创建资源对象
1. 根据yaml 配置文件一次性创建service、rc
` kubectl create -f my-service.yaml -f my-rc.yaml`
2. 查看资源对象
- 查看所有pod 列表
kubectl get pod -n
- 查看RC和service 列表
kubectl get rc,svc
3. 描述资源对象
- 显示Node的详细信息
kubectl describe node
- 显示Pod的详细信息
kubectl describe pod
4. 删除资源对象
- 基于pod.yaml 定义的名称删除pod
kubectl delete -f pod.yaml
- 删除所有包含某个label的pod 和service
kubectl delete pod,svc -l name=
- 删除所有Pod
kubectl delete pod --all
5. 执行容器的命令
- 执行pod 的date 命令
kubectl exec -- date
- 通过bash 获得pod中某个容器的TTY,相当于登陆容器
kubectl exec -it -c -- bash
6. 查看容器的日志
kubectl logs
';
第八章 部署k8s-v1.7.6 node 节点
最后更新于:2022-04-02 05:06:55
### 部署node节点
kubernetes node 节点包含如下组件:
- Flanneld:使用flanneld-0.8 支持阿里云 host-gw模式,以获取最佳性能。
- Docker17.07.0-ce:docker的安装很简单,这里也不说了。
- kubelet
- kube-proxy
- 下面着重讲kubelet和kube-proxy的安装,同时还要将之前安装的flannel集成TLS验证。
注意:每台 node 上都需要安装 flannel,master 节点上可以不必安装。
### 检查目录和文件
我们再检查一下三个节点上,经过前几步操作生成的配置文件。
# ls /etc/kubernetes/ssl/
admin-key.pem admin.pem ca-key.pem ca.pem kube-proxy-key.pem kube-proxy.pem kubernetes-key.pem kubernetes.pem
# ls /etc/kubernetes/
apiserver bootstrap.kubeconfig config controller-manager kube-proxy.kubeconfig scheduler ssl token.csv
### flannel 网络架构图



### 配置安装Flanneld,默认使用yum 安装。需要替换二进制 flanneld
下载flanned-0.8 binary.
yum install flanneld -y
wget https://github.com/coreos/flannel/releases/download/v0.8.0/flanneld-amd64
chmod +x flanneld-amd64
cp flanneld-amd64 /usr/bin/flanneld
service配置文件/usr/lib/systemd/system/flanneld.service
cat /usr/lib/systemd/system/flanneld.service
[Unit]
Description=Flanneld overlay address etcd agent
After=network.target
After=network-online.target
Wants=network-online.target
After=etcd.service
Before=docker.service
[Service]
Type=notify
EnvironmentFile=/etc/sysconfig/flanneld
EnvironmentFile=-/etc/sysconfig/docker-network
ExecStart=/usr/bin/flanneld-start $FLANNEL_OPTIONS
ExecStartPost=/usr/libexec/flannel/mk-docker-opts.sh -k DOCKER_NETWORK_OPTIONS -d /run/flannel/docker
Restart=on-failure
[Install]
WantedBy=multi-user.target
RequiredBy=docker.service
/etc/sysconfig/flanneld配置文件
cat /etc/sysconfig/flanneld
# Flanneld configuration options
# etcd url location. Point this to the server where etcd runs
FLANNEL_ETCD_ENDPOINTS="http://172.16.200.100:2379,http://172.16.200.101:2379,http://172.16.200.102:2379"
# etcd config key. This is the configuration key that flannel queries
# For address range assignment
ETCD_PREFIX="/kube-centos/network"
FLANNEL_ETCD_KEY="/kube-centos/network"
ACCESS_KEY_ID=XXXXXXX
ACCESS_KEY_SECRET=XXXXXXX
# Any additional options that you want to pass
#FLANNEL_OPTIONS=" -iface=eth0 -log_dir=/data/logs/kubernetes --logtostderr=false --v=2"
#FLANNEL_OPTIONS="-etcd-cafile=/etc/kubernetes/ssl/ca.pem -etcd-certfile=/etc/kubernetes/ssl/kubernetes.pem -etcd-keyfile=/etc/kubernetes/ssl/kubernetes-key.pem"
- 设置etcd网络,主要是flannel用于分别docker的网络,‘/coreos.com/network/config’ 这个字段必须与flannel中的"FLANNEL_ETCD_KEY="/coreos.com/network" 保持一致
- 阿里云VPN 网络模式详细配置可参考 [AliCloud VPC Backend for Flannel](https://github.com/coreos/flannel/blob/master/Documentation/alicloud-vpc-backend.md)
在etcd中创建网络配置
执行下面的命令为docker分配IP地址段。
etcdctl mkdir /kube-centos/network
etcdctl mk /kube-centos/network/config '{"Network":"10.24.0.0/16","Backend":{"Type":"ali-vpc"}}'
etcdctl mk /kube-centos/network/config '{"Network":"10.24.0.0/16","Backend":{"Type":"host-gw"}}'
### 安装kubernetes-cni 依赖kublete 强制安装
rpm -ivh --force kubernetes-cni-0.5.1-0.x86_64.rpm --nodeps
配置cni 插件
mkdir -p /etc/cni/net.d
cat > /etc/cni/net.d/10-flannel.conf << EOF
{
"name": "cbr0",
"type": "flannel",
"delegate": {
"isDefaultGateway": true,
"forceAddress": true,
"bridge": "cni0",
"mtu": 1500
}
}
EOF
**cat /etc/sysctl.d/k8s.conf 内核参数修改**
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
sysctl -p /etc/sysctl.d/k8s.conf
**查看获取的地址段**
#etcdctl ls /kube-centos/network/subnets
/kube-centos/network/subnets/10.24.15.0-24
/kube-centos/network/subnets/10.24.38.0-24
### 安装和配置 kubelet
kubelet 启动时向 kube-apiserver 发送 TLS bootstrapping 请求,需要先将 bootstrap token 文件中的 kubelet-bootstrap 用户赋予 system:node-bootstrapper cluster 角色(role), 然后 kubelet 才能有权限创建认证请求(certificate signing requests):
cd /etc/kubernetes
kubectl create clusterrolebinding kubelet-bootstrap \
--clusterrole=system:node-bootstrapper \
--user=kubelet-bootstrap
**创建 kubelet 的service配置文件**
# cat /usr/lib/systemd/system/kubelet.service
[Unit]
Description=Kubernetes Kubelet Server
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=docker.service
Requires=docker.service
[Service]
WorkingDirectory=/var/lib/kubelet
EnvironmentFile=-/etc/kubernetes/config
EnvironmentFile=-/etc/kubernetes/kubelet
ExecStart=/usr/local/kubernetes/server/bin/kubelet \
$KUBE_LOGTOSTDERR \
$KUBE_LOG_LEVEL \
$KUBELET_API_SERVER \
$KUBELET_ADDRESS \
$KUBELET_PORT \
$KUBELET_HOSTNAME \
$KUBE_ALLOW_PRIV \
$KUBELET_POD_INFRA_CONTAINER \
$KUBELET_ARGS
Restart=on-failure
[Install]
WantedBy=multi-user.target
> kubelet的配置文件/etc/kubernetes/kubelet。其中的IP地址更改为你的每台node节点的IP地址。
> 注意:/var/lib/kubelet需要手动创建。
**kubelet 配置文件**
cat > /etc/kubernetes/kubelet << EOF
###
### kubernetes kubelet (minion) config
##
### The address for the info server to serve on (set to 0.0.0.0 or "" for all interfaces)
KUBELET_ADDRESS="--address=172.16.200.100"
##
### The port for the info server to serve on
##KUBELET_PORT="--port=10250"
##
### You may leave this blank to use the actual hostname
KUBELET_HOSTNAME="--hostname-override=172.16.200.100"
##
### location of the api-server
#KUBELET_API_SERVER="--api-servers=http://172.16.200.100:8080"
##
### pod infrastructure container
KUBELET_POD_INFRA_CONTAINER="--pod-infra-container-image=gcr.io/google_containers/pause:latest"
##
### Add your own!
KUBELET_ARGS="--cgroup-driver=systemd --cluster-dns=10.254.0.2 --experimental-bootstrap-kubeconfig=/etc/kubernetes/bootstrap.kubeconfig --kubeconfig=/etc/kubernetes/kubelet.kubeconfig --require-kubeconfig --cert-dir=/etc/kubernetes/ssl --cluster-domain=cluster.local --hairpin-mode promiscuous-bridge --serialize-image-pulls=false --network-plugin=cni --cni-conf-dir=/etc/cni/net.d/ --cni-bin-dir=/opt/cni/bin/ --network-plugin-mtu=1500 --log-dir=/data/logs/kubernetes/ --v=2 --logtostderr=false"
EOF
- --address 不能设置为 127.0.0.1,否则后续 Pods 访问 kubelet 的 API 接口时会失败,因为 Pods 访问的 127.0.0.1 指向自己而不是 kubelet;
- 如果设置了 --hostname-override 选项,则 kube-proxy 也需要设置该选项,否则会出现找不到 Node 的情况;
- --cgroup-driver 配置成 systemd,不要使用cgroup,否则在 CentOS 系统中 kubelet 讲启动失败。docker修改cgroup启动参数 --exec-opt native.cgroupdriver=systemd
- --experimental-bootstrap-kubeconfig 指向 bootstrap kubeconfig 文件,kubelet 使用该文件中的用户名和 token 向 kube-apiserver 发送 TLS Bootstrapping 请求;
- 管理员通过了 CSR 请求后,kubelet 自动在 --cert-dir 目录创建证书和私钥文件(kubelet-client.crt 和 kubelet-client.key),然后写入 --kubeconfig 文件;
- 建议在 --kubeconfig 配置文件中指定 kube-apiserver 地址,如果未指定 --api-servers 选项,则必须指定 --require-kubeconfig 选项后才从配置文件中读取 kube-apiserver 的地址,否则 kubelet 启动后将找不到 kube-apiserver (日志中提示未找到 API Server),kubectl get nodes 不会返回对应的 Node 信息;
- --cluster-dns 指定 kubedns 的 Service IP(可以先分配,后续创建 kubedns 服务时指定该 IP),--cluster-domain 指定域名后缀,这两个参数同时指定后才会生效;
- --cluster-domain 指定 pod 启动时 /etc/resolve.conf 文件中的 search domain ,起初我们将其配置成了 cluster.local.,这样在解析 service 的 DNS 名称时是正常的,可是在解析 headless service 中的 FQDN pod name 的时候却错误,因此我们将其修改为 cluster.local,去掉嘴后面的 ”点号“ 就可以解决该问题,关于 kubernetes 中的域名/服务名称解析请参见我的另一篇文章。
- --kubeconfig=/etc/kubernetes/kubelet.kubeconfig中指定的kubelet.kubeconfig文件在第一次启动kubelet之前并不存在,请看下文,当通过CSR请求后会自动生成kubelet.kubeconfig文件,如果你的节点上已经生成了~/.kube/config文件,你可以将该文件拷贝到该路径下,并重命名为kubelet.kubeconfig,所有node节点可以共用同一个kubelet.kubeconfig文件,这样新添加的节点就不需要再创建CSR请求就能自动添加到kubernetes集群中。同样,在任意能够访问到kubernetes集群的主机上使用kubectl --kubeconfig命令操作集群时,只要使用~/.kube/config文件就可以通过权限认证,因为这里面已经有认证信息并认为你是admin用户,对集群拥有所有权限。
- KUBELET_POD_INFRA_CONTAINER 是基础镜像容器,需要翻墙下载。
- --network-plugin=cni 启用cni 管理docker 网络
- -cni-conf-dir=/etc/cni/net.d/ CNI 配置路径
- 注意 需要修改docker cgroup 驱动方式: --exec-opt native.cgroupdriver=systemd
> kubelet 依赖启动配置文件 bootstrap.kubeconfig
systemctl daemon-reload
systemctl enable kubelet
systemctl start kubelet
systemctl status kubelet
通过 kublet 的 TLS 证书请求
kubelet 首次启动时向 kube-apiserver 发送证书签名请求,必须通过后 kubernetes 系统才会将该 Node 加入到集群。
查看未授权的 CSR 请求
# kubectl get csr
NAME AGE REQUESTOR CONDITION
node-csr-8I8soRqLhxiH2nThkgUsL2oIaKyh15AuNOVgJddWBqA 2s kubelet-bootstrap Pending
node-csr-9byGSZPAX0eT60qME8_2PIZ0Q4GkDTFG-1tvPhVaH40 49d kubelet-bootstrap Approved,Issued
node-csr-DpvCEHT98ARavxjdLpa_yl_aNGddNTAX07MEVSAjnUM 4d kubelet-bootstrap Approved,Issued
node-csr-nAOtjarW3mJ3boQ3AtaeGCbQYbW_jo8AGscFnk1uxqw 8d kubelet-bootstrap Approved,Issued
node-csr-sgI8CYnTFQZqaZg9wdJP6OabqBiNA0DpZ5Z0wCCl4bQ 54d kubelet-bootstrap Approved,Issued
通过 CSR 请求
kubectl certificate approve node-csr-8I8soRqLhxiH2nThkgUsL2oIaKyh15AuNOVgJddWBqA
查看 通过的node
kubectl get node
NAME STATUS AGE VERSION
172.16.200.206 Ready 11m v1.7.6
172.16.200.209 Ready 49d v1.7.6
172.16.200.216 Ready 4d v1.7.6
自动生成了 kubelet.kubeconfig 文件和公私钥
ls -l /etc/kubernetes/kubelet.kubeconfig
> 注意:假如你更新kubernetes的证书,只要没有更新token.csv,当重启kubelet后,该node就会自动加入到kuberentes集群中,而不会重新发送certificaterequest,也不需要在master节点上执行kubectl certificate approve操作。前提是不要删除node节点上的/etc/kubernetes/ssl/kubelet*和/etc/kubernetes/kubelet.kubeconfig文件。否则kubelet启动时会提示找不到证书而失败。
### 配置 kube-proxy
创建 kube-proxy 的service配置文件
文件路径/usr/lib/systemd/system/kube-proxy.service
cat > /usr/lib/systemd/system/kube-proxy.service << EOF
[Unit]
Description=Kubernetes Kube-Proxy Server
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=network.target
[Service]
EnvironmentFile=-/etc/kubernetes/config
EnvironmentFile=-/etc/kubernetes/proxy
ExecStart=/usr/local/kubernetes/server/bin/kube-proxy \
$KUBE_LOGTOSTDERR \
$KUBE_LOG_LEVEL \
$KUBE_MASTER \
$KUBE_PROXY_ARGS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
kube-proxy配置文件/etc/kubernetes/proxy
cat > /etc/kubernetes/proxy << EOF
###
# kubernetes proxy config
# default config should be adequate
# Add your own!
KUBE_PROXY_ARGS="--bind-address=172.16.200.100 --hostname-override=172.16.200.100 --kube-api-burst=50 --kube-api-qps=20 --master=http://172.16.200.100:8080 --kubeconfig=/etc/kubernetes/kube-proxy.kubeconfig --cluster-cidr=10.254.0.0/16 --log-dir=/data/logs/kubernetes/ --v=2 --logtostderr=false"
EOF
- --hostname-override 参数值必须与 kubelet 的值一致,否则 kube-proxy 启动后会找不到该 Node,从而不会创建任何 iptables 规则;
- kube-proxy 根据 --cluster-cidr 判断集群内部和外部流量,指定 --cluster-cidr 或 --masquerade-all 选项后 kube-proxy 才会对访问 Service IP 的请求做 SNAT;
- --kubeconfig 指定的配置文件嵌入了 kube-apiserver 的地址、用户名、证书、秘钥等请求和认证信息;
- 预定义的 RoleBinding cluster-admin 将User system:kube-proxy 与 Role system:node-proxier 绑定,该 Role 授予了调用 kube-apiserver Proxy 相关 API 的权限;
-
### 启动 kube-proxy
systemctl daemon-reload
systemctl enable kube-proxy
systemctl start kube-proxy
systemctl status kube-proxy
';
第七章 部署k8s-master-v1.7.6节点
最后更新于:2022-04-02 05:06:53
### kubernetes master 节点包含的组件:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
目前这三个组件需要部署在同一台机器上。
- kube-scheduler、kube-controller-manager 和 kube-apiserver 三者的功能紧密相关;
- 同时只能有一个 kube-scheduler、kube-controller-manager 进程处于工作状态,如果运行多个,则需要通过选举产生一个 leader;
### 验证TLS 证书文件及token.csv文件
pem和token.csv证书文件我们在TLS证书和秘钥这一步中已经创建过了。我们再检查一下。
ls /etc/kubernetes/ssl
admin-key.pem admin.pem ca-key.pem ca.pem kube-proxy-key.pem kube-proxy.pem kubernetes-key.pem kubernetes.pem
ls /etc/kubernetes/token.csv
### 下载最新版本的二进制文件
从 [github release](https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG.md) 页面 下载发布版 tarball,解压后再执行下载脚本
wget https://dl.k8s.io/v1.7.6/kubernetes-server-linux-amd64.tar.gz
tar xf /root/k8s/kubernetes-server-linux-amd64.tar.gz -C /usr/local/
cat > /etc/profile.d/kube-apiserver.sh << EOF
export PATH=/usr/local/kubernetes/server/bin:$PATH
EOF
### 配置和启动 kube-apiserver
serivce配置文件/usr/lib/systemd/system/kube-apiserver.service内容
cat /usr/lib/systemd/system/kube-apiserver.service
[Unit]
Description=Kubernetes API Service
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=network.target
After=etcd.service
[Service]
EnvironmentFile=-/etc/kubernetes/config
EnvironmentFile=-/etc/kubernetes/apiserver
ExecStart=/usr/local/kubernetes/server/bin/kube-apiserver \
$KUBE_LOGTOSTDERR \
$KUBE_LOG_LEVEL \
$KUBE_ETCD_SERVERS \
$KUBE_API_ADDRESS \
$KUBE_API_PORT \
$KUBELET_PORT \
$KUBE_ALLOW_PRIV \
$KUBE_SERVICE_ADDRESSES \
$KUBE_ADMISSION_CONTROL \
$KUBE_API_ARGS
Restart=on-failure
Type=notify
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
#### /etc/kubernetes/config文件的内容为:
cat config
###
# kubernetes system config
#
# The following values are used to configure various aspects of all
# kubernetes services, including
#
# kube-apiserver.service
# kube-controller-manager.service
# kube-scheduler.service
# kubelet.service
# kube-proxy.service
# logging to stderr means we get it in the systemd journal
KUBE_LOGTOSTDERR="--logtostderr=true"
# journal message level, 0 is debug
KUBE_LOG_LEVEL="--v=0"
# Should this cluster be allowed to run privileged docker containers
KUBE_ALLOW_PRIV="--allow-privileged=true"
# How the controller-manager, scheduler, and proxy find the apiserver
#KUBE_MASTER="--master=http://sz-pg-oam-docker-test-001.tendcloud.com:8080"
KUBE_MASTER="--master=http://172.16.200.216:8080"
> 注意:该配置文件同时被kube-apiserver、kube-controller-manager、kube-scheduler、kubelet、kube-proxy使用。
#### apiserver配置文件/etc/kubernetes/apiserver内容为:
cat apiserver
###
## kubernetes system config
##
## The following values are used to configure the kube-apiserver
##
#
## The address on the local server to listen to.
#KUBE_API_ADDRESS="--insecure-bind-address=sz-pg-oam-docker-test-001.tendcloud.com"
KUBE_API_ADDRESS="--advertise-address=172.16.200.216 --bind-address=172.16.200.216 --insecure-bind-address=172.16.200.216"
#
## The port on the local server to listen on.
#KUBE_API_PORT="--port=8080"
#
## Port minions listen on
#KUBELET_PORT="--kubelet-port=10250"
#
## Comma separated list of nodes in the etcd cluster
KUBE_ETCD_SERVERS="--etcd-servers=http://172.16.200.100:2379,http://172.16.200.101:2379,http://172.16.200.102:2379"
#
## Address range to use for services
KUBE_SERVICE_ADDRESSES="--service-cluster-ip-range=10.254.0.0/16"
#
## default admission control policies
KUBE_ADMISSION_CONTROL="--admission-control=ServiceAccount,NamespaceLifecycle,NamespaceExists,LimitRanger,ResourceQuota"
#
## Add your own!
KUBE_API_ARGS="--authorization-mode=RBAC --runtime-config=rbac.authorization.k8s.io/v1beta1 --kubelet-https=true --experimental-bootstrap-token-auth --token-auth-file=/etc/kubernetes/token.csv --service-node-port-range=30000-32767 --tls-cert-file=/etc/kubernetes/ssl/kubernetes.pem --tls-private-key-file=/etc/kubernetes/ssl/kubernetes-key.pem --client-ca-file=/etc/kubernetes/ssl/ca.pem --service-account-key-file=/etc/kubernetes/ssl/ca-key.pem --etcd-cafile=/etc/kubernetes/ssl/ca.pem --etcd-certfile=/etc/kubernetes/ssl/kubernetes.pem --etcd-keyfile=/etc/kubernetes/ssl/kubernetes-key.pem --enable-swagger-ui=true --apiserver-count=3 --audit-log-maxage=30 --audit-log-maxbackup=3 --audit-log-maxsize=100 --audit-log-path=/var/lib/audit.log --event-ttl=1h --log-dir=/data/logs/kubernetes/ --v=2 --logtostderr=false"
- --authorization-mode=RBAC 指定在安全端口使用 RBAC 授权模式,拒绝未通过授权的请求;
- kube-scheduler、kube-controller-manager 一般和 kube-apiserver 部署在同一台机器上,它们使用非安全端口和 kube-apiserver通信;
- kubelet、kube-proxy、kubectl 部署在其它 Node 节点上,如果通过安全端口访问 kube-apiserver,则必须先通过 TLS 证书认证,再通过 RBAC 授权;
- kube-proxy、kubectl 通过在使用的证书里指定相关的 User、Group 来达到通过 RBAC 授权的目的;
- 如果使用了 kubelet TLS Boostrap 机制,则不能再指定 --kubelet-certificate-authority、--kubelet-client-certificate 和 --kubelet-client-key 选项,否则后续 kube-apiserver 校验 kubelet 证书时出现 ”x509: certificate signed by unknown authority“ 错误;
- --admission-control 值必须包含 ServiceAccount;
- --bind-address 不能为 127.0.0.1;
- runtime-config配置为rbac.authorization.k8s.io/v1beta1,表示运行时的apiVersion;
- --service-cluster-ip-range 指定 Service Cluster IP 地址段,该地址段不能路由可达;
- 缺省情况下 kubernetes 对象保存在 etcd /registry 路径下,可以通过 --etcd-prefix 参数进行调整;
-
#### 启动kube-apiserver
systemctl daemon-reload
systemctl enable kube-apiserver
systemctl start kube-apiserver
systemctl status kube-apiserver
### 配置和启动 kube-controller-manager
创建 kube-controller-manager的serivce配置文件
cat /usr/lib/systemd/system/kube-controller-manager.service
Description=Kubernetes Controller Manager
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
EnvironmentFile=-/etc/kubernetes/config
EnvironmentFile=-/etc/kubernetes/controller-manager
ExecStart=/usr/local/kubernetes/server/bin/kube-controller-manager \
$KUBE_LOGTOSTDERR \
$KUBE_LOG_LEVEL \
$KUBE_MASTER \
$KUBE_CONTROLLER_MANAGER_ARGS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
配置文件/etc/kubernetes/controller-manager
cat controller-manager
###
# The following values are used to configure the kubernetes controller-manager
# defaults from config and apiserver should be adequate
# Add your own!
KUBE_CONTROLLER_MANAGER_ARGS="--address=127.0.0.1 --service-cluster-ip-range=10.254.0.0/16 --cluster-name=kubernetes --cluster-signing-cert-file=/etc/kubernetes/ssl/ca.pem --cluster-signing-key-file=/etc/kubernetes/ssl/ca-key.pem --service-account-private-key-file=/etc/kubernetes/ssl/ca-key.pem --root-ca-file=/etc/kubernetes/ssl/ca.pem --leader-elect=true --log-dir=/data/logs/kubernetes/ --v=2 --logtostderr=false"
---
--service-cluster-ip-range 参数指定 Cluster 中 Service 的CIDR范围,该网络在各 Node 间必须路由不可达,必须和 kube-apiserver 中的参数一致;
--cluster-signing-* 指定的证书和私钥文件用来签名为 TLS BootStrap 创建的证书和私钥;
--root-ca-file 用来对 kube-apiserver 证书进行校验,指定该参数后,才会在Pod 容器的 ServiceAccount 中放置该 CA 证书文件;
--address 值必须为 127.0.0.1,因为当前 kube-apiserver 期望 scheduler 和 controller-manager 在同一台机器,否则机器不能选举
--leader-elect=true 允许集群选举
### 启动 kube-controller-manager
systemctl daemon-reload
systemctl enable kube-controller-manager
systemctl start kube-controller-manager
### 配置和启动 kube-scheduler
创建 kube-scheduler的serivce配置文件
cat /usr/lib/systemd/system/kube-scheduler.service
[Unit]
Description=Kubernetes Scheduler Plugin
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
EnvironmentFile=-/etc/kubernetes/config
EnvironmentFile=-/etc/kubernetes/scheduler
ExecStart=/usr/local/kubernetes/server/bin/kube-scheduler \
$KUBE_LOGTOSTDERR \
$KUBE_LOG_LEVEL \
$KUBE_MASTER \
$KUBE_SCHEDULER_ARGS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
kube-scheduler配置文件
###
# kubernetes scheduler config
# default config should be adequate
# Add your own!
KUBE_SCHEDULER_ARGS="--leader-elect=true --address=127.0.0.1 --log-dir=/data/logs/kubernetes/ --v=2 --logtostderr=false"
EOF
- --address 值必须为 127.0.0.1,因为当前 kube-apiserver 期望 scheduler 和 controller-manager 在同一台机器;
### 启动 kube-scheduler
systemctl daemon-reload
systemctl enable kube-scheduler
systemctl start kube-scheduler
### 验证 master 节点功能
kubectl get componentstatuses
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health": "true"}
etcd-1 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}
';
第六章 etcd 集群部署
最后更新于:2022-04-02 05:06:51
### 概述
etcd 是一个分布式一致性k-v存储系统,可用于服务注册发现与共享配置,具有以下优点。
- 简单 : 相比于晦涩难懂的paxos算法,etcd基于相对简单且易实现的raft算法实现一致性,并通过gRPC提供接口调用
- 安全:支持TLS通信,并可以针对不同的用户进行对key的读写控制
- 高性能:10,000 /秒的写性能
> etcd release [下载地址](https://github.com/coreos/etcd/releases/) 页面下载最新版本的二进制文件
### etcd 依赖go,需要先到官方站点下载最新go
tar -xf go1.8.3.linux-amd64.tar.gz -C /usr/local/
cat > /etc/profile.d/go.sh < /etc/profile.d/etcd.sh < etcd-v3.2.1 有bug 解决方法参考链接 [link](http://dockone.io/question/1408)
### 修改/etc/etcd/etcd.conf 注意修改每个node ip
[member]
ETCD_NAME=cd-test-001.drcloud.com
ETCD_DATA_DIR="/data/lib/etcd/"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_ADVERTISE_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://172.16.200.100:2380"
[cluster]
ETCD_INITIAL_CLUSTER="cd-test-001.drcloud.com=http://172.16.200.100:2380,cd-test-002.drcloud.com=http://172.16.200.101:2380,cd-test-003.drcloud.com=http://172.16.200.102:2380"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
### 参数说明
name 节点名称
data-dir 指定节点的数据存储目录
listen-peer-urls 监听URL,用于与其他节点通讯
listen-client-urls 对外提供服务的地址:比如 http://ip:2379,http://127.0.0.1:2379 ,客户端会连接到这里和 etcd 交互
initial-advertise-peer-urls 该节点member(同伴)监听地址,这个值会告诉集群中其他节点
initial-cluster 集群中所有节点的信息,格式为 node1=http://ip1:2380,node2=http://ip2:2380,… 。注意:这里的 node1 是节点的 --name 指定的名字;后面的 ip1:2380 是 --initial-advertise-peer-urls 指定的值
initial-cluster-state 新建集群的时候,这个值为 new ;假如已经存在的集群,这个值为 existing
initial-cluster-token 创建集群的 token,这个值每个集群保持唯一。这样的话,如果你要重新创建集群,即使配置和之前一样,也会再次生成新的集群和节点 uuid;否则会导致多个集群之间的冲突,造成未知的错误
advertise-client-urls 对外公告的该节点客户端监听地址,这个值会告诉集群中其他节点
### systemd 启动配置文件, 默认rpm 安装的
cat > /usr/lib/systemd/system/etcd.service << EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
WorkingDirectory=/data/lib/etcd/
EnvironmentFile=-/etc/etcd/etcd.conf
User=etcd
# set GOMAXPROCS to number of processors
ExecStart=/bin/bash -c "GOMAXPROCS=$(nproc) /usr/local/etcd/etcd --name=\"${ETCD_NAME}\" --data-dir=\"${ETCD_DATA_DIR}\" --listen-client-urls=\"${ETCD_LISTEN_CLIENT_URLS}\" --initial-advertise-peer-urls=\"${ETCD_INITIAL_ADVERTISE_PEER_URLS}\" --listen-peer-urls=\"${ETCD_LISTEN_PEER_URLS}\" --initial-cluster=\"${ETCD_INITIAL_CLUSTER}\" --advertise-client-urls=\"${ETCD_ADVERTISE_CLIENT_URLS}\" --initial-cluster-token=\"${ETCD_INITIAL_CLUSTER_TOKEN}\" --initial-cluster-state=\"${ETCD_INITIAL_CLUSTER_STATE}\""
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
### 配置防火墙规则
firewall-cmd --zone=public --add-port=2379/tcp --permanent
firewall-cmd --zone=public --add-port=2380/tcp --permanent
### etcd集群运行过程中的改配
主要用于故障节点替换,集群扩容需求。
集群运行过程中的改配不区分static和discovery方式。
1、替换的步骤:
比如集群中某一member重启后仍不能恢复时,就需要替换一个新member进来。
a、从集群中删除老member
etcdctl member remove 1609b5a3a078c227
b、向集群中新增新member
etcdctl member add
例子:敲命令
etcdctl member add etcd2 http://192.168.2.56:2380
后返回如下信息
Added member named etcd2 with ID b7d510356ee2e68b to cluster
ETCD_NAME="etcd2"
ETCD_INITIAL_CLUSTER="etcd0=http://192.168.2.55:2380,etcd2=http://192.168.2.56:2380,etcd1=http://192.168.2.54:2380"
ETCD_INITIAL_CLUSTER_STATE="existing"
c、删除老节点data目录
如果不删除,启动后节点仍旧沿用之前的老id, 其他正常节点不认,不能建立联系
d、在新member上启动etcd进程
2、扩容的步骤:
执行上面第b,d两步即可。
### etcd 集群健康检查
curl http://172.16.200.206:2379/health
etcdctl cluster-health
member 37460b828c8625a0 is healthy: got healthy result from http://0.0.0.0:2379
member 52b98a730bb6d77c is healthy: got healthy result from http://172.16.200.208:2379
member 7f453c22b9758161 is healthy: got healthy result from http://172.16.200.206:2379
';
第五章 创建kubeconfig 文件
最后更新于:2022-04-02 05:06:48
# 创建 kubeconfig 文件
> 提示:请先参考 安装kubectl命令行工具,先在 master 节点上安装 kubectl 然后再进行下面的操作。
> kubelet、kube-proxy 等 Node 机器上的进程与 Master 机器的 kube-apiserver 进程通信时需要认证和授权;
kubernetes 1.4 开始支持由 kube-apiserver 为客户端生成 TLS 证书的 TLS Bootstrapping 功能,这样就不需要为每个客户端生成证书了;该功能当前仅支持为 kubelet 生成证书;
因为我的master节点和node节点复用,所有在这一步其实已经安装了kubectl。参考安装kubectl命令行工具。
以下操作只需要在master节点上执行,生成的*.kubeconfig文件可以直接拷贝到node节点的/etc/kubernetes目录下
### 创建 TLS Bootstrapping Token
#### Token auth file
Token可以是任意的包涵128 bit的字符串,可以使用安全的随机数发生器生成。
export BOOTSTRAP_TOKEN=$(head -c 16 /dev/urandom | od -An -t x | tr -d ' ')
cat > token.csv < 后三行是一句,直接复制上面的脚本运行即可。
> **==注意==:在进行后续操作前请检查 token.csv 文件,确认其中的 ${BOOTSTRAP_TOKEN} 环境变量已经被真实的值替换。**
BOOTSTRAP_TOKEN 将被写入到 kube-apiserver 使用的 token.csv 文件和 kubelet 使用的 bootstrap.kubeconfig 文件,如果后续重新生成了 BOOTSTRAP_TOKEN,则需要:
1. 更新 token.csv 文件,分发到所有机器 (master 和 node)的 /etc/kubernetes/ 目录下,分发到node节点上非必需;
1. 重新生成 bootstrap.kubeconfig 文件,分发到所有 node 机器的 /etc/kubernetes/ 目录下;
1. 重启 kube-apiserver 和 kubelet 进程;
1. 重新 approve kubelet 的 csr 请求;
cp token.csv /etc/kubernetes/
### 创建 kubelet bootstrapping kubeconfig 文件
cd /etc/kubernetes
export KUBE_APISERVER="https://172.16.200.100:6443"
# 设置集群参数
kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=bootstrap.kubeconfig
# 设置客户端认证参数
kubectl config set-credentials kubelet-bootstrap \
--token=${BOOTSTRAP_TOKEN} \
--kubeconfig=bootstrap.kubeconfig
# 设置上下文参数
kubectl config set-context default \
--cluster=kubernetes \
--user=kubelet-bootstrap \
--kubeconfig=bootstrap.kubeconfig
# 设置默认上下文
kubectl config use-context default --kubeconfig=bootstrap.kubeconfig
- --embed-certs 为 true 时表示将 certificate-authority 证书写入到生成的 bootstrap.kubeconfig 文件中;
- 设置客户端认证参数时没有指定秘钥和证书,后续由 kube-apiserver 自动生成;
### 创建 kube-proxy kubeconfig 文件
export KUBE_APISERVER="https://172.20.0.100:6443"
# 设置集群参数
kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=kube-proxy.kubeconfig
# 设置客户端认证参数
kubectl config set-credentials kube-proxy \
--client-certificate=/etc/kubernetes/ssl/kube-proxy.pem \
--client-key=/etc/kubernetes/ssl/kube-proxy-key.pem \
--embed-certs=true \
--kubeconfig=kube-proxy.kubeconfig
# 设置上下文参数
kubectl config set-context default \
--cluster=kubernetes \
--user=kube-proxy \
--kubeconfig=kube-proxy.kubeconfig
# 设置默认上下文
kubectl config use-context default --kubeconfig=kube-proxy.kubeconfig
- 设置集群参数和客户端认证参数时 --embed-certs 都为 true,这会将 certificate-authority、client-certificate 和 client-key 指向的证书文件内容写入到生成的 kube-proxy.kubeconfig 文件中;
- kube-proxy.pem 证书中 CN 为 system:kube-proxy,kube-apiserver 预定义的 RoleBinding cluster-admin 将User system:kube-proxy 与 Role system:node-proxier 绑定,该 Role 授予了调用 kube-apiserver Proxy 相关 API 的权限;
### 分发 kubeconfig 文件
将两个 kubeconfig 文件分发到所有 Node 机器的 /etc/kubernetes/ 目录
cp bootstrap.kubeconfig kube-proxy.kubeconfig /etc/kubernetes/
';
第四章 安装kubectl命令行工具
最后更新于:2022-04-02 05:06:46
本文档介绍下载和配置 kubernetes 集群命令行工具 kubelet 的步骤。k8s 集群使用kubectl 管理,一般在master 配置kubeconfig进行管理集群
> 安装kubectl 因为kubernetes-server-linux-amd64.tar.gz server 的安装包以包含了客户端管理工具。无需重新安装
### 创建 kubectl kubeconfig 文件
export KUBE_APISERVER="https://172.16.200.100:6443"
# 设置集群参数
kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER}
# 设置客户端认证参数
kubectl config set-credentials admin \
--client-certificate=/etc/kubernetes/ssl/admin.pem \
--embed-certs=true \
--client-key=/etc/kubernetes/ssl/admin-key.pem
# 设置上下文参数
kubectl config set-context kubernetes \
--cluster=kubernetes \
--user=admin
# 设置默认上下文
kubectl config use-context kubernetes
- admin.pem 证书 OU 字段值为 system:masters,kube-apiserver 预定义的 RoleBinding cluster-admin 将 Group system:masters 与 Role cluster-admin 绑定,该 Role 授予了调用kube-apiserver 相关 API 的权限;
- 生成的 kubeconfig 被保存到 ~/.kube/config 文件;
';
第三章 创建TLS证书和秘钥
最后更新于:2022-04-02 05:06:44
# 创建TLS证书和秘钥
## 前言
### 执行下列步骤前建议你先阅读以下内容:
- [管理集群中的TLS](https://rootsongjc.gitbooks.io/kubernetes-handbook/content/guide/managing-tls-in-a-cluster.html):教您如何创建TLS证书
- [kubelet的认证授权](https://rootsongjc.gitbooks.io/kubernetes-handbook/content/guide/kubelet-authentication-authorization.html):向您描述如何通过认证授权来访问 kubelet 的 HTTPS 端点
- TLS [bootstrap](https://rootsongjc.gitbooks.io/kubernetes-handbook/content/guide/tls-bootstrapping.html):介绍如何为 kubelet 设置 TLS 客户端证书引导(bootstrap)。
> 注意:这一步是在安装配置kubernetes的所有步骤中最容易出错也最难于排查问题的一步,而这却刚好是第一步,万事开头难,不要因为这点困难就望而却步。
### kubernetes 系统的各组件需要使用 TLS 证书对通信进行加密,本文档使用 CloudFlare 的 PKI 工具集 cfssl 来生成 Certificate Authority (CA) 和其它证书;
### 生成的 CA 证书和秘钥文件如下:
- ca-key.pem
- ca.pem
- kubernetes-key.pem
- kubernetes.pem
- kube-proxy.pem
- kube-proxy-key.pem
- admin.pem
- admin-key.pem
### 使用证书的组件如下:
- etcd:使用 ca.pem、kubernetes-key.pem、kubernetes.pem;
- kube-apiserver:使用 ca.pem、kubernetes-key.pem、kubernetes.pem;
- kubelet:使用 ca.pem;
- kube-proxy:使用 ca.pem、kube-proxy-key.pem、kube-proxy.pem;
- kubectl:使用 ca.pem、admin-key.pem、admin.pem;
> kube-controller、kube-scheduler 当前需要和 kube-apiserver 部署在同一台机器上且使用非安全端口通信,故不需要证书。
#### 注意:以下操作都在 master 节点即 172.20.200.100 这台主机上执行,证书只需要创建一次即可,以后在向集群中添加新节点时只要将 /etc/kubernetes/ 目录下的证书拷贝到新节点上即可。
# 安装 CFSSL
### 直接使用二进制源码包安装
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
chmod +x cfssl_linux-amd64
mv cfssl_linux-amd64 /root/local/bin/cfssl
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
chmod +x cfssljson_linux-amd64
mv cfssljson_linux-amd64 /root/local/bin/cfssljson
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
chmod +x cfssl-certinfo_linux-amd64
mv cfssl-certinfo_linux-amd64 /root/local/bin/cfssl-certinfo
export PATH=/root/local/bin:$PATH
在$GOPATH/bin目录下得到以cfssl开头的几个命令。
> 注意:以下文章中出现的cat的文件名如果不存在需要手工创建。
### 创建 CA (Certificate Authority)
#### 创建 CA 配置文件
mkdir /root/ssl
cd /root/ssl
cfssl print-defaults config > config.json
cfssl print-defaults csr > csr.json
# 根据config.json文件的格式创建如下的ca-config.json文件
# 过期时间设置成了 87600h
cat > ca-config.json < ca-csr.json < kubernetes-csr.json << EOF
{
"CN": "kubernetes",
"hosts": [
"127.0.0.1",
"172.16.200.100",
"172.16.200.101",
"172.16.200.102",
"10.254.0.1",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
- 如果 hosts 字段不为空则需要指定授权使用该证书的 IP 或域名列表,由于该证书后续被 etcd 集群和 kubernetes master 集群使用,所以上面分别指定了 etcd 集群、kubernetes master 集群的主机 IP 和 kubernetes 服务的服务 IP(一般是 kube-apiserver 指定的 service-cluster-ip-range 网段的第一个IP,如 10.254.0.1。
#### 生成 kubernetes 证书和私钥
$ cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kubernetes-csr.json | cfssljson -bare kubernetes
$ ls kubernetes*
kubernetes.csr kubernetes-csr.json kubernetes-key.pem kubernetes.pem
### 创建 admin 证书
创建 admin 证书签名请求文件 admin-csr.json:
cat > admin-csr.json << EOF
{
"CN": "admin",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "system:masters",
"OU": "System"
}
]
}
EOF
- 后续 kube-apiserver 使用 RBAC 对客户端(如 kubelet、kube-proxy、Pod)请求进行授权;
- kube-apiserver 预定义了一些 RBAC 使用的 RoleBindings,如 cluster-admin 将 Group system:masters 与 Role cluster-admin 绑定,该 Role 授予了调用kube-apiserver 的所有 API的权限;
- OU 指定该证书的 Group 为 system:masters,kubelet 使用该证书访问 kube-apiserver 时 ,由于证书被 CA 签名,所以认证通过,同时由于证书用户组为经过预授权的 system:masters,所以被授予访问所有 API 的权限
### 生成 admin 证书和私钥
$ cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes admin-csr.json | cfssljson -bare admin
$ ls admin*
admin.csr admin-csr.json admin-key.pem admin.pem
### 创建 kube-proxy 证书
创建 kube-proxy 证书签名请求文件 kube-proxy-csr.json
cat > kube-proxy-csr.json << EOF
{
"CN": "system:kube-proxy",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
- CN 指定该证书的 User 为 system:kube-proxy;
- kube-apiserver 预定义的 RoleBinding cluster-admin 将User system:kube-proxy 与 Role system:node-proxier 绑定,该 Role 授予了调用 kube-apiserver Proxy 相关 API 的权限;
生成 kube-proxy 客户端证书和私钥
$ cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy
$ ls kube-proxy*
kube-proxy.csr kube-proxy-csr.json kube-proxy-key.pem kube-proxy.pem
### 校验证书
以 kubernetes 证书为例
- 使用 opsnssl 命令
$ openssl x509 -noout -text -in kubernetes.pem
...
Signature Algorithm: sha256WithRSAEncryption
Issuer: C=CN, ST=BeiJing, L=BeiJing, O=k8s, OU=System, CN=Kubernetes
Validity
Not Before: Apr 5 05:36:00 2017 GMT
Not After : Apr 5 05:36:00 2018 GMT
Subject: C=CN, ST=BeiJing, L=BeiJing, O=k8s, OU=System, CN=kubernetes
...
X509v3 extensions:
X509v3 Key Usage: critical
Digital Signature, Key Encipherment
X509v3 Extended Key Usage:
TLS Web Server Authentication, TLS Web Client Authentication
X509v3 Basic Constraints: critical
CA:FALSE
X509v3 Subject Key Identifier:
DD:52:04:43:10:13:A9:29:24:17:3A:0E:D7:14:DB:36:F8:6C:E0:E0
X509v3 Authority Key Identifier:
keyid:44:04:3B:60:BD:69:78:14:68:AF:A0:41:13:F6:17:07:13:63:58:CD
X509v3 Subject Alternative Name:
DNS:kubernetes, DNS:kubernetes.default, DNS:kubernetes.default.svc, DNS:kubernetes.default.svc.cluster, DNS:kubernetes.default.svc.cluster.local, IP Address:127.0.0.1, IP Address:172.20.0.112, IP Address:172.20.0.113, IP Address:172.20.0.114, IP Address:172.20.0.115, IP Address:10.254.0.1
...
- 使用 cfssl-certinfo 命令
~~~
$ cfssl-certinfo -cert kubernetes.pem
{
"subject": {
"common_name": "kubernetes",
"country": "CN",
"organization": "k8s",
"organizational_unit": "System",
"locality": "BeiJing",
"province": "BeiJing",
"names": [
"CN",
"BeiJing",
"BeiJing",
"k8s",
"System",
"kubernetes"
]
},
"issuer": {
"common_name": "Kubernetes",
"country": "CN",
"organization": "k8s",
"organizational_unit": "System",
"locality": "BeiJing",
"province": "BeiJing",
"names": [
"CN",
"BeiJing",
"BeiJing",
"k8s",
"System",
"Kubernetes"
]
},
"serial_number": "174360492872423263473151971632292895707129022309",
"sans": [
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local",
"127.0.0.1",
"10.64.3.7",
"10.254.0.1"
],
"not_before": "2017-04-05T05:36:00Z",
"not_after": "2018-04-05T05:36:00Z",
"sigalg": "SHA256WithRSA",
~~~
### 分发证书
将生成的证书和秘钥文件(后缀名为.pem)拷贝到所有机器的 /etc/kubernetes/ssl 目录下备用;
mkdir -p /etc/kubernetes/ssl
cp *.pem /etc/kubernetes/ssl
';
第二章 在CentOS上部署kubernetes1.7.6集群
最后更新于:2022-04-02 05:06:42
# 在CentOS7上部署kubernetes1.7.6集群
本系列文档介绍使用二进制部署 kubernetes 集群的所有步骤,而不是使用 kubeadm 等自动化方式来部署集群,同时开启了集群的TLS安全认证;在部署的过程中,将详细列出各组件的启动参数,给出配置文件,详解它们的含义和可能遇到的问题。部署完成后,你将理解系统各组件的交互原理,进而能快速解决实际问题。所以本文档主要适合于那些有一定 kubernetes 基础,想通过一步步部署的方式来学习和了解系统配置、运行原理的人。本系列系文档适用于 CentOS 7 及以上版本系统由于启用了 TLS 双向认证、RBAC 授权等严格的安全机制,建议从头开始部署,否则可能会认证、授权等失败!
> 注:本文档中不包括docker和私有镜像仓库的安装。
# 提供所有的配置文件
## 集群安装时所有组件用到的配置文件,包含在以下目录中:
- conf: service的环境变量配置文件
- manifest: kubernetes组件包的yaml文件
- systemd :systemd serivce服务启动配置文件
> 配置文件链接下载地址: [下载](https://gitee.com/huyipow/k8s-deploy.git)
# 集群详情
- Kubernetes 1.7.6
- Docker 17.06.0-ce(使用yum安装)
- Etcd 3.2.1
- Flanneld 0.8 vxlan 网络
- TLS 认证通信 (所有组件,如 etcd、kubernetes master 和 node )
- RBAC 授权
- kublet TLS BootStrapping
- kubedns、dashboard、使用Prometheus监控Kubernetes集群和应用、EFK(elasticsearch、fluentd、kibana) 集群插件
- 私有docker镜像仓库harbor(请自行部署,harbor提供离线安装包,直接使用docker-compose启动即可
# 环境说明
在下面的步骤中,我们将在三台CentOS系统的虚拟机上部署具有三个节点的kubernetes1.7.6集群。
角色分配如下:
Master:172.16.200.100
Node:172.16.200.100、172.16.200.101、172.16.200.102
> 注意:172.20.0.113这台主机master和node复用。所有生成证书、执行kubectl命令的操作都在这台节点上执行。一旦node加入到kubernetes集群之后就不需要再登陆node节点了
# 安装前的准备
- 在node节点上安装docker 17.06.0-ce
- 关闭所有节点的SELinux
- 清空默认系统防火墙策略
- 准备harbor私有镜像仓库
- 内核参数修改
cat /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
# 步骤介绍
1. 创建 TLS 证书和秘钥
1. 创建kubeconfig 文件
1. 创建高可用etcd集群
1. 安装kubectl命令行工具
1. 部署master节点
1. 部署node节点
1. 安装kubedns插件
1. 安装dashboard插件
1. 使用Prometheus监控Kubernetes集群和应用
1. 安装EFK插件
# 提醒
1. 由于启用了 TLS 双向认证、RBAC 授权等严格的安全机制,建议从头开始部署,而不要从中间开始,否则可能会认证、授权等失败!
1. 部署过程中需要有很多证书的操作,请大家耐心操作,不明白的操作可以参考本书中的其他章节的解释。
1. 该部署操作仅是搭建成了一个可用 kubernetes 集群,而很多地方还需要进行优化,heapster 插件、EFK 插件不一定会用于真实的生产环境中,但是通过部署这些插件,可以让大家了解到如何部署应用到集群上。
';