人生苦短,我用Python
最后更新于:2022-04-01 01:06:44
## 一门编程语言的发展简史
Python是我喜欢的语言,简洁,优美,容易使用。前两天,我很激昂的向朋友宣传Python的好处。
> “好吧,我承认Python不错,但它为什么叫Python呢?”
>
> “呃,似乎是一个电视剧的名字。”
>
> “那你说的Guido是美国人么?”
>
> “他从Google换到Dropbox工作,但他的名字像是荷兰人的。”
>
> “你确定你很熟悉Python吗?”
所以为了雪耻,我花时间调查了Python的历史。我看到了Python中许多功能的来源和Python的设计理念,看到了一门编程语言的演化历史,看到了Python与开源运动的奇妙联系。从Python的历史中,我们可以一窥开源开发的理念和成就。
这也可以作为我写的Python快速教程的序篇。
## 起源
Python的作者,Guido von Rossum,确实是荷兰人。1982年,Guido从阿姆斯特丹大学获得了数学和计算机硕士学位。然而,尽管他算得上是一位数学家,但他更加享受计算机带来的乐趣。用他的话说,尽管拥有数学和计算机双料资质,他总趋向于做计算机相关的工作,并热衷于做任何和编程相关的活儿。
在那个时候,Guido接触并使用过诸如Pascal、C、 Fortran等语言。这些语言的基本设计原则是让机器能更快运行。在80年代,虽然IBM和苹果已经掀起了个人电脑浪潮,但这些个人电脑的配置很低。比如早期的Macintosh,只有8MHz的CPU主频和128KB的RAM,一个大的数组就能占满内存。所有的编译器的核心是做优化,以便让程序能够运行。为了增进效率,语言也迫使程序员像计算机一样思考,以便能写出更符合机器口味的程序。在那个时代,程序员恨不得用手榨取计算机每一寸的能力。有人甚至认为C语言的指针是在浪费内存。至于动态类型,内存自动管理,面向对象…… 别想了,那会让你的电脑陷入瘫痪。
这种编程方式让Guido感到苦恼。Guido知道如何用C语言写出一个功能,但整个编写过程需要耗费大量的时间,即使他已经准确的知道了如何实现。他的另一个选择是shell。Bourne Shell作为UNIX系统的解释器已经长期存在。UNIX的管理员们常常用shell去写一些简单的脚本,以进行一些系统维护的工作,比如定期备份、文件系统管理等等。shell可以像胶水一样,将UNIX下的许多功能连接在一起。许多C语言下上百行的程序,在shell下只用几行就可以完成。然而,shell的本质是调用命令。它并不是一个真正的语言。比如说,shell没有数值型的数据类型,加法运算都很复杂。总之,shell不能全面的调动计算机的功能。
Guido希望有一种语言,这种语言能够像C语言那样,能够全面调用计算机的功能接口,又可以像shell那样,可以轻松的编程。ABC语言让Guido看到希望。ABC是由荷兰的数学和计算机研究所开发的。Guido在该研究所工作,并参与到ABC语言的开发。ABC语言以教学为目的。与当时的大部分语言不同,ABC语言的目标是“让用户感觉更好”。ABC语言希望让语言变得容易阅读,容易使用,容易记忆,容易学习,并以此来激发人们学习编程的兴趣。比如下面是一段来自Wikipedia的ABC程序,这个程序用于统计文本中出现的词的总数:
~~~
HOW TO RETURN words document: PUT {} IN collection FOR line IN document: FOR word IN split line: IF word not.in collection: INSERT word IN collection RETURN collection
~~~
HOW TO用于定义一个函数。一个Python程序员应该很容易理解这段程序。ABC语言使用冒号和缩进来表示程序块。行尾没有分号。for和if结构中也没有括号()。赋值采用的是PUT,而不是更常见的等号。这些改动让ABC程序读起来像一段文字。
尽管已经具备了良好的可读性和易用性,ABC语言最终没有流行起来。在当时,ABC语言编译器需要比较高配置的电脑才能运行。而这些电脑的使用者通常精通计算机,他们更多考虑程序的效率,而非它的学习难度。除了硬件上的困难外,ABC语言的设计也存在一些致命的问题:
* 可拓展性差。ABC语言不是模块化语言。如果想在ABC语言中增加功能,比如对图形化的支持,就必须改动很多地方。
* 不能直接进行IO。ABC语言不能直接操作文件系统。尽管你可以通过诸如文本流的方式导入数据,但ABC无法直接读写文件。输入输出的困难对于计算机语言来说是致命的。你能想像一个打不开车门的跑车么?
* 过度革新。ABC用自然语言的方式来表达程序的意义,比如上面程序中的HOW TO 。然而对于程序员来说,他们更习惯用function或者define来定义一个函数。同样,程序员更习惯用等号来分配变量。尽管ABC语言很特别,但学习难度也很大。
* 传播困难。ABC编译器很大,必须被保存在磁带上。当时Guido在访问的时候,就必须有一个大磁带来给别人安装ABC编译器。 这样,ABC语言就很难快速传播。
1989年,为了打发圣诞节假期,Guido开始写Python语言的编译器。Python这个名字,来自Guido所挚爱的电视剧Monty Python's Flying Circus。他希望这个新的叫做Python的语言,能符合他的理想:创造一种C和shell之间,功能全面,易学易用,可拓展的语言。Guido作为一个语言设计爱好者,已经有过设计语言的尝试。这一次,也不过是一次纯粹的hacking行为。
## 一门语言的诞生
1991年,第一个Python编译器诞生。它是用C语言实现的,并能够调用C语言的库文件。从一出生,Python已经具有了:类,函数,异常处理,包含表和词典在内的核心数据类型,以及模块为基础的拓展系统。
Python语法很多来自C,但又受到ABC语言的强烈影响。来自ABC语言的一些规定直到今天还富有争议,比如强制缩进。但这些语法规定让Python容易读。另一方面,Python聪明的选择服从一些惯例,特别是C语言的惯例。比如使用等号赋值,使用def来定义函数。Guido认为,如果“常识”上确立的东西,没有必要过度纠结。
Python从一开始就特别在意可拓展性。Python可以在多个层次上拓展。从高层上,你可以直接引入.py文件。在底层,你可以引用C语言的库。Python程序员可以快速的使用Python写.py文件作为拓展模块。但当性能是考虑的重要因素时,Python程序员可以深入底层,写C程序,编译为.so文件引入到Python中使用。Python就好像是使用钢构建房一样,先规定好大的框架。而程序员可以在此框架下相当自由的拓展或更改。
最初的Python完全由Guido本人开发。Python得到Guido同事的欢迎。他们迅速的反馈使用意见,并参与到Python的改进。Guido和一些同事构成Python的核心团队。他们将自己大部分的业余时间用于hack Python。随后,Python拓展到研究所之外。Python将许多机器层面上的细节隐藏,交给编译器处理,并凸显出逻辑层面的编程思考。Python程序员可以花更多的时间用于思考程序的逻辑,而不是具体的实现细节。这一特征吸引了广大的程序员。Python开始流行。人生苦短,我用python

## 时势造英雄
我们不得不暂停我们的Python时间,转而看一看瞬息万变的计算机行业。1990年代初,个人计算机开始进入普通家庭。Intel发布了486处理器,windows发布window 3.0开始的一系列视窗系统。计算机的性能大大提高。程序员开始关注计算机的易用性 ,比如图形化界面。
由于计算机性能的提高,软件的世界也开始随之改变。硬件足以满足许多个人电脑的需要。硬件厂商甚至渴望高需求软件的出现,以带动硬件的更新换代。C++和Java相继流行。C++和Java提供了面向对象的编程范式,以及丰富的对象库。在牺牲了一定的性能的代价下,C++和Java大大提高了程序的产量。语言的易用性被提到一个新的高度。我们还记得,ABC失败的一个重要原因是硬件的性能限制。从这方面说,Python要比ABC幸运许多。
另一个悄然发生的改变是Internet。1990年代还是个人电脑的时代,windows和Intel挟PC以令天下,盛极一时。尽管Internet为主体的信息革命尚未到来,但许多程序员以及资深计算机用户已经在频繁使用Internet进行交流,比如使用email和newsgroup。Internet让信息交流成本大大下降。一种新的软件开发模式开始流行:开源。程序员利用业余时间进行软件开发,并开放源代码。1991年,Linus在comp.os.minix新闻组上发布了Linux内核源代码,吸引大批hacker的加入。Linux和GNU相互合作,最终构成了一个充满活力的开源平台。
硬件性能不是瓶颈,Python又容易使用,所以许多人开始转向Python。Guido维护了一个maillist,Python用户就通过邮件进行交流。Python用户来自许多领域,有不同的背景,对Python也有不同的需求。Python相当的开放,又容易拓展,所以当用户不满足于现有功能,很容易对Python进行拓展或改造。随后,这些用户将改动发给Guido,并由Guido决定是否将新的特征加入到Python或者标准库中。如果代码能被纳入Python自身或者标准库,这将极大的荣誉。由于Guido至高无上的决定权,他因此被称为“终身的仁慈独裁者”。
Python被称为“Battery Included”,是说它以及其标准库的功能强大。这些是整个社区的贡献。Python的开发者来自不同领域,他们将不同领域的优点带给Python。比如Python标准库中的正则表达是参考Perl,而lambda, map, filter, reduce等函数参考了Lisp。Python本身的一些功能以及大部分的标准库来自于社区。Python的社区不断扩大,进而拥有了自己的newsgroup,网站,以及基金。从Python 2.0开始,Python也从maillist的开发方式,转为完全开源的开发方式。社区气氛已经形成,工作被整个社区分担,Python也获得了更加高速的发展。
到今天,Python的框架已经确立。Python语言以对象为核心组织代码,支持多种编程范式,采用动态类型,自动进行内存回收。Python支持解释运行,并能调用C库进行拓展。Python有强大的标准库。由于标准库的体系已经稳定,所以Python的生态系统开始拓展到第三方包。这些包,如Django、web.py、wxpython、numpy、matplotlib、PIL,将Python升级成了物种丰富的热带雨林。
## 启示录
Python崇尚优美、清晰、简单,是一个优秀并广泛使用的语言。Python在TIOBE排行榜中排行第八,它是Google的第三大开发语言,Dropbox的基础语言,豆瓣的服务器语言。Python的发展史可以作为一个代表,带给我许多启示。
在Python的开发过程中,社区起到了重要的作用。Guido自认为自己不是全能型的程序员,所以他只负责制订框架。如果问题太复杂,他会选择绕过去,也就是cut the corner。这些问题最终由社区中的其他人解决。社区中的人才是异常丰富的,就连创建网站,筹集基金这样与开发稍远的事情,也有人乐意于处理。如今的项目开发越来越复杂,越来越庞大,合作以及开放的心态成为项目最终成功的关键。
Python从其他语言中学到了很多,无论是已经进入历史的ABC,还是依然在使用的C和Perl,以及许多没有列出的其他语言。可以说,Python的成功代表了它所有借鉴的语言的成功。同样,Ruby借鉴了Python,它的成功也代表了Python某些方面的成功。每个语言都是混合体,都有它优秀的地方,但也有各种各样的缺陷。同时,一个语言“好与不好”的评判,往往受制于平台、硬件、时代等等外部原因。程序员经历过许多语言之争。其实,以开放的心态来接受各个语言,说不定哪一天,程序员也可以如Guido那样,混合出自己的语言。
无论Python未来的命运如何,Python的历史已经是本很有趣的小说。
var:[Python快速教程 - Vamei - 博客园](http://www.15yan.com/story/1JKTBQvVk5e/?f=wx)
扩展阅读(来自网络文章)
最后更新于:2022-04-01 01:06:42
常用的内建函数
最后更新于:2022-04-01 01:06:39
# 一些重要的内建函数
<table class="calibre22"><thead class="calibre23"><tr class="calibre24"><th class="calibre25">函数</th><th class="calibre25">描述</th></tr></thead><tbody class="calibre26"><tr class="calibre24"><td class="calibre27">abs(number)</td><td class="calibre27">返回一个数的绝对值</td></tr><tr class="calibre28"><td class="calibre27">apply(function[, args[, kwds]])</td><td class="calibre27">调用给定函数,可选择提供参数</td></tr><tr class="calibre24"><td class="calibre27">all(iterable)</td><td class="calibre27">如果所有iterable的元素均为真则返回True, 否则返回False</td></tr><tr class="calibre28"><td class="calibre27">any(iterable)</td><td class="calibre27">如果有任一iterable的元素为真则返回True,否则返回False</td></tr><tr class="calibre24"><td class="calibre27">basestring()</td><td class="calibre27">str和unicode抽象超类,用于检查类型</td></tr><tr class="calibre28"><td class="calibre27">bool(object)</td><td class="calibre27">返回True或False,取决于Object的布尔值</td></tr><tr class="calibre24"><td class="calibre27">callable(object)</td><td class="calibre27">检查对象是否可调用</td></tr><tr class="calibre28"><td class="calibre27">chr(number)</td><td class="calibre27">返回ASCII码为给定数字的字符</td></tr><tr class="calibre24"><td class="calibre27">classmethod(func)</td><td class="calibre27">通过一个实例方法创建类的方法</td></tr><tr class="calibre28"><td class="calibre27">cmp(x, y)</td><td class="calibre27">比较x和y——如果x<y class="calibre29">y则返回证书;如果x==y,返回0</y></td></tr><tr class="calibre24"><td class="calibre27">complex(real[, imag])</td><td class="calibre27">返回给定实部(以及可选的虚部)的复数</td></tr><tr class="calibre28"><td class="calibre27">delattr(object, name)</td><td class="calibre27">从给定的对象中删除给定的属性</td></tr><tr class="calibre24"><td class="calibre27">dict([mapping-or-sequence])</td><td class="calibre27">构造一个字典,可选择从映射或(键、值)对组成的列表构造。<br class="normal"/>也可以使用关键字参数调用。</td></tr><tr class="calibre28"><td class="calibre27">dir([object])</td><td class="calibre27">当前可见作用于域的(大多数)名称的列表,<br class="normal"/>或者是选择性地列出给定对象的(大多数)特性</td></tr><tr class="calibre24"><td class="calibre27">divmod(a, b)</td><td class="calibre27">返回(a//b, a%b)(float类型有特殊规则)</td></tr><tr class="calibre28"><td class="calibre27">enumerate(iterable)</td><td class="calibre27">对iterable中的所有项迭代(索引,项目)对</td></tr><tr class="calibre24"><td class="calibre27">eval(string[, globals[, locals]])</td><td class="calibre27">对包含表达式的字符串进行计算。<br class="normal"/>可选择在给定的全局作用域或者局部作用域中进行</td></tr><tr class="calibre28"><td class="calibre27">execfile(file[, globals[, locals]])</td><td class="calibre27">执行一个python文件,<br class="normal"/>可选在给定全局作用域或者局部作用域中进行</td></tr><tr class="calibre24"><td class="calibre27">file(filename[, mode[, bufsize]])</td><td class="calibre27">创建给定文件名的文件,<br class="normal"/>可选择使用给定的模式和缓冲区大小</td></tr><tr class="calibre28"><td class="calibre27">filter(function, sequence)</td><td class="calibre27">返回给定序列中函数返回值的元素的列表</td></tr><tr class="calibre24"><td class="calibre27">float(object)</td><td class="calibre27">将字符串或者数值转换为float类型</td></tr><tr class="calibre28"><td class="calibre27">frozenset([iterable])</td><td class="calibre27">创建一个不可变集合,这意味着不能将添加到其它集合中</td></tr><tr class="calibre24"><td class="calibre27">getattr(object, name[, default])</td><td class="calibre27">返回给定对象中所指定的特性的值,可选择给定默认值</td></tr><tr class="calibre28"><td class="calibre27">globals()</td><td class="calibre27">返回表示当前作用域的字典</td></tr><tr class="calibre24"><td class="calibre27">hasattr(object, name)</td><td class="calibre27">检查给定的对象是否有指定的属性</td></tr><tr class="calibre28"><td class="calibre27">help([object])</td><td class="calibre27">调用内建的帮助系统,或者打印给定对象的帮助信息</td></tr><tr class="calibre24"><td class="calibre27">id(number)</td><td class="calibre27">返回给定对象的唯一ID</td></tr><tr class="calibre28"><td class="calibre27">input([prompt])</td><td class="calibre27">等同于eval(raw_input(prompt)</td></tr><tr class="calibre24"><td class="calibre27">int(object[, radix])</td><td class="calibre27">将字符串或者数字(可以提供基数)转换为整数</td></tr><tr class="calibre28"><td class="calibre27">isinstance(object, classinfo)</td><td class="calibre27">检查给定的对象object是否是给定的classinfo值的实例,<br class="normal"/>classinfo可以是类对象、类型对象或者类对象和类型对象的元组</td></tr><tr class="calibre24"><td class="calibre27">issubclass(class1, class2)</td><td class="calibre27">检查class1是否是class2的子类(每个类都是自身的子类)</td></tr><tr class="calibre28"><td class="calibre27">iter(object[, sentinel])</td><td class="calibre27">返回一个迭代器对象,可以是用于迭代序列的object<em class="calibre21">iter()迭代器<br class="normal"/>(如果object支持_getitem</em>方法的话),或者提供一个sentinel,<br class="normal"/>迭代器会在每次迭代中调用object,直到返回sentinel</td></tr><tr class="calibre24"><td class="calibre27">len(object)</td><td class="calibre27">返回给定对象的长度(项的个数)</td></tr><tr class="calibre28"><td class="calibre27">list([sequence])</td><td class="calibre27">构造一个列表,可选择使用与所提供序列squence相同的项</td></tr><tr class="calibre24"><td class="calibre27">locals()</td><td class="calibre27">返回表示当前局部作用域的字典(不要修改这个字典)</td></tr><tr class="calibre28"><td class="calibre27">long(object[, radix])</td><td class="calibre27">将字符串(可选择使用给定的基数radix)或者数字转化为长整型</td></tr><tr class="calibre24"><td class="calibre27">map(function, sequence, ...)</td><td class="calibre27">创建由给定函数function应用到所提供列表sequence每个项目时返回的值组成的列表</td></tr><tr class="calibre28"><td class="calibre27">max(object1, [object2, ...])</td><td class="calibre27">如果object1是非空序列,那么就返回最大的元素。<br class="normal"/>否则返回所提供参数(object1,object2...)的最大值</td></tr><tr class="calibre24"><td class="calibre27">min(object1, [object2, ...])</td><td class="calibre27">如果object1是非空序列,那么就返回最小的元素。<br class="normal"/>否则返回所提供参数(object1,object2...)的最小值</td></tr><tr class="calibre28"><td class="calibre27">object()</td><td class="calibre27">返回所有新式类的技术Object的实例</td></tr><tr class="calibre24"><td class="calibre27">oct(number)</td><td class="calibre27">将整型数转换为八进制表示的字符串</td></tr><tr class="calibre28"><td class="calibre27">open(filename[, mode[, bufsize]])</td><td class="calibre27">file的别名(在打开文件的时候使用open而不是file</td></tr><tr class="calibre24"><td class="calibre27">ord(char)</td><td class="calibre27">返回给定单字符(长度为1的字符串或者Unicode字符串)的ASCII值</td></tr><tr class="calibre28"><td class="calibre27">pow(x, y[, z])</td><td class="calibre27">返回x的y次方,可选择模除z</td></tr><tr class="calibre24"><td class="calibre27">property([fget[, fset[, fdel[, doc]]]])</td><td class="calibre27">通过一组访问器创建属性</td></tr><tr class="calibre28"><td class="calibre27">range([start, ]stop[, step])</td><td class="calibre27">使用给定的起始值(包括起始值,默认为0)和结束值(不包括)<br class="normal"/>以及步长(默认为1)返回数值范围(以列表形式)</td></tr><tr class="calibre24"><td class="calibre27">raw_input([prompt])</td><td class="calibre27">将用户输入的数据作为字符串返回,可选择使用给定的提示符prompt</td></tr><tr class="calibre28"><td class="calibre27">reduce(function, sequence[, initializer])</td><td class="calibre27">对序列的所有渐增地应用于给定的函数,<br class="normal"/>使用累积的结果作为第一个参数,<br class="normal"/>所有的项作为第二个参数,可选择给定的起始值(initializer)</td></tr><tr class="calibre24"><td class="calibre27">reload(module)</td><td class="calibre27">重载入一个已经载入的模块并将其返回</td></tr><tr class="calibre28"><td class="calibre27">repr(object)</td><td class="calibre27">返回表示对象的字符串,一般作为eval的参数使用</td></tr><tr class="calibre24"><td class="calibre27">reversed(sequence)</td><td class="calibre27">返回序列的反向迭代器</td></tr><tr class="calibre28"><td class="calibre27">round(float[, n])</td><td class="calibre27">将给定的浮点数四舍五入,小数点后保留n位(默认为0)</td></tr><tr class="calibre24"><td class="calibre27">set([iterable)</td><td class="calibre27">返回从iterable(如果给出)生成的元素集合</td></tr><tr class="calibre28"><td class="calibre27">setattr(object, name, value)</td><td class="calibre27">设定给定对象的指定属性的值为给定的值</td></tr><tr class="calibre24"><td class="calibre27">sorted(iterable[, cmp][,key][, reverse])</td><td class="calibre27">从iterable的项目中返回一个新的排序后的列表。<br class="normal"/>可选的参数和列表方法与sort中的相同</td></tr><tr class="calibre28"><td class="calibre27">staticmethod(func)</td><td class="calibre27">从一个实例方法创建静态(类)方法</td></tr><tr class="calibre24"><td class="calibre27">str(object)</td><td class="calibre27">返回表示给定对象object的格式化好的字符串</td></tr><tr class="calibre28"><td class="calibre27">sum(seq[, start])</td><td class="calibre27">返回添加到可选参数start(默认为0)中的一系列数字的和</td></tr><tr class="calibre24"><td class="calibre27">super(type[, obj/type)</td><td class="calibre27">返回给定类型(可选为实例化的)的超类</td></tr><tr class="calibre28"><td class="calibre27">tuple([sequence])</td><td class="calibre27">构造一个元祖,可选择使用同提供的序列sequence一样的项</td></tr><tr class="calibre24"><td class="calibre27">type(object)</td><td class="calibre27">返回给定对象的类型</td></tr><tr class="calibre28"><td class="calibre27">type(name, base, dict)</td><td class="calibre27">使用给定的名称、基类和作用域返回一个新的类型对象</td></tr><tr class="calibre24"><td class="calibre27">unichr(number)</td><td class="calibre27">chr的Unicode版本</td></tr><tr class="calibre28"><td class="calibre27">unicode(object[, encoding[, errors]])</td><td class="calibre27">返回给定对象的Unicode编码版本,可以给定编码方式和处理错误的模式<br class="normal"/>('strict'、'replace'或者'ignore','strict'为默认模式)</td></tr><tr class="calibre24"><td class="calibre27">vars([object])</td><td class="calibre27">返回表示局部作用域的字典,或者对应给定对象特性的字典</td></tr><tr class="calibre28"><td class="calibre27">xrange([start, ]stop[, step])</td><td class="calibre27">类似于range,但是返回的对象使用内存较少,而且只用于迭代</td></tr><tr class="calibre24"><td class="calibre27">zip(sequence1, ...)</td><td class="calibre27">返回元组的列表,每个元组包括一个给定序列中的项。<br class="normal"/>返回的列表的长度和所提供的序列的最短长度相同</td></tr></tbody></table>
运算符
最后更新于:2022-04-01 01:06:37
# 运算符
| 运算符 | 描述 | 优先级 |
|-----|-----|-----|
| lambda | lambda表达式 | 1 |
| or | 逻辑或 | 2 |
| and | 逻辑与 | 3 |
| not | 逻辑非 | 4 |
| in | 成员资格测试 | 5 |
| not in | 非成员资格测试 | 5 |
| is | 一致性测试 | 6 |
| is not | 非一致性测试 | 6 |
| < | 小于 | 7 |
| > | 大于 | 7 |
| <= | 小于或等于 | 7 |
| >= | 大于或等于 | 7 |
| == | 等于 | 7 |
| != | 不等于 | 7 |
| \ | | 按位或 | 8 |
| ^ | 按位异或 | 9 |
| & | 按位与 | 10 |
| << | 左移 | 11 |
| >> | 右移 | 11 |
| + | 加法 | 12 |
| - | 减法 | 12 |
| * | 乘法 | 13 |
| / | 除法 | 13 |
| % | 求余 | 13 |
| + | 一元一致性 | 14 |
| - | 一元不一致性 | 14 |
| ~ | 按位补码 | 15 |
| ** | 幂 | 16 |
| x.attribute | 特性引用 | 17 |
| x[index] | 项目访问 | 18 |
| x[index1:index2[:index3]] | 切片 | 19 |
| f(arg...) | 函数调用 | 20 |
| (...) | 将表达式加圆括号或元组显示 | 21 |
| [...] | 列表显示 | 22 |
| {key:value, ...} | 字典显示 | 23 |
| 'expressions...' | 字符串转化 | 24 |
基本的(字面量)值
最后更新于:2022-04-01 01:06:35
# 基本的(字面量)值
| 类型 | 描述 | 语法示例 |
|-----|-----|-----|
| 整型 | 无小数部分的数 | 42 |
| 长整型 | 大整数 | 42L |
| 浮点型 | 有小数部分的数 | 42.5, 42.5e-2 |
| 复合型 | 实数(整数或浮点数)和虚数的和 | 38+4j, 42j |
| 字符串 | 不可变的字符序列 | "foo", 'bar', """baz""", r'\n' |
| Unicode | 不可变的Unicode字符序列 | u'foo', u"bar", u"""baz""" |
第五部分 Python备忘录
最后更新于:2022-04-01 01:06:32
defaultdict 模块和 namedtuple 模块
最后更新于:2022-04-01 01:06:30
author: Wuxiaolong
在Python中有一些内置的数据类型,比如int, str, list, tuple, dict等。Python的collections模块在这些内置数据类型的基础上,提供了几个额外的数据类型:namedtuple, defaultdict, deque, Counter, OrderedDict等,其中defaultdict和namedtuple是两个很实用的扩展类型。defaultdict继承自dict,namedtuple继承自tuple。
## 一、defaultdict
### 1\. 简介
在使用Python原生的数据结构dict的时候,如果用d[key]这样的方式访问,当指定的key不存在时,是会抛出KeyError异常的。但是,如果使用defaultdict,只要你传入一个默认的工厂方法,那么请求一个不存在的key时, 便会调用这个工厂方法使用其结果来作为这个key的默认值。
defaultdict在使用的时候需要传一个工厂函数(function_factory),defaultdict(function_factory)会构建一个类似dict的对象,该对象具有默认值,默认值通过调用工厂函数生成。
### 2\. 示例
下面给一个defaultdict的使用示例:
~~~
>>> from collections import defaultdict
>>> s = [('xiaoming', 99), ('wu', 69), ('zhangsan', 80), ('lisi', 96), ('wu', 100), ('wu', 100), ('yuan', 98), ('xiaoming', 89)]
>>> d = defaultdict(list)
>>> for k, v in s:
... d[k].append(v)
...
>>> d
defaultdict(<type 'list'>, {'lisi': [96], 'xiaoming': [99, 89], 'yuan': [98], 'zhangsan': [80], 'wu': [69, 100, 100]})
>>> for k,v in d.items():
... print '%s: %s' % (k, v)
...
lisi: [96]
xiaoming: [99, 89]
yuan: [98]
zhangsan: [80]
wu: [69, 100, 100]
>>>
~~~
对Python比较熟悉的同学可以发现defaultdict(list)的用法和dict.setdefault(key, [])比较类似,上述代码使用setdefault实现如下:
~~~
>>> s
[('xiaoming', 99), ('wu', 69), ('zhangsan', 80), ('lisi', 96), ('wu', 100), ('wu', 100), ('yuan', 98), ('xiaoming', 89)]
>>> d = {}
>>> for k,v in s:
... d.setdefault(k, []).append(v)
...
>>> d
{'lisi': [96], 'xiaoming': [99, 89], 'yuan': [98], 'zhangsan': [80], 'wu': [69, 100, 100]}
~~~
### 3\. 原理
从以上的例子中,我们可以基本了defaultdict的用法,下面我们可以通过help(defaultdict)了解一下defaultdict的原理。通过Python console打印出的help信息来看,我们可以发现defaultdict具有默认值主要是通过missing方法实现的,如果工厂函数不为None,则通过工厂方法返回默认值,具体如下:
~~~
| __missing__(...)
| __missing__(key) # Called by __getitem__ for missing key; pseudo-code:
| if self.default_factory is None: raise KeyError((key,))
| self[key] = value = self.default_factory()
| return value
~~~
从上面的说明中,我们可以发现一下几个需要注意的地方:
1. missing方法是在调用getitem方法发现KEY不存在时才调用的,所以,defaultdict也只会在使用d[key]或者d.getitem(key)的时候才会生成默认值;如果使用d.get(key)是不会返回默认值的,会出现KeyError;
2. defaultdict主要是通过missing方法实现,所以,我们也可以通过实现该方法来生成自己的defaultdict,代码入下
### 4\. 版本
defaultdict是在Python 2.5之后才加入的功能,在旧版本的Python中是不支持这个功能的,不过,知道了它的原理,我们可以自己实现一个defaultdict。
~~~
try:
from collections import defaultdict
except:
class defaultdict(dict):
def __init__(self, default_factory=None, *a, **kw):
if (default_factory is not None and not hasattr(default_factory, '__call__')):
raise TypeError('first argument must be callable')
dict.__init__(self, *a, **kw)
self.default_factory = default_factory
def __getitem__(self, key):
try:
return dict.__getitem__(self, key)
except KeyError:
return self.__missing__(key)
def __missing__(self, key):
if self.default_factory is None:
raise KeyError(key)
self[key] = value = self.default_factory()
return value
def __reduce__(self):
if self.default_factory is None:
args = tuple()
else:
args = self.default_factory,
return type(self), args, None, None, self.items()
def copy(self):
return self.__copy__()
def __copy__(self):
return type(self)(self.default_factory, self)
def __deepcopy__(self, memo):
import copy
return type(self)(self.default_factory, copy.deepcopy(self.items()))
def __repr__(self):
return 'defaultdict(%s, %s)' % (self.default_factory, dict.__repr__(self))
~~~
## 二、namedtuple
namedtuple主要用来产生可以使用名称来访问元素的数据对象,通常用来增强代码的可读性,在访问一些tuple类型的数据时尤其好用。其实,在大部分时候你应该使用namedtuple替代tuple,这样可以让你的代码更容易读懂,更加pythonic。举个例子:
~~~
from collections import namedtuple
# 变量名和namedtuple中的第一个参数一般保持一致,但也可以不一样
Student = namedtuple('Student', 'id name score')
# 或者 Student = namedtuple('Student', ['id', 'name', 'score'])
students = [(1, 'Wu', 90), (2, 'Xing', 89), (3, 'Yuan', 98), (4, 'Wang', 95)]
for s in students:
stu = Student._make(s)
print stu
# Output:
# Student(id=1, name='Wu', score=90)
# Student(id=2, name='Xing', score=89)
# Student(id=3, name='Yuan', score=98)
# Student(id=4, name='Wang', score=95)
~~~
在上面的例子中,Student就是一个namedtuple,它和tuple的使用方法一样,可以通过index直接取,而且是只读的。这种方式比tuple容易理解多了,可以很清楚的知道每个值代表的含义。
Over!
var:[http://segmentfault.com/blog/wuxianglong/1190000002399119?_ea=78694](http://segmentfault.com/blog/wuxianglong/1190000002399119?_ea=78694)
比较json/dictionary的库
最后更新于:2022-04-01 01:06:28
在某些情况下,比较两个json/dictionary,或许这样就可以实现:
~~~
>>> a
{'a': 1, 'b': 2}
>>> b
{'a': 2, 'c': 2}
>>> cmp(a,b) #-1或者1,代表两个dict不一样
-1
>>> c=a.copy()
>>> c
{'a': 1, 'b': 2}
>>> cmp(a,c) #两者相同
0
~~~
但是,这只能比较两个是不是一样,不能深入各处哪里不一样的比较结果。
有这样一个库,就能解决这个问题,它就是**json_tools**
## 安装
方法1:
~~~
>>> pip install json_tools
~~~
或者
~~~
>>> easy_install json_tools
~~~
方法2:到这里下载源码:[https://pypi.python.org/pypi/json_tools,然后进行安装](https://pypi.python.org/pypi/json_tools%EF%BC%8C%E7%84%B6%E5%90%8E%E8%BF%9B%E8%A1%8C%E5%AE%89%E8%A3%85)
## 比较json
首先看看都有哪些属性或者方法,用万能的实验室来看:
~~~
>>> import json_tools
>>> dir(json_tools)
~~~
['**builtins**', '**doc**', '**file**', '**loader**', '**name**', '**package**', '**path**', '_patch_main', '_printer_main', 'diff', 'patch', 'path', 'print_function', 'print_json', 'print_style', 'printer']
从上面的结果中,可以看到`json_tools`的各种属性和方法。
我在一个项目中使用了diff,下面演示一下使用过程
~~~
>>> a
{'a': 1, 'b': 2}
>>> b
{'a': 2, 'c': 2}
>>> json_tools.diff(a,b)
[{'prev': 1, 'value': 2, 'replace': '/a'}, {'prev': 2, 'remove': '/b'}, {'add': '/c', 'value': 2}]
~~~
上面这个比较是比较简单的,显示的是b相对于a的变化,特别注意,如果是b相对a,就要这样写:`json_tools.diff(a,b)`,如果是`json_tools.diff(b,a)`,会跟上面有所不同,请看结果:
~~~
>>> json_tools.diff(b,a)
[{'prev': 2, 'value': 1, 'replace': '/a'}, {'prev': 2, 'remove': '/c'}, {'add': '/b', 'value': 2}]
~~~
以`json_tools(a,b)`,即b相对a发生的变化为例进行说明。
* b和a都有键`'a'`,但是b相对a,键`'a'`的值发生了变化,由原来的`1`,变为了`2`。所以在比较结果的list中,有一个元素反应了这个结果`{'prev': 1, 'value': 2, 'replace': '/a'}`,其中,replace表示发生变化的键,value表示变化后即当前该键的值,prev表示该键此前的值。
* b中的`'c'`相对与a,是新增的键。于是比较结果中这样反应出来:`{'add': '/c', 'value': 2}`
* b相对于a没有`'b'`这个键,也就是在b中将其删除了,于是比较结果中这样来显示:`{'prev': 2, 'remove': '/c'}`
通过上述结果,就显示出来的详细的比较结果,不仅如此,还能对多层嵌套的json进行比较。例如:
~~~
>>> a={"a":{"aa":{"aaa":333,"aaa2":3332},"b":22}}
>>> b={"a":{"aa":{"aaa":334,"bbb":339},"b":22}}
>>> json_tools.diff(a,b)
[{'prev': 3332, 'remove': '/a/aa/aaa2'}, {'prev': 333, 'value': 334, 'replace': '/a/aa/aaa'}, {'add': '/a/aa/bbb', 'value': 339}]
~~~
这里就显明了发生变化的key的嵌套关系。比如`'/a/aa/aaa2'`,就表示`{"a":{"aa":{"aaa2":...}}}`的值发生了变化。
这里有了一个key的嵌套字符串,在真实的使用中,有时候需要将字符串转为json的格式,即`{'prev': 3332, 'remove': '/a/aa/aaa2'}`转化为`{"a":{"aa":{"aaa2":3332}}}`。
## 将字符串组装成json格式
首先,回答前面的问题,可以自己写一个函数,实现那种组装。
但是,我是懒惰地程序员,我更喜欢python的原因就是它允许我懒惰。
~~~
from itertools import izip
~~~
具体这个模块如何使用,请看官到我做过的一个小项目中看看:[https://github.com/qiwsir/json-diff](https://github.com/qiwsir/json-diff)
requests库
最后更新于:2022-04-01 01:06:25
**作者:1world0x00**(说明:在入选本教程的时候,我进行了适当从新编辑)
requests是一个用于在程序中进行http协议下的get和post请求的库。
## 安装
~~~
easy_install requests
~~~
或者用
~~~
pip install requests
~~~
安装好之后,在交互模式下运行:
~~~
>>> import requests
>>> dir(requests)
['ConnectionError', 'HTTPError', 'NullHandler', 'PreparedRequest', 'Request', 'RequestException', 'Response', 'Session', 'Timeout', 'TooManyRedirects', 'URLRequired', '__author__', '__build__', '__builtins__', '__copyright__', '__doc__', '__file__', '__license__', '__name__', '__package__', '__path__', '__title__', '__version__', 'adapters', 'api', 'auth', 'certs', 'codes', 'compat', 'cookies', 'delete', 'exceptions', 'get', 'head', 'hooks', 'logging', 'models', 'options', 'packages', 'patch', 'post', 'put', 'request', 'session', 'sessions', 'status_codes', 'structures', 'utils']
~~~
从上面的列表中可以看出,在http中常用到的get,cookies,post等都赫然在目。
## get请求
~~~
>>> r = requests.get("http://www.itdiffer.com")
~~~
得到一个请求的实例,然后:
~~~
>>> r.cookies
<<class 'requests.cookies.RequestsCookieJar'>[]>
~~~
这个网站对客户端没有写任何cookies内容。换一个看看:
~~~
>>> r = requests.get("http://www.1world0x00.com")
>>> r.cookies
<<class 'requests.cookies.RequestsCookieJar'>[Cookie(version=0, name='PHPSESSID', value='buqj70k7f9rrg51emsvatveda2', port=None, port_specified=False, domain='www.1world0x00.com', domain_specified=False, domain_initial_dot=False, path='/', path_specified=True, secure=False, expires=None, discard=True, comment=None, comment_url=None, rest={}, rfc2109=False)]>
~~~
原来这样呀。继续,还有别的属性可以看看。
~~~
>>> r.headers
{'x-powered-by': 'PHP/5.3.3', 'transfer-encoding': 'chunked', 'set-cookie': 'PHPSESSID=buqj70k7f9rrg51emsvatveda2; path=/', 'expires': 'Thu, 19 Nov 1981 08:52:00 GMT', 'keep-alive': 'timeout=15, max=500', 'server': 'Apache/2.2.15 (CentOS)', 'connection': 'Keep-Alive', 'pragma': 'no-cache', 'cache-control': 'no-store, no-cache, must-revalidate, post-check=0, pre-check=0', 'date': 'Mon, 10 Nov 2014 01:39:03 GMT', 'content-type': 'text/html; charset=UTF-8', 'x-pingback': 'http://www.1world0x00.com/index.php/action/xmlrpc'}
>>> r.encoding
'UTF-8'
>>> r.status_code
200
~~~
下面这个比较长,是网页的内容,仅仅截取显示部分:
~~~
>>> print r.text
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>1world0x00sec</title>
<link rel="stylesheet" href="http://www.1world0x00.com/usr/themes/default/style.min.css">
<link rel="canonical" href="http://www.1world0x00.com/" />
<link rel="stylesheet" type="text/css" href="http://www.1world0x00.com/usr/plugins/CodeBox/css/codebox.css" />
<meta name="description" content="爱生活,爱拉芳。不装逼还能做朋友。" />
<meta name="keywords" content="php" />
<link rel="pingback" href="http://www.1world0x00.com/index.php/action/xmlrpc" />
......
~~~
请求发出后,requests会基于http头部对相应的编码做出有根据的推测,当你访问r.text之时,requests会使用其推测的文本编码。你可以找出requests使用了什么编码,并且能够使用r.coding属性来改变它。
~~~
>>> r.content
'\xef\xbb\xbf\xef\xbb\xbf<!DOCTYPE html>\n<html lang="zh-CN">\n <head>\n <meta charset="utf-8">\n <meta name="viewport" content="width=device-width, initial-scale=1.0">\n <title>1world0x00sec</title>\n <link rel="stylesheet" href="http://www.1world0x00.com/usr/themes/default/style.min.css">\n <link ......
以二进制的方式打开服务器并返回数据。
~~~
## post请求
requests发送post请求,通常你会想要发送一些编码为表单的数据——非常像一个html表单。要实现这个,只需要简单地传递一个字典给data参数。你的数据字典在发出请求时会自动编码为表单形式。
~~~
>>> import requests
>>> payload = {"key1":"value1","key2":"value2"}
>>> r = requests.post("http://httpbin.org/post")
>>> r1 = requests.post("http://httpbin.org/post", data=payload)
~~~
r没有加data的请求,看看效果:
[](https://camo.githubusercontent.com/80c036d0c0e5842c8c30677cfbb00129edc0d400/687474703a2f2f777870696374757265732e71696e6975646e2e636f6d2f726571756574732d706f7374312e6a7067)
r1是加了data的请求,看效果:
[](https://camo.githubusercontent.com/1da3cca06274c00f49f1cbacbb9b7372ff1e4220/687474703a2f2f777870696374757265732e71696e6975646e2e636f6d2f726571756574732d706f7374322e6a7067)
多了form项。喵。
## http头部
~~~
>>> r.headers['content-type']
'application/json'
~~~
注意,在引号里面的内容,不区分大小写`'CONTENT-TYPE'`也可以。
还能够自定义头部:
~~~
>>> r.headers['content-type'] = 'adad'
>>> r.headers['content-type']
'adad'
~~~
注意,当定制头部的时候,如果需要定制的项目有很多,需要用到数据类型为字典。
* * *
## 老齐备注
网上有一个更为详细叙述有关requests模块的网页,可以参考:[http://requests-docs-cn.readthedocs.org/zh_CN/latest/index.html](http://requests-docs-cn.readthedocs.org/zh_CN/latest/index.html)
第四部分 暮然回首,灯火阑珊处
最后更新于:2022-04-01 01:06:23
模板转义
最后更新于:2022-04-01 01:06:21
列位看官曾记否?在[《玩转字符串(1)》](https://github.com/qiwsir/ITArticles/blob/master/BasicPython/107.md)中,有专门讲到了有关“转义”问题,就是在python的字符串中,有的符号要想表达其本意,需要在前面加上`\`符号,例如单引号,如果要在字符串中表现它,必须写成`\'单引号里面\'`样式,才能实现一对单引号以及里面的内容,否则,它就表示字符串了。
在HTML代码中,也有类似的问题,比如`>`等,就是代码的一部分,如果直接写,就不会显示在网页里,要向显示,同样需要转义。另外,如果在网页中有表单,总会有别有用心的人向表单中写点包含`>`等字符的东西,目的就是要攻击你的网站,为了防治邪恶之辈,也需要将用户输入的字符进行转义,转化为字符实体,让它不具有HTML代码的含义。
> 转义字符串(Escape Sequence)也称字符实体(Character Entity)。在HTML中,定义转义字符串的原因有两个:第一个原因是像“”这类符号已经用来表示HTML标签,因此就不能直接当作文本中的符号来使用。为了在HTML文档中使用这些符号,就需要定义它的转义字符串。当解释程序遇到这类字符串时就把它解释为真实的字符。在输入转义字符串时,要严格遵守字母大小写的规则。第二个原因是,有些字符在ASCII字符集中没有定义,因此需要使用转义字符串来表示。
## 模板自动转义
Tornado 2 开始的模板具有自动转义的功能,这让开发者省却了不少事情。看一个例子。就利用上一讲中建立的开发框架。要在首页模板中增加一个表单提交功能。
修改template/index.html文件,内容如下:
~~~
<DOCTYPE html>
<html>
<head>
<title>Loop in template</title>
<link rel="stylesheet" type="text/css" href="{{ static_url('css/style.css')}}">
</head>
<body>
<h1>aaaAAA</h1>
<p>There is a list, it is <b>{{info}}</b></p>
<p>I will print the elements of this list in order.</p>
{% for element in info %}
<p>{{element}}</p>
{% end %}
<br>
{% for index,element in enumerate(info) %}
<p>info[{{index}}] is {{element}}
{% if element == "python" %}
<p> <b>I love this language--{{element}}</b></p>
{% end %}
{% end %}
{% if "qiwsir@gmail.com" in info %}
<p><b>A Ha, this the python lesson of LaoQi, It is good! His email is {{info[2]}}</b></p>
{% end %}
<h2>Next, I set "python-tornado"(a string) to a variable(var)</h2>
{% set var="python-tornado" %}
<p>Would you like {{var}}?</p>
<!--增加表单-->
<form method="post" action="/option">
<p>WebSite:<input id="website" name="website" type="text"></p>
<p><input type="submit" value="ok,submit"></p>
</form>
</body>
</html>
~~~
在增加的表单中,要将内容以`post`方法提交到`"/option"`,所以,要在url.py中设置路径,并且要建立相应的类。
然后就在handler目录中建立一个新的文件,命名为optform.py,其内容就是一个类,用来接收index.html中`post`过来的表单内容。
~~~
#!/usr/bin/env python
#coding:utf-8
import tornado.web
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
class OptionForm(tornado.web.RequestHandler):
def post(self):
website = self.get_argument("website") #接收名称为'website'的表单内容
self.render("info.html",web=website)
~~~
为了达到接收表单post到上述类中内容的目的,还需要对url.py进行如下改写:
~~~
#!/usr/bin/env python
#coding:utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from handler.index import IndexHandler
from handler.optform import OptionForm
url=[
(r'/', IndexHandler),
(r'/option', OptionForm),
]
~~~
看官还要注意,我在新建立的optform.py中,当接收到来自表单内容之后,就用另外一个模板`info.html`显示所接收到的内容。这个文件放在template目录中,代码是:
~~~
<DOCTYPE html>
<html>
<head>
<title>Loop in template</title>
<link rel="stylesheet" type="text/css" href="{{ static_url('css/style.css')}}">
</head>
<body>
<h1>My Website is:</h1>
<p>{{web}}</p>
</body>
</html>
~~~
这样我们就完成表单内容的提交和显示过程。
从上面的流程中,看官是否体验到这个框架的优势了?不用重复敲代码,只需要在框架内的不同地方增加内容,即可完成网站。
演示运行效果:
我在表单中输入了`alert('bad script')`,这是多么阴险毒辣呀。
[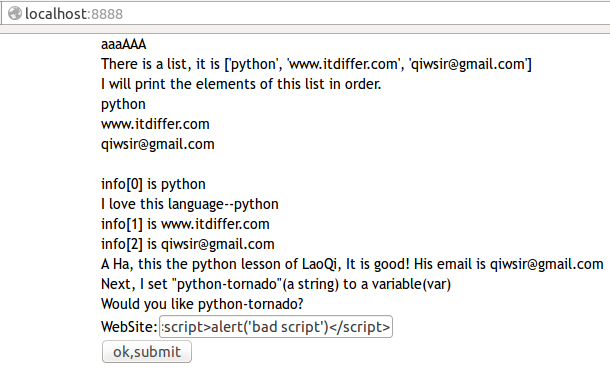](https://github.com/qiwsir/ITArticles/blob/master/Pictures/31401.png)
然而我们的tornado是不惧怕这种攻击的,因为它的模板自动转义了。当点击按钮提交内容的时候,就将那些阴险的符号实体化,成为转义之后的符号了。于是就这样了:
[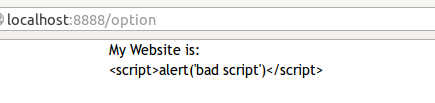](https://github.com/qiwsir/ITArticles/blob/master/Pictures/31402.png)
输入什么,就显示什么,不会因为输入的内容含有阴险毒辣的符号而网站无法正常工作。这就是转义的功劳。
## 不转义的办法
在tornado中,模板实现了自动转义,省却了开发者很多事,但是,事情往往没有十全十美的,这里省事了,一定要在别的地方费事。例如在上面那个info.html文件中,我打算在里面加入我的电子信箱,但是要像下面代码这样,设置一个变量,主要是为了以后修改方便和在其它地方也可以随意使用。
~~~
<DOCTYPE html>
<html>
...(省略)
<body>
<h1>My Website is:</h1>
<p>{{web}}</p>
{% set email="<a href='mailto:qiwsir@gmail.com'>Connect to me</a>"%}
<p>{{email}}</p>
</body>
</html>
~~~
本来希望在页面中出现的是`Connect to me`,点击它之后,就直接连接到发送电子邮件。结果,由于转义,出现的是下面的显示结果:
[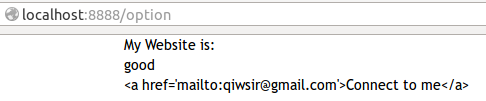](https://github.com/qiwsir/ITArticles/blob/master/Pictures/31403.png)
实现电子邮件超链接未遂。
这时候,就需要不让模板转义。tornado提供的方法是:
* 在Application函数实例化的时候,设置参数:autoescape=None。这种方法不推荐适应,因为这样就让全站模板都不转意了,看官愿意尝试,不妨进行修改试一试,我这里就不展示了。
* 在每个页面中设置{% autoescape None %},表示这个页面不转义。也不推荐。理由,自己琢磨。
* 以上都不推荐,我推荐的是:{% raw email %},想让哪里不转义,就在那里用这种方式,比如要在email超级链接那里不转移,就写成这样好了。于是修改上面的代码,看结果为:
[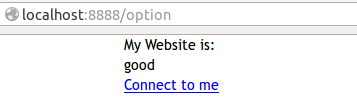](https://github.com/qiwsir/ITArticles/blob/master/Pictures/31404.png)
如此,实现了不转义。
以上都实现了模板的转义和不转义。
## url转义
本来模板转义和不转义问题已经交代清楚了。怎奈上周六一个朋友问了一个问题,那个问题涉及到url转义问题,于是在这里再补上一段,专门谈谈url转义的问题。
有些符号在URL中是不能直接传递的,如果要在URL中传递这些特殊符号,那么就要使用它们的编码了。编码的格式为:%加字符的ASCII码,即一个百分号%,后面跟对应字符的ASCII(16进制)码值。例如 空格的编码值是"%20"。
在python中,如果用utf-8写了一段地址,如何转义成url能够接收的字符呢?
在python中有一个urllib模块:
~~~
>>> import urllib
>>> #假设下面的url,是utf-8编码
>>> url_mail='http://www.itdiffer.com/email?=qiwsir@gmail.com'
>>> #转义为url能够接受的
>>> urllib.quote(url_mail)
'http%3A//www.itdiffer.com/email%3F%3Dqiwsir%40gmail.com'
~~~
反过来,一个url也能转移为utf-8编码格式,请用urllib.unquote()
下面抄录帮助文档中的内容,供用到的朋友参考:
~~~
quote(s, safe='/')
quote('abc def') -> 'abc%20def'
Each part of a URL, e.g. the path info, the query, etc., has a
different set of reserved characters that must be quoted.
RFC 2396 Uniform Resource Identifiers (URI): Generic Syntax lists
the following reserved characters.
reserved = ";" | "/" | "?" | ":" | "@" | "&" | "=" | "+" |
"$" | ","
Each of these characters is reserved in some component of a URL,
but not necessarily in all of them.
By default, the quote function is intended for quoting the path
section of a URL. Thus, it will not encode '/'. This character
is reserved, but in typical usage the quote function is being
called on a path where the existing slash characters are used as
reserved characters.
unquote(s)
unquote('abc%20def') -> 'abc def'.
quote_plus(s, safe='')
Quote the query fragment of a URL; replacing ' ' with '+'
unquote_plus(s)
unquote('%7e/abc+def') -> '~/abc def'
~~~
转义是网站开发中要特别注意的地方,不小心或者忘记了,就会纠结。
静态文件以及一个项目框架
最后更新于:2022-04-01 01:06:18
在网上浏览网页,由于现在网速也快了,大概你很少注意网页中那些所谓的静态文件。怎么找出来静态文件呢?
如果使用firefox(我特别向列位推荐这个浏览器,它是我认为的最好的浏览器,没有之一。哈哈。“你信不信?反正我信了。”),可以通过firebug组件,来研究网页的代码,当然,你直接看源码也行。
[](https://github.com/qiwsir/ITArticles/blob/master/Pictures/31301.png)
上图中,我打开了一个对天朝很多人来说不存在的网站,并且通过Firebug查看其源码,打开``,发现里面有不少`<script`和`<link`开始引入的文件,这些文件一部分是javascript文件,一部分是css文件。在一个网站中,这类文件一般是不会发生变化的,也就是它的内容稳定,直到下次文件管理员或者有权限的人修改时。而网站程序本身一般不会修改它们。因此将他们称之为**静态文件**。
此外,网站中的**静态文件**还包括一些图片,比如logo,以及做为边框的图片等。
在tornado中,有专门方法处理这些静态文件。
## 静态路径
看官是否还记得在前面写过这个模样的代码:`template_path=os.path.join(os.path.dirname(__file__), "templates")`,这里是设置了模板的路径,放置模板的目录名称是`templates`。类似的方法,我们也可以设置好静态文件的路径。
~~~
static_path=os.path.join(os.path.dirname(__file__), "static")
~~~
这里的设置,就是将所有的静态文件,放在了`static`目录中。
这样就设置了静态路径。
下面的代码是将[上一节](https://github.com/qiwsir/ITArticles/blob/master/BasicPython/312.md)的代码进行了改写,注意变化的地方
~~~
#! /usr/bin/env python
#-*- coding:utf-8 -*-
import os.path
import tornado.httpserver
import tornado.ioloop
import tornado.web
import tornado.options
from tornado.options import define, options
define("port", default=8000, help="run on the given port", type=int)
class IndexHandler(tornado.web.RequestHandler):
def get(self):
lst = ["python","www.itdiffer.com","qiwsir@gmail.com"]
self.render("index.html", info=lst)
handlers = [(r"/", IndexHandler),]
template_path = os.path.join(os.path.dirname(__file__), "temploop")
static_path = os.path.join(os.paht.dirname(__file__), "static") #这里增加设置了静态路径
if __name__ == "__main__":
tornado.options.parse_command_line()
app = tornado.web.Application(handlers, template_path, static_path, debug=True) #这里也多了点
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(options.port)
tornado.ioloop.IOLoop.instance().start()
~~~
上面的代码比前一讲中,多了两处,一处是定义了静态文件路径`static_path`,在这里将存储静态文件的目录命名为`static`。另外一个修改就是在实例化`tornado.web.Application()`的时候,在参数中,出了有静态路径参数`static_path`,还有一个参数设置`debug=True`,这个参数设置的含义是当前的tornado服务器可以不用重启,就能够体现已经修改的代码功能。回想一下,在前面进行调试的时候,是不是每次如果修改了代码,就得重启tornado服务器,才能看到修改效果。用了这个参数就不用这么麻烦了。
特别说着,`debug=True`仅仅用于开发的调试过程中,如果在生产部署的时候,就不要这么使用了。
## 编写模板文件
我们设置静态路径的目的就是要在模板中引入css和js等类型的文件以及图片等等。那么如何引入呢,下面以css为例说明。
在一般网页的`...`部分,都会引入CSS,例如下面的写法不少网站都愿意引用google的字体库,样式如下:
~~~
<link href='http://fonts.googleapis.com/css?family=Open+Sans:300,400,600&subset=latin,latin-ext' rel='stylesheet'>
~~~
这就是CSS的引入。
但是,如果看官在墙内也这么引入字体库,希望自己的网页上能使用,那就有点麻烦了,因为google的这个项目已经不行被墙,如果在网页中写了上面代码,会导致网页打开速度很慢,有的甚至出错。
怎么办?那就不用啦。不过,国内有好心网站做了整个谷歌字体的代理,可以用下面方式,墙里面就不怕了。
~~~
<link href='http://fonts.useso.com/css?family=Open+Sans:300,400,600&subset=latin,latin-ext' rel='stylesheet'>
~~~
顺便提供一个墙内的常用前端库地址:[http://libs.useso.com/,供看官参考使用。](http://libs.useso.com/%EF%BC%8C%E4%BE%9B%E7%9C%8B%E5%AE%98%E5%8F%82%E8%80%83%E4%BD%BF%E7%94%A8%E3%80%82)
那么如果我自己写CSS呢?并且按照前面的设定,已经将该CSS文件放在了static目录里面,命名为style.css,就可以这样引入
~~~
<link href="/static/style.css" rel="stylesheet">
~~~
但是,这里往往会有一个不方便的地方,如果我手闲着无聊,或者因为别的充足理由,将存储静态文件的目录static换成了sta,并且假设我已经在好几个模板中都已经写了上面的代码。接下来我就要把这些文件全打开,一个一个更改``里面的地址。
请牢记,凡是遇到重复的事情,一定要找一个函数方法解决。tornado就提供了这么一个:`static_url()`,把上面的代码写成:
~~~
<link href="{{ static_url("style.css") }}" rel="stylesheet" >
~~~
这样,就不管你如何修改静态路径,模板中的设置可以不用变。
按照这个引入再修改相应的模板文件。
## 一个项目框架
以上以及此前,我们所有写过的,都是简单的技术方法演示,如果要真的写一个基于tornado框架的网站,一般是不用这样的直接把代码都写到一个文件index.py中的,一个重要原因,就是这样做不容易以后维护,也不便于多人协作写一个项目。
所以在真实的项目中,常常要将不同部件写在不同文件中。下面的例子就是一个项目的基本框架。当然,这还是一个比较小的项目,但是“麻雀虽小,五脏俱全”。
创建一个文件夹,我给它命名为project,在这个文件里面分别创建下面的文件和目录,文件和目录里面的内容可以先不用管,“把式把式,先看架势”,先搭起项目结构来。
* 文件`application.py`:这个文件的核心任务是完成`tornado.web.Application()`的实例化
* 文件`url.py`:在这个文件中记录项目中所有URL和映射的类,即完成前面代码中`handlers=[...]`的功能
* 文件`server.py`:这是项目的入口文件,里面包含`if __name__ == "__main__"`,从这里启动项目和服务
* 目录handler:存放`.py`文件,即所谓各种请求处理类(当然,如果更大一些的项目,可能还要分配给别的目录来存储这种东西)
* 目录optsql:存放操作数据库的文件,比如各种读取或者写入数据库的类或函数,都放在这里面的某些文件中
* 目录static:存放静态文件,就是上文说的比如CSS,JS,图片等,为了更清晰,在这个目录里面,还可建立子目录,比如我就建立了:css,js,img三个子目录,分别对应上面的三种。
* 目录template:存放`.html`的模板(在更大型的项目中,可能会设计多个目录来存放不同的模板,或者在里面再有子目录进行区分)
以上就是我规划的一个项目的基本框架了。不同开发者根据自己的习惯,有不同的规划,或者有不同的命名,这没有关系。不过需要说明的,尽量使用名词(英文)。我看到过有人做过单复数之争论。我个人认为,这个无所谓,只要在一个项目中一贯就好了。我还是用单数吧,因为总忘记那个复数后面的s
下面分别把不同部分文件的内容列出来,因为都是前面代码的重复,不过是做了一点从新部署,所以,就不解释了。个别地方有一点点说明。
文件application.py的代码如下:
~~~
#!/usr/bin/env python
#coding:utf-8
from url import url
import tornado.web
import os
setting = dict(
template_path=os.path.join(os.path.dirname(__file__),"template"),
static_path=os.path.join(os.path.dirname(__file__),"static"),
)
application = tornado.web.Application(
handlers=url,
**setting
)
~~~
`from url import url`是从文件url.py引入内容
下面看看url.py文件内容:
~~~
#!/usr/bin/env python
#coding:utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from handler.index import IndexHandler
url=[
(r'/', IndexHandler),
]
~~~
在这个文件中,从`import sys`开始的三行,主要是为了解决如果文件里面有汉字,避免出现乱码。现在这个文件很简单,里面只有`(r'/', IndexHandler)`一条URL,如果多条了,就要说明每条是什么用途,如果用中文写注释,需要避免乱码。
以上两个预备好了,就开始写server.py,内容如下:
~~~
#!/usr/bin/env python
#coding:utf-8
import tornado.ioloop
import tornado.options
import tornado.httpserver
import sys
from application import application
from tornado.options import define,options
define("port",default=8888,help="run on th given port",type=int)
def main():
tornado.options.parse_command_line()
http_server = tornado.httpserver.HTTPServer(application)
http_server.listen(options.port)
print 'Development server is running at http://127.0.0.1:%s/' % options.port
print 'Quit the server with Control-C'
tornado.ioloop.IOLoop.instance().start()
if __name__=="__main__":
main()
~~~
这个就不需要解释了。接下来就看目录,首先在`static/css/`里面建立一个style.css的文件,并写样式表。我只写了下面的样式,这个样式的目的主要是去除浏览器默认的样式,在实际的工程项目中,这个步骤是非常必要的,一定要去除所有默认的样式,然后重新定义,才能便于控制。
~~~
html, body, div, span, applet, object, iframe,h1, h2, h3, h4, h5, h6, p, blockquote, pre,a, abbr, acronym, address, big, cite, code,del, dfn, em, img, ins, kbd, q, s, samp,small, strike, strong, sub, sup, tt, var,b, u, i, center,dl, dt, dd, ol, ul, li,fieldset, form, label, legend,table, caption, tbody, tfoot, thead, tr, th, td,article, aside, canvas, details, embed, figure, figcaption, footer, header, hgroup, menu, nav, output, ruby, section, summary,time, mark, audio, video {
margin: 0;
padding: 0;
border: 0;
font-size: 100%;
font: inherit;
vertical-align: baseline;
}
/* HTML5 display-role reset for older browsers */
article, aside, details, figcaption, figure, footer, header, hgroup, menu, nav, section {
display: block;
}
body {
/* standard body */
margin: 0 auto;
width: 960px;
font: 14px/20px "Trebuchet MS", Verdana, Helvetica, Arial, sans-serif;
}
~~~
为了能够在演示的时候看出样式控制的变化,多写了一个对body的控制,居中且宽度为960px。
样式表已经定义好,就要看`template/index.html`了,这个文件就是本项目中的唯一一个模板。
~~~
<DOCTYPE html>
<html>
<head>
<title>Loop in template</title>
<link rel="stylesheet" type="text/css" href="{{ static_url('css/style.css')}}">
</head>
<body>
<h1>aaaAAA</h1>
<p>There is a list, it is <b>{{info}}</b></p>
<p>I will print the elements of this list in order.</p>
{% for element in info %}
<p>{{element}}</p>
{% end %}
<br>
{% for index,element in enumerate(info) %}
<p>info[{{index}}] is {{element}}
{% if element == "python" %}
<p> <b>I love this language--{{element}}</b></p>
{% end %}
{% end %}
{% if "qiwsir@gmail.com" in info %}
<p><b>A Ha, this the python lesson of LaoQi, It is good! His email is {{info[2]}}</b></p>
{% end %}
<h2>Next, I set "python-tornado"(a string) to a variable(var)</h2>
{% set var="python-tornado" %}
<p>Would you like {{var}}?</p>
</body>
</html>
~~~
在这个文件中,特别注意就是`<link rel="stylesheet" type='text/css' href="{{ static_url('css/style.css')}}"`,这里引入了前面定义的样式表文件。引入方式就是前文讲述的方式,不过由于是在css这个子目录里面,所以写了相对路径。
行文到此,我原以为已经完成了。一检查,发现一个重要的目录`handler`里面还空着呢,那里面放index.py文件,这个文件里面是请求响应的类IndexHandler
~~~
#!/usr/bin/env python
#coding:utf-8
import tornado.web
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
class IndexHandler(tornado.web.RequestHandler):
def get(self):
lst = ["python","www.itdiffer.com","qiwsir@gmail.com"]
self.render("index.html", info=lst)
~~~
这个文件的代码没有什么增加的内容,只是多了三行设置为utf-8的配置,目的是避免汉字乱码。另外,很需要说明的是,由于这个文件在handler目录里面,要在上一层的url.py中引用(看url.py内容),必须要在本目录中建立一个名称是`__init__.py`的空文。
好了,基本结构已经完成。跑起来。效果就是这样的:
[](https://github.com/qiwsir/ITArticles/blob/master/Pictures/31302.png)
模板中的语法:tornado模板中的for,if,set等语法
最后更新于:2022-04-01 01:06:16
在[上一讲](https://github.com/qiwsir/ITArticles/blob/master/BasicPython/311.md)的练习中,列位已经晓得,模板中`{{placeholder}}`可以接收来自python文件(.py)中通过`self.render()`传过来的参数值,这样模板中就显示相应的结果。在这里,可以将`{{placeholder}}`理解为占位符,就如同变量一样啦。
这是一种最基本的模板显示方式了。但如果仅仅如此,模板的功能有点单调,无法完成比较复杂的数据传递。不仅仅是tornado,其它框架如Django等,模板都有比较“高级”的功能。在tornado的模板中,功能还是很不少的,本讲介绍模板语法先。
## 模板中循环的例子
在模板中,也能像在python中一样,可以使用某些语法,比如常用的if、for、while等语句,使用方法如下:
先看例子
先写一个python文件(命名为index.py),这个文件中有一个列表`["python", "www.itdiffer.com", "qiwsir@gmail.com"]`,要求是将这个列表通过`self.render()`传给模板。
然后在模板中,利用for语句,依次显示得到的列表中的元素。
~~~
#! /usr/bin/env python
#-*- coding:utf-8 -*-
import os.path
import tornado.httpserver
import tornado.ioloop
import tornado.web
import tornado.options
from tornado.options import define, options
define("port", default=8000, help="run on the given port", type=int)
class IndexHandler(tornado.web.RequestHandler):
def get(self):
lst = ["python","www.itdiffer.com","qiwsir@gmail.com"] #定义一个list
self.render("index.html", info=lst) #将上述定义的list传给模板
handlers = [(r"/", IndexHandler),]
template_path = os.path.join(os.path.dirname(__file__), "temploop") #模板路径
if __name__ == "__main__":
tornado.options.parse_command_line()
app = tornado.web.Application(handlers,template_path)
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(options.port)
tornado.ioloop.IOLoop.instance().start()
~~~
模板文件,名称是index.html,在目录temploop中。代码如下:
~~~
<DOCTYPE html>
<html>
<head>
<title>Loop in template</title>
</head>
<body>
<p>There is a list, it is <b>{{info}}</b></p>
<p>I will print the elements of this list in order.</p>
{% for element in info %} <!-- 循环开始,注意写法类似python中的for,但是最后没有冒号 -->
<p>{{element}}</p> <!-- 显示element的内容 -->
{% end %} <!-- 结束标志 -->
<br>
{% for index,element in enumerate(info) %}
<p>info[{{index}}] is {{element}}
{% end %}
</body>
</html>
~~~
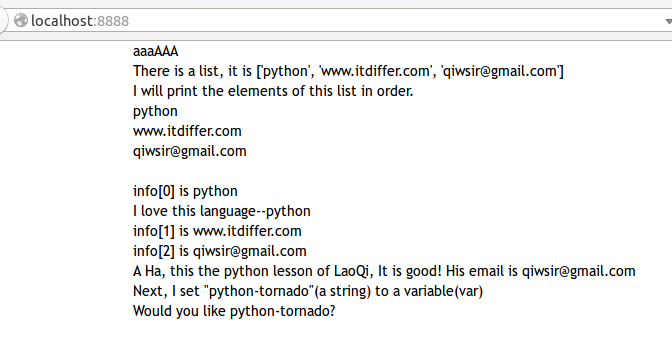
运行上面的程序:
~~~
>>> python index.py
~~~
然后在浏览器地址栏中输入:`http://localhost:8000`,显示的页面如下图:
[](https://github.com/qiwsir/ITArticles/blob/master/Pictures/31201.png)
在上面的例子中,用如下样式,实现了模板中的for循环,这是在模板中常用到的,当然,从python程序中传过来的不一定是list类型数据,也可能是其它类型的序列数据。
~~~
{% for index,element in enumerate(info) %}
<p>info[{{index}}] is {{element}}
{% end %}
~~~
特别提醒注意的是,语句要用`{% end %}`来结尾。在循环体中,用`{{ element }}`方式使用序列的元素。
## 模板中的判断语句
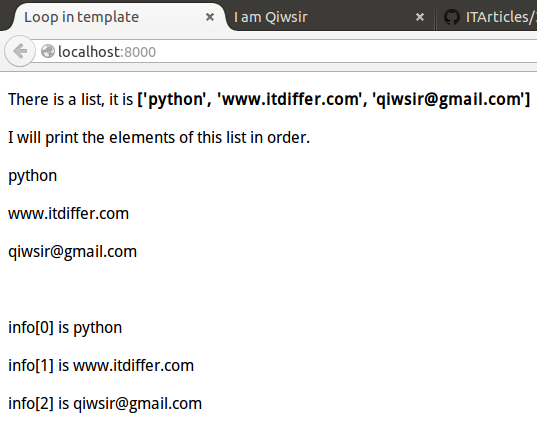
除了循环之外,在模板中也可以有判断,在上面代码的基础上,改写一下,直接上代码,看官想必也能理解了。
index.py的代码不变,只修改模板index.html的代码,重点理解模板中的语句写法。
~~~
<DOCTYPE html>
<html>
<head>
<title>Loop in template</title>
</head>
<body>
<p>There is a list, it is <b>{{info}}</b></p>
<p>I will print the elements of this list in order.</p>
{% for element in info %}
<p>{{element}}</p>
{% end %}
<br>
{% for index,element in enumerate(info) %}
<p>info[{{index}}] is {{element}}
{% if element == "python" %} <!-- 增加了一个判断语句 -->
<p> <b>I love this language--{{element}}</b></p>
{% end %}
{% end %}
{% if "qiwsir@gmail.com" in info %} <!-- 还是判断一下 -->
<p><b>A Ha, this the python lesson of LaoQi, It is good! His email is {{info[2]}}</b></p>
{% end %}
</body>
</html>
~~~
上面的模板运行结果是下图样子,看官对比一下,是否能够理解呢?
[](https://github.com/qiwsir/ITArticles/blob/master/Pictures/31202.png)
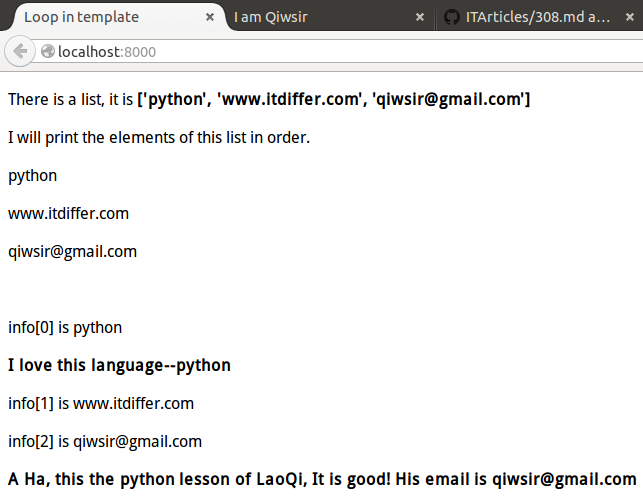
## 模板中设置变量
废话不说,直接上例子,因为例子是非常直观的:
~~~
<DOCTYPE html>
<html>
<head>
<title>Loop in template</title>
</head>
<body>
<p>There is a list, it is <b>{{info}}</b></p>
<p>I will print the elements of this list in order.</p>
{% for element in info %}
<p>{{element}}</p>
{% end %}
<br>
{% for index,element in enumerate(info) %}
<p>info[{{index}}] is {{element}}
{% if element == "python" %}
<p> <b>I love this language--{{element}}</b></p>
{% end %}
{% end %}
{% if "qiwsir@gmail.com" in info %}
<p><b>A Ha, this the python lesson of LaoQi, It is good! His email is {{info[2]}}</b></p>
{% end %}
<h2>Next, I set "python-tornado"(a string) to a variable(var)</h2>
{% set var="python-tornado" %}
<p>Would you like {{var}}?</p>
</body>
</html>
~~~
显示结果如下:
[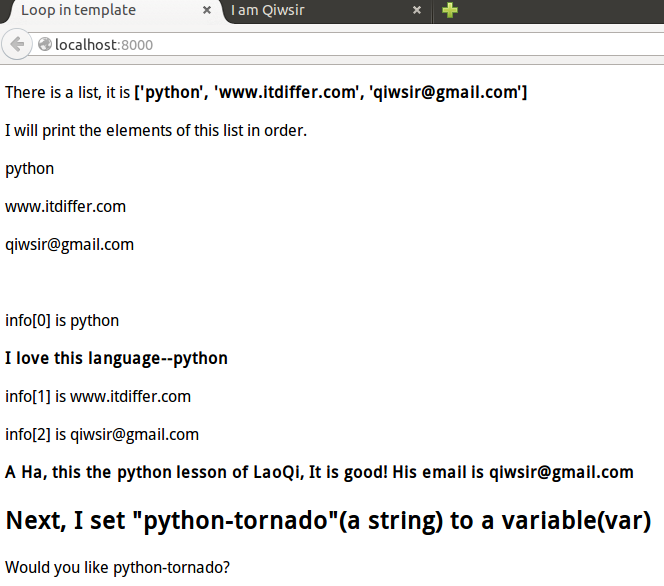](https://github.com/qiwsir/ITArticles/blob/master/Pictures/31203.png)
看官发现了吗?我用`{% set var="python-tornado" %}`的方式,将一个字符串赋给了变量`var`,在下面的代码中,就直接引用这个变量了。这样就是实现了模板中变量的使用。
Tornado的模板真的功能不少呢。不过远非这些,后面还有。敬请等待。
使用表单和模板:tornado模板self.render和模板变量传递
最后更新于:2022-04-01 01:06:14
如果像前面那么做网站,也太丑陋了。并且功能也不多。
在实际做网站中,现在都要使用一个模板,并且在用户直接看到的页面,用html语言来写页面(关于HTML,本教程默认为看官已经熟悉,如果不熟悉,可以到找有关教程来学习)。
在做网站的行业里面,常常将HTML+CSS+JS组成的网页,称作“前端”。它主要负责展示,或者让用户填写一些表格,通过JS提交给用python写的程序,让python程序来处理数据,那些处理数据的python程序称之为“后端”。我常常提醒做“后端”的,不要轻视“前端”。如果看官立志成为全栈工程师,就要从前到后都通。
在本讲中,为了突出模板和后端程序,我略去CSS+JS,虽然这样一来界面难看,而且用户的友好度也不怎么样(JS,javascript是使网页变得更友好的重要工具,如不用更换地址就能刷新页面等等,特别提醒看官,一定要学好javascript,虽然这个可能没有几个大学教的。请看维基百科对javascript简介:)。
> JavaScript,一种直译式脚本语言,是一种动态类型、弱类型、基于原型的语言,内置支持类。它的解释器被称为JavaScript引擎,为浏览器的一部分,广泛用于客户端的脚本语言,最早是在HTML网页上使用,用来给HTML网页增加动态功能。然而现在JavaScript也可被用于网络服务器,如Node.js。
>
> 在1995年时,由网景公司的布兰登·艾克,在网景导航者浏览器上首次设计实作而成。因为网景公司与升阳公司合作,网景公司管理层次结构希望它外观看起来像Java,因此取名为JavaScript。但实际上它的语法风格与Self及Scheme较为接近。
>
> 为了取得技术优势,微软推出了JScript,CEnvi推出ScriptEase,与JavaScript同样可在浏览器上运行。为了统一规格,1997年,在ECMA(欧洲计算机制造商协会)的协调下,由Netscape、Sun、微软、Borland组成的工作组确定统一标准:ECMA-262。因为JavaScript兼容于ECMA标准,因此也称为ECMAScript。
上面这段引文里面提到了一个非常著名的公司:网景,可能年青一代都忘却了。也建议有兴趣的看官到维基百科中了解这个传奇公司,它曾经有一个传奇产品,虽然名字不复存在,但是Firefox是秉承它衣钵的。
话题再转回来,还是关于本讲,主要是要演示一个用模板(HTML)写一个表单,然后提交给后端的python程序,再转到另外一个显示的前端页面显示。为了简化流程,这个过程中没有数据处理和CSS+Javascript的工作,所有界面会丑陋。但是,“我很丑,可是我很温柔”。
## 一个表单
要做一个前端的页面,显示的内容就如同下图样式
[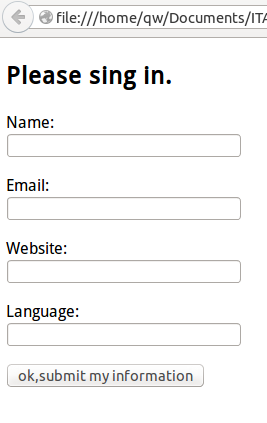](https://github.com/qiwsir/ITArticles/blob/master/Pictures/31101.png)
相应代码是,并命名为index.html,存在一个名称是template的目录中。
~~~
<!DOCTYPE html>
<html>
<head>
<title>sign in your name</title>
</head>
<body>
<h2>Please sing in.</h2>
<form method="post" action="/user">
<p>Name:<br><input type="text" name="username"></p>
<p>Email:<br><input type="text" name="email"></p>
<p>Website:<br><input type="text" name="website"></p>
<p>Language:<br><input type="text" name="language"></p>
<input type="submit" value="ok,submit my information">
</form>
</body>
</html>
~~~
上面的代码是比较简单,如果看官熟悉html的话,不熟悉也不要紧,网上搜索就能理解。注意,没有CSS+JS,所以简单。如果在真正开发中,这两个是不能少的。
有了这个表单之后,如果用户把相关信息都填写好了。点击下面的按钮,就应该提交给后端的python程序来处理。
## 后端处理程序
做为tornado驱动的网站,首先要能够把前面的index.html显示出来,这个一般用get方法,显示的样式就按照上面的样子显示。
用户填写信息之后,点击按钮提交。注意观察上面的代码表单中,设定了`post`方法,所以,在python程序中,应该有一个post方法专门来接收所提交的数据,然后把提交的数据在另外一个网页显示出来。
在表单中还要注意,有一个`action=/user`,表示的是要将表单的内容提交给`/user`路径所对应的程序来处理。这里需要说明的是,在网站中,数据提交和显示,路径是非常重要的。
按照以上意图,编写如下代码,并命名为usercontroller.py,保存在template目录中
~~~
#!/usr/bin/env python
#coding:utf-8
import os.path
import tornado.httpserver
import tornado.ioloop
import tornado.options
import tornado.web
from tornado.options import define, options
define("port", default=8000, help="run on the given port", type=int)
class IndexHandler(tornado.web.RequestHandler):
def get(self):
self.render("index.html")
class UserHandler(tornado.web.RequestHandler):
def post(self):
user_name = self.get_argument("username")
user_email = self.get_argument("email")
user_website = self.get_argument("website")
user_language = self.get_argument("language")
self.render("user.html",username=user_name,email=user_email,website=user_website,language=user_language)
handlers = [
(r"/", IndexHandler),
(r"/user", UserHandler)
]
template_path = os.path.join(os.path.dirname(__file__),"template")
if __name__ == "__main__":
tornado.options.parse_command_line()
app = tornado.web.Application(handlers, template_path)
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(options.port)
tornado.ioloop.IOLoop.instance().start()
~~~
这次代码量多一些。但是多数在前面讲述tornado基本结构的时候已经说过了,跟前面一样,这里仅仅把重点的和新出现的进行讲述,如果看官对某些内容还有疑问,可以参考前面的相关章节。
在引入的模块上,多了一个`import os.path`,这个模块主要用在:
~~~
template_path = os.path.join(os.path.dirname(__file),"template")
~~~
这是要获取存放程序的目录`template`的路径。
重点看两个类中都有的`self.render()`,用这个方法引入相应的模板。
~~~
self.render("index.html")
~~~
显示index.html模板,但是此时并没有向模板网页传递任何数据,仅仅显示罢了。下面一个:
~~~
self.render("user.html",username=user_name,email=user_email,website=user_website,language=user_language)
~~~
与前面的不同在于,不仅仅是要引用模板网页user.html,还要向这个网页传递一些数据,例如username=user_name,含义就是,在模板中,某个地方是用username来标示得到的数据,而user_name是此方法中的一个变量,也就是对应一个数据,那么模板中的username也就对应了user_name的数据,这是通过username=user_name完成的(说的有点像外语了)。后面的变量同理。
那么,user_name的数据是哪里来的呢?就是在index.html页面的表单中提交上来的。注意观察路径的设置,`r"/user", UserHandler`,也就是在form中的`action='/user'`,就是要将数据提交给UserHandler处理,并且是通过post方法。所以,在UserHandler类中,有post()方法来处理这个问题。通过self.get_argument()来接收前端提交过来的数据,接收方法就是,self.get_argument()的参数与index.html表单form中的各项的name值相同,就会得到相应的数据。例如`user_name = self.get_argument("username")`,就能够得到index.html表单中name为"username"的元素的值,并赋给user_name变量。
还差一个网页。
## 显示结果
在上面的代码中,又多了一个模板:`index.html`,对这个模板,跟前面那个模板有一点儿不一样的地方,就是要引入一些变量。它的代码是这样的:
~~~
<!DOCTYPE html>
<html>
<head>
<title>sign in your name</title>
</head>
<body>
<h2>Your Information</h2>
<p>Your name is {{username}}</p>
<p>Your email is {{email}}</p>
<p>Your website is {{website}}, it is very good. This website is make by {{language}}</p>
</body>
</html>
~~~
请将上面的代码和这句话对照:
~~~
self.render("user.html",username=user_name,email=user_email,website=user_website,language=user_language)
~~~
上面的模板代码存储为名为`user.html`的文件,并且和前面已经保存的在同一个目录中。
看HTML模板代码中,有类似`{{username}}`的变量,模板中用`{{}}`引入变量,这个变量就是在`self.render()`中规定的,两者变量名称一致,对应将相应的值对象引入到模板中。
## 运行结果
进入到template目录,执行:
~~~
qw@qw-Latitude-E4300:~/template$ python userscontroller.py
~~~
然后在浏览器的地址栏中输入
~~~
http://localhost:8000
~~~
出现如下图的表单,并填写表单内容
[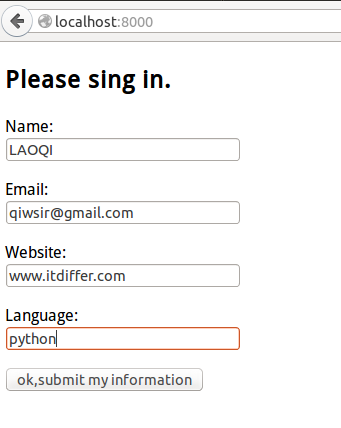](https://github.com/qiwsir/ITArticles/blob/master/Pictures/31102.png)
点击“按钮”之后:
[](https://github.com/qiwsir/ITArticles/blob/master/Pictures/31103.png)
这样就实现了一个简单表单提交的网站。
问候世界:利用GAE建立tornado框架网站
最后更新于:2022-04-01 01:06:11
按照作家韩寒的说法,这个世界存在两种逻辑,一种是逻辑,另外一种是中国逻辑。中国由于“特色”,跟世界是不同的。在网络上,也是如此,世界的网络和中国的网络有很大不同,不用多说,看官应该体会到了。那么,我这里的标题是“问候世界”,就当然不包括中国了。
已经用Tornado可以在自己的计算机上发布网站了,也就是能够在自己计算机的浏览器地址栏中输入`http://localhost:8000`,显示那个Hello,这仅仅是向自己问候了。如果要向世界问候,就需要把这个那个程序放到连接到互联网的服务器上。
在网上,有很多提供服务器租赁服务的公司,可以购买虚拟空间、VPS,现在比较时髦的就是购买云服务主机等,当然,有钱的就自己买服务器硬件设备,然后自己建立机房了。我这里演示给诸位的,不是上面这些,是按照穷人的思路来解决问题。
Google是伟大的,谁要不认同,我就跟谁急。除了因为它是一个好的搜索引擎之外,还因为它给我提供了免费的GAE。什么是GAE?GAE就是Google App Engine,维基百科上这样说的:
> Google App Engine是一个开发、托管网络应用程序的平台,使用Google管理的数据中心。它在2008年4月发布了第一个beta版本。
>
> Google App Engine使用了云计算技术。它跨越多个服务器和数据中心来虚拟化应用程序。[1] 其他基于云的平台还有Amazon Web Services和微软的Azure服务平台等。
>
> Google App Engine在用户使用一定的资源时是免费的。支付额外的费用可以获得应用程序所需的更多的存储空间、带宽或是CPU负载。
看官注意了,上面那诱人的“免费”,尽管有所限制,但是,已经足够一般用户使用了,下面是免费内容,看看是不是足够慷慨了呀。
| 项目 | 配额 |
| --- | --- |
| 每天的Email数量 | 100封 |
| 每天的输入数据 | 无限 |
| 每天的输出数据 | 1 GB |
| 每天可使用CPU | 28小时 |
| 每天调用Datastore API次数 | 50000次 |
| 数据存储 | 1 GB |
| 每天调用URLFetch API次数 | 657000次 |
如果你做一个网站,超过了上面的免费配额,说明你的网站已经不小了。也能够挣钱或者找风险投资了。中国的互联网上,尚未见到如此慷慨的,虽然也有自吹自擂的公司。
请看官注意,这个服务只能在世界范围内使用,由于你知道和不知道的原因,在中国不能使用。当然,要立志做一个优秀程序员的,一定要能够进入世界范围。
**欲进入世界,必科学上网**
否则,今天这一讲看官就无法学习。
## 官方网站
在进入学习之前,请看官登录GAE官方网站浏览:[https://cloud.google.com/appengine/docs?hl=zh-cn](https://cloud.google.com/appengine/docs?hl=zh-cn)
目前GAE支持使用的语言有:Java,Python,PHP,Go
我在这里当然是使用python了。虽然,我也喜欢PHP。
如果看官自己有能力阅读文档,直接在该网站上阅读,就能够学会如何使用GAE了,不必看我下面的啰嗦。我认为GAE网站上讲的很好了。不过,就是有一点不足,缺少趣味性。如果要享受胡扯的东西,就看我的课程啦。
## 注册
在上面的GAE官方文档中,看到下面图片中的`Try it now`按钮,点它,进入下一个界面。
[](https://github.com/qiwsir/ITArticles/blob/master/Pictures/30901.png)
进入的新页面中,开头有这样一段。
> Try Google App Engine Now
>
> Creating an App Engine app is easy, and it's free to start. Upload your app and share it with users right away, at no charge and with no commitment required.
看下面的图
[](https://github.com/qiwsir/ITArticles/blob/master/Pictures/30902.png)
首先给自己的网站取一个名字,当然这个名字以后还可以修改呢。
然后,在四种语言中选择一种,一定要选python,选别的不跟你玩了。
选好之后,看第三步,如下图。其实是一个例子罢了。不过,不是用tornado框架的。
[](https://github.com/qiwsir/ITArticles/blob/master/Pictures/30903.png)
## 下载SDK
下载SDK,看操作系统,不同的操作系统有不同的下载安装方法。如下两图所示中,都说明了安装流程。
[](https://github.com/qiwsir/ITArticles/blob/master/Pictures/30904.png)
[](https://github.com/qiwsir/ITArticles/blob/master/Pictures/39005.png)
我的操作系统是ubuntu,就选择按照上面那张图的方式安装。特别提醒,一定要让你的计算机用VPN科学上网,才能实现上面的安装流程。
从新打开一个shell, 按照上面要求,输入`curl https://sdk.cloud.google.com/ | bash`,剩下的事情就是根据shell中提示的信息向下进行了。它要询问是否需要帮助的时候,就输入y,然后选择语言(2,是python and php,也就是按照这种方法安装的SDK是python和php两者都可以使用的),还要输入一个放置SDK文件的目录名称。之后,系统就自动将google-cloud-sdk中的很多东西,放到指定目录中了。在安装过程中,还会询问工作环境,不修改用自动设置的,简单地回车即可。
如果网络差点,需要等待一段时间。最终在你指定的目录中会有一个google-cloud-sdk目录,所要安装的内容全在里面了。
还可以到:[https://cloud.google.com/appengine/downloads?hl=zh-cn](https://cloud.google.com/appengine/downloads?hl=zh-cn)
下载,这个页面也有安装帮助。安装方法可以是:
1. 将下载的文件解压,并存储到本地计算机中的某个目录内,比如我在前面安装的时候,就个放置google-cloud-sdk的目录命名为GAEPython,这里所说的目录,就跟前面的效能一样。
2. 设置本用户的工作环境,就是要在当前用户主目录下的.bashrc中设置路径。方法是:用户主目录下的.bashrc文件(有的linux是.profile文件),用vim打开该文件,并进入编辑模式,在文件最后加入PATH设置,参考格式`export PATH="$PATH:your path1/:your path2/ ..."`,然后保存,并退出该shell,则变量生效,本添加的变量只对当前用户有效。
这样两种方式折腾,就搞定了SDK
在上图中,官方给的安装流程中,接下来就是要用一个账号登录google云。关闭前面安装时使用的shell,然后新打开一个,输入命令`gcloud auth login`,会打开浏览器,出现下图
[](https://github.com/qiwsir/ITArticles/blob/master/Pictures/30906.png)
我也不用别的账号,就直接用“老齐”那个账号,点击之,进入一个授权界面,也不用怎么仔细看,要想用,就得点击网页最下面的“接受”,否则别用。网站都是这么忽悠人的。我不截图了,看官除了要科学上网,这里不会有问题的吧。然后看到下面的界面,就成功了。
[](https://github.com/qiwsir/ITArticles/blob/master/Pictures/30907.png)
在这个页面中,可以了解很多关于google云平台的内容以及操作方法。
因为我以前已经建立了一下项目,所以,我点击这个页面上“转至我的控制台”之后,会列出我已经存在的项目名称。当然,在这里可以新建项目。
不过,这里暂且搁置。先回到自己的计算机上。已经将gdk做好了。
## 在本地建立项目
在自己的计算机上,任何认为合适的地方,建立一个目录,这个目录就是你要发布到GAE上的项目名称,例如我的操作:
~~~
qw@qw-Latitude-E4300:~/Documents$ mkdir mypy
~~~
我是在这里建立了一个名字是mypy的目录,也就意味着我要发布的项目名称是mypy,然后,要把tornado的东西放进这个目录。就是这么做:
先建立一个目录,叫做tornado_source
~~~
qw@qw-Latitude-E4300:~/Documents$ cd tornado_source
qw@qw-Latitude-E4300:~/Documents/tornado_source$ git clone https://github.com/facebook/tornado.git
正克隆到 'tornado'...
remote: Counting objects: 13952, done.
remote: Total 13952 (delta 0), reused 0 (delta 0)
接收对象中: 100% (13952/13952), 7.41 MiB | 107.00 KiB/s, done.
处理 delta 中: 100% (8877/8877), done.
检查连接... 完成。
~~~
然后将tornado_source中的tornado目录,移动到mypy里面去。
接下来在mypy目录里面新建一个文件,名称必须是:app.yaml,该文件的内容是:
~~~
application: mypy
version: 1
runtime: python27
api_version: 1
threadsafe: no
handlers:
- url: /favicon\.ico
static_files: favicon.ico
upload: favicon\.ico
- url: .*
script: main.py
~~~
关于yaml,这里也引用[维基百科的内容](http://zh.wikipedia.org/wiki/YAML),补充一下:
> YAML(IPA: /ˈjæməl/,尾音类似camel骆驼)是一个可读性高,用来表达资料序列的格式。YAML参考了其他多种语言,包括:XML、C语言、Python、Perl以及电子邮件格式RFC2822。Clark Evans在2001年首次发表了这种语言[1] ,另外Ingy döt Net与Oren Ben-Kiki也是这语言的共同设计者。目前已经有数种编程语言或脚本语言支援(或者说解析)这种语言。
>
> YAML是"YAML Ain't a Markup Language"(YAML不是一种置标语言)的递回缩写。在开发的这种语言时,YAML 的意思其实是:"Yet Another Markup Language"(仍是一种置标语言),但为了强调这种语言以数据做为中心,而不是以置标语言为重点,而用返璞词重新命名。
YAML的官方网站:www.yaml.org
## 编写main.py
本来根据我以前的经验,到这里就可以运行`dev_appserver.py mypy`了。可是发现错误了,说没有找到sqlite3模块。不知道为什么,python升级之后,这个模块没有装上,本来这个模块是标准库的。看官如果在操作过程中,也遇到类似情况。解决方法就是到该模块的官方网站下载源码,然后安装,一般流程是:
~~~
tar -zxvf ***.gz
cd *** #进入解压缩后得到的目录
./configure #如果不使用默认的,可以指定目录:--prefix=**/**/
make
make install #若权限不足,可以前面加sudo,得到临时root权限。
~~~
然后,这个很重要,再将python源码中setup.py文件中该模块的路径从新设置,设置为该模块被安装的路径。一般情况可能是这里的模块路径错了。
接下来就从新安装python
搞定sqlite3模块,再尝试,我回到含有mypy项目的(/home/qw/Documents/mypy,即回到/home/qw/Documents):
~~~
dev_appserver.py mypy
~~~
结果显示:
~~~
......
google.appengine.tools.devappserver2.wsgi_server.BindError: Unable to bind localhost:8080
~~~
原来,我科学上网,用的是8080端口,已经被占用了,google.appengine也打算用这个端口。那好,因为是在本地,就不用科学了,将科学上网端口停了,再试试。
~~~
qw@qw-Latitude-E4300:~/Documents$ dev_appserver.py mypy
INFO 2014-10-07 13:57:14,275 devappserver2.py:733] Skipping SDK update check.
WARNING 2014-10-07 13:57:14,279 api_server.py:383] Could not initialize images API; you are likely missing the Python "PIL" module.
INFO 2014-10-07 13:57:14,283 api_server.py:171] Starting API server at: http://localhost:40433
INFO 2014-10-07 13:57:14,295 dispatcher.py:186] Starting module "default" running at: http://localhost:8080
INFO 2014-10-07 13:57:14,298 admin_server.py:117] Starting admin server at: http://localhost:8000
/usr/local/lib/python2.7/site-packages/setuptools-2.2-py2.7.egg/pkg_resources.py:991: UserWarning: /home/qw/.python-eggs is writable by group/others and vulnerable to attack when used with get_resource_filename. Consider a more secure location (set with .set_extraction_path or the PYTHON_EGG_CACHE environment variable).
~~~
看下图,如果在URL输入`http://localhost:8000`,打开的是本地App Engine
[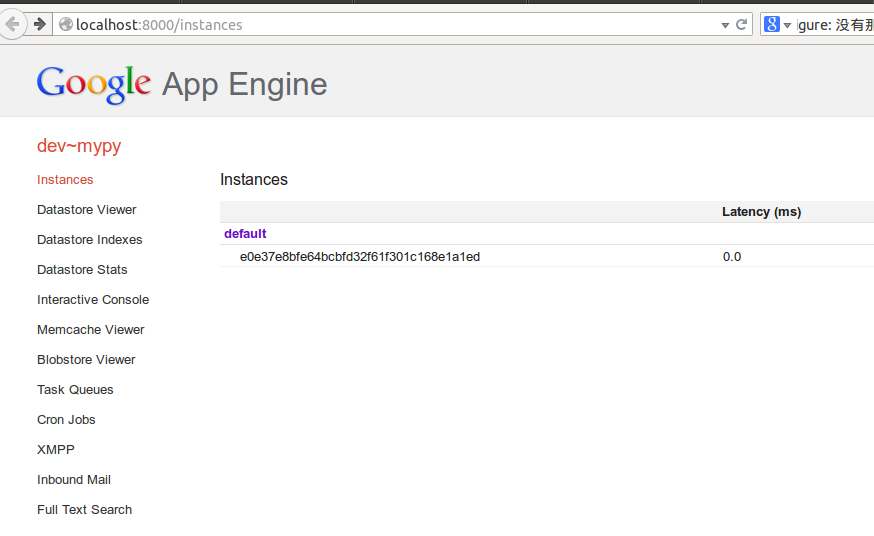](https://github.com/qiwsir/ITArticles/blob/master/Pictures/30908.png)
这个就是本地的server。
如果在URL输入`http://localhost:8080`,网页空白,什么提示没有。这就对了,因为我还没有编写那个最重要的文件,就是app.yaml里面设定的main.py
**特别提醒看官:我在上面操作的时候,出现了警告,但是当时没有引起我的注意。于是就编写main.py文件。结果,运行`http://localhost:8080`,不成功。而且告诉我无法找到tornado.wsgi模块。**
本讲有悬念了。
实例分析get和post:get()通过URL得到数据和post()通过get_argument()获取数据
最后更新于:2022-04-01 01:06:09
在开发网站的过程中,post和get是常见常用的两个方法,关于这两个方法的详细解释,请列为阅读这篇文章:[《HTTP POST GET 本质区别详解》](https://github.com/qiwsir/ITArticles/blob/master/Tornado/DifferenceHttpGetPost.md),这篇文章前面已经推荐阅读了,可以这么说,如果看官没有搞明白get和post,也可以写出web程序,但是,只要遇到“但是”,就说明另有乾坤,但是如果看官要对这方面有深入理解,并且将来能上一个档次,是必须了解的。这就如同你要练习辟邪剑谱中的剑法,不自宫,也可以练,但是无法突破某个极限,岳不群也不傻,最终他要成为超一流,就不惜按照剑谱中开篇所说“欲练神功,挥刀自宫”,“神功”是需要“自宫”为前提,否则,练出来的不是“神功”,无法问鼎江湖。
特别提醒,看官不要自宫,因为本教程不是辟邪剑谱,也不是葵花宝典,撰写本课程的人更是生理健全者。若看官自宫了,责任自负,与本作者无关。直到目前,科学上尚未有证实或证伪自宫和写程序之间是否存在某种因果关系。所以提醒看官慎重行事。
还是扯回来,看下面的代码先:
~~~
#!/usr/bin/env python
#coding:utf-8
import textwrap
import tornado.httpserver
import tornado.ioloop
import tornado.options
import tornado.web
from tornado.options import define, options
define("port", default=8000, help="Please send email to me", type=int)
class ReverseHandler(tornado.web.RequestHandler):
def get(self, input_word):
self.write(input_word[::-1])
class WrapHandler(tornado.web.RequestHandler):
def post(self):
text = self.get_argument("text")
width = self.get_argument("width", 40)
self.write(textwrap.fill(text, width))
if __name__ == "__main__":
tornado.options.parse_command_line()
app = tornado.web.Application(
handlers = [
(r"/reverse/(\w+)", ReverseHandler),
(r"/wrap", WrapHandler)
]
)
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(options.port)
tornado.ioloop.IOLoop.instance().start()
~~~
这段代码跟上一讲的代码相比,基本结构是一样的,但是在程序主体中,这次写了两个类`ReverseHandler`和`WrapHandler`,这两个类中分别有两个方法get()和post()。在`tornado.web.Application()`实例化中,handlers的参数值分别设置了不同路径对应这两个类。
其它方面跟上一讲的代码一样。
把上述代码的文件,存到某个目录下,我给他取名为:request_url.py,名字看官也可以自己定。然后进入该目录,运行:`python request_url.py`,就将这个tornado框架的网站以端口8000发布了。
打开网页,在浏览器中输入:`http://localhost:8000/reverse/qiwsirpython`
界面上输出什么结果?
[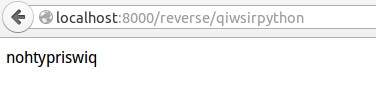](https://github.com/qiwsir/ITArticles/blob/master/Pictures/30801.png)
还可以在命令终端,用下面方式调试,跟在网页上输出是等同效果。
~~~
qw@qw-Latitude-E4300:~$ curl http://localhost:8000/reverse/qiwsirpython
nohtypriswiq
~~~
再看另外一个路径,看官运行的是否是下面的结果呢?
~~~
qw@qw-Latitude-E4300:~$ curl http://localhost:8000/wrap -d text=I+love+Python+programming+and+I+am+writing+python+lessons+on+line
I love Python programming and I am
writing python lessons on line
~~~
调试通过,就开始分析其中的奥妙。
## get()
在ReverseHandler类中,定义了这个方法。
~~~
class ReverseHandler(tornado.web.RequestHandler):
def get(self, input_word):
self.write(input_word[::-1])
~~~
这个get()方法要和下面Application实例化中的路径:
~~~
(r"/reverse/(\w+)", ReverseHandler),
~~~
关联起来看。
首先看路径设置:`r"/reverse/(\w+)"`,这个路径的意思就是可以在浏览器的url中输入:http://localhost:8000/reverse/dddd,这个样子的地址,注意路径中的`(\w+)`,是正则表达式,在reverse/的后面可以输入一个或者多个包括下划线的任何单词字符。也就是dddd可以更换为任何其它字母或者下划线,一个或者多个均可以。
在URL中输入的这个地址,就被ReverseHandler类中的get()方法接收,这就是`(r"/reverse/(\w+)", ReverseHandler)`之含义了。那么,ReverseHandler中的get()方法如何接收url中传递过来的信息呢?
前文已经说过,在`def get(self, input_word)`中,self参数在类实例化后对应的是tornado.web.RequestHandler,另外一个参数input_word用来接收来自url的信息,但是它只接收所设置的路径尾部数据,也就是路径`r"/reverse/(\w+)"`中reverse后面的第一个分割符号“/”之后的内容,都被input_word接收过来,即正则表达式的内容。
input_word接收过来的对象,是什么类型呢?猜测一下,从前面程序的运行结果看,肯定是某种序列类型的对象。具体是哪种呢?可以实验。
将get方法修改为:
~~~
def get(self, input_word):
input_type = type(input_word)
self.write("%s"%input_type)
~~~
再运行程序,打印出来的是:
~~~
qw@qw-Latitude-E4300:~$ curl http://localhost:8000/reverse/qiwei
<type 'unicode'>
~~~
这说明,get()方法通过URL接收到的数据类型是unicode编码的字符,即字符串。
原来类方法中的`self.write(input_word[::-1])`含义是,将原来的字符串倒置,并返回该数据到客户端(如页面)。
~~~
>>> a = "python,laoqi"
>>> a[::-1]
'iqoal,nohtyp'
>>> b = [1,2,3,4]
>>> b[::-1]
[4, 3, 2, 1]
>>> c = ("a","b","c")
>>> c[::-1]
('c', 'b', 'a')
~~~
这是一种将序列类型对象倒置的一种方法。
总结一下:get()通过第二个参数,获得已经设置的显示路径中最后一个/后面的数据,并且为unincode编码的字符。
这种方式通过URL得到有关数据,也就是说在URL中,只需要以`http://localhost/aaa/bbb/ccc`的形式来显示路径即可。看官是否注意到,有的网站是这么显示的:`http://localhost/aaa?name=Tom&&?age=25`,这其实是两种不同的规范也好、方法也罢的东西,前者更接近时下流行的REST规范,可能看官听说过MVC吧,我听不少的公司都强调网站要符合MVC规范,殊不知,更流行的是REST了。那么到底那个好呢?我的观点:It depends.如果有兴趣,请阅读:[《理解本真的REST架构风格》](https://github.com/qiwsir/ITArticles/blob/master/Tornado/understandREST.md),对REST了解一二。
## post()方法
post()也是web上常用的方法,在本例中,该方法写在了WrapHandler类中:
~~~
class WrapHandler(tornado.web.RequestHandler):
def post(self):
text = self.get_argument("text")
width = self.get_argument("width", 40)
self.write(textwrap.fill(text, width))
~~~
对应的Application类路径:
~~~
(r"/wrap", WrapHandler)
~~~
但是,看官要注意,post()无法从URL中获得数据。这是跟get()方法非常不一样的。关于get和post之间的区别,请看官点击[《HTTP POST GET 本质区别详解》](https://github.com/qiwsir/ITArticles/blob/master/Tornado/DifferenceHttpGetPost.md)阅读。
客户端的数据通过post方法发送到服务器,这个内在过程就是由所谓HTTP协议完成,不用去管它,因为现在我们只是研究应用层,不去深入网络协议的层面。看官可以有这样的以为:怎么传的数据,但是我也可以不讲,就算我也不会吧。不过,如果看官非要了解,请问google大神。
我要解释的是,post()方法怎么接收到客户端传过来的数据。
因为post不能从URL中得到数据,所以就不能用类似的方式在网页的url中输入要传给它的数据了,只能这样来测试:
~~~
qw@qw-Latitude-E4300:~$ curl http://localhost:8000/wrap -d text=I+love+Python+programming+and+I+am+writing+python+lessons+on+line
I love Python programming and I am
writing python lessons on line
~~~
请看官注意,URL依然是`http://localhost:8000/wrap`,后面的部分`-d text=...`,就是向这个地址对应的类WrapHandler中的post方法传送相应的数据,这个数据被`tornado.web.RequestHandler`中的get_arugment()方法获得,也就是通过`text=self.get_argument("text")`得到传过来的对象,并赋值给text。
这里需要提醒看官注意,`self.get_argument("text")`的参数中,是`"text"`,就意味着,传入数据的时候,需要用text这个变量,即必须写成`text=...`。如果`self.get_argument("word")`,那么就应该是`word=...`方式传入数据了。
看官此时是否已经晓得,get_argument()在post方法中,能够获得客户端传过来的数据,当然是unicode编码的。得到这个数据之后,就可以按照自己的需要进行操作了。
下一句`width = self.get_argumen("width", 40)`是要返回一个对象,这个对象约定变量为40,并将它用在下面的`textwrap.fill(text, width)`中。这里并没有什么特别支出,也可以写成`width = 40`,其实就是给textwrap.fill()提供参数罢了。关于textwrap模块中的fill方法,可以用help命令来看看。
~~~
>>> import textwrap
>>> help(textwrap.fill)
Help on function fill in module textwrap:
fill(text, width=70, **kwargs)
Fill a single paragraph of text, returning a new string.
Reformat the single paragraph in 'text' to fit in lines of no more
than 'width' columns, and return a new string containing the entire
wrapped paragraph. As with wrap(), tabs are expanded and other
whitespace characters converted to space. See TextWrapper class for
available keyword args to customize wrapping behaviour.
~~~
## [](https://github.com/qiwsir/ITArticles/blob/master/BasicPython/308.md#简要总结requesthandler)简要总结RequestHandler
RequestHandler就是请求处理程序的方法,从上面的流程中,可以简要地初步地认为(深奥的东西还不少,这里只能是简要地初步地肤浅地,随着学习的深入会一点点深入地):
* 通过`self.write()`向客户端返回数据
* get()中,以一个参数从URL路径末尾获取数据,特别提醒看官,这是在本讲的例子中,get()方法中,用第二个参数获得url数据。在[上一讲](https://github.com/qiwsir/ITArticles/blob/master/BasicPython/307.md)中,同样是get()方法,用到了`greeting = self.get_argument('greeting', 'Hello')`,于是不需要在get()中另外写参数,只需要通过"greeting"就可以得到URL中的数据,不过这时候的url应该写成`http://localhost:8000/?greeting=PYTHON`的样式,于是字符传'PYTHON'就能够让get()中的`self.get_argument('greeting','Hello')`获得,如果没有,就是'Hello'。
* post()中,以`self.argument("text")`的形式得到`text`为标签提交的数据。
get和post是http中用的最多的方法啦。此外,Tornado也还支持其它的HTTP请求,如:PUT、DELETE、HEAD、OPTIONS。在具体编程的时候,如果看官用到,可以搜索,一般用的不多。
最后交代一句,get和post方法,由于一个是通过URL得到数据,另外一个不是,所以,他们可以写到同一个类中,彼此互不干扰。
还要说明,我在这部分参考了一本书的讲授内容,特别是其中的代码例子,这本书就是[《Introduction to Tornado》](http://it-ebooks.info/book/687/)
Hello,第一个网页分析:tornado网站的基本结构剖析:improt模块、RequestHandler, HTTPServer, Application, IOLoop
最后更新于:2022-04-01 01:06:07
打开文本编辑器。这里要说一下啦,理论上讲,所有的文本编辑器都可以做为编写程序的工具。前面已经提到的那个python IDE,是一个很好的工具,再有别的也行,比如我就用vim(好像我的计算机只能用vim了,上次运行Libre Office都很慢,敲一个键之后喝口水,才看到那个字母出来,等有人资助我了,也搞一个苹果的什么机器玩玩。)。用什么编辑工具,全是自己的喜欢罢了,不用争论那个好,这个差,只要自己顺手即可。
把下面的代码原封不动地复制过去,并且保存为文件名是hello.py的文件,存到那个目录中,自己选好了。
~~~
#!/usr/bin/env python
#coding:utf-8
import tornado.httpserver
import tornado.ioloop
import tornado.options
import tornado.web
from tornado.options import define, options
define("port", default=8000, help="run on the given port", type=int)
class IndexHandler(tornado.web.RequestHandler):
def get(self):
greeting = self.get_argument('greeting', 'Hello')
self.write(greeting + ', welcome you to read: www.itdiffer.com')
if __name__ == "__main__":
tornado.options.parse_command_line()
app = tornado.web.Application(handlers=[(r"/", IndexHandler)])
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(options.port)
tornado.ioloop.IOLoop.instance().start()
~~~
进入到保存hello.py文件的目录,在shell或者命令输入框(windows可以用cmd)中,输入:
~~~
qw@qw-Latitude-E4300:~/codes$ python hello.py
~~~
用python运行这个文件,其实就已经发布了一个网站,只不过这个网站太简单了。
接下来,打开浏览器,在浏览器中输入:http://localhost:8000,得到如下界面:
[](https://github.com/qiwsir/ITArticles/blob/master/Pictures/30701.png)
当然,如果还可以在shell中用下面方式运行:
~~~
qw@qw-Latitude-E4300:~$ curl http://localhost:8000/
Hello, welcome you to read: www.itdiffer.com
qw@qw-Latitude-E4300:~$ curl http://localhost:8000/?greeting=Qiwsir
Qiwsir, welcome you to read: www.itdiffer.com
~~~
如果你的所有操作都正确,一定能够看到上面的结果。
恭喜你,迈出了决定性一步,已经可以用Tornado发布网站了。在这里似乎没有做什么部署,只是安装了Tornado。是的,不需要如同部署Nginx或者Apache那样,做各种设置了,因为Tornado就是一个很好的server,也是一个开发框架。
上面代码虽然跑起来了,但是每行都什么意思呢?下面就逐行解释,也就理解了Tornado这个框架的基本结构和用法。
## WEB服务器工作流程
任何一个网站都离不开Web服务器,这里所说的不是指那个更计算机一样的硬件设备,是指里面安装的软件,有时候初次接触的看官容易搞混。就来伟大的[维基百科都这么说](http://zh.wikipedia.org/wiki/%E6%9C%8D%E5%8A%A1%E5%99%A8):
> 有时,这两种定义会引起混淆,如Web服务器。它可能是指用于网站的计算机,也可能是指像Apache这样的软件,运行在这样的计算机上以管理网页组件和回应网页浏览器的请求。
在具体的语境中,看官要注意分析,到底指的是什么。
关于Web服务器比较好的解释,推荐看看百度百科的内容,我这里就不复制粘贴了,具体可以点击连接查阅:[WEB服务器](http://baike.baidu.com/view/460250.htm)
在WEB上,用的最多的就是输入网址,访问某个网站。全世界那么多网站网页,如果去访问他们,怎么能够做到彼此互通互联呢。为了协调彼此,就制定了很多通用的协议,其中http协议,就是网络协议中的一种。关于这个协议的介绍,网上随处就能找到,请看官自己google.
网上偷来的[一张图](http://kenby.iteye.com/blog/1159621)(从哪里偷来的,我都告诉你了,多实在呀。哈哈。),显示在下面,简要说明web服务器的工作过程
[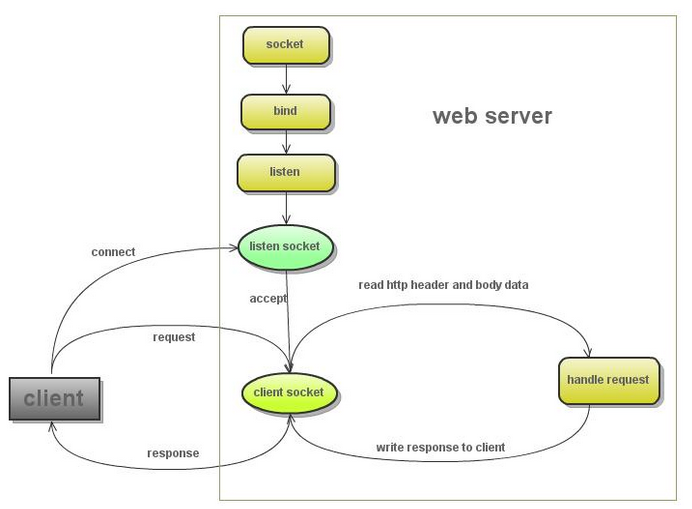](https://github.com/qiwsir/ITArticles/blob/master/Pictures/30702.png)
偷个彻底,把原文中的说明也贴上:
1. 创建listen socket, 在指定的监听端口, 等待客户端请求的到来
2. listen socket接受客户端的请求, 得到client socket, 接下来通过client socket与客户端通信
3. 处理客户端的请求, 首先从client socket读取http请求的协议头, 如果是post协议, 还可能要读取客户端上传的数据, 然后处理请求, 准备好客户端需要的数据, 通过client socket写给客户端
剽窃就此结束,下面就自己写了。
## 引入模块
~~~
import tornado.httpserver
import tornado.ioloop
import tornado.options
import tornado.web
~~~
这四个都是Tornado的模块,在本例中都是必须的。它们四个在一般的网站开发中,都要用到,基本作用分别是:
* tornado.httpserver:这个模块就是用来解决web服务器的http协议问题,它提供了不少属性方法,实现客户端和服务器端的互通。Tornado的非阻塞、单线程的特点在这个模块中体现。
* tornado.ioloop:这个也非常重要,能够实现非阻塞socket循环,不能互通一次就结束呀。
* tornado.options:这是命令行解析模块,也常用到。
* tornado.web:这是必不可少的模块,它提供了一个简单的Web框架与异步功能,从而使其扩展到大量打开的连接,使其成为理想的长轮询。
还有一个模块引入,是用from...import完成的
~~~
from tornado.options import define, options
define("port", default=8000, help="run on the given port", type=int)
~~~
这两句就显示了所谓“命令行解析模块”的用途了。在这里通过`tornado.options.define()`定义了访问本服务器的端口,就是当在浏览器地址栏中输入`http:localhost:8000`的时候,才能访问本网站,因为http协议默认的端口是80,为了区分,我在这里设置为8000,为什么要区分呢?因为我的计算机或许你的也是,已经部署了别的注入Nginx服务器了,它的端口是80,所以要区分开,并且,后面我们还会将tornado和Nginx联合起来工作,这样两个服务器在同一台计算机上,就要分开喽。
## 定义请求-处理程序类
~~~
class IndexHandler(tornado.web.RequestHandler):
def get(self):
greeting = self.get_argument('greeting', 'Hello')
self.write(greeting + ', welcome you to read: www.itdiffer.com')
~~~
所谓“请求处理”程序类,就是要定义一个类,专门应付客户端向服务器提出请求(这个请求也许是要读取某个网页,也许是要将某些信息存到服务器上),服务器要有相应的程序来接收并处理这个请求,并且反馈某些信息(或者是针对请求反馈所要的信息,或者返回其它的错误信息等)。
于是,就定义了一个类,名字是IndexHandler,当然,名字可以随便取了,但是,按照习惯,类的名字中的单词首字母都是大写的,并且如果这个类是请求处理程序类,那么就最好用Handler结尾,这样在名称上很明确,是干什么的。
类IndexHandler的参数是`tornado.web.RequestHandler`,这个参数很重要,是专门用于完成请求处理程序的,通过它定义`get()`和`post()`两个在web中应用最多的方法的内容(关于这两个方法的详细解释,可以参考:[HTTP GET POST的本质区别详解](https://github.com/qiwsir/ITArticles/blob/master/Tornado/DifferenceHttpGetPost.md),作者在这篇文章中,阐述了两个方法的本质)。
在本例中,只定义了一个`get()`方法。请看官注意,类中的方法可以没有别的参数,但是必须有`self`这个参数,关于这点请参与前面几篇关于类的讲授内容(返回[首页](https://github.com/qiwsir/ITArticles/blob/master/BasicPython/index.md)找相关文章)。
在`greeting = self.get_argument('greeting', 'Hello')`这句中,当实例化之后,`self`对应的就是`tornado.web.RequestHandler`,而`get_argument`则是`tornado.web.RequestHandler`的一个方法。官方文档对这个方法的描述如下:
> RequestHandler.get_argument(name, default=, []strip=True)
>
> > Returns the value of the argument with the given name.
> >
> > If default is not provided, the argument is considered to be required, and we raise a MissingArgumentError if it is missing.
> >
> > If the argument appears in the url more than once, we return the last value.
> >
> > The returned value is always unicode.
这段描述已经很清晰了,此外,看完这段说明,看官是否明白我在前面运行的:
~~~
qw@qw-Latitude-E4300:~$ curl http://localhost:8000/?greeting=Qiwsir
Qiwsir, welcome you to read: www.itdiffer.com
~~~
为什么通过`http://localhost:8000/?greeting=Qiwsir`,就可以实现对greeting的赋值。
接下来的那句`self.write(greeting + ',weblcome you to read: www.itdiffer.com)'`中,write也是`tornado.web.RequestHandler`的一个方法,这发方法主要功能是向客户端反馈参数中的信息。也浏览一下官方文档信息,对以后正确理解使用有帮助:
> RequestHandler.write(chunk)[source]
>
> > Writes the given chunk to the output buffer.
> >
> > To write the output to the network, use the flush() method below.
> >
> > If the given chunk is a dictionary, we write it as JSON and set the Content-Type of the response to be application/json. (if you want to send JSON as a different Content-Type, call set_header after calling write()).
## [](https://github.com/qiwsir/ITArticles/blob/master/BasicPython/307.md#main方法)main()方法
`if __name__ == "__main__"`,从这句话开始执行编写的程序,前面相当于预备工作吧。这个方法跟以往执行python程序是一样的。
`tornado.options.parse_command_line()`,这是在执行tornado的解析命令行。在tornado的程序中,只要import模块之后,就会在运行的时候自动加载,不需要了解细节,但是,在main()方法中如果有命令行解析,必须要提前将模块引入。
## Application类
下面这句是重点:
~~~
app = tornado.web.Application(handlers=[(r"/", IndexHandler)])
~~~
将tornado.web.Application实例化。这个实例化,本质上是建立了整个网站程序的请求处理集合,然后它可以被HTTPServer做为参数调用,实现http协议服务器访问。Application类的`__init__`方法参数形式:
~~~
def __init__(self, handlers=None, default_host="", transforms=None,**settings):
pass
~~~
在一般情况下,handlers是不能为空的,因为Application类通过这个参数的值处理所得到的请求。例如在本例中,`handlers=[(r"/", IndexHandler)]`,就意味着如果通过浏览器的地址栏输入根路径(`http://localhost:8000`就是根路径,如果是`http://localhost:8000/qiwsir`,就不属于根,而是一个子路径或目录了),对应这就是让名字为IndexHandler类处理这个请求。
通过handlers传入的数值格式,一定要注意,在后面做复杂结构的网站是,这里就显得重要了。它一个list,list里面的参数是列表,列表的组成包括两部分,一部分是请求路径,另外一部分是处理程序的类名称。注意请求路径可以用正则表达式书写。举例说明:
~~~
handlers = [
(r"/", IndexHandlers), #来自根路径的请求用IndesHandlers处理
(r"/qiwsir/(.*)", QiwsirHandlers), #来自/qiwsir/以及其下任何请求(正则表达式表示任何字符)都由QiwsirHandlers处理
]
~~~
**注意**
在这里我使用了`r"/"`的样式,意味着就不需要使用转义符,r后面的都表示该符号本来的含义。例如,\n,如果单纯这么来使用,就以为着换行,因为符号“\”具有转义功能(关于转义详细阅读[《玩转字符串(1)》](https://github.com/qiwsir/ITArticles/blob/master/BasicPython/107.md)),当写成`r"\n"`的形式是,就不再表示换行了,而是两个字符,\和n,不会转意。一般情况下,由于正则表达式和 \ 会有冲突,因此,当一个字符串使用了正则表达式后,最好在前面加上'r'。(关于正则表达式,看官姑且网上搜索,在后面的课程中,我也会介绍)
关于Application类的介绍,告一段落,但是并未完全讲述了,因为还有别的参数设置没有讲,看官有兴趣可以阅读官方的文档资料,地址是:[http://tornado.readthedocs.org/en/latest/_modules/tornado/web.html#Application](http://tornado.readthedocs.org/en/latest/_modules/tornado/web.html#Application)
## HTTPServer类
实例化之后,Application对象(用app做为标签的)就可以被另外一个类HTTPServer引用,形式为:
~~~
http_server = tornado.httpserver.HTTPServer(app)
~~~
HTTPServer是tornado.httpserver里面定义的类。HTTPServer是一个单线程非阻塞HTTP服务器,执行HTTPServer一般要回调Application对象,并提供发送响应的接口,也就是下面的内容是跟随上面语句的(options.port的值在IndexHandler类前面通过from...import..设置的)。
~~~
http_server.listen(options.port)
~~~
这种方法,就建立了单进程的http服务。
请看官牢记,如果在以后编码中,遇到需要多进程,请参考官方文档说明:[http://tornado.readthedocs.org/en/latest/httpserver.html#http-server](http://tornado.readthedocs.org/en/latest/httpserver.html#http-server)
## IOLoop类
剩下最后一句了:
~~~
tornado.ioloop.IOLoop.instance().start()
~~~
这句话,总是在`__main()__`的最后一句。表示可以接收来自HTTP的请求了。
以上把一个简单的hello.py剖析。想必读者对Tornado编写网站的基本概念已经有了。
python开发框架:框架介绍、Tornado安装
最后更新于:2022-04-01 01:06:04
不管是python,还是php,亦或别的做web项目的语言,乃至于做其它非web项目的开发,一般都要用到一个称之为什么什么框架的东西。
## 框架的基本概念
开发这对框架的认识,由于工作习惯和工作内容的不同,有很大差异,这里姑且截取[维基百科中的一种定义](http://zh.wikipedia.org/wiki/%E8%BB%9F%E9%AB%94%E6%A1%86%E6%9E%B6),之所以要给出一个定义,无非是让看官有所了解,但是是否知道这个定义,丝毫不影响后面的工作。
> 软件框架(Software framework),通常指的是为了实现某个业界标准或完成特定基本任务的软件组件规范,也指为了实现某个软件组件规范时,提供规范所要求之基础功能的软件产品。
>
> 框架的功能类似于基础设施,与具体的软件应用无关,但是提供并实现最为基础的软件架构和体系。软件开发者通常依据特定的框架实现更为复杂的商业运用和业务逻辑。这样的软件应用可以在支持同一种框架的软件系统中运行。
>
> 简而言之,框架就是制定一套规范或者规则(思想),大家(程序员)在该规范或者规则(思想)下工作。或者说就是使用别人搭好的舞台,你来做表演。
我比较喜欢最后一句的解释,别人搭好舞台,我来表演。这也就是说,如果我在做web项目的时候,能够省却很多开发工作。的确是。所有,做web开发,要用一个框架。
有高手工程师鄙视框架,认为自己编写的才是王道。这方面不争论,框架是开发中很流行的东西,我还是固执地认为用框架来开发,更划算。
## python框架
有人说php(什么是php,严肃的说法,这是另外一种语言,更高雅的说法,是某个活动的汉语拼音简称)框架多,我不否认,php的开发框架的确很多很多。不过,python的web开发框架,也足够使用了,列举几种常见的web框架:
* Django:这是一个被广泛应用的框架,如果看官在网上搜索,会发现很多公司在招聘的时候就说要会这个,其实这种招聘就暴露了该公司的开发水平要求不高。框架只是辅助,真正的程序员,用什么框架,都应该是根据需要而来。当然不同框架有不同的特点,需要学习一段时间。
* Flask:一个用Python编写的轻量级Web应用框架。基于Werkzeug WSGI工具箱和Jinja2模板引擎。
* Web2py:是一个为Python语言提供的全功能Web应用框架,旨在敏捷快速的开发Web应用,具有快速、安全以及可移植的数据库驱动的应用,兼容Google App Engine(这是google的元计算引擎,后面我会单独介绍)。
* Bottle: 微型Python Web框架,遵循WSGI,说微型,是因为它只有一个文件,除Python标准库外,它不依赖于任何第三方模块。
* Tornado:全称是Torado Web Server,从名字上看就可知道它可以用作Web服务器,但同时它也是一个Python Web的开发框架。最初是在FriendFeed公司的网站上使用,FaceBook收购了之后便开源了出来。
* webpy: 轻量级的Python Web框架。webpy的设计理念力求精简(Keep it simple and powerful),源码很简短,只提供一个框架所必须的东西,不依赖大量的第三方模块,它没有URL路由、没有模板也没有数据库的访问。
说明:以上信息选自:[http://blog.jobbole.com/72306/](http://blog.jobbole.com/72306/) ,这篇文章中还有别的框架,由于不是web框架,我没有选摘,有兴趣的去阅读。
## Tornado
一看到这个标题就知道,本教程中将选择使用这个框架。此前有朋友建议我用Django,首先它是一个好东西。但是,我更愿意用Tornado,为什么呢?因为......,看下边或许是理由,也或许不是。
Tornado全称Tornado Web Server,是一个用Python语言写成的Web服务器兼Web应用框架,由FriendFeed公司在自己的网站FriendFeed中使用,被Facebook收购以后框架以开源软件形式开放给大众。看来Tornado的出身高贵呀,对了,如果是在天朝的看官,可能对Facebook有风闻,但是要一睹其芳容,还要努力。或者有人是不是怀疑这个地球上就没有这个网站呢?哈哈。按照某个地方的网络,它是存在的。废话不说,还是看Tornado的性能,因为选框架,一定要选好性能的,没准儿什么时候你也开发高大上的东西了。
Tornado的性能是相当优异的,因为它试图解决一个被称之为“C10k”问题,就是处理大于或等于一万的并发。一万呀,这可是不小的量。(关于C10K问题,看官可以浏览:[C10k problem](http://en.wikipedia.org/wiki/C10k_problem))
下表是和一些其他Web框架与服务器的对比,供看官参考(数据来源: [https://developers.facebook.com/blog/post/301](https://developers.facebook.com/blog/post/301) )
条件:处理器为 AMD Opteron, 主频2.4GHz, 4核
| 服务 | 部署 | 请求/每秒 |
| --- | --- | --- |
| Tornado | nginx, 4进程 | 8213 |
| Tornado | 1个单线程进程 | 3353 |
| Django | Apache/mod_wsgi | 2223 |
| web.py | Apache/mod_wsgi | 2066 |
| CherryPy | 独立 | 785 |
看了这个对比表格,还有什么理由不选择Tornado呢?
就是它了——**Tornado**
## 安装Tornado
Tornado的官方网站:[http://www.tornadoweb.org](http://www.tornadoweb.org/en/latest/)
在官网上,有安装方法,其实,看官也可以直接在官方上学习。另外,有一个中文镜像网站,看官也可以访问:[http://www.tornadoweb.cn/](http://www.tornadoweb.cn/)
我在自己电脑中(ubuntu12.04),用下面方法安装,只需要一句话即可:
~~~
pip install tornado
~~~
这是因为Tornado已经列入PyPI,因此可以通过 pip 或者 easy_install 来安装。
如果你没有安装 libcurl 的话,你需要将其单独安装到系统中。请参见下面的安装依赖一节。
如果不用这种方式安装,下面的页面中有可以供看官下载的最新源码版本和安装方式:
[https://pypi.python.org/pypi/tornado/](https://pypi.python.org/pypi/tornado/)
此外,在github上也有托管,看官可以通过上述页面进入到github看源码。
最后要补充一个要点,就是上述下载的Tornado无法直接安装在windows上,如果要在windows上安装,建议使用pypm(这是一个什么东西,关于这个东西,可以访问官方文档:[http://docs.activestate.com/activepython/2.6/pypm.html](http://docs.activestate.com/activepython/2.6/pypm.html) ,说实话,我也没有用过它,只是看了看文档罢了。看官如果有使用的,可以写一个教程共享之。),如下安装:
~~~
C:\> pypm install tornado
~~~
用Python操作数据库(3)
最后更新于:2022-04-01 01:06:02
通过python操作数据库的行为,除了能够完成前面两讲中的操作之外(当然,那是比较常用的),其实任何对数据库进行的操作,都能够通过python-mysqldb来实现。
## 建立数据库
在[《用python操作数据库(1)》](https://github.com/qiwsir/ITArticles/blob/master/BasicPython/303.md)中,我是通过`mysql>`写SQL语句,建立了一个名字叫做qiwsirtest的数据库,然后用下面的方式跟这个数据库连接
~~~
>>> import MySQLdb
>>> conn = MySQLdb.connect(host="localhost",user="root",passwd="123123",db="qiwsirtest",charset="utf8")
~~~
在上面的连接中,参数`db="qiwsirtest"`其实可以省略,如果省略,就是没有跟任何具体的数据库连接,只是连接了mysql。
~~~
>>> import MySQLdb
>>> conn = MySQLdb.connect("localhost","root","123123",port=3306,charset="utf8")
~~~
这种连接没有指定具体数据库,接下来就可以用类似`mysql>`交互模式下的方式进行操作。
~~~
>>> conn.select_db("qiwsirtest")
>>> cur = conn.cursor()
>>> cur.execute("select * from users")
7L
>>> cur.fetchall()
((1L, u'qiwsir', u'123123', u'qiwsir@gmail.com'), (2L, u'mypython', u'123456', u'python@gmail.com'), (3L, u'google', u'111222', u'g@gmail.com'), (4L, u'facebook', u'222333', u'f@face.book'), (5L, u'github', u'333444', u'git@hub.com'), (6L, u'docker', u'444555', u'doc@ker.com'), (7L, u'\u8001\u9f50', u'9988', u'qiwsir@gmail.com'))
~~~
用`conn.select_db()`选择要操作的数据库,然后通过指针就可以操作这个数据库了。其它的操作跟前两讲一样了。
如果不选数据库,而是要新建一个数据库,如何操作?
~~~
>>> cur = conn.cursor()
>>> cur.execute("create database newtest")
1L
~~~
建立数据库之后,就可以选择这个数据库,然后在这个数据库中建立一个数据表。
~~~
>>> cur.execute("create table newusers (id int(2) primary key auto_increment, username varchar(20), age int(2), email text)")
0L
~~~
括号里面是引号,引号里面就是创建数据表的语句,看官一定是熟悉的。这样就在newtest这个数据库中创建了一个名为newusers的表
~~~
>>> cur.execute("show tables")
1L
>>> cur.fetchall()
((u'newusers',),)
~~~
这是查看表的方式。当然,看官可以在`mysql>`交互模式下查看是不是存在这个表。如下:
~~~
mysql> use newtest;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+-------------------+
| Tables_in_newtest |
+-------------------+
| newusers |
+-------------------+
1 row in set (0.00 sec)
mysql> desc newusers;
+----------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+----------------+
| id | int(2) | NO | PRI | NULL | auto_increment |
| username | varchar(20) | YES | | NULL | |
| age | int(2) | YES | | NULL | |
| email | text | YES | | NULL | |
+----------+-------------+------+-----+---------+----------------+
4 rows in set (0.00 sec)
~~~
以上就通过python-mysqldb实现了对数据库和表的建立。
当然,能建就能删除。看官可以自行尝试,在这里就不赘述,原理就是在`cur.execute()`中写SQL语句。
## 关闭一切
当进行完有关数据操作之后,最后要做的就是关闭游标(指针)和连接。用如下命令实现:
~~~
>>> cur.close()
>>> conn.close()
~~~
注意关闭顺序,和打开的顺序相反。
为什么要关闭?这个问题有点那个了。你把房子里面都收拾好了,如果离开房子,不关门吗?不要以为自己生活在那个理想社会。树欲静而风不止,小偷在行动。更何况,如果不关闭,服务器的内容总塞着那些东西而没有释放,早晚就满了。所以,必须关闭。必须的。
## 关于乱码问题
这个问题是编写web时常常困扰程序员的问题,乱码的本质来自于编码格式的设置混乱。所以,要特别提醒诸位注意。在用python-mysqldb的时候,为了放置乱码,可以做如下统一设置:
1. Python文件设置编码 utf-8(文件前面加上 #encoding=utf-8)
2. MySQL数据库charset=utf8(数据库的设置方法,可以网上搜索)
3. Python连接MySQL是加上参数 charset=utf8(在前面教程中都这么演示了,很重要)
4. 设置Python的默认编码为 utf-8 (sys.setdefaultencoding(utf-8),这个后面会讲述)
代码示例:
~~~
#encoding=utf-8
import sys
import MySQLdb
reload(sys)
sys.setdefaultencoding('utf-8')
db=MySQLdb.connect(user='root',charset='utf8')
~~~
MySQL的配置文件设置也必须配置成utf8 设置 MySQL 的 my.cnf 文件,在 [client]/[mysqld]部分都设置默认的字符集(通常在/etc/mysql/my.cnf):
~~~
[client] default-character-set = utf8
[mysqld] default-character-set = utf8
~~~
windows操作系统请看官自己google。
用Python操作数据库(2)
最后更新于:2022-04-01 01:06:00
回顾一下已有的战果:(1)连接数据库;(2)建立指针;(3)通过指针插入记录;(4)提交将插入结果保存到数据库。在交互模式中,先温故,再知新。
~~~
>>> #导入模块
>>> import MySQLdb
>>> #连接数据库
>>> conn = MySQLdb.connect(host="localhost",user="root",passwd="123123",db="qiwsirtest",port=3036,charset="utf8")
>>> #建立指针
>>> cur = conn.cursor()
>>> #插入记录
>>> cur.execute("insert into users (username,password,email) values (%s,%s,%s)",("老齐","9988","qiwsir@gmail.com"))
1L
>>> #提交保存
>>> conn.commit()
~~~
如果看官跟我似的,有点强迫症,总是想我得看到数据中有了,才放芳心呀。那就在进入到数据库,看看。
~~~
mysql> select * from users;
+----+----------+----------+------------------+
| id | username | password | email |
+----+----------+----------+------------------+
| 1 | qiwsir | 123123 | qiwsir@gmail.com |
| 2 | python | 123456 | python@gmail.com |
| 3 | google | 111222 | g@gmail.com |
| 4 | facebook | 222333 | f@face.book |
| 5 | github | 333444 | git@hub.com |
| 6 | docker | 444555 | doc@ker.com |
| 7 | 老齐 | 9988 | qiwsir@gmail.com |
+----+----------+----------+------------------+
7 rows in set (0.00 sec)
~~~
刚才温故的时候,插入的那条记录也赫然在目。不过这里特别提醒看官,我在前面建立这个数据库和数据表的时候,就已经设定好了字符编码为utf8,所以,在现在看到的查询结果中,可以显示汉字。否则,就看到的是一堆你不懂的码子了。如果看官遇到,请不要慌张,只需要修改字符编码即可。怎么改?请google。网上很多。
温故结束,开始知新。
## 查询数据
在前面操作的基础上,如果要从数据库中查询数据,当然也可以用指针来操作了。
~~~
>>> cur.execute("select * from users")
7L
~~~
这说明从users表汇总查询出来了7条记录。但是,这似乎有点不友好,告诉我7条记录查出来了,但是在哪里呢,看前面在'mysql>'下操作查询命令的时候,一下就把7条记录列出来了。怎么显示python在这里的查询结果呢?
原来,在指针实例中,还要用这样的方法,才能实现上述想法:
* fetchall(self):接收全部的返回结果行.
* fetchmany(size=None):接收size条返回结果行.如果size的值大于返回的结果行的数量,则会返回cursor.arraysize条数据.
* fetchone():返回一条结果行.
* scroll(value, mode='relative'):移动指针到某一行.如果mode='relative',则表示从当前所在行移动value条,如果mode='absolute',则表示从结果集的第一行移动value条.
按照这些规则,尝试:
~~~
>>> cur.execute("select * from users")
7L
>>> lines = cur.fetchall()
~~~
到这里,还没有看到什么,其实已经将查询到的记录(把他们看做对象)赋值给变量lines了。如果要把它们显示出来,就要用到曾经学习过的循环语句了。
~~~
>>> for line in lines:
... print line
...
(1L, u'qiwsir', u'123123', u'qiwsir@gmail.com')
(2L, u'python', u'123456', u'python@gmail.com')
(3L, u'google', u'111222', u'g@gmail.com')
(4L, u'facebook', u'222333', u'f@face.book')
(5L, u'github', u'333444', u'git@hub.com')
(6L, u'docker', u'444555', u'doc@ker.com')
(7L, u'\u8001\u9f50', u'9988', u'qiwsir@gmail.com')
~~~
很好。果然是逐条显示出来了。列位注意,第七条中的u'\u8001\u95f5',这里是汉字,只不过由于我的shell不能显示罢了,不必惊慌,不必搭理它。
只想查出第一条,可以吗?当然可以!看下面的:
~~~
>>> cur.execute("select * from users where id=1")
1L
>>> line_first = cur.fetchone() #只返回一条
>>> print line_first
(1L, u'qiwsir', u'123123', u'qiwsir@gmail.com')
~~~
为了对上述过程了解深入,做下面实验:
~~~
>>> cur.execute("select * from users")
7L
>>> print cur.fetchall()
((1L, u'qiwsir', u'123123', u'qiwsir@gmail.com'), (2L, u'python', u'123456', u'python@gmail.com'), (3L, u'google', u'111222', u'g@gmail.com'), (4L, u'facebook', u'222333', u'f@face.book'), (5L, u'github', u'333444', u'git@hub.com'), (6L, u'docker', u'444555', u'doc@ker.com'), (7L, u'\u8001\u9f50', u'9988', u'qiwsir@gmail.com'))
~~~
原来,用cur.execute()从数据库查询出来的东西,被“保存在了cur所能找到的某个地方”,要找出这些被保存的东西,需要用cur.fetchall()(或者fechone等),并且找出来之后,做为对象存在。从上面的实验探讨发现,被保存的对象是一个tuple中,里面的每个元素,都是一个一个的tuple。因此,用for循环就可以一个一个拿出来了。
看官是否理解其内涵了?
接着看,还有神奇的呢。
接着上面的操作,再打印一遍
~~~
>>> print cur.fetchall()
()
~~~
晕了!怎么什么是空?不是说做为对象已经存在了内存中了吗?难道这个内存中的对象是一次有效吗?
不要着急。
通过指针找出来的对象,在读取的时候有一个特点,就是那个指针会移动。在第一次操作了print cur.fetchall()后,因为是将所有的都打印出来,指针就要从第一条移动到最后一条。当print结束之后,指针已经在最后一条的后面了。接下来如果再次打印,就空了,最后一条后面没有东西了。
下面还要实验,检验上面所说:
~~~
>>> cur.execute('select * from users')
7L
>>> print cur.fetchone()
(1L, u'qiwsir', u'123123', u'qiwsir@gmail.com')
>>> print cur.fetchone()
(2L, u'python', u'123456', u'python@gmail.com')
>>> print cur.fetchone()
(3L, u'google', u'111222', u'g@gmail.com')
~~~
这次我不一次全部打印出来了,而是一次打印一条,看官可以从结果中看出来,果然那个指针在一条一条向下移动呢。注意,我在这次实验中,是重新运行了查询语句。
那么,既然在操作存储在内存中的对象时候,指针会移动,能不能让指针向上移动,或者移动到指定位置呢?这就是那个scroll()
~~~
>>> cur.scroll(1)
>>> print cur.fetchone()
(5L, u'github', u'333444', u'git@hub.com')
>>> cur.scroll(-2)
>>> print cur.fetchone()
(4L, u'facebook', u'222333', u'f@face.book')
~~~
果然,这个函数能够移动指针,不过请仔细观察,上面的方式是让指针相对与当前位置向上或者向下移动。即:
cur.scroll(n),或者,cur.scroll(n,"relative"):意思是相对当前位置向上或者向下移动,n为正数,表示向下(向前),n为负数,表示向上(向后)
还有一种方式,可以实现“绝对”移动,不是“相对”移动:增加一个参数"absolute"
特别提醒看官注意的是,在python中,序列对象是的顺序是从0开始的。
~~~
>>> cur.scroll(2,"absolute") #回到序号是2,但指向第三条
>>> print cur.fetchone() #打印,果然是
(3L, u'google', u'111222', u'g@gmail.com')
>>> cur.scroll(1,"absolute")
>>> print cur.fetchone()
(2L, u'python', u'123456', u'python@gmail.com')
>>> cur.scroll(0,"absolute") #回到序号是0,即指向tuple的第一条
>>> print cur.fetchone()
(1L, u'qiwsir', u'123123', u'qiwsir@gmail.com')
~~~
至此,已经熟悉了cur.fetchall()和cur.fetchone()以及cur.scroll()几个方法,还有另外一个,接这上边的操作,也就是指针在序号是1的位置,指向了tuple的第二条
~~~
>>> cur.fetchmany(3)
((2L, u'python', u'123456', u'python@gmail.com'), (3L, u'google', u'111222', u'g@gmail.com'), (4L, u'facebook', u'222333', u'f@face.book'))
~~~
上面这个操作,就是实现了从当前位置(指针指向tuple的序号为1的位置,即第二条记录)开始,含当前位置,向下列出3条记录。
读取数据,好像有点啰嗦呀。细细琢磨,还是有道理的。你觉得呢?
不过,python总是能够为我们着想的,它的指针提供了一个参数,可以实现将读取到的数据变成字典形式,这样就提供了另外一种读取方式了。
~~~
>>> cur = conn.cursor(cursorclass=MySQLdb.cursors.DictCursor)
>>> cur.execute("select * from users")
7L
>>> cur.fetchall()
({'username': u'qiwsir', 'password': u'123123', 'id': 1L, 'email': u'qiwsir@gmail.com'}, {'username': u'mypython', 'password': u'123456', 'id': 2L, 'email': u'python@gmail.com'}, {'username': u'google', 'password': u'111222', 'id': 3L, 'email': u'g@gmail.com'}, {'username': u'facebook', 'password': u'222333', 'id': 4L, 'email': u'f@face.book'}, {'username': u'github', 'password': u'333444', 'id': 5L, 'email': u'git@hub.com'}, {'username': u'docker', 'password': u'444555', 'id': 6L, 'email': u'doc@ker.com'}, {'username': u'\u8001\u9f50', 'password': u'9988', 'id': 7L, 'email': u'qiwsir@gmail.com'})
~~~
这样,在元组里面的元素就是一个一个字典。可以这样来操作这个对象:
~~~
>>> cur.scroll(0,"absolute")
>>> for line in cur.fetchall():
... print line["username"]
...
qiwsir
mypython
google
facebook
github
docker
老齐
~~~
根据字典对象的特点来读取了“键-值”。
## 更新数据
经过前面的操作,这个就比较简单了,不过需要提醒的是,如果更新完毕,和插入数据一样,都需要commit()来提交保存。
~~~
>>> cur.execute("update users set username=%s where id=2",("mypython"))
1L
>>> cur.execute("select * from users where id=2")
1L
>>> cur.fetchone()
(2L, u'mypython', u'123456', u'python@gmail.com')
~~~
从操作中看出来了,已经将数据库中第二条的用户名修改为mypython了,用的就是update语句。
不过,要真的实现在数据库中更新,还要运行:
~~~
>>> conn.commit()
~~~
这就大事完吉了。