7. COMPRESSION CODING
最后更新于:2022-04-01 04:43:00
## 7.1\. WHAT’S THE BIG PICTURE?[](http://csfieldguide.org.nz/CompressionCoding.html#what-s-the-big-picture "Permalink to this headline")
Data compression reduces the amount of space needed to store files. If you can halve the size of a file, you can store twice as many files for the same cost, or you can download the files twice as fast (and at half the cost if you’re paying for the download). Even though disks are getting bigger and high bandwidth is becoming common, it’s nice to get even more value by working with smaller, compressed files. For large data warehouses, like those kept by Google and Facebook, halving the amount of space taken can represent a massive reduction in the space and computing required, and consequently big savings in power consumption and cooling, and a huge reduction in the impact on the environment.
Common forms of compression that are currently in use include JPEG (used for photos), MP3 (used for audio), MPEG (used for videos including DVDs), and ZIP (for many kinds of data). For example, the JPEG method reduces photos to a tenth or smaller of their original size, which means that a camera can store 10 times as many photos, and images on the web can be downloaded 10 times faster.
So what’s the catch? Well, there can be an issue with the quality of the data — for example, a highly compressed JPEG image doesn’t look as sharp as an image that hasn’t been compressed. Also, it takes processing time to compress and decompress the data. In most cases, the tradeoff is worth it, but not always.
Move your cursor or tap the image to compare the two images

**Left is low quality JPEG (20Kb) - Right is high quality JPEG (88Kb)**
In this chapter we’ll look at how compression might be done, what the benefits are, and the costs associated with using compressed data that need to be considered when deciding whether or not to compress data. We’ll start with a simple example — Run Length Encoding — which gives some insight into the benefits and the issues around compression.
In this activity, students simulate writing some text using a method used by Jean-Dominique Bauby, who was completely unable to move except for blinking one eye. With a simple binary interface (blinking or not blinking) he was able to author an entire book. It is well worth getting students to work in pairs, and have one try to communicate a word or short phrase strictly by blinking only. It raises many questions, including how it could be done in the shortest time and with the minimum effort. Of course, the first step is to work out how to convey any text at all!
## 7.2\. RUN LENGTH ENCODING[](http://csfieldguide.org.nz/CompressionCoding.html#run-length-encoding "Permalink to this headline")
Imagine we have the following simple black and white image.

One very simple way a computer can store this image is by using a format where 0 means white and 1 means black. The above image would be represented in the following way
~~~
011000010000110
100000111000001
000001111100000
000011111110000
000111111111000
001111101111100
011111000111110
111110000011111
011111000111110
001111101111100
000111111111000
000011111110000
000001111100000
100000111000001
011000010000110
~~~
There are 15 (rows) by 15 (columns) = 225 bits representing this image. Can we represent the same image using fewer bits, in a way that a computer would still be able to understand it? Imagine that you had to read it out to someone... after a while you might say things like “five zeroes” instead of “zero zero zero zero zero”. This technique is used to save space for storing digital images, and is known as run length encoding (RLE). In run length encoding, we replace each row with numbers that say how many consecutive pixels are the same colour, *always starting with the number of white pixels*. For example, the first row in the image above contains 1 white, 2 black, 4 white, 1 black, 4 white, 2 black, and 1 white pixel. This could be represented as;
~~~
1, 2, 4, 1, 4, 2, 1
~~~
For the second row, because we need to say what the number of white pixels is before we say the number of black, we need to explicitly say there are 0 at the start of the row. This would give
~~~
0, 1, 5, 3, 5, 1
~~~
And the third row contains 5 whites, 5 blacks, 5 whites. This would give
~~~
5, 5, 5
~~~
So, we have determined that the first 3 rows of the file can be represented using RLE as:
~~~
1, 2, 4, 1, 4, 2, 1
0, 1, 5, 3, 5, 1
5, 5, 5
~~~
Work out what the other rows would be, and write them out as well.
Which representation takes less space to store?
One simple way to consider this is to imagine you were typing these representations, so you could think of each of the original bits being stored as one character, and each of the RLE codes using a character for each digit and comma (this is a bit crude, but it’s a starting point).
In the original representation, 225 bits were required to represent the image. Count up the number of commas and digits (but not spaces or newlines, ignore those) in the new representation. This is the number of characters required to represent the image with the new representation (to ensure you are on the right track, the first 3 rows that were given to you contain 29 characters)
Assuming you got the new image representation correct, and counted correctly, you should have found there are 119 characters in the new image (double check if your number differs!) This means that the new representation only requires around 53% as many characters to represent (calculated using 119/225)! This is a significant reduction in the amount of space required to store the image. The new representation is a *compressed* form of the old one.
In practice this method (with some extra tricks) can be used to compress images to about 15% of their original size. In real systems, the image only uses one bit for every pixel to store the black and white values (not one character, which we used for our calculations). The run length numbers are also stored much more efficiently, again using bit patterns that take very little space to represent the numbers. The bit patterns used are usually based on a technique called Huffman coding, but that is beyond what we want to get into here.
The main place that black and white scanned images are used now is on fax machines, which used this approach to compression. One reason that it works so well with scanned pages the number of consecutive white pixels is huge. In fact, there will be entire scanned lines that are nothing but white pixels. A typical fax page is 200 pixels across or more, so replacing 200 bits with one number is a big saving. The number itself can take a few bits to represent, and in some places on the scanned page only a few consecutive pixels are replaced with a number, but overall the saving is significant. In fact, fax machines would take 7 times longer to send pages if they didn’t use compression.
Just to ensure that we can reverse the compression process, what is the original representation (zeroes and ones) of this (compressed) image?
~~~
4, 11, 3
4, 9, 2, 1, 2
4, 9, 2, 1, 2
4, 11, 3
4, 9, 5
4, 9, 5
5, 7, 6
0, 17, 1
1, 15, 2
~~~
What is the image of? How good was the compression on this image? (Look back at the calculation above for the amount of compression).
[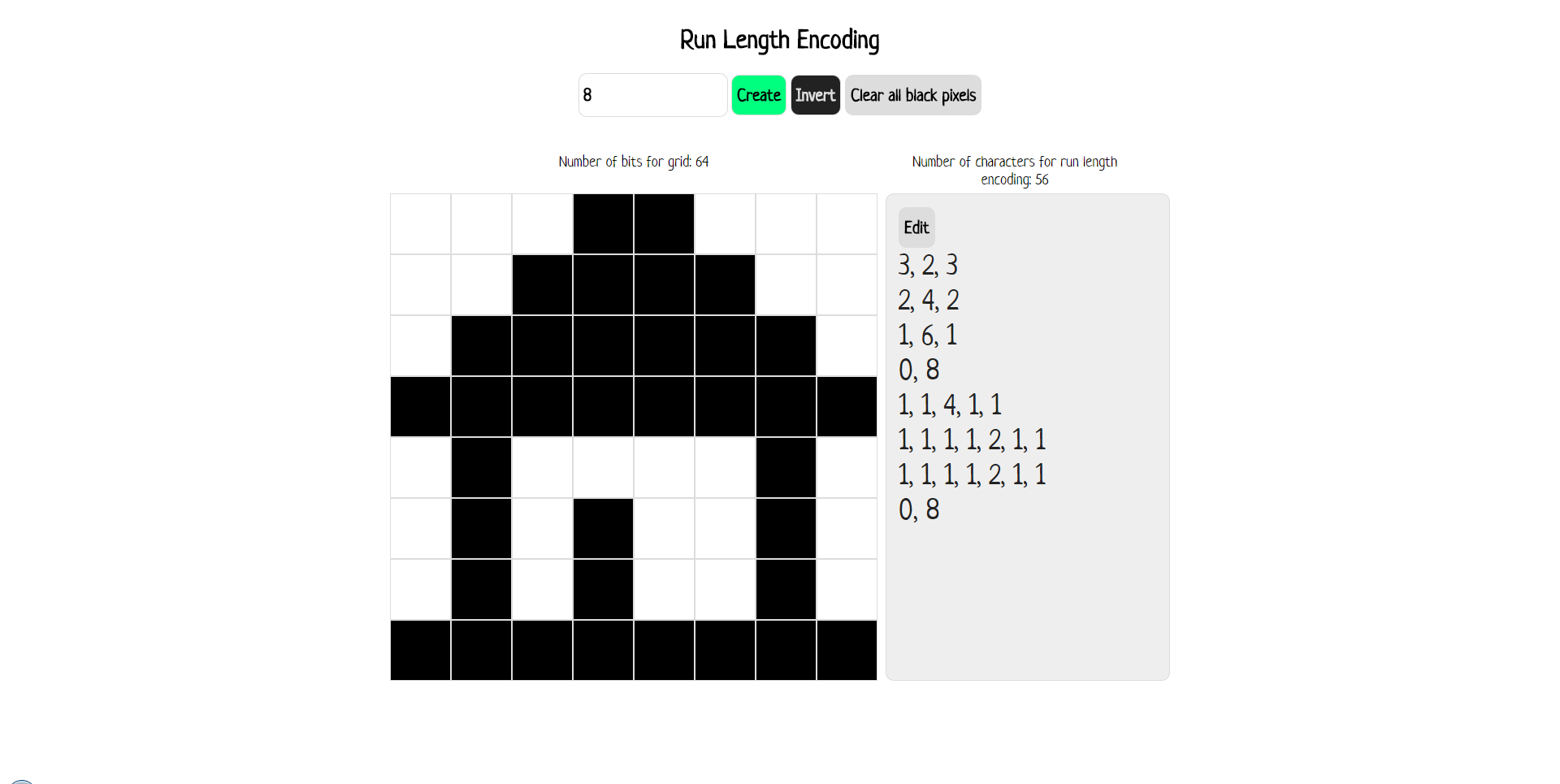Click to load
Run Length Encoding](http://csfieldguide.org.nz/_static/interactives/cc/run-length-encoding/index.html)
Created by Hannah Taylor
As the compressed representation of the image can be converted back to the original representation, and both the original representation and the compressed representation would give the same image when read by a computer, this compression algorithm is called *lossless*, i.e. none of the data was lost from compressing the image, and as a result the compression could be undone exactly.
Not all compression algorithms are lossless. In some types of files, in particular photos, sound, and videos, we are willing to sacrifice a little bit of the quality (i.e. lose a little of the data representing the image) if it allows us to make the file size a lot smaller. For downloading very large files such as movies, this can be essential to ensure the file size is not so big that it is infeasible to download! These compression methods are called *lossy*. If some of the data is lost, it is impossible to convert the file back to the exactly the original form when lossy compression was used, but the person viewing the movie or listening to the music may not mind the lower quality if the files are smaller. Later in this chapter, we will investigate the effects some lossy compression algorithms have on images and sound.
Now that you know how run length encoding works, you can come up with and compress your own black and white image, as well as uncompress an image that somebody else has given you.
Start by making your own picture with ones and zeroes. (Make sure it is rectangular — all the rows should have the same length.) You can either draw this on paper or prepare it on a computer (using a fixed width font, otherwise it can become really frustrating and confusing!) In order to make it easier, you could start by working out what you want your image to be on grid paper (such as that from a math exercise book) by shading in squares to represent the black ones, and leaving them blank to represent the white ones. Once you have done that, you could then write out the zeroes and ones for the image.
Work out the compressed representation of your image using run length coding, i.e. the run lengths separated by commas form that was explained above.
Now, swap a copy of the *compressed representation* (the run length codes, not the original uncompressed representation) with a classmate. You should each uncompress the other person’s image, to get back to the original uncompressed representations. Check to make sure the conversions back to the uncompressed representations was done correctly by making sure the images are the same.
Imagining that you and your friend are both computers, by doing this you have shown that images using these systems of representations can be compressed on one computer, and decompressed on another. It is very important for compression algorithms to have this property in order to be useful. It wouldn’t be very good if a friend gave you a song they’d compressed on their computer, but then your computer was unable to make sense of the representation the compressed song was using!
**Extra for Experts**
What is the image with the best compression (i.e. an image that has a size that is a very small percentage of the original) that you can come up with? This is the best case performance for this compression algorithm.
What about the worst compression? Can you find an image that actually has a *larger* compressed representation? (Don’t forget the commas in the version we used!) This is the worst case performance for this compression algorithm.
In fact, any *lossless* compression algorithm will have cases where the compressed version of the file is larger than the uncompressed version! Computer scientists have even proven this to be the case, meaning it is impossible for anybody to ever come up with a lossless compression algorithm that makes *all* possible files smaller. In most cases this isn’t an issue though, as a good lossless compression algorithm will tend to give the best compression on common patterns of data, and the worst compression on ones that are highly unlikley to occur.
**Extra for Experts**
There is actually an image format that uses the simple one-character-per-pixel representation we used at the start of this section. The format is called portable bitmap format (PBM). PBM files are saved with the file extension “.pbm”, and contain a simple header, along with the the image data. The data in the file can be viewed by opening it in a text editor, much like opening a .txt file, and the image itself can be viewed by opening it in a drawing or image viewing program that supports PBM files (they aren’t very well supported, but a number of image viewing and editing programs can display them). A pbm file for the diamond image used earlier would be as follows:
~~~
P1
15 15
011000010000110
100000111000001
000001111100000
000011111110000
000111111111000
001111101111100
011111000111110
111110000011111
011111000111110
001111101111100
000111111111000
000011111110000
000001111100000
100000111000001
011000010000110
~~~
The first 2 lines are the header. The first line specifies the format of the file (P1 means that the file contains ASCII zeroes and ones. The second line specifies the width and then the height of the image in pixels. This allows the computer to know the size and dimensions of the image, even if the newline characters separating the rows in the file were missing. The rest of the data is the image, just like above. If you wanted to, you could copy and paste this representation (including the header) into a text file, and save it with the file extension .pbm. If you have a program on your computer able to open PBM files, you could then view the image with it. You could even write a program to output these files, and then display them as images.
There are variations of this format that pack the pixels into bits instead of characters, and variations that can be used for grey scale and colour images. More[information about this format is available on Wikipedia](http://en.wikipedia.org/wiki/Netpbm_format).
## 7.3\. IMAGE COMPRESSION: JPEG[](http://csfieldguide.org.nz/CompressionCoding.html#image-compression-jpeg "Permalink to this headline")
Images can take up a lot of space, and most of the time that pictures are stored on a computer they are compressed to avoid wasting too much space. With a lot of images (especially photographs), there’s no need to store the image exactly as it was originally, because it contains way more detail than anyone can see. This can lead to considerable savings in space, especially if the details that are missing are the kind that people have trouble perceiving. This kind of compression is called lossy compression. There are other situations where images need to be stored exactly as they were in the original, such as for medical scans or very high quality photograph processing, and in these cases lossless methods are used, or the images aren’t compressed at all (e.g. using RAW format on cameras).
In the data representation section we looked at how the size of an image file can be reduced by using fewer bits to describe the colour of each pixel. However, image compression methods such as JPEG take advantage of patterns in the image to reduce the space needed to represent it, without impacting the image unnecessarily.
The following three images show the difference between reducing bit depth and using a specialised image compression system. The left hand image is the original, which was 24 bits per pixel. The middle image has been compressed to one third of the original size using JPEG; while it is a “lossy” version of the original, the difference is unlikely to be perceptible. The right hand one has had the number of colours reduced to 256, so there are 8 bits per pixel instead of 24, which means it is also stored in a third of the original size. Even though it has lost just as many bits, the information removed has had much more impact on how it looks. This is the advantage of JPEG: it removes information in the image that doesn’t have so much impact on the perceived quality. Furthermore, with JPEG, you can choose the tradeoff between quality and file size.
Reducing the number of bits (the colour depth) is sufficiently crude that we don’t really regard it as a compression method, but just a low quality representation. Image compression methods like JPEG, GIF and PNG are designed to take advantage of the patterns in an image to get a good reduction in file size without losing more quality than necessary.

For example, the following image shows a zoomed in view of the pixels that are part of the detail around an eye from the above (high quality) image.

Notice that the colours in adjacent pixels are often very similar, even in this part of the picture that has a lot of detail. For example, the pixels shown in the red box below just change gradually from very dark to very light.

Run-length encoding wouldn’t work in this situation. You could use a variation that specifies a pixel’s colour, and then says how many of the following pixels are the same colour, but although most adjacent pixels are nearly the same, the chances of them being identical are very low, and there would be almost no runs of identical colours.
But there is a way to take advantage of the gradually changing colours. For the pixels in the red box above, you could generate an approximate version of those colours by specifying just the first and last one, and getting the computer to interpolate the ones in between smoothly. Instead of storing 5 pixel values, only 2 are needed, yet someone viewing it probably wouldn’t notice any difference. This would be *lossy* because you can’t reproduce the original exactly, but it would be good enough for a lot of purposes, and save a lot of space.
The JPEG system, which is widely used for photos, uses a more sophisticated version of this idea. Instead of taking a 5 by 1 run of pixels as we did above, it works with 8 by 8 blocks of pixels. And instead of estimating the values with a linear function, it uses combinations of cosine waves.
**Jargon Buster**
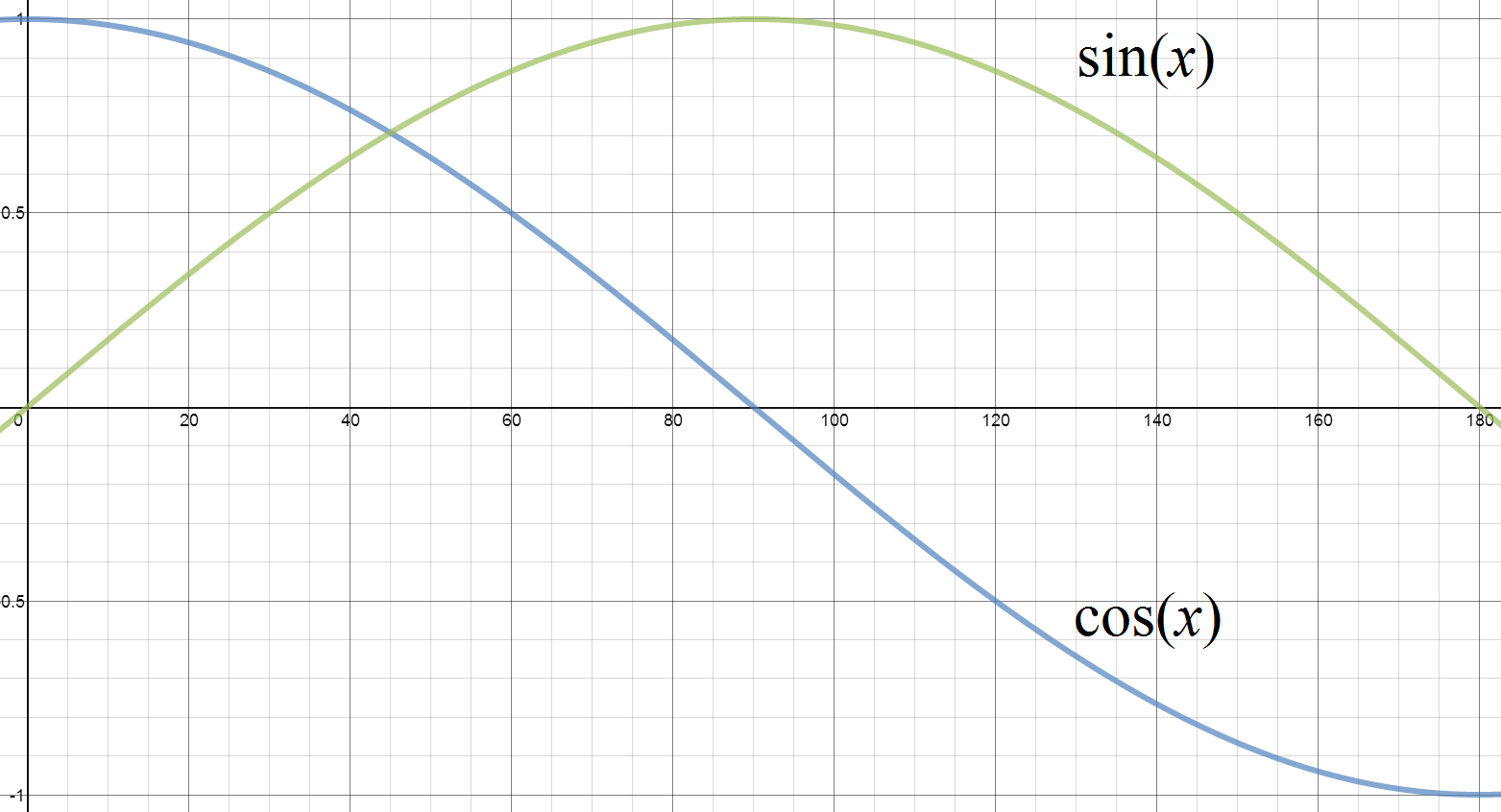
A cosine wave form is from the trig function that is often used for calculating the sides of a triangle. If you plot the cosine value from 0 to 180 degrees, you get a smooth curve going from 1 to -1\. Variations of this plot can be used to approximate the value of pixels, going from one colour to another. If you add in a higher frequency cosine wave, you can produce interesting shapes. In theory, any pattern of pixels can be created by adding together different cosine waves!
You can see the 8 by 8 blocks of pixels if you zoom in on a heavily compressed JPEG image. For example, the following image has been very heavily compressed using JPEG (it is just 1.5% of its original size).

If we zoom in on the eye area , you can see the 8 x 8 blocks of pixels:

Notice that there is very little variation across each block. In the following image the block in the red box only changes from top to bottom, and could probably be specified by giving just two values, and having the ones in between calculated by the decoder as for the line example before. The green square only varies from left to right, and again might only need 2 values stored instead of 64\. The blue block has only one colour in it! The yellow block is more complicated because there is more activity in that part of the image, which is where the cosine waves come in. A “wave” value varies up and down, so this one can be represented by a left-to-right variation from dark to light to dark, and a top-to-bottom variation mainly from dark to light. Thus still only a few values need to be stored instead of the full 64.

The quality is quite low, but the saving in space is huge — it’s more than 60 times smaller (for example, it would download 60 times faster). Higher quality JPEG images store more detail for each 8 by 8 block, which makes it closer to the original image, but makes bigger files because more details are being stored. You can experiment with these tradeoffs by saving JPEGs with differing choices of the quality, and see how the file size changes. Most image processing software offers this option when you save an image as a JPEG.
**Jargon Buster**
The name “JPEG” is short for “Joint Photographic Experts Group”, a committee that was formed in the 1980s to create standards so that digital photographs could be captured and displayed on different brands of devices. Because some file extensions are limited to three characters, it is often seen as the ”.jpg” extension.
**Extra for Experts**
The cosine waves used for JPEG images are based on a “Discrete Cosine Transform”. The “Discrete” means that the waveform is digital — it is the opposite of continuous, where any value can occur. In a JPEG wave, there are only 8 x 8 values (for the block being coded), and each of those values can have a limited range of numbers (binary integers), rather than any value at all.
An important issue arises because JPEG represents images as smoothly varying colours: what happens if the colours change suddenly? In that case, lots of values need to be stored so that lots of cosine waves can be added together to make the sudden change in colour, or else the edge of the image become fuzzy. You can think of it as the cosine waves overshooting on the sudden changes, producing artifacts like the ones in the following image where the edges are messy.

The original had sharp edges, but this zoomed in view of the JPEG version of it show that not only are the edges gradual, but some darker pixels occur further into the white space, looking a bit like shadows or echoes.

For this reason, JPEG is used for photos and natural images, but other techniques (such as GIF and PNG, which we will look at in another section) work better for artificial images like this one.
## 7.4\. IMAGE COMPRESSION: GIF AND PNG[](http://csfieldguide.org.nz/CompressionCoding.html#image-compression-gif-and-png "Permalink to this headline")
[appearing soon!]
## 7.5\. GENERAL PURPOSE COMPRESSION[](http://csfieldguide.org.nz/CompressionCoding.html#general-purpose-compression "Permalink to this headline")
General purpose compression methods need to be lossless because you can’t assume that the user won’t mind if the data is changed. The most widely used general purpose compression algorithms (such as ZIP, gzip, and rar) are based on a method called “Ziv-Lempel coding”, invented by Jacob Ziv and Abraham Lempel in the 1970s.
We’ll look at this with a text file as an example. The main idea of Ziv-Lempel coding is that sequences of characters are often repeated in files (for example, the sequence of characters “image ” appears often in this chapter), and so instead of storing the repeated occurrence, you just replace it with a reference to where it last occurred. As long as the reference is smaller than the phrase being replaced, you’ll save space. Typically this systems based on this approach can be used to reduce text files to as little as a quarter of their original size, which is almost as good as any method known for compressing text.
The following interactive allows you to explore this idea. The empty boxes have been replaced with a reference to the text occurring earlier. You can click on a box to see where the reference is, and you can type the referenced characters in to decode the text. What happens if a reference is pointing to another reference? As long as you decode them from first to last, the information will be available before you need it.
You can also enter your own text by clicking on the “Text” tab. You could paste in some text of your own to see how many characters can be replaced with references.
The references are actually two numbers: the first says how many characters to count back to where the previous phrase starts, and the second says how long the referenced phrase is. Each reference typically takes about the space of one or two characters, so the system makes a saving as long as two characters are replaced. The options in the interactive above allow you to require the replaced length to be at least two, to avoid replacing a single character with a reference. Of course, all characters count, not just letters of the alphabet, so the system can also refer back to the white spaces between words. In fact, some of the most common sequences are things like a full stop followed by a space.
This approach also works very well for black and white images, since sequences like “10 white pixels” are likely to have occurred before. Here are some of the bits from the example earlier in this chapter; you can paste them into the interactive above to see how many pointers are needed to represent it.
~~~
011000010000110
100000111000001
000001111100000
000011111110000
000111111111000
001111101111100
011111000111110
111110000011111
~~~
In fact, this is essentially what happens with GIF and PNG images; the pixel values are compressed using the Ziv-Lempel algorithm, which works well if you have lots of consecutive pixels the same colour. But it works very poorly with photographs, where pixel patterns are very unlikely to be repeated.
**Curiosity**
The method we have described here is named “Ziv-Lempel” compression after Jacob Ziv and Abraham Lempel, the two computer scientists who invented it in the 1970s. Unfortunately someone mixed up the order of their names when they wrote an article about it, and called it “LZ” compression instead of “ZL” compression. So many people copied the mistake that Ziv and Lempel’s method is now usually called “LZ compression”!
## 7.6\. AUDIO COMPRESSION[](http://csfieldguide.org.nz/CompressionCoding.html#audio-compression "Permalink to this headline")
One of the most widely used methods for compressing music is MP3, which is actually from a video compression standard. The Motion Picture Expert Group (MPEG) was a consortium of companies and researchers that got together to agree on a standard so that people could easily play the same videos on different brands of equipment (especially from DVD). The very first version of their standard (called MPEG 1) had three methods of storing the sound track (layer 1, 2 and 3). One of those methods (MPEG 1 layer 3) became very popular for compressing music, and was abbreviated to MP3.
Most other audio compression methods use a similar approach to the MP3 method, although some offer better quality for the same amount of storage (or less storage for the same quality). It’s not essential to know how this works, but the general idea is to break the sound down into bands of different frequencies, and then represent each of those bands by adding together the values of a simple formula (the sum of cosine waves, to be precise).
There is some [more detail about how MP3 coding works on the cs4fn site](http://www.cs4fn.org/mathemagic/sonic.html), and also in [an article on the I Programmer site](http://www.i-programmer.info/babbages-bag/1222-mp3.html).
Other audio compression systems that you might come across include AAC, ALAC, Ogg Vorbis, and WMA. Each of these has various advantages over others, and some are more compatible or open than others.
The main questions with compressed audio are how small the file can be made, and how good the quality is of the human ear. (There is also the question of how long it takes to encode the file, which might affect how useful the system is.) The tradeoff between quality and size of audio files can depend on the situation you’re in: if you are jogging and listening to music then the quality may not matter so much, but it’s good to reduce the space available to store it. On the other hand, someone listening to a recording at home on a good sound system might not mind about having a large device to store the music, as long as the quality is high.
To evaluate an audio compression you should choose a variety of recordings that you have high quality originals for, typically on CD (or using uncompressed WAV or AIFF files). Choose different styles of music, and other kinds of audio such as speech, and perhaps even create a recording that is totally silent. Now convert these recordings to different audio format. One system for doing this that is free to download is Apple’s iTunes, which can be used to rip CDs to a variety of formats, and gives a choice of settings for the quality and size. A lot of other audio systems are able to convert files, or have plugins that can do the conversion.
Compress each of your recordings using a variety of methods, making sure that each compressed file is created from a high quality original. Make a table showing how long it took to process each recording, the size of the compressed file, and some evaluation of the quality of the sound compared with the original. Discuss the tradeoffs involved — do you need much bigger files to store good quality sound? Is there a limit to how small you can make a file and still have it sounding ok? Do some methods work better for speech than others? Does a 2 minute recording of silence take more space than a 1 minute recording of silence? Does a 1 minute recording of music use more space than a minute of silence?
## 7.7\. THE WHOLE STORY!
The details of how compression systems work have been glossed over in this chapter, as we have been more concerned about the file sizes and speed of the methods than how they work. Most compression systems are variations of the ideas that have been covered here, although one fundamental method that we haven’t mentioned is Huffman coding, which turns out to be useful as the final stage of all of the above methods, and is often one of the first topics mentioned in textbooks discussing compression (there’s a brief [explanation of it here](http://www.cimt.plymouth.ac.uk/resources/codes/codes_u17_text.pdf). A closely related system is Arithmetic coding (there’s an [explanation of it here](http://www.cimt.plymouth.ac.uk/resources/codes/codes_u18_text.pdf)). Also, motion picture compression has been omitted, even though compressing videos saves more space than most kinds of compression. Most video compression is based on the “MPEG” standard (Motion Picture Experts Group). There is some information about how this works in the [CS4FN article on “Movie Magic”](http://www.cs4fn.org/films/mpegit.php).
The Ziv-Lempel method shown is a variation of the so-called “LZ77” method. Many of the more popular compression methods are based on this, although there are many variations, and one called “LZW” has also been used a lot. Another high-compression general-purpose compression method is bzip, based on a very clever method called the Burrows-Wheeler Transform.
Questions like “what is the most compression that can be achieved” are addressed by the field of [information theory](http://en.wikipedia.org/wiki/Information_theory). There is an [activity on information theory on the CS Unplugged site](http://csunplugged.org/information-theory), and there is a [fun activity that illustrates information theory](http://www.math.ucsd.edu/~crypto/java/ENTROPY/). Based on this theory, it seems that English text can’t be compressed to less than about 12% of its original size at the very best. Images, sound and video can get much better compression because they can use lossy compression, and don’t have to reproduce the original data exactly.
## 7.8\. FURTHER READING[](http://csfieldguide.org.nz/CompressionCoding.html#further-reading "Permalink to this headline")
* “The Data Compression Book” by Mark Nelson and Jean-Loup Gailly is a good overview of this topic
* A list of books on this topic (and lots of other information about compression) is available from [The Data Compression Site](http://www.data-compression.info/Books/).
* Gleick’s book “The Information” has some background to compression, and coding in general.
### 7.8.1\. USEFUL LINKS[](http://csfieldguide.org.nz/CompressionCoding.html#useful-links "Permalink to this headline")
* Images, run-length-coding [http://csunplugged.org/image-representation](http://csunplugged.org/image-representation) This is also relevant to binary representations in general, although is probably best used in the compression section.
* There is a detailed section on [JPEG encoding on Wikipedia](http://en.wikipedia.org/wiki/Jpeg).
* Text compression [http://csunplugged.org/text-compression](http://csunplugged.org/text-compression)