OpenCV2学习笔记(二十二)
最后更新于:2022-04-01 06:36:35
##ORB特征提取
ORB(ORiented Brief)特征提取算法,其前身Brief,是由EPFL的Calonder在ECCV2010上提出了一种可以快速计算且表达方式为二进制编码的描述子,主要思路就是在特征点附近随机选取若干点对,将这些点对的灰度值的大小,组合成一个二进制串,并将这个二进制串作为该特征点的特征描述子。BRIEF最大的优点在于速度快,然而其缺点也相当明显,主要有以下几方面:
1. 不具有旋转不变性;
2. 不具有尺度不变性;
3. 对抗噪声性能差。
ORB就是试图解决上述缺点中的1和3,即具有旋转不变性的同时具有较好的抗噪能力。运算速度方面,ORB算法是SIFT算法的100倍,是SURF算法的10倍。
**ORB算法解决旋转不变性问题的思想:**
ORB算法中采用了FAST作为特征点检测算子。在SIFT算法中,梯度直方图的把第一峰值的方向设置为特征点的主方向;如果次峰值的量度达到峰值的80%,则把第二个峰值的方向也设定为主方向,该算法相对更耗时。而在ORB的方案中,特征点的主方向是通过矩(moment)计算得来。有了主方向之后,就可以依据该主方向提取Brief描述子。
**ORB算法解决对噪声敏感问题的方法:**
由于ORB算法不直接使用像素点与点之间进行比较,而是选择以该像素为中心的一个区域作为整一个比较对象,因此提高了抗噪声的能力。
**关于尺度不变性问题:**
ORB没有解决尺度不变性的问题(因为FAST本身就不具有尺度不变性)而且这类快速的特征描述子,通常都是应用在实时的视频处理中的,可以通过跟踪还有一些启发式的策略来解决尺度不变性的问题。
**相关论文下载:**
Calonder M., Lepetit V., Strecha C., Fua P.: BRIEF:Binary Robust Independent Elementary Features. ECCV 2010
[ORB: an efficient alternative to SIFT or SURF](http://www.willowgarage.com/sites/default/files/orb_final.pdf)
作为Brief的改进,ORB早在OpenCV 2.4.2版本就已经被实现出来了。在OpenCV中,ORB类继承自Feature2D类,另外有两个类:OrbFeatureDetector和OrbDescriptorExtractor,与ORB类是等价的。
**一个简单的实验:**
**ORB特征提取与匹配结果(未筛选特征点):**

**ORB特征提取与匹配结果(已筛选特征点):**

实验代码参照《OpenCV 3 编程入门》一书的例程编写。
OpenCV2学习笔记(二十一)
最后更新于:2022-04-01 06:36:33
##GPU模块小记
接触一下OpenCV里一个之前没有接触的模块:GPU。这里只是根据教程和网上一些文章进行简单的记叙,欢迎大家批评指正。
注:在使用GPU模块之前,需要确认在使用CMake编译OpenCV时,勾选了选项WITH_CUDA和WITH_TBB使其生效生效。
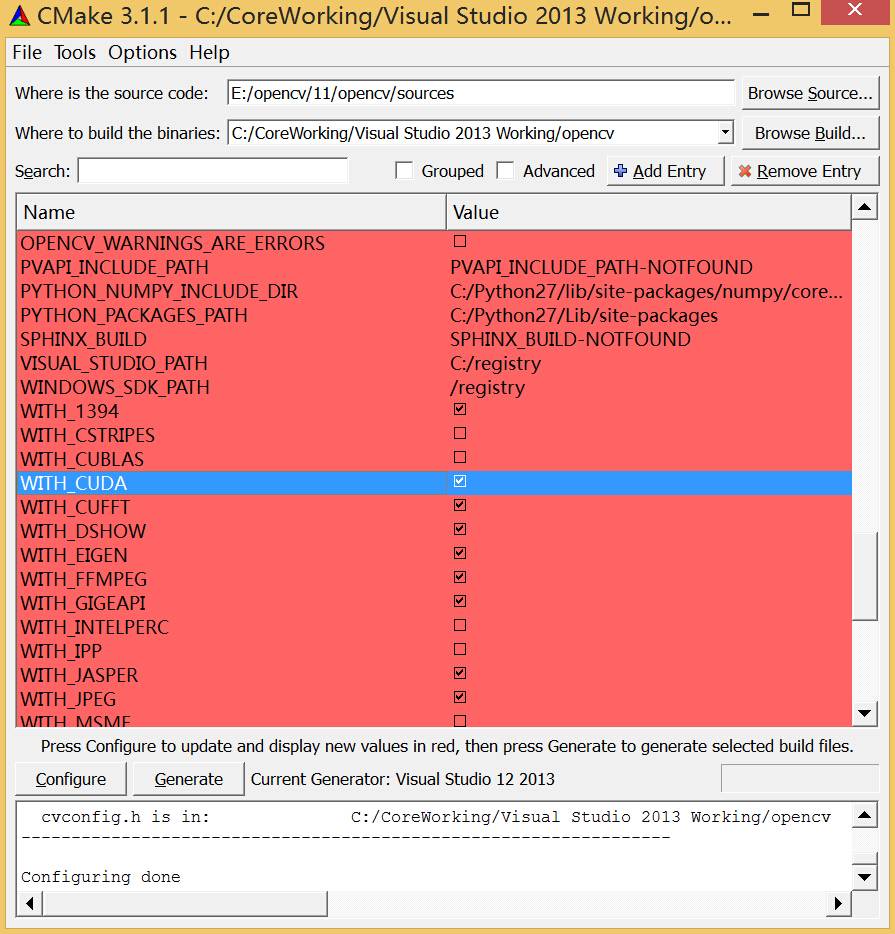
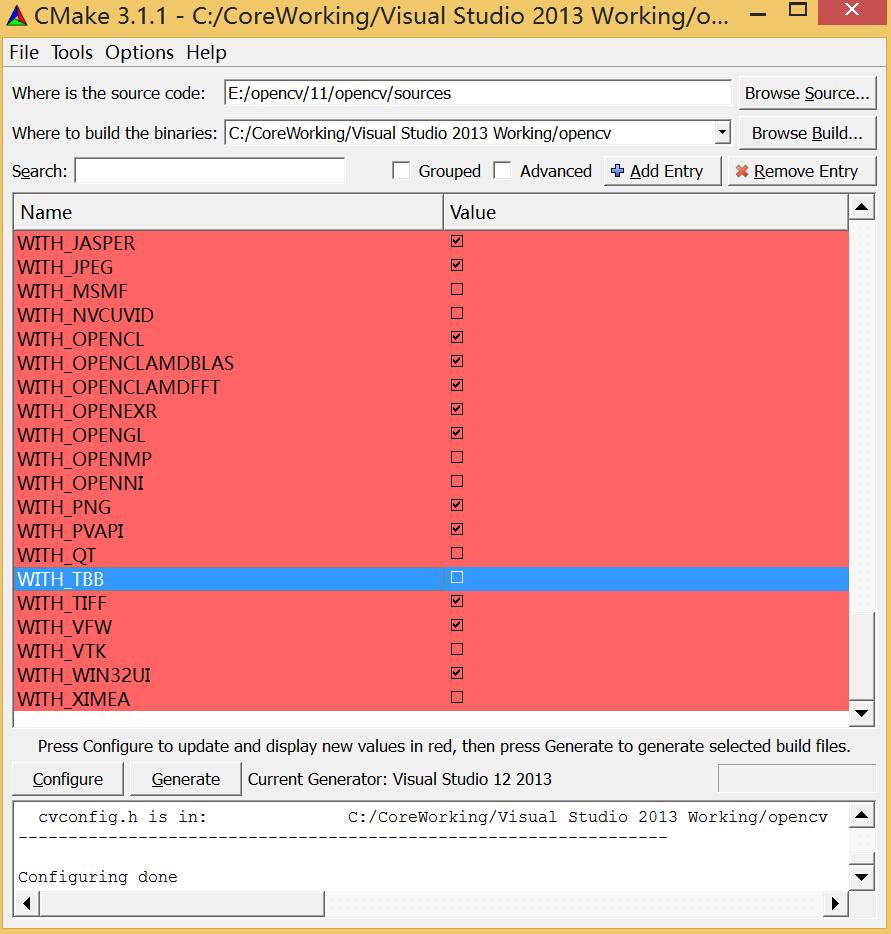
若以上配置已经完成,在使用GPU模块的函数之前,还做一下检查:调用函数gpu::getCudaEnabledDeviceCount,如果你在使用的OpenCV模块编译时不支持GPU,这个函数返回值为0;否则返回值为已安装的CUDA设备的数量。
OpenCV的GPU模块只支持NVIDIA的显卡,原因是该部分是基于NVIDIA的CUDA和NVIDIA的NPP模块实现的。而该模块的好处在于使用GPU模块无需安装CUDA工具,也无需学习GPU编程,因为不需要编写GPU相关的代码。但如果你想重新编译OpenCV的GPU模块的话,还是需要CUDA的toolkit。
由于GPU模块的发展,使大部分函数使用起来和之前在CPU下开发非常类似。首先,就是把GPU模块链接到你的工程中,并包含必要的头文件gpu.hpp。其次,就是GPU模块下的数据结构,原本在cv名字空间中的现在都在gpu名字空间中,使用时可以gpu::和cv::来防止混淆。
在GPU模块中,矩阵的类型为:GpuMat而不是OpenCV中使用的cv::Mat,其他的函数命名和CPU模块中相同。OpenCV中GPU模块函数的使用步骤如下:
~~~
1.验证OpenCV是否已启用GPU模块。
2.上传待处理数据到GPU (Mat --> GpuMat)。
3.调用OpenCV支持的GPU的处理函数。
4.下载处理结果到CPU (GpuMat ---> Mat)。
~~~
根据[http://blog.csdn.net/yang_xian521/article/details/7249532](http://blog.csdn.net/yang_xian521/article/details/7249532) 所提到的,一个问题是对于2.0的GPU模块,多通道的函数支持的并不好,推荐使用GPU模块处理灰度的图像。有些情况下,使用GPU模块的运行速度还不及CPU模块下的性能,所以可以认为,GPU模块相对而言还不够成熟,需要进一步优化。很重要的一个原因就是内存管理部分和数据转换部分对于GPU模块而言消耗了大量的时间。
一段自带的示例代码如下,实现求矩阵转置的功能:
~~~
#include <iostream>
#include "cvconfig.h"
#include "opencv2/core/core.hpp"
#include "opencv2/gpu/gpu.hpp"
#include "opencv2/core/internal.hpp" // For TBB wrappers
using namespace std;
using namespace cv;
using namespace cv::gpu;
struct Worker { void operator()(int device_id) const; };
int main()
{
int num_devices = getCudaEnabledDeviceCount();
if (num_devices < 2)
{
std::cout << "Two or more GPUs are required\n";
return -1;
}
for (int i = 0; i < num_devices; ++i)
{
DeviceInfo dev_info(i);
if (!dev_info.isCompatible())
{
std::cout << "GPU module isn't built for GPU #" << i << " ("
<< dev_info.name() << ", CC " << dev_info.majorVersion()
<< dev_info.minorVersion() << "\n";
return -1;
}
}
// Execute calculation in two threads using two GPUs
int devices[] = {0, 1};
parallel_do(devices, devices + 2, Worker());
return 0;
}
void Worker::operator()(int device_id) const
{
setDevice(device_id);
Mat src(1000, 1000, CV_32F);
Mat dst;
RNG rng(0);
rng.fill(src, RNG::UNIFORM, 0, 1);
// CPU works
transpose(src, dst);
// GPU works
GpuMat d_src(src);
GpuMat d_dst;
transpose(d_src, d_dst);
// Check results
bool passed = norm(dst - Mat(d_dst), NORM_INF) < 1e-3;
std::cout << "GPU #" << device_id << " (" << DeviceInfo().name() << "): "
<< (passed ? "passed" : "FAILED") << endl;
// Deallocate data here, otherwise deallocation will be performed
// after context is extracted from the stack
d_src.release();
d_dst.release();
}
~~~
CUDA的基本使用方法:[http://www.cnblogs.com/dwdxdy/archive/2013/08/07/3244508.html](http://www.cnblogs.com/dwdxdy/archive/2013/08/07/3244508.html)
OpenCV2学习笔记(二十)
最后更新于:2022-04-01 06:36:31
##Win8.1 64位+OpenCV 2.4.9+Python2.7.9配置
OpenCV提供了Python接口,主要特性包括:
* 提供与OpenCV 2.x中最新的C++接口极为相似的Python接口,并且包括C++中不包括的C接口
* 提供对OpenCV 2.x中所有主要部件的绑定:CxCORE (almost complete), CxFLANN (complete), Cv (complete), CvAux (C++ part almost complete, C part in progress), CvVidSurv (complete), HighGui (complete), and ML (complete)
* 在Python中访问C++中的数据结构
* 完善的内存管理,使用者无须担心内存的问题
* 可以在 OpenCV 的 Mat 与 wxWidgets, PyGTK, and PIL 中使用的 arrays 互相转换
比起C++,Python适合做原型。这里介绍如何配置OpenCV 2.4.9+Python2.7.9,以便在Python中使用OpenCV图形库。
**需要下载的东西如下**(注意版本问题):
一.opencv 2.4.9 下载链接: [http://opencv.org/](http://opencv.org/) ,关于opencv的编译与配置可参考:[http://blog.csdn.net/liyuefeilong/article/details/43526975](http://blog.csdn.net/liyuefeilong/article/details/43526975)
[http://blog.csdn.net/liyuefeilong/article/details/44872809](http://blog.csdn.net/liyuefeilong/article/details/44872809)
二.python 下载链接: [https://www.python.org/](https://www.python.org/). (版本选择python2.7.9)
三.NumPy(opencv的python版需要该模块,NumPy的版本要和Python版本相同),这里提供两种安装方法:
1.此处下载链接: [http://www.lfd.uci.edu/~gohlke/pythonlibs/](http://www.lfd.uci.edu/~gohlke/pythonlibs/) 选择最新版本numpy-1.9.2+mkl-cp27-none-win_amd64.whl,请留意不要下载成cp27对应python 2.7版本,若python选择64位,则NumPy也必须选择64版本。whl文件的安装步骤如下:
* 将下载的NumPy包移动到python安装位置(笔者的路径为C:\Python27)下的Scripts文件夹
* Shift+右键打开命令窗口cmd,输入:`pip install wheel` 安装wheel模块。
* wheel安装成功后,在命令窗口中键入以下命令即安装成功:
~~~
cd c:/Python27/Scripts
pip install numpy-1.9.2rc1+mkl-cp27-none-win_amd64.whl
~~~
2.下载链接: [http://download.csdn.net/detail/liyuefeilong/8647101](http://download.csdn.net/detail/liyuefeilong/8647101)
下载完成后,运行文件numpy-MKL-1.8.0.win-amd64-py2.7.exe,一步一步安装即可。
**简单的配置**
在opencv文件夹中,找到build->python->2.7,其中包含x86和x64两个文件夹,由于这里安装的python和NumPy均为64位版本,因此复制x64文件夹中的cv2.pyd文件到C:\Python27\Lib\site-packages 中即可。
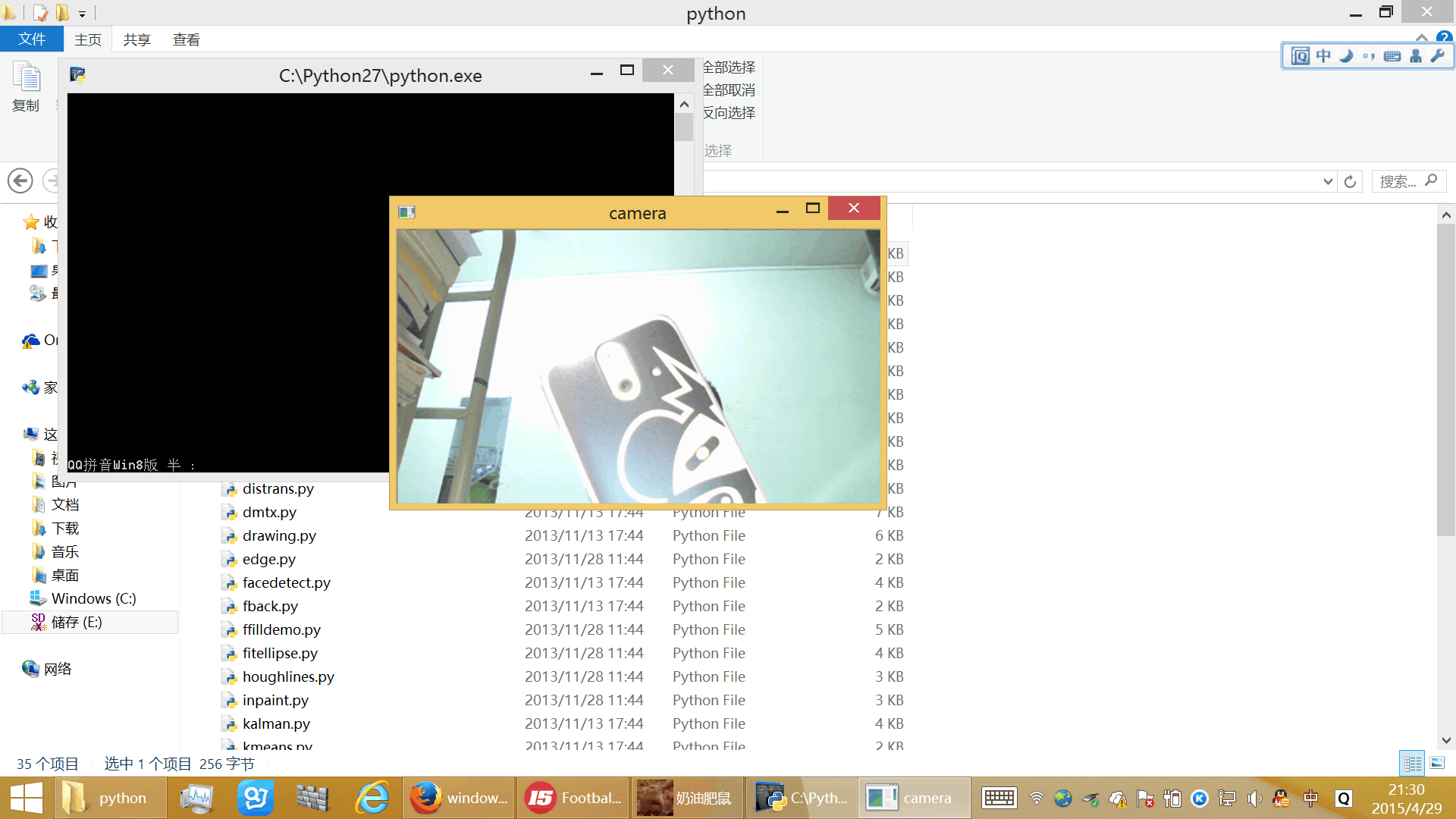
为了测试安装和配置是否成功,可以打开opencv\sources\samples\python中的例程,如:camera.py,正常情况下即可调用电脑的默认摄像头:
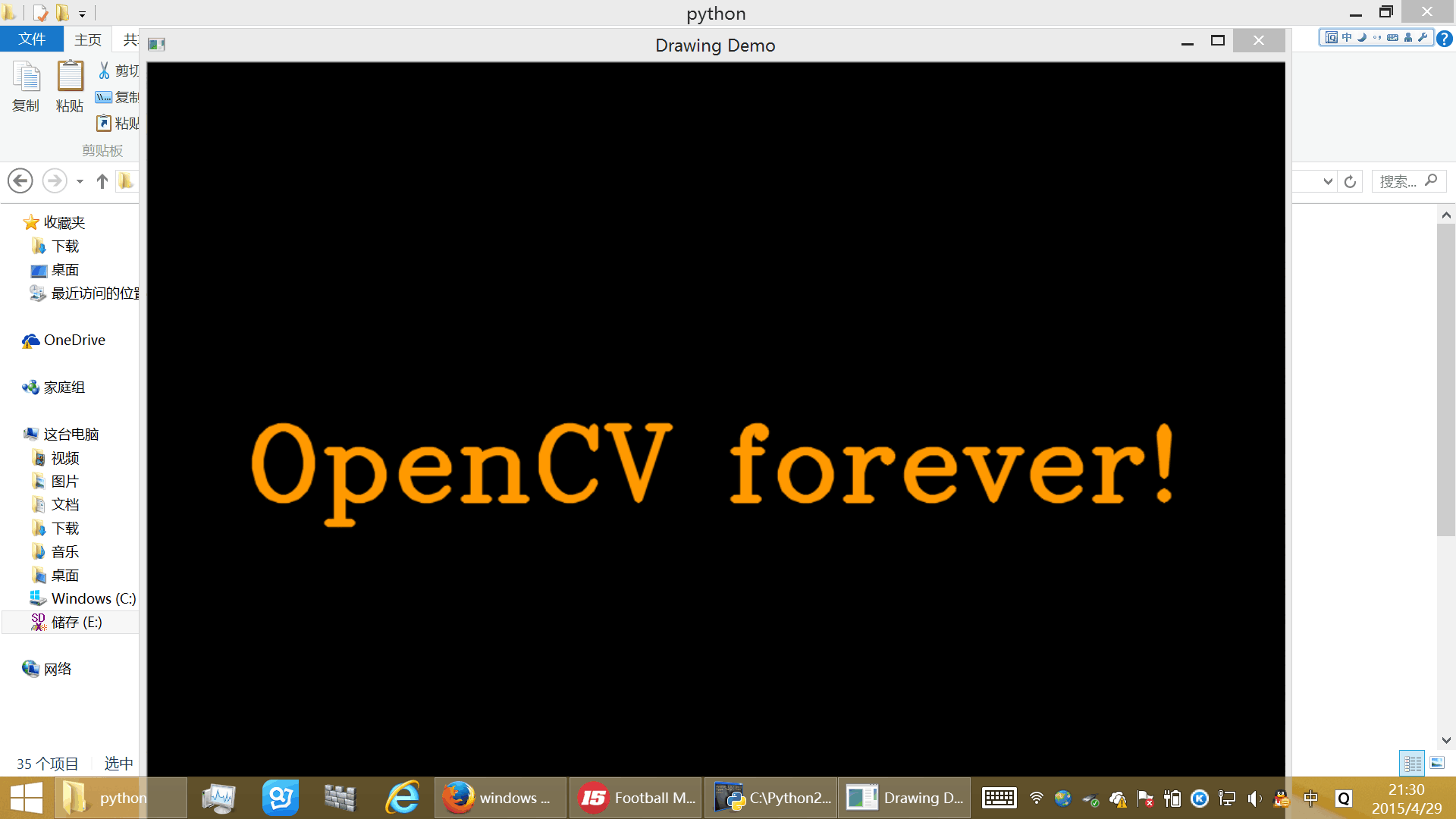
或者双击运行drawing.py,如果没有问题应该看到彩色条纹。
文件夹包含许多例程,其中一些在打开后只是一闪而过,一种原因是程序需要若干参数,这里只是验证配置是否正确,若要跑通所有例程,还是要打开代码看看。事实上,opencv里的很多宏在python里需要加上cv2.cv前缀即可生效。
参考链接:[http://blog.csdn.net/nwpulei/article/details/7277511](http://blog.csdn.net/nwpulei/article/details/7277511)
[http://blog.csdn.net/gxf1027/article/details/9324671](http://blog.csdn.net/gxf1027/article/details/9324671)
[http://www.open-open.com/lib/view/open1355657468166.html](http://www.open-open.com/lib/view/open1355657468166.html)
OpenCV2学习笔记(十九)
最后更新于:2022-04-01 06:36:28
##Kalman滤波算法
在视频跟踪处理中,预测目标运动轨迹是一项基本任务。目标运动状态估计的目的有三个:一是对目标过去的状态进行平滑;二是对目标现在的运动状态进行滤波;三是对目标未来的运动状态进行预测。物体的运动状态一般包括目标位置、速度、加速度等。著名的Kalman滤波技术就是其中一种,这是一种线性系统估计技术。
OpenCV中自带了kalman滤波的代码和例程,可参照kalman.cpp,它存在于类KalmanFilter中。kalman滤波算法的调用比较方便,主要的难点是了解多个参数和矩阵计算公式。一个总体的思路是,需要了解前一时刻的状态估计值x和当前的观测值y,然后建立状态方程和观测方程。经过一些运算后即可预测下一步的状态。
**一、离散时间线性动态系统的状态方程**
Kalman滤波利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。由于观测数据中包括系统中的噪声和干扰的影响,所以最优估计也可看作是滤波过程。一个**线性系统**是采用状态方程、观测方程及其初始条件来描述。线性离散时间系统的一般状态方程可描述为:
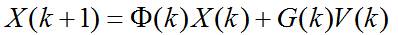
其中, 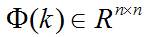是状态转移矩阵, 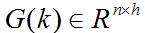是过程噪声增益矩阵。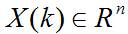是k时刻目标的状态向量, 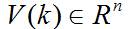是过程噪声,它是具有均值为零、方差矩阵为Q(k)的高斯噪声向量,即:
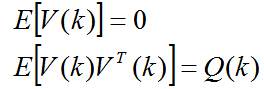
**二、传感器的观测方程**
传感器的通用观测方程为:
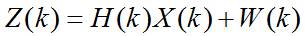
这里, 是传感器在 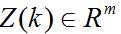时刻的观测向量,观测噪声 是具有零均值和正定协方差矩阵R(k)的高斯分布测量噪声向量,即:
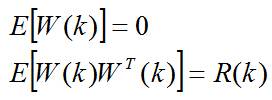
**三、初始状态的描述**
初始状态 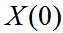是高斯的,具有均值 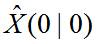和协方差 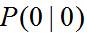,即:
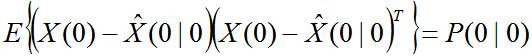
以上的描述比较抽象,因此记录一个例子加以说明:
例:目标沿x轴作匀速直线运动,过程噪声为速度噪声,试写出目标的状态方程。
解:由题意知,目标的状态为:
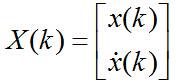
用T表示时间间隔,ux表速度噪声,则有:
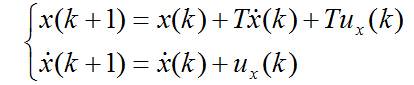
写成矩阵形式为:
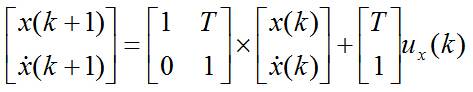
令:
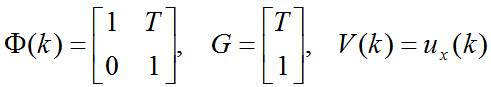
则有:
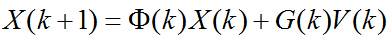
其中:
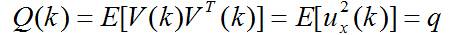
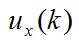为均值等于0,方差为q的高斯噪声。
在OpenCV中自带的例程里面描述了一个一维的运动跟踪,该点在一个圆弧上运动,只有一个自由度即角度。因此只需建立匀速运动模型即可。
例程的路径:C:\opencv\sources\samples\cpp\kalman.cpp
~~~
在代码中各变量的对应情况如下:
状态估计值X对应:state
当前观测值Z对应:measurement
KalmanFilter类内成员变量transitionMatrix即为状态转移方程中的矩阵A
KalmanFilter类内成员变量measurementMatrix即为量测方程中矩阵C
Mat statePre; //!< predicted state (x'(k)): x(k)=A*x(k-1)+B*u(k)
Mat statePost; //!< corrected state (x(k)): x(k)=x'(k)+K(k)*(z(k)-H*x'(k))
Mat transitionMatrix; //!< state transition matrix (A)
Mat controlMatrix; //!< control matrix (B) (not used if there is no control)
Mat measurementMatrix; //!< measurement matrix (H)
Mat processNoiseCov; //!< process noise covariance matrix (Q)
Mat measurementNoiseCov;//!< measurement noise covariance matrix (R)
Mat errorCovPre; //!< priori error estimate covariance matrix (P'(k)): P'(k)=A*P(k-1)*At + Q)*/
Mat gain; //!< Kalman gain matrix (K(k)): K(k)=P'(k)*Ht*inv(H*P'(k)*Ht+R)
Mat errorCovPost; //!< posteriori error estimate covariance matrix (P(k)): P(k)=(I-K(k)*H)*P'(k)
~~~
以下是OpenCV/modules/video/src/Kalman.cpp的源代码,后续需继续分析这些代码:
~~~
/*M///////////////////////////////////////////////////////////////////////////////////////
//
// IMPORTANT: READ BEFORE DOWNLOADING, COPYING, INSTALLING OR USING.
//
// By downloading, copying, installing or using the software you agree to this license.
// If you do not agree to this license, do not download, install,
// copy or use the software.
//
//
// Intel License Agreement
// For Open Source Computer Vision Library
//
// Copyright (C) 2000, Intel Corporation, all rights reserved.
// Third party copyrights are property of their respective owners.
//
// Redistribution and use in source and binary forms, with or without modification,
// are permitted provided that the following conditions are met:
//
// * Redistribution's of source code must retain the above copyright notice,
// this list of conditions and the following disclaimer.
//
// * Redistribution's in binary form must reproduce the above copyright notice,
// this list of conditions and the following disclaimer in the documentation
// and/or other materials provided with the distribution.
//
// * The name of Intel Corporation may not be used to endorse or promote products
// derived from this software without specific prior written permission.
//
// This software is provided by the copyright holders and contributors "as is" and
// any express or implied warranties, including, but not limited to, the implied
// warranties of merchantability and fitness for a particular purpose are disclaimed.
// In no event shall the Intel Corporation or contributors be liable for any direct,
// indirect, incidental, special, exemplary, or consequential damages
// (including, but not limited to, procurement of substitute goods or services;
// loss of use, data, or profits; or business interruption) however caused
// and on any theory of liability, whether in contract, strict liability,
// or tort (including negligence or otherwise) arising in any way out of
// the use of this software, even if advised of the possibility of such damage.
//
//M*/
#include "precomp.hpp"
CV_IMPL CvKalman*
cvCreateKalman( int DP, int MP, int CP )
{
CvKalman *kalman = 0;
if( DP <= 0 || MP <= 0 )
CV_Error( CV_StsOutOfRange,
"state and measurement vectors must have positive number of dimensions" );
if( CP < 0 )
CP = DP;
/* allocating memory for the structure */
kalman = (CvKalman *)cvAlloc( sizeof( CvKalman ));
memset( kalman, 0, sizeof(*kalman));
kalman->DP = DP;
kalman->MP = MP;
kalman->CP = CP;
kalman->state_pre = cvCreateMat( DP, 1, CV_32FC1 );
cvZero( kalman->state_pre );
kalman->state_post = cvCreateMat( DP, 1, CV_32FC1 );
cvZero( kalman->state_post );
kalman->transition_matrix = cvCreateMat( DP, DP, CV_32FC1 );
cvSetIdentity( kalman->transition_matrix );
kalman->process_noise_cov = cvCreateMat( DP, DP, CV_32FC1 );
cvSetIdentity( kalman->process_noise_cov );
kalman->measurement_matrix = cvCreateMat( MP, DP, CV_32FC1 );
cvZero( kalman->measurement_matrix );
kalman->measurement_noise_cov = cvCreateMat( MP, MP, CV_32FC1 );
cvSetIdentity( kalman->measurement_noise_cov );
kalman->error_cov_pre = cvCreateMat( DP, DP, CV_32FC1 );
kalman->error_cov_post = cvCreateMat( DP, DP, CV_32FC1 );
cvZero( kalman->error_cov_post );
kalman->gain = cvCreateMat( DP, MP, CV_32FC1 );
if( CP > 0 )
{
kalman->control_matrix = cvCreateMat( DP, CP, CV_32FC1 );
cvZero( kalman->control_matrix );
}
kalman->temp1 = cvCreateMat( DP, DP, CV_32FC1 );
kalman->temp2 = cvCreateMat( MP, DP, CV_32FC1 );
kalman->temp3 = cvCreateMat( MP, MP, CV_32FC1 );
kalman->temp4 = cvCreateMat( MP, DP, CV_32FC1 );
kalman->temp5 = cvCreateMat( MP, 1, CV_32FC1 );
#if 1
kalman->PosterState = kalman->state_pre->data.fl;
kalman->PriorState = kalman->state_post->data.fl;
kalman->DynamMatr = kalman->transition_matrix->data.fl;
kalman->MeasurementMatr = kalman->measurement_matrix->data.fl;
kalman->MNCovariance = kalman->measurement_noise_cov->data.fl;
kalman->PNCovariance = kalman->process_noise_cov->data.fl;
kalman->KalmGainMatr = kalman->gain->data.fl;
kalman->PriorErrorCovariance = kalman->error_cov_pre->data.fl;
kalman->PosterErrorCovariance = kalman->error_cov_post->data.fl;
#endif
return kalman;
}
CV_IMPL void
cvReleaseKalman( CvKalman** _kalman )
{
CvKalman *kalman;
if( !_kalman )
CV_Error( CV_StsNullPtr, "" );
kalman = *_kalman;
if( !kalman )
return;
/* freeing the memory */
cvReleaseMat( &kalman->state_pre );
cvReleaseMat( &kalman->state_post );
cvReleaseMat( &kalman->transition_matrix );
cvReleaseMat( &kalman->control_matrix );
cvReleaseMat( &kalman->measurement_matrix );
cvReleaseMat( &kalman->process_noise_cov );
cvReleaseMat( &kalman->measurement_noise_cov );
cvReleaseMat( &kalman->error_cov_pre );
cvReleaseMat( &kalman->gain );
cvReleaseMat( &kalman->error_cov_post );
cvReleaseMat( &kalman->temp1 );
cvReleaseMat( &kalman->temp2 );
cvReleaseMat( &kalman->temp3 );
cvReleaseMat( &kalman->temp4 );
cvReleaseMat( &kalman->temp5 );
memset( kalman, 0, sizeof(*kalman));
/* deallocating the structure */
cvFree( _kalman );
}
CV_IMPL const CvMat*
cvKalmanPredict( CvKalman* kalman, const CvMat* control )
{
if( !kalman )
CV_Error( CV_StsNullPtr, "" );
/* update the state */
/* x'(k) = A*x(k) */
cvMatMulAdd( kalman->transition_matrix, kalman->state_post, 0, kalman->state_pre );
if( control && kalman->CP > 0 )
/* x'(k) = x'(k) + B*u(k) */
cvMatMulAdd( kalman->control_matrix, control, kalman->state_pre, kalman->state_pre );
/* update error covariance matrices */
/* temp1 = A*P(k) */
cvMatMulAdd( kalman->transition_matrix, kalman->error_cov_post, 0, kalman->temp1 );
/* P'(k) = temp1*At + Q */
cvGEMM( kalman->temp1, kalman->transition_matrix, 1, kalman->process_noise_cov, 1,
kalman->error_cov_pre, CV_GEMM_B_T );
/* handle the case when there will be measurement before the next predict */
cvCopy(kalman->state_pre, kalman->state_post);
return kalman->state_pre;
}
CV_IMPL const CvMat*
cvKalmanCorrect( CvKalman* kalman, const CvMat* measurement )
{
if( !kalman || !measurement )
CV_Error( CV_StsNullPtr, "" );
/* temp2 = H*P'(k) */
cvMatMulAdd( kalman->measurement_matrix, kalman->error_cov_pre, 0, kalman->temp2 );
/* temp3 = temp2*Ht + R */
cvGEMM( kalman->temp2, kalman->measurement_matrix, 1,
kalman->measurement_noise_cov, 1, kalman->temp3, CV_GEMM_B_T );
/* temp4 = inv(temp3)*temp2 = Kt(k) */
cvSolve( kalman->temp3, kalman->temp2, kalman->temp4, CV_SVD );
/* K(k) */
cvTranspose( kalman->temp4, kalman->gain );
/* temp5 = z(k) - H*x'(k) */
cvGEMM( kalman->measurement_matrix, kalman->state_pre, -1, measurement, 1, kalman->temp5 );
/* x(k) = x'(k) + K(k)*temp5 */
cvMatMulAdd( kalman->gain, kalman->temp5, kalman->state_pre, kalman->state_post );
/* P(k) = P'(k) - K(k)*temp2 */
cvGEMM( kalman->gain, kalman->temp2, -1, kalman->error_cov_pre, 1,
kalman->error_cov_post, 0 );
return kalman->state_post;
}
namespace cv
{
KalmanFilter::KalmanFilter() {}
KalmanFilter::KalmanFilter(int dynamParams, int measureParams, int controlParams, int type)
{
init(dynamParams, measureParams, controlParams, type);
}
void KalmanFilter::init(int DP, int MP, int CP, int type)
{
CV_Assert( DP > 0 && MP > 0 );
CV_Assert( type == CV_32F || type == CV_64F );
CP = std::max(CP, 0);
statePre = Mat::zeros(DP, 1, type);
statePost = Mat::zeros(DP, 1, type);
transitionMatrix = Mat::eye(DP, DP, type);
processNoiseCov = Mat::eye(DP, DP, type);
measurementMatrix = Mat::zeros(MP, DP, type);
measurementNoiseCov = Mat::eye(MP, MP, type);
errorCovPre = Mat::zeros(DP, DP, type);
errorCovPost = Mat::zeros(DP, DP, type);
gain = Mat::zeros(DP, MP, type);
if( CP > 0 )
controlMatrix = Mat::zeros(DP, CP, type);
else
controlMatrix.release();
temp1.create(DP, DP, type);
temp2.create(MP, DP, type);
temp3.create(MP, MP, type);
temp4.create(MP, DP, type);
temp5.create(MP, 1, type);
}
const Mat& KalmanFilter::predict(const Mat& control)
{
// update the state: x'(k) = A*x(k)
statePre = transitionMatrix*statePost;
if( control.data )
// x'(k) = x'(k) + B*u(k)
statePre += controlMatrix*control;
// update error covariance matrices: temp1 = A*P(k)
temp1 = transitionMatrix*errorCovPost;
// P'(k) = temp1*At + Q
gemm(temp1, transitionMatrix, 1, processNoiseCov, 1, errorCovPre, GEMM_2_T);
// handle the case when there will be measurement before the next predict.
statePre.copyTo(statePost);
errorCovPre.copyTo(errorCovPost);
return statePre;
}
const Mat& KalmanFilter::correct(const Mat& measurement)
{
// temp2 = H*P'(k)
temp2 = measurementMatrix * errorCovPre;
// temp3 = temp2*Ht + R
gemm(temp2, measurementMatrix, 1, measurementNoiseCov, 1, temp3, GEMM_2_T);
// temp4 = inv(temp3)*temp2 = Kt(k)
solve(temp3, temp2, temp4, DECOMP_SVD);
// K(k)
gain = temp4.t();
// temp5 = z(k) - H*x'(k)
temp5 = measurement - measurementMatrix*statePre;
// x(k) = x'(k) + K(k)*temp5
statePost = statePre + gain*temp5;
// P(k) = P'(k) - K(k)*temp2
errorCovPost = errorCovPre - gain*temp2;
return statePost;
}
}
~~~
参考链接:[http://blog.csdn.net/yang_xian521/article/details/7050398](http://blog.csdn.net/yang_xian521/article/details/7050398)
OpenCV2学习笔记(十八)
最后更新于:2022-04-01 06:36:26
##显示视频流的帧率
最近做一个东西,需要在视频上实时显示帧速,即FPS。FPS是Frame Per Second的缩写,中文意思是每秒帧数。开发平台为VS2013+OpenCV2.4.9。
FPS是测量用于保存、显示动态视频的信息数量。通俗来讲就是指每秒变化的画面数。
在计算FPS时,需要使用的主要函数有getTickCount、getTickFrequency。而在输出图像上显示FPS水印则是使用函数putText,他们的简单声明如下:
~~~
GetTickCount(void);
在Debug版本中,设备启动后便从计时器中减去180秒。这样方便测试使用该函数的代码的正确溢出处理。
在Release版本中,该函数从0开始计时,返回自设备启动后的毫秒数(不含系统暂停时间)。
~~~
~~~
getTickFrequency函数:返回每秒的计时周期数,GetTickCount / getTickFrequency就得到一个周期的时间。
~~~
~~~
void putText(Mat& img, // 图像矩阵
const string& text, // string型内容
Point org, // 字符串的坐标,以左下角为原点
int fontFace, // 字体类型
double fontScale, // 字体大小
Scalar color, // 字体颜色
int thickness = 1, // 字体粗细
int lineType = 8, // 直线类型
bool bottomLeftOrigin = false) // 尚不知是什么功能
~~~
如果想得到一段程序的运行时间,可以套用下面的例子:
~~~
t = (double)cv::getTickCount();
if (capture.isOpened())
{
capture >> frame;
// getTickcount函数:返回从操作系统启动到当前所经过的毫秒数
// getTickFrequency函数:返回每秒的计时周期数
// t为该处代码执行所耗的时间,单位为秒,fps为其倒数
t = ((double)cv::getTickCount() - t) / cv::getTickFrequency();
fps = 1.0 / t;
~~~
**实现显示视频帧率的简单代码:**
~~~
#include <stdlib.h>
#include <iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
void main()
{
cv::Mat frame;
// 可从摄像头输入视频流或直接播放视频文件
//cv::VideoCapture capture(0);
cv::VideoCapture capture("e:/VIDEO0002.mp4");
double fps;
char string[10]; // 用于存放帧率的字符串
cv::namedWindow("Camera FPS");
double t = 0;
while (1)
{
t = (double)cv::getTickCount();
if (cv::waitKey(50) == 30){ break; }
if (capture.isOpened())
{
capture >> frame;
// getTickcount函数:返回从操作系统启动到当前所经过的毫秒数
// getTickFrequency函数:返回每秒的计时周期数
// t为该处代码执行所耗的时间,单位为秒,fps为其倒数
t = ((double)cv::getTickCount() - t) / cv::getTickFrequency();
fps = 1.0 / t;
sprintf(string, "%.2f", fps); // 帧率保留两位小数
std::string fpsString("FPS:");
fpsString += string; // 在"FPS:"后加入帧率数值字符串
// 将帧率信息写在输出帧上
putText(frame, // 图像矩阵
fpsString, // string型文字内容
cv::Point(5, 20), // 文字坐标,以左下角为原点
cv::FONT_HERSHEY_SIMPLEX, // 字体类型
0.5, // 字体大小
cv::Scalar(0, 0, 0)); // 字体颜色
cv::imshow("Camera FPS", frame);
}
else
{
std::cout << "No Camera Input!" << std::endl;
break;
}
}
}
~~~
以上这段程序可以大致测试出视频处理算法的时间消耗。主要过程是使用以上两个主要函数得到每帧之间的时间,再用putText把FPS的数值显示到屏幕上。
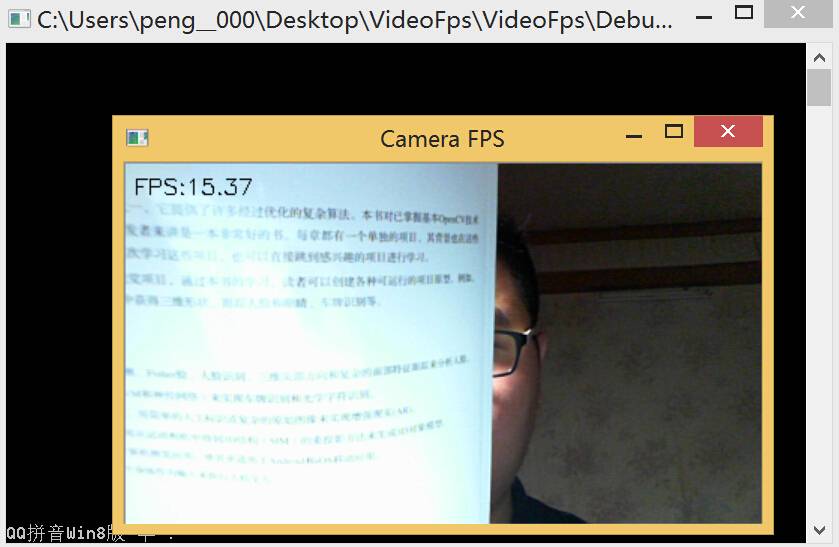
参考资料:[http://www.cnblogs.com/jxsoft/archive/2011/10/17/2215366.html](http://www.cnblogs.com/jxsoft/archive/2011/10/17/2215366.html)
[http://blog.csdn.net/boksic/article/details/7017837](http://blog.csdn.net/boksic/article/details/7017837)
OpenCV2学习笔记(十七)
最后更新于:2022-04-01 06:36:24
##VS2013中运行支持OpenGL的OpenCV工程
之前一直用Qt+OpenCV开发项目,而在VS中直接偷懒使用预编译的OpenCV进行开发,结果在使用OpenGL时提示”No OpenGL support”:
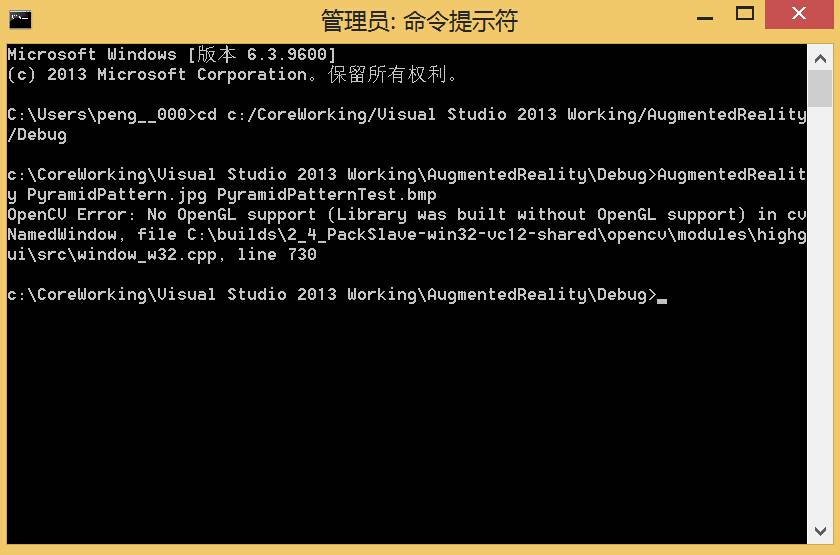
上网查了一下,原因很明显,是因为预编译好的library不支持OpenGL,因此需要使用cmake重新build工程。我的开发环境是:Win 8.1+VS2013+OpenCV 2.4.9。
> 从OpenCV2.4.2版本开始,OpenCV在可视化窗口中支持OpenGL,在highgui的模块中可找到接口。这使得OpenCV可以轻松渲染任何3D内容。但是OpenCV默认不启用OpenGL支持,因此需设置标志ENABLE_OPENGL=
> YES,(默认ENABLE_OPENGL = NO)。
在本次配置成功后,将演示在OpenCV的显示输出中嵌入OpenGL的3D物体。整个流程如下:
**一、生成OpenCV解决方案**
安装CMake并打开,在第一行“Where is the source code”后面的那个“Browse Source…”按钮,选择OpenCV的安装路径。我的Opencv2.0安装路径为E:/opencv/opencv/,这里需要选择source文件夹;点击第二行的“Browse Build…”按钮并选择生成的解决方案的路径。这里放置在E:/opencv/OpencvBuild文件夹中,设定完成后点击左下方的configure。
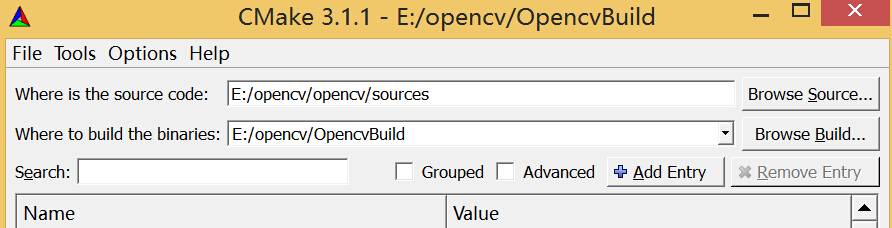
在弹出的对话框中选择编译器版本Visual Studio 12(即Visual Studio 2013),点击Finish。
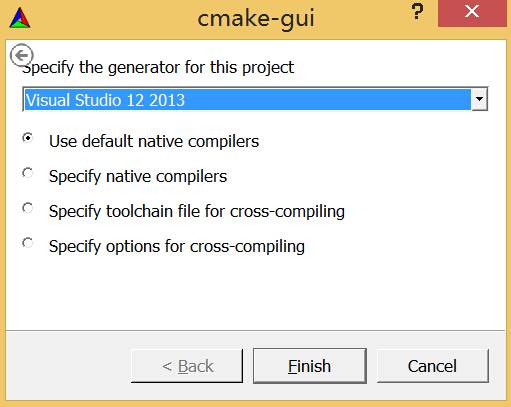
在下面的编译参数设置中找到WITH_OPENGL,打上勾,再次点击Configure。

再次点击Configure,完成后点击Generate,关闭CMake。至此编译前的配置工作全部完成。

**二、在VS中编译OpenCV**
用VS2013打开E:\opencv\OpencvBuild下的OpenCV.sln。在编译之前,确认解决方案平台为Debug|Win 32。右键点击项目ALL_BUILD,选择生成;完成之后找到CMakeTargets->INSTALL,再次选择生成。
等待生成完毕。若第一次选择的解决方案平台选择的是Debug 32位,则将解决方案配置改为Release,然后等待再次依次生成ALL_BUILD和INSTALL,至此OpenCV的编译工作完成。
(这里可能会出现编译的错误。根据网上的介绍,OpenGL在VS中是支持的,不需要安装,但若出现编译不通过的情况,可尝试在所有使用`<gl\gl.h>`头文件的地方前都添加`#include <windows.h>`)
**三、在VS中配置OpenCV**
这里用VS属性表的方式配置OpenCV工程,每次只需要添加属性表即可完成配置,比手工界面配置方便很多。 属性管理器 -> 右键 “test”(工程名) -> 添加现有属性。

修改项目属性表的名字后点击“添加”,即可在属性管理器中见到我们新建的属性表(这里取名为opencv)。
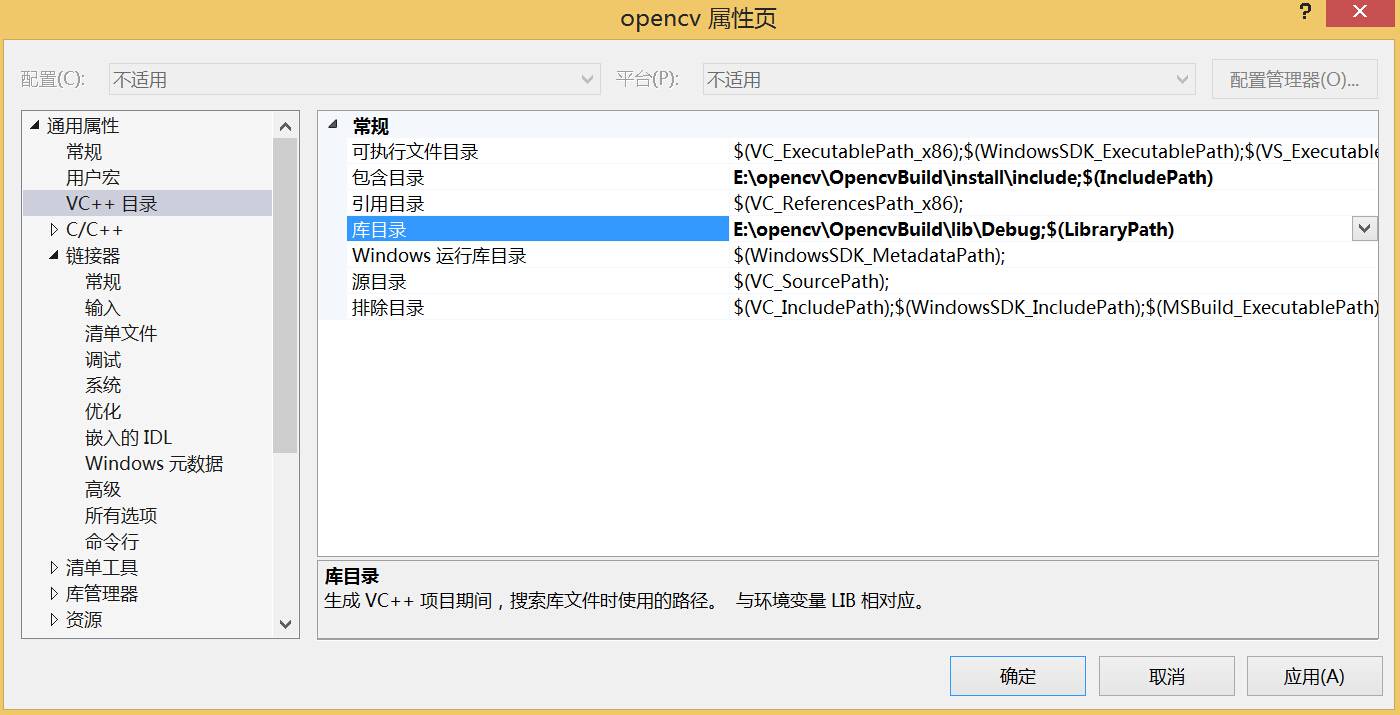
右键点击我们刚建立的属性表并点击“属性”,在弹出的窗口中点击“VC++目录”,点击右侧的“包含目录”,添加:E:\opencv\OpencvBuild\install\include
同样地,在“库目录”添加:E:\opencv\OpencvBuild\lib\Debug
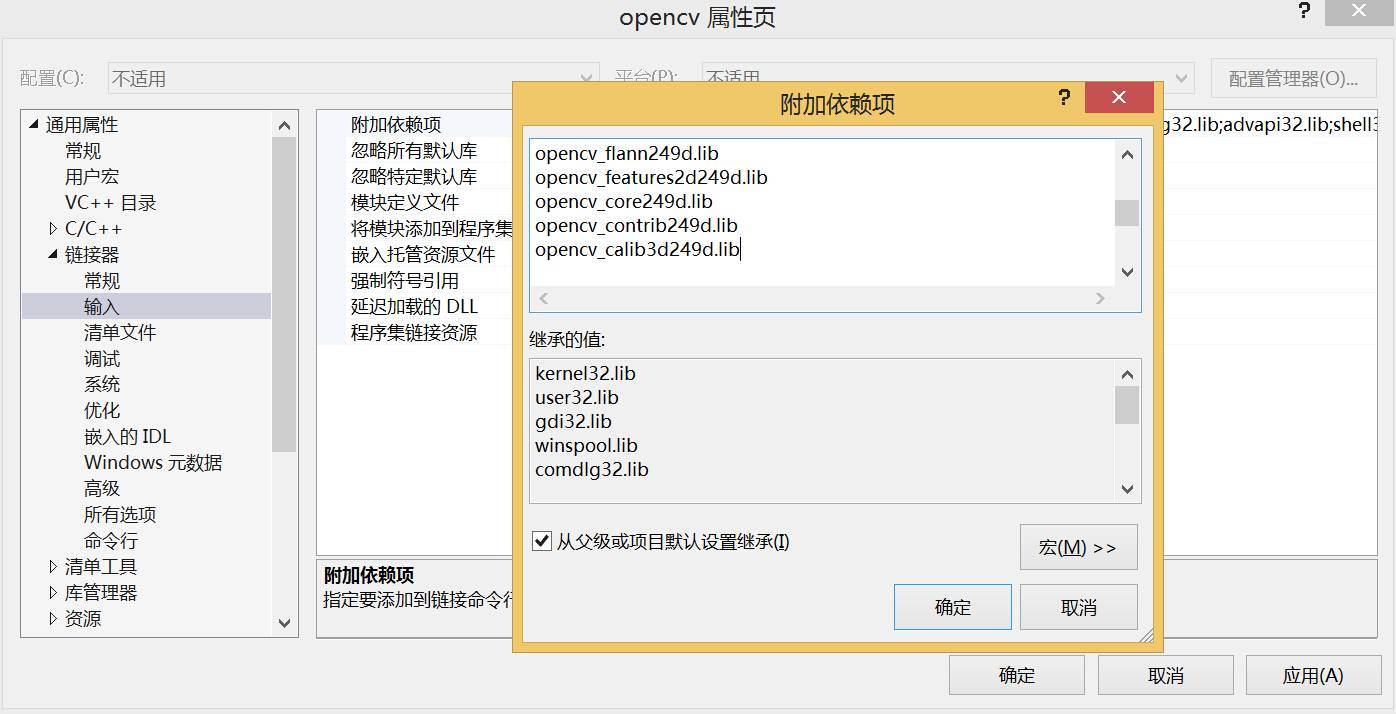
点开“链接器”->输入->附加依赖项,按照需要添加相应的库文件:
用同样的方式,向“Release | Win32”属性中添加属性表,并对属性表进行以下配置:
在“包含目录”添加:E:\opencv\OpencvBuild\install\include
在“库目录”添加:E:\opencv\OpencvBuild\lib\Release
向“附加依赖项”添加:E:\opencv\OpencvBuild\install\include\Release下的库文件。
在VS完成以上配置后,剩下的最后一步是添加系统变量Path:E:\opencv\OpencvBuild\install\x86\vc12\bin;
**四、简单的演示**
至此所有关于OpenCV和OpenGL的配置均已完成,接下来就是试验以下用OpenCV建立OpenGL窗口,这里打开一个现实增强的工程,在属性管理器中Debug|Win32处右击,选择“添加现有属性表”,选择之前生成的opencv属性表(把属性表文件事先放到该工程文件夹中):
编译现实增强项目并生成可执行文件后,输入图像即可得到OpenGL渲染的3D绘图。


OpenCV2学习笔记(十六)
最后更新于:2022-04-01 06:36:22
##Stitching图像拼接
图像拼接stitching是OpenCV2.4.0出现的一个新模块,所有的相关函数都被封装在Stitcher类当中。关于Stitcher类的详细介绍,可以参考: [http://docs.opencv.org/2.4.2/modules/stitching/doc/high_level.html?highlight=stitcher#stitcher](http://docs.opencv.org/2.4.2/modules/stitching/doc/high_level.html?highlight=stitcher#stitcher)。
这个类当中我们主要用到的成员函数有createDefault,用于创建缺省参数的stitcher;estimateTransform,用于 生成最后的拼接图像;而对于composePanorama和stitch,文档中提示如果对stitching的整过过程不熟悉的话,最好不要使用以上 两个函数,直接使用stitch就行了。整个拼接的算法实现过程十分复杂,其中涉及到图像特征点的提取和匹配、摄像机的校准、图像融合、图像的变形、曝光 补偿等算法的结合。
说得这么复杂,但实际上这些模块的接口调用,OpenCV都为我们搞定了,我们只需要调用createDefault函数生成默认的参数,再使用stitch函数进行拼接就ok了。
图像拼接的实例代码如下,在VS2013平台上运行成功:
~~~
/*M///////////////////////////////////////////////////////////////////////////////////////
//
// IMPORTANT: READ BEFORE DOWNLOADING, COPYING, INSTALLING OR USING.
//
// By downloading, copying, installing or using the software you agree to this license.
// If you do not agree to this license, do not download, install,
// copy or use the software.
//
//
// License Agreement
// For Open Source Computer Vision Library
//
// Copyright (C) 2000-2008, Intel Corporation, all rights reserved.
// Copyright (C) 2009, Willow Garage Inc., all rights reserved.
// Third party copyrights are property of their respective owners.
//
// Redistribution and use in source and binary forms, with or without modification,
// are permitted provided that the following conditions are met:
//
// * Redistribution's of source code must retain the above copyright notice,
// this list of conditions and the following disclaimer.
//
// * Redistribution's in binary form must reproduce the above copyright notice,
// this list of conditions and the following disclaimer in the documentation
// and/or other materials provided with the distribution.
//
// * The name of the copyright holders may not be used to endorse or promote products
// derived from this software without specific prior written permission.
//
// This software is provided by the copyright holders and contributors "as is" and
// any express or implied warranties, including, but not limited to, the implied
// warranties of merchantability and fitness for a particular purpose are disclaimed.
// In no event shall the Intel Corporation or contributors be liable for any direct,
// indirect, incidental, special, exemplary, or consequential damages
// (including, but not limited to, procurement of substitute goods or services;
// loss of use, data, or profits; or business interruption) however caused
// and on any theory of liability, whether in contract, strict liability,
// or tort (including negligence or otherwise) arising in any way out of
// the use of this software, even if advised of the possibility of such damage.
//
//M*/
#include <iostream>
#include <fstream>
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/stitching/stitcher.hpp"
using namespace std;
using namespace cv;
bool try_use_gpu = false;
vector<Mat> imgs;
string result_name = "result.jpg"; // 默认输出文件名及格式
void printUsage();
int parseCmdArgs(int argc, char** argv);
int main(int argc, char* argv[])
{
int retval = parseCmdArgs(argc, argv);
if (retval) return -1;
Mat pano;
Stitcher stitcher = Stitcher::createDefault(try_use_gpu);
Stitcher::Status status = stitcher.stitch(imgs, pano);
if (status != Stitcher::OK)
{
cout << "Can't stitch images, error code = " << status << endl;
return -1;
}
imwrite(result_name, pano);
return 0;
}
void printUsage()
{
cout <<
"Rotation model images stitcher.\n\n"
"stitching img1 img2 [...imgN]\n\n"
"Flags:\n"
" --try_use_gpu (yes|no)\n"
" Try to use GPU. The default value is 'no'. All default values\n"
" are for CPU mode.\n"
" --output <result_img>\n"
" The default is 'result.jpg'.\n";
}
int parseCmdArgs(int argc, char** argv)
{
if (argc == 1)
{
printUsage();
return -1;
}
for (int i = 1; i < argc; ++i)
{
if (string(argv[i]) == "--help" || string(argv[i]) == "/?")
{
printUsage();
return -1;
}
else if (string(argv[i]) == "--try_use_gpu") // 默认不使用gpu加速
{
if (string(argv[i + 1]) == "no")
try_use_gpu = false;
else if (string(argv[i + 1]) == "yes")
try_use_gpu = true;
else
{
cout << "Bad --try_use_gpu flag value\n";
return -1;
}
i++;
}
else if (string(argv[i]) == "--output") // 若定义了输出图像名,则更改result_name
{
result_name = argv[i + 1];
i++;
}
else
{
Mat img = imread(argv[i]);
if (img.empty())
{
cout << "Can't read image '" << argv[i] << "'\n";
return -1;
}
imgs.push_back(img);
}
}
return 0;
}
~~~
这里在自己的机子上实现简单的图像拼接,程序生成的可执行文件名为imageStitching.exe,如果直接运行程序将直接退出,需要在cmd中进行以下操作:
找到imageStitching.exe所在的目录,在终端里输入imageStitching+**被拼接的图像路径**(若与imageStitching.exe在同个文件夹,直接输入图像的名字和后缀名即可),如这里输入:imageStitching 1.jpg 2.jpg 3.jpg。
若输入:–output 4.jpg,就会把1.jpg、2.jpg和3.jpg 进行拼接,而输出的文件是imageStitching.exe路径下的4.jpg,由于在例程默认输出为result.jpg,可以不用设置output。
由于选取的图像在拍摄时并不平行,能拼接出这种效果的图像已是不错:
1.jpg:

2.jpg:

3.jpg:

拼接输出结果result.jpg:

代码中使用函数:`Stitcher::Status status = stitcher.stitch(imgs, pano);`就能得出一个傻瓜拼接结果…如之前所提到的,这其中涉及到很多算法的实现过程,可以看到图像拼接算法是一个值得深入的领域。更多的算法可参考:
[http://academy.nearsoft.com/project-updates/makingapanoramapicture](http://academy.nearsoft.com/project-updates/makingapanoramapicture)
OpenCV2学习笔记(十五)
最后更新于:2022-04-01 06:36:19
##利用Cmake快速查找OpenCV函数源码
在使用OpenCV时,在对一个函数的调用不是很了解的情况下,通常希望查到该函数的官方声明。而如果想进一步研究OpenCV的函数,则必须深入到源码。在VS中我们可以选中想要查看的OpenCV函数,点击右键-> 转到定义,我们可以很清楚地了解到函数的简单声明,但是并没有给出源代码。这是因为openCV将很多函数被加入了函数库,并被编译成了dll,所以只能看到函数申明,没法看到源代码。
第一个方法:在官网下载OpenCV后需要解压缩,完成后可以找到OpenCV的解压目录打开,在source/modules中存放着所有函数的源码,手动打开即可。相比之下,以下方法更为便捷。
步骤一:我的OpenCV安装(解压)目录是E:/opencv/opencv。首先需要安装Cmake,可以到官网[http://www.cmake.org](http://www.cmake.org/)去下载并按默认设置安装安装即可。
步骤二:打开Cmake,在第一行“Where is the source code”后面的那个“Browse Source...”按钮,选择OpenCV的安装路径。我的Opencv2.0安装路径为E:/opencv/opencv/,这里需要选择source文件夹,因此输入E:/opencv/opencv/source,同理点击第二行的“Browse Build...”按钮并选择生成的源码路径。这里放置在C:/OpenCV sources文件夹中,设定完成后点击左下方的configure。
步骤三:在弹出的对话框中选择第一项,并在下拉框中选择编译平台,由于本人电脑上安装的是VS2013 64位版本,因此,就选择Visual Studio 12 2013 Win64,点击Finish。
步骤四:需要一段时间,完成时出现以下界面:
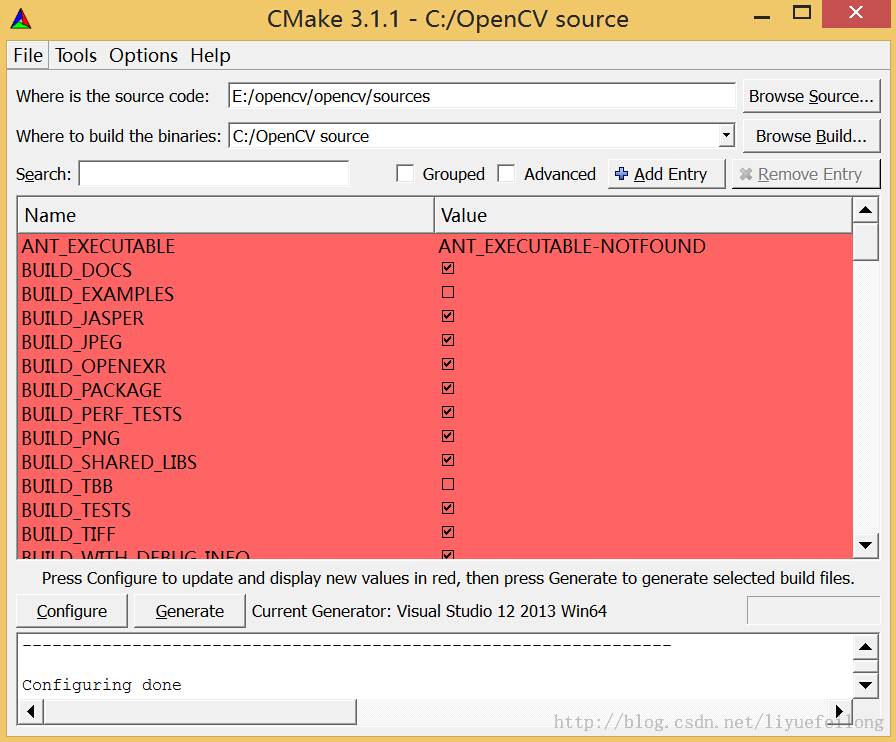
步骤五:再次点击Configure按钮,完成时红色部分消失,为以下状态:

步骤六:点击“Generate”按钮,等到最下方信息显示框显示点击“Generate done”时所有步骤完成!至此,就生成了包含OpenCV函数源代码的Visual Studio工程文件;进入工程文件所在的路径C:/OpenCV source:

可以看到opencv.sln工程了,用VS打开它,可以搜索所有函数的源码。
相比第一种方法,显然这种查阅函数的方法更加便捷~
OpenCV2学习笔记(十四)
最后更新于:2022-04-01 06:36:17
##基于OpenCV的图片卡通化处理
学习OpenCV已有一段时间,除了研究各种算法的内容,在空闲之余,根据书本及资料的引导,尝试结合图像处理算法和日常生活联系起来,首先在台式机上(带摄像头)完成一系列视频流处理功能,开发平台为Qt5.3.2+OpenCV2.4.9。
本次试验实现的功能主要有:
1. 调用摄像头捕获视频流;
2. 将帧图像转换为素描效果图片;
3. 将帧图像卡通化处理;
4. 简单地生成“怪物”形象;
5. 人脸肤色变换。
本节所有的算法均由类cartoon中的函数cartoonTransform()来实现:
~~~
// Frame:输入每一帧图像 output:输出图像
cartoonTransform(cv::Mat &Frame, cv::Mat &output)
~~~
后续将使用更多的OpenCV技巧实现更多功能,并将该应用移植到Android系统上。
一、使用OpenCV访问摄像头
OpenCV提供了一个简便易用的框架以提取视频文件和USB摄像头中的图像帧,如果你只是想读取某个视频,你只需要创建一个cv::VideoCapture实例,然后在循环中提取每一帧。这里需要访问摄像头,因此需要创建一个cv::VideoCapture对象,简单调用对象的open()方法。这里访问摄像头的函数如下,首先在Qt中创建控制台项目,在main函数中添加:
~~~
int cameraNumber = 0; // 设定摄像头编号为0
if(argc > 1)
cameraNumber = atoi(argv[1]);
// 开启摄像头
cv::VideoCapture camera;
camera.open(cameraNumber);
if(!camera.isOpened())
{
qDebug() << "Error: Could not open the camera.";
exit(1);
}
// 调整摄像头的输出分辨率
camera.set(CV_CAP_PROP_FRAME_WIDTH, 640);
camera.set(CV_CAP_PROP_FRAME_HEIGHT, 480);
~~~
在摄像头被初始化后,可以使用C++流运算符将cv::VideoCapture对象转换成cv::Mat对象,这样可以获取视频的每一帧图像。关于视频流读取可参考:[http://blog.csdn.net/liyuefeilong/article/details/44066097](http://blog.csdn.net/liyuefeilong/article/details/44066097)
二、将帧图像转换为素描效果图片
要将一幅图像转换为素描效果图,可以使用不同的边缘检测算法实现,如常用的基于Sobel、Canny、Robert、Prewitt、Laplacian等算子的滤波器均可以实现这一操作,但处理效果各异。
1.Sobel算子:边缘检测中最常用的一种方法,在技术上它是以离散型的差分算子,用来运算图像亮度函数的梯度的近似值,缺点是Sobel算子并没有将图像的主题与背景严格地区分开来,换言之就是Sobel算子并没有基于图像灰度进行处理,由于Sobel算子并没有严格地模拟人的视觉生理特征,所以提取的图像轮廓有时并不能令人满意。
2.Robert算子:根据任一相互垂直方向上的差分都用来估计梯度,Robert算子采用对角方向相邻像素之差。
3.Prewitt算子:该算子与Sobel算子类似,只是权值有所变化,但两者实现起来功能还是有差距的,据经验得知Sobel要比Prewitt更能准确检测图像边缘。
4.Laplacian算子:该算子是一种二阶微分算子,若只考虑边缘点的位置而不考虑周围的灰度差时可用该算子进行检测。对于阶跃状边缘,其二阶导数在边缘点出现零交叉,并且边缘点两旁的像素的二阶导数异号。
5.Canny算子:该算子的基本性能比前面几种要好,但是相对来说算法复杂。Canny算子是一个具有滤波,增强,检测的多阶段的优化算子,在进行处理前,Canny算子先利用高斯平滑滤波器来平滑图像以除去噪声,Canny分割算法采用一阶偏导的有限差分来计算梯度幅值和方向,在处理过程中,Canny算子还将经过一个非极大值抑制的过程,最后Canny算子还采用两个阈值来连接边缘。
相比Sobel等其他算子,Canny和Laplacian算子能得到更清晰的素描效果,而Laplacian的噪声抑制要优于Canny边缘检测,而事实上素描边缘在不同帧之间经常有剧烈的变化,因此我们选择Laplacian边缘滤波器进行图像处理。
一般在进行Laplacian检测之前,需要对图像进行的预操作有:
1. Laplacian算法只能作用于灰度图像,因此需要将彩色帧图像进行转换;
2. 平滑处理,这是因为图像的平滑处理减少了噪声的影响并且一定成都市抵消了由Laplacian算子的二阶导数引起的噪声影响。因此可使用中值滤波器来去噪。
~~~
void cartoon::cartoonTransform(cv::Mat &Frame, cv::Mat &output)
{
cv::Mat grayImage;
cv::cvtColor(Frame, grayImage, CV_BGR2GRAY);
// 设置中值滤波器参数
cv::medianBlur(grayImage, grayImage, 7);
// Laplacian边缘检测
cv::Mat edge; // 用于存放边缘检测输出结果
cv::Laplacian(grayImage, edge, CV_8U, 5);
// 对边缘检测结果进行二值化
cv::Mat Binaryzation; // 用于存放二值化输出结果
cv::threshold(edge, Binaryzation, 80, 255, cv::THRESH_BINARY_INV);
}
~~~
生成的素描效果:
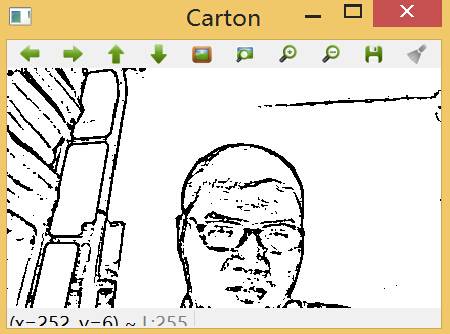
三、将图像卡通化
在项目中调用一些运算量大的算法时,通常需要考虑到效率问题,比如这里将要用到的双边滤波器。这里我们利用双边滤波器的平滑区域及保持边缘锐化的特性,将其运用到卡通图片效果生成中。而考虑到双边滤波器运行效率较低,因此考虑在更低的分辨率中使用,这对效果影响不大,但是运行速度大大加快。
这里使用的策略是将要处理的图像的宽度和高度缩小为原来的1/2,经过双边滤波器处理后,再将其恢复为原来的尺寸。在函数cartoonTransform()中添加以下代码:
~~~
// 采用双边滤波器
// 由于算法复杂,因此需减少图像尺寸
cv::Size size = Frame.size();
cv::Size reduceSize;
reduceSize.width = size.width / 2;
reduceSize.height = size.height / 2;
cv::Mat reduceImage = cv::Mat(reduceSize, CV_8UC3);
cv::resize(Frame, reduceImage, reduceSize);
// 双边滤波器实现过程
cv::Mat tmp = cv::Mat(reduceSize, CV_8UC3);
int repetitions = 7;
for (int i=0 ; i < repetitions; i++)
{
int kernelSize = 9;
double sigmaColor = 9;
double sigmaSpace = 7;
cv::bilateralFilter(reduceImage, tmp, kernelSize, sigmaColor, sigmaSpace);
cv::bilateralFilter(tmp, reduceImage, kernelSize, sigmaColor, sigmaSpace);
}
// 由于图像是缩小后的图像,需要恢复
cv::Mat magnifyImage;
cv::resize(reduceImage, magnifyImage, size);
~~~
为了得到更好的效果,在以上代码中添加以下函数,将恢复尺寸后的图像与上一部分的素描结果相叠加,得到卡通版的图像~~
~~~
cv::Mat dst;
dst.setTo(0);
magnifyImage.copyTo(dst, Binaryzation);
//output = dst; //输出
~~~
卡通效果,阈值各方面有待优化:

四、简单地生成“怪物”形象
这里是结合了边缘滤波器和中值滤波器的另一个小应用,即通过小的边缘滤波器找到图像中的各处边缘,之后使用中值滤波器来合并这些边缘。具体实现步骤如下:
1. 这里同样需要原图像的灰度图,因此格式转换依然是必要的;
2. 分别沿着x和y方向采用3*3的Scharr梯度滤波器(效果图);
3. 使用截断值很低的阈值进行二值化处理;
4. 最后使用3*3的中值平滑滤波得到“怪物”掩码。
详细代码如下,同样在函数cartoonTransform()中添加:
~~~
// 怪物模式
cv::Mat gray ,maskMonster;
cv::cvtColor(Frame, gray, CV_BGR2GRAY);
// 先对输入帧进行中值滤波
cv::medianBlur(gray, gray, 7);
// Scharr滤波器
cv::Mat edge1, edge2;
cv::Scharr(gray, edge1, CV_8U, 1, 0);
cv::Scharr(gray, edge2, CV_8U, 1, 0, -1);
edge1 += edge2; // 合并x和y方向的边缘
cv::threshold(edge1, maskMonster, 12, 255, cv::THRESH_BINARY_INV);
cv::medianBlur(maskMonster, maskMonster, 3);
output = maskMonster; //输出
~~~
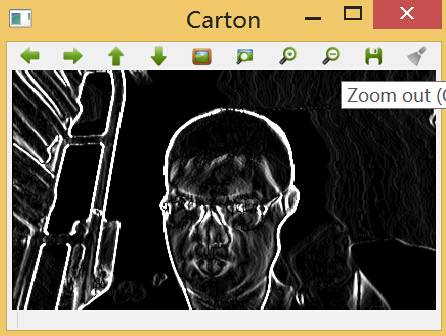
五、人脸肤色变换
皮肤检测算法有很多种,比如基于RGB color space、Ycrcb之cr分量+otsu阈值化、基于混合模型的复杂机器学习算法等。由于这里只是一个轻量级的应用,因此不考虑使用太复杂的算法。考虑到未来要将这些图像处理算法移植到安卓上,而移动设备上的微型摄像头传感器对颜色的反应往往差异很大,而且要在没有标定的情况下对不同肤色的人进行皮肤检测,因此对算法的鲁棒性要求较高。
这里使用了一个技巧,即在图像中规定一个区域,用户需要将脸部放到指定区域中来确定人脸在图像中的位置(事实上有些手机应用也会采取这种方法),对于移动设备来说这不是一件难事。
因此,我们需要规定人脸的区域,同样在函数cartoonTransform()中添加以下代码:
~~~
// 怪物模式
cv::Mat gray ,maskMonster;
cv::cvtColor(Frame, gray, CV_BGR2GRAY);
// 先对输入帧进行中值滤波
cv::medianBlur(gray, gray, 7);
// Scharr滤波器
cv::Mat edge1, edge2;
cv::Scharr(gray, edge1, CV_8U, 1, 0);
cv::Scharr(gray, edge2, CV_8U, 1, 0, -1);
edge1 += edge2; // 合并x和y方向的边缘
cv::threshold(edge1, maskMonster, 12, 255, cv::THRESH_BINARY_INV);
cv::medianBlur(maskMonster, maskMonster, 3);
output = maskMonster; //输出
// 换肤模式
// 绘制脸部区域
cv::Mat faceFrame = cv::Mat::zeros(size, CV_8UC3);
cv::Scalar color = CV_RGB(128, 0, 128); // 颜色
int thickness = 4;
// 使之占整个图像高度的70%
int width = size.width;
int height = size.height;
int faceHeight = height/2 * 70/100;
int faceWidth = faceHeight * 72/100;
cv::ellipse(faceFrame, cv::Point(width/2, height/2), cv::Size(faceWidth, faceHeight),
0, 0, 360, color, thickness, CV_AA);
// imshow("test3", faceFrame);
// 绘制眼睛区域
int eyeHeight = faceHeight * 11/100;
int eyeWidth = faceWidth * 23/100;
int eyeY = faceHeight * 13/100;
int eyeX = faceWidth * 48/100;
cv::Size eyeSize = cv::Size(eyeWidth, eyeHeight);
int eyeAngle = 15; //角度
int eyeYShift = 11;
// 画右眼的上眼皮
cv::ellipse(faceFrame, cv::Point(width/2 - eyeX, height/2 - eyeY),
eyeSize, 0, 180+eyeAngle, 360-eyeAngle, color, thickness, CV_AA);
// 画右眼的下眼皮
cv::ellipse(faceFrame, cv::Point(width/2 - eyeX, height/2 - eyeY - eyeYShift),
eyeSize, 0, 0+eyeAngle, 180-eyeAngle, color, thickness, CV_AA);
// 画左眼的上眼皮
cv::ellipse(faceFrame, cv::Point(width/2 + eyeX, height/2 - eyeY),
eyeSize, 0, 180+eyeAngle, 360-eyeAngle, color, thickness, CV_AA);
// 画左眼的下眼皮
cv::ellipse(faceFrame, cv::Point(width/2 + eyeX, height/2 - eyeY - eyeYShift),
eyeSize, 0, 0+eyeAngle, 180-eyeAngle, color, thickness, CV_AA);
char *Message = "Put your face here";
cv::putText(faceFrame, Message, cv::Point(width * 13/100, height * 10/100),
cv::FONT_HERSHEY_COMPLEX,
1.0f,
color,
2,
CV_AA);
cv::addWeighted(dst, 1.0, faceFrame, 0.7, 0, dst, CV_8UC3);
//output = dst;
~~~
效果:

皮肤变色器的实现基于OpenCV的floodFill()函数,该函数类似于一些绘图软件中的**颜料桶(颜色填充)工具**。 由于规定屏幕中间椭圆区域就是皮肤像素,因此只需要对该区域的像素进行各种颜色的漫水填充即可。
这里处理的图像是彩色图,而对于RGB格式的图像,改变颜色的效果不会太好,因为改变颜色需要脸部图像的亮度变化,而皮肤颜色也不能变化太大。这里使用YCrCb颜色空间来进行处理。在YCrCb颜色空间中,可以直接获得亮度值,而且通常的皮肤颜色取值唯一。
~~~
// 皮肤变色器
cv::Mat YUVImage = cv::Mat(reduceSize, CV_8UC3);
cv::cvtColor(reduceImage, YUVImage, CV_BGR2YCrCb);
int sw = reduceSize.width;
int sh = reduceSize.height;
cv::Mat mask, maskPlusBorder;
maskPlusBorder = cv::Mat::zeros(sh+2, sw+2, CV_8UC1);
mask = maskPlusBorder(cv::Rect(1, 1, sw, sh));
cv::resize(edge, mask, reduceSize);
const int EDGES_THRESHOLD = 80;
cv::threshold(mask, mask, EDGES_THRESHOLD, 255, cv::THRESH_BINARY);
cv::dilate(mask, mask, cv::Mat());
cv::erode(mask, mask, cv::Mat());
// output = mask;
// 创建6个点进行漫水填充算法
cv::Point skinPoint[6];
skinPoint[0] = cv::Point(sw/2, sh/2 - sh/6);
skinPoint[1] = cv::Point(sw/2 - sw/11, sh/2 - sh/6);
skinPoint[2] = cv::Point(sw/2 + sw/11, sh/2 - sh/6);
skinPoint[3] = cv::Point(sw/2, sh/2 + sh/6);
skinPoint[4] = cv::Point(sw/2 - sw/9, sh/2 + sh/6);
skinPoint[5] = cv::Point(sw/2 + sw/9, sh/2 + sh/6);
// 设定漫水填充算法的上下限
const int MIN_Y = 60;
const int MAX_Y = 80;
const int MIN_Cr = 25;
const int MAX_Cr = 15;
const int MIN_Cb = 20;
const int MAX_Cb = 15;
cv::Scalar Min = cv::Scalar(MIN_Y, MIN_Cr, MIN_Cb);
cv::Scalar Max = cv::Scalar(MAX_Y, MAX_Cr, MAX_Cb);
// 调用漫水填充算法
const int CONNECTED_COMPONENTS = 4;
const int flag = CONNECTED_COMPONENTS | cv::FLOODFILL_FIXED_RANGE \
| cv::FLOODFILL_MASK_ONLY;
cv::Mat edgeMask = mask.clone();
//
for(int i = 0; i < 6; i++)
{
cv::floodFill(YUVImage, maskPlusBorder, skinPoint[i], cv::Scalar(), NULL,
Min, Max, flag);
}
cv::Mat BGRImage;
cv::cvtColor(YUVImage, BGRImage, CV_YCrCb2BGR);
mask -= edgeMask;
int Red = 0;
int Green = 70;
int Blue = 0;
cv::Scalar color2 = CV_RGB(Red, Green, Blue); // 颜色
cv::add(BGRImage, color2, BGRImage, mask);
cv::Mat tt;
cv::resize(BGRImage, tt, size);
cv::add(dst, tt ,dst);
output = dst; // 换肤结果
~~~
由于在脸部区域中要对许多像素使用漫水填充算法,因此为了保证人脸图像的各种颜色和阴影都能得到处理,这里设置了前额、鼻子和脸颊6个点,他们的定位依赖于先前规定的脸部轮廓坐标。输出效果如下:
脸部不在识别区域内时:
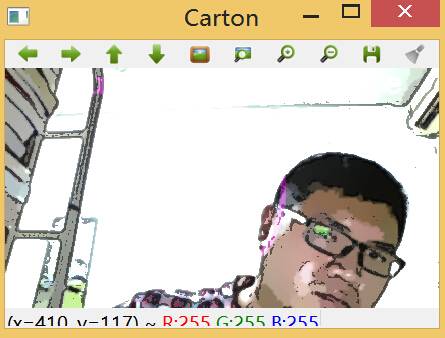
脸部进入识别区域内时:
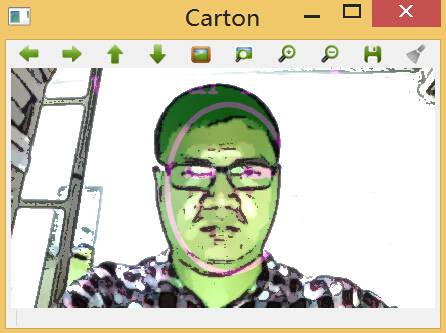
以上实现了几种图片卡通化效果,接着在学有余力时要对各种算法的效果进行优化,同时加入GUI界面,并将应用移植到移动设备上。
参考资料:《深入理解OpenCV:实用计算机视觉项目解析》
完整代码:
cartoon.h:
~~~
#ifndef CARTOON_H
#define CARTOON_H
#include <opencv2/core/core.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/highgui/highgui.hpp>
class cartoon
{
public:
void cartoonTransform(cv::Mat &Frame, cv::Mat &output);
};
#endif // CARTOON_H
~~~
cartoon.cpp:
~~~
#include "cartoon.h"
void cartoon::cartoonTransform(cv::Mat &Frame, cv::Mat &output)
{
cv::Mat grayImage;
cv::cvtColor(Frame, grayImage, CV_BGR2GRAY);
// 设置中值滤波器参数
cv::medianBlur(grayImage, grayImage, 7);
// Laplacian边缘检测
cv::Mat edge; // 用于存放边缘检测输出结果
cv::Laplacian(grayImage, edge, CV_8U, 5);
// 对边缘检测结果进行二值化
cv::Mat Binaryzation; // 用于存放二值化输出结果
cv::threshold(edge, Binaryzation, 80, 255, cv::THRESH_BINARY_INV);
// 以下操作生成彩色图像和卡通效果
// 采用双边滤波器
// 由于算法复杂,因此需减少图像尺寸
cv::Size size = Frame.size();
cv::Size reduceSize;
reduceSize.width = size.width / 2;
reduceSize.height = size.height / 2;
cv::Mat reduceImage = cv::Mat(reduceSize, CV_8UC3);
cv::resize(Frame, reduceImage, reduceSize);
// 双边滤波器实现过程
cv::Mat tmp = cv::Mat(reduceSize, CV_8UC3);
int repetitions = 7;
for (int i=0 ; i < repetitions; i++)
{
int kernelSize = 9;
double sigmaColor = 9;
double sigmaSpace = 7;
cv::bilateralFilter(reduceImage, tmp, kernelSize, sigmaColor, sigmaSpace);
cv::bilateralFilter(tmp, reduceImage, kernelSize, sigmaColor, sigmaSpace);
}
// 由于图像是缩小后的图像,需要恢复
cv::Mat magnifyImage;
cv::resize(reduceImage, magnifyImage, size);
cv::Mat dst;
dst.setTo(0);
magnifyImage.copyTo(dst, Binaryzation);
//output = dst; //输出
// 怪物模式
cv::Mat gray ,maskMonster;
cv::cvtColor(Frame, gray, CV_BGR2GRAY);
// 先对输入帧进行中值滤波
cv::medianBlur(gray, gray, 7);
// Scharr滤波器
cv::Mat edge1, edge2;
cv::Scharr(gray, edge1, CV_8U, 1, 0);
cv::Scharr(gray, edge2, CV_8U, 1, 0, -1);
edge1 += edge2; // 合并x和y方向的边缘
cv::threshold(edge1, maskMonster, 12, 255, cv::THRESH_BINARY_INV);
cv::medianBlur(maskMonster, maskMonster, 3);
output = maskMonster; //输出
// 换肤模式
// 绘制脸部区域
cv::Mat faceFrame = cv::Mat::zeros(size, CV_8UC3);
cv::Scalar color = CV_RGB(128, 0, 128); // 颜色
int thickness = 4;
// 使之占整个图像高度的70%
int width = size.width;
int height = size.height;
int faceHeight = height/2 * 70/100;
int faceWidth = faceHeight * 72/100;
cv::ellipse(faceFrame, cv::Point(width/2, height/2), cv::Size(faceWidth, faceHeight),
0, 0, 360, color, thickness, CV_AA);
// imshow("test3", faceFrame);
// 绘制眼睛区域
int eyeHeight = faceHeight * 11/100;
int eyeWidth = faceWidth * 23/100;
int eyeY = faceHeight * 13/100;
int eyeX = faceWidth * 48/100;
cv::Size eyeSize = cv::Size(eyeWidth, eyeHeight);
int eyeAngle = 15; //角度
int eyeYShift = 11;
// 画右眼的上眼皮
cv::ellipse(faceFrame, cv::Point(width/2 - eyeX, height/2 - eyeY),
eyeSize, 0, 180+eyeAngle, 360-eyeAngle, color, thickness, CV_AA);
// 画右眼的下眼皮
cv::ellipse(faceFrame, cv::Point(width/2 - eyeX, height/2 - eyeY - eyeYShift),
eyeSize, 0, 0+eyeAngle, 180-eyeAngle, color, thickness, CV_AA);
// 画左眼的上眼皮
cv::ellipse(faceFrame, cv::Point(width/2 + eyeX, height/2 - eyeY),
eyeSize, 0, 180+eyeAngle, 360-eyeAngle, color, thickness, CV_AA);
// 画左眼的下眼皮
cv::ellipse(faceFrame, cv::Point(width/2 + eyeX, height/2 - eyeY - eyeYShift),
eyeSize, 0, 0+eyeAngle, 180-eyeAngle, color, thickness, CV_AA);
char *Message = "Put your face here";
cv::putText(faceFrame, Message, cv::Point(width * 13/100, height * 10/100),
cv::FONT_HERSHEY_COMPLEX,
1.0f,
color,
2,
CV_AA);
cv::addWeighted(dst, 1.0, faceFrame, 0.7, 0, dst, CV_8UC3);
//output = dst;
// 皮肤变色器
cv::Mat YUVImage = cv::Mat(reduceSize, CV_8UC3);
cv::cvtColor(reduceImage, YUVImage, CV_BGR2YCrCb);
int sw = reduceSize.width;
int sh = reduceSize.height;
cv::Mat mask, maskPlusBorder;
maskPlusBorder = cv::Mat::zeros(sh+2, sw+2, CV_8UC1);
mask = maskPlusBorder(cv::Rect(1, 1, sw, sh));
cv::resize(edge, mask, reduceSize);
const int EDGES_THRESHOLD = 80;
cv::threshold(mask, mask, EDGES_THRESHOLD, 255, cv::THRESH_BINARY);
cv::dilate(mask, mask, cv::Mat());
cv::erode(mask, mask, cv::Mat());
// output = mask;
// 创建6个点进行漫水填充算法
cv::Point skinPoint[6];
skinPoint[0] = cv::Point(sw/2, sh/2 - sh/6);
skinPoint[1] = cv::Point(sw/2 - sw/11, sh/2 - sh/6);
skinPoint[2] = cv::Point(sw/2 + sw/11, sh/2 - sh/6);
skinPoint[3] = cv::Point(sw/2, sh/2 + sh/6);
skinPoint[4] = cv::Point(sw/2 - sw/9, sh/2 + sh/6);
skinPoint[5] = cv::Point(sw/2 + sw/9, sh/2 + sh/6);
// 设定漫水填充算法的上下限
const int MIN_Y = 60;
const int MAX_Y = 80;
const int MIN_Cr = 25;
const int MAX_Cr = 15;
const int MIN_Cb = 20;
const int MAX_Cb = 15;
cv::Scalar Min = cv::Scalar(MIN_Y, MIN_Cr, MIN_Cb);
cv::Scalar Max = cv::Scalar(MAX_Y, MAX_Cr, MAX_Cb);
// 调用漫水填充算法
const int CONNECTED_COMPONENTS = 4;
const int flag = CONNECTED_COMPONENTS | cv::FLOODFILL_FIXED_RANGE \
| cv::FLOODFILL_MASK_ONLY;
cv::Mat edgeMask = mask.clone();
//
for(int i = 0; i < 6; i++)
{
cv::floodFill(YUVImage, maskPlusBorder, skinPoint[i], cv::Scalar(), NULL,
Min, Max, flag);
}
cv::Mat BGRImage;
cv::cvtColor(YUVImage, BGRImage, CV_YCrCb2BGR);
mask -= edgeMask;
int Red = 0;
int Green = 70;
int Blue = 0;
cv::Scalar color2 = CV_RGB(Red, Green, Blue); // 颜色
cv::add(BGRImage, color2, BGRImage, mask);
cv::Mat tt;
cv::resize(BGRImage, tt, size);
cv::add(dst, tt ,dst);
output = dst; // 换肤结果
}
~~~
main函数:
~~~
#include "cartoon.h"
#include <QApplication>
#include <QDebug>
#include <opencv2/video/video.hpp>
int main(int argc, char *argv[])
{
QApplication a(argc, argv);
cartoon photo;
int cameraNumber = 0;
if(argc > 1)
cameraNumber = atoi(argv[1]);
// 开启摄像头
cv::VideoCapture camera;
camera.open(cameraNumber);
if(!camera.isOpened())
{
qDebug() << "Error: Could not open the camera.";
exit(1);
}
// 调整摄像头的分辨率
camera.set(CV_CAP_PROP_FRAME_WIDTH, 640);
camera.set(CV_CAP_PROP_FRAME_HEIGHT, 480);
while (1)
{
cv::Mat Frame;
camera >> Frame;
if(!Frame.data)
{
qDebug() << "Couldn't capture camera frame.";
exit(1);
}
// 创建一个用于存放输出图像的数据结构
cv::Mat output(Frame.size(), CV_8UC3);
photo.cartoonTransform(Frame, output);
// 使用图像处理技术将获取的帧经过处理后输入到output中
cv::imshow("Original", Frame);
cv::imshow("Carton", output);
char keypress = cv::waitKey(20);
if(keypress == 27)
{
break;
}
}
return a.exec();
}
~~~
OpenCV2学习笔记(十三)
最后更新于:2022-04-01 06:36:15
##基于SURF特征的图像匹配
SURF算法是著名的尺度不变特征检测器SIFT(Scale-Invariant Features Transform)的高效变种,它为每个检测到的特征定义了位置和尺度,其中尺度的值可用于定义围绕特征点的窗口大小,使得每个特征点都与众不同。这里便是使用SURF算法提取两幅图像中的特征点描述子,并调用OpenCV中的函数进行匹配,最后输出一个可视化的结果,开发平台为Qt5.3.2+OpenCV2.4.9。以下给出图像匹配的实现步骤:
一、输入两幅图像,使用OpenCV中的cv::FeatureDetector接口实现SURF特征检测,在实际调试中改变阈值可获得不一样的检测结果:
~~~
// 设置两个用于存放特征点的向量
std::vector<cv::KeyPoint> keypoint1;
std::vector<cv::KeyPoint> keypoint2;
// 构造SURF特征检测器
cv::SurfFeatureDetector surf(3000); // 阈值
// 对两幅图分别检测SURF特征
surf.detect(image1,keypoint1);
surf.detect(image2,keypoint2);
~~~
二、OpenCV 2.0版本中引入一个通用类,用于提取不同的特征点描述子。在这里构造一个SURF描述子提取器,输出的结果是一个矩阵,它的行数与特征点向量中的元素个数相同。每行都是一个N维描述子的向量。**在SURF算法中,默认的描述子维度为64,该向量描绘了特征点周围的强度样式。**两个特征点越相似,它们的特征向量也就越接近,因此这些描述子在图像匹配中十分有用:
~~~
cv::SurfDescriptorExtractor surfDesc;
// 对两幅图像提取SURF描述子
cv::Mat descriptor1, descriptor2;
surfDesc.compute(image1,keypoint1,descriptor1);
surfDesc.compute(image2,keypoint2,descriptor2);
~~~
提取出两幅图像各自的特征点描述子后,需要进行比较(匹配)。可以调用OpenCV中的类cv::BruteForceMatcher构造一个匹配器。cv::BruteForceMatcher是类cv::DescriptorMatcher的一个子类,定义了不同的匹配策略的共同接口,结果返回一个cv::DMatch向量,它将被用于表示一对匹配的描述子。(关于cv::BruteForceMatcher 请参考:[http://blog.csdn.net/panda1234lee/article/details/11094483?utm_source=tuicool](http://blog.csdn.net/panda1234lee/article/details/11094483?utm_source=tuicool))
三、在一批特征点匹配结果中筛选出评分(或者称距离)最理想的25个匹配结果,这通过std::nth_element实现。
~~~
void nth_element(_RandomAccessIterator _first, _RandomAccessIterator _nth, _RandomAccessIterator _last)
~~~
该函数的作用为将迭代器指向的从_first 到 _last 之间的元素进行二分排序,以_nth 为分界,前面都比 _Nth 小(大),后面都比之大(小),因此适用于找出前n个最大(最小)的元素。
四、最后一步,将匹配的结果可视化。OpenCV提供一个绘制函数以产生由两幅输入图像拼接而成的图像,而匹配的点由直线相连:
~~~
// 以下操作将匹配结果可视化
cv::Mat imageMatches;
cv::drawMatches(image1,keypoint1, // 第一张图片和检测到的特征点
image2,keypoint2, // 第二张图片和检测到的特征点
matches, // 输出的匹配结果
imageMatches, // 生成的图像
cv::Scalar(128,128,128)); // 画直线的颜色
~~~
**要注意SIFT、SURF的函数在OpenCV的nonfree模块中而不是features2d,cv::BruteForceMatcher类存放在legacy模块中**,因此函数中需要包含头文件:
~~~
#include <opencv2/legacy/legacy.hpp>
#include <opencv2/nonfree/nonfree.hpp>
~~~
完整代码如下:
~~~
#include <QCoreApplication>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/legacy/legacy.hpp>
#include <opencv2/nonfree/nonfree.hpp>
#include <QDebug>
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
// 以下两图比之
// 输入两张要匹配的图
cv::Mat image1= cv::imread("c:/Fig12.18(a1).jpg",0);
cv::Mat image2= cv::imread("c:/Fig12.18(a2).jpg",0);
if (!image1.data || !image2.data)
qDebug() << "Error!";
cv::namedWindow("Right Image");
cv::imshow("Right Image", image1);
cv::namedWindow("Left Image");
cv::imshow("Left Image", image2);
// 存放特征点的向量
std::vector<cv::KeyPoint> keypoint1;
std::vector<cv::KeyPoint> keypoint2;
// 构造SURF特征检测器
cv::SurfFeatureDetector surf(3000); // 阈值
// 对两幅图分别检测SURF特征
surf.detect(image1,keypoint1);
surf.detect(image2,keypoint2);
// 输出带有详细特征点信息的两幅图像
cv::Mat imageSURF;
cv::drawKeypoints(image1,keypoint1,
imageSURF,
cv::Scalar(255,255,255),
cv::DrawMatchesFlags::DRAW_RICH_KEYPOINTS);
cv::namedWindow("Right SURF Features");
cv::imshow("Right SURF Features", imageSURF);
cv::drawKeypoints(image2,keypoint2,
imageSURF,
cv::Scalar(255,255,255),
cv::DrawMatchesFlags::DRAW_RICH_KEYPOINTS);
cv::namedWindow("Left SURF Features");
cv::imshow("Left SURF Features", imageSURF);
// 构造SURF描述子提取器
cv::SurfDescriptorExtractor surfDesc;
// 对两幅图像提取SURF描述子
cv::Mat descriptor1, descriptor2;
surfDesc.compute(image1,keypoint1,descriptor1);
surfDesc.compute(image2,keypoint2,descriptor2);
// 构造匹配器
cv::BruteForceMatcher< cv::L2<float> > matcher;
// 将两张图片的描述子进行匹配,只选择25个最佳匹配
std::vector<cv::DMatch> matches;
matcher.match(descriptor1, descriptor2, matches);
std::nth_element(matches.begin(), // 初始位置
matches.begin()+24, // 排序元素的位置
matches.end()); // 终止位置
// 移除25位后的所有元素
matches.erase(matches.begin()+25, matches.end());
// 以下操作将匹配结果可视化
cv::Mat imageMatches;
cv::drawMatches(image1,keypoint1, // 第一张图片和检测到的特征点
image2,keypoint2, // 第二张图片和检测到的特征点
matches, // 输出的匹配结果
imageMatches, // 生成的图像
cv::Scalar(128,128,128)); // 画直线的颜色
cv::namedWindow("Matches"); //, CV_WINDOW_NORMAL);
cv::imshow("Matches",imageMatches);
return a.exec();
}
~~~
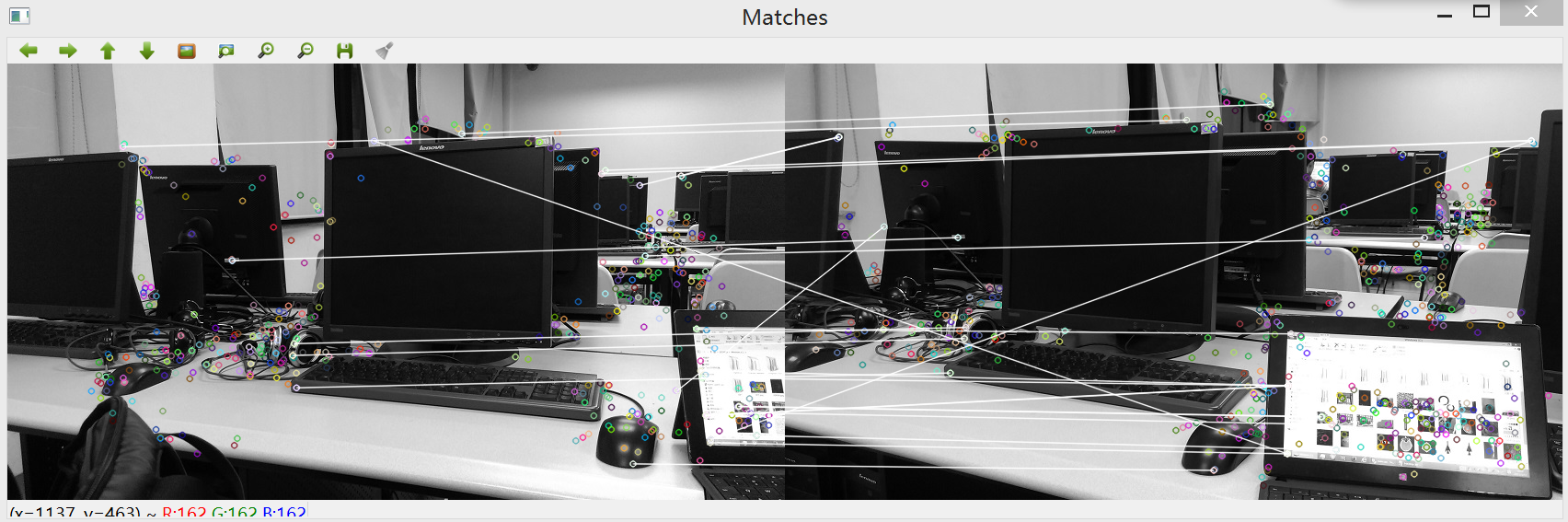
效果一,由于原图中飞机的边缘有锯齿状,因此只需观察拐角处,匹配效果良好:
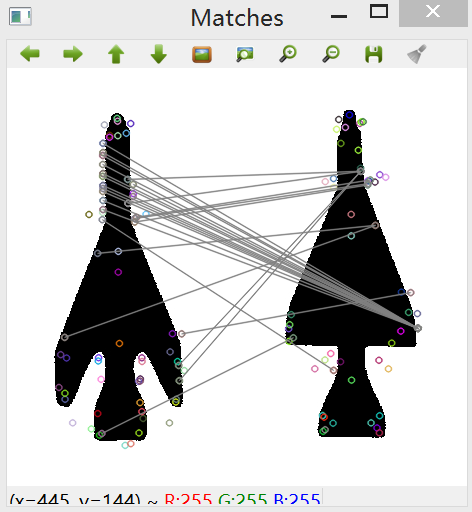
效果二,不涉及图像的旋转和变形,只是将一幅图像进行缩放后进行匹配,得出的效果自然是很好:

效果三,用两个不同的角度拍摄的图像进行匹配,其中部分特征点匹配有偏差,总体效果良好,在调试过程中还可以通过参数调整获取更好的匹配效果。
**附注**:另一种匹配方法是使用 cv::FlannBasedMatcher 接口以及函数 FLANN 实现快速高效匹配(快速最近邻逼近搜索函数库(Fast Approximate Nearest Neighbor Search Library))。网上有源代码例程如下:
~~~
#include <stdio.h>
#include <iostream>
#include "opencv2/core/core.hpp"
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/legacy/legacy.hpp>
#include "opencv2/features2d/features2d.hpp"
#include "opencv2/highgui/highgui.hpp"
using namespace cv;
void readme();
/** @function main */
int main( int argc, char** argv )
{
if( argc != 3 )
{ readme(); return -1; }
Mat img_1 = imread( argv[1], CV_LOAD_IMAGE_GRAYSCALE );
Mat img_2 = imread( argv[2], CV_LOAD_IMAGE_GRAYSCALE );
if( !img_1.data || !img_2.data )
{ std::cout<< " --(!) Error reading images " << std::endl; return -1; }
//-- Step 1: Detect the keypoints using SURF Detector
int minHessian = 400;
SurfFeatureDetector detector( minHessian );
std::vector<KeyPoint> keypoints_1, keypoints_2;
detector.detect( img_1, keypoints_1 );
detector.detect( img_2, keypoints_2 );
//-- Step 2: Calculate descriptors (feature vectors)
SurfDescriptorExtractor extractor;
Mat descriptors_1, descriptors_2;
extractor.compute( img_1, keypoints_1, descriptors_1 );
extractor.compute( img_2, keypoints_2, descriptors_2 );
//-- Step 3: Matching descriptor vectors using FLANN matcher
FlannBasedMatcher matcher;
std::vector< DMatch > matches;
matcher.match( descriptors_1, descriptors_2, matches );
double max_dist = 0; double min_dist = 100;
//-- Quick calculation of max and min distances between keypoints
for( int i = 0; i < descriptors_1.rows; i++ )
{ double dist = matches[i].distance;
if( dist < min_dist ) min_dist = dist;
if( dist > max_dist ) max_dist = dist;
}
printf("-- Max dist : %f \n", max_dist );
printf("-- Min dist : %f \n", min_dist );
//-- Draw only "good" matches (i.e. whose distance is less than 2*min_dist )
//-- PS.- radiusMatch can also be used here.
std::vector< DMatch > good_matches;
for( int i = 0; i < descriptors_1.rows; i++ )
{ if( matches[i].distance < 2*min_dist )
{ good_matches.push_back( matches[i]); }
}
//-- Draw only "good" matches
Mat img_matches;
drawMatches( img_1, keypoints_1, img_2, keypoints_2,
good_matches, img_matches, Scalar::all(-1), Scalar::all(-1),
vector<char>(), DrawMatchesFlags::NOT_DRAW_SINGLE_POINTS );
//-- Show detected matches
imshow( "Good Matches", img_matches );
for( int i = 0; i < good_matches.size(); i++ )
{ printf( "-- Good Match [%d] Keypoint 1: %d -- Keypoint 2: %d \n", i, good_matches[i].queryIdx, good_matches[i].trainIdx ); }
waitKey(0);
return 0;
}
/** @function readme */
void readme()
{ std::cout << " Usage: ./SURF_FlannMatcher <img1> <img2>" << std::endl; }
~~~
以上只是记录这种方法的实现例程,并没有验证代码的正确性。
参考资料:
[http://blog.sina.com.cn/s/blog_a98e39a201017pgn.html](http://blog.sina.com.cn/s/blog_a98e39a201017pgn.html)
[http://www.cnblogs.com/tornadomeet/archive/2012/08/17/2644903.html](http://www.cnblogs.com/tornadomeet/archive/2012/08/17/2644903.html) (SURF算法的理论介绍)
[http://blog.csdn.net/liyuefeilong/article/details/44166069](http://blog.csdn.net/liyuefeilong/article/details/44166069)
[http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/tutorials/features2d/feature_flann_matcher/feature_flann_matcher.html](http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/tutorials/features2d/feature_flann_matcher/feature_flann_matcher.html)
OpenCV2学习笔记(十二)
最后更新于:2022-04-01 06:36:12
##特征提取算法SIFT与SURF
当尝试在不同图像之间进行特征匹配时,通常会遇到图像的大小、方向等参数发生改变的问题,简而言之,就是尺度变化的问题。每幅图像在拍摄时与目标物体的距离是不同的,因此要识别的目标物体在图像中自然会存在不同的尺寸。
因此,计算机视觉中引入尺度不变的特征,主要的思想是每个检测到的特征点都伴随对应的尺度因子。1999年David Lowe提出了著名的尺度不变特征检测器SIFT(Scale Invariant Feature Transform)算法,它具有尺度,旋转,仿射,视角,光照不变性。而加速鲁棒特性特征SURF(Speeded Up Robust Features)算法是SIFT的高效变种。这两个算法申请了专利保护,其专利的拥有者为英属哥伦比亚大学。
关于SIFT和SURF的特征介绍,已经有很多的blog对其进行简介了,见参考的blog。由于还没有将2004年那篇原文精细看完,因此这里只能粗浅地分析两种算法,并描述在OpenCV中如何实现这两种算法的特征检测。
**一、基本概念**
1.1 算法背景
尺度不变特征转换SIFT是一种著名的计算机视觉的算法,主要用来检测图像中的局部特征,通过在图像中寻找极值点特征,并提取出其这些特征点的位置、尺度和旋转不变量等信息。
其应用范围包含物体辨识、机器人地图感知与导航、影像缝合、3D模型建立、手势辨识、影像追踪和动作比对。
局部影像特征的描述与侦测可以帮助辨识物体,SIFT 特征是基于物体上的一些局部外观的兴趣点而与影像的大小和旋转无关。对于光线、噪声、些微视角改变的容忍度也相当高。基于这些特性,它们是高度显著而且相对容易撷取,在母数庞大的特征数据库中,很容易辨识物体而且鲜有误认。使用 SIFT特征描述对于部分物体遮蔽的侦测率也相当高,甚至只需要3个以上的SIFT物体特征就足以计算出位置与方位。在现今的电脑硬件速度下和小型的特征数据库条件下,辨识速度可接近即时运算。SIFT特征的信息量大,适合在海量数据库中快速准确匹配。(来自百度百科的解释)
1.2 SIFT算法的主要优点
1\. SIFT特征是图像的局部特征,其对旋转、尺度缩放、亮度变化保持不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性;
2\. 独特性(Distinctiveness)好,信息量丰富,适用于在海量特征数据库中进行快速、准确的匹配;
3\. 多量性,即使少数的几个物体也可以产生大量的SIFT特征向量;
4\. 高速性,经优化的SIFT匹配算法甚至可以达到实时的要求;
5\. 可扩展性,可以很方便的与其他形式的特征向量进行联合。
1.3 SIFT算法的适用环境
目标的自身状态、场景所处的环境和成像器材的成像特性等因素影响图像配准/目标识别跟踪的性能。而SIFT算法在一定程度上可解决:
1\. 目标的旋转、缩放、平移(RST)
2\. 图像仿射/投影变换(视点viewpoint)
3\. 光照影响(illumination)
4\. 目标遮挡(occlusion)
5\. 杂物场景(clutter)
6\. 噪声
SIFT算法的实质是在不同的尺度空间上查找关键点(特征点),并计算出关键点的方向。SIFT所查找到的关键点是一些十分突出,不会因光照,仿射变换和噪音等因素而变化的点,如角点、边缘点、暗区的亮点及亮区的暗点等。
1.4 算法的基本步骤
Lowe将SIFT算法分解为如下四步:
1\. 尺度空间极值检测:搜索所有尺度上的图像位置。通过高斯微分函数来识别潜在的对于尺度和旋转不变的兴趣点。
2\. 关键点定位:在每个候选的位置上,通过一个拟合精细的模型来确定位置和尺度。关键点的选择依据于它们的稳定程度。
3\. 方向确定:基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向。所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性。
4\. 特征点描述:在每个关键点周围的邻域内,在选定的尺度上测量图像局部的梯度。这些梯度被变换成一种表示,这种表示允许比较大的局部形状的变形和光照变化。
1.5 SIFT算法的缺点
SIFT算法十分强大,精度很高,Mikolajczyk和Schmid曾经针对不同的场景,对光照变化、图像几何变形、分辨率差异、旋转、模糊和图像压缩等6种情况,就多种最具代表性的描述子(如SIFT,矩不变量,互相关等10种描述子)进行了实验和性能比较,结果表明,在以上各种情况下,SIFT描述子的性能最好。但算法的高深同样带来了一些缺点,如:
1\. 实时性不高。
2\. 有时特征点较少。
3\. 对边缘光滑或经过平滑的图像无法准确提取特征点。
针对这些问题,一些改进算法应运而生,SURF就是广为人知的其中一种算法。
2.1 SURF算法介绍
SURF算法是SIFT算法的高效变种,在满足一定效果的情况下完成两幅图像中物体的匹配,并基本实现了实时处理。SURF也检测空间域和尺度域上的局部极大值作为特征,但是使用的是Hessian行列式响应而不是Laplacian行列式。
SURF的实现如下,首先对每个像素计算Hessian矩阵以得到特征,该矩阵测量一个函数的局部曲率,定义如下:
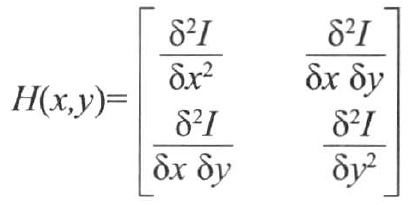
该矩阵的行列式给出曲率的强度,定义角点为具有较高局部曲率的像素点(即在多个方向都具有高曲率)。由于该函数是由二阶导数组成,因此可以使用不同的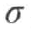 尺度的Laplacian Gaussian核进行计算,因此Hessian变成了三个变量的函数。当Hessian的值同时在空间域和尺度域上均达到局部极大值时(需要运行3*3*3的非极大值抑制),可以认为找到了尺度不变的特征。
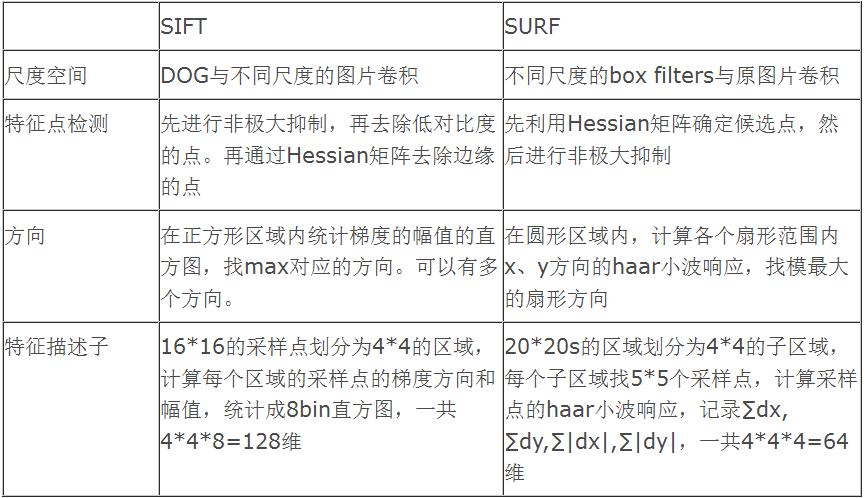
所有这些不同尺度的运算都很耗时,而SURF算法的目的是尽可能高效。因此会使用近似的高斯核,仅涉及少量整数加法,结构如下图所示:

左侧的核用于估计混合二阶导数,右侧的核则用于估算垂直方向的二阶导数,而其旋转版本则用于估计水平方向的二阶导数。
一旦识别了局部极大值,每个特征点的精确位置可以通过空间域及尺度域上进行插值获取,结果是一组具有亚像素精确度的特征点,以及一个对应的尺度值。
2.2 性能比较
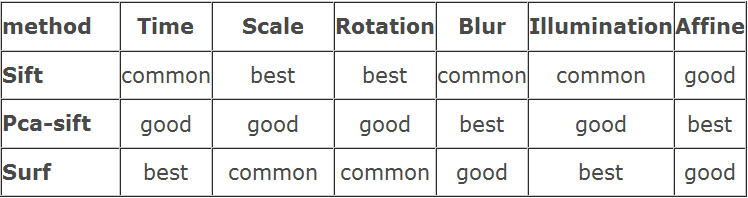
无需赘述,A comparison of SIFT, PCA-SIFT and SURF 一文给出了SIFT和SURF的性能比较,对原图像进行尺度、旋转、模糊、亮度变化、仿射变换等变化后,再与原图像进行匹配,统计匹配的效果,源图片来源于Graffiti dataset。
这里使用的开发平台是Qt5.3.2+OpenCV2.4.9。SURF、SIFT特征在OpenCV中的实现均使用了cv::FeatureDetector接口,OpenCV中的opencv_nonfree模块包含了SURF和SIFT的相关函数,因此在使用时注意添加相关的头文件。在这里,特征点的计算基于浮点核,因此这两种算法相比其他算法在空间和尺度检测上更加精确,但相对耗时。
至于理论部分有待进一步学习。
**二、实现SIFT特征检测算法**
直接在Qt中创建一个控制台项目,在main函数中添加:
~~~
#include <QCoreApplication>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <opencv2/nonfree/nonfree.hpp>
#include <QDebug>
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
// 读入图像
cv::Mat image= cv::imread("c:/018.jpg",0);
cv::namedWindow("Original Image");
cv::imshow("Original Image", image);
// 特征点的向量
std::vector<cv::KeyPoint>keypoints;
// 构造SIFT特征检测器
cv::SiftFeatureDetector sift(
0.03, // 特征的阈值
10.); // 用于降低
// 检测SIFT特征值
sift.detect(image,keypoints);
cv::drawKeypoints(image, // 原始图像
keypoints, // 特征点的向量
featureImage, // 生成图像
cv::Scalar(255,255,255), // 特征点的颜色
cv::DrawMatchesFlags::DRAW_RICH_KEYPOINTS); // 标志位
cv::namedWindow("SIFT Features");
cv::imshow("SIFT Features",featureImage);
return a.exec();
}
~~~
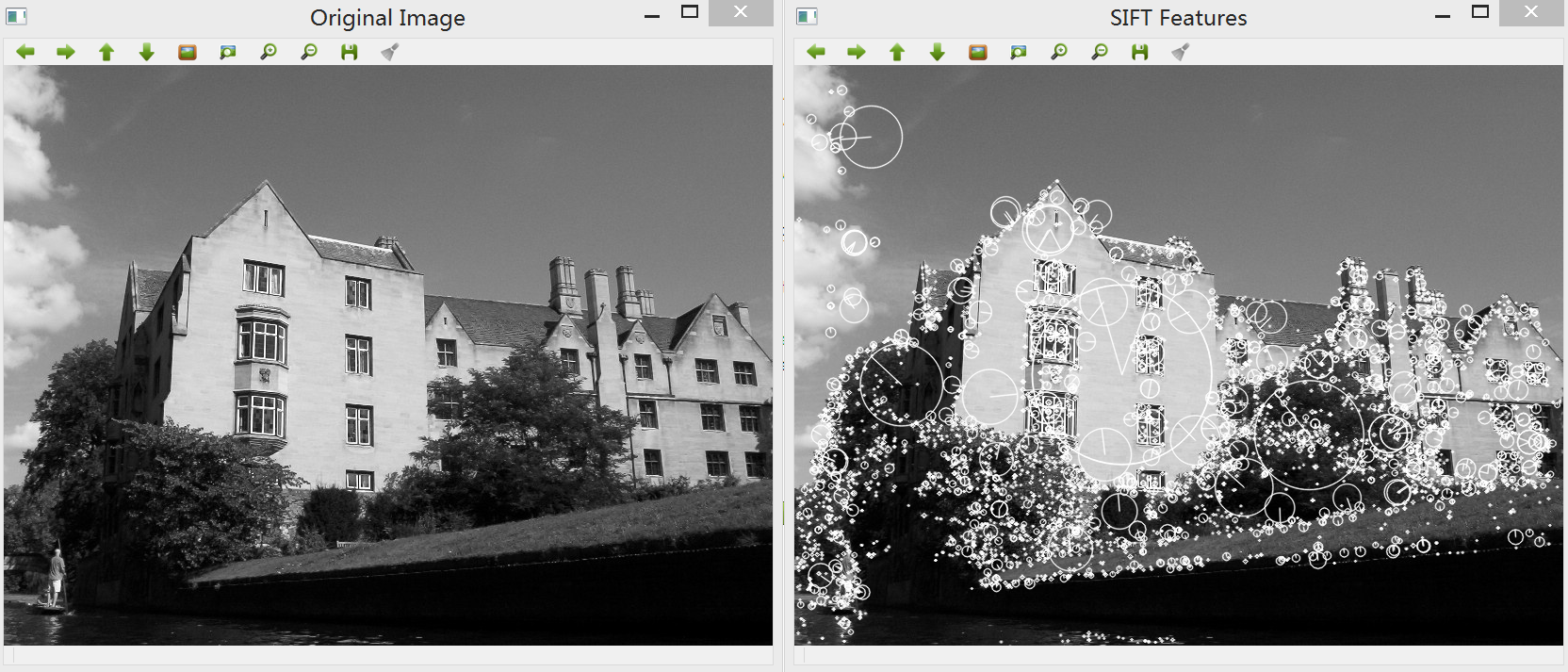
效果如下,在函数cv::drawKeypoints中我们使用cv::DrawMatchesFlags::DRAW_RICH_KEYPOINTS作为标志位,这样唉使用DRAW_RICH_KEYPOINTS之后每个关键点上圆圈的尺寸与特征的尺度成正比:
**三、实现SURF特征检测算法**
~~~
#include <QCoreApplication>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <opencv2/nonfree/nonfree.hpp>
#include <QDebug>
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
// 读入图像
cv::Mat image= cv::imread("c:/018.jpg",0);
cv::namedWindow("Original Image");
cv::imshow("Original Image", image);
// 特征点的向量
std::vector<cv::KeyPoint>keypoints;
// 构造SURF特征检测器
cv::SurfFeatureDetector surf(2500);
// 检测SURF特征
surf.detect(image,keypoints);
cv::Mat featureImage;
cv::drawKeypoints(image, // 原始图像
keypoints, // 特征点的向量
featureImage, // 生成图像
cv::Scalar(255,255,255), // 特征点的颜色
cv::DrawMatchesFlags::DRAW_RICH_KEYPOINTS); // 标志位
cv::namedWindow("SURF Features");
cv::imshow("SURF Features",featureImage);
return a.exec();
}
~~~
效果:
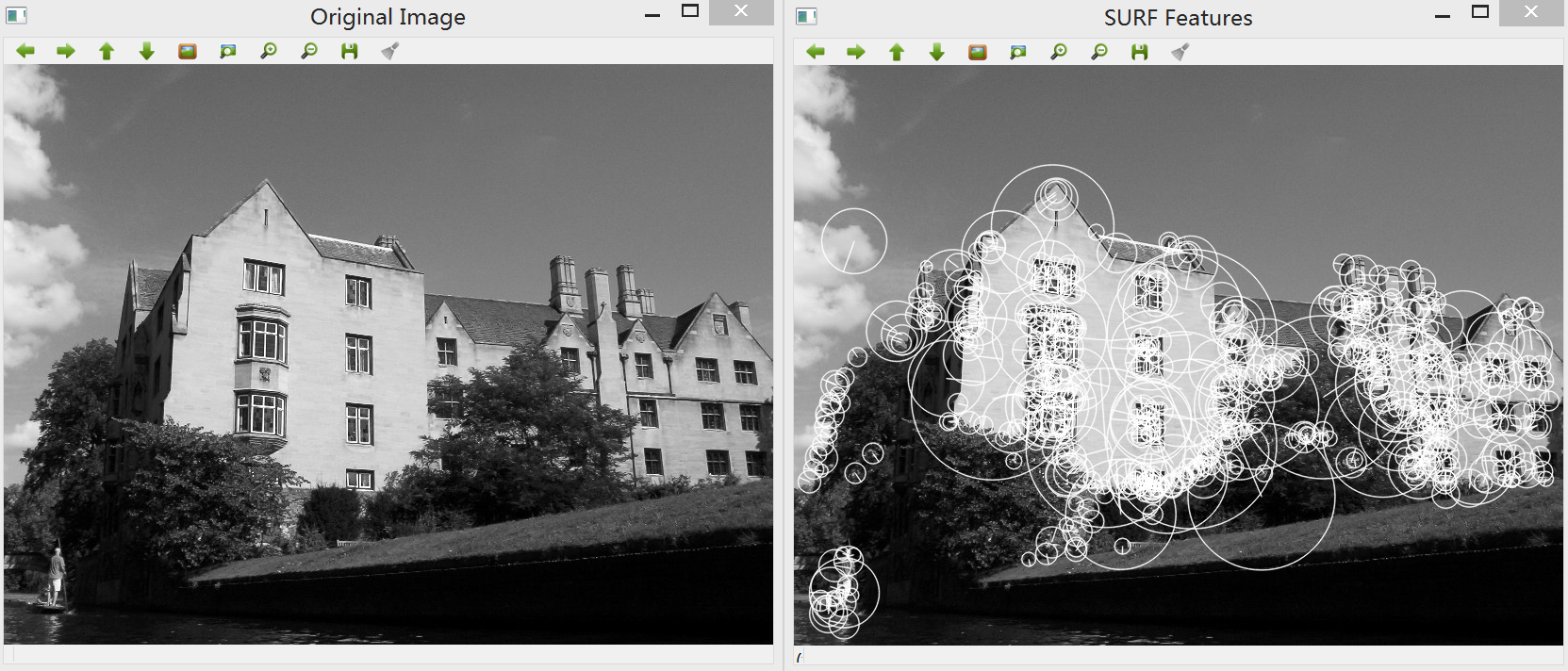
从两种算法的输出结果可以看出,SURF与SIFT描述子的区别主要是速度及精度。SURF描述子大部分基于强度的差值,计算更加快捷,而SIFT描述子通常在搜索正确的特征点时更加精确。
参考资料:
David G.Lowe Object Recognition from Local Scale-Invariant Features. 1999.
David G.Lowe Distinctive Image Features from Scale-Invariant Keypoints. January 5, 2004.
SIFT官网的Rob Hess [hess@eecs.oregonstate.edu](mailto:hess@eecs.oregonstate.edu) SIFT源码
参考博客:
[http://blog.csdn.net/zddblog/article/details/7521424](http://blog.csdn.net/zddblog/article/details/7521424) (个人认为是目前最详尽的SIFT介绍)
[http://underthehood.blog.51cto.com/2531780/658350](http://underthehood.blog.51cto.com/2531780/658350)
[http://blog.csdn.net/xiaowei_cqu/article/details/8069548](http://blog.csdn.net/xiaowei_cqu/article/details/8069548)
[http://www.cnblogs.com/tornadomeet/archive/2012/08/16/2643168.html](http://www.cnblogs.com/tornadomeet/archive/2012/08/16/2643168.html)
OpenCV2学习笔记(十一)
最后更新于:2022-04-01 06:36:10
##特征点检测之FAST算法
在上一节中,记录了Harris算子检测图像特征点的定义和基于OpenCV的实现方法,它基于两个正交方向上的强度变化率。本节记录另一种特征点检测算子FAST(Features from Accelerated Segment Test),它依赖少数像素的比较来确定是否接受一个特征点,其检测效率要好于Harris。
与Harris算法相同,FAST特征算法需要定义什么是特征点。这次的定义基于假定特征点周围的图像强度,通过检查候选像素的周围一圈像素来决定是否接受这一个特征点。与中心点差异较大的像素如果组成连续的圆弧,并且弧长大于圆周长的3/4,则可判断为特征点。
在此基础上,算法还使用了额外的技巧进行加速。首先测试一个圆圈上被90度分隔的四个点(如顶部、底部,左侧和右侧四个点),如果要满足FAST的定义条件,四个点中至少要有三个点必须同时大于或小于中心像素。如果条件不成立,则该点可以直接被移除而不需要进一步的验证。在实践中,大部分的像素点可以通过这个测试进行移除,因此该算法非常高效。
和Harris方法相同的是,可以在找到的角点上执行非极大值抑制,因此需要指定角点强度的测量方法。
这里可以使用OpenCV 2的通用接口来创建任意的特征检测器,比如FAST检测器的使用方法如下:
~~~
// 创建特征点的向量
std::vector<cv::KeyPoint>keypoints;
// 构造FAST特征检测器
cv::FastFeatureDetector fast(75);
// 进行检测
fast.detect(image, keypoints);
~~~
同时,为了方便标记特征点,OpenCV提供了通用的特征点绘制函数cv::drawKeypoints,其调用方法如下:
~~~
// 通用的特征点绘制函数
cv::drawKeypoints(image, // 输入图像
keypoints, // 特征点向量
image, // 输出图像
cv::Scalar(255,255,255), // 特征点颜色
cv::DrawMatchesFlags::DRAW_OVER_OUTIMG); // 绘制标记
~~~
通过指定选中的绘制标记,可以看到输出图像中特征点均得到了绘制:
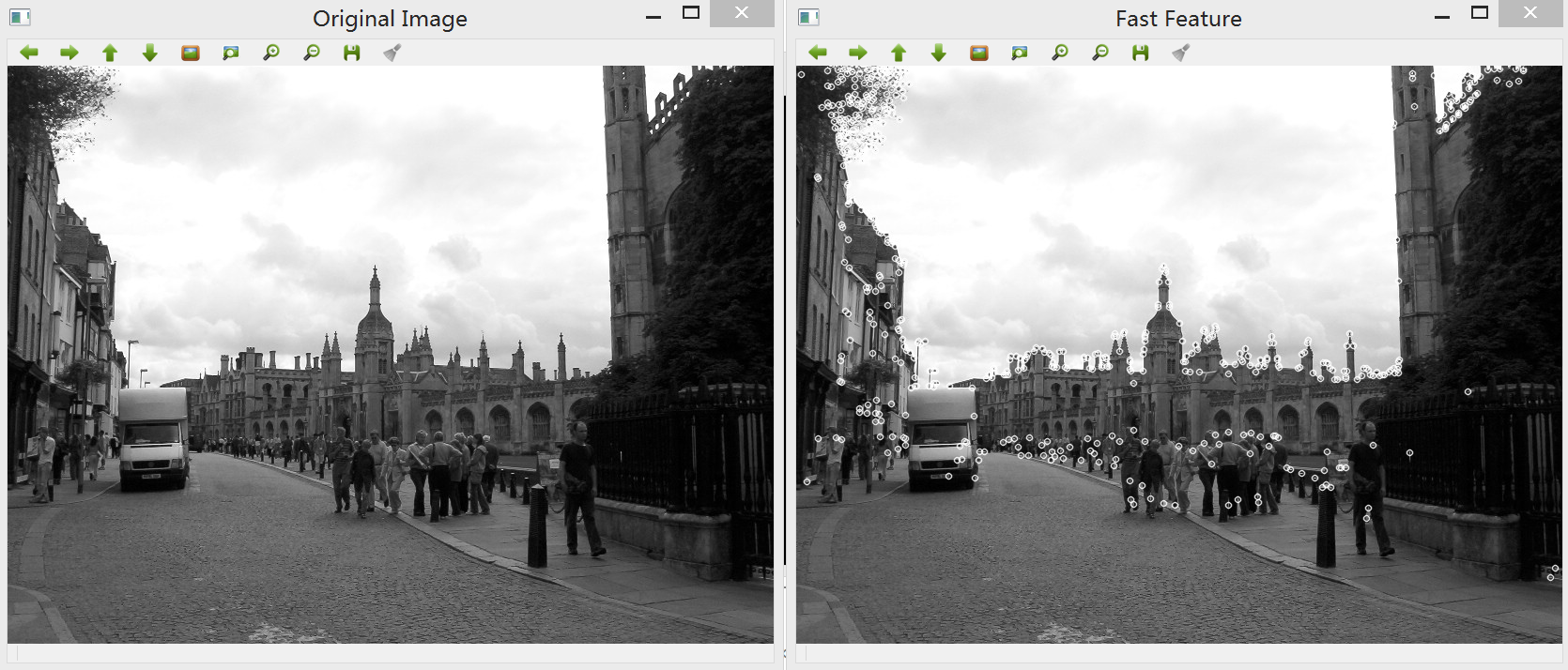
完整的实现代码如下,只需修改main函数:
~~~
#include <QCoreApplication>
#include <opencv2/core/core.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
// 输入图像
cv::Mat image = cv::imread("c:/031.jpg", 0);
cv::namedWindow("Original Image");
cv::imshow("Original Image", image);
// 特征点的向量
std::vector<cv::KeyPoint>keypoints;
// 构造FAST特征检测器
cv::FastFeatureDetector fast(75);
// 进行检测
fast.detect(image, keypoints);
// 通用的特征点绘制函数
cv::drawKeypoints(image, // 输入图像
keypoints, // 特征点向量
image, // 输出图像
cv::Scalar(255, 255, 255), // 特征点颜色
cv::DrawMatchesFlags::DRAW_OVER_OUTIMG); // 绘制标记
cv::namedWindow("Fast Feature");
cv::imshow("Fast Feature", image);
return a.exec();
}
~~~
FAST算法可以获得非常快速的特征点检测,在需要考虑运行速度的时候可以选用,比如在高帧率的视频序列中进行视觉跟踪。
关于FAST特征算法的详细描述,可参考以下论文:
The article by E.Rosten, T.Drummond, Machine Learning for High-speed Corner Detection, In European Conference on Computer Vision, pp.430-443, 2006
OpenCV2学习笔记(十)
最后更新于:2022-04-01 06:36:08
##特征点检测之Harris法
在计算机视觉中,特征点的概念被大量用于解决物体识别、图像匹配、视觉跟踪、三维重建等问题,比如图像中物体的角点,它们是在图像中可被轻易而精确地定位的二维特征。顾名思义,特征点检测的思想是无需观察整幅图像,而是通过选择某些特殊点,然后对它们执行局部分析。如果能检测到足够多的这种点,同时它们的区分度很高,并且可以精确定位稳定的特征,那么这个方法就很有效。这里主要使用Harris特征检测器检测图像角点。开发平台为Qt5.3.2+OpenCV2.4.9。
在此之前,先给出OpenCV中cv::cornerHarris函数的调用方式:
~~~
cv::cornerHarris(image, // 输入图像
cornerStrength, // 输出为表示角点强度的32位浮点图像
3, // 导数平滑的相邻像素的尺寸
3, // 梯度计算的滤波器孔径大小
0.01); // Harris参数
~~~
描述Harris算子的经典论文可参考:
The article by C.Harris, M.J. Stephens, A Combined Corner and Edge Detector, Alvey Vision Conference, pp.147-152, 1988
The article by J. Shi and C. Tomasi, Good features to track, Int. Conference on Computer Vision and Pattern Recognition, pp. 593-600, 1994
The article by K. Mikolajczyk and C. Schmid, Scale and Affine invariant interest point detectors, International Journal of Computer Vision, vol 60, no 1, pp. 63-86, 2004
在第一篇论文中提到,Harris角点检测最直观的解释是在任意两个相互垂直的方向上,都有较大变化的点。为了定义一幅图像中的角点,Harris观察一个假定的特征点周围小窗口内的方向性强度平均变化。
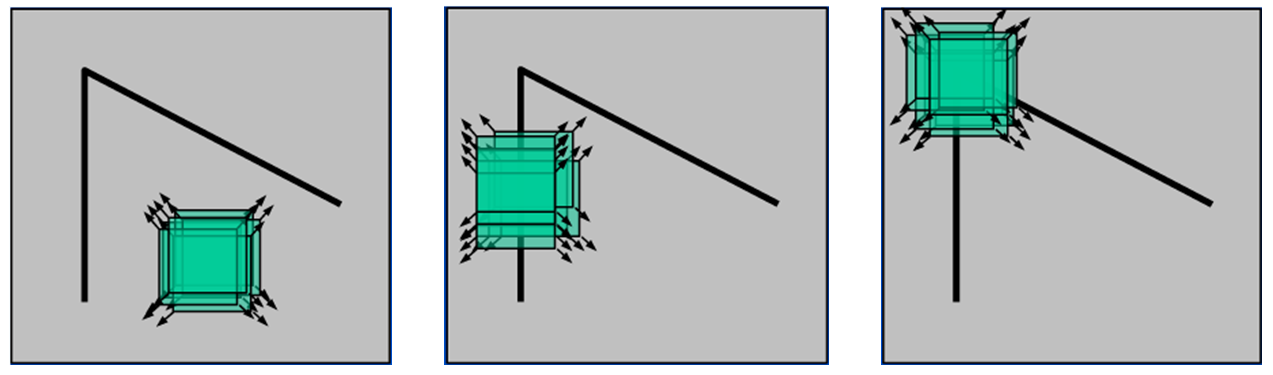
如图所示,假设一个小窗口在图像上移动,在平滑区域如左图所示,窗口在各个方向上均没有变化。对于中间图,小窗口在边缘的方向上移动时也没有变化。而知道小窗口移动到右图的角点处,窗口在各个方向上均有明显的变化。Harris角点检测正是利用了这个直观的物理现象,通过窗口在各个方向上的变化程度,决定是否存在着角点。这里我们考虑偏移量(u,v),则将图像窗口平移(u,v)产生的E(u,v)可表示为:

由以下公式可得到E(u,v):
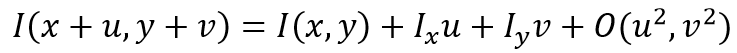
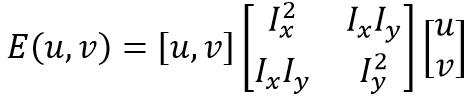
对于局部微小的移动,E(u,v)可近似表达为:
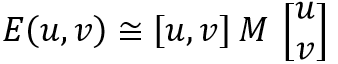
其中M的详细表达式为:
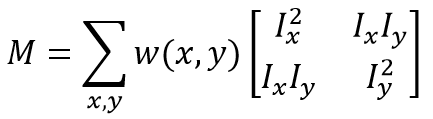
E(u,v)的椭圆形式如下:
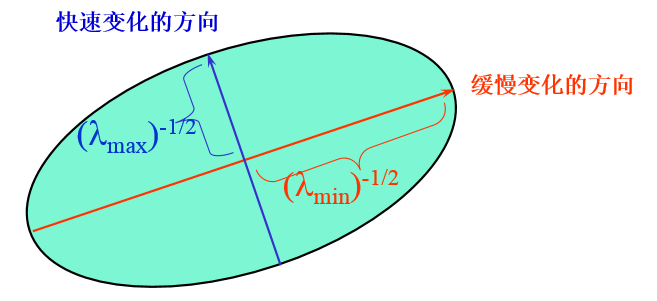
**E(u,v)是一个协方差矩阵,表现的是所有方向上强度的变化率。**该定义涉及图像的一阶导数,这通常是Sobel算子的计算结果。而在OpenCV中cv::cornerHarris函数的第四个参数对应的正是用于计算Sobel滤波器的孔径(aperture)。协方差的两个特征值给出了最大平均强度变化以及垂直方向上的平均强度变化,如果这两个特征值均较低,就认为当前是同质区域;如果其中一个特征值较高,另外一个较低,则认为当前位于边缘上;最后,若两个特征值均较高,则判定当前位于角点处。
因此,定义角点响应函数R,其中k为函数cv::cornerHarris中的最后一个参数;之后,对R进行阈值处理,设定若R大于阈值threshold,则提取出局部极大值:

Harris角点的更多的理论部分可见:
[http://blog.csdn.net/lu597203933/article/details/15088485](http://blog.csdn.net/lu597203933/article/details/15088485)
[http://blog.csdn.net/xiaowei_cqu/article/details/7805206](http://blog.csdn.net/xiaowei_cqu/article/details/7805206)。
**下面记录一下harris角点检测的几种方案。**
一、基本的Harris角点检测实现
~~~
#include <QCoreApplication>
#include <opencv2/core/core.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/highgui/highgui.hpp>
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
// Harris法的简单实现
cv::Mat image = cv::imread("c:/031.jpg", 0);
cv::Mat cornerStrength;
cv::cornerHarris(image,
cornerStrength, // 输出为表示角点强度的32位浮点图像
3, // 导数平滑的相邻像素的尺寸
3, // 梯度计算的滤波器孔径大小
0.01); // Harris的相关参数
// 要在窗口输出,需要转化为CV_8U格式,阈值化即可
// 角点强度的阈值
cv::Mat harrisCorner;
double threshold = 0.0001;
cv::threshold(cornerStrength,
harrisCorner,
threshold,
255,
cv::THRESH_BINARY_INV); // 输出为翻转的二值图像
cv::namedWindow("Original Image");
cv::imshow("Original Image", image);
cv::namedWindow("Harris Corner");
cv::imshow("Harris Corner", harrisCorner);
return a.exec();
}
~~~
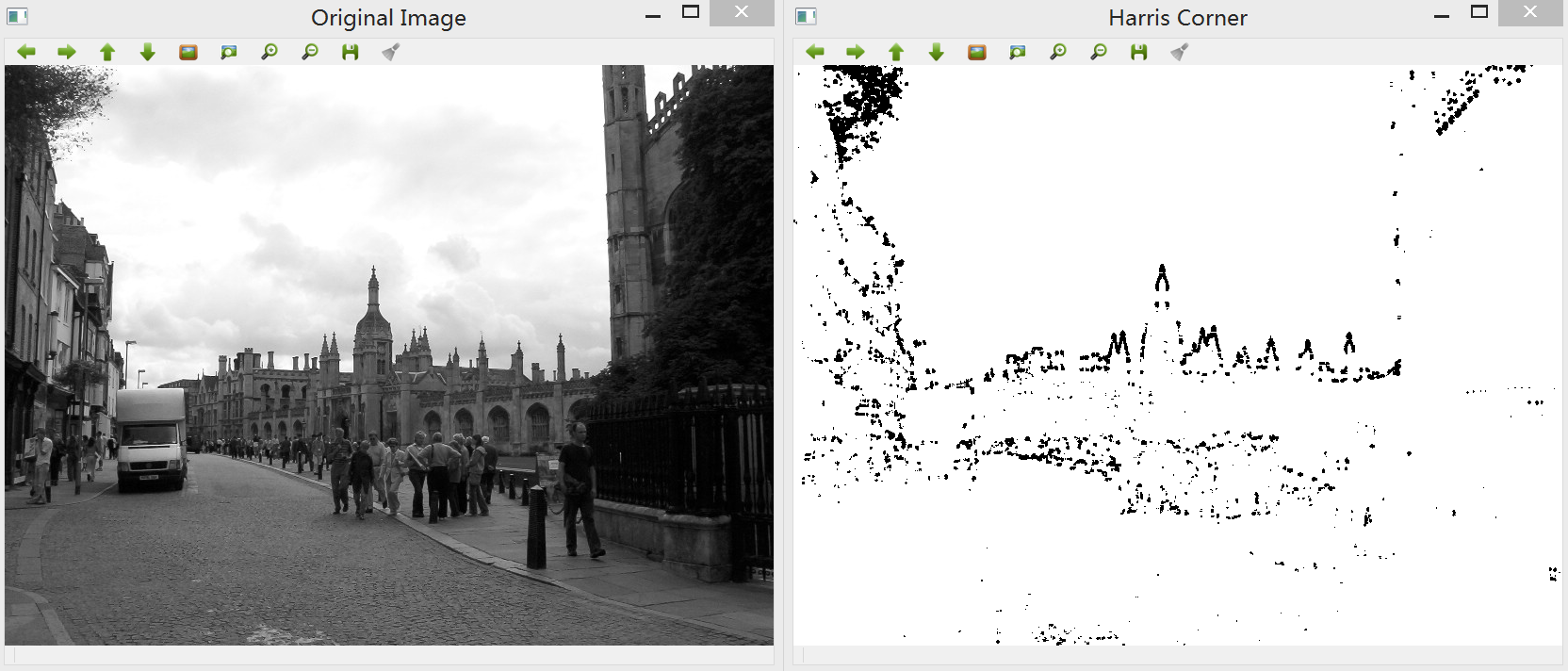
得到的结果为二值图像,可以看到图像中角点的位置包含许多圆圈,这与精确定位特征点的目标相悖:
**二、改进的Harris角点检测实现(Shi-Tomasi算法)**
这里通过封装自定义类来改进角点检测的效果。定义一个类HarrisDetector(其中已封装了Harris参数和相关函数):
~~~
#ifndef HARRISDETECTOR_H
#define HARRISDETECTOR_H
#include <opencv2/core/core.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/highgui/highgui.hpp>
class HarrisDetector
{
private:
// 表示图像角点强度的32位浮点图像
cv::Mat cornerStrength;
// 将输出图像阈值化后的32位浮点图像
cv::Mat cornerThreshold;
// 局部极大值图像
cv::Mat localMax;
// 以下三个为cornerHarris函数的必要参数
// 导数平滑的相邻像素的尺寸
int neighbourhoodPixelSize;
// 滤波器的孔径大小
int aperture;
// Harris参数
double k;
// 阈值计算的最大强度
double maxStrength;
// 计算得到的阈值
double threshold;
// 非极大值抑制的相邻像素的尺寸
int noneighbourhoodPixelSize;
// 非极大值抑制的核
cv::Mat kernel;
public:
// 初始化参数
HarrisDetector():neighbourhoodPixelSize(3),
aperture(3),
k(0.01),
maxStrength(0.0),
threshold(0.01),
noneighbourhoodPixelSize(3)
{
setLocalMaxWindowSize(noneighbourhoodPixelSize);
}
// 创建非极大值抑制的核
void setLocalMaxWindowSize(int size);
// 计算Harris角点
void detect(const cv::Mat &image);
// 由Harris的值获取角点图
cv::Mat getCornerMap(double qualityLevel);
// 由Harris的值获取特征点
void getCorners(std::vector<cv::Point> &points, double qualityLevel);
// 由角点图获取特征点
void getCorners(std::vector<cv::Point> &points, const cv::Mat& cornerMap);
// 在特征点的位置绘制图
void drawOnImage(cv::Mat &image,
const std::vector<cv::Point> &points,
cv::Scalar color = cv::Scalar(255, 255, 255),
int radius = 4, int thickness = 2);
};
#endif // HARRISDETECTOR_H
~~~
接着,在harrisdetector.cpp中定义各个函数和初始化的参数:
~~~
#include "harrisdetector.h"
// 创建非极大值抑制的核
void HarrisDetector::setLocalMaxWindowSize(int size)
{
noneighbourhoodPixelSize = size;
kernel.create(noneighbourhoodPixelSize, noneighbourhoodPixelSize, CV_8U);
}
// 计算Harris角点
void HarrisDetector::detect(const cv::Mat &image)
{
// Harris计算
cv::cornerHarris(image,cornerStrength,
neighbourhoodPixelSize,
aperture,
k);
// 内部阈值计算
double minStrength; // 未使用
cv::minMaxLoc(cornerStrength,
&minStrength,
&maxStrength);
// 局部极大值检测
cv::Mat dilate; // 临时图像
cv::dilate(cornerStrength, dilate, cv::Mat());
cv::compare(cornerStrength, dilate, localMax, cv::CMP_EQ);
}
// 由Harris的值获取角点图
cv::Mat HarrisDetector::getCornerMap(double qualityLevel)
{
cv::Mat cornerMap;
// 对角点图像进行阈值化
threshold = qualityLevel * maxStrength;
cv::threshold(cornerStrength, cornerThreshold,
threshold,255,cv::THRESH_BINARY);
// 转换为8位图像
cornerThreshold.convertTo(cornerMap, CV_8U);
// 非极大值抑制
cv::bitwise_and(cornerMap, localMax, cornerMap);
return cornerMap;
}
// 由Harris的值获取特征点
void HarrisDetector::getCorners(std::vector<cv::Point> &points, double qualityLevel)
{
// 得到角点图
cv::Mat cornerMap = getCornerMap(qualityLevel);
getCorners(points, cornerMap);
}
// 由角点图获取特征点
void HarrisDetector::getCorners(std::vector<cv::Point> &points, const cv::Mat& cornerMap)
{
// 遍历像素得到所有特征
for( int y = 0; y < cornerMap.rows; y++ )
{
const uchar* rowPtr = cornerMap.ptr<uchar>(y);
for( int x = 0; x < cornerMap.cols; x++ )
{
// 如果是特征点
if (rowPtr[x])
{
points.push_back(cv::Point(x,y));
}
}
}
}
// 在特征点的位置绘制图
void HarrisDetector::drawOnImage(cv::Mat &image,
const std::vector<cv::Point> &points,
cv::Scalar color,
int radius, int thickness)
{
std::vector<cv::Point>::const_iterator it = points.begin();
// 对于所有角点,绘制白色圆圈
while(it != points.end())
{
cv::circle(image, *it, radius, color, thickness);
++ it;
}
}
~~~
最后,使用该类的步骤如下,直接修改main函数:
~~~
#include <QCoreApplication>
#include <opencv2/core/core.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <QDebug>
#include "harrisdetector.h"
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
cv::Mat image = cv::imread("c:/031.jpg", 0);
// 创建Harris对象
HarrisDetector harris;
// 计算Harris的值
harris.detect(image);
// 检测Harris的角点
std::vector<cv::Point>pts;
harris.getCorners(pts, 0.1);
// 绘制角点图
harris.drawOnImage(image, pts);
cv::namedWindow("Harris Corners Final");
return a.exec();
}
~~~
生成的图像:
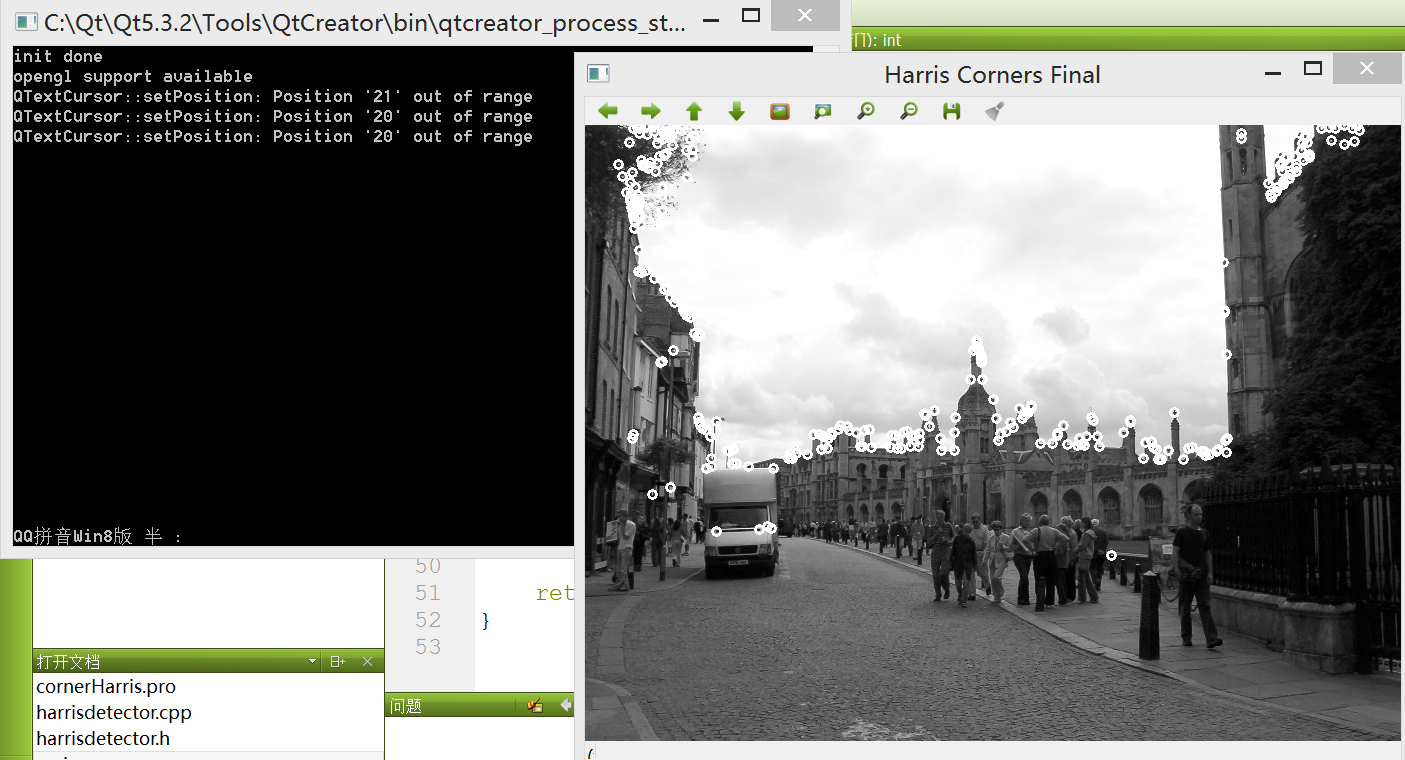
这里为了改进特征点检测结果,添加了额外的非极大值抑制步骤,目的是移除彼此相邻的Harris角点。这就要求Harris角点不只需要得分高于给定阈值,它还必须是局部极大值。在检测中使用了一个技巧,即将Harris得分的图像进行膨胀:
~~~
cv::dilate(cornerStrength, dilate, cv::Mat());
~~~
这是由于膨胀运算替换每个像素值为相邻范围内的最大值,因此只有局部极大值的点才会保留原样,并通过以下函数进行测试:
~~~
cv::compare(cornerStrength, dilate, localMax, cv::CMP_EQ);
~~~
其中,localMax矩阵仅在局部极大值的位置为真,因此又可以在getCornerMap函数中用它来抑制所有非极大值的特征(基于cv::bitwise_and函数)。
**三、引入适合跟踪的优质特征的Harris检测实现**
在浮点处理器的帮助下,为了避免特征值分解而引入的数学上的简化变得微不足道,因此Harris检测可以基于计算而得的特征值。原则上这个修改不会显著影响检测的结果,但是能够避免使用任意的k参数。
以上第二中方法引入了局部极大值的条件,改善了部分效果。然而,特征点倾向于图像中不均匀分布、普遍集中在纹理丰富的部分。这里记录一种新的解决方案:
该方案利用两个特征点之间的最小距离,从Harris得分最高的点开始,仅接受离开有效特征点距离大于特定值的那些点。在OpenCV中提供cv::goodFeaturesToTrack实现这一方法,它检测到的特征能用于视觉跟踪应用中的优质特征集合。其调用方式如下:
~~~
// 计算适合跟踪的优质特征
std::vector<cv::Point2f> corners;
cv::goodFeaturesToTrack(image,corners,
250, // 返回的最大特征点的数目
0.01, // 质量等级
8); // 两点之间的最小允许距离
~~~
除了质量等级阈值、特征点之间的最小允许距离,该函数还需要指定返回的最大特征点数目,这是因为特征点是按照强度进行排序的。以下给出该方法的实现代码,直接在main函数中添加:
~~~
// 输入图像
cv::Mat image= cv::imread("c:/031.jpg",0);
// 计算适合跟踪的优质特征
std::vector<cv::Point2f> corners;
cv::goodFeaturesToTrack(image,corners,
250, // 返回的最大特征点的数目
0.01, // 质量等级
8); // 两点之间的最小允许距离
// 遍历所有特征点并画圆圈
std::vector<cv::Point2f>::const_iterator it= corners.begin();
while (it!=corners.end())
{
cv::circle(image, *it, 3, cv::Scalar(255,255,255), 2);
++it;
}
// 显示输出结果
cv::namedWindow("Good Features to Track");
cv::imshow("Good Features to Track",image);
~~~
返回生成的结果:
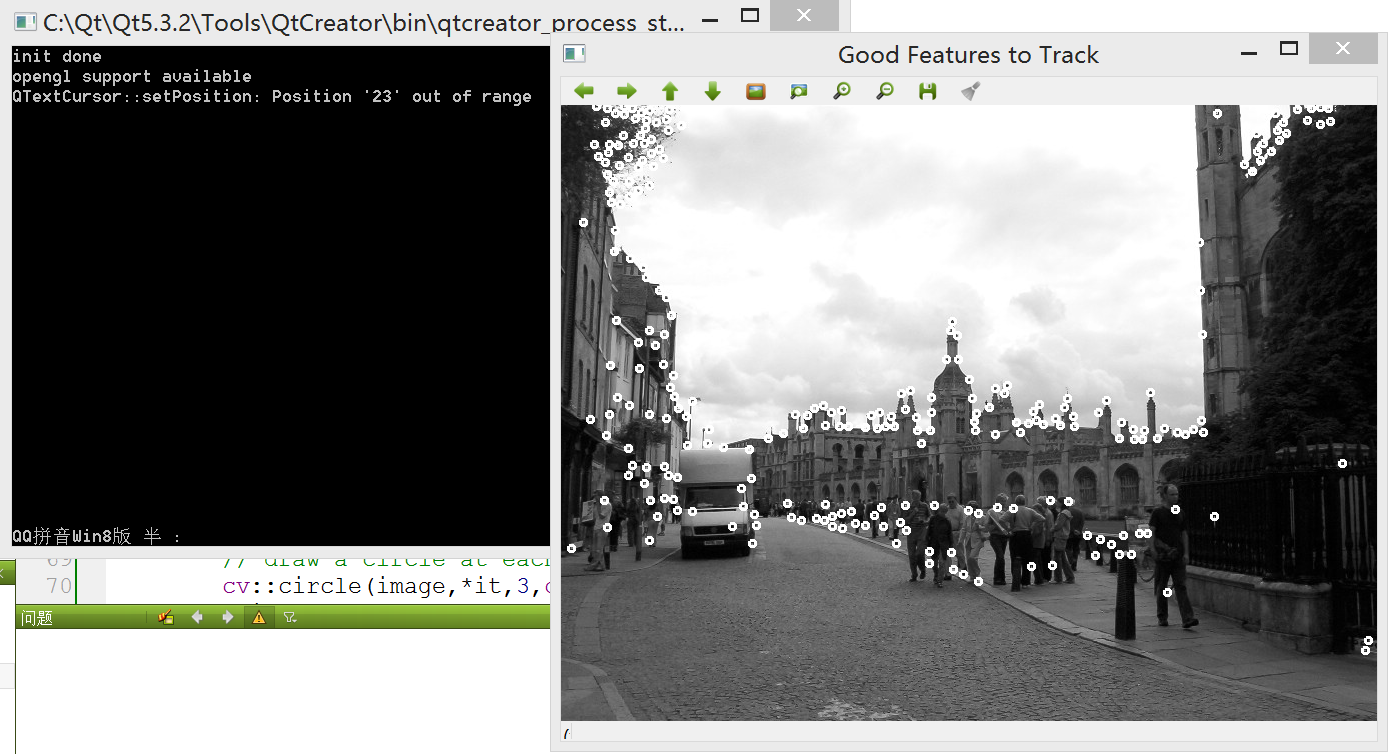
可以看到,该方法显著改进了特征点的分布情况,但是这样也增加了检测的复杂度,因为要求特征点要安装Harris的得分进行排序。该函数也可以指定一个可选的参数,使得按照经典的焦点分数定义进行计算。
其中,cv::goodFeaturesToTrack函数拥有一个封装类cv::GoodFeatureToTrackDetector,它继承自cv::FeaturesDetector类。其用法与以上的Harris类相类似:
~~~
// 特征点向量
std::vector<cv::KeyPoint> keypoints;
cv::goodFeaturesToTrackDetector gftt(
250, // 返回的最大特征点的数目
0.01, // 质量等级
8); // 两点之间的最小允许距离
// 使用FeatureDetector的函数进行检测
gftt.detect(image, keypoints);
~~~
结果与先前得到的结果是一样的,因为它们调用的是同一个函数。
本节的代码下载地址:[http://download.csdn.net/detail/liyuefeilong/8483013](http://download.csdn.net/detail/liyuefeilong/8483013)
关于Harris的理论研究有待进一步研究……
OpenCV2学习笔记(九)
最后更新于:2022-04-01 06:36:05
##视频流读取与处理
由于项目需要,计划实现九路视频拼接,因此必须熟悉OpenCV对视频序列的处理。视频信号处理是图像处理的一个延伸,所谓的视频序列是由按一定顺序进行排放的图像组成,即帧(Frame)。在这里,主要记录下如何使用Qt+OpenCV读取视频中的每一帧,之后,在这基础上将一些图像处理的算法运用到每一帧上(如使用Canny算子检测视频中的边缘)。
一. 读取视频序列
OpenCV提供了一个简便易用的框架以提取视频文件和USB摄像头中的图像帧,如果只是单单想读取某个视频,你只需要创建一个cv::VideoCapture实例,然后在循环中提取每一帧。新建一个Qt控制台项目,直接在main函数添加:
~~~
#include <QCoreApplication>
#include <opencv2/core/core.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <QDebug>
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
// 读取视频流
cv::VideoCapture capture("e:/BrokeGirls.mkv");
// 检测视频是否读取成功
if (!capture.isOpened())
{
qDebug() << "No Input Image";
return 1;
}
// 获取图像帧率
double rate= capture.get(CV_CAP_PROP_FPS);
bool stop(false);
cv::Mat frame; // 当前视频帧
cv::namedWindow("Extracted Frame");
// 每一帧之间的延迟
int delay= 1000/rate;
// 遍历每一帧
while (!stop)
{
// 尝试读取下一帧
if (!capture.read(frame))
break;
cv::imshow("Extracted Frame",frame);
// 引入延迟
if (cv::waitKey(delay)>=0)
stop= true;
}
return a.exec();
}
~~~
(注意:要正确打开视频文件,计算机中必须安装有对应的解码器,否则cv::VideoCapture无法理解视频格式!)运行后,将出现一个窗口,播放选定的视频(需要在创建cv::VideoCapture对象时指定视频的文件名)。
二. 处理视频帧
为了对视频的每一帧进行处理,这里创建自己的类VideoProcessor,其中封装了OpenCV的视频获取框架,该类允许我们指定每帧调用的处理函数。
首先,我们希望指定一个回调处理函数,每一帧中都将调用它。该函数接受一个cv::Mat对象,并输出处理后的cv::Mat对象,其函数签名如下:
~~~
void processFrame(cv::Mat& img, cv::Mat& out);
~~~
作为这样一个处理函数的例子,以下的Canny函数计算图像的边缘,使用时直接添加在mian文件中即可:
~~~
// 对视频的每帧做Canny算子边缘检测
void canny(cv::Mat& img, cv::Mat& out)
{
// 先要把每帧图像转化为灰度图
cv::cvtColor(img,out,CV_BGR2GRAY);
// 调用Canny函数
cv::Canny(out,out,100,200);
// 对像素进行翻转
cv::threshold(out,out,128,255,cv::THRESH_BINARY_INV);
}
~~~
现在我们需要创建一个VideoProcessor类,用来部署视频处理模块。而在此之前,需要先另外创建一个类,即VideoProcessor内部使用的帧处理类。这是因为在面向对象的上下文中,更适合使用帧处理类而不是一个帧处理函数,而使用类可以给程序员在涉及算法方面有更多的灵活度(书上介绍的)。将这个内部帧处理类命名为FrameProcessor,其定义如下:
~~~
#ifndef FRAMEPROCESSOR_H
#define FRAMEPROCESSOR_H
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
class FrameProcessor
{
public:
virtual void process(cv:: Mat &input, cv:: Mat &output)= 0;
};
#endif // FRAMEPROCESSOR_H
~~~
现在可以开始定义VideoProcessor类了,以下为videoprocessor.h中的内容:
~~~
#ifndef VIDEOPROCESSOR_H
#define VIDEOPROCESSOR_H
#include <opencv2/core/core.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <QDebug>
#include "frameprocessor.h"
class VideoProcessor
{
private:
// 创建视频捕获对象
cv::VideoCapture capture;
// 每帧调用的回调函数
void (*process)(cv::Mat&, cv::Mat&);
// FrameProcessor接口
FrameProcessor *frameProcessor;
// 确定是否调用回调函数的bool信号
bool callIt;
// 输入窗口的名称
std::string windowNameInput;
// 输出窗口的名称
std::string windowNameOutput;
// 延迟
int delay;
// 已处理的帧数
long fnumber;
// 在该帧停止
long frameToStop;
// 是否停止处理
bool stop;
// 当输入图像序列存储在不同文件中时,可使用以下设置
// 把图像文件名的数组作为输入
std::vector<std::string> images;
// 图像向量的迭加器
std::vector<std::string>::const_iterator itImg;
// 得到下一帧
// 可能来自:视频文件或摄像头
bool readNextFrame(cv::Mat &frame)
{
if (images.size()==0)
return capture.read(frame);
else {
if (itImg != images.end())
{
frame= cv::imread(*itImg);
itImg++;
return frame.data != 0;
}
}
}
public:
// 默认设置 digits(0), frameToStop(-1),
VideoProcessor() : callIt(false), delay(-1),
fnumber(0), stop(false),
process(0), frameProcessor(0) {}
// 创建输入窗口
void displayInput(std::string wt);
// 创建输出窗口
void displayOutput(std::string wn);
// 不再显示处理后的帧
void dontDisplay();
// 以下三个函数设置输入的图像向量
bool setInput(std::string filename);
// 若输入为摄像头,设置ID
bool setInput(int id);
// 若输入为一组图像序列时,应用该函数
bool setInput(const std::vector<std::string>& imgs);
// 设置帧之间的延迟
// 0意味着在每一帧都等待按键响应
// 负数意味着没有延迟
void setDelay(int d);
// 返回图像的帧率
double getFrameRate();
// 需要调用回调函数
void callProcess();
// 不需要调用回调函数
void dontCallProcess();
// 设置FrameProcessor实例
void setFrameProcessor(FrameProcessor* frameProcessorPtr);
// 设置回调函数
void setFrameProcessor(void (*frameProcessingCallback)(cv::Mat&, cv::Mat&));
// 停止运行
void stopIt();
// 判断是否已经停止
bool isStopped();
// 是否开始了捕获设备?
bool isOpened();
// 返回下一帧的帧数
long getFrameNumber();
// 该函数获取并处理视频帧
void run();
};
#endif // VIDEOPROCESSOR_H
~~~
然后,在videoprocessor.cpp中定义各个函数的功能:
~~~
#include "videoprocessor.h"
// 创建输入窗口
void VideoProcessor::displayInput(std::string wt)
{
windowNameInput= wt;
cv::namedWindow(windowNameInput);
}
// 创建输出窗口
void VideoProcessor::displayOutput(std::string wn)
{
windowNameOutput= wn;
cv::namedWindow(windowNameOutput);
}
// 不再显示处理后的帧
void VideoProcessor::dontDisplay()
{
cv::destroyWindow(windowNameInput);
cv::destroyWindow(windowNameOutput);
windowNameInput.clear();
windowNameOutput.clear();
}
// 设置输入的图像向量
bool VideoProcessor::setInput(std::string filename)
{
fnumber= 0;
// 释放之前打开过的视频资源
capture.release();
images.clear();
// 打开视频
return capture.open(filename);
}
// 若输入为摄像头,设置ID
bool VideoProcessor::setInput(int id)
{
fnumber= 0;
// 释放之前打开过的视频资源
capture.release();
images.clear();
// 打开视频文件
return capture.open(id);
}
// 若输入为一组图像序列时,应用该函数
bool VideoProcessor::setInput(const std::vector<std::string>& imgs)
{
fnumber= 0;
// 释放之前打开过的视频资源
capture.release();
// 输入将是该图像的向量
images= imgs;
itImg= images.begin();
return true;
}
// 设置帧之间的延迟
// 0意味着在每一帧都等待按键响应
// 负数意味着没有延迟
void VideoProcessor::setDelay(int d)
{
delay= d;
}
// 返回图像的帧率
double VideoProcessor::getFrameRate()
{
if (images.size()!=0) return 0;
double r= capture.get(CV_CAP_PROP_FPS);
return r;
}
// 需要调用回调函数
void VideoProcessor::callProcess()
{
callIt= true;
}
// 不需要调用回调函数
void VideoProcessor::dontCallProcess()
{
callIt= false;
}
// 设置FrameProcessor实例
void VideoProcessor::setFrameProcessor(FrameProcessor* frameProcessorPtr)
{
// 使回调函数无效化
process= 0;
// 重新设置FrameProcessor实例
frameProcessor= frameProcessorPtr;
callProcess();
}
// 设置回调函数
void VideoProcessor::setFrameProcessor(void (*frameProcessingCallback)(cv::Mat&, cv::Mat&))
{
// 使FrameProcessor实例无效化
frameProcessor= 0;
// 重新设置回调函数
process= frameProcessingCallback;
callProcess();
}
// 以下函数表示视频的读取状态
// 停止运行
void VideoProcessor::stopIt()
{
stop= true;
}
// 判断是否已经停止
bool VideoProcessor::isStopped()
{
return stop;
}
// 是否开始了捕获设备?
bool VideoProcessor::isOpened()
{
return capture.isOpened() || !images.empty();
}
// 返回下一帧的帧数
long VideoProcessor::getFrameNumber()
{
if (images.size()==0)
{
// 得到捕获设备的信息
long f= static_cast<long>(capture.get(CV_CAP_PROP_POS_FRAMES));
return f;
}
else // 当输入来自一组图像序列时的情况
{
return static_cast<long>(itImg-images.begin());
}
}
// 该函数获取并处理视频帧
void VideoProcessor::run()
{
// 当前帧
cv::Mat frame;
// 输出帧
cv::Mat output;
// 打开失败时
if (!isOpened())
{
qDebug() << "Error!";
return;
}
stop= false;
while (!isStopped())
{
// 读取下一帧
if (!readNextFrame(frame))
break;
// 显示输出帧
if (windowNameInput.length()!=0)
cv::imshow(windowNameInput,frame);
// 调用处理函数
if (callIt)
{
// 处理当前帧
if (process)
process(frame, output);
else if (frameProcessor)
frameProcessor->process(frame,output);
// 增加帧数
fnumber++;
}
else
{
output= frame;
}
// 显示输出帧
if (windowNameOutput.length()!=0)
cv::imshow(windowNameOutput,output);
// 引入延迟
if (delay>=0 && cv::waitKey(delay)>=0)
stopIt();
// 检查是否需要停止运行
if (frameToStop>=0 && getFrameNumber()==frameToStop)
stopIt();
}
}
~~~
定义好视频处理类,它将与一个回调函数相关联。使用该类,可以创建一个实例,指定输入的视频文件,绑定回调函数,然后开始对每一帧进行处理,要调用这个视频处理类,只需在main函数中添加:
~~~
// 定义一个视频处理类处理视频帧
// 首先创建实例
VideoProcessor processor;
// 打开视频文件
processor.setInput("e:/BrokeGirls.mkv");
// 声明显示窗口
// 分别为输入和输出视频
processor.displayInput("Input Video");
processor.displayOutput("Output Video");
// 以原始帧率播放视频
processor.setDelay(1000./processor.getFrameRate());
// 设置处理回调函数
processor.setFrameProcessor(canny);
// 开始帧处理过程
processor.run();
cv::waitKey();
~~~
效果:
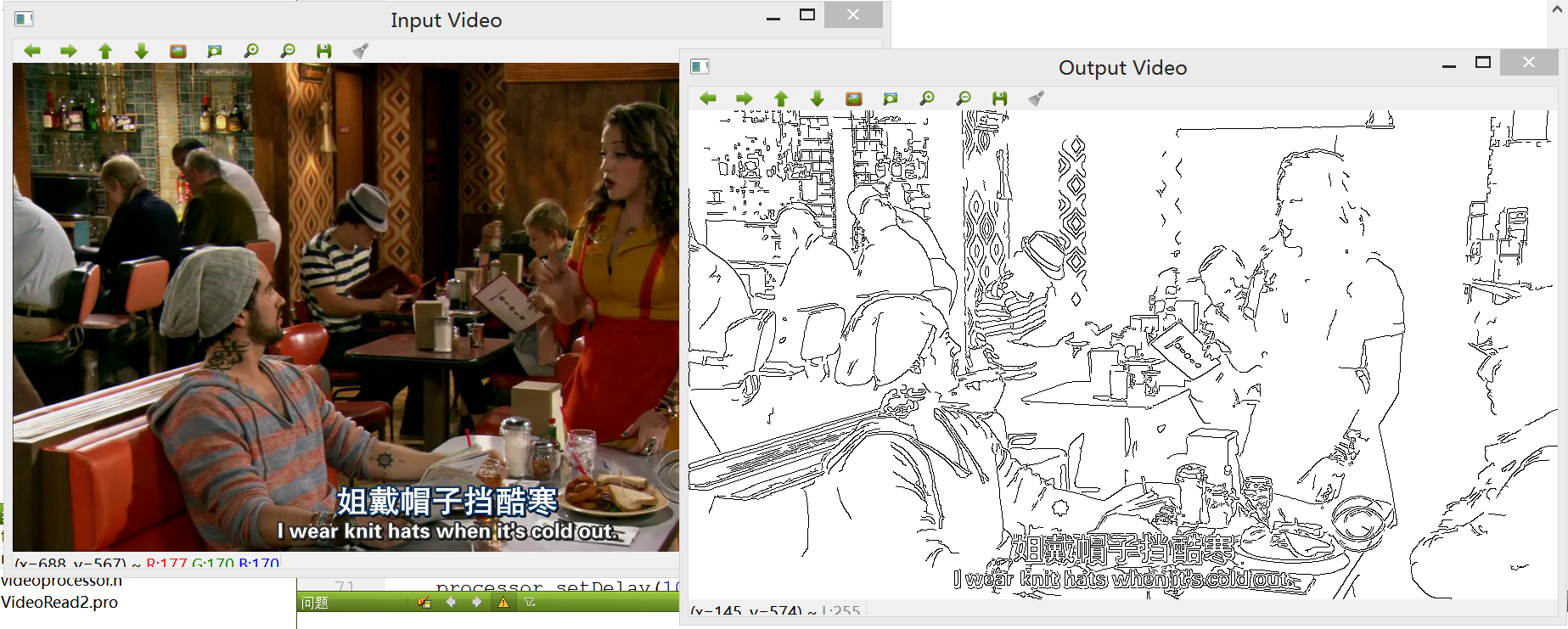
OpenCV2学习笔记(八)
最后更新于:2022-04-01 06:36:03
##使用霍夫变换检测直线和圆
在研究一幅图像时,常常会遇到一些平面或线性问题,直线在图像中频繁可见。这些富有意义的特征在物体识别等图像处理过程中扮演着重要的角色。本节主要记录一种经典的检测直线算法——霍夫变换(Hough Transform),用Hough变换检测图像中的直线和圆,开发平台为Qt5.3.2+OpenCV2.4.9。
**一:Hough变换检测图像的直线**
**1.基础Hough变换**
在霍夫变换中,直线用以下方程表示:
其中,参数表示一条直线到图像原点(左上角)的距离, 表示与直线垂直的角度。如下图所示,直线1的垂直线的角度 等于0,而水平线5的 等于二分之π。同时,直线3的角度 等于四分之π,而直线4的角度大约是0.7π。为了能够在 为区间[0,π]之间得到所有可能的直线,半径值可取为负数,这正是直线2的情况。
OpenCV提供两种霍夫变换的实现,基础版本是:cv::HoughLines。它的输入为一幅包含一组点的二值图像,其中一些排列后形成直线,通常这是一幅边缘图像,比如来自Sobel算子或Canny算子。cv::HoughLines函数的输出是cv::Vec2f向量,每个元素都是一对代表检测到的直线的浮点数(p, r0)。在设计程序时,先求出图像中每点的极坐标方程,若相交于一点的极坐标曲线的个数大于最小投票数,则将该点所对应的(p, r0)放入vector中,即得到一条直线。cv::HoughLines函数的调用方法如下:
~~~
// 基础版本的Hough变换
// 首先应用Canny算子获取图像的轮廓
cv::Mat image = cv::imread("c:/031.jpg", 0);
cv::Mat contours;
cv::Canny(image,contours,125,350);
// Hough变换检测直线
std::vector<cv::Vec2f> lines;
cv::HoughLines(contours,lines,
1,PI/180, // 步进尺寸
80); // 最小投票数
~~~
实现基础Hough变换的完整代码如下,直接在main函数中添加:
~~~
#include <QCoreApplication>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <QDebug>
#define PI 3.1415926
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
// 基础版本的Hough变换
// 首先应用Canny算子获取图像的轮廓
cv::Mat image = cv::imread("c:/031.jpg", 0);
cv::Mat contours;
cv::Canny(image,contours,125,350);
// Hough变换检测直线
std::vector<cv::Vec2f> lines;
cv::HoughLines(contours,lines,
1,PI/180, // 步进尺寸
80); // 最小投票数
// 以下步骤绘制直线
cv::Mat result(contours.rows,contours.cols,CV_8U,cv::Scalar(255));
image.copyTo(result);
// 以下遍历图像绘制每一条线
std::vector<cv::Vec2f>::const_iterator it= lines.begin();
while (it!=lines.end())
{
// 以下两个参数用来检测直线属于垂直线还是水平线
float rho= (*it)[0]; // 表示距离
float theta= (*it)[1]; // 表示角度
if (theta < PI/4. || theta > 3.*PI/4.) // 若检测为垂直线
{
// 得到线与第一行的交点
cv::Point pt1(rho/cos(theta),0);
// 得到线与最后一行的交点
cv::Point pt2((rho-result.rows*sin(theta))/cos(theta),result.rows);
// 调用line函数绘制直线
cv::line(result, pt1, pt2, cv::Scalar(255), 1);
} else // 若检测为水平线
{
// 得到线与第一列的交点
cv::Point pt1(0,rho/sin(theta));
// 得到线与最后一列的交点
cv::Point pt2(result.cols,(rho-result.cols*cos(theta))/sin(theta));
// 调用line函数绘制直线
cv::line(result, pt1, pt2, cv::Scalar(255), 1);
}
++it;
}
// 显示结果
cv::namedWindow("Detected Lines with Hough");
cv::imshow("Detected Lines with Hough",result);
return a.exec();
}
~~~
改变cv::HoughLines中的最小投票数,可以得到不同的检测结果,因此可知道投票数对于直线的判决具有重要意义。最小投票数为100时:
最小投票数为60时:
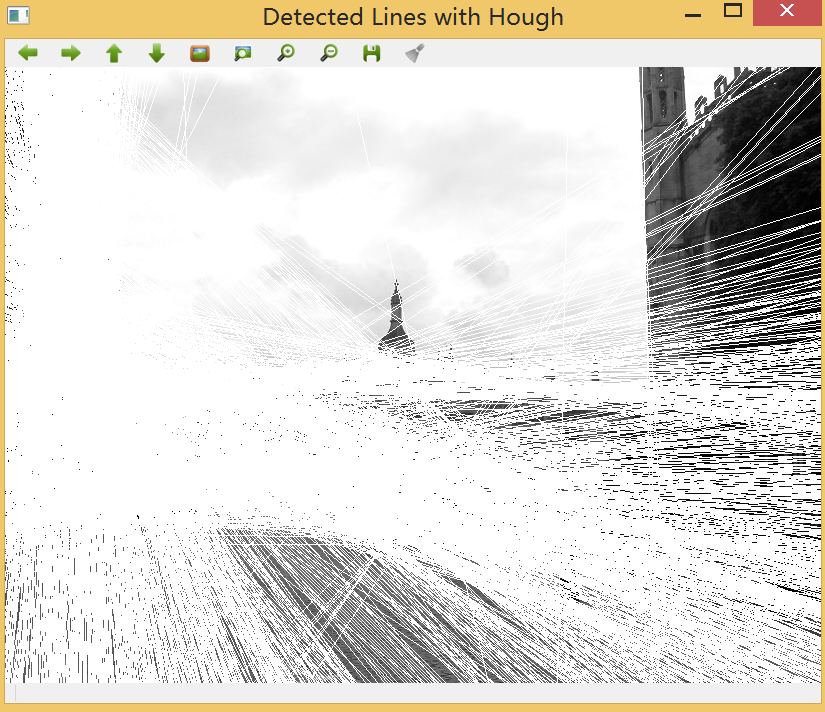
注意hough变换要求输入的是包含一组点的二值图像。
**2.概率Hough变换**
由输出结果可知,基础Hough变换检测出图像中的直线,但在许多应用场合中,我们需要的是局部的线段而非整条直线。正如代码中的情况,需要判定直线与图像边界的交点,才能确定一条线段,否则绘制的直线将穿过整幅图像。其次,霍夫变换仅仅查找边缘点的一种排列方式,由于意外的像素排列或是多条线穿过同一组像素,很有可能带来错误的检测。
为了克服这些难题,人们提出了改进后的算法,即概率霍夫变换,在OpenCV中对应函数cv::HoughLineP,以下给出该算法的实现过程,首先将其封装在类LineFinder中,linefinder.h中添加:
~~~
#ifndef LINEFINDER_H
#define LINEFINDER_H
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <QDebug>
#define PI 3.1415926
class LineFinder
{
private:
// 存放原图像
cv::Mat img;
// 向量中包含检测到的直线的端点
std::vector<cv::Vec4i> lines;
// 累加器的分辨率参数
double deltaRho; // 距离
double deltaTheta; // 角度
// 被判定为直线所需要的投票数
int minVote;
// 直线的最小长度
double minLength;
// 沿直线方向的最大缺口
double maxGap;
public:
// 默认的累加器分辨率为单个像素,角度为1度
// 不设置缺口和最小长度的值
LineFinder() : deltaRho(1), deltaTheta(PI/180), minVote(10), minLength(0.), maxGap(0.) {}
// 设置累加器的分辨率
void setAccResolution(double dRho, double dTheta);
// 设置最小投票数
void setMinVote(int minv);
// 设置缺口和最小长度
void setLineLengthAndGap(double length, double gap);
// 使用概率霍夫变换
std::vector<cv::Vec4i> findLines(cv::Mat& binary);
// 绘制检测到的直线
void drawDetectedLines(cv::Mat &image, cv::Scalar color=cv::Scalar(255,255,255));
};
#endif // LINEFINDER_H
~~~
接着对各个函数进行定义,在linefinder.cpp中添加:
~~~
#include "linefinder.h"
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <QDebug>
#define PI 3.1415926
// 设置累加器的分辨率
void LineFinder::setAccResolution(double dRho, double dTheta) {
deltaRho= dRho;
deltaTheta= dTheta;
}
// 设置最小投票数
void LineFinder::setMinVote(int minv) {
minVote= minv;
}
// 设置缺口和最小长度
void LineFinder::setLineLengthAndGap(double length, double gap) {
minLength= length;
maxGap= gap;
}
// 使用概率霍夫变换
std::vector<cv::Vec4i> LineFinder::findLines(cv::Mat& binary)
{
lines.clear();
// 调用概率霍夫变换函数
cv::HoughLinesP(binary,lines,deltaRho,deltaTheta,minVote, minLength, maxGap);
return lines;
}
// 绘制检测到的直线
void LineFinder::drawDetectedLines(cv::Mat &image, cv::Scalar color)
{
std::vector<cv::Vec4i>::const_iterator it2= lines.begin();
while (it2!=lines.end()) {
cv::Point pt1((*it2)[0],(*it2)[1]);
cv::Point pt2((*it2)[2],(*it2)[3]);
cv::line( image, pt1, pt2, color);
++it2;
}
}
~~~
最后简单修改main函数即可:
~~~
#include <QCoreApplication>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <QDebug>
#include "linefinder.h"
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
cv::Mat image = cv::imread("c:/031.jpg", 0);
if (!image.data)
{
qDebug() << "No Input Image";
return 0;
}
// 首先应用Canny算法检测出图像的边缘部分
cv::Mat contours;
cv::Canny(image, contours, 125, 350);
LineFinder finder; // 创建一对象
// 设置概率Hough参数
finder.setLineLengthAndGap(100, 20);
finder.setMinVote(80); //最小投票数
// 以下步骤检测并绘制直线
std::vector<cv::Vec4i>lines = finder.findLines(contours);
finder.drawDetectedLines(image);
cv::namedWindow("Detected Lines");
cv::imshow("Detected Lines", image);
return a.exec();
}
~~~
得到的结果如下:
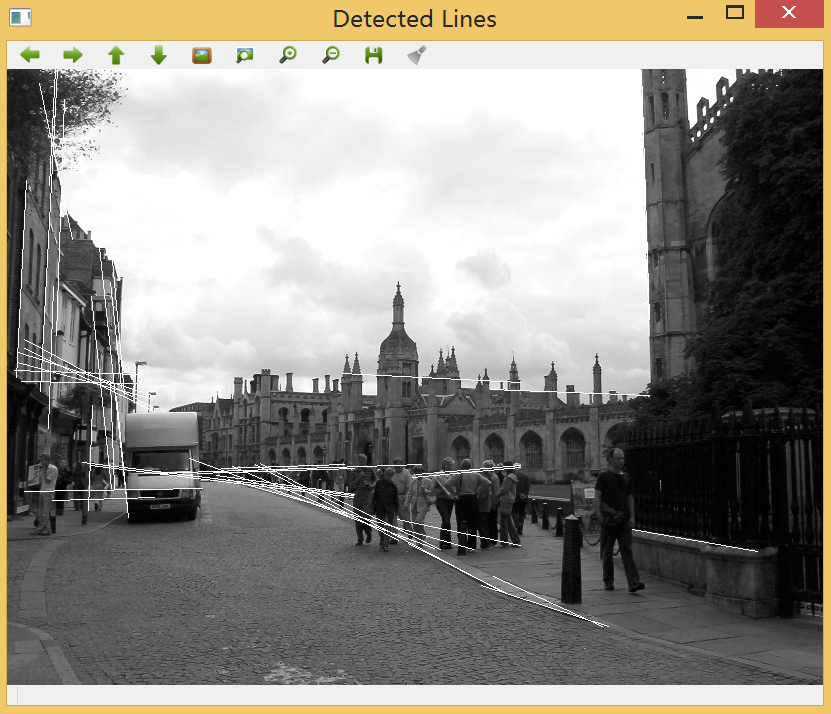
简而言之,霍夫变换的目的是找到二值图像中经过足够多数量的点的所有直线,它分析每个单独的像素点,并识别出所有可能经过它的直线。当同一直线穿过许多点,便意味着这条线的存在足够明显。
而概率霍夫变换在原算法的基础上增加了少许改动,这些改动主要体现在:
1\. 不再系统地逐行扫描图像,而是随机挑选像素点,一旦累加器中的某一项达到给定的最小值,就扫描沿着对应直线的像素并移除所有经过的点(即使它们并未投过票);
2\. 概率霍夫变换定义了两个额外的参数:一个是可以接受的线段的最小长度,另一个是允许组成连续线段的最大像素间隔,虽然这些额外的步骤必然增加算法的复杂度,但由于参与投票的点数量有所减少,因此得到了一些补偿。
**二:Hough变换检测图像中的圆**
霍夫变换可以用于检测其他几何体,事实上,可以用参数方程表示的几何体都可以尝试用霍夫变换进行检测,比如圆形,它对应的参数方程为:
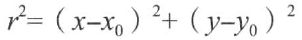
该函数包含三个参数,分别是圆心的坐标和圆的半径,这意味着需要三维的累加器。OpenCV中实现的霍夫圆检测算法通常使用两个步骤进行检测:
1\. 二维累加器用于寻找可能为圆的位置。由于在圆周上的点的梯度应该指向半径的方向,因此对于每一个点,只有沿着梯度方向的项才得到增加(这需要预先设定最大和最小的半径);
2\. 若找到了圆心,则构建一维的半径的直方图,这个直方图的峰值对应的是检测到的圆的半径。
以下给出霍夫变换检测圆形的实现方法,主要使用了函数cv::HoughCircles,它整合了Canny检测和霍夫变换,同时,在进行霍夫变换之前,建议对操作图像进行平滑,以减少可能引起误检测的噪声点:
~~~
// 在调用cv::HoughCircles函数前对图像进行平滑,减少误差
cv::GaussianBlur(image,image,cv::Size(7,7),1.5);
std::vector<cv::Vec3f> circles;
cv::HoughCircles(image, circles, CV_HOUGH_GRADIENT,
2, // 累加器的分辨率(图像尺寸/2)
50, // 两个圆之间的最小距离
200, // Canny中的高阈值
100, // 最小投票数
20, 80); // 有效半径的最小和最大值
~~~
完整代码如下,只需在main函数中添加:
~~~
// 检测图像中的圆形
image= cv::imread("c:/44.png",0);
if (!image.data)
{
qDebug() << "No Input Image";
return 0;
}
// 在调用cv::HoughCircles函数前对图像进行平滑,减少误差
cv::GaussianBlur(image,image,cv::Size(7,7),1.5);
std::vector<cv::Vec3f> circles;
cv::HoughCircles(image, circles, CV_HOUGH_GRADIENT,
2, // 累加器的分辨率(图像尺寸/2)
50, // 两个圆之间的最小距离
200, // Canny中的高阈值
100, // 最小投票数
20, 80); // 有效半径的最小和最大值
// 绘制圆圈
image= cv::imread("c:/44.png",0);
if (!image.data)
{
qDebug() << "No Input Image";
return 0;
}
// 一旦检测到圆的向量,遍历该向量并绘制圆形
// 该方法返回cv::Vec3f类型向量
// 包含圆圈的圆心坐标和半径三个信息
std::vector<cv::Vec3f>::const_iterator itc= circles.begin();
while (itc!=circles.end())
{
cv::circle(image,
cv::Point((*itc)[0], (*itc)[1]), // 圆心
(*itc)[2], // 圆的半径
cv::Scalar(255), // 绘制的颜色
6); // 圆形的厚度
++itc;
}
cv::namedWindow("Detected Circles");
cv::imshow("Detected Circles",image);
~~~
效果:

**三:广义Hough变换**
对于一些形状,其函数表达式比较复杂,如三角形、多边形等,但还是可能使用霍夫变换定位这些形状,其原理与以上的检测是一样的。先创建一个二维的累加器,用于表示所有可能存在目标形状的位置。因此必须定义一个参考点,图像上的每个特征点都对可能的参考点坐标进行投票。由于一个点可能位于形状轮廓内的任意位置,所有可能的参考位置将在累加器中描绘出一个形状,它将是目标形状的镜像。
OpenCV2学习笔记(七)
最后更新于:2022-04-01 06:36:01
##使用Canny算子检测轮廓
在:[http://blog.csdn.net/liyuefeilong/article/details/43927909](http://blog.csdn.net/liyuefeilong/article/details/43927909) 中,主要讨论了使用sobel算子和拉普拉斯变换进行边缘检测。其中主要使用了了对梯度大小进行阈值化以得到二值的边缘图像的方法。在一幅图像中,边缘往往包含着重要的视觉信息,因为它们描绘出图像元素的轮廓。然而,仅仅使用简单的二值边缘图像有两大缺陷:
1\. 使用这种方法检测得到的边缘过粗,这意味着难以实现物体的精确定位。
2\. 难以找到这样的阀值,既能足够低检测到所有重要的边缘,同时也不至于包含过多次要的边缘。
这两个问题正是此节所使用的Canny算法所要尝试解决的。Canny算子是JohnCanny于1986年提出的,它与Marr(LoG)边缘检测方法类似,属于先平滑后求导数的方法。
Canny算子通常基于Sobel算子(当然,也可以使用其他的梯度算子)。一般来说,图像梯度幅值矩阵中的元素值越大,说明图像中该像素点的梯度值越大,但这并不能说明该点就是边缘。在Canny算法中,非极大值抑制是进行边缘检测的重要步骤,通俗意义上是指寻找像素点局部最大值,将非极大值点所对应的灰度值置为0,这样可以剔除掉一大部分非边缘的点。较高的亮度梯度比较有可能是边缘,但是没有一个确切的值来限定多大的亮度梯度是边缘多大又不是,所以 Canny使用了磁滞阀值化的策略:
1\. 磁滞阀值化的原理是使用高与低两个阈值。假设图像中的重要边缘都是连续的曲线,这样就可以跟踪给定曲线中模糊的部分,并且避免将没有组成曲线的噪声像素当成边缘。所以使用一个较大的阈值,标识出比较确信的真实边缘,使用前面导出的方向信息,从这些真正的边缘开始在图像中跟踪整个的边缘。
2\. 在跟踪的时候,我们使用一个较小的阈值,这样就可以跟踪曲线的模糊部分直到我们回到起点。这样根据两个阈值分别进行划分,得到两幅边缘图。
3\. Canny算法组合两幅边缘图以生成一副“最优”的轮廓图。如果存在连续的边缘点,则将低阀值图像中的边缘点与高阀值图像中的边缘相连接,那么就保留低阀值图像中的边缘点。
Canny算法通常处理的图像为灰度图,因此若输入的是彩色图像,则需要进行灰度化。对于RGB图像,通常灰度化采用的方法主要有:
1\. Gray=(R+G+B)/3;
2\. Gray=0.299R+0.587G+0.114B;(这种参数考虑到了人眼的生理特点)
注意,在程序设计时要考虑到图像格式中RGB的顺序通常为BGR。然而,opencv支持将输入图像直接转化为灰度图像,因此可以跳过这个步骤。
Canny算法对于两个阈值的选择有一定的要求。对于较低那个阈值,应该包括所有被认为是属于明显图像轮廓的边缘像素。而较高的阈值的角色应该是定义属于所有重要轮廓的边缘,它应该排除所有异常值。
在OpenCV中,实现Canny算法的函数是cv::Canny,首先需要知道的是,cv::Canny的两个阈值都需要用户亲自输入,且使用的边缘梯度是用sobel算子,该函数的调用方法如下:
~~~
cv::contours;
cv::Canny(image, // 输入的灰度图像
contours, // 输出轮廓
125, // 低阈值
200); // 高阈值
~~~
首先创建一个Qt控制台项目,并新建一个名为Canny算法的类,修改canny.h:
~~~
#ifndef CANNY_H
#define CANNY_H
#define PI 3.1415926
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
class Canny
{
private:
cv::Mat img; // 输入图像
cv::Mat sobel;
int aperture; // 存放阈值
cv::Mat sobelMagnitude; // Sobel大小
cv::Mat sobelOrientation; // Sobel方向
public:
Canny():aperture(3){}
// 设定阈值
void setAperture(int a)
{
aperture = a;
}
// 获取阈值
int getAperture() const;
// 计算Sobel结果
void computeSobel(const cv::Mat &image);
// 获取幅度
cv::Mat getMagnitude();
// 获取Sobel方向
cv::Mat getOrientation();
// 输入门限获取二值图像
cv::Mat getBinaryMap(double Threhhold);
// 转化为CV_8U图像
cv::Mat getSobelImage();
// 获取梯度
cv::Mat getSobelOrientationImage();
};
#endif // CANNY_H
~~~
接着,对各个函数进行定义,修改canny.cpp文件:
~~~
#include "canny.h"
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
// 获取阈值
int Canny::getAperture() const
{
return aperture;
}
// 计算Sobel结果
void Canny::computeSobel(const cv::Mat &image)
{
cv::Mat sobelX;
cv::Mat sobelY;
cv::Sobel(image,sobelX,CV_32F,1,0,aperture);
cv::Sobel(image,sobelY,CV_32F,0,1,aperture);
cv::cartToPolar(sobelX,sobelY,sobelMagnitude,sobelOrientation);
}
// 获取幅度
cv::Mat Canny::getMagnitude()
{
return sobelMagnitude;
}
// 获取Sobel方向
cv::Mat Canny::getOrientation()
{
return sobelOrientation;
}
// 输入门限获取二值图像
cv::Mat Canny::getBinaryMap(double Threhhold)
{
cv::Mat bgImage;
threshold(sobelMagnitude,bgImage,Threhhold,255,cv::THRESH_BINARY_INV);
return bgImage;
}
// 转化为CV_8U图像
cv::Mat Canny::getSobelImage()
{
cv::Mat bgImage;
double minval,maxval;
cv::minMaxLoc(sobelMagnitude,&minval,&maxval);
sobelMagnitude.convertTo(bgImage,CV_8U,255/maxval);
return bgImage;
}
// 获取梯度
cv::Mat Canny::getSobelOrientationImage()
{
cv::Mat bgImage;
sobelOrientation.convertTo(bgImage,CV_8U,90/PI);
return bgImage;
}
~~~
最后修改main函数:
~~~
#include <QCoreApplication>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <QDebug>
#include "canny.h"
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
cv::Mat image = cv::imread("C:/peng.jpg",0);
if(! image.data)
qDebug() << "No input image";
cv::imshow("Original Image",image);
// 计算sobel
Canny h;
h.computeSobel(image);
// 获取sobel的大小和方向
cv::imshow("orientation of sobel",h.getSobelOrientationImage());
cv::imshow("Magnitude of sobel",h.getSobelImage());
// 使用两种阈值的检测结果
cv::imshow("The Lower Threshold",h.getBinaryMap(125));
cv::imshow("The Higher Threshold",h.getBinaryMap(225));
// 使用canny算法
cv::Mat contours;
cv::Canny(image,contours,125,225);
cv::Mat contoursInv;
cv::threshold(contours,contoursInv,128,255,cv::THRESH_BINARY_INV);
cv::imshow("Edge Image",contoursInv);
return a.exec();
}
~~~
在输出结果中,可以观察到使用Sobel算子得出的方向和大小:
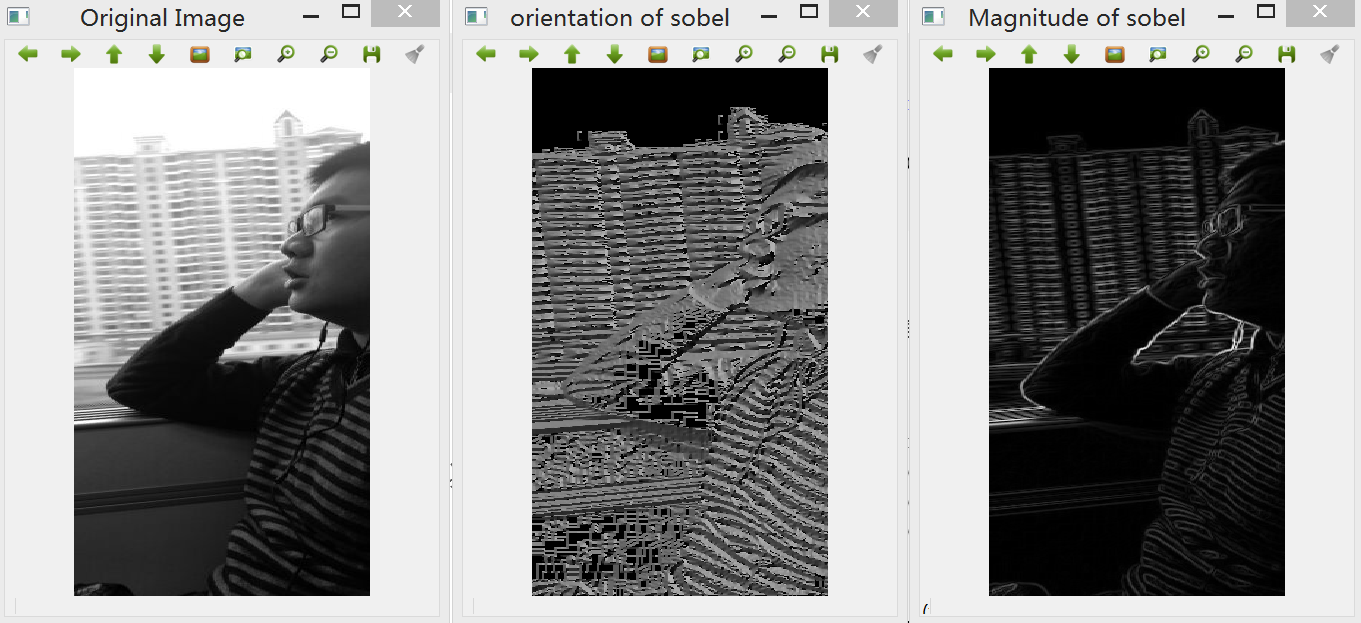
以及使用两个阈值得到的两个检测结果及融合两个结果所得出的最终结果:

当然,如果只是想直接实现Canny算法,无需建立Canny类,直接在main函数中添加以下内容即可:
~~~
#include <QCoreApplication>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <QDebug>
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
cv::Mat image = cv::imread("c:/peng.jpg", 0);
if(!image.data)
{
qDebug() << "No input image";
}
cv::Mat result;
cv::Canny(image, result, 150, 220);
cv::namedWindow("Original Image");
cv::imshow("Original Image", image);
cv::namedWindow("Canny Result");
cv::imshow("Canny Result", result);
return a.exec();
}
~~~
效果:
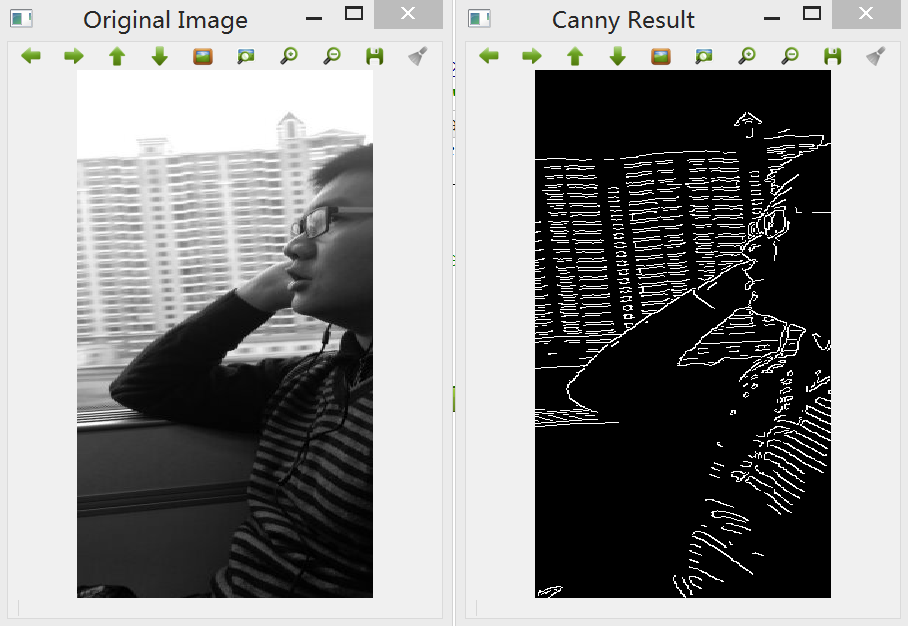
以下是Sobel算子进行边缘检测的输出效果:
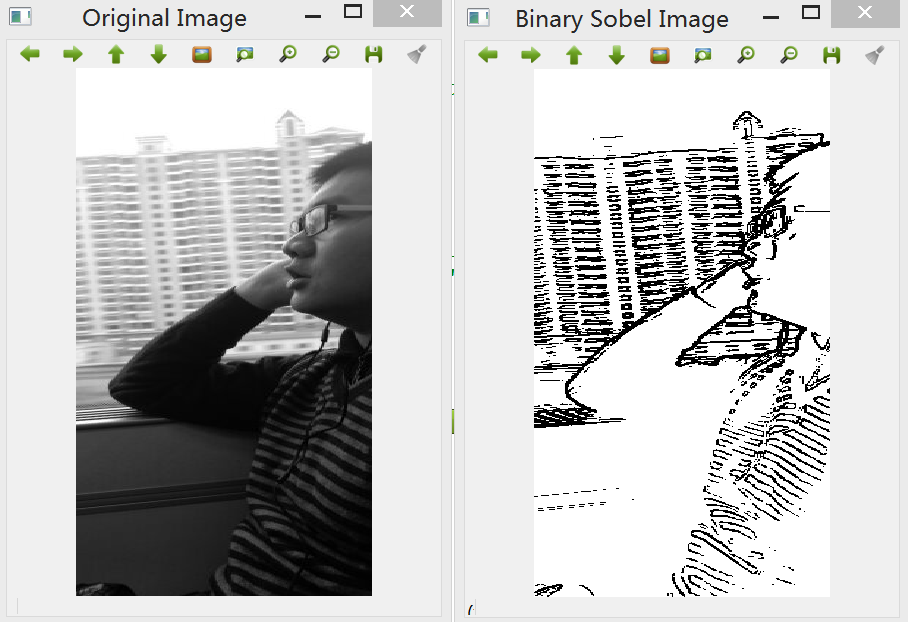
对比Sobel算子,Canny算子能得到较薄的边缘,这是因为Canny算法采用了额外的策略来提升图像的质量。在使用磁滞阈值化之前,所有在梯度大小并非最大值的边缘点都被移除。这样一来梯度的朝向总是与边缘垂直,因此该方向的局部梯度最大值对应的是轮廓强度最大的点。Canny 算法适用于不同的场合。它的参数允许根据不同实现的特定要求进行调整以识别不同的边缘特性。
需要注意的是,使用Canny 算法检测轮廓时需要考虑一些可以调整的参数,它们将影响到算法的计算的时间与实效。
1\. 高斯滤波器的大小:第一步所用的平滑滤波器将会直接影响 Canny 算法的结果。较小的滤波器产生的模糊效果也较少,这样就可以检测较小、变化明显的细线。较大的滤波器产生的模糊效果也较多,将较大的一块图像区域涂成一个特定点的颜色值。这样带来的结果就是对于检测较大、平滑的边缘更加有用,例如彩虹的边缘。
2\. 阈值:使用两个阈值比使用一个阈值更加灵活,但是它还是有阈值存在的共性问题。设置的阈值过高,可能会漏掉重要信息;阈值过低,将会把枝节信息看得很重要。很难给出一个适用于所有图像的通用阈值。目前还没有一个经过验证的实现方法。
最近发现了一篇博客,深受启发:[http://blog.csdn.net/likezhaobin/article/details/6892629](http://blog.csdn.net/likezhaobin/article/details/6892629) 给出了一个无需设定阈值的Canny算法,其效果需要进一步论证。
OpenCV2学习笔记(六)
最后更新于:2022-04-01 06:35:58
##检测图像颜色小程序
设计一个界面,用来检测一幅图像的颜色分布,开发平台为Qt5.3.2+OpenCV2.4.9。
该程序的主要步骤如下:
1\. 载入图像,选定一种颜色;
2\. 设定阈值,在该值范围内判定像素属于预设的颜色;
3\. 在界面的Label中输出结果。
首先,新建一个Qt Widgets Application,其中基类选择为QWidget,在创建完项目后,添加一个检测图像颜色的类ColorDetector。并在在Qt项目的.pro文件中添加:
~~~
INCLUDEPATH+=C:\OpenCV\install\include\opencv\
C:\OpenCV\install\include\opencv2\
C:\OpenCV\install\include
LIBS+=C:\OpenCV\lib\libopencv_calib3d249.dll.a\
C:\OpenCV\lib\libopencv_contrib249.dll.a\
C:\OpenCV\lib\libopencv_core249.dll.a\
C:\OpenCV\lib\libopencv_features2d249.dll.a\
C:\OpenCV\lib\libopencv_flann249.dll.a\
C:\OpenCV\lib\libopencv_gpu249.dll.a\
C:\OpenCV\lib\libopencv_highgui249.dll.a\
C:\OpenCV\lib\libopencv_imgproc249.dll.a\
C:\OpenCV\lib\libopencv_legacy249.dll.a\
C:\OpenCV\lib\libopencv_ml249.dll.a\
C:\OpenCV\lib\libopencv_nonfree249.dll.a\
C:\OpenCV\lib\libopencv_objdetect249.dll.a\
C:\OpenCV\lib\libopencv_ocl249.dll.a\
C:\OpenCV\lib\libopencv_video249.dll.a\
C:\OpenCV\lib\libopencv_photo249.dll.a\
C:\OpenCV\lib\libopencv_stitching249.dll.a\
C:\OpenCV\lib\libopencv_superres249.dll.a\
C:\OpenCV\lib\libopencv_ts249.a\
C:\OpenCV\lib\libopencv_videostab249.dll.a
~~~
进入图形界面文件widget.ui,在其中拖入三个按键,改名为”Open Image”,”Process”,”Color”,他们分别执行载入图像、颜色检测、颜色设定的操作。同时,拖入一个Vertical Slider,用于调整颜色的阈值。最后在下方设置一个Label,图像输出在该区域中。
设置各个按钮的objectName,分别为:
“Open Image”设定为”openImage”
“Color”设定为”colorButton”
“Process”设定为”ImageProcess”
“Vertical Slider”设定为”verticalSlider”
这是为了在程序中将信号与槽函数相对应:
~~~
Widget::Widget(QWidget *parent) :
QWidget(parent),
ui(new Ui::Widget)
{
ui -> setupUi(this);
connect(ui -> openImage, SIGNAL(clicked()), this, SLOT(openImage()));
connect(ui -> ImageProcess, SIGNAL(clicked()), this, SLOT(ImageProcess()));
connect(ui -> colorButton, SIGNAL(clicked()), this, SLOT(colorSelect()));
connect(ui -> verticalSlider, SIGNAL(valueChanged(int)), this, SLOT(changeDis(int)));
}
~~~
这里规定当未有输入图像时,图像处理按钮不可用,在以上的Widget构造函数中添加:
~~~
// 在未输入图像时,屏蔽图像处理的按钮
ui -> ImageProcess -> setEnabled(false);
ui -> colorButton -> setEnabled(false);
ui -> verticalSlider -> setEnabled(false);
~~~
接着,定义处理图像所用的类,首先是colordetector.h:
~~~
#ifndef COLORDETECTOR_H_
#define COLORDETECTOR_H_
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <string>
class ColorDetector
{
private:
int minDist;
cv::Vec3b target;
cv::Mat result;
cv::Mat image;
ColorDetector();
// 提供静态的接口来获得ColorDetector对象
static ColorDetector *singleton;
public:
cv::Mat getInputImage() const; // 载入图像
cv::Mat getResult() const; // 返回图像处理结果
void process(); // 将阈值范围内的像素点置为255,其余为0
int getDistance(const cv::Vec3b&) const;
bool setInputImage(std::string); // 判断是否已输入图像
static ColorDetector * getInstance(); // 使用单例模式创建类的实例
static void destory(); // 一个对象的析构函数
// 设置颜色阈值
void setColorDistanceThreshold(int);
int getColorDistanceThreshold() const;
// 设置颜色
void setTargetColor(unsigned char, unsigned char, unsigned char); // 颜色通道转换
void setTargetColor(cv::Vec3b);
cv::Vec3b getTargetColor() const;
};
#endif /* COLORDETECTOR_H_ */
~~~
接着在colordetector.cpp中添加各函数的定义:
~~~
#include "ColorDetector.h"
ColorDetector* ColorDetector::singleton = 0;
ColorDetector::ColorDetector():minDist(100)
{
target[0] = target[1] = target[2] = 0;
}
ColorDetector* ColorDetector::getInstance()
{
if(singleton == 0)
{
singleton = new ColorDetector;
}
return singleton;
}
void ColorDetector::destory()
{
if(singleton!=0)
{
delete singleton;
}
singleton = 0;
}
void ColorDetector::setColorDistanceThreshold(int distance)
{
if(distance < 0)
{
distance = 0;
}
minDist = distance;
}
int ColorDetector::getColorDistanceThreshold() const
{
return minDist;
}
void ColorDetector::setTargetColor(unsigned char red,
unsigned char green, unsigned char blue)
{ // 颜色通道转换
target[2] = red;
target[1] = green;
target[0] = blue;
}
void ColorDetector::setTargetColor(cv::Vec3b color)
{
target = color;
}
cv::Vec3b ColorDetector::getTargetColor() const
{
return target;
}
int ColorDetector::getDistance(const cv::Vec3b& color) const
{
return abs(color[0]-target[0])+abs(color[1]-target[1])+abs(color[2]-target[2]);
}
void ColorDetector::process()
{
result.create(image.rows, image.cols, CV_8U);
cv::Mat_<cv::Vec3b>::const_iterator it = image.begin<cv::Vec3b>();
cv::Mat_<cv::Vec3b>::const_iterator itend = image.end<cv::Vec3b>();
cv::Mat_<uchar>::iterator itout = result.begin<uchar>();
for(; it!=itend; ++it, ++itout)
{
if(getDistance(*it) < minDist)
{
*itout = 255;
}else
{
*itout = 0;
}
}
}
cv::Mat ColorDetector::getResult() const
{
return result;
}
bool ColorDetector::setInputImage(std::string filename)
{
image = cv::imread(filename);
if(!image.data)
{
return false;
}
return true;
}
cv::Mat ColorDetector::getInputImage() const
{
return image;
}
~~~
接下来定义图形界面的处理函数,首先在widget.h中添加:
~~~
#ifndef WIDGET_H
#define WIDGET_H
#include <QWidget>
#include <QFileDialog>
#include <QImage>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include "colordetector.h"
namespace Ui {
class Widget;
}
class Widget : public QWidget
{
Q_OBJECT
public:
explicit Widget(QWidget *parent = 0);
~Widget();
private:
Ui::Widget *ui;
QImage qimage;
cv::Mat image;
private slots:
void openImage();
void ImageProcess();
void colorSelect();
void changeDis(int);
};
#endif // WIDGET_H
~~~
接着在widget.cpp中定义信号与槽函数及相关操作:
~~~
#include "widget.h"
#include "ui_widget.h"
#include <QColorDialog>
#include <QDebug>
Widget::Widget(QWidget *parent) :
QWidget(parent),
ui(new Ui::Widget)
{
ui -> setupUi(this);
// 关联信号与槽函数
connect(ui -> openImage, SIGNAL(clicked()), this, SLOT(openImage()));
connect(ui -> ImageProcess, SIGNAL(clicked()), this, SLOT(ImageProcess()));
connect(ui -> colorButton, SIGNAL(clicked()), this, SLOT(colorSelect()));
connect(ui -> verticalSlider, SIGNAL(valueChanged(int)), this, SLOT(changeDistance(int)));
// 在未输入图像时,屏蔽图像处理的按钮
ui -> ImageProcess -> setEnabled(false);
ui -> colorButton -> setEnabled(false);
ui -> verticalSlider -> setEnabled(false);
}
Widget::~Widget()
{
delete ui;
}
void Widget::openImage()
{
QString fileName = QFileDialog::getOpenFileName(this,
tr("Open Image"), ".",
tr("Image Files (*.png *.jpg *.jpeg *.bmp)"));
ColorDetector::getInstance()->setInputImage(fileName.toLatin1().data());
cv::Mat input;
input = ColorDetector::getInstance()->getInputImage();
if (!input.data)
{
qDebug() << "No Input Image";
}
else
{
// 当检测到输入图像,可激活图像处理按键,并显示原图像
ui->ImageProcess->setEnabled(true);
ui->colorButton->setEnabled(true);
ui->verticalSlider->setEnabled(true);
cv::namedWindow("image");
cv::imshow("image",ColorDetector::getInstance()->getInputImage());
}
}
void Widget::ImageProcess()
{
ColorDetector::getInstance()->process();
cv::cvtColor(ColorDetector::getInstance()->getResult(),image,CV_GRAY2RGB);
qimage = QImage((const unsigned char*)(image.data),image.cols,image.rows,QImage::Format_RGB888);
ui->label->setPixmap(QPixmap::fromImage(qimage).scaledToHeight(300));
}
void Widget::colorSelect()
{
QColor color = QColorDialog::getColor(Qt::green,this);
if(color.isValid())
{
ColorDetector::getInstance()->setTargetColor(
color.red(),color.green(),color.blue());
}
}
void Widget::changeDistance(int value)
{
ColorDetector::getInstance()->setColorDistanceThreshold(value);
}
~~~
效果如下,未输入图像时,图像处理、颜色选择按钮部分不可操作:
1.未输入图像时:
2.载入图像后:
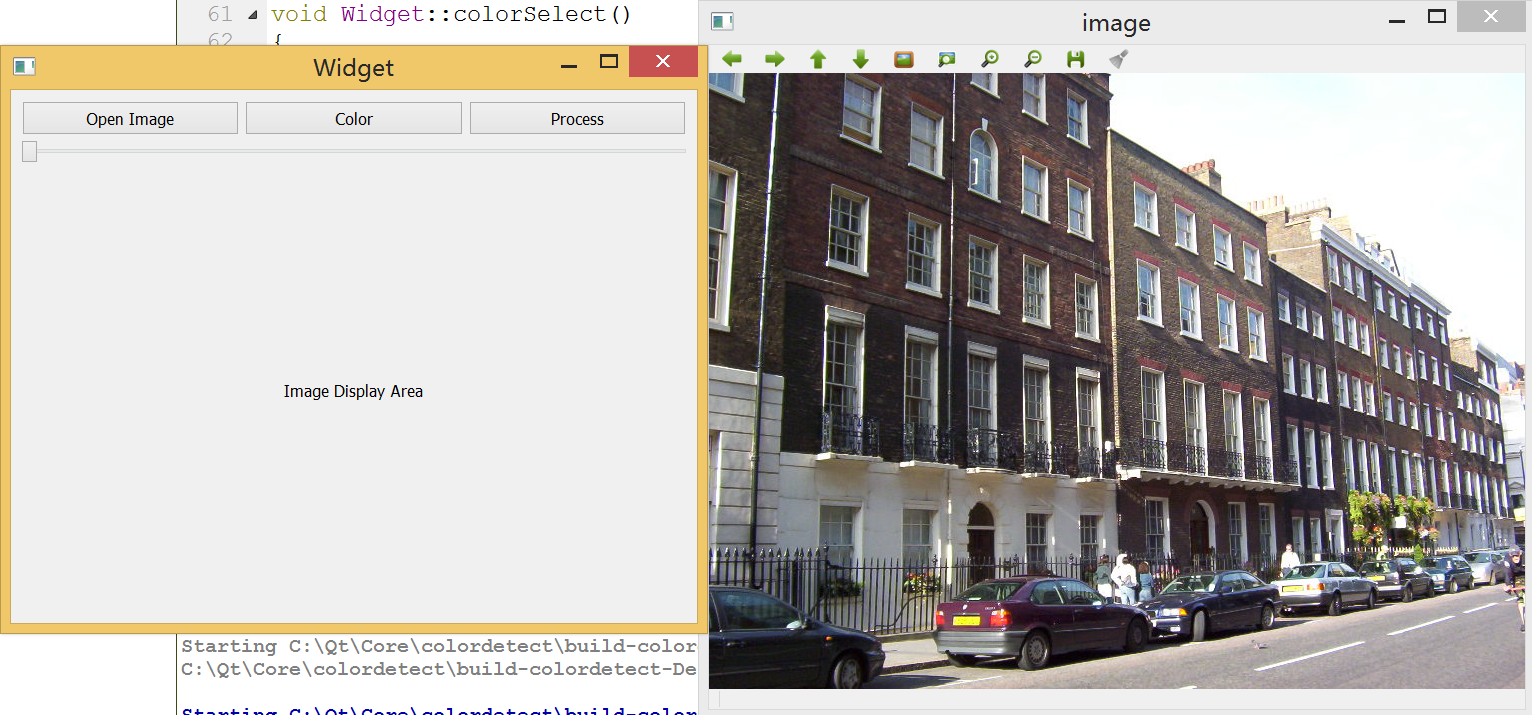
3.打开color按钮,可选择要检测的颜色:
4.选定颜色后,拖动可调节阈值,点击Process可输出检测结果。
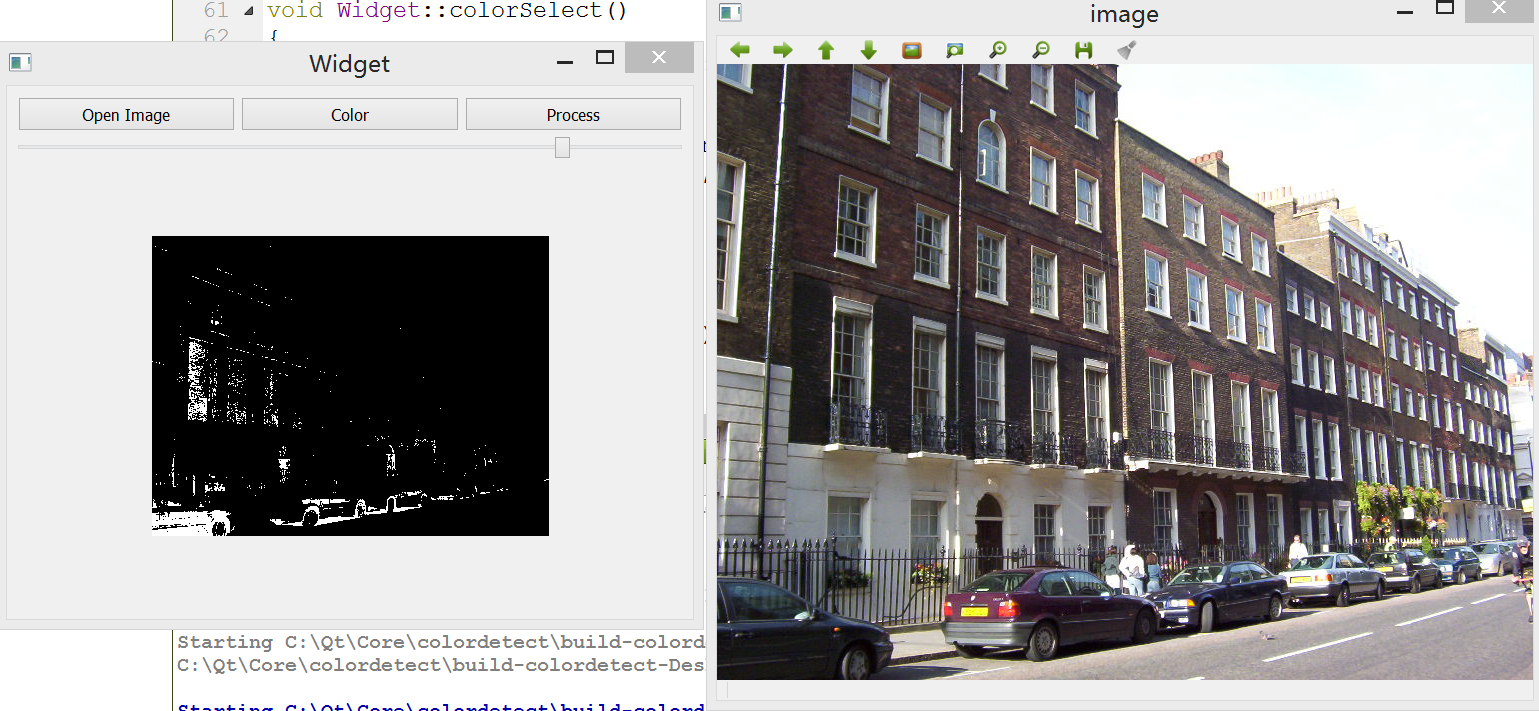
OpenCV2学习笔记(五)
最后更新于:2022-04-01 06:35:56
##图像滤波基础
**一:基本概念**
滤波是数字图像处理中的一个基本操作,在信号处理领域可以说无处不在。图像滤波,即在尽量保留图像细节特征的条件下对目标图像的噪声进行抑制,通常是数字图像处理中不可缺少的操作,其处理效果的好坏将直接影响到后续运算和分析的效果。简单来说,图像滤波的根本目的是在图像中提取出人类感兴趣的特征。
当我们观察一幅图像时,有两种处理方法:
1\. 观察不同的灰度(或彩色值)在图像中的分布情况,即空间分布。
2\. 观察图像中的灰度(或彩色值)的变化情况,这涉及到频率方面的问题。
因此,图像滤波分为频域和空域滤波,简单来说,空域指用图像的灰度值来描述一幅图像;而频域指用图像灰度值的变化来描述一幅图像。而低通滤波器和高通滤波器的概念就是在频域中产生的。低通滤波器旨在去除图像中的高频成分,而高通滤波器则是去除了图像中的低频成分。
这里简单记录以下低通滤波器中的均值和高斯滤波器(线性滤波器)、中值滤波器(非线性滤波器);高通滤波器中的sobel算子(方向滤波器)和拉普拉斯变换(二阶导数),其中,sobel算子和拉普拉斯变换均可以对图像的边缘进行检测。
**二:低通滤波器**
消除图像中的噪声成分叫作图像的平滑化或低通滤波。信号或图像的能量大部分集中在幅度谱的低频和中频段是很常见的,而在较高频段,感兴趣的信息经常被噪声淹没。因此一个能降低高频成分幅度的滤波器就能够减弱噪声的影响。
图像滤波的目的有两个:一是抽出对象的特征作为图像识别的特征模式;另一个是为适应图像处理的要求,消除图像数字化时所混入的噪声。当然,在设计低通滤波器时,要考虑到滤波对图像造成的细节丢失等问题。
平滑滤波是低频增强的空间域滤波技术。它的目的有两类:一类是图像模糊;另一类是滤除图像噪声。空间域的平滑滤波一般采用简单平均法进行,就是求邻近像元点的平均灰度值或亮度值。邻域的大小与平滑的效果直接相关,邻域越大平滑的效果越好,但邻域过大,平滑会使边缘信息损失的越大,从而使输出的图像变得模糊,因此需合理选择邻域的大小。
关于滤波器,一种形象的比喻法是:我们可以把滤波器想象成一个包含加权系数的窗口,当使用这个滤波器平滑处理图像时,就把这个窗口放到图像之上,透过这个窗口来看我们得到的图像。
滤波器的种类有很多, 在OpenCV中,提供了如下几种常用的图像平滑处理操作方法及函数:
1\. 领域均值滤波:blur函数,将图像的每个像素替换为相邻矩形内像素的平均值(均值滤波)
2\. 高斯低通滤波:GaussianBlur函数
3\. 方框滤波:boxblur函数
4\. 中值滤波:medianBlur函数
5\. 双边滤波:bilateralFilter函数
以下是均值滤波和高斯低通滤波的简单代码,在Qt中新建控制台项目,在.pro文件中添加以下内容:
~~~
INCLUDEPATH+=C:\OpenCV\install\include\opencv\
C:\OpenCV\install\include\opencv2\
C:\OpenCV\install\include
LIBS+=C:\OpenCV\lib\libopencv_calib3d249.dll.a\
C:\OpenCV\lib\libopencv_contrib249.dll.a\
C:\OpenCV\lib\libopencv_core249.dll.a\
C:\OpenCV\lib\libopencv_features2d249.dll.a\
C:\OpenCV\lib\libopencv_flann249.dll.a\
C:\OpenCV\lib\libopencv_gpu249.dll.a\
C:\OpenCV\lib\libopencv_highgui249.dll.a\
C:\OpenCV\lib\libopencv_imgproc249.dll.a\
C:\OpenCV\lib\libopencv_legacy249.dll.a\
C:\OpenCV\lib\libopencv_ml249.dll.a\
C:\OpenCV\lib\libopencv_nonfree249.dll.a\
C:\OpenCV\lib\libopencv_objdetect249.dll.a\
C:\OpenCV\lib\libopencv_ocl249.dll.a\
C:\OpenCV\lib\libopencv_video249.dll.a\
C:\OpenCV\lib\libopencv_photo249.dll.a\
C:\OpenCV\lib\libopencv_stitching249.dll.a\
C:\OpenCV\lib\libopencv_superres249.dll.a\
C:\OpenCV\lib\libopencv_ts249.a\
C:\OpenCV\lib\libopencv_videostab249.dll.a
~~~
然后修改main函数,这里设定卷积核的大小均为5*5:
~~~
#include <QCoreApplication>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <QDebug>
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
// 输入图像
cv::Mat image= cv::imread("c:/peng.jpg",0);
if (!image.data)
return 0;
cv::namedWindow("Original Image");
cv::imshow("Original Image",image);
// 对图像进行高斯低通滤波
cv::Mat result;
cv::GaussianBlur(image,result,cv::Size(5,5),1.5);
cv::namedWindow("Gaussian filtered Image");
cv::imshow("Gaussian filtered Image",result);
// 对图像进行均值滤波
cv::blur(image,result,cv::Size(5,5));
cv::namedWindow("Mean filtered Image");
cv::imshow("Mean filtered Image",result);
return a.exec();
}
~~~
效果:
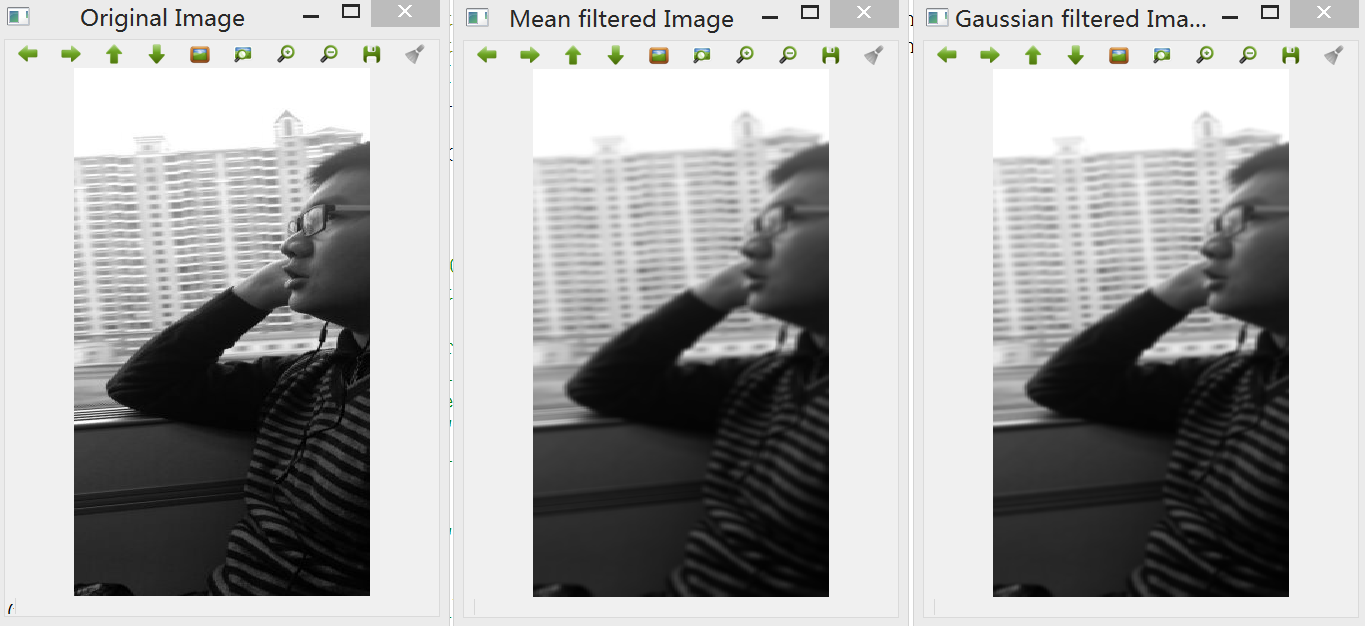
相比均值滤波,高斯低通滤波的主要不同是引入了加权方案,因为在通常情况下,对于图像的一个像素,与越靠近的临近像素有更高的关联性,因此离中心像素近的像素系数应该比远处的像素拥有更多的权重。在高斯滤波器中,像素的全重与它离开中心像素点的距离成正比,一维高斯函数可表示为以下形式:
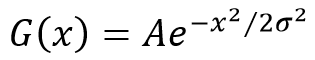
其中,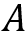为归一化系数,作用是使不同权重之和为1;称为西格玛数值,它的主要作用是控制高斯函数的高度,数值越大则函数越平坦。若要查看高斯滤波器的核,只需选择合适的西格玛数值,然后调用函数cv::getGaussianKernel,返回一个ksize*1的数组,该数组的元素满足高斯公式:
式中的参数分别对应cv::GaussianBlur函数中的参数。以下代码显示出核的值,在main函数中添加:
~~~
// 得到高斯核 (西格玛数值=1.5)
cv::Mat gauss= cv::getGaussianKernel(9,1.5,CV_32F);
// 显示高斯核的值
cv::Mat_<float>::const_iterator it= gauss.begin<float>();
cv::Mat_<float>::const_iterator itend= gauss.end<float>();
qDebug() << "[";
for ( ; it!= itend; ++it)
{
qDebug() << *it << " ";
}
qDebug() << "]";
~~~
若要对一幅图像使用二维高斯滤波器,根据二维高斯滤波器的可分离特性(即一个二维高斯滤波器可分解为两个一维高斯滤波器),可以先对图像的行使用一维高斯滤波器,再对图像的列使用一维高斯滤波器。在OpenCV中,指定高斯滤波的方法是将系数个数(第三个参数,必须是奇数)以及西格玛数值 (第四个参数)提供给cv::GaussianBlur函数。
关于GaussianBlur函数的源码解析可以参考:[http://www.cnblogs.com/tornadomeet/archive/2012/03/10/2389617.html](http://www.cnblogs.com/tornadomeet/archive/2012/03/10/2389617.html)
以上的均值滤波和高斯低通滤波均属于线性滤波,此外还存在非线性滤波器,中值滤波器就是最常用的其中一种。与均值滤波、高斯低通滤波相似,它是对一个像素的相邻区域进行操作以确定像素的值,不同的是中值滤波器仅仅统计这组数组的中值,并用该中值替换中心像素点的值。中值滤波广泛用于噪声滤除,以下给出简单的实现和效果。
首先需要编写一个简单的图像加噪函数,作用是生成若干椒盐噪声:
~~~
void salt(cv::Mat& image, int n) // 添加椒盐噪声
{
for(int k=0; k<n; k++){
int i = rand()%image.cols;
int j = rand()%image.rows;
if(image.channels() == 1)
{
if(rand() % 2 == 0)
image.at<uchar>(j,i) = 0;
else
image.at<uchar>(j,i) = 255;
}else{
if(rand() % 2 == 0)
{
image.at<cv::Vec3b>(j,i)[0] = 0;
image.at<cv::Vec3b>(j,i)[1] = 0;
image.at<cv::Vec3b>(j,i)[2] = 0;
}
else
{
image.at<cv::Vec3b>(j,i)[0] = 255;
image.at<cv::Vec3b>(j,i)[1] = 255;
image.at<cv::Vec3b>(j,i)[2] = 255;
}
}
}
}
~~~
验证中值滤波法与之前的均值滤波法的效果,修改main函数:
~~~
#include <QCoreApplication>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <QDebug>
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
// 输入图像
image = cv::imread("c:/peng.jpg",0);
if (!image.data)
return 0;
// 给图像添加椒盐噪声
salt(image, 3000);
// 显示加噪图图
cv::namedWindow("Salt&Pepper Image");
cv::imshow("Salt&Pepper Image",image);
// 对图像进行均值滤波
cv::blur(image,result,cv::Size(5,5));
cv::namedWindow("Mean filter");
cv::imshow("Mean filter",result);
// 对图像进行中值滤波
cv::medianBlur(image,result,5);
cv::namedWindow("Median Filter");
cv::imshow("Median Filter",result);
return a.exec();
}
~~~
效果如下:
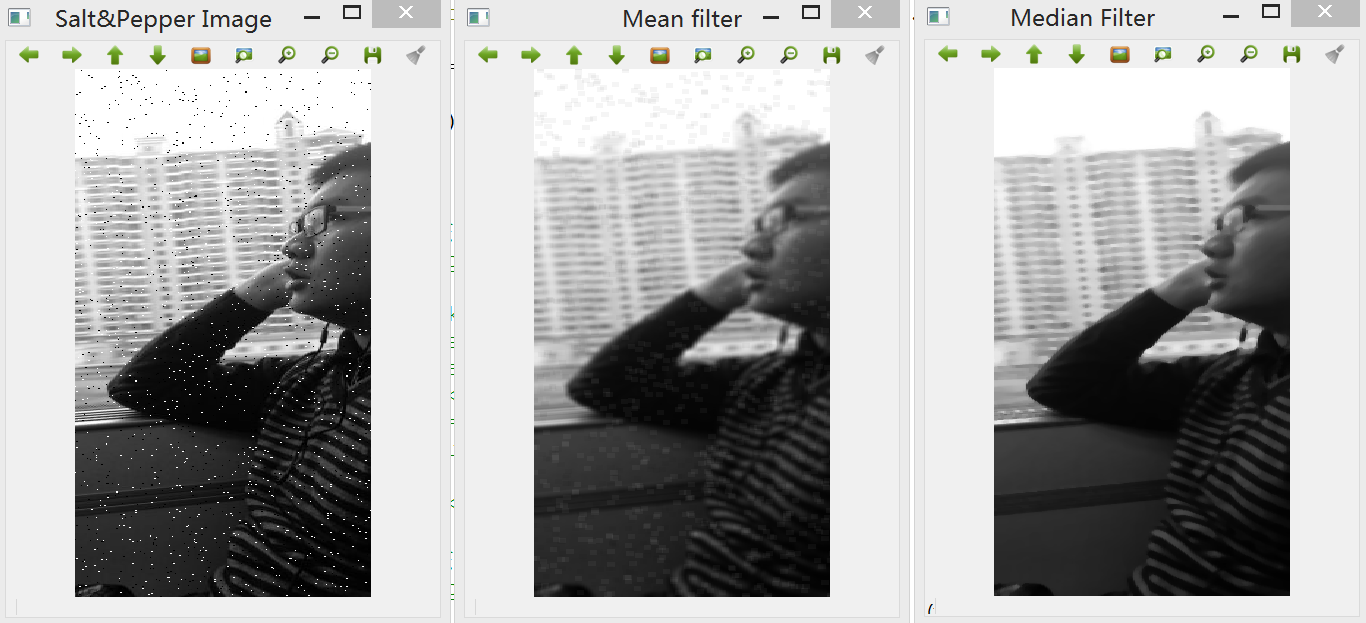

可以看到,中值滤波器对于去除椒盐噪点效果拔群,这是由于一个例外的黑点或白点像素出现在一个相邻区域时,通常不会被选为中值,因为它们代表的是0或255两个极端,因此这些噪声点总会被替换为某个相邻像素的值,而均值滤波和高斯滤波均会引入噪点信息,噪点处的像素值会极大地影响区域的结果,因此无法很好地滤除这一类噪声。
由于中值滤波器是非线性的,因此它无法表示为一个核矩阵。此外,中值滤波器还有保留边缘锐利度的优点。但是缺点是相同区域中的纹理细节也被滤除,如下图中的树木部分。
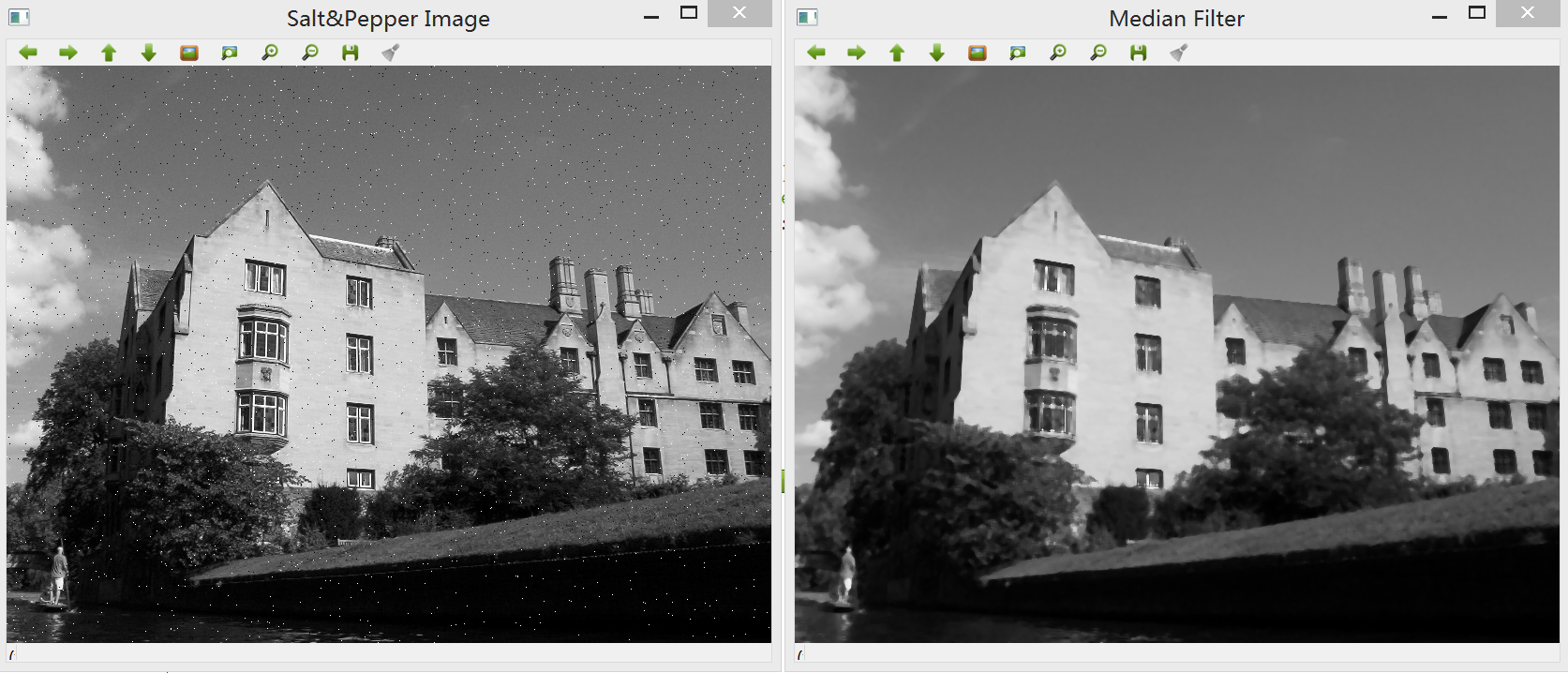
**三:高通滤波器**
前面主要介绍了低通滤波器对图像进行模糊处理,这里进行相反的变换,使用高通滤波器进行图像锐化或边缘检测。Sobel算子就是通过卷积操作来计算图像的一阶导数,由于边缘处图像灰度变化率较大,因此可以用sobel算子来进行边缘检测。提个简单的3*3 Sobel算子的核定义为:

如果将图像视为二维函数,Sobel算子可被认为是在垂直和水平方向变化的测量。这种测量在数学中被成为梯度,通常它被定义为由函数在两个正交方向上的一阶导数组成的二维向量:
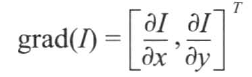
因此,Sobel算子通过在水平和垂直方向下进行像素差分给出图像梯度的近似。它在感兴趣像素的小窗口内运算,这样可减少噪声的影响。OpenCV中提供了函数cv::Sobel使用Sobel核计算图像卷积的结果,其函数的主要参数如下:
~~~
cv::Sobel(image, // 输入图像
sobel, // 输出图像
image_depth, // 图像类型
xorder, yorder, // 核的阶数
kernel_size, // 核的大小
alpha,beta); // 缩放值及偏移值
~~~
现设计算法,使用Sobel方向滤波器。在main函数中添加:
~~~
cv::Mat image= cv::imread("c:/075.png",0); // 输入图像
if (!image.data)
return 0;
cv::namedWindow("Original Image");
cv::imshow("Original Image",image);
// 水平滤波器设置
cv::Mat sobelX;
cv::Sobel(image, sobelX, CV_8U, 1, 0, 3, 0.4, 128);
cv::namedWindow("Sobel X Image");
cv::imshow("Sobel X Image", sobelX);
// 垂直滤波器设置
cv::Mat sobelY;
cv::Sobel(image, sobelY, CV_8U, 0, 1, 3, 0.4, 128);
cv::namedWindow("Sobel Y Image");
cv::imshow("Sobel Y Image", sobelY);
// 计算Sobel范式,滤波器结果保存在16位有符号整数图像中
cv::Sobel(image, sobelX, CV_16S, 1, 0);
cv::Sobel(image, sobelY, CV_16S, 0, 1);
cv::Mat sobel;
// 将水平和垂直方向相加
sobel = abs(sobelX) + abs(sobelY);
// 搜索Sobel的极大值
double sobmin, sobmax;
cv::minMaxLoc(sobel, &sobmin, &sobmax);
// 将图像转换为8位图像
cv::Mat sobelImage;
sobel.convertTo(sobelImage, CV_8U, -255./sobmax, 255);
// 输出图像
cv::namedWindow("Sobel Image");
cv::imshow("Sobel Image", sobelImage);
// 将结果阈值化得到二值图像
cv::Mat ThresholdedImage;
cv::threshold(sobelImage, ThresholdedImage, 225, 255, cv::THRESH_BINARY);
cv::namedWindow("Binary Sobel Image");
cv::imshow("Binary Sobel Image",ThresholdedImage);
~~~
得出水平、垂直方向的边缘检测和融合了两个方向的检测结果:
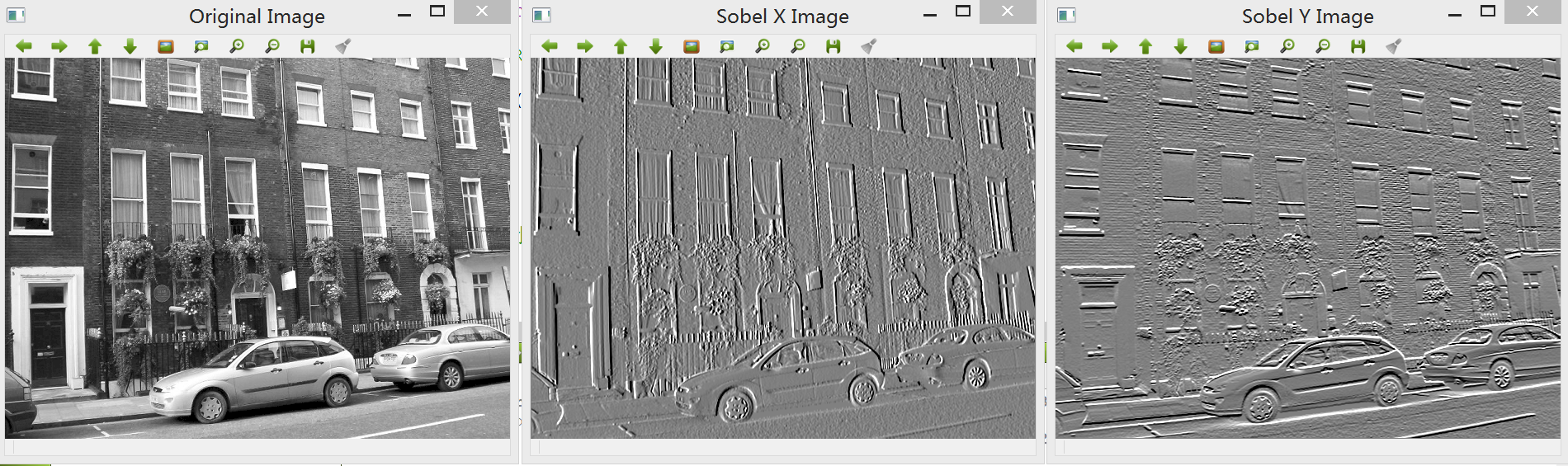
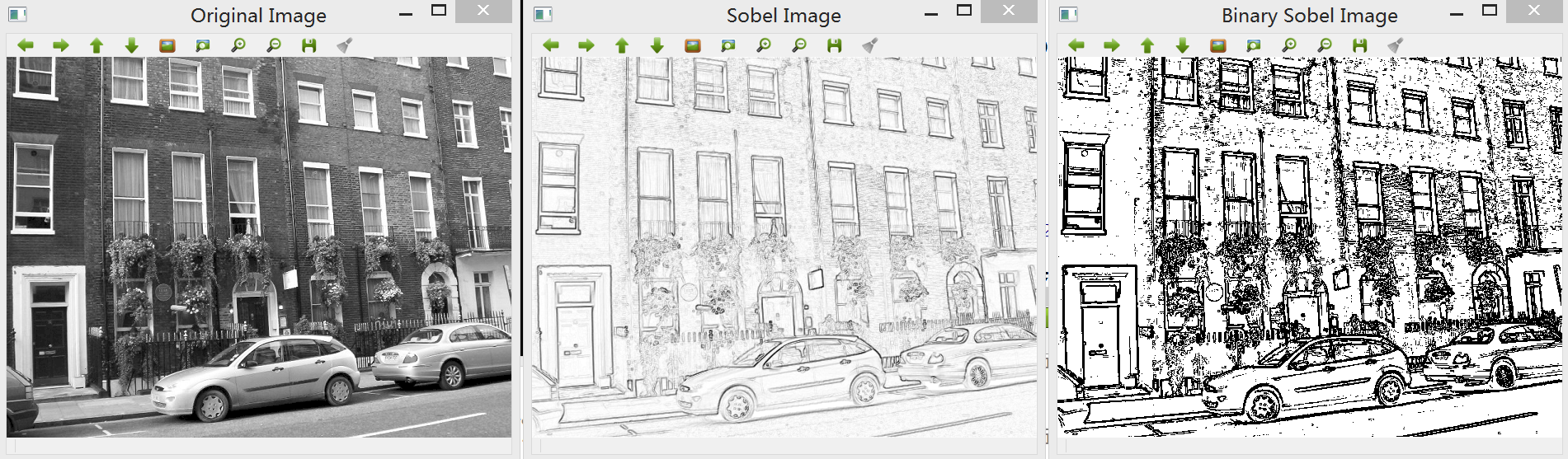
Sobel算子是一种经典的边缘检测线性滤波器,其主要介绍参考:[http://blog.csdn.net/liyuefeilong/article/details/43452711](http://blog.csdn.net/liyuefeilong/article/details/43452711)
拉普拉斯(Laplacian)是另一种基于图像导数的高斯线性滤波器,它计算二阶导数以衡量图像的弯曲度。在OpenCV中,使用cv::Laplacian函数来计算,它与cv::Sobel函数相类似。事实上,拉普拉斯与Sobel法都使用同一个函数cv::getDerivkernels来获取核矩阵。他们的唯一差别是不存在指定导数阶数的参数,因为它们都是二阶导数。,2D函数的拉普拉斯变换定义如下:
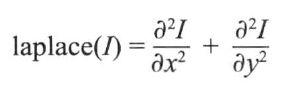
可用一个最简单的3*3核近似:
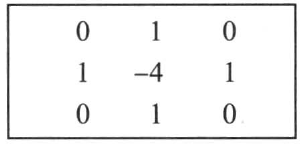
与Sobel算子相同,也能够使用更大的核计算Laplacian,同时由于Laplacian运算对于噪声十分敏感,我们倾向于这么做(除非计算效率更重要)。需要注意Laplacian核的总数为0,这保证了强度不变区域的Laplacian为0。事实上,由于Laplacian度量的是图像函数的曲率,它在平坦区域应该等于0。
拉普拉斯算子的效果可能很难解释。从核的定义来看,很明显,任何孤立的像素值(它与相邻像素值截然不同)将被算子放大。这源于算子对噪点的高灵敏度。但是拉普拉斯算子值在图像边缘处的表现更有趣。边缘的存在是图像中不同灰度区域间快速过渡的结果。沿着图像在一条边上的变化(例如,从暗处到亮处),可以观察到灰度的提升意味着从正曲率(强度值开始上升)到负曲率(当强度即将达到最高至)的渐变。因此,正、负拉普拉斯算子值(或导数)之间的过渡是存在边缘的指示器。另一种表达这个事实的方法是说,边缘位于Laplacian函数的零交叉点。
下图是取一幅图像中的一个观测窗口进行放大得出的个像素点的像素值,可以看到沿着Laplacian的零交叉点,就可以得到一条对应于图像窗口中可见的边缘曲线。

然而,跟随Laplacian图像中零交叉曲线是一件容易出错的事,因此在以下程序中将给出一个简化的算法用于检测近似的零交叉位置,即函数:
~~~
cv::Mat getZeroCrossings(float threshold = 1.0);
cv::Mat getZeroCrossingsWithSobel(float threshold);
~~~
大致的扫描过程是,比较当前像素与左侧像素,如果两者符号不同,那么说明当前像素存在零交叉。如果没有,在正上方位置重复相同的测试。在第二个函数中,还引入Sobel算子来得到零点交叉的二值图像,以下给出Laplacian变换算法的实现过程。
首先,创建一个类Laplacian来实现一些与拉普拉斯变换有关的操作,先在Laplacian.h中添加:
~~~
#ifndef LAPLACIAN_H
#define LAPLACIAN_H
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
class Laplacian
{
public:
Laplacian():aperture(3){}
// 设置卷积核的大小
void setAperture(int a);
// 计算浮点Laplacian
cv::Mat calcLaplacian(const cv::Mat &image);
// 返回8位图像存储的Laplacian结果
cv::Mat getLaplacianImage(double scale = -1.0);
// 以下函数可得到零点交叉的二值图像
cv::Mat getZeroCrossings(float threshold = 1.0);
cv::Mat getZeroCrossingsWithSobel(float threshold);
private:
cv::Mat img; // 原图像
cv::Mat laplace; // 包含Laplacian的32位浮点图像
int aperture; // 卷积核的大小
};
#endif // LAPLACIAN_H
~~~
接着在Laplacian.cpp中定义各个函数:
~~~
#include "laplacian.h"
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
// 设置卷积核的大小
void Laplacian::setAperture(int a)
{
aperture = a;
}
// 计算浮点Laplacian
cv::Mat Laplacian::calcLaplacian(const cv::Mat &image)
{
// 计算Laplacian
cv::Laplacian(image, laplace, CV_32F, aperture);
// 保留图像的局部备份(用于零点交叉)
img = image.clone();
return laplace;
}
// 返回8位图像存储的Laplacian结果
// 零点交叉于灰度值128
// 如果没有指定scale参数,则最大值缩放至强度255
// 必须在调用它之前调用calcLaplacian()
cv::Mat Laplacian::getLaplacianImage(double scale)
{
if (scale<0) {
double lapmin, lapmax;
cv::minMaxLoc(laplace,&lapmin,&lapmax);
scale= 127/ std::max(-lapmin,lapmax);
}
cv::Mat laplaceImage;
laplace.convertTo(laplaceImage,CV_8U,scale,128);
return laplaceImage;
}
// 得到零点交叉的二值图像
// 如果相邻像素的乘积小于threshold
// 则零点交叉被忽略
cv::Mat Laplacian::getZeroCrossings(float threshold)
{
// 创建迭代器
cv::Mat_<float>::const_iterator it= laplace.begin<float>()+laplace.step1();
cv::Mat_<float>::const_iterator itend= laplace.end<float>();
cv::Mat_<float>::const_iterator itup= laplace.begin<float>();
// 初始化为白色的二值图像
cv::Mat binary(laplace.size(),CV_8U,cv::Scalar(255));
cv::Mat_<uchar>::iterator itout= binary.begin<uchar>()+binary.step1();
// 对输入阈值取反
threshold *= -1.0;
for ( ; it!= itend; ++it, ++itup, ++itout)
{
// 如果相邻像素的乘积为负数,则符号发生改变
if (*it * *(it-1) < threshold)
*itout= 0; // 水平方向零点交叉
else if (*it * *itup < threshold)
*itout= 0; // 垂直方向零点交叉
}
return binary;
}
// 使用sobel算子得到零点交叉的二值图像
// 如果相邻的像素的乘积小雨threshold
// 那么零点交叉将被忽略
cv::Mat Laplacian::getZeroCrossingsWithSobel(float threshold)
{
cv::Mat sx;
cv::Sobel(img,sx,CV_32F,1,0,1);
cv::Mat sy;
cv::Sobel(img,sy,CV_32F,0,1,1);
// 创建迭代器
cv::Mat_<float>::const_iterator it= laplace.begin<float>()+laplace.step1();
cv::Mat_<float>::const_iterator itend= laplace.end<float>();
cv::Mat_<float>::const_iterator itup= laplace.begin<float>();
cv::Mat_<float>::const_iterator itx= sx.begin<float>()+sx.step1();
cv::Mat_<float>::const_iterator ity= sy.begin<float>()+sy.step1();
// 初始化为白色的二值图像
cv::Mat binary(laplace.size(),CV_8U,cv::Scalar(255));
cv::Mat_<uchar>::iterator itout= binary.begin<uchar>()+binary.step1();
for ( ; it!= itend; ++it, ++itup, ++itout, ++itx, ++ity) {
// 如果相邻像素的乘积为负数,则符号发生改变
if (*it * *(it-1) < 0.0 && fabs(*ity) > threshold)
*itout= 0; // 水平方向零点交叉
else if (*it * *itup < 0.0 && fabs(*ity) > threshold)
*itout= 0; // 垂直方向零点交叉
}
return binary;
}
~~~
最后修改main函数:
~~~
#include <QCoreApplication>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <QDebug>
#include "laplacian.h"
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
cv::Mat image= cv::imread("c:/073.jpg",0); // 输入图像
if (!image.data)
return 0;
// 显示包含感兴趣区域的灰度化原图像
cv::rectangle(image,cv::Point(362,135),cv::Point(374,147),cv::Scalar(255,255,255));
cv::namedWindow("Original Image with ROI");
cv::imshow("Original Image with ROI",image);
// 直接调用函数进行7*7的拉普拉斯变换
cv::Mat laplace;
cv::Laplacian(image,laplace,CV_8U,7,0.01,128);
cv::namedWindow("Laplacian Image");
cv::imshow("Laplacian Image",laplace);
// 使用自建类Laplacian实现拉普拉斯变换
Laplacian laplacian;
laplacian.setAperture(7);
cv::Mat flap= laplacian.calcLaplacian(image);
double lapmin, lapmax;
cv::minMaxLoc(flap,&lapmin,&lapmax);
laplace = laplacian.getLaplacianImage();
cv::namedWindow("Laplacian Image (7x7)");
cv::imshow("Laplacian Image (7x7)",laplace);
// 显示零点交叉
cv::Mat zeros;
zeros= laplacian.getZeroCrossings(lapmax);
cv::namedWindow("Zero-crossings");
cv::imshow("Zero-crossings",zeros);
// 使用Sobel算子显示零点交叉
zeros= laplacian.getZeroCrossings();
zeros= laplacian.getZeroCrossingsWithSobel(50);
cv::namedWindow("Zero-crossings (2)");
return a.exec();
}
~~~
调用函数(左)、使用自建类实现7*7拉普拉斯变换的效果对比:
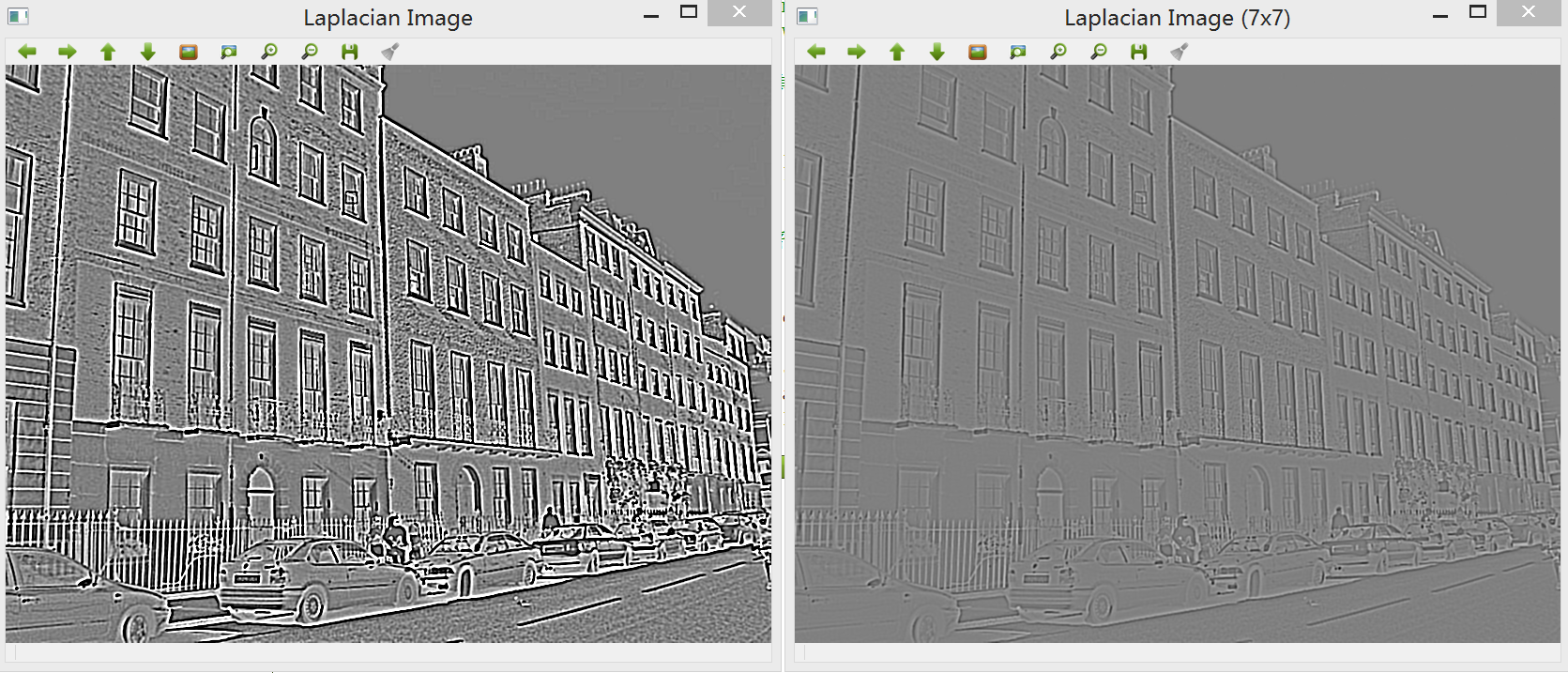
输出零点交叉检测到的所有边缘,由于Laplacian不对强边与弱边作区分,且对噪声十分敏感,因此输出结果检测到很多的边缘。
OpenCV2学习笔记(四)
最后更新于:2022-04-01 06:35:54
##两种图像分割方法比较
此次研究两种图像分割法,分别是基于形态学的分水岭算法和基于图割理论的GrabCut算法。OpenCV均提供了两张算法或其变种。鉴于研究所需,记录一些知识点,开发平台为OpenCV2.4.9+Qt5.3.2。
一、使用分水岭算法进行图像分割
分水岭变换是一种常用的图像处理算法,在网上很容易搜到详细的原理分析。简单来说,这是一种基于拓扑理论的数学形态学的图像分割方法,其基本思想是把图像看作是测地学上的拓扑地貌,图像中每一点像素的灰度值表示该点的海拔高度,每一个局部极小值及其影响区域称为集水盆,而集水盆的边界则形成分水岭。分水岭的概念和形成可以通过模拟浸入过程来说明。在每一个局部极小值表面,刺穿一个小孔,然后把整个模型慢慢浸入水中,随着浸入的加深,每一个局部极小值的影响域慢慢向外扩展,在两个集水盆汇合处构筑大坝,即形成分水岭。
分水岭算法简单,因此存在一些缺陷,如容易导致图像的过度分割。分水岭算法对微弱边缘具有良好的响应,图像中的噪声、物体表面细微的灰度变化,都会产生过度分割的现象。
为消除分水岭算法产生的过度分割,有两种常规的处理方法,一是利用先验知识去除无关边缘信息。二是修改梯度函数使得集水盆只响应想要探测的目标。
OpenCV提供了该算法的改进版本,使用预定义的一组标记来引导对图像的分割,该算法是通过cv::watershed函数来实现的。
要实现分水岭算法,首先新建一个类WaterShedSegmentation,在watershedsegmentation.h中添加:
~~~
#ifndef WATERSHEDSEGMENTATION_H
#define WATERSHEDSEGMENTATION_H
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
class WaterShedSegmentation
{
public:
void setMarkers(const cv::Mat &markerImage); // 将原图像转换为整数图像
cv::Mat process(const cv::Mat &image); // // 分水岭算法实现
// 以下是两种简化结果的特殊方法
cv::Mat getSegmentation();
cv::Mat getWatersheds();
private:
cv::Mat markers; // 用于非零像素点的标记
};
#endif // WATERSHEDSEGMENTATION_H
~~~
接着,在watershedsegmentation.cpp中添加:
~~~
#include "watershedsegmentation.h"
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
void WaterShedSegmentation::setMarkers(const cv::Mat &markerImage) // 该函数将原图像转换为整数图像
{
markerImage.convertTo(markers,CV_32S);
}
cv::Mat WaterShedSegmentation::process(const cv::Mat &image)
{
// 使用分水岭算法
cv::watershed(image,markers);
return markers;
}
// 以下是两种简化结果的特殊方法
// 以图像的形式返回分水岭结果
cv::Mat WaterShedSegmentation::getSegmentation()
{
cv::Mat tmp;
// 所有像素值高于255的标签分割均赋值为255
markers.convertTo(tmp,CV_8U);
return tmp;
}
cv::Mat WaterShedSegmentation::getWatersheds()
{
cv::Mat tmp;
markers.convertTo(tmp,CV_8U,255,255);
return tmp;
}
~~~
main函数修改如下:
~~~
#include <QCoreApplication>
#include "watershedsegmentation.h"
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
// 输入待处理的图像
cv::Mat image= cv::imread("c:/Fig4.41(a).jpg");
if (!image.data)
return 0;
cv::namedWindow("Original Image");
cv::imshow("Original Image",image);
// 输入图像,将其转化为二值图像
cv::Mat binary;
binary= cv::imread("c:/Fig4.41(a).jpg",0);
// 显示二值图像
cv::namedWindow("Binary Image");
cv::imshow("Binary Image",binary);
// 移除噪点
cv::Mat fg;
cv::erode(binary,fg,cv::Mat(),cv::Point(-1,-1),6);
// 显示前景图像
cv::namedWindow("Foreground Image");
cv::imshow("Foreground Image", fg);
// 识别背景图像,生成的黑色像素对应背景像素
cv::Mat bg;
cv::dilate(binary,bg,cv::Mat(),cv::Point(-1,-1),6);
cv::threshold(bg, bg, 1, 128, cv::THRESH_BINARY_INV);
// 显示背景图像
cv::namedWindow("Background Image");
cv::imshow("Background Image", bg);
// 显示标记图像
cv::Mat markers(binary.size(), CV_8U,cv::Scalar(0));
markers= fg + bg;
cv::namedWindow("Markers");
cv::imshow("Markers", markers);
// 以下进行分水岭算法
WaterShedSegmentation segmenter;
segmenter.setMarkers(markers);
segmenter.process(image);
// 以下是两种处理结果,显示分割结果
cv::namedWindow("Segmentation");
cv::imshow("Segmentation", segmenter.getSegmentation());
cv::namedWindow("Watersheds");
cv::imshow("Watersheds",segmenter.getWatersheds());
return a.exec();
}
~~~
效果1:算法识别出属于前景和背景的像素(有误差)。

效果2:组合前景和背景图,形成标记图形,这是分水岭的输入参数。

效果3:分割结果中,标记图像得到更新。

效果4:显示边界图像。
可以看出,分水岭算法对微弱边缘具有良好的响应,是得到封闭连续边缘的保证的。但对于不同质量的图像其分割效果不尽相同,但总的来说效果仍需要改进。
二、使用GrabCut算法分割图像
GrabCut是另一种同样较为流行的图像分割算法。GrabCut是在GraphCut基础上改进的一种图像分割算法,它并非基于图像形态学,而是基于图割理论(参考:[http://www.cnblogs.com/tornadomeet/archive/2012/11/06/2757585.html](http://www.cnblogs.com/tornadomeet/archive/2012/11/06/2757585.html))。在使用GrabCut时,需要人工给定一定区域的目标或者背景,然后算法根据设定的参数来进行分割。GrabCut在计算时比分水岭算法更加复杂,尤其适合从静态图像中提取前景照片的应用。
OpenCV中提供了cv::grabcut函数,因此只需提供图像并标记背景像素和前景像素,基于局部的标记,算法即可将图像中的像素进行分割。在这里使用的局部标记方法是定义一个矩形。cv::grabcut的函数定义如下:
~~~
cv::grabCut(image, // 输入图像
result, // 分割输出结果
rectangle,// 包含前景物体的矩形
bgModel,fgModel, // 模型
1, // 迭代次数
cv::GC_INIT_WITH_RECT); // 使用矩形进行初始化
~~~
在main函数添加:
~~~
// GrabCut算法
cv::Mat image= cv::imread("c:/Fig8.04(a).jpg");
// 设定矩形
cv::Rect rectangle(50,70,image.cols-150,image.rows-180);
cv::Mat result; // 分割结果 (4种可能取值)
cv::Mat bgModel,fgModel; // 模型(内部使用)
// 进行GrabCut分割
cv::grabCut(image, result, rectangle, bgModel, fgModel, 1, cv::GC_INIT_WITH_RECT);
// 得到可能为前景的像素
cv::compare(result, cv::GC_PR_FGD, result,cv::CMP_EQ);
// 生成输出图像
cv::Mat foreground(image.size(), CV_8UC3, cv::Scalar(255,255,255));
image.copyTo(foreground, result); // 不复制背景数据
// 包含矩形的原始图像
cv::rectangle(image, rectangle, cv::Scalar(255,255,255),1);
cv::namedWindow("Orginal Image");
cv::imshow("Orginal Image", image);
// 输出前景图像结果
cv::namedWindow("Foreground Of Segmented Image");
cv::imshow("Foreground Of Segmented Image", foreground);
~~~
效果:

在函数cv::grabCut中,最后一个参数表示我们使用的是包围盒模式,而该算法支持的输入/输出分割图像可以有四种数值,如函数cv::compare函数中的参数:
cv::GC_BGD:确定属于背景的像素;
cv::GC_FGD:确定属于前景的元素;
cv::GC_PR_BGD:可能属于背景的元素;
cv::GC_PR_FGD:可能属于前景的元素。
在上图中,GrabCut算法通过指定方框区域来提取前景物体。同时,也可将数值cv::GC_BGD和cv::GC_FGD赋予分割图像的某些特定像素,并且把这类分割图像作为cv::grabcut函数的第二个参数(此时需要指定GC_INIT_WITH_MASK作为输入模式)。
基于这些信息,GrabCut通过以下主要步骤创建分割:
1. 前景标签(cv::GC_PR_FGD)被临时赋予所有为标记的像素。基于当前的分类,算法将像素归类为颜色或灰度值相似的聚类。
2. 通过引入背景与前景像素的边界进行分割。这个优化的过程尝试将标签相似的像素相连接,这里利用了在强度相对已知的区域之间对边界像素的(惩罚?)。这个最优化问题通过GraphCut算法得到高效解决。
3. 对获取的分割结果产生新的像素标签,重复聚类过程,找到新的最优解。根据场景的复杂度,得到最佳结果,对于简单的场景,有时只需要一次迭代。
关于GrabCut算法,还需要进一步研究GraphCut才能深刻理解。
OpenCV2学习笔记(三)
最后更新于:2022-04-01 06:35:51
##形态学及边缘角点检测
形态学滤波理论于上世纪90年代提出,目前被广泛用于分析及处理离散图像。其基本运算有4个: 膨胀、腐蚀、开启和闭合, 它们在二值图像和灰度图像中各有特点。基于这些基本运算还可推导和组合成各种数学形态学实用算法,用它们可以进行图像形状和结构的分析及处理,包括图像分割、特征抽取、边缘检测、 图像滤波、图像增强和恢复等。数学形态学方法利用一个称作结构元素的“探针”收集图像的信息,当探针在图像中不断移动时, 便可考察图像各个部分之间的相互关系,从而了解图像的结构特征。数学形态学基于探测的思想,与人的FOA(Focus Of Attention)的视觉特点有类似之处。其中最重要的结构元素,可直接携带知识(形态、大小、甚至加入灰度和色度信息)来探测、研究图像的结构特点。鉴于研究所需,记录一些知识点,开发平台为OpenCV2.4.9+Qt5.3.2。
一:图像腐蚀、膨胀和开闭运算
这些运算的基本公式和原理参考:[http://blog.csdn.net/liyuefeilong/article/details/43374777](http://blog.csdn.net/liyuefeilong/article/details/43374777)
图像的腐蚀:替换为当前像素位像素集合中的最小像素值,函数为cv::erode
图像的膨胀:替换为当前像素位像素集合中的最大像素值,函数为cv::dilate
图像的开运算:先腐蚀后膨胀,函数为cv::morphologyEx,对应的参数为MORPH_CLOSE
图像的闭运算:先膨胀后腐蚀,函数为cv::morphologyEx,对应的参数为MORPH_OPEN
如morphologyEx(image, opened, cv::MORPH_OPEN, element2, cv::Point(-1,-1), 1); 中,输入图像为image,输出图像为opened,执行开操作,结构元素为element2,原点参数cv::Point(-1,-1)表示原点位于矩阵的中心(默认),最后的1则表示对图像的操作次数(注:对一幅图像多次使用开操作和闭操作时效果不会有改善,这些运算是等幂的)。形态学滤波本是基于二值图像上,但以上这些运算同样适用于灰度图像。
新建一个Qt控制台应用,创建一个类:MorphoFeatures:
~~~
#ifndef MORPHOFEATURES_H
#define MORPHOFEATURES_H
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
class MorphoFeatures
{
public:
void fourFunctions(cv::Mat &image); // 腐蚀、膨胀、开操作、闭操作
}
#endif // MORPHOFEATURES_H
~~~
~~~
void MorphoFeatures::fourFunctions(cv::Mat &image)
{
// 腐蚀运算,替换为当前像素位像素集合中的最小像素值
cv::Mat eroded;
cv::erode(image, eroded, cv::Mat());
// 膨胀运算,替换为当前像素位像素集合中的最大像素值
cv::Mat dilated;
cv::dilate(image, dilated, cv::Mat());
// 闭运算,先膨胀后腐蚀
cv::Mat closed;
cv::Mat element1(3, 3, CV_8U, cv::Scalar(1));
cv::morphologyEx(image, // 输入图像
closed, // 输出图像
cv::MORPH_CLOSE, // 指定操作
element1, // 结构元素设置
cv::Point(-1,-1), // 操作的位置
1); // 操作的次数
//开运算,先腐蚀后膨胀
cv::Mat opened;
cv::Mat element2(3, 3, CV_8U, cv::Scalar(1));
cv::morphologyEx(image, opened, cv::MORPH_OPEN, element2, cv::Point(-1,-1), 1);
cv::namedWindow("Eroded Image");
cv::imshow("Eroded Image", eroded);
cv::namedWindow("Dilated Image");
cv::imshow("Dilated Image", dilated);
cv::namedWindow("Orginal Image");
cv::imshow("Orginal Image", image);
cv::namedWindow("Closed Image");
cv::imshow("Closed Image", closed);
cv::namedWindow("Opened Image");
cv::imshow("Opened Image", opened);
}
~~~
得出四种操作的处理效果:
这里你会觉得腐蚀与膨胀、开操作与闭操作的效果和期望是相反的。这是因为我们认为图像素材中黑色字体是前景,白色为背景。而一般的,形态学规定用高像素表示前景物体,用低像素表示背景,因此**使用这些基本运算之前,可以根据实际情况给原图像取反。**
二、利用形态学滤波进行边缘检测
形态学滤波利用梯度进行边缘检测,其原理是计算膨胀后的图像和腐蚀后的图像的差值,由于两个变换后的图像不同之处主要在边缘处,图像边缘将通过求差得到强化。函数为morphologyEx,参数为MORPH_GRADIENT。若架构元素尺寸越大,检测出的边缘越厚。最简单的边缘检测运算是用原图减去腐蚀后的图像,或者用膨胀后的图像减去原图或腐蚀图像,效果很直观,缺点是得到的边缘较薄。
以下给出形态学滤波进行边缘检测的基本方法:
在class MorphoFeatures中添加几个函数:
~~~
public:
cv::Mat getEdges(const cv::Mat &image);
void setThreshold(int gate); // 设定阈值
private:
void applyThreshold(cv::Mat &result);
~~~
在morphofeatures.cpp中添加:
~~~
void MorphoFeatures::setThreshold(int gate)
{
threshold = gate;
}
cv::Mat MorphoFeatures::getEdges(const cv::Mat &image)
{
// 得到梯度图
cv::Mat result;
cv::morphologyEx(image, result, cv::MORPH_GRADIENT, cv::Mat());
// 阈值化以得到二值图像
applyThreshold(result);
return result;
}
void MorphoFeatures::applyThreshold(cv::Mat &result)
{
// 使用阈值化
if(threshold > 0)
{
cv::threshold(result, result, threshold, 255, cv::THRESH_BINARY);
}
}
~~~
简单修改main函数:
~~~
#include <QCoreApplication>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include "morphofeatures.h"
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
MorphoFeatures h;
cv::Mat image = cv::imread("c:\\gray.jpg");
// h.fourFunctions(image);
// 边缘检测
h.setThreshold(80); // 设定阈值
cv::Mat result = h.getEdges(image);
cv::namedWindow("Input Image");
cv::imshow("Input Image",image);
cv::namedWindow("Edge");
cv::imshow("Edge",result);
return a.exec();
}
~~~
效果:
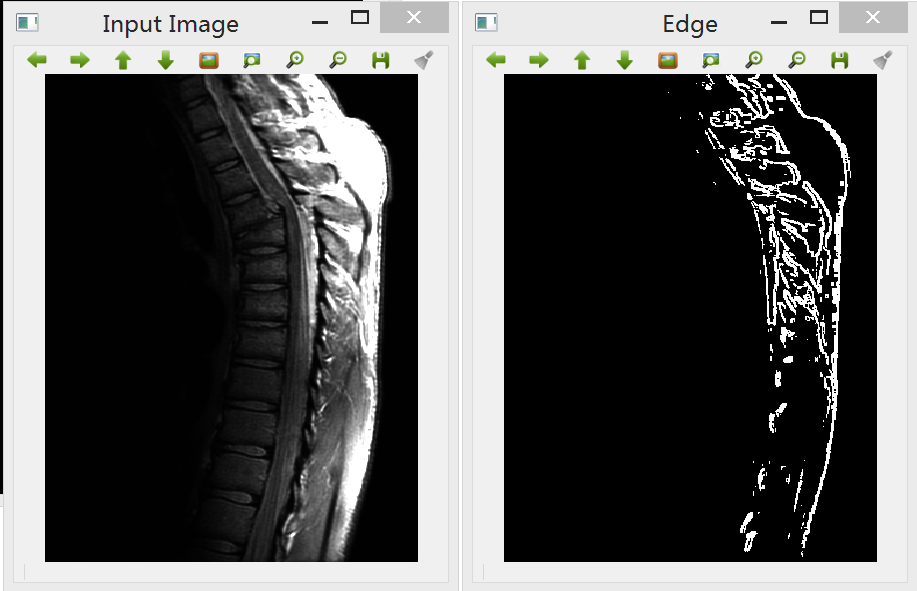
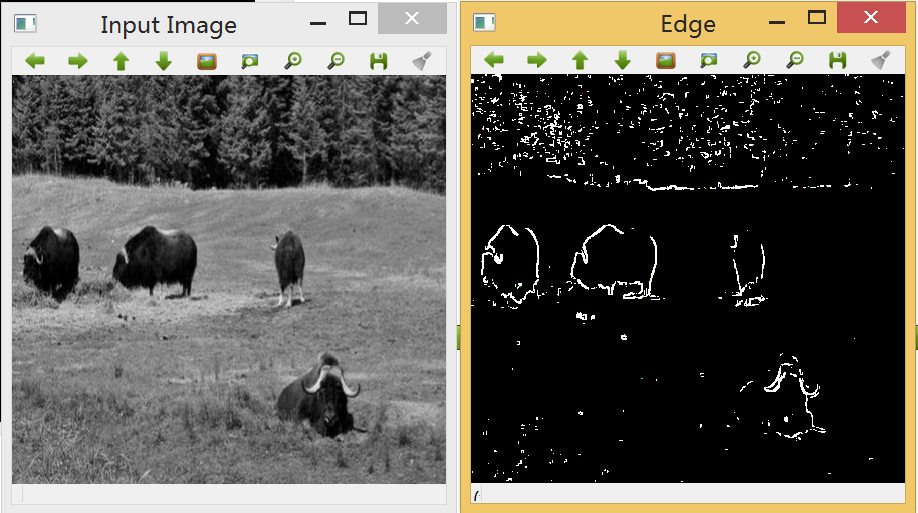
效果差强人意……除此之外,还可以用sobel算子、Canny算子等对图像进行边缘检测,这些方法都可以通过改变结构元素来实现,如下图所示为几种3*3的Sobel算子。基于Sobel算子的边缘检测见:[http://blog.csdn.net/liyuefeilong/article/details/43452711](http://blog.csdn.net/liyuefeilong/article/details/43452711)
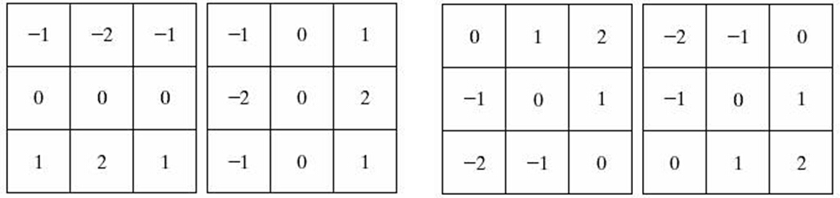
另外一个应用是对图像进行形态学tophat变换,用h表示,定义为:

其中,f是输入图像,B是结构元素函数。tophat变换对于增强灰度图像的阴影细节很有用处。
三、利用形态学滤波进行图像角点检测
这里使用四种不同的结构元素检测图像角点,分别为十字型、菱型、x型和方形元素,尺寸规定为5*5。与边缘检测不同,角点的检测复杂。运算过程主要分三步:
第一步,先用十字形的结构元素膨胀原图像,这种情况下只会在边缘处“扩张”,角点不发生变化。接着用菱形的结构元素腐蚀原图像,只有拐角处才会被“收缩”,而直线边缘不发生变化。
第二步,用X型的结构元素膨胀原图像,角点膨胀的比边要多。这样第二次用方块腐蚀时,角点恢复原状,而边要腐蚀的更多。
第三步,将一二步的两幅输出图像相减,结果只保留了各个拐角处的细节。
首先在类MorphoFeatures.h中添加:
~~~
public:
cv::Mat getCorners(const cv::Mat &image); // 角点检测函数
void drawOnImage(const cv::Mat &binary, cv::Mat &image); // 在角点处标记圆圈
// 以下构造四种不同的结构元素用来检测灰度图像的角点
MorphoFeatures():threshold(-1), cross(5,5,CV_8U,cv::Scalar(0)), diamond(5,5,CV_8U,cv::Scalar(1)), square(5,5,CV_8U,cv::Scalar(1)), x(5,5,CV_8U,cv::Scalar(0))
{
// 5*5的十字形元素
for (int i=0; i<5; i++) {
cross.at<uchar>(2,i)= 1;
cross.at<uchar>(i,2)= 1;
}
// 5*5的菱形元素
diamond.at<uchar>(0,0)= 0;
diamond.at<uchar>(0,1)= 0;
diamond.at<uchar>(1,0)= 0;
diamond.at<uchar>(4,4)= 0;
diamond.at<uchar>(3,4)= 0;
diamond.at<uchar>(4,3)= 0;
diamond.at<uchar>(4,0)= 0;
diamond.at<uchar>(4,1)= 0;
diamond.at<uchar>(3,0)= 0;
diamond.at<uchar>(0,4)= 0;
diamond.at<uchar>(0,3)= 0;
diamond.at<uchar>(1,4)= 0;
// 5*5的x型元素
for (int i=0; i<5; i++)
{
x.at<uchar>(i,i)= 1;
x.at<uchar>(4-i,i)= 1;
}
}
~~~
接着,在morphofeatures.cpp中添加:
~~~
cv::Mat MorphoFeatures::getCorners(const cv::Mat &image)
{
cv::Mat result;
// 十字膨胀
cv::dilate(image, result, cross);
// 棱形腐蚀 形态学函数支持原地操作
cv::erode(result, result, diamond);
cv::Mat result2;
// x型膨胀
cv::dilate(image, result2, x);
// 方形腐蚀
cv::erode(result2, result2, square);
// 对result和result2这两张图像相减,得到焦点图像
cv::absdiff(result2, result, result);
// 阈值化,得到二值图像
applyThreshold(result);
cv::namedWindow("Corners");
cv::imshow("Corners", result);
return result;
}
void MorphoFeatures::drawOnImage(const cv::Mat &binary, cv::Mat &image)
{
cv::Mat_<uchar>::const_iterator it = binary.begin<uchar>();
cv::Mat_<uchar>::const_iterator itend = binary.end<uchar>();
for(int i=0; it!=itend; ++it, ++i)
{
if(*it) // 若该像素被标定为角点则画白色圈圈
{
cv::circle(image, cv::Point(i%image.step, i/image.step), 5, cv::Scalar(255, 255, 255));
}
}
}
~~~
在main.cpp中简单添加:
~~~
cv::Mat corners;
corners = h.getCorners(image);
h.drawOnImage(corners, image);
cv::namedWindow("Corners On Image");
cv::imshow("Corners On Image", image);
~~~
效果:
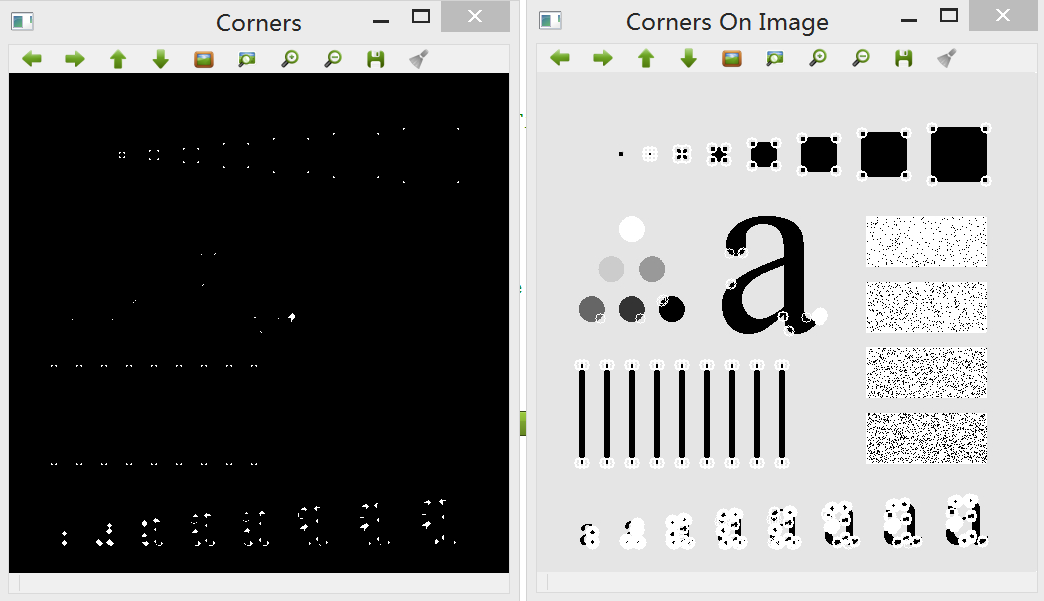
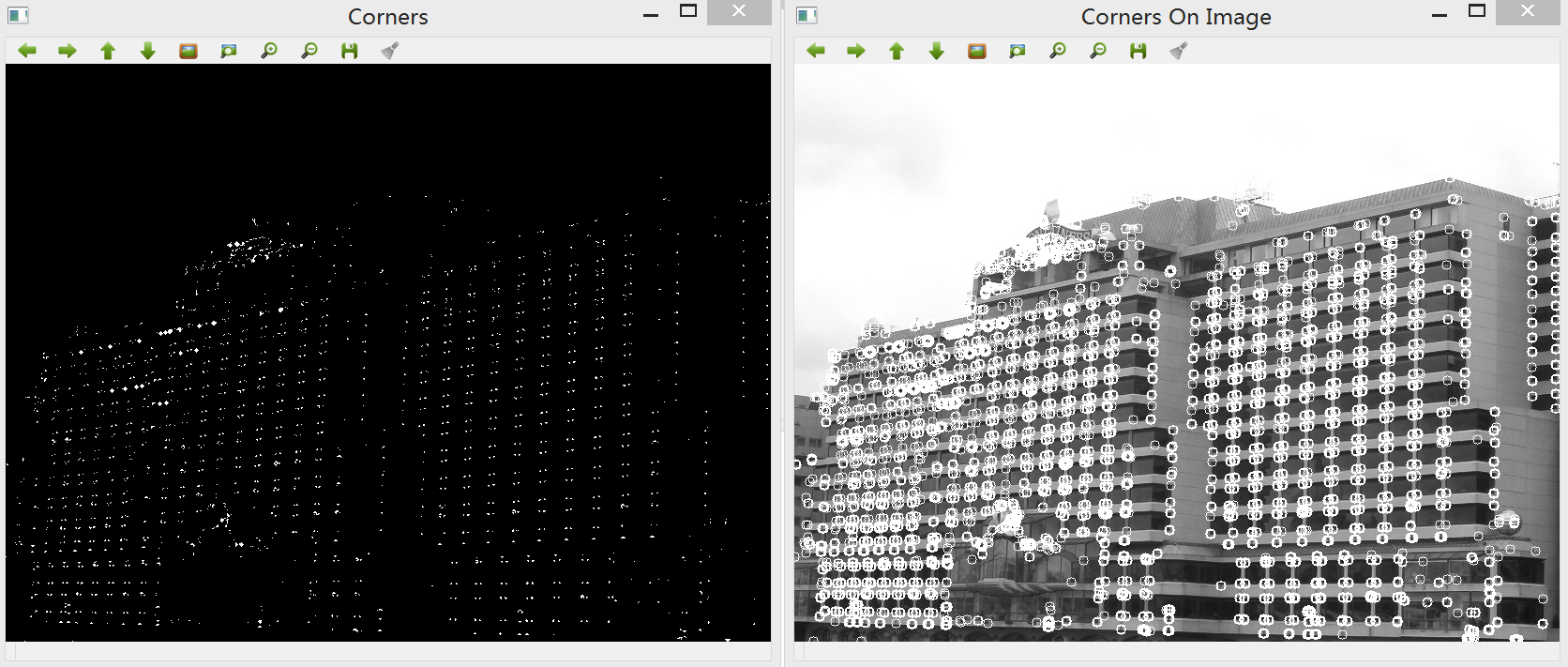
在这里,需要把输入图像转化为二值图像,因此阈值的选择会影响角点检测效果,如下图所示:
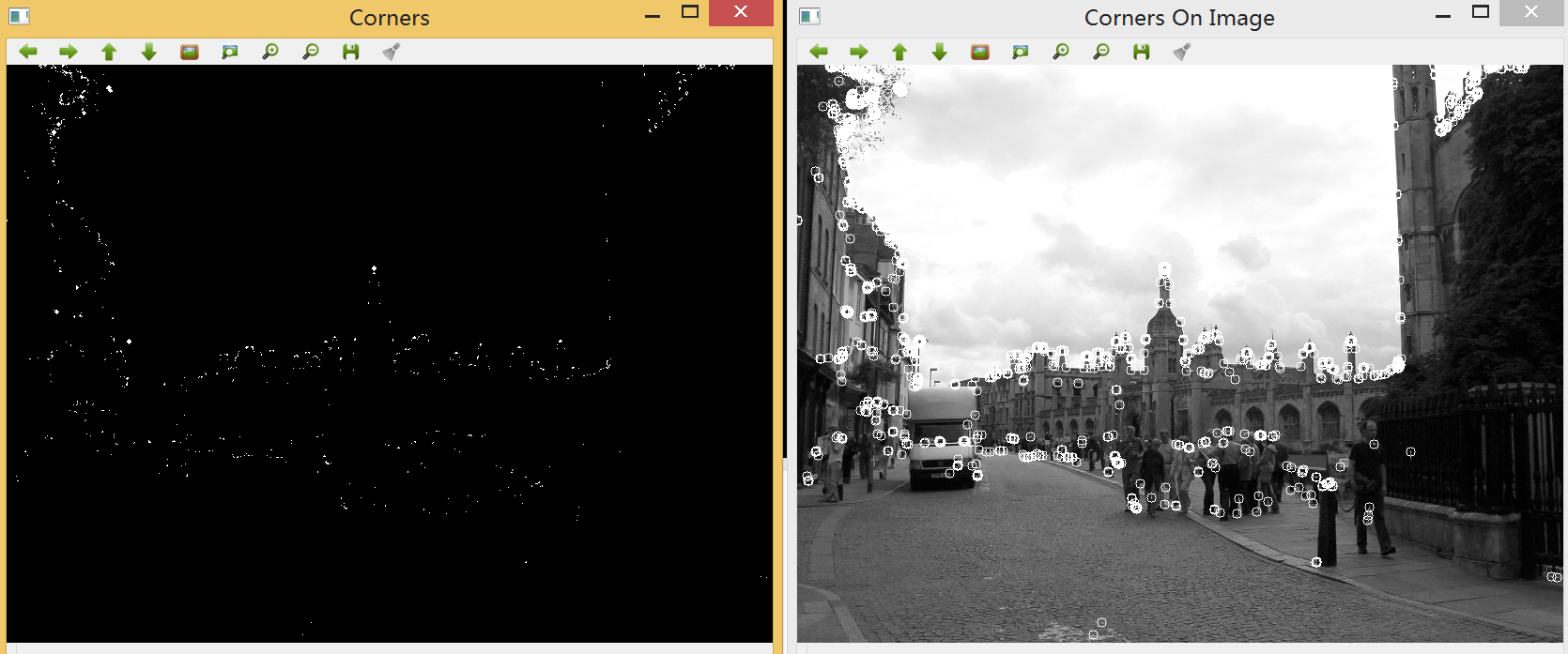
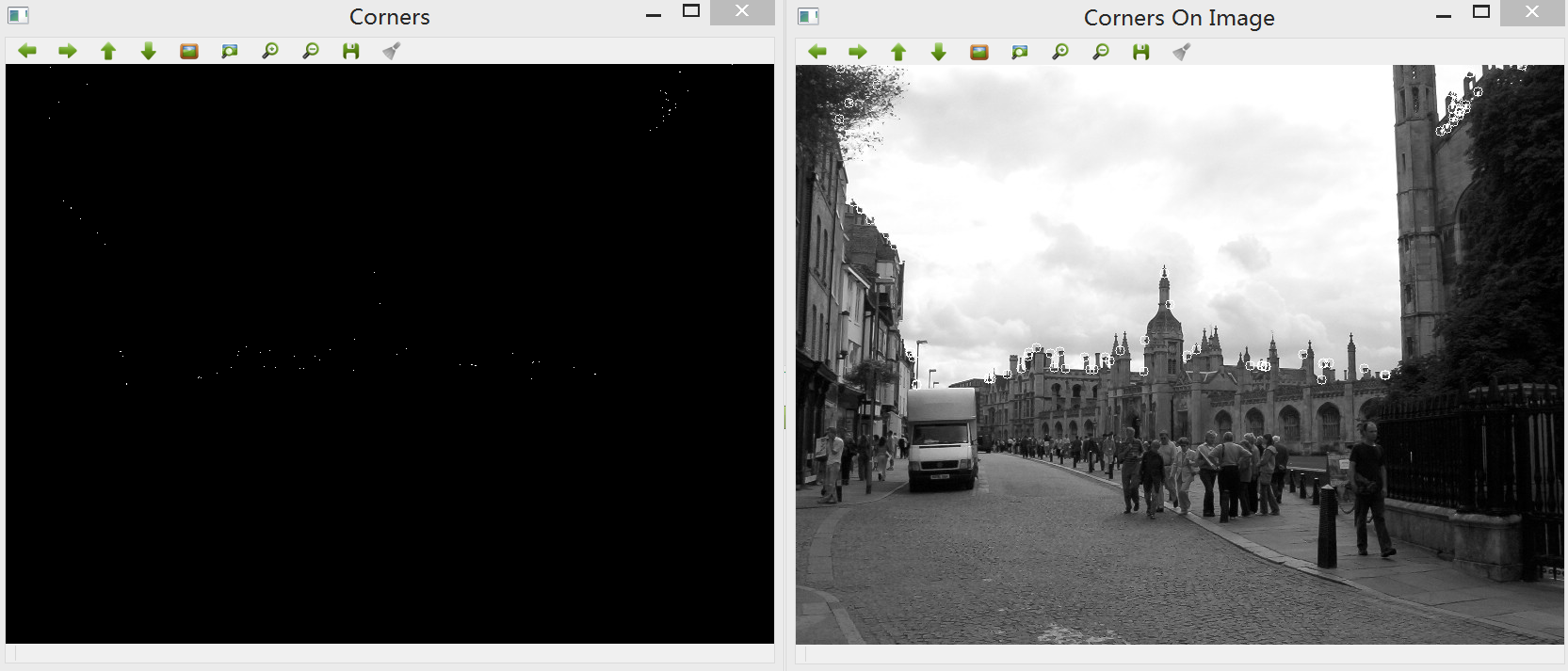
尽管角点检测效果有好有坏,不过实现该方法,对于理解腐蚀、膨胀、开操作、闭操作有很好的帮助。
欢迎转载或分享,但请务必声明文章出处~