ASCII、Unicode、GBK和UTF-8字符编码的区别联系
最后更新于:2022-04-01 11:37:25
2015-05-08 实验楼
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物。他们看到8个开关状态是好的,于是他们把这称为“字节”。
再后来,他们又做了一些可以处理这些字节的机器,机器开动了,可以用字节来组合出很多状态,状态开始变来变去。他们看到这样是好的,于是它们就这机器称为“计算机”。
开始计算机只在美国用。八位的字节一共可以组合出256(2的8次方)种不同的状态。 他们把其中的编号从0开始的32种状态分别规定了特殊的用途,一但终端、打印机遇上约定好的这些字节被传过来时,就要做一些约定的动作,如:
~~~
遇上0×10, 终端就换行;
遇上0×07, 终端就向人们嘟嘟叫;
遇上0x1b, 打印机就打印反白的字,或者终端就用彩色显示字母。
~~~
他们看到这样很好,于是就把这些0×20以下的字节状态称为“控制码”。他们又把所有的空 格、标点符号、数字、大小写字母分别用连续的字节状态表示,一直编到了第127号,这样计算机就可以用不同字节来存储英语的文字了。
大家看到这样,都感觉很好,于是大家都把这个方案叫做 ANSI的“Ascii”编码(American Standard Code for Information Interchange,美国信息互换标准代码)。当时世界上所有的计算机都用同样的ASCII方案来保存英文文字。
后来,就像建造巴比伦塔一样,世界各地的都开始使用计算机,但是很多国家用的不是英文,他们的字母里有许多是ASCII里没有的,为了可以在计算机保存他们的文字,他们决定采用 127号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需要用下到的横线、竖线、交叉等形状,一直把序号编到了最后一个状态255。
从128 到255这一页的字符集被称“扩展字符集”。从此之后,贪婪的人类再没有新的状态可以用了,美帝国主义可能没有想到还有第三世界国家的人们也希望可以用到计算机吧!
等中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存呢。
但是这难不倒智慧的中国人民,我们不客气地把那些127号之后的奇异符号们直接取消掉, 规定:
~~~
一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字;
前面的一个字节(他称之为高字节)从0xA1用到 0xF7,后面一个字节(低字节)从0xA1到0xFE;
~~~
这样我们就可以组合出大约7000多个简体汉字了。
在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的“全角”字符。
而原来在127号以下的那些就叫“半角”字符了。
中国人民看到这样很不错,于是就把这种汉字方案叫做 “GB2312”。GB2312 是对 ASCII 的中文扩展。
但是中国的汉字太多了,我们很快就就发现有许多人的人名没有办法在这里打出来,特别是某些很会麻烦别人的国家领导人。
于是我们不得不继续把 GB2312 没有用到的码位找出来老实不客气地用上。
后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK包括了GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
后来少数民族也要用电脑了,于是我们再扩展,又加了几千个新的少数民族的字,GBK扩成了 GB18030。从此之后,中华民族的文化就可以在计算机时代中传承了。
中国的程序员们看到这一系列汉字编码的标准是好的,于是通称他们叫做 “DBCS“(Double Byte Charecter Set 双字节字符集)。
在DBCS系列标准里,最大的特点是两字节长的汉字字符和一字节长的英文字符并存于同一套编码方案里,因此他们写的程序为了支持中文处理,必须要注意字串里的每一个字节的值,如果这个值是大于127的,那么就认为一个双字节字符集里的字符出现了。
那时候凡是受过加持,会编程的计算机僧侣们都要每天念下面这个咒语数百遍: “一个汉字算两个英文字符!一个汉字算两个英文字符……”
因为当时各个国家都像中国这样搞出一套自己的编码标准,结果互相之间谁也不懂谁的编码,谁也不支持别人的编码。
连大陆和台湾这样只相隔了150海里,使用着同一种语言的兄弟地区,也分别采用了不同的 DBCS 编码方案——当时的中国人想让电脑显示汉字,就必须装上一个“汉字系统”,专门用来处理汉字的显示、输入的问题,但是那个台湾的愚昧封建人士写的算命程序就必须加装另一套支持 BIG5 编码的什么“倚天汉字系统”才可以用,装错了字符系统,显示就会乱了套!这怎么办?而且世界民族之林中还有那些一时用不上电脑的穷苦人民,他们的文字又怎么办? 真是计算机的巴比伦塔命题啊!
正在这时,大天使加百列及时出现了——一个叫 ISO (国际标谁化组织)的国际组织决定着手解决这个问题。
他们采用的方法很简单:
~~~
废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号 的编码!
~~~
他们打算叫它”Universal Multiple-Octet Coded Character Set”,简称 UCS, 俗称 “unicode”。
unicode开始制订时,计算机的存储器容量极大地发展了,空间再也不成为问题了。于是 ISO 就直接规定必须用两个字节,也就是16位来统一表示所有的字符,对于ASCII里的那些“半角”字符,unicode包持其原编码不变,只是将其长度由原来的8位扩展为16位,而其他文化和语言的字符则全部重新统一编码。由于“半角”英文符号只需要用到低8位,所以其高8位永远是0,因此这种大气的方案在保存英文文本时会多浪费一倍的空间。
这时候,从旧社会里走过来的程序员开始发现一个奇怪的现象:他们的strlen函数靠不住了,一个汉字不再是相当于两个字符了,而是一个!是的,从unicode开始,无论是半角的英文字母,还是全角的汉字,它们都是统一的“一个字符”!同时,也都是统一的“两个字节”,请注意“字符”和“字节”两个术语的不同:
~~~
“字节”是一个8位的物理存贮单元,
而“字符”则是一个文化相关的符号。
~~~
在unicode中,一个字符就是两个字节。一个汉字算两个英文字符的时代已经快过去了。
unicode同样也不完美,这里就有两个的问题,
~~~
一个是,如何才能区别unicode和ascii?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?
第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储空间来说是极大的浪费,文本文件的大小会因此大出二三倍,这是难以接受的。
~~~
unicode在很长一段时间内无法推广,直到互联网的出现,为解决unicode如何在网络上传输的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了,顾名思义:
~~~
UTF-8就是每次8个位传输数据,
而UTF-16就是每次16个位。
~~~
UTF-8就是在互联网上使用最广的一种unicode的实现方式,这是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了。
UTF-8最大的一个特点,就是它是一种变长的编码方式。
它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,保留了ASCII字符一个字节的编码做为它的一部分,(注意的是unicode一个中文字符占2个字节,而UTF-8一个中文字符占3个字节)。
从unicode到uft-8并不是直接的对应,而是要过一些算法和规则来转换。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制) —————————————————————– 0000 0000-0000 007F | 0xxxxxxx 0000 0080-0000 07FF | 110xxxxx 10xxxxxx 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
之前一直对字符编码很模糊,网查资料被忽悠地晕头转向,看完这篇风趣的文章,把之前模糊的知识点串联起来,并稍加总结,我和我的小伙伴们都明白了!
via:[http://toutiao.io/](http://toutiao.io/)
原文链接:[http://dengo.org/archives/901](http://dengo.org/archives/901)
如何成为Python高手
最后更新于:2022-04-01 11:37:23
这篇文章主要是对我收集的一些文章的摘要。因为已经有很多比我有才华的人写出了大量关于如何成为优秀Python程序员的好文章。
我的总结主要集中在四个基本题目上:
* 函数式编程,
* 性能,
* 测试,
* 编码规范。
如果一个程序员能将这四个方面的内容知识都吸收消化,那他/她不管怎样都会有巨大的收获。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/n001.md#函数式编程)函数式编程
命令式的编程风格已经成为事实上的标准。命令式编程的程序是由一些描述状态转变的语句组成。虽然有时候这种编程方式十分的有效,但有时也不尽如此(比如复杂性) ―― 而且,相对于声明式编程方式,它可能会显得不是很直观。
如果你不明白我究竟是在说什么,这很正常。这里有一些文章能让你脑袋开窍。但你要注意,这些文章有点像《骇客帝国》里的红色药丸 ―― 一旦你尝试过了函数式编程,你就永远不会回头了。
* [http://www.amk.ca/python/writing/functional](http://www.amk.ca/python/writing/functional)
* [http://www.secnetix.de/olli/Python/lambda_functions.hawk](http://www.secnetix.de/olli/Python/lambda_functions.hawk)
* [http://docs.python.org/howto/functional.html](http://docs.python.org/howto/functional.html)
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/n001.md#性能)性能
你会看到有如此多的讨论都在批评这些“脚本语言”(Python,Ruby)是如何的性能低下,可是你却经常的容易忽略这样的事实:是程序员使用的算法导致了程序这样拙劣的表现。
这里有一些非常好的文章,能让你知道Python的运行时性能表现的细节详情,你会发现,通过这些精炼而且有趣的语言,你也能写出高性能的应用程序。而且,当你的老板质疑Python的性能时,你别忘了告诉他,这世界上第二大的搜索引擎就是用Python写成的 ―― 它叫做Youtube(参考Python摘录)
* [http://jaynes.colorado.edu/PythonIdioms.html](http://jaynes.colorado.edu/PythonIdioms.html)
* [http://wiki.python.org/moin/PythonSpeed/PerformanceTips](http://wiki.python.org/moin/PythonSpeed/PerformanceTips)
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/n001.md#测试)测试
如今在计算机科学界,测试可能是一个最让人不知所措的主题了。有些程序员能真正的理解它,十分重视TDD(测试驱动开发)和它的后继者BDD(行为驱动开发)。而另外一些根本不接受,认为这是浪费时间。那么,我现在将告诉你:如果你不曾开始使用TDD/BDD,那你错过了很多最好的东西!
这并不只是说引入了一种技术,可以替换你的公司里那种通过愚蠢的手工点击测试应用程序的原始发布管理制度,更重要的是,它是一种能够让你深入理解你自己的业务领域的工具 ―― 真正的你需要的、你想要的攻克问题、处理问题的方式。如果你还没有这样做,请试一下。下面的这些文章将会给你一些提示:
* [http://www.oreillynet.com/lpt/a/5463](http://www.oreillynet.com/lpt/a/5463)
* [http://www.oreillynet.com/lpt/a/5584](http://www.oreillynet.com/lpt/a/5584)
* [http://wiki.cacr.caltech.edu/danse/index.php/Unit_testing_and_Integration_testing](http://wiki.cacr.caltech.edu/danse/index.php/Unit_testing_and_Integration_testing)
* [http://docs.python.org/library/unittest.html](http://docs.python.org/library/unittest.html)
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/n001.md#编码规范)编码规范
并非所有的代码生来平等。有些代码可以被另外的任何一个好的程序员读懂和修改。但有些却只能被读,而且只能被代码的原始作者修改 ―― 而且这也只是在他或她写出了这代码的几小时内可以。为什么会这样?因为没有经过代码测试(上面说的)和缺乏正确的编程规范。
下面的文章给你描述了一个最小的应该遵守的规范合集。如果按照这些指导原则,你将能编写出更简洁和漂亮的代码。作为附加效应,你的程序会变得可读性更好,更容易的被你和任何其他人修改。
* [http://www.python.org/dev/peps/pep-0008/](http://www.python.org/dev/peps/pep-0008/)
* [http://www.fantascienza.net/leonardo/ar/python_best_practices.html](http://www.fantascienza.net/leonardo/ar/python_best_practices.html)
那就去传阅这这些资料吧。从坐在你身边的人开始。也许在下一次程序员沙龙或编程大会的时候,也已经成为一名Python编程高手了!
祝你学习旅途顺利。
> 本文来源:[http://blogread.cn/it/article/3892?f=wb](http://blogread.cn/it/article/3892?f=wb)
附:网络文摘
最后更新于:2022-04-01 11:37:20
处理股票数据
最后更新于:2022-04-01 11:37:18
这段时间某国股市很火爆,不少砖家在分析股市火爆的各种原因,更有不少人看到别人挣钱眼红了,点钞票杀入股市。不过,我还是很淡定的,因为没钱,所以不用担心任何股市风险临到。
但是,为了体现本人也是与时俱进的,就以股票数据为例子,来简要说明pandas和其它模块在处理数据上的应用。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/313.md#下载yahoo上的数据)下载yahoo上的数据
或许你稀奇,为什么要下载yahoo上的股票数据呢?国内网站上不是也有吗?是有。但是,那时某国内的。我喜欢yahoo,因为她曾经吸引我,注意我说的是[www.yahoo.com](http://www.yahoo.com/),不是后来被阿里巴巴收购并拆散的那个。
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31301.png)
虽然yahoo的世代渐行渐远,但她终究是值得记忆的。所以,我要演示如何下载yahoo财经栏目中的股票数据。
~~~
In [1]: import pandas
In [2]: import pandas.io.data
In [3]: sym = "BABA"
In [4]: finace = pandas.io.data.DataReader(sym, "yahoo", start="2014/11/11")
In [5]: print finace.tail(3)
Open High Low Close Volume Adj Close
Date
2015-06-17 86.580002 87.800003 86.480003 86.800003 10206100 86.800003
2015-06-18 86.970001 87.589996 86.320000 86.750000 11652600 86.750000
2015-06-19 86.510002 86.599998 85.169998 85.739998 10207100 85.739998
~~~
下载了阿里巴巴的股票数据(自2014年11月11日以来),并且打印最后三条。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/313.md#画图)画图
已经得到了一个DataFrame对象,就是前面已经下载并用finace变量引用的对象。
~~~
In[6]: import matplotlib.pyplot as plt
In [7]: plt.plot(finace.index, finace["Open"])
Out[]: [<matplotlib.lines.Line2D at 0xa88e5cc>]
In [8]: plt.show()
~~~
于是乎出来了下图:
[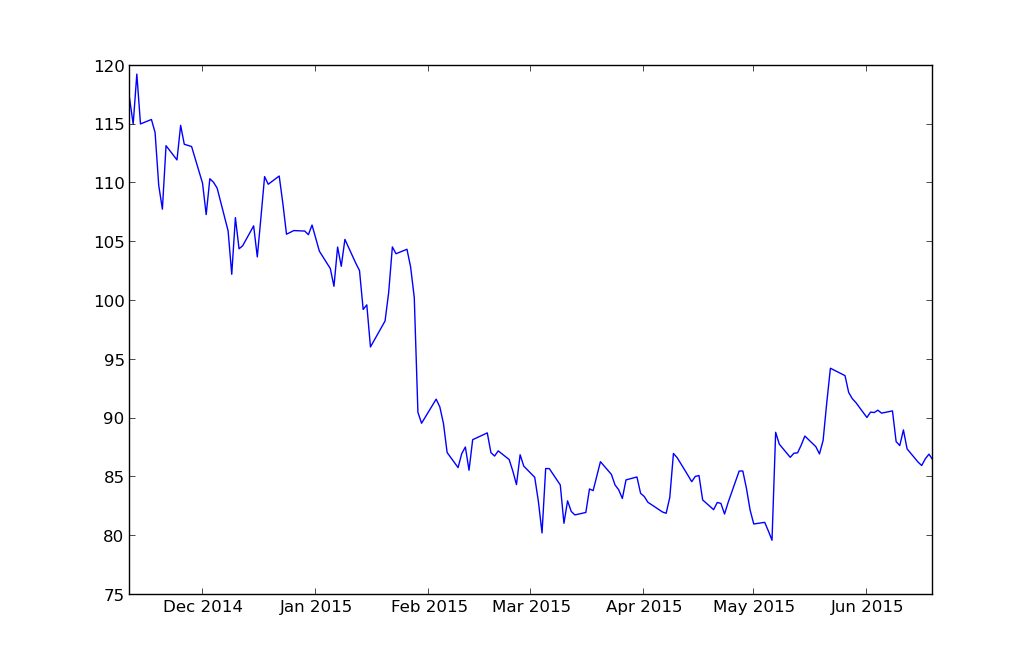](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31302.png)
从图中可以看出阿里巴巴的股票自从2014年11月11日到2015年6月19日的股票开盘价变化。看来那个所谓的“光棍节”得到了股市的认可,所以,在此我郑重地建议阿里巴巴要再造一些节日,比如3月3日、4月4日,还好,某国还有农历,阳历用完了用农历。可以维持股票高开高走了。
阿里巴巴的事情,我就不用操心了。
上面指令中的`import matplotlib.pyplot as plt`是个此前没有看到的。`matplotlib`模块是python中绘制二维图形的模块,是最好的模块。本教程在这里展示了它的一个小小地绘图功能,读者就一下看到阿里巴巴“光棍节”的力量,难道还不能说明matplotlib的强悍吗?很可惜,matplotlib的发明者——John Hunter已经于2012年8月28日因病医治无效英年早逝,这真是天妒英才呀。为了缅怀他,请读者访问官方网站:[matplotlib.org](http://matplotlib.org/),并认真学习这个模块的使用。
经过上面的操作,读者可以用`dir()`这个以前常用的法宝,来查看finace所引用的DataFrame对象的方法和属性等。只要运用此前不断向大家演示的方法——`dir+help`——就能够对这个对象进行操作,也就是能够对该股票数据进行各种操作。
再次声明,本课程仅仅是稍微演示一下相关操作,如果读者要深入研习,恭请寻找相关的专业书籍资料阅读学习。
Pandas使用(2)
最后更新于:2022-04-01 11:37:16
特别向读者生命,本教程因为篇幅限制,不能将有关pandas的内容完全详细讲述,只能“抛砖引玉”,向大家做一个简单介绍,说明其基本使用方法。当读者在实践中使用的时候,如果遇到问题,可以结合相关文档或者google来解决。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/312.md#读取csv文件)读取csv文件
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/312.md#关于csv文件)关于csv文件
csv是一种通用的、相对简单的文件格式,在表格类型的数据中用途很广泛,很多关系型数据库都支持这种类型文件的导入导出,并且excel这种常用的数据表格也能和csv文件之间转换。
> 逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须象二进制数字那样被解读的数据。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。
从上述维基百科的叙述中,重点要解读出“字段间分隔符”“最常见的是逗号或制表符”,当然,这种分隔符也可以自行制定。比如下面这个我命名为marks.csv的文件,就是用逗号(必须是半角的)作为分隔符:
~~~
name,physics,python,math,english
Google,100,100,25,12
Facebook,45,54,44,88
Twitter,54,76,13,91
Yahoo,54,452,26,100
~~~
其实,这个文件要表达的事情是(如果转化为表格形式):
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31006.png)
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/312.md#普通方法读取)普通方法读取
最简单、最直接的就是open()打开文件:
~~~
>>> with open("./marks.csv") as f:
... for line in f:
... print line
...
name,physics,python,math,english
Google,100,100,25,12
Facebook,45,54,44,88
Twitter,54,76,13,91
Yahoo,54,452,26,100
~~~
此方法可以,但略显麻烦。
python中还有一个csv的标准库,足可见csv文件的使用频繁了。
~~~
>>> import csv
>>> dir(csv)
['Dialect', 'DictReader', 'DictWriter', 'Error', 'QUOTE_ALL', 'QUOTE_MINIMAL', 'QUOTE_NONE', 'QUOTE_NONNUMERIC', 'Sniffer', 'StringIO', '_Dialect', '__all__', '__builtins__', '__doc__', '__file__', '__name__', '__package__', '__version__', 'excel', 'excel_tab', 'field_size_limit', 'get_dialect', 'list_dialects', 're', 'reader', 'reduce', 'register_dialect', 'unregister_dialect', 'writer']
~~~
什么时候也不要忘记这种最佳学习方法。从上面结果可以看出,csv模块提供的属性和方法。仅仅就读取本例子中的文件:
~~~
>>> import csv
>>> csv_reader = csv.reader(open("./marks.csv"))
>>> for row in csv_reader:
... print row
...
['name', 'physics', 'python', 'math', 'english']
['Google', '100', '100', '25', '12']
['Facebook', '45', '54', '44', '88']
['Twitter', '54', '76', '13', '91']
['Yahoo', '54', '452', '26', '100']
~~~
算是稍有改善。
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/312.md#用pandas读取)用Pandas读取
如果对上面的结果都有点不满意的话,那么看看Pandas的效果:
~~~
>>> import pandas as pd
>>> marks = pd.read_csv("./marks.csv")
>>> marks
name physics python math english
0 Google 100 100 25 12
1 Facebook 45 54 44 88
2 Twitter 54 76 13 91
3 Yahoo 54 452 26 100
~~~
看了这样的结果,你还不感觉惊讶吗?你还不喜欢上Pandas吗?这是多么精妙的显示。它是什么?它就是一个DataFrame数据。
还有另外一种方法:
~~~
>>> pd.read_table("./marks.csv", sep=",")
name physics python math english
0 Google 100 100 25 12
1 Facebook 45 54 44 88
2 Twitter 54 76 13 91
3 Yahoo 54 452 26 100
~~~
如果你有足够的好奇心来研究这个名叫DataFrame的对象,可以这样:
~~~
>>> dir(marks)
['T', '_AXIS_ALIASES', '_AXIS_NAMES', '_AXIS_NUMBERS', '__add__', '__and__', '__array__', '__array_wrap__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dict__', '__div__', '__doc__', '__eq__', '__floordiv__', '__format__', '__ge__', '__getattr__', '__getattribute__', '__getitem__', '__getstate__', '__gt__', '__hash__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__module__', '__mul__', '__ne__', '__neg__', '__new__', '__nonzero__', '__or__', '__pow__', '__radd__', '__rdiv__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rmul__', '__rpow__', '__rsub__', '__rtruediv__', '__setattr__', '__setitem__', '__setstate__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__weakref__', '__xor__', '_agg_by_level', '_align_frame', '_align_series', '_apply_broadcast', '_apply_raw', '_apply_standard', '_auto_consolidate', '_bar_plot', '_boolean_set', '_box_item_values', '_clear_item_cache', '_combine_const', '_combine_frame', '_combine_match_columns', '_combine_match_index', '_combine_series', '_combine_series_infer', '_compare_frame', '_consolidate_inplace', '_constructor', '_count_level', '_cov_helper', '_data', '_default_stat_axis', '_expand_axes', '_from_axes', '_get_agg_axis', '_get_axis', '_get_axis_name', '_get_axis_number', '_get_item_cache', '_get_numeric_data', '_getitem_array', '_getitem_multilevel', '_helper_csvexcel', '_het_axis', '_indexed_same', '_init_dict', '_init_mgr', '_init_ndarray', '_is_mixed_type', '_item_cache', '_ix', '_join_compat', '_reduce', '_reindex_axis', '_reindex_columns', '_reindex_index', '_reindex_with_indexers', '_rename_columns_inplace', '_rename_index_inplace', '_sanitize_column', '_series', '_set_axis', '_set_item', '_set_item_multiple', '_shift_indexer', '_slice', '_unpickle_frame_compat', '_unpickle_matrix_compat', '_verbose_info', '_wrap_array', 'abs', 'add', 'add_prefix', 'add_suffix', 'align', 'append', 'apply', 'applymap', 'as_matrix', 'asfreq', 'astype', 'axes', 'boxplot', 'clip', 'clip_lower', 'clip_upper', 'columns', 'combine', 'combineAdd', 'combineMult', 'combine_first', 'consolidate', 'convert_objects', 'copy', 'corr', 'corrwith', 'count', 'cov', 'cummax', 'cummin', 'cumprod', 'cumsum', 'delevel', 'describe', 'diff', 'div', 'dot', 'drop', 'drop_duplicates', 'dropna', 'dtypes', 'duplicated', 'fillna', 'filter', 'first_valid_index', 'from_csv', 'from_dict', 'from_items', 'from_records', 'get', 'get_dtype_counts', 'get_value', 'groupby', 'head', 'hist', 'icol', 'idxmax', 'idxmin', 'iget_value', 'index', 'info', 'insert', 'irow', 'iteritems', 'iterkv', 'iterrows', 'ix', 'join', 'last_valid_index', 'load', 'lookup', 'mad', 'max', 'mean', 'median', 'merge', 'min', 'mul', 'ndim', 'pivot', 'pivot_table', 'plot', 'pop', 'prod', 'product', 'quantile', 'radd', 'rank', 'rdiv', 'reindex', 'reindex_axis', 'reindex_like', 'rename', 'rename_axis', 'reorder_levels', 'reset_index', 'rmul', 'rsub', 'save', 'select', 'set_index', 'set_value', 'shape', 'shift', 'skew', 'sort', 'sort_index', 'sortlevel', 'stack', 'std', 'sub', 'sum', 'swaplevel', 'tail', 'take', 'to_csv', 'to_dict', 'to_excel', 'to_html', 'to_panel', 'to_records', 'to_sparse', 'to_string', 'to_wide', 'transpose', 'truncate', 'unstack', 'values', 'var', 'xs']
~~~
一个一个浏览一下,通过名字可以直到那个方法或者属性的大概,然后就可以根据你的喜好和需要,试一试:
~~~
>>> marks.index
Int64Index([0, 1, 2, 3], dtype=int64)
>>> marks.columns
Index([name, physics, python, math, english], dtype=object)
>>> marks['name'][1]
'Facebook'
~~~
这几个是让你回忆一下上一节的。从DataFrame对象的属性和方法中找一个,再尝试:
~~~
>>> marks.sort(column="python")
name physics python math english
1 Facebook 45 54 44 88
2 Twitter 54 76 13 91
0 Google 100 100 25 12
3 Yahoo 54 452 26 100
~~~
按照竖列"python"的值排队,结果也是很让人满意的。下面几个操作,也是常用到的,并且秉承了python的一贯方法:
~~~
>>> marks[:1]
name physics python math english
0 Google 100 100 25 12
>>> marks[1:2]
name physics python math english
1 Facebook 45 54 44 88
>>> marks["physics"]
0 100
1 45
2 54
3 54
Name: physics
~~~
可以说,当你已经掌握了通过dir()和help()查看对象的方法和属性时,就已经掌握了pandas的用法,其实何止pandas,其它对象都是如此。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/312.md#读取其它格式数据)读取其它格式数据
csv是常用来存储数据的格式之一,此外常用的还有MS excel格式的文件,以及json和xml格式的数据等。它们都可以使用pandas来轻易读取。
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/312.md#xls或者xlsx).xls或者.xlsx
在下面的结果中寻觅一下,有没有跟excel有关的方法?
~~~
>>> dir(pd)
['DataFrame', 'DataMatrix', 'DateOffset', 'DateRange', 'ExcelFile', 'ExcelWriter', 'Factor', 'HDFStore', 'Index', 'Int64Index', 'MultiIndex', 'Panel', 'Series', 'SparseArray', 'SparseDataFrame', 'SparseList', 'SparsePanel', 'SparseSeries', 'SparseTimeSeries', 'TimeSeries', 'WidePanel', '__builtins__', '__doc__', '__docformat__', '__file__', '__name__', '__package__', '__path__', '__version__', '_engines', '_sparse', '_tseries', 'concat', 'core', 'crosstab', 'datetime', 'datetools', 'debug', 'ewma', 'ewmcorr', 'ewmcov', 'ewmstd', 'ewmvar', 'ewmvol', 'fama_macbeth', 'groupby', 'info', 'io', 'isnull', 'lib', 'load', 'merge', 'notnull', 'np', 'ols', 'pivot', 'pivot_table', 'read_clipboard', 'read_csv', 'read_table', 'reset_printoptions', 'rolling_apply', 'rolling_corr', 'rolling_corr_pairwise', 'rolling_count', 'rolling_cov', 'rolling_kurt', 'rolling_max', 'rolling_mean', 'rolling_median', 'rolling_min', 'rolling_quantile', 'rolling_skew', 'rolling_std', 'rolling_sum', 'rolling_var', 'save', 'set_eng_float_format', 'set_printoptions', 'sparse', 'stats', 'tools', 'util', 'value_range', 'version']
~~~
虽然没有类似`read_csv()`的方法(在网上查询,有的资料说有`read_xls()`方法,那时老黄历了),但是有`ExcelFile`类,于是乎:
~~~
>>> xls = pd.ExcelFile("./marks.xlsx")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/pymodules/python2.7/pandas/io/parsers.py", line 575, in __init__
from openpyxl import load_workbook
ImportError: No module named openpyxl
~~~
我这里少了一个模块,看报错提示,用pip安装openpyxl模块:`sudo pip install openpyxl`。继续:
~~~
>>> xls = pd.ExcelFile("./marks.xlsx")
>>> dir(xls)
['__class__', '__delattr__', '__dict__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_parse_xls', '_parse_xlsx', 'book', 'parse', 'path', 'sheet_names', 'use_xlsx']
>>> xls.sheet_names
['Sheet1', 'Sheet2', 'Sheet3']
>>> sheet1 = xls.parse("Sheet1")
>>> sheet1
0 1 2 3 4
0 5 100 100 25 12
1 6 45 54 44 88
2 7 54 76 13 91
3 8 54 452 26 100
~~~
结果中,columns的名字与前面csv结果不一样,数据部分是同样结果。从结果中可以看到,sheet1也是一个DataFrame对象。
对于单个的DataFrame对象,如何通过属性和方法进行操作,如果读者理解了本教程从一开始就贯穿进来的思想——利用dir()和help()或者到官方网站,看文档!——此时就能比较轻松地进行各种操作了。下面的举例,纯属是为了增加篇幅和向读者做一些诱惑性广告,或者给懒惰者看看。当然,肯定是不完全,也不能在实践中照搬。基本方法还在刚才交代过的思想。
如果遇到了json或者xml格式的数据怎么办呢?直接使用本教程第贰季第陆章中[《标准库(7)](https://github.com/qiwsir/StarterLearningPython/blob/master/226.md)和[《标准库(8)》](https://github.com/qiwsir/StarterLearningPython/blob/master/227.md)中的方法,再结合Series或者DataFrame数据特点读取。
此外,还允许从数据库中读取数据,首先就是使用本教程第贰季第柒章中阐述的各种数据库([《MySQL数据库(1)》](https://github.com/qiwsir/StarterLearningPython/blob/master/230.md),[《MongoDB数据库》](https://github.com/qiwsir/StarterLearningPython/blob/master/232.md),[《SQLite数据库》](https://github.com/qiwsir/StarterLearningPython/blob/master/233.md))连接和读取方法,将相应数据查询出来,并且将结果(结果通常是列表或者元组类型,或者是字符串)按照前面讲述的Series或者DataFrame类型数据进行组织,然后就可以对其操作。``
Pandas使用(1)
最后更新于:2022-04-01 11:37:14
Pandas是基于NumPy的一个非常好用的库,正如名字一样,人见人爱。之所以如此,就在于不论是读取、处理数据,用它都非常简单。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/311.md#基本的数据结构)基本的数据结构
Pandas有两种自己独有的基本数据结构。读者应该注意的是,它固然有着两种数据结构,因为它依然是python的一个库,所以,python中有的数据类型在这里依然适用,也同样还可以使用类自己定义数据类型。只不过,Pandas里面又定义了两种数据类型:Series和DataFrame,它们让数据操作更简单了。
以下操作都是基于:
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31101.png)
为了省事,后面就不在显示了。并且如果你跟我一样是使用ipython notebook,只需要开始引入模块即可。
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/311.md#series)Series
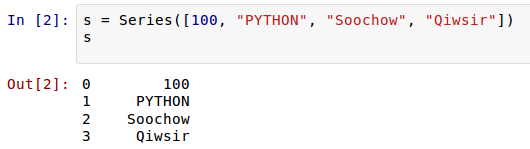
Series就如同列表一样,一系列数据,每个数据对应一个索引值。比如这样一个列表:[9, 3, 8],如果跟索引值写到一起,就是:
| data | 9 | 3 | 8 |
| --- | --- | --- | --- |
| index | 0 | 1 | 2 |
这种样式我们已经熟悉了,不过,在有些时候,需要把它竖过来表示:
| index | data |
| --- | --- |
| 0 | 9 |
| 1 | 3 |
| 2 | 8 |
上面两种,只是表现形式上的差别罢了。
Series就是“竖起来”的list:
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31102.png)
另外一点也很像列表,就是里面的元素的类型,由你任意决定(其实是由需要来决定)。
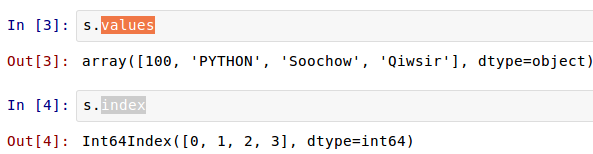
这里,我们实质上创建了一个Series对象,这个对象当然就有其属性和方法了。比如,下面的两个属性依次可以显示Series对象的数据值和索引:
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31103.png)
列表的索引只能是从0开始的整数,Series数据类型在默认情况下,其索引也是如此。不过,区别于列表的是,Series可以自定义索引:
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31104.png)
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31105.png)
自定义索引,的确比较有意思。就凭这个,也是必须的。
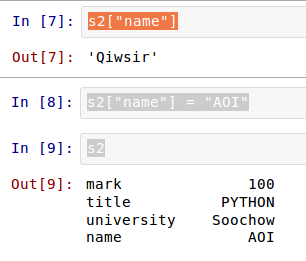
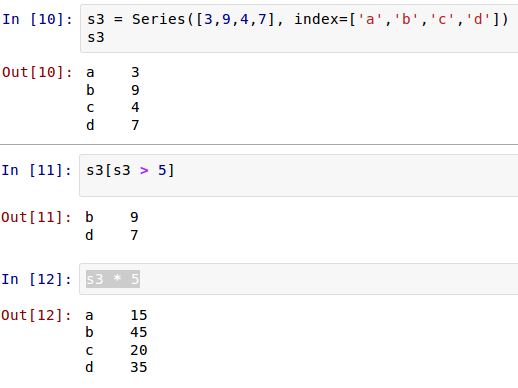
每个元素都有了索引,就可以根据索引操作元素了。还记得list中的操作吗?Series中,也有类似的操作。先看简单的,根据索引查看其值和修改其值:
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31106.png)
这是不是又有点类似dict数据了呢?的确如此。看下面就理解了。
读者是否注意到,前面定义Series对象的时候,用的是列表,即Series()方法的参数中,第一个列表就是其数据值,如果需要定义index,放在后面,依然是一个列表。除了这种方法之外,还可以用下面的方法定义Series对象:
[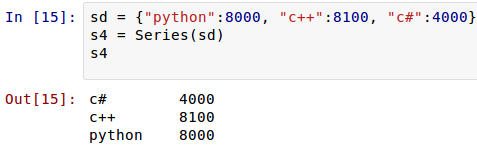](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31108.png)
现在是否理解为什么前面那个类似dict了?因为本来就是可以这样定义的。
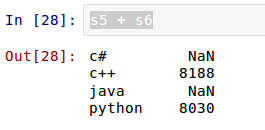
这时候,索引依然可以自定义。Pandas的优势在这里体现出来,如果自定义了索引,自定的索引会自动寻找原来的索引,如果一样的,就取原来索引对应的值,这个可以简称为“自动对齐”。
[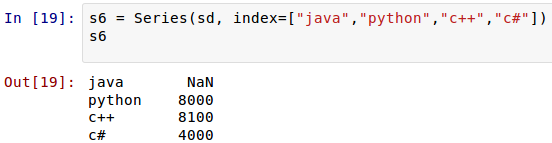](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31110.png)
在sd中,只有`'python':8000, 'c++':8100, 'c#':4000`,没有"java",但是在索引参数中有,于是其它能够“自动对齐”的照搬原值,没有的那个"java",依然在新Series对象的索引中存在,并且自动为其赋值`NaN`。在Pandas中,如果没有值,都对齐赋给`NaN`。来一个更特殊的:
[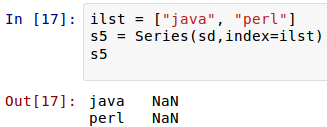](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31109.png)
新得到的Series对象索引与sd对象一个也不对应,所以都是`NaN`。
Pandas有专门的方法来判断值是否为空。
[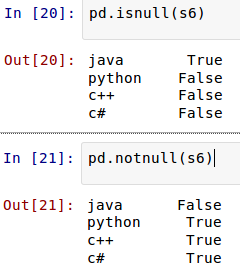](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31111.png)
此外,Series对象也有同样的方法:
[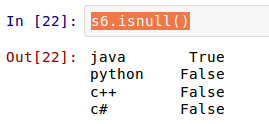](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31112.png)
其实,对索引的名字,是可以从新定义的:
[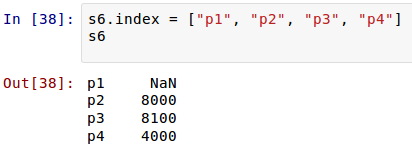](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31117.png)
对于Series数据,也可以做类似下面的运算(关于运算,后面还要详细介绍):
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31107.png)
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31113.png)
上面的演示中,都是在ipython notebook中进行的,所以截图了。在学习Series数据类型同时了解了ipyton notebook。对于后面的所有操作,读者都可以在ipython notebook中进行。但是,我的讲述可能会在python交互模式中进行。
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/311.md#dataframe)DataFrame
DataFrame是一种二维的数据结构,非常接近于电子表格或者类似mysql数据库的形式。它的竖行称之为columns,横行跟前面的Series一样,称之为index,也就是说可以通过columns和index来确定一个主句的位置。(有人把 DataFrame翻译为“数据框”,是不是还可以称之为“筐”呢?向里面装数据嘛。)
[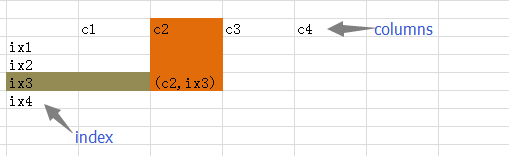](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31118.png)
下面的演示,是在python交互模式下进行,读者仍然可以在ipython notebook环境中测试。
~~~
>>> import pandas as pd
>>> from pandas import Series, DataFrame
>>> data = {"name":["yahoo","google","facebook"], "marks":[200,400,800], "price":[9, 3, 7]}
>>> f1 = DataFrame(data)
>>> f1
marks name price
0 200 yahoo 9
1 400 google 3
2 800 facebook 7
~~~
这是定义一个DataFrame对象的常用方法——使用dict定义。字典的“键”("name","marks","price")就是DataFrame的columns的值(名称),字典中每个“键”的“值”是一个列表,它们就是那一竖列中的具体填充数据。上面的定义中没有确定索引,所以,按照惯例(Series中已经形成的惯例)就是从0开始的整数。从上面的结果中很明显表示出来,这就是一个二维的数据结构(类似excel或者mysql中的查看效果)。
上面的数据显示中,columns的顺序没有规定,就如同字典中键的顺序一样,但是在DataFrame中,columns跟字典键相比,有一个明显不同,就是其顺序可以被规定,向下面这样做:
~~~
>>> f2 = DataFrame(data, columns=['name','price','marks'])
>>> f2
name price marks
0 yahoo 9 200
1 google 3 400
2 facebook 7 800
~~~
跟Series类似的,DataFrame数据的索引也能够自定义。
~~~
>>> f3 = DataFrame(data, columns=['name', 'price', 'marks', 'debt'], index=['a','b','c','d'])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/pymodules/python2.7/pandas/core/frame.py", line 283, in __init__
mgr = self._init_dict(data, index, columns, dtype=dtype)
File "/usr/lib/pymodules/python2.7/pandas/core/frame.py", line 368, in _init_dict
mgr = BlockManager(blocks, axes)
File "/usr/lib/pymodules/python2.7/pandas/core/internals.py", line 285, in __init__
self._verify_integrity()
File "/usr/lib/pymodules/python2.7/pandas/core/internals.py", line 367, in _verify_integrity
assert(block.values.shape[1:] == mgr_shape[1:])
AssertionError
~~~
报错了。这个报错信息就太不友好了,也没有提供什么线索。这就是交互模式的不利之处。修改之,错误在于index的值——列表——的数据项多了一个,data中是三行,这里给出了四个项(['a','b','c','d'])。
~~~
>>> f3 = DataFrame(data, columns=['name', 'price', 'marks', 'debt'], index=['a','b','c'])
>>> f3
name price marks debt
a yahoo 9 200 NaN
b google 3 400 NaN
c facebook 7 800 NaN
~~~
读者还要注意观察上面的显示结果。因为在定义f3的时候,columns的参数中,比以往多了一项('debt'),但是这项在data这个字典中并没有,所以debt这一竖列的值都是空的,在Pandas中,空就用NaN来代表了。
定义DataFrame的方法,除了上面的之外,还可以使用“字典套字典”的方式。
~~~
>>> newdata = {"lang":{"firstline":"python","secondline":"java"}, "price":{"firstline":8000}}
>>> f4 = DataFrame(newdata)
>>> f4
lang price
firstline python 8000
secondline java NaN
~~~
在字典中就规定好数列名称(第一层键)和每横行索引(第二层字典键)以及对应的数据(第二层字典值),也就是在字典中规定好了每个数据格子中的数据,没有规定的都是空。
~~~
>>> DataFrame(newdata, index=["firstline","secondline","thirdline"])
lang price
firstline python 8000
secondline java NaN
thirdline NaN NaN
~~~
如果额外确定了索引,就如同上面显示一样,除非在字典中有相应的索引内容,否则都是NaN。
前面定义了DataFrame数据(可以通过两种方法),它也是一种对象类型,比如变量f3引用了一个对象,它的类型是DataFrame。承接以前的思维方法:对象有属性和方法。
~~~
>>> f3.columns
Index(['name', 'price', 'marks', 'debt'], dtype=object)
~~~
DataFrame对象的columns属性,能够显示素有的columns名称。并且,还能用下面类似字典的方式,得到某竖列的全部内容(当然包含索引):
~~~
>>> f3['name']
a yahoo
b google
c facebook
Name: name
~~~
这是什么?这其实就是一个Series,或者说,可以将DataFrame理解为是有一个一个的Series组成的。
一直耿耿于怀没有数值的那一列,下面的操作是统一给那一列赋值:
~~~
>>> f3['debt'] = 89.2
>>> f3
name price marks debt
a yahoo 9 200 89.2
b google 3 400 89.2
c facebook 7 800 89.2
~~~
除了能够统一赋值之外,还能够“点对点”添加数值,结合前面的Series,既然DataFrame对象的每竖列都是一个Series对象,那么可以先定义一个Series对象,然后把它放到DataFrame对象中。如下:
~~~
>>> sdebt = Series([2.2, 3.3], index=["a","c"]) #注意索引
>>> f3['debt'] = sdebt
~~~
将Series对象(sdebt变量所引用) 赋给f3['debt']列,Pandas的一个重要特性——自动对齐——在这里起做用了,在Series中,只有两个索引("a","c"),它们将和DataFrame中的索引自动对齐。于是乎:
~~~
>>> f3
name price marks debt
a yahoo 9 200 2.2
b google 3 400 NaN
c facebook 7 800 3.3
~~~
自动对齐之后,没有被复制的依然保持NaN。
还可以更精准的修改数据吗?当然可以,完全仿照字典的操作:
~~~
>>> f3["price"]["c"]= 300
>>> f3
name price marks debt
a yahoo 9 200 2.2
b google 3 400 NaN
c facebook 300 800 3.3
~~~
这些操作是不是都不陌生呀,这就是Pandas中的两种数据对象。
为计算做准备
最后更新于:2022-04-01 11:37:11
## 闲谈
计算机姑娘是擅长进行科学计算的,本来她就是做这个的,只不过后来人们让她处理了很多文字内容罢了,乃至于现在有一些人认为她是用来打字写文章的(变成打字机了),忘记了她最擅长的计算。
每种编程语言都能用来做计算,区别在于编程过程中,是否有足够的工具包供给。比如用汇编,就得自己多劳动,如果用Fortran,就方便得多了。不知道读者是否听说过Fortran,貌似古老,现在仍被使用。(以下引文均来自维基百科)
> Fortran语言是為了滿足数值计算的需求而發展出來的。1953年12月,IBM公司工程師約翰·巴科斯(J. Backus)因深深體會編寫程序很困難,而寫了一份備忘錄給董事長斯伯特·赫德(Cuthbert Hurd),建議為IBM704系統設計全新的電腦語言以提升開發效率。當時IBM公司的顾问冯·诺伊曼强烈反对,因為他認為不切實際而且根本不必要。但赫德批准了這項計劃。1957年,IBM公司开发出第一套FORTRAN语言,在IBM704電腦上運作。歷史上第一支FORTRAN程式在馬里蘭州的西屋貝地斯核電廠試驗。1957年4月20日星期五的下午,一位IBM軟體工程師決定在電廠內編譯第一支FORTRAN程式,當程式碼輸入後,經過編譯,印表機列出一行訊息:“原始程式錯誤……右側括號後面沒有逗號”,這讓現場人員都感到訝異,修正這個錯誤後,印表機輸出了正確結果。而西屋電氣公司因此意外地成為FORTRAN的第一個商業用戶。1958年推出FORTRAN Ⅱ,幾年後又推出FORTRAN Ⅲ,1962年推出FORTRAN Ⅳ後,開始廣泛被使用。目前最新版是Fortran 2008。
还有一个广为应用的不得不说,那就是matlab,一直以来被人称赞。
> MATLAB(矩阵实验室)是MATrix LABoratory的缩写,是一款由美国The MathWorks公司出品的商业数学软件。MATLAB是一种用于算法开发、数据可视化、数据分析以及数值计算的高级技术计算语言和交互式环境。除了矩阵运算、绘制函数/数据图像等常用功能外,MATLAB还可以用来创建用户界面及与调用其它语言(包括C,C++,Java,Python和FORTRAN)编写的程序。
但是,它是收费的商业软件,虽然在某国这个无所谓。
还有R语言,也是在计算领域被多多使用的。
> R语言,一種自由軟體程式語言與操作環境,主要用于统计分析、绘图、数据挖掘。R本來是由來自新西蘭奧克蘭大學的Ross Ihaka和Robert Gentleman開發(也因此稱為R),現在由“R開發核心團隊”負責開發。R是基于S语言的一个GNU計劃项目,所以也可以当作S语言的一种实现,通常用S语言编写的代码都可以不作修改的在R环境下运行。R的語法是來自Scheme。
最后要说的就是python,近几年使用python的领域不断扩张,包括在科学计算领域,它已经成为了一种趋势。在这个过程中,虽然有不少人诟病python的这个慢那个解释动态语言之类(这种说法是值得讨论的),但是,依然无法阻挡python在科学计算领域大行其道。之所以这样,就是因为它是python。
* 开源,就这一条就已经足够了,一定要用开源的东西。至于为什么,本教程前面都阐述过了。
* 因为开源,所以有非常棒的社区,里面有相当多支持科学计算的库,不用还等待何时?
* 简单易学,这点对那些不是专业程序员来讲非常重要。我就接触到一些搞天文学和生物学的研究者,他们正在使用python进行计算。
* 在科学计算上如果用了python,能够让数据跟其它的比如web无缝对接,这不是很好的吗?
当然,最重要一点,就是本教程是讲python的,所以,在科学计算这块肯定不会讲Fortran或者R,一定得是python。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/310.md#安装)安装
如果读者使用Ubuntu或者Debian,可以这样来安装:
~~~
sudo apt-get install python-numpy python-scipy python-matplotlib ipython ipython-notebook python-pandas python-sympy python-nose
~~~
一股脑把可能用上的都先装上。在安装的时候,如果需要其它的依赖,你会明显看到的。
如果是别的系统,比如windows类,请自己网上查找安装方法吧,这里内容不少,最权威的是看官方网站列出的安装:[http://www.scipy.org/install.html](http://www.scipy.org/install.html)
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/310.md#基本操作)基本操作
在科学计算中,业界比较喜欢使用ipython notebook,前面已经安装。在shell中执行
~~~
ipython notebook --pylab=inline
~~~
得到下图的界面,这是在浏览器中打开的:
[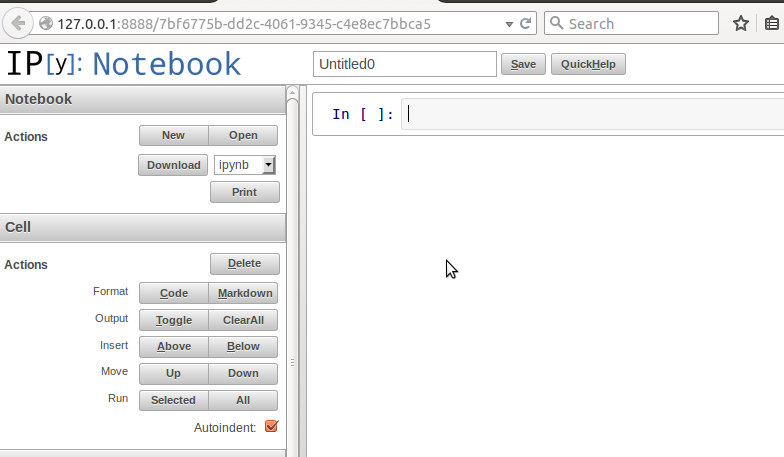](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31001.png)
在In后面的编辑去,可以写python语句。然后按下`SHIFT+ENTER`或者`CTRL+ENTER` 就能执行了,如果按下`ENTER`,不是执行,是在当前编辑区换行。
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31002.png)
Ipython Notebook是一个非常不错的编辑器,执行之后,直接显示出来输入内容和输出的结果。当然,错误是难免的,它会:
[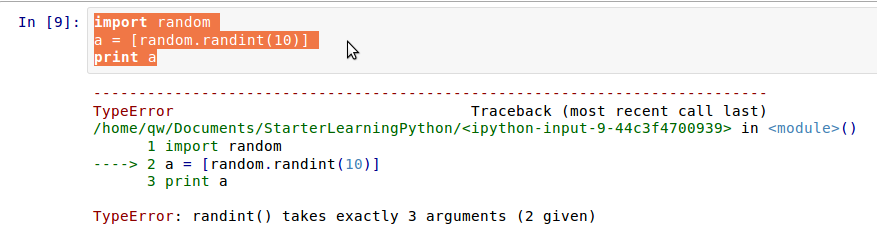](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31003.png)
注意观察图中的箭头所示,直接标出有问题的行。返回编辑区,修改之后可继续执行。
[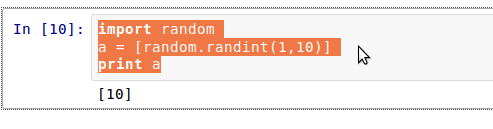](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31004.png)
不要忽视左边的辅助操作,能够让你在使用ipython notebook的时候更方便。
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/31005.png)
除了在网页中之外,如果你已经喜欢上了python的交互模式,特别是你用的计算机中有一个shell的东西,更是棒了。于是可以:
~~~
$ ipython
~~~
进入了一个类似于python的交互模式中,如下所示:
~~~
In [1]: print "hello, pandas"
hello, pandas
In [2]:
~~~
或者说ipython同样是一个不错的交互模式。
第玖章 科学计算
最后更新于:2022-04-01 11:37:09
用tornado做网站(7)
最后更新于:2022-04-01 11:37:07
到上一节结束,其实读者已经能够做一个网站了,但是,仅仅用前面的技术来做的网站,仅能算一个小网站,在[《为做网站而准备》](https://github.com/qiwsir/StarterLearningPython/blob/master/301.md)中,说明之所以选tornado,就是因为它能够解决c10k问题,即能够实现大用户量访问。
要实现大用户量访问,必须要做的就是:异步。除非你是很土的土豪。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/309.md#相关概念)相关概念
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/309.md#同步和异步)同步和异步
有不少资料对这两个概念做了不同角度和层面的解释。在我来看,一个最典型的例子就是打电话和发短信。
* 打电话就是同步。张三给李四打电话,张三说:“是李四吗?”。当这个信息被张三发出,提交给李四,就等待李四的响应(一般会听到“是”,或者“不是”),只有得到了李四返回的信息之后,才能进行后续的信息传送。
* 发短信是异步。张三给李四发短信,编辑了一句话“今晚一起看老齐的零基础学python”,发送给李四。李四或许马上回复,或许过一段时间,这段时间多长也不定,才回复。总之,李四不管什么时候回复,张三会以听到短信铃声为提示查看短信。
以上方式理解“同步”和“异步”不是很精准,有些地方或有牵强。要严格理解,需要用严格一点的定义表述(以下表述参照了[知乎](http://www.zhihu.com/question/19732473)上的回答):
> 同步和异步关注的是消息通信机制 (synchronous communication/ asynchronous communication)
>
> 所谓同步,就是在发出一个“调用”时,在没有得到结果之前,该“调用”就不返回。但是一旦调用返回,就得到返回值了。 换句话说,就是由“调用者”主动等待这个“调用”的结果。
>
> 而异步则是相反,“调用”在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在“调用”发出后,“被调用者”通过状态、通知来通知调用者,或通过回调函数处理这个调用。
可能还是前面的打电话和发短信更好理解。
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/309.md#阻塞和非阻塞)阻塞和非阻塞
“阻塞和非阻塞”与“同步和异步”常常被换为一谈,其实它们之间还是有差别的。如果按照一个“差不多”先生的思维方法,你也可以不那么深究它们之间的学理上的差距,反正在你的程序中,会使用就可以了。不过,必要的严谨还是需要的,特别是我写这个教程,要装扮的让别人看来自己懂,于是就再引用[知乎](http://www.zhihu.com/question/19732473)上的说明(我个人认为,别人已经做的挺好的东西,就别重复劳动了,“拿来主义”,也不错。或许你说我抄袭和山寨,但是我明确告诉你来源了):
> 阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.
>
> 阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
按照这个说明,发短信就是显然的非阻塞,发出去一条短信之后,你利用手机还可以干别的,乃至于再发一条“老齐的课程没意思,还是看PHP刺激”也是可以的。
关于这两组基本概念的辨析,不是本教程的重点,读者可以参阅这篇文章:[http://www.cppblog.com/converse/archive/2009/05/13/82879.html](http://www.cppblog.com/converse/archive/2009/05/13/82879.html),文章作者做了细致入微的辨析。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/309.md#tornado的同步)tornado的同步
此前,在tornado基础上已经完成的web,就是同步的、阻塞的。为了更明显的感受这点,不妨这样试一试。
在handlers文件夹中建立一个文件,命名为sleep.py
~~~
#!/usr/bin/env python
# coding=utf-8
from base import BaseHandler
import time
class SleepHandler(BaseHandler):
def get(self):
time.sleep(17)
self.render("sleep.html")
class SeeHandler(BaseHandler):
def get(self):
self.render("see.html")
~~~
其它的事情,如果读者对我在[《用tornado做网站(1)》](https://github.com/qiwsir/StarterLearningPython/blob/master/303.md)中所讲述的网站框架熟悉,应该知道如何做了,不熟悉,请回头复习。
sleep.html和see.html是两个简单的模板,内容可以自己写。别忘记修改url.py中的目录。
然后的测试稍微复杂一点点,就是打开浏览器之后,打开两个标签,分别在两个标签中输入`localhost:8000/sleep`(记为标签1)和`localhost:8000/see`(记为标签2),注意我用的是8000端口。输入之后先不要点击回车去访问。做好准备,记住切换标签可以用“ctrl-tab”组合键。
1. 执行标签1,让它访问网站;
2. 马上切换到标签2,访问网址。
3. 注意观察,两个标签页面,是不是都在显示正在访问,请等待。
4. 当标签1不呈现等待提示(比如一个正在转的圆圈)时,标签2的表现如何?几乎同时也访问成功了。
建议读者修改sleep.py中的time.sleep(17)这个值,多试试。很好玩的吧。
当然,这是比较笨拙的方法,本来是可以通过测试工具完成上述操作比较的。怎奈要用别的工具,还要进行介绍,又多了一个分散精力的东西,故用如此笨拙的方法,权当有一个体会。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/309.md#异步设置)异步设置
tornado本来就是一个异步的服务框架,体现在tornado的服务器和客户端的网络交互的异步上,起作用的是tornado.ioloop.IOLoop。但是如果的客户端请求服务器之后,在执行某个方法的时候,比如上面的代码中执行get()方法的时候,遇到了`time.sleep(17)`这个需要执行时间比较长的操作,耗费时间,就会使整个tornado服务器的性能受限了。
为了解决这个问题,tornado提供了一套异步机制,就是异步装饰器`@tornado.web.asynchronous`:
~~~
#!/usr/bin/env python
# coding=utf-8
import tornado.web
from base import BaseHandler
import time
class SleepHandler(BaseHandler):
@tornado.web.asynchronous
def get(self):
tornado.ioloop.IOLoop.instance().add_timeout(time.time() + 17, callback=self.on_response)
def on_response(self):
self.render("sleep.html")
self.finish()
~~~
将sleep.py的代码如上述一样改造,即在get()方法前面增加了装饰器`@tornado.web.asynchronous`,它的作用在于将tornado服务器本身默认的设置`_auto_fininsh`值修改为false。如果不用这个装饰器,客户端访问服务器的get()方法并得到返回值之后,两只之间的连接就断开了,但是用了`@tornado.web.asynchronous`之后,这个连接就不关闭,直到执行了`self.finish()`才关闭这个连接。
`tornado.ioloop.IOLoop.instance().add_timeout()`也是一个实现异步的函数,`time.time()+17`是给前面函数提供一个参数,这样实现了相当于`time.sleep(17)`的功能,不过,还没有完成,当这个操作完成之后,就执行回调函数`on_response()`中的`self.render("sleep.html")`,并关闭连接`self.finish()`。
过程清楚了。所谓异步,就是要解决原来的`time.sleep(17)`造成的服务器处理时间长,性能下降的问题。解决方法如上描述。
读者看这个代码,或许感觉有点不是很舒服。如果有这么一点感觉,是正常的。因为它里面除了装饰器之外,用到了一个回调函数,它让代码的逻辑不是平铺下去,而是被分割为了两段。第一段是`tornado.ioloop.IOLoop.instance().add_timeout(time.time() + 17, callback=self.on_response)`,用`callback=self.on_response`来使用回调函数,并没有如同改造之前直接`self.render("sleep.html")`;第二段是回调函数on_response(self)`,要在这个函数里面执行`self.render("sleep.html")`,并且以`self.finish()`结尾以关闭连接。
这还是执行简单逻辑,如果复杂了,不断地要进行“回调”,无法让逻辑顺利延续,那面会“眩晕”了。这种现象被业界成为“代码逻辑拆分”,打破了原有逻辑的顺序性。为了让代码逻辑不至于被拆分的七零八落,于是就出现了另外一种常用的方法:
~~~
#!/usr/bin/env python
# coding=utf-8
import tornado.web
import tornado.gen
from base import BaseHandler
import time
class SleepHandler(tornado.web.RequestHandler):
@tornado.gen.coroutine
def get(self):
yield tornado.gen.Task(tornado.ioloop.IOLoop.instance().add_timeout, time.time() + 17)
#yield tornado.gen.sleep(17)
self.render("sleep.html")
~~~
从整体上看,这段代码避免了回调函数,看着顺利多了。
再看细节部分。
首先使用的是`@tornado.gen.coroutine`装饰器,所以要在前面有`import tornado.gen`。跟这个装饰器类似的是`@tornado.gen.engine`装饰器,两者功能类似,有一点细微差别。请阅读[官方对此的解释](http://www.tornadoweb.org/en/stable/gen.html):
> This decorator(指engine) is similar to coroutine, except it does not return a Future and the callback argument is not treated specially.
`@tornado.gen.engine`是古时候用的,现在我们都使用`@tornado.gen.corroutine`了,这个是在tornado 3.0以后开始。在网上查阅资料的时候,会遇到一些使用`@tornado.gen.engine`的,但是在你使用或者借鉴代码的时候,就勇敢地将其修改为`@tornado.gen.coroutine`好了。有了这个装饰器,就能够控制下面的生成器的流程了。
然后就看到get()方法里面的yield了,这是一个生成器(参阅本教程[《生成器》](https://github.com/qiwsir/StarterLearningPython/blob/master/215.md))。`yield tornado.gen.Task(tornado.ioloop.IOLoop.instance().add_timeout, time.time() + 17)`的执行过程,应该先看括号里面,跟前面的一样,是来替代`time.sleep(17)`的,然后是`tornado.gen.Task()`方法,其作用是“Adapts a callback-based asynchronous function for use in coroutines.”(由于怕翻译后遗漏信息,引用[原文](http://tornado.readthedocs.org/en/latest/gen.html))。返回后,最后使用yield得到了一个生成器,先把流程挂起,等完全完毕,再唤醒继续执行。要提醒读者,生成器都是异步的。
其实,上面啰嗦一对,可以用代码中注释了的一句话来代替`yield tornado.gen.sleep(17)`,之所以扩所,就是为了顺便看到`tornado.gen.Task()`方法,因为如果读者在看古老的代码时候,会遇到。但是,后面你写的时候,就不要那么啰嗦了,请用`yield tornado.gen.sleep()`。
至此,基本上对tornado的异步设置有了概览,不过,上面的程序在实际中没有什么价值。在工程中,要让tornado网站真正异步起来,还要做很多事情,不仅仅是如上面的设置,因为很多东西,其实都不是异步的。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/309.md#实践中的异步)实践中的异步
以下各项同步(阻塞)的,如果在tornado中按照之前的方式只用它们,就是把tornado的非阻塞、异步优势削减了。
* 数据库的所有操作,不管你的数据是SQL还是noSQL,connect、insert、update等
* 文件操作,打开,读取,写入等
* time.sleep,在前面举例中已经看到了
* smtplib,发邮件的操作
* 一些网络操作,比如tornado的httpclient以及pycurl等
除了以上,或许在编程实践中还会遇到其他的同步、阻塞实践。仅仅就上面几项,就是编程实践中经常会遇到的,怎么解决?
聪明的大牛程序员帮我们做了扩展模块,专门用来实现异步/非阻塞的。
* 在数据库方面,由于种类繁多,不能一一说明,比如mysql,可以使用[adb](https://github.com/ovidiucp/pymysql-benchmarks)模块来实现python的异步mysql库;对于mongodb数据库,有一个非常优秀的模块,专门用于在tornado和mongodb上实现异步操作,它就是motor。特别贴出它的logo,我喜欢。官方网站:[http://motor.readthedocs.org/en/stable/](http://motor.readthedocs.org/en/stable/)上的安装和使用方法都很详细。
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30901.png)
* 文件操作方面也没有替代模块,只能尽量控制好IO,或者使用内存型(Redis)及文档型(MongoDB)数据库。
* time.sleep()在tornado中有替代:`tornado.gen.sleep()`或者`tornado.ioloop.IOLoop.instance().add_timeout`,这在前面代码已经显示了。
* smtp发送邮件,推荐改为tornado-smtp-client。
* 对于网络操作,要使用tornado.httpclient.AsyncHTTPClient。
其它的解决方法,只能看到问题具体说了,甚至没有很好的解决方法。不过,这里有一个列表,列出了足够多的库,供使用者选择:[Async Client Libraries built on tornado.ioloop](https://github.com/tornadoweb/tornado/wiki/Links),同时这个页面里面还有很多别的链接,都是很好的资源,建议读者多看看。
教程到这里,读者是不是要思考一个问题,既然对于mongodb有专门的motor库来实现异步,前面对于tornado的异步,不管是哪个装饰器,都感觉麻烦,有没有专门的库来实现这种异步呢?这不是异想天开,还真有。也应该有,因为这才体现python的特点。比如[greenlet-tornado](https://github.com/mopub/greenlet-tornado),就是一个不错的库。读者可以浏览官方网站深入了解(为什么对mysql那么不积极呢?按理说应该出来好多支持mysql异步的库才对)。
必须声明,前面演示如何在tornado中设置异步的代码,仅仅是演示理解设置方法。在工程实践中,那个代码的意义不到。为此,应该有一个近似于实践的代码示例。是的,的确应该有。当我正要写这样的代码时候,在网上发现一篇文章,这篇文章阻止了我写,因为我要写的那篇文章的作者早就写好了,而且我认为表述非常到位,示例也详细。所以,我不得不放弃,转而推荐给读者这篇好文章:
举例:[http://emptysqua.re/blog/refactoring-tornado-coroutines/](http://emptysqua.re/blog/refactoring-tornado-coroutines/)
用tornado做网站(6)
最后更新于:2022-04-01 11:37:04
在[上一节](https://github.com/qiwsir/StarterLearningPython/blob/master/307.md)中已经对安全问题进行了描述,另外一个内容是不能忽略的,那就是用户登录之后,对当前用户状态(用户是否登录)进行判断。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/308.md#用户验证)用户验证
用户登录之后,当翻到别的目录中时,往往需要验证用户是否处于登录状态。当然,一种比较直接的方法,就是在转到每个目录时,都从cookie中把用户信息,然后传到后端,跟数据库验证。这不仅是直接的,也是基本的流程。但是,这个过程如果总让用户自己来做,框架的作用就显不出来了。tornado就提供了一种用户验证方法。
为了后面更工程化地使用tornado编程。需要将前面的已经有的代码进行重新梳理。我只是将有修改的文件代码写出来,不做过多解释,必要的有注释,相信读者在前述学习基础上,能够理解。
在handler目录中增加一个文件,名称是base.py,代码如下:
~~~
#! /usr/bin/env python
# coding=utf-8
import tornado.web
class BaseHandler(tornado.web.RequestHandler):
def get_current_user(self):
return self.get_secure_cookie("user")
~~~
在这个文件中,目前只做一个事情,就是建立一个名为BaseHandler的类,然后在里面放置一个方法,就是得到当前的cookie。在这里特别要向读者说明,在这个类中,其实还可以写不少别的东西,比如你就可以将数据库连接写到这个类的初始化`__init__()`方法中。因为在其它的类中,我们要继承这个类。所以,这样一个架势,就为读者以后的扩展增加了冗余空间。
然后把index.py文件改写为:
~~~
#!/usr/bin/env python
# coding=utf-8
import tornado.escape
import methods.readdb as mrd
from base import BaseHandler
class IndexHandler(BaseHandler): #继承base.py中的类BaseHandler
def get(self):
usernames = mrd.select_columns(table="users",column="username")
one_user = usernames[0][0]
self.render("index.html", user=one_user)
def post(self):
username = self.get_argument("username")
password = self.get_argument("password")
user_infos = mrd.select_table(table="users",column="*",condition="username",value=username)
if user_infos:
db_pwd = user_infos[0][2]
if db_pwd == password:
self.set_current_user(username) #将当前用户名写入cookie,方法见下面
self.write(username)
else:
self.write("-1")
else:
self.write("-1")
def set_current_user(self, user):
if user:
self.set_secure_cookie('user', tornado.escape.json_encode(user)) #注意这里使用了tornado.escape.json_encode()方法
else:
self.clear_cookie("user")
class ErrorHandler(BaseHandler): #增加了一个专门用来显示错误的页面
def get(self): #但是后面不单独讲述,读者可以从源码中理解
self.render("error.html")
~~~
在index.py的类IndexHandler中,继承了BaseHandler类,并且增加了一个方法set_current_user()用于将用户名写入cookie。请读者特别注意那个tornado.escape.json_encode()方法,其功能是:
> tornado.escape.json_encode(value) JSON-encodes the given Python object.
如果要查看源码,可以阅读:[http://www.tornadoweb.org/en/branch2.3/escape.html](http://www.tornadoweb.org/en/branch2.3/escape.html)
这样做的本质是把user转化为json,写入到了cookie中。如果从cookie中把它读出来,使用user的值时,还会用到:
> tornado.escape.json_decode(value) Returns Python objects for the given JSON string
它们与[json模块中的dump()、load()](https://github.com/qiwsir/StarterLearningPython/blob/master/227.md)功能相仿。
接下来要对user.py文件也进行重写:
~~~
#!/usr/bin/env python
# coding=utf-8
import tornado.web
import tornado.escape
import methods.readdb as mrd
from base import BaseHandler
class UserHandler(BaseHandler):
@tornado.web.authenticated
def get(self):
#username = self.get_argument("user")
username = tornado.escape.json_decode(self.current_user)
user_infos = mrd.select_table(table="users",column="*",condition="username",value=username)
self.render("user.html", users = user_infos)
~~~
在get()方法前面添加`@tornado.web.authenticated`,这是一个装饰器,它的作用就是完成tornado的认证功能,即能够得到当前合法用户。在原来的代码中,用`username = self.get_argument("user")`方法,从url中得到当前用户名,现在把它注释掉,改用`self.current_user`,这是和前面的装饰器配合使用的,如果它的值为假,就根据setting中的设置,寻找login_url所指定的目录(请关注下面对setting的配置)。
由于在index.py文件的set_current_user()方法中,是将user值转化为json写入cookie的,这里就得用`username = tornado.escape.json_decode(self.current_user)`解码。得到的username值,可以被用于后一句中的数据库查询。
application.py中的setting也要做相应修改:
~~~
#!/usr/bin/env python
# coding=utf-8
from url import url
import tornado.web
import os
setting = dict(
template_path = os.path.join(os.path.dirname(__file__), "templates"),
static_path = os.path.join(os.path.dirname(__file__), "statics"),
cookie_secret = "bZJc2sWbQLKos6GkHn/VB9oXwQt8S0R0kRvJ5/xJ89E=",
xsrf_cookies = True,
login_url = '/',
)
application = tornado.web.Application(
handlers = url,
**setting
)
~~~
与以前代码的重要区别在于`login_url = '/',`,如果用户不合法,根据这个设置,会返回到首页。当然,如果有单独的登录界面,比如是`/login`,也可以`login_url = '/login'`。
如此完成的是用户登录到网站之后,在页面转换的时候实现用户认证。
为了演示本节的效果,我对教程的源码进行修改。读者在阅读的时候,可以参照源码。
用tornado做网站(5)
最后更新于:2022-04-01 11:37:02
## 模板继承
用前面的方法,已经能够很顺利地编写模板了。读者如果留心一下,会觉得每个模板都有相同的部分内容。在python中,有一种被称之为“继承”的机制(请阅读本教程第贰季第肆章中的[类(4)(./209.md)中有关“继承”讲述]),它的作用之一就是能够让代码重用。
在tornado的模板中,也能这样。
先建立一个文件,命名为base.html,代码如下:
~~~
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1" />
<title>Learning Python</title>
</head>
<body>
<header>
{% block header %}{% end %}
</header>
<content>
{% block body %}{% end %}
</content>
<footer>
{% set website = "<a href='http://www.itdiffer.com'>welcome to my website</a>" %}
{% raw website %}
</footer>
<script src="{{static_url("js/jquery.min.js")}}"></script>
<script src="{{static_url("js/script.js")}}"></script>
</body>
</html>
~~~
接下来就以base.html为父模板,依次改写已经有的index.html和user.html模板。
index.html代码如下:
~~~
{% extends "base.html" %}
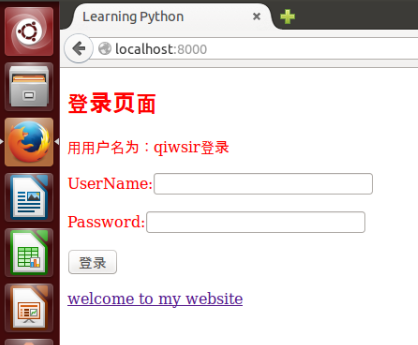
{% block header %}
<h2>登录页面</h2>
<p>用用户名为:{{user}}登录</p>
{% end %}
{% block body %}
<form method="POST">
<p><span>UserName:</span><input type="text" id="username"/></p>
<p><span>Password:</span><input type="password" id="password" /></p>
<p><input type="BUTTON" value="登录" id="login" /></p>
</form>
{% end %}
~~~
user.html的代码如下:
~~~
{% extends "base.html" %}
{% block header %}
<h2>Your informations are:</h2>
{% end %}
{% block body %}
<ul>
{% for one in users %}
<li>username:{{one[1]}}</li>
<li>password:{{one[2]}}</li>
<li>email:{{one[3]}}</li>
{% end %}
</ul>
{% end %}
~~~
看以上代码,已经没有以前重复的部分了。`{% extends "base.html" %}`意味着以base.html为父模板。在base.html中规定了形式如同`{% block header %}{% end %}`这样的块语句。在index.html和user.html中,分别对块语句中的内容进行了重写(或者说填充)。这就相当于在base.html中做了一个结构,在子模板中按照这个结构填内容。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/307.md#css)CSS
基本上的流程已经差不多了,如果要美化前端,还需要使用css,它的使用方法跟js类似,也是在静态目录中建立文件即可。然后把下面这句加入到base.html的`<head></head>`中:
~~~
<link rel="stylesheet" type="text/css" href="{{static_url("css/style.css")}}">
~~~
当然,要在style.css中写一个样式,比如:
~~~
body {
color:red;
}
~~~
然后看看前端显示什么样子了,我这里是这样的:
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30701.png)
关注字体颜色。
至于其它关于CSS方面的内容,本教程就不重点讲解了。读者可以参考关于CSS的资料。
至此,一个简单的基于tornado的网站就做好了,虽然它很丑,但是它很有前途。因为读者只要按照上述的讨论,可以在里面增加各种自己认为可以增加的内容。
建议读者在上述学习基础上,可以继续完成下面的几个功能:
* 用户注册
* 用户发表文章
* 用户文章列表,并根据文章标题查看文章内容
* 用户重新编辑文章
在后续教程内容中,也会涉及到上述功能。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/307.md#cookie和安全)cookie和安全
cookie是现在网站重要的内容,特别是当有用户登录的时候。所以,要了解cookie。维基百科如是说:
> Cookie(复数形態Cookies),中文名稱為小型文字檔案或小甜餅,指某些网站为了辨别用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密)。定義於RFC2109。是网景公司的前雇员Lou Montulli在1993年3月的發明。
关于cookie的作用,维基百科已经说的非常详细了(读者还能正常访问这么伟大的网站吗?):
> 因为HTTP协议是无状态的,即服务器不知道用户上一次做了什么,这严重阻碍了交互式Web应用程序的实现。在典型的网上购物场景中,用户浏览了几个页面,买了一盒饼干和两瓶饮料。最后结帐时,由于HTTP的无状态性,不通过额外的手段,服务器并不知道用户到底买了什么。 所以Cookie就是用来绕开HTTP的无状态性的“额外手段”之一。服务器可以设置或读取Cookies中包含信息,借此维护用户跟服务器会话中的状态。
>
> 在刚才的购物场景中,当用户选购了第一项商品,服务器在向用户发送网页的同时,还发送了一段Cookie,记录着那项商品的信息。当用户访问另一个页面,浏览器会把Cookie发送给服务器,于是服务器知道他之前选购了什么。用户继续选购饮料,服务器就在原来那段Cookie里追加新的商品信息。结帐时,服务器读取发送来的Cookie就行了。
>
> Cookie另一个典型的应用是当登录一个网站时,网站往往会请求用户输入用户名和密码,并且用户可以勾选“下次自动登录”。如果勾选了,那么下次访问同一网站时,用户会发现没输入用户名和密码就已经登录了。这正是因为前一次登录时,服务器发送了包含登录凭据(用户名加密码的某种加密形式)的Cookie到用户的硬盘上。第二次登录时,(如果该Cookie尚未到期)浏览器会发送该Cookie,服务器验证凭据,于是不必输入用户名和密码就让用户登录了。
和任何别的事物一样,cookie也有缺陷,比如来自伟大的维基百科也列出了三条:
1. cookie会被附加在每个HTTP请求中,所以无形中增加了流量。
2. 由于在HTTP请求中的cookie是明文传递的,所以安全性成问题。(除非用HTTPS)
3. Cookie的大小限制在4KB左右。对于复杂的存储需求来说是不够用的。
对于用户来讲,可以通过改变浏览器设置,来禁用cookie,也可以删除历史的cookie。但就目前而言,禁用cookie的可能不多了,因为她总要在网上买点东西吧。
Cookie最让人担心的还是由于它存储了用户的个人信息,并且最终这些信息要发给服务器,那么它就会成为某些人的目标或者工具,比如有cookie盗贼,就是搜集用户cookie,然后利用这些信息进入用户账号,达到个人的某种不可告人之目的;还有被称之为cookie投毒的说法,是利用客户端的cookie传给服务器的机会,修改传回去的值。这些行为常常是通过一种被称为“跨站指令脚本(Cross site scripting)”(或者跨站指令码)的行为方式实现的。伟大的维基百科这样解释了跨站脚本:
> 跨网站脚本(Cross-site scripting,通常简称为XSS或跨站脚本或跨站脚本攻击)是一种网站应用程序的安全漏洞攻击,是代码注入的一种。它允许恶意用户将代码注入到网页上,其他用户在观看网页时就会受到影响。这类攻击通常包含了HTML以及用户端脚本语言。
>
> XSS攻击通常指的是通过利用网页开发时留下的漏洞,通过巧妙的方法注入恶意指令代码到网页,使用户加载并执行攻击者恶意制造的网页程序。这些恶意网页程序通常是JavaScript,但实际上也可以包括Java, VBScript, ActiveX, Flash 或者甚至是普通的HTML。攻击成功后,攻击者可能得到更高的权限(如执行一些操作)、私密网页内容、会话和cookie等各种内容。
cookie是好的,被普遍使用。在tornado中,也提供对cookie的读写函数。
`set_cookie()`和`get_cookie()`是默认提供的两个方法,但是它是明文不加密传输的。
在index.py文件的IndexHandler类的post()方法中,当用户登录,验证用户名和密码后,将用户名和密码存入cookie,代码如下: def post(self): username = self.get_argument("username") password = self.get_argument("password") user_infos = mrd.select_table(table="users",column="*",condition="username",value=username) if user_infos: db_pwd = user_infos[0][2] if db_pwd == password: self.set_cookie(username,db_pwd) #设置cookie self.write(username) else: self.write("your password was not right.") else: self.write("There is no thi user.")
上面代码中,较以前只增加了一句`self.set_cookie(username,db_pwd)`,在回到登录页面,等候之后就成为:
[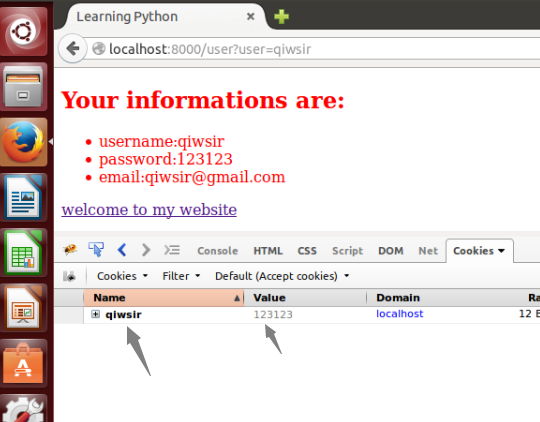](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30702.png)
看图中箭头所指,从左开始的第一个是用户名,第二个是存储的该用户密码。将我在登录是的密码就以明文的方式存储在cookie里面了。
明文存储,显然不安全。
tornado提供另外一种安全的方法:set_secure_cookie()和get_secure_cookie(),称其为安全cookie,是因为它以明文加密方式传输。此外,跟set_cookie()的区别还在于, set_secure_cookie()执行后的cookie保存在磁盘中,直到它过期为止。也是因为这个原因,即使关闭浏览器,在失效时间之间,cookie都一直存在。
要是用set_secure_cookie()方法设置cookie,要先在application.py文件的setting中进行如下配置:
~~~
setting = dict(
template_path = os.path.join(os.path.dirname(__file__), "templates"),
static_path = os.path.join(os.path.dirname(__file__), "statics"),
cookie_secret = "bZJc2sWbQLKos6GkHn/VB9oXwQt8S0R0kRvJ5/xJ89E=",
)
~~~
其中`cookie_secret = "bZJc2sWbQLKos6GkHn/VB9oXwQt8S0R0kRvJ5/xJ89E="`是为此增加的,但是,它并不是这正的加密,仅仅是一个障眼法罢了。
因为tornado会将cookie值编码为Base-64字符串,并增加一个时间戳和一个cookie内容的HMAC签名。所以,cookie_secret的值,常常用下面的方式生成(这是一个随机的字符串):
~~~
>>> import base64, uuid
>>> base64.b64encode(uuid.uuid4().bytes)
'w8yZud+kRHiP9uABEXaQiA=='
~~~
如果嫌弃上面的签名短,可以用`base64.b64encode(uuid.uuid4().bytes + uuid.uuid4().bytes)`获取。这里得到的是一个随机字符串,用它作为 cookie_secret值。
然后修改index.py中设置cookie那句话,变成:
~~~
self.set_secure_cookie(username,db_pwd)
~~~
从新跑一个,看看效果。
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30703.png)
啊哈,果然“密”了很多。
如果要获取此cookie,用`self.get_secure_cookie(username)`即可。
这是不是就安全了。如果这样就安全了,你太低估黑客们的技术实力了,甚至于用户自己也会修改cookie值。所以,还不安全。所以,又有了httponly和secure属性,用来防范cookie投毒。设置方法是:
~~~
self.set_secure_cookie(username, db_pwd, httponly=True, secure=True)
~~~
要获取cookie,可以使用`self.set_secure_cookie(username)`方法,将这句放在user.py中某个适合的位置,并且可以用print语句打印出结果,就能看到变量username对应的cookie了。这时候已经不是那个“密”过的,是明文显示。
用这样的方法,浏览器通过SSL连接传递cookie,能够在一定程度上防范跨站脚本攻击。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/307.md#xsrf)XSRF
XSRF的含义是Cross-site request forgery,即跨站请求伪造,也称之为"one click attack",通常缩写成CSRF或者XSRF,可以读作"sea surf"。这种对网站的攻击方式跟上面的跨站脚本(XSS)似乎相像,但攻击方式不一样。XSS利用站点内的信任用户,而XSRF则通过伪装来自受信任用户的请求来利用受信任的网站。与XSS攻击相比,XSRF攻击往往不大流行(因此对其 进行防范的资源也相当稀少)和难以防范,所以被认为比XSS更具危险性。
读者要详细了解XSRF,推荐阅读:[CSRF | XSRF 跨站请求伪造](http://www.cnblogs.com/lsk/archive/2008/05/26/1207467.html)
对于防范XSRF的方法,上面推荐阅读的文章中有明确的描述。还有一点需要提醒读者,就是在开发应用时需要深谋远虑。任何会产生副作用的HTTP请求,比如点击购买按钮、编辑账户设置、改变密码或删除文档,都应该使用post()方法。这是良好的RESTful做法。
> 又一个新名词:REST。这是一种web服务实现方案。伟大的维基百科中这样描述:
>
> 表徵性狀態傳輸(英文:Representational State Transfer,简称REST)是Roy Fielding博士在2000年他的博士论文中提出来的一种软件架构风格。目前在三种主流的Web服务实现方案中,因为REST模式与复杂的SOAP和XML-RPC相比更加简洁,越来越多的web服务开始采用REST风格设计和实现。例如,Amazon.com提供接近REST风格的Web服务进行图书查找;雅虎提供的Web服务也是REST风格的。
>
> 更详细的内容,读者可网上搜索来了解。
此外,在tornado中,还提供了XSRF保护的方法。
在application.py文件中,使用xsrf_cookies参数开启XSRF保护。
~~~
setting = dict(
template_path = os.path.join(os.path.dirname(__file__), "templates"),
static_path = os.path.join(os.path.dirname(__file__), "statics"),
cookie_secret = "bZJc2sWbQLKos6GkHn/VB9oXwQt8S0R0kRvJ5/xJ89E=",
xsrf_cookies = True,
)
~~~
这样设置之后,Tornado将拒绝请求参数中不包含正确的`_xsrf`值的post/put/delete请求。tornado会在后面悄悄地处理`_xsrf` cookies,所以,在表单中也要包含XSRF令牌以却表请求合法。比如index.html的表单,修改如下:
~~~
{% extends "base.html" %}
{% block header %}
<h2>登录页面</h2>
<p>用用户名为:{{user}}登录</p>
{% end %}
{% block body %}
<form method="POST">
{% raw xsrf_form_html() %}
<p><span>UserName:</span><input type="text" id="username"/></p>
<p><span>Password:</span><input type="password" id="password" /></p>
<p><input type="BUTTON" value="登录" id="login" /></p>
</form>
{% end %}
~~~
`{% raw xsrf_form_html() %}`是新增的,目的就在于实现上面所说的授权给前端以合法请求。
前端向后端发送的请求是通过ajax(),所以,在ajax请求中,需要一个_xsrf参数。
以下是script.js的代码
~~~
function getCookie(name){
var x = document.cookie.match("\\b" + name + "=([^;]*)\\b");
return x ? x[1]:undefined;
}
$(document).ready(function(){
$("#login").click(function(){
var user = $("#username").val();
var pwd = $("#password").val();
var pd = {"username":user, "password":pwd, "_xsrf":getCookie("_xsrf")};
$.ajax({
type:"post",
url:"/",
data:pd,
cache:false,
success:function(data){
window.location.href = "/user?user="+data;
},
error:function(){
alert("error!");
},
});
});
});
~~~
函数getCookie()的作用是得到cookie值,然后将这个值放到向后端post的数据中`var pd = {"username":user, "password":pwd, "_xsrf":getCookie("_xsrf")};`。运行的结果:
[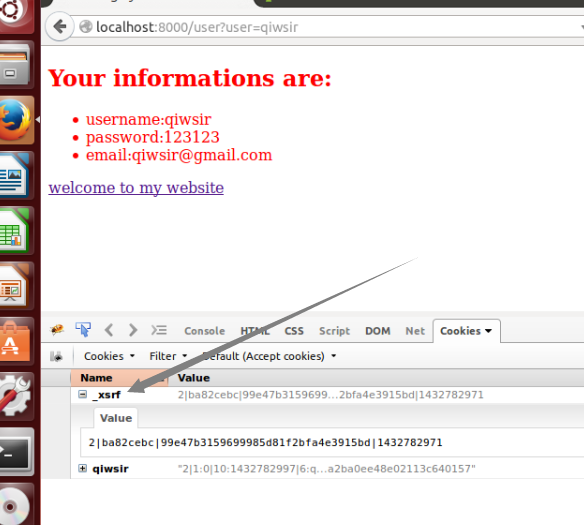](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30704.png)
这是tornado提供的XSRF防护方法。是不是这样做就高枕无忧了呢?**没这么简单。要做好一个网站,需要考虑的事情还很多**。特别推荐阅读[WebAppSec/Secure Coding Guidelines](https://wiki.mozilla.org/WebAppSec/Secure_Coding_Guidelines)
常常听到人说做个网站怎么怎么简单,客户用这种说辞来压低价格,老板用这种说辞来缩短工时成本,从上面的简单叙述中,你觉得网站还是随便几个页面就完事了吗?除非那个网站不是给人看的,是在那里摆着的。
用tornado做网站(4)
最后更新于:2022-04-01 11:37:00
## 模板
已经基本了解前端向和后端如何传递数据,以及后端如何接收数据的过程和方法之后。我突然发现,前端页面写的太难看了。俗话说“外行看热闹,内行看门道”。程序员写的网站,在更多时候是给“外行”看的,他们可没有耐心来看代码,他们看的就是界面,因此界面是否做的漂亮一点点,是直观重要的。
其实,也不仅仅是漂亮的原因,因为前端页面,还要显示从后端读取出来的数据呢。
恰好,tornado提供比较好用的前端模板(tornado.template)。通过这个模板,能够让前端编写更方便。
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/306.md#render)render()
render()方法能够告诉tornado读入哪个模板,插入其中的模板代码,并返回结果给浏览器。比如在IndexHandler类中get()方法里面的`self.render("index.html")`,就是让tornado到templates目中找到名为index.html的文件,读出它的内容,返回给浏览器。这样用户就能看到index.html所规定的页面了。当然,在前面所写的index.html还仅仅是html标记,没有显示出所谓“模板”的作用。为此,将index.html和index.py文件做如下改造。
~~~
#!/usr/bin/env python
# coding=utf-8
import tornado.web
import methods.readdb as mrd
class IndexHandler(tornado.web.RequestHandler):
def get(self):
usernames = mrd.select_columns(table="users",column="username")
one_user = usernames[0][0]
self.render("index.html", user=one_user)
~~~
index.py文件中,只修改了get()方法,从数据库中读取用户名,并且提出一个用户(one_user),然后通过`self.render("index.html", user=one_user)`将这个用户名放到index.html中,其中`user=one_user`的作用就是传递对象到模板。
提醒读者注意的是,在上面的代码中,我使用了`mrd.select_columns(table="users",column="username")`,也就是说必须要在methods目录中的readdb.py文件中有一个名为select_columns的函数。为了使读者能够理解,贴出已经修改之后的readdb.py文件代码,比上一节多了函数select_columns:
~~~
#!/usr/bin/env python
# coding=utf-8
from db import *
def select_table(table, column, condition, value ):
sql = "select " + column + " from " + table + " where " + condition + "='" + value + "'"
cur.execute(sql)
lines = cur.fetchall()
return lines
def select_columns(table, column ):
sql = "select " + column + " from " + table
cur.execute(sql)
lines = cur.fetchall()
return lines
~~~
下面是index.html修改后的代码:
~~~
<!DOCTYPE html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1" />
<title>Learning Python</title>
</head>
<body>
<h2>登录页面</h2>
<p>用用户名为:{{user}}登录</p>
<form method="POST">
<p><span>UserName:</span><input type="text" id="username"/></p>
<p><span>Password:</span><input type="password" id="password" /></p>
<p><input type="BUTTON" value="登录" id="login" /></p>
</form>
<script src="{{static_url("js/jquery.min.js")}}"></script>
<script src="{{static_url("js/script.js")}}"></script>
</body>
~~~
`<p>用用户名为:{{user}}登录</p>`,这里用了`{{ }}`方式,接受对应的变量引导来的对象。也就是在首页打开之后,用户应当看到有一行提示。如下图一样。
[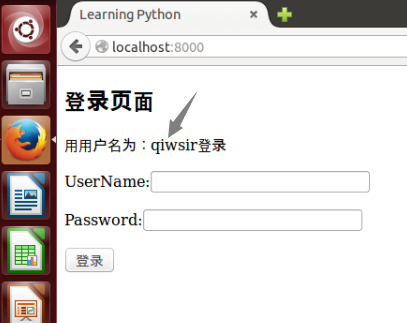](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30601.png)
图中箭头是我为了强调后来加上去的,箭头所指的,就是从数据库中读取出来的用户名,借助于模板中的双大括号`{{ }}`显示出来。
`{{ }}`本质上是占位符。当这个html被执行的时候,这个位置会被一个具体的对象(例如上面就是字符串qiwsir)所替代。具体是哪个具体对象替代这个占位符,完全是由render()方法中关键词来指定,也就是render()中的关键词与模板中的占位符包裹着的关键词一致。
用这种方式,修改一下用户正确登录之后的效果。要求用户正确登录之后,跳转到另外一个页面,并且在那个页面中显示出用户的完整信息。
先修改url.py文件,在其中增加一些内容。完整代码如下:
~~~
#!/usr/bin/env python
# coding=utf-8
"""
the url structure of website
"""
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
from handlers.index import IndexHandler
from handlers.user import UserHandler
url = [
(r'/', IndexHandler),
(r'/user', UserHandler),
]
~~~
然后就建立handlers/user.py文件,内容如下:
~~~
#!/usr/bin/env python
# coding=utf-8
import tornado.web
import methods.readdb as mrd
class UserHandler(tornado.web.RequestHandler):
def get(self):
username = self.get_argument("user")
user_infos = mrd.select_table(table="users",column="*",condition="username",value=username)
self.render("user.html", users = user_infos)
~~~
在get()中使用`self.get_argument("user")`,目的是要通过url获取参数user的值。因此,当用户登录后,得到正确返回值,那么js应该用这样的方式载入新的页面。
注意:上述的user.py代码为了简单突出本将要说明的,没有对user_infos的结果进行判断。在实际的编程中,这要进行判断或者使用try...except。
~~~
$(document).ready(function(){
$("#login").click(function(){
var user = $("#username").val();
var pwd = $("#password").val();
var pd = {"username":user, "password":pwd};
$.ajax({
type:"post",
url:"/",
data:pd,
cache:false,
success:function(data){
window.location.href = "/user?user="+data;
},
error:function(){
alert("error!");
},
});
});
});
~~~
接下来是user.html模板。注意上面的代码中,user_infos引用的对象不是一个字符串了,也就是传入模板的不是一个字符串,是一个元组。对此,模板这样来处理它。
~~~
<!DOCTYPE html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1" />
<title>Learning Python</title>
</head>
<body>
<h2>Your informations are:</h2>
<ul>
{% for one in users %}
<li>username:{{one[1]}}</li>
<li>password:{{one[2]}}</li>
<li>email:{{one[3]}}</li>
{% end %}
</ul>
</body>
~~~
显示的效果是:
[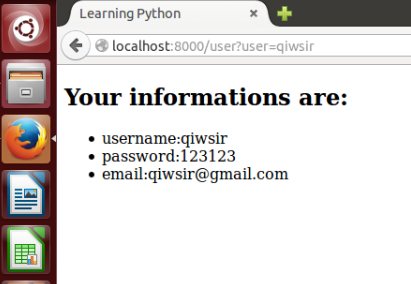](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30602.png)
在上面的模板中,其实用到了模板语法。
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/306.md#模板语法)模板语法
在模板的双大括号中,可以写类似python的语句或者表达式。比如:
~~~
>>> from tornado.template import Template
>>> print Template("{{ 3+4 }}").generate()
7
>>> print Template("{{ 'python'[0:2] }}").generate()
py
>>> print Template("{{ '-'.join(str(i) for i in range(10)) }}").generate()
0-1-2-3-4-5-6-7-8-9
~~~
意即如果在模板中,某个地方写上`{{ 3+4 }}`,当那个模板被render()读入之后,在页面上该占位符的地方就显示`7`。这说明tornado自动将双大括号内的表达式进行计算,并将其结果以字符串的形式返回到浏览器输出。
除了表达式之外,python的语句也可以在表达式中使用,包括if、for、while和try。只不过要有一个语句开始和结束的标记,用以区分那里是语句、哪里是HTML标记符。
语句的形式:`{{% 语句 %}}`
例如:
~~~
{{% if user=='qiwsir' %}}
{{ user }}
{{% end %}}
~~~
上面的举例中,第一行虽然是if语句,但是不要在后面写冒号了。最后一行一定不能缺少,表示语句块结束。将这一个语句块放到模板中,当被render读取此模板的时候,tornado将执行结果返回给浏览器显示,跟前面的表达式一样。实际的例子可以看上图输出结果和对应的循环语句。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/306.md#转义字符)转义字符
虽然读者现在已经对字符转义问题不陌生了,但是在网站开发中,它还将是一个令人感到麻烦的问题。所谓转义字符(Escape Sequence)也称字符实体(Character Entity),它的存在是因为在网页中`<, >`之类的符号,是不能直接被输出的,因为它们已经被用作了HTML标记符了,如果在网页上用到它们,就要转义。另外,也有一些字符在ASCII字符集中没有定义(如版权符号“©”),这样的符号要在HTML中出现,也需要转义字符(如“©”对应的转义字符是“&copy;”)。
上述是指前端页面的字符转义,其实不仅前端,在后端程序中,因为要读写数据库,也会遇到字符转义问题。
比如一个简单的查询语句:`select username, password from usertable where username='qiwsir'`,如果在登录框中没有输入qiwsir,而是输入了`a;drop database;`,这个查询语句就变成了`select username, password from usertable where username=a; drop database;`,如果后端程序执行了这条语句会怎么样呢?后果很严重,因为会`drop database`,届时真的是欲哭无泪了。类似的情况还很多,比如还可以输入`<input type="text" />`,结果出现了一个输入框,如果是`<form action="..."`,会造成跨站攻击了。这方面的问题还不少呢,读者有空可以到网上搜一下所谓sql注入问题,能了解更多。
所以,后端也要转义。
转义是不是很麻烦呢?
Tornado为你着想了,因为存在以上转义问题,而且会有粗心的程序员忘记了,于是Tornado中,模板默认为自动转义。这是多么好的设计呀。于是所有表单输入的,你就不用担心会遇到上述问题了。
为了能够体会自动转义,不妨在登录框中输入上面那样字符,然后可以用print语句看一看,后台得到了什么。
> print语句,在python3中是print()函数,在进行程序调试的时候非常有用。经常用它把要看个究竟的东西打印出来。
自动转义是一个好事情,但是,有时候会不需要转义,比如想在模板中这样做:
~~~
<!DOCTYPE html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1" />
<title>Learning Python</title>
</head>
<body>
<h2>登录页面</h2>
<p>用用户名为:{{user}}登录</p>
<form method="POST">
<p><span>UserName:</span><input type="text" id="username"/></p>
<p><span>Password:</span><input type="password" id="password" /></p>
<p><input type="BUTTON" value="登录" id="login" /></p>
</form>
{% set website = "<a href='http://www.itdiffer.com'>welcome to my website</a>" %}
{{ website }}
<script src="{{static_url("js/jquery.min.js")}}"></script>
<script src="{{static_url("js/script.js")}}"></script>
</body>
~~~
这是index.html的代码,我增加了`{% set website = "<a href='http://www.itdiffer.com'>welcome to my website</a>" %}`,作用是设置一个变量,名字是website,它对应的内容是一个做了超链接的文字。然后在下面使用这个变量`{{ website }}`,本希望能够出现的是有一行字“welcome to my website”,点击这行字,就可以打开对应链接的网站。可是,看到了这个:
[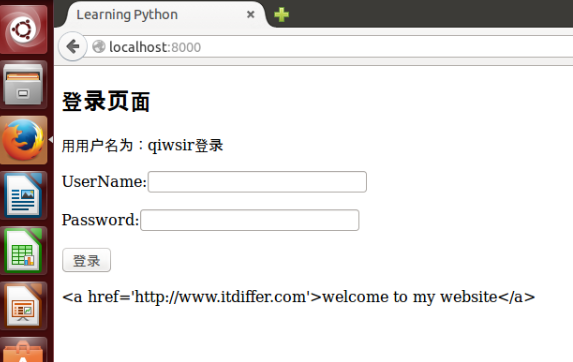](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30603.png)
下面那一行,把整个源码都显示出来了。这就是因为自动转义的结果。这里需要的是不转义。于是可以将`{{ website }}`修改为:
~~~
{% raw website %}
~~~
表示这一行不转义。但是别的地方还是转义的。这是一种最推荐的方法。
[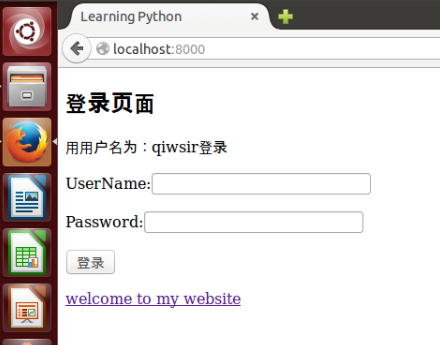](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30604.png)
如果你要全转义,可以使用:
~~~
{% autoescape None %}
{{ website }}
~~~
貌似省事,但是我不推荐。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/306.md#几个备查函数)几个备查函数
下面几个函数,放在这里备查,或许在某些时候用到。都是可以使用在模板中的。
* escape(s):替换字符串s中的&、为他们对应的HTML字符。
* url_escape(s):使用urllib.quote_plus替换字符串s中的字符为URL编码形式。
* json_encode(val):将val编码成JSON格式。
* squeeze(s):过滤字符串s,把连续的多个空白字符替换成一个空格。
此外,在模板中也可以使用自己编写的函数。但不常用。所以本教程就不啰嗦这个了。
用tornado做网站(3)
最后更新于:2022-04-01 11:36:58
## 数据传输
在已经建立了前端表单之后,就要实现前端和后端之间的数据传递。在工程中,常用到一个被称之为ajax()的方法。
关于ajax的故事,需要浓墨重彩,因为它足够精彩。
ajax是“Asynchronous Javascript and XML”(异步JavaScript和XML)的缩写,在它的发展历程中,汇集了众家贡献。比如微软的IE团队曾经将XHR(XML HttpRequest)用于web浏览器和web服务器间传输数据,并且被W3C标准采用。当然,也有其它公司为Ajax技术做出了贡献,虽然它们都被遗忘了,比如Oddpost,后来被Yahoo!收购并成为Yahoo! Mail的基础。但是,真正让Ajax大放异彩的google是不能被忽视的,正是google在Gmail、Suggest和Maps上大规模使用了Ajax,才使得人们看到了它的魅力,程序员由此而兴奋。
技术总是在不断进化的,进化的方向就是用着越来越方便。
回到上一节使用的jQuery,里面就有ajax()方法,能够让程序员方便的调用。
> ajax()方法通过 HTTP 请求加载远程数据。
>
> 该方法是jQuery底层AJAX实现。简单易用的高层实现见$.get, $.post等。$.ajax() 返回其创建的 XMLHttpRequest 对象。大多数情况下你无需直接操作该函数,除非你需要操作不常用的选项,以获得更多的灵活性。
>
> 最简单的情况下,$.ajax() 可以不带任何参数直接使用。
在上文介绍Ajax的时候,用到了一个重要的术语——“异步”,与之相对应的叫做“同步”。我引用来自[阮一峰的网络日志](http://www.ruanyifeng.com/blog/2012/12/asynchronous%EF%BC%BFjavascript.html)中的通俗描述:
> "同步模式"就是上一段的模式,后一个任务等待前一个任务结束,然后再执行,程序的执行顺序与任务的排列顺序是一致的、同步的;"异步模式"则完全不同,每一个任务有一个或多个回调函数(callback),前一个任务结束后,不是执行后一个任务,而是执行回调函数,后一个任务则是不等前一个任务结束就执行,所以程序的执行顺序与任务的排列顺序是不一致的、异步的。
>
> "异步模式"非常重要。在浏览器端,耗时很长的操作都应该异步执行,避免浏览器失去响应,最好的例子就是Ajax操作。在服务器端,"异步模式"甚至是唯一的模式,因为执行环境是单线程的,如果允许同步执行所有http请求,服务器性能会急剧下降,很快就会失去响应。
看来,ajax()是前后端进行数据传输的重要角色。
承接上一节的内容,要是用ajax()方法,需要修改script.js文件内容即可:
~~~
$(document).ready(function(){
$("#login").click(function(){
var user = $("#username").val();
var pwd = $("#password").val();
var pd = {"username":user, "password":pwd};
$.ajax({
type:"post",
url:"/",
data:pd,
cache:false,
success:function(data){
alert(data);
},
error:function(){
alert("error!");
},
});
});
});
~~~
在这段代码中,`var pd = {"username":user, "password":pwd};`意即将得到的user和pwd值,放到一个json对象中(关于json,请阅读[《标准库(8)》](https://github.com/qiwsir/StarterLearningPython/blob/master/227.md)),形成了一个json对象。接下来就是利用ajax()方法将这个json对象传给后端。
jQuery中的ajax()方法使用比较简单,正如上面代码所示,只需要`$.ajax()`即可,不过需要对立面的参数进行说明。
* type:post还是get。关于post和get的区别,可以阅读:[HTTP POST GET 本质区别详解](https://github.com/qiwsir/ITArticles/blob/master/Tornado/DifferenceHttpGetPost.md)
* url:post或者get的地址
* data:传输的数据,包括三种:(1)html拼接的字符串;(2)json数据;(3)form表单经serialize()序列化的。本例中传输的就是json数据,这也是经常用到的一种方式。
* cache:默认为true,如果不允许缓存,设置为false.
* success:请求成功时执行回调函数。本例中,将返回的data用alert方式弹出来。读者是否注意到,我在很多地方都用了alert()这个东西,目的在于调试,走一步看一步,看看得到的数据是否如自己所要。也是有点不自信呀。
* error:如果请求失败所执行的函数。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/305.md#后端接受数据)后端接受数据
前端通过ajax技术,将数据已json格式传给了后端,并且指明了对象目录`"/"`,这个目录在url.py文件中已经做了配置,是由handlers目录的index.py文件的IndexHandler类来出来。因为是用post方法传的数据,那么在这个类中就要有post方法来接收数据。所以,要在IndexHandler类中增加post(),增加之后的完善代码是:
~~~
#!/usr/bin/env python
# coding=utf-8
import tornado.web
class IndexHandler(tornado.web.RequestHandler):
def get(self):
self.render("index.html")
def post(self):
username = self.get_argument("username")
password = self.get_argument("password")
self.write(username)
~~~
在post()方法中,使用get_argument()函数来接收前端传过来的数据,这个函数的完整格式是`get_argument(name, default=[], strip=True)`,它能够获取name的值。在上面的代码中,name就是从前端传到后端的那个json对象的键的名字,是哪个键就获取该键的值。如果获取不到name的值,就返回default的值,但是这个值默认是没有的,如果真的没有就会抛出HTTP 400。特别注意,在get的时候,通过get_argument()函数获得url的参数,如果是多个参数,就获取最后一个的值。要想获取多个值,可以使用`get_arguments(name, strip=true)`。
上例中分别用get_argument()方法得到了username和password,并且它们都是unicode编码的数据。
tornado.web.RequestHandler的方法write(),即上例中的`self.write(username)`,是后端向前端返回数据。这里返回的实际上是一个字符串,也可返回json字符串。
如果读者要查看修改代码之后的网站效果,最有效的方式先停止网站(ctrl+c),在从新执行`python server.py`运行网站,然后刷新浏览器即可。这是一种较为笨拙的方法。一种灵巧的方法是开启调试模式。是否还记得?在设置setting的时候,写上`debug = True`就表示是调试模式了(参阅:[用tornado做网站(1)](https://github.com/qiwsir/StarterLearningPython/blob/master/303.md))。但是,调试模式也不是十全十美,如果修改模板,就不会加载,还需要重启服务。反正重启也不麻烦,无妨啦。
看看上面的代码效果:
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30501.png)
这是前端输入了用户名和密码之后,点击login按钮,提交给后端,后端再向前端返回数据之后的效果。就是我们想要的结果。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/305.md#验证用户名和密码)验证用户名和密码
按照流程,用户在前端输入了用户名和密码,并通过ajax提交到了后端,后端借助于get_argument()方法得到了所提交的数据(用户名和密码)。下面要做的事情就是验证这个用户名和密码是否合法,其体现在:
* 数据库中是否有这个用户
* 密码和用户先前设定的密码(已经保存在数据库中)是否匹配
这个验证工作完成之后,才能允许用户登录,登录之后才能继续做某些事情。
首先,在methods目录中(已经有了一个db.py)创建一个文件,我命名为readdb.py,专门用来存储读数据用的函数(这种划分完全是为了明确和演示一些应用方法,读者也可以都写到db.py中)。这个文件的代码如下:
~~~
#!/usr/bin/env python
# coding=utf-8
from db import *
def select_table(table, column, condition, value ):
sql = "select " + column + " from " + table + " where " + condition + "='" + value + "'"
cur.execute(sql)
lines = cur.fetchall()
return lines
~~~
上面这段代码,建议读者可以写上注释,以检验自己是否能够将以往的知识融会贯通地应用。恕我不再解释。
有了这段代码之后,就进一步改写index.py中的post()方法。为了明了,将index.py的全部代码呈现如下:
~~~
#!/usr/bin/env python
# coding=utf-8
import tornado.web
import methods.readdb as mrd
class IndexHandler(tornado.web.RequestHandler):
def get(self):
self.render("index.html")
def post(self):
username = self.get_argument("username")
password = self.get_argument("password")
user_infos = mrd.select_table(table="users",column="*",condition="username",value=username)
if user_infos:
db_pwd = user_infos[0][2]
if db_pwd == password:
self.write("welcome you: " + username)
else:
self.write("your password was not right.")
else:
self.write("There is no thi user.")
~~~
特别注意,在methods目录中,不要缺少了`__init__.py`文件,才能在index.py中实现`import methods.readdb as mrd`。
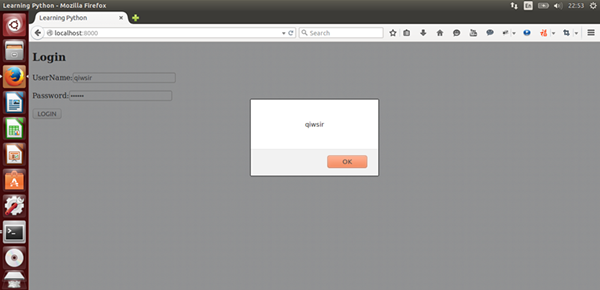
代码修改到这里,看到的结果是:
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30502.png)
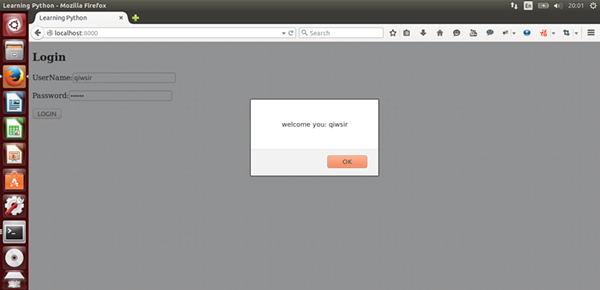
这是正确输入用户名(所谓正确,就是输入的用户名和密码合法,即在数据库中有该用户名,且密码匹配),并提交数据后,反馈给前端的欢迎信息。
[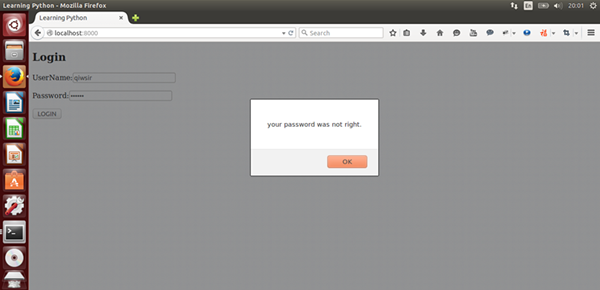](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30503.png)
如果输入的密码错误了,则如此提示。
[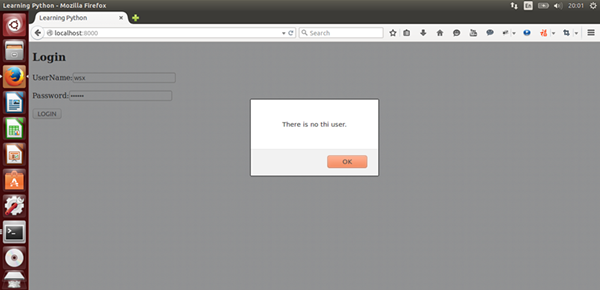](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30504.png)
这是随意输入的结果,数据库中无此用户。
需要特别说明一点,上述演示中,数据库中的用户密码并没有加密。关于密码加密问题,后续要研究。
用tornado做网站(2)
最后更新于:2022-04-01 11:36:55
既然摆好了一个网站的架势,下面就可以向里面填内容。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/304.md#连接数据库)连接数据库
要做的网站,有数据库支持,虽然这不是必须的,但是如果做一个功能强悍的网站,数据库就是必须的了。
接下来的网站,我暂且采用mysql数据库。
怎么连接mysql数据呢?其方法跟[《mysql数据库(1)》](https://github.com/qiwsir/StarterLearningPython/blob/master/230.md)中的方法完全一致。为了简单,我也不新建数据库了,就利用已经有的那个数据库。
在上一节中已经建立的文件夹methods中建立一个文件db.py,并且参考[《mysql数据库(1)》](https://github.com/qiwsir/StarterLearningPython/blob/master/230.md)和[《mysql数据库(2)》](https://github.com/qiwsir/StarterLearningPython/blob/master/231.md)的内容,分别建立起连接对象和游标对象。代码如下:
~~~
#!/usr/bin/env python
# coding=utf-8
import MySQLdb
conn = MySQLdb.connect(host="localhost", user="root", passwd="123123", db="qiwsirtest", port=3306, charset="utf8") #连接对象
cur = conn.cursor() #游标对象
~~~
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/304.md#用户登录)用户登录
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/304.md#前端)前端
很多网站上都看到用户登录功能,这里做一个简单的登录,其功能描述为:
> 当用户输入网址,呈现在眼前的是一个登录界面。在用户名和密码两个输入框中分别输入了正确的用户名和密码之后,点击确定按钮,登录网站,显示对该用户的欢迎信息。
用图示来说明,首先呈现下图:
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30401.png)
用户点击“登录”按钮,经过验证是合法用户之后,就呈现这样的界面:
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30402.png)
先用HTML写好第一个界面。进入到templates文件,建立名为index.html的文件:
~~~
<!DOCTYPE html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1" />
<title>Learning Python</title>
</head>
<body>
<h2>Login</h2>
<form method="POST">
<p><span>UserName:</span><input type="text" id="username"/></p>
<p><span>Password:</span><input type="password" id="password" /></p>
<p><input type="BUTTON" value="LOGIN" id="login" /></p>
</form>
</body>
~~~
这是一个很简单前端界面。要特别关注`<meta name="viewport" content="width=device-width, initial-scale=1" />`,其目的在将网页的默认宽度(viewport)设置为设备的屏幕宽度(width=device-width),并且原始缩放比例为1.0(initial-scale=1),即网页初始大小占屏幕面积的100%。这样做的目的,是让在电脑、手机等不同大小的屏幕上,都能非常好地显示。
这种样式的网页,就是“自适应页面”。当然,自适应页面绝非是仅仅有这样一行代码就完全解决的。要设计自适应页面,也就是要进行“响应式设计”,还需要对CSS、JS乃至于其它元素如表格、图片等进行设计,或者使用一些响应式设计的框架。这个目前暂不讨论,读者可以网上搜索有关资料阅读。
> 一提到要能够在手机上,读者是否想到了HTML5呢,这个被一些人热捧、被另一些人蔑视的家伙,毋庸置疑,现在已经得到了越来越广泛的应用。
>
> HTML5是HTML最新的修订版本,2014年10月由万维网联盟(W3C)完成标准制定。目标是取代1999年所制定的HTML 4.01和XHTML 1.0标准,以期能在互联网应用迅速发展的时候,使网络标准达到符合当代的网络需求。广义论及HTML5时,实际指的是包括HTML、CSS和JavaScript在内的一套技术组合。
>
> 响应式网页设计(英语:Responsive web design,通常缩写为RWD),又称为自适应网页设计、回应式网页设计。 是一种网页设计的技术做法,该设计可使网站在多种浏览设备(从桌面电脑显示器到移动电话或其他移动产品设备)上阅读和导航,同时减少缩放、平移和滚动。
如果要看效果,可以直接用浏览器打开网页,因为它是.html格式的文件。
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/304.md#引入jquery)引入jQuery
虽然完成了视觉上的设计,但是,如果点击那个login按钮,没有任何反应。因为它还仅仅是一个孤立的页面,这时候需要一个前端交互利器——javascript。
> 对于javascript,不少人对它有误解,总认为它是从java演化出来的。的确,两个有相像的地方。但javascript和java的关系,就如同“雷峰塔”和“雷锋”的关系一样。详细读一读来自维基百科的诠释。
>
> JavaScript,一种直译式脚本语言,是一种动态类型、弱类型、基于原型的语言,内置支持类。它的解释器被称为JavaScript引擎,为浏览器的一部分,广泛用于客户端的脚本语言,最早是在HTML网页上使用,用来给HTML网页增加动态功能。然而现在JavaScript也可被用于网络服务器,如Node.js。
>
> 在1995年时,由网景公司的布兰登·艾克,在网景导航者浏览器上首次设计实现而成。因为网景公司与昇阳公司合作,网景公司管理层希望它外观看起来像Java,因此取名为JavaScript。但实际上它的语义与Self及Scheme较为接近。
>
> 为了获取技术优势,微软推出了JScript,与JavaScript同样可在浏览器上运行。为了统一规格,1997年,在ECMA(欧洲计算机制造商协会)的协调下,由网景、昇阳、微软和Borland公司组成的工作组确定统一标准:ECMA-262。因为JavaScript兼容于ECMA标准,因此也称为ECMAScript。
但是,我更喜欢用jQuery,因为它的确让我省了不少事。
> jQuery是一套跨浏览器的JavaScript库,简化HTML与JavaScript之间的操作。由约翰·雷西格(John Resig)在2006年1月的BarCamp NYC上发布第一个版本。目前是由Dave Methvin领导的开发团队进行开发。全球前10,000个访问最高的网站中,有65%使用了jQuery,是目前最受欢迎的JavaScript库。
在index.html文件中引入jQuery的方法有多种。
原则上将,可以在HTML文件的任何地方引入jQuery库,但是通常放置的地方在html文件的开头`<head>...</head>`中,或者在文件的末尾`</body>`以内。放在开头,如果所用的库比较大、比较多,在载入页面时时间相对长点。
第一种引入方法,是国际化的一种:
~~~
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.11.2/jquery.min.js"></script>
~~~
这是直接从jQuery CDN(Content Delivery Network)上直接引用,好处在于如果这个库更新,你不用任何操作,就直接使用最新的了。但是,如果在你的网页中这么用了,如果在某个有很多自信的国家上网,并且没有梯子,会发现网页几乎打不开,就是因为连接上面那个地址的通道是被墙了。
当然,jQuery CDN不止一个,比如官方网站的:
~~~
<script src="//code.jquery.com/jquery-1.11.3.min.js"></script>
~~~
第二种引入方法,就是将jQuery下载下来,放在指定地方(比如,与自己网站在同一个存储器中,或者自己可以访问的另外服务器)。到官方网站([https://jqueryui.com/](https://jqueryui.com/))下载最新的库,然后将它放在已经建立的statics目录内,为了更清楚区分,可以在里面建立一个子目录js,jquery库放在js子目录里面。下载的时候,建议下载以min.js结尾的文件,因为这个是经过压缩之后,体积小。
我在`statics/js`目录中放置了下载的库,并且为了简短,更名为jquery.min.js。
本来可以用下面的方法引入:
~~~
<script src="statics/js/jquery.min.js"></script>
~~~
如果这样写,也是可以的。但是,考虑到tornado的特点,用下面方法引入,更具有灵活性:
~~~
<script src="{{static_url("js/jquery.min.js")}}"></script>
~~~
不仅要引入jquery,还需要引入自己写的js指令,所以要建立一个文件,我命名为script.js,也同时引用过来。虽然目前这个文件还是空的。
~~~
<script src="{{static_url("js/script.js")}}"></script>
~~~
这里用的static_url是一个函数,它是tornado模板提供的一个函数。用这个函数,能够制定静态文件。之所以用它,而不是用上面的那种直接调用的方法,主要原因是如果某一天,将静态文件目录statics修改了,也就是不指定statics为静态文件目录了,定义别的目录为静态文件目录。只需要在定义静态文件目录那里修改(定义静态文件目录的方法请参看上一节),而其它地方的代码不需要修改。
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/304.md#编写js)编写js
先写一个测试性质的东西。
用编辑器打开statics/js/script.js文件,如果没有就新建。输入的代码如下:
~~~
$(document).ready(function(){
alert("good");
$("#login").click(function(){
var user = $("#username").val();
var pwd = $("#password").val();
alert("username: "+user);
});
});
~~~
由于本教程不是专门讲授javascript或者jquery,所以,在js代码部分,只能一带而过,不详细解释。
上面的代码主要实现获取表单中id值分别为username和password所输入的值,alert函数的功能是把值以弹出菜单的方式显示出来。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/304.md#hanlers里面的程序)hanlers里面的程序
是否还记得在上一节中,在url.py文件中,做了这样的设置:
~~~
from handlers.index import IndexHandler #假设已经有了
url = [
(r'/', IndexHandler),
]
~~~
现在就去把假设有了的那个文件建立起来,即在handlers里面建立index.py文件,并写入如下代码:
~~~
#!/usr/bin/env python
# coding=utf-8
import tornado.web
class IndexHandler(tornado.web.RequestHandler):
def get(self):
self.render("index.html")
~~~
当访问根目录的时候(不论输入`localhost:8000`,还是`http://127.0.0.1:8000`,或者网站域名),就将相应的请求交给了handlers目录中的index.py文件中的IndexHandler类的get()方法来处理,它的处理结果是呈现index.html模板内容。
`render()`函数的功能在于向请求者反馈网页模板,并且可以向模板中传递数值。关于传递数值的内容,在后面介绍。
上面的文件保存之后,回到handlers目录中。因为这里面的文件要在别处被当做模块引用,所以,需要在这里建立一个空文件,命名为`__init__.py`。这个文件非常重要。在[编写模块](https://github.com/qiwsir/StarterLearningPython/blob/master/219.md)一节中,介绍了引用模块的方法。但是,那些方法有一个弊端,就是如果某个目录中有多个文件,就显得麻烦了。其实python已经想到这点了,于是就提供了`__init__.py`文件,只要在该目录中加入了这个文件,该目录中的其它.py文件就可以作为模块被python引入了。
至此,一个带有表单的tornado网站就建立起来了。读者可以回到上一级目录中,找到server.py文件,运行它:
~~~
$ python server.py
Development server is running at http://127.0.0.1:8000
Quit the server with Control-C
~~~
如果读者在前面的学习中,跟我的操作完全一致,就会在shell中看到上面的结果。
打开浏览器,输入`http://localhost:8000`或者`http://127.0.0.1:8000`,看到的应该是:
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30403.png)
这就是script.js中的开始起作用了,第一句是要弹出一个对话框。点击“确定”按钮之后,就是:
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30404.png)
在这个页面输入用户名和密码,然后点击Login按钮,就是:
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30405.png)
一个网站有了雏形。不过,当提交表单的反应,还仅仅停留在客户端,还没有向后端传递客户端的数据信息。请继续学习下一节。
用tornado做网站(1)
最后更新于:2022-04-01 11:36:53
从现在开始,做一个网站,当然,这个网站只能算是一个毛坯的,可能很简陋,但是网站的主要元素,它都会涉及到,读者通过此学习,能够了解网站的开发基本结构和内容,并且对前面的知识可以有综合应用。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/303.md#基本结构)基本结构
下面是一个网站的基本结构
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30301.png)
**前端**
这是一个不很严格的说法,但是在日常开发中,都这么说。在网站中,所谓前端就是指用浏览器打开之后看到的那部分,它是呈现网站传过来的信息的界面,也是用户和网站之间进行信息交互的界面。撰写前端,一般使用HTML/CSS/JS,当然,非要用python也不是不可以(例如上节中的例子,就没有用HTML/CSS/JS),但这势必造成以后维护困难。
MVC模式是一个非常好的软件架构模式,在网站开发中,也常常要求遵守这个模式。请阅读维基百科的解释:
> MVC模式(Model-View-Controller)是软件工程中的一种软件架构模式,把软件系统分为三个基本部分:模型(Model)、视图(View)和控制器(Controller)。
>
> MVC模式最早由Trygve Reenskaug在1978年提出,是施乐帕罗奥多研究中心(Xerox PARC)在20世纪80年代为程序语言Smalltalk发明的一种软件设计模式。MVC模式的目的是实现一种动态的程式设计,使后续对程序的修改和扩展简化,并且使程序某一部分的重复利用成为可能。除此之外,此模式通过对复杂度的简化,使程序结构更加直观。软件系统通过对自身基本部分分离的同时也赋予了各个基本部分应有的功能。专业人员可以通过自身的专长分组:
>
> * (控制器 Controller)- 负责转发请求,对请求进行处理。
> * (视图 View) - 界面设计人员进行图形界面设计。 -(模型 Model) - 程序员编写程序应有的功能(实现算法等等)、数据库专家进行数据管理和数据库设计(可以实现具体的功能)。
所谓“前端”,就对大概对应着View部分,之所以说是大概,因为MVC是站在一个软件系统的角度进行划分的,上图中的前后端,与其说是系统部分的划分,不如严格说是系统功能的划分。
前端所实现的功能主要有:
* 呈现内容。这些内容是根据url,由后端从数据库中提取出来的。前端将其按照一定的样式呈现出来。另外,有一些内容,不是后端数据库提供的,是写在前端的。
* 用户与网站交互。现在的网站,这是必须的,比如用户登录。当用户在指定的输入框中输入信息之后,该信息就是被前端提交给后端,后端对这个信息进行处理之后,在一般情况下都要再反馈给前端一个处理结果,然后前端呈现给用户。
**后端**
这里所说的后端,对应着MVC中的Controller和Model的部分或者全部功能,因为在我们的图中,“后端”是一个狭隘的概念,没有把数据库放在其内。
不在这些术语上纠结。
在我们这里,后端就是用python写的程序。主要任务就是根据需要处理由前端发过来的各种请求,根据请求的处理结果,一方面操作数据库(对数据库进行增删改查),另外一方面把请求的处理结果反馈给前端。
**数据库**
工作比较单一,就是面对后端的python程序,任其增删改查。
关于python如何操作数据库,在本教程的第贰季第柒章中已经有详细的叙述,请读者阅览。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/303.md#一个基本框架)一个基本框架
上节中,显示了一个只能显示一行字的网站,那个网站由于功能太单一,把所有的东西都写到一个文件中。在真正的工程开发中,如果那么做,虽然不是不可,但开发过程和后期维护会遇到麻烦,特别是不便于多人合作。
所以,要做一个基本框架。以后网站就在这个框架中开发。
建立一个目录,在这个目录中建立一些子目录和文件。
~~~
/.
|
handlers
|
methods
|
statics
|
templates
|
application.py
|
server.py
|
url.py
~~~
这个结构建立好,就摆开了一个做网站的架势。有了这个架势,后面的事情就是在这个基础上添加具体内容了。当然,还可以用另外一个更好听的名字,称之为设计。
依次说明上面的架势中每个目录和文件的作用(当然,这个作用是我规定的,读者如果愿意,也可以根据自己的意愿来任意设计):
* handlers:我准备在这个文件夹中放前面所说的后端python程序,主要处理来自前端的请求,并且操作数据库。
* methods:这里准备放一些函数或者类,比如用的最多的读写数据库的函数,这些函数被handlers里面的程序使用。
* statics:这里准备放一些静态文件,比如图片,css和javascript文件等。
* templates:这里放模板文件,都是以html为扩展名的,它们将直接面对用户。
另外,还有三个python文件,依次写下如下内容。这些内容的功能,已经在上节中讲过,只是这里进行分门别类。
**url.py**文件
~~~
#!/usr/bin/env python
# coding=utf-8
"""
the url structure of website
"""
import sys #utf-8,兼容汉字
reload(sys)
sys.setdefaultencoding("utf-8")
from handlers.index import IndexHandler #假设已经有了
url = [
(r'/', IndexHandler),
]
~~~
url.py文件主要是设置网站的目录结构。`from handlers.index import IndexHandler`,虽然在handlers文件夹还没有什么东西,为了演示如何建立网站的目录结构,假设在handlers文件夹里面已经有了一个文件index.py,它里面还有一个类IndexHandler。在url.py文件中,将其引用过来。
变量url指向一个列表,在列表中列出所有目录和对应的处理类。比如`(r'/', IndexHandler),`,就是约定网站根目录的处理类是IndexHandler,即来自这个目录的get()或者post()请求,均有IndexHandler类中相应方法来处理。
如果还有别的目录,如法炮制。
**application.py**文件
~~~
#!/usr/bin/env python
# coding=utf-8
from url import url
import tornado.web
import os
settings = dict(
template_path = os.path.join(os.path.dirname(__file__), "templates"),
static_path = os.path.join(os.path.dirname(__file__), "statics")
)
application = tornado.web.Application(
handlers = url,
**settings
)
~~~
从内容中可以看出,这个文件完成了对网站系统的基本配置,建立网站的请求处理集合。
`from url import url`是将url.py中设定的目录引用过来。
setting引用了一个字典对象,里面约定了模板和静态文件的路径,即声明已经建立的文件夹"templates"和"statics"分别为模板目录和静态文件目录。
接下来的application就是一个请求处理集合对象。请注意`tornado.web.Application()`的参数设置:
> tornado.web.Application(handlers=None, default_host='', transforms=None, **settings)
关于settings的设置,不仅仅是文件中的两个,还有其它,比如,如果填上`debug = True`就表示出于调试模式。调试模式的好处就在于有利于开发调试,但是,在正式部署的时候,最好不要用调试模式。其它更多的settings可以参看官方文档:[tornado.web-RequestHandler and Application classes](http://tornado.readthedocs.org/en/latest/web.html)
**server.py**文件
这个文件的作用是将tornado服务器运行起来,并且囊括前面两个文件中的对象属性设置。
~~~
#!/usr/bin/env python
# coding=utf-8
import tornado.ioloop
import tornado.options
import tornado.httpserver
from application import application
from tornado.options import define, options
define("port", default = 8000, help = "run on the given port", type = int)
def main():
tornado.options.parse_command_line()
http_server = tornado.httpserver.HTTPServer(application)
http_server.listen(options.port)
print "Development server is running at http://127.0.0.1:%s" % options.port
print "Quit the server with Control-C"
tornado.ioloop.IOLoop.instance().start()
if __name__ == "__main__":
main()
~~~
此文件中的内容,在[上节](https://github.com/qiwsir/StarterLearningPython/blob/master/302.md)已经介绍,不再赘述。
如此这般,就完成了网站架势的搭建。
后面要做的是向里面添加内容。
分析Hello
最后更新于:2022-04-01 11:36:51
打开你写python代码用的编辑器,不要问为什么,把下面的代码一个字不差地录入进去,并命名保存为hello.py(目录自己任意定)。
~~~
#!/usr/bin/env python
#coding:utf-8
import tornado.httpserver
import tornado.ioloop
import tornado.options
import tornado.web
from tornado.options import define, options
define("port", default=8000, help="run on the given port", type=int)
class IndexHandler(tornado.web.RequestHandler):
def get(self):
greeting = self.get_argument('greeting', 'Hello')
self.write(greeting + ', welcome you to read: www.itdiffer.com')
if __name__ == "__main__":
tornado.options.parse_command_line()
app = tornado.web.Application(handlers=[(r"/", IndexHandler)])
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(options.port)
tornado.ioloop.IOLoop.instance().start()
~~~
进入到保存hello.py文件的目录,执行:
~~~
$ python hello.py
~~~
用python运行这个文件,其实就已经发布了一个网站,只不过这个网站太简单了。
接下来,打开浏览器,在浏览器中输入:http://localhost:8000,得到如下界面:
[](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30201.png)
我在ubuntu的shell中还可以用下面方式运行:
~~~
$ curl http://localhost:8000/
Hello, welcome you to read: www.itdiffer.com
$ curl http://localhost:8000/?greeting=Qiwsir
Qiwsir, welcome you to read: www.itdiffer.com
~~~
此操作,读者可以根据自己系统而定。
恭喜你,迈出了决定性一步,已经可以用Tornado发布网站了。在这里似乎没有做什么部署,只是安装了Tornado。是的,不需要多做什么,因为Tornado就是一个很好的server,也是一个开发框架。
下面以这个非常简单的网站为例,对用tornado做的网站的基本结构进行解释。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/302.md#web服务器工作流程)WEB服务器工作流程
任何一个网站都离不开Web服务器,这里所说的不是指那个更计算机一样的硬件设备,是指里面安装的软件,有时候初次接触的看官容易搞混。就来伟大的[维基百科都这么说](http://zh.wikipedia.org/wiki/%E6%9C%8D%E5%8A%A1%E5%99%A8):
> 有时,这两种定义会引起混淆,如Web服务器。它可能是指用于网站的计算机,也可能是指像Apache这样的软件,运行在这样的计算机上以管理网页组件和回应网页浏览器的请求。
在具体的语境中,看官要注意分析,到底指的是什么。
关于Web服务器比较好的解释,推荐看看百度百科的内容,我这里就不复制粘贴了,具体可以点击连接查阅:[WEB服务器](http://baike.baidu.com/view/460250.htm)
在WEB上,用的最多的就是输入网址,访问某个网站。全世界那么多网站网页,如果去访问,怎么能够做到彼此互通互联呢。为了协调彼此,就制定了很多通用的协议,其中http协议,就是网络协议中的一种。关于这个协议的介绍,网上随处就能找到,请自己google.
网上偷来的[一张图](http://kenby.iteye.com/blog/1159621)(从哪里偷来的,我都告诉你了,多实在呀。哈哈。),显示在下面,简要说明web服务器的工作过程
[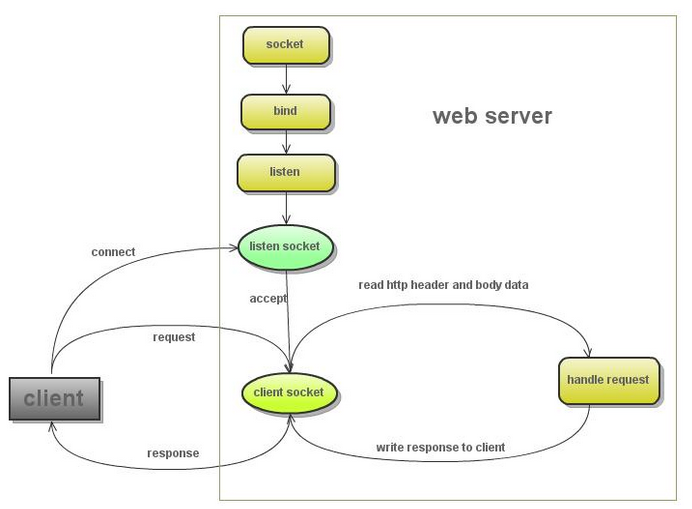](https://github.com/qiwsir/StarterLearningPython/blob/master/3images/30202.png)
偷个彻底,把原文中的说明也贴上:
1. 创建listen socket, 在指定的监听端口, 等待客户端请求的到来
2. listen socket接受客户端的请求, 得到client socket, 接下来通过client socket与客户端通信
3. 处理客户端的请求, 首先从client socket读取http请求的协议头, 如果是post协议, 还可能要读取客户端上传的数据, 然后处理请求, 准备好客户端需要的数据, 通过client socket写给客户端
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/302.md#引入模块)引入模块
~~~
import tornado.httpserver
import tornado.ioloop
import tornado.options
import tornado.web
~~~
这四个都是Tornado的模块,在本例中都是必须的。它们四个在一般的网站开发中,都要用到,基本作用分别是:
* tornado.httpserver:这个模块就是用来解决web服务器的http协议问题,它提供了不少属性方法,实现客户端和服务器端的互通。Tornado的非阻塞、单线程的特点在这个模块中体现。
* tornado.ioloop:这个也非常重要,能够实现非阻塞socket循环,不能互通一次就结束呀。
* tornado.options:这是命令行解析模块,也常用到。
* tornado.web:这是必不可少的模块,它提供了一个简单的Web框架与异步功能,从而使其扩展到大量打开的连接,使其成为理想的长轮询。
读者看到这里可能有点莫名其妙,对一些属于不理解。没关系,你可以先不用管它,如果愿意管,就把不理解属于放到google立面查查看。一定要硬着头皮一字一句地读下去,随着学习和实践的深入,现在不理解的以后就会逐渐领悟理解的。
还有一个模块引入,是用from...import完成的
~~~
from tornado.options import define, options
define("port", default=8000, help="run on the given port", type=int)
~~~
这两句就显示了所谓“命令行解析模块”的用途了。在这里通过`tornado.options.define()`定义了访问本服务器的端口,就是当在浏览器地址栏中输入`http:localhost:8000`的时候,才能访问本网站,因为http协议默认的端口是80,为了区分,我在这里设置为8000,为什么要区分呢?因为我的计算机或许你的也是,已经部署了别(或许是Nginx、Apache)服务器了,它的端口是80,所以要区分开(也可能是故意不用80端口),并且,后面我们还会将tornado和Nginx联合起来工作,这样两个服务器在同一台计算机上,就要分开喽。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/302.md#定义请求-处理程序类)定义请求-处理程序类
~~~
class IndexHandler(tornado.web.RequestHandler):
def get(self):
greeting = self.get_argument('greeting', 'Hello')
self.write(greeting + ', welcome you to read: www.itdiffer.com')
~~~
所谓“请求处理”程序类,就是要定义一个类,专门应付客户端(就是你打开的那个浏览器界面)向服务器提出的请求(这个请求也许是要读取某个网页,也许是要将某些信息存到服务器上),服务器要有相应的程序来接收并处理这个请求,并且反馈某些信息(或者是针对请求反馈所要的信息,或者返回其它的错误信息等)。
于是,就定义了一个类,名字是IndexHandler,当然,名字可以随便取了,但是,按照习惯,类的名字中的单词首字母都是大写的,并且如果这个类是请求处理程序类,那么就最好用Handler结尾,这样在名称上很明确,是干什么的。
类IndexHandler继承`tornado.web.RequestHandler`,其中再定义`get()`和`post()`两个在web中应用最多的方法的内容(关于这两个方法的详细解释,可以参考:[HTTP GET POST的本质区别详解](https://github.com/qiwsir/ITArticles/blob/master/Tornado/DifferenceHttpGetPost.md),作者在这篇文章中,阐述了两个方法的本质)。
在本例中,只定义了一个`get()`方法。
用`greeting = self.get_argument('greeting', 'Hello')`的方式可以得到url中传递的参数,比如
~~~
$ curl http://localhost:8000/?greeting=Qiwsir
Qiwsir, welcome you to read: www.itdiffer.com
~~~
就得到了在url中为greeting设定的值Qiwsir。如果url中没有提供值,就是Hello.
官方文档对这个方法的描述如下:
> RequestHandler.get_argument(name, default=, []strip=True)
>
> Returns the value of the argument with the given name.
>
> If default is not provided, the argument is considered to be required, and we raise a MissingArgumentError if it is missing.
>
> If the argument appears in the url more than once, we return the last value.
>
> The returned value is always unicode.
接下来的那句`self.write(greeting + ',weblcome you to read: www.itdiffer.com)'`中,`write()`方法主要功能是向客户端反馈信息。也浏览一下官方文档信息,对以后正确理解使用有帮助:
> RequestHandler.write(chunk)[source]
>
> Writes the given chunk to the output buffer.
>
> To write the output to the network, use the flush() method below.
>
> If the given chunk is a dictionary, we write it as JSON and set the Content-Type of the response to be application/json. (if you want to send JSON as a different Content-Type, call set_header after calling write()).
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/302.md#main方法)main()方法
`if __name__ == "__main__"`,这个方法跟以往执行python程序是一样的。
`tornado.options.parse_command_line()`,这是在执行tornado的解析命令行。在tornado的程序中,只要import模块之后,就会在运行的时候自动加载,不需要了解细节,但是,在main()方法中如果有命令行解析,必须要提前将模块引入。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/302.md#application类)Application类
下面这句是重点:
~~~
app = tornado.web.Application(handlers=[(r"/", IndexHandler)])
~~~
将tornado.web.Application类实例化。这个实例化,本质上是建立了整个网站程序的请求处理集合,然后它可以被HTTPServer做为参数调用,实现http协议服务器访问。Application类的`__init__`方法参数形式:
~~~
def __init__(self, handlers=None, default_host="", transforms=None,**settings):
pass
~~~
在一般情况下,handlers是不能为空的,因为Application类通过这个参数的值处理所得到的请求。例如在本例中,`handlers=[(r"/", IndexHandler)]`,就意味着如果通过浏览器的地址栏输入根路径(`http://localhost:8000`就是根路径,如果是`http://localhost:8000/qiwsir`,就不属于根,而是一个子路径或目录了),对应着就是让名字为IndexHandler类处理这个请求。
通过handlers传入的数值格式,一定要注意,在后面做复杂结构的网站是,这里就显得重要了。它是一个list,list里面的元素是tuple,tuple的组成包括两部分,一部分是请求路径,另外一部分是处理程序的类名称。注意请求路径可以用正则表达式书写(关于正则表达式,后面会进行简要介绍)。举例说明:
~~~
handlers = [
(r"/", IndexHandlers), #来自根路径的请求用IndesHandlers处理
(r"/qiwsir/(.*)", QiwsirHandlers), #来自/qiwsir/以及其下任何请求(正则表达式表示任何字符)都由QiwsirHandlers处理
]
~~~
**注意**
在这里我使用了`r"/"`的样式,意味着就不需要使用转义符,r后面的都表示该符号本来的含义。例如,\n,如果单纯这么来使用,就以为着换行,因为符号“\”具有转义功能(关于转义详细阅读[《字符串(1)》](https://github.com/qiwsir/StarterLearningPython/blob/master/106.md)),当写成`r"\n"`的形式是,就不再表示换行了,而是两个字符,\和n,不会转意。一般情况下,由于正则表达式和 \ 会有冲突,因此,当一个字符串使用了正则表达式后,最好在前面加上'r'。
关于Application类的介绍,告一段落,但是并未完全讲述了,因为还有别的参数设置没有讲,请继续关注后续内容。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/302.md#httpserver类)HTTPServer类
实例化之后,Application对象(用app做为标签的)就可以被另外一个类HTTPServer引用,形式为:
~~~
http_server = tornado.httpserver.HTTPServer(app)
~~~
HTTPServer是tornado.httpserver里面定义的类。HTTPServer是一个单线程非阻塞HTTP服务器,执行HTTPServer一般要回调Application对象,并提供发送响应的接口,也就是下面的内容是跟随上面语句的(options.port的值在IndexHandler类前面通过from...import..设置的)。
~~~
http_server.listen(options.port)
~~~
这种方法,就建立了单进程的http服务。
请看官牢记,如果在以后编码中,遇到需要多进程,请参考官方文档说明:[http://tornado.readthedocs.org/en/latest/httpserver.html#http-server](http://tornado.readthedocs.org/en/latest/httpserver.html#http-server)
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/302.md#ioloop类)IOLoop类
剩下最后一句了:
~~~
tornado.ioloop.IOLoop.instance().start()
~~~
这句话,总是在`__main()__`的最后一句。表示可以接收来自HTTP的请求了。
以上把一个简单的hello.py剖析。想必读者对Tornado编写网站的基本概念已经有了。
如果一头雾水,也不要着急,以来将上面的内容多看几遍。对整体结构有一个基本了解,不要拘泥于细节或者某些词汇含义。然后即继续学习。
为做网站而准备
最后更新于:2022-04-01 11:36:48
作为一个程序猿一定要会做网站。这也不一定吧,貌似是,但是,如果被人问及此事,如果说自己不会,的确羞愧难当呀。所以,本教程要讲一讲如何做网站。
> 推荐阅读:[History of the World Wide Web](http://en.wikipedia.org/wiki/History_of_the_World_Wide_Web)
首先,为自己准备一个服务器。这个要求似乎有点过分,作为一个普通的穷苦聊到的程序员,哪里有铜钿来购买服务器呢?没关系,不够买服务器也能做网站,可以购买云服务空间或者虚拟空间,这个在网上搜搜,很多。如果购买这个的铜钿也没有,还可以利用自己的电脑(这总该有了)作为服务服务器。我就是利用一台装有ubuntu操作系统的个人电脑作为本教程的案例演示服务器。
然后,要在这个服务器上做一些程序配置。一些必备的网络配置这里就不说了,比如我用的ubuntu系统,默认情况都有了。如果读者遇到一些问题,可以搜一下,网上资料多多。另外的配置就是python开发环境,这个应该也有了,前面已经在用了。
接下来,要安装一个框架。本教程中制作网站的案例采用tornado框架。
在安装这个框架之前,先了解一些相关知识。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/301.md#开发框架)开发框架
对框架的认识,由于工作习惯和工作内容的不同,有很大差异,这里姑且截取[维基百科中的一种定义](http://zh.wikipedia.org/wiki/%E8%BB%9F%E9%AB%94%E6%A1%86%E6%9E%B6),之所以要给出一个定义,无非是让看官有所了解,但是是否知道这个定义,丝毫不影响后面的工作。
> 软件框架(Software framework),通常指的是为了实现某个业界标准或完成特定基本任务的软件组件规范,也指为了实现某个软件组件规范时,提供规范所要求之基础功能的软件产品。
>
> 框架的功能类似于基础设施,与具体的软件应用无关,但是提供并实现最为基础的软件架构和体系。软件开发者通常依据特定的框架实现更为复杂的商业运用和业务逻辑。这样的软件应用可以在支持同一种框架的软件系统中运行。
>
> 简而言之,框架就是制定一套规范或者规则(思想),大家(程序员)在该规范或者规则(思想)下工作。或者说就是使用别人搭好的舞台,你来做表演。
我比较喜欢最后一句的解释,别人搭好舞台,我来表演。这也就是说,如果在做软件开发的时候,能够减少工作量。就做网站来讲,其实需要做的事情很多,但是如果有了开发框架,很多底层的事情就不需要做了(都有哪些底层的事情呢?读者能否回答?)。
有高手工程师鄙视框架,认为自己编写的才是王道。这方面不争论,框架是开发中很流行的东西,我还是固执地认为用框架来开发,更划算。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/301.md#python框架)python框架
有人说php(什么是php,严肃的说法,这是另外一种语言,更高雅的说法,是某个活动的汉语拼音简称)框架多,我不否认,php的开发框架的确很多很多。不过,python的web开发框架,也足够使用了,列举几种常见的web框架:
* Django:这是一个被广泛应用的框架。在网上搜索,会发现很多公司在招聘的时候就说要会这个。框架只是辅助,真正的程序员,用什么框架,都应该是根据需要而来。当然不同框架有不同的特点,需要学习一段时间。
* Flask:一个用Python编写的轻量级Web应用框架。基于Werkzeug WSGI工具箱和Jinja2模板引擎。
* Web2py:是一个为Python语言提供的全功能Web应用框架,旨在敏捷快速的开发Web应用,具有快速、安全以及可移植的数据库驱动的应用,兼容Google App Engine。
* Bottle: 微型Python Web框架,遵循WSGI,说微型,是因为它只有一个文件,除Python标准库外,它不依赖于任何第三方模块。
* Tornado:全称是Tornado Web Server,从名字上看就可知道它可以用作Web服务器,但同时它也是一个Python Web的开发框架。最初是在FriendFeed公司的网站上使用,FaceBook收购了之后便开源了出来。
* webpy: 轻量级的Python Web框架。webpy的设计理念力求精简(Keep it simple and powerful),源码很简短,只提供一个框架所必须的东西,不依赖大量的第三方模块,它没有URL路由、没有模板也没有数据库的访问。
说明:以上信息选自:[http://blog.jobbole.com/72306/](http://blog.jobbole.com/72306/) ,这篇文章中还有别的框架,由于不是web框架,我没有选摘,有兴趣的去阅读。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/301.md#tornado)Tornado
本教程中将选择使用Tornado框架。此前有朋友建议我用Django,首先它是一个好东西。但是,我更愿意用Tornado,为什么呢?因为......,看下边或许是理由,或许不是。
Tornado全称Tornado Web Server,是一个用Python语言写成的Web服务器兼Web应用框架,由FriendFeed公司在自己的网站FriendFeed中使用,被Facebook收购以后框架以开源软件形式开放给大众。看来Tornado的出身高贵呀,对了,某国可能风闻有Facebook,但是要一睹其芳容,还要努力。
用哪个框架,一般是要结合项目而定。我之选用Tornado的原因,就是看中了它在性能方面的优异表现。
Tornado的性能是相当优异的,因为它试图解决一个被称之为“C10k”问题,就是处理大于或等于一万的并发。一万呀,这可是不小的量。(关于C10K问题,看官可以浏览:[C10k problem](http://en.wikipedia.org/wiki/C10k_problem))
下表是和一些其他Web框架与服务器的对比,供看官参考(数据来源: [https://developers.facebook.com/blog/post/301](https://developers.facebook.com/blog/post/301) )
条件:处理器为 AMD Opteron, 主频2.4GHz, 4核
| 服务 | 部署 | 请求/每秒 |
| --- | --- | --- |
| Tornado | nginx, 4进程 | 8213 |
| Tornado | 1个单线程进程 | 3353 |
| Django | Apache/mod_wsgi | 2223 |
| web.py | Apache/mod_wsgi | 2066 |
| CherryPy | 独立 | 785 |
看了这个对比表格,还有什么理由不选择Tornado呢?
就是它了——**Tornado**
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/301.md#安装tornado)安装Tornado
Tornado的官方网站:[http://www.tornadoweb.org](http://www.tornadoweb.org/en/latest/)
我在自己电脑中(是我目前使用的服务器),用下面方法安装,只需要一句话即可:
~~~
pip install tornado
~~~
这是因为Tornado已经列入PyPI,因此可以通过 pip 或者 easy_install 来安装。
如果不用这种方式安装,下面的页面中有可以供看官下载的最新源码版本和安装方式:[https://pypi.python.org/pypi/tornado/](https://pypi.python.org/pypi/tornado/)
此外,在github上也有托管,看官可以通过上述页面进入到github看源码。
我没有在windows操作系统上安装过这个东西,不过,在官方网站上有一句话,可能在告诉读者一些信息:
> Tornado will also run on Windows, although this configuration is not officially supported and is recommended only for development use.
特别建议,在真正的工程中,网站的服务器还是用Linux比较好,你懂得(吗?)。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/301.md#技术准备)技术准备
除了做好上述准备之外,还要有点技术准备:
* HTML
* CSS
* JavaScript
我们在后面实例中,不会搞太复杂的界面和JavaScript(JS)操作,所以,只需要基本知识即可。
第捌章 用Tornado做网站
最后更新于:2022-04-01 11:36:46
电子表格
最后更新于:2022-04-01 11:36:44
一提到电子表格,可能立刻想到的是excel。殊不知,电子表格,还是“历史悠久”的呢,比word要长久多了。根据维基百科的记载整理一个简史:
> VisiCalc是第一个电子表格程序,用于苹果II型电脑。由丹·布李克林(Dan Bricklin)和鮑伯·法蘭克斯頓(Bob Frankston)發展而成,1979年10月跟著蘋果二號電腦推出,成為蘋果二號電腦上的「殺手應用軟體」。
>
> 接下来是Lotus 1-2-3,由Lotus Software(美國蓮花軟體公司)於1983年起所推出的電子試算表軟體,在DOS時期廣為個人電腦使用者所使用,是一套殺手級應用軟體。也是世界上第一个销售超过100万套的软件。
>
> 然后微软也开始做电子表格,早在1982年,它推出了它的第一款電子制表軟件──Multiplan,並在CP/M系統上大獲成功,但在MS-DOS系統上,Multiplan敗給了Lotus 1-2-3。
>
> 1985年,微软推出第一款Excel,但它只用於Mac系統;直到1987年11月,微软的第一款適用於Windows系統的Excel才诞生,不过,它一出来,就与Windows系统直接捆綁,由于此后windows大行其道,并且Lotus1-2-3遲遲不能適用於Windows系統,到了1988年,Excel的銷量超過了1-2-3。
>
> 此后就是微软的天下了,Excel后来又并入了Office里面,成为了Microsoft Office Excel。
>
> 尽管Excel已经发展了很多代,提供了大量的用戶界面特性,但它仍然保留了第一款電子制表軟件VisiCalc的特性:行、列組成單元格,數據、與數據相關的公式或者對其他單元格的絕對引用保存在單元格中。
>
> 由于微软独霸天下,Lotus 1-2-3已经淡出了人们的视线,甚至于误认为历史就是从微软开始的。
>
> 其实,除了微软的电子表格,在Linux系统中也有很好的电子表格,google也提供了不错的在线电子表格(可惜某国内不能正常访问)。
从历史到现在,电子表格都很广泛的用途。所以,python也要操作一番电子表格,因为有的数据,或许就是存在电子表格中。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/234.md#openpyl)openpyl
openpyl模块是解决Microsoft Excel 2007/2010之类版本中扩展名是Excel 2010 xlsx/xlsm/xltx/xltm的文件的读写的第三方库。(差点上不来气,这句话太长了。)
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/234.md#安装)安装
安装第三方库,当然用法力无边的pip install
~~~
$ sudo pip install openpyxl
~~~
如果最终看到下面的提示,恭喜你,安装成功。
~~~
Successfully installed openpyxl jdcal
Cleaning up...
~~~
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/234.md#workbook和sheet)workbook和sheet
第一步,当然是要引入模块,用下面的方式:
~~~
>>> from openpyxl import Workbook
~~~
接下来就用`Workbook()`类里面的方法展开工作:
~~~
>>> wb = Workbook()
~~~
请回忆Excel文件,如果想不起来,就打开Excel,我们第一眼看到的是一个称之为工作簿(workbook)的东西,里面有几个sheet,默认是三个,当然可以随意增删。默认又使用第一个sheet。
~~~
>>> ws = wb.active
~~~
每个工作簿中,至少要有一个sheet,通过这条指令,就在当前工作簿中建立了一个sheet,并且它是当前正在使用的。
还可以在这个sheet后面追加:
~~~
>>> ws1 = wb.create_sheet()
~~~
甚至,还可以加塞:
~~~
>>> ws2 = wb.create_sheet(1)
~~~
排在了第二个位置。
在Excel文件中一样,创建了sheet之后,默认都是以"Sheet1"、"Sheet2"样子来命名的,然后我们可以给其重新命名。在这里,依然可以这么做。
~~~
>>> ws.title = "python"
~~~
ws所引用的sheet对象名字就是"python"了。
此时,可以使用下面的方式从工作簿对象中得到sheet
~~~
>>> ws01 = wb['python'] #sheet和工作簿的关系,类似键值对的关系
>>> ws is ws01
True
~~~
或者用这种方式
~~~
>>> ws02 = wb.get_sheet_by_name("python") #这个方法名字也太直接了,方法的参数就是sheet名字
>>> ws is ws02
True
~~~
整理一下到目前为止我们已经完成的工作:建立了工作簿(wb),还有三个sheet。还是显示一下比较好:
~~~
>>> print wb.get_sheet_names()
['python', 'Sheet2', 'Sheet1']
~~~
Sheet2这个sheet之所以排在了第二位,是因为在建立的时候,用了一个加塞的方法。这跟Excel中差不多少,如果sheet命名了,就按照那个名字显示,否则就默认为名字是"Sheet1"形状的(注意,第一个字母大写)。
也可以用循环语句,把所有的sheet名字打印出来。
~~~
>>> for sh in wb:
... print sh.title
...
python
Sheet2
Sheet1
~~~
如果读者去`dir(wb)`工作簿对象的属性和方法,会发现它具有迭代的特征`__iter__`方法。说明,工作簿是可迭代的。
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/234.md#cell)cell
为了能够清楚理解填数据的过程,将电子表中约定的名称以下图方式说明:
[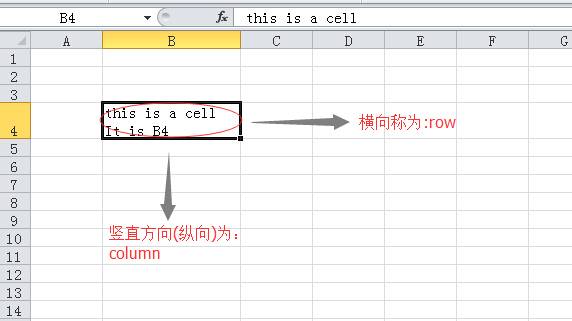](https://github.com/qiwsir/StarterLearningPython/blob/master/2images/23401.jpg)
对于sheet,其中的cell是它的下级单位。所以,要得到某个cell,可以这样:
~~~
b4 = ws['B4']
~~~
如果B4这个cell已经有了,用这种方法就是将它的值赋给了变量b4;如果sheet中没有这个cell,那么就创建这个cell对象。
请读者注意,当我们打开Excel,默认已经画好了好多cell。但是,在python操作的电子表格中,不会默认画好那样一个表格,一切都要创建之后才有。所以,如果按照前面的操作流程,上面就是创建了B4这个cell,并且把它作为一个对象被b4变量引用。
如果要给B4添加数据,可以这么做:
~~~
>>> ws['B4'] = 4444
~~~
因为b4引用了一个cell对象,所以可以利用这个对象的属性来查看其值:
~~~
>>> b4.value
4444
~~~
要获得(或者建立并获得)某个cell对象,还可以使用下面方法:
~~~
>>> a1 = ws.cell("A1")
~~~
或者:
~~~
>>> a2 = ws.cell(row = 2, column = 1)
~~~
刚才已经提到,在建立了sheet之后,内存中的它并没有cell,需要程序去建立。上面都是一个一个地建立,能不能一下建立多个呢?比如要类似下面的:
|A1|B1|C1| |A2|B2|C2| |A3|B3|C3|
就可以如同切片那样来操作:
~~~
>>> cells = ws["A1":"C3"]
~~~
可以用下面方法看看创建结果:
~~~
>>> tuple(ws.iter_rows("A1:C3"))
((<Cell python.A1>, <Cell python.B1>, <Cell python.C1>),
(<Cell python.A2>, <Cell python.B2>, <Cell python.C2>),
(<Cell python.A3>, <Cell python.B3>, <Cell python.C3>))
~~~
这是按照横向顺序数过来来的,即A1-B1-C1,然后下一横行。还可以用下面的循环方法,一个一个地读到每个cell对象:
~~~
>>> for row in ws.iter_rows("A1:C3"):
... for cell in row:
... print cell
...
<Cell python.A1>
<Cell python.B1>
<Cell python.C1>
<Cell python.A2>
<Cell python.B2>
<Cell python.C2>
<Cell python.A3>
<Cell python.B3>
<Cell python.C3>
~~~
也可以用sheet对象的`rows`属性,得到按照横向顺序依次排列的cell对象(注意观察结果,因为没有进行范围限制,所以是目前sheet中所有的cell,前面已经建立到第四行了B4,所以,要比上面的操作多一个row):
~~~
>>> ws.rows
((<Cell python.A1>, <Cell python.B1>, <Cell python.C1>),
(<Cell python.A2>, <Cell python.B2>, <Cell python.C2>),
(<Cell python.A3>, <Cell python.B3>, <Cell python.C3>),
(<Cell python.A4>, <Cell python.B4>, <Cell python.C4>))
~~~
用sheet对象的`columns`属性,得到的是按照纵向顺序排列的cell对象(注意观察结果):
~~~
>>> ws.columns
((<Cell python.A1>, <Cell python.A2>, <Cell python.A3>, <Cell python.A4>),
(<Cell python.B1>, <Cell python.B2>, <Cell python.B3>, <Cell python.B4>),
(<Cell python.C1>, <Cell python.C2>, <Cell python.C3>, <Cell python.C4>))
~~~
不管用那种方法,只要得到了cell对象,接下来就可以依次赋值了。比如要将上面的表格中,依次填写上1,2,3,...
~~~
>>> i = 1
>>> for cell in ws.rows:
... cell.value = i
... i += 1
~~~
... Traceback (most recent call last): File "", line 2, in AttributeError: 'tuple' object has no attribute 'value'
报错了。什么错误。关键就是没有注意观察上面的结果。tuple里面是以tuple为元素,再里面才是cell对象。所以,必须要“时时警醒”,常常谨慎。
~~~
>>> for row in ws.rows:
... for cell in row:
... cell.value = i
... i += 1
...
~~~
如此,就给每个cell添加了数据。查看一下,不过要换一个属性:
~~~
>>> for col in ws.columns:
... for cell in col:
... print cell.value
...
1
4
7
10
2
5
8
11
3
6
9
12
~~~
虽然看着有点不舒服,但的确达到了前面的要求。
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/234.md#保存)保存
把辛苦工作的结果保存一下吧。
~~~
>>> wb.save("23401.xlsx")
~~~
如果有同名文件存在,会覆盖。
此时,可以用Excel打开这个文件,看看可视化的结果:
[](https://github.com/qiwsir/StarterLearningPython/blob/master/2images/23402.jpg)
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/234.md#读取已有文件)读取已有文件
如果已经有一个.xlsx文件,要读取它,可以这样来做:
~~~
>>> from openpyxl import load_workbook
>>> wb2 = load_workbook("23401.xlsx")
>>> print wb2.get_sheet_names()
['python', 'Sheet2', 'Sheet1']
>>> ws_wb2 = wb2["python"]
>>> for row in ws_wb2.rows:
... for cell in row:
... print cell.value
...
1
2
3
4
5
6
7
8
9
10
11
12
~~~
很好,就是这个文件。
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/234.md#其它第三方库)其它第三方库
针对电子表格的第三方库,除了上面这个openpyxl之外,还有别的,列出几个,供参考,使用方法大同小异。
* xlsxwriter:针对Excel 2010格式,如.xlsx,官方网站:[https://xlsxwriter.readthedocs.org/](https://xlsxwriter.readthedocs.org/),这个官方文档写的图文并茂。非常好读。
下面两个用来处理.xls格式的电子表表格。
* xlrd:网络文件:[https://secure.simplistix.co.uk/svn/xlrd/trunk/xlrd/doc/xlrd.html?p=4966](https://secure.simplistix.co.uk/svn/xlrd/trunk/xlrd/doc/xlrd.html?p=4966)
* xlwt:网络文件:[http://xlwt.readthedocs.org/en/latest/](http://xlwt.readthedocs.org/en/latest/)
SQLite数据库
最后更新于:2022-04-01 11:36:41
SQLite是一个小型的关系型数据库,它最大的特点在于不需要服务器、零配置。在前面的两个服务器,不管是MySQL还是MongoDB,都需要“安装”,安装之后,它运行起来,其实是已经有一个相应的服务器在跑着呢。而SQLite不需要这样,首先python已经将相应的驱动模块作为标准库一部分了,只要安装了python,就可以使用;另外,它也不需要服务器,可以类似操作文件那样来操作SQLite数据库文件。还有一点也不错,SQLite源代码不受版权限制。
SQLite也是一个关系型数据库,所以SQL语句,都可以在里面使用。
跟操作mysql数据库类似,对于SQLite数据库,也要通过以下几步:
* 建立连接对象
* 连接对象方法:建立游标对象
* 游标对象方法:执行sql语句
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/233.md#建立连接对象)建立连接对象
由于SQLite数据库的驱动已经在python里面了,所以,只要引用就可以直接使用
~~~
>>> import sqlite3
>>> conn = sqlite3.connect("23301.db")
~~~
这样就得到了连接对象,是不是比mysql连接要简化了很多呢。在`sqlite3.connect("23301.db")`语句中,如果已经有了那个数据库,就连接上它;如果没有,就新建一个。注意,这里的路径可以随意指定的。
不妨到目录中看一看,是否存在了刚才建立的数据库文件。
~~~
/2code$ ls 23301.db
23301.db
~~~
果然有了一个文件。
连接对象建立起来之后,就要使用连接对象的方法继续工作了。
~~~
>>> dir(conn)
['DataError', 'DatabaseError', 'Error', 'IntegrityError', 'InterfaceError', 'InternalError', 'NotSupportedError', 'OperationalError', 'ProgrammingError', 'Warning', '__call__', '__class__', '__delattr__', '__doc__', '__enter__', '__exit__', '__format__', '__getattribute__', '__hash__', '__init__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'close', 'commit', 'create_aggregate', 'create_collation', 'create_function', 'cursor', 'enable_load_extension', 'execute', 'executemany', 'executescript', 'interrupt', 'isolation_level', 'iterdump', 'load_extension', 'rollback', 'row_factory', 'set_authorizer', 'set_progress_handler', 'text_factory', 'total_changes']
~~~
## [](https://github.com/qiwsir/StarterLearningPython/blob/master/233.md#游标对象)游标对象
这步跟mysql也类似,要建立游标对象。
~~~
>>> cur = conn.cursor()
~~~
接下来对数据库内容的操作,都是用游标对象方法来实现了:
~~~
>>> dir(cur)
['__class__', '__delattr__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__iter__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'arraysize', 'close', 'connection', 'description', 'execute', 'executemany', 'executescript', 'fetchall', 'fetchmany', 'fetchone', 'lastrowid', 'next', 'row_factory', 'rowcount', 'setinputsizes', 'setoutputsize']
~~~
是不是看到熟悉的名称了:`close(), execute(), executemany(), fetchall()`
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/233.md#创建数据库表)创建数据库表
在mysql中,我们演示的是利用mysql的shell来创建的表。其实,当然可以使用sql语句,在python中实现这个功能。这里对sqlite数据库,就如此操作一番。
~~~
>>> create_table = "create table books (title text, author text, lang text) "
>>> cur.execute(create_table)
<sqlite3.Cursor object at 0xb73ed5a0>
~~~
这样就在数据库23301.db中建立了一个表books。对这个表可以增加数据了:
~~~
>>> cur.execute('insert into books values ("from beginner to master", "laoqi", "python")')
<sqlite3.Cursor object at 0xb73ed5a0>
~~~
为了保证数据能够保存,还要(这是多么熟悉的操作流程和命令呀):
~~~
>>> conn.commit()
>>> cur.close()
>>> conn.close()
~~~
支持,刚才建立的那个数据库中,已经有了一个表books,表中已经有了一条记录。
整个流程都不陌生。
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/233.md#查询)查询
存进去了,总要看看,这算强迫症吗?
~~~
>>> conn = sqlite3.connect("23301.db")
>>> cur = conn.cursor()
>>> cur.execute('select * from books')
<sqlite3.Cursor object at 0xb73edea0>
>>> print cur.fetchall()
[(u'from beginner to master', u'laoqi', u'python')]
~~~
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/233.md#批量插入)批量插入
多增加点内容,以便于做别的操作:
~~~
>>> books = [("first book","first","c"), ("second book","second","c"), ("third book","second","python")]
~~~
这回来一个批量插入
~~~
>>> cur.executemany('insert into books values (?,?,?)', books)
<sqlite3.Cursor object at 0xb73edea0>
>>> conn.commit()
~~~
用循环语句打印一下查询结果:
~~~
>>> rows = cur.execute('select * from books')
>>> for row in rows:
... print row
...
(u'from beginner to master', u'laoqi', u'python')
(u'first book', u'first', u'c')
(u'second book', u'second', u'c')
(u'third book', u'second', u'python')
~~~
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/233.md#更新)更新
正如前面所说,在cur.execute()中,你可以写SQL语句,来操作数据库。
~~~
>>> cur.execute("update books set title='physics' where author='first'")
<sqlite3.Cursor object at 0xb73edea0>
>>> conn.commit()
~~~
按照条件查处来看一看:
~~~
>>> cur.execute("select * from books where author='first'")
<sqlite3.Cursor object at 0xb73edea0>
>>> cur.fetchone()
(u'physics', u'first', u'c')
~~~
### [](https://github.com/qiwsir/StarterLearningPython/blob/master/233.md#删除)删除
在sql语句中,这也是常用的。
~~~
>>> cur.execute("delete from books where author='second'")
<sqlite3.Cursor object at 0xb73edea0>
>>> conn.commit()
>>> cur.execute("select * from books")
<sqlite3.Cursor object at 0xb73edea0>
>>> cur.fetchall()
[(u'from beginner to master', u'laoqi', u'python'), (u'physics', u'first', u'c')]
~~~
不要忘记,在你完成对数据库的操作是,一定要关门才能走人:
~~~
>>> cur.close()
>>> conn.close()
~~~
作为基本知识,已经介绍差不多了。当然,在实践的编程中,或许会遇到问题,就请读者多参考官方文档:[https://docs.python.org/2/library/sqlite3.html](https://docs.python.org/2/library/sqlite3.html)