第六章 分区
最后更新于:2022-04-02 04:18:36
[TOC]
## 概述
分区主要是为了**可扩展性**。不同的分区可以放在不共享集群中的不同节点上
## 方案
### 根据键的范围分区
### 根据键的散列分区
通过使用Key散列进行分区,我们失去了键范围分区的一个很好的属性:高效执行范围查询的能力。曾经相邻的密钥现在分散在所有分区中,所以它们之间的顺序就丢失了
## 分区再平衡
随着时间的推移,数据库会有各种变化。
* 查询吞吐量增加,所以您想要添加更多的CPU来处理负载。
* 数据集大小增加,所以您想添加更多的磁盘和RAM来存储它。
* 机器出现故障,其他机器需要接管故障机器的责任。
### 反面教材:hash mod N
模$N$方法的问题是,如果节点数量N发生变化,大多数密钥将需要从一个节点移动到另一个节点
### 固定数量的分区
有一个相当简单的解决方案:创建比节点更多的分区,并为每个节点分配多个分区。例如,运行在10个节点的集群上的数据库可能会从一开始就被拆分为1,000个分区,因此大约有100个分区被分配给每个节点
现在,如果一个节点被添加到集群中,新节点可以从当前每个节点中**窃取**一些分区
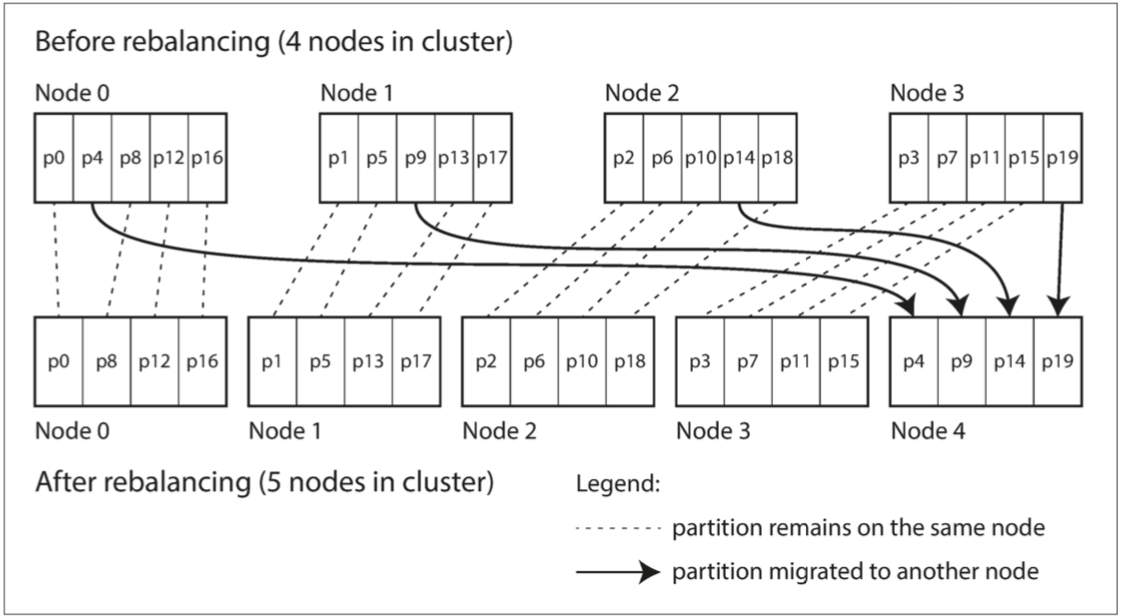
**将新节点添加到每个节点具有多个分区的数据库群集**
### 动态分区
具有固定边界的固定数量的分区将非常不便:如果出现边界错误,则可能会导致一个分区中的所有数据或者其他分区中的所有数据为空。手动重新配置分区边界将非常繁琐
当分区增长到超过配置的大小时(在HBase上,默认值是10GB),会被分成两个分区,每个分区约占一半的数据【26】。与之相反,如果大量数据被删除并且分区缩小到某个阈值以下,则可以将其与相邻分区合并
## 按节点比例分区
通过动态分区,分区的数量与数据集的大小成正比,因为拆分和合并过程将每个分区的大小保持在固定的最小值和最大值之间。另一方面,对于固定数量的分区,每个分区的大小与数据集的大小成正比。在这两种情况下,分区的数量都与节点的数量无关
';